Custom Filter Tutorial
by 3D_MAMA
With version 2.0.2 of MCA Selector (hereinafter referred to as "MCA") it was finally possible to create our own filters. We no longer have to rely on the pre-made filters but can create your own. We can customize them to our liking and filter for any chunk data we want. This includes blocks, entities, block entities, poi, biomes, etc. The only limit is the data that's stored inside a chunk.
If you want to create your own custom filter but don't know how, then read further, this is the perfect guide for you.
In order to use the custom filters you need two things.
First, you need to have MCA (Version 2.0.2 or later) installed of course. This guide is for the GUI Version of MCA but the custom filters do work with the CLI version too.
For a guide on how to install MCA, look here.
And second, you need to know the basics of JavaScript or basically any other object oriented programming language! In order to fully understand this guide you need to have at least a basic understanding of:
- Functions and how to use them
- Classes and inheritance
- Basic datatypes like arrays/lists, maps/dictionaries, strings, integers, etc. and how to access their values
- Comparison operators like
==or!=
If you have no idea what the above means, please stop reading and learn the basics of JavaScript first! It helps neither you nor anyone who's trying to help you, if you don't understand what they say. So please, if you want help, help yourself first and learn the basics. If you're familiar with the above, keep reading 🙂
Minecraft uses the Named Binary Tag (NBT) format to store data in the saves files. This format is a tree data structure which is comprised of a handful of tags. This tree structure and the tags is exactly what you see, when you open the chunk editor (CTRL + B) in MCA.
To open the chunk editor in MCA, first use CTRL + L to clear the selection (make sure to save the selection if you want to work with it again), then select a single chunk and press CTRL + B to open the chunk editor. If you selected more than one chunk, the editor won't open. Now that the chunk editor is opened you may see something like this:

What you can see now is all of the data that is stored inside this chunk, split into the 3 tabs region, poi and entities (they are important later).
Below that is the tree structure representation of the current tab. Browse a bit around and make yourself familiar with it as it will be important later.
At the bottom you can see 13 icons. These icons are used for insertion (and removal  ) of tags from the chunk data. A trashcan (not important) and 12 other icons, each representing a different tag.
) of tags from the chunk data. A trashcan (not important) and 12 other icons, each representing a different tag.
Each tag holds a different value. Most are numbers but there are also string-tags and even tags that contain other tags.
For a more detailed explanation of the tags look here.
I strongly recommend to take a look at it as it is useful for a better understanding of the custom filter!
As you may have noticed, the tag icons in the chunk editor are different from those in the wiki. So, to prevent misunderstandings, here is a list of the tag icons, their name in MCA and their ID in the NBT library:
| Icon | Name | ID |
|---|---|---|
 |
ByteTag | 1 |
 |
ShortTag | 2 |
 |
IntTag | 3 |
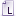 |
LongTag | 4 |
 |
FloatTag | 5 |
 |
DoubleTag | 6 |
 |
StringTag | 8 |
 |
ListTag | 9 |
 |
CompoundTag | 10 |
 |
ByteArrayTag | 7 |
 |
IntArrayTag | 11 |
 |
LongArrayTag | 12 |
Please note that this paragraph is only my personal interpretation and not based on or supported by the official documentation.
To better understand the NBT structure you can divide the different tags into 3 groups:
- The first group () consists of tags that can hold only one value like numbers or strings. They only contain a single value. Tags of the first group will show in the editor always as
TagIconkey:valuewhen they are inside a, and as TagIconvaluewhen inside a. - The second group () is comprised of tags that can hold multiple values. They each can hold none or more values. Tags of the second group will show in the editor always as
TagIconkey(number of values in it) when inside a, and as TagIcon(number of values in it) when inside a. Editing these kinds of values opens a separate window with more options. - The third group () are tags that can hold other tags. They each can hold none or multiple other tags. Tags of the third group will show in the editor always as
TagIconkey(number of tags in it) when inside a and as TagIcon(number of tags in it) when inside a. The tags inside a are indexed by unique string keys, and the order is not persistent. The tags inside a are indexed by their persistent order, and they do not have string keys. Tags inside a can only ever be of the same type.
You can imagine the first and second group as files and the third group as folders. Folders can hold other folders and files, but no actual data and files can hold only data and nothing else. In this example the key of a tag would be the filename and the value the content of the file. The first and the third group both share similarities with the second group.
Now that you know everything you need to know about the NBT format we can move on to the most difficult (but actually not that difficult) part of this guide, the NBT library (by Querz too). It is used by MCA internally to handle all NBT data of the loaded world. This library is also used for the custom filter. Although the filter itself is actually written in Groovy (based on Java), we can also use almost all functions from the NBT library (written in Java) to to create custom filters.
In order to interact with the chunk data and to compare it we first need to get the data. This is where all the different functions come into play. Basically you just string together a couple of these functions, and you get your desired value that you can then compare.
There are a couple functions you can work with. Some of them can only be used on a specific tag type. You can find more functions in the nbt7 branch of the NBT library by Querz, but the following should be enough for now:
size() -> int
get(String key) -> Tag
get<TagType>(String key) -> Value
getOrDefault(String key, default) -> Tag|default
get<TagType>OrDefault(String key, default) -> Value|default
isEmpty() -> boolean
get<TagType>Tag(String key) -> <TagType>
contains(String key, int typeId) -> boolean
containsKey(String key) -> boolean
containsValue(Tag value) -> booleansize() -> int
get(int index) -> Tag
get<TagType>(int index) -> Value
getOrDefault(int index, default) -> Tag|default
get<TagType>OrDefault(int index, default) -> Value|default
isEmpty() -> booleansize() -> int
get(int index) -> Value
getElementType(int index) -> ElementType-
<TagType>can be any of the types described in Appearance in MCA but without theTagat the end (ShortTagbecomesShort,IntArrayTagbecomesIntArray, etc.) -
Valueis the value of a Tag (e.g. the string of aStringTag) -
defaultis the value that is returned if the requested value does not exist. It should match with the requested tag type. -
ElementTypeis the type of the elements in an array (e.g.IntArrayTaghas only elements of the typeint) -
keyis the key I referred to in Tag Groups -
indexis the position of an item in a list, starting at 0 -
typeIdis the internal id of a tag used by the NBT library - You can also use built in functions from groovy like
contains(value)for lists.
Now that you know how the chunk data is stored, what tag types there are and what functions you can use to access this data, we can start creating our first custom filters.
It's also important to know that the custom filter must be a valid Groovy return statement, that returns either true or false, indicating whether the chunk should be selected or not. If it doesn't return a valid value, the filter will be ignored.
To get started, let's recreate the DataVersion filter. This way we can easily check whether our custom filter works and get to know the basic syntax and the most important function. Lets say we want to check if the DataVersion of a chunk is 3218 (MC Version 1.19.2):
- The filter should start with the
returnstatement. - Since the DataVersion tag is in the
regiontab in the chunk editor we useregionas our starting object. - We can also see in the chunk editor that the DataVersion tag is an IntTag, since it's a whole number and we already know the icons from Appearance in MCA.
- Together with the key "DataVersion" that gives us the function
getInt("DataVersion") - If we put all that together we get
return region.getInt("DataVersion"), and we are almost done. Now we only need to compare that value to any value we like. - To compare the value of DataVersion we need a comparison operator. We can use
==,!=,>=,<=,>and<. Because we want to check whether the DataVersion IS3218we use the equals operator==, followed by our value3218. - And with this last step done we get our final filter:
return region.getInt("DataVersion") == 3218. In this caseregion.getInt("DataVersion")is the path to the value we want to compare,==is the operator we use to compare the chunk value to our custom value and3218is our custom value. So, if theDataVersiontag equals3218, we returntruewhich tells MCA to select the chunk. If it's not equal, we returnfalseand the chunk will NOT be selected.
You can also invert the output by using != instead of == to invert the comparison. So return region.getInt("DataVersion") != 3218 would select the chunk only if the DataVersion is NOT equal to 3218.
Let's create a more complex filter to filter for values that are "deeper" down in the nbt tree. For this we need to chain multiple functions together to get the desired output. Let's say we want to select only chunks that contain at least 2 block entities.
- We start again with the return statement
return - Since we want to compare the
block_entitiestag we need to "navigate" to it usingregion.getList("block_entities"). Because theblock_entitiestag is aListTag, which we can see because of the icon for theListTag, we use getList(), instead ofgetInt()like we did before. - Now we got the list itself but we want to compare its size. That's why we need to append the
size()function to get the size (length) of the list. - We want to check if the chunk (the
block_entiteslist) contains at least 2 block entities, so we need the "greater than or equal to" (>=) operator. - Our value is 2, since we want to check if the list has 2 or more values (tags) in it.
- So our final filter is
return region.getList("block_entities").size() >= 2. First, we got theblock_entitiesListTagwhere all the block entities inside the chunk are stored. Then we get its size and compare that to our value using the>=operator. This way we can select all chunks that contain at least 2 block entities.
If you want to invert the output (select all chunks that have a maximum of 2 block entities) you can either use the <= operator or put the comparison in brackets and invert it by putting an exclamation mark (!) in front of it. So return region.getList("block_entities").size() <= 2 and return !(region.getList("block_entities").size() > 2) return the same value.
Now let's create a filter that is a bit more difficult. If you understand this, you should be able to create any filter you desire.
We will create a filter that checks if the chunk section at the bottom of the world (y=-64 to y=-49) contains the deep dark biome.
-
For the first part of the comparison we need to "navigate" to the biomes palette of the section with the section y value of
-4. Every section in a chunk has its own y coordinate. The lowest value is-4(y=-64toy=-49) and the highest is19(y=304toy=319). So we need to find the section with a y value of-4. This would be pretty complicated if we would actually need to check for this but minecraft stores the sections in a list from lowest y value to highest so it's pretty easy to get the desired section.
As you can see in the image above, every section has a y value. As I mentioned the sections are stored in a list (
ListTag) from lowest to highest y value. So-4should be at the top, right? But above-4is another section, so there is a bug? No. Minecraft actually stores one section more below-4, which I guess resembles the void. So there are actually sections stored from-5to19. Knowing this we now know that our desired section is stored at the list index1(instead of0). Putting all this together we getregion.getList("sections").get(1)which gives us the section with the y value of-4. Now we just need to navigate to the biomes list using.getCompound("biomes").getList("palette")and if we string both paths together and save it in a variable we getvar palette = region.getList("sections").get(1).getCompound("biomes").getList("palette")which gives us the biomes palette (the different biome types existing in this section) of the lowest chunk section we can build in. -
Now that we have the biomes palette we need to check if there is a
StringTagwith a value ofminecraft:deep_darkin it. Since this is a list, we can use the built in (groovy)contains(value)function. But we need to be careful what we pass as thevalueparameter. The intuitive way would be to just pass the string"minecraft:deep_dark"to it but that would select nothing, because our list does not contain any string object but justStringTagobjects. So instead of passing the string to thecontains(value)function we need aStringTagobject with our desired value (in this caseminecraft:deep_dark). To create aStringTagobject we typenew StringTag(). However this only creates an empty object. Since we want to create aStringTagwith a value ofminecraft:deep_darkwe need to pass it during the object creation like this:new StringTag("minecraft:deep_dark")(the"becauseminecraft:deep_darkis still a string). So now we can put our function together and get:palette.contains(new StringTag("minecraft:deep_dark")) -
Now we have the path to the biome palette and the function that checks for a biome. Since those ar two separate lines, we can terminate a line with a semicolon
;and chain them together:var palette = region.getList("sections").get(1).getCompound("biomes").getList("palette"); palette.contains(new StringTag("minecraft:deep_dark"))
-
To finish the filter we just put a
returnin front of the last statement and we're done:var palette = region.getList("sections").get(1).getCompound("biomes").getList("palette"); return palette.contains(new StringTag("minecraft:deep_dark"))
In this case the comparison operator isn't needed since the
contains(value)function already returns a boolean (trueorfalse). But we could add it to understand better what's going on or to invert it: Same but with comparison:return palette.contains(new StringTag("minecraft:deep_dark")) == trueInverted:return palette.contains(new StringTag("minecraft:deep_dark")) == falseorreturn palette.contains(new StringTag("minecraft:deep_dark")) != trueorreturn !palette.contains(new StringTag("minecraft:deep_dark"))
Here can be examples added. Maybe also recreations of existing filters to understand them better.

Getting started
Advanced editing
Articles and Tutorials
Development