{kind=link}
{kind=link}
This is an overview of a coreference project starting from training data preparation to using the trained model for coreference.
This is a installation tutorial for brat rapid annotation tool on Mac OS. This tutorial is based on their official instruction.
Make sure you have python 2 on your device. If you don't have python, please follow the following steps for python 2 installation.
- Open "Terminal", first you can install Xcode by running the command:
xcode-select --install
If you are using SIL lab computer or your mac system is <= macOS Catalina version 10.15.3, download the Xcode package from here and then install.
- Next you can install Homebrew by running the command:
ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
- Now you can install python 2 by running the command:
cd ~
wget https://raw.githubusercontent.com/Homebrew/homebrew-core/86a44a0a552c673a05f11018459c9f5faae3becc/Formula/[email protected]
brew install [email protected]
rm [email protected]
You can check whether python2 has been successfully installed by:
python2 --version
It should return something like
Python 2.7.16
You can also check whether python3 is on your device by:
python --version
It should return something like
Python 3.7.6
If you do not have python3 on your device, run the command to install:
brew install python
-
Download brat installation package
-
Unzip the package, then open terminal and go to the unzipped folder. For instance, if you put the folder (whose name is "brat-v1.3_Crunchy_Frog") in Desktop, then you may run:
cd Desktop/brat-v1.3_Crunchy_Frog
- Run the install shell script
./install.sh -u
It should prompt you to answer the following three questions: Please the user name that you want to use when logging into brat (Enter your username) Please enter a brat password (this shows on screen) (Enter your password) Please enter the administrator contact email (Enter your email)
- Set up working directory Allow brat server to read and write data to several directories:
mkdir -p data work
- Find your apache group
./apache-group.sh
If it returns for instance "staff", run the following command:
sudo chgrp -R staff data work
chmod -R g+rwx data work
Basically it follows
sudo chgrp -R ${YOUR_APACHE_GROUP} data work
chmod -R g+rwx data work
- Run the standalone.py file
python2 standalone.py
where USER is your username on your device, and it could be found out by this command:
whoami
It should provide a link to brat, which looks like
Serving brat at http://127.0.0.1:8080
- If your data is not cleaned, do this step:
0.1 Download this repository if you haven't.
0.2 Open terminal and go to the repository's folder. For instance, if you put the folder (whose name is "brat_coreference_project") in Desktop, then you may run:
cd Desktop/brat_coreference_project
0.3 Copy the uncleaned txt file in this folder and run the following command:
python3 data_cleanning.py example.txt
example_cleaned.txt should be created. Use this cleaned txt for brat annotation.
-
Create new folders in brat-v1.3_Crunchy_Frog/data/. Put the text you would like to annotate in the new folders in txt format.For our current project, download annotation.conf and visual.conf.
-
Open a new terminal. Go to your brat directory.For instance, if you put the folder (whose name is "brat-v1.3_Crunchy_Frog") in Desktop, then you may run:
cd Desktop/brat-v1.3_Crunchy_Frog
- Create ann file for txt files by running the command:
find data -name '*.txt' | sed -e 's|\.txt|.ann|g' | xargs touch
-
Open the brat link in your web browser (Chrome would be the best choice). Move your mouse to the blue chunk on the top, and click "Login". Enter your username and password you just set in your terminal during the installation.
-
Go to "Colletion" on the top left corner. Go to your new folders and click on the text you want to work on. Start annotating!
-
If you would like to edit the entity, relation, and color of each entity, before annotating you need to do the following:
Find "annotation.conf" and "visual.conf" files. They're both in the /data folder of your brat installation (depending on how your corpora are set up they may be in the same folder as your .txt and .ann files.) Edit these two files as following:
For annotation.conf, if you see this in brat when you select a word:

and see this in brat when you link two words:
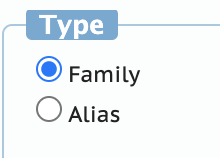
your "annotation.conf" file probably contains the following:
[entities]
Person
Organization
Geo-political entity
[relations]
Family
Alias
If you would like to add a new entity type, just add the type name on a new line under "[entities]".
Relations are a bit more complicated as they can take a variety of restrictions (e.g., the relation can only exist between entities of particular types). I believe you can just add another type in the same way as with entity types, but if you want to restrict by type, you can do something like:
Family Arg1:<Person>, Arg2:<Person>
or even
Family Arg1:<Person>, Arg2:<Person>, <REL-TYPE>:symmetric-transitive
(notice that there should be a tab between Family and the rest of it, not a space)
The "visual.conf" file will then control the corresponding visualization of each entity type. You'll want to add a new line under the [drawing] section to specify a color for the highlighting, like this:
Family bgColor:#EDC1F0
(specify your color in hex notation)
(notice that there should be a tab between Family and the rest of it, not a space)
More details could be found in their official instruction.
-
Download this repository if you haven't.
-
Copy your txt and ann file from brat folder to this repository's folder on your device.
-
Rename your ann files by adding "_pretransformed" at the end. For instance, if the original ann file is called "example.ann", rename it to "example_pretransformed.ann".
-
Open terminal and go to the repository's folder. For instance, if you put the folder (whose name is "brat_coreference_project") in Desktop, then you may run:
cd Desktop/brat_coreference_project
- Run the following command to create Transformed ann and conll files (replace "example" with your file name):
python3 annconll_transformation.py example.txt example_pretransformed.ann
Two files end with ann and conll should be created in the same folder.
Step3: Training (Credit to UCB Professor David Bamman's GitHub repo)
-
Enter brat github repository through this link
-
Click on the green button says "Code" and choose "Download ZIP"
-
Unzip the downloaded folder. The folder's name should be "lrec2020-coref-master".
-
Go to lrec2020-coref-master/data/original/tsv folder. Delete the data originally in there and copy the ann file (transformed) you just created and txt file from brat into this folder. Make sure eventually the name of txt, ann and conll files are the same. You can delete the "_transformed" in the name of ann file.
-
Go to lrec2020-coref-master/data/original/conll folder, copy the conll file you just created into this folder.
-
Go to lrec2020-coref-master/data/litbank_tenfold_splits folder, in this folder there are 10 folders named from "0" to "9". Each folder represents a fold for training. In each of the ten folder, there are three files end with "ids". Each ids file represents training, testing and developing set. Randomly split your data into three subsets for each fold. (Code in progress)
7.Open terminal, go to lrec2020-coref folder For instance, if you put lrec2020-coref folder in Desktop, run the command:
cd Desktop/lrec2020-coref
- Run the command:
pip3 install -r requirements.txt
If you see some errors in the end, saying probabily something like this:
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
spacy 2.1.0 requires jsonschema<3.0.0,>=2.6.0, but you have jsonschema 3.0.1 which is incompatible.
As long as the package in the requirment.txt is the correct version, ignore the error.
- Create 10-fold cross-validation data
python3 scripts/create_crossval.py data/litbank_tenfold_splits data/original/conll/ data/litbank_tenfold_splits
mkdir -p models/crossval
mkdir -p preds/crossval
mkdir -p logs/crossval
- Download benchmark coreference scorers
git clone https://github.com/conll/reference-coreference-scorers
- Generate cross-validation training and prediction script
SCORER=reference-coreference-scorers/scorer.pl
python3 scripts/create_crossval_train_predict.py $SCORER scripts/crossval-train.sh scripts/crossval-predict.sh
chmod 755 scripts/crossval-train.sh
chmod 755 scripts/crossval-predict.sh
- Train 10 models (each on their own training partition)
./scripts/crossval-train.sh
You can check progress in log folder.
- Create all.conll
cat data/original/conll/*conll > data/original/conll/all.conll
- Use each trained model to make predictions for its own held-out test data.
./scripts/crossval-predict.sh
cat preds/crossval/{0,1,2,3,4,5,6,7,8,9}.goldmentions.test.preds > preds/crossval/all.goldmentions.test.preds
- Evaluate
python3 scripts/calc_coref_metrics.py data/original/conll/all.conll preds/crossval/all.goldmentions.test.preds $SCORER
-
Create a folder in lrec2020-coref-master/data, named it data_new. Create a folder in lrec2020-coref-master/preds, named it preds_new
-
Put the conll file of the new data in lrec2020-coref-master/data/data_new.
-
Open terminal, go to lrec2020-coref-master.
-
Run the following command:
python3 scripts/bert_coref.py -m predict -w models/crossval/[model name] -v data/data_new/[conll name] -o preds/preds_new/[output name] -s reference-coreference-scorers/scorer.pl
For instance, if you want to use "0.model", with a new data whose conll file is called "example.conll", and you would like the output named as "example_output.preds" , you should run:
python3 scripts/bert_coref.py -m predict -w models/crossval/0.model -v data/data_new/example.conll -o preds/preds_new/example_output.preds -s reference-coreference-scorers/scorer.pl
- You should find your output conll file in lrec2020-coref-master/preds/preds_new.
-
For instance, we would like to view example_output.conll in brat:
-
Create a new folder in brat data folder called "trained"
-
Copy example_output.preds and it's corresponding txt file into that folder; copy conll2brat.py in this repo to the same folder as well.
-
Open terminal, go to the "trained" folder
-
Run the following command
python3 conll2brat.py example_output
example_output.ann file should be generated in the same foler
-
Change example_output.ann and its corresponding txt file to a same name (e.g. example_output.ann -> example.ann; corresponding.txt -> example.txt)
-
View it in brat