SwarmNL #2201
There are no files selected for viewing
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,156 @@ | ||
| # SwarmNL | ||
| - **Team Name:** Algorealm, Inc. | ||
| - **Payment Address:** TBA | ||
| - **Level:** 2 | ||
|
|
||
| ## Project Overview :page_facing_up: | ||
|
|
||
| ### Overview | ||
|
|
||
| SwarmNL is a configurable P2P networking layer designed to be used in distributed system architectures that require data transfer solutions for off-chain communication in a scalable way. | ||
|
|
||
| It's goal is to provide a lightweight and configurable P2P networking layer for web applications designed to interact with on-chain data. | ||
sacha-l marked this conversation as resolved.
Show resolved
Hide resolved
There was a problem hiding this comment. I thought the whole key difference between the previous storage solutions you mentioned e.g. polkadot native storage is that you planning to create a decentralized networking layer that is completely off-chain. Thats how I understand this section:
But in the next sentence you mention that this will be used to interact with on-chain data
Where I'm wondering why would anybody want to use this or the distributed storage solution you envision. Because as soon as on-chain data is involved there is the need to make sure this data is correct. Hence you will probably just ask the nodes for the on-chain data directly, wouldn't you? I every entity in this network equipped with a light-client to stay up to date on the chainstate? As you can see I'm a little clueless how this will play out and I'm thankful for any explanation you can give me :) There was a problem hiding this comment. What we meant is that it could be extended to serve as the networking stack for on-chain data transfer. Of course, there will be a need for a subsystem for verification etc. But with what we envision for SwarmNL, adding things like that would not have too much overhead. There was a problem hiding this comment. Indeed, adding "could" would be more accurate. The networking layer could be extended to integrate some on-chain verification mechanism an application requires it. |
||
|
|
||
| ### Project Details | ||
|
|
||
| Algorealm has been building [SamaritanDB](https://algorealm.gitbook.io/samaritandb/), a database management system that allows app users to share parts of their personal data with applications on the internet while retaining control of what data they share. To achieve this, it uses Kilt DIDs and relies on an ink! smart contract to enforce access control. | ||
|
|
||
| As we started building the [SamaritanDB prototype](https://github.com/thewoodfish/samaritan-db) we realized that the networking layer will be a critical building block that can be abstracted into its own subsystem. This gave birth to the idea of creating SwarmNL: a networking layer that can be easily integrated into existing infrastructure without deep technical overhead and knowledge. As a standalone library, it will help teams building applications that require networking to move faster, reliably. | ||
|
|
||
| Our goal is to build this for our own purposes and to make it available for any other project to use. Here's a diagram illustrating the integration of SwarmNL to SamaritanDB: | ||
|
|
||
| 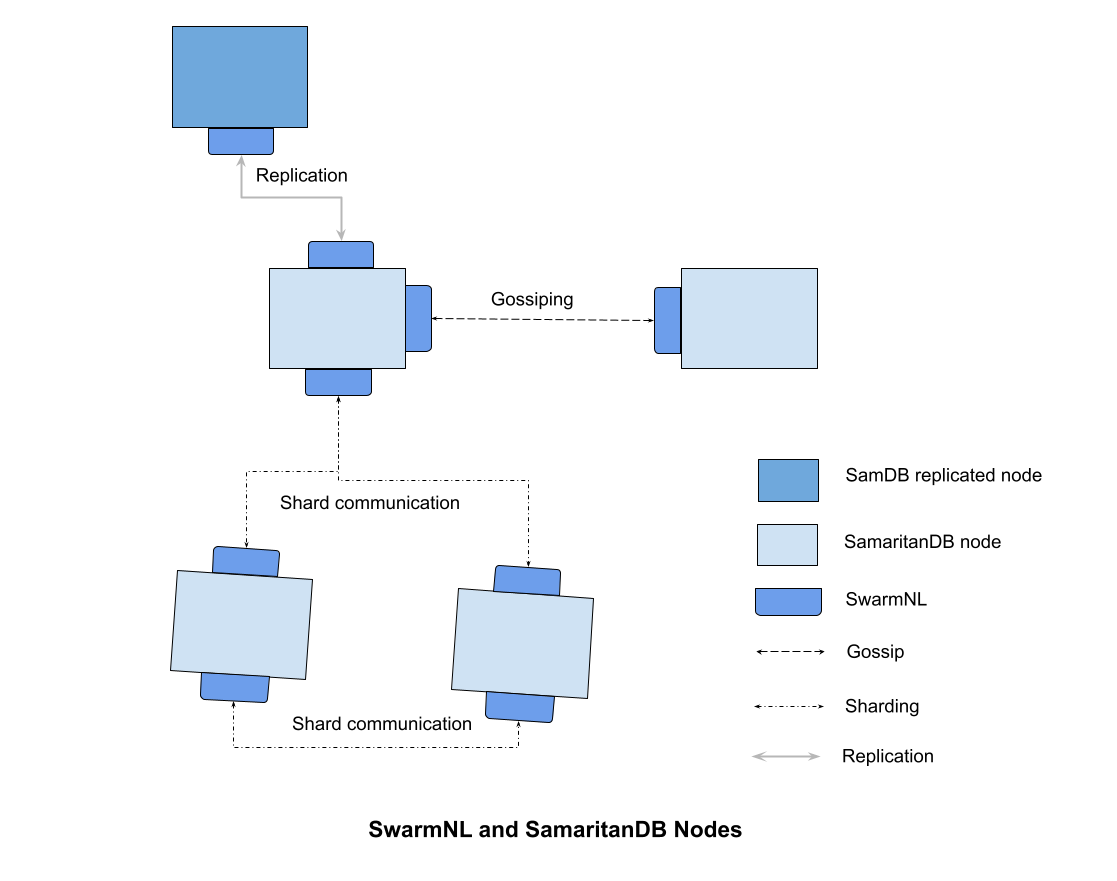 | ||
|
|
||
|
|
||
| ### Features | ||
|
|
||
| After some research, here are the features we decided to focus on. | ||
|
|
||
| * **Node Communication** -- SwarmNL enables P2P node communication by providing an interface for the following: | ||
| * **Node Configuration** -- SwarmNL would provide a simple interface to configure the node and specify parameters to dictate its behaviour. This includes: | ||
| * Selection and configuration of the transport layers to be supported by the node. | ||
| * Selection of the cryptographic keypair to use for identity generation e.g Edwards. | ||
| * Storage and retrieval of keypair locally. | ||
|
There was a problem hiding this comment.
Why would you want to have this configurable? Whats the benefit over a static solution? Or is this referring to an initial setup instead of configurability? There was a problem hiding this comment. I believe this has been addressed here |
||
| * PeerID and multiaddress generation. | ||
| * Protocol specification and handlers. | ||
| * Event handlers for network events and logging. | ||
|
|
||
| * **Gossiping** -- SwarmNL will implement the [Gossipsub 1.1](https://github.com/libp2p/specs/blob/master/pubsub/gossipsub/gossipsub-v1.1.md) protocol, specified by the [libp2p spec](https://github.com/libp2p/specs). This would be easily configurable to accommodate varying and peculiar network conditions. | ||
|
|
||
| * **Scaling** -- SwarmNL needs to efficiently handle a growing (or shrinking) number of nodes while maintaining performance and reliability. Here's what we plan to implement to this effect: | ||
|
There was a problem hiding this comment. The way I see it the gossipsub libp2p version already has strategies (e.g. heartbeat mechanism) built in to deal with varying amount and availability of nodes. Whats the benefit of you creating new strategies? There was a problem hiding this comment. Absolutely, the gossipsub implementation in libp2p provides valuable strategies like the heartbeat mechanism for addressing varying node availability. However, our approach isn't about reinventing these strategies; it's about leveraging and enhancing them for more specialized use cases.
There was a problem hiding this comment. You know what I think the bullet points you listed are so helpful and I'm amazed that you are able to so excplicitly state the features. I wish you take those listed features for the categories you named and include them as deliverabled in the respective subsection. Very helpful to understand what you envision! There was a problem hiding this comment. I've updated the PR with @thewoodfish's comments here as I think they do add more clarity on what we mean for implementing gossipsub. |
||
| * **Sharding** -- implementation of a flexible generic sharding protocol that allows application specify configurations like sharding hash functions and locations for shards. | ||
|
There was a problem hiding this comment. Do you already know which protocol you plan to implement? There was a problem hiding this comment. Yes, indeed. We are planning to implement sharding as part of our network scaling strategy. While we have a clear understanding of what sharding entails and the different techniques available, we haven't finalized the specific protocol yet. However, we aim to support a diverse range of sharding techniques to cater to various use cases and requirements. Some of the sharding techniques we are considering include Range-based, key-based and hash-based sharding. |
||
| * **Data Forwarding** -- definition of a protocol for forwarding messages between nodes in different shards and establishment of efficient routing mechanisms for inter-shard communication. | ||
| * **Fault Tolerance** -- implementation of fault-tolerant mechanisms for detecting (and recovering from) node failures. This might involve redundancy, node replication, erasure encoding/decoding or re-routing strategies. | ||
|
There was a problem hiding this comment. Can you please elaborate on the fault tolerance you want to introduce that has a benefit over the already existing fault tolerance / error correction in the TCP / IP stack? I assume re-routing strategies are already handled by gossipsub but node replication sounds especially interesting. There was a problem hiding this comment. The fault tolerance mechanisms introduced in SwarmNL are designed to complement and extend the fault tolerance and error correction features provided by the traditional TCP/IP stack. While TCP/IP ensures reliable point-to-point communication, decentralized and peer-to-peer networks face unique challenges, such as dynamic node behaviors, varying network conditions, and potential node failures. SwarmNL enhances fault tolerance by introducing additional strategies beyond those typically found in the TCP/IP stack. |
||
|
|
||
| * **IPFS**: | ||
| * **Upload** -- provision of interfaces to upload to IPFS, pin on current node and post arbitrary data to remote servers. Encryption is also easily pluggable and will be provided. | ||
| * **Download** -- retrieval and possible decryption of data from the IPFS network. | ||
|
|
||
|
|
||
| #### Technology Stack | ||
|
|
||
| * Libp2p | ||
| * Rust | ||
|
|
||
|
|
||
| #### What is not included in SwarmNL | ||
| SwarmNL will not be involved in providing a storage solution. Because SwarmNL will be generic over the networking layer, it will be possible to easily plug in any storage interface in a flexible and configurable way. | ||
|
There was a problem hiding this comment. SwarmNL is the network layer you are proposing itself, right? Why would it be generic over the network layer? I assume you meant to say that it will be generic over the storage layer, correct? There was a problem hiding this comment. YES, we meant the storage layer. Thank you |
||
|
|
||
| Storage maintained by the library will mostly be in memory with the exception of config files and other node state keeping data. | ||
|
|
||
| ### Ecosystem Fit | ||
| - Where and how does your project fit into the ecosystem? | ||
| - SwarmNL can be used by applications or projects that require a bespoke decentralized communication layer for transporting and exchanging off-chain data. | ||
| - Who is your target audience (parachain/dapp/wallet/UI developers, designers, your own user base, some dapp's userbase, yourself)? | ||
| - Our priority is to build this for [SamaritanDB](https://github.com/thewoodfish/samaritan-db). However, SwarmNL will be generic enough to be used by any developer in the ecosystem that would require a primitive networking layer | ||
|
There was a problem hiding this comment. Could you name some other good use cases where swarmNL could be leveraged? There was a problem hiding this comment. Thank you for your question. swarmNL could be leveraged in Content Delivery Networks (CDNs), distributed storage systems, IoT (Internet of Things), multiplayer online games and file hosting and sharing systems |
||
| - What need(s) does your project meet? | ||
| - It provides an open-source and flexible communication layer for distributed networking and off-chain data exchange. | ||
| - Are there any other projects similar to yours in the Substrate / Polkadot / Kusama ecosystem? | ||
| - While projects like [Crust network](https://crust.network/) provide a full stack decentralized cloud storage solution for the ecosystem as a dedicated blockchain with an opinionated programming interface, SwarmNL is one subsystem that can be used as a core networking component to build all sorts of decentralized applications, including a bespoke storage solution. Other initiatives like [Polkadot Native Storage](https://forum.polkadot.network/t/polkadot-native-storage/4551) who also piggy back on existing libp2p networking implementations differ as SwarmNL provides the pluggable and interoperable networking layer only. | ||
|
|
||
| ## Team :busts_in_silhouette: | ||
|
|
||
| ### Team members | ||
|
|
||
| * Adedeji Adebayo (Engineering Lead and Core Developer) | ||
| * Sacha Lansky (Project Lead, Documentation and Testing) | ||
|
|
||
|
|
||
| ### Contact | ||
|
|
||
| - **Contact Name:** Sacha Lansky | ||
| - **Contact Email:** [email protected] | ||
|
|
||
| ### Legal Structure | ||
|
|
||
| - **Registered Address:** 254 CHAPMAN RD STE 209, NEWARK, DE. | ||
| - **Registered Legal Entity:** Algorealm, Inc. | ||
|
|
||
| ### Team's experience | ||
|
|
||
| Adedeji Adebayo is a dynamic and inquisitive programmer, spanning over five years of experience in web development, systems software, and blockchain technologies and is also the founder of Algorealm. His notable achievements include securing a position among the top three winners in the Web3 and Tooling category of the [Polkadot Hackathon: North America Edition](https://polkadot-na.devpost.com). Additionally, he emerged as the sole winner in the KILT category during the [Polkadot Hackathon: Europe Edition](https://www.polkadotglobalseries.com/europe/), where he presented a solution for property management issues in West Africa. | ||
|
|
||
| Sacha Lansky started his journey into the Polkadot ecosystem in 2020 and joined Parity to lead developer advocate related activities in 2021. Since then he has written a number of guides and tutorials to help newcomers learn how to build on Polkadot, with a focus on Substrate. He's launched initiatives such as the Substrate Newsletter, Substrate Seminar, SDK Unwinds as well as played a key role in the content launch for the first wave of the Polkadot Blockchain Academy. | ||
|
|
||
| Sacha and Adedeji met during a Polkadot hackathon back in 2022 where Sacha was his hackathon mentor at the time and helped him flesh out the vision for realising SamaritanDB. Since then, they have been iterating on the required infrastructure to be able to create a decentralized operating system for building applications powered by SamaritanDB. | ||
|
|
||
| ### Team Code Repos | ||
|
|
||
| The SwarmNL Github repository: https://github.com/algorealminc/SwarmNL | ||
|
|
||
| ### Team Github Profiles | ||
|
|
||
| - https://github.com/thewoodfish | ||
| - https://github.com/sacha-l | ||
|
|
||
| ## Development Status :open_book: | ||
|
|
||
| We have built a PoC for SamaritanDB (see [the Github repo here](https://github.com/thewoodfish/samaritandb-proto1)). A very small inflexible version of SwarmNL was used in the development of the PoC, as an inclusive non-distinguishable part of the system. This grant will help us work towards isolating and making this component robust, configurable and pluggable for any project. | ||
|
|
||
| ## Development Roadmap :nut_and_bolt: | ||
| ### Overview | ||
|
|
||
| - **Total Estimated Duration:** 3 months | ||
| - **Full-Time Equivalent (FTE):** 1 | ||
| - **Total Costs:** $24,000 | ||
|
|
||
| ### Milestone 1 | ||
|
|
||
| - **Estimated duration:** 1.5 months | ||
| - **FTE:** 1 | ||
| - **Costs:** $12,000 | ||
|
|
||
| | Number | Deliverable | Specification | | ||
| | -----: | ----------- | ------------- | | ||
| | **0a.** | License | Apache 2.0 | | ||
| | **0b.** | Documentation | We will provide both **inline documentation** of the code and a basic **tutorial** that explains how a user can integrate SwarmNL and configure nodes on the network. | | ||
|
There was a problem hiding this comment. What network are you referring to here? There was a problem hiding this comment. Thank you. We are talking about the custom network of the application which uses SwarmNL as its underlying backbone. When SwarmNL is in use, you require the benefits it provides, hence you would be configuring your own network as you configure and tweak SwarmNL configurable interfaces. There was a problem hiding this comment. I understand. But for the tutorial and testing deliverables, you will have to provide an example. What will this example be based on? SamaritanDB? Also, could you answer my first question from the top comment? There was a problem hiding this comment. Okay, i will say no. The goal is to provide a detailed means of understanding for the users/devs. Hence, the example will be based on a very simple easy to understand use-case and model. It is unlikely SamaritanDB will be able to achieve that effectively, so i can say it will be something else, simple to understand e.g a simple Ti-Tac-Toe game. What we have is a goal in mind (the mechanism -> a detailed and easy to understand tutorial, test, example etc.), we will find the best and most effective means (the policy -> which project/use-case/application to use for the tutorials, tests, examples etc) to carry that out. @sacha-l will respond to your first question shortly. Thank you There was a problem hiding this comment. I see what you're asking @semuelle but it's true that an actual integration to a dummy app is outside the scope of this milestone. For this milestone, our focus is a lot more on the configurability feature set. The envisioned tutorial will outline how to configure the Node Communication features we'll be delivering in this milestone. So for the tutorial its not: "how to configure your nodes for a simple tic-tac-toe game" but rather "what are all the configuration options with SwarmNL you have". There was a problem hiding this comment.
So what functionality will be covered by the testing and Docker deliverables? There was a problem hiding this comment. The testing will cover the functionalities in the deliverables 1 and 2 for Milestone 1. The Docker will contain simple programs (Rust binaries) that will showcase these functionalities. Hope that clarifies things! |
||
| | **0c.** | Testing and Testing Guide | Core functions will be fully covered by comprehensive unit tests to ensure functionality and robustness. In the guide, we will describe how to run these tests. | | ||
| | **0d.** | Docker | We will provide a Dockerfile(s) that can be used to test all the functionality delivered with this milestone. | | ||
| | 1. | SwarmNL configuration module | Implementation of the configuration interfaces to define the behaviour of the nodes and the network. | | ||
|
There was a problem hiding this comment. May I ask what led you to this milestone structuring? To me it would make sense to structure the deliverables in a way that each milestone is one coherent block of deliverables that work together and can be tested together. In this very project I can see it making a lot of sense to first implement the tech needed for a single node and build all the functionalities one node should incorporate and then later on in milestone 2 deliver on the tech thats needed to make the network as a whole work. Yet it looks like you have now mixed it. In milestone 2 you have the ipfs integration which would be one of the node-specific functionalities and less those of the network. When you say "define the behaviour of the nodes and the network" what does that mean exactly? To my understanding that is defining the behaviour of a node which collectively but not centrally influenced define the behaviour of the network itself. What is a configuration interface for the network? There was a problem hiding this comment. You’re absolutely correct. Our milestone structuring aligns with the approach you mentioned. We've organized the deliverables in a way that each milestone forms a coherent unit, ensuring that the components work together seamlessly and can be tested effectively. Initially, we focus on implementing the technology required for a single node, encompassing all the functionalities that a node should incorporate. This includes configuration parameters that influence both scaling and communication aspects. By addressing these in Milestone 1, we establish a foundation where configured nodes can communicate with peers, paving the way for scaling techniques. Milestone 2 builds upon this foundation by refining node communication to accommodate our scaling strategies. This includes implementing techniques like sharding and replication, which are interdependent and require integrated testing. While IPFS integration is indeed a node-specific functionality, we've positioned it within Milestone 2 to balance the workload, considering that a significant portion of effort is dedicated to achieving flexible communication in Milestone 1. Furthermore, interfaces for posting data to remote servers are crucial for enabling nodes to respond to various network events effectively. By including this in Milestone 2, we ensure that these interfaces are ready for integration, contributing to the overall flexibility of the system. Due to the interconnected nature of the deliverables, i think combining the milestones into a continuous 12-week period appears to be the best decision. This approach will allow for comprehensive testing at each stage, ensuring that the system functions smoothly across all components. There was a problem hiding this comment. When you say "define the behaviour of the nodes and the network" what does that mean exactly? To my understanding that is defining the behaviour of a node which collectively but not centrally influenced define the behaviour of the network itself. What is a configuration interface for the network? When we talk about defining the behavior of nodes and the network in the context of SwarmNL, it essentially refers to configuring various parameters and settings that govern how nodes interact with each other and collectively form the network's behavior. Let me break it down further: Static Node Parameters: These are fixed settings that are typically set during node initialization and remain constant during operation. Examples include cryptographic key pairs, network authentication secrets, and bootstrapping parameters. These parameters establish the fundamental identity and connectivity of the node within the network. Scaling Parameters: These parameters are crucial for achieving scalability in the network. They encompass settings related to sharding, replication, and other scaling techniques. By adjusting these parameters, nodes can adapt to changes in network size and workload, ensuring efficient resource utilization and performance optimization. Dynamic Configurable Interfaces: These interfaces provide flexible mechanisms for nodes to interact with the network and respond to dynamic conditions and events. They include functionalities such as:
These configurations play a pivotal role in shaping the behavior of both individual nodes and the network as a whole. By adjusting these settings, developers can fine-tune the network's performance, scalability, fault tolerance, and overall behavior to suit specific use cases and requirements. Ultimately, the goal is to provide a flexible and adaptable networking framework that empowers developers to build resilient and efficient decentralized applications. There was a problem hiding this comment. As @thewoodfish mentioned, the structure is around first delivering a way to make this library flexible and configurable. Then, delivering a way to make it scalable and usable. We think these building it this way stays closer to our design goals for making this networking layer as flexible and configurable as it can be. @PieWol we would happily include any suggestions you might have on breaking down the milestones further if you think anything is missing. Note that a lot of this is detailed in the "Features" section which we plan to use as our north start for the deliverables. |
||
| | 2. | Gossipsub | Implementation of the gossipsub communication algorithm and configurable interfaces for application level data filtering and authentication. | | ||
|
There was a problem hiding this comment. Can you please explain what the deliverable 2 means? What do mean with "configurable interfaces for application level data filtering and authentication"? There was a problem hiding this comment. Our goal is to create a seamless and user-friendly experience for setting up network nodes, facilitating communication between nodes, and ensuring fault tolerance and scalability. Deliverable 2 focuses on enhancing the Gossipsub protocol, which serves as the backbone of our networking infrastructure. However, we aim to shield developers from its complexities, such as implementing features like backoff, pruning, and cancellation transparently. One key aspect of this deliverable is to empower developers to customize their nodes' behavior in response to incoming messages. This includes implementing custom data filtering logic and defining actions to be taken based on message content or validation results. Additionally, developers will have the flexibility to implement custom authentication logic for verifying data received from peers in the network. There was a problem hiding this comment. I added some more details @thewoodfish wrote in a previous comment into the "Features" section to add more clarity on this deliverable (under "node communication"). |
||
|
|
||
| ### Milestone 2 | ||
|
|
||
| - **Estimated Duration:** 1.5 months (6 weeks) | ||
| - **FTE:** 1 | ||
| - **Costs:** $12,000 | ||
|
|
||
| | Number | Deliverable | Specification | | ||
| | -----: | ----------- | ------------- | | ||
| | **0a.** | License | Apache 2.0 | | ||
| | **0b.** | Documentation | We will provide both **inline documentation** of the code and a basic **tutorial** that explains how a user can add new nodes to SwarmNL. | | ||
| | **0c.** | Testing and Testing Guide | Core functions will be fully covered by comprehensive unit tests to ensure functionality and robustness. In the guide, we will describe how to run these tests. | | ||
| | **0d.** | Docker | We will provide a Dockerfile(s) that can be used to test all the functionality delivered with this milestone. | | ||
| | 0e. | Demo API usage | Showcase API usage with short guides using different configurations. | | ||
| | 1. | Scaling | Implementation of sharding, data-forwarding and fault-tolerant algorithms into SwarmNL. | | ||
| | 2. | IPFS integration | Implementation of interfaces to upload, download and pin IPFS files. | | ||
| | 3. | Additional Extendability | Implementation of interfaces to POST arbitrary data to remote servers. | | ||
|
|
||
|
|
||
| ## Future Plans | ||
|
|
||
| With milestones 1 and 2 completed, we plan to continue the development of SamaritanDB and launch an MVP that we will use to roll out the first wave of applications powered by SamaritanDB. | ||
|
There was a problem hiding this comment. Can you please tell us more about the applications you reference here? There was a problem hiding this comment. The reason we want SwarmNL is because it plays an important role in what we’ve been trying to build (SamaritanOS). SamaritanOS or SamOS for short is a collection of technologies that work together to give users self-sovereignty and control of data they input (and can retrieve) across applications compatible with it. It can be thought of as software that operates as a hub of online applications. Let’s say every user visiting an application on the internet is authenticated cryptographically and is represented by a DID. The application recognises this DID and stores every data inputted into it in relation to the DID, allowing the user to retain control over that underlying data stored. In our architecture for SamOS, the data is stored in a DB called SamaritanDB. A document (for now) database that is built to store data and cryptographically bind it to a DID. This DB will be made capable of listening to on-chain state changes made by the user concerning the data. The onchain state in this design contains DID-based permissioned sources of truth, allowing other applications to access application data, in a permissioned way. As a result, this database must be distributed across nodes. It must be capable of retrieving data from IPFS and adopt network protocols for scaling, replication, sharding support to ensure data availability and censorship resistance.. This is majorly where SwarmNL comes into play, to help achieve this and function at the heart of the databases. The applications we are referring to here are the applications that are built to be compatible with the SamaritanOS infrastructure and achieve our goals of allowing users to interact with them, preserving the users sovereignty over what is being stored and shared within the application. There was a problem hiding this comment. I added this into the "Ecosystem fit" section:
|
||
|
|
||
| ## Additional Information :heavy_plus_sign: | ||
|
|
||
| **How did you hear about the Grants Program?** Personal recommendation. | ||
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
Have you decided on your desired form of payment already? That should be represented here :)