Paddle Lite is an updated version of Paddle-Mobile, an open-open source deep learning framework designed to make it easy to perform inference on mobile, embeded, and IoT devices. It is compatible with PaddlePaddle and pre-trained models from other sources.
For tutorials, please see PaddleLite Document.
On mobile devices, execution module can be deployed without third-party libraries, because our excecution module and analysis module are decoupled.
On ARM V7, only 800KB are taken up, while on ARM V8, 1.3MB are taken up with the 80 operators and 85 kernels in the dynamic libraries provided by Paddle Lite.
Paddle Lite enables immediate inference without extra optimization.
Paddle Lite enables device-optimized kernels, maximizing ARM CPU performance.
It also supports INT8 quantizations with PaddleSlim model compression tools, reducing the size of models and increasing the performance of models.
On Huawei NPU and FPGA, the performance is also boosted.
The latest benchmark is located at benchmark
Hardware compatibility: Paddle Lite supports a diversity of hardwares — ARM CPU, Mali GPU, Adreno GPU, Huawei NPU and FPGA. In the near future, we will also support AI microchips from Cambricon and Bitmain.
Model compatibility: The Op of Paddle Lite is fully compatible to that of PaddlePaddle. The accuracy and performance of 18 models (mostly CV models and OCR models) and 85 operators have been validated. In the future, we will also support other models.
Framework compatibility: In addition to models trained on PaddlePaddle, those trained on Caffe and TensorFlow can also be converted to be used on Paddle Lite, via X2Paddle. In the future to come, we will also support models of ONNX format.
Paddle Lite is designed to support a wide range of hardwares and devices, and it enables mixed execution of a single model on multiple devices, optimization on various phases, and leight-weighted applications on devices.
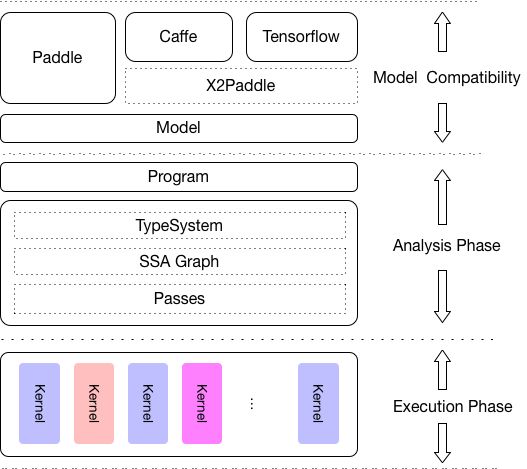
As is shown in the figure above, analysis phase includes Machine IR module, and it enables optimizations like Op fusion and redundant computation pruning. Besides, excecution phase only involves Kernal exevution, so it can be deployed on its own to ensure maximized light-weighted deployment.
The earlier Paddle-Mobile was designed to be compatible with PaddlePaddle and multiple hardwares, including ARM CPU, Mali GPU, Adreno GPU, FPGA, ARM-Linux and Apple's GPU Metal. Within Baidu, inc, many product lines have been using Paddle-Mobile. For more details, please see: mobile/README.
As an update of Paddle-Mobile, Paddle Lite has incorporated many older capabilities into the new architecture. For the time being, the code of Paddle-mobile will be kept under the directory mobile/, before complete transfer to Paddle Lite.
For demands of Apple's GPU Metal and web front end inference, please see ./metal and ./web . These two modules will be further developed and maintained.
Paddle Lite has referenced the following open-source projects:
- ARM compute library
- Anakin. The optimizations under Anakin has been incorporated into Paddle Lite, and so there will not be any future updates of Anakin. As another high-performance inference project under PaddlePaddle, Anakin has been forward-looking and helpful to the making of Paddle Lite.
- Questions, reports, and suggestions are welcome through Github Issues!
- Forum: Opinions and questions are welcome at our PaddlePaddle Forum!
- WeChat Official Account: PaddlePaddle
- QQ Group Chat: 696965088


WeChat Official Account QQ Group Chat