2015.09.24: random forest
Steven gave an overview of Julia. Ben played Andrew Ng's introduction to machine learning lecture video from his course on Coursera.
A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.
We then discussed different ideas in machine learning.
- POMDPs for Dummies - partially observable Markov decision processes
- Supervised vs. unsupervised learning
- Decision tree learning - Wikipedia, the free encyclopedia and more specifically Random forests
- boosting vs bagging
- Classification
Ben showed another video on linear regression but should've showed this more specific follow-on video about a very high level overview of random forests.
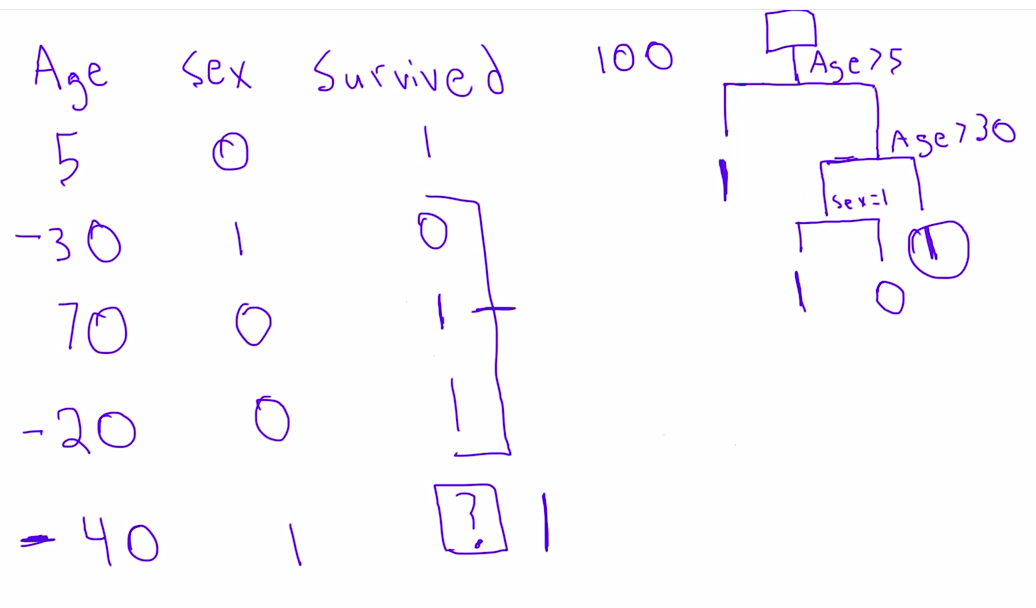
Then Haroldur and Steven explained how support vector machines are basically linear classifiers that add additional dimensions to the data to create complex classification boundaries in the original, lower dimensional space. They also warned how they are notoriously bad at overfitting.
Next we split into groups and learned about random forests (an advanced, over-fitting resistant form of decision trees).
-
Check out this continued Python Titanic tutorial based on Kaggle's Titanic challenge, including a very excellent discussion on why you want to use decision trees, how they fall short, and what you can do to make them more accurate.
-
Everything tree from this github repo from Andrew Ng's Practical Machine Learning
-
Courses:
- Python data science tracks | Dataquest
- R tutorials on dplyr, data.table, ggvis, R Markdown & more | DataCamp
- DataScienceSpecialization/courses - free github repo to last year's Johns Hopkins Data Science certificate curriculum now charged on Coursera
-
How to get better at data science | DataSchool.io with book recommendations like:
Links based on some of Morgan's work, and Ben's googling:
- Google Prediction API
- TextBlob: Simplified Text Processing — TextBlob 0.10.0-dev documentation: TextBlob is a Python (2 and 3) library for processing textual data. It provides a simple API for diving into common natural language processing (NLP) tasks such as part-of-speech tagging, noun phrase extraction, sentiment analysis, classification, translation, and more.
- Bag of Words Meets Bags of Popcorn | Kaggle
- Haroldur suggested Statistics for hackers
https://speakerdeck.com/jakevdp/statistics-for-hackers
- Both Steven and Haroldur expressed interest in discussin Bayesian methods. Haruldur mentioned Probalistic Programming and Bayesian Methods for Hackers which is a book made up of ipython notebooks.