🚀 A detailed tutorial on the theory and implementation of AlphaZero is available in this repo; see alphazero.pdf!
🚀 A pre-trained model is included so you can simply clone this repo and try it out!
Keywords: board game, MCTS, deep convolutional neural network, self-play, PyTorch
This is a learning resource, and likely will not be tractable for games using bigger boards.
Feel free to ask questions through Github Issues.
Connect4 is a middle ground between Connect3 (tic-tac-toe) and Connect5 (Gomoku or Gobang). It is much more difficult than Connect3 but much easier than Connect5. Also, in Connect4, if the first-hand player plays optimally, it will win for sure; this makes it easier to verify how well AlphaZero learned. Here, we use a 6x6 board for Connect4.
四子棋是三子棋(tic-tac-toe)和五子棋的过渡。之所以选择四子棋,是因为四子棋比三子棋难很多,但又比五子棋简单很多。此外,在四子棋中,一个完美玩家在先手的情况下可以百分百获胜,方便我们验证AlphaZero学习的结果。在这里,我们使用6x6的棋盘。
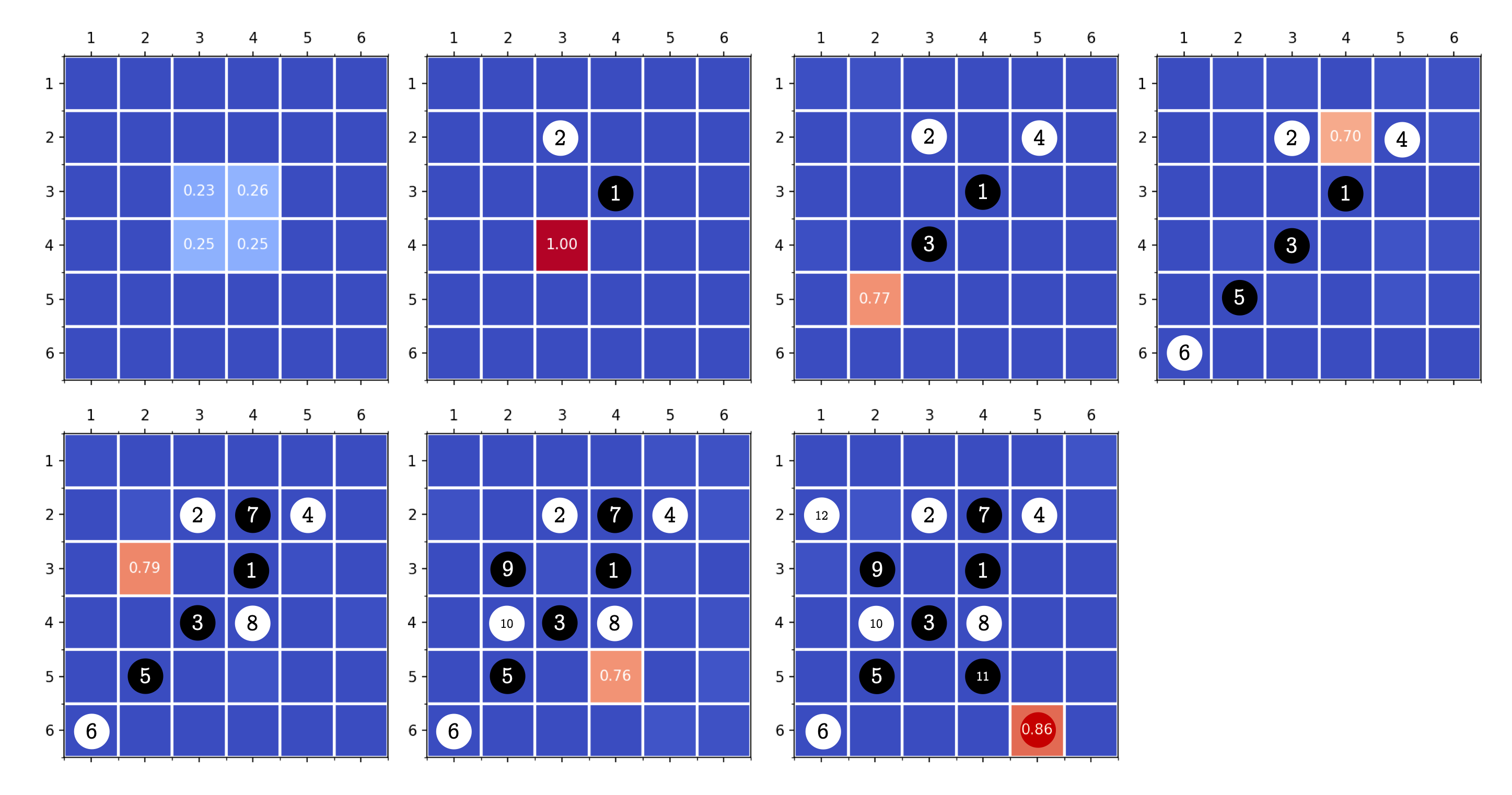
Before we talk about theory and code, let's see what AlphaZero can do after 3000 self-play games.
During training, AlphaZero uses 500 MCTS simulations for each move; during evaluation (for the games below), AlphaZero uses 50-1000 MCTS iterations (randomly picked between this range) to induce some stochasticity.
In all games below, AlphaZero is the first-hand player and holds the black stone, and the values in the background show the prior move probabilities predicted by the convolutional neural network. The human player (me) is the second-hand player and holds the white stone. The final winning move AlphaZero is shadowed.
在讨论理论和代码之前,我们来看看AlphaZero在3000局self-play之后能达到什么样的效果。
在训练当中,AlphaZero每一步使用500次MCTS simuation;在测试中(以下对弈),AlphaZero每一步使用50到1000次(np.random.randint)MCTS simuation来产生一定的随机性。
在以下对弈中,AlphaZero是先手玩家并持有黑棋。棋盘上显示的数字是卷积神经网络预测出的prior move probabilities。人类玩家(我)是后手并持有白棋。AlphaZero最后的放棋位置用深色标出。
Game 1:

Game 2:

Game 3:
A detailed tutorial is available in this repo; see alphazero.pdf.
这个代码库包含一份详细的理论教程,请见alphazero.pdf.
Please first make sure that your working directory is alpha_zero by cd alpha_zero.
How to play against pure MCTS (early moves can take up to 25 seconds but later moves are quicker):
python connect4_mcts_vs_human.py
How to play against pre-trained AlphaZero (moves are fast):
python connect4_alphazero_vs_human.py
How to train AlphaZero from scratch (3000 self-play games & supervised learning takes around 7-8 hours on GPU):
python connect4_train_alphazero.py
Within the training script, you will see wandb.init. wandb stands for Weights and Biases, a website for tracking machine learning training runs. You can learn about it from their website or their YouTube channel, and change my username and run name to yours. Here, during training, the parameters of the convolutional policy-value network is saved locally as a pth file, but they are all uploaded to the cloud (i.e., to wandb). This was convenient for me because I didn't know how to download a file from a remote machine.
After training has finished, you can put pvnet_3000.pth in trained_models (in alpha_zero) and connect4_alphazero_vs_human.py will automatically use it.
AlphaZero involves both MCTS and deep learning. Python isn't the best language for implementing MCTS because it is slow. However, Python is one of the best languages for doing deep learning. These two factors together form a dilemma because I want to use C++ for MCTS but I don't know how to do supervised learning using C++.
In short, I'm much more familiar with Python than C++.
AlphaZero同时包含MCTS和深度学习的元素。Python并不是最适合实现MCTS的语言,因为它太慢了。但Python确实是做deep learning最好的语言之一。这两个因素加在一起让我有些为难,因为我希望用C++来写MCTS,但我并不知道如何在C++中做深度学习。
总而言之,相比于C++,我对Python的熟悉度高很多。
- AlphaGo paper, AlphaGo Zero paper, AlphaZero paper
- A Survey of Monte Carlo Tree Search Methods by Browne et. al
- https://github.com/junxiaosong/AlphaZero_Gomoku
- My policy-value net was almost a direct copy of the policy-value net in this repo. This repo also gave me a lot of help in implementating MCTS. However, my repo has a totally different structure as compared to this repo, and many implementation details are very different.