MoCo-Flow: Neural Motion Consensus Flow for Dynamic Humans in Stationary Monocular Cameras (Eurographics 2022)
⭐ Building the dynamic digital human by only using a mobile phone!
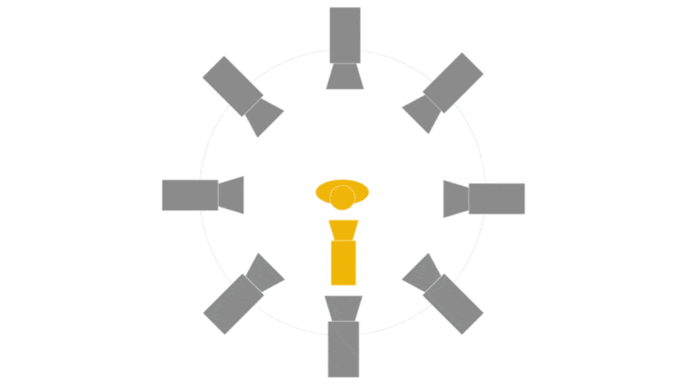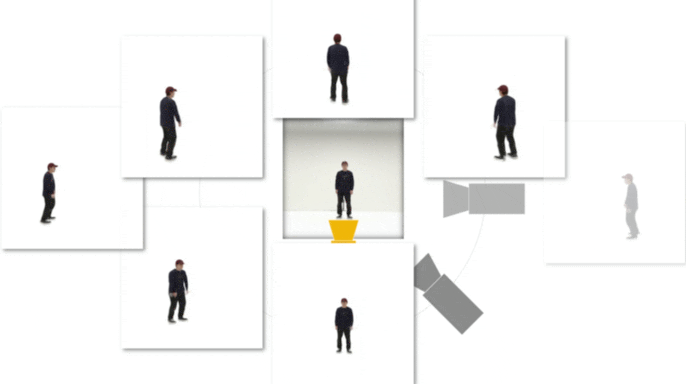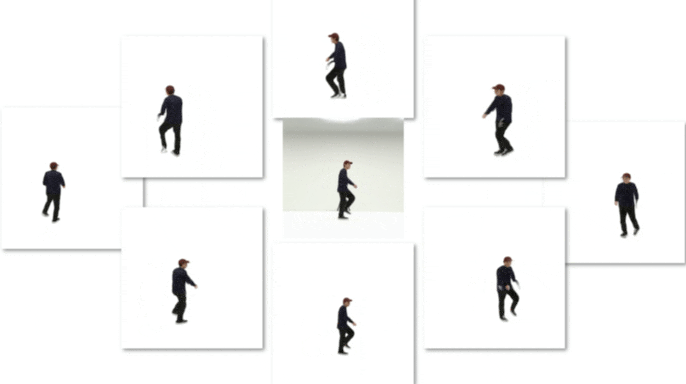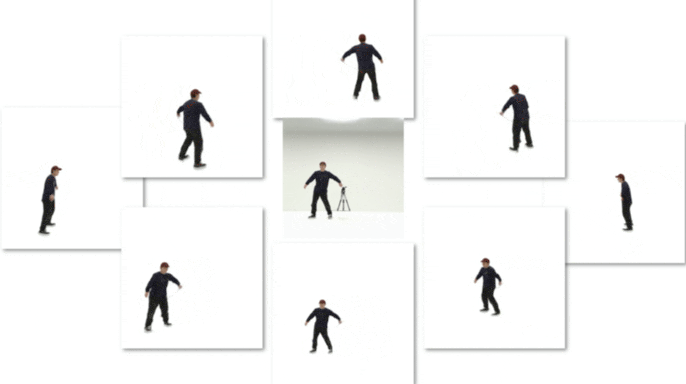
This is an official implementation. Any questions or discussions are welcomed!
- Our main contribution is to propose an easy and general solution to constrain the dynamic motion flow.
- Our method can produce smooth motion and rendering results even if the pose estimation is jitter and inaccurate.
- We treat all the data are in-the-wild in the main paper and only use a video without other annotated data.
- Following the TAVA, we show the design differences of different dynamic NeRFs.
| Methods | Template-free | No Per-frame Latent Code | 3D Canonical | Space Deformation |
|---|---|---|---|---|
| NARF | ✔️ | ✔️ | ❌ | Inverse |
| A-NeRF | ✔️ | ❌ | ❌ | Inverse |
| Animatable-NeRF | ❌ | ❌ | ✔️ | Inverse |
| HumanNeRF | ❌ | ✔️ | ✔️ | Inverse |
| NeuralBody | ❌ | ❌ | ✔️ | Forward |
| TAVA | ✔️ | ✔️ | ✔️ | Forward |
| Ours(MoCo-Flow) | ✔️ | ❌ | ✔️ | Inverse+Forward |
- Our work is placed to strict monocular, more details can be seen in Monocular Dynamic View Synthesis A Reality Check.

- Our approach is based on the naive NeRF, therefore, a long training time (~2 days) is required, which can be improved using Instant-ngp as in InstantAvatar. Longer training time will lead to better quality.
- We do not assume the hard surface of the human, although a background loss is used for optimization, some minor density artifacts in background can be found in depth images. Using Hard Surface Regularization proposed by LOLNeRF may tackle this.
- The accurate masks are not used for sampling in our work, better visual quality can be achieved by using a finer sampling strategy.
- Our template-free method has difficulty handling very complex motions such as entangled feet, partly due to the wrong pose estimation, and may produce incorrect results and artifacts.
- Python 3.8
- PyTorch 1.9.0
- KNN_CUDA
- VIBE for human pose estimation. Please follow their installation tutorial, and move it to scripts folder.
- SMPL. Download the SMPL models, and unpack to utils/smpl/data.
- RobustVideoMatting for video matting.
The final file structure shuold be as following:
├── scripts
│ ├── VIBE
│ └── ...
└── utils
└── smpl
└── data
├── basicmodel_f_lbs_10_207_0_v1.1.0.pkl
├── basicmodel_m_lbs_10_207_0_v1.1.0.pkl
└── basicmodel_neutral_lbs_10_207_0_v1.1.0.pkl
Install the required packages.
pip install -r docker/requirements.txt
** We also provide a Dockerfile for easy installation.
docker build -t moco_flow:latest ./
** Please note that we do not use any annotated data, such as GT SMPL parameters from People-Snapshot/ZJU-Mocap dataset. We treat all the monocular videos are in-the-wild for practicality.**
** To get the best result, we highly recommend a video clip that meets the similar requirements like Human-NeRF:
First, get a video and place into a folder, such as data/people-snapshot/videos/xxx.mp4.
Second, run the data preprocessing script.
VIDEO_PATH='../data/people-snapshot/videos/xxx.mp4' # input video path
SAVE_PATH='../data/people-snapshot/xxx' # output folder
START_FRAME=0 # start frame of the video
END_FRAME=320 # end frame of the video
INTERVAL=2 # sampling interval
cd scripts
python preprocess_data.py --input_video $VIDEO_PATH \
--output_folder $SAVE_PATH \
--start_frame $START_FRAME \
--end_frame $END_FRAME \
--interval $INTERVAL
cd ..
Then you shoud get a folder in $SAVE_PATH as following:
└── data
└── people-snapshot
└── xxx
├── images # images without background
├── images_w_bkgd # images with background
├── init_nerf # rendered images to initialize canonical NeRF
├── background.png # static background image, a trick to handle imperfect matting (deprecated)
├── train.json # annotated file
├── val.json # annotated file
├── xxx.mp4 # rendered video for pose estimation
└── vibe_output.pkl # raw VIBE output file
| video_vibe_result | background image |
|---|---|
 |
 |
Finally, modify the yaml file in configs, change the dataloader.root_dir in init_nerf.yaml, init_nof.yaml and c2f.yaml. We provide a template in ./configures, you can check the comments in the configuration file.
We use 8 GPUs (NVIDIA Tesla V100) to train the models, which takes about 2~3 days as mentioned in our paper. In fact, you can get reasonable results after running for two or three hours after starting joint training stage.
First, you should initialize the canonical NeRF model. This may takes ~6 hours using 4 GPUs.
python -m torch.distributed.launch \
--nproc_per_node=4 train.py \
-c configs/xxx/init_nerf.yaml \
--dist
Second, for fast convergence, you should initialize the forward/backward NoF model separately. This stage can be processed simultaneously and may takes ~6 hours using 4 GPUs.
python -m torch.distributed.launch \
--nproc_per_node=4 train.py \
-c configs/xxx/init_nof.yaml \
--dist
Finally, joint training using coarse to fine. This may takes ~1.5 days using 8 GPUs. For distributed training, you should use:
python -m torch.distributed.launch \
--nproc_per_node=8 train.py \
-c ./configs/xxx/c2f.yaml \
--dist
Or, for sanity check, you can use:
python train.py -c configs/xxx/c2f.yaml
We provide some of the pre-trained model in link. (Due to privacy issue, we only provide the pre-trained models of people-snapshot.) Please place the folder downloaded to ./ckpts.
Render the frame input (i.e., observed motion sequence).
python test.py -c ./ckpts/male-3-casual/config.yaml \
--resume ./ckpts/male-3-casual/ckpts/final.pth \
--test_json ./ckpts/male-3-casual/val.json \
--out_dir ./render_results/male-3-casual \
--render_training_poses \
# --render_gt # Uncomment if you want to visualize GT images

Run free-viewpoint rendering on a particular frame (e.g., frame 75).
python test.py -c ./ckpts/male-3-casual/config.yaml \
--resume ./ckpts/male-3-casual/ckpts/final.pth \
--test_json ./ckpts/male-3-casual/val.json \
--out_dir ./render_results/male-3-casual \
--render_spherical_poses \
--spherical_poses_frame 75 \
# --render_gt # Uncomment if you want to visualize GT images

Extract the learned mesh on a particular frame (e.g., frame 75).
python test.py -c ./ckpts/male-3-casual/config.yaml \
--resume ./ckpts/male-3-casual/ckpts/final.pth \
--test_json ./ckpts/male-3-casual/val.json \
--out_dir ./render_results/male-3-casual \
--extract_mesh \
--mesh_frame 75
Render the learned canonical appearance.
python test.py -c ./ckpts/male-3-casual/config.yaml \
--resume ./ckpts/male-3-casual/ckpts/final.pth \
--test_json ./ckpts/male-3-casual/val.json \
--out_dir ./render_results/male-3-casual \
--render_spherical_poses \
--spherical_poses_frame -1

Extract the learned canonical mesh.
python test.py -c ./ckpts/male-3-casual/config.yaml \
--resume ./ckpts/male-3-casual/ckpts/final.pth \
--test_json ./ckpts/male-3-casual/val.json \
--out_dir ./render_results/male-3-casual \
--extract_mesh \
--mesh_frame -1
The implementation partly took reference from nerf_pl. We thank the authors for their generosity to release code.
If you find our work useful for your research, please consider citing using the following BibTeX entry.
@article{mocoflow,
title = {MoCo-Flow: Neural Motion Consensus Flow for Dynamic Humans in Stationary Monocular Cameras},
author = {Xuelin Chen and Weiyu Li and Daniel Cohen-Or and Niloy J. Mitra and Baoquan Chen},
year = {2022},
journal = {Computer Graphics Forum},
volume = {41},
number = {2},
organization = {Wiley Online Library}
}