Bandwidth Expansion
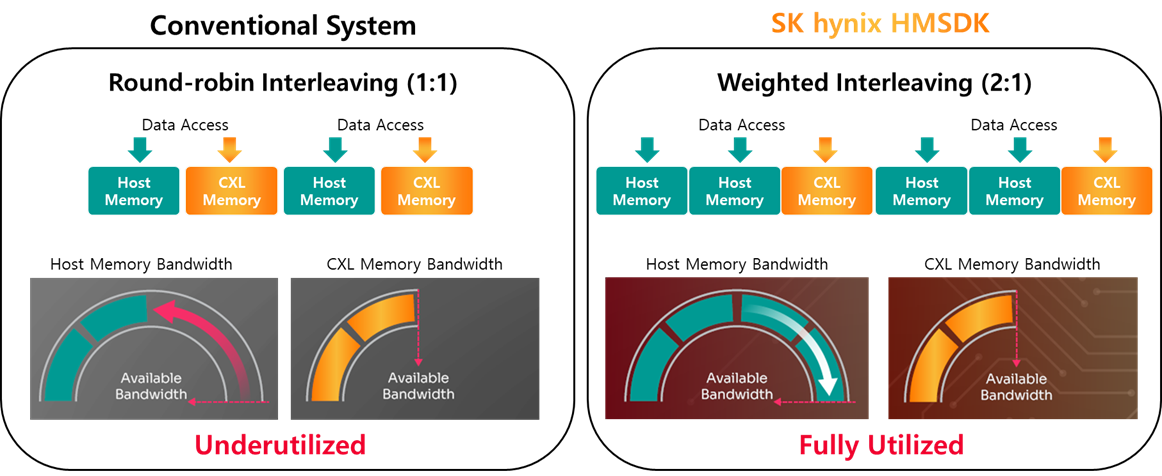
To maximize memory throughput, the interleaving techniques distribute data across each memory module, allowing parallel access simultaneously. In a heterogeneous memory system, each type of memory is recognized as a different NUMA node, and interleaving across these memory nodes can also expand peak throughput. For effective memory interleaving between memory modules with different performance characteristics, a new mempolicy called weighted interleaving has landed into upstream linux kernel v6.9 (it was co-developed by MemVerge).
Conventional NUMA memory interleaving allocates pages to each memory at the same rate in a round-robin manner. However, performance differences between memory devices can refrain the utilization of high-speed memory, which could cause overall degradation of the system performance.
Weighted interleaving is a new memory policy that increases the memory utilization of high-speed memory by determining weight based on the bandwidth differences between the memory nodes. By allocating pages to each memory according to its bandwidth ratio, it can increase total memory throughput and reduce average latency in bandwidth-hungry system.
Weighted interleaving can be applied using the numactl and bwactl tools.
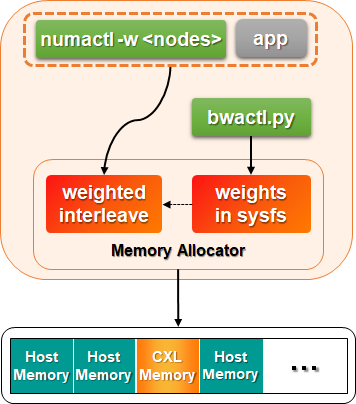
It is important that accurate weight values are provided for effective use of weighted interleaving. HMSDK provides bwactl.py tool, which automatically calculates the bandwidth ratio based on actual measurements using Intel MLC(Memory Latency Checker). The calculated weights among NUMA nodes are written to /sys/kernel/mm/mempolicy/weighted_interleave/nodeN where N are node numbers.
To maximize memory throughput with weighted interleaving, it is recommended to utilize the memory bandwidth among memory nodes within the directly linked package, rather than across processor interconnect such as UPI as depicted below.
+-----------+ +-----------+
| node0 | | node1 |
| +-------+ | UPI | +-------+ |
| | CPU 0 |-+-----+-| CPU 1 | |
| +-------+ | | +-------+ |
| | DRAM0 | | | | DRAM1 | |
| +---+---+ | | +---+---+ |
| | | | | |
| +---+---+ | | +---+---+ |
| | CXL 0 | | | | CXL 1 | |
| +---+---+ | | +---+---+ |
| node2 | | node3 |
+-----------+ +-----------+
weighted weighted
interleaving interleaving
group 1 group 2
The weighted interleaving groups do not go beyond across UPI because the bandwidth ratio can be different when the location of CPU cores is on the other side of package.
For example, the bandwidth of CXL 0 is different when accessing from CPU 0 and CPU 1 because CPU 1 has to go through UPI overhead to access CXL 0.
Therefore, bwactl.py reads the system topology by running the lstopo command and parse the result to get the package layout. For example, when you run bwactl.py in a system with the following topology:
$ lstopo-no-graphics -p | grep -E 'Machine|Package|NUMANode'
Machine
Package P#0
NUMANode P#0 # DRAM
NUMANode P#2 # CXL
Package P#1
NUMANode P#1 # DRAM
NUMANode P#3 # CXL
you can get the following results:
$ sudo tools/bwactl.py
Bandwidth ratio for all NUMA nodes
from node0 compute cores:
echo 1 > /sys/kernel/mm/mempolicy/weighted_interleave/node0
echo 1 > /sys/kernel/mm/mempolicy/weighted_interleave/node2
from node1 compute cores:
echo 6 > /sys/kernel/mm/mempolicy/weighted_interleave/node1
echo 5 > /sys/kernel/mm/mempolicy/weighted_interleave/node3Since the package 0 contains numa node 0 and node2, while package 1 has numa node1 and node3 so the interleaving is expected to be applied among the nodes inside the same package. It updates the optimal interleaving ratio (in this case 1:1 for node0 and node2, 6:5 for node1 and node3) for all nodes with CPU to any nodes with memory directly attached to them. The result may vary based on the system configurations.
If user wants to change the topology manually for some reasons, bwactl.py also provides a way to manually set the topology with --topology option. The argument should be 2 level nested set of nodes as follows.
<topology> := [<packages>]
<packages> := [<node_ids>] | [<node_ids>] "," <packages>
<node_ids> := <node_id> | <node_id> "," <node_ids>
The argument looks like 2 dimensional array list of python, which has greater or equal to 1 length of inner list. For example, the above topology can be represented as [[0,2],[1,3]] and you can run the following command.
$ sudo ./bwactl.py --topology "[[0,2],[1,3]]"
Bandwidth ratio for all NUMA nodes
from node0 compute cores:
echo 8 > /sys/kernel/mm/mempolicy/weighted_interleave/node0
echo 3 > /sys/kernel/mm/mempolicy/weighted_interleave/node2
from node1 compute cores:
echo 8 > /sys/kernel/mm/mempolicy/weighted_interleave/node1
echo 3 > /sys/kernel/mm/mempolicy/weighted_interleave/node3Another topology example can be used as follows.
$ sudo ./bwactl.py --topology "[[0],[1,2,3]]"
Bandwidth ratio for all NUMA nodes
from node0 compute cores:
echo 1 > /sys/kernel/mm/mempolicy/weighted_interleave/node0
from node1 compute cores:
echo 8 > /sys/kernel/mm/mempolicy/weighted_interleave/node1
echo 2 > /sys/kernel/mm/mempolicy/weighted_interleave/node2
echo 3 > /sys/kernel/mm/mempolicy/weighted_interleave/node3The above topology represents the following lstopo like result.
$ lstopo-no-graphics -p | grep -E 'Machine|Package|NUMANode'
Machine
Package P#0
NUMANode P#0 # DRAM
Package P#1
NUMANode P#1 # DRAM
NUMANode P#2 # CXL
NUMANode P#3 # CXL
numactl can apply weighted interleaving policy for each process. The next version after 2.0.18 of numactl will provide the -w/--weighted-interleave option as follows. Its usage is same as i/--interleave option and node IDs for interleaving should be given together.
--weighted-interleave=nodes, -w nodes
Set a weighted memory interleave policy. Memory will be allocated
using the weighted ratio for each node, which can be read from
/sys/kernel/mm/mempolicy/weighted_interleave/node*.
When memory cannot be allocated on the current interleave target
fall back to other nodes.
As mentioned in the above bwactl section, weighted interleaving is recommended to be used among memory nodes in the same package to maximize bandwidth. For the same reason, it is also recommended to specify the CPU node where the workload is executed along with the weighted interleaving memory policy. By doing so, the CPU node and the memory nodes that use weighted interleaving can be located within the same package. -N/--cpunodebind option of numactl specifies the CPU node on which to run workload.
When the program is executed as follows, numactl runs the program on node0 and it reads the interleaving weight values of /sys/kernel/mm/mempolicy/weighted_interleave/node{0,2}, and allocates memory pages in a weighted manner accordingly.
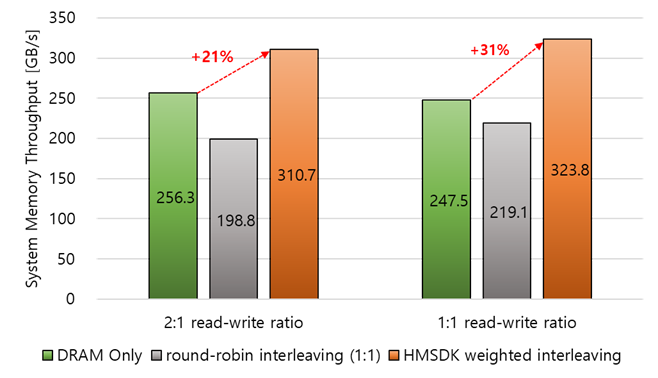
$ numactl -N 0 -w 0,2 ./programThe following graph shows the effectiveness of weighted interleaving. The experimental server contains 8 channels of DDR5 with 4 channels of CXL memory, which both have 5200 Mbps. The interleaving ratio was calculated and set with bwactl.py, then the system memory throughput was measured using the Intel MLC (Memory Latency Checker) tool. The HMSDK weighted interleaving leads to a 21% and 31% increase in throughput with read-write ratios of 2:1 and 1:1, respectively.