Cassandra
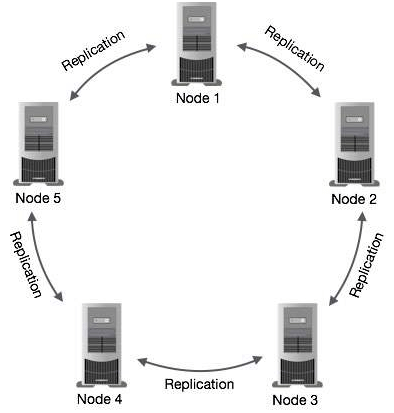
Cassandra is a peer-to-peer distributed database that runs on a cluster of homogeneous nodes. Cassandra has been architected from the ground up to handle large volumes of data while providing high availability. Cassandra provides high write and read throughput. A Cassandra cluster has no special nodes i.e. the cluster has no masters, no slaves or elected leaders. This enables Cassandra to be highly available while having no single point of failure.In Cassandra, nodes in a cluster act as replicas for a given piece of data. If some of the nodes are responded with an out-of-date value, Cassandra will return the most recent value to the client. After returning the most recent value, Cassandra performs a read repair in the background to update the stale values.
Step 1: Install Oracle Java (JRE)
Cassandra requires your using Oracle Java SE (JRE) installed on your server. We can now install Oracle JRE with the following: sudo apt-get install oracle-java8-set-default
Step 2: Installing Apache Cassandra
First, we have to install the Cassandra repository to /etc/apt/sources.list.d/cassandra.sources.list directory by running following command: echo "deb http://www.apache.org/dist/cassandra/debian 36x main" | sudo tee -a /etc/apt/sources.list.d/cassandra.sources.list
Next, run the cURL command to add the repository keys : curl https://www.apache.org/dist/cassandra/KEYS | sudo apt-key add -
We can now update the repositories: sudo apt-get update
Finally, finish installing by entering the following: sudo apt-get install cassandra
Verify the installation of Cassandra by running: nodetool status
Step 3: Connect with cqlsh Start using Cassandra with the cqlsh command. cqlsh
We should see something similar to this: Connected to Test Cluster at 127.0.0.1:9042. [cqlsh 5.0.1 | Cassandra 3.6 | CQL spec 3.4.2 | Native protocol v4] Use HELP for help.
Cassandra is the most suitable platform where there is less secondary index needs, simple setup, and maintenance, very high velocity of random read & writes & wide column requirements.
When one has multiple replicas, its important to make sure that all replicas are absolutely in sync to determine consistency. So when one does a write operation and sets tuneable consistency at the highest which implies that all have to be properly in sync. So every time one does a write operation, it writes on the replica but the write does not come back with success until all the replicas in cluster are in sync with the data. Thus, the latency of the write increases because of the consistency in data before you have written a success for your write. This is basically the consistency concept. Thus, every request coming from client application results in the same requirement going back.