As Katherine recently wrote, we presented a brief history of humanities computing (digital humanities or DH), an overview of how DH often interfaces with libraries, and demonstrated a number of easily-adopted tools that reference librarians might recommend to students/researchers curious about what computing approaches can do for humanities inquiry. This primer, along with our slides, are hosted at dhreadyreference on GitHub.1 We may go back and annotate or expand the entries, but for anyone curious about digital humanities and libraries, or tools with low learning curves, I hope this provides a useful introduction.
+
+
Should you find it useful—or should you like to add things or ask for clarification—feel free to get in touch.
+
+
+
+
+
We specifically chose to put it on GitHub because, as graduate students, we knew we’d have access to it beyond our years at IU-Bloomington. On top of that, we wanted to demonstrate the relative ease with which it can be used as a repository for these sorts of things. ↩
Thanks for coming by, and for indulging my Depeche Mode reference.1 This new site is decidedly in an early state of becoming, as I figure out how to use Jekyll and this particular theme.
+
+
I’ll probably use this for more long-form writing and keep the shorter things over at my Tumblr site, Foureyedsoul. The Tumblarians over there are a good bunch—sociable, generous, witty, and insightful. Why not check them out for yourself?
+
+
+
+
+
Clicking the title of this post should take you to YouTube, to help you know the song if you’re not already humming along. ↩
Here’s a test of Bigfoot.js, a rather awesome addition to the web. 1 (edit: It’ll remain elusive, see footnote #2.)2 (edit № 2: I’ve gotten it to work, as of 2015-05-31! It wasn’t an issue with Jekyll or GitHub Pages, but rather with my understanding of how Jekyll & GitHub plugins work. Once I realized that, it just took some more tinkering to get the appropriate JavaScript calls and SCSS things working.)
+
+
Sooner or later I’ll write about how I’ve made this site so far. I would still like to add two main things to it:
+
+
+
the Bigfoot.js inline footnote functionality @done(2015-05-31)!
+
an alternate stylesheet in the vein of Brett Terpstra’s SuperReadable.
+
+
+
Terpstra’s alternate stylesheet hides under a gear in the top right corner of his site, and allows visitors to switch to a stylesheet that uses OpenDyslexic, a free and open source font designed for dyslexic readers. (They might not speak up, but you’ve got students, users, or patrons who’d appreciate being told about OpenDyslexic in your syllabi or other handouts.)
+
+
The process of making this site with Jekyll has been a rewarding foray into using the command line interface, but it initially took quite a bit longer than I’d hoped. So I anticipate creating a brief series of “how-to” posts from my old process notes as I was putting this together. Jekyll’s a great blogging alternative to WordPress that uses fewer resources (i.e. doesn’t require a database) and can be hosted for free on GitHub pages, making it great for LibSchool students who want to create a site that will be a bit more of a learning opportunity.
+
+
For now, here’s a list of links I’d recommend for learning about Jekyll:
If you have questions about making a site of your own using Jekyll—or any of this, really—don’t be shy about contacting me on Twitter.
+
+
+
+
+
You can find this arcane, hirsute magick here courtesy of Chris Sauvé, a Canadian otherwise known as lemonmade. ↩
+
+
+
After an afternoon of tweaking, tinkering, asking questions, and reading specifications sheets, it seems that Bigfoot.js won’t work with Kramdown, the parser that Github pages uses to convert Markdown into html. It comes down to Bigfoot needing the footnote definitions list items to have a class="footnote" attribute, but there doesn’t seem to be a way to make this happen with Kramdown. As awesome as Bigfoot.js appears, it will remain elusive around here until this aspect of Kramdown syntax changes or I decide to do a fundamental overhaul of how I make my site. I’m adding this edit so that this can be useful to anyone else hoping to make Bigfoot.js work with Jekyll and to anyone heartened by seeing others tinker and fail. ↩
This post was originally an assignment for John Walsh’s “Z652 Digital Libraries” course at IU-Bloomington.
+
+
+
+
A fantastic clearing house of information about Californian collections, the Online Archive of California serves as a centralized set of links to and descriptions of an enormous number of collections from various archives, historical societies, libraries, museums, and special collections in California, including each campus of the University of California. According to the OAC’s about page, this makes for over 200 contributing institutions, more than 20,000 online collection guides, and more than 220,000 digital images and documents.1 Administered by the Digital Special Collections program of University of California’s California Digital Library (CDL), the Collection aims to increase the ease with which collections held throughout a variety of Californian institutions can be found by researchers. In addition to increasing this “findability,” the Archive benefits the involved member institutions by giving access to a variety of tools, services, and training from the OAC, as well as by expanding grant opportunities as a result of the partnership with the CDL.
+
+
As a project, the OAC goes back to a prototype finding aid standard made in 1993 at the UC Berkeley Libraries. In 1995, several University of California libraries began “UC-EAD” to test Encoded Archival Description to integrate access to collections information across the UC campuses. The project outgrew its initial UC cross-campus scope and was renamed the Online Archive of California in 1998 when it began including information about collections housed elsewhere.2 Due to its consortial nature, it’s difficult to determine when the resources available through the OAC were last available. The site also does not provide an easily-found list of when collections were added to its list, but for what it is worth, the CDL’s page about the OAC was last updated on 13 December, 2013.3 The CDL Digital Special Collections administers the OAC, but its component descriptions and representative digital files come from the member institutions.
+
+
This Digital Special Collections team includes six people: a “Director,” “Technical Lead,” “Program Coordinator,” “Contributor Support Specialist,” “Programmer Analyst,” and “Data Consultant.” It appears that five work in Oakland and one in San Diego. Although the team does not list every member’s background, their previous experience appears to vary in precisely the way that seems common to digital humanities/digital libraries work: Catherine Mitchell, the Director, has a Ph.D. in English Literature from UC Berkeley and was previously the Web Director at the Commonwealth Club of San Francisco; Brian Tingle, the Technical Lead, received a B.S. in Ecology, Behavior, & Evolution from UC San Diego and has worked from the UC Libraries since 1996; and Adrian Turner, the Data Consultant, earned an M.L.I.S. from UCLA and an M.A. from UC Santa Cruz and has worked as an archivist and manuscripts processor at UC Irvine Special Collections and Archives, among other places.4 The OAC has a broad focus, taking any collection held by a Californian archive, college, historical society, library, museum, special collection, or university as its subject. As shown in the image below, content in the OAC is browsable by institution, by collection, and by location on a map—the last of which must be particularly useful to visiting researchers unfamiliar with the size and geography of California.
+
+
+
+
Not surprisingly, considering its history as a means of testing the Encoded Archival Description (EAD) metadata standard, the OAC uses EAD extensively. As of July 2008, the site allows for searches across MARC records and EAD through a single search system.5 According to its technical information page, the Metadata Encoding and Transmission Standard (METS) and the Archival Resource Key (ARK) schema are also used for the content in the repository shared by the OAC and Calisphere.6 The Archive makes its metadata records available for other aggregators through OAI-PMH.7 The project began in part to test EAD, but the MARC records (specifically MARC21) that were later integrated likely preceded the OAC. It’s unclear how these records were converted to digital format when and if it was necessary.
+
+
According to the “Calisphere and OAC Technical Information” page, CDL developed a platform based on XML and XSLT for the repository at the heart of the OAC and Calisphere projects. This platform is packaged as the eXtensible Text Framework, or XTF, containing Java Servlets, Lucene indexing technology, and XSLT stylesheets. Lucene, made by Apache, seems to be the only off-the-shelf software package used by the OAC, with the bulk instead being programmed in-house—or else customized, as the OAC has done with LuraTech’s Image Content Server. The images used in the OAC are JPG-2000 files, derived from TIFF images. The OAC employs XTF for search and delivery of TEI, PDF, or imaged text-based digital objects, as well as EAD collection guides and MARC records. CDL’s Guidelines for Digital Objects details the OAC’s use of files.8 Due to the range of object types, there is a wide range of format choice: JPG, JPG-2000, PNG, TIFF, HTML, XML, PDF/A, UTF-8, ASCII, AIFF, WAVE, GZIP, and ZIP files are the listed preferred format choices. QuickTime VR and GIF are also mentioned, but they are not on the list of “preferred formats” stated above. If a production TIFF is submitted, it will be used for to derive the displayed JGP-2000 image and then deleted rather than used as a preservation format.
+
+
The OAC aims to aid “research-oriented users who want to go beyond what is available online and locate the actual, physical item,” whereas its sibling Calisphere draws from the same digital content to serve a website targeting “users whose primary interest is to view digitized images and documents.”9 Searches can be performed from a single bar, which then allows limiters to be placed on the results. Results can be ordered by relevance and title, with limits available by institution, by date (to the decade), and whether online items are available (i.e. images or text beyond the OAC’s description). The OAC seems to place an equal emphasis on browsing, for its landing page highlights that the Archive can be browsed by institution, collection, and map. Not only are these functions accessible from a menu bar across the top, but the visitor will immediately recognize these capabilities because they present themselves in three columns, already populated with information (see image below).
+
+
+
+
In a section of its “Help” page, the OAC clarifies what users may do with materials they find through the Archive.10 The OAC alerts users to the fact that copyright may pertain to the Archive’s materials and that it neither owns nor houses any of the listed materials. The OAC then refers users to the institution housing the relevant collection, noting that each collection guide contains a link to contact information at the top.
+
+
While it is not an exclusively digital library, as it does not contain digital versions of everything it mentions or indexes, the OAC provides a profoundly useful service in offering a centralized access point to descriptions of collections throughout California. Beyond the time researchers save, this centralized repository vastly increases the likelihood that holdings in less prominent venues will be used by researchers from outside those locales. My brother, a journalist currently writing a book on the history of Malibu, had to rely on Google searching in order to determine that Pepperdine University holds the main archives he has consulted thus far. When I sent him a link to the OAC, he seemed ecstatic, despite the fact that he has already submitted his initial drafts to his publisher. Although he and I both lived in California for more than 15 years, we had never heard of this resource, and he now lives in Brooklyn. As a distant researcher whose knowledge of Californian collections will be heavily mediated by online resources, this Archive already offers excellent utility, should he require further research for future edits or subsequence projects.
+
+
+
+
+
“About OAC.”Online Archive of California. California Digital Library. Web. 19 Sept. 2014. ↩
It wasn’t quite Tron: I jumped into the world of computing for two days while taking a Software Carpentry workshop and it turned out highly illuminating without being threatening. This post aims to summarize what I learned & its relevance to librarians and/or digital humanities folks, encourage others to take/give similar workshops, and explain what I’d change about the workshop for librarians or digital humanities scholars.
+
+
+
+
Software Carpentry
+
+
Since 1998 Software Carpentry, a volunteer organization, has been introducing basic computing skills to scientists. The workshops focus on Unix commands & programs, Python programming basics, Git for version control, and MySQL for database management. From a pedagogical standpoint, I particularly like that their teaching materials introduce different personae and scenarios to help participants grasp the real-world relevance of the technologies as they learn. From a “these tools should be universally accessible” standpoint, I’m grateful that Software Carpentry puts all their materials online for free. If you’re interested in the specifics of their lessons, check them out here. As part of my campus’s ASIS&T Student Chapter, I can easily imagine selecting portions of their materials as the basis for much shorter workshops, then pointing people to the full online materials to learn more on their own.
+
+
My Perspective
+
+
I came into the workshop familiar with some basic Unix commands and use of GitHub from the graphic user interface. For instance, I generate my website from the command line using a program called Jekyll and then push it to GitHub’s servers using their Mac app. So although I had a functional mental model for how these things work, the Software Carpentry lessons helped extend my knowledge into much more powerful tools. Much like when learning a foreign language, the immersive aspect of grappling with these systems for a sustained period of time seems to have helped things “stick.” Since you probably know whether a programming language (Python) or a database (MySQL) would be useful or interesting for you, I’ll only write about Git in depth.
+
+
If you ever write anything for school or work, you could benefit from using Git. It’s version control software, meaning that it helps keep track of changes in files. Unlike the “track changes” functionality you’re probably familiar with in Microsoft Word, Git accomodates collaboration at huge scales. For software or anything else that benefits from separating stable and development versions, Git uses a model of branching. Say you’ve made a simple script that works, and you want to share it but also want to keep adding new features. Git lets you simultaneously have a reliable output and others that are under constant revision and improvement. When you’re satisfied that the new features haven’t added anything undesirable into those versions, you can pull the new developments into the reliable version with ease.
+
+
Moreover, Git isn’t just for programs or scripts—it’s equally superb for good ‘ol paragraphs of text! Since I’ve previously been burned by losing files due to hard drives crashing and programs becoming obsolete, I’ve taken to writing in plain text using Markdown. (If you want to see how it works, here’s a useful playpen.) I can use Git to track the development of a particular file that I’m working on, with brief annotations for every stage that I save (or “commit”). This is great news! I wouldn’t necessarily want to put the working draft of an academic article on GitHub for just anyone to stumble across, but by using Git through the command line I can have that same version control power in the cozy confines of my own hard drive. (If you’re not into the whole brevity Markdown thing, it’s apparently possible to use Git with Microsoft Word as well, should you so desire. But seriously, just do yourself a favor and write in Markdown, especially if anything you do is destined for the web.)
+
+
Recommendations for Workshops Aimed at Librarians and Digital Humanities Folks
+
+
Using an EtherPad allowed us to take live collaborative notes, as well as chatting in a side bar. This, along with using blue and orange sticky notes to indicate whether we’re doing well or having trouble, made what could have been an isolating, each-to-their-own-screen experience much more collective. Our particular EtherPad persists after the end of the workshop, so we can all go back and brush up on the different commands and things. Sadly, far fewer people showed up to the workshop than signed up, which meant that there were a lot of spaces that could have been used by others. The incentive model that Indiana’s Statewide IT conference apparently uses is that they charge nothing to attend but charge about $15 if you don’t show up, which seems the best way of making these accessible to the greatest number of possible participants. I’d highly recommend that model for anyone giving one of these in the future. If you’re interested in taking or leading a workshop, they’ve got a page for more information. The EtherPad, sticky notes, and incentive model would all be useful strategies for any workshop.
+
+
For librarians and DH people, the MySQL portion of the Software Carpentry workshop could have been greatly reduced. It does certainly seem worth demonstrating how nicely MySQL interacts with Python scripts and with the iPython Notebook viewer. However—and this is a complement to its ease of use!—MySQL seems straightforward enough that anyone interested could learn from Software Carpentry’s online documentation rather than walking through it in detail as a group. What felt far more useful to do in person was something that Jeremiah Lant, one of our presenters, improvised in our last 45 minutes after we collectively decided to skip the remainder of the MySQL stuff: we walked through writing a Unix shell script that combines the concept of for loops (covered in the Python section) to determine something about a data set, then write those findings to a text file. This exercise neatly tied together many of the new skills that we’d gained and applied them to a scenario that our Assessment Librarian, Andrew Asher, faces routinely.
+
+
As a librarian, I can certainly see that these particular tech tools would work well for any countable data: circulation, gate counts, collection statistics, etc. They have less immediate relevance to digital humanities, since what’s interesting about humanities texts rarely arrives in enumerated form. However, having spent two days familiarizing myself with how these tools operate makes it much easier for me to conceive of how to formulate questions about texts using these tools. Immersing myself in the command line has also made me generally more comfortable exploring a side of my computer I’d hitherto treated as a threatening realm. I’m not going to register for a lightcycle just yet, but the Software Carpentry workshop certainly made me even more eager to continue learning more programming tools.
If you lead one for librarians and digital humanities people, downplay MySQL in favor of building scripts to handle bulk tasks.
+
Use EtherPad if you’re leading a workshop and want people to have collaborative notes & chat in the same place. (It’s like Google Docs only without needing accounts, permissions, etc.)
+
Consider having a “pay if you don’t come” policy to create an incentive for all who register to show up.
This post was originally an assignment for John Walsh’s “Z652 Digital Libraries” course at IU-Bloomington.
+
+
Two talks given at IU in the last month offer insights for digital libraries, one benefiting from direct experimentation with forms of scholarly communication and sustained analysis of academic practices, while the other’s scope provides an intriguing provocation about what libraries might consider as “digital” material. On 2014-10-30, Kathleen Fitzpatrick gave a talk related to her book Planned Obsolescence as part of the celebrations of the new Scholars’ Commons. Soon after, on 2014-11-13, Nicholas Basbanes gave a talk entitled “Paper: A Defining Technology” at the Lilly Library. Surprisingly, each presentation highlighted the practices and situated use of their subject matter, a feature which makes them work well together to discuss digital libraries. Below are abstracts and screenshots of the promotional pages for each talk:
+
+
+
+
+
On Thursday, October 30, the IU Libraries will be celebrating the grand opening of the Scholars’ Commons on the first floor of Wells Library East Tower. This celebration will include a free public lecture by Kathleen Fitzpatrick in 219 Hodge Hall at 2:00 pm and a grand opening ceremony in the Scholars’ Commons at 4:00.
+
+Kathleen Fitzpatrick, Director of Scholarly Communication at the Modern Language Association and Visiting Research Professor of English at New York University. Her talk, titled “Planned Obsolescence: Publishing, Technology and the Future of the Academy,” will focus on the future of scholarly communication, which, she says, undoubtedly lies online, but the most significant challenges faced in transforming scholarly practices are not technological, but instead social and institutional. How must scholars, publishers, librarians, and administrators all reconsider their ways of thinking in order to give digital scholarly communication its future? This talk will explore some of those changes and their implications for our lives and work within universities.
+
+Immediately following this lecture, the grand opening ceremony will take place in the Scholars’ Commons, on the first floor of the Wells Library East Tower, and will feature remarks by Dean Brenda L. Johnson and Provost Lauren Robel as well as self-guided tours and refreshments.
+
+We hope you will join us in this celebration.
+
+
+
+
+
+
The Friends of the Lilly Library annual meeting will take place on November 13, at 5:30 p.m. After the general business meeting, eminent writer and bibliophile Nicholas Basbanes will present a talk titled “Paper: A Defining Technology.” A prolific writer on all things related to books and book collecting, Basbanes is the author of A Gentle Madness: Bibliophiles, Bibliomanes, and the Eternal Passion for Books, which was a finalist in 1995 for the National Book Critics Circle Award for nonfiction and was named a New York Times Notable Book of the Year. His most recent book, On Paper: The Everything of Its Two Thousand Year History (Alfred A. Knopf, 2013), was the recipient of a National Endowment for the Humanities research fellowship in 2008, and was selected as one of three finalists for the Andrew Carnegie Medal for Excellence in Nonfiction for 2014. It was also named a notable book of the year by the American Library Association, one of the best books of the year by Booklist, Kirkus Reviews, Mother Jones, and Bloomberg News, and a “favourite” book of 2013 by the National Post (Canada). A paperback edition was issued by Vintage Press in 2014. A reception will follow the talk.
Furthermore, she argued that academic publishers now function more as content filters than true gatekeepers, for it is increasingly trivial to effectively “publish” one’s writing by posting it publicly online. Despite their economic death—the average academic book sells fewer than 400 copies—academic books remain in an unsettling zombie-like state, animated primarily by the crucial role they plan in tenure practices. Fitzpatrick suggests that we must change tenure committees’ exaltation of paper-printed books over other peer-reviewed forms in order to advance disciplines that have predominantly used that form for the last 60-odd years.
+
+
This expansion of scholarly publication formats is relevant to digital libraries for a number of interconnected reasons. Librarians with technical skills can help with the publication of academic works online, of course. More generally, librarians can also help online scholarly practices become more common and respected within academia by demonstrating how they allow for extra affordances that paper does not. Fitzpatrick mentioned how online communication can help reveal the labor obscured in traditional academic publishing practices, but online publications can also make academic work more readily accessible to screen readers and similar technologies. Additionally, helping budding researchers distinguish between quality, peer-reviewed scholarship that will have credence in their fields and something masquerading as such will remain a core part of instruction, both for librarians and traditional faculty, for as long as these differences matter.
+
+
In addition to indirectly bolstering the role that librarians can play for academic publishing, Fitzpatrick’s talk has implications for the creators of online projects. She argues that communities engage far more around open, in-process work than around finished products, using her own born-digital publication of Planned Obsolescence as a commentable online text as an example. While scholars like Michael Warner contend that every text rhetorically invokes a public, online resources do so demonstrably. Above and beyond merely tracking “engagement” through screen hits and mentions, librarians and others making digital projects can attempt to engage visitors in meaningful ways. The New York Public Libraries have begun allowing online users to assist with transcribing and marking items in the “What’s on the Menu?” project, for instance. Librarians can use digital technologies to extend scholarly communication practices to new audiences, as well as enhance current practices such as peer review in meaningful new ways often obscured by the dominant, paper-centered publishing practices.
+
+
Basbanes and “Paper”
+
+
The two most striking aspects of Basbanes’ talk were its capacious scope and its predilection to emphasize storytelling over analysis. Basbanes’ talk moved far beyond treating paper as a vehicle for scholarly communication, ranging into the technology’s affordances for modern sanitation (toilet paper) and warfare (prepared musket cartridges tripling the number of shots a gunner could shoot in a minute). While being quite flexible in terms of the range of applications of paper considered, Basbanes held to a relatively narrow definition of the substance: when the question of papyrus was raised, Basbanes cut the questioner off with an explanation that he was interested in the cellulose material and its spread, not the laminate that was geographically constrained to the Nile area. Despite their similar use, Basbanes clearly prefers paper due to its more global potential for production. Indeed, paper’s global nigh-ubiquity seems to have motivated his preferred title for the book, “Common Bond,” which he admitted is a “cute” pun on a particular grade of durable paper.
+
+
This talk’s relevance for a digital libraries class is twofold. First, it helps establish the breadth of potential artifacts on paper beyond books, reinforcing the nuance of description that could be relevant when representing items digitally. Basbanes exemplifies the sort of scholar for whose work the descriptor “paper” would not be sufficient. While not relevant to every digital library project, his work serves as a reminder to consider the users and their needs when creating descriptions. Second, the scope of what he considers “paper” makes one think about what might be considered the “digital” for libraries and collections. What range of digital objects might future scholars wish to see preserved, and what are we already losing to the rapid obsolescence of operating systems, file types, or programs? How can we preserve the experience of working with digital programs and files for future scholars, when it’s often difficult to even preserve files that are meant to be outcomes, such as “stable” documents in proprietary formats?
+
+
Commonalities
+
+
Despite their very distinct subjects, these talks share a focus on the varied practices and applications that users bring to their respective materials. Fitzpatrick admitted to having a techno-utopian streak, yet recognized that tenure committees’ expectations around publication will continue to limit scholarly communication practices. Digital librarians would be wise to remember that we can help alter these practices by not only conscientiously creating projects, but also demonstrating the labor and scholarly choices that go into them. Basbanes showed the breadth of what can matter to a scholar, and digital librarians can certainly take guidance from the wide-lens scope of his inquiry when considering what to include when creating projects that focus on born-digital items.
Here’s a post I wrote for Hack Libary School on critical librarianship and the #critlib chats on Twitter. I also discuss student-led interests groups, metacognition, and Bloom’s Taxonomy of educational objectives. There’s even a brief bibliography of anthologies to check out for more on critical librarianship.
Here’s a post I wrote for Hack Library School discussing Markdown and the Bullet Journal system for note-taking. Markdown is a simplified way of writing html, and happens to also be what I use when writing this site through Jekyll and GitHub Pages. Bullet Journals are a system not for classroom or lecture note-taking, but rather for everyday notes about actions, ideas, or projects.
+
+
An aside on Markdown not in that Hack Library School article: Sometime I plan to write a few posts on this blog about how I made this site with Jekyll and GitHub Pages, both of which use Markdown. I actually write all the notes that I type in Markdown format (or a variant) because I prefer plain text files and being able to output from there to all sorts of different presentation formats like .docx, .pdf, or .rtf. Oddly enough, I starting using it because earlier versions of iOS didn’t have a way of writing notes that allowed for formatted text, so Markdown started taking off among people who had iPhones but wanted to write links (or italics for academic citations). I’m glad I started using Markdown, even if I do so because of technical limitations, because I think it’s a highly useful way not just for writing for the web but also for taking notes and writing in the most lightweight, future-proof format possible.
That’s what strikes me most about the first three chapters of Freire’s The Pedagogy of the Oppressed: his insistence on processes of becoming, of history, of liberation, and of course, of pedagogy through dialogue.1 This insistence on processes profoundly helps make sense of Chapter Two, the chapter most commonly referenced among educators intent on discussing critical pedagogy. The other main thing that sticks out is Freire’s particular brand of humanism—a humanism made palatable to someone fond of Foucault’s deep questioning of anything like an inherent “human nature” precisely by Freire’s attention to historical and interpersonal processes of becoming.2
+
+
Freire’s humanism-of-becoming also works due to his use of words like “love” and “generosity,” which focus on actions toward others rather than supposedly interior attributes or essences that have been repeatedly been shown to be historically and socially produced. Two great reads about this social & historical specificity are Shawn Michelle Smith’s American Archives: Gender, Race, and Class in Visual Culture and Allan Sekula’s “The Body and the Archive.” I mention these in particular as they focus on the role of archives in helping to produce these social effects, something to be kept in mind by fellow critical library & information studies people.
+
+
Freire’s problem-posing method aims to develop agency within those who are oppressed—those who see their position as timeless, static, and therefore impossible to change. The details in Chapter Three make it abundantly clear that he’s discussing adult education rather than the K-12 and higher education settings to which his thought is often directed in America. While this shift certainly doesn’t mean that his discussion of the “banking model” or his preference for problem-posing and dialogue are misguided, it’s still worth paying close attention to the specifics of current education to anticipate the snags that might arise if one tried to unthinkingly wrench his problem-posing method out of his particular historical situation. One could certainly argue that someone who thinks that education is ultimately justified to the degree it accomodates a student to the workplace has been oppressed by neoliberal ideology. Even for those hesitant to take this tack, Freire’s problem-posing, dialogic method makes a great case for preparing students to become agents capable of critical thinking and thoughtful engagement with the world.
+
+
What I’m left wondering about with importing Freire’s method to American education, particularly higher education, is ultimately less about the problem-posing, dialogic method itself and more about what sorts of structural changes might be necessary to help educators pursue it. To wit, here’s a partial list of conundrums:
+
+
+
the increasing “feminization” of educators, particularly librarians, teaching assistants, and/or adjuncts
+
the tendency of educators to think of how Freire can apply to “their own” classrooms rather than to departments, campuses, or wider educational systems
+
the tendency for some educators & students to look at librarians primarily in their “service” rather than instructional capacities
+
the pervasive gender bias that many women, particularly those of color, experience in STEM professions and in educational settings
+
+
+
In differing ways, each of these concerns decreases the ability of educators to function as “guides on the side,” a useful metaphor and interface from the University of Arizona Libraries whose use of active learning was amplified by Meredith Farkas.
+
+
Ultimately, my question is less about how we should foster Freire’s problem-posing pedagogy within individual classrooms and more about how we can reshape education to enable it throughout our campuses and society. To me, critical librarianship is one approach, as it helps students become capable lifelong learners. Although librarians like Emily Drabinski and Barbara Fister have advocated critical approaches to librarianship for years, posts such as Brian Mathews’ recent column for the Chronicle of Higher Education show that “#critlib” is receiving attention in venues beyond libraryland.
+
+
Revisiting Freire also has helped me work toward a more succinct personal vision of critical librarianship, one attentive to critical theory while always placing it in the service of “the continuing transformation of reality” (92). As Freire writes, “Problem-posing education affirms men and women in the process of becoming—as unfinished, uncompleted being in and with a likewise unfinished reality. […] The unfinished character of human beings and the transformational character of reality necessitate that education be an ongoing activity” (84).
+
+
Here’s hoping that more educators look to being “guides on the side” who help learners of all ages confront systems of information, knowledge, and education that might not be designed with generosity—and that critical librarianship helps us learn to design information systems with such generosity in mind.
+
+
+
+
+
All page numbers refer to the 30th Anniversary Edition, whose pagination seems to differ from those used elsewhere in this MOOC MOOC. ↩
+
+
+
While I have a few small quarrels with Freire when he writes about things like “the individual’s ontological and historical vocation to be more fully human” (55) as if they are true in an ahistorical sense, overall it’s hard not to appreciate a pedagogy aimed at confronting “a culture of domination” (54). Since I’ve been reading Gilles Deleuze as critiqued by Rosi Braidotti, I’ll just call this a humanism-of-becoming in hope that this will allow for an expansive humanism that allows for affectivity, intersectional identities, and non-unitary subjects. ↩
I recently had the pleasure of moderating a #critlib chat on Makerspaces. These spaces have been enjoying increasing popularity in libraries, demonstrating how libraries function as far more than warehouses for documents. At their best, makerspaces help community members learn by doing, regardless of whether these spaces operate in libraries or as institutions of their own. Participants can make critical interventions into their own lives using technology that would be prohibitively expensive, esoteric, or complicated to purchase and maintain for a single individual or household.
+
+
At the same time, makerspaces go beyond 3D printers or Raspberry Pi-based constructions. They bring along a host of explicit and implicit rhetorical, pedagogical, and cultural constructs—possibly bolstering neoliberal ideas about labor or education.1 With this potent brew of possibilities, it seemed a particularly worthwhile topic for a #critlib chat. In particular, I wanted to discuss the pedagogical possibilities in these spaces.
+
+
+
+
#critlib?
+
+
If you’re unfamiliar with #critlib chats, they take the form of hour-long Twitter conversations on issues of critical librarianship. Using the hashtag “#critlib,” a moderator posts a series of questions and other participants respond. The conversations often get really lively, so it’s useful to use something like Tweetdeck to follow the hashtag in a dedicated column. Some chats are based on readings shared in advance and others revolve around recent events, participants’ experiences, or other knowledge.
For anyone else interested in volunteering to moderate a #critlib chat, here’s a walk-through of the process. I initially proposed the following through the convenient online form on the #critlib Google Doc:
+
+
+
The “Makerspace” is an increasingly popular form that encourages lifelong learning, collective ownership of means of production, and active learning. At the same time, there are substantive concerns about such spaces’ ecological impact, their advocates’ propensity toward entrepreneurial boosterism, and their general tendency to promote “making” as producing individuated skills and physical outcomes rather than, for instance, fostering collective experiences or abstract insights.
+
+
+
+
What aspects of #critlib mesh well with Makerspaces (including, potentially, the active “making” pedagogy of digital humanities)? What aspects could benefit from substantive critique? What might a #critlib version of a Makerspace look like?
+
+
+
After getting confirmation from the moderators, I came up with a set of questions and looked for appropriate readings. Between proposing & moderating this chat, I participated in the moocmooc: Critical Pedagogies held by Hybrid Pedagogy journal. This provided a great reading for the connection I wanted to make between some opportunities shared by infoshops and makerspaces. I emailed the questions to the moderators for their feedback. After receiving it, I posted the questions a few days in advance so that anyone who wanted to could think about their contributions in advance—dealing with 140 characters is a skill, and time helps! I also made the two meme images here and used them to help spread the word about the upcoming chat on Twitter the couple days before.
+
+
Go ahead and check out the #critlib Google Doc to see when the next chat is taking place, or to propose a topic yourself! While you’re there, you can also see the links to a shared Zotero library of readings on critical librarianship and information about the past chats and any Storify transcripts that exist for them.
+
+
+
+
Edit: Here’s a link to a great interview with Wendy Brown in which she discusses neoliberalism. It’s one of the better treatments I’ve seen of that term, which gets thrown around much more frequently than definitions of it do. Had this interview come out before the chat, I would certainly have asked people to read it. It would help distinguish between “making” in service of pedagogy (like the old Bauhaus or other constructivist pedagogical approaches) and a vision of libraries, passtimes, and recreation that must always be in service of easily marketable skills. ↩
This post is currently under construction. The actual project grew out of an assignment for John Walsh’s “Z652 Digital Libraries” course at IU-Bloomington.
+
+
When I learned that we would be doing a mapping project for John Walsh’s Digital Humanities course, two artists quickly sprang to mind due to their extensive use of spatial imagery in their works. Although I began the project intending to map Laurie Anderson’s career of gallery shows, I was able to find a complete set of source data for David Wojnarowicz’s exhibitions through his gallery’s site. As I discovered throughout that class, much of the digital humanities mindset revolves around learning which meaningful parts of humanities inquiry can be captured through data points.
+
+
+
+
2015-06-28:
+
+
I’ve gone ahead and put this up on YouTube, at least for now, as the best way to stream the video showing how this project worked.
Here’s something I constantly rediscover, sometimes painfully: although I’m a capable writer, I’m predisposed toward research. This orientation seems both a boon and a hindrance as an aspiring academic librarian.
+
+
Research calls to me in large part because of its rhizomatic nature—I jump into searching & reading, then giddily test out new possibilities along the way. It feels a lot like being in an exuberant dancefloor, with connections of myriad types & durations constantly occurring and altering. At the other extreme, too often when I am “writing,” I want things to already be perfected and stable. I prioritize the product rather than embracing the process.
+
+
If I were to make a goal—some sort of objective for myself from participating in #rhizo15—I’d have it be something about getting used to writing in ways that are more like this rhizomatic unfurling and becoming rather than the more linear, hierarchical, arborial notion that academic disciplines expect us to produce all too often.1
+
+
Phrasing this another way, in terms of actions rather than affect, I’m going to try to post things perhaps a little before I feel they are “ready,” to share stages in a process rather than try to produce stable documents intended for longer durations. At least here, at the beginning of #rhizo15, I’m going to try to post midway-pieces, thoughts that dwell long enough for linguistic articulation, but not necessarily long enough to have any presumptions beyond being points in an as-yet-unstable trajectory. Rather than a draft, this is just a sketch, one ball of a pinball game, or one turn in a skateboarding videogame; with so little at stake, I’ll likely remain more open to discovering & learning. Speaking of games, the possibilities of alternate, explorative models are part of what excites me about digital humanities tools and how they might allow for demonstrating humanities thought processes more readily than essays do.
+
+
Interestingly, I had a delightful and productive research interview while these thoughts circled in the back of my mind. I’m not quite going to argue that thinking in terms of rhizomatic learning helped me settle that much more comfortably into a “guide on the side” mode of reference, but it certainly didn’t seem to hurt. In addition to making more space for the patron to explore at his own pace, I also mentioned my own connection to his paper’s jumping-off point (the 1963 & 1964 Civil Rights actions in St. Augustine, Florida, particularly those targeting the Monson Motor Lodge). This brings rhizomatic learning a bit into the #critlib wheelhouse, for critical librarianship needs to consider these fleeting pedagogical moments.
+
+
While I’ve heard that the claim that “neutral” in library discourse properly refers to issues of access and collection rather than questions of librarian demeanor or information, the notion of “neutrality” more commonly seems taken to mean that librarians should be dispassionate about topics, should aspire to a mask of “objectivity” rather than showing enthusiasm, or that libraries should be considered as containing knowledge that lies magically outside or devoid of politics. In today’s case, my breaking of this “neutral” demeanor just involved sharing familiarity with the events and the spaces—nothing that would cloud the student’s space of making meaning—and it seems like this only reinforced his willingness to be patient while exploring the depths of the JSTOR and ProjectMUSE databases.
+
+
+
+
+
Writing this in subjunctive mood was not intended to be clever, but I’m leaving it to show much distance I felt from wanting to decide on an overarching outcome while typing this sentence. ↩
A new post of mine recently went up at Hack Library School. It’s about a simple technique that I’ve noticed can help instruction sessions or resource demonstrations feel a bit more exciting and memorable: highlighting a quirky result or aspect of the interface.
+
+
As a bonus, I talk about Batman, Wikipedia, and Google’s simple Ngrams viewer!
Over the last week I’ve effectively been teaching myself Zurb’s Foundation website framework as part of using it to make a prototype website for an information architecture course. Participating in #rhizo15 has primed me to really notice how the process mixes aspects of playful discovery with more structured “learning” outcomes.
+
+
If I were to measure this as a learning process, I could count:
+
+
+
the new skills I’ve learned (even kludgey ones such as using the same naming convention in this prototype as for my regular website so that placeholder images appear when I’m testing it on my phone)
+
the hours I’ve spent on it
+
the features in whatever form the project becomes in the short-term and map them to intended “learning objectives”
+
the features in the final form and compare what I added & what I changed along the way
+
+
+
More interestingly, and to address this week’s question of “What can we count that isn’t learning?” I could count:
+
+
+
the hours I’ve spent enjoying bits of the process
+
the hours I’ve spent frustrated or perplexed
+
how many items that produced these types of affective reactions
the times I’ve committed something via Git (both to “save” it and so that I could try it out on my phone rather than using my laptop (more on Git below))
+
+
+
This list hews close to learning, but nevertheless feels as though it remains just adjacent to what we normally conceive of as “learning” when we focus on outcomes rather than processes. I wonder whether one might discuss zones of proximal affective engagement in addition to zones of proximal development? Enumerating the things in that zone would be a strange approach—but one that might let us dance just enough of that ‘ol defamiliarization/distantiation rag to truly consider affect and learning in new ways.
+
+
Affect isn’t quite countable, as it’s not discrete. It rapidly varies in intensity and mutates into inarticulable mutants of frustration, delight, and anticipation. This is something that we know as educators attentive to pedagogy, but it would be fascinating to find new ways to capture this process. Although this capture is not quite “counting,” it feels something other than the negative space around what is countable. Learning, affect, countable and non-count aspects all seem to flow through each other when we examine closely enough.
+
+
…An Extended Aside on Git and Open Humanities Notebooks
+
+
Git is version tracking software that allows users to annotate, compare differences, or roll back any changes that they save in text documents. It’s primarily used for software development, but as the Chronicle of Higher Education’s ProfHacker series on GitHub attests, Git and GitHub have a lot of potential for humanities and other forms of writing. For instance, if you were the curious type, you could see how many times I’ve edited this post after it went live. Typos are pesky and thoughts don’t stop arriving just because you’ve press a button.
+
+
Franny Gaede started an excellent Twitter discussion on “what a lab notebook for the humanities would look like”:
+
+
I’m still super interested in what a lab notebook for the humanities would look like… what tools could we build or adapt? #arcs20105
Although W. Caleb McDaniel doesn’t discuss Git’s potential in explicitly rhizomatic terms, his post makes clear many of the ways that Git helps document the messy process of assembling thoughts, evidence, discoveries, language, guiding questions, argumentative writing, and the other things that go into and get edited out of humanities writing.
+
+
I’m going on this extended aside on Git, GitHub, and open notebooks in part just to document what I’m learning at the moment and in part to tie this post back to my #rhizo15 post from last week, in which I mentioned that one of my learning subjectives for the course would be to share things a little before they’re ready. By directing people to Git, I’m highlighting the actual process of learning. I could then annotate it with all the subjective, affective, experiential, etc. aspects of the process adjacent to learning as I’d like and language allows.
This post is for Week Three of #rhizo15: “The Myth of Content.” Even though I’m writing this during Week Five, I’m trying to put my thoughts out a little quicker than usual in this post, in keeping with my post from Week One.
+
+
For Week Three, Dave asked:
+
+
+
So what happens when we peek under the word ‘content’ to see what lives there? What does it mean for a course to ‘contain’ information? What choices are being made… what power is being used?
+or
+Content is people. Discuss.
+
+
+
I’d say that in order to avoid routinely reifying “content,” the healthiest approach is to assume that content is always just what a particular system can capture. Most of what can be “contained” in a course are documents or bibliographies, and the beauty of a course is that participants then interrogate, alter, and perhaps incorporate aspects of what they think as a result of meeting these documents into their own ways of knowing. Perhaps they change their ways of knowing?
+
+
An adjacent question would be what course management software can “contain,” and what we think we’re doing when we observe its use. Some of the newer systems allow instructors to see how often students interact with different portions of the course content within the management system. What I worry about is how often professors might overlook this last clause—within the management system—and forget that students might have their own ways of managing their information.
+
+
Dropbox, email, iBooks, Box, Spider Oak, Google Drive/Google Keep/Google Whatever They’ve Recently Introduced and Will Likely Sunset in a Few Years—observant knowledge management professionals know that users will continue to rely on the tools that are most comfortable to them and already most well-integrated into their lives, not the “official” ones that best serve administrative purposes.
+
+
To chase a tangential set of thoughts, this week’s prompt reminds me of Barbara Fister’s excellent article “Teaching the Rhetorical Dimensions of Research”, in which she discusses the fact that “most of our systems don’t retrieve information, they retrieve texts.” What we hope as instructors or (critical) information literacy librarians isn’t for students to magically be able to find information as a thing divorced from human processes (of rhetoric, persuasion, interpretation, etc.), but instead for students to be able to perform actions that showcase critical thinking skills and increasingly sophisticated approaches to the information that lies in these documents. How did these documents come about? What structures might inhere in them, perhaps hidden even to the authors? How might these things distort the information or require us to reconsider how we contextualize it within other relevant structures?
+
+
So yes, Virginia Dave, content is people. More specifically, course content is the outcome of people’s actions, the inadequate ways that these actions can be captured by and appear within processes of composition, behavior tracking in learning management software systems, or planning of a course syllabus. Extending good faith toward our students and patrons will help us understand that there might be (desired) behaviors beyond what we can observe through learning management systems, website analytics, even assignments and term papers. Continually attempting to challenge reification—attending to the discontents that might accompany the observable content—should help us to take a more critical, potentially Freirean approach to learning and education.
Earlier today I saw a few #critlib threads swirling around on Twitter—here’s one and here’s another. The ones that caught my eyes mostly had to do with how open #critlib twitter chats & their participants seem to critique or criticism, the extent to which critical theory has to do with social justice, and what critical theory does or doesn’t include.
+
+
That’s a lot to think about, particularly on the first truly summery Friday afternoon of the year. Good thing we’ve got a “critiquing #critlib from within” coming up on June 30th, right?
+
+
Another person’s comment mused something along the lines of “What’s interesting to me [as someone with a science background] is that I thought people in the Arts were better prepared to talk about critical theory, but it seems like that might not be the case.” I suspect that thinker might have removed it out of fear of being seen as snarky, but I believe they were very much onto something.1
+
+
So, all this tweeting has me thinking about how we teach method in (parts of) the humanities.
+
+
In my experience, I encountered many theories in my literature & film courses but this was almost always to apply or debate them, not discuss their genealogies.2 Even though we’d discuss or situate each theory’s history briefly, theories chiefly were lenses to apply, not subjects to study of themselves.
+
+
My memories of undergrad are somewhat clouded by having taken MA courses with many of the same faculty, but it feels like my undergrad experience was pretty theory-heavy (perhaps due to my own interest in it). Oddly enough, I don’t remember having a proper “methods” course.3 Later, as a PhD student, I enjoyed the opportunity to TA for a “senior seminar” on various critical (Marxist, feminist, postcolonial, etc) theories for comparative literature majors, as well as TA for a couple “writing on art” courses for art history & studio arts students. But even though these courses did excellent work of exposing students to theory & interpretive methods, I believe their final papers were to apply multiple theories to various literary or visual texts, not to evaluate various methods of making truth claims. Having learned more about pedagogy, I think it’s seriously worth considering the results of these decisions.4
+
+
I think this leads humanities majors—with the likely exceptions of history & philosophy, who I believe focus on method earlier—to do two main things.
+
+
First, I suspect that many humanities degree holders feel quite uncomfortable discussing “critical theory” as an entity, and will equally avoid situating various theories’ relationships to each other. We know in our bones that they’re complicated, contested, & possibly even interlocking, intersectional, or some kinda interpenetrating—but at the undergraduate level we have never been tasked to do much more than select among them & apply them to texts. Certainly we haven’t been asked to consider at length or trace the evolution of different strains of thought as they became genealogies of knowledge spanning multiple years, schools of thought, contested keywords, etc., etc. This makes it difficult to feel equipped to appraise something as nebulous, sprawling, and challenging a beast as “critical theory”/ “Critical Theory”/ “are you talking the one with capital letters? does it matter?” later on, even though we recall having been handed appropriate tools for thorny considerations of age, class, complexion, dis/ability, ethnicity, gender, nationality, race, region, sexuality, et. al. as well as many of their possible permutations and combinations.
+
+
Second, more unsettlingly, I fear that we rarely feel equipped to discuss knowledges, practices, truth claims, ontology, epistemology, or similar sorts of method-focused concerns. This might well be why so many humanities & liberal arts graduates emerge with enormous facility with argumentation, empathy, historical specificity, etc., but simultaneously stumble when asked to give a succinct answer to explain their “reason” for choosing a humanities major or what it offers them throughout their lives. Constructivist pedagogy suggests that we learn by doing. I believe that most of us have applied critical theory routinely but in a somewhat piecemeal fashion and never really evaluated their various ways of making and practicing knowledge.
+
+
Since most readers will be coming to this with a background in library & information science, critical pedagogy, or perhaps digital humanities, I’d love to hear your experience of your own undergraduate coursework with regard to method, or of how you teach method to undergraduates if you do so in any capacity. Does this Friday evening musing ring true with you? Is it different in social sciences or science?
+
+
What might we do to help foster a bit more critical understanding of method in arts & humanities courses? Does it seem like social justice, critical theory, and/or critical information literacy can be woven into discussions of method for arts & humanities courses?
+
+
Until I sort out whether/how to put comments on this blog, I guess the best way to have a conversation with me would be through Twitter if you use it. Perhaps you might write a post of your own & link me to it? Maybe you’ll join in the critiquing #critlib from within conversation in a few weeks?
+
+
+
+
Seriously, thanks, Twitter friend, for spurring me to think about this more! ↩
+
+
+
In case you’re morbidly curious, I ended up with an English major, a film & media studies minor, and a “philosophy” minor that really was primarily focused on 20th century critical theory/continental thought. Among other things, this what happens when you (a) start out wanting to do philosophy but then start to wonder why these are the only courses that don’t approach the diversity present in the syllabi, faculty, and classrooms of your other arts & humanities courses and (b) have the historical privilege of relatively affordable in-state tuition at an amazing, open-minded state institution in the 1990s. I seriously doubt I’d financially or emotionally afford to wind my way through what’s effectively an expanded cultural studies degree were I attending undergraduate anywhere with today’s tuition rates. ↩
+
+
+
This may have changed for later students when my English department became more regimented. Among other things, I vaguely remember them instituting required prerequisites for upper- vs lower-division courses rather than treating them more as fluid guidelines. ↩
+
+
+
Iowa State University has a page I’ve found very useful when I want to revisit Bloom’s Taxonomy of Educational Objectives, which is a classic when discussing educational tasks like applying or evaluating. ↩
Here’s a post I wrote for Hack Library School talking about my experience with the Reveal.js JavaScript presentation framework. Not only does it hew to my goal of choosing open-source tools over proprietary formats whenever feasible, its functionality and inherent ability to make presentations shareable on the web make it vastly preferable to tools like PowerPoint or Keynote.
+
+
As librarians, academics, archivists, and/or instructors, we should consider the effects of the formats we choose. How durable are they? How accessible are they? Whose interests do they serve? Whether you frame this as “format information creation as a process”, something closer to “format as culture,” or even “we jam econo,” please be deliberate.
+
+
The post at Hack Library School sits within a series introducing and explaining alternatives to PowerPoint, so it’s not quite a how-to sort of post. If you’d like pointers, please do feel free to get in touch via Twitter or when I add them—which I expect will be soon not happen until GitHub Pages adds an appropriate plugin—the Jekyll Static Comments system that I’m slowly working out.1
+
+
edits on 2016-04-04 & 2016-04-05:
+
+
I found a great tutorial today: Reveal.js for Beginners. If you’re looking at implementing this on your own site, I’d highly recommend starting there.
+
+
Also, I’d like to elaborate a little on the multiple, intersecting types of accessibility I think this type of mobile, audience-member-controllable slide presentations promotes:
+
+
+
mobile device
+
+
economic
+
+
+
people with disabilities
+
+
low-vision / blind (i.e. users of screen reader technology)
+
people with attention disabilities or cognitive disabilities (ADHD, dyslexia, executive dysfunction resulting from a wide variety of causes, learning disabilities, etc.)
+
+
+
pedagogical accessibility
+
+
+
Many of these overlap, of course. For instance, it’s quite common for economically underprivileged people to own or have access to a mobile device but not a laptop. We see this continually at the community college where I work! We also work with—and indeed, are ourselves—students, instructors, librarians, and staff with what I’m calling attention or cognitive disabilities. (I’m lumping those together not because they have the same root causes, but because they all seem to be best addressed by providing a way for the person to control how much time they spend engaging with something.)
+
+
These attention disabilities bring us to pedagogical accessibility. How many times have you wanted to write down a link or reference that was the last thing on a slide, but the speaker advances it just a few moments too quickly? How many times do you wish you could go back to see a term or definition introduced earlier in the talk, but couldn’t?
+
+
Giving your audience the ability to engage with your slides as you talk effectively aides your audience in becoming actual interlocutors, able to engage with your ideas on their terms & at their speeds. Why choose to ensnare them within your own timing? This slide framework promotes the attitude of generosity and loving kindness that I associate with bell hooks’ writings.2
+
+
All that said, one still needs to add alt descriptions to images in Reveal.js talks! Since I initially made my current information literacy slides for my position interview, which happened as I was still learning how to make slides with this javascript framework, I neglected to do this. I have just gone back and fixed that now. I’ll have to find someone who uses screen readers to see how accessible they feel these slides are now.
If there’s one “should” statement I feel comfortable making, it’s that we should continually try to do better, collectively and individually. Part of doing better involves, to the degree individually possible, being willing to point out our own mistakes and how we’re improving what we’ve done.
+
+
Or in the immortal words of Bill S. Preston, Esq., “Be Excellent to Each Other.”
+
+
+
+
+
+
Edit on 2016-04-05: At the moment, it’s unlikely I’ll be adding a Jekyll Static Comments plugin. I prefer this type of system over using Disqus since this is based on emails, and therefore people wouldn’t have to sign up for yet another web service. However, that means I’d have to work out per-post emails and then dial in a spam filter. Also, it’s not one of the few plug-ins GitHub Pages supports. That means that I have to build my site locally, then sync it to GitHub’s servers. I’d never be able to update my site from my phone, which I have done on occasion and want to continue being able to do. So until (a) GitHub allows a version of email-based commenting to work on GitHub Pages, (b) I learn enough and/or choose to move my site to GitLibs or Heroku, or (c) I actually get multiple people reaching out on Twitter or elsewhere saying that they’d want to leave comments, I’m deep-freezing this task in carbonite. ↩
This post responds to the prompt for Week Four of #rhizo15: “How Do We Teach Rhizomatically?”.
+
+
For Week Four, Dave asked:
+
+
+
“I think there is value in the ‘course’ in the sense of the eventedness that it represents. It’s a chance for people to come together and focus on a particular topic… it’s one of the ways to garden the internet. But what is the role of the facilitator/teacher/professor where we are using learning subjectives, where learning isn’t measured and where content is actually other people? What cultural concepts do we have that we can use as models? Do we need a new model?
+
+
How do we ‘teach’ rhizomatically? Or, even… do we?”
+
+
+
This is a great question, particularly since it helps us think about the differences between “teaching” or “facilitating” and a more general “online learning community.” In order to help me think it through, I’ll examine the online community with which I’m most familiar, #critlib, which mostly happens online through Twitter & Tumblr, plus a few blogs.
+
+
#critlib operates more along a facilitation model than teaching model, for while there’s a small core of moderators who organize regular (weekly or biweekly) Twitter chats using the hashtag, the online conversation is most often an open, hour-long Q & A session around that session’s proposed topic. In my mind, at least, the hashtag abbreviates “critical librar*”; the * is sort of a Boolean wildcard, so it can be interpreted as librarian, librarians, librarianship, library workers, library activity, library institutions etc. equally. Critical librarianship, of course, predates the community that has connected through the hashtag on social media—thankfully! The tag’s ability to ambiguously refer to the moderated Twitter chats, the social media community that uses the tag during chats & otherwise, the pages on Tumblr and a Google Document moderated by the Twitter chats’ originators, and/or to critical librarianship has been an occasional nuisance, particularly during the Twitter chats when character limitations hinder disambiguation.
+
+
A “teaching” model—even its most open, Freirean variation that actively seeks to recognize the authority of the students and trouble the student/teacher distinction—seems to revolve around an established person or people who have some authority that persists from instance to instance. A “facilitation” model acts a little more “nomadically,” with facilitators only assuming the role of “central authority” on an ad-hoc basis, even if they do so successively over multiple sessions; put another way “facilitating” seems to refer more to the action currently being performed while “teaching” implies more of an identity and sense of authority. As Dave’s prompt implies, one of the great things about these models is that they help produce an “event,” either in the sense of a shift in perception—”okay, brain, gotta focus now!”—or in the more temporal sense of “Oh! I’ve gotta make it to Twitter between 9p-10p ET or I’ll miss #critlib!” As I’m writing this knowing that the prompt for Week Five concerns community learning, I’m going to leave that for my next post and focus here just on what teaching rhizomatically might mean.
I’m not going to write a summary the “critiquing #critlib from within” session, since that seems against the motivation of the event. However, I do recommend you read through the Storify of it! Instead of a summary, I’m offering what it made me think in response.
+
+
The most striking thing to me about the recent chat was how different participants perceived barriers around the tag, seeing it more as an established community than group of people mediated by a tag. Perhaps online activities allow for more projection than in-person ones do, in that it’s not as easy to check our ideas with the people we’re physically capable of seeing/asking? Perhaps the rapid pace of an online chat it makes some people feel less comfortable asking for clarification? Perhaps it feels like going “on the record” for some people, rather than just chatting?
The other striking thing was how the participants ended up gauging shared experience/attributes. Much as we conversed by using a particular intermediary—the #critlib string—we also appealed to employment types of the moderators, to having read any Freire in order to see who had any pedagogical theory background, and to having read any Foucault. Since the online introductions are brief, there’s little chance to quickly learn the deeper background of the participants. I’m having a hard time imagining a twitter chat where people wrote up more detailed bios on other webpages and then linked to them instead of just using a couple tweets or the twitter bio, since that doesn’t really scale.
+
+
What we like to think of as “teaching” or “facilitating” often fundamentally remains closer to “shuttling thoughts around an incoherently, differently understood intermediary.” I’d apply this gloss equally to learning online and off, although the degree of play and range of different interpretation might be larger for online actions, since there are fewer constraints on understanding, attention, following up, etc. Indeed, if the goal of this post is coming up with another figure or model, as Dave invites us to do, I’m thrown back into thinking of queer theory’s insistence that terms operate as sites of resistance, struggle, and production of meaning.
+
+
Emily Drabinski has neatly outlined this aspect of queer theory in “Queering the Catalog”:
+
+
+
Where lesbian and gay studies takes gender and sexual identities as its object of study, queer theory is interested in how those identities come discursively and socially into being and the kind of work they do in the world. Lesbian and gay studies is concerned with what homosexuality is. Queer theory is concerned with what homosexuality does. (page 96) 1
+
+
+
Perhaps we can expand this into saying that it’s worth keeping in mind how even terms like #critlib function as shape-shifting hot potatoes as we shuttle them around, pliable boundary objects that continually morph as they move, taking on new facets that appear as distinct and obvious to one handler while remaining invisible, inaccurate, or even entirely fictitious to another—all of this play/change/deferred communication happening in a “community” built out of the people who touch the hot potato in whatever way makes meaning out of it for them.2 None of this happens exclusively within online learning communities, but perhaps they are more open to it.
+
+
If I’m going to offer a new model for online communities, I’ll do exactly what I’m describing, and mutate an extant term— #critpotato—into my (current) new figure of how online learning functions. We’ll see how long I sustain this model, or if it functions alongside another later.
+
+
More interestingly, does this slightly ridiculous & ludic figure of a critical, conceptual hot potato offer you anything useful? To tease out a link between Deleuze’s stance on what philosophy is for & Freire’s version of praxis: what actions might this conceptual tool support?
+
+
+
+
+
Drabinski, Emily. “Queering the Catalog: Queer Theory and the Politics of Correction.” The Library Quarterly: Information, Community, Policy, Vol. 83, No. 2 (April 2013), pp. 94-111. Get it here!↩
+
+
+
On top of being a lurid run-on, this sentence owes a lot to a couple images I dimly remember from past readings. One is of a soccer ball articulating—but not defining—the community who use it. I think this is an article on actor-network theory, but I spent an hour looking for it thinking it was by either Lawrence Lessig or Bruno Latour, and it seems to be neither. Any ideas for what it might actually be? edit 2015-07-05: It turns out the soccer ball image seems to originally come from Michel Serres’ chapter “The Theory of the Quasi-Object” in The Parasite. Quite fittingly, this image has later been kicked around by Brian Massumi, Patricia Clough, and others…including being mentioned on the last page of Latour’s “On actor-network theory. A few clarifications plus more than a few complications”…which I’m not sure I’ve actually read after all. Clearly I could use a better system for reading notes! The other image comes from somewhere in Roland Barthes—I think?—where he compares words to onions, as neither has a proper “inside,” only layers upon layers of external skin. ↩
What I didn’t include were particular recommendations for other programs that integrate nicely with Dropbox. Perhaps it’s my college dj training that makes me super hesitant to encourage people to buy a particular program or product when I’m in a more public forum?
+
+
In any case, this is my own space, so here are the programs that I have linked to Dropbox that I use almost daily. None of these are affiliate links, I just think highly of them:
+
+
+
nvALT A free program from Brett Terpstra that stores any number of text files. Using a search bar as the file-picking interface takes a bit of getting used to, but the program’s profoundly useful as a place to store ideas for the future. Just start using breadcrumbs that can help you recall the terms you’ve used—things like adding multiple “q” characters in a row for things of increasing importance, for instance. Michael Schechter shows you which settings to change in order to save your files individually rather than as a single database.
+
Editorial Ole Moritz’s program for iOS lets you work in plain text files and understands Markdown, TaskPaper, and Fountain formatting. It also has templates, automation, and Python scripting, so it’s ridiculously customizable and extendable.
#radlibchat “Librarians’ views on critical theories and critical practices”
+
+
On Tuesday, 2015-09-01, there was a great #radlibchat focused on librarians’ views of critical theories and critical practices. Hosted by the Radical Librarians Collective, this recently-begun set of chats take place once a month. Much like #critlib chats, they suggest readings that work as frames or guides for discussion, but the readings aren’t required for participation. I particularly like that the #radlibchats choose Open Access readings (or pre-print versions) and that they have a Safer Spaces Policy for the chats.
+
+
They’ve said that an archive of the chat will be produced, so I’ll edit this post with a link to that once it’s available.
+
+
Overall, I definitely recommend reading the Schroeder and Hollister article that framed this chat. Rather than looking for a philosophy of librarianship or investigating critical theory for the sake of abstract cogitation, the authors assert the primacy of social justice within librarianship and suggest that critical theory offers a useful way to articulate and reinforce this type of work within professional literature and LIS curricula.
+
+
As I mentioned in the chat, I’d love for there to be a series of zines and blog posts that introduce social justice issues, #radlib, #critlib, etc. viewpoints / theories / approaches to praxis / what have you. If you’re interested in contributing or have ideas about the best way to facilitate that, please get in touch. I’ve already seen some great zines along those lines and believe it’s an excellent format for discussing this kind of work.
+
+
Alison Macrina & the Library Freedom Project at IU Bloomington
+
+
Yesterday, 2015-09-04, Alison Macrina presented on her Library Freedom Project at IU Bloomington. On top of being an excellent presentation, I enjoyed the chance to see Staša Milojevic, Ron Day, and Andrew Asher at least once more before leaving town!
+
+
Kyle Shockey was intrepid enough to live-tweet it, but I was having a hard time thinking in suitably short bursts. So instead, I’ll go ahead and post my notes below. Any errors in understanding, note-taking, and spelling of names are all my own. These notes are far from perfect, and I suggest you check the Library Freedom Project website for more authoritative descriptions of their work, resources, and links. But until you get a chance to see a talk from the LFP in person, here’s a flawed reflection of a talk!
+
+
Library Freedom Project
+
+
Will give an overview of why she runs it, what LFP is, how she got started, what it involves
+
+
Prior Context
+
+
started: July 2013. June 2013 was when Edward Snowden come out with his revelations
+
+
Alison points out that she’s not “anything new” in librarianship, privacy work & intellectual freedom has been a part of librar* for a long time. (image of Jessamyn West’s FBI National Security Letter canary sign, which she’s been doing since about 2002)
+
+
2005 Connecticut Librarians who challenged the constitutionality of the gag order (Connecticut 5?)
+
+
Library Awareness Program, late Cold War FBI program targeted libraries, believing them to be KGB houses, she recommends a great book on this called Surveillance in the Stacks
+
+
Current Things
+
+
Recent backlash against privacy, i.e. “Why protest unless you have something to hide?” standpoint
+
+
NSA hoovering up both metadata and content full-take programs, they siphon it out, “Collect it All” is their approach
+
+
XKeyscore, their data retrieval system, uses selectors to look at data & metadata they’ve already collected with other methods; “It’s kind of like their Google search for what they hold”. Gets down to “Germans who use chat forums in Pakistan” level specificity
+
+
PRISM program, involves a lot of services
+
+
Section 215 of the USA PATRIOT Act, to request any tangible thing; technically sunsetted, but brought back in zombie form, now “anything related to terrorism” verbiage but we know that’s something that can be wildly used & misused because when claimed, don’t have to
+
+
Section 702 of FISA act. We know that US person data caught up in this, which is both unconstitutional & unethical.
+
+
Clapper or (someone else) says that “We kill people based on metadata,” i.e. helps show when the materiality of the message differs from the content, i.e. not in Miami (said) when transmission shown to be in Bloomington
+
+
1033 Program of moving military equipment to police departments. NYPD has something like 30 foreign offices, usually done on tourist visas. Do lots of surveillance abroad, closed-circuit cameras & license plate reading cameras that read the numbers & catch people as well. Basically real-time tracking cameras. Then “domain awareness centers” share all this info. Often target neighborhoods where many POC live.
+
+
Black Lives Matter program, spying on by Department of Homeland Security, local police have, etc. This is all protected 1st Amendment action aimed at civil rights, but heavily surveilled anyway. Muslim communities also heavily surveilled. “Countering Violent Extremism” programs as well.
+
+
Should see all these things (War on Drugs, War on Terror, Profiling & Policing of POC, the unequal incarceration of POC) all involved. Assemblage all comes together. Law around it is either too outdated or the law directly supports these actions. Also DEA routinely breaks the law with no repercussions. Used against lawful activities by marginalized peoples/communities.
+
+
Everyone is caught up in the dragnet, but certain communities are currently & historically have been the target of these. This historical context lets us know the purpose of these surveillance programs.
+
+
Letter to MLK from the FBI
+
+
Letter telling MLK to take his own life or be shown to be “a fraud” who has slept with other women besides his wife. (Apparently based on recordings of his hotel rooms.)
+
+
Determined to be from the FBI, information about MLK’s sex life as blackmail
+
+
Companies & Data Mining
+
+
No right to privacy because of Third Party Doctrine, if given to a non-governmental agency, you have no expectation of privacy
+
+
Google is the scariest one. They have a total picture of who you are & use it for advertising. They have a troubling relationship with
+
+
Google Ideas (Jared Cohen) also works with US on counterterrorism, he’s a State Department guy who also works for Google. Worth reading Julian Assange’s interviews with Schmidt & Cohen.
+
+
NSA is ~70% (?) private contractors.
+
+
Great image of Google as Iron Giant, looming behind Facebook & Big Brother robots lurking over laptop user
+
+
Libraries!
+
+
“Nothing to hide” approach suffers from profound failure of imagination. We all have curtains in our home windows & are all wearing clothes.
+
+
Pew Research Center: “Public Perceptions of Privacy and Security in the Post-Snowden Era”
+
+
PEN America, “Chilling Effects: NSA Surveillance Drives U.S. Writers to Self-Censor”, 1 in 6 writers has avoided writing or topics because of security. Another 1 in 6 has seriously considered doing so.
+
+
There’s also a newer, even more profound study out (also by PEN America)?
+
+
Would someone write Lolita today? Probably not. No one is putting those search terms into Google.
+
+
Librarians and Technologists Can Fight Back!
+
+
Teaching & building freedom-protecting technologies
+
+
This is what she does with the Library Freedom Project!
+
+
She teaches librarians because librarians have relationship to all kinds of people, varied in academic libraries & even more so in public libraries. Libraries are often the only free public computer system in a community. Her high school still doesn’t have a computer tech class, for instance.
+
+
Kade Crawford writes the Privacy SOS website, ACLU Massachusetts
+ACLU lawyers as well
+
+
Works with TOR Project, the TOR browser, etc. They build the tools that she ends up teaching; she does outreach & informs them on how to make tools more user-friendly.
+
+
What she teaches:
+
+
Threat modeling
+
Encryption
+
Free & Open-Source tools
+
+
+
“Encryption works” - Edward Snowden
+
+
Tools:
+
+
+
TOR Browser
+
How to run TOR relays, easier for institutions to assume some of the legal risks
+
DuckDuckGo & other search browsers
+
Privacy Badger
+
No Script
+
Disconnect Me
+
Jabber
+
Red Phone
+
TXT Secure / Signal (works automatically), What’sApp is based on similar encryption but doesn’t work as well by default or advanced implementations
+
TAILS, Linux Debian (The Amnesiac Incognito L~? System), useful for using a computer that’s not your own w/o leaving anything behind; lets you subvert computer filters
+
KeyPass
+
Dice Generator (?)
+
+
+
Principles:
+
+
+
If it’s not saved, it can’t be subpoenaed
+
Encrypting sites with HTTPS, also how to do HTTPS Everywhere
Jeremy Hammond, now in prison, hacker responsible for the leak that exposed the Dow Chemical disaster in Bhopal, India. He was caught because his password was Chewy123 (his cat is named Chewy).
+
+
We can make surveillance more expensive for the spies, makes more work, therefore make a sort of herd immunity, harder to de-anonymize a particular person.
+
+
Libraries are great places to teach this because we’re a trusted space that already is structured around privacy issues.
+
+
A lot of these security-building institutions are excited that librar* are involved.
+
+
Q & A
+
+
Q1. What’s a PGP Key?
+
+
She uses Thunderbird, Enigmail, a PGP suite, then make your keys, etc. It gets easier as you go along, other person also has to use it.
+
+
Q2. Epistemological question: how do we know these technologies work? We seem to be safe in aggregate already, but that’s changing?
+
+
We’re not already safe in the aggregate. Google’s ties with the security department. Shouldn’t overtrust any software. She trusts free & open-source software because she can look at it & how it works. She might not read that particular programming language, many people can look at it together. Many eyes that scrutinize it; it’s the most transparently examined. She says that individuals should think for themselves.
+
+
Sandstorm, is all former Google security people doing a self-hosted Google Drive alternative.
+
+
Q3. I have made a straw man out of your nuanced positions and talk. Discuss?
+
+
Alison calmly & politely interjected “Do you want me to answer your question or not?” when the asker made a litany of supposed—yet demonstrably incorrect & counter to the talk’s content— premises. I thought she handled this exceedingly well.
+
+
Alison says she teaches domestic violence victims about privacy tools, which is often over their heads but their threat model means that they’re willing to learn about it. She desperately wants to make these tools better.
+
+
She wants people to know what decisions they are making. Leave it up to the users.
+
+
Q4. What’s out there that is accessible for disabled users?
+
+
TAILS is good because Debian has accessibility tools built into it.
+
+
TOR project could use expertise on disability issues.
+
+
Q5. Ron: I think what you’re doing with public libraries, gives us a mission & is empowering. With so many library things outsourced to private enterprises, how does this sit with librarians who have their collections pushed out to private vendors?
+
+
If there’s a relationship between LFP & that outsourced problem, it’s that thinking through privacy leads to thinking through outsourced. Adobe data breach, for example. She also shows that there’s a way to have relationship with community-based efforts (FOSS), not just privatized ones.
+
+
Q6. Currently having a lot of data isn’t equal to being able to use the data. But as artificial intelligence & other technologies become more sophisticated, will they be better able to actually use the data?
+
+
She disagrees with premise that data isn’t currently being used. It’ll definitely get worse as analysis of large data sets becomes easier, also important how individual circumstances change & people become surveillance targets.
+
+
Q7. Why is Snowden such a purportedly revelatory thing?
+
+
Stasi archives in Berlin, 2 city blocks, 4 stories high. Great tourist thing. If make NSA to equal height, it’d cover all of North America, down almost to bottom of Mexico, plus parts of the ocean.
+
+
Q8. What about the arms race of escalating privacy technologies?
+Did her answer imply that Silk Road dude got powned by NSA because of social engineering rather than the technology itself?
+
+
Alison: If I were NSA, I’d try to run every TOR exit node so I could analyze things.
+
+
Q9. Hacking Team leaks, a malware for surveillance thing
+
+
Hacking Team also works with campus police departments!
+
+
When leaked, read Email, learned source code, capabilities, had 3 zero-day exploits just for Flash, which made Flash immediately get patched.
+
+
Leaks work well for this.
+
+
WikiLeaks has Hacking Team data dump, you can search for it.
+
+
Q10. Internet of Things
+
+
Don’t use smart fridges, basically. Avoid Internet of Things.
+
+
Someone hacked into an IoT rifle, hacker does it. Sousveillance (the things we carry are watching us), also watching people who are watching us.
+
+
Q11. Statement: Insurance companies & data logging
+
+
ACLU & EFF are trying to fight back against data logging. EasyPASS trying to make it so that you can’t pay toll roads with cash, only cards. “It’s like trying to catch a tornado with a teaspoon.”
+
+
EFF was trying to get classic car tinkerers fired up about this, because new things make it impossible to alter things with your equipment.
+
+
Q12. Ron: General question about how you set up these sessions, how it sets in with ACLU. Why is this different than ECHELON? It affects the perversion of entire state. Now dealing with vast corruption, Fisk court pretty dubious. How do these problematic issues of national corruption get displaced by arms race idea? Does it lead to escalation of tools & entrepreneurial class?
+
+
Not technological determinism, not buy/get new thing. She’s interested in technology for what it can do for us while we continue fighting for legal change & other justice issues without fear of reprisal. Reforming law takes a long time, tools necessary in the interim. Also technology is an easier first step than legal fights.
+
+
Ron: almost like an addiction (as William Burroughs argued) between the hackers hired by NSA & then the counter-hacking. Interesting that it’s really a 4th Amendment issue. I want to apologize if I implied criticism.
#critlib chat on Information & Migrant Populations
+
+
Tuesday, 2015-09-08, saw a #critlib Twitter chat on information & migrant populations. Amiably—and admirably—moderated by Greg Bemb, this chat took a broad approach to considering the information and access needs of different migrant communities. Participants considered international migration, urbanization within a particular country, and students moving to a larger college town.
+
+
Looking back at the Storify put together by Violet Fox, I’m struck at the degree to which the chat participants envisioned the role of libraries and library workers as supporting the agency and actions of migrants, rather than presuming that we or our various institutions bestow information upon others. It’s perhaps an obvious stance, but that outlook of assisting and collaborating with library users seems vital to critical library praxis.
+
+
Tor Exit Node Threatened at Kilton Public Library in Lebanon, NH
+
+
If you’re interested in helping protect patron privacy, you may be interested signing this petition: Support Tor and Intellectual Freedom in Libraries. According to this Propublica article, the Lebanon Public Libraries board of trustees will vote on Tuesday, 2015-09-15, to decide whether to reinstate the Tor exit relay run by the Kilton Public Library, having suspended it after being contacted by law enforcement.
Call for Papers: Topographies of Whiteness: Mapping Whiteness in Library and Information Science
+
+
Submissions of proposals are due this week—on Tuesday, 2015-09-15, to be precise—for papers and essays addressing whiteness in library and information science with the goal of working toward anti-racist librarianship. For more information, check out editor Gina Schlesselman-Tarango’s full call for proposals at Library Juice Press. This book will be part of the Press’s Series on Critical Race Studies and Multiculturalism in LIS, whose series editor Sujei Lugo also is accepting queries, proposals, and manuscripts.
+
+
Philips and Lowery’s “The Hard-Knock Life? Whites Claim Hardships in Response to Racial Inequity”
+
+
An illuminating study on white Americans’ responses to evidence of racial privilege has been published by L. Taylor Phillips and Brian Lowery, respectively a Ph.D. student and Professor at Stanford’s Organizational Behavior program. As Kerry A Dolan’s article at Insights by Stanford Business distills:
+
+
+
Experiments 1a and 1b show that Whites exposed to evidence of racial privilege claim to have suffered more personal life hardships than those not exposed to evidence of privilege. Experiment 2 shows that self-affirmation reverses the effect of exposure to evidence of privilege on hardship claims, implicating the motivated nature of hardship claims. Further, affirmed participants acknowledge more personal privilege, which is associated with increased support for inequity-reducing policies.
+
+
+
It’s heartening that the study found that asking participants to rank their 12 highest values and explain their top-ranked value could effectively turn off the denial effect, with participants expressing a significantly higher belief in personal privilege and expressing more support for affirmative action policies. I wonder how this this sort of affirmation exercise could be used in ethnic studies, critical race, American studies, etc. courses, as well as whether similar “openness” to challenging ideas could be established by affirmation exercises around information literacy.
I’m posting this week’s write-up a bit late since this week was basically spent furiously packing and then on the road, moving from Bloomington, Indiana all the way to Boise, Idaho! This week we’ve got photos of that trip, plus reflections on a book I read before the trip.
+
+
Westward, Idaho!
+
+
Here’s a few of the photos I took along the way. We had time to take a northern route from the midwest, so we drove: Indiana, Illinois, Iowa, Minnesota, South Dakota, Wyoming, Montana, Wyoming again (for a corner of Yellowstone), and then into Idaho! Along with getting to see the college(-ish) towns of Grinnell, Rapid City, and Bozeman, this means that I’m down to only needing to visit 9 more states before I’ll have been to each of them.
Luciano Floridi’s Information: A Very Short Introduction
+
+
Before leaving Bloomington, I finished an e-book I’d been reading through IU’s Wells Library: Luciano Floridi’s 2010 Information: A Very Short Introduction. There’s a slight chance I’ll go back and re-read it in order to write a more sustained “review” since I’m now just looking at reading notes from a few weeks back, but I’d be much more inclined to engage with his less introductory works, particularly on the topic of information ethics. For now, here are some reflections on my first, admittedly somewhat scattered reading of it.
+
+
I was motivated to read Floridi’s work because I’d like to find a good introductory read to suggest to friends & family who ask what it means that I study “information”—and to re-visit myself when looking for a mental “reset button.” I’m ultimately glad I read this book, but I’m going to keep searching for an introductory text. Each of Floridi’s chapters feels like an adaptation of a different week’s seminar or set of lectures. He usefully gives definitions, but his discussion of these occasionally leaps between ideas that could benefit from more explicit linkage. If you were already considering reading it, it’s worth your time—it’s a reasonably quick read for anyone already familiar with the topics and works well considering the substantial constraints of producing a “very short” introductory work to the topics. I certainly don’t envy the task of producing a work so short it’ll inevitably disappoint your most interested readers!
+
+
One main reason I’m considering re-reading this—or more likely, other works by him—is his treatment of “the ethics of information.” At IU I had enrolled in an “information ethics” seminar that was ultimately cancelled due to low enrollment—a too-frequent occurrence for non-required courses offered over summer—and was hoping that this would touch on some #critlib-style ideas. Instead, he presents something that reminds me of Bill Brown’s “thing theory”, in that Floridi’s ethics seeks to grant agency and ethical consideration to information on its own terms, rather than in particular relation to humans. However, Brown’s theory seems to primarily concern encounters between humans and things, whereas Floridi describes information existing on its own. Coming largely from a cultural & media studies background, it’s difficult for me not to immediately think “Reification! Information ethics treats objects like they’re people, man!” However, much like with the thing theory I’ve encountered, I’m intrigued enough not to dismiss the idea outright. As with almost everything, the causes for my reservations would be ironed out in practice rather than guaranteed beforehand. While it’s been about five years since I really engaged with Brown, his theory’s turn to materiality certainly appeals to me. Floridi’s assertion that we should grant information & information-bearing constructs ethical consideration does not worry me as a move in itself, but rather I’m concerned that it would likely distract from more urgent questions about determining how to best produce ethical distribution and access to information for humans.
+
+
In other words, on first blush, my concern is not so much “this is wrong,” but rather, “is this really a question we should devote our efforts to right now?” To me, it’s certainly not a question of “whether” information-bearing objects should be granted ethical standing (in a binary, all-or-nothing sense) but a question of how much ethical consideration they should bear when compared to those of humans (in a graduated, exists-on-a-spectrum sense). On this, I’m pretty sure that Floridi and I would agree. To his credit, Floridi’s definition of information ethics frequently includes the words “minimal” and “overridable” when talking about the types of moral claims attendant to anything understood informationaly:
+
+
+
This ontological equality principle means that any form of reality (any instance of information/being), simply for the fact of being what it is, enjoys a minimal, initial, overridable, equal right to exist and develop in a way which is appropriate to its nature. The conscious recognition of the ontological equality principle presupposes a disinterested judgement of the moral situation from an objective perspective, i.e. a perspective which is as non-anthropocentric as possible. (p. 113)
+
+
+
I certainly appreciate this attempt to enlarge the scope of what bears ethical consideration, but the main sticking point for me is that I’m having difficulty squaring my poststructuralist suspicion of words like “essence” with Floridi’s phrasing of what constitutes an informational entity: “information ethics holds that every entity, as an expression of being, has a dignity, constituted by its mode of existence and essence (the collection of all the elementary proprieties that constitute it for what it is), which deserve to be respected (at least in a minimal and overridable sense), and hence place moral claims on the interacting agent and ought to contribute to the constraint and guidance of his ethical decisions and behaviour” (p. 113, emphasis added).
+
+
If I haven’t already passed it a while back, this is probably the point at which this reflection threatens to turn from an overview to a full-on critique or “proper review,” so I’ll stop now.
+
+
As I said before, I appreciate Floridi’s book and encourage anyone who was already considering reading it to do so. You might also consider reading it if you’re looking for a solid, although occasionally slightly rushed, overview of information. It’s provoked some unexpected thoughts on my part, which I always like. If someone has a thirst for similar readings from a more #critlib perspective, I’d be inclined to suggest something by Lawrence Grossberg on communication, perhaps his 1979 “Interpreting the ‘Crisis’ of Culture in Communications Theory,” which is also collected in his 1997 Bringing It All Back Home: Essays on Cultural Studies. For anyone looking for a longer read on information, I’m currently about 2/3 through Ronald E. Day’s 2001 The Modern Invention of Information: Discourse, History, and Power and profoundly appreciating it. Of course, if you have a candidate for a better introduction or “reset button” read than Floridi’s, please let me know!
This week my two main library-related things were going to the Boise Library! (adorably, that exclamation mark appears in most of their branding and even on their building’s signage—they certainly know how libraries make me feel) and to Boise State University’s Albertsons Library for cards. Nope, I’m not affiliated with BSU. Many state universities have some provision for access to their collections for residents of the state, particularly ones that, like BSU, are part of the Federal Depository Library Program for government publications. You may be eligible for a “Special Borrowers’” or “Community Borrowers’” card at a nearly state institution of higher learning as well, even if you’re not directly affiliated.
+
+
Beyond that, I also finished reading Maria Accardi’s excellent Feminist Pedagogy for Library Instruction sometime around this week. On top of the fantastic writing and insights in each chapter, I particularly appreciate how she has included Further Reading sections and appendices of instruction exercises with feminist aspects.
I recently wrote a post for Hack Library School on examples of how we might break humanities methodologies to bear on information studies. In part, I wrote this in response to the recent statement by the editors of College & Research Libraries that they are looking for papers that use critical theory, among other methodologies beyond LIS strictly conceived as a social science. Paul T. Jager also usefully compares LIS to education in that practitioners in both fields tend to have a Master’s degree and emphasize practice over research.
+
+
There’s also brief summaries of a few articles that use humanities methodologies and critical theory quite well. If you have other examples that you’re fond of, I’d love to hear about them!
Here’s another decidedly-after-the-fact post—who knew that moving could upend so many things?
+
+
This week I began my position as the Instruction and Outreach Librarian at the College of Western Idaho! Peculiarly enough, my starting date aligned with the annual conference of the Idaho state library association. Rather than have me attempt to man the library as a brand-new librarian with no experience regarding CWI’s procedures, policies, or systems, they were kind enough to let me attend the conference. That way I was able to rapidly get perspective on how the Boise metropolitan area’s community college fits into the state’s overall public library and educational systems.
+
+
The conference and panels I attended merit their own post, but for now I’ll just say that Idaho has tons of personable, knowledgable, and passionate librarians working at all kinds of libraries. Here’s a link to Kate Radford’s Storify of #ILABoise2015 tweets.
Danielle Brena has made a nice and succinct Storify summary of the chat. I don’t normally rephrase what I tweet during the chats, but I will this time, as the topic helped me articulate some things that have been knocking about in my head for a while now. Effectively, I’m beginning to be able to put into sentences how cultural studies can inform information literacy instruction.
+
+
It seems to me that the use of binary language around what we call “objectivity” (as in “value free”) aids skeptics in too-eagerly dismissing valid studies. Overly simplifying the initial terms of information literacy in this way actually impairs debate rather than scaffolding learners towards reaching a subsequently more sophisticated understanding. Instead of asserting that “good” information sources are those that are somehow “truly objective,” it’s better to treat objectivity as a value in itself. Claims to objectivity become tenable when we understand “objectivity” not as an all-or-nothing attribute of the source being discussed, but rather as an aspiration: the source seeks to minimize the influence of biases below a particular threshold. Much as engineers and physicists know that the forces of gravity are never truly escapable, yet find utility in saying “zero gravity” as a shorthand term to distinguish spacecraft from “low gravity” high-orbit planes, “objective” sources are ones of which we might say “there is as of yet no discernible influence on the subjects at hand.”
+
+
This “as of yet” is the crucial element, and why we should avoid binary frames that close down critical thinking and subsequent reflective investigation. Owning up to the inescapable aspects of our subjectivity can help us come to understand when & why we fail to perceive influence: our cultural practices of language, culture, racialization, class, gender, sexuality, identity, corporeality, ideology, and all other aspects of identity or ways of interacting with the world can and will creep in even when we attempt to work outside of them.
+
+
This sort of Cultural Studies approach, which views humans as influenced by multiple and myriad values or impulses as much as by obdurate “truths” or sinister biases, seems to offer us some handy ways of respecting patrons’ agency while reinforcing the need to critically engage all sources. For instance, we might turn to genres and communities of practice to contextualize information sources: “Here’s a source of the sort that most medical professionals would recognize as valid. And here’s one supporting anti-vaccination.” This would neither tell a patron what to think nor steer them away from sources with anti-vaccination claims, but it can encourage reflective engagement with all of the sources.1
+
+
April Hathcock’s “White Librarianship in Blackface: Diversity Initiatives in LIS”
+
+
A great example of reflectively analyzing values in librarianship was published last week at In the Library with the Lead Pipe. April Hathcock’s “White Librarianship in Blackface” article was the best thing I read this week. Hathcock admirably takes the time to spell out that by “whiteness” she doesn’t mean a simple happenstance of ancestry but rather a more abstract “system of exclusion based on hegemony.” If I understand her article correctly, she’s warning against how even well-intentioned diversity initiatives can reproduce systems of privilege. For instance, requiring letters of recommendation only from professors rather than community members, such as the applicant’s local public or academic librarians, whose relationship with the applicant might provide many more relevant insights into their aptitude for the profession.
+
+
Rather than relying on application requirements that effectively bar applicants who could most benefit from the mentoring aspects of these initiatives, aspiring to actual inclusivity requires that we intentionally work against accidental exclusion and encourage diversity along multiple axes. I’ve been meaning to read Eduardo Bonilla-Silva’s Racism Without Racists: Color-Blind Racism and the Persistence of Racial Inequality in America for a while now, but I think I’ll turn to the library-focused articles and chapters in Hathcock’s bibliography first. (Sorry, Eduardo. You’ve been bumped again.)
+
+
+
+
Of course, this kind of engagement might be a lot more comfortable to perform in an academic setting than a public library. I’ve only answered reference questions in college settings, where patrons might be somewhat more predisposed to a librarian giving them conflicting sources and embellishing them with context—or at least, patrons might just be more patient with librarians doing so. ↩
Sarah Crissinger’s recent “Being ‘Human’ in the Classroom: A Case for Personal Testimony in Pedagogy” post at ACRLog does a wonderful job of giving specifics on how librarians can use our personal experiences with the research process while instructing students. Maybe it’s because I’ve been listening to Back to Work episodes on my commute, but Crissinger’s article reminds me a lot of Merlin Mann’s occasional assertion that he’s insightful about productivity not because he’s got a perfect track record with being productive but rather because he’s so intimately familiar with and observant of the struggle with distractions and how we can lose our way during projects. I think we convey our authority as instructors better through discussions of experience than through the talismanic trophies of accomplishments our students might not yet understand. What does having authored a host of peer-reviewed journal articles mean to a first-year student whose mental maps of knowledge, let alone personal life experience, doesn’t involve peer-review yet?
+
+
I think it might serve us—and our students/patrons—better when we present ourselves more as process experts than domain experts. By “process expert” I don’t mean that we claim “we do it perfectly” but rather something more akin to “we are familiar with many different approaches & their associated benefits and pitfalls.” Admitting that we too have occasional scholarly difficulties helps us model our critical thinking processes of engaging with information and sources, as well as giving openings for patrons to see us not as stern shushers but rather as willing guides who value sharing our hard-won insights. This is the tack that most Writing Centers I’ve been acquainted with take toward teaching composition. While it can be more nerve-wracking, I do think that sharing our vulnerability leads to a better connection with our students, and therefore better pedagogical potential.
+
+
Code Camps & Watter’s “Technology Imperialism, the Californian Ideology, and the Future of Higher Education”
+
+
An article on new Boise area code schools by Zach Kyle came out this week, which handily provides local context for the question of what role higher education can play in the lives of local students. Looking at the prices for these programs and weighing them against something like freeCodeCamp recalls the age-old discussion of what mixture of vocational preparation, historical context, and interpersonal contacts higher education “ought” to provide students & society at large.
+
+
On a very related note, if you aren’t familiar with the 1960s history of California’s Master Plan for Higher Education, or with what Richard Barbrook and Andy Cameron term “The Californian Ideology,” I highly recommend you take the time to read Audrey Watter’s recent keynote “Technology Imperialism, the Californian Ideology, and the Future of Higher Education”.
+
+
Fister’s “Library of Forking Paths” and Open Access
+
+
This week was my first week getting to do reference desk shifts in my new position, which means that I’m getting to meet more of the students at the College of Western Idaho. I’m also getting more ever familiar with the sources we have, which made Barbara Fister’s “Library of Forking Paths” article at Inside Higher Ed resonate even more.
We’ve had two notable projects at our library this week: working on a “Five Year Vision of the Library” document and preparing for the Halloween outreach events. I’ll post photos of the outreach things next week, but this week I’ll just mention that a shared, editable Google Doc has worked surprisingly well for having everyone get involved and coordinate ideas despite being spread out across different rooms & different days.
+
+
#critlib chat on Gender & Leadership in LIS
+
+
Annie Pho moderated a great #critlib Twitter chat on the topic of gender & leadership in libraries. The questions and suggested readings focused on questions of women’s history and on a more intersectionally-minded revisiting of the idea of the “glass elevator” that masculine folks tend to experience. Kyle Shockey made a thorough Storify of the conversation.
+
+
Two main things struck me over the course of this chat. The first was how little LIS education seems to emphasize the history of libraries beyond perhaps a cursory, uncritical intro along the lines of “Here’s Melville Dewey & a brief overview of librarianship as a profession.” As others pointed out, graduate education in fields like anthropology, literature, education, or history involves a substantial engagement with each fields’ own history and changing (intellectual, practical, etc.) approaches to its topic. If anyone would want to add articles or books on (critical) histories of libraries or librarianship to the Zotero group library, I’d profoundly appreciate it.
+
+
Here’s a few other things related to the history of librarianship:
ALA’s GLBT Round Table has a review series called “Off the Shelf” about the history of LGBT librarianship.
+
There’s a publicly visible course site, wiki, and blog for a [2008 “History of American Librarianship” course] at UW-Madison’s SLIS program, replete with a syllabus and student-led wiki posts.
+
+
+
The second thing that dawned on me during the Twitter chat was the degree to which gendered language rapidly became a tricky thing, with the language of the two readings reinforcing binary views of gender. When we attempt to discuss the effects of gender within librarianship, our analysis should take the time to address complications of gender presentation and include the contributions & experiences of transgender and genderqueer library workers. Folks like Chris Bourg and Jennifer Vinopal do a great job of routinely & inclusively addressing gender in librarianship and technology professions, which is something I hope we’ll all aspire to doing more conscientiously. Here’s a 2013 round up of gender-related readings by Jennifer Vinopal.
+
+
If you’ve got any other favorite readings, blog posts, or other resources related to gender, I hope you’ll consider adding those to the #critlib Zotero group as well.
A couple of the CWI Library student workers suggested Once Upon a Time as a theme for our Halloween decorations, and we ended up embracing it enthusiastically. I admittedly had to do some ahem “binge watching research” on Netflix, but our approach to the theme said that any fairy tale character would be fair game. I decided to go with Hook, even though I’m just now getting to his character’s introduction in the show.
+
+
Here’s the photo from Halloween day in the library:
+
+
+
+
Day 2 in the Enchanted Forest at the Nampa Library. Come and explore our Once Upon a Time decor!
+And here’s a set of photos of library decorations (which I intentionally took without patrons):
+
+
+
+
If you haven't had a chance to see the Enchanted Forest yet, here's what you've been missing. Our student workers have been super creative with the Once Upon a Time theme!
+Most of our students seem to have Monday/Wednesday or Tuesday/Thursday schedules, so we chose to start dressing up on Wednesday. This meant that I got to teach my first library resources instruction session as Hook! It seemed to go rather well. We also did CWI’s Trunk or Treat, bringing a game of bag toss (that’s “corn hole” for you Midwesterners) that the children used steadily for a few hours.
+
+
Readings for This Month
+
+
Now that the move has mostly settled down, here’s a few things I’m hoping to read in the next month or so:
We’ll see how rapidly I get through them, but I’m hoping to be able to chat about these soon enough since I’ve heard them praised or referenced repeatedly.
As an Instruction & Outreach Librarian, one of the things I’m currently trying to do is revamp our fliers and other materials that broadcast what we can do for instructors. Our current materials were written before the ACRL Framework came out, so I’m trying to update them with a snappy, compelling, & brief description of “critical information literacy.” While I haven’t found one yet, I am quite glad that this search led me James Elmborg’s “Literacies Large and Small: the Case of Information Literacy.”
+
+
Besides packing a number of insights into few pages, I appreciate how widely this piece ranges—approaching library work in terms of knowledge practices and a librarian ethos enables the connecting of dots often held apart by title or department. He identifies a “fiduciary fallacy” along the lines of Freire’s sense of the banking model of education; he describes how the reference interview operates most felicitously when questions hew to already-established disciplines and their established ways of organizing knowledge; he links Bakhtin’s account of the roles people play in “speech genres” to a plausible explanation for library anxiety, putting the onus for change on librarians rather than unfamiliar patrons; he refers to Hope Olson’s critiques of subject classification; he calls for approaching the library’s holdings as a “library-text”; he recognizes the materiality of the library and how it makes librarianship different from many other disciplines.
+
+
I’m being somewhat breathless here, intentionally trying to convey how invigorating it felt to read something that bursts with ideas. For the moment, this is currently my favorite #critlib read and one I’d suggest to academic librarians or anyone interested in reference or information literacy.
+
+
Two More Mighty Fine Links
+
+
I always appreciate when people share their processes, so reading Ryan McRae’s Ultimate ADHD Guide to Time Management made my day. Videos are low on my ladder of preferred ways of engaging, so I haven’t watched them, but the rest of the post has a lot of tips to offer. If you’re like me, different approaches to time management work according to my mood or the tasks before me, so hopefully this will help you along if you’re looking for ways to keep focused on doing what you want to accomplish.
+
+
Cecilia Gaposchkin published a nice article at the Conversation on liberal arts and STEM which reminds us that historically, many of the things now considered STEM were viewed as liberal arts. More importantly, she asserts that a “liberal arts education (STEM-based or otherwise) is not just about learning content, but about knowing how to sort through ambiguity; work with inexact or incomplete information, evaluate contexts and advance a conclusion or course of action.” Her whole article is well worth a read.
This has been a week of reading things that help me frame librarianship in new ways. The first regards what image of thought we might recognize in libraries or library work—“library work” here meaning actions of assembling, maintaining, and/or using libraries in multiple, expansive modes. “Speculative pragmatism” as Massumi describes it sounds much more apt to encourage the sort of vibrant, generative, transformative library use I hope for than a librarianship that primarily regards its holdings as objects representative of larger generalities. The second offers a way of thinking about how the educational possibilities libraries & librarians can offer their users—I’m explicitly including public libraries here!—differ from other areas for education.
+
+
“Undigesting Deleuze”
+
+
Massumi has translated, explicated, & extended much of Deleuze’s work for English speakers, which helps explain how he can distill so much into this brief summary of Deleuze’s work and its reception by the Anglophone academy. In addition to encapsulating a lot of what Deleuze’s writing forwards about things as processes of becoming, my reading of this short piece sees it offering excellent provocations for librarianship.
+
+
The first provocation would be the championing of singularities over generalities and how this would trouble classification systems—but I’ll just leave that alone for the moment, in part because I’d have a hard time not just asking you to read Emily Drabinski’s “Queering the Catalog: Queer Theory and the Politics of Correction” as a starting point. Basically, I think there’s a lot in common between Queer Theory and many of Deleuze’s insights.
+
+
For the moment, I’m most interested in another, second potential within the piece, the “speculative pragmatism” Massumi terms Deleuze’s approach. When reading about critical librarianship, information literacy instruction, or reference, I’ve often come across passages that resonate with Massumi’s words in the second-to-last paragraph, the one that conveys what he thinks matters about speculative pragmatism’s ethics of engagement:
+
+
+
To prove equal to the import, to follow the trail of the mattering-on, to honor the potential of the process, it is necessary to participate with great pragmatic and speculative care — and just as much artfulness. There is by the nature of this activity a political element to it. The art of mutual inclusion, with care: that could stand as the very definition of the political.
+
+
+
Librarianship as a profession that is simultaneously caring, pragmatic, and deeply political? One that attends to the tendencies and specifics of people or works, in hopes of witnessing their transformations? An image of information professionals who proceed not by authoritarian detachment or a priori assumptions, but by participation in processes of research & evaluation?
+
+
Yes. Let’s recognize this type of library work where it’s already under way & aim to make it so elsewhere. If you’ve got tactics, please share ‘em.
+
+
“The Idea of a Writing Center”
+
+
North’s piece—certainly offering itself as a corrective, possibly verging on an exasperated intervention—aims to clarify a college writing center’s purpose as well as explain why it’s particularly painful to learn that the calls for student to go there to focus on “fixing errors” are coming from… inside the house!!! More specifically, the focus on sentence and grammar-level errors over higher-order organizational and rhetorical concerns often comes from fellow English and Writing faculty. Why am I so intrigued by a piece on writing centers?1
+
+
His discussion addresses how Writing Centers stand as the material investments made by institutions for modes of learning that recognize more agency within students than they often are granted within classrooms. Writing Centers tend to aim at a collaborative pedagogical approach, one that is student-centered in one of the strongest senses possible. Despite offering a one-on-one dialogic approach that harkens back toward Socratic engagement, North attests that Writing Centers too often are seen as “fix-it” services, with instructors seeing them as serving primarily students who need supplemental guidance rather than places that can aid any writer seeking to hone their mental, rhetorical, organizational, grammatical, etc. skills.
+
+
You can probably anticipate where this is headed by now. The “guide on the side” approach involves a student-initiated interaction, much as does a Writing Center appointment. Libraries can just as readily be seen as material investments in the capacity for students to integrate and extend what they learn in classrooms, doing so with guidance by experts but in ways lead by the students themselves. Much as Writing Center staff and faculty aim for far more than the “fix-it” center they can be misunderstood to be, library instruction aims to be not just where to click, but opportunities to help patrons think critically about information.
+
+
Behind every “Ask a Librarian!” chat interface, there’s the pedagogical potential for something like an incursive “Research Center,” an opportunity for one-on-one instruction that’s initiated by the student when they might be at their most attuned to learning and engaging in depth. I’m intrigued to see what other parallels there might be between Writing Centers and libraries. I’m well aware that this isn’t a new idea—“Learning Commons” and/or Writing Centers located in libraries have become quite a Thing—but I think it’s a notion worth looking at in much more detail.
+
+
At my own campus, I started by asking the Writing Center director if the staff there has any shared approach to discussing how research and sources fit into writing, any common rhetoric or key phrases that we could reinforce in our library instruction sessions. He said that they share the phrase “sources support ideas, not supply ideas.” In addition to pointing me to North’s piece—“It’s kind of a rant,” he smiled broadly—he also suggested Rewriting: How to Do Things with Texts, which I’m looking forward to reading. I’ll keep posting other readings I find—and I’ll look forward to hearing what other people find as well.
+
+
Totally Separate Tech Note
+
+
I’m publishing this a few days later than I’d like (it’s Wednesday, not the weekend), which is oddly due to the fact that I have been able to get more into the writing itself. This is the first time I’m using Working Copy and Textastic to edit the Jekyll repository on my phone before pushing it to GitHub.
+
+
Somehow, typing on my phone brought out more liveliness in my writing than these weekly things often tend to have. Maybe I’m just getting more comfortable with these write-ups, maybe the platform puts me into a different headspace, or maybe the mobile device means I can write whenever I happen to be in the preferred headspace? I’m not going to claim simple causality here, but I will say that it’s been a nice additional option for working with a Jekyll blog.
+
+
+
+
Ok, you got me. It is indeed in part because I’ve worked in Writing Centers for years, on-and-off since I was a senior in undergrad. But wait… there’s more! That’s not the main reason at all! So head back out of these footnotes and keep reading the main ideas, Turbo Overachiever McReadsItAll. ↩
How did I forget about the LOEX Quarterly’s articles being effectively open access after a year? This means it’s a great place to look for articles to share, such as for #critlib discussions. These two are both short enough that I won’t really reprise much of them here, just connect them to other ideas.
+
+
Bob Schoofs, “The Flow of Learning: It’s Not Just in the Classroom”
Here Schoofs discusses learning as a “flow” of actions that spread across campus. He encourages librarians to trust students’ abilities to move to new ways of learning and also suggests that librarians create intentional strategies to help students engage with new learning opportunities.
+
+
This “flow of learning” idea broadly links up with both North’s “The Idea of a Writing Center” and one of my all-time favorite LIS articles, Wayne Wiegand’s “To Reposition a Research Agenda: What American Studies Can Teach the LIS Community about the Library in the Life of the User”. As I wrote last week, North’s “The Idea of a Writing Center” discusses how to orient library instruction toward a holistic sense of learning, to help students integrate disparate tasks into larger habits of mind and process that engage critically with information. Wiegand’s article similarly exhorts librarians to shift from thinking about users within libraries to the larger questions of how libraries fit into the broader personal, historical, and cultural lives of users.
+
+
Andrew Battista, “From a ‘Crusade against Ignorance’ to a ‘Crisis of Authenticity’: Cultivating Information Literacy for a 21st Century Democracy”
Andrew Battista, formerly a Information Literacy Librarian at the University of Montevallo and now a Librarian for Geospatial Information Systems at New York University, compellingly situates information literacy within democratic rhetoric. Then, he advocates for student curation of information rather than consumption or deployment of it, asserting that curation moves from simplistic task-based notions of information use and instead toward critical evaluations that help students situate themselves as participants in public discourse.
+
+
As with Schoofs’ and Wiegand’s articles, I appreciate this article’s stress on what lies outside of the library “proper,” the emphasis on situating the users’ engagement with sources and information. Really, this is an article that you should just go read if you haven’t yet—I’d basically just quote the whole thing if I tried to summarize it here!
It’s 2015-12-12 and I’m still looking at the rough draft of this post languishing unpublished. So instead of trying to annotate why I like these so much, I’m just going to grab a quote that I hope entices you to read each of them. Clearly, I’m still figuring out what these “Weekly Assemblages” will be!
When we’re told to do more with less, we end up building a costly apparatus for generating income while cutting things that actually support the organization’s mission. That distorts everything.
The MakerLab is secretly a digital fluency lab because we help anyone. With each workshop, we focus on the outcome: that the workshop attendee has made a video, made a podcast, made a green screen photo. We want to give them great confidence, and steps so that they can do it again!
It’s 2015-12-12 and I’m still looking at the rough draft of this post languishing unpublished. So instead of heavily annotating why I like these so much, I’m just going to grab a quote that I hope entices you to read each of them. Clearly, I’m still figuring out what these “Weekly Assemblages” will be!
+
+
Will Holman’s “Makerspace: Towards a New Civic Infrastructure”
For makerspaces to become similarly ubiquitous and sustainable platforms, they need to offer the kind of institutional stability that will support meaningful community programming, educational opportunity, and grassroots economic growth. A glance at the history of makerspaces illustrates both the challenges and opportunities of building communities, and businesses, around the ethos of shared making.
+
+
+
History, infrastructure, pedagogy, awareness of current limitations—this piece has bits of all of what I appreciate when talking about culture and technology.
These new social functions — which may require new physical infrastructures to support them — broaden the library’s narrative to include everyone, not only the “have-nots.” This is not to say that the library should abandon the needy and focus on an elite patron group; rather, the library should incorporate the “enfranchised” as a key public, both so that the institution can reinforce its mission as a social infrastructure for an inclusive public, and so that privileged, educated users can bring their knowledge and talents to the library and offer them up as social-infrastructural resources.
+
+
+
Library as platform, as social infrastructure, as technological-intellectual infrastructure, as embedded within a larger assemblages of infrastructure—this is worth making time to read in depth.
+
+
Simon Barron’s “Safe Spaces at Library Conferences”
This is a post for the upcoming #critlib chat: “#feelings”.
+
+
Why are you a critical librarian?
+
+
Libraries exist as spaces for transformation and change. Without being convinced about the effects of library access on his own life, Andrew Carnegie almost certainly wouldn’t have helped fund so many libraries with free public service and open stacks plans that encourage direct access, browsing, and discoverability.1
+
+
As spaces for transformation, libraries are not intended to be neutral. They have been funded, built, and organized with particular outcomes in mind.
+
+
I’m a critical librarian because it is important—both for patrons and for myself—for me to recognize that libraries have never been neutral, then do the difficult and sometimes uncomfortable work of uncovering and questioning my own assumptions. How might libraries have been unintentionally complicit with systems that oppress? How might I be perpetuating these systems? Whether due to oversight or overt bias, when policies, collections, programming, etc. make access or service less welcoming or accessible for some patrons than others, that’s a problem that needs to be recognized and remedied.
+
+
Why do you identify with these ideas?
+
+
I grew up on the campuses of a couple different state schools for the Deaf/deaf, surrounded by people with different abilities and attributes than my own. If being part of this type of diversity taught me anything, it’s that another, more inclusive and just world is possible, but it will not happen on its own.
+
+
As an infrastructure that places profound potential for access in the hands of patrons and also respects their agency in determining what they want to pursue, libraries remain more open and accessible than our educational systems.
+
+
By identifying as a critical librarian, I hope to make this type of goal more visible & more common in libraryland, as well as just make it easier to find more like-minded people. As with other facets of identity, “critical librarian” is something I work with, through, and sometimes even against. I definitely believe that critical theory—particularly cultural studies—equips us with ways of investigating humans, human society, and producing social theory that can improve librarianship.
+
+
While I realize that some excellent librarians find the critical theory elements of critical librarianship off-putting, elitist, or otherwise exclusionary, I approach it as a set of useful tools for us to think through to improve what we do. More specifically, it’s a set of tools that work for me and my ways of thinking—I not only expect that your mileage will vary, but I’d love to learn more about what tools you’ve found most suitable.
+
+
Why do you participate in these chats?
+
+
As I’ve written elsewhere, I gravitate toward “why?” questions. I wanted a discussion group that addressed social issues in librarianship and hadn’t found one yet in my library school program. One thing I love about the chats is that it’s a unique opportunity to learn from a wide swath of people, some of whom are far more focused on “how?” questions.
+
+
I was quite close to deleting my Twitter account, but the #critlib chats & the people I’ve found through them kept me around! My understanding of library history, library pedagogy, and the many critiques of library practice would be completely impoverished if I didn’t have this network of people to learn from. More importantly, my toolbox of lenses to articulate, reflect upon, and improve my library practice would be far smaller—meaning that I’d be that much more likely to perpetuate systems of exclusion I don’t want to have existed in the first place.
+
+
Just as I hope to instill a life-long love of learning in my students and patrons, I hope to be a life-long learner. I’ve learned tons from these chats, and I look forward to learning much more.
+
+
+
+
I don’t actually know whether Carnegie’s primary intention with open stacks was to minimize staffing requirements, with increased discoverability merely a felicitous by-product, or whether he viewed direct access as desirable itself. I’m still delving into these parts of library history, starting with Dee Garrison’s Apostles of Culture: The Public Librarian and American Society, 1876-1920.↩
Having written these for a while, I think I’ve finally got an inkling of what they are do & how to describe them!
+
+
tl;dr version
+
+
For the tl:dr version, I want to share things in a form that accommodates things outside of well-crafted shorter essays, “proper” blog posts, or posts of links. It’s more like Tumblr, only with a more “Domain of One’s Own” approach.1
+
+
Wordier Version
+
+
I look forward to reading other peoples’ occasional round-ups, whether they’re weekly like at Hack Library School or the automated Web Excursions that Brett Terpstra does in addition to his periodic Recaps. So I’d like to do something similar, to help lower any access barriers to knowledge & just to share things that delight or inspire me.
+
+
Having a weekly schedule’s a good way for me to counteract my “keep tinkering until I finally feel comfortable sharing something” tendencies. As much as composition and other instructors tout the importance of metacognition2 or self-reflection, I might as well aim to include some of it into what passes for my weekly routine.
+
+
With “assemblage,” I’m implying that the format will vary according to how I’m feeling & what’s goin’ on with me each week. Sometimes I’ll annotate a reading or two, sometimes I’ll just have pull quotes, and maybe sometimes there will be photos or tips of things I find. Approaching the post as a combine or assemblage lets me get to closer to a Fluxus headspace.3 Plus, I really like assemblage thinking: it’s an approach in critical theory I find compelling since it allows for analyzing how complex effects emerge despite intentions.4 It emphasizes a sort of humility that I feel produces the best types of analysis.5 An assemblage is also a nice metaphor for a research notebook like some digital humanities people produce.6
+
+
+
+
+
Audrey Watters ends that keynote by referencing the same “Sous les pavés, la plage”/”Underneath the cobblestones, the beach” May ‘68 refrain that I enjoy so much. She says “It’s so punk rock — the idea that if we dig under the infrastructure of society, we’ll find something beautiful. The idea that in our hands, this infrastructure — quite frankly — becomes a weapon.” I’d prefer to think of those cobblestones as potential interventions than primarily as weapons, but the sentiment is largely the same. ↩
I’ll probably re-read Hannah Higgins’ Fluxus Experience in the next few months, at which point I’ll have a better way to put into words why I think it’s a fruitful way to think about process, experience, incompleteness, intersubjectivity, DIY, questioning links between objects and subject positions, etc. These things strike me as important both to critical librarianship and my plain ‘ol preferred ways of being in the world in general. That link has a preview of the book, with her first chapter, “Information and Experience.” ↩
In Hannah Higgin’s Fluxus Experience, she quotes Martin Heidegger on epistemological humility as adopting “a rigorously experimental attitude, always provisional, always questioning, always alert to the fact that the being of beings is such that beings continually offer themselves to a multiplicity of interpretations.” (p. 55) ↩
+
+
+
To pick two DH folks off the top of my head, Miriam Posner or Scott Weingart both have extensive blogs that help show their thinking in public as it evolves. For the idea of open notebooks more specifically, W. Caleb McDaniel and Carl Boettiger have each written about their own approaches. ↩
#critlib chat on Information Resources & Incarcerated People
+
+
On Monday, 2016-01-04, I was lucky to co-moderate a #critlib chat with Seattle’s Books to Prisoners on information resources & incarcerated people. With my previous knowledge of prison libraries only being a bit of volunteering for Bloomington, Indiana’s Midwest Pages to Prisoners Project, I’m grateful that Books to Prisoners took the time to select background information and that so many people joined in the conversation during, before, and after the chat’s designated time.
From 2016-01-25—2016-02-12, the fine folks at Digital Pedagogy Lab and Hybrid Pedagogy will be propagating1 the #moocmooc on Instructional Design.
+
+
Here’s how they describe the intent:
+
+
+
This year, we’ve chosen to jump down the throat of instructional design for a few different reasons. First and foremost, as more learning goes digital, instructional design is no longer a peripheral preoccupation in education: it is a force to be reckoned with, discussed, and understood. Additionally, more and more learning is being turned over to instructional designers, who sometimes must push the round peg of teachers’ content into the square hole of the learning management system. Teaching is rapidly becoming an effort between experts in the field and experts in design, with only the rare conversation about pedagogy. Efficiency has become the modus operandi of the educational institution, which leaves inquiry, agency, and emergence to find other arenas for expression.
+
+
+
I hope you’ll join in the fun—the past one I participated was full of a generous spirit of learning together, so I always benefited no matter how much or how little I could read that week.
+
+
Useful App: Nuzzel
+
+
I actually first heard of that upcoming #moocmooc not through Twitter directly, but instead through a new (to me) app, Nuzzel. It’s a bit like an RSS reader, except it aggregates the news or links most commonly shared by the people you follow on Twitter. Plus, the logo’s a hedgehog!
+
+
+
+
What’s a good verb for one of these somewhat anarchic, delightfully sprawling meta-MOOCs that involve weekly Twitter chats, readings, prompts for writing on personal blogs, and instructional challenges? ↩
Giroux’s “Schooling and the Culture of Positivism: Notes on the Death of History”
+
+
Over the holidays I read Giroux’s On Critical Pedagogy, a collection of some older and new essays. The one that particularly sticks with me is “Schooling and the Culture of Positivism: Notes on the Death of History.” It’s a bummer that he hasn’t figured out a way to make this open access. If you can get ahold of it—perhaps you have access to the Educational Theory journal or can get On Critical Pedagogy through ILL—I definitely recommend it.
+
+
Of all the essays in this volume, this might have the most relevance for librarianship / archivists / LIS / etc., for it deals at length with the myth of “neutrality.”
+
+
This essay links the ways that history is taught with ways that produce “common sense” understandings of the world—a production of a particular, politically-inflected common sense that Antonio Gramsci terms “ideological hegemony,” which legitimizes the present distributions of power while attempting to foreclose thoughts that the world should be otherwise.
+
+
Giroux is careful to clarify that:
+
+
+
“Culture of positivism,” in this context, is used to make a distinction between a specific philosophic movement and a form of cultural hegemony. The distinction is important because it shifts the focus of debate about the tenets of positivism from the terrain of philosophy to the field of ideology. […Furthermore…] the culture of positivism undermines any viable notion of critical historical consciousness. (p. 25)
+
+
+
Among its other insights, this essay helps articulate the difference between certain types of theory and what I consider properly critical theory. Theory in the culture of positivism attempts primarily to refine methods and attempts to limit “knowledge” to only things that are value-free. On the other hand, Giroux reminds us:
+
+
+
In classical thought, theory was seen as a way men could free themselves from dogma and opinions in order to provide an orientation for ethical action. In other words, theory was viewed as an extension of ethics and was linked to the search for truth and justice. The prevailing positivist consciousness has forgotten the function that theory once served. Under the prevailing dominant ideology, theory has been stripped of its concern with ends and ethics, and “appears unable to free itself from the ends set and given to science by the pre-given empirical reality.” (p. 26)
+
+
+
Believing that this sort of research and education has successfully evacuated itself of history and values, however, comes with the cost of not recognizing or contending with the socially-embedded foundation of its own pursuits.
+
+
Giroux again distinguishes between “objectivity” and “objectivism”—both of which promote rationality and minimize bias, but only one of which can reflect on its own uses and outcomes:
+
+
+
Missing from this form of educational rationality is the complex interplay among knowledge, power, and ideology. The sources of this failing can be traced to the confusion between objectivity and objectivism, a confusion which once lays bare the conservative ideological underpinnings of the positivist educational paradigm. If objectivity in classroom teaching refers to the attempt to be scrupulously careful about minimizing biases, false beliefs, and discriminating behavior in rationalizing and developing pedagogical thought and practice, then this is a laudable notion that should govern our work. By contrast, objectivism refers to an orientation that is atemporal and ahistorical in nature. In this orientation, “fact” becomes the foundation for all forms of knowledge, and values and intentionality lose their political potency by being abstracted from the notion of meaning. When objectivism replaces objectivity, as Bernstein points out, “is not an innocent mistaken epistemological doctrine.” It becomes a potent form of ideology that smothers the tug of conscience and blinds its adherents to the ideological nature of their own frame of reference. (p. 34)
+
+
+
This lack of reflection about outcomes and ways of being embedded within societal structures is not only a false claim to neutrality, it leaves educators unwilling to consider how they might be located in institutional oppression. 1
+
+
+
Objectivism suggests more than a false expression of neutrality. In essence, it tacitly represents a denial of ethical values. Its commitment to rigorous techniques, mathematical expression, and law-like regularities supports not only one form of scientific inquiry but social formations that are inherently repressive and elitist as well. Its elimination of “ideology” works in the service of the ideology of social engineers. By denying the relevance of certain norms in guiding and shaping how we ought to live with each other, it tacitly supports principles of hierarchy and control. Built into its objective quest for certainty is not simply the elimination of intellectual and valuative conflict, but the suppression of free will, intentionality, and collective struggle. Clearly, such interests can move beyond the culture of positivism only to the degree that they are able to make a distinction between emancipatory political practice and technological administrative control. (p. 35)
If you’re looking for a reading on library values, hegemony, and what claims of neutrality promote, Giroux’s essay provides a lot to think through! I can only hope that as LIS seems to continue moving from “library studies” and towards calling ourselves library science, information science, and operating with metrics, we recognize that these cannot operate without social values and ethics. If we do not make these values explicit objects of intentional reflection, we run the risk of implicitly accepting the larger social structures around us.
+
+
+
+
+
Indeed, the situation goes beyond individual predisposition or “will.” By structuring professional education rhetoric away from considering the complexities of values and toward technical certainty, a self-congratulatory belief in neutrality steers journals and publishers away from publishing works that prioritize considerations of ethics or how the present configuration came to be. It therefore leaves individuals wary of attempting research on values or history, for these imperil their ability to publish and thereby make a solid case for tenure. In other words, to the extent that this false neutrality afflicts education and related disciplines such as LIS, it goes beyond individual will and instead materially structures the professional literature, the professoriate, other administrators, and the institutions’ practices. ↩
“The Case for Scholarly Reparations” and #critlib scholarly communication
+
+
A great read starting off this week was Julian Go’s The Case for Scholarly Reparations, a review essay on Aldon Morris’ The Scholar Denied. The main argument—seemingly shared by Morris and Go—is that Du Bois’ Atlanta School began scientific sociology, despite the fact that the standard historical narrative gives that honor to the University of Chicago.
+
+
+
This is the story Morris tells: Du Bois was marginalized partly because Du Bois and his colleagues were right, and mainstream sociology was wrong, and yet mainstream sociology had all the power to define right and wrong in the first place. - Go
+
+
+
Go acknowledges that it’s a startling claim, so I’ll suggest you read the review in full. It’s worth thinking about how this argument pertains to current scholarship. To the extent that LIS is a social science, this sort of history remains crucial for who our received narratives legitimize and who they cast as marginal.
+
+
+
So yes, all social science is parochial. The difference is that some of these standpoints get valorized as universal and others get marginalized as particularistic. Some become heralded as objective and true, others get resisted as subjective or irrelevant. - Go
+
+
+
If you teach scholarly communication, LIS, or other social sciences, wouldn’t this make a rousing conversation starter? Whose claims to insight get treated by scholarly networks as valid, perhaps even universalizable, and whose claims to insight are dismissed or constrained?
These pics are Creative Commons CC BY 2.0 licensed, and would do well for the next time you need an image for informatics, computer coding, knowledge workers, information professionals, etc.
Mental health issues and mental illness have in various ways affected almost everyone I know and hold dear. The more we recognize how pervasive these issues are for our patrons and ourselves, the better.
Libraries are places that manage a bunch of data about a bunch of other people.
+
+
Data:
+ - Collection processes. Do we need all the fields that we request? Do we need someone’s gender identity? Do we need their birthdate? Do we need their name, even? Is the point to use these things as collateral, so that we can retrieve things / take things from them?
+ - What about anonymous identity cards? What about allowing patrons to put down i.e. $100.00 in cash in exchange for borrowing privileges, and then limit them to ~$100 in material at any time?
+ - Data retention: How long are we retaining data? Do we need it for this long? They’re working with law enforcement systems on body cameras, can be valuable but also involves bulk data collection that exists with NSA. Classic example is if a place has a hand-written sign-in sheet (like a spreadsheet) vs individuated slips. How to atomize data as much as possible, vs having to turn over data in bulk?
+ - Data protection: Time spent on this builds off of collection & retention processes. Can just not even collect things like gender identity.
+
+
Once something’s returned, we might make sure not to keep that data. Instead, just keep records on what is currently checked out to a patron.
Best kind of software to protect privacy is free, open-source software (FOSS). This is relevant to your privacy because transparency of code allows for review and therefore avoidance of secret backdoor for privacy.
+
+
Firefox:
+
+
easy to use, modern browser
+
not secure by design
+
use it when Tor browser gets weird
+
many privacy extensions are available
+
+
+
Tor Browser:
+
+
actually a patched version of Firefox
+
some usability barriers
+
very secure
+
use until it does something you don’t understand
+
bundled with HTTPS Everywhere and NoScript extensions
+
don’t add any more extensions!
+
have both it and Firefox on each machine. Have firefox with “use internet” and Tor browser with “use internet privately” in background.
+
slower
+
+
+
Tor Browser obscures location in a circuit, and each thing in a circuit knows only about where it’s going next, no where about where it came from or its eventual internet destination. Privacy going forward.
+Every new tab you open thinks you’re a totally different person.
+This is application-level privacy. Also doesn’t save browsing history, your settings, a cache, anything. It information is saved, it can be subpoenaed or exploited.
+
+
Even after using tools like DeepFreeze & CleanSlate, information can be recovered with forensic things
+
+
Tor relays in libraries:
+
+
you’ll need one PC or virtual machine with Linux Debian
+
fast relays are 10 Mbytes
+
more relays mean faster browsing and more anonymity
+
won’t affect patron traffic, lives on its own ISP
+
can also run a non-exit relay with a lot less than 10 Mbytes
+
+
+
Vice Motherboard article on Lebanon, NH: 80 emails, only 2 negative, the rest were really glowing in praise of privacy.
Weekly Whaaa…? I’m doing a few of these quite after the fact.
+
+
One of the highlights of this week was the #critlib chat on Patience and Impatience, moderated by Lisa Hinchliffe , Cecily Walker, and April Hathcock. It was “a chance for everyone to talk about the struggles we face in wanting to do important social justice work and to see change immediately when reality is often much different.” Violet Fox was kind enough to make a Storify archive of it!
+
+
Another highlight was reading Alison Hick’s LibGuides: Pedagogy to Oppress? article at HybridPedagogy after seeing it highly recommended on Twitter. I particularly appreciate how she both links the customary uses of LibGuides to Freirean ideas of liberation pedagogy AND gives a number of examples of alternate routes to take either within the LibGuides platform or augmenting it with other tools.
Weekly Whaaa…? Here’s another post I’m doing well after the fact.
+
+
The highlight of this week was attending #THATCampBSU, an unconference around The Humanities and Technology. I met an awful lot of cool people ranging from local activists to coders to librarians. Thankfully, almost everyone there seemed to wear multiple of those hats, too!
+
+
Organized by a three-person team including Memo Cordova, I’m definitely hoping they get the funds to do it again next year.
+
+
In case you haven’t heard of THATCamp before, they’re put on routinely in many places. Here’s the calendar of upcoming ones—maybe there’s one near you?
Weekly Whaaa…? Here’s another post I’m writing well after the fact.
+
+
This week I taught a ton of information literacy/Library 101-style sessions.
+
+
Tools for Thinking
+
+
The main “new” things for me this week were that I found a few great handouts to use in these sessions—these are the type of handout I think of as “Tools for Thinking.” I’m currently slightly modifying one of them to be a better fit for how we discuss these topics, but here’s links to both the originals:
I also found a great theme for the free Atom text editor designed for the sort of plain text bullet journal / GitHub-flavored Markdown todo lists that keep me passably close to on top of things! It’s made me finally switch away from Paraíso Dark.
+
+
This minimal-syntax-dark syntax package works profoundly well in tandem with language-markdown—perhaps not surprising, since they’re both made by a nice gent who goes by burodepeper online. Once you’ve installed language-markdown, which replaces the default markdown package in Atom to give it far more compatibility with extended flavors of Markdown, the editor view will interpret what you’ve written by darkening the words as you type. Atom, it turns out, is based on the Chrome browser, which lets developers do this kind of awesome customization.
+
+
What does this look like in practice?
+
+
+
+
As you can see, the things that still need to be done stay brighter while the stuff that you’ve gotten done becomes greyed out. This is one of the features that I really like about the FoldingText application I’ve been using for Mac, but since I got that program on a discount while Atom is free, I feel much more confident recommending Atom to anyone interested in using a text editor this way. This package is being developed further, and will also currently highlight any other bracket pairs that have something different besides an x in them, which helps draw your eye to things that have other letters in there if you use a system to indicate statuses like “somewhat,” “waiting,” etc.
+
+
I’ve started writing up a big explainer post that details the various packages I’ve added to Atom, the features they offer, and how to use Dropbox and CodeAnywhere to work on them anywhere—so feel free to start getting giddy now if you plain text files as much as I’ve ended up doing!
This week was #CLAPS2016, more formally known as the Critical Librarianship and Pedagogy Symposium at the University of Arizona in Tucson. It was fantastic meeting in person with folks I’ve conversed with online.
+
+
I’m still mentally processing all of the different sessions, so here’s a couple links for the moment:
the Google Drive with shared notes from many of the sessions, plus the slides from David James Hudson’s keynote and Julia Glassman’s “Teaching Alternative Media” session
+
+
+
In lieu of a more full write-up, here’s some photos!
Although I aspire to write these “Weekly Assemblage” posts every week, in the spirit of a sort of weekly Library Day in the Life Project, that clearly doesn’t always happen. The last few weeks have been busy in various ways, so I’ll just do a quick round-up of a few things I wanted to record from the last week or so.
+
+
DERAIL 2016 at Simmons
+
+
Foremost, I’m profoundly impressed by the awesome students at Simmons who put on DERAIL 2016, a student-run forum on Diversity, Equity, Race, Accessibility, and Identity in LIS. They’ve also got a lively Twitter account and hashtag. (Spoiler: their gif level is .)
+
+
I’m hoping that the presentations are made available through videos or slides or something before long. But more than anything, I’m hoping that the trend of powerful student-led conferences that address important social justice issues continues.
+
+
Updates to my site
+
+
Recommended Reads
+
+
Having thought about doing so for a while, I’ve added a recommended readings page, which has sort of an overview of my very favorite readings. I also added expanded pages on critical librarianship and critical theory since it’s hard for me to stop writing once I’ve started!
+
+
The plan is to annotate these recommended readings somewhat, to explain why I find the readings compelling and useful.
+
+
My recommendations will almost certainly have a Cultural Studies bent, since I’ve always found that tradition of critical theory to be the most pragmatic and intent on making timely interventions.
+
+
Added deep anchor links with Anchor.js
+
+
I’ve added deep anchor links using Bryan Braun’s Anchor.js. I went with the # marker because:
+
+
+
(a) that’s what one uses in Markdown to designate headings
+
(b) that’s what shows up in the url when you go to an anchor ID in a page, and
+
(c) I really like the idea of people repeatedly thinking “lumberyard” when reading these posts
+
+
+
In case you want to add something similar on your site, you’d need to download Anchor.js from Braun’s site, then add the javascript to your site depending on however you’re making it. If you’re doing a Jekyll blog like mine, here’s the lines of code I added to _includes/_scripts.html to effectively make the “settings” for Anchor.js:
For the anchors.options settings, icon: '#' makes the interface icon be a #, while visible: 'touch' tells it to have the selected icon show up on mouse-over for desktop/laptop browsers but always be visible for mobile browsers.
+
+
The anchors.add settings line tells it to add the icon for heading levels h1 - h4. One could make it only do them for a particular set of heading levels or for all of them.
Among many other suggestions and insights throughout the chat, one by Ray Maxwell really caught my eye. He suggested #critLAM—a fantastic idea! With my visual culture background, I’d like to add “galleries” and go with #critGLAM. Galleries, libraries, archives, and museums share an awful lot of overlap in terms of the critical questions we need to ask about representation, marginalization, preservation, self-understanding, access, etc., etc., etc.
+
+
Revised my post on Reveal.js
+
+
As a result of this #critlib chat, I went back and edited my post on Reveal.js. More importantly, I also went back and added alt tags for the images in one of my most common information literacy talks.
+
+
Makerspace stuff at Trailhead in Boise
+
+
For First Thursday, our local open gallery walk thing in Boise, Trailhead had their first-ever Maker’s Showcase.
Unsurprisingly, the sound-makers caught my attention first. Amy Vecchione showed off her cool Sonic Scarf, which had been so well-loved by the time I experienced it that the batteries seemed to have run low, so I couldn’t hear it as well as I’d have liked.
A BSU student named Scott Schmader—the head of BSU’s Creative Technologies Association, a Maker student group—showed off his Plosiphone and let at least a few other folks test it out.
I was perhaps most impressed by Donovan Kay’s use of 3D printing to make statistics more readily accessible to people with vision impairments. He showed off a few iterations of his attempt to make standard deviations tangible to blind students.
As Chris Bourg points out, this is an excellent example of why web archiving can be useful.
+
+
Infrastructures of Student Engagement & Dissent
+
+
Having proudly graduated from University of California, Riverside for both undergrad and an MA in English, I believe it’s paramount to keep the student protesting history readily accessible. This type of involvement in democracy is both healthy and necessary. Similarly, we need to keep the history of administrators’ attempts to quell this type of involvement readily accessible.
+
+
As just one of many examples, UC San Diego’s Che Cafe is a continually imperiled student-run space that provides both institutional memory and an infrastructure of student-led agitation for better governance of the UC system.
+
+
Students also produce disorientation guides that reframe, question, and contest official rhetoric about institutions and the goals of education. Here’s links to a few disorientation manuals:
In keeping with this theme of dissent, it’s worth linking to Revolting Librarians and Revolting librarians redux : radical librarians speak out as instances of dissent within librarianship. I’d love it if someone were to do a sort of “history of critical librarianship,” and I certainly expect these books would play a role.
The Southwest Idaho Library UnConference, held at the Collister branch of the Boise Public Library, went wonderfully! Here’s what people tweeted about it. For me, the (unplanned!) outreach session was a highlight, as well as the very planned user experience one.
+
+
Read Hansson on Mouffe in LIS
+
+
After being recommended it by someone on Twitter (probably Lauren Smith, but it’s been a while so I’m not sure), I read Joacim Hansson’s chapter “Chantal Mouffe’s theory of agonistic pluralism and its relevance for library and information science research” from Critical theory for library and information science: exploring the social from across the disciplines. It’s a very good introduction of her thought and definitely worth reading if you’ve any interest in how libraries play a role in democracies. I very well may write up reading notes on it before long.
Having kicked the idea around for a while, I finally took a couple evenings to work out how I’ll attempt an Open Humanities Research Notebook. Behold: it lives!
+
+
As I say over there, I realized that I often feel a need to wrap posts up tidily here somehow. Perhaps that’s a lingering impulse from my days as a high school newspaper editor? In any case, I’d like a place for things that are very obviously “in process,” and it seems like things here stand a good chance of being confused for Studied Opinions rather than Thoughts in Process. Plus, having a research notebook that lives in a different instance of Jekyll means that the tags of the two blogs won’t speak to each other. At the moment this seems like a good thing, but we’ll see how it plays out.
+
+
I reserve the right to eventually just fold it all back into this main site. That’s one of the many nice things about blogging with Jekyll and Markdown—since I settled on using the same theme for both, I’d just have to do some simple “find and replace in project” action in my text editor of choice1 and merging the two should only take 15 minutes at most.
+
+
The first night consisted of me trying to figure out how I’d likely use the separate site and looking for themes to visually distinguish it from this one, my main site and blog. I knew I wanted a darker theme so it’d be distinctly different from this site. I also tend to use dark themes in my text editors, so it’ll trick my brain into thinking that things-in-process live there, even when it’s published and open for others to see. So I ended up finding BlackDoc, a very promising theme that looks a lot like nvALT’s interface, and starting off with it.
+
+
But once I started trying to use dummy entries with tags, I finally realized that BlackDoc doesn’t have tag logic built into it…and that I didn’t want to spend more than the 30 minutes or so I’d already spent on trying to make tags happen. So I instead took the path of made another version of the same theme I use with this site, and chose colors from the Atom theme I’ve been using: Burodeper’s Minimal Syntax Dark. So far I’m definitely content with it.
+
+
For the foreseeable future, I’ll put my reading notes and other research stuff over there. I may also put up working drafts of my public talks or other papers as I see fit. I’ll probably also link to what I do over there in these weekly assemblage posts, just to help make sure that the two speak to each other.
I wasn’t able to engage too deeply in this one, but I do have a few thoughts that I need to get off my chest in response to the criticism that one participant maintained about the topic of “emotional labor.” This person repeatedly asserted a false binary between “real” work (literacy, housing, etc.) and what she seemed to think was “indulgent” concerns about the emotional labor we perform.1 Professions that focus distinctly on emotional labor—therapists, social workers, even special education teachers as far as I am aware—spend part of their education and training to equip people to cope with how taxing and vexing it can be to perform emotional labor. Even though I imagine this training isn’t sufficient in every program or done to the same degree among these professions, it seems that their professional discourses and practices at least valorize and respect the difficulty of emotional labor.
+
+
To assert that time spent discussing how to keep ourselves mentally and emotionally healthy enough to engage with our patrons at our best is like telling a marathon runner that time spent recuperating from a run is merely time spent not training. We are human. Humans have limits. Castigating fellow librarians for recognizing that they need to equip themselves with methods for healing in order to better work with patrons does nothing to help your fellow librarians or to provide their patrons better service.
+
+
It’s well worth noting that the dismissive attitude toward recognizing and recuperating from emotional labor took the guise of focusing on things that are “more real” or “more practical.” This argument against recognizing emotional labor reminded me more than a little of David James Hudson’s keynote at CLAPS2016. While it’s not quite the same as a perceived tension between clear language and critical theory, the recognition of emotional labor does imply a distinct element of social theory and abstract thinking beyond the more direct provision of service.
+
+
Perhaps we need to have LIS programs introduce (at least cursory) tools for recognizing and recuperating from emotional labor, as do other service-heavy professions. This would not only equip us with the tools to continue learning how to do self-care when emotional labor takes its toll, but also do the more fundamental work of recognizing that this can take a toll.
+
+
As always, librarians and the people we work for and with include a sizable portion of people for whom social nets are fraying, whom society and economics are failing. It’s inevitable that we’ll engage with people experiencing profoundly difficult circumstances. Without preparing for that, we’re doing ourselves, our patrons, our institutions, our profession, and our communities a profound disservice.
+
+
+
+
+
I’m not directly quoting her here; the words in those scare quotes are more my attempt to encapsulate her contentions. I’m also not keen on calling her out or engaging unproductively, so I’m leaving her name out here in favor of focusing on this as an example of how emotional labor becomes dismissed within our profession. ↩
Social Justice and Libraries Student-Run Open Conference in Seattle
+
+
SJL Seattle happened on 2016-05-14. Congratulations to the student organizers, Reed Garber-Pearson, Allison Reibel, and Marisa Petrich on what appears to have been a fantastic day! I considered driving over from Boise, but ultimately wasn’t able to make it. Thankfully, participants were generous enough to live-tweet parts of the day. Here are the tweets with the conference hashtag if you’d like to read them.
+
+
On top of this being a student-led event, I really like the idea of there being more local groups that meet to work on how libraries and library workers can focus “on dismantling structural oppression” and “empower people and ideas!” This localization and in-person discussion seems like the next step for critical librarianship and the people who’ve perhaps become more interested in or familiar with these issues through the #critlib conversations on Twitter.
+
+
Lots of Reading Links
+
+
“Valuing Librarianship: Core Values in Theory and Practice” issue of Library Trends isn’t behind a paywall!
+
+
Library Trends Vol. 64, No. 3 (Winter 2016), “Valuing Librarianship: Core Values in Theory and Practice” promises a lot that’s relevant to critical librarianship: disability justice, privacy, social responsibility, diversity, lifelong learning, intellectual freedom, unexplored histories, public good, democracy, professionalism, discourse, and advocacy, just to pick some of the keywords out of the article titles. Kudos to editors Selinda A. Berg and Heidi LM Jacobs for putting this issue together, and to all the authors for their articles.
+
+
I’m profoundly looking forward to digging into them—and I appreciate that I can, because this issue is at least currently not behind a paywall. Normally I don’t have access to Library Trends, but I’ll be eating this particular issue up.
+
+
Popowich’s “Public Libraries, History, and the State”
+
+
Sam Popowich wrote a great post on his blog looking at, you guessed it, public libraries, history, and the state. Using Hobsbawm and Habermas, he gives a succinct yet insightful overview of the ways that public libraries have furthered various class interests throughout their history in Europe since about the 1600s. It’s a good reminder that libraries do not operate in a historical vacuum but instead produce their effects within a constantly shifting constellation of other socio-economic forces.
+
+
#ArchivesSoWhite Intro & Bibliography
+
+
Shout-out to Natalie Baur and Sam Winn for Tweeting about this resource from the Issues & Advocacy Roundtable of the Society of American Archivists… and, of course, to that Roundtable for putting this together. I’m looking forward to engaging with the readings more before long. On top of the Intro and Bibliography, there are interviews with Jarrett Drake, Samantha Winn, and Ariel Schudson, so there will be a lot to dig into!
+
+
Love and Rockets in the Guardian
+
+
The Guardian recently wrote a story on Love & Rockets, the comic series published by Jaime, Gilbert, and Mario Hernandez since 1981. If you don’t have many comics in your collection, this would be a great place to start. Read the article if you’d find Neil Gaiman’s enthusiasm more convincing than my own!
I read a lot this last week or so—too much to annotate each in depth. So I’ll just quickly post links to all of these and suggest you go check them out:
Kate Rubick’s “Flashlight: Using Bizup’s BEAM to Illuminate the Rhetoric of Research” usefully explains Bizup’s BEAM model for engaging with sources. I’d already heard of the BEAM model while I was taking a course on library instruction from Andrea Baer, and Rubick’s article reinforces how useful Bizup’s approach can be. (That’s a link to the open access version, which I’m linking to in case you don’t have access to the version of record.)
It’s been a while since I’ve had time to post one of these. I realized that there were a few design related things in my “I should post about this” file, so here they are!
Turning the Revolution into an Evolution by John J. Meier and Rebecca K. Miller connects to a lot of other design-thinking things that have been floating around here in Idaho lately.1 I particularly like how they talk about rapid prototyping for library instruction, as that’s how I’ve been trying out different ways of teaching information literacy; seeing which metaphors or analogies work with students, seeing what connects with different professors, etc. as we gear up to make lots of new videos and tools.
+
+
Finally, here on the site, I’ve made the font sizes generally larger and changed the fonts to be exclusively sans serif. Currently the fonts are Alegreya Sans and PT Sans Narrow. I also added James Walsh’s Academicons, a project that supplements FontAwesome with Academia-dot-edu (), Open Access lock (), Zotero (), and other relevant icons.
+
+
+
+
+
Design thinking has been quite a topic locally. A few months ago, I was fortunate to work with people from BSU’s Albertsons Library on the Acumen + IDEO Design Kit course. Shelly Doty, Lindsay Dwyer (who’s also a fantastic colleague at CWI in addition to working at BSU), and Margie Ruppel were all excellent at shifting hats between being creative, critical, and practical as the course suggests. At the Southwest Idaho Library Association Unconference, Natalie Nation and Deana Brown lead an illuminating presentation on design thinking. And Amy Vecchione keeps doing lots of great work with students at BSU’s MakerLab and representing librarianship more broadly at Boise’s Trailhead startup incubator & coworking space. ↩
Here’s a handful of links that I either shared or meant to share on Twitter:
+
+
Rachael Neu linked to Richard Van Heertum’s “How Objective is Objectivity?” article in UCLA InterActions journal recently in a list-serv. I’m eagerly awaiting reading that article, but in the meanwhile wanted to share the link to the InterActions overall. It looks like a great, open access, peer-reviewed LIS and education publication that focuses on information studies, not strictly information science. In other words, it’s very much up my alley!
I saw that the Conference Proceedings of JITP 2010: The Politics of Open Source is online and open access. I found that while searching for a copy of John Sullivan’s “Free, Open Source Software Advocacy as a Social Justice Movement: The Discourse of Digital Rights in the 21st Century” article, which I’m still very much looking forward to reading.
+
+
Library Juice Press recently posted an interview with Dr. Annie Downey, author of Critical Information Literacy. It’s a great read and makes me look forward to getting my grubby paws my strenuously professional hands on a copy of the book that I can annotate for my very own!
+
+
Here’s a fun bread closing taxonomy. I hope to eventually work it into our information literacy for the sciences somehow.
+
+
Tara Robertson and Jenna Freedman moderated a #critlib Twitter conversation on the ethics of digitization. I wasn’t able to participate directly (only chiming in with a couple half-formed thoughts well afterward) but it looked great.
+
+
Comments Have Arrived
+
+
I’ve long wanted to add comments to the site without making people sign up for yet another service, as is required by most ways of adding comments to static sites (i.e. those made with Jekyll and similar site generators). So I was super excited when I saw that Michael Rose had added Staticman to the newest version of the Minimal Mistakes theme! The present site is still running on a much older version, but I managed to get the comments working and he was kind enough to help me figure out how to make them display properly.
+
+
You’re very welcome to submit a comment. I will of course moderate them, which Staticman cleverly allows by making use of GitHub’s branching feature. I’m excited by the prospect of this site becoming more collegial and interactive! 1
+
+
+
+
+
Simultaneously, I’m not above wielding the moderation hammer with all the wanton glee of the Designers Republic’s Sissy. Cheers! ↩
Lisa Hubbell’s commitment to making this chat about critical reflection more accessible to people for whom Twitter isn’t optimal inspired me enough to want to do a “seeding” blog post of my own. The topic itself seems to beg for a different kind of engagement. I’ve got a few different facets of “reflection” in mind, so I’ll try to address all of them here.
+
+
Tools for Thinking
+
+
Prompts work well for me, as do other tools for thinking.
+
+
The most basic of these prompts was drilled into me while I was on high school newspaper, if not earlier: the old, reliable “who, what, when, where, why, and how?” questions.
+
+
Here’s a few more that I believe help nuance those and make our answers more critically reflective:1
+
+
+
For whom is this accurate, in what ways, and under what conditions?
+
Who does this obscure?
+
Whose participation is left out?
+
Does this way of thinking frame people as passive or active?
+
How is this useful? What does it help us do in the world?
+
+
+
David Seah’s various productivity tools profoundly help reinforce a practice of reflection. Unlike a lot of people who write about productivity, his site and tools don’t trip my spidey sense for boosterism or selling things. He gives the documents away as free downloads! (He does sell pre-printed ones as well.) Instead, between his explanations of the various tools and his own blog about things like his “groundhog resolutions”, he seems very committed to the idea that review is a (maybe the?) path to progress.
+
+
I like Seah’s phrase “tools for thinking” enough that it’s what I call most of the relevant library handouts I make at my library: simple templates for expanding & narrowing search terms, for brainstorming keywords, that kind of thing.
+
+
My Actual Practice
+
+
For readings, I take lots of marginal notes. This semester I read Casey Boyle’s …something like a reading ethics…, and I intend to start doing something along those lines from here on out.
+
+
My reading notes—and all of my notes, really—are plain text, in Markdown format, and stored in Dropbox. That way I can always sync them between whatever computer or device I’m using. I usually use Atom on my laptop or at work, plus Editorial on my phone.
+
+
Plain text synced through Dropbox means that I don’t have to fret about leaving a notebook filled in my insights somewhere. I profoundly enjoy writing by hand, but I don’t enjoy the anxiety that builds up the more I have in a notebook and nowhere else. When I want to go back and somehow do revisions on earlier ideas in plain text, I’ll usually use Critic Markup for most of my jotting-ideas-down writing, or much more rarely I’ll track changes for more formal writing through Git.
+
+
I also have a sort of bullet journal with plain text files for each month, with the idea that I’ll go back and do some review every night as well as again on weekends. It helps, but I certainly don’t do it as consistently as I’d like.
+
+
The Pomodoro technique (and time-blocking more generally) also sometimes helps when I need extra push to focus on something that I know I also want to examine critically. Pomodoros seem to give me permission to toggle between the “make stuff!” and “wait, what’s this leading toward?” habits of mind. Beyond just each 30 minute cycle (25 minutes of GO!!!!!, 5 minutes reflection), the broader technique also invites more substantive reflection every few hours and at the beginning & end of the day. I’m not great with experiencing time, and therefore really not great at estimating time. Since pomodoros turn nicely into time tracking, it’s a practice with many interlocking benefits.2
+
+
My Desired Practice
+
+
Since Lisa Hubbell’s second “seeding” post for this critlib chat delves into broader teachings and reflective practices, I’ll mention that Buddhist thought has worked well for me since about high school. I wouldn’t claim to be a practicing Buddhist and don’t really identify as one, just as sort of a long-time beginner or appreciator; I don’t go to a regular meeting place, don’t have a consistent meditation practice, and couldn’t recall the details of the noble eightfold path or any other fundamental precepts off the top of my head. All the same, Buddhist teachings around liberation, loving kindness, and mindfulness more than merely resonate with me. They help me make sense of the world. They work for me, and they’ve worked for other people I care about deeply.
+
+
I’ve found helpful things in writings by bell hooks (that’s to her posts at Lion’s Roar magazine/website, although my introduction to her Buddhism was the “Agent of Change” article for which Tricycle occasionally lifts its paywall), Shunryu Suzuki’s Zen Mind, Beginner’s Mind, Brad Warner’s Hardcore Zen, and Chade-Meng Tan’s endearingly self-deprecating Search Inside Yourself.3
+
+
Years ago, when I desperately needed to hear something along its lines, the Back to Work “The Second Arrow” episode on ADD, Buddhism, and mindfulness was profoundly helpful, too.
I don’t recall seeing these anywhere in particular; they’re sort of a distillation of what I’ve picked up from various types of what I consider “critical theory,” ranging from Cultural Studies to various types of activism to rhetorical analysis. ↩
+
+
+
If you want to get next-level geeky with this, Ugo Landini’s Pomodoro app for Mac can sync up with Growl notifications and then even to your phone with Prowl notifications. Time’s passage can follow you even when you wander away from your keyboard, as long as you carry your phone with you. If you’re like me, you’ll be humbled by how rapidly & repeatedly your monkey mind runs away from your intentions. ↩
+
+
+
I feel I’m obligated to also gesture toward whatever second-hand Alan Watts books I read back in high school, but I suspect they’d strike me as pretty Orientalist if I re-read them now. Choose your own adventure with those. Looking at titles & cover images, it probably included The Way of Zen and This is It. ↩
+
+
+
It has enough Buddhist terminology that I occasionally felt more like an eavesdropper than a listener, but I kind of feel like that’s an especially productive approach to this topic. It’s good practice to sit with not being centered by a conversation. ↩
Perhaps it was due to participating in the #critlib chat on reflection, moderated by Lisa Hubbell? Perhaps it was because I miss using DayOne, which I slowly abandoned after they changed how they sync the files? Perhaps it’s just that I’ve gotten really used to using Jekyll, and this is another interesting use of that familiar technology?
+
+
In any event, I started using Craig Eley’s “Trophy Logbook” theme for Jekyll over the holidays and really appreciate it so far. I even submitted My First Pull Request™, helping organize the tags alphabetically with Liquid rather than strictly chronologically. (I’m going to try to help figure out how to sort by tags frequency, but that’s on the back-burner for probably at least another week.)
+
+
If you’d like to try journaling with it—or if you’d just like to give Jekyll a try without your first attempt being public—Eley’s theme works quite well. Craig explains in his Medium post that it’s designed to use tags to track people’s name and categories to track places. For my own use, I’m doing that, but also tracking regular topic tags with the simple blunt strategy of adding 0- before the tag, so they’re all sorted prior to the names. So instead of just writing meta in the tag field, I’m writing 0-meta. I don’t track physical locations very often, so I’m mostly using categories to track the media I watch or read. I’ve started putting some reading notes in there as well. I’ve been hankering for a place to put reading notes, and having the option of using both the work’s title and topic tags seems like a very promising set-up for them.
+
+
This theme uses Jekyll plugins that make it incompatible with Github Pages—not a bad thing, unless you’re exhibitionist enough to want your journal rendered publicly. If you want a private place to store your journal and perhaps write to it from a different device than your computer, GitLab lets you have private repos for free.
Bryan Alexander’s We Make the Path by Walking group read
+
+
The first of Bonnie Stewart’s two above articles mentions We Make the Road by Walking, a book by Myles Horton and Paulo Freire. If you haven’t already notice how much of a touchstone Freire has become among instruction librarians, Joshua F. Beatty presented an excellent paper at the 2015 CAPAL conference, which he has open-access here.
+
+
Bryan Alexander up some of the activities on an online group read of We Make the Road by Walking in “Reading Horton and Freire in 2017”. I’m going to have a busy semester with a lot of reading, but I’m aiming to read this book as well. It’s important to not just acknowledge, but also learn from, histories of what works domestically. Horton’s Highlander Folk School certainly has a history to learn from.
+
+
Meredith Farkas’ “Never Neutral: Critical librarianship and technology”
+
+
It’s great to see that Meredith Farkas’ article on the impossibility of neutrality and the harm perpetuated by failing to advocate for our patrons is reading the readers of American Libraries Magazine.
+
+
It’s short and worth reading in its entirety. Here are a couple excellent quotes that resonate strongly with my week-to-week work:
+
+
+
Librarians may not be able to change Google or Facebook, but we can educate our patrons and support the development of the critical-thinking skills they need to navigate an often-biased online world. We can empower our patrons when we help them critically evaluate information and teach them about bias in search engines, social media, and publishing.
+
+
+
+
We are not doing our job if we remain neutral when it comes to library technologies. Accepting many of the technologies available to support our missions means accepting technologies that are biased, not accessible, not protective of the privacy of our users, and not easily usable by some of our patrons. A commitment to social justice is a commitment to equal access, which is at the heart of our professional values. We are not being neutral when we advocate for our patrons, but we are being good librarians.
I really like this article and appreciate Emily Ford’s perspective here. Oddly enough, we’ve gone ahead with a variant of badging at my college just this semester. It’s really more about flipping the content than a “badging” system, and I think we’re doing it in a way that avoids the pitfalls she’s laid out nicely in this article. At least, I hope we are. We’re doing assessment, so we’ll find out!
However, I really like the idea of using simplified citekeys, so I’m putting together a system around this now, as I’m in the middle of a writing project that uses a lot of articles I’m highly likely to use again in the future.
+
+
Which is where VukanJ’s bibtext-helper comes in. I’ve taken to using the Atom editor whenever I can, and VukanJ’s tool is basically a set of snippets I can invoke by typing the citation style (e.g. @inproceedings or @article), which prompts Atom to expand the snippet into a citation template with all the appropriate fields for that type of citation. At first I couldn’t figure out how to add it to Atom, since VukanJ’s documentation is…let’s say “light.” I eventually just hit select-all on this file, copied everything, then pasted it into my snippets.cson file in Atom. At first it didn’t work, so I changed the '.text.bibtex' in line 1 to '.text.md'. Now it sings! I did alter a few things—specifically adding @crossref = {} to the @inbook, @incollection, @inproceedings, and @inreference snippets, as Nelson H. F. Beebe’s super-helpful guide suggests. I also added address = {} to the relevant snippets.
+
+
For the last few things I’ve written, I used Zotero to collate the info and then Bibdesk to put the citation into my writing. But I profoundly didn’t like how that combination wouldn’t let me change the citekey. Numbers and time aren’t intrinsically meaningful to my mind, so I’d much rather cite something as @hall_local_and_global than @hall_1989a. I also didn’t like how the Zotero + Bibdesk citations would seem to arbitrarily decide to force capitalization.
+
+
I’m thinking I might put up my main bibliography file on Github somewhere, either as part of this site or somewhere else. It’d be nice to be able to refer to those citekeys from anywhere I might be writing or making reading notes. But for now—actually almost a month after I first wrote the paragraphs above—I’m just going to mention this as one the next citation approach I’m exploring.
I haven’t been to an Annual ALA Conference yet, so it’ll be interesting to see how my attention can hold up to meeting so many people and hearing so many ideas. I’ve been to a number of smaller conferences, but nothing on this scale.
+
+
Building from the Critical ALA Annual 2018 list of “sessions of possible interest to critical library workers” made by Eamon Tewell and others, here’s a schedule of where I intend to be while in NOLA. I’ll do my best to update this throughout the week, so we can try to meet up if you’d like. Messaging me on Mastodon or Twitter would be great ways to get in touch.
+
+
I’ll do my best to always have an In the Library with the Lead Pipe button on my backpack or lanyard to make it easier to spot me. Please feel free to chat about the journal’s submission or open peer review processes, talk about ideas you have, or anything else. I’ll bring a few buttons with the journal logo’s to give away as well.
+
+
+
+
I’ll probably also bring a small number of earplugs. So if you plan to go out dancing or if you see me out somewhere loud, ask and I might have some for you & your ears.
+
+
Group Note-taking > Live Tweeting
+
+
There’s a growing practice of shared note-taking at unconferences and conferences, like at CLAPS2016 and at the #critlib Unconference 2017 in Baltimore. Let’s keep that going and try using more privacy-respecting platforms this time around.
+
+
If you’re interested in helping take group notes—which seem like a more hospitable format than live tweeting for many of us—I’m planning to make publicly-editable Etherpad notes hosted at RiseUp. It’ll be like shared Google Docs, only on a platform that helps avoid Google’s many privacy-destroying tentacles.
+
+
My plan is to:
+
+
+
+ [x] make a pad for each session I'll attend @done
+
+
+ [x] give each pad a 1 year lifespan (which anyone can do as they create a pad) @done
+
+
+ [x] link to those pads here @done
+
+
+ultimately move our collectively-written notes somewhere else to be determined, such as my site or maybe something like a Sandstorm.io instance for library workers and/or other folks interested in #critlib-type things.1
+
+
+
+
If you can think of a better process or make other pads/notes that you want added to shared list, let me know on Mastodon or Twitter!
+
+
Lastly, please: if there’s a microphone, always use the microphone.
+
+
My Schedule
+
+
Thursday
+
+
I’m flying in today—and I wish I could be listening to KEXP’s breakdown of Public Enemy’s It Takes a Nation of Millions to Hold Us Back while in flight. Hopefully they record it or at least spell out the playlist somewhere. Fear of a Black Planet was much more formative for me but I’d love to learn anything I could about the Bomb Squad’s production process for any of their albums.
+
+
I might be down to meet up for vegetarian/vegan food, coffee, or other stuff this evening. Let me know!
+
+
Friday
+
+
In the morning & early afternoon I’ll be exploring NOLA and the convention center.
Making a Sandstorm instance is kind of pie-in-the-sky as a goal for me at the moment, but I can definitely put the notes on my blog at minimum. If you’re interested in helping with a Sandstorm instance for library workers, let’s talk! ↩
This post was prompted by a few things I saw on Mastodon and Twitter, plus having wanted to write something during LIS Mental Health Week for a few years now. I started drafting it as a short thread that brought in the social model of disability as a response to @chaotic_kat’s thread, then things sort of snowballed, and here we are!
+
+
There’s a good chance I’ll tweak this post further, but I want to share it before the last day of this year’s LIS Mental Health Week.
+
+
Some of our mental starting points include:
+
+
A.:
+
I saw the best minds of my generation destroyed by austerity
In case that “Howl” allusion and the one in this post’s title don’t leap out at you, you might want to take the time to read it and its related “footnote” poem. Ideally read them aloud, as incandescently or woefully as you’d like.
+
+
B.:
+
Hey #ADHD#neurodiversesquad - I want to talk about how stigma, lack of education & support, and toxic masculinity has affected the the ADHD men in my life.
I was diagnosed with ADHD by third or fourth grade, i.e. the later 1980s—and a bunch of that thread rings true for me. The bits that resonate most are years of hiding my diagnosis, avoiding meds/accommodations, later repeated bouts of shame/anxiety/depression, struggling to maintain friendships, etc. A lot of those negative things have been far worse for my cousins—and I believe my parents were a crucial difference in our experiences of all this because they gave me an early understanding of the social model of disability.
+
+
C.:
+Meredith Wolfwater’s piece about a toxic workplace and how she’s worked to change herself since leaving it.
+
+
Meredith’s post reminds me a lot of the grad program I was in before taking the route of librarianship. I’m still not ready to write about my experiences in that program in much depth—basically, it was fantastic, right up until it was the opposite. For now, it’ll suffice to say that I’m not particularly good at reading internal politics—and that I was particularly unprepared to navigate having a couple of “advisors” who never gave advice about my project or substantive feedback on the contents of my project, only reminders that time was passing.
+
+
Social Model of Disability
+
+
When I said above that my parents helped mitigate the negative aspects of unmedicated ADHD, I mean that I 💯 lucked out by having special ed & d/Deaf educators as parents. The social model of disability influenced a lot of our talks, their emotional support, their “hey, let’s see if this technique helps” encouragement, etc.
+
+
Although I don’t remember my parents using the phrase “the social model of disability,” they often talked about how deafness, blindness, and other perceptual impairments are not inherently barriers in and of themselves. Instead, these impairments become “disabilities” due to way we’ve built social and material structures without accounting & preparing for these differences. The social and material exclusion people with impairments face becomes physical and social oppression.
+
+
Growing up around schools for the Deaf and Blind also meant that I was constantly around children and adults with very different abilities and ways of interacting than my own, getting to partake in their joy at dances and basketball games, where sound pressure and bass & drum vibrations helped everyone keep time or rally in support of their teams.
+
+
Bringing this back around to @chaotic_kat’s thread on toxic masculinity and what parents can do to help support children they expect to be neurodivergent, I believe my early internalization of the social model of disability profoundly lessened how much power ADHD stigma has had over my mental health. It meant that I never bought in to the notion that just “trying harder” was an adequate or appropriate answer to things. I recognized that I was different, even if the 1980s & 1990s discourse around ADHD didn’t understand the broader range of how my differences would manifest.
+
+
It is what also primed me to see the structural/social aspects of toxic masculinity by early high school. Reading Fugazi lyrics, riot grrrl, Sassy & Dirt magazines, having a group of weirdo friends, etc also didn’t hurt, of course—and I also didn’t have those words for it yet. But between my own dad’s example of kindness and the cultural questioning of “tough guy” poses (“your bulldog front”), it was increasingly clear that there are many ways of being a guy in the world—although many of the commons ways of doing so are toxic to others and oneself.
+
+
This social model made it way easier for me to get how race, gender, sexuality, class, etc often are linked to material structures of oppression, not just simple “differences” without consequences or histories. Knowing that model isn’t sufficient, of course. And I now know first hand that it’s nowhere the same as actually taking meds, getting accommodations, etc. But knowing and internalizing that model leads more rapidly to solidarity, to coalitional thinking, to working to make more accessible websites, conferences, classrooms, workplaces, etc.
+
+
Sadly, the social model alone doesn’t overcome my deep Gen X knowledge that every institution—even & especially ones you love, like that grad program—will betray you, that any disclosure or first-hand advocacy can nudge that betrayal machinery into motion if it hasn’t already started.
+
+
But “ah, Carl, while you are not safe I am not safe”—so I need to be louder about my experiences, my joys, frustrations, and ways of being in the world, since that kind of coalition building across differences and identities is what will help dismantle the structures of oppression that continue diminishing and hurting neurodivergent folks, folks with mental health issues, folks from communities with racial, ethnic, or sexual identities that have been historically oppressed, etc. Collectively creating new identities like “neurodiverse” is one way of negotiating and advocating for justice, both for ourselves & for others. This kind of coalitional work is indeed how we get free.
+
+
Poetry & Other Infrastructures of Support
+
+
Riverside Underground Poetry Organization in many ways got me through the depression of not being in school after undergrad, then through the anxiety of being back in grad school. An all ages open mic held in the basement of a coffeeshop owned by Darren (a gay Black man, whom I had the pleasure of interviewing for my high school newspaper the summer he opened the place), it’s one of the more radically inclusive communities I’ve been part of—even though I now realize the problems posed by the lack of physical accessibility to this kind of basement event.
+
+
The open mics offered an infrastructure for questioning society’s expectations and boundaries, a platform for performing multiple facets of your being in the span of three pieces or 10 minutes, whichever came first. That community carried me and others through quite a few years of ups and downs, heartbreaks and breakdowns and elations and achievements. I didn’t realize how much the loss of that community would affect me when I followed a professor’s recommendation to uproot myself and move across the country for a different program—I figured that something akin to that simply must exist in other towns, since Southern California dumps on Riverside and the greater Inland Empire constantly for being a cultural backwater.
+
+
Fred Moten & Stefano Harney write a lot about study in their book The Undercommons: Fugitive Planning and Black Study. I’ll readily admit that I’m still figuring out what they mean by study, by debt, and by many of the other terms in that book. But to the extent I feel I understand “study” as a mode of collective questioning and relating to others outside of individuating institutions like academia, those open mic nights and the group of us who milled about and asked questions, shared drinks and embraces and tears and pitched in for gas and for rent, who carried each other through hard times and cheered at each others’ achievements and performances… that’s a model for questioning our current world and finding ways toward a better one.
+
+
This post doesn’t have a tidy conclusion—and I’m not sure it should.
+
+
I’m mostly just giving thanks and expressing solidarity with the #NeurodiverseSquad folks, with the LIS Mental Health Week people, with #critlib, and with the other online communities I learn from constantly. Although we’re distributed across the internet instead of sitting on the ground in a basement, these communities have become part of who I think with and for, who provide me much-needed models for subverting the status quo, for opening up new mental, physical, social, and technical spaces of possibility.
It’s pretty clear that my weekly assemblage posts aren’t particularly sustainable, at least at the moment. All the same, I want to get back to regular posts. With these I aim at boosting—sometimes also critiquing—things that I appreciate.
I’m really good at reading and engaging widely—but I’m not as great at keeping notes or forcing myself to reflect. So I’ll experiment with the exact way I’ll annotate or respond to what I mention in these.
+
+
I’m planning to start a post at the beginning of each month, then edit it throughout the month. So each will be a monthly log, pretty much, of stuff I want to amplify.
+
+
Is That It?
+
+
As I’m writing this introduction to these posts, I’m also working on putting together my dissertation qualifying exam lists. I’m intrigued by the ethos / approach of working in public, so I’m considering doing some sort of “evergreen notes”—most likely a set of pages that I continually edit as I refine ideas, definitions, connections, bibliographies, etc.
+
+
I’m not sure quite yet how that sort of note will live on my site, but again: we’ll find out!
Organizing Ideas Podcast: Episode 20 with Jessica Schomberg Jessica Schomberg talks about their book, other readings they’ve learned from, how workplace improvements for disabled folks will lead to better workplaces for everyone, about relationships and solidarity in library work. It’s a really engaging listen!
+
+
The Latino Card: Episode — Mask-ulinity Talking about different approaches people are taking to social distancing. Discusses ?Tommy Simmons? article at the Idaho Press, which talks about psychology of adhering to government guidelines. How wearing a mask is a signal to the world that COVID19 is a problem & we need to work together on addressing it. Masculinity and admitting vulnerability.
+
+
The Better Bozo: Episode 6 I wasn’t sure about listening to this whole episode for the first few minutes, since it sounded a little too much like listening in on a sporpsball conversation or general talk radio. But it ended up featuring a fascinating discussion about how privileged white guys can get better at asking themselves “who benefits by me staying silent at this moment?”, as well as how to apply organizing principles to help forward collective liberation. One portion that seems particularly relevant to library work is when the guest, Abraham Lateiner of Freedom Beyond!, mentions that it’s important to be attuned to both the macro and micro levels in a situation, as well as the tension between two poles. (Apparently polarity work is an organizing tool?) The main polarized tension he discusses is between challenge and affirmation.
+
+
He uses the example of how America has praised individual freedoms for so long that it’s become incredibly difficult to champion equitable outcomes. As I’m typing this, I can’t help but wonder what an ALA Office of Intellectual Responsibility would look like, or even an ALA Office of Intellectual Equity.
+
+
Articles
+
+
“Starting Points” by Andrew Cooper was written for the Buddhist Peace Fellowship’s Turning Wheel magazine in 1993, on the second anniversary of the beating of Rodney King. Cooper explains, “The question is not whether or not a community is ‘racist’—the question is how this racism operates.” He also quotes a psychiatrist’s explanation that “in the human realm, the law of survival is not kill or be killed; it is define or be defined.”
+
+
I was living in Riverside and in high school for the King verdict and the uprisings, all of which were very much huge local news. Witnessing such a wanton failure of the legal system to produce justice profoundly influenced my understanding of our legal, social, economic, representational, and other systems. This article encapsulates a lot about those systems into surprisingly few words. As we still seek to improve upon these current systems, it’s an article well worth your time.
2020 has not been a kind year. This last month has been hectic and at times very overwhelming. Here’s some of what has worked to keep my spirits up.
+
+
Mindfulness
+
+
I’ve been trying to get back into mindfulness & meditation practices, since I’d like to more skillfully recognize when my mind or emotions wander to realms I’d prefer they not go. It’s also good practice at finding joy in small things, to better recharge and practice the hopefulness necessary to keep doing difficult things.
+
+
I’ve only listened to the first few practices of the Waking Up app by Sam Harris, but it seems like a great fit for anyone interested in mindfulness practices—and particularly anyone of a more analytical bent. Tai chi (offered as P.E. classes at UC Riverside!) was the first way I was able to connect with a mindfulness practice in a sustained way. I think this was largely because the slow physical exercises kept my ADHD tendencies occupied just enough to help me also pay attention to my breath, my sensations, and whatever else entered into my attention. Waking Up is the mindfulness instruction I’ve encountered that’s closest my experience of learning moving mediation though tai chi, largely because of how deftly Harris blends his verbal instructions with periods of silence to help you experience what he presents. I’m not sure yet if a subscription would be right for me, but I definitely recommend trying the first few (free!) days of the app if you’ve been curious about mindfulness. That’s especially true if you’ve tried mindfulness previously but were turned off by some aspects how it was taught. Harris’s approach seems resolutely non-religious and non-spiritual/mystical.
+
+
The Plum Village app, on the other hand, clearly centers mindfulness practices in the engaged Buddhist approach of Thích Nhất Hạnh. The app is entirely free and features guided meditations, other practices, texts, and more from the Plum Village community. If you’ve previously encountered the original version of the app (released back in 2018), the newest versions (up to 2.2 as of mid-August) are greatly expanded and refined. I can’t speculate what it would be like to learn mindfulness or Buddhist practices primarily through this app, but I definitely appreciate what the Plum Village community has made available through it.
+
+
Music
+
+
Love Genius by Sonic D has consistently brought a goofy grin to my face since the first time I heard it. It’s a footwork / bass music version of a Tom Tom Club tune you might recognize through a bunch of songs that sample or remix it—in particular Mariah Carey’s “Fantasy.” You might also dig some of his other stuff, such as what he’s got on Soundcloud or his Math & Science mixes.
+
+
Time Flex is basically a compilation of early releases by John Tejada under the moniker Autodidact. Originally released in 1996 & 1997, these tunes have more of a Warp Records / Polygon Window vibe than Tejada’s later stuff. If you’ve ever wanted something like Polygon Window but with more groove & shuffle, this will be right up your alley.
Blog posts feel to me like they should involve a few paragraphs, and probably shouldn’t happen more than once a day. Maybe just a few a week is what feels right for them on my own site. (This feeling is just for my own writerly headspace, not a feeling about how others should conceive of posts on their sites!) I’m looking for something in between this more considered blog post and a thought I’d put on a microblogging site like Mastodon, and one that will play nicely with RSS, unlike the “meant to be revised continually” notes in my digital garden.
+
+
Therefore, I’m trying out this separate category of posts, for things that can be as off-the-cuff as Jekyll allows, including multiple a day. Let’s see where this takes us!
+
+
I’ve also reflecting on the fact that I’ve added a fair number of things in the notes section since 2020, which is the last time I wrote a blog post—and so to RSS feedss, nothing has happened in that whole time. So I’m thinking I might also start making a new blogpost whenever I add a note, or at least make round-up posts of “these are recently added notes.” Either of these mean that notes will show up in RSS feeds once, but not automatically re-appear with each revision.
+
+
Link Rhizomes
+
+
As I’ve been tinkering with this site this holiday break, I noticed that the links in the sidebar author profile had grown unruly and could stand a very substantial pruning. Alongside this, I’ve also noticed people using Linktree, Link Me, and similar services for sharing “hey! I’m also over here!” in a centralized space.
+
+
So I figured I’d move the trimmed links into a new page, using that “other places I exist online” link page pattern.
+
+
However, I wanted to follow something like the POSSE principle, where I publish (on my) own site and share elsewhere, rather than relying on other services that can easily go the way of the dodo Twitter.
+
+
Putting this together with my fondness of Dave Cormier’s repeated use of rhizome metaphors (as well as uses of that metaphor by other folks, like Deleuze & Guattari), it dawned on me that “rhizome” would be a great name for this pattern.
With a cat snoozing on my lap and less than 10 minutes before I’m supposed to start watching a new-to-me episode of Star Trek: The Next Generation, the thought occurred to me: how quickly could I make a blog post happen?
+
+
Long ago I set up Working Copy on my iPhone. It’s an app that helps you handle a Git repository. If I recall correctly, I set it up as an extra “safety net” for giving presentations using Reveal; I wanted to make sure I had a way to fix typos or other last-minute edits.
+
+
Now I’m instead trying to see whether this app could be repurposed as an POSSE-mindset alternative to Mastodon or other microblogging platforms.
+
+
It’s been 10 minutes! Let’s commit this!
+
+
Edit, After the Episode
+
+
Here’s a Mastodon post I made minutes after publishing the above:
+
+
With more practice, I’m certain I could make this go more quickly. These 10 minutes included trying to figure out what I’d write about, plus re-familiarizing myself with how Working Copy actually works.
+
+
I spent a few minutes looking in Textastic, a text editor app. Instead, it was easiest to:
+
+
make the new file with Working Copy
+
copy and paste the relevant front matter from another post in the same category
+
edit the front matter
+
actually write
+
save and commit
+
+
+
Then I had to wait about 3 to 5 minutes for GitHub to process that commit and turn it into a published page.
+
+
It might sound closer to a Rube Goldberg machine than fully automated queer space blogging, but it’s a workable solution for a mostly-POSSE approach to blogging.
+
+
And I still have the cat snoozing on my lap!
+
+
Summary
+
+
Overall, this seems like a pretty useful alternative to posting longer thoughts on Mastodon or other social media.
+
+
There’s probably an extra 5-ish minutes of work involved.
+
+
This 5 minutes of labor (not 5 “real-time” minutes) includes:
+
+
+
set-up (generating the new file with appropriate lines of YAML)
+
file management (committing and pushing the new file to GitHub),
+
then (after waiting a few minutes outside of these “5-ish” ones for GitHub to process and publish the new file), getting the URL to share in Mastodon and actually sharing it.
+
+
+
So this is clearly somewhat more involved than just posting a routine idea or thread on Mastodon. But it’s a workable alternative!
+
+
Some thoughts (or other purposes) might well be worth that 5-ish minutes of labor. (And yes, for those following closely: even after that episode and all these edits, the cat is still snoozing away on my lap.)
For whatever reason, I’ve been using daily notes in Dendron this week, and it’s been a pleasant and useful addition to my usual practices.
+
+
Although many people who use tools like Dendron or Obsidian seem to prefer working out of daily notes, I do most of my task management out of weekly notes. So what am I doing with these daily notes? They’re a good place to have more of a “journal” instead of a “log,” a place for writing down and processing emotions and thoughts, outside of where I try to mostly work on the things I intend to accomplish each day. My “regular” notes are a sort of log and pomodoro “potential tasks” space, so it feels good to have a separate space for a different sort of processing and to recognize different types of patterns. The two types of notes so far seem quite complementary.
+
+
Weekly Notes in Dendron as Well
+
+
Why do I tend to use weekly notes? This is probably partially a holdover from when I started using linked text files for this sort of thing, and tools for linking notes weren’t as robust as they have become.
+
+
It’s probably also because I tend to have regular weekly meetings, so from a “pattern management” perspective, it seems easier to create a single weekly template and then update it than it would be to make 7 different templates. It’s also simpler to carry tasks over when you can select and move a few lines in a text editor, rather than having to have multiple notes open.
+
+
The downside is of this approach is that it’s easier to lose track of when you first intended to do a task, and find that you’ve been carrying a task over longer than you’d like.
+
+
Patterning
+
+
Writing about daily & weekly note patterns recalls the discussion in Purdon’s Modernist Informatics of information patterns and documentary/information film production. It’s a really generative book, and I’d certainly recommend it to anyone interested in what I’m starting to call “information humanities” when thinking about my dissertation project!
+
+
Information Humanities
+
+
Here “information humanities” would overlap with “critical information studies” as outlined by Said Vaidyanathan as well as journals like the Journal of Critical Library and Information Studies. Its interdisciplinary approach would slightly emphasize humanistic methods, such as attention to specifics of form and representation. It would allow greater emphasis on questions of how we make meaning, adopting epistemological and rhetorical analyses as well as historically-situated inquiry. It would also invite recognition of how artists and curators have been some of the most critical among GLAM practitioners, taking note of practices like Fred Wilson’s Mining the Museum, the work of folks like James Luna or Coco Fusco, and institutional critique more generally.
+
+
As “critical” ideally has become a core aspect of “humanities” at this point, it seems like “information humanities” would be mostly equivalent to “critical information humanities.” It also echoes “digital humanities,” for better or worse.
+
+
This terminology is something I’m realizing I’d love feedback on!
+
+
Digital Garden Updates
+
+
I also updated my Daybreak theme note this week, specifically mentioning how I’ve made the scrollbar more visible by adding more color contrast.
In many ways, this week has felt like a bundle of sidequests, with little obvious at the end. But hey, some weeks are like that. I ended up spending a lot of time doing spring cleaning of my task notes.
+
+
FOSS and Crafts Podcasts
+
+
For the first time in weeks—possibly months?—I found the urge to listen to podcasts. I used to listen to lots of podcasts while commuting, but now I mostly do so only while doing chores or riding my stationary bike. I skimmed through the episodes I’d noted as ones I wanted to hear, and quickly chose to listen to an episode of FOSS and Crafts… and I’m very glad I did!
+
+
Episode 23: “Get Organized!” really spoke to me in terms of recounting the many ways that neurotypical planning practices utterly fail ADHD minds. I also appreciate the reminder about using a HipsterPDA1, as well as the enthusiasm about Org-mode in Emacs.
+
+
This led to me listening to Episode 41: “Learning Emacs” just a day or two later. I’m very happy using VS Code, as my VS Code notes should make clear. However, I’ve often hear Org-mode spoken of as the ultimate final form of outlining and task management in plain text files—a sentiment decidedly reinforced by this episode!
+
+
So I ended up spending a few hours on Saturday afternoon thinking through the irritations I find with my current note setup—the main one being that I don’t have the fully automagical agenda I’ve heard Org-mode can offer. But after doing more digging, and considering how much yak shaving might go into fully switching from Dendron, I’m instead just going to try to lean harder into practicing the task management strategies I have, and see if they’ll suffice when done more consistently.
+
+
A Question of Tasks
+
+
I’m not going to take the time right now to fully write up my current task-wrangling practices in another note. But in brief, I’m using Todo Tree and Dendron’s Task Notes with a particular hierarchy.
+
+
The main “innovation” here is that I’ve made placeholder task-viewing notes with wildcards in the paths. When I use Dendron’s preview on one of these, I can see all notes whose path matches specific patterns. I’m using tp as a hierarchy for any open tasks in a project, and ta for task archive in a project.
+
+
Provided I’m following those patterns in making notes, this means I can have a note whose body text consists entirely of ![[diss.**.tp.**]]. Then, when I use Dendron’s preview on this, I’ll see links to any notes in my dissertation (“diss”) set of notes that have a parent note named tp.
+
+
I can do the same for other hierarchies of notes, too: a ![[work.**.tp.**]] and ![[home.**.tp.**]] file would let me see matching notes for those domains.
+
+
So I’m currently using that set up to track and differentiate tasks, to keep from being overwhelmed. The main question still is how to tag things for urgency and findability, without being dispirited by how many things I also could be doing. This trap of overwhelming Future Me is what has driven me away from my past approaches, like OmniFocus, Tasks, Taskpaper, etc.
+
+
Here’s hoping that by using Todo Tree’s tags for just my most important and rewarding tasks, then tracking the rest with those wildcard-viewing notes, I’ll get the balance right.2 I’ll be sure to write more extensive notes on the process, if this experiment pans out well.
+
+
+
+
+
It’s just a bunch of notecards held together with a binderclip. That’s it, that’s the thing. ↩
+
+
+
I guess I could have woven only a single Depeche Mode allusion in here, but I just can’t get enough. ↩
The last couple of weeks I’ve been helping some faculty members create more accessible data tables. That kind of repetitive structure is a great candidate for a code snippet—so I made a few!
+
+
Here’s the surprisingly long VS Code Snippets note I just wrote explaining how I use snippets, and annotating a few examples I think others might find useful.
+
+
Auroras Unseen
+
+
There were notable aurora in the sky one night this week, but our local conditions were drizzly or overcast, with a side helping of snow flurries.
+
+
However, we’ve got a new plan in place for the next time the conditions are favorable! Last time we tried to see them, we drove out to Bruneau Dunes State Park, which is lovely for seeing the night sky. However, for aurora, we’d probably want to head north of Boise, so now we’ve got an updated destination in mind that won’t take nearly as much driving time.
+
+
Executive Function as a Public Good
+
+
As I wrote on Mastodon, I recently found out that our local Ridge to Rivers trail system has started posting QR codes that link to an interactive trail map.
+
+
+
+
+
I’d found myself out exploring and absentmindedly had the impulse “let’s go up,” even though if I’d taken a second to consider, I’d have realized that our drizzle and snow flurries had been perfect weather for muddy trails.
+
+
So I appreciated how bluntly this sign reminded me to check the trail conditions, before accidentally contributing to the gouges, ruts, and other damage the trails have suffered in recent years. I certainly don’t want to have those guilty feet I’ve heard described in song!
Wow! This month has kept me busy—so much that I haven’t been updating this weekly.
+
+
VS Code Snippets and Spellcheck Customizations
+
+
At the beginning of the month, I made a couple of new notes.
+
+
One explains some snippets I often use, both in VS Code and other places. Right now, as I started writing this, I also made a new one for the Jekyll frontmatter for these Weekly Assemblage notes. Hopefully being able to create 17 lines of code just by typing out ;wa will help me write these more regularly! (Or maybe I’ll switch to doing monthly updates?)
As I’ve been (perpetually) trying to refine my text-based system for keeping track of tasks and projects, I’m realizing yet again that one missing component is rewarding myself and designing patterns that increase motivation.
+
+
I’m going to revisit Sri Seah’s Productivity Tools and see what elements I might glean from them, as well as figure out what’s the minimum viable use of pomodoros that will help me feel like I’m moving forward when the work I’m involved with can take weeks or months.
Today—the day after I finished up a “16 weeks condensed into 4” Spanish class—I happened to read some folks on Mastodon talking about light themes on websites.
+
+
I’ve been wanting to add one to my site for years, my brain apparently wanted a project I could reasonably accomplish make noticeable progress toward within a day, and I vaguely remembered having seen other Minimal Mistakes theme users discussing how to implement this.
+
+
Thus far today I’ve managed to have my Jekyll-based site correctly generate two different themes: the dark one I’ve been using for years and another light one that’s basically the default theme with a couple of colors switched out. That’s a success!
+
+
Currently this site defaults to my regular dark theme, but will serve a light theme if it sense that you have “prefers light mode” set in your browser or operating system.
+
+
Today’s work also lays the foundation for adding a toggle. That’s successfully building toward a future success!
+
+
There are going to be some surprises along the way to a fully-featured light mode, such as noticing and also fixing the fact that the Bigfoot pop-up colors aren’t really legible at the moment. I’ll need to figure out how many of these things I can avoid hard-coding in the future. But it’s nice to finally work on it, even if doing so was somewhat of a surprise today.
+
+
Update
+
+
As of 2023-10-12, I’ve mostly fixed the things I had noticed with the theme. (They were inaccessible text and background colors related to footnotes and notices.)
+
+
My next ambitious stretch goal will be to make a few user-selectable themes, like Sarah L. Fossheim has done on their site. I’m also considering a move from Bigfoot to Littlefoot for the fancy pop-up footnotes.
As I recently mentioned on Mastodon, I’m going to try doing Academic Writing Month (aka “AcWriMo”; a fellow traveler of National Novel Writing Month, or “NaNoWriMo”) this year. Here I’m detailing my approach—I’ll likely also update this with my progress throughout the experiment.
+
+
La Lucha Continúa
+
+
My most consistent writing challenge has always been that writing anything longer than a blog post involves a noticeable state shift. I move—sometimes with effort, sometimes all-too-effortlessly—from mild-mannered riotnrrrd mode to superhuman hyperfocus mode, and occasionally veer into full-on ADHD lasereyes goblin mode.
+
+
This routinely produces good class & conference papers, but isn’t exactly compatible with what one might call responsible adulting.
+
+
So the crux of my dilemma: how to flip my brain into writing mode in sustainable ways that are in fact compatible with responsible adulting?
+
+
AcWriMo2023 Piece
+
+
Here are this year’s AcWriMo experiment parameters, written up somewhat as a Fluxus piece:
+
+
+
Aspire to get into the “writing headspace” for 30 minutes to an hour every other day, i.e. Mon or Tue, Wed or Thu, Fri or Sat., through November 2023.
+
Track the attempts. Probably share the progress & results.
+
“Writing headspace” here ≅ “successfully opened up my writing app and/or successfully annotated readings in one of my two reading apps.”
+
+
+
As you can see, this is taking a process-based approach, not a product-based one. The aim is to see how much I can make a habit of writing in rally mode (i.e. sustained movement) rather than sprinting mode.
+
+
To provide more structure and internal support, I’ve made myself a set of tasks, using Obsidian’s Tasks plugin. Whatever stands a good chance of supporting beneficial progress, right?
+
+
Obsidian & Tasks Details
+
+
+
+
+
While I haven’t yet written a post or note about the Tasks plugin specifically, it’s essentially what has drawn me from Dendron to Obsidian. [Update on 2023-11-29: I now have written about [[obsidian tasks plugin patterns
+
how I currently use the Tasks plugin]]. I don’t repeat much of what’s below in that other note, so reading both might be worth your while if you’re interested in that aspect of Obsidian.]
+
+
+
+
+
So here I’ll detail how I’m using Tasks to help out with AcWriMo2023, in case you’re the sort of person who appreciates worked examples. If you’re also an Obsidian user, maybe it’ll be a useful example of how you might approach projects & to-dos, using the Tasks plugin?
+
+
Here’s a link to the project tracking file I’ve made for this month’s challenge. Please adapt it to your own use as you’d like! (Here’s a link direct to the file’s raw view, if you just want to copy & paste it from your browser without seeing all the GitHub interface.)
+
+
A few important use/configuration notes:
+
+
I use #tt as a global filter for Tasks. This tells the plugin not to track every single line that starts with a - [ ] checkbox, but only pay attention to the ones that start with - [ ] #tt. I’ll explain my reasons further in that eventual note, but for now, you’ll likely want to find & delete all of those tags, or find & replace them all with your own global filter if you use one.
+
I have #td/writing as an additional tag on each of these tasks. Using this sort of tag lets me use #td as a tag for all my “todo” tasks, then use the /whatever content to create subsets to display anywhere I want to have a Tasks query. Again, I’ll eventually explain this further; for now, I’m just giving any potential users of this a heads up.
+
I’ve also included the due dates for my own purposes. Again, you’ll want to change those for your own scenario. I’m just sharing all this, both to document it for Future Me and to help provide potential structures for anyone else who wants to give AcWriMo a go, last-minute.
+
There’s a Tasks query included in the file, under the Tasks View heading. This will display all the tasks on this very file, putting them in a dynamic pane that lets you change dates and interact with things more handily than you can with the Markdown / text view alone.
+
I feel like way too many people approach Obsidian as though there’s a single “correct way” to use it for tasks or projects. If you’ve read this far—and especially if you’re actually considering using my file—please approach it just as a springboard for your own experimentation. What I think might work for me, right now, isn’t guaranteed to work for me—let alone for you! I’d love it if you let me know that you found it handy or inspiring, of course.
As I’ve mentioned a few times, I began using Obsidian earlier this year. Ultimately, the Tasks plugin was what convinced me to adopt it, despite my fondness for Dendron and my general hesitations/frustrations about Obsidian.
+
+
It took quite a bit of delving into the Obsidian Discord forums and subsequent experimentation to figure out some of the queries and filters that best suit my brain.
+
+
If you’re considering using a Markdown-related tool for tracking tasks, you might take a look at my note on the Obsidian Tasks plugin patterns I’ve found most useful.
For those of us who work in the humanities and social sciences, it’s common for sources to have been published in multiple versions. But Zotero only has a single date field! Great Scott! How do we deal with the complexities of time?
+
+
For instance, how would one indicate that Samuel Delany’s Nova was initially published in 1968, even though the edition we’re referencing was published in 2002?
+
+
Here’s where Zotero’s Extra field comes in handy! I’ve just added a new [[Zotero Advanced Features]] note where I explain how to do this. I’ll continue adding to that note as I learn to do additional less-than-obvious things with Zotero.
I probably should start calling these something more like “Aperiodic Notes,” shouldn’t I? I average less than ten “weekly” ones most years! The “weekly” conceit remains a useful structure and mental boundary for when I do try a brief recap, however, so I’ll keep the name for now.
+
+
Rua Williams’ “Writing with Executive Dysfunction” Webinar
+
+
It was a pleasure participating in Rua Williams’ Writing with Executive Dysfunction collaborative session. They began by outlining a few approaches that work for them, and then we participants all began collaboratively writing a writing guide with our own tips and approaches. Through, Rua emphasized that what works for neurodivergent folks will be different than what works for neurotypical folks, and that it’s likely not healthy to hold ourselves up to the expectations we’ve learned from neurotypicals.
+
+
I really appreciate what Rua calls a “fractal scaffold,” which they emphasize is not a rule for writing, just an approach that can be applied at any level of a text. (In fact, I’ll probably make a separate note about this approach in my Digital Garden before long.)
+
+
Here are the elements of the fractal scaffold:
+ - Premise: main point or thesis.
+ - Context: prior work or background.
+ - can look like “for example…” or “other people have said”;
+ - in literature, can be reminders of previous events in the text.
+ - Substantiate: corroboration, support, or illustration of the premise.
+ - can look like an explanation of the method of inquiry analysis, analysis, or argument.
+ - Acknowledge: note complicating contexts, limitations, counterarguments, contested factors, or controversies.
+ - Reaffirm: justify and restate your own premise or approach.
+ - Point the way: transitions, foreshadowing, sign-posting, summarizing.
+ - pointing doesn’t have to be linear! it can involve pointing or calling back to previous things as well.
+
+
As of today (2023-12-10), the video on YouTube has a corrected transcript, and the writing guide will be linked from YouTube once it’s in a refined state. This session was part of their “Neurodivergent Burnout” series, which is in part a fundraiser for their friend Jonmeshia. Maybe consider donating or spreading the word, if you can?
+
+
Rua Wiliams has a number of other resources available at Fractal Seeds on Substack, and apparently tends to use “fractalseeds” as a user name on most social media.
+
+
WorkingOnIt, a group on Mastodon
+
+
Sustaining motivation and perceiving one’s progress are some perpetual difficulties involved in doing basically anything that happens over a long period of time. So I’m very appreciative of WorkingOnIt, a group on Mastodon where people can update each other about what they’re working toward. In case you’re curious, this group is the brainchild of Erin Kissane, whose work is well worth your time.
+
+
People check in periodically on how their language learning or other aspirations are going. I’m using it as a sort of minimal version of accountability buddies or AcWriMo, and giving occasional updates on how re-learning Spanish is going and my work toward my Qualifying Exams.
+
+
If you’re also on Mastodon—or considering joining—maybe the WorkingOnIt group will be useful for you? (If you’re considering joining Mastodon, I definitely recommend HCommons.social as your home community, aka “instance.”)
+
+
Links Rhizome styling and other potential changes around here
+
+
Links Rhizome
+
+
I toyed around a little this week with the CSS on my Linktree-inspired Links Rhizome page, with the goal of making both the headings and buttons more prominent.
+
+
If you’ve already got a website of your own, why not emulate that sort of “I exist… here” type of directory, instead of relying on yet another platform?
+
+
Here are the lurid details for my own page, for those who’d like to know: I use the “extra large” buttons already put into my website’s “Minimal Mistakes” theme, and make them expand to fill up the entire column by adding style="display: block;" to each of them. I also override the default font size for each <h2> heading by adding {: style="font-size: 1.7rem;"} using kramdown’s block inline attribute syntax.
+
+
Plausible Analytics
+
+
I’m also trying out Plausible analytics this month. Plausible’s are the most privacy-respecting analytics I’ve seen, and the small script they use was immediately blocked by the uBlock Origin extension I use in Firefox without any extra effort. So it seems like anyone who generally prefers to block this sort of thing will have their preferences respected without any extra effort on their part.
+
+
Although Matomo is an option on my website host (Reclaim Hosting), I’m not really interested in the level of depth that Matomo provides compared to Plausible. It’s nice to know that people are reading posts and notes here, but I certainly don’t need to reference that in-depth data, or use the extra processing and downloading involved in collecting it.
+
+
Giscus Comments
+
+
Along those lines of “it’s nice to know when people visit,” I’m considering bringing some level of comments back. Once upon a yesteryear, I used Staticman comments, but they quickly became overwhelmed with spam rather than messages from actual humans.
+
+
Now I’m thinking I might try Giscus, which uses GitHub Discussions to store the comments. For me, a counterintuitive benefit of this approach is that people will need GitHub accounts to leave comments, which should massively minimize spam. But this requirement also obviously means that any actual human readers who don’t have GitHub accounts won’t be able to comment.
+
+
As it stands right now, of course, no one at all can comment directly on a post, although they can always reach out to me another way if they’d like. Since moderating spam is one of the main thorns in my side as a volunteer editor for an open access online academic journal, I have zero interest in signing up for that on my own site and increasing my propensity toward burnout. But I would love to hear from people about my digital garden notes and the dissertation-related things I plan to start posting in the new year. So at least at the moment, GitHub-based comments seem like the most reasonable, maintainable compromise on my end.
When I first got a smartphone so many years ago, I was excited mostly about having a device that could help with some of my ADHD issues; basically the same “keeping track of ideas and intentions” things I’d used a day planner or bullet journal for previously. I’d seen people with PDAs and thought “wow, those could be useful!”
+
+
Now it’s odd to have a global communicator in my pocket and constantly be drawn to the immediacy of that kind of communication. I’m sitting in a parking lot at the moment and was just checking in on folks I know on Mastodon and on Discord, who live not only in different states or countries but entirely different continents. It’s kind of mind blowing how mundane that feels.
+
+
I’d like to attempt writing more frequently in these little liminal/interstitial moments, rather than going directly to social media. That’s part of why I’m using Obsidian now, for instance, and why I’ve made a Digital Garden that I can always prune or refine. I’m also interested in seeing what beneficial friction I encounter when writing for Jekyll here from my phone. It’s harder to make sure that wikilinks are going to the correct file and to use UTC time codes. I’ll probably want to make some keyboard shortcuts for the patterns I often use but don’t have committed character-by-character to memory.
+
+
(Edit after I got home: Yep, still need to refine this process. Something about the time I initially specified in the post frontmattwr seems to have kept it from publishing. Most likely I did the time zone conversion incorrectly. I’ve just made a snippet in TextEditor, a snippets that works in my preferred iOS code editor, Textastic. I guess alternately I could just comment out the date field?)
This past week was the last official week of 2023 Fall Semester, and I took my final exam for Spanish 2202. It’s been a lot of fun re-learning Spanish, and I’m glad I’ve got another semester of it in 2024 Spring!
+
+
I initially learned Spanish from middle school through junior year of high school, then promptly took a year of French from Monsieur Gutekunst (whose Alsace-Lorraine accent didn’t exactly prepare me for spoken French elsewhere). Then in undergrad I did Latin, and for my English grad program at UC Riverside, I did French for reading purposes.
+
+
So by the time I began re-learning Spanish, I’ve gotten a lot of familiarity with Romance languages and cognates, but also completely lost my memory for any verb tenses beyond the present. It’ll be interesting to see how much I can keep this time around, after next semester ends.
+
+
Enjoying Lee’s Overwhelmed
+
+
I’m really enjoying my reading of Maurice S. Lee’s [[Overwhelmed: Literature, Aesthetics, and the Nineteenth-Century Information Revolution]].
+
+
The introduction offers a very useful summary of information studies—one that I think would be useful not only for Lee’s intended humanities audience but also for LIS students, professors, and anyone else who thinks about what counts as “information.”
+
+
Toxic Positivism, Petro-Masculinity, and Reply Guys
+
+
The term “reply guy” simultaneously is incredibly useful shorthand and extremely amorphous. It points to some particularly gendered behaviors, but it also ambiguously points to something like “posting while… guy.” In other words, it’s a term that makes perfect sense in context (here, particular social media platforms) but can benefit from further elaboration.
+
+
I might eventually try to elaborate on this, but I think we might use “toxic positivism” as one aspect of what’s happening with reply guy behavior.
Thankfully, many people have written useful guides to getting started with the community-run social media network called Mastodon. Instead of writing up my own, I’m curating a short list of the most useful ones I find over at my [[Mastodon starting points]] note.
+
+
Most of these guides will be aimed at people in higher education trying to find similar folks, rather than users more broadly.
You might think of this as a Weekly Assemblage for 2023 Weeks 51 & 52. You’re also very welcome to hear Pearl Jam’s “rearviewmirror” in your head as you read this.
This was my first full calendar year working as an instructional designer, rather than as a (mostly instruction) librarian. I’ve enjoyed the shift even more than I anticipated.
+
+
Being able to take a “user-centered” perspective goes a long way in each position. One thing I’ve carried over from my library instruction is to highlight repeated patterns and ways of knowing, aiming for transparency and clarity about what you’re doing and why.
+
+
What I didn’t expect was how much more frequently I’d do project management-type functions. Aspects of this come naturally to me, like brainstorming, or recognizing which aspects of something reinforce or distract from the main ideas. Other aspects, like working on a “rally mode” rather than a “sprint mode” and providing supplemental executive function for other people, don’t come so naturally.
+
+
So that’s a major thing I’m aiming to work on in the next year: developing patterns that help me reinforce my intentions and ways of working.
+
+
Website Changes and Experiments
+
+
This year I’ve made a few changes, updates, and experiments here on my site. I’m proud of the outcome of all this tinkering and pattern-examination, so here’s a quick review! (The next section has more abstract reflection, so skip there if website nerdery isn’t yr jam—but the reflection does build off what’s in this section.)
+
+
I’ve recently added a bookmarks page, inspired by what I’ve seen other people do with services like Raindrop. I ended up lifting & adapting Franck Chester’s code to give my bookmarks workable tags that are separate from Jekyll’s built-in tags for posts. I’ll probably continue refining the Liquid code, since I don’t think the current method is the most elegant or efficient way of doing it… but it is effective—and for now, that’s the important thing! I’ve also just updated the layouts to include the IndieWeb Bookmark markup, as well as make better use of Minimal Mistake’s Post Link format.
+
+
Just yesterday, I also adapted Maxime Vaillancourt’s bidirectional links generator plugin. Now when I use a [[backlink]] in posts on my site to refer to a note, it will make a workable link and also show up in the “Other places I mention this note” section (which I also just reworded to reflect this change).
+
+
This last month I’ve also been experimenting with backcombingPlausible analytics. I think I’ll use Plausible in lieu of self-hosting Matomo, the other option I’d been considering. Plausible at least claims to be lighter weight and more privacy-respecting than Motomo, so if I’m going to use analytics at all, it feels like a better choice. I might end up trying to self-host Plausible somewhere (like Hugh Rundle does)—but for now, after learning how much more it would cost to self-host it with my current host rather than use Plausible themselves, I’ll pay Plausible for the service (as well as supporting the tool and having them do the labor).
+
+
As of this week, I’m also experimenting with Giscus-based comments. I used to use Staticman, but eventually got so annoyed by the continual spam that I removed comments entirely. I’m not entirely thrilled by a commenting system that requires commenters to have a GitHub account, but that’s a tradeoff that makes sense for something entirely optional. As much as I love the idea of using webmentions or using Mastodon-based commenting, I can’t wrap my head around how I’d handle spam with those. (The amount of spam—and occasional very ugly abuse—I see through a certain Wordpress site has made me decidedly jaded when it comes to comments sections.) An open question is whether or not I’ll add comments to the notes in my digital garden… but before jumping into that, I’m going to see how it goes with comments on the posts in my blog. I’m slowly learning to take website tinkering bird by bird yak by yak.
+
+
I also added my reading page and have mostly kept it updated, taking a more POSSE approach than using Goodreads or even Bookwyrm. As much as I love the idea of Bookwyrm, I’m more interested in doing something closer to Mandy Brown’s A Working Library by adding book notes and annotations to my blog, my notes pages, or something else along those lines. (I still want to figure out how her site creates the “related reading” and “related writing” sections.)
+
+
I’ve similarly been refining the styling of my links rhizome page a bit throughout the year, after initially adding it in the last week of 2022. It’s nice to have something functionally similar to a LinkTree page, but entirely my own. (If I had all the time in the world, creating a LinkTree-style theme for GitHub Pages seems like it would be a great way to introduce people to creating static sites.)
+
+
Patterning for Motivation
+
+
Looking back on all these additions to my site has me thinking about not just the patterns of how the files and code fit together, but also the patterns of how days and weeks fit together to encourage or hinder things I aspire to do.
+
+
When I’m someone who’s often motivated by the give-and-take of conversation, discussion, and experimentation, how do I channel that impulse away from the short bursts of social media interaction and toward less-immediate but more substantive patterns for motivation?
+
+
I’m thinking both of tools, like those made by DSri Seah, as well as intentional communities, like those on Mastodon or Discord, or the audiences of things like Rua Williams’ Neurodivergent Burnout Series. What other communities, patterns, and interactions can we co-create? What can I do to make them more likely?
+
+
I expect I’m going to keep casting about for better patterns into the new year, and probably well beyond. But it’s good to clarify that these sorts of interaction and motivation are a large part of my aspiration with this site, even as adding comments feels somehow both “too small” and “more likely to invite spam than substance.”
+
+
Consider this an open invitation to reach out—through a comment here, on Mastodon, in Discussions, etc.—if you’ve got ideas to share, if you’re looking for something like a dissertation writing group, or etc.
Professors’ anxieties around AI tend to cut at the emotional core of teaching.
+
There’s a distinct worry that students might circumvent the learning process we try to offer, which produces anxieties of being undermined/cheated in disciplinary, interpersonal, and emotional senses.
+
Professors might have students engage the AI in a dialogue. The assessment might be something close to a Socratic rhetorical dialog, rather than a more customary essay final product.
+
Using AI highlights nuances of language when prompting, with the output often shifting noticeably based on the specific terms and grammar used.
+
Asking students what they meant with particular words or concepts remains one of the best ways of knowing whether they’ve used generative AI inappropriately—an approach that’s likely the best outside of AI concerns as well.
+
+
+
+
+
+
Although I have far less direct experience with uses of AI than these professors, I’ve felt for a while that one of the best responses instructors can take will be to repeatedly emphasize and reinforce disciplinary ways of knowing. This can help highlight that disciplines aren’t static bodies of content in what [[freire and critical librarianship
+
Paulo Freire would call a “banking model” of education]]. Instead, it might help professors hew to a more Cultural Studies-style view of disciplines as “ways of making meaning.” AI might also let students who aren’t already familiar with a discipline’s or genre’s ways of knowing and communicating, or who otherwise aren’t yet well-disposed to generate their own ideas, feel less anxiety in the brainstorming / pre-writing stages. If instructors allow students to transparently and critically engage with generative AI for pre-writing, these less-familiar students could potentially find the desired disciplinary ways of knowing more approachable.
+
+
+
+
+
Therefore, it was very heartening to hear Ernst and Hicks share similar ideas about what AI might make more perceptible and engaging for students, if instructors move from an anxious “students will cheat” model to “how can we engage meaningfully with AI-informed processes?” approach.
+
+
Home Page Changes
+
+
I realized recently that my website’s home page presents the reader with a huge wall of text. So instead, I’m currently going with greatly trimmed-down introduction (with the former moved to my About page), plus a few buttons that hopefully invite readers to explore my site. I’ve also trimmed down my top navigation menu a bit.
+
+
While it’s certainly an improvement, I fully expect that this isn’t even my home pages final form!
+
+
Gearing Up for 2024 Spring Semester
+
+
Our Spring semester starts tomorrow, and I’ll be taking fourth-semester Spanish. I’m still quite excited to be refreshing my abilities with Spanish, which have definitely been clouded by the other languages (French and Latin) I’ve studied since learning Spanish in middle school and high school.
+
+
I’m not sure if I’m quite ready to start reading academic theory originally written in Spanish, but I’m looking forward to that potential!
+
+
For now, I’m just enjoying occasionally dipping into Netflix’s show Pasteleros contra el tiempo, a Mexican variant of Sugar Rush.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git a/_sass/minimal-mistakes.scss b/_sass/minimal-mistakes.scss
new file mode 100755
index 00000000..0ba5c2f5
--- /dev/null
+++ b/_sass/minimal-mistakes.scss
@@ -0,0 +1,50 @@
+/*!
+ * Minimal Mistakes Jekyll Theme 4.17.2 by Michael Rose
+ * Copyright 2013-2019 Michael Rose - mademistakes.com | @mmistakes
+ * Licensed under MIT (https://github.com/mmistakes/minimal-mistakes/blob/master/LICENSE)
+*/
+
+/* Variables */
+@import "minimal-mistakes/variables";
+
+/* Mixins and functions */
+@import "minimal-mistakes/vendor/breakpoint/breakpoint";
+@include breakpoint-set("to ems", true);
+@import "minimal-mistakes/vendor/magnific-popup/magnific-popup"; // Magnific Popup
+@import "minimal-mistakes/vendor/susy/susy";
+@import "minimal-mistakes/mixins";
+
+/* Core CSS */
+@import "minimal-mistakes/reset";
+@import "minimal-mistakes/base";
+@import "minimal-mistakes/forms";
+@import "minimal-mistakes/tables";
+@import "minimal-mistakes/animations";
+
+/* Components */
+@import "minimal-mistakes/buttons";
+@import "minimal-mistakes/notices";
+@import "minimal-mistakes/masthead";
+@import "minimal-mistakes/navigation";
+@import "minimal-mistakes/footer";
+@import "minimal-mistakes/search";
+@import "minimal-mistakes/syntax";
+
+/* Utility classes */
+@import "minimal-mistakes/utilities";
+
+/* Layout specific */
+@import "minimal-mistakes/page";
+@import "minimal-mistakes/archive";
+@import "minimal-mistakes/sidebar";
+@import "minimal-mistakes/print";
+
+/* My additions */
+
+.pagination li a.disabled {
+ color: mix(#fff, $text-color, 25% /* 20% */); /* rgba(241,241,241,0.8); */
+}
+
+.sidebar {
+ opacity: 1;
+}
\ No newline at end of file
diff --git a/_sass/vendor/bigfoot/bigfoot-mixins.scss b/_sass/vendor/bigfoot/bigfoot-mixins.scss
new file mode 100644
index 00000000..60bda6dd
--- /dev/null
+++ b/_sass/vendor/bigfoot/bigfoot-mixins.scss
@@ -0,0 +1,27 @@
+// ___ ___ ___ ___
+// /__/\ ___ /__/| ___ /__/\ / /\
+// | |::\ / /\ | |:| / /\ \ \:\ / /:/_
+// | |:|:\ / /:/ | |:| / /:/ \ \:\ / /:/ /\
+// __|__|:|\:\ /__/::\ __|__|:| /__/::\ _____\__\:\ / /:/ /::\
+// /__/::::| \:\\__\/\:\__/__/::::\____\__\/\:\__ /__/::::::::\/__/:/ /:/\:\
+// \ \:\~~\__\/ \ \:\/\ ~\~~\::::/ \ \:\/\\ \:\~~\~~\/\ \:\/:/~/:/
+// \ \:\ \__\::/ |~~|:|~~ \__\::/ \ \:\ ~~~ \ \::/ /:/
+// \ \:\ /__/:/ | |:| /__/:/ \ \:\ \__\/ /:/
+// \ \:\ \__\/ | |:| \__\/ \ \:\ /__/:/
+// \__\/ |__|/ \__\/ \__\/
+
+@mixin print-styles {
+ // These styles restore the original footnote numbers and texts when the page is printed
+ @media not print {
+ .footnote-print-only {
+ display: none !important;
+ }
+ }
+
+ @media print {
+ .bigfoot-footnote,
+ .bigfoot-footnote__button {
+ display: none !important;
+ }
+ }
+}
diff --git a/_sass/vendor/bigfoot/bigfoot-number.scss b/_sass/vendor/bigfoot/bigfoot-number.scss
new file mode 100644
index 00000000..a0bade3a
--- /dev/null
+++ b/_sass/vendor/bigfoot/bigfoot-number.scss
@@ -0,0 +1,686 @@
+// bigfoot - v2.1.1 - 2015.04.04
+
+
+// ___ ___ ___ ___ ___ ___
+// / /\ / /\ / /\ / /\ ___ / /\ / /\
+// / /::\ / /::\ / /::\ / /::\ /__/\ / /:/_ / /::\
+// / /:/\:\ / /:/\:\ / /:/\:\ / /:/\:\ \ \:\ / /:/ /\ / /:/\:\
+// / /:/~/:// /:/ \:\ / /:/~/:// /:/ \:\ \ \:\ / /:/ /:/_ / /:/~/:/
+// /__/:/ /://__/:/ \__\:\/__/:/ /://__/:/ \__\:\ ___ \__\:\/__/:/ /:/ /\/__/:/ /:/___
+// \ \:\/:/ \ \:\ / /:/\ \:\/:/ \ \:\ / /://__/\ | |:|\ \:\/:/ /:/\ \:\/:::::/
+// \ \::/ \ \:\ /:/ \ \::/ \ \:\ /:/ \ \:\| |:| \ \::/ /:/ \ \::/~~~~
+// \ \:\ \ \:\/:/ \ \:\ \ \:\/:/ \ \:\__|:| \ \:\/:/ \ \:\
+// \ \:\ \ \::/ \ \:\ \ \::/ \__\::::/ \ \::/ \ \:\
+// \__\/ \__\/ \__\/ \__\/ ~~~~ \__\/ \__\/
+//
+// These are the key variables for styling the popover.
+// Just set the variable to none if you don't want that styling.
+
+// KEY VARIABLES
+// =============================================================================
+
+// STYLES
+$popover-width: 22em !default; // Ideal width of the popover
+$popover-max-width: 90% !default; // Best as a % to accommodate smaller viewports
+$popover-max-height: 15em !default; // Maximum size of the content area
+$popover-color-background: rgb(250, 250, 250) !default; // Color of the popover background
+$popover-border-radius: 0.5em !default; // Radius of the corners of the popover
+$popover-border: 1px solid rgb(195, 195, 195) !default; // Border of the popover/ tooltip
+$popover-inactive-opacity: 0 !default; // Opacity of the popover when instantiated/ deactivating
+$popover-active-opacity: 0.97 !default; // Opacity of the popover when active
+$popover-box-shadow: 0px 0px 8px rgba(0, 0, 0, 0.3) !default; // Sets the box shadow under the popover/ tooltip
+$popover-bottom-position: auto !default; // Sets the bottom position of the popover. Use only when setting positionPopover to false in the script
+$popover-left-position: auto !default; // Sets the left position of the popover. Use only when setting positionPopover to false in the script
+$popover-tooltip-size: 1.3em !default; // Sets the side lengths of the tooltip
+$popover-scroll-indicator-width: 0.625em !default; // The width of the scroll indicator
+$popover-scroll-indicator-aspect-ratio: (15/12) !default; // The ratio of the height over the width of the scroll indicator
+$popover-scroll-indicator-opacity: 0.1 !default; // The active opacity of scroll indicators
+$popover-initial-transform-state: scale(0.1) translateZ(0) !default; // The inital transform state for the popover
+$popover-active-transform-state: scale(1) translateZ(0) !default; // The transform state for the popover once it is fully activated
+
+// OPTIONAL ELEMENTS
+$popover-include-tooltip: true !default; // Adds a tooltip pointing to the footnote button
+$popover-include-scroll-indicator: true !default; // Adds an elipsis at the bottom of scrollable popovers
+$popover-include-scrolly-fades: true !default; // Fades content in on scrollable popovers
+$popover-scroll-indicator-icon: url("data:image/svg+xml;base64,PHN2ZyB3aWR0aD0iMTJweCIgaGVpZ2h0PSIxNXB4IiB2aWV3Qm94PSIwIDAgMTIgMTUiIHZlcnNpb249IjEuMSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIiB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgcHJlc2VydmVBc3BlY3RSYXRpbz0ieE1pbllNaW4iPgogICAgPGcgc3Ryb2tlPSJub25lIiBzdHJva2Utd2lkdGg9IjEiIGZpbGw9Im5vbmUiIGZpbGwtcnVsZT0iZXZlbm9kZCI+CiAgICAgICAgPGcgaWQ9IkFycm93IiB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxLjAwMDAwMCwgMS4wMDAwMDApIiBzdHJva2U9ImJsYWNrIiBzdHJva2Utd2lkdGg9IjIiIHN0cm9rZS1saW5lY2FwPSJzcXVhcmUiPgogICAgICAgICAgICA8cGF0aCBkPSJNNSwwIEw1LDExLjUiIGlkPSJMaW5lIj48L3BhdGg+CiAgICAgICAgICAgIDxwYXRoIGQ9Ik0wLjUsNy41IEw1LjAyNzY5Mjc5LDEyLjAyNzY5MjgiIGlkPSJMaW5lIj48L3BhdGg+CiAgICAgICAgICAgIDxwYXRoIGQ9Ik00LjUsNy41IEw5LjAyNzY5Mjc5LDEyLjAyNzY5MjgiIGlkPSJMaW5lLTIiIHRyYW5zZm9ybT0idHJhbnNsYXRlKDcuMDAwMDAwLCAxMC4wMDAwMDApIHNjYWxlKC0xLCAxKSB0cmFuc2xhdGUoLTcuMDAwMDAwLCAtMTAuMDAwMDAwKSAiPjwvcGF0aD4KICAgICAgICA8L2c+CiAgICA8L2c+Cjwvc3ZnPgo=") !default;
+
+
+// OTHER VARIABLES
+// =============================================================================
+
+// POPOVER
+$popover-margin-top: 0.1em !default;
+$popover-padding-content-horizontal: 1.3em !default;
+$popover-padding-content-top: 1.1em !default;
+$popover-padding-content-bottom: 1.2em !default;
+$popover-z-index: 10 !default; // Set the base so that it's above the other body children
+$popover-initial-transform-origin: 50% 0 !default;
+
+// POPOVER CONTENT WRAPPER
+$popover-content-color-background: $popover-color-background !default;
+$popover-content-border-radius: $popover-border-radius !default;
+
+// OTHER POPOVER ELEMENTS
+$popover-tooltip-background: $popover-color-background !default;
+$popover-tooltip-radius: 0 !default;
+$popover-scroll-indicator-bottom-position: 0.45em !default;
+$popover-scrolly-fade-gradient-start-location: 50% !default;
+$popover-scroll-indicator-padding: (($popover-padding-content-horizontal/2) - ($popover-scroll-indicator-width/2)) !default;
+
+// TRANSITIONS
+$popover-transition-default-duration: 0.25s !default;
+$popover-scroll-indicator-transition-properties: opacity !default;
+
+// Use none for areas you don't want to transition
+$popover-transition-properties: opacity, transform !default; // no mixin to do proper prefixing of the transform, so I have to do it manually; see mixin below
+$popover-scroll-indicator-transition-properties: opacity !default;
+$popover-scroll-up-transition-delay: 0.4s !default; // Sets the delay for the transition of the scroll indicator when scrolling upwards
+$popover-transition-default-timing-function: ease !default;
+
+
+
+
+
+// ___ ___ ___
+// _____ /__/\ ___ ___ / /\ /__/\
+// / /::\ \ \:\ / /\ / /\ / /::\ \ \:\
+// / /:/\:\ \ \:\ / /:/ / /:/ / /:/\:\ \ \:\
+// / /:/~/::\ ___ \ \:\ / /:/ / /:/ / /:/ \:\ _____\__\:\
+// /__/:/ /:/\:|/__/\ \__\:\ / /::\ / /::\ /__/:/ \__\:\/__/::::::::\
+// \ \:\/:/~/:/\ \:\ / /://__/:/\:\ /__/:/\:\\ \:\ / /:/\ \:\~~\~~\/
+// \ \::/ /:/ \ \:\ /:/ \__\/ \:\\__\/ \:\\ \:\ /:/ \ \:\ ~~~
+// \ \:\/:/ \ \:\/:/ \ \:\ \ \:\\ \:\/:/ \ \:\
+// \ \::/ \ \::/ \__\/ \__\/ \ \::/ \ \:\
+// \__\/ \__\/ \__\/ \__\/
+//
+// These are the key variables for styling the button.
+// Just set the variable to none if you don't want that styling.
+
+// KEY VARIABLES
+// =============================================================================
+
+$button-height: 0.95em !default; // The total height of the button
+$button-width: auto !default; // The total button width (applies only if $button-apply-dimensions is true)
+$button-inner-circle-size: 0.25em !default; // Total height/width of the ellipsis circles
+$button-border-radius: 0.3em !default; // Border radius on the button itself
+$button-left-margin: 0.2em !default; // Margin between the button and the text to its left
+$button-right-margin: 0.1em !default; // Margin between the button and the text to its right
+$button-vertical-adjust: -0.1em !default; // Pushes the buttons along the vertical axis to align it with text as desired
+$button-inner-circle-left-margin: 1*$button-inner-circle-size !default; // Space between the ellipsis circles
+
+$button-color: rgb(110, 110, 110) !default; // Background color of the button
+$button-hovered-color: $button-color !default; // Background color of the button when being hovered
+$button-activating-color: $button-color !default; // Background color of the button when being clicked
+$button-active-color: $button-color !default; // Background color of the button when active
+$button-standard-opacity: 0.2 !default; // Opacity for when the button is just sittin' there
+$button-hovered-opacity: 0.5 !default; // Opacity for when the button is being hovered over
+$button-activating-opacity: $button-hovered-opacity !default; // Opacity for when the button is being clicked
+$button-active-opacity: 1 !default; // Opacity for when the button is active
+$button-active-style-delay: 0.1s !default; // Delay before applying .active styles; this can be used to match to the popover activation transition
+
+$button-inner-circle-color: white !default; // Background color of the ellipsis circle
+$button-inner-circle-border: none !default; // Border of the ellipsis circle
+
+
+// OTHER VARIABLES
+// =============================================================================
+
+$button-total-padding: $button-height - $button-inner-circle-size !default;
+$button-per-side-padding: 0.5*$button-total-padding !default;
+$button-transition-properties: background-color !default;
+
+
+
+// -----
+
+
+// ___ ___ ___ ___
+// /__/\ ___ /__/| ___ /__/\ / /\
+// | |::\ / /\ | |:| / /\ \ \:\ / /:/_
+// | |:|:\ / /:/ | |:| / /:/ \ \:\ / /:/ /\
+// __|__|:|\:\ /__/::\ __|__|:| /__/::\ _____\__\:\ / /:/ /::\
+// /__/::::| \:\\__\/\:\__/__/::::\____\__\/\:\__ /__/::::::::\/__/:/ /:/\:\
+// \ \:\~~\__\/ \ \:\/\ ~\~~\::::/ \ \:\/\\ \:\~~\~~\/\ \:\/:/~/:/
+// \ \:\ \__\::/ |~~|:|~~ \__\::/ \ \:\ ~~~ \ \::/ /:/
+// \ \:\ /__/:/ | |:| /__/:/ \ \:\ \__\/ /:/
+// \ \:\ \__\/ | |:| \__\/ \ \:\ /__/:/
+// \__\/ |__|/ \__\/ \__\/
+
+@mixin print-styles {
+ // These styles restore the original footnote numbers and texts when the page is printed
+ @media not print {
+ .footnote-print-only {
+ display: none !important;
+ }
+ }
+
+ @media print {
+ .bigfoot-footnote,
+ .bigfoot-footnote__button {
+ display: none !important;
+ }
+ }
+}
+
+
+
+// -----
+
+
+// ___ ___ ___
+// _____ /__/\ ___ ___ / /\ /__/\
+// / /::\ \ \:\ / /\ / /\ / /::\ \ \:\
+// / /:/\:\ \ \:\ / /:/ / /:/ / /:/\:\ \ \:\
+// / /:/~/::\ ___ \ \:\ / /:/ / /:/ / /:/ \:\ _____\__\:\
+// /__/:/ /:/\:|/__/\ \__\:\ / /::\ / /::\ /__/:/ \__\:\/__/::::::::\
+// \ \:\/:/~/:/\ \:\ / /://__/:/\:\ /__/:/\:\\ \:\ / /:/\ \:\~~\~~\/
+// \ \::/ /:/ \ \:\ /:/ \__\/ \:\\__\/ \:\\ \:\ /:/ \ \:\ ~~~
+// \ \:\/:/ \ \:\/:/ \ \:\ \ \:\\ \:\/:/ \ \:\
+// \ \::/ \ \::/ \__\/ \__\/ \ \::/ \ \:\
+// \__\/ \__\/ \__\/ \__\/
+
+
+
+//*
+// The button that activates the footnote. By default, this will appear as a
+// flat button that has an ellipse contained inside of it.
+
+// @state .is-active - The associated popover has been activated and is visible.
+
+// @since 2.1.0
+// @author Chris Sauve
+
+.bigfoot-footnote__button {
+ // POSITIONING
+ position: relative;
+ z-index: 5;
+ top: $button-vertical-adjust;
+
+ // DISPLAY AND SIZING
+ box-sizing: border-box;
+ -moz-box-sizing: border-box;;
+ display: inline-block;
+ padding: $button-per-side-padding;
+ margin: 0 $button-right-margin 0 $button-left-margin;
+
+ // BACKDROP
+ border: none;
+ border-radius: $button-border-radius;
+ cursor: pointer;
+ background-color: rgba($button-color, $button-standard-opacity);
+ backface-visibility: hidden;
+
+ // TEXT
+ font-size: 1rem;
+ line-height: 0;
+ vertical-align: middle;
+ text-decoration: none;
+ -webkit-font-smoothing: antialiased;
+
+ // TRANSITIONS
+ transition-property: $button-transition-properties;
+ transition-duration: $popover-transition-default-duration;
+
+ &:hover,
+ &:focus {
+ outline: none;
+ background-color: rgba($button-hovered-color, $button-hovered-opacity);
+ }
+
+ &:active {
+ background-color: rgba($button-activating-color, $button-activating-opacity);
+ }
+
+ &.is-active {
+ background-color: rgba($button-active-color, $button-active-opacity);
+ transition-delay: $button-active-style-delay;
+ }
+
+ // Clearfix
+ &:after {
+ content: '';
+ display: table;
+ clear: both;
+ }
+}
+
+
+
+
+
+// _____ ___ ___
+// / /::\ / /\ ___ / /\
+// / /:/\:\ / /::\ / /\ / /:/_
+// / /:/ \:\ / /:/\:\ / /:/ / /:/ /\
+// /__/:/ \__\:| / /:/ \:\ / /:/ / /:/ /::\
+// \ \:\ / /://__/:/ \__\:\ / /::\ /__/:/ /:/\:\
+// \ \:\ /:/ \ \:\ / /://__/:/\:\\ \:\/:/~/:/
+// \ \:\/:/ \ \:\ /:/ \__\/ \:\\ \::/ /:/
+// \ \::/ \ \:\/:/ \ \:\\__\/ /:/
+// \__\/ \ \::/ \__\/ /__/:/
+// \__\/ \__\/
+
+//*
+// Each of the three circles forming the ellipse within the button.
+
+// @since 2.1.0
+// @author Chris Sauve
+
+.bigfoot-footnote__button__circle {
+ // DISPLAY AND SIZING
+ display: inline-block;
+ width: $button-inner-circle-size;
+ height: $button-inner-circle-size;
+ margin-right: $button-inner-circle-left-margin;
+ float: left;
+
+ // Gets rid of margin on the last circle
+ &:last-child { margin-right: 0; }
+}
+
+
+
+
+
+// ___ ___ ___ ___ ___
+// / /\ / /\ /__/\ ___ / /\ ___ /__/\
+// / /:/ / /::\ \ \:\ / /\ / /::\ / /\ \ \:\
+// / /:/ / /:/\:\ \ \:\ / /:/ / /:/\:\ / /:/ \ \:\
+// / /:/ ___ / /:/ \:\ _____\__\:\ / /:/ / /:/~/::\ /__/::\ _____\__\:\
+// /__/:/ / /\/__/:/ \__\:\/__/::::::::\ / /::\ /__/:/ /:/\:\\__\/\:\__ /__/::::::::\
+// \ \:\ / /:/\ \:\ / /:/\ \:\~~\~~\//__/:/\:\\ \:\/:/__\/ \ \:\/\\ \:\~~\~~\/
+// \ \:\ /:/ \ \:\ /:/ \ \:\ ~~~ \__\/ \:\\ \::/ \__\::/ \ \:\ ~~~
+// \ \:\/:/ \ \:\/:/ \ \:\ \ \:\\ \:\ /__/:/ \ \:\
+// \ \::/ \ \::/ \ \:\ \__\/ \ \:\ \__\/ \ \:\
+// \__\/ \__\/ \__\/ \__\/ \__\/
+
+//*
+// The container for the button and popover. This is required so that the popover
+// is guaranteed to have a relatively-positioned container, and to help with the
+// positioning calculation.
+
+// @since 2.1.0
+// @author Chris Sauve
+
+.bigfoot-footnote__container {
+ display: inline-block;
+ position: relative;
+ text-indent: 0;
+}
+
+
+
+
+
+// ___ ___ ___
+// / /\ / /\ ___ /__/\ ___
+// / /::\ / /::\ / /\ \ \:\ / /\
+// / /:/\:\ / /:/\:\ / /:/ \ \:\ / /:/
+// / /:/~/:// /:/~/:/ /__/::\ _____\__\:\ / /:/
+// /__/:/ /://__/:/ /:/___\__\/\:\__ /__/::::::::\ / /::\
+// \ \:\/:/ \ \:\/:::::/ \ \:\/\\ \:\~~\~~\//__/:/\:\
+// \ \::/ \ \::/~~~~ \__\::/ \ \:\ ~~~ \__\/ \:\
+// \ \:\ \ \:\ /__/:/ \ \:\ \ \:\
+// \ \:\ \ \:\ \__\/ \ \:\ \__\/
+// \__\/ \__\/ \__\/
+
+@include print-styles;
+
+
+
+// -----
+
+
+// ___ ___ ___ ___ ___ ___
+// / /\ / /\ / /\ / /\ ___ / /\ / /\
+// / /::\ / /::\ / /::\ / /::\ /__/\ / /:/_ / /::\
+// / /:/\:\ / /:/\:\ / /:/\:\ / /:/\:\ \ \:\ / /:/ /\ / /:/\:\
+// / /:/~/:// /:/ \:\ / /:/~/:// /:/ \:\ \ \:\ / /:/ /:/_ / /:/~/:/
+// /__/:/ /://__/:/ \__\:\/__/:/ /://__/:/ \__\:\ ___ \__\:\/__/:/ /:/ /\/__/:/ /:/___
+// \ \:\/:/ \ \:\ / /:/\ \:\/:/ \ \:\ / /://__/\ | |:|\ \:\/:/ /:/\ \:\/:::::/
+// \ \::/ \ \:\ /:/ \ \::/ \ \:\ /:/ \ \:\| |:| \ \::/ /:/ \ \::/~~~~
+// \ \:\ \ \:\/:/ \ \:\ \ \:\/:/ \ \:\__|:| \ \:\/:/ \ \:\
+// \ \:\ \ \::/ \ \:\ \ \::/ \__\::::/ \ \::/ \ \:\
+// \__\/ \__\/ \__\/ \__\/ ~~~~ \__\/ \__\/
+//
+
+
+
+//*
+// The popover for the footnote. This popover will be, by default, be sized and positioned
+// by the script. However, many of the sizes can be established in this stylesheet and
+// will be respected by the script. `max-width` will limit the width of the popover
+// relative to the viewport. `width` (on `bigfoot-footnote__wrapper`) will set the
+// absolute max width. Max height can be set via a `max-height` property
+// on `bigfoot-footnote__content`.
+
+// By default, the popover has a light gray background, a shadow for some depth,
+// rounded corners, and a tooltip pointing to the footnote button.
+
+// @state .is-active - The popover has been activated and is visible.
+// @state .is-positioned-top - The popover is above the button.
+// @state .is-positioned-bottom - The popover is below the button.
+// @state .is-scrollable - The popover content is greater than the popover height.
+// @state .is-fully-scrolled - The popover content is scrolled to the bottom.
+
+// @since 2.1.0
+// @author Chris Sauve
+
+.bigfoot-footnote {
+ // POSITIONING
+ position: absolute;
+ z-index: $popover-z-index;
+ top: 0; left: 0;
+
+ // DISPLAY AND SIZING
+ display: inline-block;
+ box-sizing: border-box;
+ // Height is set in .footnote-content-wrapper
+ max-width: $popover-max-width;
+ // 1.414213... is to get the diagonal height of the tooltip using pythagorus, yo.
+ margin: ((1.4142135624 * $popover-tooltip-size / 2) + $button-height + $popover-margin-top) 0;
+ // fits the popover to the contents
+
+ // BACKDROP
+ background: $popover-color-background;
+ opacity: $popover-inactive-opacity;
+ border-radius: $popover-border-radius;
+ border: $popover-border;
+ box-shadow: $popover-box-shadow;
+
+ // TEXT
+ line-height: 0;
+
+ // TRANSITIONS
+ transition-property: $popover-transition-properties;
+ transition-duration: $popover-transition-default-duration;
+ transition-timing-function: $popover-transition-default-timing-function;
+
+ // TRANSFORMS
+ transform: $popover-initial-transform-state;
+ transform-origin: $popover-initial-transform-origin;
+
+ &.is-positioned-top {
+ top: auto;
+ bottom: 0;
+ }
+
+ &.is-active {
+ transform: $popover-active-transform-state;
+ opacity: $popover-active-opacity;
+ }
+
+ &.is-bottom-fixed {
+ // POSITIONING
+ position: fixed;
+ bottom: 0; top: auto;
+ left: 0; right: auto;
+ transform: translateY(100%);
+
+ // DISPLAY AND SIZING
+ width: 100%;
+ margin: 0;
+
+ // BACKDROP
+ border-radius: 0;
+ opacity: 1;
+ border-width: 1px 0 0;
+
+ // TRANSITIONS
+ transition: transform 0.3s ease;
+
+ &.is-active {
+ transform: translateY(0);
+ }
+
+ .bigfoot-footnote__wrapper {
+ margin: 0 0 0 50%;
+ transform: translateX(-50%);
+ max-width: 100%;
+ }
+
+ .bigfoot-footnote__wrapper,
+ .bigfoot-footnote__content {
+ border-radius: 0;
+ }
+
+ .bigfoot-footnote__tooltip {
+ display: none;
+ }
+ }
+
+ &.is-scrollable {
+ // A scrollable indicator in the left margin of the popover.
+ &:after {
+ // CONTENT
+ content: '';
+
+ // POSITIONING
+ position: absolute;
+ bottom: $popover-scroll-indicator-padding;
+ left: $popover-scroll-indicator-padding;
+ z-index: ($popover-z-index + 4);
+
+ // DISPLAY AND SIZING
+ display: block;
+ height: ($popover-scroll-indicator-width*$popover-scroll-indicator-aspect-ratio);
+ width: $popover-scroll-indicator-width;
+
+ // BACKDROP
+ background-image: $popover-scroll-indicator-icon;
+ background-size: cover;
+ opacity: $popover-scroll-indicator-opacity;
+ transition-properties: $popover-scroll-indicator-transition-properties;
+ transition-duration: $popover-transition-default-duration;
+ transition-timing-function: $popover-transition-default-timing-function;
+ }
+
+ .bigfoot-footnote__wrapper {
+ &:before,
+ &:after {
+ content: '';
+ position: absolute;
+ width: 100%;
+ // Above the content
+ z-index: ($popover-z-index + 2);
+ left: 0;
+ }
+
+ &:before {
+ top: -1px;
+ height: $popover-padding-content-top;
+ border-radius: $popover-border-radius $popover-border-radius 0 0;
+ background-image: linear-gradient(to bottom, $popover-color-background $popover-scrolly-fade-gradient-start-location, transparentize($popover-color-background, 1) 100%);
+ }
+
+ &:after {
+ bottom: -1px;
+ height: $popover-padding-content-bottom;
+ border-radius: 0 0 $popover-border-radius $popover-border-radius;
+ background-image: linear-gradient(to top, $popover-color-background $popover-scrolly-fade-gradient-start-location, transparentize($popover-color-background, 1) 100%);
+ }
+ }
+
+ ::-webkit-scrollbar { display: none; }
+ }
+
+ &.is-fully-scrolled {
+ &:after,
+ &:before {
+ opacity: 0;
+ transition-delay: 0;
+ }
+ }
+}
+
+
+
+//*
+// Wraps around the footnote content. This is necessary in order to have an element
+// above the tooltip and that can provide top and bottom indicators that there is
+// additional content on scrollable popovers.
+
+// @since 2.1.0
+// @author Chris Sauve
+
+.bigfoot-footnote__wrapper {
+ // POSITIONING
+ position: relative;
+ // Above the outer tooltip, below the inner tooltip
+ z-index: ($popover-z-index + 4);
+
+ // DISPLAY AND SIZING
+ width: $popover-width;
+ display: inline-block;
+ box-sizing: inherit;
+ overflow: hidden;
+ margin: 0;
+
+ // BACKDROP
+ background-color: $popover-color-background;
+ border-radius: $popover-border-radius;
+
+ // TEXT
+ line-height: 0;
+}
+
+
+
+//*
+// Contains the actual footnote content. There is very little prescription here
+// on the footnote content itself, except for removing and top margin on the first
+// element and bottom margin on the last child.
+
+// @since 2.1.0
+// @author Chris Sauve
+
+.bigfoot-footnote__content {
+ // POSITIONING
+ position: relative;
+ z-index: ($popover-z-index - 2); // Below fading bars
+
+ // DISPLAY AND SIZING
+ display: inline-block;
+ max-height: $popover-max-height;
+ padding: $popover-padding-content-top $popover-padding-content-horizontal $popover-padding-content-bottom;
+ box-sizing: inherit;
+ overflow: auto;
+ -webkit-overflow-scrolling: touch;
+
+ // BACKDROP
+ background: $popover-content-color-background;
+ border-radius: $popover-content-border-radius;
+
+ // TEXT
+ -webkit-font-smoothing: subpixel-antialiased;
+ line-height: normal;
+
+ // INTERIOR ELEMENTS
+ img { max-width: 100%; }
+ *:last-child { margin-bottom: 0 !important; }
+ *:first-child { margin-top: 0 !important; }
+}
+
+
+
+//*
+// A triangular shape pointing towards the footnote button.
+
+// @since 2.1.0
+// @author Chris Sauve
+
+.bigfoot-footnote__tooltip {
+ // POSITIONING
+ position: absolute;
+ // Above the footnote-main-wrapper and the outer tooltip
+ z-index: ($popover-z-index + 2);
+
+ // DISPLAY AND SIZING
+ box-sizing: border-box;
+ margin-left: (-0.5 * $popover-tooltip-size);
+ // Smaller by one border-width's worth
+ width: $popover-tooltip-size;
+ height: $popover-tooltip-size;
+ transform: rotate(45deg);
+
+ // BACKDROP
+ background: $popover-tooltip-background;
+ border: $popover-border;
+ box-shadow: $popover-box-shadow;
+ border-top-left-radius: $popover-tooltip-radius;
+
+ .is-positioned-bottom & {
+ top: (-0.5 * $popover-tooltip-size);
+ }
+
+ .is-positioned-top & {
+ bottom: (-0.5 * $popover-tooltip-size);
+ }
+}
+
+
+
+// -----
+
+
+// ___ ___ ___ ___ ___
+// /__/\ /__/\ /__/\ _____ / /\ / /\
+// \ \:\ \ \:\ | |::\ / /::\ / /:/_ / /::\
+// \ \:\ \ \:\ | |:|:\ / /:/\:\ / /:/ /\ / /:/\:\
+// _____\__\:\ ___ \ \:\ __|__|:|\:\ / /:/~/::\ / /:/ /:/_ / /:/~/:/
+// /__/::::::::\/__/\ \__\:\/__/::::| \:\/__/:/ /:/\:|/__/:/ /:/ /\/__/:/ /:/___
+// \ \:\~~\~~\/\ \:\ / /:/\ \:\~~\__\/\ \:\/:/~/:/\ \:\/:/ /:/\ \:\/:::::/
+// \ \:\ ~~~ \ \:\ /:/ \ \:\ \ \::/ /:/ \ \::/ /:/ \ \::/~~~~
+// \ \:\ \ \:\/:/ \ \:\ \ \:\/:/ \ \:\/:/ \ \:\
+// \ \:\ \ \::/ \ \:\ \ \::/ \ \::/ \ \:\
+// \__\/ \__\/ \__\/ \__\/ \__\/ \__\/
+
+
+
+//*
+// A button that has no ellipse, but instead shows the footnote's number on the
+// page. Note that the number will be reset to 1 depending on the selector passed
+// to bigfoot's `numberResetSelector` option.
+
+// @since 2.1.0
+// @author Chris Sauve
+
+.bigfoot-footnote__button {
+ position: relative;
+ height: $button-height;
+ width: 1.5em;
+ border-radius: $button-height/2;
+
+ &:after {
+ // CONTENT
+ content: attr(data-footnote-number);
+
+ // POSITION
+ position: absolute;
+ top: 50%; left: 50%;
+ transform: translate(-50%, -50%);
+
+ // DISPLAY AND SIZING
+ display: block;
+
+ // TEXT
+ font-size: $button-height*0.6;
+ font-weight: bold;
+ color: mix(#fff, $link-color, 30%); // #ff6600;
+// originally: color: rgba($button-color, 0.5);
+
+ // TRANSITIONS
+ transition: color $popover-transition-default-duration $popover-transition-default-timing-function;
+ }
+
+ &:hover,
+ &.is-active {
+ &:after {
+ color: white;
+ }
+ }
+}
+
+.bigfoot-footnote__button__circle {
+ display: none;
+}
diff --git a/_sass/vendor/bigfoot/bigfoot-popover.scss b/_sass/vendor/bigfoot/bigfoot-popover.scss
new file mode 100644
index 00000000..df92609b
--- /dev/null
+++ b/_sass/vendor/bigfoot/bigfoot-popover.scss
@@ -0,0 +1,286 @@
+// ___ ___ ___ ___ ___ ___
+// / /\ / /\ / /\ / /\ ___ / /\ / /\
+// / /::\ / /::\ / /::\ / /::\ /__/\ / /:/_ / /::\
+// / /:/\:\ / /:/\:\ / /:/\:\ / /:/\:\ \ \:\ / /:/ /\ / /:/\:\
+// / /:/~/:// /:/ \:\ / /:/~/:// /:/ \:\ \ \:\ / /:/ /:/_ / /:/~/:/
+// /__/:/ /://__/:/ \__\:\/__/:/ /://__/:/ \__\:\ ___ \__\:\/__/:/ /:/ /\/__/:/ /:/___
+// \ \:\/:/ \ \:\ / /:/\ \:\/:/ \ \:\ / /://__/\ | |:|\ \:\/:/ /:/\ \:\/:::::/
+// \ \::/ \ \:\ /:/ \ \::/ \ \:\ /:/ \ \:\| |:| \ \::/ /:/ \ \::/~~~~
+// \ \:\ \ \:\/:/ \ \:\ \ \:\/:/ \ \:\__|:| \ \:\/:/ \ \:\
+// \ \:\ \ \::/ \ \:\ \ \::/ \__\::::/ \ \::/ \ \:\
+// \__\/ \__\/ \__\/ \__\/ ~~~~ \__\/ \__\/
+//
+
+
+
+//*
+// The popover for the footnote. This popover will be, by default, be sized and positioned
+// by the script. However, many of the sizes can be established in this stylesheet and
+// will be respected by the script. `max-width` will limit the width of the popover
+// relative to the viewport. `width` (on `bigfoot-footnote__wrapper`) will set the
+// absolute max width. Max height can be set via a `max-height` property
+// on `bigfoot-footnote__content`.
+
+// By default, the popover has a light gray background, a shadow for some depth,
+// rounded corners, and a tooltip pointing to the footnote button.
+
+// @state .is-active - The popover has been activated and is visible.
+// @state .is-positioned-top - The popover is above the button.
+// @state .is-positioned-bottom - The popover is below the button.
+// @state .is-scrollable - The popover content is greater than the popover height.
+// @state .is-fully-scrolled - The popover content is scrolled to the bottom.
+
+// @since 2.1.0
+// @author Chris Sauve
+
+.bigfoot-footnote {
+ // POSITIONING
+ position: absolute;
+ z-index: $popover-z-index;
+ top: 0; left: 0;
+
+ // DISPLAY AND SIZING
+ display: inline-block;
+ box-sizing: border-box;
+ // Height is set in .footnote-content-wrapper
+ max-width: $popover-max-width;
+ // 1.414213... is to get the diagonal height of the tooltip using pythagorus, yo.
+ margin: ((1.4142135624 * $popover-tooltip-size / 2) + $button-height + $popover-margin-top) 0;
+ // fits the popover to the contents
+
+ // BACKDROP
+ background: $popover-color-background;
+ opacity: $popover-inactive-opacity;
+ border-radius: $popover-border-radius;
+ border: $popover-border;
+ box-shadow: $popover-box-shadow;
+
+ // TEXT
+ line-height: 0;
+
+ // TRANSITIONS
+ transition-property: $popover-transition-properties;
+ transition-duration: $popover-transition-default-duration;
+ transition-timing-function: $popover-transition-default-timing-function;
+
+ // TRANSFORMS
+ transform: $popover-initial-transform-state;
+ transform-origin: $popover-initial-transform-origin;
+
+ &.is-positioned-top {
+ top: auto;
+ bottom: 0;
+ }
+
+ &.is-active {
+ transform: $popover-active-transform-state;
+ opacity: $popover-active-opacity;
+ }
+
+ &.is-bottom-fixed {
+ // POSITIONING
+ position: fixed;
+ bottom: 0; top: auto;
+ left: 0; right: auto;
+ transform: translateY(100%);
+
+ // DISPLAY AND SIZING
+ width: 100%;
+ margin: 0;
+
+ // BACKDROP
+ border-radius: 0;
+ opacity: 1;
+ border-width: 1px 0 0;
+
+ // TRANSITIONS
+ transition: transform 0.3s ease;
+
+ &.is-active {
+ transform: translateY(0);
+ }
+
+ .bigfoot-footnote__wrapper {
+ margin: 0 0 0 50%;
+ transform: translateX(-50%);
+ max-width: 100%;
+ }
+
+ .bigfoot-footnote__wrapper,
+ .bigfoot-footnote__content {
+ border-radius: 0;
+ }
+
+ .bigfoot-footnote__tooltip {
+ display: none;
+ }
+ }
+
+ &.is-scrollable {
+ // A scrollable indicator in the left margin of the popover.
+ &:after {
+ // CONTENT
+ content: '';
+
+ // POSITIONING
+ position: absolute;
+ bottom: $popover-scroll-indicator-padding;
+ left: $popover-scroll-indicator-padding;
+ z-index: ($popover-z-index + 4);
+
+ // DISPLAY AND SIZING
+ display: block;
+ height: ($popover-scroll-indicator-width*$popover-scroll-indicator-aspect-ratio);
+ width: $popover-scroll-indicator-width;
+
+ // BACKDROP
+ background-image: $popover-scroll-indicator-icon;
+ background-size: cover;
+ opacity: $popover-scroll-indicator-opacity;
+ transition-properties: $popover-scroll-indicator-transition-properties;
+ transition-duration: $popover-transition-default-duration;
+ transition-timing-function: $popover-transition-default-timing-function;
+ }
+
+ .bigfoot-footnote__wrapper {
+ &:before,
+ &:after {
+ content: '';
+ position: absolute;
+ width: 100%;
+ // Above the content
+ z-index: ($popover-z-index + 2);
+ left: 0;
+ }
+
+ &:before {
+ top: -1px;
+ height: $popover-padding-content-top;
+ border-radius: $popover-border-radius $popover-border-radius 0 0;
+ background-image: linear-gradient(to bottom, $popover-color-background $popover-scrolly-fade-gradient-start-location, transparentize($popover-color-background, 1) 100%);
+ }
+
+ &:after {
+ bottom: -1px;
+ height: $popover-padding-content-bottom;
+ border-radius: 0 0 $popover-border-radius $popover-border-radius;
+ background-image: linear-gradient(to top, $popover-color-background $popover-scrolly-fade-gradient-start-location, transparentize($popover-color-background, 1) 100%);
+ }
+ }
+
+ ::-webkit-scrollbar { display: none; }
+ }
+
+ &.is-fully-scrolled {
+ &:after,
+ &:before {
+ opacity: 0;
+ transition-delay: 0;
+ }
+ }
+}
+
+
+
+//*
+// Wraps around the footnote content. This is necessary in order to have an element
+// above the tooltip and that can provide top and bottom indicators that there is
+// additional content on scrollable popovers.
+
+// @since 2.1.0
+// @author Chris Sauve
+
+.bigfoot-footnote__wrapper {
+ // POSITIONING
+ position: relative;
+ // Above the outer tooltip, below the inner tooltip
+ z-index: ($popover-z-index + 4);
+
+ // DISPLAY AND SIZING
+ width: $popover-width;
+ display: inline-block;
+ box-sizing: inherit;
+ overflow: hidden;
+ margin: 0;
+
+ // BACKDROP
+ background-color: $popover-color-background;
+ border-radius: $popover-border-radius;
+
+ // TEXT
+ line-height: 0;
+}
+
+
+
+//*
+// Contains the actual footnote content. There is very little prescription here
+// on the footnote content itself, except for removing and top margin on the first
+// element and bottom margin on the last child.
+
+// @since 2.1.0
+// @author Chris Sauve
+
+.bigfoot-footnote__content {
+ // POSITIONING
+ position: relative;
+ z-index: ($popover-z-index - 2); // Below fading bars
+
+ // DISPLAY AND SIZING
+ display: inline-block;
+ max-height: $popover-max-height;
+ padding: $popover-padding-content-top $popover-padding-content-horizontal $popover-padding-content-bottom;
+ box-sizing: inherit;
+ overflow: auto;
+ -webkit-overflow-scrolling: touch;
+
+ // BACKDROP
+ background: $popover-content-color-background;
+ border-radius: $popover-content-border-radius;
+
+ // TEXT
+ -webkit-font-smoothing: subpixel-antialiased;
+ line-height: normal;
+
+ // INTERIOR ELEMENTS
+ img { max-width: 100%; }
+ *:last-child { margin-bottom: 0 !important; }
+ *:first-child { margin-top: 0 !important; }
+}
+
+
+
+//*
+// A triangular shape pointing towards the footnote button.
+
+// @since 2.1.0
+// @author Chris Sauve
+
+.bigfoot-footnote__tooltip {
+ // POSITIONING
+ position: absolute;
+ // Above the footnote-main-wrapper and the outer tooltip
+ z-index: ($popover-z-index + 2);
+
+ // DISPLAY AND SIZING
+ box-sizing: border-box;
+ margin-left: (-0.5 * $popover-tooltip-size);
+ // Smaller by one border-width's worth
+ width: $popover-tooltip-size;
+ height: $popover-tooltip-size;
+ transform: rotate(45deg);
+
+ // BACKDROP
+ background: $popover-tooltip-background;
+ border: $popover-border;
+ box-shadow: $popover-box-shadow;
+ border-top-left-radius: $popover-tooltip-radius;
+
+ .is-positioned-bottom & {
+ top: (-0.5 * $popover-tooltip-size);
+ }
+
+ .is-positioned-top & {
+ bottom: (-0.5 * $popover-tooltip-size);
+ }
+}
diff --git a/_sass/vendor/bigfoot/bigfoot-variables.scss b/_sass/vendor/bigfoot/bigfoot-variables.scss
new file mode 100644
index 00000000..99dc64cf
--- /dev/null
+++ b/_sass/vendor/bigfoot/bigfoot-variables.scss
@@ -0,0 +1,127 @@
+// ___ ___ ___ ___ ___ ___
+// / /\ / /\ / /\ / /\ ___ / /\ / /\
+// / /::\ / /::\ / /::\ / /::\ /__/\ / /:/_ / /::\
+// / /:/\:\ / /:/\:\ / /:/\:\ / /:/\:\ \ \:\ / /:/ /\ / /:/\:\
+// / /:/~/:// /:/ \:\ / /:/~/:// /:/ \:\ \ \:\ / /:/ /:/_ / /:/~/:/
+// /__/:/ /://__/:/ \__\:\/__/:/ /://__/:/ \__\:\ ___ \__\:\/__/:/ /:/ /\/__/:/ /:/___
+// \ \:\/:/ \ \:\ / /:/\ \:\/:/ \ \:\ / /://__/\ | |:|\ \:\/:/ /:/\ \:\/:::::/
+// \ \::/ \ \:\ /:/ \ \::/ \ \:\ /:/ \ \:\| |:| \ \::/ /:/ \ \::/~~~~
+// \ \:\ \ \:\/:/ \ \:\ \ \:\/:/ \ \:\__|:| \ \:\/:/ \ \:\
+// \ \:\ \ \::/ \ \:\ \ \::/ \__\::::/ \ \::/ \ \:\
+// \__\/ \__\/ \__\/ \__\/ ~~~~ \__\/ \__\/
+//
+// These are the key variables for styling the popover.
+// Just set the variable to none if you don't want that styling.
+
+// KEY VARIABLES
+// =============================================================================
+
+// STYLES
+$popover-width: 35em; // Ideal width of the popover
+$popover-max-width: 90% !default; // Best as a % to accommodate smaller viewports
+$popover-max-height: 20em; // Maximum size of the content area
+$popover-color-background: mix(#00b386, #252a34, 30%) !default; // Color of the popover background
+$popover-border-radius: 0.5em !default; // Radius of the corners of the popover
+$popover-border: 1px solid rgb(195, 195, 195) !default; // Border of the popover/ tooltip
+$popover-inactive-opacity: 0 !default; // Opacity of the popover when instantiated/ deactivating
+$popover-active-opacity: 0.99 !default; // Opacity of the popover when active
+$popover-box-shadow: 0px 0px 8px rgba(0, 0, 0, 0.3) !default; // Sets the box shadow under the popover/ tooltip
+$popover-bottom-position: auto !default; // Sets the bottom position of the popover. Use only when setting positionPopover to false in the script
+$popover-left-position: auto !default; // Sets the left position of the popover. Use only when setting positionPopover to false in the script
+$popover-tooltip-size: 1.3em !default; // Sets the side lengths of the tooltip
+$popover-scroll-indicator-width: 0.625em !default; // The width of the scroll indicator
+$popover-scroll-indicator-aspect-ratio: (15/12) !default; // The ratio of the height over the width of the scroll indicator
+$popover-scroll-indicator-opacity: 0.1 !default; // The active opacity of scroll indicators
+$popover-initial-transform-state: scale(0.1) translateZ(0) !default; // The inital transform state for the popover
+$popover-active-transform-state: scale(1) translateZ(0) !default; // The transform state for the popover once it is fully activated
+
+// OPTIONAL ELEMENTS
+$popover-include-tooltip: true !default; // Adds a tooltip pointing to the footnote button
+$popover-include-scroll-indicator: true !default; // Adds an elipsis at the bottom of scrollable popovers
+$popover-include-scrolly-fades: true !default; // Fades content in on scrollable popovers
+$popover-scroll-indicator-icon: url("data:image/svg+xml;base64,PHN2ZyB3aWR0aD0iMTJweCIgaGVpZ2h0PSIxNXB4IiB2aWV3Qm94PSIwIDAgMTIgMTUiIHZlcnNpb249IjEuMSIgeG1sbnM9Imh0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnIiB4bWxuczp4bGluaz0iaHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluayIgcHJlc2VydmVBc3BlY3RSYXRpbz0ieE1pbllNaW4iPgogICAgPGcgc3Ryb2tlPSJub25lIiBzdHJva2Utd2lkdGg9IjEiIGZpbGw9Im5vbmUiIGZpbGwtcnVsZT0iZXZlbm9kZCI+CiAgICAgICAgPGcgaWQ9IkFycm93IiB0cmFuc2Zvcm09InRyYW5zbGF0ZSgxLjAwMDAwMCwgMS4wMDAwMDApIiBzdHJva2U9ImJsYWNrIiBzdHJva2Utd2lkdGg9IjIiIHN0cm9rZS1saW5lY2FwPSJzcXVhcmUiPgogICAgICAgICAgICA8cGF0aCBkPSJNNSwwIEw1LDExLjUiIGlkPSJMaW5lIj48L3BhdGg+CiAgICAgICAgICAgIDxwYXRoIGQ9Ik0wLjUsNy41IEw1LjAyNzY5Mjc5LDEyLjAyNzY5MjgiIGlkPSJMaW5lIj48L3BhdGg+CiAgICAgICAgICAgIDxwYXRoIGQ9Ik00LjUsNy41IEw5LjAyNzY5Mjc5LDEyLjAyNzY5MjgiIGlkPSJMaW5lLTIiIHRyYW5zZm9ybT0idHJhbnNsYXRlKDcuMDAwMDAwLCAxMC4wMDAwMDApIHNjYWxlKC0xLCAxKSB0cmFuc2xhdGUoLTcuMDAwMDAwLCAtMTAuMDAwMDAwKSAiPjwvcGF0aD4KICAgICAgICA8L2c+CiAgICA8L2c+Cjwvc3ZnPgo=") !default;
+
+
+// OTHER VARIABLES
+// =============================================================================
+
+// POPOVER
+$popover-margin-top: 0.1em !default;
+$popover-padding-content-horizontal: 1.3em !default;
+$popover-padding-content-top: 1.1em !default;
+$popover-padding-content-bottom: 1.2em !default;
+$popover-z-index: 10 !default; // Set the base so that it's above the other body children
+$popover-initial-transform-origin: 50% 0 !default;
+
+// POPOVER CONTENT WRAPPER
+$popover-content-color-background: $popover-color-background !default;
+$popover-content-border-radius: $popover-border-radius !default;
+
+// OTHER POPOVER ELEMENTS
+$popover-tooltip-background: $popover-color-background !default;
+$popover-tooltip-radius: 0 !default;
+$popover-scroll-indicator-bottom-position: 0.45em !default;
+$popover-scrolly-fade-gradient-start-location: 50% !default;
+$popover-scroll-indicator-padding: (($popover-padding-content-horizontal/2) - ($popover-scroll-indicator-width/2)) !default;
+
+// TRANSITIONS
+$popover-transition-default-duration: 0.25s !default;
+$popover-scroll-indicator-transition-properties: opacity !default;
+
+// Use none for areas you don't want to transition
+$popover-transition-properties: opacity, transform !default; // no mixin to do proper prefixing of the transform, so I have to do it manually; see mixin below
+$popover-scroll-indicator-transition-properties: opacity !default;
+$popover-scroll-up-transition-delay: 0.4s !default; // Sets the delay for the transition of the scroll indicator when scrolling upwards
+$popover-transition-default-timing-function: ease !default;
+
+
+
+
+
+// ___ ___ ___
+// _____ /__/\ ___ ___ / /\ /__/\
+// / /::\ \ \:\ / /\ / /\ / /::\ \ \:\
+// / /:/\:\ \ \:\ / /:/ / /:/ / /:/\:\ \ \:\
+// / /:/~/::\ ___ \ \:\ / /:/ / /:/ / /:/ \:\ _____\__\:\
+// /__/:/ /:/\:|/__/\ \__\:\ / /::\ / /::\ /__/:/ \__\:\/__/::::::::\
+// \ \:\/:/~/:/\ \:\ / /://__/:/\:\ /__/:/\:\\ \:\ / /:/\ \:\~~\~~\/
+// \ \::/ /:/ \ \:\ /:/ \__\/ \:\\__\/ \:\\ \:\ /:/ \ \:\ ~~~
+// \ \:\/:/ \ \:\/:/ \ \:\ \ \:\\ \:\/:/ \ \:\
+// \ \::/ \ \::/ \__\/ \__\/ \ \::/ \ \:\
+// \__\/ \__\/ \__\/ \__\/
+//
+// These are the key variables for styling the button.
+// Just set the variable to none if you don't want that styling.
+
+// KEY VARIABLES
+// =============================================================================
+
+$button-height: 0.95em !default; // The total height of the button
+$button-width: auto !default; // The total button width (applies only if $button-apply-dimensions is true)
+$button-inner-circle-size: 0.25em !default; // Total height/width of the ellipsis circles
+$button-border-radius: 0.3em !default; // Border radius on the button itself
+$button-left-margin: 0.2em !default; // Margin between the button and the text to its left
+$button-right-margin: 0.1em !default; // Margin between the button and the text to its right
+$button-vertical-adjust: -0.1em !default; // Pushes the buttons along the vertical axis to align it with text as desired
+$button-inner-circle-left-margin: 1*$button-inner-circle-size !default; // Space between the ellipsis circles
+
+$button-color: #00b386 !default; // Background color of the button
+$button-hovered-color: $button-color !default; // Background color of the button when being hovered
+$button-activating-color: $button-color !default; // Background color of the button when being clicked
+$button-active-color: $button-color !default; // Background color of the button when active
+$button-standard-opacity: 0.2 !default; // Opacity for when the button is just sittin' there
+$button-hovered-opacity: 0.5 !default; // Opacity for when the button is being hovered over
+$button-activating-opacity: $button-hovered-opacity !default; // Opacity for when the button is being clicked
+$button-active-opacity: 1 !default; // Opacity for when the button is active
+$button-active-style-delay: 0.1s !default; // Delay before applying .active styles; this can be used to match to the popover activation transition
+
+$button-inner-circle-color: white !default; // Background color of the ellipsis circle
+$button-inner-circle-border: none !default; // Border of the ellipsis circle
+
+
+// OTHER VARIABLES
+// =============================================================================
+
+$button-total-padding: $button-height - $button-inner-circle-size !default;
+$button-per-side-padding: 0.5*$button-total-padding !default;
+$button-transition-properties: background-color !default;
diff --git a/about/index.html b/about/index.html
new file mode 100644
index 00000000..f8446a9a
--- /dev/null
+++ b/about/index.html
@@ -0,0 +1,459 @@
+
+
+
+
+
+
+About — Ryan P. Randall
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
As an Instructional Designer at Idaho State University, I work to help faculty design engaging, clear, and accessible online courses that improve outcomes for every learner. I’m enthusiastic about open educational resources (OERs) and open pedagogical approaches.
In my previous role as the Instruction Coordinator and Faculty Outreach Librarian for the College of Western Idaho, I worked with students, other librarians, faculty, and staff to promote critical information literacy and library use.
+
+
Prior to librarianship, I earned an MA in English from the University of California, Riverside and an MA in Visual and Cultural Studies from the University of Rochester. While a graduate student, then as an adjunct, I taught what librarians call information literacy skills as the instructor for many first-year writing seminar courses and lower-division American Studies and Film/Media courses. I was also a college writing tutor for undergraduate and graduate students. The path of librarianship took me to IU Bloomington’s MLS program, where my favorite courses emphasized critical information literacy, humanities subject librarianship, and digital humanities.
As I recently mentioned on Mastodon, I’m going to try doing Academic Writing Month (aka “AcWriMo”; a fellow traveler of National Novel Writing Month, or “NaNoWriMo”) this year. Here I’m detailing my approach—I’ll likely also update this with my progress throughout the experiment.
+
+
La Lucha Continúa
+
+
My most consistent writing challenge has always been that writing anything longer than a blog post involves a noticeable state shift. I move—sometimes with effort, sometimes all-too-effortlessly—from mild-mannered riotnrrrd mode to superhuman hyperfocus mode, and occasionally veer into full-on ADHD lasereyes goblin mode.
+
+
This routinely produces good class & conference papers, but isn’t exactly compatible with what one might call responsible adulting.
+
+
So the crux of my dilemma: how to flip my brain into writing mode in sustainable ways that are in fact compatible with responsible adulting?
+
+
AcWriMo2023 Piece
+
+
Here are this year’s AcWriMo experiment parameters, written up somewhat as a Fluxus piece:
+
+
+
Aspire to get into the “writing headspace” for 30 minutes to an hour every other day, i.e. Mon or Tue, Wed or Thu, Fri or Sat., through November 2023.
+
Track the attempts. Probably share the progress & results.
+
“Writing headspace” here ≅ “successfully opened up my writing app and/or successfully annotated readings in one of my two reading apps.”
+
+
+
As you can see, this is taking a process-based approach, not a product-based one. The aim is to see how much I can make a habit of writing in rally mode (i.e. sustained movement) rather than sprinting mode.
+
+
To provide more structure and internal support, I’ve made myself a set of tasks, using Obsidian’s Tasks plugin. Whatever stands a good chance of supporting beneficial progress, right?
+
+
Obsidian & Tasks Details
+
+
While I haven’t yet written a post or note about the Tasks plugin specifically, it’s essentially what has drawn me from Dendron to Obsidian. [Update on 2023-11-29: I now have written about how I currently use the Tasks plugin. I don’t repeat much of what’s below in that other note, so reading both might be worth your while if you’re interested in that aspect of Obsidian.]
+
+
So here I’ll detail how I’m using Tasks to help out with AcWriMo2023, in case you’re the sort of person who appreciates worked examples. If you’re also an Obsidian user, maybe it’ll be a useful example of how you might approach projects & to-dos, using the Tasks plugin?
+
+
Here’s a link to the project tracking file I’ve made for this month’s challenge. Please adapt it to your own use as you’d like! (Here’s a link direct to the file’s raw view, if you just want to copy & paste it from your browser without seeing all the GitHub interface.)
+
+
A few important use/configuration notes:
+
+
I use #tt as a global filter for Tasks. This tells the plugin not to track every single line that starts with a - [ ] checkbox, but only pay attention to the ones that start with - [ ] #tt. I’ll explain my reasons further in that eventual note, but for now, you’ll likely want to find & delete all of those tags, or find & replace them all with your own global filter if you use one.
+
I have #td/writing as an additional tag on each of these tasks. Using this sort of tag lets me use #td as a tag for all my “todo” tasks, then use the /whatever content to create subsets to display anywhere I want to have a Tasks query. Again, I’ll eventually explain this further; for now, I’m just giving any potential users of this a heads up.
+
I’ve also included the due dates for my own purposes. Again, you’ll want to change those for your own scenario. I’m just sharing all this, both to document it for Future Me and to help provide potential structures for anyone else who wants to give AcWriMo a go, last-minute.
+
There’s a Tasks query included in the file, under the Tasks View heading. This will display all the tasks on this very file, putting them in a dynamic pane that lets you change dates and interact with things more handily than you can with the Markdown / text view alone.
+
I feel like way too many people approach Obsidian as though there’s a single “correct way” to use it for tasks or projects. If you’ve read this far—and especially if you’re actually considering using my file—please approach it just as a springboard for your own experimentation. What I think might work for me, right now, isn’t guaranteed to work for me—let alone for you! I’d love it if you let me know that you found it handy or inspiring, of course.
What I didn’t include were particular recommendations for other programs that integrate nicely with Dropbox. Perhaps it’s my college dj training that makes me super hesitant to encourage people to buy a particular program or product when I’m in a more public forum?
+
+
In any case, this is my own space, so here are the programs that I have linked to Dropbox that I use almost daily. None of these are affiliate links, I just think highly of them:
+
+
+
nvALT A free program from Brett Terpstra that stores any number of text files. Using a search bar as the file-picking interface takes a bit of getting used to, but the program’s profoundly useful as a place to store ideas for the future. Just start using breadcrumbs that can help you recall the terms you’ve used—things like adding multiple “q” characters in a row for things of increasing importance, for instance. Michael Schechter shows you which settings to change in order to save your files individually rather than as a single database.
+
Editorial Ole Moritz’s program for iOS lets you work in plain text files and understands Markdown, TaskPaper, and Fountain formatting. It also has templates, automation, and Python scripting, so it’s ridiculously customizable and extendable.
';
+ }
+ resultdiv.append(searchitem);
+ }
+ });
+});
diff --git a/assets/js/lunr/lunr-store.js b/assets/js/lunr/lunr-store.js
new file mode 100644
index 00000000..2adcb350
--- /dev/null
+++ b/assets/js/lunr/lunr-store.js
@@ -0,0 +1,925 @@
+var store = [{
+ "title": "Accessibility Maze",
+ "excerpt":"This is a great way to practice keyboard navigation, as well as learn more about web accessibility more generally. ","categories": [],
+ "tags": [],
+ "url": "/bookmarks/accessibility-maze",
+ "teaser": null
+ },{
+ "title": "Alt-Texts: The Ultimate Guide",
+ "excerpt":"This is a great guide to writing alt text for images. ","categories": [],
+ "tags": [],
+ "url": "/bookmarks/alt-texts-ultimate-guide",
+ "teaser": null
+ },{
+ "title": "ASCCC's OER by Discipline",
+ "excerpt":"I can’t remember how I first encountered this. ","categories": [],
+ "tags": [],
+ "url": "/bookmarks/asccc-oer-by-discipline",
+ "teaser": null
+ },{
+ "title": "Copy-as-Markdown Browser Tool",
+ "excerpt":"I can’t remember where I first encountered Copy as Markdown, but it’s long been one of my favorite small tech tools. I use it multiple times a week—if not multiple times a day—to make a list of all my browser tabs open in a given window. For me, this is...","categories": [],
+ "tags": [],
+ "url": "/bookmarks/copy-as-markdown-browser-tool",
+ "teaser": null
+ },{
+ "title": "Open Encyclopedia of Anthropology",
+ "excerpt":"This looks really useful! It seems like a great resource that could help make it easier to share ways of thinking from social sciences. ","categories": [],
+ "tags": [],
+ "url": "/bookmarks/open-encyclopedia-of-anthology",
+ "teaser": null
+ },{
+ "title": "Stanford Encyclopedia of Philosophy",
+ "excerpt":"I’ve been aware of this for so long that I can’t remember how I first encountered it. ","categories": [],
+ "tags": [],
+ "url": "/bookmarks/standford-encyclopedia-of-philosophy",
+ "teaser": null
+ },{
+ "title": "Apple Watch ADHD",
+ "excerpt":"I’ve been wanting to write about some ways that my smartwatch has helped me deal with the fact that I perceive time differently than most neurotypical people. It’s an example of what Aimi Hamraie has called “ADHD technologies.”1 Timers I use the timer function often—especially when I’m doing any kind...","categories": [],
+ "tags": [],
+ "url": "/notes/ADHD-tech/apple-watch-ADHD",
+ "teaser": null
+ },{
+ "title": "About ADHD technologies",
+ "excerpt":"I recently saw this tweet by Aimi Hamraie, with the hashtag ADHDtechnologies: Have been getting lots of questions about how to be an academic with ADHD. Different for all of us but here is one of my #adhdtechnologies: a flip-top notebook with running to do lists that I keep on...","categories": [],
+ "tags": [],
+ "url": "/notes/ADHD-tech/about-ADHD-technologies",
+ "teaser": null
+ },{
+ "title": "ADHD tech",
+ "excerpt":" Pinned ADHD tech notes 📌 About ADHD technologies :seedling: All ADHD tech items 📌 About ADHD technologies :seedling: Apple Watch ADHD :herb: ","categories": [],
+ "tags": [],
+ "url": "/notes/ADHD-tech/index",
+ "teaser": null
+ },{
+ "title": "ADHD",
+ "excerpt":" All ADHD items There's nothing here yet! ","categories": [],
+ "tags": [],
+ "url": "/notes/ADHD/index",
+ "teaser": null
+ },{
+ "title": "Accessibility",
+ "excerpt":" All Accessibility items Math Accessibility :seedling: ","categories": [],
+ "tags": [],
+ "url": "/notes/Accessibility/index",
+ "teaser": null
+ },{
+ "title": "Listening",
+ "excerpt":"Welcome to my Listening notes! All Listening items There's nothing here yet! ","categories": [],
+ "tags": [],
+ "url": "/notes/Listening/index",
+ "teaser": null
+ },{
+ "title": "Approaches",
+ "excerpt":" All Approaches items Casey Boyle's …something like a reading ethics… :seedling: Rhetorical Précis :seedling: ","categories": [],
+ "tags": [],
+ "url": "/notes/Note-taking/Approaches/index",
+ "teaser": null
+ },{
+ "title": "Dendron",
+ "excerpt":" All Dendron items Beginning to Use Dendron :seedling: Literature Notes in Dendron :seedling: Task Tracking in Dendron :seedling: ","categories": [],
+ "tags": [],
+ "url": "/notes/Note-taking/Dendron/index",
+ "teaser": null
+ },{
+ "title": "Literature Notes in Dendron",
+ "excerpt":"I’ve been refining a system for taking literature notes in Dendron, which complements keeping citations with Zotero. My systems remain perpetually in flux, but this is at least my most current write-up, if not my most current approach. Dendron is an extension for the text editor VS Code. If you...","categories": [],
+ "tags": [],
+ "url": "/notes/Note-taking/Dendron/literature-notes-dendron",
+ "teaser": null
+ },{
+ "title": "Obsidian",
+ "excerpt":" All Obsidian items Beginning to Use Obsidian :seedling: Obsidian Plugins :herb: Obsidian Tasks Plugin :herb: ","categories": [],
+ "tags": [],
+ "url": "/notes/Note-taking/Obsidian/index",
+ "teaser": null
+ },{
+ "title": "Social Media",
+ "excerpt":" All Social Media items Mastodon Apps :herb: Mastodon Settings :seedling: Mastodon Starting Points :seedling: ","categories": [],
+ "tags": [],
+ "url": "/notes/Technology/Social-Media/index",
+ "teaser": null
+ },{
+ "title": "VS Code",
+ "excerpt":" All VS Code items Daybreak Theme :herb: VS Code Snippets :herb: VS Code Spellcheck Squiggles :herb: VS Code note :seedling: ","categories": [],
+ "tags": [],
+ "url": "/notes/Technology/VS-Code/index",
+ "teaser": null
+ },{
+ "title": "VS Code note",
+ "excerpt":"Here’s where I’ll detail aspects of how I set up and use of VS Code, which I adopted so I could use Dendron in particular. You can learn more about how I use Dendron in literature notes in dendron. ","categories": [],
+ "tags": [],
+ "url": "/notes/Technology/VS-Code/vs-code",
+ "teaser": null
+ },{
+ "title": "Daybreak Theme",
+ "excerpt":"Horizon, then Daybreak I’m a big fan of dark themes. I’ve been using variants of Horizon for quite a while now in VS Code (as you can read about in vs code note), since I like the overall warmth of the theme’s color palette. Unfortunately, the person who initially designed...","categories": [],
+ "tags": [],
+ "url": "/notes/Technology/VS-Code/daybreak-theme",
+ "teaser": null
+ },{
+ "title": "Beginning to Use Dendron",
+ "excerpt":"What is Dendron? Dendron lets you create—and more importantly, organize—plain text notes in VS Code. It not only lets you link between notes like a wiki, it makes notes findable through a tree view and customizable, hierarchical organization. I’m such a fan that I switched from Atom to VS Code...","categories": [],
+ "tags": [],
+ "url": "/notes/Note-taking/Dendron/beginning-to-use-dendron",
+ "teaser": null
+ },{
+ "title": "Math Accessibility",
+ "excerpt":"Assumed audience People relatively—or almost entirely—new to web publishing I’ve lately done some work to improve the accessibility of math notation (equations, symbols, etc.) for users of screen readers online, particularly for the creation of open educational resources (OER). It’s been an unexpectedly engrossing investigation, so I figured I’d share...","categories": [],
+ "tags": [],
+ "url": "/notes/Accessibility/math-a11y",
+ "teaser": null
+ },{
+ "title": "Keywords",
+ "excerpt":"All Keywords folders Pinned Keywords notes All Keywords items There's nothing here yet! ","categories": [],
+ "tags": [],
+ "url": "/notes/Keywords/index",
+ "teaser": null
+ },{
+ "title": "Task Tracking in Dendron",
+ "excerpt":"My notes in Dendron are an unruly, monstrous hybrid of a bullet journal, a log, a set of resources, and other information. And I like it like that! They’re a continuation of the monthly planning files I used before Dendron came along. So if I use Dendron as a combination...","categories": [],
+ "tags": [],
+ "url": "/notes/Note-taking/Dendron/task-tracking-in-dendron",
+ "teaser": null
+ },{
+ "title": "Actively Engaging Students in Asynchronous Online Classes.",
+ "excerpt":"From the paper’s own abstract: This paper suggests a three-pronged approach for conceptualizing active learning in the online asynchronous class: the creation of an architecture of engagement in the online classroom, the use of web-based tools in addition to the learning management system, and a re-imagining of discussion boards as...","categories": [],
+ "tags": [],
+ "url": "/notes/Reading/Articles/riggs-and-linder-actively-engaging-students",
+ "teaser": null
+ },{
+ "title": "Jekyll",
+ "excerpt":" All Jekyll items Jekyll Guides :seedling: ","categories": [],
+ "tags": [],
+ "url": "/notes/Technology/Jekyll/index",
+ "teaser": null
+ },{
+ "title": "Mastodon Apps",
+ "excerpt":"I’ve been using Mastodon for a while. Apparently at least since April of 2017‽?! I tend to use Mastodon on my phone at least as much as I do through a browser. At various times I’ve used Toot!, Metatext, Mast, Amaroq, and just a browser tab pinned to appear as...","categories": [],
+ "tags": [],
+ "url": "/notes/Technology/Social-Media/mastodon-apps",
+ "teaser": null
+ },{
+ "title": "Mastodon Settings",
+ "excerpt":"Assumed Audience and Scope This isn’t trying to be comprehensive, or even an overview. This is just me briefly writing up some notes, as if I were explaining the settings to someone in my family. I’m not checking every setting to see if my recommendation varies from the default. If...","categories": [],
+ "tags": [],
+ "url": "/notes/Technology/Social-Media/mastodon-settings",
+ "teaser": null
+ },{
+ "title": "Jekyll Guides",
+ "excerpt":"I really enjoy using Jekyll, enough that I’d recommend it to anyone who is both looking to make their own site and has the time or inclination to do more “behind the scenes” than necessary for site made with WordPress or Squarespace. Jekyll’s own documentation is one of the most...","categories": [],
+ "tags": [],
+ "url": "/notes/Technology/Jekyll/jekyll-guides",
+ "teaser": null
+ },{
+ "title": "Casey Boyle's …something like a reading ethics…",
+ "excerpt":"This strategy for reading is meant to build better habits of reading, as well as better note-taking. It’s a nice complement to a rhetorical-precis, but more open-ended. Casey Boyle’s “…something like a reading ethics…” Casey’s post on his approach (via the WaybackMachine) explains it in excellent detail. It’s very much...","categories": [],
+ "tags": [],
+ "url": "/notes/Note-taking/Approaches/casey-boyle-something-like-reading-ethics",
+ "teaser": null
+ },{
+ "title": "Rhetorical Précis",
+ "excerpt":"One of the most frustrating things about reading widely is the situation where you’ve read something, but can’t recall any details or situate that piece among the other things you’ve read. As with Casey Boyle’s “…something like a reading ethics…,” writing a rhetorical précis is a great, brief method for...","categories": [],
+ "tags": [],
+ "url": "/notes/Note-taking/Approaches/rhetorical-precis",
+ "teaser": null
+ },{
+ "title": "Articles",
+ "excerpt":" All my notes on articles I've read Actively Engaging Students in Asynchronous Online Classes. :herb: All my reading notes on articles by year There's nothing here yet! ","categories": [],
+ "tags": [],
+ "url": "/notes/Reading/Articles/index",
+ "teaser": null
+ },{
+ "title": "Books",
+ "excerpt":"All my notes on books I've read Capital is Dead. Is This Something Worse? :herb: Policing the Crisis: Mugging, the State, and Law and Order :herb: Overwhelmed: Literature, Aesthetics, and the Nineteenth-Century Information Revolution :herb: Modernist Informatics: Literature, Information, and the State :herb: All my reading notes on books by...","categories": [],
+ "tags": [],
+ "url": "/notes/Reading/Books/index",
+ "teaser": null
+ },{
+ "title": "Capital is Dead. Is This Something Worse?",
+ "excerpt":"Wark asks us to think about information less like Marxists and more like Marx. ","categories": [],
+ "tags": [],
+ "url": "/notes/Reading/Books/wark-capital-is-dead",
+ "teaser": null
+ },{
+ "title": "Modernist Informatics: Literature, Information, and the State",
+ "excerpt":"Purdon examines modernist fiction to trace how writers experienced information culture as a disturbing interruption and governmental intrusion. ","categories": [],
+ "tags": [],
+ "url": "/notes/Reading/Books/purdon-modernist-informatics",
+ "teaser": null
+ },{
+ "title": "Policing the Crisis: Mugging, the State, and Law and Order",
+ "excerpt":"Hall and cowriters provide a classic analysis of the rhetoric of a moral panic. ","categories": [],
+ "tags": [],
+ "url": "/notes/Reading/Books/hall-policing-the-crisis",
+ "teaser": null
+ },{
+ "title": "VS Code Snippets",
+ "excerpt":"This is one of my longest notes. Please don’t forget that the Table of Contents can help you jump to a particular section! I’m a fan of keeping a Bullet Journal in a text editor, as I’ve written about in task-tracking-in-dendron. A Digital Bullet Journal might not seem like a...","categories": [],
+ "tags": [],
+ "url": "/notes/Technology/VS-Code/vs-code-snippets",
+ "teaser": null
+ },{
+ "title": "VS Code Spellcheck Squiggles",
+ "excerpt":"There are a number of spellchecking extensions available for VS Code. I realized recently that I’d disabled the spellcheck I installed because of how distracting I found VS Code’s default squiggly lines. So I set about making them less intrusive, but still easily perceptible. Step 1: Check the Notification Class...","categories": [],
+ "tags": [],
+ "url": "/notes/Technology/VS-Code/vs-code-spellcheck-squiggles",
+ "teaser": null
+ },{
+ "title": "Beginning to Use Obsidian",
+ "excerpt":"What is Obsidian? Well, it’s complicated. And so are my feelings. The simple version is that Obsidian is an app that lets you write linked notes, mostly in Markdown format, and can render dynamically-updated sections of those notes. This last piece—the dynamic updating—is what makes it compelling and complicated. The...","categories": [],
+ "tags": [],
+ "url": "/notes/Note-taking/Obsidian/beginning-to-use-obsidian",
+ "teaser": null
+ },{
+ "title": "Obsidian Plugins",
+ "excerpt":"Assumed audience People at least passably familiar with Obsidian. See my other notes on Obsidian for more context. What’s the Big Deal about Obsidian Plugins? One of the best—and most anxiety-producing, from the viewpoint of long-term stability—aspects of Obsidian is how the developers have opened up the app to community...","categories": [],
+ "tags": [],
+ "url": "/notes/Note-taking/Obsidian/obsidian-plugins",
+ "teaser": null
+ },{
+ "title": "Obsidian Tasks Plugin",
+ "excerpt":"Assumed audience People at least passably familiar with Obsidian. See my other notes on Obsidian for more context. beginning-to-use-obsidian obsidian-plugins What is the Tasks plugin? Originally written by Martin Schenck and now expertly maintained by Clare Macrae, the Tasks plugin is the thing that ultimately convinced me to switch from...","categories": [],
+ "tags": [],
+ "url": "/notes/Note-taking/Obsidian/obsidian-tasks-plugin-patterns",
+ "teaser": null
+ },{
+ "title": "Zotero",
+ "excerpt":" All Zotero items Zotero Advanced Features :herb: ","categories": [],
+ "tags": [],
+ "url": "/notes/Note-taking/Zotero/index",
+ "teaser": null
+ },{
+ "title": "Information Informatics",
+ "excerpt":"Here are some insightful snippets about “information” & “informatics” that I’ve found. 2020 Purdon, Modernist Informatics Modernist Informatics: Literature, Information, and the State In the company kept by the word—public service and business, agency and control—we can begin to discern the outline of a modern understanding of information as a...","categories": [],
+ "tags": [],
+ "url": "/notes/Snippets/information-informatics",
+ "teaser": null
+ },{
+ "title": "Zotero Advanced Features",
+ "excerpt":"Assumed audience People at least passably familiar with Zotero, a free to use, cross-platform research tool. Original Publication Date For those of us who work in the humanities and social sciences, it’s common for sources to have been published in multiple versions. But Zotero only has a single date field!...","categories": [],
+ "tags": [],
+ "url": "/notes/Note-taking/Zotero/zotero-advanced-features",
+ "teaser": null
+ },{
+ "title": "Note taking",
+ "excerpt":"All Note taking folders Approaches Dendron Obsidian Zotero All Note taking items Casey Boyle's …something like a reading ethics… :seedling: Rhetorical Précis :seedling: Beginning to Use Dendron :seedling: Literature Notes in Dendron :seedling: Task Tracking in Dendron :seedling: Beginning to Use Obsidian :seedling: Obsidian Plugins :herb: Obsidian Tasks Plugin :herb:...","categories": [],
+ "tags": [],
+ "url": "/notes/Note-taking/index",
+ "teaser": null
+ },{
+ "title": "Pedagogy",
+ "excerpt":" All Pedagogy items There's nothing here yet! ","categories": [],
+ "tags": [],
+ "url": "/notes/Pedagogy/index",
+ "teaser": null
+ },{
+ "title": "Overwhelmed: Literature, Aesthetics, and the Nineteenth-Century Information Revolution",
+ "excerpt":"Lee explores the history of how various cultural formations around literature and information grew through the 19th Century Information Revolution. ","categories": [],
+ "tags": [],
+ "url": "/notes/Reading/Books/lee-overwhelmed",
+ "teaser": null
+ },{
+ "title": "Reading",
+ "excerpt":"All Reading folders Articles Books All notes on what I've read Overwhelmed: Literature, Aesthetics, and the Nineteenth-Century Information Revolution :herb: Capital is Dead. Is This Something Worse? :herb: Policing the Crisis: Mugging, the State, and Law and Order :herb: Actively Engaging Students in Asynchronous Online Classes. :herb: Modernist Informatics: Literature,...","categories": [],
+ "tags": [],
+ "url": "/notes/Reading/index",
+ "teaser": null
+ },{
+ "title": "Snippets",
+ "excerpt":" All Snippets items Information Informatics :seedling: ","categories": [],
+ "tags": [],
+ "url": "/notes/Snippets/index",
+ "teaser": null
+ },{
+ "title": "Mastodon Starting Points",
+ "excerpt":"Assumed Audience and Scope This is for people who are interested in Mastodon and looking for tips to become more comfortable using it and finding people on it. There have been many, many “how to” articles written about Mastodon. So many that I figure it might be useful to curate...","categories": [],
+ "tags": [],
+ "url": "/notes/Technology/Social-Media/mastodon-starting-points",
+ "teaser": null
+ },{
+ "title": "Technology",
+ "excerpt":"All Technology folders Jekyll Social Media VS Code All Technology items Jekyll Guides :seedling: Mastodon Apps :herb: Mastodon Settings :seedling: Mastodon Starting Points :seedling: Daybreak Theme :herb: VS Code Snippets :herb: VS Code Spellcheck Squiggles :herb: VS Code note :seedling: ","categories": [],
+ "tags": [],
+ "url": "/notes/Technology/index",
+ "teaser": null
+ },{
+ "title": "Critical Thinking Formula",
+ "excerpt":"“Critical” in Thinking or Theory It’s long struck me as peculiar that both “critical thinking” and “critical theory” distinguish themselves with the word “critical”—but mean different things with that word. My best attempt to make sense of this difference is that “critical thinking” aims to uncover the hidden assumptions in...","categories": [],
+ "tags": [],
+ "url": "/notes/Thinking/critical-thinking-formula",
+ "teaser": null
+ },{
+ "title": "Thinking",
+ "excerpt":"All Thinking folders All Thinking items Critical Thinking Formula :seedling: ","categories": [],
+ "tags": [],
+ "url": "/notes/Thinking/index",
+ "teaser": null
+ },{
+ "title": "Emerging Notes",
+ "excerpt":"Welcome to my notes! This is my digital garden—a loosely tended succulent collection of lines of thought represented in pixels. Unlike my blog posts, which remain largely static, these notes grow and change. Show yourself around! :seedling: Emerging Notes _notes/ADHD-tech/about-ADHD-technologies.md :seedling: _notes/Accessibility/math-a11y.md :seedling: _notes/Note-taking/Approaches/casey-boyle-something-like-reading-ethics.md :seedling: _notes/Note-taking/Approaches/rhetorical-precis.md :seedling: _notes/Note-taking/Dendron/beginning-to-use-dendron.md :seedling: _notes/Note-taking/Dendron/literature-notes-dendron.md...","categories": [],
+ "tags": [],
+ "url": "/notes/emerging-notes",
+ "teaser": null
+ },{
+ "title": "Notes Index, aka my Digital Garden",
+ "excerpt":"Welcome to my digital garden of notes! This is my digital garden—a loosely tended succulent collection of lines of thought represented in pixels. Unlike my blog posts, which remain largely static, these notes grow and change. Show yourself around! All folders ADHD ADHD-tech Accessibility Keywords Listening Note-taking Pedagogy Reading Snippets...","categories": [],
+ "tags": [],
+ "url": "/notes/index",
+ "teaser": null
+ },{
+ "title": "New Site",
+ "excerpt":"Complicating, circulating…new site, new site. Operating, generating…new site, new site. Thanks for coming by, and for indulging my Depeche Mode reference.1 This new site is decidedly in an early state of becoming, as I figure out how to use Jekyll and this particular theme. I’ll probably use this for more...","categories": [],
+ "tags": ["meta"],
+ "url": "/new-site",
+ "teaser": null
+ },{
+ "title": "Test One",
+ "excerpt":" If everything is ready from the dark side of the moon… …play the five tones. ","categories": [],
+ "tags": ["meta"],
+ "url": "/test-one",
+ "teaser": null
+ },{
+ "title": "New Directions in Information Fluency",
+ "excerpt":"On April 4th & 5th, I drove up to Augustana College in Rock Island, Illinois with my friend & colleague Katherine Ahnberg for the New Directions in Information Literacy conference at Augustana College. As Katherine recently wrote, we presented a brief history of humanities computing (digital humanities or DH), an...","categories": ["blog"],
+ "tags": ["conferences","presentations","digital humanities"],
+ "url": "/blog/new-directions-in-information-fluency",
+ "teaser": null
+ },{
+ "title": "Bigfoot Spotting and Other Jekyll Adventures",
+ "excerpt":"Here’s a test of Bigfoot.js, a rather awesome addition to the web. 1 (edit: It’ll remain elusive, see footnote #2.)2 (edit № 2: I’ve gotten it to work, as of 2015-05-31! It wasn’t an issue with Jekyll or GitHub Pages, but rather with my understanding of how Jekyll & GitHub...","categories": [],
+ "tags": ["meta","tech tools"],
+ "url": "/bigfoot-spotting",
+ "teaser": null
+ },{
+ "title": "Review of Online Archive of California",
+ "excerpt":"This post was originally an assignment for John Walsh’s “Z652 Digital Libraries” course at IU-Bloomington. A fantastic clearing house of information about Californian collections, the Online Archive of California serves as a centralized set of links to and descriptions of an enormous number of collections from various archives, historical societies,...","categories": [],
+ "tags": ["digital humanities","coursework"],
+ "url": "/review-of-online-archive-of-california",
+ "teaser": null
+ },{
+ "title": "Software Carpentry Workshop Reflections",
+ "excerpt":"Welcome to the Command Line It wasn’t quite Tron: I jumped into the world of computing for two days while taking a Software Carpentry workshop and it turned out highly illuminating without being threatening. This post aims to summarize what I learned & its relevance to librarians and/or digital humanities...","categories": [],
+ "tags": ["digital humanities"],
+ "url": "/software-carpentry-workshop-reflections",
+ "teaser": null
+ },{
+ "title": "“Paper,” “Planned Obsolescence,” and Digital Libraries",
+ "excerpt":"This post was originally an assignment for John Walsh’s “Z652 Digital Libraries” course at IU-Bloomington. Two talks given at IU in the last month offer insights for digital libraries, one benefiting from direct experimentation with forms of scholarly communication and sustained analysis of academic practices, while the other’s scope provides...","categories": [],
+ "tags": ["digital libraries","coursework"],
+ "url": "/paper-planned-obsolescence-and-digital-libraries",
+ "teaser": null
+ },{
+ "title": "#critlib Chatty Critical Librarianship on Twitter",
+ "excerpt":"Here’s a post I wrote for Hack Libary School on critical librarianship and the #critlib chats on Twitter. I also discuss student-led interests groups, metacognition, and Bloom’s Taxonomy of educational objectives. There’s even a brief bibliography of anthologies to check out for more on critical librarianship. ","categories": [],
+ "tags": ["critlib chats","hack library school"],
+ "url": "/critlib-chatty-critical-librarianship-on-twitter",
+ "teaser": null
+ },{
+ "title": "How Do You Take Notes (or Markdown and Bullet Journals)",
+ "excerpt":"Here’s a post I wrote for Hack Library School discussing Markdown and the Bullet Journal system for note-taking. Markdown is a simplified way of writing html, and happens to also be what I use when writing this site through Jekyll and GitHub Pages. Bullet Journals are a system not for...","categories": [],
+ "tags": ["hack library school","markdown","meta","notetaking"],
+ "url": "/how-do-you-take-notes-or-markdown-and-bullet-journals",
+ "teaser": null
+ },{
+ "title": "Freire and Critical Librarianship",
+ "excerpt":"This post is for Week One of MOOC MOOC: Critical Pedagogy. Processes. Processes, all the way down. That’s what strikes me most about the first three chapters of Freire’s The Pedagogy of the Oppressed: his insistence on processes of becoming, of history, of liberation, and of course, of pedagogy through...","categories": [],
+ "tags": ["critlib chats","pedagogy","moocmooc","critical theory","featured"],
+ "url": "/freire-and-critical-librarianship",
+ "teaser": null
+ },{
+ "title": "#critlib Makerspaces",
+ "excerpt":"Friend or Foe? I recently had the pleasure of moderating a #critlib chat on Makerspaces. These spaces have been enjoying increasing popularity in libraries, demonstrating how libraries function as far more than warehouses for documents. At their best, makerspaces help community members learn by doing, regardless of whether these spaces...","categories": [],
+ "tags": ["critlib chats","pedagogy","makerspaces"],
+ "url": "/critlib-makerspaces",
+ "teaser": null
+ },{
+ "title": "Wojnarowicz on a Sphere",
+ "excerpt":":warning: :construction: This post is currently under construction. The actual project grew out of an assignment for John Walsh’s “Z652 Digital Libraries” course at IU-Bloomington. When I learned that we would be doing a mapping project for John Walsh’s Digital Humanities course, two artists quickly sprang to mind due to...","categories": [],
+ "tags": ["coursework","digital humanities","visual culture"],
+ "url": "/wojnarowicz-on-a-sphere",
+ "teaser": null
+ },{
+ "title": "Learning Subjectives",
+ "excerpt":"This post is for Week One of #rhizo15. Here’s something I constantly rediscover, sometimes painfully: although I’m a capable writer, I’m predisposed toward research. This orientation seems both a boon and a hindrance as an aspiring academic librarian. Research calls to me in large part because of its rhizomatic nature—I...","categories": [],
+ "tags": ["rhizo15","neutrality","pedagogy","digital humanities"],
+ "url": "/learning-subjectives",
+ "teaser": null
+ },{
+ "title": "Hack Quirk Your Presentations",
+ "excerpt":"A new post of mine recently went up at Hack Library School. It’s about a simple technique that I’ve noticed can help instruction sessions or resource demonstrations feel a bit more exciting and memorable: highlighting a quirky result or aspect of the interface. As a bonus, I talk about Batman,...","categories": [],
+ "tags": ["hack library school","instructional design & tools","digital humanities"],
+ "url": "/del-hack-del-quirk-your-presentations",
+ "teaser": null
+ },{
+ "title": "Everything Counts in Affective Amounts",
+ "excerpt":"This post is for Week Two of #rhizo15. Typing Hands Type What They Can Over the last week I’ve effectively been teaching myself Zurb’s Foundation website framework as part of using it to make a prototype website for an information architecture course. Participating in #rhizo15 has primed me to really...","categories": [],
+ "tags": ["rhizo15","digital humanities","tech tools"],
+ "url": "/everything-counts-in-affective-amounts",
+ "teaser": null
+ },{
+ "title": "#Rhizo15 Week Three: "Content is People"",
+ "excerpt":"This post is for Week Three of #rhizo15: “The Myth of Content.” Even though I’m writing this during Week Five, I’m trying to put my thoughts out a little quicker than usual in this post, in keeping with my post from Week One. For Week Three, Dave asked: So what...","categories": [],
+ "tags": ["rhizo15","pedagogy","critical information literacy"],
+ "url": "/rhizo15-week-three",
+ "teaser": null
+ },{
+ "title": "Quick Thoughts on Method & Knowledge Practices in Arts & Humanities",
+ "excerpt":"Earlier today I saw a few #critlib threads swirling around on Twitter—here’s one and here’s another. The ones that caught my eyes mostly had to do with how open #critlib twitter chats & their participants seem to critique or criticism, the extent to which critical theory has to do with...","categories": [],
+ "tags": ["critlib chats","pedagogy","method"],
+ "url": "/quick-thoughts-on-method",
+ "teaser": null
+ },{
+ "title": "Presentation Alternatives: Reveal.js",
+ "excerpt":"Here’s a post I wrote for Hack Library School talking about my experience with the Reveal.js JavaScript presentation framework. Not only does it hew to my goal of choosing open-source tools over proprietary formats whenever feasible, its functionality and inherent ability to make presentations shareable on the web make it...","categories": [],
+ "tags": ["presentations","tech tools","pedagogy","critical theory","a11y","hack library school"],
+ "url": "/reveal-js-hack-library-school",
+ "teaser": null
+ },{
+ "title": "Critical Hot Potato! aka #Rhizo15 Week Four",
+ "excerpt":"This post responds to the prompt for Week Four of #rhizo15: “How Do We Teach Rhizomatically?”. For Week Four, Dave asked: “I think there is value in the ‘course’ in the sense of the eventedness that it represents. It’s a chance for people to come together and focus on a...","categories": [],
+ "tags": ["rhizo15","critlib chats","critical theory"],
+ "url": "/critpotato-rhizo15-week-four",
+ "teaser": null
+ },{
+ "title": "All Hail Cloud Storage",
+ "excerpt":"I wrote for Hack Library School about why & how I use Dropbox. What I didn’t include were particular recommendations for other programs that integrate nicely with Dropbox. Perhaps it’s my college dj training that makes me super hesitant to encourage people to buy a particular program or product when...","categories": [],
+ "tags": ["hack library school","markdown","meta","tech tools"],
+ "url": "/all-hail-cloud-storage",
+ "teaser": null
+ },{
+ "title": "Weekly Assemblage 2015 Week 36",
+ "excerpt":"#radlibchat “Librarians’ views on critical theories and critical practices” On Tuesday, 2015-09-01, there was a great #radlibchat focused on librarians’ views of critical theories and critical practices. Hosted by the Radical Librarians Collective, this recently-begun set of chats take place once a month. Much like #critlib chats, they suggest readings...","categories": ["weekly-assemblage"],
+ "tags": ["critical theory","privacy"],
+ "url": "/weekly-assemblage/weekly-assemblage-2015-week-36",
+ "teaser": null
+ },{
+ "title": "Weekly Assemblage 2015 Week 37",
+ "excerpt":"#critlib chat on Information & Migrant Populations Tuesday, 2015-09-08, saw a #critlib Twitter chat on information & migrant populations. Amiably—and admirably—moderated by Greg Bemb, this chat took a broad approach to considering the information and access needs of different migrant communities. Participants considered international migration, urbanization within a particular country,...","categories": ["weekly-assemblage"],
+ "tags": ["critlib chats","privacy","cfp","critical race studies"],
+ "url": "/weekly-assemblage/weekly-assemblage-2015-week-37",
+ "teaser": null
+ },{
+ "title": "Weekly Assemblage 2015 Week 38",
+ "excerpt":"I’m posting this week’s write-up a bit late since this week was basically spent furiously packing and then on the road, moving from Bloomington, Indiana all the way to Boise, Idaho! This week we’ve got photos of that trip, plus reflections on a book I read before the trip. Westward,...","categories": ["weekly-assemblage"],
+ "tags": ["critical theory"],
+ "url": "/weekly-assemblage/weekly-assemblage-2015-week-38",
+ "teaser": null
+ },{
+ "title": "Weekly Assemblage 2015 Week 39",
+ "excerpt":"I’m publishing this week’s write-up rather late—but I do want to document the experience of moving somewhat, for other future librarians who move! Couple new library cards to really help me feel welcomed! #westwardidaho A photo posted by Ryan Randall (@foureyedsoul) on Sep 26, 2015 at 5:07pm PDT This...","categories": ["weekly-assemblage"],
+ "tags": ["pedagogy","critical information literacy"],
+ "url": "/weekly-assemblage/weekly-assemblage-2015-week-39",
+ "teaser": null
+ },{
+ "title": "This Is Not a Pipette: Bringing Humanities Methods into LIS Programs",
+ "excerpt":"I recently wrote a post for Hack Library School on examples of how we might break humanities methodologies to bear on information studies. In part, I wrote this in response to the recent statement by the editors of College & Research Libraries that they are looking for papers that use...","categories": [],
+ "tags": ["hack library school","critical theory"],
+ "url": "/this-is-not-a-pipette",
+ "teaser": null
+ },{
+ "title": "Weekly Assemblage 2015 Week 40",
+ "excerpt":"Here’s another decidedly-after-the-fact post—who knew that moving could upend so many things? This week I began my position as the Instruction and Outreach Librarian at the College of Western Idaho! Peculiarly enough, my starting date aligned with the annual conference of the Idaho state library association. Rather than have me...","categories": ["weekly-assemblage"],
+ "tags": ["conferences"],
+ "url": "/weekly-assemblage/weekly-assemblage-2015-week-40",
+ "teaser": null
+ },{
+ "title": "Weekly Assemblage 2015 Week 41",
+ "excerpt":"#critlib chat on Scientific Objectivity Rory Litwin of Library Juice Press recently moderated a #critlib Twitter chat on neutrality and objectivity in scientific information. Referencing the “Scientific Objectivity” article by Julian Reiss and Jan Sprenger from the excellent, open-access Stanford Encyclopedia of Philosophy, this chat dealt with the tension between...","categories": ["weekly-assemblage"],
+ "tags": ["critlib chats","critical information literacy","critical race studies"],
+ "url": "/weekly-assemblage/weekly-assemblage-2015-week-41",
+ "teaser": null
+ },{
+ "title": "Weekly Assemblage 2015 Week 42",
+ "excerpt":"Crissinger’s “Being ‘Human’ in the Classroom” Live! Real! Human! Sarah Crissinger’s recent “Being ‘Human’ in the Classroom: A Case for Personal Testimony in Pedagogy” post at ACRLog does a wonderful job of giving specifics on how librarians can use our personal experiences with the research process while instructing students. Maybe...","categories": ["weekly-assemblage"],
+ "tags": ["critical information literacy","pedagogy"],
+ "url": "/weekly-assemblage/weekly-assemblage-2015-week-42",
+ "teaser": null
+ },{
+ "title": "Weekly Assemblage 2015 Week 43",
+ "excerpt":"We’ve had two notable projects at our library this week: working on a “Five Year Vision of the Library” document and preparing for the Halloween outreach events. I’ll post photos of the outreach things next week, but this week I’ll just mention that a shared, editable Google Doc has worked...","categories": ["weekly-assemblage"],
+ "tags": ["critlib chats","gender","librar* history"],
+ "url": "/weekly-assemblage/weekly-assemblage-2015-week-43",
+ "teaser": null
+ },{
+ "title": "Weekly Assemblage 2015 Week 44",
+ "excerpt":"This Is Halloween A couple of the CWI Library student workers suggested Once Upon a Time as a theme for our Halloween decorations, and we ended up embracing it enthusiastically. I admittedly had to do some ahem “binge watching research” on Netflix, but our approach to the theme said that...","categories": ["weekly-assemblage"],
+ "tags": ["outreach"],
+ "url": "/weekly-assemblage/weekly-assemblage-2015-week-44",
+ "teaser": null
+ },{
+ "title": "Weekly Assemblage 2015 Week 45",
+ "excerpt":"Read of the Week As an Instruction & Outreach Librarian, one of the things I’m currently trying to do is revamp our fliers and other materials that broadcast what we can do for instructors. Our current materials were written before the ACRL Framework came out, so I’m trying to update...","categories": ["weekly-assemblage"],
+ "tags": ["critical information literacy","meta"],
+ "url": "/weekly-assemblage/weekly-assemblage-2015-week-45",
+ "teaser": null
+ },{
+ "title": "WA 2015 Week 46 Massumi and North",
+ "excerpt":"Reads of the Week! “Undigesting Deleuze” by Brian Massumi, accessible at LA Review of Books “The Idea of a Writing Center” by Stephen M. North in College English v46 n5 p433-46 Sep 1984 This has been a week of reading things that help me frame librarianship in new ways. The...","categories": ["weekly-assemblage"],
+ "tags": ["critical theory","infrastucture","critical information literacy"],
+ "url": "/weekly-assemblage/WA-2015-week-46-Massumi-and-North",
+ "teaser": null
+ },{
+ "title": "WA 2015 Week 47 Schoofs and Battista",
+ "excerpt":"Reads this Week How did I forget about the LOEX Quarterly’s articles being effectively open access after a year? This means it’s a great place to look for articles to share, such as for #critlib discussions. These two are both short enough that I won’t really reprise much of them...","categories": ["weekly-assemblage"],
+ "tags": ["critical information literacy"],
+ "url": "/weekly-assemblage/wa-2015-week-47",
+ "teaser": null
+ },{
+ "title": "WA 2015 Week 48 Fister, Kurz, Vecchione",
+ "excerpt":"Reads this Week It’s 2015-12-12 and I’m still looking at the rough draft of this post languishing unpublished. So instead of trying to annotate why I like these so much, I’m just going to grab a quote that I hope entices you to read each of them. Clearly, I’m still...","categories": ["weekly-assemblage"],
+ "tags": ["makerspaces"],
+ "url": "/weekly-assemblage/wa-2015-week-48",
+ "teaser": null
+ },{
+ "title": "WA 2015 Week 49 Holman, Mattern, Barron, Students",
+ "excerpt":"Reads This Week It’s 2015-12-12 and I’m still looking at the rough draft of this post languishing unpublished. So instead of heavily annotating why I like these so much, I’m just going to grab a quote that I hope entices you to read each of them. Clearly, I’m still figuring...","categories": ["weekly-assemblage"],
+ "tags": ["makerspaces","infrastucture"],
+ "url": "/weekly-assemblage/wa-2015-week-49",
+ "teaser": null
+ },{
+ "title": "critlib #feelings",
+ "excerpt":"This is a post for the upcoming #critlib chat: “#feelings”. Why are you a critical librarian? Libraries exist as spaces for transformation and change. Without being convinced about the effects of library access on his own life, Andrew Carnegie almost certainly wouldn’t have helped fund so many libraries with free...","categories": [],
+ "tags": ["critlib chats","critical theory","featured"],
+ "url": "/critlib-feelings",
+ "teaser": null
+ },{
+ "title": "Weekly Whaaa…?",
+ "excerpt":"Having written these for a while, I think I’ve finally got an inkling of what they are do & how to describe them! tl;dr version For the tl:dr version, I want to share things in a form that accommodates things outside of well-crafted shorter essays, “proper” blog posts, or posts...","categories": ["weekly-assemblage"],
+ "tags": ["meta"],
+ "url": "/weekly-assemblage/weekly-whaaa",
+ "teaser": null
+ },{
+ "title": "WA 2016 Week 01: #critlib chat on information resources & incarcerated people",
+ "excerpt":"Weekly Whaaa…? #critlib chat on Information Resources & Incarcerated People On Monday, 2016-01-04, I was lucky to co-moderate a #critlib chat with Seattle’s Books to Prisoners on information resources & incarcerated people. With my previous knowledge of prison libraries only being a bit of volunteering for Bloomington, Indiana’s Midwest Pages...","categories": ["weekly-assemblage"],
+ "tags": ["critlib chats","moocmooc","tech tools"],
+ "url": "/weekly-assemblage/wa-2016-week-01",
+ "teaser": null
+ },{
+ "title": "WA 2016 Week 02: Giroux on Neutrality",
+ "excerpt":"Weekly Whaaa…? Giroux’s “Schooling and the Culture of Positivism: Notes on the Death of History” Over the holidays I read Giroux’s On Critical Pedagogy, a collection of some older and new essays. The one that particularly sticks with me is “Schooling and the Culture of Positivism: Notes on the Death...","categories": ["weekly-assemblage"],
+ "tags": ["critical theory","neutrality"],
+ "url": "/weekly-assemblage/wa-2016-week-02",
+ "teaser": null
+ },{
+ "title": "WA 2016 Week 03: Du Bois & scientific sociology, #WOCinTechChat stock photos, LIS Mental Health Week",
+ "excerpt":"Weekly Whaaa…? “The Case for Scholarly Reparations” and #critlib scholarly communication A great read starting off this week was Julian Go’s The Case for Scholarly Reparations, a review essay on Aldon Morris’ The Scholar Denied. The main argument—seemingly shared by Morris and Go—is that Du Bois’ Atlanta School began scientific...","categories": ["weekly-assemblage"],
+ "tags": ["scholarly communication","librar* history","outreach"],
+ "url": "/weekly-assemblage/wa-2016-week-03",
+ "teaser": null
+ },{
+ "title": "WA 2016 Week 04: Library Privacy",
+ "excerpt":"Weekly Whaaa…? I’m doing a few of these quite a bit after the fact. ACLU Idaho & Alison Macrina at Meridian Public Library These two presenters were stellar. Here’s just a bit of my notes from each. If you want notes in their entirety, feel free to contact me to...","categories": ["weekly-assemblage"],
+ "tags": ["privacy"],
+ "url": "/weekly-assemblage/wa-2016-week-04",
+ "teaser": null
+ },{
+ "title": "WA 2016 Week 05: #critlib chat on Patience and Impatience; Alison Hicks' LibGuides: Pedagogy to Oppress?",
+ "excerpt":"Weekly Whaaa…? I’m doing a few of these quite after the fact. One of the highlights of this week was the #critlib chat on Patience and Impatience, moderated by Lisa Hinchliffe , Cecily Walker, and April Hathcock. It was “a chance for everyone to talk about the struggles we face...","categories": ["weekly-assemblage"],
+ "tags": ["critlib chats","pedagogy"],
+ "url": "/weekly-assemblage/wa-2016-week-05",
+ "teaser": null
+ },{
+ "title": "WA 2016 Week 06: THATCampBoiseState 2016",
+ "excerpt":"Weekly Whaaa…? Here’s another post I’m doing well after the fact. The highlight of this week was attending #THATCampBSU, an unconference around The Humanities and Technology. I met an awful lot of cool people ranging from local activists to coders to librarians. Thankfully, almost everyone there seemed to wear multiple...","categories": ["weekly-assemblage"],
+ "tags": ["conferences"],
+ "url": "/weekly-assemblage/wa-2016-week-06",
+ "teaser": null
+ },{
+ "title": "WA 2016 Week 07: Tools for Thinking",
+ "excerpt":"Weekly Whaaa…? Here’s another post I’m writing well after the fact. This week I taught a ton of information literacy/Library 101-style sessions. Tools for Thinking The main “new” things for me this week were that I found a few great handouts to use in these sessions—these are the type of...","categories": ["weekly-assemblage"],
+ "tags": ["tech tools","tools for thinking"],
+ "url": "/weekly-assemblage/wa-2016-week-07",
+ "teaser": null
+ },{
+ "title": "WA 2016 Week 08: CLAPS2016 Critical Librarianship and Pedagogy Symposium",
+ "excerpt":"Weekly Whaaa…? This week was :clap: :clap: :clap: #CLAPS2016, more formally known as the Critical Librarianship and Pedagogy Symposium at the University of Arizona in Tucson. It was fantastic meeting in person with folks I’ve conversed with online. I’m still mentally processing all of the different sessions, so here’s a...","categories": ["weekly-assemblage"],
+ "tags": ["conferences"],
+ "url": "/weekly-assemblage/wa-2016-week-08",
+ "teaser": null
+ },{
+ "title": "WA 2016 Week 12: DERAIL, Site Updates",
+ "excerpt":"Weekly Whaaa…? Although I aspire to write these “Weekly Assemblage” posts every week, in the spirit of a sort of weekly Library Day in the Life Project, that clearly doesn’t always happen. The last few weeks have been busy in various ways, so I’ll just do a quick round-up of...","categories": ["weekly-assemblage"],
+ "tags": ["conferences","meta"],
+ "url": "/weekly-assemblage/wa-2016-week-12",
+ "teaser": null
+ },{
+ "title": "WA 2016 Week 14: Intro to #critlib chat, Reveal.js image alt tags",
+ "excerpt":"Weekly Whaaa…? Intro to #critlib chat Courtney Boudreau hosted the second intro to #critlib chat, having co-hosted one earlier with Annie Pho. Here’s a link to the Storify made by Alice Prael. A3. It would be cool to see #critlib extend across all of LAM. Fascinating stuff is going on...","categories": ["weekly-assemblage"],
+ "tags": ["critlib chats","makerspaces","a11y"],
+ "url": "/weekly-assemblage/wa-2016-week-14",
+ "teaser": null
+ },{
+ "title": "WA 2016 Week 15: UC Davis Wants Some Scrubs",
+ "excerpt":"Weekly Whaaa…? Radical Librarians #radlibchat This week, the Radical Librarians hosted a chat with April Hathcock. UC Davis wants some scrubs UC Davis paid consultants at least $175,000 for attempts to scrub the Internet of links about their pepper spraying of nonviolent student protestors. someones going to write about how...","categories": ["weekly-assemblage"],
+ "tags": ["dissent","critical librarianship history"],
+ "url": "/weekly-assemblage/wa-2016-week-15",
+ "teaser": null
+ },{
+ "title": "WA 2016 Week 16: SWILA 2016; Joacim Hansson on Chantal Mouffe",
+ "excerpt":"Weekly Whaaa…? SWILA UnConference 2016 The Southwest Idaho Library UnConference, held at the Collister branch of the Boise Public Library, went wonderfully! Here’s what people tweeted about it. For me, the (unplanned!) outreach session was a highlight, as well as the very planned user experience one. Read Hansson on Mouffe...","categories": ["weekly-assemblage"],
+ "tags": ["conferences"],
+ "url": "/weekly-assemblage/wa-2016-week-16",
+ "teaser": null
+ },{
+ "title": "WA 2016 Week 17: Research Notebook is Go!",
+ "excerpt":"Weekly Whaaa…? Having kicked the idea around for a while, I finally took a couple evenings to work out how I’ll attempt an Open Humanities Research Notebook. Behold: it lives! As I say over there, I realized that I often feel a need to wrap posts up tidily here somehow....","categories": ["weekly-assemblage"],
+ "tags": ["meta"],
+ "url": "/weekly-assemblage/wa-2016-week-17",
+ "teaser": null
+ },{
+ "title": "WA 2016 Week 18: First Reading Notes and #critlib on Emotional Labor",
+ "excerpt":"Weekly Whaaa…? Reading Notes I posted the first reading notes on my open research notebook, as well as starting to read the Information Literacy chapter from Handbook for Community College Librarians by Michael A. Crumpton and Nora J. Bird. #critlib on Emotional Labor There was a #critlib chat focused on...","categories": ["weekly-assemblage"],
+ "tags": ["instruction assessment","critlib chats"],
+ "url": "/weekly-assemblage/wa-2016-week-18",
+ "teaser": null
+ },{
+ "title": "WA 2016 Week 19: SJL Seattle and Lots of Great Readings",
+ "excerpt":"Weekly Whaaa…? Social Justice and Libraries Student-Run Open Conference in Seattle SJL Seattle happened on 2016-05-14. Congratulations to the student organizers, Reed Garber-Pearson, Allison Reibel, and Marisa Petrich on what appears to have been a fantastic day! I considered driving over from Boise, but ultimately wasn’t able to make it....","categories": ["weekly-assemblage"],
+ "tags": ["conferences","critical librarianship","critical librarianship history","librar* history"],
+ "url": "/weekly-assemblage/wa-2016-week-19",
+ "teaser": null
+ },{
+ "title": "WA 2016 Week 27: Weekly Roundup and Website Housekeeping",
+ "excerpt":"Weekly Whaaa…? Weekly Roundup I read a lot this last week or so—too much to annotate each in depth. So I’ll just quickly post links to all of these and suggest you go check them out: Rebecca Halpern and Chimene Tucker’s “Leveraging Adult Learning Theory with Online Tutorials” article gave...","categories": ["weekly-assemblage"],
+ "tags": ["tools for thinking"],
+ "url": "/weekly-assemblage/wa-2016-week-27",
+ "teaser": null
+ },{
+ "title": "WA 2016 Week 31: Design Things Galore",
+ "excerpt":"Weekly Whaaa…? Design Things, Here, There, and Everywhere It’s been a while since I’ve had time to post one of these. I realized that there were a few design related things in my “I should post about this” file, so here they are! The buttons templates and tutorials from Librarian...","categories": ["weekly-assemblage"],
+ "tags": ["design","meta"],
+ "url": "/weekly-assemblage/wa-2016-week-31",
+ "teaser": null
+ },{
+ "title": "WA 2016 Week 32: Lots of Linkage; Comments Have Arrived",
+ "excerpt":"Weekly Whaaa…? Lots of Linkage Here’s a handful of links that I either shared or meant to share on Twitter: Rachael Neu linked to Richard Van Heertum’s “How Objective is Objectivity?” article in UCLA InterActions journal recently in a list-serv. I’m eagerly awaiting reading that article, but in the meanwhile...","categories": ["weekly-assemblage"],
+ "tags": ["meta"],
+ "url": "/weekly-assemblage/wa-2016-week-32",
+ "teaser": null
+ },{
+ "title": "Critical Reflection #critlib chat",
+ "excerpt":"Here’s a post in preparation for the “Critical Reflection” #critlib chat moderated by Lisa Hubbell. Lisa Hubbell’s commitment to making this chat about critical reflection more accessible to people for whom Twitter isn’t optimal inspired me enough to want to do a “seeding” blog post of my own. The topic...","categories": [],
+ "tags": ["critlib chats","tools for thinking"],
+ "url": "/critical-reflection",
+ "teaser": null
+ },{
+ "title": "WA 2017 Week 01: Journaling, Pedagogy, and Advocating for our Patrons",
+ "excerpt":"Weekly Whaaa…? Craig Eley’s Jekyll logbook theme Perhaps it was due to participating in the #critlib chat on reflection, moderated by Lisa Hubbell? Perhaps it was because I miss using DayOne, which I slowly abandoned after they changed how they sync the files? Perhaps it’s just that I’ve gotten really...","categories": ["weekly-assemblage"],
+ "tags": ["meta","critlib chats","neutrality","pedagogy"],
+ "url": "/weekly-assemblage/wa-2017-week-01",
+ "teaser": null
+ },{
+ "title": "WA 2017 Week 09: Badges, Type, BibTeX",
+ "excerpt":"Weekly Whaaa…? Emily Ford’s “To badge or not to badge? From ‘yes’ to ‘never again’” “To badge or not to badge? From ‘yes’ to ‘never again’” I really like this article and appreciate Emily Ford’s perspective here. Oddly enough, we’ve gone ahead with a variant of badging at my college...","categories": ["weekly-assemblage"],
+ "tags": ["badging","tech tools","type"],
+ "url": "/weekly-assemblage/wa-2017-week-09",
+ "teaser": null
+ },{
+ "title": "ALA Annual 2018: My Schedule, Our Notes",
+ "excerpt":"#ALAAC2018 I haven’t been to an Annual ALA Conference yet, so it’ll be interesting to see how my attention can hold up to meeting so many people and hearing so many ideas. I’ve been to a number of smaller conferences, but nothing on this scale. Building from the Critical ALA...","categories": [],
+ "tags": ["conferences"],
+ "url": "/my-ala-annual-2018-schedule",
+ "teaser": null
+ },{
+ "title": "ah, Carl, while you are not safe I am not safe",
+ "excerpt":"Braiding Together a Few Strands of Thought This post was prompted by a few things I saw on Mastodon and Twitter, plus having wanted to write something during LIS Mental Health Week for a few years now. I started drafting it as a short thread that brought in the social...","categories": [],
+ "tags": ["neurodiversity","LISMentalHealth","a11y"],
+ "url": "/while-you-are-not-safe-i-am-not-safe",
+ "teaser": null
+ },{
+ "title": "Introducing Monthly Signal Boosts",
+ "excerpt":"What’s This About? It’s pretty clear that my weekly assemblage posts aren’t particularly sustainable, at least at the moment. All the same, I want to get back to regular posts. With these I aim at boosting—sometimes also critiquing—things that I appreciate. Seeing Jessica Schomberg’s Monthly Reading Lists gave me the...","categories": ["monthly-signal-boost"],
+ "tags": [],
+ "url": "/monthly-signal-boost/introducing-monthly-signal-boosts",
+ "teaser": null
+ },{
+ "title": "July 2020 Monthly Signal Boost",
+ "excerpt":"Monthly What? Podcasts Organizing Ideas Podcast: Episode 20 with Jessica Schomberg Jessica Schomberg talks about their book, other readings they’ve learned from, how workplace improvements for disabled folks will lead to better workplaces for everyone, about relationships and solidarity in library work. It’s a really engaging listen! The Latino Card:...","categories": ["monthly-signal-boost"],
+ "tags": [],
+ "url": "/monthly-signal-boost/july-2020-monthly-signal-boost",
+ "teaser": null
+ },{
+ "title": "SIFT Links",
+ "excerpt":"Here are some links related to my submission to the “innovative ideas” lightning talk / virtual poster session of the 2020 MOSS Meetup organized by ICfL. The SIFT Moves Introducing SIFT, a Four Moves Acronym, Mike Caulfield’s initial post about the moves Check, Please! Course, an OER textbook with explanations...","categories": [],
+ "tags": ["conferences","pedagogy"],
+ "url": "/sift-links",
+ "teaser": null
+ },{
+ "title": "New note on Apple Watches and ADHD",
+ "excerpt":"I just published a new note on Apple Watches and ADHD in my digital garden / wonky wiki. It’s one of my first! ","categories": ["notes"],
+ "tags": [],
+ "url": "/notes/new-note-on-apple-watch-and-adhd",
+ "teaser": null
+ },{
+ "title": "August 2020 Monthly Signal Boost",
+ "excerpt":"Monthly What? 2020 has not been a kind year. This last month has been hectic and at times very overwhelming. Here’s some of what has worked to keep my spirits up. Mindfulness I’ve been trying to get back into mindfulness & meditation practices, since I’d like to more skillfully recognize...","categories": ["monthly-signal-boost"],
+ "tags": [],
+ "url": "/monthly-signal-boost/august-2020-monthly-signal-boost",
+ "teaser": null
+ },{
+ "title": "New note on ADHD technologies",
+ "excerpt":"I just published a new note on ADHD technologies in my digital garden / wonky wiki. It’s one of my first! ","categories": ["notes"],
+ "tags": [],
+ "url": "/notes/new-note-on-adhd-technologies",
+ "teaser": null
+ },{
+ "title": "New note on reading snippets about Information and Informatics",
+ "excerpt":"I just published a new note with some snippets about information and informatics in my digital garden / wonky wiki. ","categories": ["notes"],
+ "tags": [],
+ "url": "/notes/new-note-on-informatics-readings",
+ "teaser": null
+ },{
+ "title": "New note on the VS Code editor",
+ "excerpt":"I’ve just made a new note about the VS Code text editor, and why I like it. ","categories": ["notes"],
+ "tags": [],
+ "url": "/notes/new-note-on-vs-code",
+ "teaser": null
+ },{
+ "title": "New note on keeping literature notes in Dendron",
+ "excerpt":"I’ve just made a new note about how I keep literature notes in Dendron. ","categories": ["notes"],
+ "tags": [],
+ "url": "/notes/new-note-on-keeping-literature-notes-in-dendron",
+ "teaser": null
+ },{
+ "title": "New note on the Daybreak theme for VS Code",
+ "excerpt":"I’ve just made a new note about the Daybreak theme for VS Code, and my customizations to it. ","categories": ["notes"],
+ "tags": [],
+ "url": "/notes/new-note-on-the-daybreak-theme",
+ "teaser": null
+ },{
+ "title": "New note on beginning to use Dendron",
+ "excerpt":"I’ve just made a new note where I’ll keep suggestions for beginning to use Dendron. ","categories": ["notes"],
+ "tags": [],
+ "url": "/notes/new-note-beginning-to-use-dendron",
+ "teaser": null
+ },{
+ "title": "New note on math accessibility",
+ "excerpt":"I’ve written a new note with what I’ve recently learned about ways to make equations and other math notation more accessible online. ","categories": ["notes"],
+ "tags": [],
+ "url": "/notes/new-note-on-math-accessibility",
+ "teaser": null
+ },{
+ "title": "New note on task tracking in Dendron",
+ "excerpt":"I just published a new note on how I track tasks in Dendron in my digital garden / wonky wiki. ","categories": ["notes"],
+ "tags": [],
+ "url": "/notes/new-note-on-task-tracking-in-dendron",
+ "teaser": null
+ },{
+ "title": "New note on Mastodon iOS apps",
+ "excerpt":"I’ve just made a new note where I’ll keep annotated links to particularly useful Jekyll guides. ","categories": ["notes"],
+ "tags": [],
+ "url": "/notes/new-note-on-mastodon-ios-apps",
+ "teaser": null
+ },{
+ "title": "New note on Mastodon Settings",
+ "excerpt":"I’ve just made a new note where I’ll keep annotated links to particularly useful Jekyll guides. ","categories": ["notes"],
+ "tags": [],
+ "url": "/notes/new-note-on-mastodon-settings",
+ "teaser": null
+ },{
+ "title": "Introducing Blips and Link Rhizomes",
+ "excerpt":"Here We Go, What’s Our Scenarios? Blips Blog posts feel to me like they should involve a few paragraphs, and probably shouldn’t happen more than once a day. Maybe just a few a week is what feels right for them on my own site. (This feeling is just for my...","categories": ["blips"],
+ "tags": [],
+ "url": "/blips/introducing-blips-and-link-rhizomes",
+ "teaser": null
+ },{
+ "title": "New note on Jekyll Guides",
+ "excerpt":"I’ve just made a new note where I’ll keep annotated links to particularly useful Jekyll guides. ","categories": ["notes"],
+ "tags": [],
+ "url": "/notes/jekyll-guides-note",
+ "teaser": null
+ },{
+ "title": "Phone to Blog Blip Workflow",
+ "excerpt":"Couch to Internet With a cat snoozing on my lap and less than 10 minutes before I’m supposed to start watching a new-to-me episode of Star Trek: The Next Generation, the thought occurred to me: how quickly could I make a blog post happen? Long ago I set up Working...","categories": ["blips"],
+ "tags": [],
+ "url": "/blips/phone-to-blog-blip-workflow",
+ "teaser": null
+ },{
+ "title": "New note on Rhetorical Précis",
+ "excerpt":"I’ve just made a new note about the rhetorical précis format for taking reading notes. ","categories": ["notes"],
+ "tags": [],
+ "url": "/notes/new-note-on-rhetorical-precis",
+ "teaser": null
+ },{
+ "title": "New note on Casey Boyle's …something like a reading ethics…",
+ "excerpt":"I’ve just made a new note about Casey Boyle’s …something like a reading ethics…, which is a very useful approach to reading and taking notes. ","categories": ["notes"],
+ "tags": [],
+ "url": "/notes/new-note-on-casey-boyles-something-like-a-reading-ethics",
+ "teaser": null
+ },{
+ "title": "Weekly Assemblage for 2023 Week 09",
+ "excerpt":"Weekly Whaaa…? Daily Notes in Dendron For whatever reason, I’ve been using daily notes in Dendron this week, and it’s been a pleasant and useful addition to my usual practices. Although many people who use tools like Dendron or Obsidian seem to prefer working out of daily notes, I do...","categories": ["weekly-assemblage"],
+ "tags": [],
+ "url": "/weekly-assemblage/wa-2023-week-09",
+ "teaser": null
+ },{
+ "title": "Weekly Assemblage for 2023 Week 10",
+ "excerpt":"Weekly Whaaa…? Week of Sidequests In many ways, this week has felt like a bundle of sidequests, with little obvious at the end. But hey, some weeks are like that. I ended up spending a lot of time doing spring cleaning of my task notes. FOSS and Crafts Podcasts For...","categories": ["weekly-assemblage"],
+ "tags": [],
+ "url": "/weekly-assemblage/wa-2023-week-10",
+ "teaser": null
+ },{
+ "title": "Weekly Assemblage for 2023 Week 12",
+ "excerpt":"Weekly Whaaa…? Patterns for VS Code The last couple of weeks I’ve been helping some faculty members create more accessible data tables. That kind of repetitive structure is a great candidate for a code snippet—so I made a few! Here’s the surprisingly long VS Code Snippets note I just wrote...","categories": ["weekly-assemblage"],
+ "tags": [],
+ "url": "/weekly-assemblage/wa-2023-week-12",
+ "teaser": null
+ },{
+ "title": "New note on Snippets and VS Code",
+ "excerpt":"Last week I made a new note about some snippets I often use, both in VS Code and other places. I’m continuing to update the note with additional snippets. In fact, I just added three about time and dates. ","categories": ["notes"],
+ "tags": [],
+ "url": "/notes/new-note-on-snippets-and-vs-code",
+ "teaser": null
+ },{
+ "title": "New note on Spellcheck Squiggles in VS Code",
+ "excerpt":"I made a new note about spellcheck squiggles in VS Code, and how to make them just perceptible enough. ","categories": ["notes"],
+ "tags": [],
+ "url": "/notes/new-note-on-spellcheck-squiggles-in-vs-code",
+ "teaser": null
+ },{
+ "title": "Weekly Assemblage for 2023 Week 17",
+ "excerpt":"Weekly Whaaa…? Wow! This month has kept me busy—so much that I haven’t been updating this weekly. VS Code Snippets and Spellcheck Customizations At the beginning of the month, I made a couple of new notes. One explains some snippets I often use, both in VS Code and other places....","categories": ["weekly-assemblage"],
+ "tags": [],
+ "url": "/weekly-assemblage/wa-2023-week-17",
+ "teaser": null
+ },{
+ "title": "Light Mode in Progress",
+ "excerpt":"Today—the day after I finished up a “16 weeks condensed into 4” Spanish class—I happened to read some folks on Mastodon talking about light themes on websites. I’ve been wanting to add one to my site for years, my brain apparently wanted a project I could reasonably accomplish make noticeable...","categories": [],
+ "tags": [],
+ "url": "/light-mode-in-progress",
+ "teaser": null
+ },{
+ "title": "I've Been Using Obsidian",
+ "excerpt":"I’ve been using Obsidian, the app for linked notes. I’ve written a note with some first thoughts, and I’m planning to write more already. ","categories": ["notes"],
+ "tags": [],
+ "url": "/notes/beginning-to-use-obsidian",
+ "teaser": null
+ },{
+ "title": "My Obsidian plugins shortlist",
+ "excerpt":"Over the weekend, I wrote a note with a short list of the Obsidian plugins that do the most to make it feel like “my” notes. I’m already planning to detail some of these further in separate notes. If that’s somehow your sort of preferred reading, stay tuned! ","categories": ["notes"],
+ "tags": [],
+ "url": "/notes/obsidian-plugins",
+ "teaser": null
+ },{
+ "title": "AcWriMo2023",
+ "excerpt":"As I recently mentioned on Mastodon, I’m going to try doing Academic Writing Month (aka “AcWriMo”; a fellow traveler of National Novel Writing Month, or “NaNoWriMo”) this year. Here I’m detailing my approach—I’ll likely also update this with my progress throughout the experiment. La Lucha Continúa My most consistent writing...","categories": [],
+ "tags": [],
+ "url": "/acwrimo2023",
+ "teaser": null
+ },{
+ "title": "Obsidian Tasks patterns",
+ "excerpt":"As I’ve mentioned a few times, I began using Obsidian earlier this year. Ultimately, the Tasks plugin was what convinced me to adopt it, despite my fondness for Dendron and my general hesitations/frustrations about Obsidian. It took quite a bit of delving into the Obsidian Discord forums and subsequent experimentation...","categories": ["notes"],
+ "tags": [],
+ "url": "/notes/obsidian-tasks-patterns",
+ "teaser": null
+ },{
+ "title": "Original publication dates in Zotero",
+ "excerpt":"For those of us who work in the humanities and social sciences, it’s common for sources to have been published in multiple versions. But Zotero only has a single date field! Great Scott! How do we deal with the complexities of time? For instance, how would one indicate that Samuel...","categories": ["notes"],
+ "tags": [],
+ "url": "/notes/new-note-on-original-publication-dates-in-zotero",
+ "teaser": null
+ },{
+ "title": "Weekly Assemblage for 2023 Week 49",
+ "excerpt":"Weekly Whaaa…? I probably should start calling these something more like “Aperiodic Notes,” shouldn’t I? I average less than ten “weekly” ones most years! The “weekly” conceit remains a useful structure and mental boundary for when I do try a brief recap, however, so I’ll keep the name for now....","categories": ["weekly-assemblage"],
+ "tags": [],
+ "url": "/weekly-assemblage/wa-2023-week-49",
+ "teaser": null
+ },{
+ "title": "A formula of questions for critical thinking",
+ "excerpt":"I just wrote a new note on a set of questions I realize I’ve come to use as a handy starter critical thinking formula. The list started out as me reminding myself to ask “for whom, under what conditions”—effectively, Frederic Jameson’s “always historicize!” suggestion in a nut shell. Then I...","categories": ["notes"],
+ "tags": [],
+ "url": "/notes/new-note-on-a-critical-thinking-formula",
+ "teaser": null
+ },{
+ "title": "Parking Lot Posting",
+ "excerpt":"When I first got a smartphone so many years ago, I was excited mostly about having a device that could help with some of my ADHD issues; basically the same “keeping track of ideas and intentions” things I’d used a day planner or bullet journal for previously. I’d seen people...","categories": ["blips"],
+ "tags": [],
+ "url": "/blips/parking-lot-posting",
+ "teaser": null
+ },{
+ "title": "Weekly Assemblage for 2023 Week 50",
+ "excerpt":"Weekly Whaaa…? Wrapping Up 2023 Fall Semester This past week was the last official week of 2023 Fall Semester, and I took my final exam for Spanish 2202. It’s been a lot of fun re-learning Spanish, and I’m glad I’ve got another semester of it in 2024 Spring! I initially...","categories": ["weekly-assemblage"],
+ "tags": [],
+ "url": "/weekly-assemblage/wa-2023-week-50",
+ "teaser": null
+ },{
+ "title": "A small, curated set of Mastodon starting points.",
+ "excerpt":"Thankfully, many people have written useful guides to getting started with the community-run social media network called Mastodon. Instead of writing up my own, I’m curating a short list of the most useful ones I find over at my Mastodon starting points note. Most of these guides will be aimed...","categories": ["notes"],
+ "tags": [],
+ "url": "/notes/new-note-curating-mastodon-starting-points",
+ "teaser": null
+ },{
+ "title": "rearview mirror 2023",
+ "excerpt":"You might think of this as a Weekly Assemblage for 2023 Weeks 51 & 52. You’re also very welcome to hear Pearl Jam’s “rearviewmirror” in your head as you read this. Weekly Whaaa…? Instructional Design This was my first full calendar year working as an instructional designer, rather than as...","categories": ["weekly-assemblage"],
+ "tags": [],
+ "url": "/weekly-assemblage/rearviewmirror-2023",
+ "teaser": null
+ },{
+ "title": "Weekly Assemblage for 2024 Week 01",
+ "excerpt":"Weekly Whaaa…? AI and Teaching College Writing I profoundly appreciated this week’s Future Trends Forum on AI and Teaching College Writing, featuring Daniel Ernst and Troy Hicks. These English professors not only summarized their March 2023 survey of college writing faculty, but also shared many potential uses of technology. Here...","categories": ["weekly-assemblage"],
+ "tags": [],
+ "url": "/weekly-assemblage/wa-2024-week-01",
+ "teaser": null
+ }]
diff --git a/assets/js/lunr/lunr.js b/assets/js/lunr/lunr.js
new file mode 100644
index 00000000..6aa370fb
--- /dev/null
+++ b/assets/js/lunr/lunr.js
@@ -0,0 +1,3475 @@
+/**
+ * lunr - http://lunrjs.com - A bit like Solr, but much smaller and not as bright - 2.3.9
+ * Copyright (C) 2020 Oliver Nightingale
+ * @license MIT
+ */
+
+;(function(){
+
+/**
+ * A convenience function for configuring and constructing
+ * a new lunr Index.
+ *
+ * A lunr.Builder instance is created and the pipeline setup
+ * with a trimmer, stop word filter and stemmer.
+ *
+ * This builder object is yielded to the configuration function
+ * that is passed as a parameter, allowing the list of fields
+ * and other builder parameters to be customised.
+ *
+ * All documents _must_ be added within the passed config function.
+ *
+ * @example
+ * var idx = lunr(function () {
+ * this.field('title')
+ * this.field('body')
+ * this.ref('id')
+ *
+ * documents.forEach(function (doc) {
+ * this.add(doc)
+ * }, this)
+ * })
+ *
+ * @see {@link lunr.Builder}
+ * @see {@link lunr.Pipeline}
+ * @see {@link lunr.trimmer}
+ * @see {@link lunr.stopWordFilter}
+ * @see {@link lunr.stemmer}
+ * @namespace {function} lunr
+ */
+var lunr = function (config) {
+ var builder = new lunr.Builder
+
+ builder.pipeline.add(
+ lunr.trimmer,
+ lunr.stopWordFilter,
+ lunr.stemmer
+ )
+
+ builder.searchPipeline.add(
+ lunr.stemmer
+ )
+
+ config.call(builder, builder)
+ return builder.build()
+}
+
+lunr.version = "2.3.9"
+/*!
+ * lunr.utils
+ * Copyright (C) 2020 Oliver Nightingale
+ */
+
+/**
+ * A namespace containing utils for the rest of the lunr library
+ * @namespace lunr.utils
+ */
+lunr.utils = {}
+
+/**
+ * Print a warning message to the console.
+ *
+ * @param {String} message The message to be printed.
+ * @memberOf lunr.utils
+ * @function
+ */
+lunr.utils.warn = (function (global) {
+ /* eslint-disable no-console */
+ return function (message) {
+ if (global.console && console.warn) {
+ console.warn(message)
+ }
+ }
+ /* eslint-enable no-console */
+})(this)
+
+/**
+ * Convert an object to a string.
+ *
+ * In the case of `null` and `undefined` the function returns
+ * the empty string, in all other cases the result of calling
+ * `toString` on the passed object is returned.
+ *
+ * @param {Any} obj The object to convert to a string.
+ * @return {String} string representation of the passed object.
+ * @memberOf lunr.utils
+ */
+lunr.utils.asString = function (obj) {
+ if (obj === void 0 || obj === null) {
+ return ""
+ } else {
+ return obj.toString()
+ }
+}
+
+/**
+ * Clones an object.
+ *
+ * Will create a copy of an existing object such that any mutations
+ * on the copy cannot affect the original.
+ *
+ * Only shallow objects are supported, passing a nested object to this
+ * function will cause a TypeError.
+ *
+ * Objects with primitives, and arrays of primitives are supported.
+ *
+ * @param {Object} obj The object to clone.
+ * @return {Object} a clone of the passed object.
+ * @throws {TypeError} when a nested object is passed.
+ * @memberOf Utils
+ */
+lunr.utils.clone = function (obj) {
+ if (obj === null || obj === undefined) {
+ return obj
+ }
+
+ var clone = Object.create(null),
+ keys = Object.keys(obj)
+
+ for (var i = 0; i < keys.length; i++) {
+ var key = keys[i],
+ val = obj[key]
+
+ if (Array.isArray(val)) {
+ clone[key] = val.slice()
+ continue
+ }
+
+ if (typeof val === 'string' ||
+ typeof val === 'number' ||
+ typeof val === 'boolean') {
+ clone[key] = val
+ continue
+ }
+
+ throw new TypeError("clone is not deep and does not support nested objects")
+ }
+
+ return clone
+}
+lunr.FieldRef = function (docRef, fieldName, stringValue) {
+ this.docRef = docRef
+ this.fieldName = fieldName
+ this._stringValue = stringValue
+}
+
+lunr.FieldRef.joiner = "/"
+
+lunr.FieldRef.fromString = function (s) {
+ var n = s.indexOf(lunr.FieldRef.joiner)
+
+ if (n === -1) {
+ throw "malformed field ref string"
+ }
+
+ var fieldRef = s.slice(0, n),
+ docRef = s.slice(n + 1)
+
+ return new lunr.FieldRef (docRef, fieldRef, s)
+}
+
+lunr.FieldRef.prototype.toString = function () {
+ if (this._stringValue == undefined) {
+ this._stringValue = this.fieldName + lunr.FieldRef.joiner + this.docRef
+ }
+
+ return this._stringValue
+}
+/*!
+ * lunr.Set
+ * Copyright (C) 2020 Oliver Nightingale
+ */
+
+/**
+ * A lunr set.
+ *
+ * @constructor
+ */
+lunr.Set = function (elements) {
+ this.elements = Object.create(null)
+
+ if (elements) {
+ this.length = elements.length
+
+ for (var i = 0; i < this.length; i++) {
+ this.elements[elements[i]] = true
+ }
+ } else {
+ this.length = 0
+ }
+}
+
+/**
+ * A complete set that contains all elements.
+ *
+ * @static
+ * @readonly
+ * @type {lunr.Set}
+ */
+lunr.Set.complete = {
+ intersect: function (other) {
+ return other
+ },
+
+ union: function () {
+ return this
+ },
+
+ contains: function () {
+ return true
+ }
+}
+
+/**
+ * An empty set that contains no elements.
+ *
+ * @static
+ * @readonly
+ * @type {lunr.Set}
+ */
+lunr.Set.empty = {
+ intersect: function () {
+ return this
+ },
+
+ union: function (other) {
+ return other
+ },
+
+ contains: function () {
+ return false
+ }
+}
+
+/**
+ * Returns true if this set contains the specified object.
+ *
+ * @param {object} object - Object whose presence in this set is to be tested.
+ * @returns {boolean} - True if this set contains the specified object.
+ */
+lunr.Set.prototype.contains = function (object) {
+ return !!this.elements[object]
+}
+
+/**
+ * Returns a new set containing only the elements that are present in both
+ * this set and the specified set.
+ *
+ * @param {lunr.Set} other - set to intersect with this set.
+ * @returns {lunr.Set} a new set that is the intersection of this and the specified set.
+ */
+
+lunr.Set.prototype.intersect = function (other) {
+ var a, b, elements, intersection = []
+
+ if (other === lunr.Set.complete) {
+ return this
+ }
+
+ if (other === lunr.Set.empty) {
+ return other
+ }
+
+ if (this.length < other.length) {
+ a = this
+ b = other
+ } else {
+ a = other
+ b = this
+ }
+
+ elements = Object.keys(a.elements)
+
+ for (var i = 0; i < elements.length; i++) {
+ var element = elements[i]
+ if (element in b.elements) {
+ intersection.push(element)
+ }
+ }
+
+ return new lunr.Set (intersection)
+}
+
+/**
+ * Returns a new set combining the elements of this and the specified set.
+ *
+ * @param {lunr.Set} other - set to union with this set.
+ * @return {lunr.Set} a new set that is the union of this and the specified set.
+ */
+
+lunr.Set.prototype.union = function (other) {
+ if (other === lunr.Set.complete) {
+ return lunr.Set.complete
+ }
+
+ if (other === lunr.Set.empty) {
+ return this
+ }
+
+ return new lunr.Set(Object.keys(this.elements).concat(Object.keys(other.elements)))
+}
+/**
+ * A function to calculate the inverse document frequency for
+ * a posting. This is shared between the builder and the index
+ *
+ * @private
+ * @param {object} posting - The posting for a given term
+ * @param {number} documentCount - The total number of documents.
+ */
+lunr.idf = function (posting, documentCount) {
+ var documentsWithTerm = 0
+
+ for (var fieldName in posting) {
+ if (fieldName == '_index') continue // Ignore the term index, its not a field
+ documentsWithTerm += Object.keys(posting[fieldName]).length
+ }
+
+ var x = (documentCount - documentsWithTerm + 0.5) / (documentsWithTerm + 0.5)
+
+ return Math.log(1 + Math.abs(x))
+}
+
+/**
+ * A token wraps a string representation of a token
+ * as it is passed through the text processing pipeline.
+ *
+ * @constructor
+ * @param {string} [str=''] - The string token being wrapped.
+ * @param {object} [metadata={}] - Metadata associated with this token.
+ */
+lunr.Token = function (str, metadata) {
+ this.str = str || ""
+ this.metadata = metadata || {}
+}
+
+/**
+ * Returns the token string that is being wrapped by this object.
+ *
+ * @returns {string}
+ */
+lunr.Token.prototype.toString = function () {
+ return this.str
+}
+
+/**
+ * A token update function is used when updating or optionally
+ * when cloning a token.
+ *
+ * @callback lunr.Token~updateFunction
+ * @param {string} str - The string representation of the token.
+ * @param {Object} metadata - All metadata associated with this token.
+ */
+
+/**
+ * Applies the given function to the wrapped string token.
+ *
+ * @example
+ * token.update(function (str, metadata) {
+ * return str.toUpperCase()
+ * })
+ *
+ * @param {lunr.Token~updateFunction} fn - A function to apply to the token string.
+ * @returns {lunr.Token}
+ */
+lunr.Token.prototype.update = function (fn) {
+ this.str = fn(this.str, this.metadata)
+ return this
+}
+
+/**
+ * Creates a clone of this token. Optionally a function can be
+ * applied to the cloned token.
+ *
+ * @param {lunr.Token~updateFunction} [fn] - An optional function to apply to the cloned token.
+ * @returns {lunr.Token}
+ */
+lunr.Token.prototype.clone = function (fn) {
+ fn = fn || function (s) { return s }
+ return new lunr.Token (fn(this.str, this.metadata), this.metadata)
+}
+/*!
+ * lunr.tokenizer
+ * Copyright (C) 2020 Oliver Nightingale
+ */
+
+/**
+ * A function for splitting a string into tokens ready to be inserted into
+ * the search index. Uses `lunr.tokenizer.separator` to split strings, change
+ * the value of this property to change how strings are split into tokens.
+ *
+ * This tokenizer will convert its parameter to a string by calling `toString` and
+ * then will split this string on the character in `lunr.tokenizer.separator`.
+ * Arrays will have their elements converted to strings and wrapped in a lunr.Token.
+ *
+ * Optional metadata can be passed to the tokenizer, this metadata will be cloned and
+ * added as metadata to every token that is created from the object to be tokenized.
+ *
+ * @static
+ * @param {?(string|object|object[])} obj - The object to convert into tokens
+ * @param {?object} metadata - Optional metadata to associate with every token
+ * @returns {lunr.Token[]}
+ * @see {@link lunr.Pipeline}
+ */
+lunr.tokenizer = function (obj, metadata) {
+ if (obj == null || obj == undefined) {
+ return []
+ }
+
+ if (Array.isArray(obj)) {
+ return obj.map(function (t) {
+ return new lunr.Token(
+ lunr.utils.asString(t).toLowerCase(),
+ lunr.utils.clone(metadata)
+ )
+ })
+ }
+
+ var str = obj.toString().toLowerCase(),
+ len = str.length,
+ tokens = []
+
+ for (var sliceEnd = 0, sliceStart = 0; sliceEnd <= len; sliceEnd++) {
+ var char = str.charAt(sliceEnd),
+ sliceLength = sliceEnd - sliceStart
+
+ if ((char.match(lunr.tokenizer.separator) || sliceEnd == len)) {
+
+ if (sliceLength > 0) {
+ var tokenMetadata = lunr.utils.clone(metadata) || {}
+ tokenMetadata["position"] = [sliceStart, sliceLength]
+ tokenMetadata["index"] = tokens.length
+
+ tokens.push(
+ new lunr.Token (
+ str.slice(sliceStart, sliceEnd),
+ tokenMetadata
+ )
+ )
+ }
+
+ sliceStart = sliceEnd + 1
+ }
+
+ }
+
+ return tokens
+}
+
+/**
+ * The separator used to split a string into tokens. Override this property to change the behaviour of
+ * `lunr.tokenizer` behaviour when tokenizing strings. By default this splits on whitespace and hyphens.
+ *
+ * @static
+ * @see lunr.tokenizer
+ */
+lunr.tokenizer.separator = /[\s\-]+/
+/*!
+ * lunr.Pipeline
+ * Copyright (C) 2020 Oliver Nightingale
+ */
+
+/**
+ * lunr.Pipelines maintain an ordered list of functions to be applied to all
+ * tokens in documents entering the search index and queries being ran against
+ * the index.
+ *
+ * An instance of lunr.Index created with the lunr shortcut will contain a
+ * pipeline with a stop word filter and an English language stemmer. Extra
+ * functions can be added before or after either of these functions or these
+ * default functions can be removed.
+ *
+ * When run the pipeline will call each function in turn, passing a token, the
+ * index of that token in the original list of all tokens and finally a list of
+ * all the original tokens.
+ *
+ * The output of functions in the pipeline will be passed to the next function
+ * in the pipeline. To exclude a token from entering the index the function
+ * should return undefined, the rest of the pipeline will not be called with
+ * this token.
+ *
+ * For serialisation of pipelines to work, all functions used in an instance of
+ * a pipeline should be registered with lunr.Pipeline. Registered functions can
+ * then be loaded. If trying to load a serialised pipeline that uses functions
+ * that are not registered an error will be thrown.
+ *
+ * If not planning on serialising the pipeline then registering pipeline functions
+ * is not necessary.
+ *
+ * @constructor
+ */
+lunr.Pipeline = function () {
+ this._stack = []
+}
+
+lunr.Pipeline.registeredFunctions = Object.create(null)
+
+/**
+ * A pipeline function maps lunr.Token to lunr.Token. A lunr.Token contains the token
+ * string as well as all known metadata. A pipeline function can mutate the token string
+ * or mutate (or add) metadata for a given token.
+ *
+ * A pipeline function can indicate that the passed token should be discarded by returning
+ * null, undefined or an empty string. This token will not be passed to any downstream pipeline
+ * functions and will not be added to the index.
+ *
+ * Multiple tokens can be returned by returning an array of tokens. Each token will be passed
+ * to any downstream pipeline functions and all will returned tokens will be added to the index.
+ *
+ * Any number of pipeline functions may be chained together using a lunr.Pipeline.
+ *
+ * @interface lunr.PipelineFunction
+ * @param {lunr.Token} token - A token from the document being processed.
+ * @param {number} i - The index of this token in the complete list of tokens for this document/field.
+ * @param {lunr.Token[]} tokens - All tokens for this document/field.
+ * @returns {(?lunr.Token|lunr.Token[])}
+ */
+
+/**
+ * Register a function with the pipeline.
+ *
+ * Functions that are used in the pipeline should be registered if the pipeline
+ * needs to be serialised, or a serialised pipeline needs to be loaded.
+ *
+ * Registering a function does not add it to a pipeline, functions must still be
+ * added to instances of the pipeline for them to be used when running a pipeline.
+ *
+ * @param {lunr.PipelineFunction} fn - The function to check for.
+ * @param {String} label - The label to register this function with
+ */
+lunr.Pipeline.registerFunction = function (fn, label) {
+ if (label in this.registeredFunctions) {
+ lunr.utils.warn('Overwriting existing registered function: ' + label)
+ }
+
+ fn.label = label
+ lunr.Pipeline.registeredFunctions[fn.label] = fn
+}
+
+/**
+ * Warns if the function is not registered as a Pipeline function.
+ *
+ * @param {lunr.PipelineFunction} fn - The function to check for.
+ * @private
+ */
+lunr.Pipeline.warnIfFunctionNotRegistered = function (fn) {
+ var isRegistered = fn.label && (fn.label in this.registeredFunctions)
+
+ if (!isRegistered) {
+ lunr.utils.warn('Function is not registered with pipeline. This may cause problems when serialising the index.\n', fn)
+ }
+}
+
+/**
+ * Loads a previously serialised pipeline.
+ *
+ * All functions to be loaded must already be registered with lunr.Pipeline.
+ * If any function from the serialised data has not been registered then an
+ * error will be thrown.
+ *
+ * @param {Object} serialised - The serialised pipeline to load.
+ * @returns {lunr.Pipeline}
+ */
+lunr.Pipeline.load = function (serialised) {
+ var pipeline = new lunr.Pipeline
+
+ serialised.forEach(function (fnName) {
+ var fn = lunr.Pipeline.registeredFunctions[fnName]
+
+ if (fn) {
+ pipeline.add(fn)
+ } else {
+ throw new Error('Cannot load unregistered function: ' + fnName)
+ }
+ })
+
+ return pipeline
+}
+
+/**
+ * Adds new functions to the end of the pipeline.
+ *
+ * Logs a warning if the function has not been registered.
+ *
+ * @param {lunr.PipelineFunction[]} functions - Any number of functions to add to the pipeline.
+ */
+lunr.Pipeline.prototype.add = function () {
+ var fns = Array.prototype.slice.call(arguments)
+
+ fns.forEach(function (fn) {
+ lunr.Pipeline.warnIfFunctionNotRegistered(fn)
+ this._stack.push(fn)
+ }, this)
+}
+
+/**
+ * Adds a single function after a function that already exists in the
+ * pipeline.
+ *
+ * Logs a warning if the function has not been registered.
+ *
+ * @param {lunr.PipelineFunction} existingFn - A function that already exists in the pipeline.
+ * @param {lunr.PipelineFunction} newFn - The new function to add to the pipeline.
+ */
+lunr.Pipeline.prototype.after = function (existingFn, newFn) {
+ lunr.Pipeline.warnIfFunctionNotRegistered(newFn)
+
+ var pos = this._stack.indexOf(existingFn)
+ if (pos == -1) {
+ throw new Error('Cannot find existingFn')
+ }
+
+ pos = pos + 1
+ this._stack.splice(pos, 0, newFn)
+}
+
+/**
+ * Adds a single function before a function that already exists in the
+ * pipeline.
+ *
+ * Logs a warning if the function has not been registered.
+ *
+ * @param {lunr.PipelineFunction} existingFn - A function that already exists in the pipeline.
+ * @param {lunr.PipelineFunction} newFn - The new function to add to the pipeline.
+ */
+lunr.Pipeline.prototype.before = function (existingFn, newFn) {
+ lunr.Pipeline.warnIfFunctionNotRegistered(newFn)
+
+ var pos = this._stack.indexOf(existingFn)
+ if (pos == -1) {
+ throw new Error('Cannot find existingFn')
+ }
+
+ this._stack.splice(pos, 0, newFn)
+}
+
+/**
+ * Removes a function from the pipeline.
+ *
+ * @param {lunr.PipelineFunction} fn The function to remove from the pipeline.
+ */
+lunr.Pipeline.prototype.remove = function (fn) {
+ var pos = this._stack.indexOf(fn)
+ if (pos == -1) {
+ return
+ }
+
+ this._stack.splice(pos, 1)
+}
+
+/**
+ * Runs the current list of functions that make up the pipeline against the
+ * passed tokens.
+ *
+ * @param {Array} tokens The tokens to run through the pipeline.
+ * @returns {Array}
+ */
+lunr.Pipeline.prototype.run = function (tokens) {
+ var stackLength = this._stack.length
+
+ for (var i = 0; i < stackLength; i++) {
+ var fn = this._stack[i]
+ var memo = []
+
+ for (var j = 0; j < tokens.length; j++) {
+ var result = fn(tokens[j], j, tokens)
+
+ if (result === null || result === void 0 || result === '') continue
+
+ if (Array.isArray(result)) {
+ for (var k = 0; k < result.length; k++) {
+ memo.push(result[k])
+ }
+ } else {
+ memo.push(result)
+ }
+ }
+
+ tokens = memo
+ }
+
+ return tokens
+}
+
+/**
+ * Convenience method for passing a string through a pipeline and getting
+ * strings out. This method takes care of wrapping the passed string in a
+ * token and mapping the resulting tokens back to strings.
+ *
+ * @param {string} str - The string to pass through the pipeline.
+ * @param {?object} metadata - Optional metadata to associate with the token
+ * passed to the pipeline.
+ * @returns {string[]}
+ */
+lunr.Pipeline.prototype.runString = function (str, metadata) {
+ var token = new lunr.Token (str, metadata)
+
+ return this.run([token]).map(function (t) {
+ return t.toString()
+ })
+}
+
+/**
+ * Resets the pipeline by removing any existing processors.
+ *
+ */
+lunr.Pipeline.prototype.reset = function () {
+ this._stack = []
+}
+
+/**
+ * Returns a representation of the pipeline ready for serialisation.
+ *
+ * Logs a warning if the function has not been registered.
+ *
+ * @returns {Array}
+ */
+lunr.Pipeline.prototype.toJSON = function () {
+ return this._stack.map(function (fn) {
+ lunr.Pipeline.warnIfFunctionNotRegistered(fn)
+
+ return fn.label
+ })
+}
+/*!
+ * lunr.Vector
+ * Copyright (C) 2020 Oliver Nightingale
+ */
+
+/**
+ * A vector is used to construct the vector space of documents and queries. These
+ * vectors support operations to determine the similarity between two documents or
+ * a document and a query.
+ *
+ * Normally no parameters are required for initializing a vector, but in the case of
+ * loading a previously dumped vector the raw elements can be provided to the constructor.
+ *
+ * For performance reasons vectors are implemented with a flat array, where an elements
+ * index is immediately followed by its value. E.g. [index, value, index, value]. This
+ * allows the underlying array to be as sparse as possible and still offer decent
+ * performance when being used for vector calculations.
+ *
+ * @constructor
+ * @param {Number[]} [elements] - The flat list of element index and element value pairs.
+ */
+lunr.Vector = function (elements) {
+ this._magnitude = 0
+ this.elements = elements || []
+}
+
+
+/**
+ * Calculates the position within the vector to insert a given index.
+ *
+ * This is used internally by insert and upsert. If there are duplicate indexes then
+ * the position is returned as if the value for that index were to be updated, but it
+ * is the callers responsibility to check whether there is a duplicate at that index
+ *
+ * @param {Number} insertIdx - The index at which the element should be inserted.
+ * @returns {Number}
+ */
+lunr.Vector.prototype.positionForIndex = function (index) {
+ // For an empty vector the tuple can be inserted at the beginning
+ if (this.elements.length == 0) {
+ return 0
+ }
+
+ var start = 0,
+ end = this.elements.length / 2,
+ sliceLength = end - start,
+ pivotPoint = Math.floor(sliceLength / 2),
+ pivotIndex = this.elements[pivotPoint * 2]
+
+ while (sliceLength > 1) {
+ if (pivotIndex < index) {
+ start = pivotPoint
+ }
+
+ if (pivotIndex > index) {
+ end = pivotPoint
+ }
+
+ if (pivotIndex == index) {
+ break
+ }
+
+ sliceLength = end - start
+ pivotPoint = start + Math.floor(sliceLength / 2)
+ pivotIndex = this.elements[pivotPoint * 2]
+ }
+
+ if (pivotIndex == index) {
+ return pivotPoint * 2
+ }
+
+ if (pivotIndex > index) {
+ return pivotPoint * 2
+ }
+
+ if (pivotIndex < index) {
+ return (pivotPoint + 1) * 2
+ }
+}
+
+/**
+ * Inserts an element at an index within the vector.
+ *
+ * Does not allow duplicates, will throw an error if there is already an entry
+ * for this index.
+ *
+ * @param {Number} insertIdx - The index at which the element should be inserted.
+ * @param {Number} val - The value to be inserted into the vector.
+ */
+lunr.Vector.prototype.insert = function (insertIdx, val) {
+ this.upsert(insertIdx, val, function () {
+ throw "duplicate index"
+ })
+}
+
+/**
+ * Inserts or updates an existing index within the vector.
+ *
+ * @param {Number} insertIdx - The index at which the element should be inserted.
+ * @param {Number} val - The value to be inserted into the vector.
+ * @param {function} fn - A function that is called for updates, the existing value and the
+ * requested value are passed as arguments
+ */
+lunr.Vector.prototype.upsert = function (insertIdx, val, fn) {
+ this._magnitude = 0
+ var position = this.positionForIndex(insertIdx)
+
+ if (this.elements[position] == insertIdx) {
+ this.elements[position + 1] = fn(this.elements[position + 1], val)
+ } else {
+ this.elements.splice(position, 0, insertIdx, val)
+ }
+}
+
+/**
+ * Calculates the magnitude of this vector.
+ *
+ * @returns {Number}
+ */
+lunr.Vector.prototype.magnitude = function () {
+ if (this._magnitude) return this._magnitude
+
+ var sumOfSquares = 0,
+ elementsLength = this.elements.length
+
+ for (var i = 1; i < elementsLength; i += 2) {
+ var val = this.elements[i]
+ sumOfSquares += val * val
+ }
+
+ return this._magnitude = Math.sqrt(sumOfSquares)
+}
+
+/**
+ * Calculates the dot product of this vector and another vector.
+ *
+ * @param {lunr.Vector} otherVector - The vector to compute the dot product with.
+ * @returns {Number}
+ */
+lunr.Vector.prototype.dot = function (otherVector) {
+ var dotProduct = 0,
+ a = this.elements, b = otherVector.elements,
+ aLen = a.length, bLen = b.length,
+ aVal = 0, bVal = 0,
+ i = 0, j = 0
+
+ while (i < aLen && j < bLen) {
+ aVal = a[i], bVal = b[j]
+ if (aVal < bVal) {
+ i += 2
+ } else if (aVal > bVal) {
+ j += 2
+ } else if (aVal == bVal) {
+ dotProduct += a[i + 1] * b[j + 1]
+ i += 2
+ j += 2
+ }
+ }
+
+ return dotProduct
+}
+
+/**
+ * Calculates the similarity between this vector and another vector.
+ *
+ * @param {lunr.Vector} otherVector - The other vector to calculate the
+ * similarity with.
+ * @returns {Number}
+ */
+lunr.Vector.prototype.similarity = function (otherVector) {
+ return this.dot(otherVector) / this.magnitude() || 0
+}
+
+/**
+ * Converts the vector to an array of the elements within the vector.
+ *
+ * @returns {Number[]}
+ */
+lunr.Vector.prototype.toArray = function () {
+ var output = new Array (this.elements.length / 2)
+
+ for (var i = 1, j = 0; i < this.elements.length; i += 2, j++) {
+ output[j] = this.elements[i]
+ }
+
+ return output
+}
+
+/**
+ * A JSON serializable representation of the vector.
+ *
+ * @returns {Number[]}
+ */
+lunr.Vector.prototype.toJSON = function () {
+ return this.elements
+}
+/* eslint-disable */
+/*!
+ * lunr.stemmer
+ * Copyright (C) 2020 Oliver Nightingale
+ * Includes code from - http://tartarus.org/~martin/PorterStemmer/js.txt
+ */
+
+/**
+ * lunr.stemmer is an english language stemmer, this is a JavaScript
+ * implementation of the PorterStemmer taken from http://tartarus.org/~martin
+ *
+ * @static
+ * @implements {lunr.PipelineFunction}
+ * @param {lunr.Token} token - The string to stem
+ * @returns {lunr.Token}
+ * @see {@link lunr.Pipeline}
+ * @function
+ */
+lunr.stemmer = (function(){
+ var step2list = {
+ "ational" : "ate",
+ "tional" : "tion",
+ "enci" : "ence",
+ "anci" : "ance",
+ "izer" : "ize",
+ "bli" : "ble",
+ "alli" : "al",
+ "entli" : "ent",
+ "eli" : "e",
+ "ousli" : "ous",
+ "ization" : "ize",
+ "ation" : "ate",
+ "ator" : "ate",
+ "alism" : "al",
+ "iveness" : "ive",
+ "fulness" : "ful",
+ "ousness" : "ous",
+ "aliti" : "al",
+ "iviti" : "ive",
+ "biliti" : "ble",
+ "logi" : "log"
+ },
+
+ step3list = {
+ "icate" : "ic",
+ "ative" : "",
+ "alize" : "al",
+ "iciti" : "ic",
+ "ical" : "ic",
+ "ful" : "",
+ "ness" : ""
+ },
+
+ c = "[^aeiou]", // consonant
+ v = "[aeiouy]", // vowel
+ C = c + "[^aeiouy]*", // consonant sequence
+ V = v + "[aeiou]*", // vowel sequence
+
+ mgr0 = "^(" + C + ")?" + V + C, // [C]VC... is m>0
+ meq1 = "^(" + C + ")?" + V + C + "(" + V + ")?$", // [C]VC[V] is m=1
+ mgr1 = "^(" + C + ")?" + V + C + V + C, // [C]VCVC... is m>1
+ s_v = "^(" + C + ")?" + v; // vowel in stem
+
+ var re_mgr0 = new RegExp(mgr0);
+ var re_mgr1 = new RegExp(mgr1);
+ var re_meq1 = new RegExp(meq1);
+ var re_s_v = new RegExp(s_v);
+
+ var re_1a = /^(.+?)(ss|i)es$/;
+ var re2_1a = /^(.+?)([^s])s$/;
+ var re_1b = /^(.+?)eed$/;
+ var re2_1b = /^(.+?)(ed|ing)$/;
+ var re_1b_2 = /.$/;
+ var re2_1b_2 = /(at|bl|iz)$/;
+ var re3_1b_2 = new RegExp("([^aeiouylsz])\\1$");
+ var re4_1b_2 = new RegExp("^" + C + v + "[^aeiouwxy]$");
+
+ var re_1c = /^(.+?[^aeiou])y$/;
+ var re_2 = /^(.+?)(ational|tional|enci|anci|izer|bli|alli|entli|eli|ousli|ization|ation|ator|alism|iveness|fulness|ousness|aliti|iviti|biliti|logi)$/;
+
+ var re_3 = /^(.+?)(icate|ative|alize|iciti|ical|ful|ness)$/;
+
+ var re_4 = /^(.+?)(al|ance|ence|er|ic|able|ible|ant|ement|ment|ent|ou|ism|ate|iti|ous|ive|ize)$/;
+ var re2_4 = /^(.+?)(s|t)(ion)$/;
+
+ var re_5 = /^(.+?)e$/;
+ var re_5_1 = /ll$/;
+ var re3_5 = new RegExp("^" + C + v + "[^aeiouwxy]$");
+
+ var porterStemmer = function porterStemmer(w) {
+ var stem,
+ suffix,
+ firstch,
+ re,
+ re2,
+ re3,
+ re4;
+
+ if (w.length < 3) { return w; }
+
+ firstch = w.substr(0,1);
+ if (firstch == "y") {
+ w = firstch.toUpperCase() + w.substr(1);
+ }
+
+ // Step 1a
+ re = re_1a
+ re2 = re2_1a;
+
+ if (re.test(w)) { w = w.replace(re,"$1$2"); }
+ else if (re2.test(w)) { w = w.replace(re2,"$1$2"); }
+
+ // Step 1b
+ re = re_1b;
+ re2 = re2_1b;
+ if (re.test(w)) {
+ var fp = re.exec(w);
+ re = re_mgr0;
+ if (re.test(fp[1])) {
+ re = re_1b_2;
+ w = w.replace(re,"");
+ }
+ } else if (re2.test(w)) {
+ var fp = re2.exec(w);
+ stem = fp[1];
+ re2 = re_s_v;
+ if (re2.test(stem)) {
+ w = stem;
+ re2 = re2_1b_2;
+ re3 = re3_1b_2;
+ re4 = re4_1b_2;
+ if (re2.test(w)) { w = w + "e"; }
+ else if (re3.test(w)) { re = re_1b_2; w = w.replace(re,""); }
+ else if (re4.test(w)) { w = w + "e"; }
+ }
+ }
+
+ // Step 1c - replace suffix y or Y by i if preceded by a non-vowel which is not the first letter of the word (so cry -> cri, by -> by, say -> say)
+ re = re_1c;
+ if (re.test(w)) {
+ var fp = re.exec(w);
+ stem = fp[1];
+ w = stem + "i";
+ }
+
+ // Step 2
+ re = re_2;
+ if (re.test(w)) {
+ var fp = re.exec(w);
+ stem = fp[1];
+ suffix = fp[2];
+ re = re_mgr0;
+ if (re.test(stem)) {
+ w = stem + step2list[suffix];
+ }
+ }
+
+ // Step 3
+ re = re_3;
+ if (re.test(w)) {
+ var fp = re.exec(w);
+ stem = fp[1];
+ suffix = fp[2];
+ re = re_mgr0;
+ if (re.test(stem)) {
+ w = stem + step3list[suffix];
+ }
+ }
+
+ // Step 4
+ re = re_4;
+ re2 = re2_4;
+ if (re.test(w)) {
+ var fp = re.exec(w);
+ stem = fp[1];
+ re = re_mgr1;
+ if (re.test(stem)) {
+ w = stem;
+ }
+ } else if (re2.test(w)) {
+ var fp = re2.exec(w);
+ stem = fp[1] + fp[2];
+ re2 = re_mgr1;
+ if (re2.test(stem)) {
+ w = stem;
+ }
+ }
+
+ // Step 5
+ re = re_5;
+ if (re.test(w)) {
+ var fp = re.exec(w);
+ stem = fp[1];
+ re = re_mgr1;
+ re2 = re_meq1;
+ re3 = re3_5;
+ if (re.test(stem) || (re2.test(stem) && !(re3.test(stem)))) {
+ w = stem;
+ }
+ }
+
+ re = re_5_1;
+ re2 = re_mgr1;
+ if (re.test(w) && re2.test(w)) {
+ re = re_1b_2;
+ w = w.replace(re,"");
+ }
+
+ // and turn initial Y back to y
+
+ if (firstch == "y") {
+ w = firstch.toLowerCase() + w.substr(1);
+ }
+
+ return w;
+ };
+
+ return function (token) {
+ return token.update(porterStemmer);
+ }
+})();
+
+lunr.Pipeline.registerFunction(lunr.stemmer, 'stemmer')
+/*!
+ * lunr.stopWordFilter
+ * Copyright (C) 2020 Oliver Nightingale
+ */
+
+/**
+ * lunr.generateStopWordFilter builds a stopWordFilter function from the provided
+ * list of stop words.
+ *
+ * The built in lunr.stopWordFilter is built using this generator and can be used
+ * to generate custom stopWordFilters for applications or non English languages.
+ *
+ * @function
+ * @param {Array} token The token to pass through the filter
+ * @returns {lunr.PipelineFunction}
+ * @see lunr.Pipeline
+ * @see lunr.stopWordFilter
+ */
+lunr.generateStopWordFilter = function (stopWords) {
+ var words = stopWords.reduce(function (memo, stopWord) {
+ memo[stopWord] = stopWord
+ return memo
+ }, {})
+
+ return function (token) {
+ if (token && words[token.toString()] !== token.toString()) return token
+ }
+}
+
+/**
+ * lunr.stopWordFilter is an English language stop word list filter, any words
+ * contained in the list will not be passed through the filter.
+ *
+ * This is intended to be used in the Pipeline. If the token does not pass the
+ * filter then undefined will be returned.
+ *
+ * @function
+ * @implements {lunr.PipelineFunction}
+ * @params {lunr.Token} token - A token to check for being a stop word.
+ * @returns {lunr.Token}
+ * @see {@link lunr.Pipeline}
+ */
+lunr.stopWordFilter = lunr.generateStopWordFilter([
+ 'a',
+ 'able',
+ 'about',
+ 'across',
+ 'after',
+ 'all',
+ 'almost',
+ 'also',
+ 'am',
+ 'among',
+ 'an',
+ 'and',
+ 'any',
+ 'are',
+ 'as',
+ 'at',
+ 'be',
+ 'because',
+ 'been',
+ 'but',
+ 'by',
+ 'can',
+ 'cannot',
+ 'could',
+ 'dear',
+ 'did',
+ 'do',
+ 'does',
+ 'either',
+ 'else',
+ 'ever',
+ 'every',
+ 'for',
+ 'from',
+ 'get',
+ 'got',
+ 'had',
+ 'has',
+ 'have',
+ 'he',
+ 'her',
+ 'hers',
+ 'him',
+ 'his',
+ 'how',
+ 'however',
+ 'i',
+ 'if',
+ 'in',
+ 'into',
+ 'is',
+ 'it',
+ 'its',
+ 'just',
+ 'least',
+ 'let',
+ 'like',
+ 'likely',
+ 'may',
+ 'me',
+ 'might',
+ 'most',
+ 'must',
+ 'my',
+ 'neither',
+ 'no',
+ 'nor',
+ 'not',
+ 'of',
+ 'off',
+ 'often',
+ 'on',
+ 'only',
+ 'or',
+ 'other',
+ 'our',
+ 'own',
+ 'rather',
+ 'said',
+ 'say',
+ 'says',
+ 'she',
+ 'should',
+ 'since',
+ 'so',
+ 'some',
+ 'than',
+ 'that',
+ 'the',
+ 'their',
+ 'them',
+ 'then',
+ 'there',
+ 'these',
+ 'they',
+ 'this',
+ 'tis',
+ 'to',
+ 'too',
+ 'twas',
+ 'us',
+ 'wants',
+ 'was',
+ 'we',
+ 'were',
+ 'what',
+ 'when',
+ 'where',
+ 'which',
+ 'while',
+ 'who',
+ 'whom',
+ 'why',
+ 'will',
+ 'with',
+ 'would',
+ 'yet',
+ 'you',
+ 'your'
+])
+
+lunr.Pipeline.registerFunction(lunr.stopWordFilter, 'stopWordFilter')
+/*!
+ * lunr.trimmer
+ * Copyright (C) 2020 Oliver Nightingale
+ */
+
+/**
+ * lunr.trimmer is a pipeline function for trimming non word
+ * characters from the beginning and end of tokens before they
+ * enter the index.
+ *
+ * This implementation may not work correctly for non latin
+ * characters and should either be removed or adapted for use
+ * with languages with non-latin characters.
+ *
+ * @static
+ * @implements {lunr.PipelineFunction}
+ * @param {lunr.Token} token The token to pass through the filter
+ * @returns {lunr.Token}
+ * @see lunr.Pipeline
+ */
+lunr.trimmer = function (token) {
+ return token.update(function (s) {
+ return s.replace(/^\W+/, '').replace(/\W+$/, '')
+ })
+}
+
+lunr.Pipeline.registerFunction(lunr.trimmer, 'trimmer')
+/*!
+ * lunr.TokenSet
+ * Copyright (C) 2020 Oliver Nightingale
+ */
+
+/**
+ * A token set is used to store the unique list of all tokens
+ * within an index. Token sets are also used to represent an
+ * incoming query to the index, this query token set and index
+ * token set are then intersected to find which tokens to look
+ * up in the inverted index.
+ *
+ * A token set can hold multiple tokens, as in the case of the
+ * index token set, or it can hold a single token as in the
+ * case of a simple query token set.
+ *
+ * Additionally token sets are used to perform wildcard matching.
+ * Leading, contained and trailing wildcards are supported, and
+ * from this edit distance matching can also be provided.
+ *
+ * Token sets are implemented as a minimal finite state automata,
+ * where both common prefixes and suffixes are shared between tokens.
+ * This helps to reduce the space used for storing the token set.
+ *
+ * @constructor
+ */
+lunr.TokenSet = function () {
+ this.final = false
+ this.edges = {}
+ this.id = lunr.TokenSet._nextId
+ lunr.TokenSet._nextId += 1
+}
+
+/**
+ * Keeps track of the next, auto increment, identifier to assign
+ * to a new tokenSet.
+ *
+ * TokenSets require a unique identifier to be correctly minimised.
+ *
+ * @private
+ */
+lunr.TokenSet._nextId = 1
+
+/**
+ * Creates a TokenSet instance from the given sorted array of words.
+ *
+ * @param {String[]} arr - A sorted array of strings to create the set from.
+ * @returns {lunr.TokenSet}
+ * @throws Will throw an error if the input array is not sorted.
+ */
+lunr.TokenSet.fromArray = function (arr) {
+ var builder = new lunr.TokenSet.Builder
+
+ for (var i = 0, len = arr.length; i < len; i++) {
+ builder.insert(arr[i])
+ }
+
+ builder.finish()
+ return builder.root
+}
+
+/**
+ * Creates a token set from a query clause.
+ *
+ * @private
+ * @param {Object} clause - A single clause from lunr.Query.
+ * @param {string} clause.term - The query clause term.
+ * @param {number} [clause.editDistance] - The optional edit distance for the term.
+ * @returns {lunr.TokenSet}
+ */
+lunr.TokenSet.fromClause = function (clause) {
+ if ('editDistance' in clause) {
+ return lunr.TokenSet.fromFuzzyString(clause.term, clause.editDistance)
+ } else {
+ return lunr.TokenSet.fromString(clause.term)
+ }
+}
+
+/**
+ * Creates a token set representing a single string with a specified
+ * edit distance.
+ *
+ * Insertions, deletions, substitutions and transpositions are each
+ * treated as an edit distance of 1.
+ *
+ * Increasing the allowed edit distance will have a dramatic impact
+ * on the performance of both creating and intersecting these TokenSets.
+ * It is advised to keep the edit distance less than 3.
+ *
+ * @param {string} str - The string to create the token set from.
+ * @param {number} editDistance - The allowed edit distance to match.
+ * @returns {lunr.Vector}
+ */
+lunr.TokenSet.fromFuzzyString = function (str, editDistance) {
+ var root = new lunr.TokenSet
+
+ var stack = [{
+ node: root,
+ editsRemaining: editDistance,
+ str: str
+ }]
+
+ while (stack.length) {
+ var frame = stack.pop()
+
+ // no edit
+ if (frame.str.length > 0) {
+ var char = frame.str.charAt(0),
+ noEditNode
+
+ if (char in frame.node.edges) {
+ noEditNode = frame.node.edges[char]
+ } else {
+ noEditNode = new lunr.TokenSet
+ frame.node.edges[char] = noEditNode
+ }
+
+ if (frame.str.length == 1) {
+ noEditNode.final = true
+ }
+
+ stack.push({
+ node: noEditNode,
+ editsRemaining: frame.editsRemaining,
+ str: frame.str.slice(1)
+ })
+ }
+
+ if (frame.editsRemaining == 0) {
+ continue
+ }
+
+ // insertion
+ if ("*" in frame.node.edges) {
+ var insertionNode = frame.node.edges["*"]
+ } else {
+ var insertionNode = new lunr.TokenSet
+ frame.node.edges["*"] = insertionNode
+ }
+
+ if (frame.str.length == 0) {
+ insertionNode.final = true
+ }
+
+ stack.push({
+ node: insertionNode,
+ editsRemaining: frame.editsRemaining - 1,
+ str: frame.str
+ })
+
+ // deletion
+ // can only do a deletion if we have enough edits remaining
+ // and if there are characters left to delete in the string
+ if (frame.str.length > 1) {
+ stack.push({
+ node: frame.node,
+ editsRemaining: frame.editsRemaining - 1,
+ str: frame.str.slice(1)
+ })
+ }
+
+ // deletion
+ // just removing the last character from the str
+ if (frame.str.length == 1) {
+ frame.node.final = true
+ }
+
+ // substitution
+ // can only do a substitution if we have enough edits remaining
+ // and if there are characters left to substitute
+ if (frame.str.length >= 1) {
+ if ("*" in frame.node.edges) {
+ var substitutionNode = frame.node.edges["*"]
+ } else {
+ var substitutionNode = new lunr.TokenSet
+ frame.node.edges["*"] = substitutionNode
+ }
+
+ if (frame.str.length == 1) {
+ substitutionNode.final = true
+ }
+
+ stack.push({
+ node: substitutionNode,
+ editsRemaining: frame.editsRemaining - 1,
+ str: frame.str.slice(1)
+ })
+ }
+
+ // transposition
+ // can only do a transposition if there are edits remaining
+ // and there are enough characters to transpose
+ if (frame.str.length > 1) {
+ var charA = frame.str.charAt(0),
+ charB = frame.str.charAt(1),
+ transposeNode
+
+ if (charB in frame.node.edges) {
+ transposeNode = frame.node.edges[charB]
+ } else {
+ transposeNode = new lunr.TokenSet
+ frame.node.edges[charB] = transposeNode
+ }
+
+ if (frame.str.length == 1) {
+ transposeNode.final = true
+ }
+
+ stack.push({
+ node: transposeNode,
+ editsRemaining: frame.editsRemaining - 1,
+ str: charA + frame.str.slice(2)
+ })
+ }
+ }
+
+ return root
+}
+
+/**
+ * Creates a TokenSet from a string.
+ *
+ * The string may contain one or more wildcard characters (*)
+ * that will allow wildcard matching when intersecting with
+ * another TokenSet.
+ *
+ * @param {string} str - The string to create a TokenSet from.
+ * @returns {lunr.TokenSet}
+ */
+lunr.TokenSet.fromString = function (str) {
+ var node = new lunr.TokenSet,
+ root = node
+
+ /*
+ * Iterates through all characters within the passed string
+ * appending a node for each character.
+ *
+ * When a wildcard character is found then a self
+ * referencing edge is introduced to continually match
+ * any number of any characters.
+ */
+ for (var i = 0, len = str.length; i < len; i++) {
+ var char = str[i],
+ final = (i == len - 1)
+
+ if (char == "*") {
+ node.edges[char] = node
+ node.final = final
+
+ } else {
+ var next = new lunr.TokenSet
+ next.final = final
+
+ node.edges[char] = next
+ node = next
+ }
+ }
+
+ return root
+}
+
+/**
+ * Converts this TokenSet into an array of strings
+ * contained within the TokenSet.
+ *
+ * This is not intended to be used on a TokenSet that
+ * contains wildcards, in these cases the results are
+ * undefined and are likely to cause an infinite loop.
+ *
+ * @returns {string[]}
+ */
+lunr.TokenSet.prototype.toArray = function () {
+ var words = []
+
+ var stack = [{
+ prefix: "",
+ node: this
+ }]
+
+ while (stack.length) {
+ var frame = stack.pop(),
+ edges = Object.keys(frame.node.edges),
+ len = edges.length
+
+ if (frame.node.final) {
+ /* In Safari, at this point the prefix is sometimes corrupted, see:
+ * https://github.com/olivernn/lunr.js/issues/279 Calling any
+ * String.prototype method forces Safari to "cast" this string to what
+ * it's supposed to be, fixing the bug. */
+ frame.prefix.charAt(0)
+ words.push(frame.prefix)
+ }
+
+ for (var i = 0; i < len; i++) {
+ var edge = edges[i]
+
+ stack.push({
+ prefix: frame.prefix.concat(edge),
+ node: frame.node.edges[edge]
+ })
+ }
+ }
+
+ return words
+}
+
+/**
+ * Generates a string representation of a TokenSet.
+ *
+ * This is intended to allow TokenSets to be used as keys
+ * in objects, largely to aid the construction and minimisation
+ * of a TokenSet. As such it is not designed to be a human
+ * friendly representation of the TokenSet.
+ *
+ * @returns {string}
+ */
+lunr.TokenSet.prototype.toString = function () {
+ // NOTE: Using Object.keys here as this.edges is very likely
+ // to enter 'hash-mode' with many keys being added
+ //
+ // avoiding a for-in loop here as it leads to the function
+ // being de-optimised (at least in V8). From some simple
+ // benchmarks the performance is comparable, but allowing
+ // V8 to optimize may mean easy performance wins in the future.
+
+ if (this._str) {
+ return this._str
+ }
+
+ var str = this.final ? '1' : '0',
+ labels = Object.keys(this.edges).sort(),
+ len = labels.length
+
+ for (var i = 0; i < len; i++) {
+ var label = labels[i],
+ node = this.edges[label]
+
+ str = str + label + node.id
+ }
+
+ return str
+}
+
+/**
+ * Returns a new TokenSet that is the intersection of
+ * this TokenSet and the passed TokenSet.
+ *
+ * This intersection will take into account any wildcards
+ * contained within the TokenSet.
+ *
+ * @param {lunr.TokenSet} b - An other TokenSet to intersect with.
+ * @returns {lunr.TokenSet}
+ */
+lunr.TokenSet.prototype.intersect = function (b) {
+ var output = new lunr.TokenSet,
+ frame = undefined
+
+ var stack = [{
+ qNode: b,
+ output: output,
+ node: this
+ }]
+
+ while (stack.length) {
+ frame = stack.pop()
+
+ // NOTE: As with the #toString method, we are using
+ // Object.keys and a for loop instead of a for-in loop
+ // as both of these objects enter 'hash' mode, causing
+ // the function to be de-optimised in V8
+ var qEdges = Object.keys(frame.qNode.edges),
+ qLen = qEdges.length,
+ nEdges = Object.keys(frame.node.edges),
+ nLen = nEdges.length
+
+ for (var q = 0; q < qLen; q++) {
+ var qEdge = qEdges[q]
+
+ for (var n = 0; n < nLen; n++) {
+ var nEdge = nEdges[n]
+
+ if (nEdge == qEdge || qEdge == '*') {
+ var node = frame.node.edges[nEdge],
+ qNode = frame.qNode.edges[qEdge],
+ final = node.final && qNode.final,
+ next = undefined
+
+ if (nEdge in frame.output.edges) {
+ // an edge already exists for this character
+ // no need to create a new node, just set the finality
+ // bit unless this node is already final
+ next = frame.output.edges[nEdge]
+ next.final = next.final || final
+
+ } else {
+ // no edge exists yet, must create one
+ // set the finality bit and insert it
+ // into the output
+ next = new lunr.TokenSet
+ next.final = final
+ frame.output.edges[nEdge] = next
+ }
+
+ stack.push({
+ qNode: qNode,
+ output: next,
+ node: node
+ })
+ }
+ }
+ }
+ }
+
+ return output
+}
+lunr.TokenSet.Builder = function () {
+ this.previousWord = ""
+ this.root = new lunr.TokenSet
+ this.uncheckedNodes = []
+ this.minimizedNodes = {}
+}
+
+lunr.TokenSet.Builder.prototype.insert = function (word) {
+ var node,
+ commonPrefix = 0
+
+ if (word < this.previousWord) {
+ throw new Error ("Out of order word insertion")
+ }
+
+ for (var i = 0; i < word.length && i < this.previousWord.length; i++) {
+ if (word[i] != this.previousWord[i]) break
+ commonPrefix++
+ }
+
+ this.minimize(commonPrefix)
+
+ if (this.uncheckedNodes.length == 0) {
+ node = this.root
+ } else {
+ node = this.uncheckedNodes[this.uncheckedNodes.length - 1].child
+ }
+
+ for (var i = commonPrefix; i < word.length; i++) {
+ var nextNode = new lunr.TokenSet,
+ char = word[i]
+
+ node.edges[char] = nextNode
+
+ this.uncheckedNodes.push({
+ parent: node,
+ char: char,
+ child: nextNode
+ })
+
+ node = nextNode
+ }
+
+ node.final = true
+ this.previousWord = word
+}
+
+lunr.TokenSet.Builder.prototype.finish = function () {
+ this.minimize(0)
+}
+
+lunr.TokenSet.Builder.prototype.minimize = function (downTo) {
+ for (var i = this.uncheckedNodes.length - 1; i >= downTo; i--) {
+ var node = this.uncheckedNodes[i],
+ childKey = node.child.toString()
+
+ if (childKey in this.minimizedNodes) {
+ node.parent.edges[node.char] = this.minimizedNodes[childKey]
+ } else {
+ // Cache the key for this node since
+ // we know it can't change anymore
+ node.child._str = childKey
+
+ this.minimizedNodes[childKey] = node.child
+ }
+
+ this.uncheckedNodes.pop()
+ }
+}
+/*!
+ * lunr.Index
+ * Copyright (C) 2020 Oliver Nightingale
+ */
+
+/**
+ * An index contains the built index of all documents and provides a query interface
+ * to the index.
+ *
+ * Usually instances of lunr.Index will not be created using this constructor, instead
+ * lunr.Builder should be used to construct new indexes, or lunr.Index.load should be
+ * used to load previously built and serialized indexes.
+ *
+ * @constructor
+ * @param {Object} attrs - The attributes of the built search index.
+ * @param {Object} attrs.invertedIndex - An index of term/field to document reference.
+ * @param {Object} attrs.fieldVectors - Field vectors
+ * @param {lunr.TokenSet} attrs.tokenSet - An set of all corpus tokens.
+ * @param {string[]} attrs.fields - The names of indexed document fields.
+ * @param {lunr.Pipeline} attrs.pipeline - The pipeline to use for search terms.
+ */
+lunr.Index = function (attrs) {
+ this.invertedIndex = attrs.invertedIndex
+ this.fieldVectors = attrs.fieldVectors
+ this.tokenSet = attrs.tokenSet
+ this.fields = attrs.fields
+ this.pipeline = attrs.pipeline
+}
+
+/**
+ * A result contains details of a document matching a search query.
+ * @typedef {Object} lunr.Index~Result
+ * @property {string} ref - The reference of the document this result represents.
+ * @property {number} score - A number between 0 and 1 representing how similar this document is to the query.
+ * @property {lunr.MatchData} matchData - Contains metadata about this match including which term(s) caused the match.
+ */
+
+/**
+ * Although lunr provides the ability to create queries using lunr.Query, it also provides a simple
+ * query language which itself is parsed into an instance of lunr.Query.
+ *
+ * For programmatically building queries it is advised to directly use lunr.Query, the query language
+ * is best used for human entered text rather than program generated text.
+ *
+ * At its simplest queries can just be a single term, e.g. `hello`, multiple terms are also supported
+ * and will be combined with OR, e.g `hello world` will match documents that contain either 'hello'
+ * or 'world', though those that contain both will rank higher in the results.
+ *
+ * Wildcards can be included in terms to match one or more unspecified characters, these wildcards can
+ * be inserted anywhere within the term, and more than one wildcard can exist in a single term. Adding
+ * wildcards will increase the number of documents that will be found but can also have a negative
+ * impact on query performance, especially with wildcards at the beginning of a term.
+ *
+ * Terms can be restricted to specific fields, e.g. `title:hello`, only documents with the term
+ * hello in the title field will match this query. Using a field not present in the index will lead
+ * to an error being thrown.
+ *
+ * Modifiers can also be added to terms, lunr supports edit distance and boost modifiers on terms. A term
+ * boost will make documents matching that term score higher, e.g. `foo^5`. Edit distance is also supported
+ * to provide fuzzy matching, e.g. 'hello~2' will match documents with hello with an edit distance of 2.
+ * Avoid large values for edit distance to improve query performance.
+ *
+ * Each term also supports a presence modifier. By default a term's presence in document is optional, however
+ * this can be changed to either required or prohibited. For a term's presence to be required in a document the
+ * term should be prefixed with a '+', e.g. `+foo bar` is a search for documents that must contain 'foo' and
+ * optionally contain 'bar'. Conversely a leading '-' sets the terms presence to prohibited, i.e. it must not
+ * appear in a document, e.g. `-foo bar` is a search for documents that do not contain 'foo' but may contain 'bar'.
+ *
+ * To escape special characters the backslash character '\' can be used, this allows searches to include
+ * characters that would normally be considered modifiers, e.g. `foo\~2` will search for a term "foo~2" instead
+ * of attempting to apply a boost of 2 to the search term "foo".
+ *
+ * @typedef {string} lunr.Index~QueryString
+ * @example
Simple single term query
+ * hello
+ * @example
Multiple term query
+ * hello world
+ * @example
term scoped to a field
+ * title:hello
+ * @example
term with a boost of 10
+ * hello^10
+ * @example
term with an edit distance of 2
+ * hello~2
+ * @example
terms with presence modifiers
+ * -foo +bar baz
+ */
+
+/**
+ * Performs a search against the index using lunr query syntax.
+ *
+ * Results will be returned sorted by their score, the most relevant results
+ * will be returned first. For details on how the score is calculated, please see
+ * the {@link https://lunrjs.com/guides/searching.html#scoring|guide}.
+ *
+ * For more programmatic querying use lunr.Index#query.
+ *
+ * @param {lunr.Index~QueryString} queryString - A string containing a lunr query.
+ * @throws {lunr.QueryParseError} If the passed query string cannot be parsed.
+ * @returns {lunr.Index~Result[]}
+ */
+lunr.Index.prototype.search = function (queryString) {
+ return this.query(function (query) {
+ var parser = new lunr.QueryParser(queryString, query)
+ parser.parse()
+ })
+}
+
+/**
+ * A query builder callback provides a query object to be used to express
+ * the query to perform on the index.
+ *
+ * @callback lunr.Index~queryBuilder
+ * @param {lunr.Query} query - The query object to build up.
+ * @this lunr.Query
+ */
+
+/**
+ * Performs a query against the index using the yielded lunr.Query object.
+ *
+ * If performing programmatic queries against the index, this method is preferred
+ * over lunr.Index#search so as to avoid the additional query parsing overhead.
+ *
+ * A query object is yielded to the supplied function which should be used to
+ * express the query to be run against the index.
+ *
+ * Note that although this function takes a callback parameter it is _not_ an
+ * asynchronous operation, the callback is just yielded a query object to be
+ * customized.
+ *
+ * @param {lunr.Index~queryBuilder} fn - A function that is used to build the query.
+ * @returns {lunr.Index~Result[]}
+ */
+lunr.Index.prototype.query = function (fn) {
+ // for each query clause
+ // * process terms
+ // * expand terms from token set
+ // * find matching documents and metadata
+ // * get document vectors
+ // * score documents
+
+ var query = new lunr.Query(this.fields),
+ matchingFields = Object.create(null),
+ queryVectors = Object.create(null),
+ termFieldCache = Object.create(null),
+ requiredMatches = Object.create(null),
+ prohibitedMatches = Object.create(null)
+
+ /*
+ * To support field level boosts a query vector is created per
+ * field. An empty vector is eagerly created to support negated
+ * queries.
+ */
+ for (var i = 0; i < this.fields.length; i++) {
+ queryVectors[this.fields[i]] = new lunr.Vector
+ }
+
+ fn.call(query, query)
+
+ for (var i = 0; i < query.clauses.length; i++) {
+ /*
+ * Unless the pipeline has been disabled for this term, which is
+ * the case for terms with wildcards, we need to pass the clause
+ * term through the search pipeline. A pipeline returns an array
+ * of processed terms. Pipeline functions may expand the passed
+ * term, which means we may end up performing multiple index lookups
+ * for a single query term.
+ */
+ var clause = query.clauses[i],
+ terms = null,
+ clauseMatches = lunr.Set.empty
+
+ if (clause.usePipeline) {
+ terms = this.pipeline.runString(clause.term, {
+ fields: clause.fields
+ })
+ } else {
+ terms = [clause.term]
+ }
+
+ for (var m = 0; m < terms.length; m++) {
+ var term = terms[m]
+
+ /*
+ * Each term returned from the pipeline needs to use the same query
+ * clause object, e.g. the same boost and or edit distance. The
+ * simplest way to do this is to re-use the clause object but mutate
+ * its term property.
+ */
+ clause.term = term
+
+ /*
+ * From the term in the clause we create a token set which will then
+ * be used to intersect the indexes token set to get a list of terms
+ * to lookup in the inverted index
+ */
+ var termTokenSet = lunr.TokenSet.fromClause(clause),
+ expandedTerms = this.tokenSet.intersect(termTokenSet).toArray()
+
+ /*
+ * If a term marked as required does not exist in the tokenSet it is
+ * impossible for the search to return any matches. We set all the field
+ * scoped required matches set to empty and stop examining any further
+ * clauses.
+ */
+ if (expandedTerms.length === 0 && clause.presence === lunr.Query.presence.REQUIRED) {
+ for (var k = 0; k < clause.fields.length; k++) {
+ var field = clause.fields[k]
+ requiredMatches[field] = lunr.Set.empty
+ }
+
+ break
+ }
+
+ for (var j = 0; j < expandedTerms.length; j++) {
+ /*
+ * For each term get the posting and termIndex, this is required for
+ * building the query vector.
+ */
+ var expandedTerm = expandedTerms[j],
+ posting = this.invertedIndex[expandedTerm],
+ termIndex = posting._index
+
+ for (var k = 0; k < clause.fields.length; k++) {
+ /*
+ * For each field that this query term is scoped by (by default
+ * all fields are in scope) we need to get all the document refs
+ * that have this term in that field.
+ *
+ * The posting is the entry in the invertedIndex for the matching
+ * term from above.
+ */
+ var field = clause.fields[k],
+ fieldPosting = posting[field],
+ matchingDocumentRefs = Object.keys(fieldPosting),
+ termField = expandedTerm + "/" + field,
+ matchingDocumentsSet = new lunr.Set(matchingDocumentRefs)
+
+ /*
+ * if the presence of this term is required ensure that the matching
+ * documents are added to the set of required matches for this clause.
+ *
+ */
+ if (clause.presence == lunr.Query.presence.REQUIRED) {
+ clauseMatches = clauseMatches.union(matchingDocumentsSet)
+
+ if (requiredMatches[field] === undefined) {
+ requiredMatches[field] = lunr.Set.complete
+ }
+ }
+
+ /*
+ * if the presence of this term is prohibited ensure that the matching
+ * documents are added to the set of prohibited matches for this field,
+ * creating that set if it does not yet exist.
+ */
+ if (clause.presence == lunr.Query.presence.PROHIBITED) {
+ if (prohibitedMatches[field] === undefined) {
+ prohibitedMatches[field] = lunr.Set.empty
+ }
+
+ prohibitedMatches[field] = prohibitedMatches[field].union(matchingDocumentsSet)
+
+ /*
+ * Prohibited matches should not be part of the query vector used for
+ * similarity scoring and no metadata should be extracted so we continue
+ * to the next field
+ */
+ continue
+ }
+
+ /*
+ * The query field vector is populated using the termIndex found for
+ * the term and a unit value with the appropriate boost applied.
+ * Using upsert because there could already be an entry in the vector
+ * for the term we are working with. In that case we just add the scores
+ * together.
+ */
+ queryVectors[field].upsert(termIndex, clause.boost, function (a, b) { return a + b })
+
+ /**
+ * If we've already seen this term, field combo then we've already collected
+ * the matching documents and metadata, no need to go through all that again
+ */
+ if (termFieldCache[termField]) {
+ continue
+ }
+
+ for (var l = 0; l < matchingDocumentRefs.length; l++) {
+ /*
+ * All metadata for this term/field/document triple
+ * are then extracted and collected into an instance
+ * of lunr.MatchData ready to be returned in the query
+ * results
+ */
+ var matchingDocumentRef = matchingDocumentRefs[l],
+ matchingFieldRef = new lunr.FieldRef (matchingDocumentRef, field),
+ metadata = fieldPosting[matchingDocumentRef],
+ fieldMatch
+
+ if ((fieldMatch = matchingFields[matchingFieldRef]) === undefined) {
+ matchingFields[matchingFieldRef] = new lunr.MatchData (expandedTerm, field, metadata)
+ } else {
+ fieldMatch.add(expandedTerm, field, metadata)
+ }
+
+ }
+
+ termFieldCache[termField] = true
+ }
+ }
+ }
+
+ /**
+ * If the presence was required we need to update the requiredMatches field sets.
+ * We do this after all fields for the term have collected their matches because
+ * the clause terms presence is required in _any_ of the fields not _all_ of the
+ * fields.
+ */
+ if (clause.presence === lunr.Query.presence.REQUIRED) {
+ for (var k = 0; k < clause.fields.length; k++) {
+ var field = clause.fields[k]
+ requiredMatches[field] = requiredMatches[field].intersect(clauseMatches)
+ }
+ }
+ }
+
+ /**
+ * Need to combine the field scoped required and prohibited
+ * matching documents into a global set of required and prohibited
+ * matches
+ */
+ var allRequiredMatches = lunr.Set.complete,
+ allProhibitedMatches = lunr.Set.empty
+
+ for (var i = 0; i < this.fields.length; i++) {
+ var field = this.fields[i]
+
+ if (requiredMatches[field]) {
+ allRequiredMatches = allRequiredMatches.intersect(requiredMatches[field])
+ }
+
+ if (prohibitedMatches[field]) {
+ allProhibitedMatches = allProhibitedMatches.union(prohibitedMatches[field])
+ }
+ }
+
+ var matchingFieldRefs = Object.keys(matchingFields),
+ results = [],
+ matches = Object.create(null)
+
+ /*
+ * If the query is negated (contains only prohibited terms)
+ * we need to get _all_ fieldRefs currently existing in the
+ * index. This is only done when we know that the query is
+ * entirely prohibited terms to avoid any cost of getting all
+ * fieldRefs unnecessarily.
+ *
+ * Additionally, blank MatchData must be created to correctly
+ * populate the results.
+ */
+ if (query.isNegated()) {
+ matchingFieldRefs = Object.keys(this.fieldVectors)
+
+ for (var i = 0; i < matchingFieldRefs.length; i++) {
+ var matchingFieldRef = matchingFieldRefs[i]
+ var fieldRef = lunr.FieldRef.fromString(matchingFieldRef)
+ matchingFields[matchingFieldRef] = new lunr.MatchData
+ }
+ }
+
+ for (var i = 0; i < matchingFieldRefs.length; i++) {
+ /*
+ * Currently we have document fields that match the query, but we
+ * need to return documents. The matchData and scores are combined
+ * from multiple fields belonging to the same document.
+ *
+ * Scores are calculated by field, using the query vectors created
+ * above, and combined into a final document score using addition.
+ */
+ var fieldRef = lunr.FieldRef.fromString(matchingFieldRefs[i]),
+ docRef = fieldRef.docRef
+
+ if (!allRequiredMatches.contains(docRef)) {
+ continue
+ }
+
+ if (allProhibitedMatches.contains(docRef)) {
+ continue
+ }
+
+ var fieldVector = this.fieldVectors[fieldRef],
+ score = queryVectors[fieldRef.fieldName].similarity(fieldVector),
+ docMatch
+
+ if ((docMatch = matches[docRef]) !== undefined) {
+ docMatch.score += score
+ docMatch.matchData.combine(matchingFields[fieldRef])
+ } else {
+ var match = {
+ ref: docRef,
+ score: score,
+ matchData: matchingFields[fieldRef]
+ }
+ matches[docRef] = match
+ results.push(match)
+ }
+ }
+
+ /*
+ * Sort the results objects by score, highest first.
+ */
+ return results.sort(function (a, b) {
+ return b.score - a.score
+ })
+}
+
+/**
+ * Prepares the index for JSON serialization.
+ *
+ * The schema for this JSON blob will be described in a
+ * separate JSON schema file.
+ *
+ * @returns {Object}
+ */
+lunr.Index.prototype.toJSON = function () {
+ var invertedIndex = Object.keys(this.invertedIndex)
+ .sort()
+ .map(function (term) {
+ return [term, this.invertedIndex[term]]
+ }, this)
+
+ var fieldVectors = Object.keys(this.fieldVectors)
+ .map(function (ref) {
+ return [ref, this.fieldVectors[ref].toJSON()]
+ }, this)
+
+ return {
+ version: lunr.version,
+ fields: this.fields,
+ fieldVectors: fieldVectors,
+ invertedIndex: invertedIndex,
+ pipeline: this.pipeline.toJSON()
+ }
+}
+
+/**
+ * Loads a previously serialized lunr.Index
+ *
+ * @param {Object} serializedIndex - A previously serialized lunr.Index
+ * @returns {lunr.Index}
+ */
+lunr.Index.load = function (serializedIndex) {
+ var attrs = {},
+ fieldVectors = {},
+ serializedVectors = serializedIndex.fieldVectors,
+ invertedIndex = Object.create(null),
+ serializedInvertedIndex = serializedIndex.invertedIndex,
+ tokenSetBuilder = new lunr.TokenSet.Builder,
+ pipeline = lunr.Pipeline.load(serializedIndex.pipeline)
+
+ if (serializedIndex.version != lunr.version) {
+ lunr.utils.warn("Version mismatch when loading serialised index. Current version of lunr '" + lunr.version + "' does not match serialized index '" + serializedIndex.version + "'")
+ }
+
+ for (var i = 0; i < serializedVectors.length; i++) {
+ var tuple = serializedVectors[i],
+ ref = tuple[0],
+ elements = tuple[1]
+
+ fieldVectors[ref] = new lunr.Vector(elements)
+ }
+
+ for (var i = 0; i < serializedInvertedIndex.length; i++) {
+ var tuple = serializedInvertedIndex[i],
+ term = tuple[0],
+ posting = tuple[1]
+
+ tokenSetBuilder.insert(term)
+ invertedIndex[term] = posting
+ }
+
+ tokenSetBuilder.finish()
+
+ attrs.fields = serializedIndex.fields
+
+ attrs.fieldVectors = fieldVectors
+ attrs.invertedIndex = invertedIndex
+ attrs.tokenSet = tokenSetBuilder.root
+ attrs.pipeline = pipeline
+
+ return new lunr.Index(attrs)
+}
+/*!
+ * lunr.Builder
+ * Copyright (C) 2020 Oliver Nightingale
+ */
+
+/**
+ * lunr.Builder performs indexing on a set of documents and
+ * returns instances of lunr.Index ready for querying.
+ *
+ * All configuration of the index is done via the builder, the
+ * fields to index, the document reference, the text processing
+ * pipeline and document scoring parameters are all set on the
+ * builder before indexing.
+ *
+ * @constructor
+ * @property {string} _ref - Internal reference to the document reference field.
+ * @property {string[]} _fields - Internal reference to the document fields to index.
+ * @property {object} invertedIndex - The inverted index maps terms to document fields.
+ * @property {object} documentTermFrequencies - Keeps track of document term frequencies.
+ * @property {object} documentLengths - Keeps track of the length of documents added to the index.
+ * @property {lunr.tokenizer} tokenizer - Function for splitting strings into tokens for indexing.
+ * @property {lunr.Pipeline} pipeline - The pipeline performs text processing on tokens before indexing.
+ * @property {lunr.Pipeline} searchPipeline - A pipeline for processing search terms before querying the index.
+ * @property {number} documentCount - Keeps track of the total number of documents indexed.
+ * @property {number} _b - A parameter to control field length normalization, setting this to 0 disabled normalization, 1 fully normalizes field lengths, the default value is 0.75.
+ * @property {number} _k1 - A parameter to control how quickly an increase in term frequency results in term frequency saturation, the default value is 1.2.
+ * @property {number} termIndex - A counter incremented for each unique term, used to identify a terms position in the vector space.
+ * @property {array} metadataWhitelist - A list of metadata keys that have been whitelisted for entry in the index.
+ */
+lunr.Builder = function () {
+ this._ref = "id"
+ this._fields = Object.create(null)
+ this._documents = Object.create(null)
+ this.invertedIndex = Object.create(null)
+ this.fieldTermFrequencies = {}
+ this.fieldLengths = {}
+ this.tokenizer = lunr.tokenizer
+ this.pipeline = new lunr.Pipeline
+ this.searchPipeline = new lunr.Pipeline
+ this.documentCount = 0
+ this._b = 0.75
+ this._k1 = 1.2
+ this.termIndex = 0
+ this.metadataWhitelist = []
+}
+
+/**
+ * Sets the document field used as the document reference. Every document must have this field.
+ * The type of this field in the document should be a string, if it is not a string it will be
+ * coerced into a string by calling toString.
+ *
+ * The default ref is 'id'.
+ *
+ * The ref should _not_ be changed during indexing, it should be set before any documents are
+ * added to the index. Changing it during indexing can lead to inconsistent results.
+ *
+ * @param {string} ref - The name of the reference field in the document.
+ */
+lunr.Builder.prototype.ref = function (ref) {
+ this._ref = ref
+}
+
+/**
+ * A function that is used to extract a field from a document.
+ *
+ * Lunr expects a field to be at the top level of a document, if however the field
+ * is deeply nested within a document an extractor function can be used to extract
+ * the right field for indexing.
+ *
+ * @callback fieldExtractor
+ * @param {object} doc - The document being added to the index.
+ * @returns {?(string|object|object[])} obj - The object that will be indexed for this field.
+ * @example
Extracting a nested field
+ * function (doc) { return doc.nested.field }
+ */
+
+/**
+ * Adds a field to the list of document fields that will be indexed. Every document being
+ * indexed should have this field. Null values for this field in indexed documents will
+ * not cause errors but will limit the chance of that document being retrieved by searches.
+ *
+ * All fields should be added before adding documents to the index. Adding fields after
+ * a document has been indexed will have no effect on already indexed documents.
+ *
+ * Fields can be boosted at build time. This allows terms within that field to have more
+ * importance when ranking search results. Use a field boost to specify that matches within
+ * one field are more important than other fields.
+ *
+ * @param {string} fieldName - The name of a field to index in all documents.
+ * @param {object} attributes - Optional attributes associated with this field.
+ * @param {number} [attributes.boost=1] - Boost applied to all terms within this field.
+ * @param {fieldExtractor} [attributes.extractor] - Function to extract a field from a document.
+ * @throws {RangeError} fieldName cannot contain unsupported characters '/'
+ */
+lunr.Builder.prototype.field = function (fieldName, attributes) {
+ if (/\//.test(fieldName)) {
+ throw new RangeError ("Field '" + fieldName + "' contains illegal character '/'")
+ }
+
+ this._fields[fieldName] = attributes || {}
+}
+
+/**
+ * A parameter to tune the amount of field length normalisation that is applied when
+ * calculating relevance scores. A value of 0 will completely disable any normalisation
+ * and a value of 1 will fully normalise field lengths. The default is 0.75. Values of b
+ * will be clamped to the range 0 - 1.
+ *
+ * @param {number} number - The value to set for this tuning parameter.
+ */
+lunr.Builder.prototype.b = function (number) {
+ if (number < 0) {
+ this._b = 0
+ } else if (number > 1) {
+ this._b = 1
+ } else {
+ this._b = number
+ }
+}
+
+/**
+ * A parameter that controls the speed at which a rise in term frequency results in term
+ * frequency saturation. The default value is 1.2. Setting this to a higher value will give
+ * slower saturation levels, a lower value will result in quicker saturation.
+ *
+ * @param {number} number - The value to set for this tuning parameter.
+ */
+lunr.Builder.prototype.k1 = function (number) {
+ this._k1 = number
+}
+
+/**
+ * Adds a document to the index.
+ *
+ * Before adding fields to the index the index should have been fully setup, with the document
+ * ref and all fields to index already having been specified.
+ *
+ * The document must have a field name as specified by the ref (by default this is 'id') and
+ * it should have all fields defined for indexing, though null or undefined values will not
+ * cause errors.
+ *
+ * Entire documents can be boosted at build time. Applying a boost to a document indicates that
+ * this document should rank higher in search results than other documents.
+ *
+ * @param {object} doc - The document to add to the index.
+ * @param {object} attributes - Optional attributes associated with this document.
+ * @param {number} [attributes.boost=1] - Boost applied to all terms within this document.
+ */
+lunr.Builder.prototype.add = function (doc, attributes) {
+ var docRef = doc[this._ref],
+ fields = Object.keys(this._fields)
+
+ this._documents[docRef] = attributes || {}
+ this.documentCount += 1
+
+ for (var i = 0; i < fields.length; i++) {
+ var fieldName = fields[i],
+ extractor = this._fields[fieldName].extractor,
+ field = extractor ? extractor(doc) : doc[fieldName],
+ tokens = this.tokenizer(field, {
+ fields: [fieldName]
+ }),
+ terms = this.pipeline.run(tokens),
+ fieldRef = new lunr.FieldRef (docRef, fieldName),
+ fieldTerms = Object.create(null)
+
+ this.fieldTermFrequencies[fieldRef] = fieldTerms
+ this.fieldLengths[fieldRef] = 0
+
+ // store the length of this field for this document
+ this.fieldLengths[fieldRef] += terms.length
+
+ // calculate term frequencies for this field
+ for (var j = 0; j < terms.length; j++) {
+ var term = terms[j]
+
+ if (fieldTerms[term] == undefined) {
+ fieldTerms[term] = 0
+ }
+
+ fieldTerms[term] += 1
+
+ // add to inverted index
+ // create an initial posting if one doesn't exist
+ if (this.invertedIndex[term] == undefined) {
+ var posting = Object.create(null)
+ posting["_index"] = this.termIndex
+ this.termIndex += 1
+
+ for (var k = 0; k < fields.length; k++) {
+ posting[fields[k]] = Object.create(null)
+ }
+
+ this.invertedIndex[term] = posting
+ }
+
+ // add an entry for this term/fieldName/docRef to the invertedIndex
+ if (this.invertedIndex[term][fieldName][docRef] == undefined) {
+ this.invertedIndex[term][fieldName][docRef] = Object.create(null)
+ }
+
+ // store all whitelisted metadata about this token in the
+ // inverted index
+ for (var l = 0; l < this.metadataWhitelist.length; l++) {
+ var metadataKey = this.metadataWhitelist[l],
+ metadata = term.metadata[metadataKey]
+
+ if (this.invertedIndex[term][fieldName][docRef][metadataKey] == undefined) {
+ this.invertedIndex[term][fieldName][docRef][metadataKey] = []
+ }
+
+ this.invertedIndex[term][fieldName][docRef][metadataKey].push(metadata)
+ }
+ }
+
+ }
+}
+
+/**
+ * Calculates the average document length for this index
+ *
+ * @private
+ */
+lunr.Builder.prototype.calculateAverageFieldLengths = function () {
+
+ var fieldRefs = Object.keys(this.fieldLengths),
+ numberOfFields = fieldRefs.length,
+ accumulator = {},
+ documentsWithField = {}
+
+ for (var i = 0; i < numberOfFields; i++) {
+ var fieldRef = lunr.FieldRef.fromString(fieldRefs[i]),
+ field = fieldRef.fieldName
+
+ documentsWithField[field] || (documentsWithField[field] = 0)
+ documentsWithField[field] += 1
+
+ accumulator[field] || (accumulator[field] = 0)
+ accumulator[field] += this.fieldLengths[fieldRef]
+ }
+
+ var fields = Object.keys(this._fields)
+
+ for (var i = 0; i < fields.length; i++) {
+ var fieldName = fields[i]
+ accumulator[fieldName] = accumulator[fieldName] / documentsWithField[fieldName]
+ }
+
+ this.averageFieldLength = accumulator
+}
+
+/**
+ * Builds a vector space model of every document using lunr.Vector
+ *
+ * @private
+ */
+lunr.Builder.prototype.createFieldVectors = function () {
+ var fieldVectors = {},
+ fieldRefs = Object.keys(this.fieldTermFrequencies),
+ fieldRefsLength = fieldRefs.length,
+ termIdfCache = Object.create(null)
+
+ for (var i = 0; i < fieldRefsLength; i++) {
+ var fieldRef = lunr.FieldRef.fromString(fieldRefs[i]),
+ fieldName = fieldRef.fieldName,
+ fieldLength = this.fieldLengths[fieldRef],
+ fieldVector = new lunr.Vector,
+ termFrequencies = this.fieldTermFrequencies[fieldRef],
+ terms = Object.keys(termFrequencies),
+ termsLength = terms.length
+
+
+ var fieldBoost = this._fields[fieldName].boost || 1,
+ docBoost = this._documents[fieldRef.docRef].boost || 1
+
+ for (var j = 0; j < termsLength; j++) {
+ var term = terms[j],
+ tf = termFrequencies[term],
+ termIndex = this.invertedIndex[term]._index,
+ idf, score, scoreWithPrecision
+
+ if (termIdfCache[term] === undefined) {
+ idf = lunr.idf(this.invertedIndex[term], this.documentCount)
+ termIdfCache[term] = idf
+ } else {
+ idf = termIdfCache[term]
+ }
+
+ score = idf * ((this._k1 + 1) * tf) / (this._k1 * (1 - this._b + this._b * (fieldLength / this.averageFieldLength[fieldName])) + tf)
+ score *= fieldBoost
+ score *= docBoost
+ scoreWithPrecision = Math.round(score * 1000) / 1000
+ // Converts 1.23456789 to 1.234.
+ // Reducing the precision so that the vectors take up less
+ // space when serialised. Doing it now so that they behave
+ // the same before and after serialisation. Also, this is
+ // the fastest approach to reducing a number's precision in
+ // JavaScript.
+
+ fieldVector.insert(termIndex, scoreWithPrecision)
+ }
+
+ fieldVectors[fieldRef] = fieldVector
+ }
+
+ this.fieldVectors = fieldVectors
+}
+
+/**
+ * Creates a token set of all tokens in the index using lunr.TokenSet
+ *
+ * @private
+ */
+lunr.Builder.prototype.createTokenSet = function () {
+ this.tokenSet = lunr.TokenSet.fromArray(
+ Object.keys(this.invertedIndex).sort()
+ )
+}
+
+/**
+ * Builds the index, creating an instance of lunr.Index.
+ *
+ * This completes the indexing process and should only be called
+ * once all documents have been added to the index.
+ *
+ * @returns {lunr.Index}
+ */
+lunr.Builder.prototype.build = function () {
+ this.calculateAverageFieldLengths()
+ this.createFieldVectors()
+ this.createTokenSet()
+
+ return new lunr.Index({
+ invertedIndex: this.invertedIndex,
+ fieldVectors: this.fieldVectors,
+ tokenSet: this.tokenSet,
+ fields: Object.keys(this._fields),
+ pipeline: this.searchPipeline
+ })
+}
+
+/**
+ * Applies a plugin to the index builder.
+ *
+ * A plugin is a function that is called with the index builder as its context.
+ * Plugins can be used to customise or extend the behaviour of the index
+ * in some way. A plugin is just a function, that encapsulated the custom
+ * behaviour that should be applied when building the index.
+ *
+ * The plugin function will be called with the index builder as its argument, additional
+ * arguments can also be passed when calling use. The function will be called
+ * with the index builder as its context.
+ *
+ * @param {Function} plugin The plugin to apply.
+ */
+lunr.Builder.prototype.use = function (fn) {
+ var args = Array.prototype.slice.call(arguments, 1)
+ args.unshift(this)
+ fn.apply(this, args)
+}
+/**
+ * Contains and collects metadata about a matching document.
+ * A single instance of lunr.MatchData is returned as part of every
+ * lunr.Index~Result.
+ *
+ * @constructor
+ * @param {string} term - The term this match data is associated with
+ * @param {string} field - The field in which the term was found
+ * @param {object} metadata - The metadata recorded about this term in this field
+ * @property {object} metadata - A cloned collection of metadata associated with this document.
+ * @see {@link lunr.Index~Result}
+ */
+lunr.MatchData = function (term, field, metadata) {
+ var clonedMetadata = Object.create(null),
+ metadataKeys = Object.keys(metadata || {})
+
+ // Cloning the metadata to prevent the original
+ // being mutated during match data combination.
+ // Metadata is kept in an array within the inverted
+ // index so cloning the data can be done with
+ // Array#slice
+ for (var i = 0; i < metadataKeys.length; i++) {
+ var key = metadataKeys[i]
+ clonedMetadata[key] = metadata[key].slice()
+ }
+
+ this.metadata = Object.create(null)
+
+ if (term !== undefined) {
+ this.metadata[term] = Object.create(null)
+ this.metadata[term][field] = clonedMetadata
+ }
+}
+
+/**
+ * An instance of lunr.MatchData will be created for every term that matches a
+ * document. However only one instance is required in a lunr.Index~Result. This
+ * method combines metadata from another instance of lunr.MatchData with this
+ * objects metadata.
+ *
+ * @param {lunr.MatchData} otherMatchData - Another instance of match data to merge with this one.
+ * @see {@link lunr.Index~Result}
+ */
+lunr.MatchData.prototype.combine = function (otherMatchData) {
+ var terms = Object.keys(otherMatchData.metadata)
+
+ for (var i = 0; i < terms.length; i++) {
+ var term = terms[i],
+ fields = Object.keys(otherMatchData.metadata[term])
+
+ if (this.metadata[term] == undefined) {
+ this.metadata[term] = Object.create(null)
+ }
+
+ for (var j = 0; j < fields.length; j++) {
+ var field = fields[j],
+ keys = Object.keys(otherMatchData.metadata[term][field])
+
+ if (this.metadata[term][field] == undefined) {
+ this.metadata[term][field] = Object.create(null)
+ }
+
+ for (var k = 0; k < keys.length; k++) {
+ var key = keys[k]
+
+ if (this.metadata[term][field][key] == undefined) {
+ this.metadata[term][field][key] = otherMatchData.metadata[term][field][key]
+ } else {
+ this.metadata[term][field][key] = this.metadata[term][field][key].concat(otherMatchData.metadata[term][field][key])
+ }
+
+ }
+ }
+ }
+}
+
+/**
+ * Add metadata for a term/field pair to this instance of match data.
+ *
+ * @param {string} term - The term this match data is associated with
+ * @param {string} field - The field in which the term was found
+ * @param {object} metadata - The metadata recorded about this term in this field
+ */
+lunr.MatchData.prototype.add = function (term, field, metadata) {
+ if (!(term in this.metadata)) {
+ this.metadata[term] = Object.create(null)
+ this.metadata[term][field] = metadata
+ return
+ }
+
+ if (!(field in this.metadata[term])) {
+ this.metadata[term][field] = metadata
+ return
+ }
+
+ var metadataKeys = Object.keys(metadata)
+
+ for (var i = 0; i < metadataKeys.length; i++) {
+ var key = metadataKeys[i]
+
+ if (key in this.metadata[term][field]) {
+ this.metadata[term][field][key] = this.metadata[term][field][key].concat(metadata[key])
+ } else {
+ this.metadata[term][field][key] = metadata[key]
+ }
+ }
+}
+/**
+ * A lunr.Query provides a programmatic way of defining queries to be performed
+ * against a {@link lunr.Index}.
+ *
+ * Prefer constructing a lunr.Query using the {@link lunr.Index#query} method
+ * so the query object is pre-initialized with the right index fields.
+ *
+ * @constructor
+ * @property {lunr.Query~Clause[]} clauses - An array of query clauses.
+ * @property {string[]} allFields - An array of all available fields in a lunr.Index.
+ */
+lunr.Query = function (allFields) {
+ this.clauses = []
+ this.allFields = allFields
+}
+
+/**
+ * Constants for indicating what kind of automatic wildcard insertion will be used when constructing a query clause.
+ *
+ * This allows wildcards to be added to the beginning and end of a term without having to manually do any string
+ * concatenation.
+ *
+ * The wildcard constants can be bitwise combined to select both leading and trailing wildcards.
+ *
+ * @constant
+ * @default
+ * @property {number} wildcard.NONE - The term will have no wildcards inserted, this is the default behaviour
+ * @property {number} wildcard.LEADING - Prepend the term with a wildcard, unless a leading wildcard already exists
+ * @property {number} wildcard.TRAILING - Append a wildcard to the term, unless a trailing wildcard already exists
+ * @see lunr.Query~Clause
+ * @see lunr.Query#clause
+ * @see lunr.Query#term
+ * @example
+ * query.term('foo', {
+ * wildcard: lunr.Query.wildcard.LEADING | lunr.Query.wildcard.TRAILING
+ * })
+ */
+
+lunr.Query.wildcard = new String ("*")
+lunr.Query.wildcard.NONE = 0
+lunr.Query.wildcard.LEADING = 1
+lunr.Query.wildcard.TRAILING = 2
+
+/**
+ * Constants for indicating what kind of presence a term must have in matching documents.
+ *
+ * @constant
+ * @enum {number}
+ * @see lunr.Query~Clause
+ * @see lunr.Query#clause
+ * @see lunr.Query#term
+ * @example
query term with required presence
+ * query.term('foo', { presence: lunr.Query.presence.REQUIRED })
+ */
+lunr.Query.presence = {
+ /**
+ * Term's presence in a document is optional, this is the default value.
+ */
+ OPTIONAL: 1,
+
+ /**
+ * Term's presence in a document is required, documents that do not contain
+ * this term will not be returned.
+ */
+ REQUIRED: 2,
+
+ /**
+ * Term's presence in a document is prohibited, documents that do contain
+ * this term will not be returned.
+ */
+ PROHIBITED: 3
+}
+
+/**
+ * A single clause in a {@link lunr.Query} contains a term and details on how to
+ * match that term against a {@link lunr.Index}.
+ *
+ * @typedef {Object} lunr.Query~Clause
+ * @property {string[]} fields - The fields in an index this clause should be matched against.
+ * @property {number} [boost=1] - Any boost that should be applied when matching this clause.
+ * @property {number} [editDistance] - Whether the term should have fuzzy matching applied, and how fuzzy the match should be.
+ * @property {boolean} [usePipeline] - Whether the term should be passed through the search pipeline.
+ * @property {number} [wildcard=lunr.Query.wildcard.NONE] - Whether the term should have wildcards appended or prepended.
+ * @property {number} [presence=lunr.Query.presence.OPTIONAL] - The terms presence in any matching documents.
+ */
+
+/**
+ * Adds a {@link lunr.Query~Clause} to this query.
+ *
+ * Unless the clause contains the fields to be matched all fields will be matched. In addition
+ * a default boost of 1 is applied to the clause.
+ *
+ * @param {lunr.Query~Clause} clause - The clause to add to this query.
+ * @see lunr.Query~Clause
+ * @returns {lunr.Query}
+ */
+lunr.Query.prototype.clause = function (clause) {
+ if (!('fields' in clause)) {
+ clause.fields = this.allFields
+ }
+
+ if (!('boost' in clause)) {
+ clause.boost = 1
+ }
+
+ if (!('usePipeline' in clause)) {
+ clause.usePipeline = true
+ }
+
+ if (!('wildcard' in clause)) {
+ clause.wildcard = lunr.Query.wildcard.NONE
+ }
+
+ if ((clause.wildcard & lunr.Query.wildcard.LEADING) && (clause.term.charAt(0) != lunr.Query.wildcard)) {
+ clause.term = "*" + clause.term
+ }
+
+ if ((clause.wildcard & lunr.Query.wildcard.TRAILING) && (clause.term.slice(-1) != lunr.Query.wildcard)) {
+ clause.term = "" + clause.term + "*"
+ }
+
+ if (!('presence' in clause)) {
+ clause.presence = lunr.Query.presence.OPTIONAL
+ }
+
+ this.clauses.push(clause)
+
+ return this
+}
+
+/**
+ * A negated query is one in which every clause has a presence of
+ * prohibited. These queries require some special processing to return
+ * the expected results.
+ *
+ * @returns boolean
+ */
+lunr.Query.prototype.isNegated = function () {
+ for (var i = 0; i < this.clauses.length; i++) {
+ if (this.clauses[i].presence != lunr.Query.presence.PROHIBITED) {
+ return false
+ }
+ }
+
+ return true
+}
+
+/**
+ * Adds a term to the current query, under the covers this will create a {@link lunr.Query~Clause}
+ * to the list of clauses that make up this query.
+ *
+ * The term is used as is, i.e. no tokenization will be performed by this method. Instead conversion
+ * to a token or token-like string should be done before calling this method.
+ *
+ * The term will be converted to a string by calling `toString`. Multiple terms can be passed as an
+ * array, each term in the array will share the same options.
+ *
+ * @param {object|object[]} term - The term(s) to add to the query.
+ * @param {object} [options] - Any additional properties to add to the query clause.
+ * @returns {lunr.Query}
+ * @see lunr.Query#clause
+ * @see lunr.Query~Clause
+ * @example
adding a single term to a query
+ * query.term("foo")
+ * @example
adding a single term to a query and specifying search fields, term boost and automatic trailing wildcard
")),e.inlineElement=o}return h.updateStatus("ready"),h._parseMarkup(t,{},e),t}}});function N(){I&&l(document.body).removeClass(I)}function j(){N(),h.req&&h.req.abort()}var I,L="ajax";l.magnificPopup.registerModule(L,{options:{settings:null,cursor:"mfp-ajax-cur",tError:'The content could not be loaded.'},proto:{initAjax:function(){h.types.push(L),I=h.st.ajax.cursor,c(u+"."+L,j),c("BeforeChange."+L,j)},getAjax:function(r){I&&l(document.body).addClass(I),h.updateStatus("loading");var e=l.extend({url:r.src,success:function(e,t,n){n={data:e,xhr:n};d("ParseAjax",n),h.appendContent(l(n.data),L),r.finished=!0,N(),h._setFocus(),setTimeout(function(){h.wrap.addClass(w)},16),h.updateStatus("ready"),d("AjaxContentAdded")},error:function(){N(),r.finished=r.loadError=!0,h.updateStatus("error",h.st.ajax.tError.replace("%url%",r.src))}},h.st.ajax.settings);return h.req=l.ajax(e),""}}});var D;l.magnificPopup.registerModule("image",{options:{markup:'
',cursor:"mfp-zoom-out-cur",titleSrc:"title",verticalFit:!0,tError:'The image could not be loaded.'},proto:{initImage:function(){var e=h.st.image,t=".image";h.types.push("image"),c(b+t,function(){"image"===h.currItem.type&&e.cursor&&l(document.body).addClass(e.cursor)}),c(u+t,function(){e.cursor&&l(document.body).removeClass(e.cursor),C.off("resize"+x)}),c("Resize"+t,h.resizeImage),h.isLowIE&&c("AfterChange",h.resizeImage)},resizeImage:function(){var e,t=h.currItem;t&&t.img&&h.st.image.verticalFit&&(e=0,h.isLowIE&&(e=parseInt(t.img.css("padding-top"),10)+parseInt(t.img.css("padding-bottom"),10)),t.img.css("max-height",h.wH-e))},_onImageHasSize:function(e){e.img&&(e.hasSize=!0,D&&clearInterval(D),e.isCheckingImgSize=!1,d("ImageHasSize",e),e.imgHidden&&(h.content&&h.content.removeClass("mfp-loading"),e.imgHidden=!1))},findImageSize:function(t){var n=0,r=t.img[0],o=function(e){D&&clearInterval(D),D=setInterval(function(){0
',srcAction:"iframe_src",patterns:{youtube:{index:"youtube.com",id:"v=",src:"//www.youtube.com/embed/%id%?autoplay=1"},vimeo:{index:"vimeo.com/",id:"/",src:"//player.vimeo.com/video/%id%?autoplay=1"},gmaps:{index:"//maps.google.",src:"%id%&output=embed"}}},proto:{initIframe:function(){h.types.push(P),c("BeforeChange",function(e,t,n){t!==n&&(t===P?H():n===P&&H(!0))}),c(u+"."+P,function(){H()})},getIframe:function(e,t){var n=e.src,r=h.st.iframe;l.each(r.patterns,function(){if(-1',preload:[0,2],navigateByImgClick:!0,arrows:!0,tPrev:"Previous (Left arrow key)",tNext:"Next (Right arrow key)",tCounter:"%curr% of %total%"},proto:{initGallery:function(){var i=h.st.gallery,e=".mfp-gallery";if(h.direction=!0,!i||!i.enabled)return!1;g+=" mfp-gallery",c(b+e,function(){i.navigateByImgClick&&h.wrap.on("click"+e,".mfp-img",function(){if(1=h.index,h.index=e,h.updateItemHTML()},preloadNearbyImages:function(){for(var e=h.st.gallery.preload,t=Math.min(e[0],h.items.length),n=Math.min(e[1],h.items.length),r=1;r<=(h.direction?n:t);r++)h._preloadItem(h.index+r);for(r=1;r<=(h.direction?t:n);r++)h._preloadItem(h.index-r)},_preloadItem:function(e){var t;e=q(e),h.items[e].preloaded||((t=h.items[e]).parsed||(t=h.parseEl(e)),d("LazyLoad",t),"image"===t.type&&(t.img=l('').on("load.mfploader",function(){t.hasSize=!0}).on("error.mfploader",function(){t.hasSize=!0,t.loadError=!0,d("LazyLoadError",t)}).attr("src",t.src)),t.preloaded=!0)}}});var _="retina";l.magnificPopup.registerModule(_,{options:{replaceSrc:function(e){return e.src.replace(/\.\w+$/,function(e){return"@2x"+e})},ratio:1},proto:{initRetina:function(){var n,r;1t.durationMax?t.durationMax:t.durationMin&&e=u)return b.cancelScroll(!0),e=t,n=g,0===(t=r)&&document.body.focus(),n||(t.focus(),document.activeElement!==t&&(t.setAttribute("tabindex","-1"),t.focus(),t.style.outline="none"),x.scrollTo(0,e)),E("scrollStop",m,r,o),!(y=f=null)},h=function(e){var t,n,r;l+=e-(f=f||e),d=i+s*(n=d=1<(d=0===c?0:l/c)?1:d,"easeInQuad"===(t=m).easing&&(r=n*n),"easeOutQuad"===t.easing&&(r=n*(2-n)),"easeInOutQuad"===t.easing&&(r=n<.5?2*n*n:(4-2*n)*n-1),"easeInCubic"===t.easing&&(r=n*n*n),"easeOutCubic"===t.easing&&(r=--n*n*n+1),"easeInOutCubic"===t.easing&&(r=n<.5?4*n*n*n:(n-1)*(2*n-2)*(2*n-2)+1),"easeInQuart"===t.easing&&(r=n*n*n*n),"easeOutQuart"===t.easing&&(r=1- --n*n*n*n),"easeInOutQuart"===t.easing&&(r=n<.5?8*n*n*n*n:1-8*--n*n*n*n),"easeInQuint"===t.easing&&(r=n*n*n*n*n),"easeOutQuint"===t.easing&&(r=1+--n*n*n*n*n),"easeInOutQuint"===t.easing&&(r=n<.5?16*n*n*n*n*n:1+16*--n*n*n*n*n),(r=t.customEasing?t.customEasing(n):r)||n),x.scrollTo(0,Math.floor(d)),p(d,a)||(y=x.requestAnimationFrame(h),f=e)},0===x.pageYOffset&&x.scrollTo(0,0),t=r,e=m,g||history.pushState&&e.updateURL&&history.pushState({smoothScroll:JSON.stringify(e),anchor:t.id},document.title,t===document.documentElement?"#top":"#"+t.id),"matchMedia"in x&&x.matchMedia("(prefers-reduced-motion)").matches?x.scrollTo(0,Math.floor(a)):(E("scrollStart",m,r,o),b.cancelScroll(!0),x.requestAnimationFrame(h)))};function t(e){if(!e.defaultPrevented&&!(0!==e.button||e.metaKey||e.ctrlKey||e.shiftKey)&&"closest"in e.target&&(o=e.target.closest(r))&&"a"===o.tagName.toLowerCase()&&!e.target.closest(v.ignore)&&o.hostname===x.location.hostname&&o.pathname===x.location.pathname&&/#/.test(o.href)){var t,n;try{n=a(decodeURIComponent(o.hash))}catch(e){n=a(o.hash)}if("#"===n){if(!v.topOnEmptyHash)return;t=document.documentElement}else t=document.querySelector(n);(t=t||"#top"!==n?t:document.documentElement)&&(e.preventDefault(),n=v,history.replaceState&&n.updateURL&&!history.state&&(e=(e=x.location.hash)||"",history.replaceState({smoothScroll:JSON.stringify(n),anchor:e||x.pageYOffset},document.title,e||x.location.href)),b.animateScroll(t,o))}}function i(e){var t;null!==history.state&&history.state.smoothScroll&&history.state.smoothScroll===JSON.stringify(v)&&("string"==typeof(t=history.state.anchor)&&t&&!(t=document.querySelector(a(history.state.anchor)))||b.animateScroll(t,null,{updateURL:!1}))}b.destroy=function(){v&&(document.removeEventListener("click",t,!1),x.removeEventListener("popstate",i,!1),b.cancelScroll(),y=n=o=v=null)};return function(){if(!("querySelector"in document&&"addEventListener"in x&&"requestAnimationFrame"in x&&"closest"in x.Element.prototype))throw"Smooth Scroll: This browser does not support the required JavaScript methods and browser APIs.";b.destroy(),v=w(S,e||{}),n=v.header?document.querySelector(v.header):null,document.addEventListener("click",t,!1),v.updateURL&&v.popstate&&x.addEventListener("popstate",i,!1)}(),b}}),function(e,t){"function"==typeof define&&define.amd?define([],function(){return t(e)}):"object"==typeof exports?module.exports=t(e):e.Gumshoe=t(e)}("undefined"!=typeof global?global:"undefined"!=typeof window?window:this,function(c){"use strict";function f(e,t,n){n.settings.events&&(n=new CustomEvent(e,{bubbles:!0,cancelable:!0,detail:n}),t.dispatchEvent(n))}function n(e){var t=0;if(e.offsetParent)for(;e;)t+=e.offsetTop,e=e.offsetParent;return 0<=t?t:0}function d(e){e&&e.sort(function(e,t){return n(e.content)=Math.max(document.body.scrollHeight,document.documentElement.scrollHeight,document.body.offsetHeight,document.documentElement.offsetHeight,document.body.clientHeight,document.documentElement.clientHeight)}function p(e,t){var n,r,o=e[e.length-1];if(n=o,r=t,!(!s()||!a(n.content,r,!0)))return o;for(var i=e.length-1;0<=i;i--)if(a(e[i].content,t))return e[i]}function h(e,t){var n;!e||(n=e.nav.closest("li"))&&(n.classList.remove(t.navClass),e.content.classList.remove(t.contentClass),r(n,t),f("gumshoeDeactivate",n,{link:e.nav,content:e.content,settings:t}))}var m={navClass:"active",contentClass:"active",nested:!1,nestedClass:"active",offset:0,reflow:!1,events:!0},r=function(e,t){!t.nested||(e=e.parentNode.closest("li"))&&(e.classList.remove(t.nestedClass),r(e,t))},g=function(e,t){!t.nested||(e=e.parentNode.closest("li"))&&(e.classList.add(t.nestedClass),g(e,t))};return function(e,t){var n,o,i,r,a,s={setup:function(){n=document.querySelectorAll(e),o=[],Array.prototype.forEach.call(n,function(e){var t=document.getElementById(decodeURIComponent(e.hash.substr(1)));t&&o.push({nav:e,content:t})}),d(o)}};s.detect=function(){var e,t,n,r=p(o,a);r?i&&r.content===i.content||(h(i,a),t=a,!(e=r)||(n=e.nav.closest("li"))&&(n.classList.add(t.navClass),e.content.classList.add(t.contentClass),g(n,t),f("gumshoeActivate",n,{link:e.nav,content:e.content,settings:t})),i=r):i&&(h(i,a),i=null)};function u(e){r&&c.cancelAnimationFrame(r),r=c.requestAnimationFrame(s.detect)}function l(e){r&&c.cancelAnimationFrame(r),r=c.requestAnimationFrame(function(){d(o),s.detect()})}s.destroy=function(){i&&h(i,a),c.removeEventListener("scroll",u,!1),a.reflow&&c.removeEventListener("resize",l,!1),a=r=i=n=o=null};return a=function(){var n={};return Array.prototype.forEach.call(arguments,function(e){for(var t in e){if(!e.hasOwnProperty(t))return;n[t]=e[t]}}),n}(m,t||{}),s.setup(),s.detect(),c.addEventListener("scroll",u,!1),a.reflow&&c.addEventListener("resize",l,!1),s}}),$(document).ready(function(){$("#main").fitVids();function e(){(0===$(".author__urls-wrapper button").length?1024<$(window).width():!$(".author__urls-wrapper button").is(":visible"))?$(".sidebar").addClass("sticky"):$(".sidebar").removeClass("sticky")}e(),$(window).resize(function(){e()}),$(".author__urls-wrapper button").on("click",function(){$(".author__urls").toggleClass("is--visible"),$(".author__urls-wrapper button").toggleClass("open")}),$(document).keyup(function(e){27===e.keyCode&&$(".initial-content").hasClass("is--hidden")&&($(".search-content").toggleClass("is--visible"),$(".initial-content").toggleClass("is--hidden"))}),$(".search__toggle").on("click",function(){$(".search-content").toggleClass("is--visible"),$(".initial-content").toggleClass("is--hidden"),setTimeout(function(){$(".search-content input").focus()},400)});new SmoothScroll('a[href*="#"]',{offset:20,speed:400,speedAsDuration:!0,durationMax:500});0<$("nav.toc").length&&new Gumshoe("nav.toc a",{navClass:"active",contentClass:"active",nested:!1,nestedClass:"active",offset:20,reflow:!0,events:!0}),$("a[href$='.jpg'],a[href$='.jpeg'],a[href$='.JPG'],a[href$='.png'],a[href$='.gif'],a[href$='.webp']").addClass("image-popup"),$(".image-popup").magnificPopup({type:"image",tLoading:"Loading image #%curr%...",gallery:{enabled:!0,navigateByImgClick:!0,preload:[0,1]},image:{tError:'Image #%curr% could not be loaded.'},removalDelay:500,mainClass:"mfp-zoom-in",callbacks:{beforeOpen:function(){this.st.image.markup=this.st.image.markup.replace("mfp-figure","mfp-figure mfp-with-anim")}},closeOnContentClick:!0,midClick:!0}),$(".page__content").find("h1, h2, h3, h4, h5, h6").each(function(){var e,t=$(this).attr("id");t&&((e=document.createElement("a")).className="header-link",e.href="#"+t,e.innerHTML='Permalink',e.title="Permalink",$(this).append(e))})});
\ No newline at end of file
diff --git a/assets/js/plugins/bigfoot.min.js b/assets/js/plugins/bigfoot.min.js
new file mode 100644
index 00000000..35d201ce
--- /dev/null
+++ b/assets/js/plugins/bigfoot.min.js
@@ -0,0 +1,39 @@
+(function(){(function($){return $.bigfoot=function(options){var addBreakpoint,baseFontSize,bigfoot,buttonHover,calculatePixelDimension,cleanFootnoteLinks,clickButton,createPopover,defaults,deleteEmptyOrHR,escapeKeypress,footnoteInit,getSetting,makeDefaultCallbacks,popoverStates,positionTooltip,removeBackLinks,removeBreakpoint,removePopovers,replaceWithReferenceAttributes,repositionFeet,roomCalc,settings,touchClick,unhoverFeet,updateSetting,viewportDetails;bigfoot=void 0;defaults={actionOriginalFN:"hide",activateCallback:function(){},activateOnHover:!1,allowMultipleFN:!1,anchorPattern:/(fn|footnote|note)[:\-_\d]/gi,anchorParentTagname:'sup',breakpoints:{},deleteOnUnhover:!1,footnoteParentClass:'footnote',footnoteTagname:'li',hoverDelay:250,numberResetSelector:void 0,popoverDeleteDelay:300,popoverCreateDelay:100,positionContent:!0,preventPageScroll:!0,scope:!1,useFootnoteOnlyOnce:!0,contentMarkup:"",buttonMarkup:"
"}
+footnoteButton=settings.buttonMarkup.replace(/\{\{FOOTNOTENUM\}\}/g,footnoteNum).replace(/\{\{FOOTNOTEID\}\}/g,footnoteIDNum).replace(/\{\{FOOTNOTECONTENT\}\}/g,footnoteContent);footnoteButton=replaceWithReferenceAttributes(footnoteButton,"SUP",$relevantFNLink);footnoteButton=replaceWithReferenceAttributes(footnoteButton,"FN",$relevantFootnote);$footnoteButton=$(footnoteButton).insertBefore($relevantFNLink);$parent=$relevantFootnote.parent();switch(settings.actionOriginalFN.toLowerCase()){case "hide":$relevantFNLink.addClass("footnote-print-only");$relevantFootnote.addClass("footnote-print-only");_results.push(deleteEmptyOrHR($parent));break;case "delete":$relevantFNLink.remove();$relevantFootnote.remove();_results.push(deleteEmptyOrHR($parent));break;default:_results.push($relevantFNLink.addClass("footnote-print-only"))}}
+return _results};cleanFootnoteLinks=function($footnoteAnchors,footnoteLinks){var $parent,$supChild,linkHREF,linkID;if(footnoteLinks==null){footnoteLinks=[]}
+$parent=void 0;$supChild=void 0;linkHREF=void 0;linkID=void 0;$footnoteAnchors.each(function(){var $child,$this;$this=$(this);linkHREF="#"+($this.attr("href")).split("#")[1];$parent=$this.closest(settings.anchorParentTagname);$child=$this.find(settings.anchorParentTagname);if($parent.length>0){linkID=($parent.attr("id")||"")+($this.attr("id")||"");return footnoteLinks.push($parent.attr({"data-footnote-backlink-ref":linkID,"data-footnote-ref":linkHREF}))}else if($child.length>0){linkID=($child.attr("id")||"")+($this.attr("id")||"");return footnoteLinks.push($this.attr({"data-footnote-backlink-ref":linkID,"data-footnote-ref":linkHREF}))}else{linkID=$this.attr("id")||"";return footnoteLinks.push($this.attr({"data-footnote-backlink-ref":linkID,"data-footnote-ref":linkHREF}))}})};deleteEmptyOrHR=function($el){var $parent;$parent=void 0;if($el.is(":empty")||$el.children(":not(.footnote-print-only)").length===0){$parent=$el.parent();if(settings.actionOriginalFN.toLowerCase()==="delete"){$el.remove()}else{$el.addClass("footnote-print-only")}
+return deleteEmptyOrHR($parent)}else if($el.children(":not(.footnote-print-only)").length===$el.children("hr:not(.footnote-print-only)").length){$parent=$el.parent();if(settings.actionOriginalFN.toLowerCase()==="delete"){$el.remove()}else{$el.children("hr").addClass("footnote-print-only");$el.addClass("footnote-print-only")}
+return deleteEmptyOrHR($parent)}};removeBackLinks=function(footnoteHTML,backlinkID){var regex;if(backlinkID.indexOf(' ')>=0){backlinkID=backlinkID.trim().replace(/\s+/g,"|").replace(/(.*)/g,"($1)")}
+regex=new RegExp("(\\s| )*<\\s*a[^#<]*#"+backlinkID+"[^>]*>(.*?)<\\s*/\\s*a>","g");return footnoteHTML.replace(regex,"").replace("[]","")};replaceWithReferenceAttributes=function(string,referenceKeyword,$referenceElement){var refMatches,refRegex,refReplaceRegex,refReplaceText;refRegex=new RegExp("\\{\\{"+referenceKeyword+":([^\\}]*)\\}\\}","g");refMatches=void 0;refReplaceText=void 0;refReplaceRegex=void 0;refMatches=refRegex.exec(string);while(refMatches){if(refMatches[1]){refReplaceText=$referenceElement.attr(refMatches[1])||"";string=string.replace("{{"+referenceKeyword+":"+refMatches[1]+"}}",refReplaceText)}
+refMatches=refRegex.exec(string)}
+return string};buttonHover=function(event){var $buttonHovered,dataIdentifier,otherPopoverSelector;if(settings.activateOnHover){$buttonHovered=$(event.target).closest(".bigfoot-footnote__button");dataIdentifier="[data-footnote-identifier='"+($buttonHovered.attr("data-footnote-identifier"))+"']";if($buttonHovered.hasClass("is-active")){return}
+$buttonHovered.addClass("is-hover-instantiated");if(!settings.allowMultipleFN){otherPopoverSelector=".bigfoot-footnote:not("+dataIdentifier+")";removePopovers(otherPopoverSelector)}
+createPopover(".bigfoot-footnote__button"+dataIdentifier).addClass("is-hover-instantiated")}};touchClick=function(event){var $nearButton,$nearFootnote,$target;$target=$(event.target);$nearButton=$target.closest(".bigfoot-footnote__button");$nearFootnote=$target.closest(".bigfoot-footnote");if($nearButton.length>0){event.preventDefault();clickButton($nearButton)}else if($nearFootnote.length<1){if($(".bigfoot-footnote").length>0){removePopovers()}}};clickButton=function($button){var dataIdentifier;$button.blur();dataIdentifier="data-footnote-identifier='"+($button.attr("data-footnote-identifier"))+"'";if($button.hasClass("changing")){return}else if(!$button.hasClass("is-active")){$button.addClass("changing");setTimeout((function(){return $button.removeClass("changing")}),settings.popoverCreateDelay);createPopover(".bigfoot-footnote__button["+dataIdentifier+"]");$button.addClass("is-click-instantiated");if(!settings.allowMultipleFN){removePopovers(".bigfoot-footnote:not(["+dataIdentifier+"])")}}else{if(!settings.allowMultipleFN){removePopovers()}else{removePopovers(".bigfoot-footnote["+dataIdentifier+"]")}}};createPopover=function(selector){var $buttons,$popoversCreated;$buttons=void 0;if(typeof selector!=="string"&&settings.allowMultipleFN){$buttons=selector}else if(typeof selector!=="string"){$buttons=selector.first()}else if(settings.allowMultipleFN){$buttons=$(selector).closest(".bigfoot-footnote__button")}else{$buttons=$(selector+":first").closest(".bigfoot-footnote__button")}
+$popoversCreated=$();$buttons.each(function(){var $content,$contentContainer,$this,content;$this=$(this);content=void 0;try{content=settings.contentMarkup.replace(/\{\{FOOTNOTENUM\}\}/g,$this.attr("data-footnote-number")).replace(/\{\{FOOTNOTEID\}\}/g,$this.attr("data-footnote-identifier")).replace(/\{\{FOOTNOTECONTENT\}\}/g,$this.attr("data-bigfoot-footnote")).replace(/\>sym\;/g,">").replace(/\<sym\;/g,"<");return content=replaceWithReferenceAttributes(content,"BUTTON",$this)}finally{$content=$(content);try{settings.activateCallback($content,$this)}catch(_error){}
+$content.insertAfter($buttons);popoverStates[$this.attr("data-footnote-identifier")]="init";$content.attr("bigfoot-max-width",calculatePixelDimension($content.css("max-width"),$content));$content.css("max-width",10000);$contentContainer=$content.find(".bigfoot-footnote__content");$content.attr("data-bigfoot-max-height",calculatePixelDimension($contentContainer.css("max-height"),$contentContainer));repositionFeet();$this.addClass("is-active");$content.find(".bigfoot-footnote__content").bindScrollHandler();$popoversCreated=$popoversCreated.add($content)}});setTimeout((function(){return $popoversCreated.addClass("is-active")}),settings.popoverCreateDelay);return $popoversCreated};baseFontSize=function(){var el,size;el=document.createElement("div");el.style.cssText="display:inline-block;padding:0;line-height:1;position:absolute;visibility:hidden;font-size:1em;";el.appendChild(document.createElement("M"));document.body.appendChild(el);size=el.offsetHeight;document.body.removeChild(el);return size};calculatePixelDimension=function(dim,$el){if(dim==="none"){dim=10000}else if(dim.indexOf("rem")>=0){dim=parseFloat(dim)*baseFontSize()}else if(dim.indexOf("em")>=0){dim=parseFloat(dim)*parseFloat($el.css("font-size"))}else if(dim.indexOf("px")>=0){dim=parseFloat(dim);if(dim<=60){dim=dim/parseFloat($el.parent().css("width"))}}else if(dim.indexOf("%")>=0){dim=parseFloat(dim)/100}
+return dim};$.fn.bindScrollHandler=function(){if(!settings.preventPageScroll){return $(this)}
+$(this).on("DOMMouseScroll mousewheel",function(event){var $popover,$this,delta,height,prevent,scrollHeight,scrollTop,up;$this=$(this);scrollTop=$this.scrollTop();scrollHeight=$this[0].scrollHeight;height=parseInt($this.css("height"));$popover=$this.closest(".bigfoot-footnote");if($this.scrollTop()>0&&$this.scrollTop()<10){$popover.addClass("is-scrollable")}
+if(!$popover.hasClass("is-scrollable")){return}
+delta=event.type==="DOMMouseScroll"?event.originalEvent.detail*-40:event.originalEvent.wheelDelta;up=delta>0;prevent=function(){event.stopPropagation();event.preventDefault();event.returnValue=!1;return!1};if(!up&&-delta>scrollHeight-height-scrollTop){$this.scrollTop(scrollHeight);$popover.addClass("is-fully-scrolled");return prevent()}else if(up&&delta>scrollTop){$this.scrollTop(0);$popover.removeClass("is-fully-scrolled");return prevent()}else{return $popover.removeClass("is-fully-scrolled")}});return $(this)};unhoverFeet=function(e){if(settings.deleteOnUnhover&&settings.activateOnHover){return setTimeout((function(){var $target;$target=$(e.target).closest(".bigfoot-footnote, .bigfoot-footnote__button");if($(".bigfoot-footnote__button:hover, .bigfoot-footnote:hover").length<1){return removePopovers()}}),settings.hoverDelay)}};escapeKeypress=function(event){if(event.keyCode===27){return removePopovers()}};removePopovers=function(footnotes,timeout){var $buttonsClosed,$linkedButton,$this,footnoteID;if(footnotes==null){footnotes=".bigfoot-footnote"}
+if(timeout==null){timeout=settings.popoverDeleteDelay}
+$buttonsClosed=$();footnoteID=void 0;$linkedButton=void 0;$this=void 0;$(footnotes).each(function(){$this=$(this);footnoteID=$this.attr("data-footnote-identifier");$linkedButton=$(".bigfoot-footnote__button[data-footnote-identifier='"+footnoteID+"']");if(!$linkedButton.hasClass("changing")){$buttonsClosed=$buttonsClosed.add($linkedButton);$linkedButton.removeClass("is-active is-hover-instantiated is-click-instantiated").addClass("changing");$this.removeClass("is-active").addClass("disapearing");return setTimeout((function(){$this.remove();delete popoverStates[footnoteID];return $linkedButton.removeClass("changing")}),timeout)}});return $buttonsClosed};repositionFeet=function(e){var type;if(settings.positionContent){type=e?e.type:"resize";$(".bigfoot-footnote").each(function(){var $button,$contentWrapper,$mainWrap,$this,dataIdentifier,identifier,lastState,marginSize,maxHeightInCSS,maxHeightOnScreen,maxWidth,maxWidthInCSS,positionOnTop,relativeToWidth,roomLeft,totalHeight;$this=$(this);identifier=$this.attr("data-footnote-identifier");dataIdentifier="data-footnote-identifier='"+identifier+"'";$contentWrapper=$this.find(".bigfoot-footnote__content");$button=$this.siblings(".bigfoot-footnote__button");roomLeft=roomCalc($button);marginSize=parseFloat($this.css("margin-top"));maxHeightInCSS=+($this.attr("data-bigfoot-max-height"));totalHeight=2*marginSize+$this.outerHeight();maxHeightOnScreen=10000;positionOnTop=roomLeft.bottomRoomroomLeft.bottomRoom;lastState=popoverStates[identifier];if(positionOnTop){if(lastState!=="top"){popoverStates[identifier]="top";$this.addClass("is-positioned-top").removeClass("is-positioned-bottom");$this.css("transform-origin",(roomLeft.leftRelative*100)+"% 100%")}
+maxHeightOnScreen=roomLeft.topRoom-marginSize-15}else{if(lastState!=="bottom"||lastState==="init"){popoverStates[identifier]="bottom";$this.removeClass("is-positioned-top").addClass("is-positioned-bottom");$this.css("transform-origin",(roomLeft.leftRelative*100)+"% 0%")}
+maxHeightOnScreen=roomLeft.bottomRoom-marginSize-15}
+$this.find(".bigfoot-footnote__content").css({"max-height":Math.min(maxHeightOnScreen,maxHeightInCSS)+"px"});if(type==="resize"){maxWidthInCSS=parseFloat($this.attr("bigfoot-max-width"));$mainWrap=$this.find(".bigfoot-footnote__wrapper");maxWidth=maxWidthInCSS;if(maxWidthInCSS<=1){relativeToWidth=(function(){var jq,userSpecifiedRelativeElWidth;userSpecifiedRelativeElWidth=10000;if(settings.maxWidthRelativeTo){jq=$(settings.maxWidthRelativeTo);if(jq.length>0){userSpecifiedRelativeElWidth=jq.outerWidth()}}
+return Math.min(window.innerWidth,userSpecifiedRelativeElWidth)})();maxWidth=relativeToWidth*maxWidthInCSS}
+maxWidth=Math.min(maxWidth,$this.find(".bigfoot-footnote__content").outerWidth()+1);$mainWrap.css("max-width",maxWidth+"px");$this.css({left:(-roomLeft.leftRelative*maxWidth+parseFloat($button.css("margin-left"))+$button.outerWidth()/2)+"px"});positionTooltip($this,roomLeft.leftRelative)}
+if(parseInt($this.outerHeight())<$this.find(".bigfoot-footnote__content")[0].scrollHeight){return $this.addClass("is-scrollable")}})}};positionTooltip=function($popover,leftRelative){var $tooltip;if(leftRelative==null){leftRelative=0.5}
+$tooltip=$popover.find(".bigfoot-footnote__tooltip");if($tooltip.length>0){$tooltip.css("left",""+(leftRelative*100)+"%")}};roomCalc=function($el){var elHeight,elLeftMargin,elWidth,leftRoom,topRoom,w;elLeftMargin=parseFloat($el.css("margin-left"));elWidth=parseFloat($el.outerWidth())-elLeftMargin;elHeight=parseFloat($el.outerHeight());w=viewportDetails();topRoom=$el.offset().top-w.scrollY+elHeight/2;leftRoom=$el.offset().left-w.scrollX+elWidth/2;return{topRoom:topRoom,bottomRoom:w.height-topRoom,leftRoom:leftRoom,rightRoom:w.width-leftRoom,leftRelative:leftRoom/w.width,topRelative:topRoom/w.height}};viewportDetails=function(){var $window;$window=$(window);return{width:window.innerWidth,height:window.innerHeight,scrollX:$window.scrollLeft(),scrollY:$window.scrollTop()}};addBreakpoint=function(size,trueCallback,falseCallback,deleteDelay,removeOpen){var falseDefaultPositionSetting,minMax,mqListener,mql,query,s,trueDefaultPositionSetting;if(deleteDelay==null){deleteDelay=settings.popoverDeleteDelay}
+if(removeOpen==null){removeOpen=!0}
+mql=void 0;minMax=void 0;s=void 0;if(typeof size==="string"){s=size.toLowerCase()==="iphone"?"<320px":size.toLowerCase()==="ipad"?"<768px":size;minMax=s.charAt(0)===">"?"min":s.charAt(0)==="<"?"max":null;query=minMax?"("+minMax+"-width: "+(s.substring(1))+")":s;mql=window.matchMedia(query)}else{mql=size}
+if(mql.media&&mql.media==="invalid"){return{added:!1,mq:mql,listener:null}}
+trueDefaultPositionSetting=minMax==="min";falseDefaultPositionSetting=minMax==="max";trueCallback=trueCallback||makeDefaultCallbacks(removeOpen,deleteDelay,trueDefaultPositionSetting,function($popover){return $popover.addClass("is-bottom-fixed")});falseCallback=falseCallback||makeDefaultCallbacks(removeOpen,deleteDelay,falseDefaultPositionSetting,function(){});mqListener=function(mq){if(mq.matches){trueCallback(removeOpen,bigfoot)}else{falseCallback(removeOpen,bigfoot)}};mql.addListener(mqListener);mqListener(mql);settings.breakpoints[size]={added:!0,mq:mql,listener:mqListener};return settings.breakpoints[size]};makeDefaultCallbacks=function(removeOpen,deleteDelay,position,callback){return function(removeOpen,bigfoot){var $closedPopovers;$closedPopovers=void 0;if(removeOpen){$closedPopovers=bigfoot.close();bigfoot.updateSetting("activateCallback",callback)}
+return setTimeout((function(){bigfoot.updateSetting("positionContent",position);if(removeOpen){return bigfoot.activate($closedPopovers)}}),deleteDelay)}};removeBreakpoint=function(target,callback){var b,breakpoint,mq,mqFound;mq=null;b=void 0;mqFound=!1;if(typeof target==="string"){mqFound=settings.breakpoints[target]!==undefined}else{for(b in settings.breakpoints){if(settings.breakpoints.hasOwnProperty(b)&&settings.breakpoints[b].mq===target){mqFound=!0}}}
+if(mqFound){breakpoint=settings.breakpoints[b||target];if(callback){callback({matches:!1})}else{breakpoint.listener({matches:!1})}
+breakpoint.mq.removeListener(breakpoint.listener);delete settings.breakpoints[b||target]}
+return mqFound};updateSetting=function(newSettings,value){var oldValue,prop;oldValue=void 0;if(typeof newSettings==="string"){oldValue=settings[newSettings];settings[newSettings]=value}else{oldValue={};for(prop in newSettings){if(newSettings.hasOwnProperty(prop)){oldValue[prop]=settings[prop];settings[prop]=newSettings[prop]}}}
+return oldValue};getSetting=function(setting){return settings[setting]};$(document).ready(function(){footnoteInit();$(document).on("mouseenter",".bigfoot-footnote__button",buttonHover);$(document).on("touchend click",touchClick);$(document).on("mouseout",".is-hover-instantiated",unhoverFeet);$(document).on("keyup",escapeKeypress);$(window).on("scroll resize",repositionFeet);return $(document).on("gestureend",function(){return repositionFeet()})});bigfoot={removePopovers:removePopovers,close:removePopovers,createPopover:createPopover,activate:createPopover,repositionFeet:repositionFeet,reposition:repositionFeet,addBreakpoint:addBreakpoint,removeBreakpoint:removeBreakpoint,getSetting:getSetting,updateSetting:updateSetting};return bigfoot}})(jQuery)}).call(this)
\ No newline at end of file
diff --git a/assets/js/plugins/gumshoe.js b/assets/js/plugins/gumshoe.js
new file mode 100644
index 00000000..713b6eb3
--- /dev/null
+++ b/assets/js/plugins/gumshoe.js
@@ -0,0 +1,484 @@
+/*!
+ * gumshoejs v5.1.1
+ * A simple, framework-agnostic scrollspy script.
+ * (c) 2019 Chris Ferdinandi
+ * MIT License
+ * http://github.com/cferdinandi/gumshoe
+ */
+
+(function (root, factory) {
+ if ( typeof define === 'function' && define.amd ) {
+ define([], (function () {
+ return factory(root);
+ }));
+ } else if ( typeof exports === 'object' ) {
+ module.exports = factory(root);
+ } else {
+ root.Gumshoe = factory(root);
+ }
+})(typeof global !== 'undefined' ? global : typeof window !== 'undefined' ? window : this, (function (window) {
+
+ 'use strict';
+
+ //
+ // Defaults
+ //
+
+ var defaults = {
+
+ // Active classes
+ navClass: 'active',
+ contentClass: 'active',
+
+ // Nested navigation
+ nested: false,
+ nestedClass: 'active',
+
+ // Offset & reflow
+ offset: 0,
+ reflow: false,
+
+ // Event support
+ events: true
+
+ };
+
+
+ //
+ // Methods
+ //
+
+ /**
+ * Merge two or more objects together.
+ * @param {Object} objects The objects to merge together
+ * @returns {Object} Merged values of defaults and options
+ */
+ var extend = function () {
+ var merged = {};
+ Array.prototype.forEach.call(arguments, (function (obj) {
+ for (var key in obj) {
+ if (!obj.hasOwnProperty(key)) return;
+ merged[key] = obj[key];
+ }
+ }));
+ return merged;
+ };
+
+ /**
+ * Emit a custom event
+ * @param {String} type The event type
+ * @param {Node} elem The element to attach the event to
+ * @param {Object} detail Any details to pass along with the event
+ */
+ var emitEvent = function (type, elem, detail) {
+
+ // Make sure events are enabled
+ if (!detail.settings.events) return;
+
+ // Create a new event
+ var event = new CustomEvent(type, {
+ bubbles: true,
+ cancelable: true,
+ detail: detail
+ });
+
+ // Dispatch the event
+ elem.dispatchEvent(event);
+
+ };
+
+ /**
+ * Get an element's distance from the top of the Document.
+ * @param {Node} elem The element
+ * @return {Number} Distance from the top in pixels
+ */
+ var getOffsetTop = function (elem) {
+ var location = 0;
+ if (elem.offsetParent) {
+ while (elem) {
+ location += elem.offsetTop;
+ elem = elem.offsetParent;
+ }
+ }
+ return location >= 0 ? location : 0;
+ };
+
+ /**
+ * Sort content from first to last in the DOM
+ * @param {Array} contents The content areas
+ */
+ var sortContents = function (contents) {
+ if(contents) {
+ contents.sort((function (item1, item2) {
+ var offset1 = getOffsetTop(item1.content);
+ var offset2 = getOffsetTop(item2.content);
+ if (offset1 < offset2) return -1;
+ return 1;
+ }));
+ }
+ };
+
+ /**
+ * Get the offset to use for calculating position
+ * @param {Object} settings The settings for this instantiation
+ * @return {Float} The number of pixels to offset the calculations
+ */
+ var getOffset = function (settings) {
+
+ // if the offset is a function run it
+ if (typeof settings.offset === 'function') {
+ return parseFloat(settings.offset());
+ }
+
+ // Otherwise, return it as-is
+ return parseFloat(settings.offset);
+
+ };
+
+ /**
+ * Get the document element's height
+ * @private
+ * @returns {Number}
+ */
+ var getDocumentHeight = function () {
+ return Math.max(
+ document.body.scrollHeight, document.documentElement.scrollHeight,
+ document.body.offsetHeight, document.documentElement.offsetHeight,
+ document.body.clientHeight, document.documentElement.clientHeight
+ );
+ };
+
+ /**
+ * Determine if an element is in view
+ * @param {Node} elem The element
+ * @param {Object} settings The settings for this instantiation
+ * @param {Boolean} bottom If true, check if element is above bottom of viewport instead
+ * @return {Boolean} Returns true if element is in the viewport
+ */
+ var isInView = function (elem, settings, bottom) {
+ var bounds = elem.getBoundingClientRect();
+ var offset = getOffset(settings);
+ if (bottom) {
+ return parseInt(bounds.bottom, 10) < (window.innerHeight || document.documentElement.clientHeight);
+ }
+ return parseInt(bounds.top, 10) <= offset;
+ };
+
+ /**
+ * Check if at the bottom of the viewport
+ * @return {Boolean} If true, page is at the bottom of the viewport
+ */
+ var isAtBottom = function () {
+ if (window.innerHeight + window.pageYOffset >= getDocumentHeight()) return true;
+ return false;
+ };
+
+ /**
+ * Check if the last item should be used (even if not at the top of the page)
+ * @param {Object} item The last item
+ * @param {Object} settings The settings for this instantiation
+ * @return {Boolean} If true, use the last item
+ */
+ var useLastItem = function (item, settings) {
+ if (isAtBottom() && isInView(item.content, settings, true)) return true;
+ return false;
+ };
+
+ /**
+ * Get the active content
+ * @param {Array} contents The content areas
+ * @param {Object} settings The settings for this instantiation
+ * @return {Object} The content area and matching navigation link
+ */
+ var getActive = function (contents, settings) {
+ var last = contents[contents.length-1];
+ if (useLastItem(last, settings)) return last;
+ for (var i = contents.length - 1; i >= 0; i--) {
+ if (isInView(contents[i].content, settings)) return contents[i];
+ }
+ };
+
+ /**
+ * Deactivate parent navs in a nested navigation
+ * @param {Node} nav The starting navigation element
+ * @param {Object} settings The settings for this instantiation
+ */
+ var deactivateNested = function (nav, settings) {
+
+ // If nesting isn't activated, bail
+ if (!settings.nested) return;
+
+ // Get the parent navigation
+ var li = nav.parentNode.closest('li');
+ if (!li) return;
+
+ // Remove the active class
+ li.classList.remove(settings.nestedClass);
+
+ // Apply recursively to any parent navigation elements
+ deactivateNested(li, settings);
+
+ };
+
+ /**
+ * Deactivate a nav and content area
+ * @param {Object} items The nav item and content to deactivate
+ * @param {Object} settings The settings for this instantiation
+ */
+ var deactivate = function (items, settings) {
+
+ // Make sure their are items to deactivate
+ if (!items) return;
+
+ // Get the parent list item
+ var li = items.nav.closest('li');
+ if (!li) return;
+
+ // Remove the active class from the nav and content
+ li.classList.remove(settings.navClass);
+ items.content.classList.remove(settings.contentClass);
+
+ // Deactivate any parent navs in a nested navigation
+ deactivateNested(li, settings);
+
+ // Emit a custom event
+ emitEvent('gumshoeDeactivate', li, {
+ link: items.nav,
+ content: items.content,
+ settings: settings
+ });
+
+ };
+
+
+ /**
+ * Activate parent navs in a nested navigation
+ * @param {Node} nav The starting navigation element
+ * @param {Object} settings The settings for this instantiation
+ */
+ var activateNested = function (nav, settings) {
+
+ // If nesting isn't activated, bail
+ if (!settings.nested) return;
+
+ // Get the parent navigation
+ var li = nav.parentNode.closest('li');
+ if (!li) return;
+
+ // Add the active class
+ li.classList.add(settings.nestedClass);
+
+ // Apply recursively to any parent navigation elements
+ activateNested(li, settings);
+
+ };
+
+ /**
+ * Activate a nav and content area
+ * @param {Object} items The nav item and content to activate
+ * @param {Object} settings The settings for this instantiation
+ */
+ var activate = function (items, settings) {
+
+ // Make sure their are items to activate
+ if (!items) return;
+
+ // Get the parent list item
+ var li = items.nav.closest('li');
+ if (!li) return;
+
+ // Add the active class to the nav and content
+ li.classList.add(settings.navClass);
+ items.content.classList.add(settings.contentClass);
+
+ // Activate any parent navs in a nested navigation
+ activateNested(li, settings);
+
+ // Emit a custom event
+ emitEvent('gumshoeActivate', li, {
+ link: items.nav,
+ content: items.content,
+ settings: settings
+ });
+
+ };
+
+ /**
+ * Create the Constructor object
+ * @param {String} selector The selector to use for navigation items
+ * @param {Object} options User options and settings
+ */
+ var Constructor = function (selector, options) {
+
+ //
+ // Variables
+ //
+
+ var publicAPIs = {};
+ var navItems, contents, current, timeout, settings;
+
+
+ //
+ // Methods
+ //
+
+ /**
+ * Set variables from DOM elements
+ */
+ publicAPIs.setup = function () {
+
+ // Get all nav items
+ navItems = document.querySelectorAll(selector);
+
+ // Create contents array
+ contents = [];
+
+ // Loop through each item, get it's matching content, and push to the array
+ Array.prototype.forEach.call(navItems, (function (item) {
+
+ // Get the content for the nav item
+ var content = document.getElementById(decodeURIComponent(item.hash.substr(1)));
+ if (!content) return;
+
+ // Push to the contents array
+ contents.push({
+ nav: item,
+ content: content
+ });
+
+ }));
+
+ // Sort contents by the order they appear in the DOM
+ sortContents(contents);
+
+ };
+
+ /**
+ * Detect which content is currently active
+ */
+ publicAPIs.detect = function () {
+
+ // Get the active content
+ var active = getActive(contents, settings);
+
+ // if there's no active content, deactivate and bail
+ if (!active) {
+ if (current) {
+ deactivate(current, settings);
+ current = null;
+ }
+ return;
+ }
+
+ // If the active content is the one currently active, do nothing
+ if (current && active.content === current.content) return;
+
+ // Deactivate the current content and activate the new content
+ deactivate(current, settings);
+ activate(active, settings);
+
+ // Update the currently active content
+ current = active;
+
+ };
+
+ /**
+ * Detect the active content on scroll
+ * Debounced for performance
+ */
+ var scrollHandler = function (event) {
+
+ // If there's a timer, cancel it
+ if (timeout) {
+ window.cancelAnimationFrame(timeout);
+ }
+
+ // Setup debounce callback
+ timeout = window.requestAnimationFrame(publicAPIs.detect);
+
+ };
+
+ /**
+ * Update content sorting on resize
+ * Debounced for performance
+ */
+ var resizeHandler = function (event) {
+
+ // If there's a timer, cancel it
+ if (timeout) {
+ window.cancelAnimationFrame(timeout);
+ }
+
+ // Setup debounce callback
+ timeout = window.requestAnimationFrame((function () {
+ sortContents(contents);
+ publicAPIs.detect();
+ }));
+
+ };
+
+ /**
+ * Destroy the current instantiation
+ */
+ publicAPIs.destroy = function () {
+
+ // Undo DOM changes
+ if (current) {
+ deactivate(current, settings);
+ }
+
+ // Remove event listeners
+ window.removeEventListener('scroll', scrollHandler, false);
+ if (settings.reflow) {
+ window.removeEventListener('resize', resizeHandler, false);
+ }
+
+ // Reset variables
+ contents = null;
+ navItems = null;
+ current = null;
+ timeout = null;
+ settings = null;
+
+ };
+
+ /**
+ * Initialize the current instantiation
+ */
+ var init = function () {
+
+ // Merge user options into defaults
+ settings = extend(defaults, options || {});
+
+ // Setup variables based on the current DOM
+ publicAPIs.setup();
+
+ // Find the currently active content
+ publicAPIs.detect();
+
+ // Setup event listeners
+ window.addEventListener('scroll', scrollHandler, false);
+ if (settings.reflow) {
+ window.addEventListener('resize', resizeHandler, false);
+ }
+
+ };
+
+
+ //
+ // Initialize and return the public APIs
+ //
+
+ init();
+ return publicAPIs;
+
+ };
+
+
+ //
+ // Return the Constructor
+ //
+
+ return Constructor;
+
+}));
\ No newline at end of file
diff --git a/assets/js/plugins/jquery.ba-throttle-debounce.js b/assets/js/plugins/jquery.ba-throttle-debounce.js
new file mode 100644
index 00000000..fa30bdff
--- /dev/null
+++ b/assets/js/plugins/jquery.ba-throttle-debounce.js
@@ -0,0 +1,252 @@
+/*!
+ * jQuery throttle / debounce - v1.1 - 3/7/2010
+ * http://benalman.com/projects/jquery-throttle-debounce-plugin/
+ *
+ * Copyright (c) 2010 "Cowboy" Ben Alman
+ * Dual licensed under the MIT and GPL licenses.
+ * http://benalman.com/about/license/
+ */
+
+// Script: jQuery throttle / debounce: Sometimes, less is more!
+//
+// *Version: 1.1, Last updated: 3/7/2010*
+//
+// Project Home - http://benalman.com/projects/jquery-throttle-debounce-plugin/
+// GitHub - http://github.com/cowboy/jquery-throttle-debounce/
+// Source - http://github.com/cowboy/jquery-throttle-debounce/raw/master/jquery.ba-throttle-debounce.js
+// (Minified) - http://github.com/cowboy/jquery-throttle-debounce/raw/master/jquery.ba-throttle-debounce.min.js (0.7kb)
+//
+// About: License
+//
+// Copyright (c) 2010 "Cowboy" Ben Alman,
+// Dual licensed under the MIT and GPL licenses.
+// http://benalman.com/about/license/
+//
+// About: Examples
+//
+// These working examples, complete with fully commented code, illustrate a few
+// ways in which this plugin can be used.
+//
+// Throttle - http://benalman.com/code/projects/jquery-throttle-debounce/examples/throttle/
+// Debounce - http://benalman.com/code/projects/jquery-throttle-debounce/examples/debounce/
+//
+// About: Support and Testing
+//
+// Information about what version or versions of jQuery this plugin has been
+// tested with, what browsers it has been tested in, and where the unit tests
+// reside (so you can test it yourself).
+//
+// jQuery Versions - none, 1.3.2, 1.4.2
+// Browsers Tested - Internet Explorer 6-8, Firefox 2-3.6, Safari 3-4, Chrome 4-5, Opera 9.6-10.1.
+// Unit Tests - http://benalman.com/code/projects/jquery-throttle-debounce/unit/
+//
+// About: Release History
+//
+// 1.1 - (3/7/2010) Fixed a bug in where trailing callbacks
+// executed later than they should. Reworked a fair amount of internal
+// logic as well.
+// 1.0 - (3/6/2010) Initial release as a stand-alone project. Migrated over
+// from jquery-misc repo v0.4 to jquery-throttle repo v1.0, added the
+// no_trailing throttle parameter and debounce functionality.
+//
+// Topic: Note for non-jQuery users
+//
+// jQuery isn't actually required for this plugin, because nothing internal
+// uses any jQuery methods or properties. jQuery is just used as a namespace
+// under which these methods can exist.
+//
+// Since jQuery isn't actually required for this plugin, if jQuery doesn't exist
+// when this plugin is loaded, the method described below will be created in
+// the `Cowboy` namespace. Usage will be exactly the same, but instead of
+// $.method() or jQuery.method(), you'll need to use Cowboy.method().
+
+(function(window,undefined){
+ '$:nomunge'; // Used by YUI compressor.
+
+ // Since jQuery really isn't required for this plugin, use `jQuery` as the
+ // namespace only if it already exists, otherwise use the `Cowboy` namespace,
+ // creating it if necessary.
+ var $ = window.jQuery || window.Cowboy || ( window.Cowboy = {} ),
+
+ // Internal method reference.
+ jq_throttle;
+
+ // Method: jQuery.throttle
+ //
+ // Throttle execution of a function. Especially useful for rate limiting
+ // execution of handlers on events like resize and scroll. If you want to
+ // rate-limit execution of a function to a single time, see the
+ // method.
+ //
+ // In this visualization, | is a throttled-function call and X is the actual
+ // callback execution:
+ //
+ // > Throttled with `no_trailing` specified as false or unspecified:
+ // > ||||||||||||||||||||||||| (pause) |||||||||||||||||||||||||
+ // > X X X X X X X X X X X X
+ // >
+ // > Throttled with `no_trailing` specified as true:
+ // > ||||||||||||||||||||||||| (pause) |||||||||||||||||||||||||
+ // > X X X X X X X X X X
+ //
+ // Usage:
+ //
+ // > var throttled = jQuery.throttle( delay, [ no_trailing, ] callback );
+ // >
+ // > jQuery('selector').bind( 'someevent', throttled );
+ // > jQuery('selector').unbind( 'someevent', throttled );
+ //
+ // This also works in jQuery 1.4+:
+ //
+ // > jQuery('selector').bind( 'someevent', jQuery.throttle( delay, [ no_trailing, ] callback ) );
+ // > jQuery('selector').unbind( 'someevent', callback );
+ //
+ // Arguments:
+ //
+ // delay - (Number) A zero-or-greater delay in milliseconds. For event
+ // callbacks, values around 100 or 250 (or even higher) are most useful.
+ // no_trailing - (Boolean) Optional, defaults to false. If no_trailing is
+ // true, callback will only execute every `delay` milliseconds while the
+ // throttled-function is being called. If no_trailing is false or
+ // unspecified, callback will be executed one final time after the last
+ // throttled-function call. (After the throttled-function has not been
+ // called for `delay` milliseconds, the internal counter is reset)
+ // callback - (Function) A function to be executed after delay milliseconds.
+ // The `this` context and all arguments are passed through, as-is, to
+ // `callback` when the throttled-function is executed.
+ //
+ // Returns:
+ //
+ // (Function) A new, throttled, function.
+
+ $.throttle = jq_throttle = function( delay, no_trailing, callback, debounce_mode ) {
+ // After wrapper has stopped being called, this timeout ensures that
+ // `callback` is executed at the proper times in `throttle` and `end`
+ // debounce modes.
+ var timeout_id,
+
+ // Keep track of the last time `callback` was executed.
+ last_exec = 0;
+
+ // `no_trailing` defaults to falsy.
+ if ( typeof no_trailing !== 'boolean' ) {
+ debounce_mode = callback;
+ callback = no_trailing;
+ no_trailing = undefined;
+ }
+
+ // The `wrapper` function encapsulates all of the throttling / debouncing
+ // functionality and when executed will limit the rate at which `callback`
+ // is executed.
+ function wrapper() {
+ var that = this,
+ elapsed = +new Date() - last_exec,
+ args = arguments;
+
+ // Execute `callback` and update the `last_exec` timestamp.
+ function exec() {
+ last_exec = +new Date();
+ callback.apply( that, args );
+ };
+
+ // If `debounce_mode` is true (at_begin) this is used to clear the flag
+ // to allow future `callback` executions.
+ function clear() {
+ timeout_id = undefined;
+ };
+
+ if ( debounce_mode && !timeout_id ) {
+ // Since `wrapper` is being called for the first time and
+ // `debounce_mode` is true (at_begin), execute `callback`.
+ exec();
+ }
+
+ // Clear any existing timeout.
+ timeout_id && clearTimeout( timeout_id );
+
+ if ( debounce_mode === undefined && elapsed > delay ) {
+ // In throttle mode, if `delay` time has been exceeded, execute
+ // `callback`.
+ exec();
+
+ } else if ( no_trailing !== true ) {
+ // In trailing throttle mode, since `delay` time has not been
+ // exceeded, schedule `callback` to execute `delay` ms after most
+ // recent execution.
+ //
+ // If `debounce_mode` is true (at_begin), schedule `clear` to execute
+ // after `delay` ms.
+ //
+ // If `debounce_mode` is false (at end), schedule `callback` to
+ // execute after `delay` ms.
+ timeout_id = setTimeout( debounce_mode ? clear : exec, debounce_mode === undefined ? delay - elapsed : delay );
+ }
+ };
+
+ // Set the guid of `wrapper` function to the same of original callback, so
+ // it can be removed in jQuery 1.4+ .unbind or .die by using the original
+ // callback as a reference.
+ if ( $.guid ) {
+ wrapper.guid = callback.guid = callback.guid || $.guid++;
+ }
+
+ // Return the wrapper function.
+ return wrapper;
+ };
+
+ // Method: jQuery.debounce
+ //
+ // Debounce execution of a function. Debouncing, unlike throttling,
+ // guarantees that a function is only executed a single time, either at the
+ // very beginning of a series of calls, or at the very end. If you want to
+ // simply rate-limit execution of a function, see the
+ // method.
+ //
+ // In this visualization, | is a debounced-function call and X is the actual
+ // callback execution:
+ //
+ // > Debounced with `at_begin` specified as false or unspecified:
+ // > ||||||||||||||||||||||||| (pause) |||||||||||||||||||||||||
+ // > X X
+ // >
+ // > Debounced with `at_begin` specified as true:
+ // > ||||||||||||||||||||||||| (pause) |||||||||||||||||||||||||
+ // > X X
+ //
+ // Usage:
+ //
+ // > var debounced = jQuery.debounce( delay, [ at_begin, ] callback );
+ // >
+ // > jQuery('selector').bind( 'someevent', debounced );
+ // > jQuery('selector').unbind( 'someevent', debounced );
+ //
+ // This also works in jQuery 1.4+:
+ //
+ // > jQuery('selector').bind( 'someevent', jQuery.debounce( delay, [ at_begin, ] callback ) );
+ // > jQuery('selector').unbind( 'someevent', callback );
+ //
+ // Arguments:
+ //
+ // delay - (Number) A zero-or-greater delay in milliseconds. For event
+ // callbacks, values around 100 or 250 (or even higher) are most useful.
+ // at_begin - (Boolean) Optional, defaults to false. If at_begin is false or
+ // unspecified, callback will only be executed `delay` milliseconds after
+ // the last debounced-function call. If at_begin is true, callback will be
+ // executed only at the first debounced-function call. (After the
+ // throttled-function has not been called for `delay` milliseconds, the
+ // internal counter is reset)
+ // callback - (Function) A function to be executed after delay milliseconds.
+ // The `this` context and all arguments are passed through, as-is, to
+ // `callback` when the debounced-function is executed.
+ //
+ // Returns:
+ //
+ // (Function) A new, debounced, function.
+
+ $.debounce = function( delay, at_begin, callback ) {
+ return callback === undefined
+ ? jq_throttle( delay, at_begin, false )
+ : jq_throttle( delay, callback, at_begin !== false );
+ };
+
+})(this);
diff --git a/assets/js/plugins/jquery.fitvids.js b/assets/js/plugins/jquery.fitvids.js
new file mode 100644
index 00000000..5c2f85c9
--- /dev/null
+++ b/assets/js/plugins/jquery.fitvids.js
@@ -0,0 +1,82 @@
+/*jshint browser:true */
+/*!
+* FitVids 1.1
+*
+* Copyright 2013, Chris Coyier - http://css-tricks.com + Dave Rupert - http://daverupert.com
+* Credit to Thierry Koblentz - http://www.alistapart.com/articles/creating-intrinsic-ratios-for-video/
+* Released under the WTFPL license - http://sam.zoy.org/wtfpl/
+*
+*/
+
+;(function( $ ){
+
+ 'use strict';
+
+ $.fn.fitVids = function( options ) {
+ var settings = {
+ customSelector: null,
+ ignore: null
+ };
+
+ if(!document.getElementById('fit-vids-style')) {
+ // appendStyles: https://github.com/toddmotto/fluidvids/blob/master/dist/fluidvids.js
+ var head = document.head || document.getElementsByTagName('head')[0];
+ var css = '.fluid-width-video-wrapper{width:100%;position:relative;padding:0;}.fluid-width-video-wrapper iframe,.fluid-width-video-wrapper object,.fluid-width-video-wrapper embed {position:absolute;top:0;left:0;width:100%;height:100%;}';
+ var div = document.createElement("div");
+ div.innerHTML = '
x
';
+ head.appendChild(div.childNodes[1]);
+ }
+
+ if ( options ) {
+ $.extend( settings, options );
+ }
+
+ return this.each(function(){
+ var selectors = [
+ 'iframe[src*="player.vimeo.com"]',
+ 'iframe[src*="youtube.com"]',
+ 'iframe[src*="youtube-nocookie.com"]',
+ 'iframe[src*="kickstarter.com"][src*="video.html"]',
+ 'object',
+ 'embed'
+ ];
+
+ if (settings.customSelector) {
+ selectors.push(settings.customSelector);
+ }
+
+ var ignoreList = '.fitvidsignore';
+
+ if(settings.ignore) {
+ ignoreList = ignoreList + ', ' + settings.ignore;
+ }
+
+ var $allVideos = $(this).find(selectors.join(','));
+ $allVideos = $allVideos.not('object object'); // SwfObj conflict patch
+ $allVideos = $allVideos.not(ignoreList); // Disable FitVids on this video.
+
+ $allVideos.each(function(count){
+ var $this = $(this);
+ if($this.parents(ignoreList).length > 0) {
+ return; // Disable FitVids on this video.
+ }
+ if (this.tagName.toLowerCase() === 'embed' && $this.parent('object').length || $this.parent('.fluid-width-video-wrapper').length) { return; }
+ if ((!$this.css('height') && !$this.css('width')) && (isNaN($this.attr('height')) || isNaN($this.attr('width'))))
+ {
+ $this.attr('height', 9);
+ $this.attr('width', 16);
+ }
+ var height = ( this.tagName.toLowerCase() === 'object' || ($this.attr('height') && !isNaN(parseInt($this.attr('height'), 10))) ) ? parseInt($this.attr('height'), 10) : $this.height(),
+ width = !isNaN(parseInt($this.attr('width'), 10)) ? parseInt($this.attr('width'), 10) : $this.width(),
+ aspectRatio = height / width;
+ if(!$this.attr('id')){
+ var videoID = 'fitvid' + count;
+ $this.attr('id', videoID);
+ }
+ $this.wrap('').parent('.fluid-width-video-wrapper').css('padding-top', (aspectRatio * 100)+'%');
+ $this.removeAttr('height').removeAttr('width');
+ });
+ });
+ };
+// Works with either jQuery or Zepto
+})( window.jQuery || window.Zepto );
\ No newline at end of file
diff --git a/assets/js/plugins/jquery.greedy-navigation.js b/assets/js/plugins/jquery.greedy-navigation.js
new file mode 100644
index 00000000..d8f32378
--- /dev/null
+++ b/assets/js/plugins/jquery.greedy-navigation.js
@@ -0,0 +1,127 @@
+/*
+GreedyNav.js - http://lukejacksonn.com/actuate
+Licensed under the MIT license - http://opensource.org/licenses/MIT
+Copyright (c) 2015 Luke Jackson
+*/
+
+$(function() {
+
+ var $btn = $("nav.greedy-nav .greedy-nav__toggle");
+ var $vlinks = $("nav.greedy-nav .visible-links");
+ var $hlinks = $("nav.greedy-nav .hidden-links");
+ var $nav = $("nav.greedy-nav");
+ var $logo = $('nav.greedy-nav .site-logo');
+ var $logoImg = $('nav.greedy-nav .site-logo img');
+ var $title = $("nav.greedy-nav .site-title");
+ var $search = $('nav.greedy-nav button.search__toggle');
+
+ var numOfItems, totalSpace, closingTime, breakWidths;
+
+ // This function measures both hidden and visible links and sets the navbar breakpoints
+ // This is called the first time the script runs and everytime the "check()" function detects a change of window width that reached a different CSS width breakpoint, which affects the size of navbar Items
+ // Please note that "CSS width breakpoints" (which are only 4) !== "navbar breakpoints" (which are as many as the number of items on the navbar)
+ function measureLinks(){
+ numOfItems = 0;
+ totalSpace = 0;
+ closingTime = 1000;
+ breakWidths = [];
+
+ // Adds the width of a navItem in order to create breakpoints for the navbar
+ function addWidth(i, w) {
+ totalSpace += w;
+ numOfItems += 1;
+ breakWidths.push(totalSpace);
+ }
+
+ // Measures the width of hidden links by making a temporary clone of them and positioning under visible links
+ function hiddenWidth(obj){
+ var clone = obj.clone();
+ clone.css("visibility","hidden");
+ $vlinks.append(clone);
+ addWidth(0, clone.outerWidth());
+ clone.remove();
+ }
+ // Measure both visible and hidden links widths
+ $vlinks.children().outerWidth(addWidth);
+ $hlinks.children().each(function(){hiddenWidth($(this))});
+ }
+ // Get initial state
+ measureLinks();
+
+ var winWidth = $( window ).width();
+ // Set the last measured CSS width breakpoint: 0: <768px, 1: <1024px, 2: < 1280px, 3: >= 1280px.
+ var lastBreakpoint = winWidth < 768 ? 0 : winWidth < 1024 ? 1 : winWidth < 1280 ? 2 : 3;
+
+ var availableSpace, numOfVisibleItems, requiredSpace, timer;
+
+ function check() {
+
+ winWidth = $( window ).width();
+ // Set the current CSS width breakpoint: 0: <768px, 1: <1024px, 2: < 1280px, 3: >= 1280px.
+ var curBreakpoint = winWidth < 768 ? 0 : winWidth < 1024 ? 1 : winWidth < 1280 ? 2 : 3;
+ // If current breakpoint is different from last measured breakpoint, measureLinks again
+ if(curBreakpoint !== lastBreakpoint) measureLinks();
+ // Set the last measured CSS width breakpoint with the current breakpoint
+ lastBreakpoint = curBreakpoint;
+
+ // Get instant state
+ numOfVisibleItems = $vlinks.children().length;
+ // Decrease the width of visible elements from the nav innerWidth to find out the available space for navItems
+ availableSpace = /* nav */ $nav.innerWidth()
+ - /* logo */ ($logo.length !== 0 ? $logo.outerWidth(true) : 0)
+ - /* title */ $title.outerWidth(true)
+ - /* search */ ($search.length !== 0 ? $search.outerWidth(true) : 0)
+ - /* toggle */ (numOfVisibleItems !== breakWidths.length ? $btn.outerWidth(true) : 0);
+ requiredSpace = breakWidths[numOfVisibleItems - 1];
+
+ // There is not enought space
+ if (requiredSpace > availableSpace) {
+ $vlinks.children().last().prependTo($hlinks);
+ numOfVisibleItems -= 1;
+ check();
+ // There is more than enough space. If only one element is hidden, add the toggle width to the available space
+ } else if (availableSpace + (numOfVisibleItems === breakWidths.length - 1?$btn.outerWidth(true):0) > breakWidths[numOfVisibleItems]) {
+ $hlinks.children().first().appendTo($vlinks);
+ numOfVisibleItems += 1;
+ check();
+ }
+ // Update the button accordingly
+ $btn.attr("count", numOfItems - numOfVisibleItems);
+ if (numOfVisibleItems === numOfItems) {
+ $btn.addClass('hidden');
+ } else $btn.removeClass('hidden');
+ }
+
+ // Window listeners
+ $(window).resize(function() {
+ check();
+ });
+
+ $btn.on('click', function() {
+ $hlinks.toggleClass('hidden');
+ $(this).toggleClass('close');
+ clearTimeout(timer);
+ });
+
+ $hlinks.on('mouseleave', function() {
+ // Mouse has left, start the timer
+ timer = setTimeout(function() {
+ $hlinks.addClass('hidden');
+ }, closingTime);
+ }).on('mouseenter', function() {
+ // Mouse is back, cancel the timer
+ clearTimeout(timer);
+ })
+
+ // check if page has a logo
+ if($logoImg.length !== 0){
+ // check if logo is not loaded
+ if(!($logoImg[0].complete || $logoImg[0].naturalWidth !== 0)){
+ // if logo is not loaded wait for logo to load or fail to check
+ $logoImg.one("load error", check);
+ // if logo is already loaded just check
+ } else check();
+ // if page does not have a logo just check
+ } else check();
+
+});
diff --git a/assets/js/plugins/jquery.magnific-popup.js b/assets/js/plugins/jquery.magnific-popup.js
new file mode 100644
index 00000000..7d1d1978
--- /dev/null
+++ b/assets/js/plugins/jquery.magnific-popup.js
@@ -0,0 +1,1860 @@
+/*! Magnific Popup - v1.1.0 - 2016-02-20
+* http://dimsemenov.com/plugins/magnific-popup/
+* Copyright (c) 2016 Dmitry Semenov; */
+;(function (factory) {
+ if (typeof define === 'function' && define.amd) {
+ // AMD. Register as an anonymous module.
+ define(['jquery'], factory);
+ } else if (typeof exports === 'object') {
+ // Node/CommonJS
+ factory(require('jquery'));
+ } else {
+ // Browser globals
+ factory(window.jQuery || window.Zepto);
+ }
+ }(function($) {
+
+ /*>>core*/
+ /**
+ *
+ * Magnific Popup Core JS file
+ *
+ */
+
+
+ /**
+ * Private static constants
+ */
+ var CLOSE_EVENT = 'Close',
+ BEFORE_CLOSE_EVENT = 'BeforeClose',
+ AFTER_CLOSE_EVENT = 'AfterClose',
+ BEFORE_APPEND_EVENT = 'BeforeAppend',
+ MARKUP_PARSE_EVENT = 'MarkupParse',
+ OPEN_EVENT = 'Open',
+ CHANGE_EVENT = 'Change',
+ NS = 'mfp',
+ EVENT_NS = '.' + NS,
+ READY_CLASS = 'mfp-ready',
+ REMOVING_CLASS = 'mfp-removing',
+ PREVENT_CLOSE_CLASS = 'mfp-prevent-close';
+
+
+ /**
+ * Private vars
+ */
+ /*jshint -W079 */
+ var mfp, // As we have only one instance of MagnificPopup object, we define it locally to not to use 'this'
+ MagnificPopup = function(){},
+ _isJQ = !!(window.jQuery),
+ _prevStatus,
+ _window = $(window),
+ _document,
+ _prevContentType,
+ _wrapClasses,
+ _currPopupType;
+
+
+ /**
+ * Private functions
+ */
+ var _mfpOn = function(name, f) {
+ mfp.ev.on(NS + name + EVENT_NS, f);
+ },
+ _getEl = function(className, appendTo, html, raw) {
+ var el = document.createElement('div');
+ el.className = 'mfp-'+className;
+ if(html) {
+ el.innerHTML = html;
+ }
+ if(!raw) {
+ el = $(el);
+ if(appendTo) {
+ el.appendTo(appendTo);
+ }
+ } else if(appendTo) {
+ appendTo.appendChild(el);
+ }
+ return el;
+ },
+ _mfpTrigger = function(e, data) {
+ mfp.ev.triggerHandler(NS + e, data);
+
+ if(mfp.st.callbacks) {
+ // converts "mfpEventName" to "eventName" callback and triggers it if it's present
+ e = e.charAt(0).toLowerCase() + e.slice(1);
+ if(mfp.st.callbacks[e]) {
+ mfp.st.callbacks[e].apply(mfp, $.isArray(data) ? data : [data]);
+ }
+ }
+ },
+ _getCloseBtn = function(type) {
+ if(type !== _currPopupType || !mfp.currTemplate.closeBtn) {
+ mfp.currTemplate.closeBtn = $( mfp.st.closeMarkup.replace('%title%', mfp.st.tClose ) );
+ _currPopupType = type;
+ }
+ return mfp.currTemplate.closeBtn;
+ },
+ // Initialize Magnific Popup only when called at least once
+ _checkInstance = function() {
+ if(!$.magnificPopup.instance) {
+ /*jshint -W020 */
+ mfp = new MagnificPopup();
+ mfp.init();
+ $.magnificPopup.instance = mfp;
+ }
+ },
+ // CSS transition detection, http://stackoverflow.com/questions/7264899/detect-css-transitions-using-javascript-and-without-modernizr
+ supportsTransitions = function() {
+ var s = document.createElement('p').style, // 's' for style. better to create an element if body yet to exist
+ v = ['ms','O','Moz','Webkit']; // 'v' for vendor
+
+ if( s['transition'] !== undefined ) {
+ return true;
+ }
+
+ while( v.length ) {
+ if( v.pop() + 'Transition' in s ) {
+ return true;
+ }
+ }
+
+ return false;
+ };
+
+
+
+ /**
+ * Public functions
+ */
+ MagnificPopup.prototype = {
+
+ constructor: MagnificPopup,
+
+ /**
+ * Initializes Magnific Popup plugin.
+ * This function is triggered only once when $.fn.magnificPopup or $.magnificPopup is executed
+ */
+ init: function() {
+ var appVersion = navigator.appVersion;
+ mfp.isLowIE = mfp.isIE8 = document.all && !document.addEventListener;
+ mfp.isAndroid = (/android/gi).test(appVersion);
+ mfp.isIOS = (/iphone|ipad|ipod/gi).test(appVersion);
+ mfp.supportsTransition = supportsTransitions();
+
+ // We disable fixed positioned lightbox on devices that don't handle it nicely.
+ // If you know a better way of detecting this - let me know.
+ mfp.probablyMobile = (mfp.isAndroid || mfp.isIOS || /(Opera Mini)|Kindle|webOS|BlackBerry|(Opera Mobi)|(Windows Phone)|IEMobile/i.test(navigator.userAgent) );
+ _document = $(document);
+
+ mfp.popupsCache = {};
+ },
+
+ /**
+ * Opens popup
+ * @param data [description]
+ */
+ open: function(data) {
+
+ var i;
+
+ if(data.isObj === false) {
+ // convert jQuery collection to array to avoid conflicts later
+ mfp.items = data.items.toArray();
+
+ mfp.index = 0;
+ var items = data.items,
+ item;
+ for(i = 0; i < items.length; i++) {
+ item = items[i];
+ if(item.parsed) {
+ item = item.el[0];
+ }
+ if(item === data.el[0]) {
+ mfp.index = i;
+ break;
+ }
+ }
+ } else {
+ mfp.items = $.isArray(data.items) ? data.items : [data.items];
+ mfp.index = data.index || 0;
+ }
+
+ // if popup is already opened - we just update the content
+ if(mfp.isOpen) {
+ mfp.updateItemHTML();
+ return;
+ }
+
+ mfp.types = [];
+ _wrapClasses = '';
+ if(data.mainEl && data.mainEl.length) {
+ mfp.ev = data.mainEl.eq(0);
+ } else {
+ mfp.ev = _document;
+ }
+
+ if(data.key) {
+ if(!mfp.popupsCache[data.key]) {
+ mfp.popupsCache[data.key] = {};
+ }
+ mfp.currTemplate = mfp.popupsCache[data.key];
+ } else {
+ mfp.currTemplate = {};
+ }
+
+
+
+ mfp.st = $.extend(true, {}, $.magnificPopup.defaults, data );
+ mfp.fixedContentPos = mfp.st.fixedContentPos === 'auto' ? !mfp.probablyMobile : mfp.st.fixedContentPos;
+
+ if(mfp.st.modal) {
+ mfp.st.closeOnContentClick = false;
+ mfp.st.closeOnBgClick = false;
+ mfp.st.showCloseBtn = false;
+ mfp.st.enableEscapeKey = false;
+ }
+
+
+ // Building markup
+ // main containers are created only once
+ if(!mfp.bgOverlay) {
+
+ // Dark overlay
+ mfp.bgOverlay = _getEl('bg').on('click'+EVENT_NS, function() {
+ mfp.close();
+ });
+
+ mfp.wrap = _getEl('wrap').attr('tabindex', -1).on('click'+EVENT_NS, function(e) {
+ if(mfp._checkIfClose(e.target)) {
+ mfp.close();
+ }
+ });
+
+ mfp.container = _getEl('container', mfp.wrap);
+ }
+
+ mfp.contentContainer = _getEl('content');
+ if(mfp.st.preloader) {
+ mfp.preloader = _getEl('preloader', mfp.container, mfp.st.tLoading);
+ }
+
+
+ // Initializing modules
+ var modules = $.magnificPopup.modules;
+ for(i = 0; i < modules.length; i++) {
+ var n = modules[i];
+ n = n.charAt(0).toUpperCase() + n.slice(1);
+ mfp['init'+n].call(mfp);
+ }
+ _mfpTrigger('BeforeOpen');
+
+
+ if(mfp.st.showCloseBtn) {
+ // Close button
+ if(!mfp.st.closeBtnInside) {
+ mfp.wrap.append( _getCloseBtn() );
+ } else {
+ _mfpOn(MARKUP_PARSE_EVENT, function(e, template, values, item) {
+ values.close_replaceWith = _getCloseBtn(item.type);
+ });
+ _wrapClasses += ' mfp-close-btn-in';
+ }
+ }
+
+ if(mfp.st.alignTop) {
+ _wrapClasses += ' mfp-align-top';
+ }
+
+
+
+ if(mfp.fixedContentPos) {
+ mfp.wrap.css({
+ overflow: mfp.st.overflowY,
+ overflowX: 'hidden',
+ overflowY: mfp.st.overflowY
+ });
+ } else {
+ mfp.wrap.css({
+ top: _window.scrollTop(),
+ position: 'absolute'
+ });
+ }
+ if( mfp.st.fixedBgPos === false || (mfp.st.fixedBgPos === 'auto' && !mfp.fixedContentPos) ) {
+ mfp.bgOverlay.css({
+ height: _document.height(),
+ position: 'absolute'
+ });
+ }
+
+
+
+ if(mfp.st.enableEscapeKey) {
+ // Close on ESC key
+ _document.on('keyup' + EVENT_NS, function(e) {
+ if(e.keyCode === 27) {
+ mfp.close();
+ }
+ });
+ }
+
+ _window.on('resize' + EVENT_NS, function() {
+ mfp.updateSize();
+ });
+
+
+ if(!mfp.st.closeOnContentClick) {
+ _wrapClasses += ' mfp-auto-cursor';
+ }
+
+ if(_wrapClasses)
+ mfp.wrap.addClass(_wrapClasses);
+
+
+ // this triggers recalculation of layout, so we get it once to not to trigger twice
+ var windowHeight = mfp.wH = _window.height();
+
+
+ var windowStyles = {};
+
+ if( mfp.fixedContentPos ) {
+ if(mfp._hasScrollBar(windowHeight)){
+ var s = mfp._getScrollbarSize();
+ if(s) {
+ windowStyles.marginRight = s;
+ }
+ }
+ }
+
+ if(mfp.fixedContentPos) {
+ if(!mfp.isIE7) {
+ windowStyles.overflow = 'hidden';
+ } else {
+ // ie7 double-scroll bug
+ $('body, html').css('overflow', 'hidden');
+ }
+ }
+
+
+
+ var classesToadd = mfp.st.mainClass;
+ if(mfp.isIE7) {
+ classesToadd += ' mfp-ie7';
+ }
+ if(classesToadd) {
+ mfp._addClassToMFP( classesToadd );
+ }
+
+ // add content
+ mfp.updateItemHTML();
+
+ _mfpTrigger('BuildControls');
+
+ // remove scrollbar, add margin e.t.c
+ $('html').css(windowStyles);
+
+ // add everything to DOM
+ mfp.bgOverlay.add(mfp.wrap).prependTo( mfp.st.prependTo || $(document.body) );
+
+ // Save last focused element
+ mfp._lastFocusedEl = document.activeElement;
+
+ // Wait for next cycle to allow CSS transition
+ setTimeout(function() {
+
+ if(mfp.content) {
+ mfp._addClassToMFP(READY_CLASS);
+ mfp._setFocus();
+ } else {
+ // if content is not defined (not loaded e.t.c) we add class only for BG
+ mfp.bgOverlay.addClass(READY_CLASS);
+ }
+
+ // Trap the focus in popup
+ _document.on('focusin' + EVENT_NS, mfp._onFocusIn);
+
+ }, 16);
+
+ mfp.isOpen = true;
+ mfp.updateSize(windowHeight);
+ _mfpTrigger(OPEN_EVENT);
+
+ return data;
+ },
+
+ /**
+ * Closes the popup
+ */
+ close: function() {
+ if(!mfp.isOpen) return;
+ _mfpTrigger(BEFORE_CLOSE_EVENT);
+
+ mfp.isOpen = false;
+ // for CSS3 animation
+ if(mfp.st.removalDelay && !mfp.isLowIE && mfp.supportsTransition ) {
+ mfp._addClassToMFP(REMOVING_CLASS);
+ setTimeout(function() {
+ mfp._close();
+ }, mfp.st.removalDelay);
+ } else {
+ mfp._close();
+ }
+ },
+
+ /**
+ * Helper for close() function
+ */
+ _close: function() {
+ _mfpTrigger(CLOSE_EVENT);
+
+ var classesToRemove = REMOVING_CLASS + ' ' + READY_CLASS + ' ';
+
+ mfp.bgOverlay.detach();
+ mfp.wrap.detach();
+ mfp.container.empty();
+
+ if(mfp.st.mainClass) {
+ classesToRemove += mfp.st.mainClass + ' ';
+ }
+
+ mfp._removeClassFromMFP(classesToRemove);
+
+ if(mfp.fixedContentPos) {
+ var windowStyles = {marginRight: ''};
+ if(mfp.isIE7) {
+ $('body, html').css('overflow', '');
+ } else {
+ windowStyles.overflow = '';
+ }
+ $('html').css(windowStyles);
+ }
+
+ _document.off('keyup' + EVENT_NS + ' focusin' + EVENT_NS);
+ mfp.ev.off(EVENT_NS);
+
+ // clean up DOM elements that aren't removed
+ mfp.wrap.attr('class', 'mfp-wrap').removeAttr('style');
+ mfp.bgOverlay.attr('class', 'mfp-bg');
+ mfp.container.attr('class', 'mfp-container');
+
+ // remove close button from target element
+ if(mfp.st.showCloseBtn &&
+ (!mfp.st.closeBtnInside || mfp.currTemplate[mfp.currItem.type] === true)) {
+ if(mfp.currTemplate.closeBtn)
+ mfp.currTemplate.closeBtn.detach();
+ }
+
+
+ if(mfp.st.autoFocusLast && mfp._lastFocusedEl) {
+ $(mfp._lastFocusedEl).focus(); // put tab focus back
+ }
+ mfp.currItem = null;
+ mfp.content = null;
+ mfp.currTemplate = null;
+ mfp.prevHeight = 0;
+
+ _mfpTrigger(AFTER_CLOSE_EVENT);
+ },
+
+ updateSize: function(winHeight) {
+
+ if(mfp.isIOS) {
+ // fixes iOS nav bars https://github.com/dimsemenov/Magnific-Popup/issues/2
+ var zoomLevel = document.documentElement.clientWidth / window.innerWidth;
+ var height = window.innerHeight * zoomLevel;
+ mfp.wrap.css('height', height);
+ mfp.wH = height;
+ } else {
+ mfp.wH = winHeight || _window.height();
+ }
+ // Fixes #84: popup incorrectly positioned with position:relative on body
+ if(!mfp.fixedContentPos) {
+ mfp.wrap.css('height', mfp.wH);
+ }
+
+ _mfpTrigger('Resize');
+
+ },
+
+ /**
+ * Set content of popup based on current index
+ */
+ updateItemHTML: function() {
+ var item = mfp.items[mfp.index];
+
+ // Detach and perform modifications
+ mfp.contentContainer.detach();
+
+ if(mfp.content)
+ mfp.content.detach();
+
+ if(!item.parsed) {
+ item = mfp.parseEl( mfp.index );
+ }
+
+ var type = item.type;
+
+ _mfpTrigger('BeforeChange', [mfp.currItem ? mfp.currItem.type : '', type]);
+ // BeforeChange event works like so:
+ // _mfpOn('BeforeChange', function(e, prevType, newType) { });
+
+ mfp.currItem = item;
+
+ if(!mfp.currTemplate[type]) {
+ var markup = mfp.st[type] ? mfp.st[type].markup : false;
+
+ // allows to modify markup
+ _mfpTrigger('FirstMarkupParse', markup);
+
+ if(markup) {
+ mfp.currTemplate[type] = $(markup);
+ } else {
+ // if there is no markup found we just define that template is parsed
+ mfp.currTemplate[type] = true;
+ }
+ }
+
+ if(_prevContentType && _prevContentType !== item.type) {
+ mfp.container.removeClass('mfp-'+_prevContentType+'-holder');
+ }
+
+ var newContent = mfp['get' + type.charAt(0).toUpperCase() + type.slice(1)](item, mfp.currTemplate[type]);
+ mfp.appendContent(newContent, type);
+
+ item.preloaded = true;
+
+ _mfpTrigger(CHANGE_EVENT, item);
+ _prevContentType = item.type;
+
+ // Append container back after its content changed
+ mfp.container.prepend(mfp.contentContainer);
+
+ _mfpTrigger('AfterChange');
+ },
+
+
+ /**
+ * Set HTML content of popup
+ */
+ appendContent: function(newContent, type) {
+ mfp.content = newContent;
+
+ if(newContent) {
+ if(mfp.st.showCloseBtn && mfp.st.closeBtnInside &&
+ mfp.currTemplate[type] === true) {
+ // if there is no markup, we just append close button element inside
+ if(!mfp.content.find('.mfp-close').length) {
+ mfp.content.append(_getCloseBtn());
+ }
+ } else {
+ mfp.content = newContent;
+ }
+ } else {
+ mfp.content = '';
+ }
+
+ _mfpTrigger(BEFORE_APPEND_EVENT);
+ mfp.container.addClass('mfp-'+type+'-holder');
+
+ mfp.contentContainer.append(mfp.content);
+ },
+
+
+ /**
+ * Creates Magnific Popup data object based on given data
+ * @param {int} index Index of item to parse
+ */
+ parseEl: function(index) {
+ var item = mfp.items[index],
+ type;
+
+ if(item.tagName) {
+ item = { el: $(item) };
+ } else {
+ type = item.type;
+ item = { data: item, src: item.src };
+ }
+
+ if(item.el) {
+ var types = mfp.types;
+
+ // check for 'mfp-TYPE' class
+ for(var i = 0; i < types.length; i++) {
+ if( item.el.hasClass('mfp-'+types[i]) ) {
+ type = types[i];
+ break;
+ }
+ }
+
+ item.src = item.el.attr('data-mfp-src');
+ if(!item.src) {
+ item.src = item.el.attr('href');
+ }
+ }
+
+ item.type = type || mfp.st.type || 'inline';
+ item.index = index;
+ item.parsed = true;
+ mfp.items[index] = item;
+ _mfpTrigger('ElementParse', item);
+
+ return mfp.items[index];
+ },
+
+
+ /**
+ * Initializes single popup or a group of popups
+ */
+ addGroup: function(el, options) {
+ var eHandler = function(e) {
+ e.mfpEl = this;
+ mfp._openClick(e, el, options);
+ };
+
+ if(!options) {
+ options = {};
+ }
+
+ var eName = 'click.magnificPopup';
+ options.mainEl = el;
+
+ if(options.items) {
+ options.isObj = true;
+ el.off(eName).on(eName, eHandler);
+ } else {
+ options.isObj = false;
+ if(options.delegate) {
+ el.off(eName).on(eName, options.delegate , eHandler);
+ } else {
+ options.items = el;
+ el.off(eName).on(eName, eHandler);
+ }
+ }
+ },
+ _openClick: function(e, el, options) {
+ var midClick = options.midClick !== undefined ? options.midClick : $.magnificPopup.defaults.midClick;
+
+
+ if(!midClick && ( e.which === 2 || e.ctrlKey || e.metaKey || e.altKey || e.shiftKey ) ) {
+ return;
+ }
+
+ var disableOn = options.disableOn !== undefined ? options.disableOn : $.magnificPopup.defaults.disableOn;
+
+ if(disableOn) {
+ if($.isFunction(disableOn)) {
+ if( !disableOn.call(mfp) ) {
+ return true;
+ }
+ } else { // else it's number
+ if( _window.width() < disableOn ) {
+ return true;
+ }
+ }
+ }
+
+ if(e.type) {
+ e.preventDefault();
+
+ // This will prevent popup from closing if element is inside and popup is already opened
+ if(mfp.isOpen) {
+ e.stopPropagation();
+ }
+ }
+
+ options.el = $(e.mfpEl);
+ if(options.delegate) {
+ options.items = el.find(options.delegate);
+ }
+ mfp.open(options);
+ },
+
+
+ /**
+ * Updates text on preloader
+ */
+ updateStatus: function(status, text) {
+
+ if(mfp.preloader) {
+ if(_prevStatus !== status) {
+ mfp.container.removeClass('mfp-s-'+_prevStatus);
+ }
+
+ if(!text && status === 'loading') {
+ text = mfp.st.tLoading;
+ }
+
+ var data = {
+ status: status,
+ text: text
+ };
+ // allows to modify status
+ _mfpTrigger('UpdateStatus', data);
+
+ status = data.status;
+ text = data.text;
+
+ mfp.preloader.html(text);
+
+ mfp.preloader.find('a').on('click', function(e) {
+ e.stopImmediatePropagation();
+ });
+
+ mfp.container.addClass('mfp-s-'+status);
+ _prevStatus = status;
+ }
+ },
+
+
+ /*
+ "Private" helpers that aren't private at all
+ */
+ // Check to close popup or not
+ // "target" is an element that was clicked
+ _checkIfClose: function(target) {
+
+ if($(target).hasClass(PREVENT_CLOSE_CLASS)) {
+ return;
+ }
+
+ var closeOnContent = mfp.st.closeOnContentClick;
+ var closeOnBg = mfp.st.closeOnBgClick;
+
+ if(closeOnContent && closeOnBg) {
+ return true;
+ } else {
+
+ // We close the popup if click is on close button or on preloader. Or if there is no content.
+ if(!mfp.content || $(target).hasClass('mfp-close') || (mfp.preloader && target === mfp.preloader[0]) ) {
+ return true;
+ }
+
+ // if click is outside the content
+ if( (target !== mfp.content[0] && !$.contains(mfp.content[0], target)) ) {
+ if(closeOnBg) {
+ // last check, if the clicked element is in DOM, (in case it's removed onclick)
+ if( $.contains(document, target) ) {
+ return true;
+ }
+ }
+ } else if(closeOnContent) {
+ return true;
+ }
+
+ }
+ return false;
+ },
+ _addClassToMFP: function(cName) {
+ mfp.bgOverlay.addClass(cName);
+ mfp.wrap.addClass(cName);
+ },
+ _removeClassFromMFP: function(cName) {
+ this.bgOverlay.removeClass(cName);
+ mfp.wrap.removeClass(cName);
+ },
+ _hasScrollBar: function(winHeight) {
+ return ( (mfp.isIE7 ? _document.height() : document.body.scrollHeight) > (winHeight || _window.height()) );
+ },
+ _setFocus: function() {
+ (mfp.st.focus ? mfp.content.find(mfp.st.focus).eq(0) : mfp.wrap).focus();
+ },
+ _onFocusIn: function(e) {
+ if( e.target !== mfp.wrap[0] && !$.contains(mfp.wrap[0], e.target) ) {
+ mfp._setFocus();
+ return false;
+ }
+ },
+ _parseMarkup: function(template, values, item) {
+ var arr;
+ if(item.data) {
+ values = $.extend(item.data, values);
+ }
+ _mfpTrigger(MARKUP_PARSE_EVENT, [template, values, item] );
+
+ $.each(values, function(key, value) {
+ if(value === undefined || value === false) {
+ return true;
+ }
+ arr = key.split('_');
+ if(arr.length > 1) {
+ var el = template.find(EVENT_NS + '-'+arr[0]);
+
+ if(el.length > 0) {
+ var attr = arr[1];
+ if(attr === 'replaceWith') {
+ if(el[0] !== value[0]) {
+ el.replaceWith(value);
+ }
+ } else if(attr === 'img') {
+ if(el.is('img')) {
+ el.attr('src', value);
+ } else {
+ el.replaceWith( $('').attr('src', value).attr('class', el.attr('class')) );
+ }
+ } else {
+ el.attr(arr[1], value);
+ }
+ }
+
+ } else {
+ template.find(EVENT_NS + '-'+key).html(value);
+ }
+ });
+ },
+
+ _getScrollbarSize: function() {
+ // thx David
+ if(mfp.scrollbarSize === undefined) {
+ var scrollDiv = document.createElement("div");
+ scrollDiv.style.cssText = 'width: 99px; height: 99px; overflow: scroll; position: absolute; top: -9999px;';
+ document.body.appendChild(scrollDiv);
+ mfp.scrollbarSize = scrollDiv.offsetWidth - scrollDiv.clientWidth;
+ document.body.removeChild(scrollDiv);
+ }
+ return mfp.scrollbarSize;
+ }
+
+ }; /* MagnificPopup core prototype end */
+
+
+
+
+ /**
+ * Public static functions
+ */
+ $.magnificPopup = {
+ instance: null,
+ proto: MagnificPopup.prototype,
+ modules: [],
+
+ open: function(options, index) {
+ _checkInstance();
+
+ if(!options) {
+ options = {};
+ } else {
+ options = $.extend(true, {}, options);
+ }
+
+ options.isObj = true;
+ options.index = index || 0;
+ return this.instance.open(options);
+ },
+
+ close: function() {
+ return $.magnificPopup.instance && $.magnificPopup.instance.close();
+ },
+
+ registerModule: function(name, module) {
+ if(module.options) {
+ $.magnificPopup.defaults[name] = module.options;
+ }
+ $.extend(this.proto, module.proto);
+ this.modules.push(name);
+ },
+
+ defaults: {
+
+ // Info about options is in docs:
+ // http://dimsemenov.com/plugins/magnific-popup/documentation.html#options
+
+ disableOn: 0,
+
+ key: null,
+
+ midClick: false,
+
+ mainClass: '',
+
+ preloader: true,
+
+ focus: '', // CSS selector of input to focus after popup is opened
+
+ closeOnContentClick: false,
+
+ closeOnBgClick: true,
+
+ closeBtnInside: true,
+
+ showCloseBtn: true,
+
+ enableEscapeKey: true,
+
+ modal: false,
+
+ alignTop: false,
+
+ removalDelay: 0,
+
+ prependTo: null,
+
+ fixedContentPos: 'auto',
+
+ fixedBgPos: 'auto',
+
+ overflowY: 'auto',
+
+ closeMarkup: '',
+
+ tClose: 'Close (Esc)',
+
+ tLoading: 'Loading...',
+
+ autoFocusLast: true
+
+ }
+ };
+
+
+
+ $.fn.magnificPopup = function(options) {
+ _checkInstance();
+
+ var jqEl = $(this);
+
+ // We call some API method of first param is a string
+ if (typeof options === "string" ) {
+
+ if(options === 'open') {
+ var items,
+ itemOpts = _isJQ ? jqEl.data('magnificPopup') : jqEl[0].magnificPopup,
+ index = parseInt(arguments[1], 10) || 0;
+
+ if(itemOpts.items) {
+ items = itemOpts.items[index];
+ } else {
+ items = jqEl;
+ if(itemOpts.delegate) {
+ items = items.find(itemOpts.delegate);
+ }
+ items = items.eq( index );
+ }
+ mfp._openClick({mfpEl:items}, jqEl, itemOpts);
+ } else {
+ if(mfp.isOpen)
+ mfp[options].apply(mfp, Array.prototype.slice.call(arguments, 1));
+ }
+
+ } else {
+ // clone options obj
+ options = $.extend(true, {}, options);
+
+ /*
+ * As Zepto doesn't support .data() method for objects
+ * and it works only in normal browsers
+ * we assign "options" object directly to the DOM element. FTW!
+ */
+ if(_isJQ) {
+ jqEl.data('magnificPopup', options);
+ } else {
+ jqEl[0].magnificPopup = options;
+ }
+
+ mfp.addGroup(jqEl, options);
+
+ }
+ return jqEl;
+ };
+
+ /*>>core*/
+
+ /*>>inline*/
+
+ var INLINE_NS = 'inline',
+ _hiddenClass,
+ _inlinePlaceholder,
+ _lastInlineElement,
+ _putInlineElementsBack = function() {
+ if(_lastInlineElement) {
+ _inlinePlaceholder.after( _lastInlineElement.addClass(_hiddenClass) ).detach();
+ _lastInlineElement = null;
+ }
+ };
+
+ $.magnificPopup.registerModule(INLINE_NS, {
+ options: {
+ hiddenClass: 'hide', // will be appended with `mfp-` prefix
+ markup: '',
+ tNotFound: 'Content not found'
+ },
+ proto: {
+
+ initInline: function() {
+ mfp.types.push(INLINE_NS);
+
+ _mfpOn(CLOSE_EVENT+'.'+INLINE_NS, function() {
+ _putInlineElementsBack();
+ });
+ },
+
+ getInline: function(item, template) {
+
+ _putInlineElementsBack();
+
+ if(item.src) {
+ var inlineSt = mfp.st.inline,
+ el = $(item.src);
+
+ if(el.length) {
+
+ // If target element has parent - we replace it with placeholder and put it back after popup is closed
+ var parent = el[0].parentNode;
+ if(parent && parent.tagName) {
+ if(!_inlinePlaceholder) {
+ _hiddenClass = inlineSt.hiddenClass;
+ _inlinePlaceholder = _getEl(_hiddenClass);
+ _hiddenClass = 'mfp-'+_hiddenClass;
+ }
+ // replace target inline element with placeholder
+ _lastInlineElement = el.after(_inlinePlaceholder).detach().removeClass(_hiddenClass);
+ }
+
+ mfp.updateStatus('ready');
+ } else {
+ mfp.updateStatus('error', inlineSt.tNotFound);
+ el = $('
 +
+ 
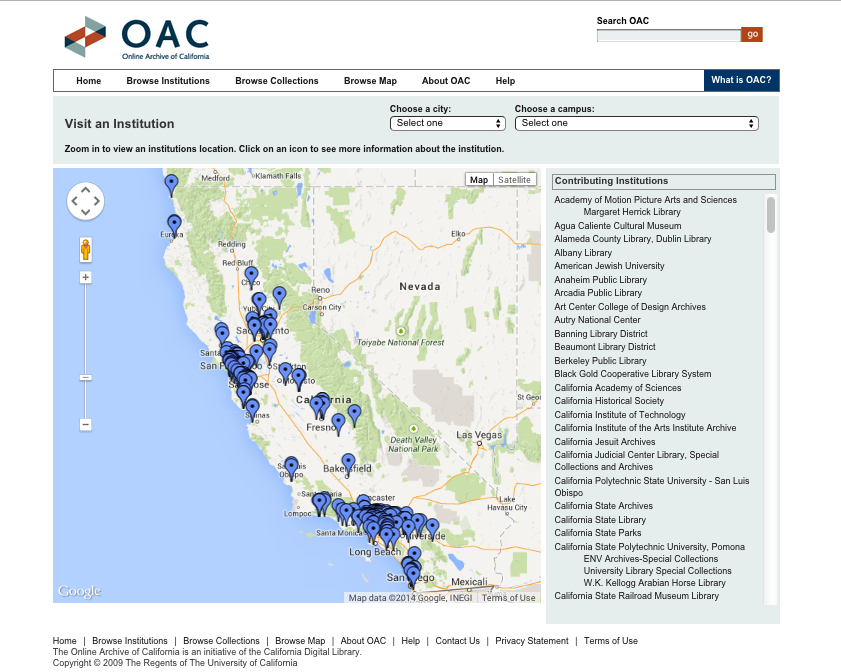
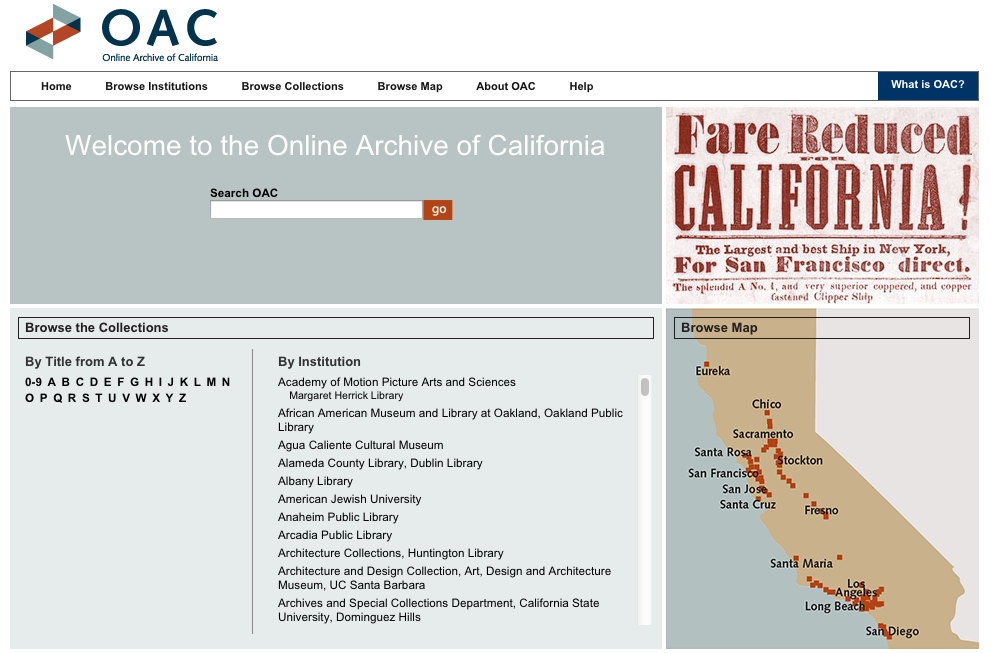








Leave a comment
+ + +