Data Science Project: Students' Dropout and Academic Success Analysis

Metodologi manajemen proyek yang digunakan dalam proyek ini adalah CRISP-DM. Metodologi ini merupakan salah satu dari beberapa metodologi yang sering digunakan dalam dunia industri. Selain CRISP-DM, terdapat beberapa metodologi manajemen proyek yaitu Ad Hoc, Waterfall, Agile Scrum & Kanban.
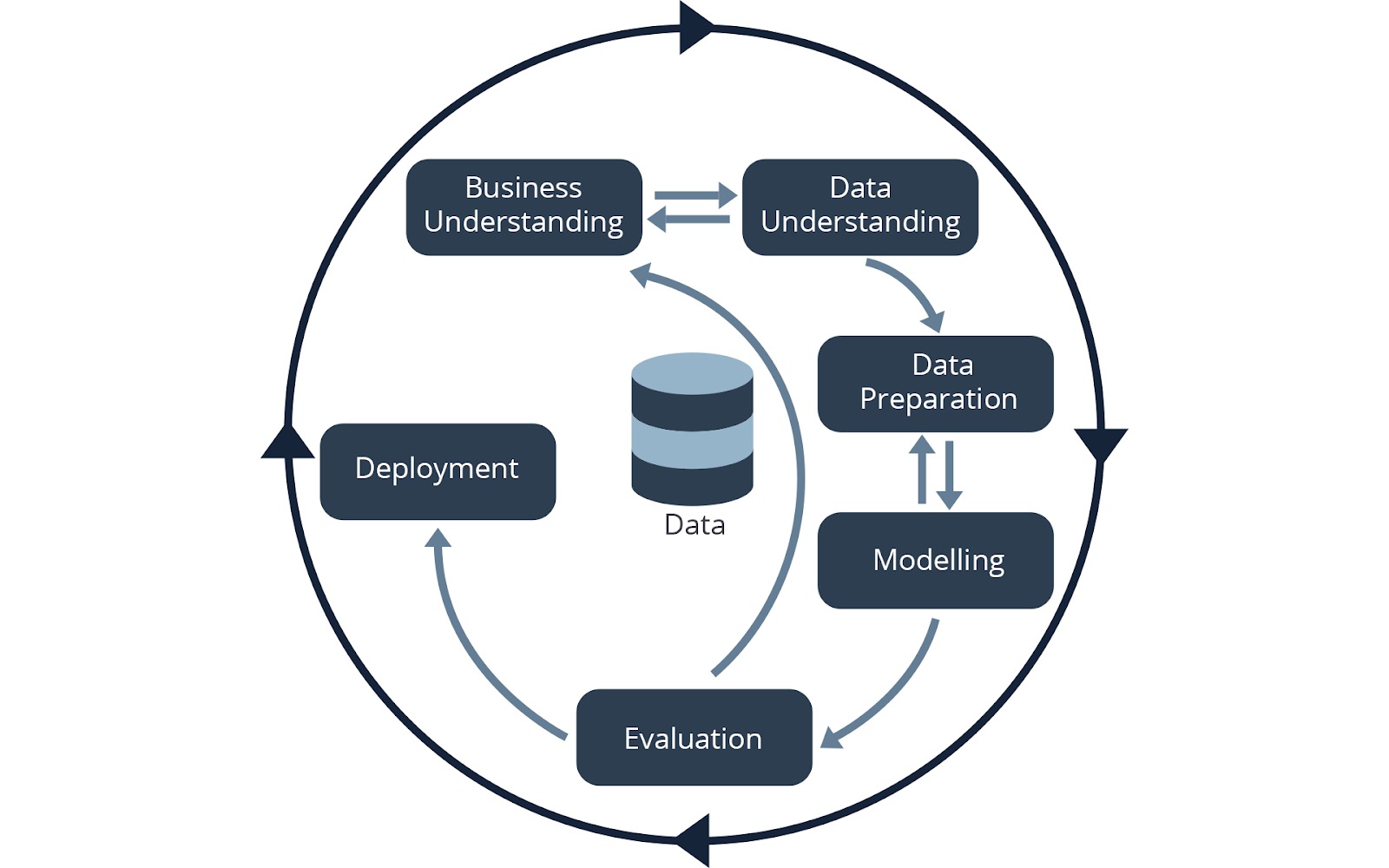
CRISP-DM (Cross-Industry Standard Process for Data Mining) adalah pendekatan yang menggambarkan proses standar untuk proyek data mining, data science, dan machine learning. Dalam metodologi ini, pengerjaan suatu proyek diawali dengan tahap business understanding sehingga dapat membantu memastikan proyek terlaksana sesuai dengan kebutuhan bisnis. Keunggulan lain dari metodologi ini adalah proses kerjanya bersifat iteratif, sehingga proses kerjanya dapat disesuaikan dengan kebutuhan eksperimen proyek data science. Berbeda dengan metodologi waterfall yang hanya berjalan satu arah.
CRISP-DM terdiri dari 6 fase dan disusun sebagai sebuah siklus, yang bertujuan untuk memaksimalkan hasil proyek ilmu data. Tahapan CRISP-DM dapat dilihat pada gambar berikut:
Jaya Jaya Institut merupakan salah satu institusi pendidikan perguruan yang telah berdiri sejak tahun 2000. Hingga saat ini ia telah mencetak banyak lulusan dengan reputasi yang sangat baik. Akan tetapi, terdapat banyak juga siswa yang tidak menyelesaikan pendidikannya alias dropout. Jumlah dropout yang tinggi ini tentunya menjadi salah satu masalah yang besar untuk sebuah institusi pendidikan.
Untuk mencegah permasalahan Jaya Jaya Institut menjadi lebih parah. Maka perlu diidentifikasi faktor apa saja yang berpengaruh terhadap tingkat dropout yang tinggi dan mendeteksi secepat mungkin siswa yang mungkin akan melakukan dropout, sehingga dapat diberi bimbingan khusus.
Berdasarkan permasalahan yang telah diuraikan, maka untuk menjawab permasalahan bisnis tersebut akan dibuat sistem machine learning dengan menggunakan algoritma Random Forest Classification. Sehingga dapat diidentifikasi faktor-faktor yang berkontribusi terhadap tingginya tingkat dropout pada Jaya Jaya Institut.
Selain itu juga akan dibuat business dashboard yang dapat digunakan oleh Jaya Jaya Institut untuk membantu memantau data dan memonitor performa siswa.
Berikut beberapa pertanyaan yang akan dijawab dalam proyek ini dengan mengikuti konsep SMART-Question:
- Specific : Faktor-faktor apa saja yang berkontribusi terhadap students dropout rate Jaya Jaya Institut?
- Measurable : Berapa jumlah atau persentase faktor yang mempengaruhi students dropout rate Jaya Jaya Institut?
- Action oriented: Tindakan apa yang dapat dilakukan Jaya Jaya Institut untuk menangani faktor penyebab tingginya students dropout rate dan menguranginya?
- Relevant : Apakah tindakan yang akan dilakukan tersebut dapat mengurangi students dropout rate?
- Time bond : Berapa lama implementasi dari rencana untuk mengurangi students dropout rate tersebut?
-
Dataset Proyek Data Science ini menggunakan Dataset Predict Students' Dropout and Academic Success
-
Tech Stack
- Programming Languages : Python
- AI/ML : Tensorflow, numpy, pandas, scipy, matplotlib, seaborn, jupyter, sqlalchemy, scikit-learn, joblib, streamlit, psycopg2-binary, imbalanced-learn, XGBClassifier, KNeighborsClassifier, LogisticRegression, DecisionTreeClassifier, & RandomForestClassifier
- Business intelligence tools : Tableau
- Other : Visual Studio Code, Git & PyCharm
-
Setup Environment
pip install numpy pandas scipy matplotlib seaborn jupyter sqlalchemy scikit-learn==1.3.2 joblib==1.3.1 streamlit==1.24.0 psycopg2-binary imbalanced-learn xgboost
Dataset yang digunakan pada proyek data science ini adalah Dataset Predict Students' Dropout and Academic Success. Dataset tersebut terdiri dari 4424 records data dan 37 features.
| Column Name | Description |
|---|---|
| Marital status | The marital status of the student. (Categorical) |
| Application mode | The method of application used by the student. (Categorical) |
| Application order | The order in which the student applied. (Numerical) |
| Course | The course taken by the student. (Categorical) |
| Daytime/evening attendance | Whether the student attends classes during the day or in the evening. (Categorical) |
| Previous qualification | The qualification obtained by the student before enrolling in higher education. (Categorical) |
| Nationality | The nationality of the student. (Categorical) |
| Mother's qualification | The qualification of the student's mother. (Categorical) |
| Father's qualification | The qualification of the student's father. (Categorical) |
| Mother's occupation | The occupation of the student's mother. (Categorical) |
| Father's occupation | The occupation of the student's father. (Categorical) |
| Displaced | Whether the student is a displaced person. (Categorical) |
| Educational special needs | Whether the student has any special educational needs. (Categorical) |
| Debtor | Whether the student is a debtor. (Categorical) |
| Tuition fees up to date | Whether the student's tuition fees are up to date. (Categorical) |
| Gender | The gender of the student. (Categorical) |
| Scholarship holder | Whether the student is a scholarship holder. (Categorical) |
| Age at enrollment | The age of the student at the time of enrollment. (Numerical) |
| International | Whether the student is an international student. (Categorical) |
| Curricular units 1st sem (credited) | The number of curricular units credited by the student in the first semester. (Numerical) |
| Curricular units 1st sem (enrolled) | The number of curricular units enrolled by the student in the first semester. (Numerical) |
| Curricular units 1st sem (evaluations) | The number of curricular units evaluated by the student in the first semester. (Numerical) |
| Curricular units 1st sem (approved) | The number of curricular units approved by the student in the first semester. (Numerical) |
Tahapan Data preparation mencakup proses data gathering, data assessing, data cleaning, atau feature engineering. Dalam proyek ini dilakukan beberapa teknik seperti penanganan missing value, penanganan duplikasi data, dan beberapa teknik lainnya. Berikut adalah tahapan data preparation pada proyek ini :
-
Handling missing value
- Missing value merupakan salah satu masalah yang paling sering dijumpai dalam proyek analisis data di industri. Masalah ini muncul karena adanya nilai yang hilang dari sebuah data dan biasanya direpresentasikan sebagai nilai NaN dalam library pandas. Hal ini biasanya terjadi karena adanya human error, masalah privasi, proses merging/join, dll.
- Tujuan dari langkah ini adalah untuk memastikan keakuratan dan keandalan data yang digunakan untuk analisis atau pemodelan. Missing value dapat menyebabkan bias dan kesalahan dalam analisis data, sehingga penting untuk mengidentifikasi dan mengatasi nilai yang hilang ini agar hasil analisis menjadi lebih akurat dan dapat diandalkan.
- Terdapat beberapa cara atau metode yang dapat digunakan untuk menangani missing value, yaitu Dropping, Imputation, Interpolation, dan lainnya.
-
Handling duplicated data
- Duplicated data adalah masalah lain yang umum dijumpai di industri. Ia terjadi ketika terdapat sebuah observasi (semua nilai dalam satu unit baris) yang memiliki nilai yang sama persis pada setiap kolomnya.Tujuan dari langkah ini adalah untuk memastikan integritas data. Duplicated data dapat mempengaruhi analisis data dan membuat hasil yang tidak akurat. Oleh karena itu, dengan mengidentifikasi dan menghapus data yang terduplikat, dapat memastikan bahwa data yang digunakan untuk analisis atau pemodelan adalah data yang valid dan representatif.
- Salah satu teknik yang dapat digunakan dalam mengatasi duplicated data adalah dengan menghapus data yang terduplikat (dropping).
-
Handling outliers
- Outliers adalah nilai yang jauh berbeda dari nilai lainnya dalam kumpulan data. Nilai ini muncul sebagai pengecualian dalam pola data yang ada. Nilai yang ada di outlier bisa jauh lebih tinggi maupun lebih rendah dibandingkan dengan nilai-nilai lain dalam dataset. Outlier bisa terjadi karena berbagai alasan, termasuk kesalahan pengukuran, kejadian langka, atau karena faktor lain yang tidak terduga.
- Tujuan dari langkah ini adalah untuk memastikan bahwa outlier tidak mempengaruhi analisis statistik yang dilakukan atau model machine learning yang dibangun. Outliers memiliki potensi untuk memberikan informasi yang salah atau mengganggu hasil analisis, sehingga penting untuk mengatasi mereka agar hasil analisis menjadi lebih akurat dan dapat dipercaya.
-
Handling imbalanced data
- Imbalanced data merupakan sebuah kondisi di mana distribusi dari kelas yang terdapat pada dataset tidak seimbang jumlahnya.
- Tujuan dari menangani imbalanced data adalah untuk meningkatkan performa model dalam memprediksi kelas minoritas.
- Terdapat beberapa cara atau metode yang dapat digunakan untuk menangani imbalanced data. Pertama, oversampling yaitu memperbanyak sampel dari kelas minoritas sehingga jumlahnya seimbang dengan kelas mayoritas. Ini dapat dilakukan dengan menggandakan sampel yang ada atau dengan membuat sampel sintetis baru. Cara lainnya, undersampling yaitu mengurangi jumlah sampel dari kelas mayoritas sehingga jumlahnya seimbang dengan kelas minoritas. Ini dapat dilakukan dengan menghapus sebagian sampel dari kelas mayoritas. Pada proyek ini penanganan imbalanced data dilakukan dengan metode SMOTE (Synthetic Minority Over-sampling Technique): SMOTE digunakan untuk membuat sampel sintetis dari kelas minoritas (dalam hal ini, kelas "1" dari kolom 'Outcome') sehingga jumlahnya seimbang dengan kelas mayoritas. Hal ini membantu mencegah bias pada model machine learning ke kelas mayoritas dan meningkatkan kinerja model untuk kelas minoritas.
Gambar 1.*Handling imbalanced data*

-
Data Splitting
- Data Splitting adalah proses membagi dataset menjadi dua atau lebih bagian yang berbeda untuk digunakan dalam tahapan tertentu dari proses analisis data, seperti pelatihan model, validasi model, dan pengujian model.
- Tujuan dari langkah ini adalah pembagian data menjadi menjadi dua bagian: satu untuk melatih model (set pelatihan) dan yang lainnya untuk menguji model (set pengujian).
- Teknik yang digunakan adalah dengan menggunakan metode Train-test split.
-
Standardization
- Standardisasi adalah proses mengubah data sehingga memiliki rata-rata (mean) nol dan varians (variance) satu.
- Salah satu tujuan standardisasi adalah karena banyak algoritma pembelajaran mesin yang berkinerja lebih baik atau stabil ketika fitur numerik diaktifkan. skala yang sama. Dengan standarisasi, fitur-fitur ini diperlakukan secara seragam, sehingga dapat meningkatkan performa model.
- Teknik yang digunakan pada proyek ini adalah menggunakan StandardScaler scikit-learn.
Pada proyek ini algoritma machine learning yang digunakan yaitu XGBoost (Extreme Gradient Boosting).
Metode XGBoost adalah algoritma pengembangan dari gradient tree boosting yang berbasis algoritma ensemble, secara efektif bisa menanggulangi kasus machine learning yang berskala besar. Metode XGBoost dipilih karena memiliki beberapa fitur tambahan yang berguna untuk mempercepat sistem perhitungan dan mencegah overfitting. XGBoost dapat menyelesaikan berbagai contoh klasifikasi, regresi, dan ranking. XGBoost adalah perhitungan pengumpulan pohon yang terdiri dari bermacam-macam pohon sebelumnya (CART). Komponen utama di balik kemakmuran XGBoost adalah kemampuan beradaptasinya dalam berbagai situasi, fleksibilitas ini karena perbaikan dari perhitungan masa lalu. REFERENSI
Kelebihan :
- XGBoost menggunakan teknik boosting dan mengoptimalkan proses pembelajaran dengan gradien berdasarkan fungsi objektif. Hal ini menghasilkan model yang kuat dengan performa yang tinggi dan kemampuan prediksi yang akurat.
- XGBoost dirancang untuk menangani dataset yang besar dengan efisiensi tinggi. Algoritma ini menggunakan pengoptimalan yang cerdas, seperti kompresi kolom dan pembagian paralel untuk meningkatkan kinerja dan mengurangi penggunaan sumber daya.
- XGBoost dapat menangani kombinasi variabel numerik dan kategorikal tanpa memerlukan pra-pemrosesan tambahan. Ini mengurangi kompleksitas dan waktu yang dibutuhkan untuk pra-pemrosesan data.
Kekurangan :
- XGBoost memerlukan tuning parameter yang cermat untuk mendapatkan model yang optimal. Hal ini dapat memakan waktu dan mengharuskan penggunaan cross-validation dan teknik tuning parameter lainnya.
- XGBoost dapat cenderung overfit pada data training jika tidak dilakukan pengaturan parameter yang baik. Overfitting terjadi ketika model terlalu kompleks dan terlalu menyesuaikan dengan data training, sehingga tidak dapat melakukan generalisasi dengan baik pada data yang belum pernah dilihat sebelumnya.
- XGBoost memerlukan jumlah data yang besar untuk memperoleh model yang akurat dan stabil. Jika jumlah data terlalu sedikit, algoritma ini dapat menjadi tidak stabil dan menghasilkan model yang tidak akurat.
Tahapan evaluasi model merupakan langkah penting dalam data science. Evaluasi model dapat membantu untuk mengetahui mengetahui seberapa baik model dalam memberikan hasil prediksi yang tepat.
Pada proyek machine learning ini evaluasi model akan menggunakan confussion matrix. Confussion matrix memberi gambaran bagaimana performa model pada berbagai kelas. Ia menunjukkan berapa banyak jumlah prediksi yang benar (True) dan salah (False) untuk setiap label.
Dengan menggunakan confussion matrix, maka dapat diketahui seberapa baik performa dari model machine learning yang dikembangkan. Hasil dari confussion matrix ini akan digunakan untuk menghitung berbagai metrik lainnya, seperti accuracy, precision, recall, dan F-1 score.
| Metric | Definition |
|---|---|
| Accuracy | Metrik evaluasi yang mengukur seberapa baik model membuat prediksi yang benar dari total prediksi yang dilakukan. |
| Precision | Metrik evaluasi yang digunakan untuk mengukur berapa banyak model menghasilkan prediksi yang benar untuk suatu kelas tertentu. Precision didefinisikan sebagai perbandingan antara jumlah hasil prediksi yang benar untuk kelas tertentu dengan jumlah total prediksi untuk kelas tersebut. |
| Recall | Metrik yang digunakan untuk mengukur seberapa baik model dalam memprediksi suatu kelas tertentu. Recall didefinisikan sebagai perbandingan antara jumlah hasil prediksi yang benar untuk kelas tertentu dengan jumlah total sampel pada kelas tersebut. |
| F1-score | Merupakan kombinasi antara nilai precision dan recall dari suatu kelas tertentu. |
Berdasarkan tahapan evaluasi pada proyek ini, model terbaik yang dikembangkan adalah model Algoritma XGBoost. Model ini dipilih karena mendapatkan performa lebih baik dibanding dengan beberapa hasil eksperimen model machine learning lainnya. Berikut adalah detail dari performa model XGBoost pada proyek ini :
Gambar 2.*Confussion Matrix*

Tabel 1.Classification Report pada testing dataset
| precision | recall | f1-score | support | |
|---|---|---|---|---|
| 0 | 0.88 | 0.81 | 0.84 | 423 |
| 1 | 0.81 | 0.90 | 0.85 | 452 |
| 2 | 0.81 | 0.81 | 0.82 | 451 |
| accuracy | 0.84 | 1326 | ||
| macro avg | 0.84 | 0.84 | 0.84 | 1326 |
| weight avg | 0.84 | 0.84 | 0.84 | 1326 |
Machine learning deployment merupakan tahapan mengintegrasikan model machine learning ke dalam sistem atau aplikasi yang akan digunakan secara live. Pada proyek ini deployment model machine learning ke dalam aplikasi prototype akan menggunakan tools Streamlit.
Streamlit merupakan salah satu open-source web app framework untuk bahasa pemrograman Python yang memungkinkan pengguna untuk membuat web app yang baik dan interaktif. Selain itu, Streamlit juga kompatibel dengan berbagai library populer seperti NumPy, pandas, matplotlib, dan library lainnya.
Prototype application Link :
Student Dropout Analysis School Education 🏫
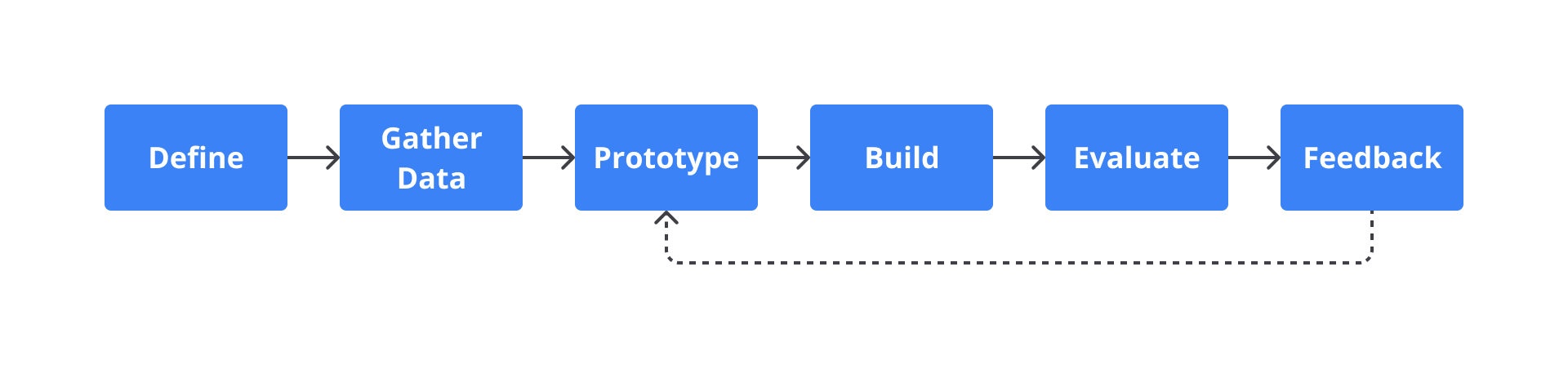
Berikut merupakan beberapa tahapan yang umum dijumpai dalam pengembangan sebuah business dashboard.
-
Define
Pada tahap awal tentunya kita perlu memahami audiens dari dashboard yang akan dibuat. Selain itu, kita juga perlu menentukan tujuan atau keluaran dari dashboard tersebut serta pertanyaan bisnis yang ingin dijawab melalui visualisasi data. -
Gather Data
Tahap berikutnya adalah menentukan atau mengumpulkan data yang akan digunakan untuk menjawab pertanyaan bisnis. Pada tahap ini, kita perlu mempertimbangkan sumber dan kualitas data yang akan digunakan. -
Prototype
Setelah mengetahui tujuan dan data yang akan digunakan, tahap selanjutnya adalah membuat prototipe/sketsa/mockup dari dashboard yang akan dibuat. Hal ini akan membantu Anda dalam membuat susunan dashboard yang baik dan efektif. Pada prosesnya, Anda perlu mempertimbangkan ukuran tampilan serta penggunaan sweet spot yang tepat. -
Build
Jika prototipe yang dibuat telah selesai, Anda dapat mulai membuat dan menyusun dashboard sesuai prototipe yang telah dibuat. Pada prosesnya Anda perlu menentukan bentuk grafik yang tepat untuk menjawab pertanyaan bisnis tersebut. -
Evaluasi
Tahap berikutnya adalah mengevaluasi dashboard yang telah dibuat. Hal ini dilakukan untuk memastikan grafik dan komponen visual lain yang terdapat di dalam dashboard telah efektif dan mudah dipahami. -
Feedback
Terakhir kita juga perlu meminta feedback kepada audiens atau user terkait dashboard yang telah dibuat. Hal ini tentunya akan sangat membantu kita dalam membuat business dashboard yang lebih baik ke depannya.
Business dashboard pada proyek ini dapat diakses melalui pranala (link) Tableau berikut :
SMART (Specific - Measurable - Action oriented - Relevant - Time bond)
Berdasarkan insights yang diperoleh dari hasil analisis, dapat disimpulkan bahwa terdapat beberapa faktor yang berpengaruh kuat terhadap students dropout rate di Jaya Jaya Institute. Beberapa faktor tersebut meliputi scholarship holder, age at enrollment, daytime / evening attendance, tuition fees up to date, academic semester 1 and semester 2. (Specific).
Dari business dashboard yang telah dibuat sebelumnya dapat diperoleh beberapa insights di antaranya yaitu :
-
Terdapat 29% atau 1287 mahasiwa dari total keseluruhan yang bukan penerima beasiswa berstatus dropout. Sementara untuk kelompok mahasiswa penerima beasiswa (scholarship holder) presentase dropout hanya sebesar 3% atau 134 mahasiswa dari total keseluruhan. (Measurable) Tindakan yang dapat dilkukan untuk mengatasi permasalahan ini di antaranya yaitu :
- Melakukan pendekatan holistik dalam memberikan beasiswa, termasuk memberikan dukungan akademik, finansial, dan sosial kepada penerima beasiswa maupun non-penerima beasiswa, sehingga beasiswa dapat disalurkan secara tepat. Selain itu, apabila memungkinkan menambah jumlah kuota penerima beasiswa lebih banyak. Sehingga dropout rate dapat berkurang.(Action oriented & Relevant)
- Membangun jaringan dukungan antara penerima beasiswa untuk saling mendukung dan berbagi pengalaman dalam mengatasi tantangan akademik. Karena dalam hasil analisis, jumlah mahasiswa dengan status dropout dari total keseluruhan penerima beasiswa yaitu sebesar 12%. Dengan tindakan tersebut, diharapkan para jumlah penerima beasiswa yang berstatus dropout dapat lebih berkurang.(Action oriented & Relevant)
-
Sebesar 85% atau 3762 mahasiswa yang berusia (age at enrollment) 17-30 tahun, dengan mahasiswa yang berstatus dropout sebesar 24% dari total keseluruhan mahasiswa.(Measurable) Tindakan yang dapat diambil berkaitan dengan hal tersebut di antaranya yaitu memberikan program mentoring atau bimbingan khusus bagi mahasiswa yang mendaftar pada kelompok usia tersebut untuk membantu mereka beradaptasi dengan lingkungan akademik. Tindalkan lain yang dapat dilakukan yaitu memberikan dukungan psikologis kepada mahasiswa yang mungkin mengalami kesulitan dalam menyesuaikan diri. Sehingga jumlah mahasiswa dropout dapat berkurang secara berkala.(Action oriented & Relevant)
-
Jumlah mahasiswa kelas evening yang berstatus dropout sebesar 42% (207 mahasiswa) dari keseluruhan mahasiswa yang mengambil kelas Evening. Jumlah tersebut berarti hampir setengah dari kelas malam (evening) berstatus dropout, dan jumlah tersebut sangat banyak. (Measurable) Beberapa tindakan yang dapat diambil untuk mengatasi hal ini adalah menyelenggarakan program bimbingan khusus bagi mahasiswa yang mengikuti kelas malam untuk membantu mereka mengelola waktu dan tugas kuliah dengan lebih efektif. Selain itu, dapat juga memberikan fleksibilitas waktu dalam penyelesaian tugas dan ujian bagi mahasiswa yang mengikuti kelas malam untuk mengakomodasi jadwal kerja atau komitmen lainnya. Sehingga diharapkan dengan cara tersebut dapat membantu para mahasiswa yang mengambil kelas malam (evening) dan dapat mengurangi tingkat dropout. (Action oriented & Relevant)
-
Sebesar 21% atau 964 mahasiwa dengan tuitions fee up to date dari total keseluruhan mahasiswa berstatus dropout. Jumlah tersebut 2 kali lebih banyak dari mahasiswa yang melakukan pembayaran tuitions fee tidak dalam kategori up to date yaitu 10%. (Measurable) Kondisi ini tentunya dapat dijadikan pertimbangan bagi Jaya Jaya Institut untuk minjau atau mengatur ulang sistem pembayaran agar lebih fleksibel atau tidak menyulitkan para mahasiswa, misalnya dengan memberikan opsi pembayaran per semester atau tahunan. Sehingga mahasiswa misalnya tidak perlu membayar setiap bulan atau periode beberapa bulan. Selain itu, dapat diberikan pengingat (reminder) secara ruti kepada mahasiswa tentang jatuh tempo pembayaran tuitions fee agar melakukan pembayaran sesuai dengan ketentuan yang berlaku.(Action oriented & Relevant)
Hasil analisis atau insights yang diperoleh beserta beberapa rekomendasi aksi/tindakan di atas dapat dilakukan oleh Jaya Jaya Institut untuk mengurangi students dropout rate dalam jangka waktu yang jelas. Sebagai langkah awal, beberapa program tertentu yang telah dirancang dapat dilaksanakan selama 1 semester atau dua semester pertama. Kemudian dilakukan evaluasi terhadap program yang telah dilaksanakan tersebut untuk mengetahui apakah terdapat perubahan signifikan terhadap students dropout rate pada Jaya Jaya Institut. (Time Bond)
If you have any feedback, please reach out at [email protected]