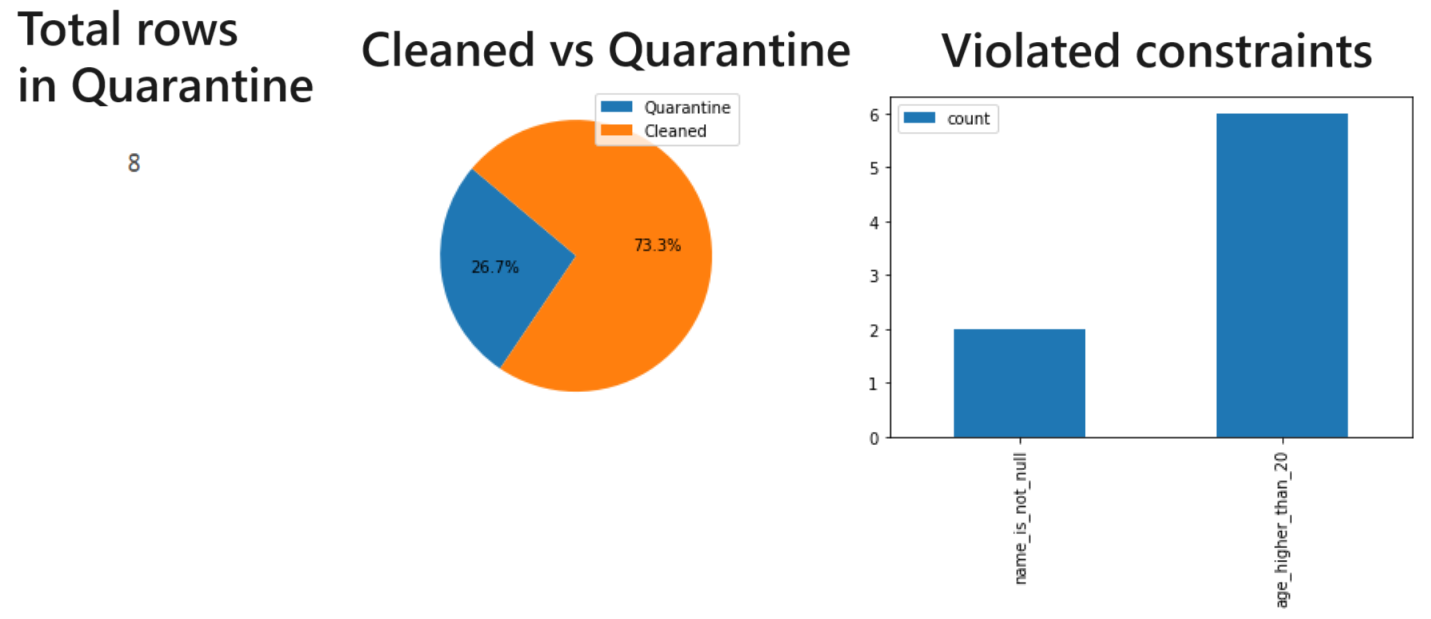
rezQ is a Python library designed to help ensure data quality in Delta Lake. It provides functions to add constraints to data, remove existing constraints, and separate a DataFrame based on those constraints.
You can install rezQ using pip:
pip install rezq
To add a constraint to a delta table:
from rezq import add_constraint
from delta import DeltaTable
delta_table = DeltaTable.forPath(spark, 'my_table_path')
add_constraint(spark_session=spark,
delta_table=delta_table,
constraint_name='age_higher_than_20',
constraint_code='age > 20')To add multiple a constraints to a delta table:
from rezq import add_constraints
from delta import DeltaTable
delta_table = DeltaTable.forPath(spark, 'my_table_path')
add_constraints(spark_session=spark,
delta_table=mock_delta_table,
constraints={"name_is_not_null": "name is not null",
"age_higher_than_20": "age > 20"})To remove a constraint to a delta table:
from rezq import, remove_constraint
from delta import DeltaTable
delta_table = DeltaTable.forPath(spark, 'my_table_path')
remove_constraint(spark_session=spark,
delta_table=delta_table,
constraint_name='age_higher_than_20')To get delta table constraints:
from rezq import, remove_constraint
from delta import DeltaTable
delta_table = DeltaTable.forPath(spark, 'my_table_path')
constraint = get_constraints(delta_table)To return the cleaned_df (An DataFrame of the valid rows according to constraints) and quarantine_df (An DataFrame of the invalid rows according to constraints.):
from rezq import get_cleaned_and_quarantine
delta_table = DeltaTable.forPath(spark, 'mybucket')
cleaned_df, quarantine_df = get_cleaned_and_quarantine(delta_table=delta_table,
merge_df=df)
 You can use the cleaned_df to create a new delta, append or merge to an existent one
and use quarantine_df to get metrics about data quality and decide later what to do
with this rows
You can use the cleaned_df to create a new delta, append or merge to an existent one
and use quarantine_df to get metrics about data quality and decide later what to do
with this rows