{kind=link}
“天池 Better Synth - 多模态大模型数据合成挑战赛”旨在鼓励参赛者探究合成数据对于多模态大模型训练的影响,以及促使参赛者追求高效的数据合成方法与策略,共同推进多模态大模型数据合成从 0-1 以及从 1-100 的前沿创新探索。
本次比赛关注于多模态大模型在图片理解任务上的能力,核心任务是在给定的种子数据集的基础上,通过高效的数据合成方法与模型生成出更优的数据,并在给定计算量的约束下,实现对图像理解多模态大模型的高效训练,再一次探索“数据-模型”协同研发的优势。为助力参赛者更高效地对数据集进行分析与合成,本次竞赛使用一站式大模型数据处理系统 Data-Juicer,提供了大量系统化、可复用的数据处理与生成算子和工具。
本次比赛基于 Mini-Gemini 模型进行训练,只关注于预训练(模态间对齐)阶段的数据合成与清洗,指令微调阶段为固定数据集。为了选手更高效地迭代数据合成方案,本次比赛选用 MGM-2B 规模的模型作为比赛模型
该报告旨在分享初/复赛的实验结果(见附录)及分析。
初赛实验文档(文档中详细记录了各种算子的参数值,训练脚本,处理后得到的数据,以及提交训练之后得到的评分):https://c2e0u86auj.feishu.cn/docx/T7ZUdAqRsoca4exLYpDcSmmbnOH?from=from_copylink
初赛的最优成绩是使用文本相似度过滤(image_text_similarity_filter )加上使用blip2重新生产重新生成120k的caption,并从中选取了35K caption取得的(image_captioning_mapper)最终线上赛最优的结果。
此外我们进行了其他的尝试:我们用allava-7B生成了总计60K高质量描述,并用重新生成的caption和图片对进行训练,模型性能大幅度下降。所以我们放弃了该方案
初赛采用官方提供的400k图文对数据作为训练数据,数据集是MGM原预训练数据集(1.2M)的子集,来源于SBU-558K和ALLaVA-4V。并基于官方数据进行数据合成,没有自己添加全新的数据集。测评指标基于 TextVQA 和 MMBench 来进行
本队伍在这次比赛中使用了大约8张A40,4张A100,16张A800,并且含有不能联网的机器,所以,服务器数据会有一些乱,比较难管理,但是对于每次处理的数据集都使用线上赛和线下赛中转并记录。初赛环境为官方给定环境,没有自己添加额外包。
实验记录文档:https://c2e0u86auj.feishu.cn/docx/BXJvdySBxosyexxoNUTcWpa2nnh
由于复赛基于初赛训练结果继续进行训练。然而我们初赛模型效果较差,在复赛过程中不占有任何优势。所以在复赛过程中,我们将初赛和复赛的数据集合并,继续重头做训练。总共数据量为410k(初赛400k+复赛10k)。
复赛过程中,不再像初赛过程中盲目尝试各种算子,启发式的设置各种超参数。复赛中我们先使用dj-analyze对数据进行分析。并基于分析结果选最终需要的数据。整个实验变得更加合理且直观。(这里也建议大家清洗数据之前,先用dj-analyze对数据进行分析,在更了解数据分布的情况下,往往事半功倍)。
我们的最开始思路是参考论文里提供的思路做一个多算子的叠加,得到最优数据。数据分析如下下边的图所示。
论文中算子叠加图如下:

相关数据分析图:
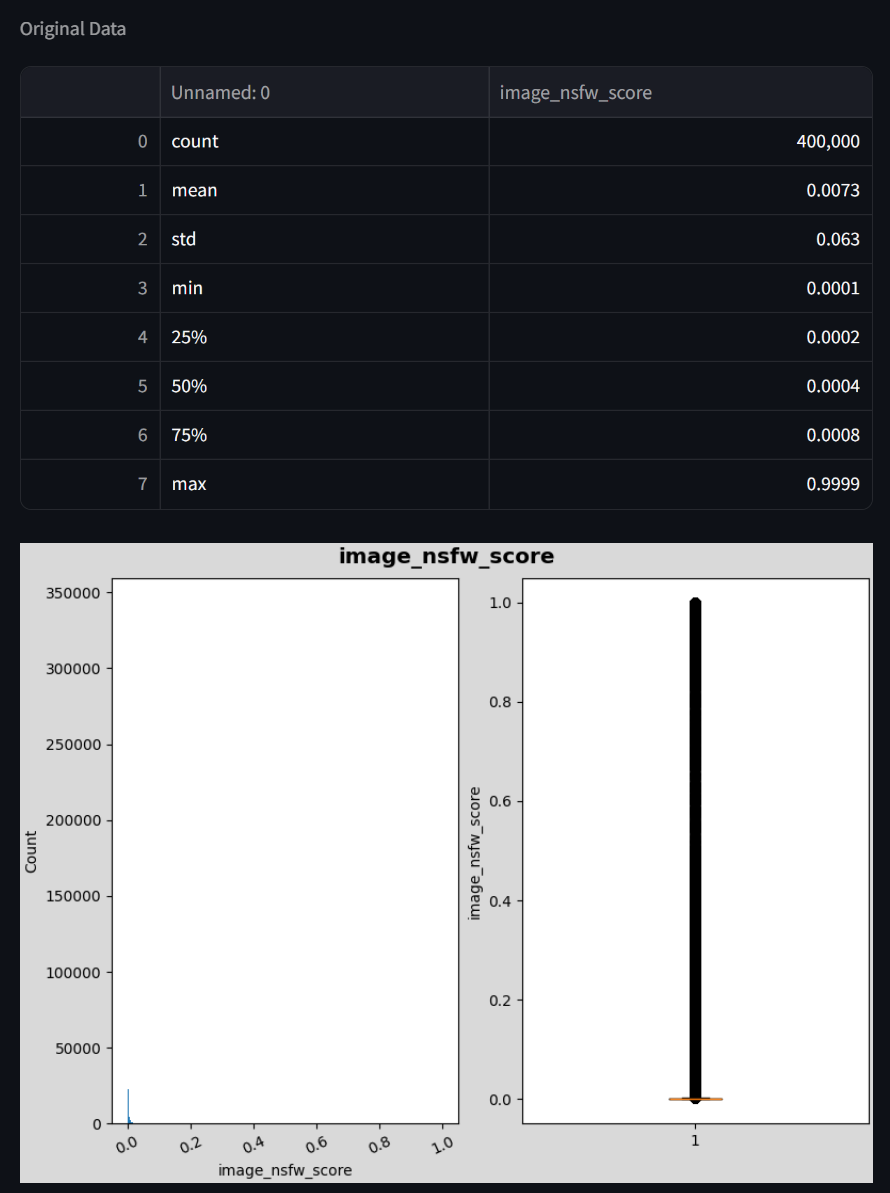
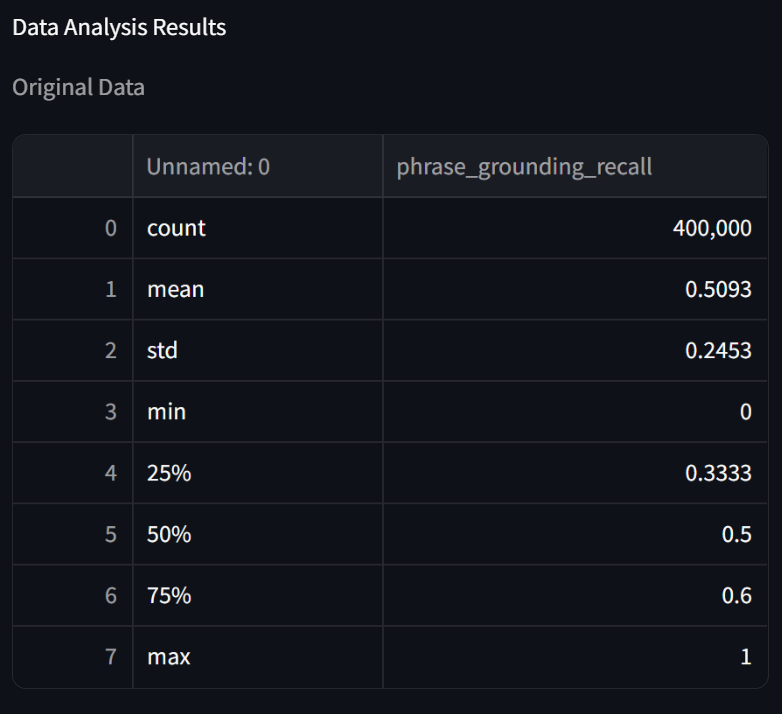
可以看到,其实400K的数据集中,结果已经满足nsfw,action的要求了。所以,我们使用phrase_grounding_recall_filter过滤出一半的数据,进行训练,结果并不好。然后,我们使用image_text_matching_filter过滤一半的数据,最后得到123037条数据,我们将其复制一份进行训练,得到较好的结果,我们次优的结果。
接下来,为了成绩可以继续提升,我们使用image_text_similarity_filter过滤出分数在0.01-0.28之内的数据得到】5.9K数据,使用image_captioning_mapper生成这些数据的caption,再使用image_text_similarity_filter大于0.28的条件进行过滤,得到4K数据,然后将其替换进去。得到我们最优的结果。
注意:我们同时使用llava和sd模型对数据进行重新合成,但是发现质量很差,过滤后加入到原始数据集中也没有取得较好结果。这张图片是使用sd模型重新生成图片后进行图文匹配度分数的分析,发现呈现两端分布。
sd模型生成数据的iamge_text_matching_score的分布图:
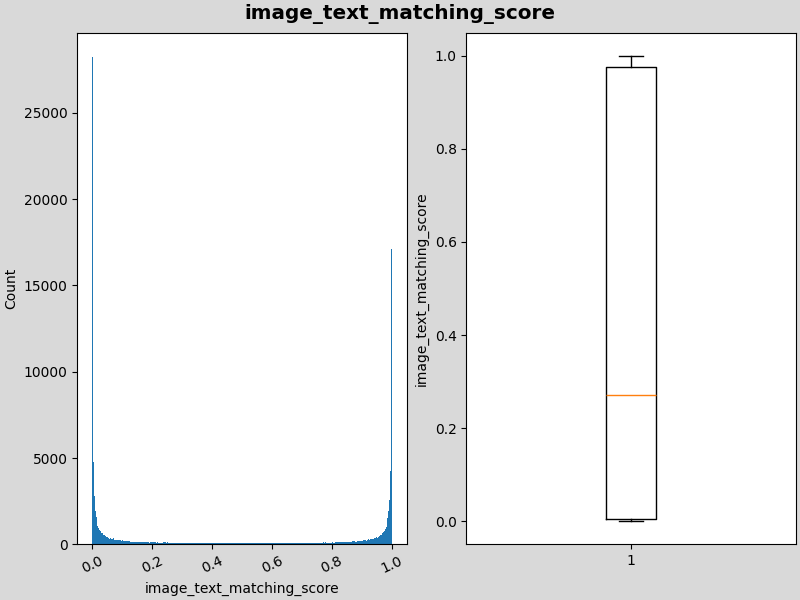
用官方提供的训练脚本进行训练和评测
我们发现,数据质量对模型的性能在很大程度上有着决定作用。但是训练的初始化也很大程度影响最终结果。模型的最终性能可以通过第一阶段预训练的loss进行判断,基本loss收敛效果越好,最后的模型性能也会更好。但是模型的初始化是随机的,即使是很好的数据,由于初始化的问题,模型可能陷入局部最优解。所以,如果得到一版较好的数据,可以多提交几次训练,选取初始loss较好的模型完成整个训练流程。其他初始loss较差的可以直接放弃掉(大概率最终结果是会比较差的)。此外测试过程中的随机性也会影响最终的结果,我们测试线上赛的测评过结果会有0.02左右的浮动。
同时可能由于模型较小,从而导致很不稳定,较大的llama就会更加稳定。
此外还有从其他团队中收获的一些启发,可以作为参考
算子设置列名称解释
方案a:image_text_similarity_filter 0.32 | image_aesthetics_filter
方案b:image_text_similarity_filter 0.32 | image_aesthetics_filter 0.5
算子名称后面跟着数字,这个数字代表这个算子的参数设置量,如果没有跟着数字就代表使用默认配置进行过滤。比如image_aesthetics_filter,方案a使用默认配置,方案b使用0.5进行过滤
| 方法 | 算子设置 | 数据量 | MMBench | TextVQA |
|---|---|---|---|---|
| 美学过滤 | image_aesthetics_filter 0.5 | 120k | 1.0392 | 1.0733 |
| 图文匹配度过滤 | image_text_matching_filter 0.5 | 385k | 1.0458 | 1.0617 |
| 图文相似度过滤 | image_text_similarity_filter 0.32 | 222k | 2.9151 | 1.0606 |
| 字数过滤 | words_num_filter | 240k | 0.9412 | 1.0191 |
| 方法1 | 方法2 | 算子设置 | 数据量 | MMBench | TextVQA | 备注 |
|---|---|---|---|---|---|---|
| 水印过滤 | caption 生成 | image_watermark_filter | image_captioning_mapper | 277k | 1.3530 | 0.9967 | |
| 图文相似度过滤 | caption 生成 | image_text_similarity_filter 0.32 | image_captioning_mapper | 222k | 2.6602 | 1.0498 | 这里图文相似度的初始数据集采用的单算子方案中成绩最高的 |
| 美学过滤 | image_text_similarity_filter 0.32 | image_aesthetics_filter | 222k | 2.9804 | 1.0995 | ||
| 图文匹配 | image_text_similarity_filter 0.32 | image_text_matching_filter 0.98 | 198k | 2.0850 | 1.0008 | ||
| 美学过滤 | image_text_similarity_filter 0.32 | image_aesthetics_filter 0.5 | 60k | 0.8562 | 1.0542 |
我们根据双算子方案中的最优成绩前两名确定新的方案
image_text_similarity_filter 0.32 |image_aesthetics_filter | image_captioning_mapper组合但是结果并不理想,成绩为MMBench:1.3464TextVQA:1.0313
接着我们使用llava和QwenVL来生成caption,发现结果并不好(后期线下交流学习到:这些模型生成的caption很复杂,2b的小模型无法学习这么复杂的描述)
同时还尝试了将数据集复制几次,这个方法会带来小幅度提升
| 方法1 | 方法2 | 方法3 | 算子设置 | 数据量 | MMBench | TextVQA | 备注 |
|---|---|---|---|---|---|---|---|
| 图文相似度过滤 | 美学过滤 | 默认caption生成 | image_text_similarity_filter 0.32 | image_aesthetics_filter 0.5 | image_captioning_mapper | 60k | 0.8628 | 1.0139 | |
| image_text_similarity_filter 0.32 | image_aesthetics_filter 0.5 | image_captioning_mapper | 240k | 2.183 | 1.0404 | 60K 的数据量太少复制4遍扩充到240k | |||
| image_text_similarity_filter 0.32 | image_aesthetics_filter | image_captioning_mapper | 222k | 1.3464 | 1.0313 | ||||
| llava caption生成 | image_text_similarity_filter 0.32 | image_aesthetics_filter 0.5 | image_captioning_mapper lava-1.5-7b-hf | 48k | 0.7909 | 1.0533 | |||
| 96k | 0.8235 | 1.0467 | 把48k数据复制两份 | ||||
| 192k | 0.9739 | 1.0445 | 把48k数据复制四份 |
由于三算子方案的成绩并不理想,所以我们又将方案进行回退。
初赛的最优成绩是使用文本相似度过滤(image_text_similarity_filter )加上使用blip2重新生产重新生成120k的caption,并从中选取了,35K caption取得的(image_captioning_mapper)最终线上赛最优的结果。
复赛生成数据上similarity_score,num_action,phrase_grounding_recall分析
image_diffusion_mapper(stable-diffusion-v1-5)
| similarity_score | num_action | phrase_grounding_recall | ||
| 原始数据 | 25% | 0.319 | 0 | 0.5 |
| 50% | 0.343 | 0 | 0.5 | |
| 75% | 0.367 | 0 | 0.667 | |
| 生成数据 | 25% | 0.27718 | 0 | 0.5 |
| 50% | 0.319114 | 0 | 0.5 | |
| 75% | 0.351331 | 0 | 0.667 |
image_captioning_mapper(llava-1.5-7b-hf)
| similarity_score | num_action | phrase_grounding_recall | ||
|---|---|---|---|---|
| 原始数据 | 25% | 0.319 | 0 | 0.5 |
| 50% | 0.343 | 0 | 0.5 | |
| 75% | 0.367 | 0 | 0.667 | |
| 生成数据 | 25% | 0.291 | 0 | 0.25 |
| 50% | 0.318 | 2 | 0.9 | |
| 75% | 0.344 | 6 | 1.0 |