aiozipkin is Python 3.5+ module that adds distributed tracing capabilities from asyncio applications with zipkin (http://zipkin.io) server instrumentation.
zipkin is a distributed tracing system. It helps gather timing data needed to troubleshoot latency problems in microservice architectures. It manages both the collection and lookup of this data. Zipkin’s design is based on the Google Dapper paper.
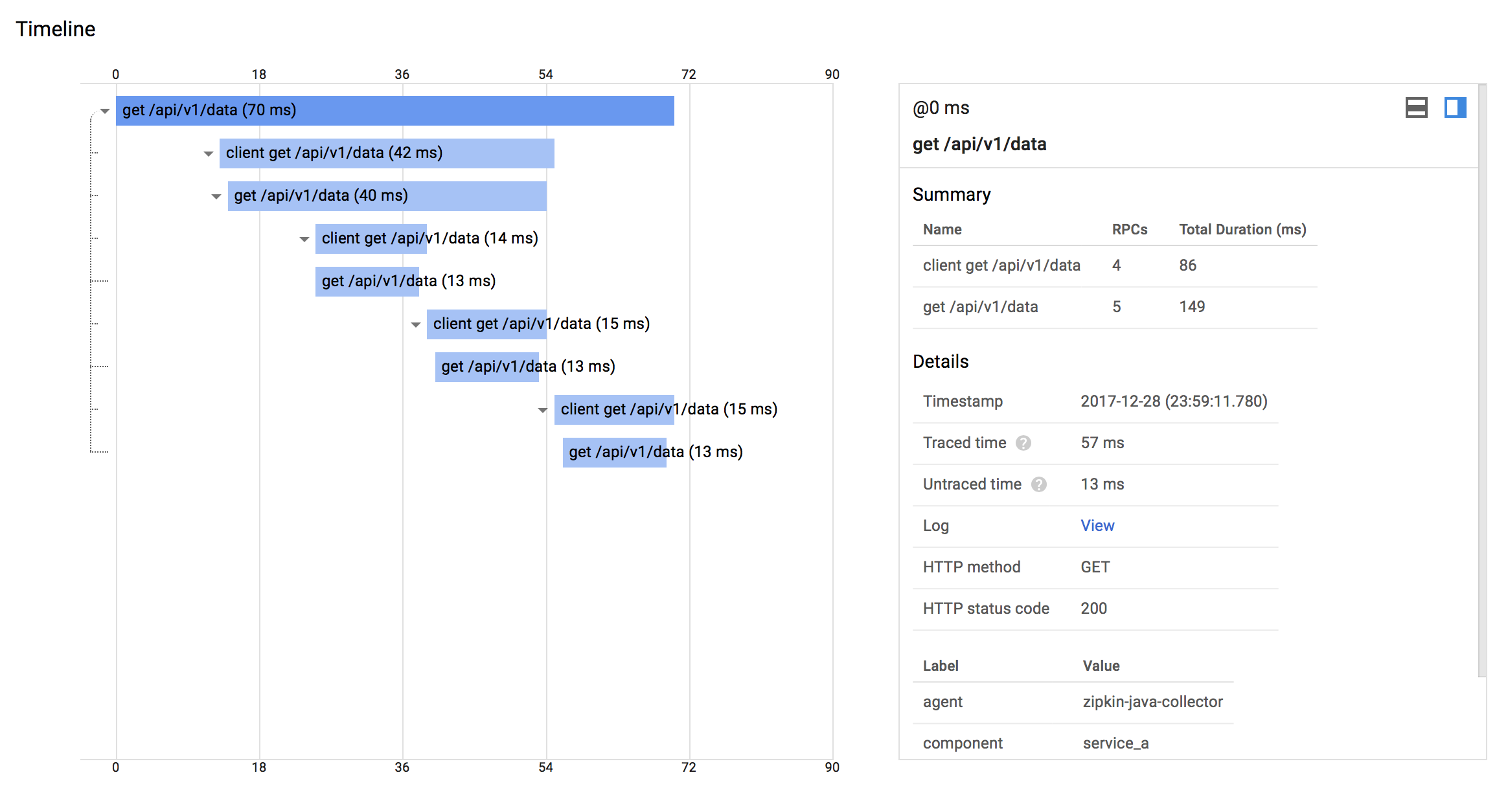
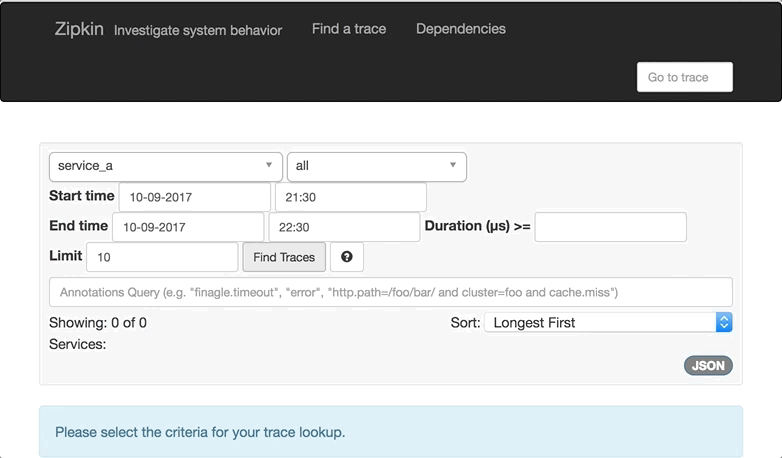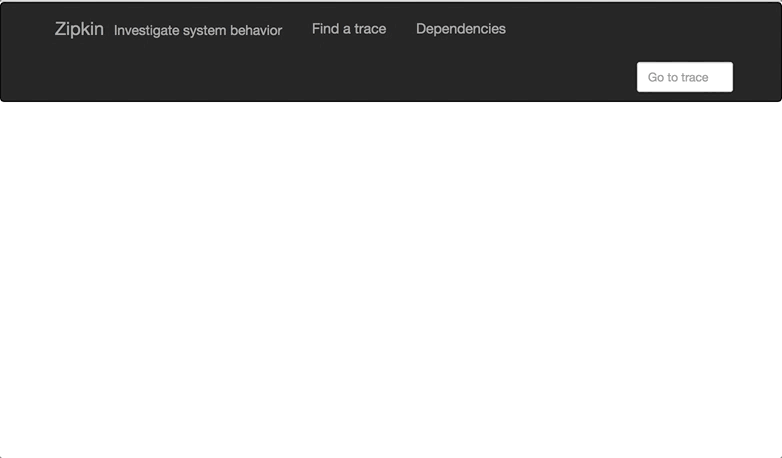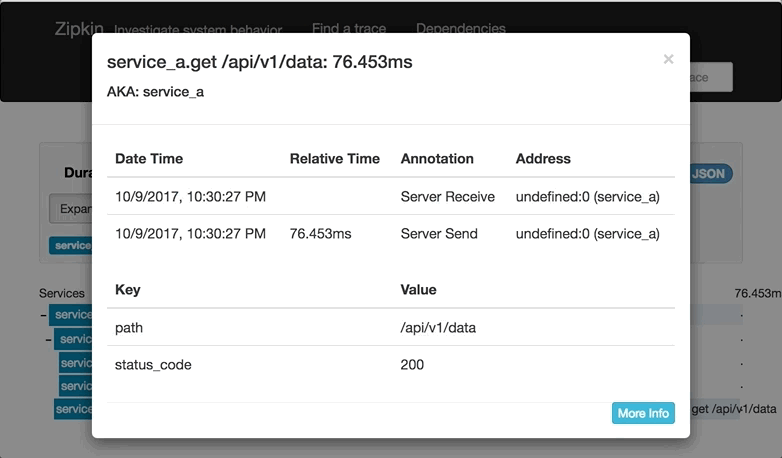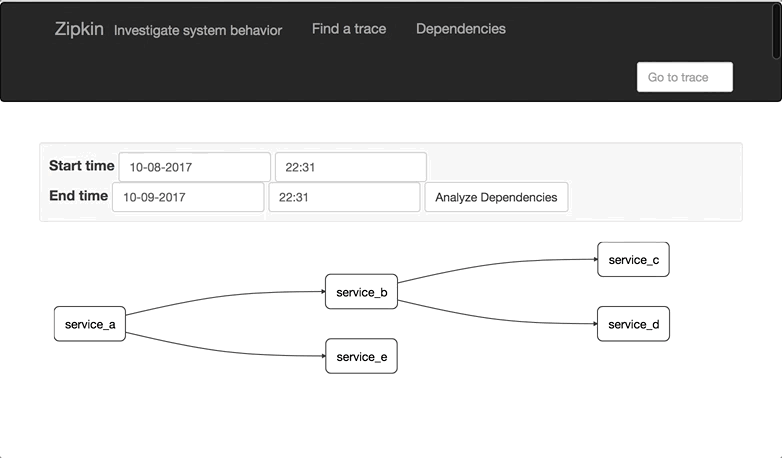
Applications are instrumented with aiozipkin report timing data to zipkin. The Zipkin UI also presents a Dependency diagram showing how many traced requests went through each application. If you are troubleshooting latency problems or errors, you can filter or sort all traces based on the application, length of trace, annotation, or timestamp.
- Distributed tracing capabilities to asyncio applications.
- Support zipkin
v2protocol. - Easy to use API.
- Explicit context handling, no thread local variables.
- Can work with jaeger and stackdriver through zipkin compatible API.
Before code lets learn important zipkin vocabulary, for more detailed information please visit https://zipkin.io/pages/instrumenting
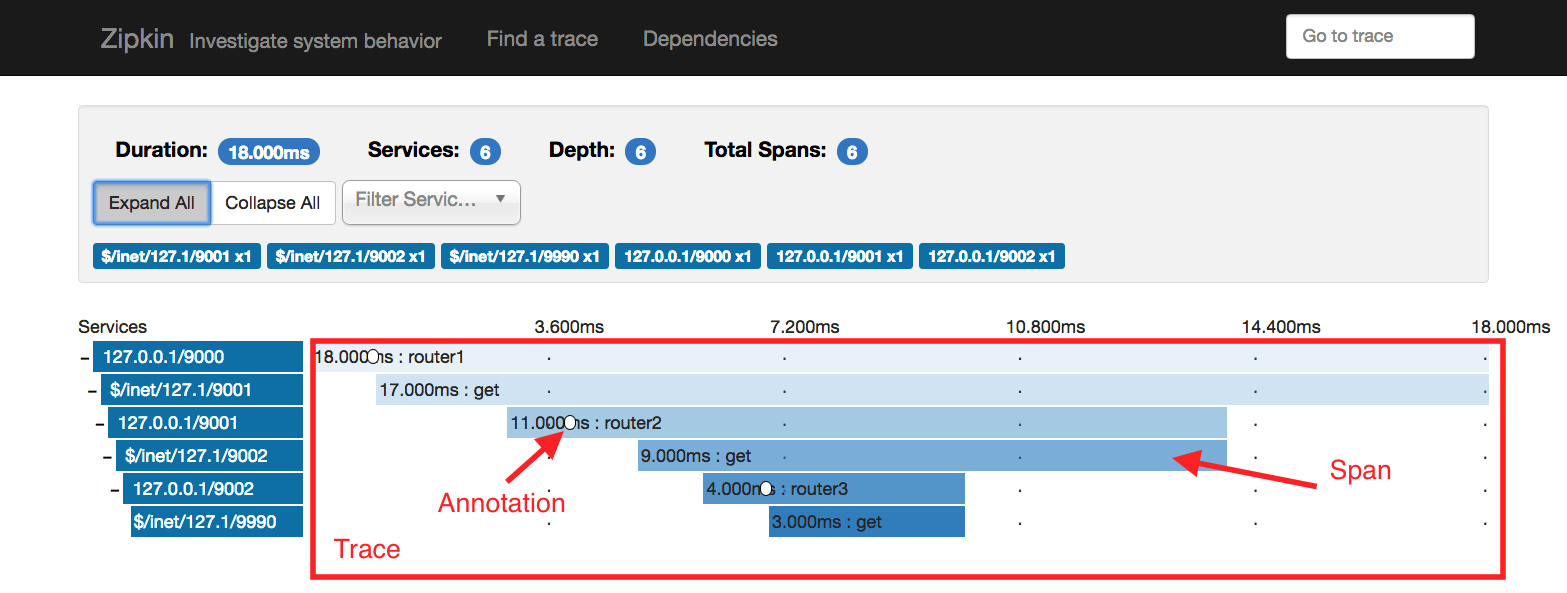
- Span represents one specific method (RPC) call
- Annotation string data associated with a particular timestamp in span
- Tag - key and value associated with given span
- Trace - collection of spans, related to serving particular request
import asyncio
import aiozipkin as az
async def run():
# setup zipkin client
zipkin_address = 'http://127.0.0.1:9411/api/v2/spans'
endpoint = az.create_endpoint(
"simple_service", ipv4="127.0.0.1", port=8080)
tracer = await az.create(zipkin_address, endpoint, sample_rate=1.0)
# create and setup new trace
with tracer.new_trace(sampled=True) as span:
# give a name for the span
span.name("Slow SQL")
# tag with relevant information
span.tag("span_type", "root")
# indicate that this is client span
span.kind(az.CLIENT)
# make timestamp and name it with START SQL query
span.annotate("START SQL SELECT * FROM")
# imitate long SQL query
await asyncio.sleep(0.1)
# make other timestamp and name it "END SQL"
span.annotate("END SQL")
await tracer.close()
if __name__ == "__main__":
loop = asyncio.get_event_loop()
loop.run_until_complete(run())aiozipkin includes aiohttp server instrumentation, for this create web.Application() as usual and install aiozipkin plugin:
import aiozipkin as az
def init_app():
host, port = "127.0.0.1", 8080
app = web.Application()
endpoint = az.create_endpoint("AIOHTTP_SERVER", ipv4=host, port=port)
tracer = await az.create(zipkin_address, endpoint, sample_rate=1.0)
az.setup(app, tracer)That is it, plugin adds middleware that tries to fetch context from headers, and create/join new trace. Optionally on client side you can add propagation headers in order to force tracing and to see network latency between client and server.
import aiozipkin as az
endpoint = az.create_endpoint("AIOHTTP_CLIENT")
tracer = await az.create(zipkin_address, endpoint)
with tracer.new_trace() as span:
span.kind(az.CLIENT)
headers = span.context.make_headers()
host = "http://127.0.0.1:8080/api/v1/posts/{}".format(i)
resp = await session.get(host, headers=headers)
await resp.text()http://aiozipkin.readthedocs.io/
Installation process is simple, just:
$ pip install aiozipkin
aiozipkin can work with any other zipkin compatible service, currently we tested it with jaeger and stackdriver.
jaeger supports zipkin span format as result it is possible to use aiozipkin with jaeger server. You just need to specify jaeger server address and it should work out of the box. Not need to run local zipkin server. For more informations see tests and jaeger documentation.
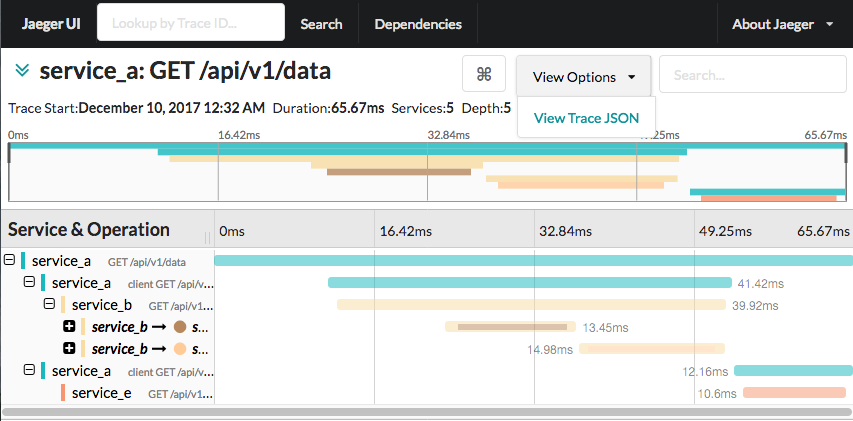
Google stackdriver supports zipkin span format as result it is possible to use aiozipkin with this google service. In order to make this work you need to setup zipkin service locally, that will send trace to the cloud. See google cloud documentation how to setup make zipkin collector: