This is an "UX wrapper" to make video style transfer a bit easier to do on your videos if you are not a ML engineer/scientist, and the instructions are really detailed because of that. If you are more into artistic / creative uses of video style transfer, and do not know much of code.
Original project from
Wenjing Wang, Shuai Yang, Jizheng Xu, and Jiaying Liu. "Consistent Video Style Transfer via Relaxation and Regularization", IEEE Trans. on Image Processing (TIP), 2020. https://doi.org/10.1109/TIP.2020.3024018 (see citing papers on Scholar Google)
Project Website: https://daooshee.github.io/ReReVST/ - https://github.com/daooshee/ReReVST-Code
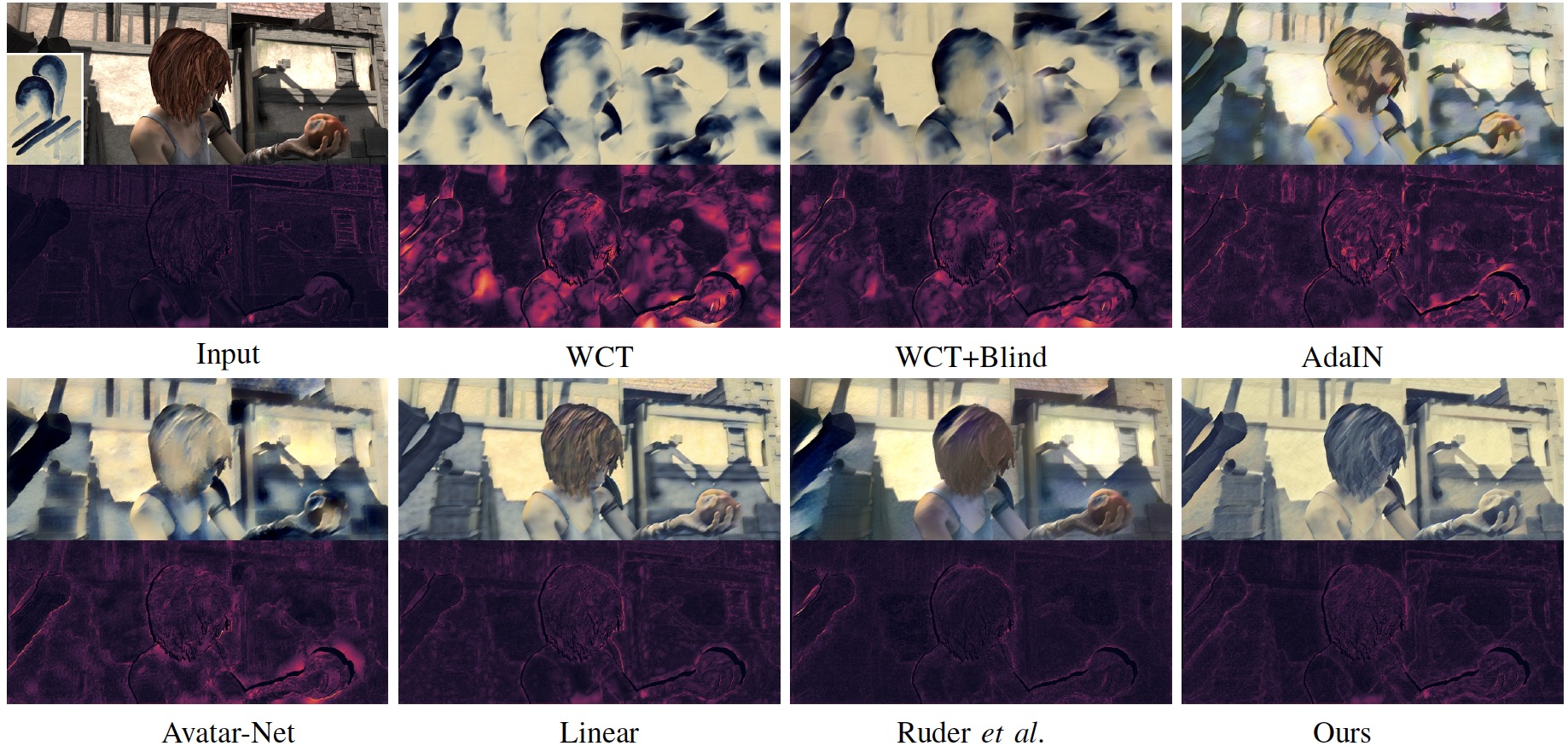
The publication tries to address the issue of "old school" frame-based style transfer techniques that do not take into account the whole video in analysis, which in practice causes annoying "flickering" between successive frames (which might also be appealing visually to some people, up to you)

illustrated e.g. by Characterizing and Improving Stability in Neural Style Transfer
This repo is a "wrapper repo" basically making the code a bit easier to run, if you for example want to quickly make artistic video style transfer and don't want to wrestle with the code forever.
- Added virtual environment to make the work a bit more reproducible
- Removed the need to do the mp4 -> png conversion as it got a bit annoying. No the inputs are just whatever video files that
imageio ffmpegsupports - Original repository did not keep audio at all, which was annoying if you wanted to stylize videos with audio tracks. This now handled with
MoviePy - TODO! At the moment the workflow does not handle high-resolution videos automagically as you probably very easily run out of RAM when trying to process high-res videos. The sample video
scatman.mp4provided with this repo is256 x 256 px. If you wanna do HD/4K videos, you probably better just do this with some cloud provider.
Everything is easier on Ubuntu (Linux), but you should get this working on Windows with a GPU, and on Mac with a CPU.
- Install Anaconda3.8 Linux
- Install Git, if you are
pulling this repo (you could just download the zip as well if you really do not know what this is) - GO to terminal (Ctrl+Alt+T on Ubuntu)
Clone this repository
git clone https://github.com/petteriTeikari/ReReVST-UX-Wrapper
cd ReReVST-UX-WrapperDownload style_net-TIP-final.pth [~60MB] from the links provided by the authors of the original repo:
Links: Google Drive, Baidu Pan [397w]
And place this .pth file to test/Model inside your cloned repository ReReVST-UX-Wrapper. This is the actual model that stylizes your videos, pretrained by Wang et al. 2020 for you.
If you do not know what this, you could check for example Python Virtual Environments: A Primer or What Virtual Environments Are Good For . In practice, these are used so that you can easily make other people's code work on your own machine without hours of battling with compatible libraries.
GPU (assuming you have NVIDIA's GPU and it is okay with CUDA 11.1)
python3.8 -m venv rerevst_venv_py38
source rerevst_venv_py38/bin/activate
python -m pip install --upgrade pip
pip install wheel
pip install -r requirements.txt
Here a ~2 GB Pytorch package is installed, so if your internet is poor, this might take some time (again execute the pip command, it downloads the Pytorch package and installs it for you).
pip install torch==1.8.0+cu111 torchvision==0.9.0+cu111 torchaudio==0.8.0 -f https://download.pytorch.org/whl/torch_stable.html
pip install torch==1.8.0+cpu torchvision==0.9.0+cpu torchaudio==0.8.0 -f https://download.pytorch.org/whl/torch_stable.html
In machine learning jargon, you are now "testing" your model (running inference) after you initially trained it with a bunch of examples. If you just to want to quickly style your videos, you do not care about the training part of the code.
generate_real_video.py applies style transfer for your input video defined in --input_video based on the style in an image --style_img.
To test the code with the default values and examples given with this repo:
cd test
python generate_real_video.py --style_img ../inputs/styles/3d_4.jpg --input_video ../inputs/video/scatman.mp4
If you get like the Pickle - EOFError: Ran out of input you maybe forgot to download the model .pth file, as by default the .pth was there, but it was 0 bytes, so just an empty file with the correct name.
Output video is saved to results/video

You probably do not know that well how different style images in the end will be transferred to the video, so you can copy all possible images that you could want to test to a single folder (e.g. inputs/styles/), and do something else while you get the results.
You can batch stylize a bunch of videos with a single style:
python generate_real_video.py --style_img ../inputs/styles/3d_4.jpg --input_video_dir ../inputs/video/
Single video file with multiple styles:
python generate_real_video.py --style_img_dir ../inputs/styles/ --input_video ../inputs/video/scatman.mp4
Bunch of videos with multiple styles:
python generate_real_video.py --style_img_dir ../inputs/styles/ --input_video_dir ../inputs/video/

Single video file, batch processed with 4 different style images
Additionally there is an interval flag that you can increase to 16, 32 if you run out of RAM (if you use too high-res or/and too long videos). Depends on your laptop/desktop on how much lifting you can do.
Then, you can find stylized video in ./results/videos/.
With these optional setting, the inference call would look like:
python generate_real_video.py --style_img ../inputs/styles/3d_4.jpg --input_video ../inputs/video/scatman.mp4 --interval 16
If you run out of GPU memory, or you have some issues with CUDA, you can force the computations to be done with CPU, makes things a lot slower as well.
On i7-7700K CPU @ 4.20GHz ~1.30 frames are stylized per second compared to ~30 frames per second with NVIDIA RTX 2070 Super 8GB, i.e. stylizing a ~9sec video takes 3 min 20 sec on CPU, and around ~9seconds on a GPU. So definitely get a machine with a GPU if you plan to do these a lot :)
python generate_real_video.py --style_img ../inputs/styles/huygens_multiphoton_embryo.png --input_video ../inputs/video/scatman.mp4 --force_on_CPU True
So you could even make this work real-time with a proper GPU if you want to do visuals for a VJ set from a live video feed (e.g. imageio supports webcam input with the <video0> uri). You can downsample a bit the input video feed for higher processing frame rates.
For example TouchDesigner has the PyTorchTOP library that you could possibly to use this model in your TouchDesigner project?
Breakdown of the processing times (Model building only need to be done once when starting your VJ set, and then the preparations probably okay from some initial buffering?):
Opened style image "3d_4.jpg"
Opened input video "scatman.mp4" for style transfer (fps = 30.0)
Stylization Model built in 0:00:07.734979
Preparations finished in 0:00:03.043060!
Video style transferred in 0:00:08.868579
Prcessing as a whole took 0:00:19.874647
See the original repository https://github.com/daooshee/ReReVST-Code for instructions
You probably want to use the created virtual environment in some IDE then, like in VS Code or PyCharm