Distributed, Decentralized Sharding Framework for building distributed storage or similar solutions, inspired by Amazon Dynamo
Peer-ring is designed to be storage or use case agnostic. It acts as a base framework for building distributed solutions. Some sample applications that can be built on top of peer-ring include:
- Distributed KV store: Distributed In-memory key-value store that can be embedded into your application.
- Distributed Rate Limiter: Rate limiter that can be deployed close to your application for greater performance.
- Distributed Pub-Sub: In-memory pub-sub/queue system for application synchronization. ... and many more.
@peer-ring uses consistent hashing to distribute data efficiently. Writes are spread across replicas, ensuring resilience without compromising speed.
@peer-ring/kv-store is one such application built on top of peer-ring, currently only supports only k8s based peer discovery, which means you can only use it if you are running your apps on kubernetes.
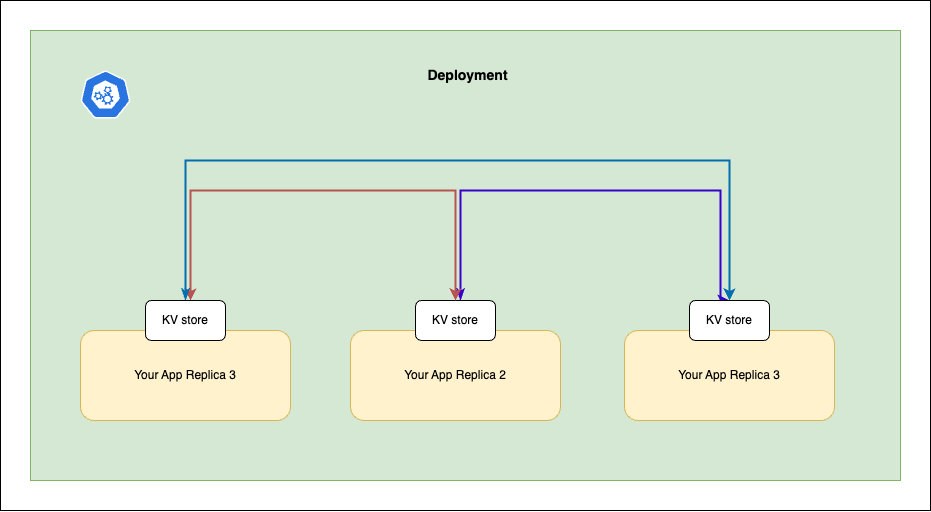
Peer-ring is divided into three major modules:
- Peer Discovery: Responsible for membership management. Supported peer discovery strategies include:
- K8s based
- Registry based (etcd/ZooKeeper)
- SWIM or gossip based
- Core: The core module is responsible for distributed sharding, key ownership identification, P2P communication, quorum, and replication management. It uses a custom request/response model built on top of gRPC bidirectional stream for efficient P2P communication.
- Applications: This is the end-user layer built on top of peer-ring/core and utilizes one of the peer discovery strategies. Examples include:
- Distributed KV store: In-memory key-value store.
- Distributed Rate Limiter: Rate limiter that can be deployed close to your application for greater performance.
- Distributed Pub-Sub: In-memory pub-sub/queue system for application synchronization.
Peer-ring provides replication and sloppy quorum for high availability. You can tweak the behavior using replicationFactor and quorumCount. You can choose among these characteristics:
- Consistency (default): Choose
replicationFactor=1andquorumCount=1for better consistency and low latency, but you will sacrifice availability and durability (i.e., your data is lost if the owner replica dies). - Availability: Choose
replicationFactor>=3andquorumCount=1for high availability. You can tweakquorumCountaccording to your consistency needs, higherreplicationFactorandquorumCountmeans more latency. - Durability: The current implementation does not offer strong durability. If all replicas holding a particular
keydie, you will lose thekey. A better durability solution (maintaining the replication factor when a node goes down, redistributing when a new node comes up) is WIP.
This roadmap outlines the planned development and milestones for the project. Contributions and suggestions are welcome.
Status: In Progress
- Design system architecture
- Develop basic peer discovery module with k8s
- Implement core sharding functionality
- Implement replication and quorum
- Implement in-memory KV store
- Handle failures by token transfer when a peer goes down or comes back up [in Alpha]
- steal data/tokens from peer when new node is added
- when data owner node goes down, the previous node will own the tokens of the node went down, it should copy data/tokens from replicas.
- when replica goes down, the previous node will own the tokens of the node went down, it should copy the data/tokens from other replicas/owner
- Write comprehensive documentation
- Create a contribution guide and code of conduct
- Set up continuous integration (CI) pipeline
Status: Planned
- deployment as sidecar
- Conduct thorough testing and validation
Status: Planned
- Develop distributed rate limiter
- Support custom reconciliation/read repair by the client
- Implement advanced peer discovery strategies
- Registry based (etcd/ZooKeeper)
- SWIM or gossip based
- Create distributed pub-sub system
- Optimize performance and resource usage
Status: Planned
- Develop monitoring/metrics layer
- Create a guide for building custom applications on top of peer-ring
- Provide detailed usage examples and tutorials
- improve data sync with Anti-entropy
Contributions are more than welcome. Reading Amazon Dynamo before contributing can make your life easier but is not a strict requirement. Read more about contributing here.
- pnpm changeset
- commit changes
- pnpm prepare:publish
- pnpm publish -r --filter=!e2e --filter=!peer-ring --dry-run