Documentation | Athina SDK Demo Video | Athina Platform Demo Video →
Athina is an open-source library with plug-and-play preset evals designed to help engineers systematically improve their LLM reliability and performance through eval-driven-development.

Quick Links
- Documentation
- Quick Start
- Preset Evals
- Run an eval
- Run an eval suite
- Customize an eval
- View Results on Athina Dashboard
- Loading Data for Evals
- Cookbooks
- Production Monitoring
Evaluations (evals) play a crucial role in assessing the performance of LLM responses, especially when scaling from prototyping to production.
They are akin to unit tests for LLM applications, allowing developers to:
- Catch and prevent hallucinations and bad outputs
- Measure the performance of model
- Run quantifiable experiments against ambiguous, unstructured text data
- A/B test different models and prompts rapidly
- Detect regressions before they get to production
- Monitor production data with confidence
The journey from a demo AI to a reliable production application is not easy.
Developers usually start iterating on performance by manually inspecting the outputs. Eventually they progress to using spreadsheets, CSVs, or evaluating against a golden dataset.
Each method has drawbacks, requires different tooling, and evaluation methods. See more
A lot of manual effort is required to set up a good infrastructure for running evals - creating a dataset, reviewing the responses, creating evals, and internal tooling / dashboard, tracking experiment parameters and metrics for historical record.
Eventually every LLM developer realizes the indispensable need for evals and an infrastructure to consistently run and track iterations to improve performance and reliability systematically.
Github | Watch Demo Video | Docs
Athina is an open-source library that offers a system for eval-driven development, overcoming the limitations of traditional workflows.
Our solution allows for rapid experimentation, and customizable evaluators with consistent metrics.
Here’s why this is better than building in-house eval infrastructure:
- Plug-and-Play Preset Evals: Ready-to-use evals for immediate application
- Integrated Dashboard: For tracking experiments and inspecting the results in a web UI.
- Custom Evaluators : A flexible framework to craft tailored evals.
- Consistent Metrics: Uniform evaluation standards across all stages. Evaluate your model in dev and prod using a consistent set of metrics.
- Historical Record: Automatic tracking of every prompt iteration.
- Quick Start: Easy 5-min set up.
Here’s a demo video.
The easiest way to get started is to use one of our Example Notebooks as a starting point.
To get started with Athina Evals:
1. Install the athina package
pip install athina
2. Set your API keys
If you are using the python SDK, then can set the API keys like this:
from athina.keys import AthinaApiKey, OpenAiApiKey
OpenAiApiKey.set_key(os.getenv('OPENAI_API_KEY'))
AthinaApiKey.set_key(os.getenv('ATHINA_API_KEY'))If you are using the CLI, then run athina init, and enter the API keys when prompted.
3. Load your dataset like this:
You can also load data using a CSV or Python Dictionary
from athina.loaders import RagLoader
dataset = RagLoader().load_json(json_filepath)4. Now you can run evals like this.
from athina.evals import DoesResponseAnswerQuery
DoesResponseAnswerQuery().run_batch(data=dataset)For more detailed guides, you can follow the links below to get started running evals using Athina.
- Quick Start Guide
- Run an eval
- Run an eval suite
- Customize an eval
- View Results on Athina Dashboard
- Loading Data for Evals
You can use our preset evaluators to add evaluation to your dev stack rapidly.
Here are the preset evaluators in this library:
These evals are useful for evaluating LLM applications with Retrieval Augmented Generation (RAG).
- Context Contains Enough Information
- Context Relevance
- Answer Relevance
- Does Response Answer Query
- Response Faithfulness
We have also built other evaluators that are not yet a part of this library (but will soon be) You can find more information about these in our documentation.
These evals are useful for evaluating LLM-powered summarization performance.
See this page for more information, on how to write your own custom evals.
You could build your own eval system from scratch, but here's why Athina might be better for you:
- Athina provides you with plug-and-play preset evals that have been well-tested
- Athina evals can run on both development and production, giving you consistent metrics for evaluating model performance and drift.
- Athina removes the need for your team to write boilerplate loaders, implement LLMs, normalize data formats, etc
- Athina offers a modular, extensible framework for writing and running evals
- Athina calculate analytics like pass rate and flakiness, and allows you to batch run evals against live production data or dev datasets

- Athina eval runs automatically write into Athina Dashboard, so you can view results and analytics in a beautiful UI.
- Athina track your experiments automatically, so you can view a historical record of previous eval runs.
- Athina calculates analytics segmented at every level possible, so you can view and compare your model performance at very granular levels.
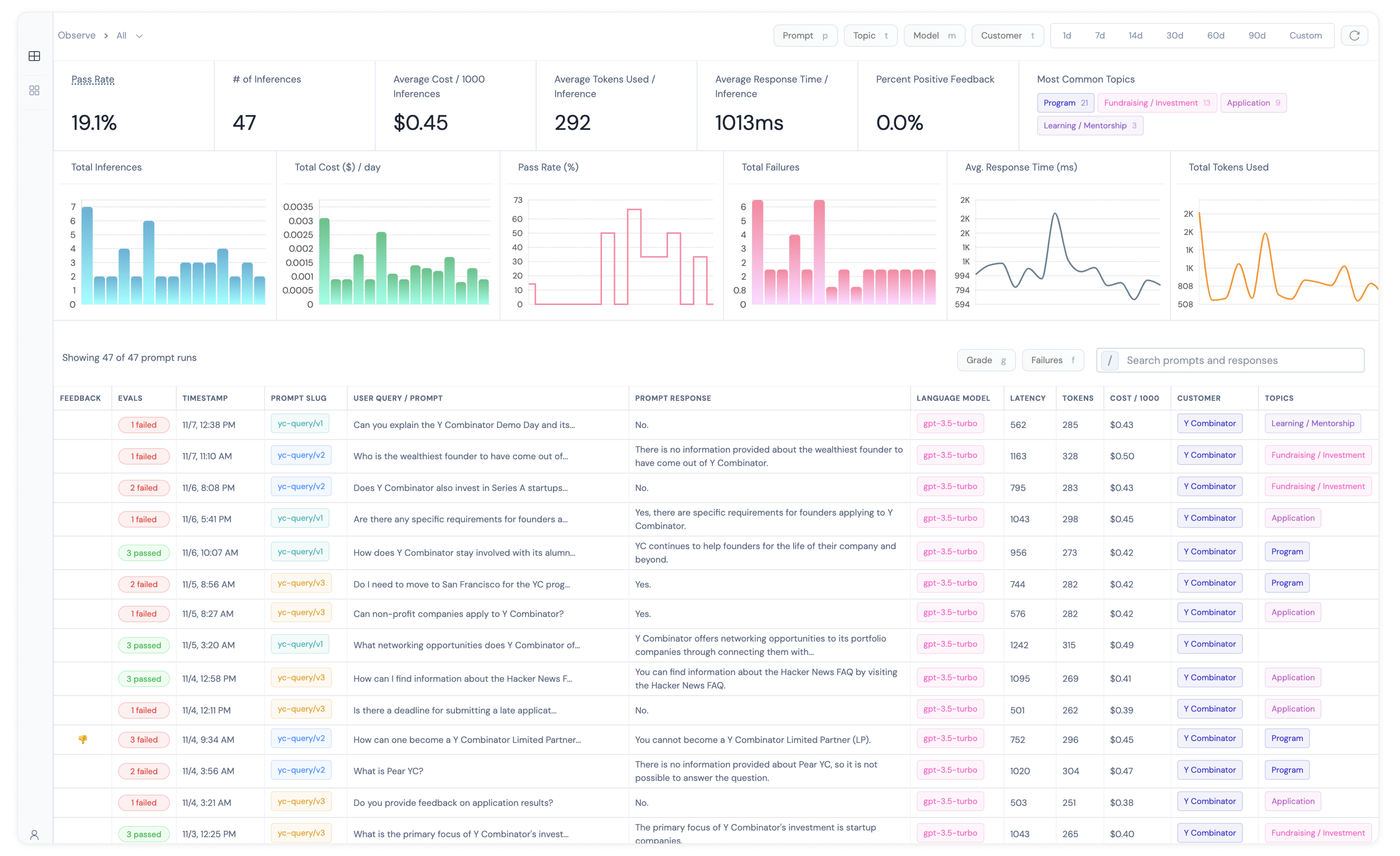
Athina is building an end-to-end LLM monitoring and evaluation platform.
Contact us at [email protected] for any questions about the eval library.