Création d'une plateforme IoT Cloud et Big Data pour le diagnostique de la maladie de parkinson via des données de capteurs
Dans ce tutoriel nous allons voir comment réaliser un pipeline permettant de récupérer des données de capteur et les exploiter de manière optimal afin d'obtenir une plateforme scalable permettant de se mettre à jour aisément dans le cadre du diagnostique de parkison.
Le pipeline réalisé dans ce tutoriel sera comme illustré dans la figure ci dessous :
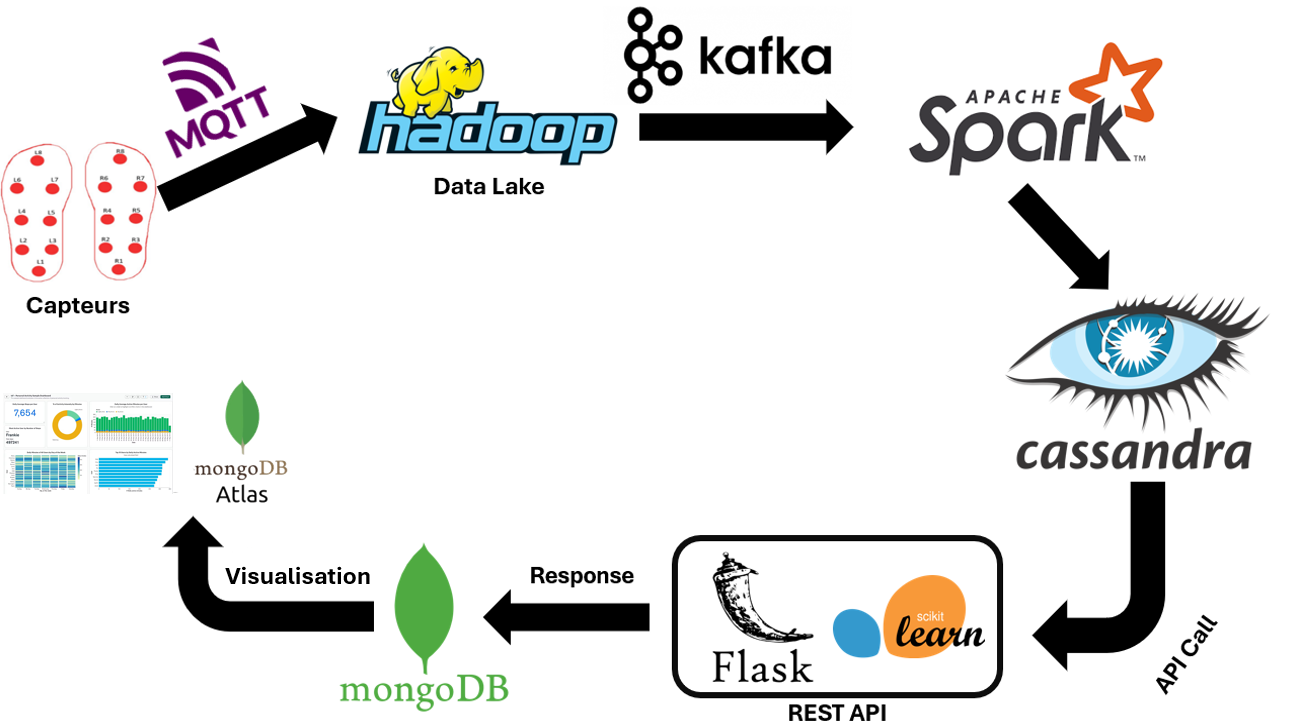
Ce data pipeline collecte des données de capteurs, d'API et d'appareils IoT via MQTT. Les données sont ensuite stockées dans un data lake Hadoop envoyé ensuite via kafka vers Spark qui traite les données et les stocke dans Cassandra. Ces données sont par la suite communiqué à une API REST créer avec flask conteant un modèle de machine learning disponible dans la bibliothéque Sickit-Learn retournant les résultats du modèle qui sont par la suite stocké dans MongoDB et puis envoyé vers Atlas permetant de visualiser les différentes métriques obtenus.
Ce pipeline est un exemple de la façon dont les données peuvent être collectées, stockées, traitées et analysées pour générer des informations utiles. Il peut être utilisé dans une variété d'applications, telles que la surveillance des performances, la détection de fraude, l'analyse des sentiments et la recommandation de produits.
L'intégralité des outils illustré dans le pipeline seront intégrés en localhost via le langage de programmation Python et avec le système d'exploitation Ubuntu, nous passerons en revue l'integralité des installations nécessaire ainsi que la programation et paramètrage à réaliser pour faire fonctionner la pipeline.
Dans un but d'accéssebilité et de simplicité nous simulerons les capteurs en utilisant le dataset Gait in Parkinson's Disease un dataset contenant différent fichier txt représentant les données retourner par les capteurs sur différents patients.
Etant donné que nous utilisons Ubuntu comme système d'exploitation Python est dèja installé cependant si vous ne l'avez pas il suffit simplement d'exécuter la commande suivante dans votre terminal :
sudo apt install python3Ce guide explique comment installer le broker MQTT Mosquitto sur Ubuntu.
Étape 1 : Ajout du dépôt Mosquitto Ajoutez le PPA Mosquitto à vos sources de logiciels pour obtenir la dernière version de Mosquitto.
sudo apt-add-repository ppa:mosquitto-dev/mosquitto-ppa
Mettez à jour la liste des paquets avec la commande suivante :
sudo apt-get update
Étape 2 : Installation de Mosquitto Installez le broker Mosquitto avec la commande suivante :
sudo apt-get install mosquittoLa sortie indique les paquets qui seront installés, y compris les dépendances et le paquet Mosquitto lui-même.

Étape 3 : Installation des clients Mosquitto Installez les clients Mosquitto, qui fournissent les commandes 'mosquitto_pub' et 'mosquitto_sub' pour publier et s'abonner aux topics MQTT.
sudo apt-get install mosquitto-clients
Étape 4 : Vérification du statut du service Mosquitto Vérifiez que le service Mosquitto est actif et en cours d'exécution :
sudo service mosquitto status Le service Mosquitto MQTT Broker est maintenant actif et fonctionnel.
Le service Mosquitto MQTT Broker est maintenant actif et fonctionnel.
Étape 5 : Installation de la librairie python pour l'utilisation de MQTT
pip install paho-mqttCe guide vous aidera à installer et démarrer Apache Kafka.
Étape 1 : Extraction de Kafka Après avoir téléchargé la dernière version de Kafka depuis le site officiel, extrayez le contenu du fichier tar.gz en utilisant la commande suivante :
tar -xzf kafka_2.13-3.6.1.tgzEnsuite, accédez au répertoire de Kafka :
cd kafka_2.13-3.6.1
Étape 2 : Démarrage du Serveur Kafka Initialisez le stockage de Kafka et démarrez le serveur avec les commandes suivantes :
- Générez un UUID pour le stockage Kafka et formatez-le :
bin/kafka-storage.sh random-uuid
bin/kafka-storage.sh format -t <UUID> -c config/kraft/server.properties- Démarrez le serveur Kafka :
bin/kafka-server-start.sh config/kraft/server.propertiesLa sortie dans le terminal devrait ressembler à ce qui suit, indiquant que le serveur est actif.

Étape 3 : Installation de la librairie python pour l'utilisation de kafka
pip install kafka-python confluent_kafkaCe guide vous aidera à installer Apache Cassandra sur votre système.
Étape 1 : Prérequis Vérifiez la version de Java installée sur votre système avec la commande suivante :
java -version

Étape 2 : Téléchargement de Cassandra Téléchargez la dernière version de Cassandra à l'aide de 'curl' :
curl -OL https://dlcdn.apache.org/cassandra/4.1.3/apache-cassandra-4.1.3-bin.tar.gz
Étape 3 : Vérification de l'intégrité du téléchargement Vérifiez l'intégrité du fichier téléchargé avec :
gpg --print-md SHA256 apache-cassandra-4.1.3-bin.tar.gz
Téléchargez le fichier de signature SHA256 et vérifiez-le avec :
curl -L https://downloads.apache.org/cassandra/4.1.3/apache-cassandra-4.1.3-bin.tar.gz.sha256
Étape 4 : Extraction de l'archive Cassandra Extrayez Cassandra avec :
tar xzvf apache-cassandra-4.1.3-bin.tar.gz
Étape 5 : Démarrage de Cassandra Accédez au répertoire de Cassandra et démarrez le serveur :
cd apache-cassandra-4.1.3 && bin/cassandra
Étape 6 : Vérification du statut de Cassandra Utilisez la commande nodetool pour vérifier l'état du cluster Cassandra :
bin/nodetool status
Étape 7 : Installation de la librairie python pour l'utilisation de Cassandra
pip install cassandra-driverCe guide explique comment installer MongoDB sur Ubuntu.
Étape 1 : Installation des dépendances Installez les paquets nécessaires pour ajouter un nouveau référentiel sur votre système :
sudo apt install software-properties-common gnupg apt-transport-https ca-certificates -y

Étape 2 : Ajout du référentiel MongoDB Ajoutez la clé GPG officielle de MongoDB :
curl -fsSL https://www.mongodb.com/server-7.0.asc | sudo gpg --dearmor -o /usr/share/keyrings/mongodb-server-7.0.gpgAjoutez le référentiel de MongoDB à votre système :
echo "deb [ arch=amd64,arm64 signed-by=/usr/share/keyrings/mongodb-server-7.0.gpg ] https://repo.mongodb.org/apt/ubuntu jammy/mongodb-org/7.0 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-7.0.list
Étape 3 : Mise à jour de la liste des paquets Mettez à jour la liste des paquets pour inclure les paquets de MongoDB :
sudo apt update
Étape 4 : Installation de MongoDB Installez MongoDB en utilisant la commande suivante :
sudo apt install mongodb-org -y
Étape 5 : Démarrage du service MongoDB Démarrez le service MongoDB et vérifiez son statut :
sudo systemctl start mongod
sudo systemctl status mongodÉtape 6 : Vérification de l'installation Vérifiez que MongoDB est correctement installé en vérifiant la version :
mongod --version
Étape 7 : Installation de la librairie python pour l'utilisation de MongoDB
pip install pymongoSuivez ce guide pour configurer un environnement Hadoop sur votre système.
Étape 1 : Installation de Java Vérifiez que Java est correctement installé et configuré sur votre système.

Étape 2 : Création d'un utilisateur Hadoop Créez un utilisateur spécifique pour Hadoop et configurez les informations d'utilisateur nécessaires.

Étape 3 : Génération des clés SSH Générez une paire de clés SSH pour permettre à l'utilisateur Hadoop de se connecter en SSH sans mot de passe.

Étape 4 : Téléchargement de Hadoop Utilisez wget pour télécharger la distribution tarball de Hadoop depuis le site officiel d'Apache.

Étape 5 : Extraction de Hadoop Extrayez l'archive téléchargée et déplacez le dossier Hadoop vers un emplacement souhaité.

Étape 6 : Configuration de l'environnement Hadoop
Définissez les variables d'environnement pour Java et Hadoop dans le fichier .bashrc de l'utilisateur.

Mettez à jour le fichier .bashrc pour prendre en compte les nouvelles variables d'environnement.

Ajoutez le chemin d'accès à Java dans le fichier de configuration Hadoop.

Étape 7 : Configuration du système de fichiers HDFS
Configurez le système de fichiers HDFS en modifiant les fichiers de configuration de Hadoop, notamment core-site.xml.


Définissez le répertoire pour le NameNode et le DataNode.

Étape 8 : Configuration de MapReduce
Définissez le framework MapReduce en modifiant le fichier mapred-site.xml.

Étape 9 : Configuration de YARN Configurez YARN en modifiant le fichier yarn-site.xml pour définir le gestionnaire de ressources et d'autres propriétés.

Étape 10 : Formatage du NameNode Formatez le NameNode pour initialiser le système de fichiers HDFS.

Étape 11 : Démarrage des daemons Hadoop Démarrez les daemons Hadoop, y compris le NameNode, le DataNode et les services YARN.




Étape 12 : Installation de la librairie python pour l'utilisation de Hadoop
pip install hdfsÉtape 1 : Mettre à jour les paquets système Pour commencer le processus d'installation, ouvrez un terminal et mettez à jour les paquets de votre système en exécutant la commande suivante :
sudo apt-get updateÉtape 2 : Télécharger Apache Spark Accédez au site officiel d'Apache Spark et téléchargez la dernière version stable d'Apache Spark en sélectionnant le package approprié pour votre système. Vous pouvez utiliser la commande wget pour télécharger le package directement depuis le terminal.
wget https://dlcdn.apache.org/spark/spark-3.4.0/spark-3.4.0-bin-hadoop3.tgzÉtape 3 : Extraire le package Apache Spark Une fois le téléchargement terminé, extrayez le package en utilisant la commande tar :
tar xvf spark-3.4.0-bin-hadoop3.tgzÉtape 4 : Déplacer le répertoire Spark
Déplacez le répertoire Spark extrait vers l'emplacement souhaité, tel que /opt :
sudo mv spark-3.4.0-bin-hadoop3 /opt/sparkÉtape 5 : Configurer les variables d'environnement
Pour garantir que Apache Spark sur Ubuntu est accessible de n'importe où sur votre système, vous devez configurer les variables d'environnement nécessaires. Ouvrez le fichier .bashrc à l'aide d'un éditeur de texte :
nano ~/.bashrcRajouter les lignes suivantes a la fin du fichier :
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/binSave the file and exit the text editor. Then, reload the .bashrc file:
source ~/.bashrcÉtape 6 : Vérifier l'installation Pour vérifier que Apache Spark est correctement installé sur Ubuntu, ouvrez un nouveau terminal et saisissez la commande suivante :
spark-shellÉtape 7 : Installation de la librairie python pour l'utilisation de Spark
pip install pysparkPour installer flask et sickit learn il suffit d'executer la commande suivante :
pip install Flask scikit-learnOn commence par créer le fichier python sensors_data_receiver.py et on y importe les libraires nécessaire :
import paho.mqtt.client as mqttClient
import time
import os
import pandas as pdPar la suite on crée les fonctions permettant de nous connecter et d'envoyer des messages avec notre broket MQTT comme suit :
def on_connect(client, userdata, flags, rc):
"""
Fonction de rappel pour gérer la connexion au courtier MQTT.
"""
if rc == 0:
print("Connecté au courtier MQTT")
global Connected
Connected = True
else:
print("Échec de la connexion")
def on_publish(client, userdata, result):
"""
Fonction de rappel pour gérer la publication réussie des données.
"""
print("Données publiées \n")
passMaintenant qu'on a notre fonction nous permettant de nous connecter à notre broker MQTT et de publier des messages nous pouvons passer a la création de notre client MQTT :
Connected = False
broker_address = "localhost"
port = 1883
client = mqttClient.Client("Python_publisher") # Créer une nouvelle instance
client.on_connect = on_connect # Attacher la fonction à l'événement de connexion
client.on_publish = on_publish # Attacher la fonction à l'événement de publication
client.connect(broker_address, port=port) # Se connecter au courtier
client.loop_start() # Démarrer la boucle
while not Connected: # Attendre la connexion
time.sleep(0.1)
print("Maintenant connecté au courtier: ", broker_address, "\n")Pour résumer jusqu'ici nous avons créé un client MQTT qui se connecte à un courtier local via le protocole MQTT. Il initialise des variables, définit des fonctions de rappel pour la gestion des événements de connexion et de publication, puis tente de se connecter au courtier. La boucle principale attend que la connexion soit établie, utilisant une pause de 0.1 seconde pour éviter une consommation excessive de ressources. Une fois la connexion réussie, le programme affiche un message confirmant la connexion au courtier.
La prochaine étape consiste à envoyer les données, pour cela nous récupérons les données de notre dataset fichier par fichier et ligne par la ligne que nous envoyons sous format JSON qui est le format supporté par les messages MQTT.
try:
while True:
folder_path = 'gait-in-parkinsons-disease-1.0.0'
txt_files = [file for file in os.listdir(folder_path) if file.endswith('.txt')][2:]
# Obtenir l'index du fichier 'SHA256SUMS.txt'
txt_files.index('SHA256SUMS.txt')
# Retirer l'index de la liste
txt_files.pop(txt_files.index('SHA256SUMS.txt'))
for file in txt_files:
df_p = pd.read_csv(folder_path + "/" + file, sep='\t')
# Renommer les colonnes pour un accès plus facile
df_p.columns = ['time', 'L1', 'L2', 'L3', 'L4', 'L5', 'L6', 'L7', 'L8', 'R1', 'R2', 'R3', 'R4', 'R5', 'R6', 'R7', 'R8', 'L', 'R']
for row in df_p.to_numpy():
message = {"Patient": file.split('.')[0]}
for c, r in zip(df_p.columns, row):
message[c] = r
topic = "test/parkinson"
client.publish(topic, payload=str(message))
time.sleep(1)
print("Message publié avec succès vers test/parkinson")
except KeyboardInterrupt:
print("Sortie de la boucle")
client.disconnect()
client.loop_stop()Comme dit précédement nous effectuons une lecture continue de fichiers texte contenant des données liées à la maladie de Parkinson. En utilisant la bibliothèque Pandas, il renomme les colonnes pour faciliter l'accès, extrait le nom du patient du nom du fichier, puis publie ces données sous forme de messages structurés sous format json sur le topic MQTT "test/parkinson". La boucle infinie assure une exécution continue, avec une pause d'une seconde entre chaque publication. Le tout pouvant etre interrompue à n'importe quel moment via le clavier.
La réception se faisant dans un programme a part nous créeons le fichier sensors_data_receiver.py ou nous y important toutes les librairies dont nous avons besoin :
import paho.mqtt.client as mqtt
import time
import json
from hdfs import InsecureClientUne fois fait comme lors de l'envoie nous créeons la fonction de connexion et la fonction de réception a la place de la fonction d'envoie :
def on_connect(client, userdata, flags, rc):
"""
Fonction de rappel pour gérer la connexion au courtier MQTT.
"""
if rc == 0:
print("Connecté au broker")
global Connected
Connected = True
else:
print("Échec de la connexion")
def on_message(client, userdata, message):
"""
Fonction de rappel pour gérer les messages MQTT.
"""
json_object = json.loads(str(message.payload.decode("utf-8")).replace("'", '"'))
# Stocker les valeurs de données du message dans une chaîne
data_values = ""
for key, value in json_object.items():
if key != "Patient":
data_values += str(value) + ";"
data_values = data_values[:-1]
# Enregistrer la chaîne dans un fichier CSV avec la clé comme nom de colonne du fichier
local_file = json_object["Patient"]+'.csv'
with open("csv data/"+local_file, 'a') as file:
file.write(data_values + "\n")
hdfs_file_path = f"{data_lake_path}/{local_file}"
if not hdfs_client.status(hdfs_file_path, strict=False): # Si le fichier n'existe pas dans HDFS on le sauvegarde
hdfs_client.upload(hdfs_file_path, "csv data/"+local_file)
print("Données enregistrées dans HDFS")Ici la fonction on_message est une fonction de rappel pour la gestion des messages MQTT. Elle convertit le payload JSON du message, extrait les valeurs de données à l'exception de la clé "Patient", les enregistre localement dans un fichier CSV portant le nom du patient, et effectue un téléchargement vers un data lake en utilisant le système de stockage distribué Hadoop Distributed File System (HDFS) sur lequel nous reviendrons par la suite.
Maintenant nous pouvons créer notre client MQTT chargé de recevoir les messages mais aussi d'initialisé notre data lake avec hadoop qui se doit d'etre créer avant le lancement de notre client.
print("Création d'une nouvelle instance")
client = mqtt.Client("python_test")
client.on_message = on_message # Attacher la fonction au rappel
client.on_connect = on_connect
print("Connexion au broker")
# Création du data lake
hdfs_url = "http://localhost:9870"
hdfs_client = InsecureClient(hdfs_url)
data_lake_path = "data_lake/parkinson_data"
if not hdfs_client.status(data_lake_path, strict=False): # Si le répertoire n'existe pas dans HDFS on le crée
hdfs_client.makedirs(data_lake_path)
client.connect(broker_address, port) # Connexion au broker
client.loop_start() # Démarrer la boucle
while not Connected: # Attendre la connexion
time.sleep(0.1)
print("Abonnement au sujet", "test/parkinson")
client.subscribe("test/parkinson")
try:
while True:
time.sleep(1)
except KeyboardInterrupt:
print("Sortie")
client.disconnect()
client.loop_stop()Ce segment de code réalise tout ce qu'on avait décrit précédemment en établissant une connexion avec un courtier MQTT en utilisant la bibliothèque paho.mqtt.client. Une instance du client est créée, des fonctions de rappel sont attachées pour la gestion des événements de connexion et de réception de messages, et une connexion est établie avec le courtier spécifié. Parallèlement, un système de stockage distribué, représenté par Hadoop Distributed File System (HDFS), est préparé avec un répertoire dédié ("parkinson_data") pour le stockage des fichiers. Le programme s'abonne au sujet MQTT "test/parkinson" pour recevoir les messages correspondants. En entrant dans une boucle infinie, le code réagit aux messages reçus en utilisant la fonction de rappel on_message, enregistrant les données localement dans des fichiers CSV nommés par le patient, puis transférant ces données vers le Data Lake. L'exécution de la boucle peut être interrompue par un signal de clavier, déclenchant la déconnexion du client MQTT du courtier.
IMPORTANT : Les deux programmes sensors_data_receiver.py et sensors_data_receiver.py doivent etre exécuté simultanément pour le bon fonctionnement de la plateforme.
Pour cette étape nous créons un nouveau fichier python se nommant hdfs_read.py et on y importe les librairies nécessaires :
from hdfs import InsecureClient
from confluent_kafka import Producer
import json
import pandas as pdDans ce programme 2 fonctions sont nécessaire la première assez simple consiste simplement à indiquer si kafka a été en mesure de déliver le message.
def delivery_report(err, msg):
"""
Fonction de rappel pour gérer les retours de livraison des messages Kafka.
"""
if err is not None:
print('Échec de livraison du message : {}'.format(err))
else:
print('Message livré pour le prétraitement')la seconde fonction elle est celle de l'envoie du message via kafka :
def produce_sensor_data(producer, topic, file_name, file_content):
"""
Fonction pour produire des données de capteur vers Kafka.
"""
group = file_name[2:4]
message = {
"file_name": file_name,
"content": file_content,
"group": group
}
producer.produce(topic, key=file_name, value=json.dumps(message), callback=delivery_report)
producer.poll(0)
producer.flush()la focntion prend en paramètres un producteur Kafka (producer), un sujet Kafka (topic), le nom d'un fichier (file_name), et le contenu de ce fichier (file_content). La fonction extrait la classe du patient (malade ou saint) à partir des deux premiers caractères du nom de fichier. Elle crée ensuite un message structuré avec le nom du fichier, son contenu, et sa classe. Ce message est ensuite produit sur le sujet Kafka en utilisant la méthode produce du producteur Kafka, avec le nom du patient comme clé, la représentation JSON du message comme valeur, et une fonction de rappel (delivery_report). Enfin, la fonction assure que le message est envoyé immédiatement en utilisant producer.poll(0) et termine en vidant le tampon du producteur avec producer.flush().
La prochaine étape consiste simplement à récupérer les données de notre datalake comme suit :
# Remplacez avec les détails de votre cluster HDFS
hdfs_url = "http://localhost:9870"
data_lake_path = "data_lake/parkinson_data"
client = InsecureClient(hdfs_url)
# Liste des fichiers dans le répertoire Data Lake
files_in_data_lake = client.list(data_lake_path)Après ça, on se connecter à notre producer kafka avec le code suivant :
# Configuration du producteur Kafka
producer_conf = {
'bootstrap.servers': 'localhost:9092',
'client.id': 'python-producer'
}
# Création de l'instance du producteur Kafka
producer = Producer(producer_conf)Maintenant qu'on accès aux données de note data lake et que notre producer kafka est pret nous envoyons le contenu de nos fichier CSV ligne par ligne pour ne pas dépasser la limite de taille des messages autorisé sur kafka on parcours donc l'intégralité de nos fichier ligne par ligne comme montrer dans la code suivant :
# Lire le contenu de chaque fichier
for file_name in files_in_data_lake:
hdfs_file_path = f"{data_lake_path}/{file_name}"
with client.read(hdfs_file_path, encoding='utf-8') as reader:
file_content = reader.read()
for line in file_content.split("\n"):
if line == "":
continue
produce_sensor_data(producer, "sensor_data", file_name.split(".")[0], line)
print("Toutes les données du data lake on était transmises pour prétraitement")Une fois terminé le programme indique qu'il envoyé l'integralité des données et s'arrete.
Les données sont transmises à un notre programme coder dans le fichier data_preprocess.py qui a recours aux librairies suivantes :
from confluent_kafka import Consumer, KafkaError
import json
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, IntegerType, FloatType
from pyspark.sql.functions import col, row_number
from pyspark.sql import Window
from pyspark.sql.functions import mean
import numpy as npCette partie nécessite 2 fonctions la première consistant à récupérer les données transmises par kafka comme montrer dans le bloc de code ci dessous :
def retrieve_data(consumer, topic):
"""
Récupérer les données à partir d'un topic Kafka.
"""
consumer.subscribe([topic])
patient_data = dict()
print("En attente de messages...")
first_message = False
count = 0
while True:
msg = consumer.poll(1.0)
if msg is None:
if first_message:
break
else:
continue
if msg.error():
if msg.error().code() == KafkaError._PARTITION_EOF:
continue
else:
print(msg.error())
break
try:
first_message = True
data = json.loads(msg.value())
row = data["content"].split(";")
if len(row) == 19:
row = [float(x) for x in row]
row.append(0 if data["group"] == "Co" else 1)
if data["file_name"] not in patient_data:
patient_data[data["file_name"]] = []
patient_data[data["file_name"]].append(row)
except json.JSONDecodeError as e:
print(f"Erreur de décodage JSON : {e}")
except KeyError as e:
print(f"Clé manquante dans le JSON : {e}")
consumer.close()
print("Terminé")
return patient_dataCette fonction est conçue pour récupérer des données depuis un topic Apache Kafka. Elle prend en paramètres un consommateur Kafka (consumer) et le sujet Kafka depuis lequel les données doivent être récupérées (topic). La fonction souscrit au sujet spécifié, initialise un dictionnaire vide pour stocker les données des patients, puis entre dans une boucle qui écoute continuellement les messages Kafka. Lorsqu'un message est reçu, la fonction le décode depuis le format JSON, extrait et transforme les données de la colonne "content" au format liste de nombres, ajoute une valeur binaire indiquant le groupe du patient, et stocke la ligne résultante dans le dictionnaire sous la clé correspondant au nom du fichier. La boucle continue jusqu'à ce qu'aucun nouveau message ne soit reçu pendant une seconde. Finalement, le consommateur Kafka est fermé, et le dictionnaire contenant les données des patients est renvoyé.
Cela facilitant le travail de la deuxième fonction chargé du prétraitement des données qui prend en entré le résultat de la fonction précédante et qui réalise le traitement des données comme suit :
def preprocess_data(patient_data):
"""
Prétraiter les données en calculant la moyenne pour chaque groupe de 100 lignes.
"""
spark = SparkSession.builder.appName('PatientData').getOrCreate()
spark.sparkContext.setLogLevel("ERROR")
schema = StructType([
StructField("Time", FloatType(), True),
StructField("L1", FloatType(), True),
StructField("L2", FloatType(), True),
StructField("L3", FloatType(), True),
StructField("L4", FloatType(), True),
StructField("L5", FloatType(), True),
StructField("L6", FloatType(), True),
StructField("L7", FloatType(), True),
StructField("L8", FloatType(), True),
StructField("R1", FloatType(), True),
StructField("R2", FloatType(), True),
StructField("R3", FloatType(), True),
StructField("R4", FloatType(), True),
StructField("R5", FloatType(), True),
StructField("R6", FloatType(), True),
StructField("R7", FloatType(), True),
StructField("R8", FloatType(), True),
StructField("L", FloatType(), True),
StructField("R", FloatType(), True),
StructField("Class", IntegerType(), True)
])
for patient in patient_data:
mean_values = []
patient_data[patient] = spark.createDataFrame(patient_data[patient], schema)
lenght = patient_data[patient].count()
for i in range(0, lenght, 100):
df_with_row_number = patient_data[patient].withColumn("row_number", row_number().over(Window.orderBy("Time")))
if i+100 > lenght:
end = lenght
else:
end = i+100
result_df = df_with_row_number.filter((col("row_number") >= i) & (col("row_number") < end))
result_df = result_df.drop("row_number")
mean_values.append(np.asarray(result_df.select(mean(result_df.L1), mean(result_df.L2), mean(result_df.L3), \
mean(result_df.L4), mean(result_df.L5), mean(result_df.L6), \
mean(result_df.L7), mean(result_df.L8), mean(result_df.R1), \
mean(result_df.R2), mean(result_df.R3), mean(result_df.R4), \
mean(result_df.R5), mean(result_df.R6), mean(result_df.R7), \
mean(result_df.R8), mean(result_df.L), mean(result_df.R), \
mean(result_df.Class)).collect()).tolist()[0])
patient_data[patient] = mean_values
return patient_dataConçue pour effectuer le prétraitement des données en utilisant Apache Spark. Elle prend en entrée un dictionnaire de données de patients (patient_data) et calcule la moyenne pour chaque groupe de 100 lignes dans chaque jeu de données du patient. La fonction utilise la bibliothèque Spark pour créer un DataFrame avec un schéma spécifié, puis itère sur chaque patient dans le dictionnaire. Pour chaque patient, elle divise le DataFrame en groupes de 100 lignes, calcule la moyenne pour chaque groupe sur les colonnes spécifiées, et stocke les valeurs moyennes dans une liste. Le résultat final est une mise à jour du dictionnaire patient_data avec les nouvelles valeurs moyennes pour chaque patient.
Une fois terminer il suffit simplement de lancer le consomateur kafka et de faire appel à nos 2 fonctions :
# Configuration du consommateur Kafka
consumer_conf = {
'bootstrap.servers': 'localhost:9092',
'group.id': 'python-consumer',
'auto.offset.reset': 'earliest'
}
# Création de l'instance du consommateur Kafka
consumer = Consumer(consumer_conf)
patient_data = retrieve_data(consumer, "sensor_data")
preprocessed_data = preprocess_data(patient_data)Cela nous donne un ensemble de données prétraitées qui suffit simplement de stocker pour les utiliser ultérieurement.
Tojours sur le meme fichier python data_preprocess.py nous stockons les données obtenu après le prétraitement dans une base de données cassandra, pour cela nous rajoutons à nos import la ligne de code suivante :
from cassandra.cluster import ClusterPar la suite nous créons la classe suivante :
class Cassandra:
def __init__(self, create_keyspace_command, data):
"""
Initialiser une connexion à Cassandra, créer un espace de clés et une table,
puis insérer des données dans la table.
"""
self.cluster = Cluster()
self.session = self.cluster.connect()
self.session.execute(create_keyspace_command)
self.session.execute("USE Parkinson")
self.session.execute("""
CREATE TABLE IF NOT EXISTS data (
L1 FLOAT,
L2 FLOAT,
L3 FLOAT,
L4 FLOAT,
L5 FLOAT,
L6 FLOAT,
L7 FLOAT,
L8 FLOAT,
R1 FLOAT,
R2 FLOAT,
R3 FLOAT,
R4 FLOAT,
R5 FLOAT,
R6 FLOAT,
R7 FLOAT,
R8 FLOAT,
L FLOAT,
R FLOAT,
Class INT,
)
""")
self.session.execute("TRUNCATE data")
self.insert_data(data)
def insert_data(self, data):
"""
Insérer des données dans la table Cassandra.
"""
for d in data:
self.session.execute(f"""
INSERT INTO data (
L1, L2, L3, L4, L5, L6, L7, L8, R1, R2, R3, R4, R5, R6, R7, R8, L, R, Class
) VALUES (
{d[0]}, {d[1]}, {d[2]}, {d[3]}, {d[4]}, {d[5]}, {d[6]}, {d[7]}, {d[8]}, {d[9]}, {d[10]}, {d[11]}, {d[12]}, {d[13]}, {d[14]}, {d[15]}, {d[16]}, {d[17]}, {d[18]}
)
""")
def close(self):
"""
Fermer la connexion Cassandra.
"""
self.cluster.shutdown()Cette classe Python, nommée Cassandra, est conçue pour faciliter l'intégration et la manipulation de données dans Cassandra. Son constructeur prend en paramètres une commande pour créer un keyspace Cassandra (create_keyspace_command) et des données à insérer (data). La classe initialise une connexion à Cassandra, crée un keyspace et une table appelée "data" avec des colonnes spécifiques représentant des valeurs de capteur et une classe. Ensuite, elle insère les données fournies dans la table à l'aide de la méthode insert_data.
La méthode insert_data itère sur les données fournies et exécute des requêtes d'insertion Cassandra pour chaque ensemble de données. La méthode close permet de fermer proprement la connexion à Cassandra.
Pour finir, nous créons la requete permettant de créer l'espace de clés cassandra et nous sauvegardons les données dans la base de données :
# Définition des paramètres de l'espace de clés Cassandra
keyspace_name = 'ParkinsonData'
replication_strategy = 'SimpleStrategy'
replication_factor = 3
# Création de la requête de création de l'espace de clés
create_keyspace_query = f"""
CREATE KEYSPACE IF NOT EXISTS {keyspace_name}
WITH replication = {{'class': '{replication_strategy}', 'replication_factor': {replication_factor}}};
"""
# Initialisation de l'instance Cassandra, insertion des données, sélection des données et fermeture de la connexion
cassandra = Cassandra(create_keyspace_query, preprocessed_data)
cassandra.close()L'objectif principale de notre plateforme étant le diagnostique des patient il est temps de créer l'API REST contenant le modèle réalisant le diagnostic. Pour cela nous créons le fichier model_api.py et nous importons les librairies suivantes :
from flask import Flask, request, jsonify
from flask_cors import CORS, cross_origin
import pandas as pd
import numpy as np
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score, roc_curve, auc
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
from mlxtend.evaluate import bias_variance_decomp
from sklearn.neighbors import KNeighborsClassifier
import pickleNous commençons par initialiser notre application flask comme suit :
app = Flask(__name__)
CORS(app, resources={r"/*": {"origins": "*", "allow_headers": {"Access-Control-Allow-Origin"}}})
app.config['CORS_HEADERS'] = 'Content-Type'Puis nous créons notre endpoint de la manière suivante :
@app.route('/api/model', methods=['POST'])
@cross_origin(origin='*', headers=['content-type'])
def model():
"""
API endpoint pour entraîner un modèle KNN sur les données fournies.
"""
if request.method == 'POST':
data = request.files.get('data')
columns_name = ["L1", "L2", "L3", "L4", "L5", "L6", "L7", "L8", "R1", "R2", "R3", "R4", "R5", "R6", "R7", "R8", "L", "R", 'Class']
df = pd.DataFrame(data)
X = df.drop('Class', axis=1)
y = df['Class']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
clf = KNeighborsClassifier(n_neighbors=5)
clf.fit(X_train, y_train)
# sauvegarder le modèle avec pickle
filename = 'knn.sav'
pickle.dump(clf, open(filename, 'wb'))
# charger le modèle avec pickle
loaded_model = pickle.load(open(filename, 'rb'))
y_pred = clf.predict(X_test)
# Évaluer les performances du classifieur
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred, average='weighted')
recall = recall_score(y_test, y_pred, average='weighted')
f1 = f1_score(y_test, y_pred, average='weighted')
# Courbe ROC pour une classification multi-classe
y_prob = clf.predict_proba(X_test).argmax(axis=1)
macro_roc_auc_ovo = roc_auc_score(y_test.to_numpy(), y_prob, multi_class="ovo", average="macro")
# Matrice de confusion
cm = confusion_matrix(y_test, y_pred)
# Obtenir les valeurs TP, TN, FP, FN
FP = cm.sum(axis=0) - np.diag(cm)
FN = cm.sum(axis=1) - np.diag(cm)
TP = np.diag(cm)
TN = cm.sum() - (FP + FN + TP)
# Obtenir le biais et la variance du classifieur
loss, bias, var = bias_variance_decomp(clf, X_train, y_train.to_numpy(), X_test, y_test.to_numpy(), loss='0-1_loss', random_seed=23)
return jsonify({'model': filename,
'accuracy': accuracy,
'precision': precision,
'recall': recall,
'f1': f1,
'macro_roc_auc_ovo': macro_roc_auc_ovo,
'confusion_matrix': cm,
'TP': TP,
'TN': TN,
'FP': FP,
'FN': FN,
'bias': bias,
'variance': var,
'loss': loss})Notre endpoint est accessible par la méthode HTTP POST. Lorsqu'une requête POST est reçue, la fonction model est déclenchée. Cette fonction charge des données envoyées dans la requête, les transforme en DataFrame Pandas, puis divise les données en ensembles d'entraînement et de test. Un modèle de classification des k plus proches voisins (KNN) est ensuite entraîné sur les données d'entraînement. Le modèle est sauvegardé en utilisant le module pickle, puis rechargé. Les performances du modèle sont évaluées à l'aide de métriques telles que l'exactitude, la précision, le rappel et le score F1. Une courbe ROC est générée pour une classification multi-classe, et une matrice de confusion est calculée. Les valeurs des vrais positifs, vrais négatifs, faux positifs et faux négatifs sont obtenues, tout comme le biais, la variance et la perte du classifieur. Les résultats de l'évaluation du modèle ainsi que diverses métriques sont renvoyés sous forme de réponse JSON.
Pour terminer on lance notre API avec le code suivant :
if __name__ == '__main__':
app.run(debug=True)Notre API étant maintenant opérationel il est temps de lui faire appel en lui envoyant les données qu'on avait stocké sur cassandra. Nous réaliserons cela dans un programme créer dans le fichier request_model.py. Comme à notre habitude nous débutons par importer les libraires dont nous avons besoin :
import requests
from cassandra.cluster import Cluster
import numpy as npEnsuite, nous recréons notre classe Cassandra sans cependant recréer les espaces de clés ou la table et sans non plus réaliser l'insertion cela ayant dèja été effectué plus tot, cependant nous ajoutons une nouvelle fonction get_data dans notre classe qui via une requete CQL très simple nous permet de récupérer l'intégralité de nos données stockées.
class Cassandra:
def __init__(self):
"""
Initialiser une connexion à Cassandra et utiliser l'espace de clés Parkinson.
"""
self.cluster = Cluster()
self.session = self.cluster.connect()
self.session.execute("USE Parkinson")
def get_data(self):
"""
Récupérer les données à partir de la table Cassandra.
"""
return np.asarray(self.session.execute("SELECT * FROM data"))
def close(self):
"""
Fermer la connexion à Cassandra.
"""
self.cluster.shutdown()Maintenant nous récupérons nos données de la base sous format de numpy array et nous les envoyons à notre API via une requete POST nous et en utilisant son endpoint comme url.
url = 'http://127.0.0.1:5000/api/model'
# Initialiser la connexion à Cassandra, récupérer les données et fermer la connexion
cassandra = Cassandra()
dataset = cassandra.get_data()
cassandra.close()
# Envoyer les données au serveur Flask
response = requests.post(url, files={'data': dataset})Les résultats de notre modèle ayant été récupéré il faut maintenant les stocker, pour cela nous utilisons MongoDB et cela toujours dans le meme programme en ajoutant simplement pour commencer cette ligne de code à nos import :
import pymongoEt a la fin de notre code nous ajoutons ceci :
# Initialiser la connexion à MongoDB
myclient = pymongo.MongoClient("mongodb://localhost:27017")
mydb = myclient["mydatabase"]
mycol = mydb["parkinson"]
# Insérer un document de test, puis le supprimer
mycol.insert_one({"test": "test"})
mycol.drop()
# Réinitialiser la collection
mycol = mydb["parkinson"]
# Vérifier si la base de données existe
dblist = myclient.list_database_names()
if "mydatabase" in dblist:
print("La base de données existe.")
else:
print("La base de données n'existe pas.")
# Insérer le résultat de la requête Flask dans MongoDB
mycol.insert_one(response.json())
print("Modèle et métriques d'évaluation sauvegardés dans MongoDB.")Une connexion à une base de données MongoDB locale. une base de données nommée mydatabase aisni qu'une collection appelée parkinson sont créé au sein de cette base de données. Ensuite, la collection est réinitialisée et vérifiée pour confirmer son existence. Si la base de données mydatabase existe, elle est imprimée dans la console, sinon, un message indiquant qu'elle n'existe pas est affiché.
Le script insère ensuite le résultat de notre requête Flask dans la collection MongoDB parkinson. Enfin, un message indiquant que le modèle et les métriques d'évaluation ont été sauvegardés dans MongoDB est affiché dans la console.
Pour la visualisation des données, on va avoir recours à la plateforme MongoDB Atlas vu sa simplicité d'utilisation et son intégration avec la MongoDB
On commence d'abord par créer un compte sur le site de MongoDB atlas et choisir le plan "gratuit"

Une fois le compte crée, il faut se connecter sur la base de données MongoDB en local. Pour ce faire, il suffit d'aller sur l'onglet Database et puis choisir l'option connect pour configurer la connexion. On va choisir de se connecter via Compass.

On va ensuite installer Compass en choisissant la configuration de notre système

Finalement, on va copier le string de connexion qui va permettre de se connecter à Atlas

Après, on va exporter la base de données depuis le local en utilisant cette commande:
mongodump --uri="mongodb://localhost:27017/parkinson" --archive=mydatabase.dumpPour ensuite l'importer avec le string de connection qu'on a eu:
mongorestore --uri="String ici" --archive=mydatabase.dumpMaintenant qu'on a les données sur Atlas, on procède au volet Charts et on construit les graphes désirés. Pour notre cas, on a obtenu ceci:


