CodeImprovements
The original performance form the first paper was:
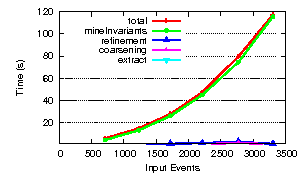
This section contains results for an incremental benchmark suite (see package benchmarks) run on Bisim (not BisimH).
As background, currently the implementation is as follows:
- Inputs: Synoptic event-based model, invariants in LTL form
- convert event-based model to state-based form (expensive, 2/3 of total time)
- convert invariants (negated) to Buchi automaton (cheap, only done once, implemented by code from NASA)
- convert state-based model to "did-can state-based model" (cheap, but unnecessary; blows up the size of the model, which causes problems later)
- combine did-can state-based model and Buchi automaton into "product automaton" (expensive, 1/3 of total time, reducing did-can model would speed this up)
- from product automaton, find counterexamples; this is the model-checking stage proper (fast)
- convert the counterexamples into our model (speed unknown, probably fast)
The results are as follows:
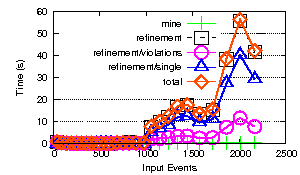
- The mining overhead is now insignificant.
- The refinement phase is dominated by the model checking. The model checking phase itself is dominated by the cost to translate from our rep to the model checkers domain (transMC), and the final product automaton construction (prod). Note that the prod section at least could be improved by removing the did/can capabilities.
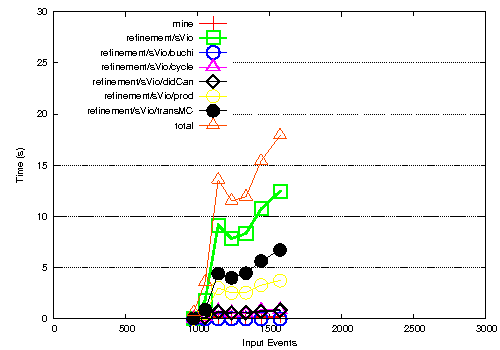
We are currently using LTL2Büchi to obtain a büchi-automanton from an LTL formula. The model checking implementation is taken from here.
-
Action was removed where a relations was needed.
-
Actions can be interned, with and without respect to datafields (final boolean flag)
-
Profiling for speed and size is done; bottom line: most of the execution time is spend in transitive closure lookup and model checking. Most objects are created during model checking.
-
Only check invariants that are (i) not known to be satisfied and (ii) could have changed, because they provided the counterexample.
-
The split-all-at-once idea is also in the code. Benchmark results are as follows:
Overall improvements yield the following performance on the data-set from the paper: (note the scale changed on each axis).
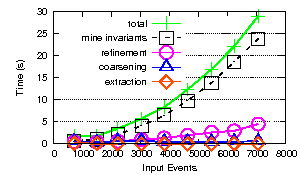
- Triple splits are not yet available
The model checker was designed to perform set up once, and to spend most of its time performing model checking. In our case, the model checking stage is relatively short, and the setup stage dominates running time. For example, we do tens of thousands of model checking runs on the reverse traceroute event input. As a result, the model checker spends most of its time setting up data structures. As a result, we could improve the model checker in multiple ways:
- The model checker checks stronger properties than we need, therefore we can elide the creation of some of its data structures.
- The model checker associates a hashmap with every node\edge element. This is expensive. We could simplify its data structures.
- There are a total of four data structure translations before the model checker can kick in -- Synoptic's representation is converted to an intermediate form X, and form X is converted to the model checker's representation. After the model checking, the output is converted into form X, and this form is converted to the Synoptic form. Perhaps we can convert from Synoptic's representation to the model checker's representation directly?
- A radical change would be to use a different model checker -- one that is optimized for short set up time.
- Another radical change would be to modify how often Synoptic performs model checking -- to make Synoptic's use of the model checker better reflect the intended use of the model checker.