In this repository you will find a script to fine-tune a Wav2Vec 2.0 model over an Italian and English dataset by using the joint language learning. Furthermore, also inference of a dataset of self-recorded sentences was done.
A fine-tuning of 19 hours was done and the error achieved over the common_voice dataset was 3.3% WER. No information on the language was given to the network so the language was understood directly by the network during inference.
One thing that was possible to notice when decoding the recordings recorded by myself is that, when recognizing a recording mainly in one language, the network was not able to "switch" to another language for recognizing some words in that other language. Example: Label: "mi piace molto il corso di speech recognition" (translation: I really like the Speech Recognition course) Prediction: "mi piace molto il corso di spiecede kegonition"
It is likely that by fine-tuning on bigger datasets with also some "language switch" inside the single recordings, the network will be able to understand more easily this special cases.
The results of the decoding can be found in the file iten_model_both_dataset
The training script was inspired by https://github.com/huggingface/transformers/blob/main/examples/pytorch/speech-recognition/run_speech_recognition_ctc.py while the decoding script was entirely written by myself.
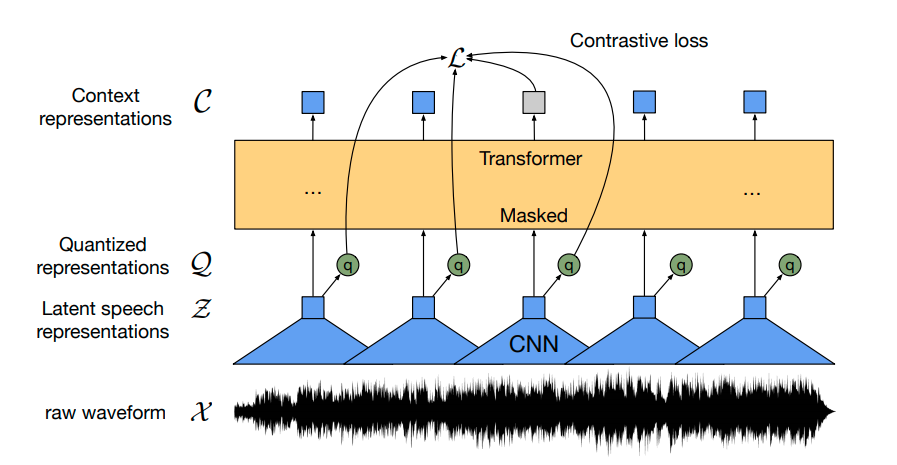
Wav2Vec 2.0 is a pre-trained state-of-the-art transformer-based network released by Facebook mainly relying on the idea of self-supervised learning. More information can be found on the official site or in the official paper.