There were 193,460 European patent applications filed at the European Patent Office in 2022.
The EPO, and several other agencies are really interested in trends associated with the filings of patents to specific areas such as ‘Green Plastics’ (e.g., plastics that can be recycled, or that are made from biodegradable materials).
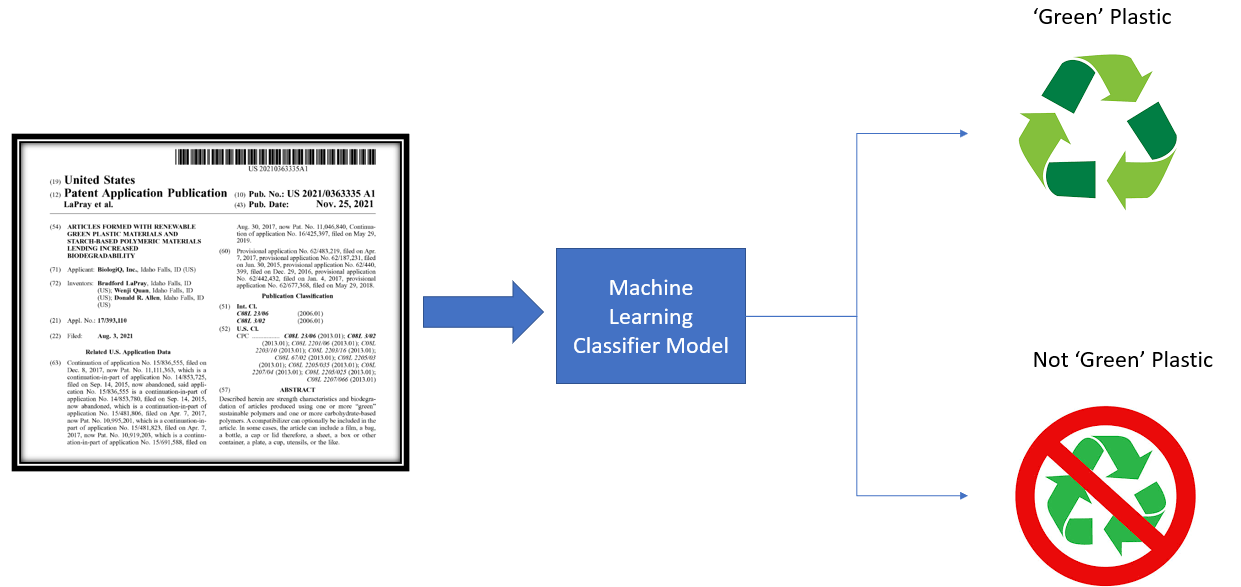
Typically, to identify whether a patent is related to a certain topic or not, a person would have to manually read through a patent application and assign classification labels to it based on their opinions. Patent applications can be hunderds of pages long, and with the sheer amount of applications that the EPO receive annually, it's easy to see why patent classification is a tedious task!
Hence, there is a need for quick and robust methods of accurately classifying the plethora of patents being submitted to the EPO to highlight any trends in ‘Green Plastics’ filings, or filings in any other areas of interest (e.g., renewable energies, artificial intelligence, augmented reality, drug discovery)
By employing machine learning, in the form of Natural Language Processing algorithms, the cost, and likelihood of misclassification of patents, in any technical area, can be significantly reduced, while speeding up the process.
To address the challenge of classifying patents, the EPO held its first ever Codefest, where it challenged entrants to develop creative and reliable artificial intelligence (AI) models for automating the identification of patents related to green plastics.
To enable contestants to develop their models, the EPO provided access to its extensive dataset of patents and patent classifications. From this, we created a smaller, binary classification dataset, with half of the entries being related to 'Green Plastics' patents, and the other half being related to other patent areas.
- Why we need to classify patents.
- What is Tensorflow?
- Loading datasets into your workspace.
- What Tokenisation, Vectorisation and Word Embeddings are in the context of NLP.
- Methods to analyse and understand a dataset.
- Training a model using the Term-Frequency - Inverse Document Frequency (TF-IDF) vectorisation technique with a Multinomial Bayes algorithm.
- What a MultiLayer Perceptron is, and how they can be used for text classification.
- How to train a Multilayer Perceptron using Tensorflow's Keras.
- Making predictions using a Multilayer Perceptron.
- What are hyperparameters and how do they affect the training and performance of machine learning models.
- Optimise a model's training pipeline using Callbacks
- Visualise a model and plotting training loss curves.
- Visualising the structure of a compiled model.
- Evaluating the performance of a MultiLayer Perceptron.
- What a LSTM is, and how they can be used for text classification.
- How to train a LSTM using Tensorflow's Keras.
- Evaluating the performance of the LSTM.
One-Dimensional Convolutional Neural Networks (1D-CNN) (Complete after Intro and Multi-Layer Perceptron Notebooks)
- What a 1D-CNN is, and how they can be used for text classification.
- How to train a 1D-CNN using Tensorflow's Keras.
- What a pooling layer is?
- Evaluating the performance of the 1D-CNN.
- What a Transformer is, and how they can be used for text classification.
- How to train a Transformer using Tensorflow's Keras and Object Oriented Programming.
- What is attention?
- What is a softmax layer?
- Evaluating the performance of the Transformer.
| Task | Time |
|---|---|
| Reading | 25 hours |
| Practising | 20 hours |
It would help a lot if you went through the following Graduate School courses before going through this exemplar:
Data Exploration and Visualisation
Data Processing with Python Pandas
Plotting in Python with Matplotlib
Introduction to Machine Learning
Mathematics for Machine Learning Specialisation (Coursera)
- Access to Google Colaboratory
- Basic Math (matrices, averages)
- Programming skills (python, pandas, numpy, tensorflow)
- Machine learning theory (at level of intro to machine learning course)
Just open up the 'Introduction_and_Data_Handling' notebook and click on the blue 'Open in Colab' button to get started.
├── Datasets
| ├── GreenPatents_Dataset.csv
| ├── NotGreenPatents_Dataset.csv
├── docs
| ├── 1_Introduction_and_Data_Handling.ipynb
| ├── 2_Multilayer_Perceptron_Classification.ipynb
| ├── 3_LSTM_Classification.ipynb
| ├── 4_Transfomer_Classification.ipynb
| ├── 5_Convolutional_1D_Network_Classification.ipynb
This project is licensed under the BSD-3-Clause license