No, you cannot create an instance of an abstract class because it does not have a complete implementation. The purpose of an abstract class is to function as a base for subclasses. It acts like a template, or an empty or partially empty structure, you should extend it and build on it before you can use it.
In general both equals() and “==” operator in Java are used to compare objects to check equality but here are some of the differences between the two:
Main difference between .equals() method and == operator is that one is method and other is operator.
We can use == operators for reference comparison (address comparison) and .equals() method for content comparison. In simple words, == checks if both objects point to the same memory location whereas .equals() evaluates to the comparison of values in the objects.
If a class does not override the equals method, then by default it uses equals(Object o) method of the closest parent class that has overridden this method. See this for detail Coding Example:
// Java program to understand
// the concept of == operator
public class Test {
public static void main(String[] args)
{
String s1 = new String("HELLO");
String s2 = new String("HELLO");
System.out.println(s1 == s2);
System.out.println(s1.equals(s2));
}
}
Output:
false
true
WebSockets are a way to communicate between a client and a server.
The communication is bi-directional that is data can flow in both directions: from the client to the server and from the server to the client. Since WebSockets are always open, they allow for real-time data flow in an application, which makes way for real-time information flow back and forth.

WebSockets are an advanced technology that makes it possible to open an interactive communication session between the user’s browser and a server.
WebSockets lets you send messages to a server and trigger event-driven responses. They are not required to poll the server all the time for replies.
A socket is a “port” through which data goes in and out of. A socket is a “port” through which data goes in and out of. Protocols interpret the data going to and from the socket and the machines/ applications that are communicating with each other. A major protocol is HTTP.
Every time you request to download html, video or an image, a port is opened, data is transferred, and the port closes. The consecutive closing and opening form overhead, and for a few applications, particularly those that need swift replies, real-time communications, or display chunks of data, this doesn’t work.
Another constraint with HTTP is the “pull” paradigm. The browser pulls the info from servers. The server doesn’t push data to the browser when it wants to. This means that browsers must poll the server for fresh info by echoing requests every so many seconds or minutes to learn if there is something new. The need to add Sockets to browsers was mounting.
The WebSockets were made a standard in 2011. This lets public to employ the WebSocket protocol, which is flexible for exchanging data between servers and the browser, as well as Peer-to-Peer (P2P), or direct communication between browsers. Unlike HTTP, the socket that is connected to the server stays “open” for communication. That means data can be “pushed” to the browser in near real-time whenever required.
Modern logistics solutions are software-based and are generally hosted on the client’s server and almost all of them include real-time tracking of their fleet vehicles.

If we look at the above example, these different clients are different people around the world in their browser or app. They either enter a URL in their web browser or download the app to access their part of taxi booking system. Of all the person trying to access the system, John requests a taxi with the app. He enters the destination, and clicks ‘Ride Now’. That request is going to instantly be updated in all the nearby drivers to John connected to the server. This is WebSockets in action.
When John requested the taxi from the app and a driver accepted his request, he is opening up WebSocket between him and the driver. We have all of these different clients, browsers, and ecosystems with their own WebSocket connection to the server. Data can flow back and forth between it in real time because these are always open. When John requests a ride, he is actually sending that message down this WebSocket to the server.
The server receives it and sends it down all these other WebSockets, which are connecting these clients to each individual client. They can see that updating message in their app. The message is going to send the WebSocket to the server. Then the server sends it to each WebSocket and to all the remaining clients. That is why they see this message instantaneously.
The data transfer occurs in real time. We’re not using any kind of AJAX request from each of these different clients to request any new data from the server. It’s all happening without the client having to make any additional requests at all.
There’s tons of different uses for WebSockets that go beyond chat rooms and real-time tracking system. They include making multiply multiplayer browser games, collaborative code editing software, some kind of live text for sports on news websites, online drawing canvases, real time to-do apps, etc. There are tons of different uses for WebSockets.
We use WebSockets to send data to a server. the server then sends it down to this client and shows it in real time. There is no need to make any kind of requests from this client to the server at all. It’s just open and listening through this WebSocket and receiving data.
A WebSocket opens up between the drivers and passenger as soon as the driver accepts the passenger request to ride. WebSockets facilitates the entire riding experience till the driver completes a ride. The entire tracking system is event triggered. For example, when a driver accepts a ride, the taxi software counts it as the event and notifies the passengers by updating his current app screen with driver’s name and other details. The same goes when a driver arrives or is waiting for you. A different set of events triggers owing to change of the driver’s position with that of the passenger. WebSockets are the primary reason Uber is so precise with its notifications and mapping services.
You would be like why there is a need of WebSockets when the same can be achieved with push notification services too. The problem is push notifications are unreliable. If the either of the communicating client is offline, push notification services won’t know the difference and will still attempt to deliver the notification and, ultimately, fail.
WebSockets, on the other hand, will suspend notifications to its client whenever they are offline. They will wait for the client to come online before reattempting. The server will know of the condition the whole time and won’t settle unless it learns the notifications has been successfully delivered to the client.
As defined by Techopedia: “Object-relational mapping (ORM) is a programming technique in which a metadata descriptor is used to connect object code to a relational database. Object code is written in object-oriented programming (OOP) languages such as Java or C#. ORM converts data between type systems that are unable to coexist within relational databases and OOP languages.”
ORMs make a developer's life easy. It allows them to avoid the struggle of developing queries by concatenating strings or handling the connections with database manually. Even typos aren’t a major threat to the queries. The security can be managed without worrying about the resistance to injecting attacks. This means a developer can focus on application functionalities while allowing the database to perform its job.
However, there are many ORMs available out there. We have highlighted the most popular ones below.
Android application (APK) files contain executable bytecode files in the form of Dalvik Executable (DEX) files, which contain the compiled code used to run your app. The Dalvik Executable specification limits the total number of methods that can be referenced within a single DEX file to 65,536, including Android framework methods, library methods, and methods in your own code. Getting past this limit requires that you configure your app build process to generate more than one DEX file, known as a multidex configuration.
So, the feature is: it allows your complex app to compile. The scenarios for using it are when your app fails to compile due to hitting the 64K DEX method reference limit. This appears as a build error, such as:
Conversion to Dalvik format failed: Unable to execute dex: method ID not in [0, 0xffff]: 65536
The Java ClassLoader is a part of the Java Runtime Environment that dynamically loads Java classes into the Java Virtual Machine. The Java run time system does not need to know about files and file systems because of classloaders.
Java classes aren’t loaded into memory all at once, but when required by an application. At this point, the Java ClassLoader is called by the JRE and these ClassLoaders load classes into memory dynamically.
Not all classes are loaded by a single ClassLoader. Depending on the type of class and the path of class, the ClassLoader that loads that particular class is decided. To know the ClassLoader that loads a class the getClassLoader() method is used. All classes are loaded based on their names and if any of these classes are not found then it returns a NoClassDefFoundError or ClassNotFoundException.
A Java Classloader is of three types:
A Bootstrap Classloader is a Machine code which kickstarts the operation when the JVM calls it. It is not a java class. Its job is to load the first pure Java ClassLoader. Bootstrap ClassLoader loads classes from the location rt.jar. Bootstrap ClassLoader doesn’t have any parent ClassLoaders. It is also called as the Primodial ClassLoader.
The Extension ClassLoader is a child of Bootstrap ClassLoader and loads the extensions of core java classes from the respective JDK Extension library. It loads files from jre/lib/ext directory or any other directory pointed by the system property java.ext.dirs.
An Application ClassLoader is also known as a System ClassLoader. It loads the Application type classes found in the environment variable CLASSPATH, -classpath or -cp command line option. The Application ClassLoader is a child class of Extension ClassLoader.
The ClassLoader Delegation Hierarchy Model always functions in the order
Application ClassLoader->
Extension ClassLoader->
Bootstrap ClassLoader.
The Bootstrap ClassLoader is always given the higher priority, next is Extension ClassLoader and then Application ClassLoader.
You can create bound services which acts as a server in client-server interface.
There are three ways to create a bound service:
If application and service are running in same process which is mostly the case then create your own interface by extending Binder class and return an instance of it in onBind().
The following code snippet is taken from here. This implementation of Binder defines a function to return the instance of currently running service. This instance then can be used to call public functions of the service.
public class LocalService extends Service {
...
// This is the object that receives interactions from clients.
private final IBinder mBinder = new LocalBinder();
public class LocalBinder extends Binder {
LocalService getService() {
return LocalService.this;
}
}
@Override
public void onCreate() {
...
}
@Override
public int onStartCommand(Intent intent, int flags, int startId
{
...
}
@Override
public void onDestroy() {
...
}
@Override
public IBinder onBind(Intent intent) {
return mBinder;
}
Now put the following code in activity to bind to the service and get the instance of the service. private LocalService mBoundService;
private ServiceConnection mConnection = new ServiceConnection() {
public void onServiceConnected(ComponentName className, IBinder service) {
// This is called when the connection with the service has
// been established, giving us the service object we can use
// to interact with the service. Because we have bound to a
// explicit service that we know is running in our own
// process, we can cast its IBinder to a concrete class and
// directly access it.
mBoundService = ((LocalService.LocalBinder)service).getService();
// Tell the user about this for our demo.
Toast.makeText(Binding.this,
R.string.local_service_connected,
Toast.LENGTH_SHORT).show();
}
public void onServiceDisconnected(ComponentName className) {
// This is called when the connection with the service has
// been unexpectedly disconnected -- that is, its process
// crashed. Because it is running in our same process, we
// should never see this happen.
mBoundService = null;
Toast.makeText(Binding.this,
R.string.local_service_disconnected,
Toast.LENGTH_SHORT).show();
}
};
void doBindService() {
// Establish a connection with the service. We use an explicit
// class name because we want a specific service implementation
// that we know will be running in our own process (and thus
// won't be supporting component replacement by other
// applications).
bindService(new Intent(Binding.this, LocalService.class),
mConnection,
Context.BIND_AUTO_CREATE);
mIsBound = true;
}
void doUnbindService() {
if (mIsBound) {
// Detach our existing connection.
unbindService(mConnection);
mIsBound = false;
}
}
@Override
protected void onDestroy() {
super.onDestroy();
doUnbindService();
}
If service is running in separate process then you can create an AIDL interface. Most applications should not use this as it may require a lot of multi-threading capabilities and may make code more complex. If you need an interface to communicate across processes you can create a Messenger. It handles communication on single thread. See Using Messenger. Client can also define a messenger and pass it to service using which service can send data back to client. Here is a sample demo.
Following is the code snippet taken from here.
public class MessengerService extends Service {
/** Command to the service to display a message */
static final int MSG_SAY_HELLO = 1;
/**
* Handler of incoming messages from clients.
*/
class IncomingHandler extends Handler {
@Override
public void handleMessage(Message msg) {
switch (msg.what) {
case MSG_SAY_HELLO:
Toast.makeText(getApplicationContext(),
"hello!",
Toast.LENGTH_SHORT).show();
break;
default:
super.handleMessage(msg);
}
}
}
/**
* Target we publish for clients to send messages to
* IncomingHandler.
*/
final Messenger mMessenger = new Messenger(
new IncomingHandler()
);
/**
* When binding to the service, we return an interface to our
* messenger for sending messages to the service.
*/
@Override
public IBinder onBind(Intent intent) {
Toast.makeText(getApplicationContext(),
"binding",
Toast.LENGTH_SHORT).show();
return mMessenger.getBinder();
}
}
If you want to send broadcasts to your application components only then use LocalBroadcastManager. If you want to send broadcasts across applications then use BroadcastReceiver.
You can use EventBus from greenrobot or otto from square. You can use Result Receiver It can be used to send data across processes. Here is SO Question for implementation. I have used only these so far. If there are some other better suggestions please comment.
Officially, the Java language provides the keyword 'final' that is supposed to fulfill this task. Consider the following code sample:
//FinalDemo.java
public final class FinalDemo {
}
Let's make another class that is supposed to be inherited from the above class. The Java language provides the 'extends' keyword that enables a class to be inherited from an existing class.
But, that's not the only way to stop your class from being inherited by some other class. Consider the following code where I declare the constructor as private, and I declare a static method that returns an object of the class:
public class PrivateTest{
private PrivateTest(){
System.out.println("Private Default Constructor");
}
public static PrivateTest getInstance(){
return new PrivateTest();
}
}
A modified form of the above code is also known as the "Singleton Pattern," where the getInstance method always returns only one instance of the class. But why does this code stop this class from being inherited? Consider the following code that is supposed to be inherited from the above class:
public class PrivateTest2 extends PrivateTest{
}
After compiling the first class, if you compile the second class, the JDK compiler will complain and you will get the following error message:
PrivateTest2.java:1: PrivateTest() has private access in PrivateTest
public class PrivateTest2 extends PrivateTest{
^
}
1 error
The second class is unable to inherit the first class. But what does this error mean? The Java language makes it compulsory to provide at least one constructor in your class. If you do not provide any constructor in your class, the JDK compiler will insert the so-called default constructor in your class; in other words, that constructor with no arguments, with an empty body, and with a public access modifier. But if you define a constructor by yourself, the JDK compiler will not insert a default constructor for you. What we did in class PrivateTest was that we declared the default constructor, but we changed the access modifier to private, which is legal by the rules of JDK compiler.
Now comes the second part. The Java language also makes it compulsory that you put the call to the super class constructor as the first call in your constructor. This is necessary to enable the inheritance features. We achieve this functionality by calling the appropriate super() method in Java, that should map to appropriate super class constructor. If you do not provide a default constructor, than JDK compiler will insert a default super constructor call in your constructor.
What I did in the first class that I make the constructor private. Now, when I inherit that class in the other class, the compiler tries to put in the default super constructor call. Because the scope of the super class constructor is set to private, the compiler complains that it is unable to call the super constructor. Hence, we stopped a class being inherited by some other class, the unofficial way.
you refer to Android resources , which are already defined in Android system, with @android:id/.. while to access resources that you have defined/created in your project, you use @id/..
More Info
As per your clarifications in the chat, you said you have a problem like this :
If we use android:id="@id/layout_item_id" it doesn't work. Instead @+id/ works so what's the difference here? And that was my original question.
Well, it depends on the context, when you're using the XML attribute of android:id, then you're specifying a new id, and are instructing the parser (or call it the builder) to create a new entry in R.java, thus you have to include a + sign.
While in the other case, like android:layout_below="@id/myTextView" , you're referring to an id that has already been created, so parser links this to the already created id in R.java.
More Info Again
As you said in your chat, note that android:layout_below="@id/myTextView" won't recognize an element with id myTextViewif it is written after the element you're using it in.
First we need to undestand Typing
To understand these keywords, we have to understand two of the major categories of type systems a language can follow – manifest typing and inferred typing.
All languages offer a range of primitive data types to store and manipulate data within a program. Programming languages following the manifest typing discipline must have their data types explicitly defined within the program.
Java, up until version 10, strictly follows this discipline. For example, if we want to store a number within a program, we must define a data type such as int:
int myVariable = 3;
Unlike Java, Kotlin follows the inferred typing discipline. Languages supporting type inference automatically detect data types within the program at compile-time.
This detection means that we, as developers, don't need to worry about the data types we're using.
Firstly, we'll start with var, Kotlin's keyword representing mutable, non-final variables. Once initialized, we're free to mutate the data held by the variable.
Let's take a look at how this works:
var myVariable = 1
Behind the scenes, myVariable initializes with the Int data type.
Although Kotlin uses type inference, we also have the option to specify the data type when we initialize the variable:
var myVariable: Int = 1
Variables declared as one data type and then initialized with a value of the wrong type will result in an error:
var myVariable: Int = b //ERROR!
Kotlin's val keyword works much in the same as the var keyword, but with one key difference – the variable is read-only. The use of val is much like declaring a new variable in Java with the final keyword.
For example, in Kotlin, we'd write:
val name: String = "Baeldung"
Whereas in Java, we'd write:
final String name = "Baeldung";
Much like final variables in Java, val variables must be assigned at declaration, or in a Class constructor:
class Address(val street: String) {
val name: String = "Baeldung"
}
Like val, variables defined with the const keyword are immutable. The difference here is that const is used for variables that are known at compile-time.
Declaring a variable const is much like using the static keyword in Java.
Let's see how to declare a const variable in Kotlin:
const val WEBSITE_NAME = "Baeldung"
And the analogous code written in Java would be:
final static String WEBSITE_NAME = "Baeldung";
In this article, we've taken a quick look at the difference between manifest and inferred typing.
Then, we looked at the difference between Kotlin's var, val, and const keywords.
If you don't want duplicates in a Collection, you should consider why you're using a Collection that allows duplicates. The easiest way to remove repeated elements is to add the contents to a Set (which will not allow duplicates) and then add the Set back to the ArrayList:
Set<String> set = new HashSet<>(yourList);
yourList.clear();
yourList.addAll(set);
Of course, this destroys the ordering of the elements in the ArrayList.
import java.io.*;
import java.util.*;
public class HelloWorld
{
public static void main(String[] args)
{
// Get the array
int arr[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
// Print the array
System.out.println("Array: "+ Arrays.toString(arr));
}
}
HashMap is a part of Java’s collection since Java 1.2. It provides the basic implementation of the Map interface of Java. It stores the data in (Key, Value) pairs. To access a value one must know its key. HashMap is known as HashMap because it uses a technique called Hashing. Hashing is a technique of converting a large String to small String that represents the same String. A shorter value helps in indexing and faster searches. HashSet also uses HashMap internally. It internally uses a link list to store key-value pairs already explained in HashSet in detail and further articles.
HashMap is a part of java.util package.
HashMap extends an abstract class AbstractMap which also provides an incomplete implementation of Map interface. It also implements Cloneable and Serializable interface. K and V in the above definition represent Key and Value respectively.
HashMap doesn’t allow duplicate keys but allows duplicate values. That means A single key can’t contain more than 1 value but more than 1 key can contain a single value. HashMap allows null key also but only once and multiple null values.
This class makes no guarantees as to the order of the map; in particular, it does not guarantee that the order will remain constant over time. It is roughly similar to HashTable but is unsynchronized.
Internally HashMap contains an array of Node and a node is represented as a class which contains 4 fields:
1.int hash 2.K key 3.V value 4.Node next
array
node_hash_map
1.Initial Capacity 2.Load Factor
As already said, Capacity is simply the number of buckets whereas the Initial Capacity is the capacity of HashMap instance when it is created. The Load Factor is a measure that when rehashing should be done. Rehashing is a process of increasing the capacity. In HashMap capacity is multiplied by 2. Load Factor is also a measure that what fraction of the HashMap is allowed to fill before rehashing. When the number of entries in HashMap increases the product of current capacity and load factor the capacity is increased that is rehashing is done. If the initial capacity is kept higher then rehashing will never be done. But by keeping it higher it increases the time complexity of iteration. So it should be chosen very cleverly to increase performance. The expected number of values should be taken into account to set initial capacity. Most generally preferred load factor value is 0.75 which provides a good deal between time and space costs. Load factor’s value varies between 0 and 1.
As it is told that HashMap is unsynchronized i.e. multiple threads can access it simultaneously. If multiple threads access this class simultaneously and at least one thread manipulates it structurally then it is necessary to make it synchronized externally. It is done by synchronizing some object which encapsulates the map. If No such object exists then it can be wrapped around Collections.synchronizedMap() to make HashMap synchronized and avoid accidental unsynchronized access. As in the following example:
Map m = Collections.synchronizedMap(new HashMap(...));
Now the Map m is synchronized.
Iterators of this class are fail-fast if any structure modification is done after the creation of iterator, in any way except through the iterator’s remove method. In a failure of iterator, it will throw ConcurrentModificationException.
A Set is a generic set of values with no duplicate elements.
A TreeSet is a set where the elements are sorted.
A HashSet is a set where the elements are not sorted or ordered. It is faster than a TreeSet. The HashSet is an implementation of a Set.
Set is a parent interface of all set classes like TreeSet, HashSet, etc.
import java.util.*;
public class Demo {
public static void main(String args[]) {
int a[] = {77, 23, 4, 66, 99, 112, 45, 56, 39, 89};
Set<Integer> s = new HashSet<Integer>();
try {
for(int i = 0; i < 5; i++) {
s.add(a[i]);
}
System.out.println(s);
TreeSet sorted = new TreeSet<Integer>(s);
System.out.println("Sorted list = ");
System.out.println(sorted);
}
catch(Exception e) {}
}
}
Output
[66, 99, 4, 23, 77]
Sorted list =
[4, 23, 66, 77, 99]
// Java program to demonstrate working of
// HashSet
import java.util.HashSet;
class HashSetDemo {
public static void main(String[] args)
{
// Create a HashSet
HashSet<String> hset = new HashSet<String>();
// add elements to HashSet
hset.add("geeks");
hset.add("for");
hset.add("practice");
hset.add("contribute");
// Duplicate removed
hset.add("geeks");
// Displaying HashSet elements
System.out.println("HashSet contains: ");
for (String temp : hset) {
System.out.println(temp);
}
}
}
Output:
HashSet contains:
practice
geeks
for
contribute
// Java program to demonstrate working of
// TreeSet.
import java.util.TreeSet;
class TreeSetDemo {
public static void main(String[] args)
{
// Create a TreeSet
TreeSet<String> tset = new TreeSet<String>();
// add elements to HashSet
tset.add("geeks");
tset.add("for");
tset.add("practice");
tset.add("contribute");
// Duplicate removed
tset.add("geeks");
// Displaying TreeSet elements
System.out.println("TreeSet contains: ");
for (String temp : tset) {
System.out.println(temp);
}
}
}
TreeSet contains:
contribute
for
geeks
practice
1.The HashMap class is roughly equivalent to Hashtable, except that it is non-synchronized and permits nulls. (HashMap allows null values as key and value whereas Hashtable doesn't allow nulls).
-
One of the major differences between HashMap and Hashtable is that HashMap is non-synchronized whereas Hashtable is synchronized, which means Hashtable is thread-safe and can be shared between multiple threads but HashMap can not be shared between multiple threads without proper synchronization. Java 5 introduces ConcurrentHashMap which is an alternative of Hashtable and provides better scalability than Hashtable in Java.
-
Another significant difference between HashMap vs Hashtable is that Iterator in the HashMap is a fail-fast iterator while the enumerator for the Hashtable is not and throw ConcurrentModificationException if any other Thread modifies the map structurally by adding or removing any element except Iterator's own remove() method. But this is not a guaranteed behavior and will be done by JVM on best effort. This is also an important difference between Enumeration and Iterator in Java.
-
One more notable difference between Hashtable and HashMap is that because of thread-safety and synchronization Hashtable is much slower than HashMap if used in Single threaded environment. So if you don't need synchronization and HashMap are only used by one thread, it outperforms Hashtable in Java.
-
HashMap does not guarantee that the order of the map will remain constant over time

-
One of the most important differences between List and ArrayList is that list is an interface and ArrayList is a standard Collection class.
-
List interface extends the Collection framework whereas, the ArrayList extends AbstractList Class and it implements List interfaces.
-
The namespace for List interface is System.Collection.Generic whereas, the namespace for ArrayList is System.Collection.
4.List interface creates a collection of elements that is stored in a sequence and are identified or accessed by their index number. On the other hand, ArrayList creates an array of objects where the array can dynamically grow when required.
The following code is the example of how an Activity uses the SDK in order to provide a ViewModel that is retained on configuration changes.
public class MainActivity extends Activity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
MyViewModel viewModel = ViewModelProviders.of(this).get(MyViewModel.class);
viewModel.getUsers().observer(this, new Observer() {
@Override
public void onChanged(@Nullable User data) {
// update the ui.
}
});
}
}
public class MyViewModel extends ViewModel {
private MutableLiveData<List<User>> users;
public LiveData<List<User>> getUsers() {
if (users == null) {
users = new MutableLiveData<List<User>>();
loadUsers();
}
return users;
}
private void loadUsers() {
// perform an asynchronous operation to fetch users.
}
}
ViewModelProviders.of(this).get(MyViewModel.class); From the above snippet, we can infer that it’s retrieving a ViewModel of type MyViewModel.
In this post, I explored the very basics of the new ViewModel class. The key takeaways are:
-
The ViewModel class is designed to hold and manage UI-related data in a life-cycle conscious way. This allows data to survive configuration changes such as screen rotations.
-
ViewModels separate UI implementation from your app’s data.
*The lifecycle of a ViewModel extends since the time when associated UI controller is first created, till it is completely destroyed.
-
Never store a UI controller or Context directly or indirectly in a ViewModel. This includes storing a View in a ViewModel. Direct or indirect references to UI controllers defeat the purpose of separating the UI from the data and can lead to memory leaks.
-
A HolderFragment is a headless Fragment (without UI) that is added to the Fragment stack with setRetainInstance(true). If you feel like something was not clear, have any suggestions or something to add up, please drop your comments below.

You can evaluate your app's logic using local unit tests when you need to run tests more quickly and don't need the fidelity and confidence associated with running tests on a real device. With this approach, you normally fulfill your dependency relationships using either Robolectric or a mocking framework, such as Mockito. Usually, the types of dependencies associated with your tests determine which tool you use:
If you have dependencies on the Android framework, particularly those that create complex interactions with the framework, it's better to include framework dependencies using Robolectric.
If your tests have minimal dependencies on the Android framework, or if the tests depend only on your own objects, it's fine to include mock dependencies using a mocking framework like Mockito.
Testing forces you to think in a different way and implicitly makes your code cleaner in the process. You feel more confident about your code if it has tests. Shiny green status bars and cool reports detailing how much of your code is covered are both consequences of writing tests. Regression testing is made a lot easier, as automated tests would pick up the bugs first.
A unit test generally exercises the functionality of the smallest possible unit of code (which could be a method, class, or component) in a repeatable way.
Tools that are used to do this testing:
normal test assertions.
mocking out other classes that are not under test.
mocking out static classes such as Android Environment class etc.
A UI Test or Instrumentation Test mocks typical user interactions with your app. Clicking on buttons, typing in text are some of the things UI Tests can complete.
Used for testing within your app, selecting items, making sure something is visible.
Used for testing interaction between different apps.
Mockito is a JAVA library that is used for Unit Testing the Java applications. It is used to mock the interfaces so that dummy objects can be created and used to provide the dependencies for the class being tested.
@Test is an annotation provided by JUnit Framework for marking a method as a test case. As you can see here, each method is a test case testing the input field for a possible input. This instructs the compiler to consider the method as a test case in the test suit.
assertTrue is a method provided by Junit Framework to assert (force) the value inside it’s parentheses as TRUE. If the value inside the parentheses evaluates to be false, the test case fails.
Same as the assertTrue method except that it asserts the argument inside the parentheses to be false instead of true. If the passed parameter is true, the test case fails.
Espresso is an open source testing framework launched by Google in Oct 2013 which provides an API that allows creating UI tests to simulate user interactions in an Android application (in version 2.2). onward .
Here in this case We start with annotations at the start to indicate testing file having LargeTest suite.
@RunWith(AndroidJUnit4.class)
@LargeTest
Add below line which indicates to which file or activity the testing file belongs and we annotate with @Rule annotation.
@Rule
public ActivityTestRule<MainActivity> mainActivityActivityTestRule = new ActivityTestRule<>(MainActivity.class);
Run once before any of the test methods in the class, as the name suggests it will run only once in entire class . Used basically for creating database connection , connection pool requests etc
Run once after all the tests in the class have been run, as the name suggests it will run only once in entire class . Used basically for closing database connection , clean up purpose etc
- Example -
@RunWith(JUnit4.class)
public class BeforeClassAndAfterClassAnnotationsUnitTest {
// ...
@BeforeClass
public static void setup() {
LOG.info("startup - creating DB connection");
}
@AfterClass
public static void tearDown() {
LOG.info("closing DB connection");
}
}
Run before @Test, this method runs before each function having @Test Annotation which means it can run multiple times depending on functions having @Test annotations.
Run after @Test,this method runs after each function having @Test Annotation which means it can run multiple times depending on functions having @Test annotations.
- Example -
@RunWith(JUnit4.class)
public class BeforeAndAfterAnnotationsUnitTest {
// ...
private List<String> list;
@Before
public void init() {
LOG.info("startup");
list = new ArrayList<>(Arrays.asList("test1", "test2"));
}
@After
public void finalize() {
LOG.info("finalize");
list.clear();
}
}
This is the test method to run .
- Example -
@Test
public void whenCheckingListSize_thenSizeEqualsToInit() {
LOG.info("executing test");
assertEquals(2, list.size());
list.add("another test");
}
@Test
public void whenCheckingListSizeAgain_thenSizeEqualsToInit() {
LOG.info("executing another test");
assertEquals(2, list.size());
list.add("yet another test");
}
Entry point to interactions with views (via onView() and onData()). Also exposes APIs that are not necessarily tied to any view, such as pressBack().
A collection of objects that implement the Matcher<? super View> interface. You can pass one or more of these to the onView() method to locate a view within the current view hierarchy.
A collection of ViewAction objects that can be passed to the ViewInteraction.perform() method, such as click().
A collection of ViewAssertion objects that can be passed the ViewInteraction.check() method. Most of the time, you will use the matches assertion, which uses a View matcher to assert the state of the currently selected view.
// Code snippet for Valid Test Login
@Test
public void validLogin() {
// Enter View User Id with Espresso word and close soft keyboard
onView(withId(R.id.edtUserId))
.perform(typeText(mStringToBetyped), closeSoftKeyboard());
// Enter View User Id with Espresso word and close soft keyboard
onView(withId(R.id.edtPass))
.perform(typeText(mValidPass), closeSoftKeyboard());
// Click on Login Button
onView(withId(R.id.loginBtn)).perform(click());
/* Once Clicked on Login we have set condition if Login text Content matches Password Content then The Login is a success */
// Fetch Content of Password Edit Text using Matcher
String textFromPasswordFld = getText(withId(R.id.edtPass));
//Check User Id Content with Content Retreived from Password Edit Text Field
onView(withId(R.id.edtUserId)).check(matches(isEditTextValueEqualTo(R.id.edtUserId, textFromPasswordFld)));
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}

Android KTX
Part of Android Jetpack.
Android KTX is a set of Kotlin extensions that are included with Android Jetpack and other Android libraries. KTX extensions provide concise, idiomatic Kotlin to Jetpack, Android platform, and other APIs. To do so, these extensions leverage several Kotlin language features, including the following:
1.Extension functions 2.Extension properties 3.Lambdas 4.Named parameters 5.Parameter default values 6.Coroutines
As an example, when working with SharedPreferences, you must create an editor before you can make modifications to the preferences data. You must also apply or commit those changes when you are finished editing, as shown in the following * * example:
sharedPreferences
.edit() // create an Editor
.putBoolean("key", value)
.apply() // write to disk asynchronously
Kotlin lambdas are a perfect fit for this use case. They allow you to take a more concise approach by passing a block of code to execute after the editor is created, letting the code execute, and then letting the SharedPreferences API apply the changes atomically.
Here, Co means cooperation and Routines means functions. It means that when functions cooperate with each other, we call it as Coroutines.
Coroutines and the threads both are multitasking. But the difference is that threads are managed by the OS and coroutines by the users as it can execute a few lines of function by taking advantage of the cooperation.
Coroutines do not replace threads, it’s more like a framework to manage it.
Coroutines are available in many languages. Basically, there are two types of Coroutines:
- Stackless
- Stackful
Let's understand this with an example. I have written the below code in a different way just for the sake of understanding. Suppose we have two functions as functionA and functionB.
functionA as below:
fun functionA(case: Int) {
when (case) {
1 -> {
taskA1()
functionB(1)
}
2 -> {
taskA2()
functionB(2)
}
3 -> {
taskA3()
functionB(3)
}
4 -> {
taskA4()
functionB(4)
}
}
}
And functionB as below:
fun functionB(case: Int) {
when (case) {
1 -> {
taskB1()
functionA(2)
}
2 -> {
taskB2()
functionA(3)
}
3 -> {
taskB3()
functionA(4)
}
4 -> {
taskB4()
}
}
}
Then, we can call the functionA as below:
functionA(1) Here, functionA will do the taskA1 and give the control to the functionB to execute the taskB1.
Then, functionB will do the taskB1 and give the control back to the functionA to execute the taskA2 and so on.
The important thing is that functionA and functionB are cooperating with each other.
With Kotlin Coroutines, the above cooperation can be done very easily which is without the use of when or switch case which I have used in the above example for the sake of understanding.
Now that, we have understood what are coroutines when it comes to cooperation between the functions. There are endless possibilities which open up because of the cooperative nature of functions.
coroutines are a great solution to two problems:
Long running tasks are tasks that take too long to block the main thread.
Main-safety allows you to ensure that any suspend function can be called from the main thread.
A CoroutineScope keeps track of all your coroutines, and it can cancel all of the coroutines started in it.
It’s important to note that you can’t just call a suspend function from anywhere. The suspend and resume mechanism requires that you switch from normal functions to a coroutine.
- There are two ways to start coroutines, and they have different uses:
1.launch builder will start a new coroutine that is “fire and forget” — that means it won’t return the result to the caller.
2.async builder will start a new coroutine, and it allows you to return a result with a suspend function called await. In almost all cases, the right answer for how to start a coroutine from a regular function is to use launch. Since the regular function has no way to call await (remember, it can’t call suspend functions directly) it doesn’t make much sense to use async as your main entry to coroutines. We’ll talk later about when it makes sense to use async.
launch builder will start a new coroutine that is “fire and forget” — that means it won’t return the result to the caller.
async builder will start a new coroutine, and it allows you to return a result with a suspend function called await.
The difference is that the launch{} does not return anything and the async{}returns an instance of Deferred, which has an await()function that returns the result of the coroutine like we have future in Java in which we do future.get() to the get the result.
Let's take an example to learn launch and async.
We have a function fetchUserAndSaveInDatabase like below:
fun fetchUserAndSaveInDatabase() {
// fetch user from network
// save user in database
// and do not return anything
}
Now, we can use the launch like below:
GlobalScope.launch(Dispatchers.IO) {
fetchUserAndSaveInDatabase() // do on IO thread
}
As the fetchUserAndSaveInDatabase do not return anything, we can use the launch.
But when we need the result back, we need to use the async.
We have two functions which return User like below:
fun fetchFirstUser(): User {
// make network call
// return user
}
fun fetchSeconeUser(): User {
// make network call
// return user
}
No need to make the above functions as suspend as we are not calling any other suspend function from them.
Now, we can use the async like below:
GlobalScope.launch(Dispatchers.Main) {
val userOne = async(Dispatchers.IO) { fetchFirstUser() }
val userTwo = async(Dispatchers.IO) { fetchSeconeUser() }
showUsers(userOne.await(), userTwo.await()) // back on UI thread
}
Here, it makes both the network call in parallel, await for the results and then call the showUsers function.
So, now that, we have understood the difference between the launch function and the async function.
There is something called withContext.
suspend fun fetchUser(): User {
return GlobalScope.async(Dispatchers.IO) {
// make network call
// return user
}.await()
}
withContext is nothing but an another way writing the async where we do not have to write await().
suspend fun fetchUser(): User {
return withContext(Dispatchers.IO) {
// make network call
// return user
}
}
Work Manager is a library part of Android Jetpack which makes it easy to schedule deferrable, asynchronous tasks that are expected to run even if the app exits or device restarts i.e. even your app restarts due to any issue Work Manager makes sure the scheduled task executes again. Isn't that great?
In this blog, we will talk about how to integrate the work manager in your project and much more advanced feature and customization which makes your life easy in scheduling tasks.
To Integrate work manager in your project,
dependencies {
def work_version = "2.2.0"
implementation "androidx.work:work-runtime:$work_version"
}
Now, as a next step, we will create a Worker class. Worker class is responsible to perform work synchronously on a background thread provided by the work manager.
class YourWorkerClass(appContext: Context, workerParams: WorkerParameters): Worker(appContext, workerParams) {
override fun doWork(): Result {
// Your work here.
// Your task result
return Result.success()
}
}
In this above class,
- doWork() method is responsible to execute your task on the background thread. Whatever task you want to perform has to be written here.
- Result returns the status of the work done in doWork() method. If it returns Result.success() it means the task was successful if the status is Result.failure(), the task was not-successful and lastly, if it returns Result.retry() it means the task will execute again after some time.
We need to create a WorkRequest which defines how and when work should be run. It has two types,
-
OneTimeWorkRequest - Runs the task only once
-
PeriodicWorkTimeRequest - Runs the task after certain time interval.
-
constraints -
val myConstraints = Constraints.Builder()
.setRequiresDeviceIdle(true) //checks whether device should be idle for the WorkRequest to run
.setRequiresCharging(true) //checks whether device should be charging for the WorkRequest to run
.setRequiredNetworkType(NetworkType.CONNECTED) //checks whether device should have Network Connection
.setRequiresBatteryNotLow(true) // checks whether device battery should have a specific level to run the work request
.setRequiresStorageNotLow(true) // checks whether device storage should have a specific level to run the work request
.build()
- One Time Request -
val yourWorkRequest = OneTimeWorkRequestBuilder<YourWorkerClass>()
.setConstraints(myConstraints)
.build()
Here, we set the above-defined constraints to the previously defined workRequest. Now, this work request will only run if all the constraints are satisfied.
We can also set Periodic Task which will run after certain time interval. To run a workRequest which runs periodically we use,
- Periodic Request
val yourPeriodicWorkRequest =
PeriodicWorkRequestBuilder<YourPeriodicWorkerClass>(1, TimeUnit.HOURS)
.setConstraints(myConstraints)
.build()
- Minimum time interval to run a periodic task is 15mins
If you do not want the task to be run immediately, you can specify your work to start after a minimum initial delay using,
val yourWorkRequest = OneTimeWorkRequestBuilder<YourWorkerClass>()
.setInitialDelay(10, TimeUnit.MINUTES)
.build()
This will run after an initial delay of 10minutes.
Check Status of your WorkManager If we want to do some task when WorkManager executes the task successfully like showing a Toast or something else we need to check the status of the task. To check the status we use,
WorkManager.getInstance(context).getWorkInfoByIdLiveData(yourWorkRequest.id)
.observe(lifecycleOwner, Observer { workInfo ->
if (workInfo != null && workInfo.state == WorkInfo.State.SUCCEEDED) {
//Toast
}
})
We can chain multiple tasks in two ways.
- Chaining in Series
- Parallel Chaining
Let's say we have two workRequest,
val yourWorkRequestOne = ...
val yourWorkRequestTwo = ...
and we need to chain them in series. To do this we will use
WorkManager.getInstance(context).beginWith(yourWorkRequestOne)
.then(yourWorkRequestTwo)
.enqueue()
Here, first, the execution will start with the yourWorkRequestOne WorkRequest and then it will execute the second one. This is called series chaining of the tasks.
In this, we can chain the task in parallel using the following
WorkManager.getInstance(myContext)
.beginWith(listOf(work1, work2, work3))
.then(work4)
.then(work5)
.enqueue()
Here, work1,work2, and work3 will execute parallelly and then when all of them are executed then only work4 will execute and work5 sequentially.
Raw strings are strings placed inside triple quotes. We don’t have to escape characters in triple-quoted strings. These strings can be used in multi lines without the need to concatenate each line.
var rawString = """Hi How you're Doing
I'm doing fine.
I owe you $5.50"""
print(rawString)
//Prints the following in the console
Hi How you're Doing
I'm doing fine.
I owe you $5.50
Note: Since escape characters are not parsed, adding a \n or \t won’t have any effect.
var rawString = """Hi How you're Doing
I'm doing fine\n.
I owe you $5.50"""
print(rawString)
//prints the following
Hi How you're Doing
I'm doing fine\n.
I owe you $5.50
Raw strings are handy when you need to specify a file/directory path in a string. We can indent raw strings or remove the whitespacing in multi-lines using the function trimMargin().
var rawString = """Hi How you're Doing
|I'm doing fine.
|I owe you $5.50""".trimMargin("|")
print(rawString)
//Prints the following to the console.
Hi How you're Doing
I'm doing fine.
I owe you $5.50
Note: We can’t pass a blank string as the trim margin. The trimMargin() function trims the string till the marginPrefix specified.
String templates and Raw Strings can be combined together as shown below.
var str = "Kotlin"
var rawString = """Hi How you're Doing $str
|I'm doing fine.
|I owe you $5.50""".trimMargin("|")
print(rawString)
//The following gets printed on the console
Hi How you're Doing Kotlin
I'm doing fine.
I owe you $5.50
- For each Activity/Fragment (View) we require a Presenter. This is a hard bound rule. Presenter holds the reference to the Activity and Activity Holds the reference to presenter. 1:1 relationship and thats where the biggest issue lies.
As the complexity of view increases, so does the maintenance and handling of this relationship.
This eventually lead to same issue we faced earlier as in for quick changes in design, we actually need to modify the whole relationship. Picking a statement from our end goal “Build things in a distributed manner”, In order to achieve it and to avoid this tight relationship ViewModels were introduced.
ViewModels are simples classes that interacts with the logic/model layer and just exposes states/data and actually has no idea by whom or how that data will be consumed. Only View(Activity) holds the reference to ViewModel and not vice versa, this solves our tight coupling issue. A single view can hold reference to multiple ViewModels.
Even for complex views we can actually have different ViewModels within same hierarchy.
- Since Presenters are hard bound to Views, writing unit test becomes slightly difficult as there is a dependency of a View. ViewModels are even more Unit Test friendly as they just expose the state and hence can be independently tested without requiring the need for testing how data will be consumed, In short there is no dependency of the View.


MutableLiveData is a subclass of LiveData which is used for some of it’s properties (setValue/postValue) and using these properties we can easily notify the ui when onChange() is called. Only using LiveData object we can’t do this. So, we have to convert the target object to MutableLiveData/MediatorLiveData for notifying on each time of changing data.
- androidTest - (Instrumentation)- Mockito,JUnit,(UI) - Expresso
- test (Unit)- Mockito, JUnit
== operator is used to compare the data of two variables. Please don’t misunderstand this equality operator with the Java == operator as both are different. == operator in Kotlin only compares the data or variables, whereas in Java or other languages == is generally used to compare the references. The negated counterpart of == in Kotlin is != which is used to compare if both the values are not equal to each other.
=== operator is used to compare the reference of two variable or object. It will only be true if both the objects or variables pointing to the same object. The negated counterpart of === in Kotlin is !== which is used to compare if both the values are not equal to each other. For values which are represented as primitive types at runtime (for example, Int), the === equality check is equivalent to the == check.
equals(other: Any?) method is implemented in Any class and can be overridden in any extending class. .equals method also compares the content of the variables or objects just like == operator but it behaves differently in case of Float and Double comparison.
The difference between == and .equals is in case of Float and Double comparison, .equals disagrees with the IEEE 754 Standard for Floating-Point Arithmetic.
And what does disagree with IEEE 754 Standard for Floating-Point Arithmetic mean?
It means,
NaN is considered equal to itself NaN is considered greater than any other element including POSITIVE_INFINITY -0.0 is considered less than 0.0
Sealed classes are used for representing restricted class hierarchies, when a value can have one of the types from a limited set, but cannot have any other type. They are, in a sense, an extension of enum classes: the set of values for an enum type is also restricted, but each enum constant exists only as a single instance, whereas a subclass of a sealed class can have multiple instances which can contain state.
- How to declare sealed class?
Just put the sealed modifier before the name of the class.
sealed class Car {
data class Maruti(val speed: Int) : Car()
data class Bugatti(val speed: Int, val boost: Int) : Car()
object NotACar : Car()
}
The key benefit of using sealed classes comes into play when you use them in a when expression. If it’s possible to verify that the statement covers all cases, you don’t need to add an else clause to the statement.
fun speed(car: Car): Int = when (car) {
is Car.Maruti -> car.speed
is Car.Bugatti -> car.speed + car.boost
Car.NotACar -> INVALID_SPEED
// else clause is not required as we've covered all the cases
}
So , whenever you get the situation like this, consider using sealed class.
The Data Binding Library is a support library that allows you to bind UI components in your layouts to data sources in your app using a declarative format rather than programmatically.
1. Step 1 - build.gradle
android {
...
dataBinding {
enabled = true
}
}
2. Step 2 - activity_eligibilit.xml
<data>
<variable
name="eligibility"
type="com.greenlightplanet.kazi.task.model.request.EligibilityModel" />
</data>
3. Step 3 -
Note : binding name should be of layout name
Example: content_eligibility - > ContentEligibilityBinding
private lateinit var binding: ContentEligibilityBinding
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
binding= DataBindingUtil.setContentView(this, R.layout.content_eligibility)
}
4. Stetp 4 -
Note - To Set a Data you should execute method
binding.eligibility=eligibilityModel
binding.executePendingBindings()
5. Step 5 -
Note - To set data to TextView
<TextView
android:id="@+id/tvCustomerName"
style="@style/LabelStyle"
android:layout_width="0dp"
android:layout_height="match_parent"
android:layout_weight="1"
android:gravity="center_vertical"
android:text="@{eligibility.ownerName}"
/>
- In data tag in xml file
<data>
<import type="android.view.View" />
<variable
name="eligibility"
type="com.greenlightplanet.kazi.task.model.request.EligibilityModel" />
</data>
- in view
<LinearLayout
android:id="@+id/linearLayout17"
android:layout_width="match_parent"
android:layout_height="55dp"
android:visibility="@{eligibility.accountNumber!=null ? View.VISIBLE: View.GONE}"
>
- Publish Subject
- Replay Subject
- Behavior Subject
- Async Subject
A Subject is a sort of bridge or proxy that is available in some implementations of ReactiveX that acts both as an observer and as an Observable. Because it is an observer, it can subscribe to one or more Observables, and because it is an Observable, it can pass through the items it observes by re-emitting them, and it can also emit new items.
Assume that a professor is an observable. The professor teaches about some topic.
Assume that a student is an observer. The student observes the topic being taught by the professor.
It emits all the subsequent items of the source Observable at the time of subscription.
- Note : Here, if a student entered late into the classroom, he just wants to listen from that point of time when he entered the classroom. So, Publish will be the best for this use-case.
See the below example:
PublishSubject<Integer> source = PublishSubject.create();
// It will get 1, 2, 3, 4 and onComplete
source.subscribe(getFirstObserver());
source.onNext(1);
source.onNext(2);
source.onNext(3);
// It will get 4 and onComplete for second observer also.
source.subscribe(getSecondObserver());
source.onNext(4);
source.onComplete();
It emits all the items of the source Observable, regardless of when the subscriber subscribes.
- Note : Here, if a student entered late into the classroom, he wants to listen from the beginning. So, here we will use Replay to achieve this.
See the below example:
ReplaySubject<Integer> source = ReplaySubject.create();
// It will get 1, 2, 3, 4
source.subscribe(getFirstObserver());
source.onNext(1);
source.onNext(2);
source.onNext(3);
source.onNext(4);
source.onComplete();
// It will also get 1, 2, 3, 4 as we have used replay Subject
source.subscribe(getSecondObserver());
It emits the most recently emitted item and all the subsequent items of the source Observable when an observer subscribes to it.
- Note : Here, if a student entered late into the classroom, he wants to listen the most recent things(not from the beginning) being taught by the professor so that he gets the idea of the context. So, here we will use Behavior.
See the below example:
BehaviorSubject<Integer> source = BehaviorSubject.create();
// It will get 1, 2, 3, 4 and onComplete
source.subscribe(getFirstObserver());
source.onNext(1);
source.onNext(2);
source.onNext(3);
// It will get 3(last emitted)and 4(subsequent item) and onComplete
source.subscribe(getSecondObserver());
source.onNext(4);
source.onComplete();
It only emits the last value of the source Observable(and only the last value) only after that source Observable completes.
- Note : Here, if a student entered at any point of time into the classroom, and he wants to listen only about the last thing(and only the last thing) being taught, after class is over. So, here we will use Async.
See the below example:
AsyncSubject<Integer> source = AsyncSubject.create();
// It will get only 4 and onComplete
source.subscribe(getFirstObserver());
source.onNext(1);
source.onNext(2);
source.onNext(3);
// It will also get only get 4 and onComplete
source.subscribe(getSecondObserver());
source.onNext(4);
source.onComplete();
Single is an Observable which only emits one item or throws an error. Single emits only one value and applying some of the operator makes no sense. Like we don’t want to take value and collect it to a list.
interface SingleObserver<T> {
void onSubscribe(Disposable d);
void onSuccess(T value);
void onError(Throwable error);
}
Maybe is similar to Single only difference being that it allows for no emissions as well.
interface MaybeObserver<T> {
void onSubscribe(Disposable d);
void onSuccess(T value);
void onError(Throwable error);
void onComplete();
}
We will see example how to implement this
//Some Emission
Maybe<String> singleSource = Maybe.just("single item");
singleSource.subscribe(
s -> System.out.println("Item received: from singleSource " + s),
Throwable::printStackTrace,
() -> System.out.println("Done from SingleSource")
);
//no emission
Maybe<Integer> emptySource = Maybe.empty();
emptySource.subscribe(
s -> System.out.println("Item received: from emptySource" + s),
Throwable::printStackTrace,
() -> System.out.println("Done from EmptySource")
);
As we run the above code snippet
Item received: from singleSource single item Done from EmptySource would be printed.
Completable is only concerned with execution completion whether the task has reach to completion or some error has occurred.
interface CompletableObserver<T> {
void onSubscribe(Disposable d);
void onComplete();
void onError(Throwable error);
}
As Completable only concern is completeness it does not have onNext() and onSucess() method.
Example: There are certain scenario where only concern in completion or error. Suppose we update any User model in the app and want to just notify the server about it. We don’t care about the response because app already has the latest object.
public interface APIClient {
@PUT("user")
Completable updateUser(@Body User);
}
- Call the ApiClient updateUser
apiClient.updateUser(user)
.subscribe(() -> {
// handle the completion server has update the user object
},error -> {
//handle error
})
Threading in RxJava is done with help of Schedulers. Scheduler can be thought of as a thread pool managing 1 or more threads. Whenever a Scheduler needs to execute a task, it will take a thread from its pool and run the task in that thread.
Let’s summarize available Scheduler types and their common uses:
is backed by an unbounded thread pool. It is used for non CPU-intensive I/O type work including interaction with the file system, performing network calls, database interactions, etc. This thread pool is intended to be used for asynchronously performing blocking IO.
is backed by a bounded thread pool with size up to the number of available processors. It is used for computational or CPU-intensive work such as resizing images, processing large data sets, etc. Be careful: when you allocate more computation threads than available cores, performance will degrade due to context switching and thread creation overhead as threads vie for processors’ time.
creates a new thread for each unit of work scheduled. This scheduler is expensive as new thread is spawned every time and no reuse happens.
creates and returns a custom scheduler backed by the specified executor. To limit the number of simultaneous threads in the thread pool, use Scheduler.from(Executors.newFixedThreadPool(n)). This guarantees that if a task is scheduled when all threads are occupied, it will be queued. The threads in the pool will exist until it is explicitly shutdown.
is provided by the RxAndroid extension library to RxJava. Main thread (also known as UI thread) is where user interaction happens. Care should be taken not to overload this thread to prevent janky non-responsive UI or, worse, Application Not Responding” (ANR) dialog. Schedulers.single() is new in RxJava 2. This scheduler is backed by a single thread executing tasks sequentially in the order requested.
executes tasks in a FIFO (First In, First Out) manner by one of the participating worker threads. It’s often used when implementing recursion to avoid growing the call stack.
Operators: It translates the input into the required format of the output.
Map transforms the items emitted by an Observable by applying a function to each item.
- Example -
getUserObservable()
.map(new Function<ApiUser, User>() {
@Override
public User apply(ApiUser apiUser) throws Exception {
// here we get the ApiUser from the server
User user = new User(apiUser);
// then by converting it into the user, we are returning
return user;
}
})
.subscribeOn(Schedulers.io())
.observeOn(AndroidSchedulers.mainThread())
.subscribe(getObserver());
FlatMap transforms the items emitted by an Observable into Observables.
- Examples -
getUserObservable()
.flatMap(new Function<ApiUser, ObservableSource<UserDetail>>() {
@Override
public ObservableSource<UserDetail> apply(ApiUser apiUser) throws Exception {
return getUserDetailObservable(apiUser);
}
})
.subscribeOn(Schedulers.io())
.observeOn(AndroidSchedulers.mainThread())
.subscribe(getObserver());
Here, we are getting the ApiUser and then we are making a network call to get the UserDetail for that apiUser by using the getUserDetailObservable(apiUser). The flatMap mapper returns an observable itself. The getUserDetailObservable is an asynchronous operation.
This is how we should use the Map and the FlatMap operators in RxJava.
- Obserbable
- Observer
- Scheduler
- Operator
1. Observable -
- Observable are data stream. they are responsible for emmiting data.
2. Observer -
- Observer consumes data emmitted by observable.
3. Scheduler -
- It manages Thread
- It tells Observable and Observer on which thread they should run.
4. Operator -
- Operator are all horse power behind observable.
- provides elegent and declarative solution to complex async task.
Observable — Operator — Observer
An Observable is like speaker which emit value. It does some work and emits some values.
An Operator is like translator which translate/modify a data from one form to another form.
An Observer gets those values.
This post is all about the different types of Observables available in RxJava.
The following are the different types of Observables in RxJava:
1.Observable
2.Flowable
3.Single
4.Maybe
5.Completable
As there are different types of Observables, there are different types of Observers also.
So, the following are the different types of Observers in RxJava:
1.Observer
2.SingleObserver
3.MaybeObserver
4.CompletableObserver
Now, let’s see how they are different and when to use which one.
This is the simplest Observable which can emit more than one value.
Example use-case: Let’s say you are downloading a file and you have to push the current status of download percentage. Here, you will have to emit more than one value.
* Creating a simple Observable

* Observer for the Observable:

Flowable comes to picture when there is a case that the Observable is emitting huge numbers of values which can’t be consumed by the Observer. In this case, the Observable needs to skip some values on the basis of some strategy else it will throw an exception. The Flowable Observable handles the exception with a strategy. The strategy is called BackPressureStrategy and the exception is called MissingBackPressureException. Creating a Flowable Observable
Similar to normal Observable, you can create Flowable using Flowable.create().
Observer for Flowable Observable
The Observer for Flowable is exactly same as normal Observer.
Single is used when the Observable has to emit only one value like a response from a network call.
* Creating a Single Observable

* SingleObserver for Single Observable

Maybe is used when the Observable has to emit a value or no value.
* Creating a Maybe Observable

* MaybeObserver for Maybe Observable

Completable is used when the Observable has to do some task without emitting a value.
* Creating a Completable Observable

* CompletableObserver for Completable Observable

- Obserbable
- Observer
- Scheduler
- Subscription
- Composite Subscription
1. Retry and RetryWhen
RxJava has operator called retry, you can also specify when to retry.it means you can retry after particular time.
2. timer -
It elemenets timer,you can specify time interval and delay
onCompleted Called when ex. take(20) after 20 intervals.
3. debounce -
(It is use to call api on textChangeListner after particular time text has been type so it reduces multiple calls for each later)
4. combinelatest -
it use of validation, you can check all form's editext and shows error at end of form's edittext, once it is called at end than it starts calling every edittext in form.
5. map -
6. filter -
- Error handeling - onError (in Observer)
- LifeCycle Changes
- Caching (Rotation)
- Composing multiple calls
Map transforms the items emitted by an Observable by applying a function to each item.

FlatMap transforms the items emitted by an Observable into Observables.

So, the main difference between Map and FlatMap that FlatMap mapper returns an observable itself, so it is used to map over asynchronous operations.
Very important: FlatMap is used to map over asynchronous operations.
getUserObservable()
.map(new Function<ApiUser, User>() {
@Override
public User apply(ApiUser apiUser) throws Exception {
// here we get the ApiUser from the server
User user = new User(apiUser);
// then by converting it into the user, we are returning
return user;
}
})
.subscribeOn(Schedulers.io())
.observeOn(AndroidSchedulers.mainThread())
.subscribe(getObserver()
Here, the observable gives us ApiUser object which we are converting into User object by using the map operator.
getUserObservable()
.flatMap(new Function<ApiUser, ObservableSource<UserDetail>>() {
@Override
public ObservableSource<UserDetail> apply(ApiUser apiUser) throws Exception {
return getUserDetailObservable(apiUser);
}
})
.subscribeOn(Schedulers.io())
.observeOn(AndroidSchedulers.mainThread())
.subscribe(getObserver());
Here, we are getting the ApiUser and then we are making a network call to get the UserDetail for that apiUser by using the getUserDetailObservable(apiUser). The flatMap mapper returns an observable itself. The getUserDetailObservable is an asynchronous operation.
To detect when our app is coming to the foreground or when it comes to background, leveraging the ProcessLifecycleOwner class and its events are easy to achieve:
It provides lifecycle for the whole application process. It can be used to react to our app coming to the foreground or going to the background with very little code:
public class AppLifecycleObserver implements LifecycleObserver {
public static final String TAG = AppLifecycleObserver.class.getName();
@OnLifecycleEvent(Lifecycle.Event.ON_START)
public void onEnterForeground() {
//run the code we need
}
@OnLifecycleEvent(Lifecycle.Event.ON_STOP)
public void onEnterBackground() {
//run the code we need
}
}
Now, when need to register the LifeCycleObserver class within the app. To achieve this is mandatory to have an Application class in the app (if not, we need to create it) and then in its onCreate() method call the observer class and then registered, as follows:
public class MyApp extends MultiDexApplication {
private static final String TAG = MyApp.class.getName();
@Override
public void onCreate() {
super.onCreate();
AppLifecycleObserver appLifecycleObserver = new AppLifecycleObserver();
ProcessLifecycleOwner.get().getLifecycle().addObserver(appLifecycleObserver);
}
}
The above tells the application: every time you come background as there is a class observing this, the app is entering to ON_STOP lifecycle process, then please run the onEnterBackground() method. The same will apply to onEnterForeground() method when the app comes to the foreground, because the app is entering ON_START.
In order to not break the design consistency amongst different UI components in android,the onCreate() method will have similar functionality across all of them.
When linking Containers to Contents like Window to Activity and Activity to Fragment a preliminary check needs to be done to determine the state of container. And that explains the use and position of onAttach() in the fragment lifecycle.
Too short;Need longer:
The answer is in the archetype code itself,
@Override
public void onAttach(Activity activity) {
super.onAttach(activity);
try {
mListener = (OnFragmentInteractionListener) activity;
} catch (ClassCastException e) {
throw new ClassCastException(activity.toString()
+ " must implement OnFragmentInteractionListener");
}
}
Another example would be in Jake Wharton's ActionBarSherlock library.
Why would you want to use a method like onCreate() which is has the same purpose in an activity ,service.
The onCreate() is meant to handle issues with respect to that particular context creation.It does not make sense if onCreate() is used to check the state of its container.
The second reason that I can come determine is that a fragment is designed to be activity independent.The onAttach() provides an interface to determine the state/type/(other detail that matters to the fragment) of the containing activity with reference to the fragment before you initialize a fragment.
EDIT:
An activity exists independently and therefore has a self sustaining lifecycle.
for a fragment :
The independent lifecycle components(same as any other components):
onCreate()
onStart()
onResume()
onPause()
onStop()
onDestroy()
The interaction based components:
onAttach()
onCreateView()
onActivityCreated()
onDestroyView()
onDetach()
- Null Pointer Exception Handling
- data class which elemenates boilerplate code
- Extension Functions - with(object),.let,.run,.apply,.also
- scope functions
- Supports Full Java Interoperability
- Optional Parameters in Kotlin
So what this exactly mean?
Cleartext is any transmitted or stored information that is not encrypted or meant to be encrypted. When an app communicates with servers using a cleartext network traffic, such as HTTP, it could raise a risk of eavesdropping and tampering of content. Third parties can inject unauthorized data or leak information about the users. That is why developers are encouraged to a secure traffic only, such as HTTPS.
- But just in case using cleartext is inevitable, developers can fix the error by
- Editing useCleartextTraffic attribute in manifest file, or
- Adding Network Security Config
Coroutines are a new way of writing asynchronous, non-blocking code (and much more)
But the first question arises in our mind is that how the Coroutines are different from the threads?
Coroutine are light-weight threads. A light weight thread means it doesn’t map on native thread, so it doesn’t require context switching on processor, so they are faster.
Coroutines are available in many languages.
Stackless
Stackful
Coroutines and the threads both are multitasking. But the difference is that threads are managed by the OS and coroutines by the users.
launch{}
async{}
The difference is that the launch{} does not return anything and the async{} returns an instance of Deferred, which has an await()function that returns the result of the coroutine like we have future in Java. and we do future.get() in Java to the get the result.
// Serial execution
private fun doWorksInSeries() {
launch(CommonPool) {
val one = doWorkFor1Seconds()
val two = doWorkFor2Seconds()
println("Kotlin One : " + one)
println("Kotlin Two : " + two)
}
}
Output
// The output is
// Kotlin One : doWorkFor1Seconds
// Kotlin Two : doWorkFor2Seconds
// Parallel execution
private fun doWorksInParallel() {
val one = async(CommonPool) {
doWorkFor1Seconds()
}
val two = async(CommonPool) {
doWorkFor2Seconds()
}
launch(CommonPool) {
val combined = one.await() + "_" + two.await()
println("Kotlin Combined : " + combined)
}
}
Output
// The output is
// Kotlin Combined : doWorkFor1Seconds_doWorkFor2Seconds
If you do not want to initialize a property in the constructor, then these are two important ways of property initialisation in Kotlin.
1.lateinit
2.lazy
lateinit is late initialization.
Normally, properties declared as having a non-null type must be initialized in the constructor. However, fairly often this is not convenient. For example, properties can be initialized through dependency injection, or in the setup method of a unit test. In this case, you cannot supply a non-null initializer in the constructor, but you still want to avoid null checks when referencing the property inside the body of a class.
To handle this case, you can mark the property with the lateinit modifier.
Example
public class Test {
lateinit var mock: Mock
@SetUp fun setup() {
mock = Mock()
}
@Test fun test() {
mock.do()
}
}
The modifier can only be used on var properties declared inside the body of a class (not in the primary constructor), and only when the property does not have a custom getter or setter. The type of the property must be non-null, and it must not be a primitive type.
lazy is lazy initialization.
lazy() is a function that takes a lambda and returns an instance of lazy which can serve as a delegate for implementing a lazy property: the first call to get() executes the lambda passed to lazy() and remembers the result, subsequent calls to get() simply return the remembered result.
Example
public class Example{
val name: String by lazy { “Siddhant Patil” }
}
So the first call and the subsequent calls, name will return “Siddhant Patil”
Source : https://blog.mindorks.com/learn-kotlin-lateinit-vs-lazy
lazy can only be used for val properties, whereas lateinit can only be applied to vars because it can’t be compiled to a final field, thus no immutability can be guaranteed. lateinit var can be initialized from anywhere the object is seen from. If you want your property to be initialized from outside in a way probably unknown beforehand, use lateinit.
-
The most important feature of this framework is the separation of concerns. It lets the developer to create tasks(Runnables, Callables), and let the framework decide when, how and where to execute that task on a Thread which is totally configurable.
-
It relieves the developer from thread management.
-
It provides the developers various types of queues for storing the tasks. It also provides various mechanisms for handling the scenario in which a task is rejected by the queue when it is full.
To simply put, the work of an executor is to execute tasks . The executor picks up a thread from the threadpool to execute a task. If a thread is not available and new threads cannot be created, then the executor stores these tasks in a queue. A task can also be removed from the queue. If the queue is full, then the queue will start rejecting the tasks.(Rejection of tasks can be handled).
After the task is completed, the framework will not terminate the executing thread immediately. The executor keeps a minimum number of threads in the thread pool even if all of them are not executing some task. But it will terminate the extra threads (number of threads which are greater than the minimum number of threads) after the specified duration.
Executor is the base interface of this framework which has only one method execute(Runnable command). ExecutorService and ScheduledExecutorService are two other interfaces which extends Executor. These two interfaces have a lot of important methods like submit(Runnable task), shutdown(), schedule(Callable callable,long delay, TimeUnit unit) etc which actually make this framework really useful. The most commonly used implementations of these interfaces are ThreadPoolExecutor and ScheduledThreadPoolExecutor. You can find other implementations here.
While creating an instance of ThreadPoolExecutor, we can give various configurations. We specify the minimum and maximum number of threads that should be present in the ThreadPool. We also specify the duration after which the extra threads(current threads — minimum threads) should be terminated. There are various types of queues which can be used for storing the tasks which cannot be executed immediately. Based on the application requirements we specify the type of queue to be used. Below is the code snippet for creating an instance of ThreadPoolExecutor.
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
RejectedExecutionHandler handler) {
Now lets understand the parameters of ThreadPoolExecutor. For optimal performance of the application, each parameter to the executor needs to be passed very carefully.
- corePoolSize : The minimum number of threads to keep in the pool.
- maximumPoolSize : The maximum number of threads to keep in the pool.
- keepAliveTime : If current number of threads are greater than the minimum threads, then wait for this time to terminate the extra threads.
- unit: The time unit for the previous argument.
- workQueue : The queue used for holding the tasks.
- handler : An instance of RejectionExecutionHandler, which handles the task which is rejected by the executor.
- Source - https://proandroiddev.com/8-steps-to-implement-paging-library-in-android-d02500f7fffe
- Youtube - https://www.youtube.com/watch?v=BE5bsyGGLf4
- https://www.youtube.com/watch?v=QVMqCRs0BNA
This is the base class for data loading, used in list paging. DataSource can be implemented using any one of these 3 classes:
We can use this class if we need to load data based on the number of pages in the dataSource. For instance, we pass page number as a query parameter in the request. The page number will increment sequentially until all the pages are fetched and displayed.
The first step is to define the key that will be used to determine the next page of data. For instance, if it is a User class, then the id would typically be the userId value. The size of the list is generally unknown, and fetching the next set of the data usually depends on the last known Id. So if we fetch items 1 to 10 in the first result, then ItemKeyedDataSource will automatically fetch the next set of 11 to 20.
This class would be useful for sources that provide a fixed size list that can be fetched with arbitrary positions and sizes.
In this scenario, we would be using a PageKeyedDataSource. The following code shows how we can create PageKeyedDataSource for our FeedDataSource class.
public class FeedDataSource extends PageKeyedDataSource<Long, Article> {
private static final String TAG = FeedDataSource.class.getSimpleName();
/*
* Step 1: Initialize the restApiFactory.
* The networkState and initialLoading variables
* are for updating the UI when data is being fetched
* by displaying a progress bar
*/
private RestApiFactory restApiFactory;
private MutableLiveData networkState;
private MutableLiveData initialLoading;
public FeedDataSource() {
this.restApiFactory = RestApiFactory.create();
networkState = new MutableLiveData();
initialLoading = new MutableLiveData();
}
public MutableLiveData getNetworkState() {
return networkState;
}
public MutableLiveData getInitialLoading() {
return initialLoading;
}
/*
* Step 2: This method is responsible to load the data initially
* when app screen is launched for the first time.
* We are fetching the first page data from the api
* and passing it via the callback method to the UI.
*/
@Override
public void loadInitial(@NonNull LoadInitialParams<Long> params,
@NonNull LoadInitialCallback<Long, Article> callback) {
initialLoading.postValue(NetworkState.LOADING);
networkState.postValue(NetworkState.LOADING);
appController.getRestApi().fetchFeed(QUERY, API_KEY, 1, params.requestedLoadSize)
.enqueue(new Callback<Feed>() {
@Override
public void onResponse(Call<Feed> call, Response<Feed> response) {
if(response.isSuccessful()) {
callback.onResult(response.body().getArticles(), null, 2l);
initialLoading.postValue(NetworkState.LOADED);
networkState.postValue(NetworkState.LOADED);
} else {
initialLoading.postValue(new NetworkState(NetworkState.Status.FAILED, response.message()));
networkState.postValue(new NetworkState(NetworkState.Status.FAILED, response.message()));
}
}
@Override
public void onFailure(Call<Feed> call, Throwable t) {
String errorMessage = t == null ? "unknown error" : t.getMessage();
networkState.postValue(new NetworkState(NetworkState.Status.FAILED, errorMessage));
}
});
}
@Override
public void loadBefore(@NonNull LoadParams<Long> params,
@NonNull LoadCallback<Long, Article> callback) {
}
/*
* Step 3: This method it is responsible for the subsequent call to load the data page wise.
* This method is executed in the background thread
* We are fetching the next page data from the api
* and passing it via the callback method to the UI.
* The "params.key" variable will have the updated value.
*/
@Override
public void loadAfter(@NonNull LoadParams<Long> params,
@NonNull LoadCallback<Long, Article> callback) {
Log.i(TAG, "Loading Rang " + params.key + " Count " + params.requestedLoadSize);
networkState.postValue(NetworkState.LOADING);
appController.getRestApi().fetchFeed(QUERY, API_KEY, params.key, params.requestedLoadSize).enqueue(new Callback<Feed>() {
@Override
public void onResponse(Call<Feed> call, Response<Feed> response) {
/*
* If the request is successful, then we will update the callback
* with the latest feed items and
* "params.key+1" -> set the next key for the next iteration.
*/
if(response.isSuccessful()) {
long nextKey = (params.key == response.body().getTotalResults()) ? null : params.key+1;
callback.onResult(response.body().getArticles(), nextKey);
networkState.postValue(NetworkState.LOADED);
} else networkState.postValue(new NetworkState(NetworkState.Status.FAILED, response.message()));
}
@Override
public void onFailure(Call<Feed> call, Throwable t) {
String errorMessage = t == null ? "unknown error" : t.getMessage();
networkState.postValue(new NetworkState(NetworkState.Status.FAILED, errorMessage));
}
});
}
}
DataSourceFactory is responsible for retrieving the data using the DataSource and PagedList configuration which we will create later in this article in our ViewModel class.
public class FeedDataFactory extends DataSource.Factory {
private MutableLiveData<FeedDataSource> mutableLiveData;
private FeedDataSource feedDataSource;
public FeedDataFactory() {
this.mutableLiveData = new MutableLiveData<FeedDataSource>();
}
@Override
public DataSource create() {
feedDataSource = new FeedDataSource();
mutableLiveData.postValue(feedDataSource);
return feedDataSource;
}
public MutableLiveData<FeedDataSource> getMutableLiveData() {
return mutableLiveData;
}
}
The view model will responsible for creating the PagedList along with its configurations and send it to the activity so it can observe the data changes and pass it to the adapter.
PagedList is a wrapper list that holds your data items (in our case the list of articles we need to display) and invokes the DataSource to load the elements. It typically consists of a background executor (which fetches the data) and the foreground executor (which updates the UI with the data).
For instance, let’s say we have some data that we add to the DataSource in the background thread. The DataSource invalidates the PagedList and updates its value. Then on the main thread, the PagedList notifies its observers of the new value. Now the PagedListAdapter knows about the new value.
A PageList takes in 4 important parameters:
-
setEnablePlaceholders(boolean enablePlaceholders) —
Enabling placeholders mean there is a placeholder that is visible to the user till the data is fully loaded. So for instance, if we have 20 items that are needed to be loaded and each item contains an image, when we scroll through the screen, we can see placeholders instead of the image since it is not fully loaded. -
setInitialLoadSizeHint(int initialLoadSizeHint) —
The number of items to load initially. -
setPageSize(int pageSize) —
The number of items to load in the PagedList. -
setPrefetchDistance(int prefetchDistance) —
The number of preloads that occur. For instance, if we set this to 10, it will fetch the first 10 pages initially when the screen loads.
Below is the ViewModel class implemented for this project:
public class FeedViewModel extends ViewModel {
private Executor executor;
private LiveData<NetworkState> networkState;
private LiveData<PagedList<Article>> articleLiveData;
public FeedViewModel() {
init();
}
/*
* Step 1: We are initializing an Executor class
* Step 2: We are getting an instance of the DataSourceFactory class
* Step 3: We are initializing the network state liveData as well.
* This will update the UI on the network changes that take place
* For instance, when the data is getting fetched, we would need
* to display a loader and when data fetching is completed, we
* should hide the loader.
* Step 4: We need to configure the PagedList.Config.
* Step 5: We are initializing the pageList using the config we created
* in Step 4 and the DatasourceFactory we created from Step 2
* and the executor we initialized from Step 1.
*/
private void init() {
executor = Executors.newFixedThreadPool(5);
FeedDataFactory feedDataFactory = new FeedDataFactory();
networkState = Transformations.switchMap(feedDataFactory.getMutableLiveData(),
dataSource -> dataSource.getNetworkState());
PagedList.Config pagedListConfig =
(new PagedList.Config.Builder())
.setEnablePlaceholders(false)
.setInitialLoadSizeHint(10)
.setPageSize(20).build();
articleLiveData = (new LivePagedListBuilder(feedDataFactory, pagedListConfig))
.setFetchExecutor(executor)
.build();
}
/*
* Getter method for the network state
*/
public LiveData<NetworkState> getNetworkState() {
return networkState;
}
/*
* Getter method for the pageList
*/
public LiveData<PagedList<Article>> getArticleLiveData() {
return articleLiveData;
}
}
PagedListAdapter is an implementation of RecyclerView.Adapter that presents data from a PagedList. It uses DiffUtil as a parameter to calculate data differences and do all the updates for you.
The DiffUtil is defined in the Model Class in our case:
DiffUtil is a utility class that can calculate the difference between two lists and output a list of update operations that converts the first list into the second one.
It can be used to calculate updates for a RecyclerView Adapter. See ListAdapter and AsyncListDiffer which can compute diffs using DiffUtil on a background thread.
DiffUtil uses Eugene W. Myers's difference algorithm to calculate the minimal number of updates to convert one list into another. Myers's algorithm does not handle items that are moved so DiffUtil runs a second pass on the result to detect items that were moved.
Android Architecture Component

It have reference of below class because we can change its lower structure without solving inter dependancies.





























If we look at with and T.run, both functions are actually pretty similar. The below does the same thing.
with(webview.settings) {
javaScriptEnabled = true
databaseEnabled = true
}
// similarly
webview.settings.run {
javaScriptEnabled = true
databaseEnabled = true
}
However, their different is one is a normal function i.e. with, while the other is an extension function i.e. T.run.
So the question is, what is the advantage of each?
Imagine if webview.settings could be null, they will look as below.
// Yack!
with(webview.settings) {
this?.javaScriptEnabled = true
this?.databaseEnabled = true
}
}
// Nice.
webview.settings?.run {
javaScriptEnabled = true
databaseEnabled = true
}
In this case, clearly T.run extension function is better, as we could apply check for nullability before using it.
If we look at T.run and T.let, both functions are similar except for one thing, the way they accept the argument. The below shows the same logic for both functions.
stringVariable?.run {
println("The length of this String is
The T.let does provide a clearer distinguish use the given variable function/member vs. the external class function/member In the event that this can’t be omitted e.g. when it is sent as a parameter of a function, it is shorter to write than this and clearer. The T.let allow better naming of the converted used variable i.e. you could convert it to some other name.
stringVariable?.let {
nonNullString ->
println("The non null string is $nonNullString")
}
The Kotlin documentation on data classes notes that there are some basic restrictions in order to maintain consistency/behaviour of generated code:
- The primary constructor needs to have at least one parameter;
- All primary constructor parameters need to be marked as val or var;
- Data classes cannot be abstract, open, sealed or inner;
- Data classes may not extend other classes (but may implement interfaces).
Tired of writing (or generating) lengthy, boilerplate code for objects which do nothing but store data?
Well, Kotlin has the solution for you!
Almost every software project we create has a number of classes which exist solely to store data/state but have almost no actual functionality in terms of operations. In more complex apps, this number can be rather high (applications which feature a clean architecture approach often have 2–3 times as many due to a separation of entities between layers).
These generally contain the same concepts every time:
A constructor Fields to store data Getter and setter functions hashCode(), equals() and toString() functions
Example — Storing Video Game Data If we wanted to store some data about a video game in Java, we would usually create a class similar to this:
public class VideoGame {
private String name;
private String publisher;
private int reviewScore;
public VideoGame(String name, String publisher, int reviewScore) {
this.name = name;
this.publisher = publisher;
this.reviewScore = reviewScore;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPublisher() {
return publisher;
}
public void setPublisher(String publisher) {
this.publisher = publisher;
}
public int getReviewScore() {
return reviewScore;
}
public void setReviewScore(int reviewScore) {
this.reviewScore = reviewScore;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
VideoGame that = (VideoGame) o;
if (reviewScore != that.reviewScore)
return false;
if (name != null ? !name.equals(that.name) :
that.name != null) {
return false;
}
return publisher != null ?
publisher.equals(that.publisher) :
that.publisher == null;
}
@Override
public int hashCode() {
int result = name != null ? name.hashCode() : 0;
result = 31 * result + (publisher != null ?
publisher.hashCode() : 0);
result = 31 * result + reviewScore;
return result;
}
@Override
public String toString() {
return "VideoGame{" +
"name='" + name + '\'' +
", publisher='" + publisher + '\'' +
", reviewScore=" + reviewScore +
'}';
}
}
Fortunately for us, the above code is no longer necessary in Kotlin due to the useful data class concept provided by the language. A data class is a class in Kotlin created to encapsulate all of the above functionality in a succinct manner.
To recreate the VideoGame class in Kotlin, we can simply write:
data class VideoGame(val name: String, val publisher: String, var reviewScore: Int)
Much better!
When we specify the data keyword in our class definition, Kotlin automatically generates field accessors, hashCode(), equals(), toString(), as well as the useful copy() and componentN() functions (more on these later).
Any of the functions above which are manually defined by us in the class will not be generated.
We can control the visibility modifiers of the getters/setters generated by providing them in the constructor:
data class VideoGame(private val name: String, val publisher: String, private var reviewScore: Int
If we only wish to expose getters and not setters, we just provide val instead of var for each field (val properties are Kotlin’s equivalent of final in Java). In the below example, name and reviewScore have read/write access, while publisher is read-only:
data class VideoGame(var name: String, val publisher: String, private var reviewScore: Int
Since our data classes are immutable, we must create a copy if we wish to change some data. We are also able to specify if we only wish to change specific attributes for the new copy. For example, if we wish to change the review score of a game, this can be done by writing:
val game: VideoGame = VideoGame("Gears of War", "Epic Games", 8)
val betterGame = game.copy(reviewScore = 10)
apply plugin: 'kotlin-android-extensions'
android
{
androidExtensions
{
experimental = true
}
}
In data class
@Parcelize data class Error(var ErrorCause:String,var MessageToUser:String,var Code: Int?):Parcelable

LiveData is an observable data holder. It is also a lifecycle aware. By lifecycle aware I mean, it can only be observed in the context of a lifecycle, more precisely in the context of an Activity or Fragment lifecycle. By passing the reference of an Activity or Fragment, it can understand whether your UI onScreen, offScreen or Destroyed. After passing the UI object to LiveData, whenever the data in the live data changes. It notifies the lifecycle owner with updates and then the UI redraw itself with updates.
Observers are bound to Lifecycle objects and clean up after themselves when their associated life cycle destroyed.
It means if an activity is in the back stack, then it doesn’t receive any LiveData stream.
It receives the latest data upon becoming active again.
cycling handle: Observers just observe relevant data and don’t stop or resume observation. LiveData manages all of this under the hood.
LiveData notifies the observer object whenever lifecycle state changes. Instead of updating the UI every-time when the data changes, your observer can update the UI every time there’s a change.
If an observer is recreated due to a configuration change, like device rotation, it immediately receives the latest available data.
You can extend LiveData object using the singleton pattern to wrap system services so that they can be shared in your app.
Concepts -
- Constraints
- Margins
- Baselines
- Chains
- Guidelines
- Barriers
- Groups
- Helpers
This holds the data of the application. It cannot directly talk to the View. Generally, it’s recommended to expose the data to the ViewModel through Observables.
It represents the UI of the application devoid of any Application Logic. It observes the ViewModel.
It acts as a link between the Model and the ViewModel. It’s responsible for transforming the data from the Model. It provides data streams to the View. It also uses hooks or callbacks to update the View. It’ll ask for the data from the Model. The following flow illustrates the core MVVM Pattern.

ViewModel replaces the Presenter in the Middle Layer. The Presenter holds references to the View. The ViewModel doesn’t. The Presenter updates the View using the classical way (triggering methods). The ViewModel sends data streams. The Presenter and View are in a 1 to 1 relationship. The View and the ViewModel are in a 1 to many relationship. The ViewModel does not know that the View is listening to it.
- Data Binding
- RXJava
https://stackoverflow.com/questions/37518745/evenly-spacing-views-using-constraintlayout
https://antonioleiva.com/kotlin-android-extensions/
In particular if you have the following code:
class Book{
fun update(title: String, subtitle : String = "No Subtitle", abridged : Boolean = false){
}
}
In kotlin you can simply make a call like the following:
book.update("Arbian Nights")
Or just specify a particular parameter that you want:
book.update("Arabian Nights", abridged = true) Or even change the optional parameter order:
book.update("Arabian Nights", abridged = true, subtitle = "An Oxford Translation")
Going back to the question, since Java doesn’t have support for optional parameters how is this handled? Does Kotlin generate all the different variations making any combination safe? I can see how trying to support this on the Java side could lead to problems with allowing changeable order. For example if the function was defined as this:
class Book{
fun update(title: String, subtitle : String = "No Subtitle", author : String = “Jim Baca”){
}
}
And we wanted to call this from the Java side. How would the compiler know the difference between:
book.update("Arabian Nights", “No Subtitle”);
And this method call?
book.update("Arabian Nights", “Jim Baca”);
Given the above it’s not surprising that Kotlin doesn’t support optional parameters on the Java side. I was hoping for optional parameters would define the following functions:
update(String title)
update(String title, String subtitle)
update(String title, String subtitle, String author)
Update: Thanks Kirill Rakhman for pointing out that you can use @JvmOverloads annotation before your method definition you get this desired effect.
Of course this would create an odd situation since it doesn’t allow for parameter reordering which. Optional parameters in Kotlin become mandatory in Java and the parameter order is the exact same as it is defined in Kotlin, unless @JvmOverloads annotation is used. E.g. if we had this definition in Kotlin:
class Book{
fun update(title: String, subtitle : String = "No Subtitle", author : String = “Jim Baca”){
}
}
Then the correct way of calling the function would be:
book.update("Arabian Nights", “No Subtitle”, “Jim Baca”);
However if we had this:
class Book{
@JvmOverloads fun update(title: String, subtitle : String = "No Subtitle", author : String = “Jim Baca”){
}
}
Then we could call it with any of the following
book.update("Arabian Nights");
book.update("Arabian Nights", "No Subtitle");
book.update("Arabian Nights", "No Subtitle", "Jim Baca");
You can't create arbitrary tuples in Kotlin, instead, you can use data classes. One option is using the built in Pair and Triple classes that are generic and can hold two or three values, respectively. You can use these combined with destructuring declarations like this:
fun getPair() = Pair(1, "foo")
val (num, str) = getPair()
You can also destructure a List or Array, for up to the first 5 elements:
fun getList() = listOf(1, 2, 3, 4, 5)
val (a, b, c, d, e) = getList()
The most idiomatic way however would be to define your own data class, which allows you to return a meaningful type from your function:
data class Time(val hour: Int, val minute: Int, val second: Int)
fun getTime(): Time {
...
return Time(hour, minute, second)
}
val (hour, minute, second) = getTime()
Functional Interfaces In Java A functional interface is an interface that contains only one abstract method. They can have only one functionality to exhibit. From Java 8 onwards, lambda expressions can be used to represent the instance of a functional interface. A functional interface can have any number of default methods. Runnable, ActionListener, Comparable are some of the examples of functional interfaces. Before Java 8, we had to create anonymous inner class objects or implement these interfaces.
// Java program to demonstrate functional interface
class Test
{
public static void main(String args[])
{
// create anonymous inner class object
new Thread(new Runnable()
{
@Override
public void run()
{
System.out.println("New thread created");
}
}).start();
}
}
https://www.javatpoint.com/difference-between-abstract-class-and-interface
No, you cannot create an instance of an abstract class because it does not have a complete implementation. The purpose of an abstract class is to function as a base for subclasses. It acts like a template, or an empty or partially empty structure, you should extend it and build on it before you can use it.
At first, lateinit var and by lazy {...} sound quite similar. However, there are significant differences between the two of them:
The lazy {...} delegate can only be used for val properties; lateinit can only be used for var properties.
A lateinit var property can't be compiled into a final field, hence you can't achieve immutability.
A lateinit var property has a backing field to store the value, whereas lazy {...} creates a delegate object that acts as a container for the value once created and provides a getter for the property. If you need the backing field to be present in the class, you will have to use lateinit.
The lateinit property cannot be used for nullable properties or Java primitive types. This is a restriction imposed ...
Variables defined with var are mutable (Read and Write)
Variables defined with val are immutable (Read only)


ButterKnife
https://www.androidhive.info/2017/10/android-working-with-butterknife-viewbinding-library/
https://stackoverflow.com/questions/44402024/why-android-change-compile-to-implementation-configuration-in-gradle-depende https://stackoverflow.com/questions/44493378/whats-the-difference-between-implementation-and-compile-in-gradle
https://medium.com/upday-devs/android-architecture-patterns-part-3-model-view-viewmodel-e7eeee76b73b https://medium.com/@husayn.hakeem/android-by-example-mvvm-data-binding-introduction-part-1-6a7a5f388bf7
https://github.com/codepath/android_guides/wiki/Understanding-the-Android-Application-Class
https://android.jlelse.eu/how-to-configure-multidex-in-an-application-android-f221198707ed https://stackoverflow.com/questions/33588459/what-is-android-multidex
Firebase App Indexing gets your app into Google Search. If users have your app installed, they can launch your app and go directly to the content they're searching for. App Indexing reengages your app users by helping them find both public and personal content right on their device, even offering query autocompletions to help them more quickly find what they need. If users don’t yet have your app, relevant queries trigger an install card for your app in Search results.
https://firebase.google.com/docs/app-indexing/
https://searchengineland.com/app-indexing-matters-future-search-216884
Google Play currently requires that your APK file be no more than 100MB. For most applications, this is plenty of space for all the application's code and assets. However, some apps need more space for high-fidelity graphics, media files, or other large assets. Previously, if your app exceeded 100MB, you had to host and download the additional resources yourself when the user opens the app. Hosting and serving the extra files can be costly, and the user experience is often less than ideal. To make this process easier for you and more pleasant for users, Google Play allows you to attach two large expansion files that supplement your APK.
Google Play hosts the expansion files for your application and serves them to the device at no cost to you. The expansion files are saved to the device's shared storage location (the SD card or USB-mountable partition; also known as the "external" storage) where your app can access them. On most devices, Google Play downloads the expansion file(s) at the same time it downloads the APK, so your application has everything it needs when the user opens it for the first time. In some cases, however, your application must download the files from Google Play when your application starts.
https://developer.android.com/google/play/expansion-files
https://support.google.com/googleplay/android-developer/answer/2481797?hl=en
Deeplinks are a concept that help users navigate between the web and applications. They are basically URLs which navigate users directly to the specific content in applications.
What is Android App Links?
On the other hand, Android App Links allow an app to designate itself as the default handler of application domain or URL. Unfortunately It works only on on Android 6.0 (API level 23) and higher.
Tags -
action category data
P.S - Please check link to clearly understand - https://medium.com/@muratcanbur/intro-to-deep-linking-on-android-1b9fe9e38abd
AsyncTaskLoader is the loader equivalent of AsyncTask. AsyncTaskLoader provides a method, loadInBackground(), that runs on a separate thread. The results of loadInBackground() are automatically delivered to the UI thread, by way of the onLoadFinished() LoaderManager callback
You can have a look at the compatibility library's source code to get more info. What a FragmentActivity does is:
keep a list of LoaderManager's make sure they don't get destroyed when you flip your phone (or another configuration change occurs) by saving instances using onRetainNonConfigurationInstance() kick the right loader when you call initLoader() in your Activity You need to use the LoaderManager to interface with the loaders, and provide the needed callbacks to create your loader(s) and populate your views with the data they return.
Generally it should be easier than managing AsyncTask's yourself. However, AsyncTaskLoader is not exactly well documented, so you should study the example in the docs and/or model your code after CursorLoader.
AsyncTask is an abstract Android class which helps the Android applications to handle the Main UI thread in efficient way. AsyncTask class allows us to perform long lasting tasks/background operations and show the result on the UI thread without affecting the main thread.
AsyncTask processes are not automatically killed by the OS. AsyncTask processes run in the background and is responsible for finishing it's own job in any case. You can cancel your AsycnTask by calling cancel(true) method. This will cause subsequent calls to isCancelled() to return true. After invoking this method, onCancelled(Object) method is called instead of onPostExecute() after doInBackground() returns.
setContentView is an Activity method only. Each Activity is provided with a FrameLayout with id "@+id/content" (i.e. the content view). Whatever view you specify in setContentView will be the view for that Activity. Note that you can also pass an instance of a view to this method, e.g. setContentView(new WebView(this)); The version of the method that you are using will inflate the view for you behind the scenes.
Fragments, on the other hand, have a lifecycle method called onCreateView which returns a view (if it has one). The most common way to do this is to inflate a view in XML and return it in this method. In this case you need to inflate it yourself though. Fragments don't have a setContentView method
UI Thread
Return a private FragmentManager for placing and managing Fragments inside of this Fragment.
Return the FragmentManager for interacting with fragments associated with this fragment’s activity.
https://www.journaldev.com/21095/java-equals-hashcode
Difference between == and .equals() method in Java In general both equals() and “==” operator in Java are used to compare objects to check equality but here are some of the differences between the two:
Main difference between .equals() method and == operator is that one is method and other is operator. We can use == operators for reference comparison (address comparison) and .equals() method for content comparison. In simple words, == checks if both objects point to the same memory location whereas .equals() evaluates to the comparison of values in the objects. If a class does not override the equals method, then by default it uses equals(Object o) method of the closest parent class that has overridden this method. See this for detail Coding Example: // Java program to understand // the concept of == operator
public class Test {
public static void main(String[] args)
{
String s1 = new String("HELLO");
String s2 = new String("HELLO");
System.out.println(s1 == s2);
System.out.println(s1.equals(s2));
}
}
A wait can be "woken up" by another thread calling notify on the monitor which is being waited on whereas a sleep cannot. Also a wait (and notify) must happen in a block synchronized on the monitor object whereas sleep does not:
Object mon = ...;
synchronized (mon) {
mon.wait();
}
At this point the currently executing thread w aits and releases the monitor. Another thread may do
synchronized (mon) { mon.notify(); }
(On the same mon object) and the first thread (assuming it is the only thread waiting on the monitor) will wake up.
You can also call notifyAll if more than one thread is waiting on the monitor - this will wake all of them up. However, only one of the threads will be able to grab the monitor (remember that the wait is in a synchronized block) and carry on - the others will then be blocked until they can acquire the monitor's lock.
Another point is that you call wait on Object itself (i.e. you wait on an object's monitor) whereas you call sleep on Thread.
Yet another point is that you can get spurious wakeups from wait (i.e. the thread which is waiting resumes for no apparent reason). You should always wait whilst spinning on some condition as follows:
synchronized {
while (!condition) { mon.wait(); }
}
Inter-thread communication in Java Inter-thread communication or Co-operation is all about allowing synchronized threads to communicate with each other.
Cooperation (Inter-thread communication) is a mechanism in which a thread is paused running in its critical section and another thread is allowed to enter (or lock) in the same critical section to be executed.It is implemented by following methods of Object class:
wait() notify() notifyAll()
Discovering devices is only the first step to any Bluetooth operations, such as listening for incoming connection, requesting a connection, accepting a connection, and exchanging data. The connection mechanism follows that of the client-server model. In general, to implement a connection between two devices, one of them has to act as the server and the other the client. The server makes itself discoverable and waits for connection request from client. The client on the other hand initiates the connection using the server device's MAC address discovered during a discovery process.
1.Call the "listenUsingRfcommWithServiceRecord()" method of the "BluetoothAdapter" handle to return a secure RFCOMM (Radio Frequency Communication) "BluetoothServerSocket" with Service Record. For example:
BluetoothServerSocket bluetoothServerSocket = bluetoothAdapter.listenUsingRfcommWithServiceRecord(getString(R.string.app_name), uuid);
The first string parameter is the service name which could be the app name. The second parameter is a Universally Unique Identifier (UUID) which is a standardized 128-bit format for a string ID that is used to uniquely identify the Bluetooth service in the app. The system will automatically write the service name, UUID, and the RFCOMM channel to the Service Discovery Protocol (SDP) database on the device. Remote Bluetooth devices can then use this same UUID to query the SDP server and discover which channel and service to connect to. You can generate a UUID string using some online UUID generator, and then convert the string to a UUID like this:
private final static UUID uuid = UUID.fromString("fc5ffc49-00e3-4c8b-9cf1-6b72aad1001a");
- Call the "accept()" method of the "BluetoothServerSocket" to start listening for connection requests. The call will block the current thread until a connection is accepted or an exception has occurred. The "BluetoothServerSocket" will only accept a connection request that has a matching UUID. Once a connection is accepted, "accept()" will return a "BluetoothSocket" to manage the connection. Once the "BluetoothSocket" is acquired, you should close "BluetoothServerSocket" by calling its "close()" method as it is no longer needed. For example:
BluetoothSocket bluetoothSocket = bluetoothServerSocket.accept();
bluetoothServerSocket.close();
Once you have set up a device as a discoverable server holding an open "BluetoothServerSocket" and listening for connection request, any other Bluetooth device within range can discover and initiate connection request to it as a client. For that to happen, this client device must know the MAC address of that server device and a matching UUID to that particular connection.
listview.setOnItemClickListener(new AdapterView.OnItemClickListener() {
@Override
public void onItemClick(AdapterView<?> parent, View view, int position, long id) {
String itemValue = (String) listview.getItemAtPosition(position);
String MAC = itemValue.substring(itemValue.length() - 17);
BluetoothDevice bluetoothDevice = bluetoothAdapter.getRemoteDevice(MAC);
// Initiate a connection request in a separate thread
ConnectingThread t = new ConnectingThread(bluetoothDevice);
t.start();
}
});
https://www.codeproject.com/Articles/814814/Android-Connectivity
The classic method to do this is to use a transactional database (so there's no clashes) and to do a tentative allocation of the seat to you that expires after some length of time (e.g., 10 minutes for kiosks) that gives you enough time to pay. If the (customer-visible) transaction falls through or times out, the seat allocation can be released back into the pool. (All state changes are processed via the transactional database, and one customer-visible transaction might require many database-level transactions.)
Airlines will use a similar system (though much more complex due to the need to handle multiple flight legs!) for booking seats online. I would imagine that the timeout would be considerably longer; airline tickets are usually booked further ahead than movie tickets, and are more expensive as well.
categories of sensors.
- TYPE_ACCELEROMETER
Measures the acceleration force in m/s2 that is applied to a device on all three physical axes (x, y, and z), including the force of gravity.
- TYPE_AMBIENT_TEMPERATURE
Measures the ambient room temperature in degrees Celsius (°C). See note below.
- TYPE_GYROSCOPE
Measures a device's rate of rotation in rad/s around each of the three physical axes (x, y, and z).
- TYPE_PROXIMITY
Measures the proximity of an object in cm relative to the view screen of a device. This sensor is typically used to determine whether a handset is being held up to a person's ear.
- TYPE_TEMPERATURE
Measures the temperature of the device in degrees Celsius (°C). This sensor implementation varies across devices and this sensor was replaced with the TYPE_AMBIENT_TEMPERATURE sensor in API Level 14
A complex enterprise application with many collaborators will require a solid foundation of planning and clear, concise communication among team members as the project progresses.
Visualizing user interactions, processes, and the structure of the system you're trying to build will help save time down the line and make sure everyone on the team is on the same page.
- Class diagram
- Package diagram
- Object diagram
- Component diagram
- Composite structure diagram
- Deployment diagram
- Activity diagram
- Sequence diagram
- Use case diagram
- State diagram
- Communication diagram
- Interaction overview diagram
- Timing diagram
Wifi:
WifiManager wifiManager = (WifiManager)context.getSystemService(Context.WIFI_SERVICE);
int linkSpeed = wifiManager.getConnectionInfo().getRssi();
In case of mobile it should work:
TelephonyManager telephonyManager = (TelephonyManager)this.getSystemService(Context.TELEPHONY_SERVICE);
CellInfoGsm cellinfogsm = (CellInfoGsm)telephonyManager.getAllCellInfo().get(0);
CellSignalStrengthGsm cellSignalStrengthGsm = cellinfogsm.getCellSignalStrength();
cellSignalStrengthGsm.getDbm();
Then You should compare this signal levels and if WIFI signal is better keep it turn on, but if mobile is better disconnect wifi
Whenever an app runs in the background, it consumes some of the device's limited resources, like RAM. This can result in an impaired user experience, especially if the user is using a resource-intensive app, such as playing a game or watching video. To improve the user experience, Android 8.0 (API level 26) imposes limitations on what apps can do while running in the background. This document describes the changes to the operating system, and how you can update your app to work well under the new limitations.
Many Android apps and services can be running simultaneously. For example, a user could be playing a game in one window while browsing the web in another window, and using a third app to play music. The more apps are running at once, the more load is placed on the system. If additional apps or services are running in the background, this places additional loads on the system, which could result in a poor user experience; for example, the music app might be suddenly shut down.
To lower the chance of these problems, Android 8.0 places limitations on what apps can do while users aren't directly interacting with them. Apps are restricted in two ways:
While an app is idle, there are limits to its use of background services. This does not apply to foreground services, which are more noticeable to the user.
With limited exceptions, apps cannot use their manifest to register for implicit broadcasts. They can still register for these broadcasts at runtime, and they can use the manifest to register for explicit broadcasts targeted specifically at their app.
https://androidresearch.wordpress.com/2013/05/10/dealing-with-asynctask-and-screen-orientation/
If the Fragment inside activity & activity screen roatated while making network call, apps may crash, so how to handle that crash?
Manage the Object Inside a Retained Fragment
Ever since the introduction of Fragments in Android 3.0, the recommended means of retaining active objects across Activity instances is to wrap and manage them inside of a retained “worker” Fragment. By default, Fragments are destroyed and recreated along with their parent Activitys when a configuration change occurs. Calling Fragment#setRetainInstance(true) allows us to bypass this destroy-and-recreate cycle, signaling the system to retain the current instance of the fragment when the activity is recreated. As we will see, this will prove to be extremely useful with Fragments that hold objects like running Threads, AsyncTasks, Sockets, etc.
The sample code below serves as a basic example of how to retain an AsyncTask across a configuration change using retained Fragments. The code guarantees that progress updates and results are delivered back to the currently displayed Activity instance and ensures that we never accidentally leak an AsyncTask during a configuration change.
better options for list :
https://androidresearch.wordpress.com/2013/05/10/dealing-with-asynctask-and-screen-orientation/
res/layout/main_activity.xml # For handsets (smaller than 600dp available width)
res/layout-sw600dp/main_activity.xml # For 7” tablets (600dp wide and bigger)
or you can use
res/layout/main_activity.xml # For handsets (smaller than 640dp x 480dp)
res/layout-large/main_activity.xml # For small tablets (640dp x 480dp and bigger)
res/layout-xlarge/main_activity.xml # For large tablets (960dp x 720dp and bigger)
To share data betweem two apps we can use content provider, in that we can use content resolver to perform CRUD Operation.
and we can take value using content values. please read arictle for details.
http://codetheory.in/android-sharing-application-data-with-content-provider-and-content-resolver/
To restrict app from sharing data, we can make custom permission for provider to give access to another app.
https://www.codementor.io/maker-abhi/share-data-between-your-android-apps-only-securely-a0pa8ea0j
Rooting detection is a cat and mouse game and it is hard to make rooting detection that will work on all devices for all cases.
If you still need some basic rooting detection check the code below:
/**
* Checks if the device is rooted.
*
* @return <code>true</code> if the device is rooted, <code>false</code> otherwise.
*/
public static boolean isRooted() {
// get from build info
String buildTags = android.os.Build.TAGS;
if (buildTags != null && buildTags.contains("test-keys")) {
return true;
}
// check if /system/app/Superuser.apk is present
try {
File file = new File("/system/app/Superuser.apk");
if (file.exists()) {
return true;
}
} catch (Exception e1) {
// ignore
}
// try executing commands
return canExecuteCommand("/system/xbin/which su")
|| canExecuteCommand("/system/bin/which su") || canExecuteCommand("which su");
}
// executes a command on the system
private static boolean canExecuteCommand(String command) {
boolean executedSuccesfully;
try {
Runtime.getRuntime().exec(command);
executedSuccesfully = true;
} catch (Exception e) {
executedSuccesfully = false;
}
return executedSuccesfully;
}
AsyncTask<Void, Void, HttpEntity> editProfileTask = new AsyncTask<Void, Void, HttpEntity>() {
@Override
protected HttpEntity doInBackground(Void... params) {
HttpClient httpclient = new DefaultHttpClient();
HttpPost httppost = new HttpPost("Your url"); // your url
try {
MultipartEntity reqEntity = new MultipartEntity();
reqEntity.addPart("firstname",new StringBody(firstnameEV.getText().toString(),
"text/plain",Charset.forName("UTF-8")));
"text/plain",Charset.forName("UTF-8")));
if (file != null) {
reqEntity.addPart("image",new FileBody(((File) file),"application/zip"));
}
httppost.setEntity(reqEntity);
HttpResponse resp = httpclient.execute(httppost);
HttpEntity resEntity = resp.getEntity();
return resEntity;
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}return null;
}
@Override
protected void onPostExecute(HttpEntity resEntity) {
if (resEntity != null) {
try {
JSONObject responseJsonObject = new JSONObject(EntityUtils.toString(resEntity));
String status = responseJsonObject.getString("status");
if (status.equals("success")) {
Toast.makeText(activity, "Your Profile is updated", Toast.LENGTH_LONG).show();
String data = responseJsonObject.getString("data");
isUpdatedSuccessfully=true;
} else {
Toast.makeText(activity, "Profile not updated", Toast.LENGTH_LONG).show();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
};
editProfileTask.execute(null, null, null)
Types of broadcast :Local,Normal,Ordered and Sticky
- Normal Broadcast
:- use sendBroadcast()
:- asynchronous broadcast
:- any receiver receives broadcast not any particular order - Ordered Broadcast
:- use sendOrderedBroadcast()
:- synchronous broadcast
:- receiver receives broadcast in priority base
:- we can also simply abort broadcast in this type - Local Broadcast
:- use only when broadcast is used only inside application - Sticky Broadcast
:- normal broadcast intent is not available any more after is was send and processed by the system.
:- use sendStickyBroadcast(Intent)
:- the corresponding intent is sticky, meaning the intent you are sending stays around after the broadcast is complete.
:- because of this others can quickly retrieve that data through the return value of registerReceiver(BroadcastReceiver, IntentFilter).
:- apart from this same as sendBroadcast(Intent).
https://www.rishabhsoft.com/blog/payment-gateway-integration-android-ios
-
Add PayPal Android SDK dependency to your build.gradle file as shown in README.md
-
Create a PayPalConfiguration object
private static PayPalConfiguration config = new PayPalConfiguration()
// Start with mock environment. When ready, switch to sandbox (ENVIRONMENT_SANDBOX)
// or live (ENVIRONMENT_PRODUCTION)
.environment(PayPalConfiguration.ENVIRONMENT_NO_NETWORK)
.clientId("<YOUR_CLIENT_ID>");
- Start PayPalService when your activity is created and stop it upon destruction:
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
Intent intent = new Intent(this, PayPalService.class);
intent.putExtra(PayPalService.EXTRA_PAYPAL_CONFIGURATION, config);
startService(intent);
}
@Override
public void onDestroy() {
stopService(new Intent(this, PayPalService.class));
super.onDestroy();
}
- Create the payment and launch the payment intent, for example, when a button is pressed:
public void onBuyPressed(View pressed) {
// PAYMENT_INTENT_SALE will cause the payment to complete immediately.
// Change PAYMENT_INTENT_SALE to
// - PAYMENT_INTENT_AUTHORIZE to only authorize payment and capture funds later.
// - PAYMENT_INTENT_ORDER to create a payment for authorization and capture
// later via calls from your server.
PayPalPayment payment = new PayPalPayment(new BigDecimal("1.75"), "USD", "sample item",
PayPalPayment.PAYMENT_INTENT_SALE);
Intent intent = new Intent(this, PaymentActivity.class);
// send the same configuration for restart resiliency
intent.putExtra(PayPalService.EXTRA_PAYPAL_CONFIGURATION, config);
intent.putExtra(PaymentActivity.EXTRA_PAYMENT, payment);
startActivityForResult(intent, 0);
}
Note: To provide a shipping address for the payment, see addAppProvidedShippingAddress(...) in the sample app. To enable retrieval of shipping address from the user's PayPal account, see enableShippingAddressRetrieval(...) in the sample app.
5.Implement onActivityResult():
@Override
protected void onActivityResult (int requestCode, int resultCode, Intent data) {
if (resultCode == Activity.RESULT_OK) {
PaymentConfirmation confirm = data.getParcelableExtra(PaymentActivity.EXTRA_RESULT_CONFIRMATION);
if (confirm != null) {
try {
Log.i("paymentExample", confirm.toJSONObject().toString(4));
// TODO: send 'confirm' to your server for verification.
// see https://developer.paypal.com/webapps/developer/docs/integration/mobile/verify-mobile-payment/
// for more details.
} catch (JSONException e) {
Log.e("paymentExample", "an extremely unlikely failure occurred: ", e);
}
}
}
else if (resultCode == Activity.RESULT_CANCELED) {
Log.i("paymentExample", "The user canceled.");
}
else if (resultCode == PaymentActivity.RESULT_EXTRAS_INVALID) {
Log.i("paymentExample", "An invalid Payment or PayPalConfiguration was submitted. Please see the docs.");
}
}
- Send the proof of payment to your servers for verification, as well as any other processing required for your business, such as fulfillment.
Handling the Configuration Change Yourself If your application doesn't need to update resources during a specific configuration change and you have a performance limitation that requires you to avoid the activity restart, then you can declare that your activity handles the configuration change itself, which prevents the system from restarting your activity.
To declare that your activity handles a configuration change, edit the appropriate element in your manifest file to include the android:configChanges attribute with a value that represents the configuration you want to handle. Possible values are listed in the documentation for the android:configChanges attribute (the most commonly used values are "orientation" to prevent restarts when the screen orientation changes and "keyboardHidden" to prevent restarts when the keyboard availability changes). You can declare multiple configuration values in the attribute by separating them with a pipe | character.
For example, the following manifest code declares an activity that handles both the screen orientation change and keyboard availability change:
<activity android:name=".MyActivity"
android:configChanges="orientation|keyboardHidden"
android:label="@string/app_name">
Now, when one of these configurations change, MyActivity does not restart. Instead, the MyActivity receives a call to onConfigurationChanged(). This method is passed a Configuration object that specifies the new device configuration. By reading fields in the Configuration, you can determine the new configuration and make appropriate changes by updating the resources used in your interface. At the time this method is called, your activity's Resources object is updated to return resources based on the new configuration, so you can easily reset elements of your UI without the system restarting your activity.
@Override
public void onConfigurationChanged(Configuration newConfig) {
super.onConfigurationChanged(newConfig);
// Checks the orientation of the screen
if (newConfig.orientation == Configuration.ORIENTATION_LANDSCAPE) {
Toast.makeText(this, "landscape", Toast.LENGTH_SHORT).show();
} else if (newConfig.orientation == Configuration.ORIENTATION_PORTRAIT){
Toast.makeText(this, "portrait", Toast.LENGTH_SHORT).show();
}
}
Intent filter declares the capabilities of its parent component — what an activity or service can do and what types of broadcasts a receiver can handle.
<activity
android:name=".ActivityTest"
android:label="@string/app_name" >
<intent-filter>
<action android:name="android.intent.action.SEND" />
<category android:name="android.intent.category.DEFAULT" />
<data android:mimeType="text/plain" />
</intent-filter>
</activity>
https://github.com/siddhpatil6/Java/wiki/Thread-Interview-Questions
Android has an Executor framework using which you can automatically manage a pool of threads with a task queue. Multiple threads will run in parellel executing tasks from the queue (BlockingQueue usually).
https://github.com/siddhpatil6/Kotlin-Executor
A thread pool manages a pool of worker threads (the exact number varies depending upon how it’s implementation).
A task queue holds tasks waiting to be executed by any one of the idle threads in the pool. Tasks are added to the queue by producers, whereas the worker threads act as consumers by consuming the tasks from the queue whenever there’s an idle thread ready to perform a new background execution.
The ThreadPoolExecutor executes a given task using one of its threads from the thread pool. https://blog.mindorks.com/threadpoolexecutor-in-android-8e9d22330ee3
https://developer.android.com/topic/performance/graphics/cache-bitmap.html
-
FLAG_ACTIVITY_NEW_TASK - If set, this activity will become the start of a new task on this history stack. A task (from the activity that started it to the next task activity) defines an atomic group of activities that the user can move to. Tasks can be moved to the foreground and background; all of the activities inside of a particular task always remain in the same order.
-
FLAG_ACTIVITY_CLEAR_TOP - If set, and the activity being launched is already running in the current task, then instead of launching a new instance of that activity, all of the other activities on top of it will be closed and this Intent will be delivered to the (now on top) old activity as a new Intent.
-
FLAG_ACTIVITY_SINGLE_TOP - If set, the activity will not be launched if it is already running at the top of the history stack.
class RetrieveFeedTask extends AsyncTask<Void, Void, String> {
private Exception exception;
protected void onPreExecute() {
progressBar.setVisibility(View.VISIBLE);
responseView.setText("");
}
protected String doInBackground(Void... urls) {
String email = emailText.getText().toString();
// Do some validation here
try {
URL url = new URL(API_URL + "email=" + email + "&apiKey=" + API_KEY);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
try {
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(urlConnection.getInputStream()));
StringBuilder stringBuilder = new StringBuilder();
String line;
while ((line = bufferedReader.readLine()) != null) {
stringBuilder.append(line).append("\n");
}
bufferedReader.close();
return stringBuilder.toString();
}
finally{
urlConnection.disconnect();
}
}
catch(Exception e) {
Log.e("ERROR", e.getMessage(), e);
return null;
}
}
protected void onPostExecute(String response) {
if(response == null) {
response = "THERE WAS AN ERROR";
}
progressBar.setVisibility(View.GONE);
Log.i("INFO", response);
responseView.setText(response);
}
}
String bitmapPath = MediaStore.Images.Media.insertImage(getContentResolver(), bitmap,"title", null);
Uri bitmapUri = Uri.parse(bitmapPath);
Intent intent = new Intent(Intent.ACTION_SEND);
intent.setType("image/png");
intent.putExtra(Intent.EXTRA_STREAM, bitmapUri);
startActivity(Intent.createChooser(intent, "Share"));
https://blog.mindorks.com/android-core-looper-handler-and-handlerthread-bd54d69fe91a
- Both codes are only relevant when the phone runs out of memory and kills the service before it finishes executing. START_STICKY tells the OS to recreate the service after it has enough memory and call onStartCommand() again with a null intent. START_NOT_STICKY tells the OS to not bother recreating the service again. There is also a third code START_REDELIVER_INTENT that tells the OS to recreate the service and redeliver the same intent to onStartCommand().
ServiceConnection
android.content.ServiceConnection is an interface which is used to monitor the state of service. We need to override following methods.
onServiceConnected(ComponentName name, IBinder service) : This is called when service is connected to the application.
onServiceDisconnected(ComponentName name) : This is called when service is disconnected.
When you rotate your device, your present activity gets completely destroyed, ie goes through
-
onSaveInstanceState()
-
onPause()
-
onStop()
-
onDestroy() and a new activity is created completely which goes through
-
onCreate()
-
onStart()
-
onRestoreInstanceState()
The Two Methods in the bold, onSaveInstanceState() saves the instance of the present activity which is going to be destroyed. onRestoreInstanceState This method restores the saved state of the previous activity. This way you don't lose your previous state of the app.
Here is how you use these methods.
@Overridepublic void onSaveInstanceState(Bundle outState, PersistableBundle outPersistentState) {super.onSaveInstanceState(outState, outPersistentState);`outState.putString("theWord", theWord); // Saving the Variable theWord` `outState.putStringArrayList("fiveDefns", fiveDefns); // Saving the ArrayList fiveDefns`}@Overridepublic void onRestoreInstanceState(Bundle savedInstanceState, PersistableBundle persistentState) {super.onRestoreInstanceState(savedInstanceState, persistentState);`theWord = savedInstanceState.getString("theWord"); // Restoring theWord` `fiveDefns = savedInstanceState.getStringArrayList("fiveDefns"); //Restoring fiveDefns`}
final is a keyword in the java language. It is used to apply restrictions on class, method and variable. Final class can't be inherited, final method can't be overridden and final variable value can't be changed.
class FinalExample {
public static void main(String[] args) {
final int x=100;
x=200;//Compile Time Error because x is final
}
}
finally is a code block and is used to place important code, it will be executed whether exception is handled or not.
class FinallyExample {
public static void main(String[] args) {
try {
int x=300;
}catch(Exception e) {
System.out.println(e);
}
finally {
System.out.println("finally block is executed");
}
}
}
Finalize is a method used to perform clean up processing just before object is garbage collected.
class FinalizeExample {
public void finalize() {
System.out.println("finalize called");
}
public static void main(String[] args) {
FinalizeExample f1=new FinalizeExample();
FinalizeExample f2=new FinalizeExample();
f1=null;
f2=null;
System.gc();
}
}
If we have mentioned launcher to two activity it will create two icons which will make different launcher screen.
Parcelable and Serialization are used for marshaling and unmarshaling Java objects. Differences between the two are often cited around implementation techniques and performance results. From my experience, I have come to identify the following differences in both the approaches:
Parcelable is well documented in the Android SDK; serialization on the other hand is available in Java. It is for this very reason that Android developers prefer Parcelable over the Serialization technique.
In Parcelable, developers write custom code for marshaling and unmarshaling so it creates less garbage objects in comparison to Serialization. The performance of Parcelable over Serialization dramatically improves (around two times faster), because of this custom implementation.
Serialization is a marker interface, which implies the user cannot marshal the data according to their requirements. In Serialization, a marshaling operation is performed on a Java Virtual Machine (JVM) using the Java reflection API. This helps identify the Java objects member and behavior, but also ends up creating a lot of garbage objects. Due to this, the Serialization process is slow in comparison to Parcelable
If you have a repetitive task in your Android app, you need to consider that activities and services can be terminated by the Android system to free up resources. Therefore you can not rely on standard Java schedule like the TimerTasks class.
The Android system currently has two main means to schedule tasks:
- the (outdated) AlarmManager
- the JobScheduler API.
Modern Android applications should use the JobScheduler API. Apps can schedule jobs while letting the system optimize based on memory, power, and connectivity conditions.
Read this article if you have time : - http://www.vogella.com/tutorials/AndroidTaskScheduling/article.html
The Firebase JobDispatcher is a library for scheduling background jobs in your Android app. It provides a JobScheduler-compatible API that works on all recent versions of Android (API level 14+) that have Google Play services installed.
public void getData() {
public String[] getAppCategorydetail() {
String Table_Name="cytaty";
String selectQuery = "SELECT * FROM " + Table_Name;
SQLiteDatabase db = this.getReadableDatabase();
Cursor cursor = db.rawQuery(selectQuery, null);
String[] data = null;
if (cursor.moveToFirst()) {
do {
// get the data into array,or class variable
} while (cursor.moveToNext());
}
db.close();
return data;
}
}
apply() was added in 2.3, it commits without returning a boolean indicating success or failure.
commit() returns true if the save works, false otherwise.
FragmentPagerAdapter stores the whole fragment in memory, and could increase a memory overhead if a large amount of fragments are used in ViewPager. In contrary its sibling, FragmentStatePagerAdapter only stores the savedInstanceState of fragments, and destroys all the fragments when they lose focus
It can be achieve by 1.Interface 2.Broadcast Reciever
NotificationCompat.Builder mBuilder = new NotificationCompat.Builder(this, CHANNEL_ID)
.setSmallIcon(R.drawable.notification_icon)
.setContentTitle("My notification")
.setContentText("Much longer text that cannot fit one line...")
.setStyle(new NotificationCompat.BigTextStyle()
.bigText("Much longer text that cannot fit one line..."))
.setPriority(NotificationCompat.PRIORITY_DEFAULT);
There are four launch modes for activity. They are:
- standard
- singleTop
- singleTask
- singleInstance
https://android.jlelse.eu/android-activity-launch-mode-e0df1aa72242 https://inthecheesefactory.com/blog/understand-android-activity-launchmode/en
Android Components:Four pillars of every Android app
- Activity.
- Service.
- Content providers.
- Broadcast Receivers.
Updating UI from the separate thread is the most encountered scenario. for such scenarios, Android has provided us API which is called as AsyncTask.
- PreExecute
- DoInBackground (must override)
- ProgressUpdate
- PostExecute
Android runs long running task in doInBackground, android runs doInBackground in Separate Thread.
Android Itself creates the separate thread for doInBackground.
It is initialised before doInBackground
Anything initialisation is to be done before performing any task in the background is to be done in PreExecute.
it is called after DoInBackground
It executes on UI Thread.
after performing task in background to update result on UIThread PostExecute Method get called.
Prgressupdate is called when You want to continually update UI of UIThread from doInBackground and also wants to come back and perform task in doInBackground.
to do that you have to call
publishProgress in doInbackground
Each App is executed by different process
for example
Proccess 1 Executes App1
Process 2 Executes App2
Each Process Contains Multiple Threads
For Example-
Process 1- Thread1, Thread2, Thread3
There is Main Thread where we all UI related Task we Perform
For Example -
Button Click, Button Rendering, All task related to UI
If the Task is very Resource Intensive Task which requires more than 5 Seconds to execute, it not good idea to execute it on UI Thread.It will give ANR.
So We Can use seprate thread to execute such task.
https://www.youtube.com/watch?v=kpFwxJFYnOo
In order to prevent it, first we need to know the reasons of "Out of Memory" exception:
- The biggest reason is memory leak i.e, Context leaking or can say Activity Leaking, a Service has the same problems as Activity in this regard.
- You are doing the process that demands continuous memory and at a point, it goes beyond max memory limit of a process.
- When you are dealing with large Bitmap and load all of them at runtime.
https://www.youtube.com/watch?v=HY9aaXHx8yA
https://stackoverflow.com/questions/477572/strange-out-of-memory-issue-while-loading-an-image-to-a-bitmap-object
This is an API for scheduling various types of jobs against the framework that will be executed in your application's own process.
JobInfo for more description of the types of jobs that can be run and how to construct them. You will construct these JobInfo objects and pass them to the JobScheduler with schedule(JobInfo). When the criteria declared are met, the system will execute this job on your application's JobService. You identify the service component that implements the logic for your job when you construct the JobInfo using JobInfo.Builder(int, android.content.ComponentName). Code:
```
var componentName=ComponentName(this,com.kotlin.siddhant.jobschedulerexample.MJobService::class.java)
var builder=JobInfo.Builder(JOB_ID,componentName) // we build Job here and assign job id to identify JOB Uniquely
builder.setPeriodic(5000) // we set Period for job to be executed
builder.setRequiredNetworkType(JobInfo.NETWORK_TYPE_ANY) // to define required network type
builder.setPersisted(true) //if set true this job will exist after system reboot as well
// builder.setRequiresBatteryNotLow(true) // schedule job when battery not low
//builder.setRequiresStorageNotLow(true) // schedule job when Storage is not low
builder.setRequiresCharging(true) // schedule job when charging
jobInfo=builder.build()
```
https://dzone.com/articles/java-volatile-keyword-0
Before understanding the transient keyword, one has to understand the concept of serialization. If the reader knows about serialization, please skip the first point.
-
What is serialization?
Serialization is the process of making the object's state persistent. That means the state of the object is converted into a stream of bytes and stored in a file. In the same way, we can use the deserialization to bring back the object's state from bytes. This is one of the important concepts in Java programming because serialization is mostly used in networking programming. The objects that need to be transmitted through the network have to be converted into bytes. For that purpose, every class or interface must implement the Serializable interface. It is a marker interface without any methods. -
Now what is the transient keyword and its purpose?
By default, all of object's variables get converted into a persistent state. In some cases, you may want to avoid persisting some variables because you don't have the need to persist those variables. So you can declare those variables as transient. If the variable is declared as transient, then it will not be persisted. That is the main purpose of the transient keyword.
I want to explain the above two points with the following example: package javabeat.samples;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
class NameStore implements Serializable{
private String firstName;
private transient String middleName;
private String lastName;
`public NameStore (String fName, String mName, String lName){`
`this.firstName = fName;`
`this.middleName = mName;`
`this.lastName = lName;`
`}`
`public String toString(){`
`StringBuffer sb = new StringBuffer(40);`
`sb.append("First Name : ");`
`sb.append(this.firstName);`
`sb.append("Middle Name : ");`
`sb.append(this.middleName);`
`sb.append("Last Name : ");`
`sb.append(this.lastName);`
`return sb.toString();`
`}`
}
public class TransientExample
{
public static void main(String args[]) throws Exception
{
NameStore nameStore = new NameStore("Steve", "Middle","Jobs");
`ObjectOutputStream o = new ObjectOutputStream(new FileOutputStream("nameStore"));`
`o.writeObject(nameStore);`
`o.close();`
`ObjectInputStream in = new ObjectInputStream(new FileInputStream("nameStore"));`
`NameStore nameStore1 = (NameStore)in.readObject();`
`System.out.println(nameStore1);`
`}`
}
https://www.simplifiedcoding.net/android-service-example/
- DDMS is short for Dalvik Debug Monitor Server. It ships natively with Android and contains a number of useful debugging features including: location data spoofing, port-forwarding, network traffic tracking, incoming call/SMS spoofing, thread and heap information, screen capture, and the ability to simulate network state, speed, and latenc
https://stackoverflow.com/questions/4858026/android-alternate-layout-xml-for-landscape-mode
https://stackoverflow.com/questions/10126845/handle-screen-rotation-without-losing-data-android
A Handler allows communicating back with UI thread from other background thread. This is useful in android as android doesn’t allow other threads to communicate directly with UI thread.
- Why
If you need to update the UI from another main Thread, you need to synchronize with the main thread. Because of this restrictions and complexity, Android provides additional constructed classes to handle concurrently in comparison with standard Java i.e. Handler or AsyncTask.
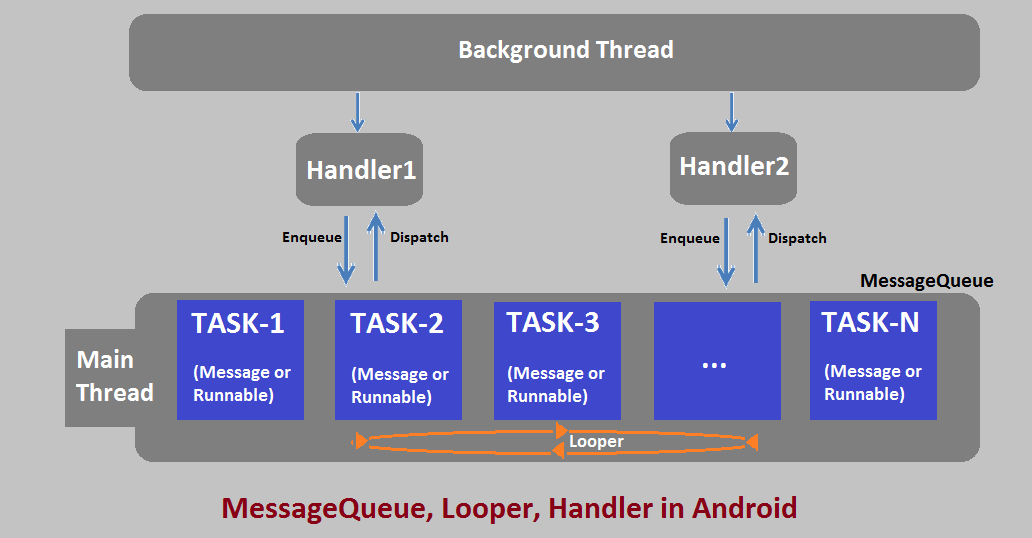
https://medium.com/@ankit.sinhal/handler-in-android-d138c1f4980e
https://blog.mindorks.com/android-core-looper-handler-and-handlerthread-bd54d69fe91a
https://stackoverflow.com/questions/7597742/what-is-the-purpose-of-looper-and-how-to-use-it
https://www.javatpoint.com/difference-between-throw-and-throws-in-java
https://thebhwgroup.com/blog/how-android-sqlite-onupgrade
- Open source OS
- based on linux kernal-(not linux os)
- NOT programming language
what can we use for SQLite Security?
- SQLCipher
what is Intent?
- It is messaging object.
- It uses when you want to pass data from one screen to another.
Types -
- Explicit Where you have to specify target component. ex. Intent i=new Intent(ActivityOne.this,ActivityTwo.class)
- Implicit- where you dont have to specify target component,System specifies what action has to be done. ex - Intent chooser=Intent.createChooser(send,title)
What is ANR?
When the application tries to run a long operation on the main thread, but gets no response after a long time.
which are orientations?
- vertical
- Horizontal
What is ADB(Android Debug Bridge)?
It provides a connection between System and Emulator.
What Android Architecture Consist of?
-
Android Architecture - Camera Calculator
-
Framework - Content Provider ,View System,Managers-(Activity,Location,Package,Notification)
-
Libraries -
-
Linux Kernal
- Activity -Runs always on Foreground
- Service -Runs on Background,Useful to run the long process.
- Play important role in app
- where we declare all permissions-location, internet.
- declare all Services
- declare all Activities
- Analytics
- Cloud Messaging
- Authentication
- Realtime Database
- Storage
- Performance Monitoring
- Remote Config
- Test Lab
- Sign in with Google
- Maps
- Places
- cleverTap
- BaseAdapter as the name suggests, is a base class for all the adapters.
- When you are extending the Base adapter class you need to implement all the methods like getCount(), getId() etc.
- ArrayAdapter is a class which can work with array of data. You need to override only getview() method.
- ListAdapter is a an interface implemented by concrete adapter classes.
- BaseAdapter is an abstract class whereas ArrayAdapter and ListAdapter are the concrete classes.
- ArrayAdapter and ListAdapter classes are developed since in general we deal with the array data sets and list data sets.
RecyclerView was created as a ListView improvement, so yes, you can create an attached list with ListView control, but using RecyclerView is easier as it
Reuses cells while scrolling up/down - this is possible with implementing View Holder in the listView adapter, but it was an optional thing, while in the RecycleView it's the default way of writing adapter.
Decouples list from its container - so you can put list items easily at run time in the different containers (linearLayout, gridLayout) with setting LayoutManager.
Example:
mRecyclerView = (RecyclerView) findViewById(R.id.my_recycler_view);
mRecyclerView.setLayoutManager(new LinearLayoutManager(this));
//or
mRecyclerView.setLayoutManager(new GridLayoutManager(this, 2));
Animates common list actions - Animations are decoupled and delegated to ItemAnimator.
- The RecyclerView widget is a more advanced and flexible version of ListView.
Why RecyclerView?
- RecyclerView is a container for displaying large data sets that can be scrolled very efficiently by maintaining a limited number of views.
When you should use RecyclerView?
- You can use the RecyclerView widget when you have data collections whose elements changes at runtime based on user action or network events
new extended functionalities available in RecyclerView that are not directly supported by ListView as following:
- Direct horizontal scrolling is not supported in ListView. Whereas in RecyclerView you can easily implement horizontal and vertical scrolling.
- ListView supports only simple linear list view with vertical scrolling. Whereas RecyclerView supports three types of lists using RecyclerView.LayoutManager. 1) StaggeredGridLayoutManager 2) GridLayoutManager, 3) LinearLayoutManager. I will give you brief introduction about all these 3 lists later.
- ListView gives you an option to add divider using dividerHeight parameter whereas RecyclerView enable you to customize divider (spacing) between two element
Any of the following 5 possible options are acceptable:
- SharedPreferences
- Internal Storage
- External Storage
- SQLite Database
- Network connection
Answer: The developer should name at least 4 of these 6 items below, as these are essential within each Android project:
- AndroidManifest.xml
- build.xml
- bin/
- src/
- res/
- assets/
Containers hold objects and widgets together, depending on which items are needed and in what arrangement they need to be in. Containers may hold labels, fields, buttons, or even child containers, as examples.
What is AIDL?
You want to find out that this person will seek to truly understand what you are trying to accomplish with your app, and the functionality. The following items are good to hear:
- Objective statement or purpose of the app for the app publisher
- Description of the target audience or user demographics
- Any existing apps that it might be similar to
- Wireframes
- Artwork; The best developers will say they require the artwork to be completed before development. This avoids delays, and helps the developer understand the look, feel and branding you are trying to achieve .
- A service is a component which runs in the background without direct interaction with the user
- service has no user interface, it is not bound to the lifecycle of an activity.
- Services are used for repetitive and potentially long running operations, i.e., Internet downloads, checking for new data, data processing, updating content providers and the like.
States of Services?
- Started- A service is started when an application component, such as an activity, starts it by calling startService(). Once started, a service can run in the background indefinitely, even if the component that started it is destroyed.
- Bound-
A service is bound when an application component binds to it by calling bindService(). A bound service offers a client-server interface that allows components to interact with the service, send requests, get results, and even do so across processes with interprocess communication (IPC).
These are the three different types of services:
1. Foreground
A foreground service performs some operation that is noticeable to the user. For example, an audio app would use a foreground service to play an audio track. Foreground services must display a status bar icon. Foreground services continue running even when the user isn't interacting with the app.
2. Background
A background service performs an operation that isn't directly noticed by the user. For example, if an app used a service to compact its storage, that would usually be a background service.
Note: If your app targets API level 26 or higher, the system imposes restrictions on running background services when the app itself is not in the foreground. In most cases like this, your app should use a scheduled job instead.
3. Bound
A service is bound when an application component binds to it by calling bindService(). A bound service offers a client-server interface that allows components to interact with the service, send requests, receive results, and even do so across processes with interprocess communication (IPC). A bound service runs only as long as another application component is bound to it. Multiple components can bind to the service at once, but when all of them unbind, the service is destroyed
You can use broadcast receiver to restart service,
<action android:name="android.intent.action.BOOT_COMPLETED" />
BOOT_COMPLETED event we can use to identify system is booted which calls broadcast receiver and broadcast receiver will startservice again.
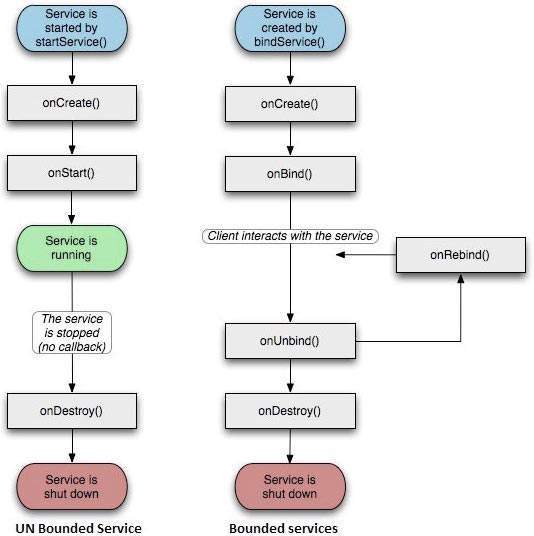
- Broadcast Receivers simply respond to broadcast messages from other applications or from the system itself. These messages are sometime called events or intents to make BroadcastReceiver works for the system broadcasted intents −
- Creating the Broadcast Receiver.
- Registering Broadcast Receiver
- A broadcast receiver is implemented as a subclass of BroadcastReceiver class and overriding the onReceive() method where each message is received as a Intent object parameter.
public class MyReceiver extends BroadcastReceiver {
@Override
public void onReceive(Context context, Intent intent) {
Toast.makeText(context, "Intent Detected.", Toast.LENGTH_LONG).show();
}
}
An application listens for specific broadcast intents by registering a broadcast receiver in AndroidManifest.xml file.
<application
android:icon="@drawable/ic_launcher"
android:label="@string/app_name"
android:theme="@style/AppTheme" >
<receiver android:name="MyReceiver">
`<intent-filter>`
`<action android:name="android.intent.action.BOOT_COMPLETED">`
`</action>`
`</intent-filter>`
</receiver>
</application>
http://skillgun.com/android/receivers/interview-questions-and-answers/paper/30
- A content provider component supplies data from one application to others on request. Such requests are handled by the methods of the ContentResolver class.
- A content provider can use different ways to store its data and the data can be stored in a database, in files, or even over a network.
onCreate() This method is called when the provider is started.
query() This method receives a request from a client. The result is returned as a Cursor object.
insert() This method inserts a new record into the content provider.
delete() This method deletes an existing record from the content provider.
update() This method updates an existing record from the content provider.
getType() This method returns the MIME type of the data at the given URI.
https://www.androidauthority.com/android-7-0-features-673002/
- Multi-window Support
- Notification Bar Toggles
- Notifications: redesigned, bundled and Quick Reply-able
- Notification prioritization
- Customizable Quick Settings
- Doze Mode on the Go
- Multi-language support, emoji and app links
- New Settings menu - The essential information contained in each Settings section is now displayed on the main page.
- Do Not Disturb
- Data Saver - Data Saver denies internet access to background apps when you're connected to cellular data.
- Seamless updates
- File-based encryption
- Emergency info
https://www.android.com/versions/oreo-8-0/
AutoFill:
With your permission, AutoFill remembers your logins to get you into your favourite apps at supersonic speed.
Picture-in-picture:
Allows you to see two apps at once. It's like having super strength and laser vision.
Dive into more apps with fewer taps
- Notification dots:
Press the notification dots to quickly see what's new, and easily clear them by swiping away.
Teleport directly into new apps straight from your browser, no installation needed.
** What is the difference between Activity and AppCompatActivity?**
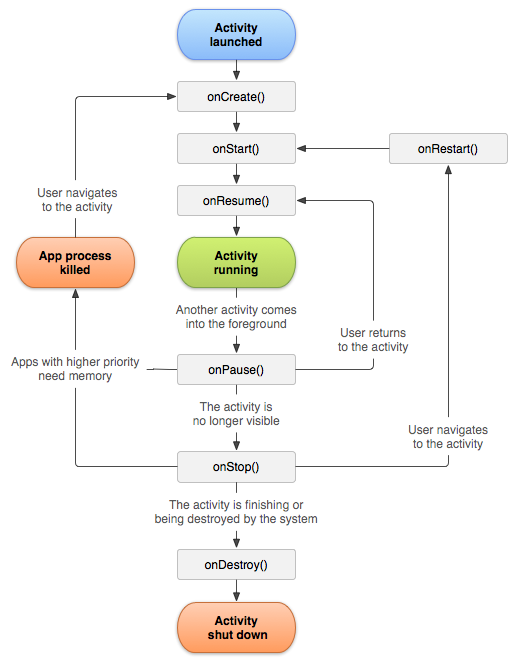
- AppCompatActivity provides native ActionBar support that is consistent across the application. Also it provides backward compatibility for other material design components till SDK version 7(ActionBar was natively available since SDK 11). Extending an Activity doesn’t provide any of these.
Activity, AppCompatActivity, FragmentActivity and ActionBarActivity. How are they related?
- Activity is the base class. FragmentActivity extends Activity. AppCompatActivity extends FragmentActivity. ActionBarActivity extends AppCompatActivity.
- FragmentActivity is used for fragments.
- Since the build version 22.1.0 of the support library, ActionBarActivity is deprecated. It was the base class of appcompat-v7.
- At present, AppCompatActivity is the base class of the support library. It has come up with many new features like ToolBar, tinted widgets, material design color pallets etc.
Describe the structure of Android Support Library?
-
Android Support Library is not just a single library. It’s a collection of libraries that have different naming conventions and usages. On a higher level, it’s divided into three types;
-
Compatibility Libraries: These focus on back porting features so that older frameworks can take advantage of newer releases. The major libraries include v4 and v7-appcompat. v4 includes classes like DrawerLayout and ViewPager while appcompat-v7 provides classes for support ActionBar and ToolBar.
-
Component Libraries: These include libraries of certain modules that don’t depend on other support library dependencies. They can be easily added or removed. Examples include v7-recyclerview and v7-cardview.
-
Miscellaneous libraries: The Android support libraries consists of few other libraries such as v8 which provides support for RenderScript, annotations for supporting annotations like @NonNull.
Mention two ways to clear the back stack of Activities when a new Activity is called using intent.
-
The first approach is to use a FLAG_ACTIVITY_CLEAR_TOP flag.
Intent intent= new Intent(ActivityA.this, ActivityB.class);
intent.setFlags(Intent.FLAG_ACTIVITY_CLEAR_TOP);
startActivity(intent);
finish(); -
The second way is by using FLAG_ACTIVITY_CLEAR_TASK and FLAG_ACTIVITY_NEW_TASK in conjunction.
Intent intent= new Intent(ActivityA.this, ActivityB.class);
intent.setFlags(Intent.FLAG_ACTIVITY_NEW_TASK | Intent.FLAG_ACTIVITY_CLEAR_TASK);
startActivity(intent);
FLAG_ACTIVITY_CLEAR_TASK is used to clear all the activities from the task including any existing instances of the class invoked. The Activity launched by intent becomes the new root of the otherwise empty task list. This flag has to be used in conjunction with FLAG_ ACTIVITY_NEW_TASK.
FLAG_ACTIVITY_CLEAR_TOP on the other hand, if set and if an old instance of this Activity exists in the task list then barring that all the other activities are removed and that old activity becomes the root of the task list. Else if there’s no instance of that activity then a new instance of it is made the root of the task list. Using FLAG_ACTIVITY_NEW_TASK in conjunction is a good practice, though not necessary.
How do you disable onBackPressed()?
The onBackPressed() method is defined as shown below:
@Override
public void onBackPressed() {
super.onBackPressed();
}
- To disable the back button and preventing it from destroying the current activity and going back we have to remove the line super.onBackPressed();

getFragmentManager()
-
Return the FragmentManager for interacting with fragments associated with this activity.
-
FragmentManager which is used to create transactions for adding, removing or replacing fragments.
fragmentManager.beginTransaction();
-
Start a series of edit operations on the Fragments associated with this FragmentManager.
-
The FragmentTransaction object which will be used.
-
fragmentTransaction.replace(R.id.fragment_container, mFeedFragment);
-
Replaces the current fragment with the mFeedFragment on the layout with the id: R.id.fragment_container
fragmentTransaction.addToBackStack(null);
Add this transaction to the back stack. This means that the transaction will be remembered after it is committed, and will reverse its operation when later popped off the stack.
Useful for the return button usage so the transaction can be rolled back. The parameter name:
Is an optional name for this back stack state, or null.
Basically fragments are divided as three stages as shown below.
-
Single frame fragments − Single frame fragments are using for hand hold devices like mobiles, here we can show only one fragment as a view.
-
List fragments − fragments having special list view is called as list fragment
-
Fragments transaction − Using with fragment transaction. we can move one fragment to another fragment.
Difference between add and replace?
-
replace removes the existing fragment and adds a new fragment.
-
add retains the existing fragments and adds a new fragment that means existing fragment will be active and they wont be in 'paused' state hence when a back button is pressed onCreateView() is not called for the existing fragment(the fragment which was there before new fragment was added).
why to use replace?
- Replace is the first removal of the same id all the fragments, and then add the current fragment.
- multi-layer is certainly more than a layer of waste, so it is recommended to use replace
Difference Between Service,Thread,IntentService,AsyncTask?
- Holding reference of ui specific object in the background.
- Using static views
- Using static context
- Using Context
Be careful while using context, deciding which context is suitable at places is most important. Use application context possible and use activity context only if required. - Never forget to say goodbye to listeners after being served.
- Using inner class
- Using anonymous class
- Using views in collection
https://mindorks.com/blog/detecting-and-fixing-memory-leaks-in-android
What is SQLite and Methods?
- SQLite is an Open Source database. SQLite supports standard relational database features like SQL syntax, transactions and prepared statements. The database requires limited memory at runtime (approx. 250 KByte).
Methods -
onCreate(SQLiteDatabase db)-
- called only once when database is created for the first time onUpgrade(SQLiteDatabase db, int oldVersion, int newVersion) -
- called when database needs to be upgraded.
How to Use Cursor?
public Contact getContact(int id) {
SQLiteDatabase db = this.getReadableDatabase();
`Cursor cursor = db.query(TABLE_CONTACTS, new String[] { KEY_ID,`<br>
`KEY_NAME, KEY_PH_NO }, KEY_ID + "=?",`<br>
`new String[] { String.valueOf(id) }, null, null, null, null);`<br>
`if (cursor != null)`<br>
`cursor.moveToFirst();`<br>
`Contact contact = new Contact(Integer.parseInt(cursor.getString(0)),`<br>
`cursor.getString(1), cursor.getString(2));`<br>
`// return contact`<br>
`return contact;`<br>
}
-
SQLite supports the following data types:
-
TEXT(similar to String in Java)
-
INTEGER(similar to long in Java)
-
REAL (similar to double in Java)
When to use dependancies?
- In Android Studio, dependencies allows us to include external library or local jar files or other library modules in our Android project.
add Dependancies -
What is Proguard?
-
Proguard is free Java class file shrinker, optimizer, obfuscator, and preverifier. It detects and removes unused classes, fields, methods, and attributes. It optimizes bytecode and removes unused instructions. It renames the remaining classes, fields, and methods using short meaningless names.
-
Shrinking – detects and removes unused classes, fields, methods, and attributes.
-
Optimization – analyzes and optimizes the bytecode of the methods.
-
Obfuscation – renames the remaining classes, fields, and methods using short meaningless names.
-
Shrink Your Code and Resources
detects and removes unused classes, fields, methods, and attributes from your packaged app, including those from included code libraries (making it a valuable tool for working around the 64k reference limit). ProGuard also optimizes the bytecode, removes unused code instructions, and obfuscates the remaining classes, fields, and methods with short names. -
Shrink Your Code
-
add minifyEnabled true to the appropriate build type in your build.gradle file.
-
enable code shrinking on your final APK used for testing, because it might introduce bugs if you do not sufficiently customize which code to keep.
ProGuard outputs the following files:
dump.txt
Describes the internal structure of all the class files in the APK.
mapping.txt
Provides a translation between the original and obfuscated class, method, and field names.
seeds.txt
Lists the classes and members that were not obfuscated.
usage.txt>
Lists the code that was removed from the APK.
These files are saved at /build/outputs/mapping/release/.
- To fix errors and force ProGuard to keep certain code, add a -keep line in the ProGuard configuration file. For example:
-keep public class MyClass
Security Practices in android?
- IMPLEMENT A GOOD MOBILE ENCRYPTION POLICY
- HAVE A SOLID API SECURITY STRATEGY - Use SSL,Pinned Certificate
- PUT IDENTIFICATION, AUTHENTICATION, AND AUTHORIZATION MEASURES IN PLACE.
- App Data Access Permission
- Password security
- Use Proguard - Obfuscation
What is AIDL?
- AIDL (Android Interface Definition Language) is similar to other IDLs you might have worked with. It allows you to define the programming interface that both the client and service agree upon in order to communicate with each other using interprocess communication (IPC). On Android, one process cannot normally access the memory of another process. So to talk, they need to decompose their objects into primitives that the operating system can understand, and marshall the objects across that boundary for you. The code to do that marshalling is tedious to write, so Android handles it for you with AIDL.
AsyncTask?
When an asynchronous task is executed, the task goes through 4 steps:
class AsyncTaskExample extends AsyncTask<Void, Integer, String> {
`private final String TAG = AsyncTaskExample.class.getName();`<br>
`protected void onPreExecute(){`<br>
`Log.d(TAG, "On preExceute...");`<br>
`}`<br>
`protected String doInBackground(Void...arg0) {`<br>
<br>
`Log.d(TAG, "On doInBackground...");`<br>
`for(int i = 0; i<5; i++){`<br>
`Integer in = new Integer(i);`<br>
`publishProgress(i);`<br>
`}`<br>
`return "You are at PostExecute";}`<br>
<br>
`protected void onProgressUpdate(Integer...a){`<br>
`Log.d(TAG,"You are in progress update ... " + a[0]);`<br>
`}`<br>
<br>
`protected void onPostExecute(String result) {`<br>
`Log.d(TAG,result); `<br>
`}`
}
- onPreExecute(), invoked on the UI thread before the task is executed. This step is normally used to setup the task, for instance by showing a progress bar in the user interface.
- doInBackground(Params...), invoked on the background thread immediately after onPreExecute() finishes executing. This step is used to perform background computation that can take a long time. The parameters of the asynchronous task are passed to this step. The result of the computation must be returned by this step and will be passed back to the last step. This step can also use publishProgress(Progress...) to publish one or more units of progress. These values are published on the UI thread, in the onProgressUpdate(Progress...) step.
- onProgressUpdate(Progress...), invoked on the UI thread after a call to publishProgress(Progress...). The timing of the execution is undefined. This method is used to display any form of progress in the user interface while the background computation is still executing. For instance, it can be used to animate a progress bar or show logs in a text field.
- onPostExecute(Result), invoked on the UI thread after the background computation finishes. The result of the background computation is passed to this step as a parameter.
which material Design you used?
- RecyclerView
- Navigation Drawer
- TextInputLayout
- Snackbar
- Floation Action Button
- SlidingTabLayout
Differennce between Thread and asyncTask?
When you use a Thread, you have to update the result on the main thread using the runOnUiThread() method, while an AsyncTask has the onPostExecute() method which automatically executes on the main thread after doInBackground() returns.