Load grid from URL #256
Load grid from URL #256
Conversation
Add download_file_from_s3 and parse_s3_uri functions Refactor download_file function to handle S3 URLs
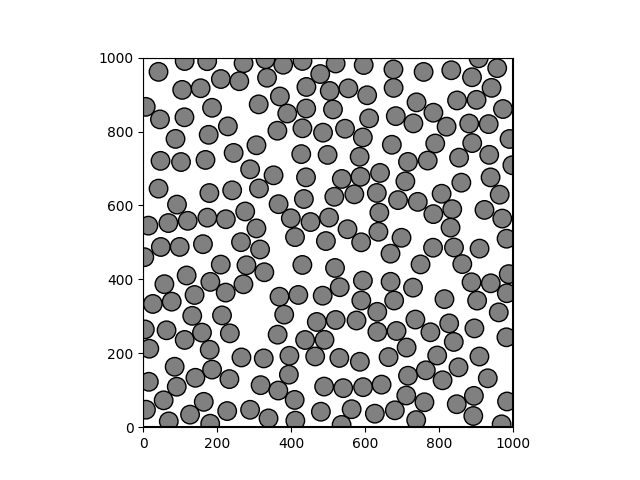
Packing analysis reportAnalysis for packing results located at cellpack/tests/outputs/test_spheres/spheresSST
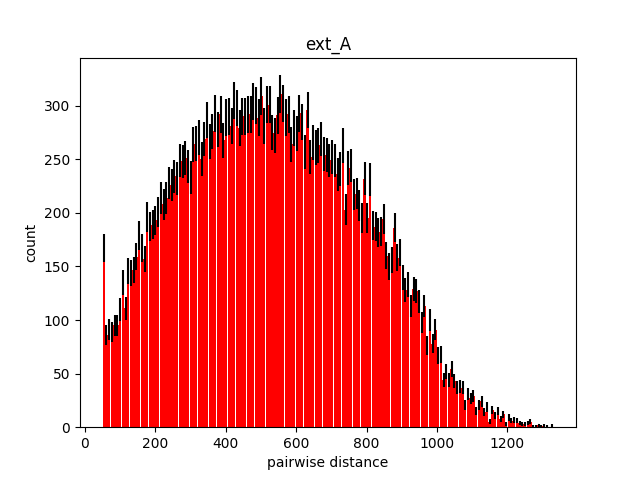
Packing imageDistance analysisExpected minimum distance: 50.00
|

| @@ -261,8 +250,49 @@ def updateReplacePath(newPaths): | |||
| REPLACE_PATH[w[0]] = w[1] | |||
|
|
|||
|
|
|||
| def download_file_from_s3(s3_uri, local_file_path): | |||
There was a problem hiding this comment.
it seems like this function does the same thing as def download_file() and isn't being used. we can keep one of them and remove the other
| def download_file(url, local_file_path, reporthook): | ||
| if url_exists(url): | ||
| if is_s3_url(url): | ||
| # download from s3 |
There was a problem hiding this comment.
These steps you've commented out are indeed the correct way to initiate the s3 client, we have functionality in AWSHandler that handles the initiation of clients and manages multiple existing clients. I'd suggest moving either download_file or download_file_from_s3 to AWSHandler to keep aws related util functions more organized and avoid potential client conflicts in the future. What do you think?
There was a problem hiding this comment.
Makes sense! It looks like you have moved these files in your branch already? In that case, I will leave these S3 related functions here so the refactoring in your branch doesn't have merge conflicts.
There was a problem hiding this comment.
The cache cleaning and grid file loading parts look great! For the S3 part, I created a branch to dig around and moved download_file_from_s3 to AWSHandler, and it works the same as this branch does. Here is the comparison link for you to take a look at. We can also chat about tomorrow if you like:)
Nit: the file name has some repeated parts in it: saved to out/test/test_s3_mesh/spheresSST/results_test_s3_mesh_test_s3_mesh_config_1.0.0_seed_0.simularium. We might want to reconstruct it.
There was a problem hiding this comment.
Thanks for taking a look @rugeli!
I suggest we merge this branch with the s3 related functions in __init__.py and then move them to AWSHandler in a later PR from the branch you linked to earlier. Would that work? The refactoring from the other branch looks good to me!
Nit: the file name has some repeated parts in it: saved to out/test/test_s3_mesh/spheresSST/results_test_s3_mesh_test_s3_mesh_config_1.0.0_seed_0.simularium. We might want to reconstruct it.
This is because my recipe is called test_s3_mesh and the config is called test_s3_mesh_config. I'll rename these for clarity.
| @@ -261,8 +250,49 @@ def updateReplacePath(newPaths): | |||
| REPLACE_PATH[w[0]] = w[1] | |||
|
|
|||
|
|
|||
| def download_file_from_s3(s3_uri, local_file_path): | |||
| def download_file(url, local_file_path, reporthook): | ||
| if url_exists(url): | ||
| if is_s3_url(url): | ||
| # download from s3 |
There was a problem hiding this comment.
Makes sense! It looks like you have moved these files in your branch already? In that case, I will leave these S3 related functions here so the refactoring in your branch doesn't have merge conflicts.
Problem
Closes #253
Solution
Type of change
Steps to Verify:
Run Packing
Details
The packing should download and save a file
test_s3_mesh_test_s3_mesh_config_1.0.0_grid.datto.cache/grids/folder at the top level of the repositoryClean Cache
Since some grid files can be large, we want to clean the cache periodically
Option 1
Set the
clean_grid_cacheoption totruein the config file. This will delete the downloaded grid file after the packing is completed.Option 2 (Destructive)
Run
python cellpack/bin/clean.py.WARNING: This will remove all the files in the cache!