Dynamic Allocation Tests #406
Conversation
|
/run standalone |
SDL/Quintuplet.h
Outdated
| printf("Unhandled case in createEligibleModulesListForQuintupletsGPU! Module index = %i\n", i); | ||
| #endif | ||
| } | ||
| occupancy = 2 * tripletsInGPU.nTriplets[i]; |
There was a problem hiding this comment.
this will look bad; probably more so at high pt.
But we need breakdown plots; CI is not showing them
There was a problem hiding this comment.
Here are the breakdown plots. I don't see any issues, maybe I'm missing something though. You can also see the breakdown plots from the CI by downloading the full zip file. (The mywork_4d67cfD-PU200/ one is the breakdown for this PR):
There was a problem hiding this comment.
ehm, I was wrong at least at base/integrated level ;)
There was a problem hiding this comment.
You can also see the breakdown plots from the CI by downloading the full zip file.
ah OK.
Here are the breakdown plots. I don't see any issues, maybe I'm missing something though.
yes, it looks OK; it takes an effort to see a difference.
The other side (opposite to high pt high occupancy) to worry about is the low end: a module with one triplet can have more than two matching. This may become more visible without PU.
There was a problem hiding this comment.
the low occupancy end could be moderated by e.g. 2*n_T3 + 10 ("random" guess for values; I'm still implying some plots need to be made to show the boundary is OK).
|
The PR was built and ran successfully in standalone mode. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
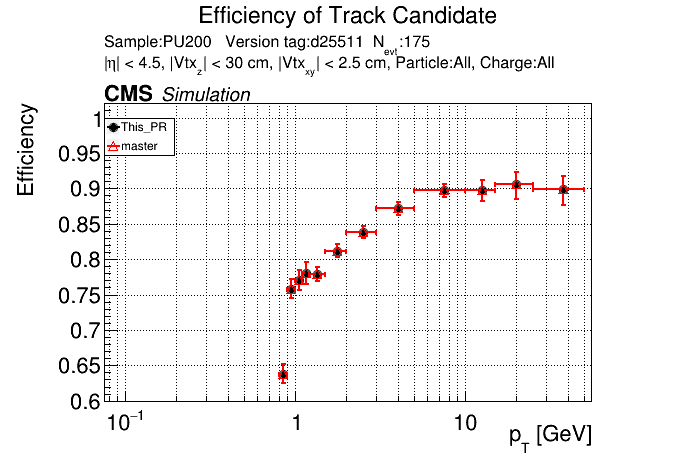
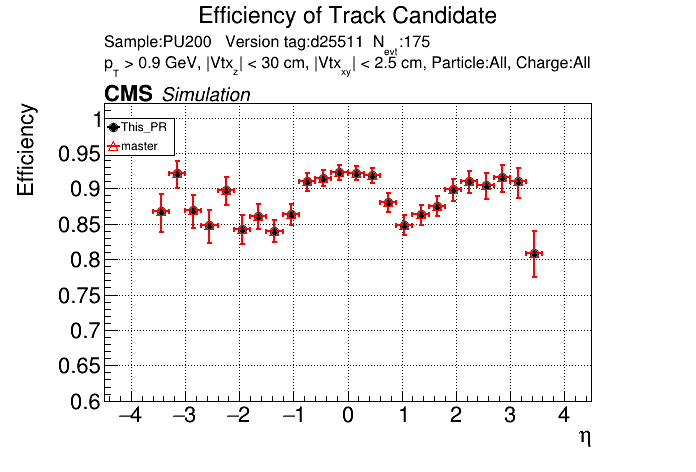
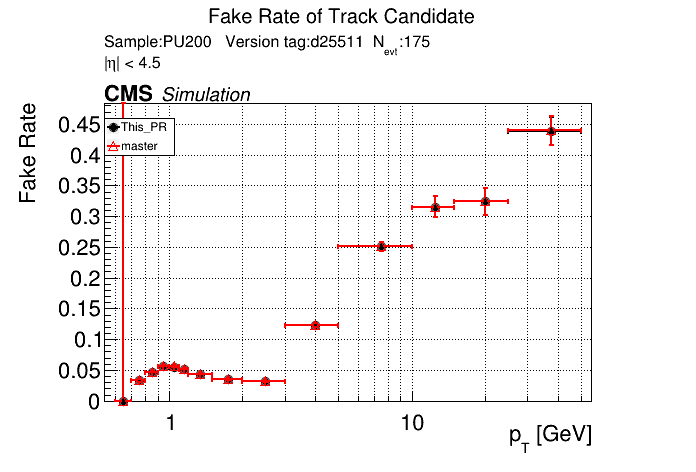
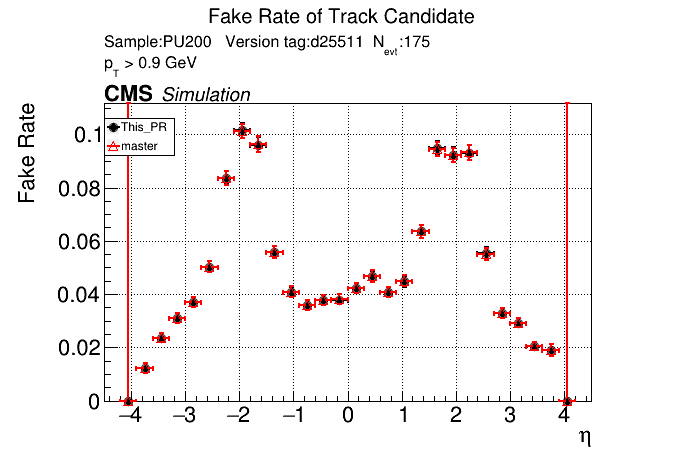
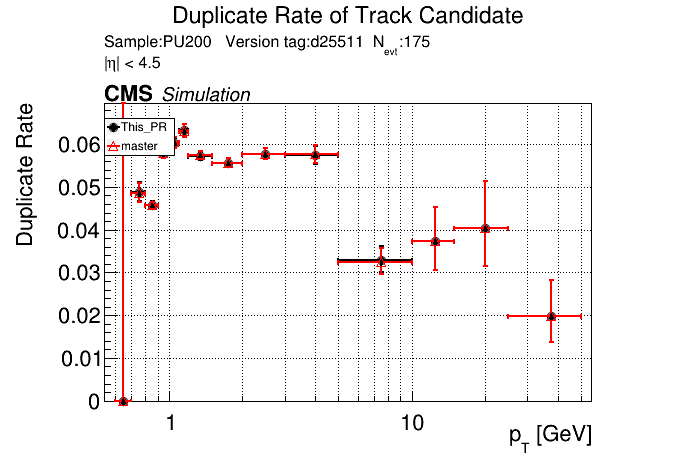
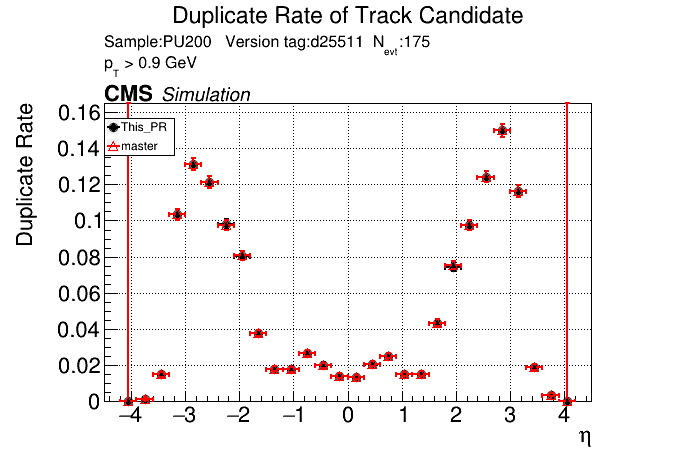
|
@GNiendorf |
|
I'll check the warning printouts and post the results soon. I also want to try this method out on the other objects. The 2x number is arbitrary btw. You can set it to 1x but the efficiency goes down by a hair so I figured I would keep it at 2x for now. |
|
The PR was built and ran successfully with CMSSW. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |
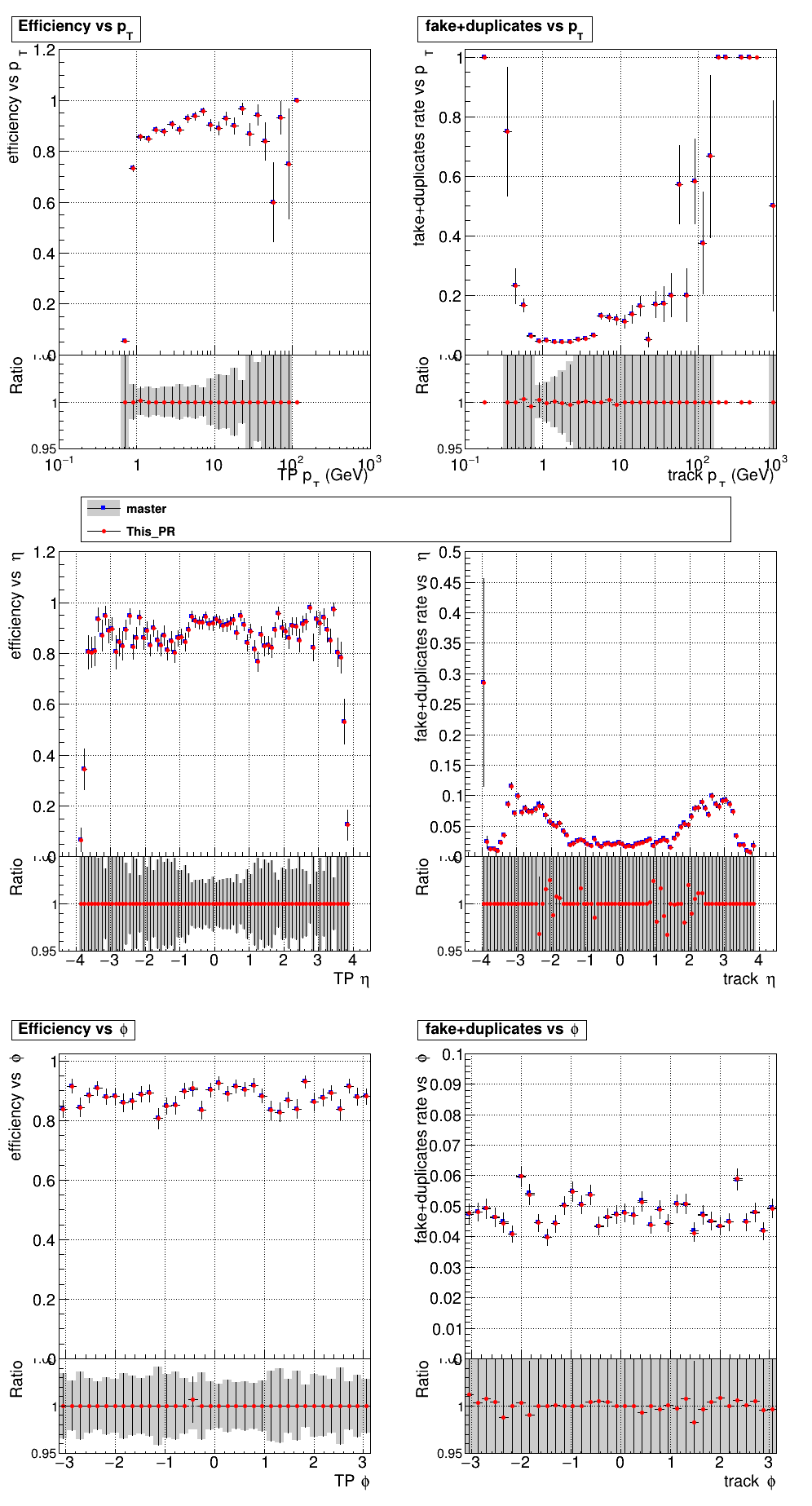
|
@slava77 Excess alert printouts go way up with these changes, although a lot of these alerts come from the same module numbers. Maybe these are mostly duplicates that get cleaned up later on? t5 excess warnings (175 events)- Here are the current excess alerts for the other objects as a reference. |
Are the counts on low end of the distribution or somewhat spread out? do we have per-module truncated and non-truncated occupancies to be able to get some more detail where to truncate? |
it could be. The main problem I can expect now would be in variability of results. Unless there are exact duplicates that contribute significantly; offhand I think we don't have any, but then I seem to recall that there was a recent thread suggestive that there may be. |
Oh yeah, it looks like the warnings are coming from modules with low occupancy. Seems like your suggestion might be an easy fix. |
|
I'm not sure what an acceptable amount of cutoff would be, especially since the other objects seem to get cutoff at a much higher rate. Here I added an offset of +30 and the excess printouts go from 45,927 to 3,106. We still see a 5x improvement on most events over the current master for the nQuints allocation size. |
|
/run standalone |
|
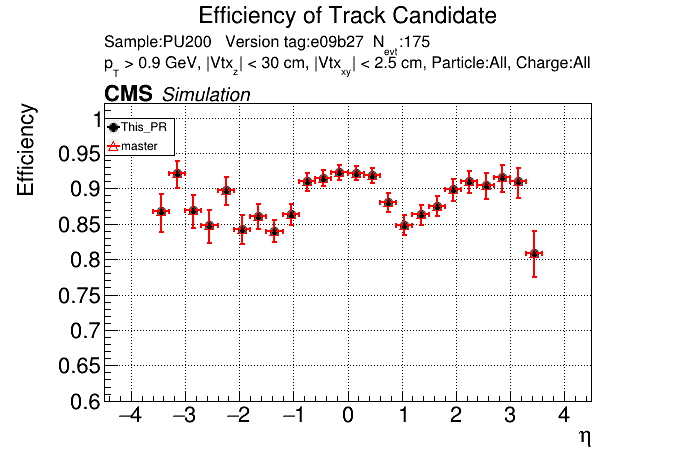
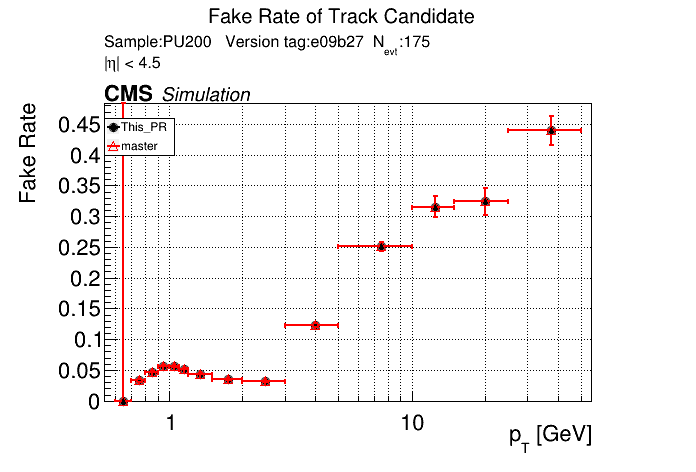
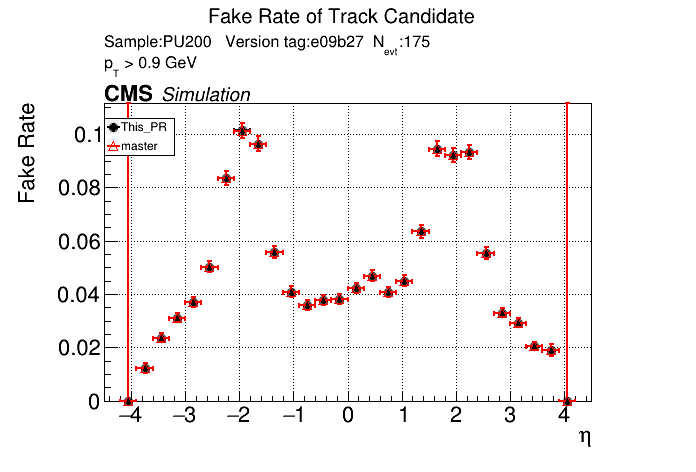
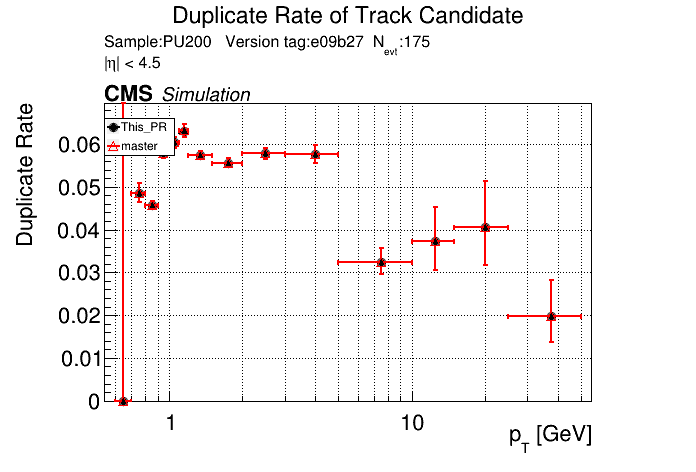
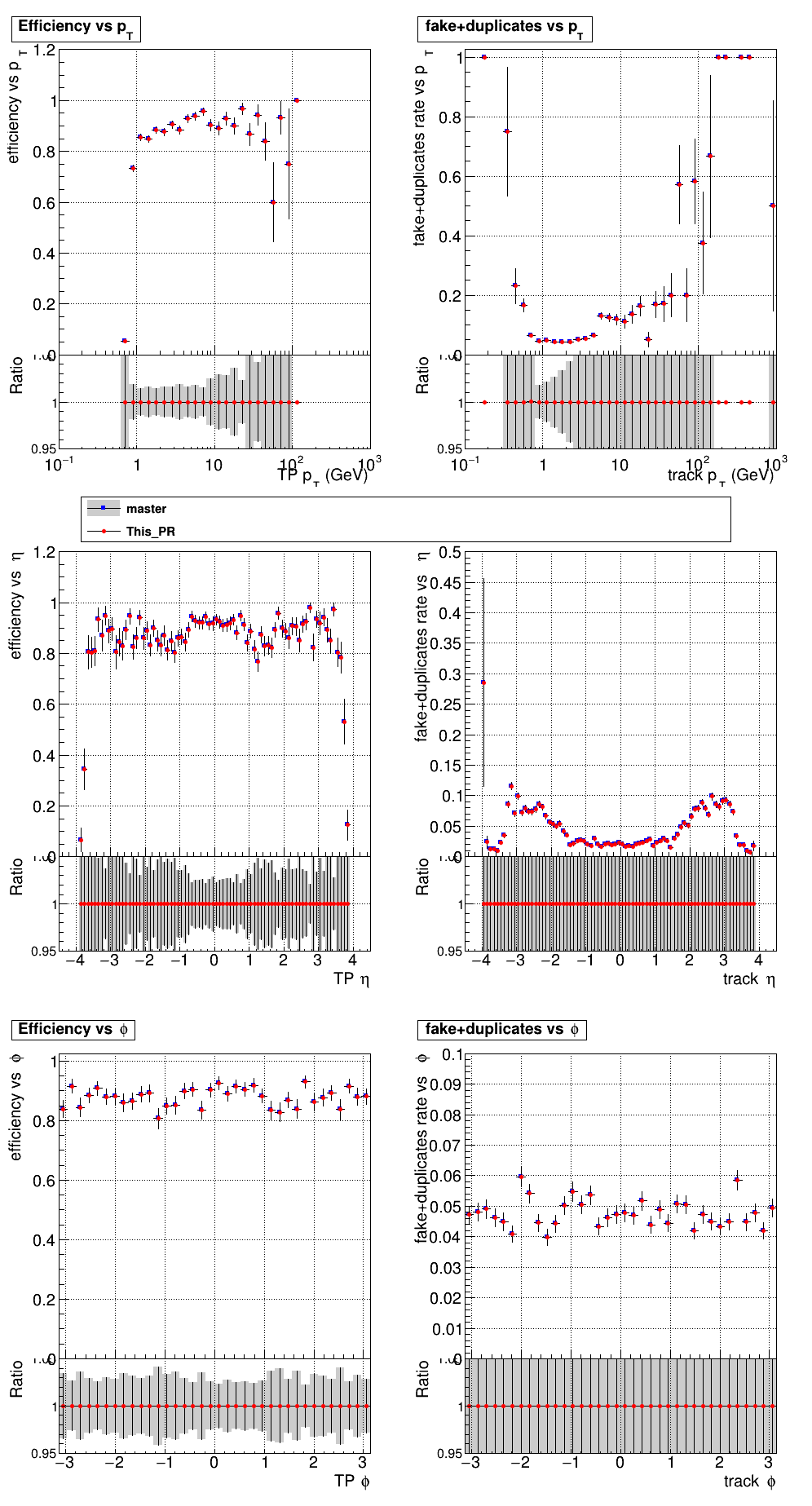
The PR was built and ran successfully in standalone mode. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
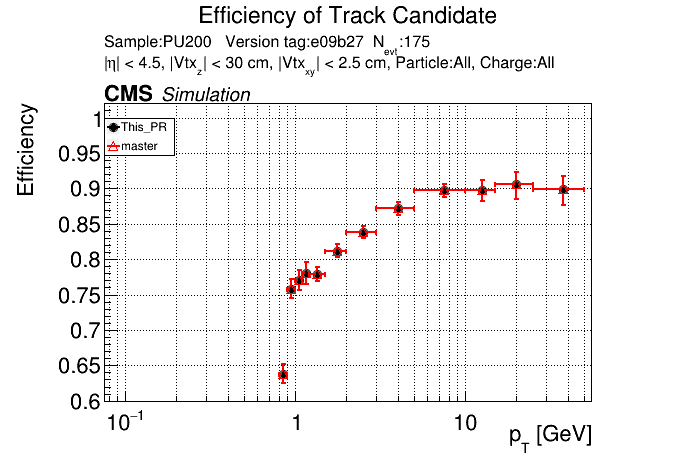
|
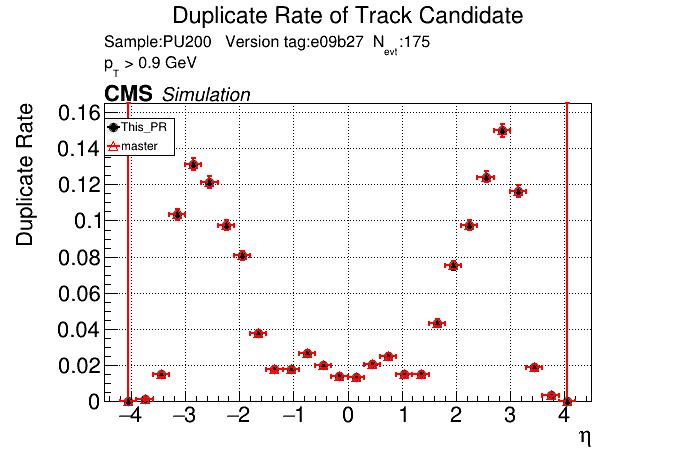
The PR was built and ran successfully with CMSSW. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |
|
Closing this PR since Tracklooper is discontinued. |
|
Do you intend to port it to SegmentLinking/cmssw, or is this development discontinued as a whole? |
|
Not in the short-term, since this isn't necessary right now for the low pT stuff. If memory becomes an issue this will have to be revisited. |
I see a 5x-10x reduction (from 500k to 50k-100k per event) in the nTotalQuintuplets variable from the changes below from @slava77's suggestion. Using this PR for tests. Obviously no timing difference with the cache enabled, but I do see improvement when it is turned off:
Timing with dynamic allocation (this PR)

Master Timing
