In this project, I have done sentiment classification on IMDB Movie Review Dataset using BERT & Hugging face.
After downloading dataset, preprocessign is done to accumulate all the reviews in different text files to 2 CSV files train and test.
Pandas library is used while to load the text and process this.
Labels Distribution
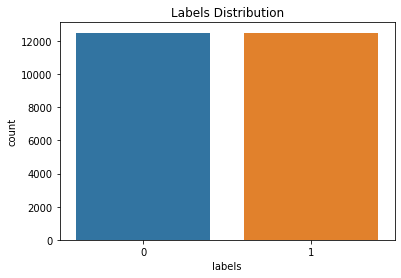
This is very balanced data set. The frequency of each class is equal. Which makes our model building easier.
# of Words
Using pandas count of words has been computed for each sentence.
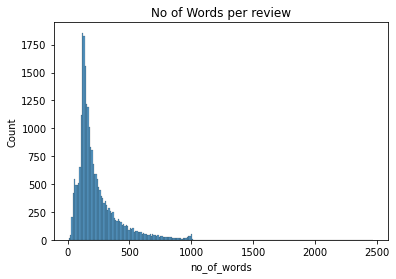
This is a skewed distribution. Most of the sentences have around 250 words.
After splitting training data ito train and validation dataframe. The Dataset object is created for train, validation and test data.
class IMDBDataset(Dataset):
def __init__(self, data):
self.data = data
def __getitem__(self, idx):
# tokenizing and converting them to index
encodings = tokenizer(self.data.iloc[idx][0], truncation=True, padding="max_length")
encodings['labels'] = self.data.iloc[idx][1]
return encodings
def __len__(self):
return self.data.shape[0]The truncation makes sure the max length of text doesnt go beyond the max input length of bert model, and padding will be applied with length of text is less then max input length.
We are doing tokenization while retrib=ving each data point
I have usign the DistilBertSequenceClassification model with pretrain weights from distilbert-base-uncased.
In order to reduce the time taken for training and memory utilisation I have used distil-bert instead of bert model.
The Huggingface library provides us Trainer object, which can we used to train our model without the need of making a training loop ourselfs.
The training loss is as follows
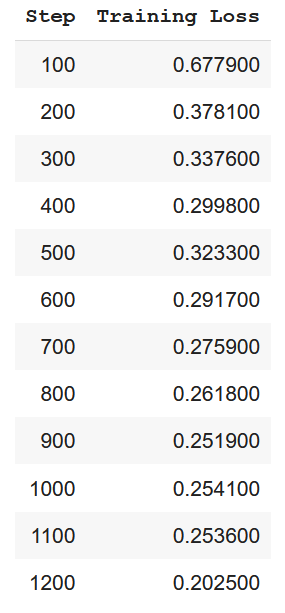
The model is ran for 1 epoch and 1250 steps. We can see from the above table the model loss is reducing from 0.67 to 0.2 at the end of training.
A random test input has been taken to infer the model.
test = test_df.iloc[random.randint(0, test_df.shape[0])]The input text is tokenized and converted to the torch tensors with batch size of 1.
input = tokenizer(test[0], return_tensors="pt").to("cuda")
label = torch.tensor([test[1]]).unsqueeze(0).to('cuda')The inputs and labels are passed to model. The model gives logit values for 2 classes. Using argmax of pytorch we have found the max logit class.
outputs = model(**input, labels = label)
pred = torch.argmax(outputs.logits, dim=-1)
# output [1]For the following sentence
The movie was good. Really the only reason I watched it was Alan Rickman. Which he didn't pull off the southern accent,but he did pretty well with it.Know Emma Thompson did really good she definitely pulled off the southern accent. I like all the character in my opinion not one of them did bad,another thing I have notice. I have read all these comment and not one person has comment on Alan 5 0'clock shadow. Which made him look even better and he pretty much had one through the whole movie. I would give the movie a 9 out of 10. Another one of my opinions is the movie would been better if there wasn't any sex. Still it was alright. Love the scene were he says "Aw sh*t" when he is setting in his car and see them in his mirror.
The true and predicted outputs are
True : 1
Predicted : 1