Documentation

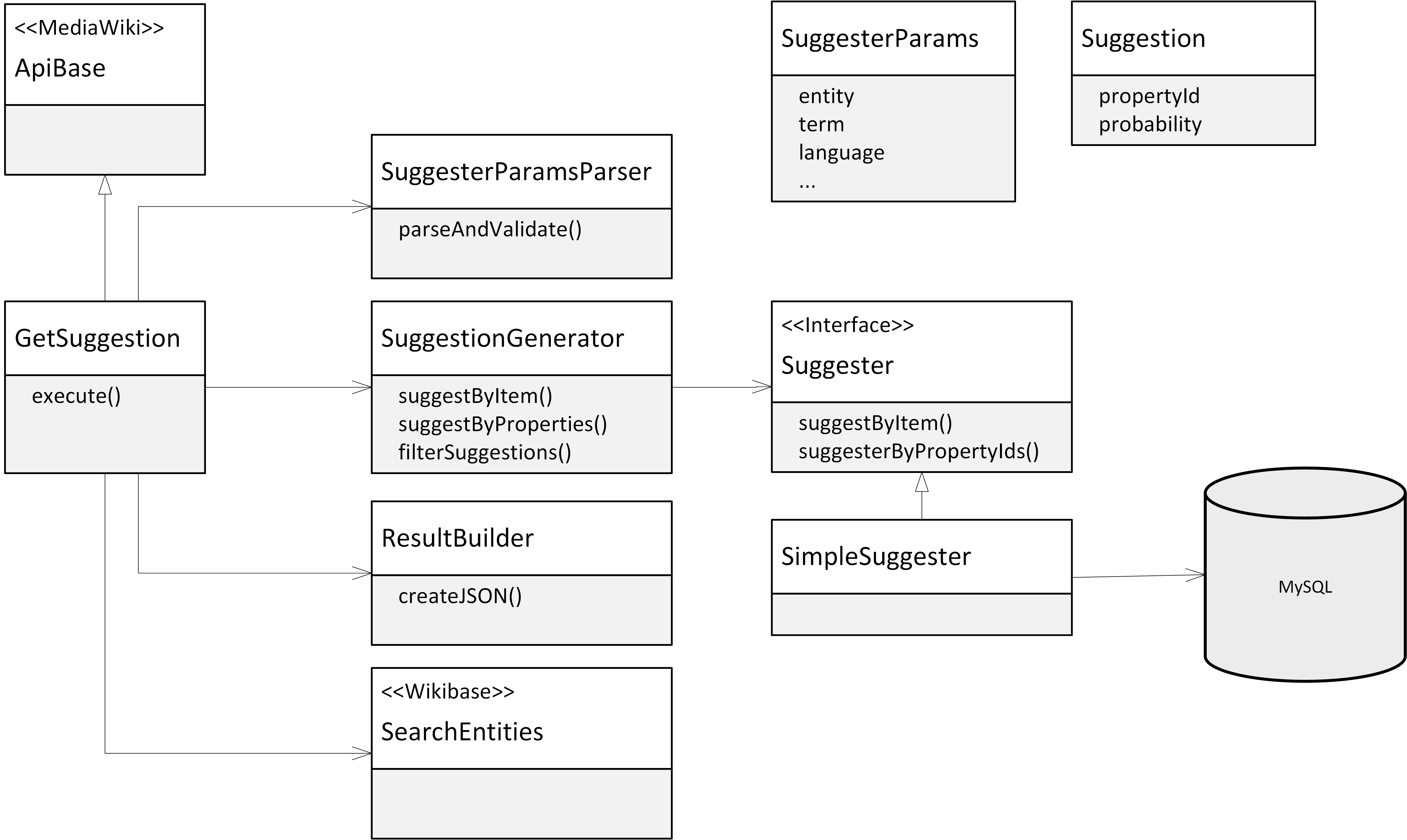
There can be any number of concrete Suggesters that implement the Suggester Interface which provides a function to obtain fitting attributes for an entity or a certain set of attributes (optionally values can be suggested). This interface may be used at different places. E.g. for adding attribute suggestions to the edit item page.
It is essential to define on what data a suggester-engine is basing its suggestions and how it can access this data/how the data is generated - this can vary depending on the suggester that is used - for the SimplePHPSuggester we have the following approach in mind:
|XML or JSON dump| -> (dump parser) -> |feature CSV| -> (data analyzer) -> |suggester data| -> (suggester engine)
|XML or JSON dump| is a dump of the full entity data of all entities, provided as a compressed file. The XML also wraps JSON, but that "internal" JSON should be avoided as soon as "real" JSON dumps are available.
(dump parser) is a script that reads the dump and extracts the information("features") needed by the data analyzer, and outputs them to a CSV file (which can then be loaded into MySQL, or processed with Hadoop, or whatever).
|feature CSV| is a CSV file containing the features needed by the data analyzer. In the most basic form, the file consists of two columns: |subject| and |feature|. For suggesting properties based on existing properties, that would mean |itemid| |propertyid| (for suggesting products to customers, like on amazon, it would correspond to |customer| |product|). For some use cases like finding classifiers (see here) or suggesting values it might also be useful to have additional columns for storing the value and type of a property.
(data analyzer) generates the information used by the suggester (the data could either be stored into files to be loaded into a database, or directly into the database). This includes finding correlations between features by counting co-occurences of properties and possibly property/value pairs as well as computing their usage frequencies. Filtering and perhaps clustering could also well be integral parts in this process.
|suggester data| is the information used by the suggester engine. It resides in a database that can be accessed from the application servers. The goal is to structure and index the data in such a way that the suggester engine can generate suggestions instantly.
For example the Data that is accessed by the SimplePHPSuggester is stored according to the following schema:
wbs_PropertyPairs(pid1 INT, pid2 INT, count INT, correlation FLOAT, primary key(pid1, pid2))
- Explanation: One entry for each occuring binary combination of properties, count (how often does the combination occur), correlation(how like is it to find pid1 in combination with pid2)
1. Use Case:
Assumptions:
- we are given an entity E described by a list of Properties L
- we want the top X property-suggestions for the given set of properties
- we only wish to suggest properties that correlate well with the properties in L(their rating has to pass a certain threshold T) and that are not already contained in L of course
SELECT pid2, sum(correlation) AS cor
FROM wbs_PropertyPairs
WHERE pid1 IN L AND pid2 NOT IN L
GROUP BY pid2
HAVING sum(correlation) > T
ORDER BY cor DESC
LIMIT X
(suggester engine) generates suggestions based on the provided data set. It has information about how the data is structured, and how it should be interpreted. It's written in PHP and is called directly from (or is part of) a MediaWiki extension.
- Nilesh's idea
- Ziawasch Abedjan, Felix Naumann Improving RDF Data Through Association Rule Mining
While the input field is still empty, the best property suggestions are displayed based on existing attributes of the current item. When the user starts typing, the input is used to filter the suggested properties: Properties that do not match the current input are replaced by traditional search results. Another approach (which we are not working on currently) is to rank all properties that match the input and display the top n of them.