![]()
High Available Reverse Proxy for Asynchronous Message Consumption


The project started because of a common usecase for an endpoint (HTTP) to ingest data, where the user on the client side expects to receive a delivery confirmation that the message has been received, yet the response itself doens't matter.

On a company that I used to work for, that was the case for the entry point of leads, which is the source of 💰 that must be always available.
As the image above shows, both the database writes and mailing were triggered on time of the request. We'll have seen that, is a pretty common pattern. The problem is that scaling it creates all sorts of issues, mostly unnecessary ones. People try to scale the database to handle the back-pressure, which even if you have to do it, you don't want to depend entirely on a database write to handle enormous data ingestion.
Also, you probably handle different loads during the day, or time of the year, which would make you pay for a database on the worst-case-scenario but only make use of it during the spikes.
e.g.:
Request:
POST /leads HTTP/1.1
Content-Type: application/json
Accept: application/json
Content-Length: 327
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_1) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/12.0.1 Safari/605.1.15
{"message":"this is a lead message", "shop": "a23m07b23"}
Response:
HTTP/1.1 200
Content-Type: application/json;charset=UTF-8
Vary: Accept-Encoding
Connection: keep-alive
Date: Sun, 09 Dec 2018 11:07:54 GMT
Content-Encoding: gzip
Transfer-Encoding: Identity
{"status": "OK"}
The whole point of crowd is to have a high available endpoint to avoid package loss, disregarding the processing. If you need to return something to the user on the time of the request, it's probably not for you.
Which is a quite common pattern for data-ingestion in general: statistics, events, tracking, order-placement, queue items, ...
That way you can easily control an acceptable throughput to the rest of your system.
You can use crowd to handle back-pressure on existing endpoints and scale your current REST APIs to consume the messages later:
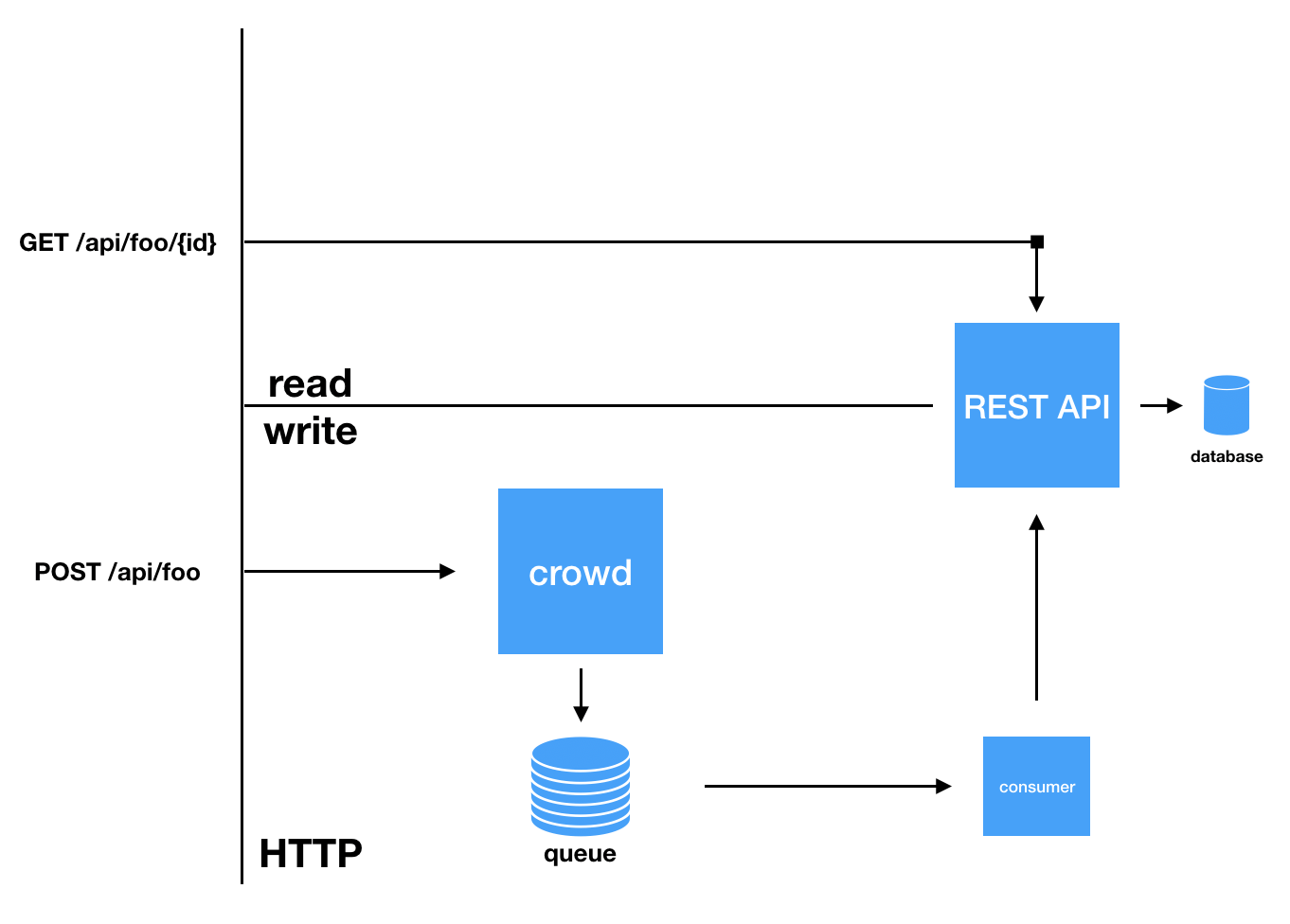
Or even as an entrypoint to your stream/queues with multiple consumers:

It is important to notice that, for most projects, you could probably rewrite your endpoints to push directly to queues and call it a day. However, the scenario where this idea was conceived would involve having to come up with a standard way of doing this across multiple languages, frameworks, teams,... which would be more expensive than implementing only once and solving it as an infrastructural problem.
make help Lists the available commands
make install Installs app dependencies
make run Runs the app
make test Runs tests
make compose Runs docker compose dependencies
make decompose Stops docker compose dependencies