Ali Reza Omrani, Davide Moroni
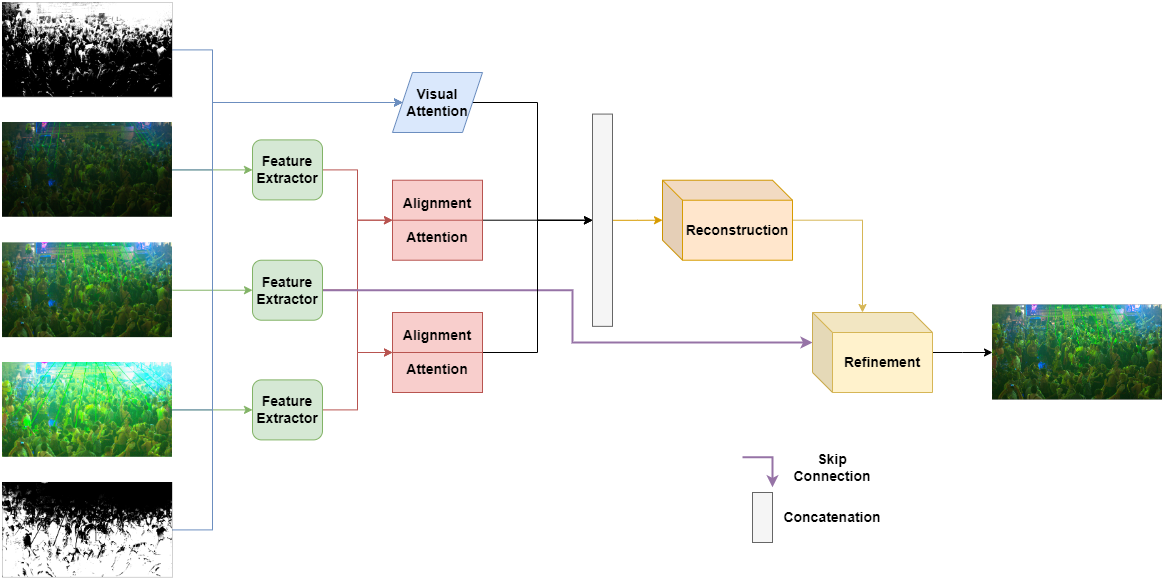
Thanks to High Dynamic Range (HDR) imaging methods, the scope of photography has seen profound changes recently. To be more specific, such methods try to reconstruct the lost luminosity of the real world caused by the limitation of regular cameras from the Low Dynamic Range (LDR) images. Additionally, although the State-Of-The-Art (SOTA) methods in this topic perform well, they mainly concentrate on combining different exposures and pay less attention to extracting the informative parts of the images. Thus, this paper aims to introduce a new model capable of incorporating information from the most visible areas of each image extracted by a Visual Attention Module (VAM) which is a result of a segmentation strategy. In particular, the model, based on a deep learning architecture, utilizes the extracted areas to produce the final HDR image. The results demonstrate that our method outperformed most of the SOTA algorithms.
You can Register in Codalab and download the dataset.
https://codalab.lisn.upsaclay.fr/competitions 1514#participate-get-data
Sort the data into the following subfolders:
Train:
LDR:
short:
short exposure files
exposure files
medium:
medium exposure files
long:
long exposure files
HDR:
GT files
align ratio files
Valid:
$ Same subfolders as Train $
Test:
$ Same subfolders as Train $
To train the model you need to change the train_dir and val_dir in the train.py file.

For more information please refer to the paper https://ieeexplore.ieee.org/document/10494534. Additionally, if you use this code for your research, please cite our paper:
A. R. Omrani and D. Moroni, "High Dynamic Range Imaging via Visual Attention Modules," in IEEE Access, doi: 10.1109/ACCESS.2024.3386096. keywords: {Deep Neural Network;High Dynamic Range imaging;Image Segmentation;Multi-exposure Image;Visual Attention Module},