forked from iswbm/python-guide
-
Notifications
You must be signed in to change notification settings - Fork 0
/
md2rst.py
140 lines (117 loc) · 4.54 KB
/
md2rst.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
# coding:utf-8
import os
# import commands
import subprocess
import platform
osName = platform.system()
repo_path ='.'
if (osName == 'Windows'):
repo_path = 'E:\\MING-Git\\python-guide'
blog_path = 'E:\\MING-Git\\python-guide\\source'
index_path = 'E:\\MING-Git\\python-guide\\README.md'
elif (osName == 'Darwin'):
repo_path = '/Users/iswbm/Documents/Github/python-guide/'
blog_path = '/Users/iswbm/Documents/Github/python-guide/source'
index_path = '/Users/iswbm/Documents/Github/python-guide/README.md'
base_link = "https://python.iswbm.com/en/latest/"
readme_header = '''

<p align="center">
<img src='https://img.shields.io/badge/language-Python-blue.svg' alt="Build Status">
<img src='https://img.shields.io/badge/framwork-Sphinx-green.svg'>
<a href='https://www.zhihu.com/people/wongbingming'><img src='https://img.shields.io/badge/dynamic/json?color=0084ff&logo=zhihu&label=%E7%8E%8B%E7%82%B3%E6%98%8E&query=%24.data.totalSubs&url=https%3A%2F%2Fapi.spencerwoo.com%2Fsubstats%2F%3Fsource%3Dzhihu%26queryKey%3Dwongbingming'></a>
<a href='https://juejin.im/user/5b08d982f265da0db3502c55'><img src='https://img.shields.io/badge/掘金-2481-blue'></a>
<a href='http://image.iswbm.com/20200607114246.png'><img src='http://img.shields.io/badge/%E5%85%AC%E4%BC%97%E5%8F%B7-30k+-brightgreen'></a>
</p>
## [项目主页](https://python.iswbm.com/)
在线阅读:[Python 编程时光](https://python.iswbm.com/)
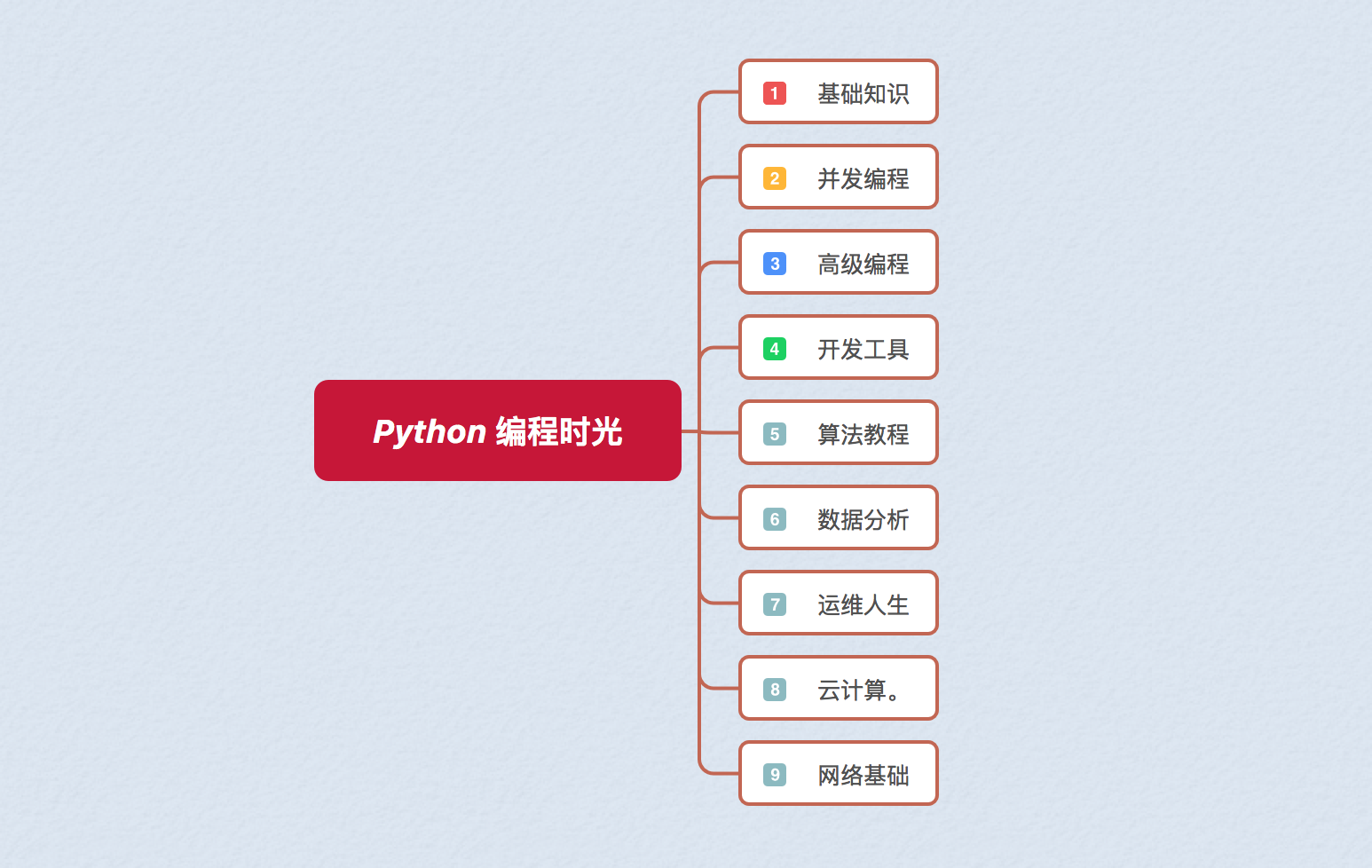
## 文章结构
'''
readme_tooter = '''
---

'''
def get_file_info(filename):
with open(filename, 'r', encoding="utf-8") as file:
first_line = file.readline().replace("#", "").strip()
return first_line.split(' ', 1)
def make_line(chapter, file):
page_name, _ = os.path.splitext(file)
(index, title) = get_file_info(file)
url = base_link + chapter + "/" + page_name + ".html"
item_list = ["-", index, "[{}]({})\n".format(title, url)]
return " ".join(item_list)
def render_index_page(index_info):
'''
生成 readme.md 索引文件,包含所有文件目录
'''
# 重新排序
index_info = sorted(index_info.items(), key=lambda item:item[0], reverse=False)
# 写入文件
with open(index_path, 'w+', encoding="utf-8") as file:
file.write(readme_header)
for chp, info in index_info:
chp_name = info["name"]
file.write("## " + chp_name + "\n")
for line in info["contents"]:
file.write(line)
file.write("\n")
file.write(readme_tooter)
def convert_md5_to_rst(file):
'''
转换格式:md5转换成rst
'''
(filename, extension) = os.path.splitext(file)
convert_cmd = 'pandoc -V mainfont="SimSun" -f markdown -t rst {md_file} -o {rst_file}'.format(
md_file=filename+'.md', rst_file=filename+'.rst'
)
# status, output = commands.getstatusoutput(convert_cmd)
status = subprocess.call(convert_cmd.split(" "))
if status != 0:
print("命令执行失败: " + convert_cmd)
os._exit(1)
if status == 0:
print(file + ' 处理完成')
else:
print(file + '处理失败')
def get_all_dir():
'''
获取所有的目录
'''
dir_list = []
file_list = os.listdir(blog_path)
for item in file_list:
abs_path = os.path.join(blog_path, item)
if os.path.isdir(abs_path):
dir_list.append(abs_path)
return dir_list
def init_index_info():
'''
初始化索引
'''
index_info = {}
chapter_dir = os.path.join(blog_path, "chapters")
os.chdir(chapter_dir)
for file in os.listdir(chapter_dir):
name, _ = os.path.splitext(file)
with open(file, 'r', encoding="utf-8") as f:
chapter_name = f.readlines()[1].strip()
index_info[name.replace("p", "")] = {"name": chapter_name, "contents": []}
return index_info
def main(index_info):
for folder in get_all_dir():
os.chdir(folder)
chapter = os.path.split(folder)[1]
all_file = os.listdir(folder)
all_md_file = sorted([file for file in all_file if file.endswith('md')])
for file in all_md_file:
line = make_line(chapter, file)
index_info[chapter.replace("c", "")]["contents"].append(line)
convert_md5_to_rst(file)
if __name__ == '__main__':
index_info = init_index_info()
main(index_info)
# render_index_page(index_info)
print("OK")