This repository is just an collection of my trail code while learning C++ primer. It also helps me familarize with the git usages.
So, noted that this repo does not make any sense. It is just my own playground.
I was familiar with git in an IDE, such as Pycharm and IDEA. But when confronted with actual commands especially for authorization and branches, I was confused. So, in this chapter, I will try several use cases, selecting proper commands and understand them.
Initially, I already have some cpp files locally. Now, I want to creat a github repo and put everyting up-to-date on it. Can we do that just using shell?
I find the solution from this githubdocs. It suggestes us do it with Github CLI, which enables us use command line to control our repo on Github. At first, we need to initialize the local directory as a Git repository:
git init -b mainAfter this command, one .git folder will be created under the curent folder. Then, stage and commit all the files in our project with:
git add . && git commit -m "initial commit"To create a repository for your project on GitHub, use the gh repo create subcommand. When prompted, select Push an existing local repository to GitHub and enter the desired name for your repository.

Now, we have successfully created a Github repo based on our working directory.
Initially, I am confused with the git concepts and lingos, such as master, origin, remote. Now, I start to understand that master is the branch, which usually serves as a main branch, and origin is the alias of the remote host, which can be monitored by git remote -v. With this command, we can know the exact host where we fetch the online code in the current branch from, and push our code to.
For example, if we want to add a remote from Paul, with the url https://github.com/paulboone/ticgit and fetch the code from this new remote:
$ git remote
origin
$ git remote add pb https://github.com/paulboone/ticgit
$ git remote -v
origin https://github.com/schacon/ticgit (fetch)
origin https://github.com/schacon/ticgit (push)
pb https://github.com/paulboone/ticgit (fetch)
pb https://github.com/paulboone/ticgit (push)Now we can use the string pb on the command line, standing for the whole URL. For example, if you want to fetch all the information that Paul has but that you don't yet have in your repository, you can run git fetch pb:
$ git fetch pb
remote: Counting objects: 43, done.
remote: Compressing objects: 100% (36/36), done.
remote: Total 43 (delta 10), reused 31 (delta 5)
Unpacking objects: 100% (43/43), done.
From https://github.com/paulboone/ticgit
* [new branch] master -> pb/master
* [new branch] ticgit -> pb/ticgitPaul’s master branch is now accessible locally as pb/master — you can merge it into one of your branches, or you can check out a local branch at that point if you want to inspect it.
From then on, it has been a little bit tricky. Because it leads to merge, checkout and some other concepts. But they are all centered around branches. So, that is why I want to play with branches in this section.
This repo is mainly for three different tasks:
- cpp primer trail;
- labuladong algorithm;
- csapp labs
So, I might as well create three different braches corresponding to these tasks, practicing usage of branches of github. And I am required to conduct the task under the specific branch.
Firstly, I need to create branch named cpp-trail:
git brach cpp-trailThen, stage the modifications and upload it to the remote:
$ git commit -m "add branch"
$ git push -u origin cpp-trail
Enumerating objects: 7, done.
Counting objects: 100% (7/7), done.
Delta compression using up to 8 threads
Compressing objects: 100% (4/4), done.
Writing objects: 100% (4/4), 2.00 KiB | 2.00 MiB/s, done.
Total 4 (delta 2), reused 0 (delta 0), pack-reused 0
remote: Resolving deltas: 100% (2/2), completed with 2 local objects.
remote:
remote: Create a pull request for 'cpp-trail' on GitHub by visiting:
remote: https://github.com/Steven-cpp/MyCasualRepo/pull/new/cpp-trail
remote:
To https://github.com/Steven-cpp/MyCasualRepo.git
* [new branch] cpp-trail -> cpp-trail
Branch 'cpp-trail' set up to track remote branch 'cpp-trail' from 'origin'.We can see that, this branch has also been created in the remote.
Now we continue our C++ Primer learning path from containers. Grasping the STL containers in C++ is of great importance. So I created /01_containers for all my practices that play with containers.
In C++, container is divided into sequential container, associative container, and container adapters. There are three container adapters: stack, queue, and priority_queue. Essentially, an adaptor is a mechanism for making one thing act like another. A container adaptor takes an existing container type and makes it act like a different type. For example, the stack adaptor takes a sequential container (other than array or forward_list) and makes it operate as if it were a stack.
By default both stack and queue are implemented in terms of deque, and a priority_queue is implemented on a vector. We can override the default container type by naming a sequential container as a second type argument when we create the adaptor:
// empty stack implemented on top of vector
stack<string, vector<string>> str_stk;
// str_stk2 is implemented on top of vector and initially holds a copy of svec
stack<string, vector<string>> str_stk2(svec);For the most part, the containers define surprisingly few operations, only including construct, add & remove elements, return specific iterators. Other useful operations, such as sorting or searching, are defined not by the container types but by the standard algorithms. In this way, we just need to define and remember the independent generalized algorithm, saving ourselves from dealing with every container.
All the containers (except array) provide efficient dynamic memory management. We may add elements to the container without worrying about where to store the elements. The container itself manages its storage. Both vector and string provide more detailed control over memory management through their reserve and capacity members.
The library containers define a surprisingly small set of operations. Rather than adding lots of functionality to each container, the library provides a set of algorithms, most of which are independent of any particular container type. These algorithms are generic: They operate on different types of containers and on elements of various types. We just need to pass in the iterators and target value to use it, such as searching and sorting.
Noted that, the generic algorithms do not themselves execute container operations. They operate solely in terms of iterators and iterator operations. The fact that the algorithms operate in terms of iterators and not container operations has a perhaps surprising but essential implication: Algorithms never change the size of the underlying container. Algorithms may change the values of the elements stored in the container, and they may move elements around within the container. They do not, however, ever add or remove elements directly.
However, one method can implicitily invoke push_back() method of the container, and thus change the size of the container. This method is defined in <iterator> named back_inserter(1), taking a container as input, returning an insert iterator bound to that container. We can assign value i to the dereferenced insert iterator, which is equivalent to calling push_back(i) of this container:
vector<int> vec; // empty vector
auto it = back_inserter(vec); // assigning through it adds elements to vec
*it = 42; // vec now has one element with value 42By further extending this usage, we can also combine this with algorithms, enabling change of container size:
vector<int> vec; // empty vector
// ok: back_inserter creates an insert iterator that adds elements to vec
fill_n(back_inserter(vec), 10, 0); // appends ten elements to vecRead-only Algorithms
Use find(3) to find target value val from the given interval in a container. It returns an iterator to the first element that is equal to that value. If there is no match, find returns the second parameter (always end of the interval) to indicate failure.
// value we’ll look for
int val = 42;
// result will denote the element we want if it’s in vec,
// OR vec.cend() if not
auto result = find(vec.cbegin(), vec.cend(), val);
// report the result
cout << "The value " << val << (result == vec.cend() ? " is not present" : " is present") << endl;Use accumulate(3) to sum up over the given interval. Thanks to its third parameter, we can calculate the sum as long as the type supports + operator.
// Basic case: integer sum
int sum = accumulate(vec.cbegin(), vec.cend(), 0);
// Can also be used to concatenate strings together
string sum = accumulate(v.cbegin(), v.cend(), string(""));🔍 When to Use Const Iterators
Ordinarily it is best to use
cbegin()andcend()with algorithms that read, but do not write, the elements. However, if you plan to use the iterator returned by the algorithm to change an element’s value, then you need to passbegin()andend().
Algorithms that Replace Container Elements
When we use an algorithm that assigns to elements, we must take care to ensure that the sequence into which the algorithm writes is at least as large as the number of elements we ask the algorithm to write.
Use copy(3) to copy values from a given range to the destination range starting from the target iterator. Here is an example usage of built-in arrays:
int a1[] = {0,1,2,3,4,5,6,7,8,9};
int a2[sizeof(a1)/sizeof( * a1)]; // a2 has the same size as a1
// ret points just past the last element copied into a2
auto ret = copy(begin(a1), end(a1), a2); // copy a1 into a2Noted that the returned value ret points to the element just next to the last element copied into a2.
Use sort(2) and unique(2) to reoder the array, and finally use erase(2) to remove all the rudundant elements, as is shown in the figure below:

Once vec is sorted, we want to keep only one copy of each word. The unique algorithm rearranges the input range to "eliminate" adjacent duplicated entries, and returns an iterator that denotes the end of the range of the unique values. The overall code is shown below:
// sort words alphabetically so we can find the duplicates
sort(words.begin(),words.end());
// unique reorders the input range so that each word appears once in the front portion of the range and returns an iterator one past the unique range
auto end_unique = unique(words.begin(), words.end());
// erase uses a vector operation to remove the nonunique elements
words.erase(end_unique, words.end());Use stable_sort(2) to sort a container, keeping the relative order of the quivalent values (judeged by the predicate). This algorithms is implemented by MergeSort. While merging two ordered list, it compares whether left <= right, if so, push the left element to the array. Therefore, for any pair of the equivalent elements, if they are:
- Adjacent: this sort will not change their order;
- NOT adjacent: they will generally be divided to two groups (left and right), and then merge from left to right, still keeping the original order.
Therefore, we can safely make a conclusion that mergeSort can keep the relative order of the equivalent elments in one container.
Use for_each(3) to apply the given method to elements in the given range:
// print words of the given size or longer, each one followed by a space
for_each(wc, words.end(), [](const string &s){cout << s << " ";});
cout << endl;We can use vec.rbegin() (reverseBegin) and vec.rend() to get the reverse iterator and iterate the container reversely.
vector<int> vec = {0,1,2,3,4,5,6,7,8,9};
// reverse iterator of vector from back to front
for (auto r_iter = vec.crbegin(); // binds r_iter to the last element
r_iter != vec.crend(); // crend refers 1 before 1st element
++r_iter) // decrements the iterator one element
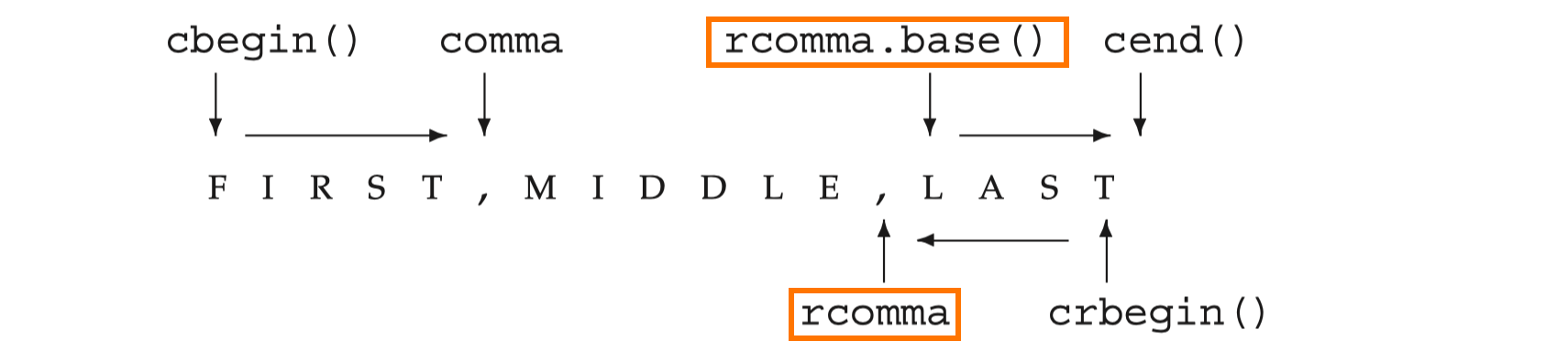
cout << * r_iter << endl; // prints 9, 8, 7, . . . 0Now supposing we want to find the last element seperated by , in a word list s = "Fist, Middle, Last". One possible solution is to use reverse iterator:
auto lastComma = find(s.crbegin(), s.crend(), ',');
cout << string(lastComma.base(), s.cend()) << endl;
// OUTPUT: LastDue to the lastComma generated from reverse iterator, so it is also a reverse iterator. We can use base() method to convert a reverse iterator to the corresponding forward iterator. And it may in turn point to the next forwarding element as is shown in the diagram below:
Suppossing that we want to count the words not in the exclude word list, we should better use associative container to implement it.
set<string> exclude = {"the", "an", "a"};
map<string, int> wordcnt;
while (cin << word){
if (exclude.find(word) == exclude.end())
wordcnt[word]++;
}Apart from the commonly used map and set, C++ also provides multiple-key associative container, such as multi-set. The use case for a std::multiset is when you need to store elements that may have multiple occurrences, and you want to maintain the order of the elements. For example, you might use a std::multiset to store a list of words in a document, and you want to maintain the order of the words as they appear in the document.
Finding elements in a multi-map
// definitions of authors and search_item as above
// beg and end denote the range of elements for this author
for (auto beg = authors.lower_bound(search_item),
end = authors.upper_bound(search_item);
beg != end; ++beg)
cout << beg->second << endl; // print each titleAdding elements to map
When we insert into a map, we must remember that the element type is a pair. Often, we don't have a pair object that we want to insert. Instead, we create a pair in the argument list to insert:
// four ways to add word to word_count
word_count.insert({word, 1});
word_count.insert(make_pair(word, 1));C++11 is a version of the C++ programming language that was published as an ISO standard in 2011. It introduced a number of significant changes to the language, including support for concurrency, improved support for type inference, and the inclusion of several new features, such as lambda expressions and the auto keyword.
C++11 has been widely adopted and is now considered a "modern" version of C++. It is supported by most modern C++ compilers and is the default version of C++ used in many newer projects. It helps us to write more efficient and effective code.
The lambda expression in C++ is an isolated callable object, just like a inline function, but can just use the variable in capture list. Essentially, when we define a lambda, the compiler generates a new (unnamed) class type that corresponds to that lambda. A lamba expression has the form
[capture list](parameter list) -> return type { function body }where capture list is an (often empty) list of local variables defined in the enclosing function (where this expression is defined); return type, parameter list, and function body are the same as in any ordinary function. However, unlike ordinary functions, a lambda must use a trailing return (§ 6.3.3, p. 229) to specify its return type.
📖 Trailing Return
In C++, a "trailing return" refers to the use of the
->operator to specify the return type of a function when it is defined, and we useautoat the beginning to signal the use of trailing return. This is typically used when the return type depends on template arguments and cannot be specified directly. Instead, the return type can only be infered during compile time.Here is an example of a function with a trailing return type:
template <typename T, typename U> auto add(T t, U u) -> decltype(t + u) { return t + u; }
We can omit either or both of the parameter list and return type but must always include the capture list and function body. So we can define a simple lambda expression that returns one constant integer:
auto f = [] { return 42; };
cout << f() << endl;By filling all the parts, we can then obtain one complete lambda expression:
[sz](const string &a) { return a.size() >= sz; };Lambda is actually an unnamed class type. For now, what’s useful to understand is that when we pass a lambda to a function, we are defining both a new type and an object of that type: The argument is an unnamed object of this compiler-generated class type. Similarly, when we use auto to define a variable initialized by a lambda, we are defining an object of the type generated from that lambda.
By default, the capture is passed by value. The parameters will be stored as a copy when we define the lambda function.
void fcn1() {
size_t v1 = 42; // local variable
// copies v1 into the callable object named f
auto f = [v1] { return v1; };
v1 = 0;
auto j = f(); // j is 42; f stored a copy of v1 when we created it
}But we can also specify how to pass the parameters either in the capture list, and the function body:
for_each(words.begin(), words.end(),
[&os, c](const string &s) { os << s << c; });Noted that we cannot copy ostream objects; the only way to capture os is by reference (or through a pointer to os).
What's more, rather than explicitly listing the variables used in the function body, we can also let the compiler to infer which variable to import, by using = to imply passing by value and & by reference:
void biggies(vector<string> &words,
vector<string>::size_type sz,
ostream &os = cout, char c = ’ ’) {
// other processing as before
// os implicitly captured by reference; c explicitly captured by value
for_each(words.begin(), words.end(),
[&, c](const string &s) { os << s << c; });
// os explicitly captured by reference; c implicitly captured by value
for_each(words.begin(), words.end(),
[=, &os](const string &s) { os << s << c; });
}It is not so easy to write a function to replace a lambda that captures local variables. But C++11 provides a new keyword bind defined in the functional header. It takes a callable object and generates a new callable that “adapts” the parameter list of the original object. The common form of a call to bind is:
auto newCallable = bind(callable, __n, arg);which means replacing the arg in the original parameter list (still starting from
Due to the potential risks of using raw pointers, such as memory leak, and invalid use of freed address, C++ 11 provides a smart pointer that can manage the objects using dynamic memory automatically. It is defiend in the <memory> header.
There are two types of smart pointers: shared_ptr and unique_ptr, where shared_ptr allows multiple pointers to refer one same object, while the unique_ptr owns the object.
The safest way to allocate and use dynamic memory is to call a library function named make_shared. This function allocates and initializes an object in dynamic memory and returns a shared_ptr that points to that object.
It is always a good practice to add clear and concise comment to our codes. When it comes to cpp, what is the best practice to document our code?
A series of @param tags, usually one for each parameter. Each tag should have a description following the parameter name. You do not usually need to document default arguments; Doxygen will provide the default automatically. If the description extends over multiple lines, each line after the first must be indented.
Parameters should be listed in the same order as they appear in the function or method signature. Make sure to keep the parameter list in sync with the actual parameters; Doxygen will issue a warning if they don’t match.
@param should be given with the [in], [out], or [in, out] tag if the function method contains any output parameters. The [in] tag is optional if all parameters are input, even if other functions or methods in the same class or package use output parameters.
/**
* Compute mean and standard deviation for a collection of data.
*
* @param[out] mean the mean of `data`, or `NaN` if `data` is empty
* @param[out] stdDev the unbiased (sample) standard deviation, or `NaN`
* if `data` contains fewer than 2 elements
* @param[in] data the data to analyze
*/
void computeStatistics(double & mean, double & stdDev, std::vector<double> const & data);When two or more consecutive parameters have exactly the same description, they can be combined:
/**
* @param x, y the coordinates where the function is evaluated
*/Recently, I am working for my master project, optimizing the GiST index in PostgreSQL. I have complied the original project, getting the executable programs. But now, I need to modify some constants in the source code, and I'm wondering whether the modification will affect the program. Therefore, I need to make it out theoratically and practically.