
Hey everyone! In this repo I'll talk about my experience in Google HashCode challenge, how to think in the problems and how to solve the Pizza problem and the scheduling problem as well.
Hash Code is a programming competition organized by Google in Europe, Middle-East and Africa. The problems are real engineering problem from Google and that what make it special so you may learn more how to recruit your skills in math, programming, data structure and more to solve a real problem.
You may check the past editions to learn more about what real problem Google has.
The challenge has three rounds:
- Practice Round
- Online Qualification Round
- Final Round
Google is not looking after your code! They are looking for the way you analyze the problem, how you are going to build your algorithm and what data structure techniques that you are going to use.
They are expecting two types of solutions, classic and modern.
- The classic solution should work fine in a small dataset but not for big one. Also don't expect the get out with the optimum solution.
- The modern solution focus on the performance and to reduce the complexity so it'll work fast for any dataset size. Also it works to optimize the solution and to minimize the error.
In this repo we'll talk about the first and second rounds. The third round will be held in Dublin for the top scoring teams. We'll show a classic solution and a modern solution for each round.
The practice round is about slicing pizza, easy! Google is asking you to slice the pizza to get the maximum number of slices with a condition. Each slice should have a certain number from each ingredient
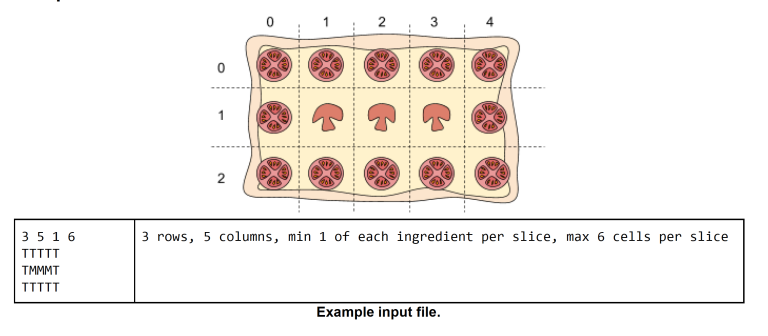
You may read the problem statement and check the data from here
So how to solve it? let us go through both solutions, classic and modern.
- Pizza Classic Solution
Classic solutions are fine for small scale, small datasets and small projects as well. At the end you'll have what you need and it works. In the Classic solutions we'll use loops, nested loops and more loops!! and most of the times the big O notation will not be happy because it'll have exponential complexity as the data grow things will get more complex and costly.
Let's go with the flow and see where things will lead us ...
To solve the problem, we'll loop over all the items and check for all possible combinations for each cell, choose one combination then move to the next point. That simple !!
This algorithm called The Greedy Algorithm. It is easier to code and makes the choice that looks best at the moment. In our case we hope that the local optimal choice will lead to a global optimal solution. But that is not true in this because there are no guarantees that your local choice will be the optimal for the next cell. Also you blocked a group of choices by your decision.
To avoid this we may find all the possible combinations for each cell then iterate over all the possible combinations to find the best solution. And this is a solid plan.
For small pizza this will work like a charm. But if you move to medium pizza mostly will code will take a very long time before it may crush! Your memory will not be able to handle it. As a quick eyeliner, break down your pizza into many small pieces and run your algorithm on each piece and it'll work. The thing is you'll lose the possible combinations at edges for each slice. There are some solutions to improve this method but at the end this is not the optimal solution.
Finally, to avoid nested loops there are a couple of methods that can be used. For example, you can convert the 2d array (x, y) into a single row array (1, Number_Of_All_Elements) then loop over them. But you need to find the right formula to get the combinations for each cell. Another way is to us a shifted version from the original 2d array then you can multiply them to get the combinations.
- Pizza Modern Solution
Modern solution is the place where magic happens. We'll show how to use data structure algorithm to solve this problem. First, the pizza problem is not about pizza, surprise. The pizza problem representation of a spatial analysis problem. Spatial analysis defined as (Wiki): Spatial analysis or spatial statistics includes any of the formal techniques which study entities using their topological, geometric, or geographic properties. Spatial analysis used in games engines, geo analysis as in Uber and many other fields.
The most common algorithms to solve spatial problems are Rtree and QuadTree.
One of the clearest explanations for the rtree (sometimes the algorithm named by Rbush or KDTree) found here written by Vladimir Agafonkin, a software engineer at Mapbox.
Almost all spatial data structures share the same principle to enable efficient search: branch and bound. It means arranging data in a tree-like structure that allows discarding branches at once if they do not fit our search criteria.

The trick in the pizza problem that it has 3-dimensions. The X dimension, refer to the row location. The Y dimension, refer to the column location. And the Z dimension that refer to the ingredient. We need to solve with the KDTree. Where the K refer to the dimension number. We may visualize the 3D problem as in the following image:

Most of the programming languages have a libraries for Rtree so all what you need to do is to fit the data into the algorithm and run it. It is very fast and provide an optimum solution.
You may work to optimize the algorithm by derive more features or you may try different tree algorithms. In this reference there is a benchmark for a group of tree algorithms.
The solution is not limited to these algorithms. There are other algorithms and methods to get the pizza sliced. If you have any, please share it with us.
