{kind=link}
{kind=link}
- дедлайн для задания: 14.11.2019, 23:59
- задания не предполагают использование каких-то других пакетов или датасетов, кроме тех, что указаны в соответсвтующих файлах
- не стесняйтесь задавать вопросы (но лучше открывать issue, а не писать в телеграме). Помните, что я не смогу помочь, если все начнут писать в последний вечер перед дедлайном, так что начните делать задания заранее.
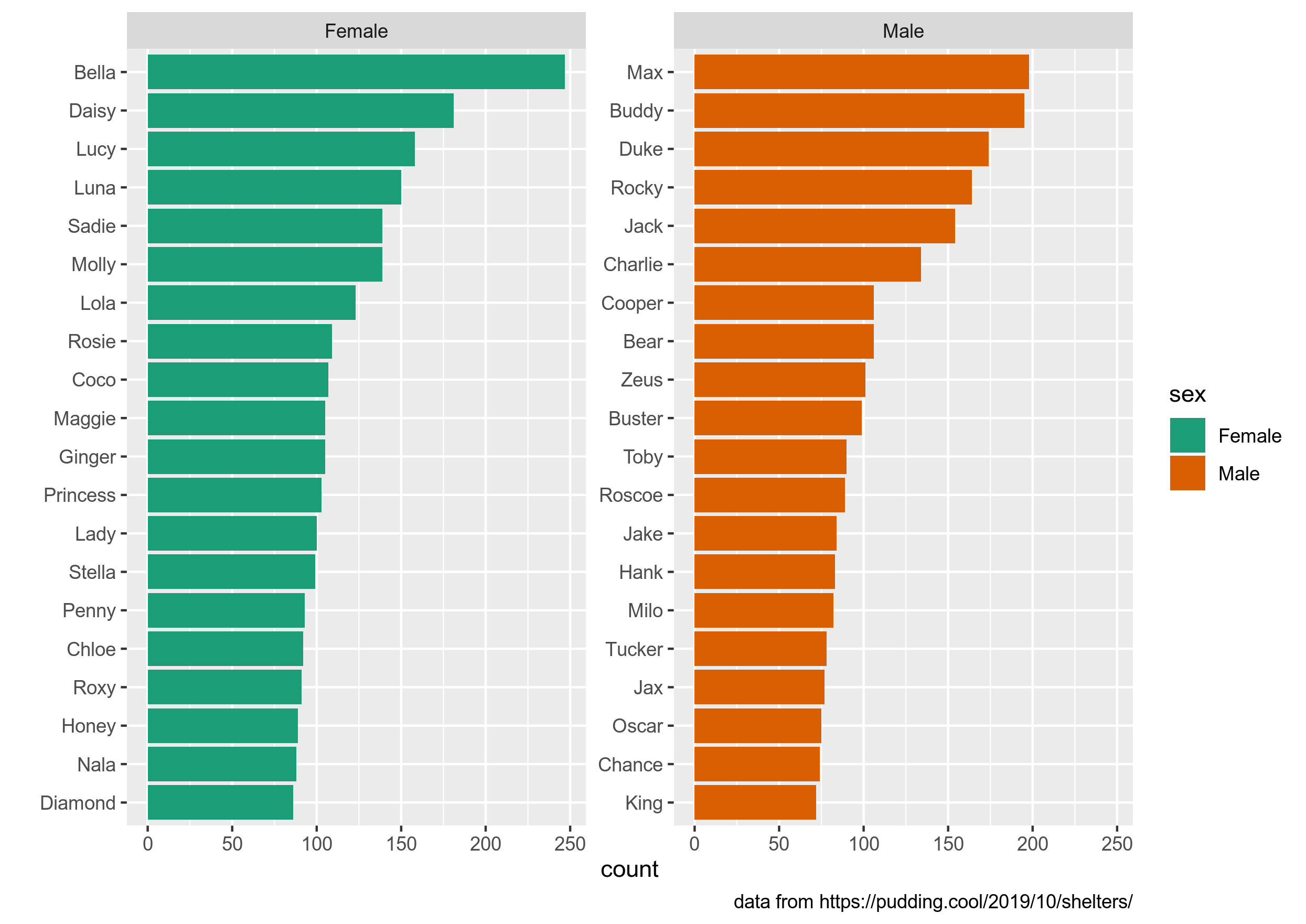
На Pudding недавно вышла статья "Finding Forever Homes", посвященная миграции и эмиграции собак в США. Здесь лежит немного обработанный датасет, которые использовался в статье. Датасет состоит из 58 113 строк и 5 переменных:
id-- уникальный id с сервиса PetFindername-- кличка собакиsex-- пол собаки (Female,Male, orUnknown)age-- категориальная переменная с возрастом собаки (Baby,Young,Adult,Senior)contact_state-- штат, в котором находиться приют
Заполните пропуски в файле task_2.1.R в Вашем репозитории, так чтобы получился следующий график. На нем изображено по 20 самых популярных кличек собак живущих в приютах в США для каждого пола. Обратите внимание на подписи осей. Нестанадртные цвета на этом графике появились благодаря команде scale_fill_brewer(palette="Dark2") (см. файл task_2.1.R).
Используя датасет из предыдущего задания, заполните пропуски в файле task_2.2.R в Вашем репозитории, так чтобы получившаяся программа считала, какую долю составляют собаки разного возраста в подгруппах по полу. Должно получиться что-то такое:
# A tibble: 4 x 3
age Male Female
<chr> <dbl> <dbl>
1 Adult 0.476 ...
2 Young ... ...
3 Baby ... ...
4 Senior ... ...
На всякий случай: доли в каждом из столбцов должны давать в сумме 1 (при округлении), если у Вас выходит значительно больше -- значит что-то Вы делаете не так, как ожидается.
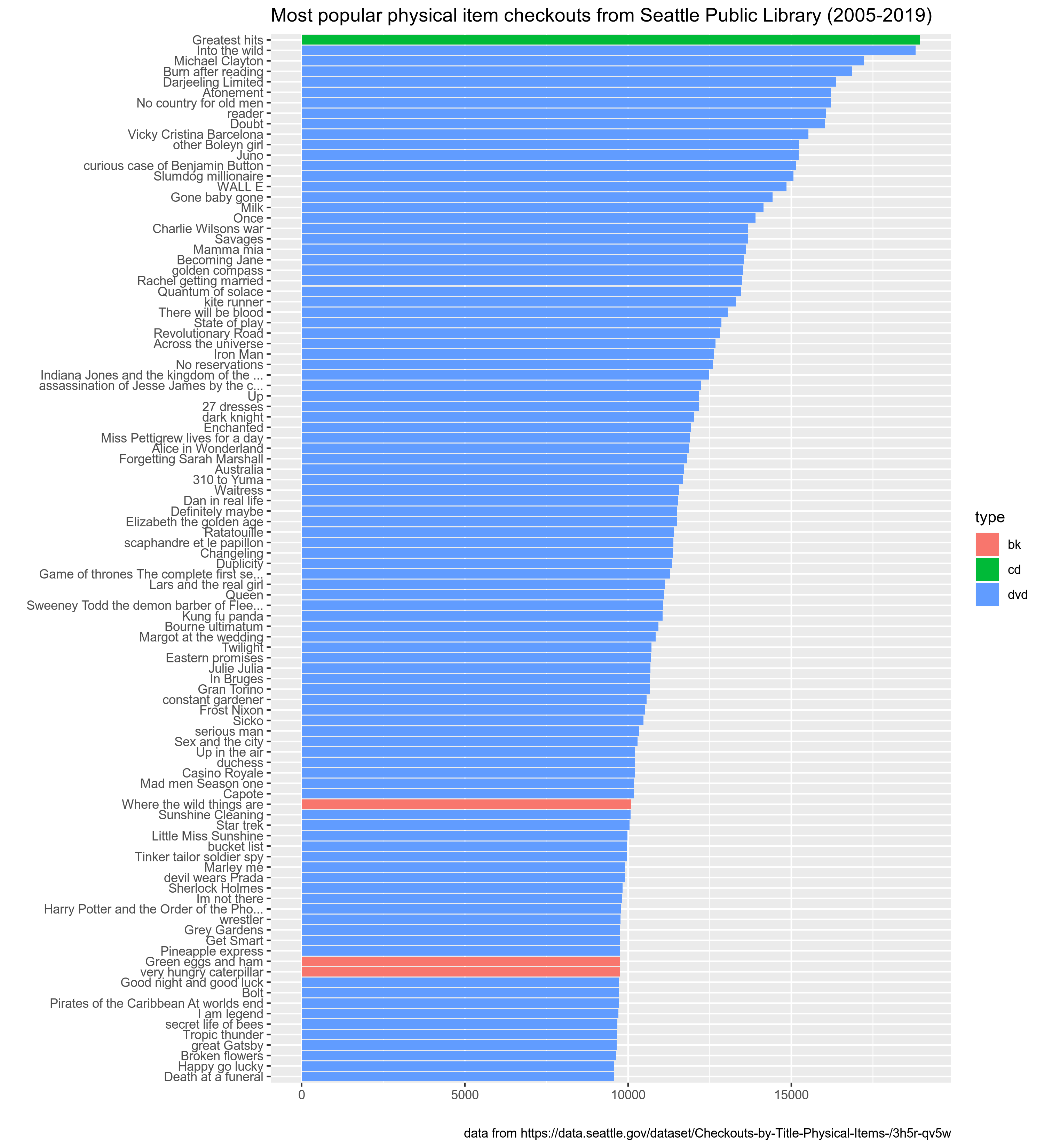
В датасете содержаться информация об объектах, выданных библиотекой Сиэтла 100 и более раз (исходные данные доступны здесь). Датасет состоит из разбитых на листы файла .xlsx 180 495 строк и 5 переменных:
id-- идентификационный номер объектаtype-- тип объекта (bk-- книга,bknh-- другая категория с книгами,cas-- кассеты,cd-- CD,dvd-- DVD,kit-- комплект (я сам пока не разобрался что там...),vhs-- видеокассеты VHS)name-- названиеn-- сколько раз взяли в том или иному годуyear-- год
Используя вот этот датасет, заполните пропуски в файле task_2.3.R в Вашем репозитории, так чтобы получившаяся программа нарисовала следующий график. На графике изображены 100 самых популярных объектов за все годы.