Composable & modular pipeline for Multimodal Retrieval Augmented Generation with citation logic to link to underlying multimodal sources.
Sravan Jayanthi
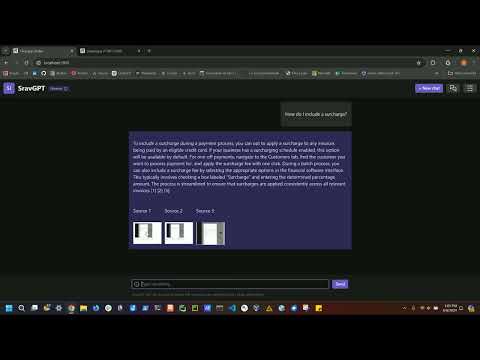
Multimodal Multi-hop RAG is a powerful and modular framework designed for closed-domain question answerring that supports multiple data modalities with several rounds of information retrieval & reasoning. This repository provides a robust infrastructure to build and deploy models that can retrieve and generate text, images, and other types of data in a cohesive pipeline. This application deonstrates the usage of DSPy & image verbalization with GPT-4o to enable dynamic pipelines for contextual multi-hop question answering over multimodal content.
Before setting up the project, ensure you have the following installed:
-
Clone the repository:
git clone https://github.com/yourusername/Multimodal-RAG.git cd Multimodal-RAG -
Create and activate a new Conda environment:
conda create -n mrag python=3.8 conda activate mrag
-
Install PyTorch with CUDA toolkit packaged:
conda install anaconda::pillow==9.2.0 pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
-
Install Detectron2 (Windows):
Follow the instructions here.
-
Install Layout Parser:
Follow the instructions here.
In glean/chatapp, use the command reflex run.
It will take a few minutes on the first setup to successfully chunk, verbalizer & serialize the document contents.
To setup the backend service, in a separate shell run python backend\qa_service.py
With both services setup, you can visit http://localhost:3000/ & start submitting queries!
The Multimodal-RAG system follows a client-server architecture to provide efficient and scalable Retrieval Augmented Generation (RAG) for multimodal data.
The system utilizes the unstructured library for document ingestion. This library allows for the seamless processing and structuring of various document types, enabling the extraction of useful information from unstructured data sources.
For image data, the system uses GPT-4o for image verbalization. This involves generating descriptive text based on the visual content of images, which is then used in conjunction with other textual data to enhance the retrieval and generation process.
For complex queries that require reasoning across multiple pieces of information, the system implements multi-hop question answering. This is achieved using DSPy, which dynamically specifies prompts and optional examples to improve the performance of the program. DSPy enables the system to compile programs that can effectively handle multi-hop reasoning, enhancing the accuracy and relevance of the generated responses.
The backend is powered by FastAPI & user interface (UI) of the system is built using Reflex. This client-server structure ensures a robust system that can deliver quick responses to user queries.
- unstructured
- dspy-ai
- qdrant-client[fastembed]
- onnx
- cudatoolkit
- torch
- pdf2image
- pillow
- charset-normalizer
- layoutparser
- detectron2
This project is licensed under the MIT License - see the LICENSE file for details.