背景介绍
作为非科班的程序员,在代码规范和程序思维上是有欠缺的(仅代表我个人)。
这些问题会在合作开发项目中暴露出来(阅读其他成员代码以及在其他成员代码上续写功能这类型的任务中暴露的更加明显),比如:对程序模块的封装、底层架构的了解(底层架构对于阅读代码和理解代码很重要)、Python语言的标准库以及装饰器使用等等……
2024年的主题就是:“还债”。目标是尽快补齐在程序架构和工程领域的能力。
TL;DR
在Python工程中,模块是一个包含Python定义和语句的文件,一般以.py作为后缀。模块中的定义可以导入到其他模块或者主程序(main)中,这样做的的目的是方便程序的维护和复用。
- 模块的代入:通过
import导入模块。模块不会直接把模块自身的函数名称添加到当前命名空间中,而是将模块名称添加到命名空间中。再通过模块名称访问其中的函数,例如:import torch \ torch.nn.functional() - 模块的作用:可执行的语句以及函数定义,用于初始化模块。每个模块都有自己的私有命名空间,它会被用作模块中定义的所有函数的全局命名空间。模块可以导入其他模块,被导入的模块名称会被添加到该模块的全局命名空间。(每个模块都有自己的命名空间,防止与用户的全局变量发生冲突)。
模块功能所做的一切就是为了:代码的复用和方便维护。
总览:
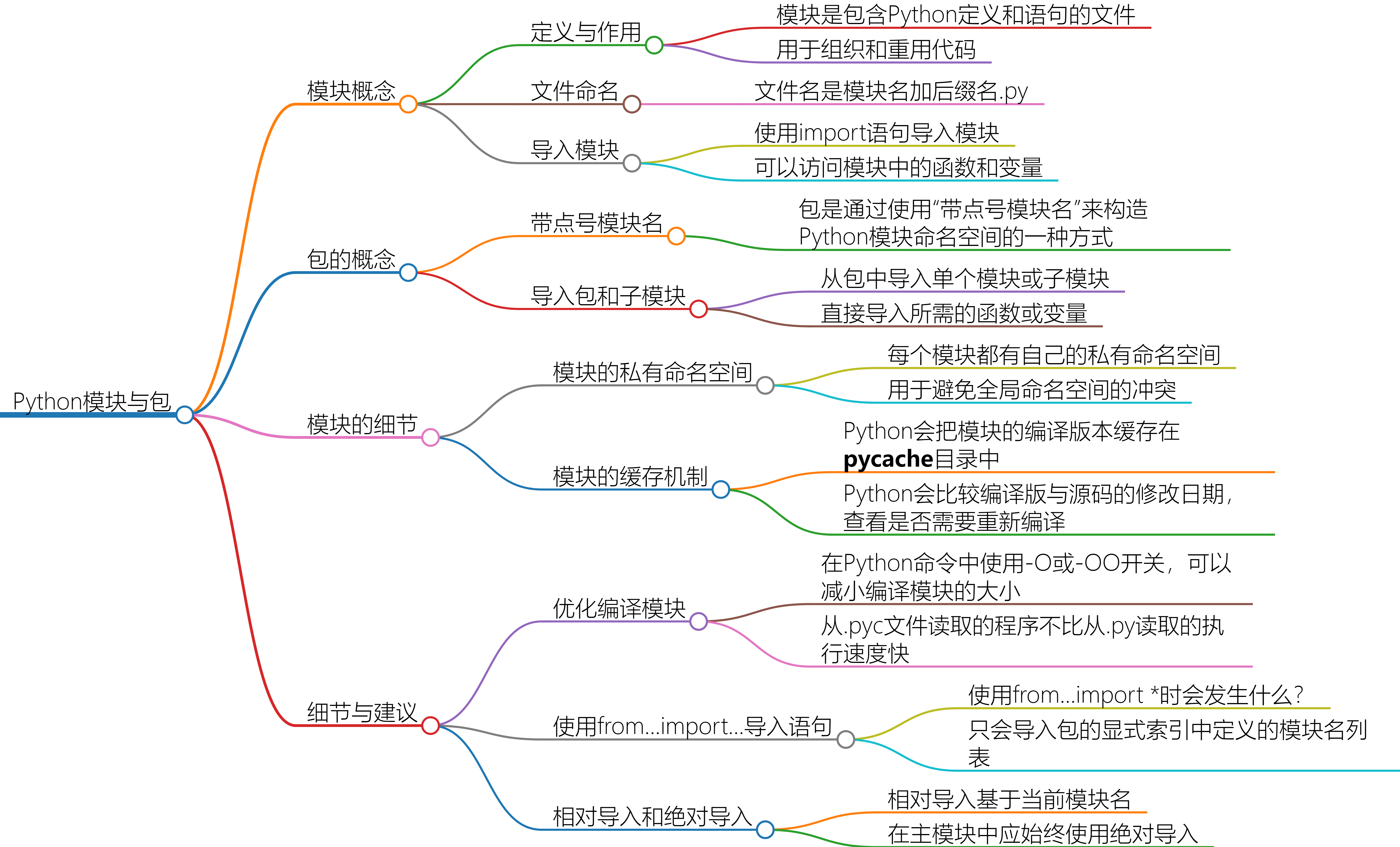
模块
快速理解
现在有个程序模块名称为fibo.py,通过它的名字大致猜测应该是斐波那契数列的功能实现。
打开这个.py文件,内容如下:
1 | # Fibonacci numbers module |
可以看到该模块中有两个方法,分别是:fib和fib2。
如果我想在该模块中使用这两个函数的功能,可以直接调用函数名称并传入参数即可:
1 | fib(1000) |
这时自然而然的诞生一个新的问题,如果在这个函数之外,我依然想使用这两个函数的功能在怎办呢?
先展示结果,最后再讲解细节。
现在,新建一个脚本文件(保证该脚本文件和fibo.py在同一目录下),内容如下:
1 | import fibo |
可以看到,新建的脚本文件中通过import fibo调用了开头写的斐波那契数列功能的模块。
当想要使用模块中的函数方法,仅需要用导入的模块名称加上”.功能函数名称”,就可以实现功能的调用甚至重新命名变量等操作。
导入方式
使用import导入包的方式现列出4种,例如:
导入模块中的方法名称
1
2from fibo import fib, fib2
fib(500)导入模块内定义的所有名称(不包括含
_开头的名称,并且不建议使用这种方法导入)1
2
3from fibo import *
fib(500)
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377模块名使用
as,直接把as后的名称与导入模块绑定1
2import fibo as fibo
>> fib.fib(500)结合
from一起使用1
2from fibo import fib as fibonacci
fibonacci(500)
以脚本方式运行模块
通常在命令行执行脚本文件的语句:
1 | python fibo.py <arguments> |
直接运行.py脚本会在我们看不见的地方默认的执行一个事情,即:**把__name__赋值为"__main__"**。
也就是把下列代码添加到了模块的末尾
1 | if __name__ == "__main__": |
这样做的含义是,在模块作为”main”文件(脚本)进行执行的时候才会运行。
举个例子:
当模块作为脚本文件执行时(会执行):
1
2$ python fibo.py 50
0 1 1 2 3 5 8 13 21 34当模块被导入到其它模块或主程序时(不会执行):
1
2>>> import fibo
>>>
Python文件的编译
这部分在官网文档讲解的非常清晰,参考6.1.3. “已编译的” Python 文件
这里附上“Python模块快速加载”的决策细节流程图:

使用内置函数dir()查看模型定义的名称
dir()用于查找模块定义的名称,返回值为排序之后的字符串列表。
上实例:
dir()含参数时:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25import fibo, sys
dir(fibo)
['__name__', 'fib', 'fib2']
dir(sys)
['__breakpointhook__', '__displayhook__', '__doc__', '__excepthook__',
'__interactivehook__', '__loader__', '__name__', '__package__', '__spec__',
'__stderr__', '__stdin__', '__stdout__', '__unraisablehook__',
'_clear_type_cache', '_current_frames', '_debugmallocstats', '_framework',
'_getframe', '_git', '_home', '_xoptions', 'abiflags', 'addaudithook',
'api_version', 'argv', 'audit', 'base_exec_prefix', 'base_prefix',
'breakpointhook', 'builtin_module_names', 'byteorder', 'call_tracing',
'callstats', 'copyright', 'displayhook', 'dont_write_bytecode', 'exc_info',
'excepthook', 'exec_prefix', 'executable', 'exit', 'flags', 'float_info',
'float_repr_style', 'get_asyncgen_hooks', 'get_coroutine_origin_tracking_depth',
'getallocatedblocks', 'getdefaultencoding', 'getdlopenflags',
'getfilesystemencodeerrors', 'getfilesystemencoding', 'getprofile',
'getrecursionlimit', 'getrefcount', 'getsizeof', 'getswitchinterval',
'gettrace', 'hash_info', 'hexversion', 'implementation', 'int_info',
'intern', 'is_finalizing', 'last_traceback', 'last_type', 'last_value',
'maxsize', 'maxunicode', 'meta_path', 'modules', 'path', 'path_hooks',
'path_importer_cache', 'platform', 'prefix', 'ps1', 'ps2', 'pycache_prefix',
'set_asyncgen_hooks', 'set_coroutine_origin_tracking_depth', 'setdlopenflags',
'setprofile', 'setrecursionlimit', 'setswitchinterval', 'settrace', 'stderr',
'stdin', 'stdout', 'thread_info', 'unraisablehook', 'version', 'version_info',
'warnoptions']dir()不含参数时:1
2
3
4
5a = [1, 2, 3, 4, 5]
import fibo
fib = fibo.fib
dir()
['__builtins__', '__name__', 'a', 'fib', 'fibo', 'sys']
包
包是通过使用“带点号模块名”来构造 Python 模块命名空间的一种方式。
例如,模块名 A.B 表示名为 A 的包中名为 B 的子模块。
使用
modules.func的这种调用方式还有一个好处,就是避免在不同模块中的功能函数命名冲突。例如:在 NumPy 或 Pillow 等多模块包中很多功能函数命名相同,这样使用
np.func或Pillow.func就不必担心彼此的func模块名冲突了。
假设要为统一处理声音文件与声音数据设计一个模块集(“包”)。声音文件的格式很多(通常以扩展名来识别,例如:.wav,.aiff,.au),因此,为了不同文件格式之间的转换,需要创建和维护一个不断增长的模块集合。
为了实现对声音数据的不同处理(例如,混声、添加回声、均衡器功能、创造人工立体声效果),还要编写无穷无尽的模块流。
下面这个分级文件树展示了这个包的架构:
1 | sound/ Top-level package |
导入包时,Python搜索sys.path里的目录,查找包的子目录。
需要有__init__.py文件才能让Python将包含改文件的目录当做“包”来处理。这样可以防止重名目录如string在无意中屏蔽后续出现在模块搜索路径中的有效模块。
最简单的情况就是,__init__.py可以是一个空文件,但是它也可以执行包的初始化代码或设置__all__变量,这将在稍后详细描述。
一些例子说明:
1 | import sound.effects.echo |
另一种导入子模块的方法:
1 | from sound.effects import echo |
还有一种,直接导入所需的函数或变量:
1 | from sound.effect.echo import echofilter |
从包中导入*
同理于模块的导入,同样不建议这样做。
一些需要提及的知识点:如果直接使用*进行导入,一般执行的操作为通过包中的__init__.py代码部分的以下__all__中的模块名列表。
1 | __all__ = ["echo", "surround", "reverse"] |
子模块的命名有可能会受到本地定义名称的影响!
模块中的模块如果和环境中已存在的模块重名,则会被本地先定义过的函数名称遮挡。以reverse函数为例:
1 | __all__ = [ |
官方文档中,推荐的做法是:frome package import submodule.
相对导入
当包由多个子包构成(如示例中的 sound 包)时,可以使用绝对导入来引用同级包的子模块。
例如,如果 sound.filters.vocoder 模块需要使用 sound.effects 包中的 echo 模块,它可以使用 from sound.effects import echo。
你还可以编写相对导入代码,即使用 from module import name 形式的 import 语句。
这些导入使用前导点号来表示相对导入所涉及的当前包和上级包。
例如对于 surround 模块,可以使用:
1 | from . import echo |
注意,相对导入基于当前模块名。
因为主模块名永远是 "__main__" ,所以如果计划将一个模块用作 Python 应用程序的主模块,那么该模块内的导入语句必须始终使用绝对导入。
多目录中的包
通过 __path__ 可以传入字符串列表,找到所有 __init__.py坐在目录的位置。该功能不常用,知道就好。
相关参考:
]]>背景介绍
作为非科班的程序员,在代码规范和程序思维上是有欠缺的(仅代表我个人)。
这些问题会在合作开发项目中暴露出来(阅读其他成员代码以及在其他成员代码上续写功能这类型的任务中暴露的更加明显),比如:对程序模块的封装、底层架构的了解(底层架构对于阅读代码和理解代码很重要)、Python语言的标准库以及装饰器使用等等……
2024年的主题就是:“还债”。目标是尽快补齐在程序架构和工程领域的能力。
TL;DR
在Python工程中,模块是一个包含Python定义和语句的文件,一般以.py作为后缀。模块中的定义可以导入到其他模块或者主程序(main)中,这样做的的目的是方便程序的维护和复用。
- 模块的代入:通过
import导入模块。模块不会直接把模块自身的函数名称添加到当前命名空间中,而是将模块名称添加到命名空间中。再通过模块名称访问其中的函数,例如:import torch \ torch.nn.functional() - 模块的作用:可执行的语句以及函数定义,用于初始化模块。每个模块都有自己的私有命名空间,它会被用作模块中定义的所有函数的全局命名空间。模块可以导入其他模块,被导入的模块名称会被添加到该模块的全局命名空间。(每个模块都有自己的命名空间,防止与用户的全局变量发生冲突)。
模块功能所做的一切就是为了:代码的复用和方便维护。
总览:
模块
快速理解
现在有个程序模块名称为fibo.py,通过它的名字大致猜测应该是斐波那契数列的功能实现。
打开这个.py文件,内容如下:
1 | # Fibonacci numbers module |
可以看到该模块中有两个方法,分别是:fib和fib2。
如果我想在该模块中使用这两个函数的功能,可以直接调用函数名称并传入参数即可:
1 | fib(1000) |
这时自然而然的诞生一个新的问题,如果在这个函数之外,我依然想使用这两个函数的功能在怎办呢?
先展示结果,最后再讲解细节。
现在,新建一个脚本文件(保证该脚本文件和fibo.py在同一目录下),内容如下:
1 | import fibo |
可以看到,新建的脚本文件中通过import fibo调用了开头写的斐波那契数列功能的模块。
当想要使用模块中的函数方法,仅需要用导入的模块名称加上”.功能函数名称”,就可以实现功能的调用甚至重新命名变量等操作。
导入方式
使用import导入包的方式现列出4种,例如:
导入模块中的方法名称
1
2from fibo import fib, fib2
fib(500)导入模块内定义的所有名称(不包括含
_开头的名称,并且不建议使用这种方法导入)1
2
3from fibo import *
fib(500)
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377模块名使用
as,直接把as后的名称与导入模块绑定1
2import fibo as fibo
fib.fib(500)结合
from一起使用1
2from fibo import fib as fibonacci
fibonacci(500)
以脚本方式运行模块
通常在命令行执行脚本文件的语句:
1 | python fibo.py <arguments> |
直接运行.py脚本会在我们看不见的地方默认的执行一个事情,即:**把__name__赋值为"__main__"**。
也就是把下列代码添加到了模块的末尾
1 | if __name__ == "__main__": |
这样做的含义是,在模块作为”main”文件(脚本)进行执行的时候才会运行。
举个例子:
当模块作为脚本文件执行时(会执行):
1
2$ python fibo.py 50
0 1 1 2 3 5 8 13 21 34当模块被导入到其它模块或主程序时(不会执行):
1
2>>> import fibo
>>>
Python文件的编译
这部分在官网文档讲解的非常清晰,参考6.1.3. “已编译的” Python 文件
这里附上“Python模块快速加载”的决策细节流程图:
使用内置函数dir()查看模型定义的名称
dir()用于查找模块定义的名称,返回值为排序之后的字符串列表。
上实例:
dir()含参数时:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25import fibo, sys
dir(fibo)
['__name__', 'fib', 'fib2']
dir(sys)
['__breakpointhook__', '__displayhook__', '__doc__', '__excepthook__',
'__interactivehook__', '__loader__', '__name__', '__package__', '__spec__',
'__stderr__', '__stdin__', '__stdout__', '__unraisablehook__',
'_clear_type_cache', '_current_frames', '_debugmallocstats', '_framework',
'_getframe', '_git', '_home', '_xoptions', 'abiflags', 'addaudithook',
'api_version', 'argv', 'audit', 'base_exec_prefix', 'base_prefix',
'breakpointhook', 'builtin_module_names', 'byteorder', 'call_tracing',
'callstats', 'copyright', 'displayhook', 'dont_write_bytecode', 'exc_info',
'excepthook', 'exec_prefix', 'executable', 'exit', 'flags', 'float_info',
'float_repr_style', 'get_asyncgen_hooks', 'get_coroutine_origin_tracking_depth',
'getallocatedblocks', 'getdefaultencoding', 'getdlopenflags',
'getfilesystemencodeerrors', 'getfilesystemencoding', 'getprofile',
'getrecursionlimit', 'getrefcount', 'getsizeof', 'getswitchinterval',
'gettrace', 'hash_info', 'hexversion', 'implementation', 'int_info',
'intern', 'is_finalizing', 'last_traceback', 'last_type', 'last_value',
'maxsize', 'maxunicode', 'meta_path', 'modules', 'path', 'path_hooks',
'path_importer_cache', 'platform', 'prefix', 'ps1', 'ps2', 'pycache_prefix',
'set_asyncgen_hooks', 'set_coroutine_origin_tracking_depth', 'setdlopenflags',
'setprofile', 'setrecursionlimit', 'setswitchinterval', 'settrace', 'stderr',
'stdin', 'stdout', 'thread_info', 'unraisablehook', 'version', 'version_info',
'warnoptions']dir()不含参数时:1
2
3
4
5a = [1, 2, 3, 4, 5]
import fibo
fib = fibo.fib
dir()
['__builtins__', '__name__', 'a', 'fib', 'fibo', 'sys']
包
包是通过使用“带点号模块名”来构造 Python 模块命名空间的一种方式。
例如,模块名 A.B 表示名为 A 的包中名为 B 的子模块。
使用
modules.func的这种调用方式还有一个好处,就是避免在不同模块中的功能函数命名冲突。例如:在 NumPy 或 Pillow 等多模块包中很多功能函数命名相同,这样使用
np.func或Pillow.func就不必担心彼此的func模块名冲突了。
假设要为统一处理声音文件与声音数据设计一个模块集(“包”)。声音文件的格式很多(通常以扩展名来识别,例如:.wav,.aiff,.au),因此,为了不同文件格式之间的转换,需要创建和维护一个不断增长的模块集合。
为了实现对声音数据的不同处理(例如,混声、添加回声、均衡器功能、创造人工立体声效果),还要编写无穷无尽的模块流。
下面这个分级文件树展示了这个包的架构:
1 | sound/ Top-level package |
导入包时,Python搜索sys.path里的目录,查找包的子目录。
需要有__init__.py文件才能让Python将包含改文件的目录当做“包”来处理。这样可以防止重名目录如string在无意中屏蔽后续出现在模块搜索路径中的有效模块。
最简单的情况就是,__init__.py可以是一个空文件,但是它也可以执行包的初始化代码或设置__all__变量,这将在稍后详细描述。
一些例子说明:
1 | import sound.effects.echo |
另一种导入子模块的方法:
1 | from sound.effects import echo |
还有一种,直接导入所需的函数或变量:
1 | from sound.effect.echo import echofilter |
从包中导入*
同理于模块的导入,同样不建议这样做。
一些需要提及的知识点:如果直接使用*进行导入,一般执行的操作为通过包中的__init__.py代码部分的以下__all__中的模块名列表。
1 | __all__ = ["echo", "surround", "reverse"] |
子模块的命名有可能会受到本地定义名称的影响!
模块中的模块如果和环境中已存在的模块重名,则会被本地先定义过的函数名称遮挡。以reverse函数为例:
1 | __all__ = [ |
官方文档中,推荐的做法是:frome package import submodule.
相对导入
当包由多个子包构成(如示例中的 sound 包)时,可以使用绝对导入来引用同级包的子模块。
例如,如果 sound.filters.vocoder 模块需要使用 sound.effects 包中的 echo 模块,它可以使用 from sound.effects import echo。
你还可以编写相对导入代码,即使用 from module import name 形式的 import 语句。
这些导入使用前导点号来表示相对导入所涉及的当前包和上级包。
例如对于 surround 模块,可以使用:
1 | from . import echo |
注意,相对导入基于当前模块名。
因为主模块名永远是 "__main__" ,所以如果计划将一个模块用作 Python 应用程序的主模块,那么该模块内的导入语句必须始终使用绝对导入。
多目录中的包
通过 __path__ 可以传入字符串列表,找到所有 __init__.py坐在目录的位置。该功能不常用,知道就好。
相关参考:
]]>