Performance Results
Important
Please read Performance Results instead because the current document is deprecated and no longer valid.
With HMSDK, CXL Memory enables extending memory capacity and maximizing memory bandwidth. To verify the performance effect of each, we performed two experiments: 1) Capacity Expander, and 2) Bandwidth Expander.
The figure below shows the HMSDK components and memory configuration of this experiment. DDR5-4800 32GB are used as Host Memory and CXL 2.0/ PCIe Gen5 x8 with DDR5-4800 96GB x 2 is used as CXL Memory.

We evaluate the effectiveness of capacity expansion with HMSDK's Capacity Expander. It enables allocating memory to CXL Memory selectively and allocating to both Host and CXL Memory according to user-defined ratio.
Java applications mainly used in data centers reclaim memory through garbage collection when memory is insufficient. We measured execution time using HiBench RandomForest, and compared the Memory Capacity Expander case to Host Memory only case.
The result shows that execution time can be reduced by 34% due to a decrease in garbage collection time with the Capacity Expander.

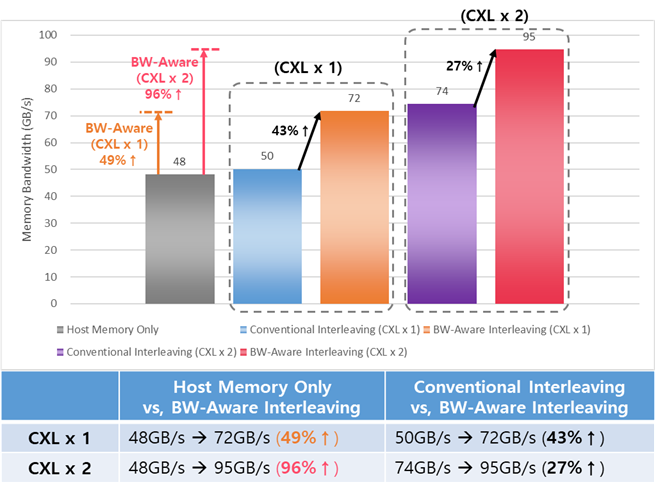
We evaluate the effectiveness of bandwidth expansion with HMSDK. System memory bandwidth can be maximized through HMSDK's new memory policy, Bandwidth-aware Interleaving. Bandwidth-aware Interleaving is a memory allocation policy that increases the memory utilization of the fast memory (usually the host memory) by determining the page allocation ratio based on the bandwidth difference between NUMA memory nodes.
In this experiment, since host memory has twice higher bandwidth compared to CXL memory (check Experiment Environments), we applied 2:1 page allocation ratio to host memory and CXL memory. We measured the peak memory bandwidth using Intel MLC (Memory Latency Checker) tool.
The bandwidth expander detects the memory bandwidth of each NUMA nodes and applies the bandwidth difference to the memory allocation policy to maximize the overall bandwidth among local DRAM and CXL memory nodes as follows.