Predict stock price of MAG-7 by building the LSTM neutral network on Keras framework.
Compare the outcomes when epoch is 10, 100, and 1,000 and plot the results.
- Extract historical price on Yahoo Finance using Selenium:
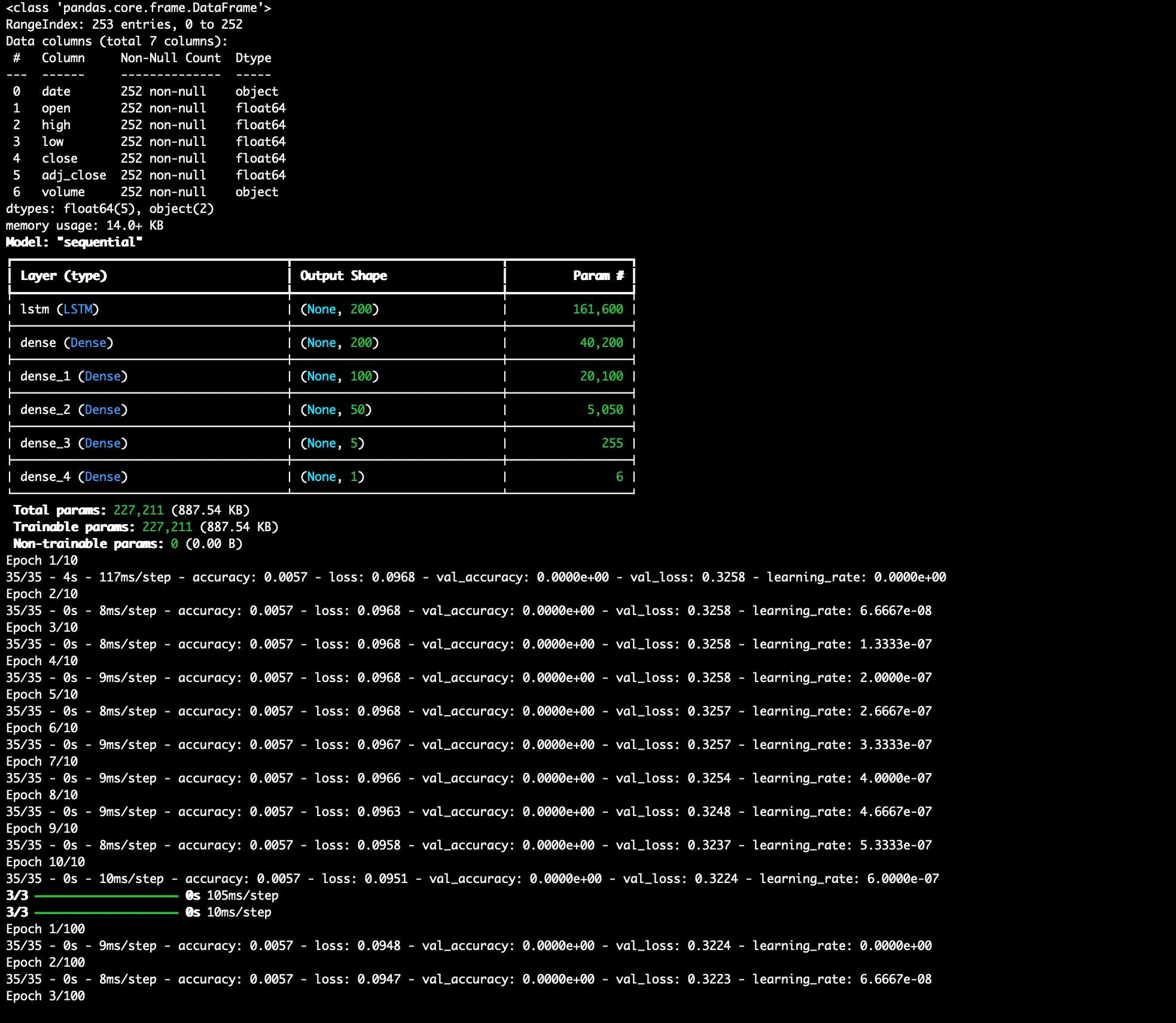
- Compile and train the LSTM network:
- The future stock price predicted (Plotted 3 patterns by epoch in red for each stock):
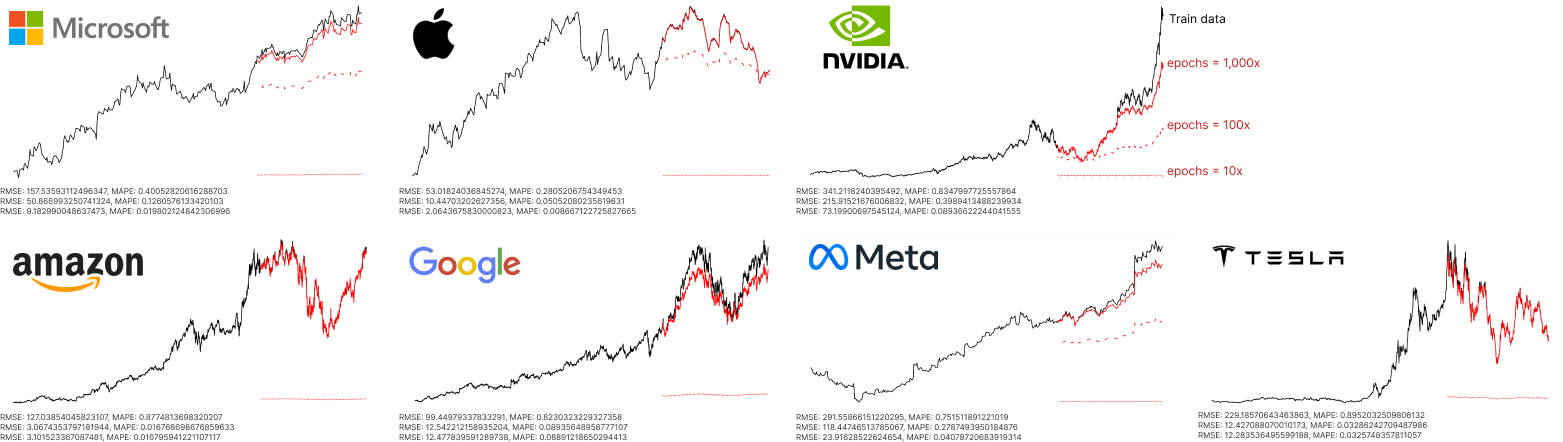
Predict future stock price using LSTM networks.
-
Data Preparation:
- Scrape historical stock price from Yahoo Finance using Selenium Webdriver
- Remove null valeues and store the dataset in the CSV file
- Run EDA to understand the data structure
-
Train/Test Data
- Take the adj. close price as data frame and split them into train and test dataset
- Nominalize the datasets from 0 to 1 using the MinMaxScaler preprocessing class from the scikit-learn
- Split the dataset into train and test data and reform those into NumPy array
-
Compile LSTM Network:
- Compile LSTM network using Keras Sequential framework with 5 dense layers
- Train the network using datasets
-
Stock Price Prediction:
- Visualize the results on graph. (Compare results by epoch = 10, 100, and 1,000)
-
Evaluation:
- Evaluate the results using RMSE and MAPE.
- Python: Primary programming language. We use ver 3.12
[data-scraping]
- Selenium WebDriver: Scrape data from the website
- BeatifulSoup4: A library that makes it easy to scrape information from web pages
- XMLX: A simple and compact XML parser
[eda]
- Matplotlib: A library for data visualization, typically in the form of plots, graphs and charts.
[ml-stack]
- TensorFlow: A ML/AI software library
- keras: An open-source API for artifitial neutral network
- NumPy: A Python library to operate large, multi-dimensional arrays and matrices
- pandas: An open source library with data structures and data analysis tools
- scikit-learn: A Python ML module built on top of SciPy
- scikeras: keras x scikit-learn
[deployment]
- pip, pipenv: Python package manager
.
├── __init__.py
├── predict.py
├── utils/
│ ├── web_scraper.py
│ └── ext_analysis.py
└── sample_data/ # Store the scraped dataset
└── requirements.txt
-
Install the
pipenvpackage manager:pip install pipenv -
Install dependencies:
pipenv shell pip install -r requirements.txt -v
-
Scrape the latest stock price data:
pipenv shell python utils/web_scraper.pyYou will be asked to enter a specific ticker or use default tickers of MAG7.
-
Run EDA:
pipenv shell python utils/ext_analysis.pyYou will be asked to select a ticker and title. You can skip them simply pressing enter.
-
Predict stock price:
pipenv shell python main.pyYou will be asked to input a ticker or you can skip this by pressing enter. (Default ticker is GOOG)
- Add a package:
pipenv install <package> - Remove a package:
pipenv uninstall <package> - Run a command in the virtual environment:
pipenv run <command>
-
After adding/removing the package, update
requirements.txtaccordingly or runpip freeze > requirements.txtto reflect the changes in dependencies. -
To reinstall all the dependencies, delete
PipfileandPipfile.lockfiles, then run:pipenv shell pipenv install -r requirements.txt -v
To customize LSTM, edit the main.py file.
To add more EDA, edit the ext_analysis.py file.
- Fork the repository
- Create your feature branch (
git checkout -b feature/your-amazing-feature) - Commit your changes (
git commit -m 'Add your-amazing-feature') - Push to the branch (
git push origin feature/your-amazing-feature) - Open a pull request
Common issues and solutions:
- Memory errors: If processing large contracts, you may need to increase the available memory for the Python process.
- Data scraping issues: Selenium relies on the hard-coded HTML structures. Update
web_scraper.pyaccordingly to see if the data was properly scraped.