As a collection agent for log services, iLogtail is currently running on 100W+ machines and provides services for applications with tens of thousands of levels. In order to better achieve integration with the open source ecosystem and meet the ever-increasing access needs of users, we have introduced iLogtail Plugin system. At present, we have supported several data sources through the plugin system, including HTTP, MySQL Query, MySQL Binlog, etc.
This article will briefly introduce the iLogtail plugin system, including the implementation principle of the plugin system, the composition and design of the plugin system.
In this section, we use the following flowchart to show the implementation principle of the iLogtail plugin system.
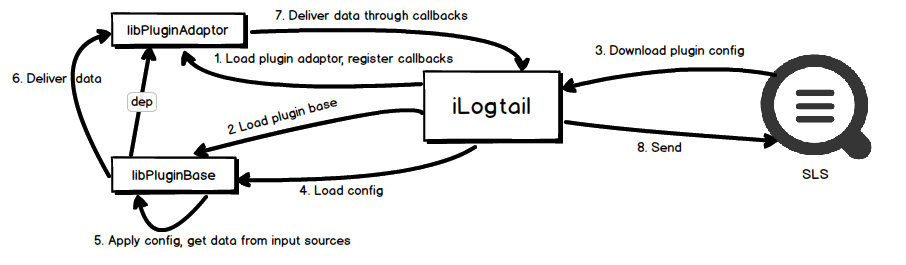
In order to support the plugin system, we have introduced two dynamic libraries, libPluginAdaptor and libPluginBase (hereinafter referred to as adaptor and base). The relationship between them and iLogtail is as follows:
- iLogtail dynamically depends on these two dynamic libraries (that is, it is not dependent in binary). During initialization, iLogtail will try to use the dynamic library interface (such as dlopen) to dynamically load them to obtain the required symbols. The advantage of this design is that even if the dynamic loading fails, the plug-in function is only unavailable and does not affect the existing functions of iLogtail itself.
- Adaptor acts as an intermediate layer. Both iLogtail and base rely on it. iLogtail first registers callbacks, and the adpator records these callbacks and exposes them to the base as an interface. This indirectly constitutes the base calling the iLogtail method, so that base does not depend on iLogtail. One of the key methods of these callbacks is SendPb, through which the base can add data to the sending queue of iLogtail, and then submit it to LogHub.
- Base is the main body of the plug-in system, which contains the collection, processing, aggregation and output (submission to iLogtail can be regarded as one of them) necessary for the plug-in system. Therefore, the extension of the plug-in system is essentially an extension of base.
Back to the flowchart, let's briefly explain the steps below:
- In the initialization phase of iLogtail, the adaptor is dynamically loaded, and the callback is registered with the obtained symbol.
- During iLogtail initialization phase, base is dynamically loaded and symbols are obtained, including the LoadConfig symbols used in this process. Base relies on adaptor on binary, so it will load adaptor in this step.
- iLogtail obtains the user's configuration (plug-in type) from LogHub.
- iLogtail passes the configuration to the base through LoadConfig.
- Base applies the configuration and starts the configuration, and obtains data from the specified data source.
- Base calls the interface provided by adaptor to submit data.
- Adaptor sends the data submitted by base directly to iLogtail via callback.
- iLogtail adds the data to the sending queue and sends it to LogHub.
In this section, we will focus on libPluginBase and introduce the overall architecture of the plug-in system and some system designs.
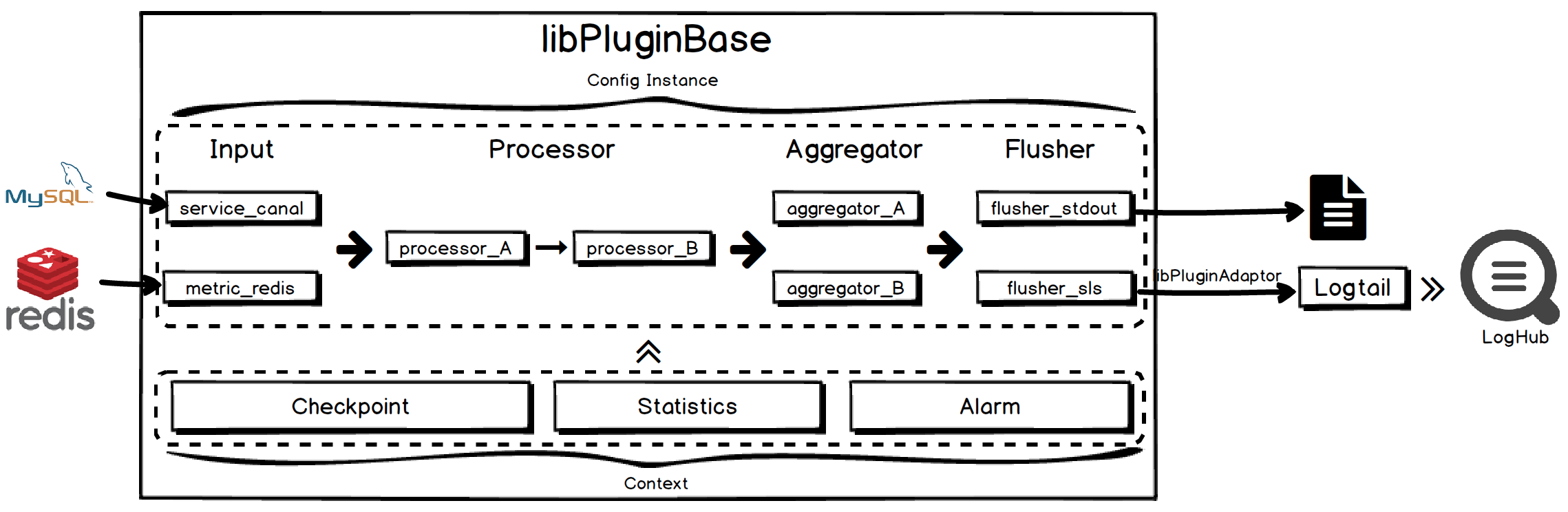
As shown in the figure above, the current main body of the plug-in system consists of four parts: Input, Processor, Aggregator and Flusher. For each configuration, the relationship between them:
- Input: As the input layer, a configuration can configure multiple inputs at the same time, they can work at the same time, and the collected data will be submitted to the processor.
- Processor: As the processing layer, you can filter the input data, such as checking whether a specific field meets the requirements or adding, deleting, and modifying fields. Each configuration can be configured with multiple processors at the same time, and a serial structure is adopted between them, that is, the output of the previous processor is used as the input of the next processor, and the output of the last processor will be passed to the aggregator.
- Aggregator: As an aggregation layer, data can be aggregated in the required form, such as packaging multiple data into groups, and statistics on the maximum and minimum values of certain fields in the data. Similar to input, a configuration can configure multiple aggregators at the same time to achieve different purposes. Aggregator can actively submit processed data to flusher when new data arrives, or set a refresh interval to periodically submit data to flusher.
- Flusher: As the output layer, it outputs the data to the specified target according to the configuration, such as local files, iLogtail (via adaptor interface), etc. A configuration can configure multiple flushers at the same time, so that a piece of data can be output to multiple targets at the same time.
- In addition, the plug-in system also provides three parts: Checkpoint, Statistics, and Alarm, which are responsible for providing checkpoint, statistics, and alarm-related functions. We encapsulate them as a whole and provide them in the form of context to all plug-ins. The plug-ins are only You need to call the interface provided by the context (such as creating checkpoints, loading checkpoints, sending alarms, etc.) without worrying about how to complete it. For these functions, we will introduce them later.
Below we will briefly introduce a few key designs in the plug-in system, which contains some of our goals at the beginning of the design:
- Easy to expand and easy to develop: use Go language to achieve
- Compatible with iLogtail's existing system, reducing user learning costs: configuration dynamic update, unified Alarm / Statistics
- Provide general functions for plug-in development: Checkpoint
In order to achieve the goal of easy expansion and easy development, we finally chose Go as the implementation language of the plug-in system. The specific considerations are as follows:
- Concurrency isolation: In a production environment, iLogtail may run multiple plug-ins at the same time to meet different collection requirements. Isolation and concurrency between different plug-ins must be solved. The design of Go language oriented to concurrent programs allows us to easily achieve isolation and concurrency requirements, so that when developing the iLogtail plug-in, developers can pay more attention to their own logic without having to care about the system as a whole.
- Dynamic loading: Since iLogtail already has a large installed capacity, using dynamic loading to isolate the plug-in system as much as possible and reduce the impact on the main body of iLogtail is also one of the factors we consider. Go's native support for generating as a dynamic library can meet our needs well.
- Close to the community: At present, the two open source agents, Telegraf and Beats, are implemented in Go. Therefore, using Go can make our plug-in system closer to the community and reduce the learning difficulty for community developers.
- Go plugin: We are also watching the progress of Go plugin. Once we feel that the time is right, fully dynamic expansion through Go plugin will be able to provide better assistance to users.
- Easy development: The development efficiency of Go language is generally higher than that of C++ used by iLogtail, and is more suitable for scenarios that require rapid development such as plug-ins.
Currently, Log Service supports collection and configuration through the console, and then automatically sends it to iLogtail for application execution. When the configuration changes, iLogtail will also obtain these configurations in a timely manner and perform dynamic updates. As part of the configuration content, the plug-in system must also have the ability to dynamically update the configuration.
In the plug-in system, we organize the plug-ins by configuration. Each configuration instance creates and maintains the input, processor and other plug-in instances according to the specific content of the configuration. In order to realize the ability to dynamically update the configuration, libPluginBase provides the corresponding HoldOn/Resume/LoadConfig interface for support. The update process is as follows:
- iLogtail checks whether there is an update of the plug-in system in the content of the configuration update, if so, call HoldOn to suspend the plug-in system;
- When the plug-in system executes HoldOn, it will stop all current configuration instances in turn, and the necessary checkpoint data will be stored during this process;
- After the HoldOn call is completed, iLogtail loads the updated or newly added configuration through LoadConfig. This call will create a new configuration instance in the plug-in system, and the new instance will overwrite the previous instance. In order to avoid data loss, the newly created instance will transfer the data in the overwritten instance, so that the data can be processed after recovery;
- After the configuration update is completed, iLogtail calls Resume to resume the operation of the plug-in system, and the dynamic update configuration is completed.
In iLogtail, in order to better help users with statistical data analysis and troubleshooting, we have implemented Statistics and Alarm mechanisms. The plug-in system also has such a requirement (each plug-in may generate its own statistics or alarm data during operation). For this, we hope to be able to unify with iLogtail's existing Statistics and Alarm mechanisms. Therefore, in addition to the user configuration, we constructed two global configurations, which are used to receive Statistics and Alarm data from the plug-ins in other configurations, and then output them in a unified manner.

As shown in the figure, on the right are two independent global configuration examples, corresponding to the reception and output of Statistics and Alarm respectively. They use the same structure as the user configuration. A built-in input plug-in is used at the entrance to read data from the channel. , After intermediate processing and transmission, the data is output to iLogtail by the fluxer plug-in. Any plug-in in the user configuration instance on the left can output statistics or alarm data according to its own logic and send it to the global configuration instance on the right through the Go channel.
In the process of implementing the collection agent, in order to ensure that no data is lost in the event of a crash, update, restart, etc., the collection progress is generally maintained by recording checkpoints. For some plug-ins, this is also a necessary function. For example, the MySQL Binlog plug-in needs to record the name and offset of the binlog file it currently collects. Therefore, we have implemented a general checkpoint function in the plug-in system, and output the corresponding key-value API for plug-in use through context.
type Context interface {
SaveCheckPoint(key string, value []byte) error
GetCheckPoint(key string) (value []byte, exist bool)
SaveCheckPointObject(key string, obj interface{}) error
GetCheckPointObject(key string, obj interface{}) (exist bool)
# ...
}