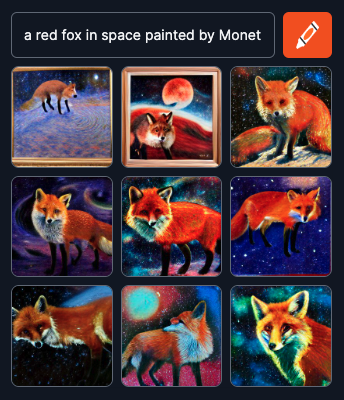
You can use the model on 🖍️ craiyon
Refer to our reports:
- DALL·E mini - Generate Images from Any Text Prompt
- DALL·E mini - Explained
- DALL·E mega - Training Journal
For inference only, use pip install dalle-mini.
For development, clone the repo and use pip install -e ".[dev]".
Before making a PR, check style with make style.
You can experiment with the pipeline step by step through our inference pipeline notebook
Use tools/train/train.py.
You can also adjust the sweep configuration file if you need to perform a hyperparameter search.
Trained models are on 🤗 Model Hub:
- VQGAN-f16-16384 for encoding/decoding images
- DALL·E mini or DALL·E mega for generating images from a text prompt
The "armchair in the shape of an avocado" was used by OpenAI when releasing DALL·E to illustrate the model's capabilities. Having successful predictions on this prompt represents a big milestone for us.
Join the community on the LAION Discord. Any contribution is welcome, from reporting issues to proposing fixes/improvements or testing the model with cool prompts!
You can also use these great projects from the community:
-
spin off your own app with DALL-E Playground repository (thanks Sahar)
-
try DALL·E Flow project for generating, diffusion, and upscaling in a Human-in-the-Loop workflow (thanks Han Xiao)
-
run on Replicate, in the browser or via API
- 🤗 Hugging Face for organizing the FLAX/JAX community week
- Google TPU Research Cloud (TRC) program for providing computing resources
- Weights & Biases for providing the infrastructure for experiment tracking and model management
DALL·E mini was initially developed by:
- Boris Dayma
- Suraj Patil
- Pedro Cuenca
- Khalid Saifullah
- Tanishq Abraham
- Phúc Lê Khắc
- Luke Melas
- Ritobrata Ghosh
Many thanks to the people who helped make it better:
- the DALLE-Pytorch and EleutherAI communities for testing and exchanging cool ideas
- Rohan Anil for adding Distributed Shampoo optimizer and always giving great suggestions
- Phil Wang has provided a lot of cool implementations of transformer variants and gives interesting insights with x-transformers
- Katherine Crowson for super conditioning
- the Gradio team made an amazing UI for our app
If you find DALL·E mini useful in your research or wish to refer, please use the following BibTeX entry.
@misc{Dayma_DALL·E_Mini_2021,
author = {Dayma, Boris and Patil, Suraj and Cuenca, Pedro and Saifullah, Khalid and Abraham, Tanishq and Lê Khắc, Phúc and Melas, Luke and Ghosh, Ritobrata},
doi = {10.5281/zenodo.5146400},
month = {7},
title = {DALL·E Mini},
url = {https://github.com/borisdayma/dalle-mini},
year = {2021}
}
Original DALL·E from "Zero-Shot Text-to-Image Generation" with image quantization from "Learning Transferable Visual Models From Natural Language Supervision".
Image encoder from "Taming Transformers for High-Resolution Image Synthesis".
Sequence to sequence model based on "BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension" with implementation of a few variants:
- "GLU Variants Improve Transformer"
- "Deepnet: Scaling Transformers to 1,000 Layers"
- "NormFormer: Improved Transformer Pretraining with Extra Normalization"
- "Swin Transformer: Hierarchical Vision Transformer using Shifted Windows"
- "CogView: Mastering Text-to-Image Generation via Transformers"
- "Root Mean Square Layer Normalization"
- "Sinkformers: Transformers with Doubly Stochastic Attention"
- "Foundation Transformers
Main optimizer (Distributed Shampoo) from "Scalable Second Order Optimization for Deep Learning".
@misc{
title={Zero-Shot Text-to-Image Generation},
author={Aditya Ramesh and Mikhail Pavlov and Gabriel Goh and Scott Gray and Chelsea Voss and Alec Radford and Mark Chen and Ilya Sutskever},
year={2021},
eprint={2102.12092},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@misc{
title={Learning Transferable Visual Models From Natural Language Supervision},
author={Alec Radford and Jong Wook Kim and Chris Hallacy and Aditya Ramesh and Gabriel Goh and Sandhini Agarwal and Girish Sastry and Amanda Askell and Pamela Mishkin and Jack Clark and Gretchen Krueger and Ilya Sutskever},
year={2021},
eprint={2103.00020},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@misc{
title={Taming Transformers for High-Resolution Image Synthesis},
author={Patrick Esser and Robin Rombach and Björn Ommer},
year={2021},
eprint={2012.09841},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@misc{
title={BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension},
author={Mike Lewis and Yinhan Liu and Naman Goyal and Marjan Ghazvininejad and Abdelrahman Mohamed and Omer Levy and Ves Stoyanov and Luke Zettlemoyer},
year={2019},
eprint={1910.13461},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{
title={Scalable Second Order Optimization for Deep Learning},
author={Rohan Anil and Vineet Gupta and Tomer Koren and Kevin Regan and Yoram Singer},
year={2021},
eprint={2002.09018},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
@misc{
title={GLU Variants Improve Transformer},
author={Noam Shazeer},
year={2020},
url={https://arxiv.org/abs/2002.05202}
}
@misc{
title={DeepNet: Scaling transformers to 1,000 layers},
author={Wang, Hongyu and Ma, Shuming and Dong, Li and Huang, Shaohan and Zhang, Dongdong and Wei, Furu},
year={2022},
eprint={2203.00555}
archivePrefix={arXiv},
primaryClass={cs.LG}
}
@misc{
title={NormFormer: Improved Transformer Pretraining with Extra Normalization},
author={Sam Shleifer and Jason Weston and Myle Ott},
year={2021},
eprint={2110.09456},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@inproceedings{
title={Swin Transformer V2: Scaling Up Capacity and Resolution},
author={Ze Liu and Han Hu and Yutong Lin and Zhuliang Yao and Zhenda Xie and Yixuan Wei and Jia Ning and Yue Cao and Zheng Zhang and Li Dong and Furu Wei and Baining Guo},
booktitle={International Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2022}
}
@misc{
title = {CogView: Mastering Text-to-Image Generation via Transformers},
author = {Ming Ding and Zhuoyi Yang and Wenyi Hong and Wendi Zheng and Chang Zhou and Da Yin and Junyang Lin and Xu Zou and Zhou Shao and Hongxia Yang and Jie Tang},
year = {2021},
eprint = {2105.13290},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}
@misc{
title = {Root Mean Square Layer Normalization},
author = {Biao Zhang and Rico Sennrich},
year = {2019},
eprint = {1910.07467},
archivePrefix = {arXiv},
primaryClass = {cs.LG}
}
@misc{
title = {Sinkformers: Transformers with Doubly Stochastic Attention},
url = {https://arxiv.org/abs/2110.11773},
author = {Sander, Michael E. and Ablin, Pierre and Blondel, Mathieu and Peyré, Gabriel},
publisher = {arXiv},
year = {2021},
}
@misc{
title = {Smooth activations and reproducibility in deep networks},
url = {https://arxiv.org/abs/2010.09931},
author = {Shamir, Gil I. and Lin, Dong and Coviello, Lorenzo},
publisher = {arXiv},
year = {2020},
}
@misc{
title = {Foundation Transformers},
url = {https://arxiv.org/abs/2210.06423},
author = {Wang, Hongyu and Ma, Shuming and Huang, Shaohan and Dong, Li and Wang, Wenhui and Peng, Zhiliang and Wu, Yu and Bajaj, Payal and Singhal, Saksham and Benhaim, Alon and Patra, Barun and Liu, Zhun and Chaudhary, Vishrav and Song, Xia and Wei, Furu},
publisher = {arXiv},
year = {2022},
}