Client‐Server Data Flow
In the traditional client-server model, client's request hits server for data retrieving and modifying. Under this framework, modern architecture has many additional roles like gateway, proxy, and cache server. Matters does the same, for high performance and availability.
To increase the API cache hit rate, we break GraphQL queries into public and private. The public query acts as an anonymous user to retrieve public data while the private query for user-related private data. More technically, only private queries are cookies-included.
Take the homepage as an example, the user & data flow will be:

- Open matters.news;
- SSR (server-side rendering) server fires a public query for the main feed, which includes fields like
Article.title; - Client fires a private query for user info;
- Client fires a private query if the user is logged-in, which includes fields like
Article.subscribed;
Note: protected routes are login required and SSR skipped (Step 2).
When the user logs in, the API server will set cookies with token and user group, there are slightly different between them:
-
Token (
__token) is used to identify the user and included by private queries, which is HttpOnly on. -
User Group (
__user_group) is used to identify the user's group and injected into a custom HTTP headerx-user-group, which is HttpOnly off, otherwise client won't be able to access it.
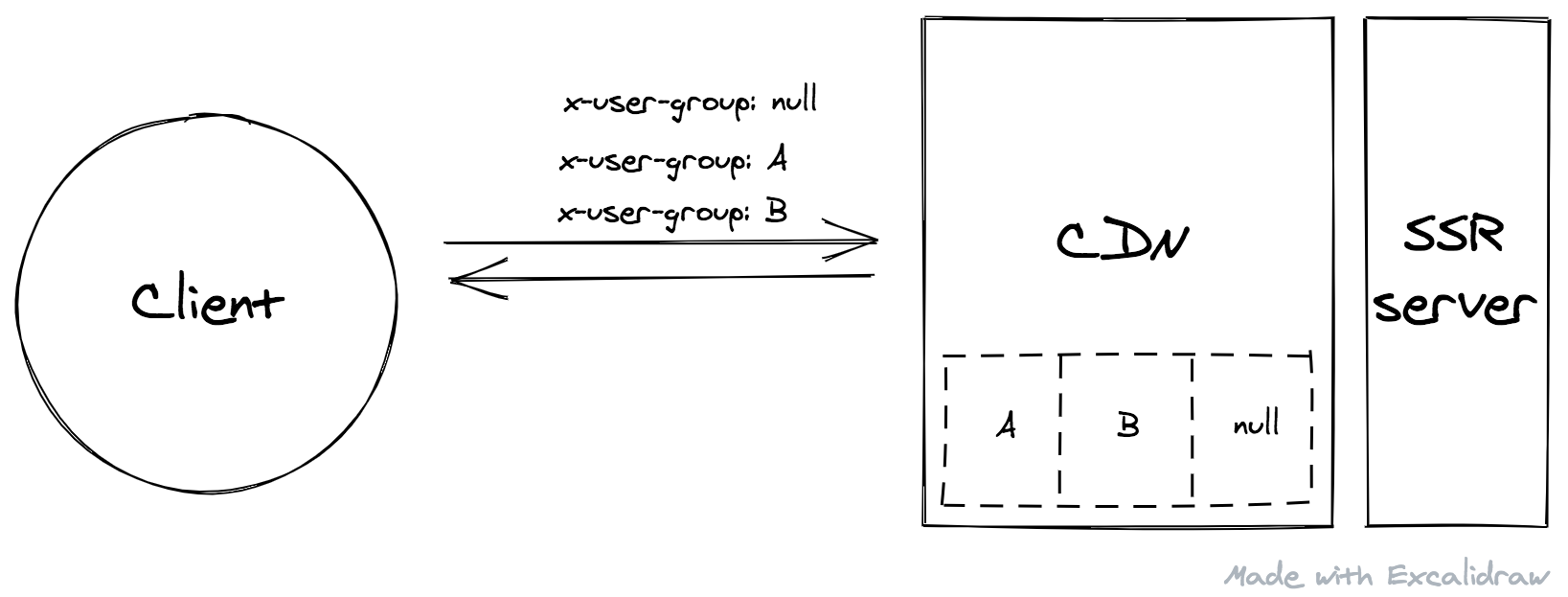
We have two caching components: CDN (CloudFront) in front of the SSR server and Redis (ElasticCache) behind the API server.
CDN will be hit when the user initially opens the website (Step 1 & 2), which caches the response from the SSR server based on x-user-group HTTP header.
Let's say we split users into groups A and B, there will be 3 kinds of cache copies: one for A, one for B, and one for requests without x-user-group.
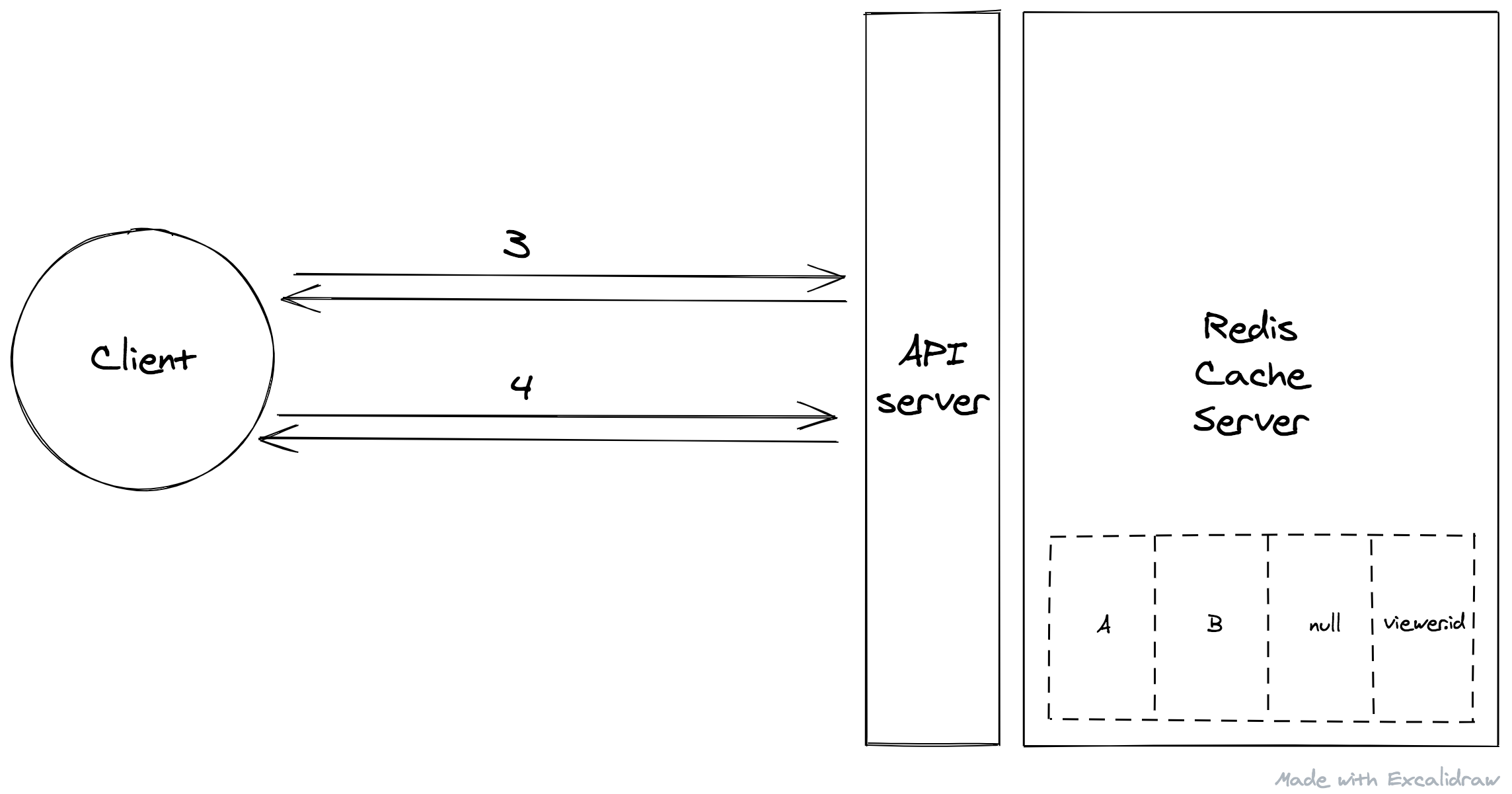
Since CDN only caches public queries from the SSR server and the vast amount of others are hit the API server directly, we have put a Redis to back it, which is managing by an Apollo plugin we built.
There will be 4 kinds of cache copies. For public queries, it splits caches into three based on the user group, just like CDN does. For private queries (Step 4 & 5), based on viewer.id.