+
+Feature engineering, time series stationarity checks are few of the use-cases that are compiled in this gists. Check
+individual module defination and functionalities as follows.
+
+## Stationarity & Unit Roots
+
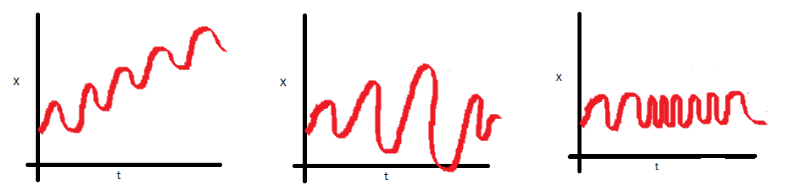
+Stationarity is one of the fundamental concepts in time series analysis. The
+**time series data model works on the principle that the [_data is stationary_](https://www.analyticsvidhya.com/blog/2021/04/how-to-check-stationarity-of-data-in-python/)
+and [_data has no unit roots_](https://www.analyticsvidhya.com/blog/2018/09/non-stationary-time-series-python/)**, this means:
+ * the data must have a constant mean (across all periods),
+ * the data should have a constant variance, and
+ * auto-covariance should not be dependent on time.
+
+Let's understand the concept using the following example, for more information check [this link](https://www.analyticsvidhya.com/blog/2018/09/non-stationary-time-series-python/).
+
+
+
+
+
+| ADF Test | KPSS Test | Series Type | Additional Steps |
+| :---: | :---: | :---: | --- |
+| ✅ | ✅ | _stationary_ | |
+| ❌ | ❌ | _non-stationary_ | |
+| ✅ | ❌ | _difference-stationary_ | Use differencing to make series stationary. |
+| ❌ | ✅ | _trend-stationary_ | Remove trend to make the series _strict stationary. |
+
+
+
+```{eval-rst}
+.. automodule:: pandaswizard.timeseries.stationarity
+ :members:
+ :undoc-members:
+ :show-inheritance:
+```
+
+## Time Series Featuring
+
+Time series analysis is a special segment of AI/ML application development where a feature is dependent on time. The code here
+is desgined to create a *sequence* of `x` and `y` data needed in a time series problem. The function is defined with two input
+parameters (I) **Lootback Period (T) `n_lookback`**, and (II) **Forecast Period (H) `n_forecast`** which can be visually
+presented below.
+
+
+
+
+
+
+
+```{eval-rst}
+.. automodule:: pandaswizard.timeseries.ts_featuring
+ :members:
+ :undoc-members:
+ :show-inheritance:
+```
+
+