
🧙 A modern replacement for Airflow.
Documentation 🌪️ Watch 2 min demo 🌊 Play with live tool 🔥 Get instant help





Integrate and synchronize data from 3rd party sources
Build real-time and batch pipelines to transform data using Python, SQL, and R
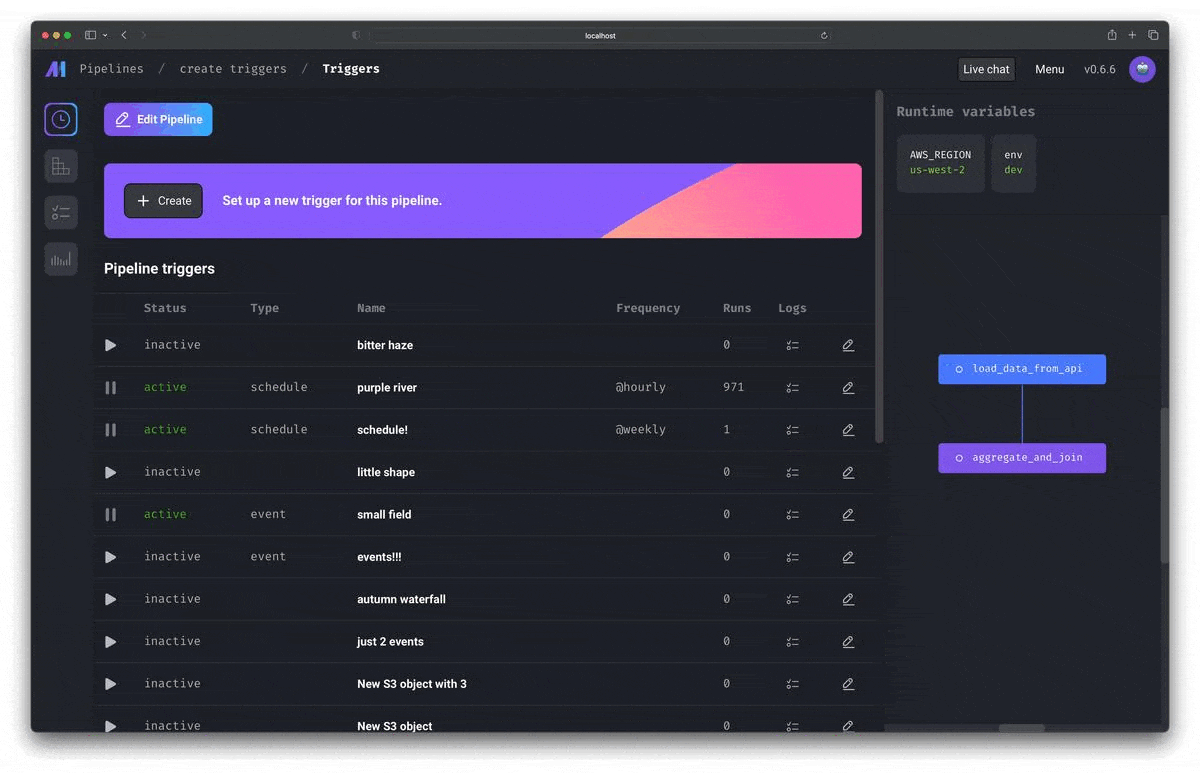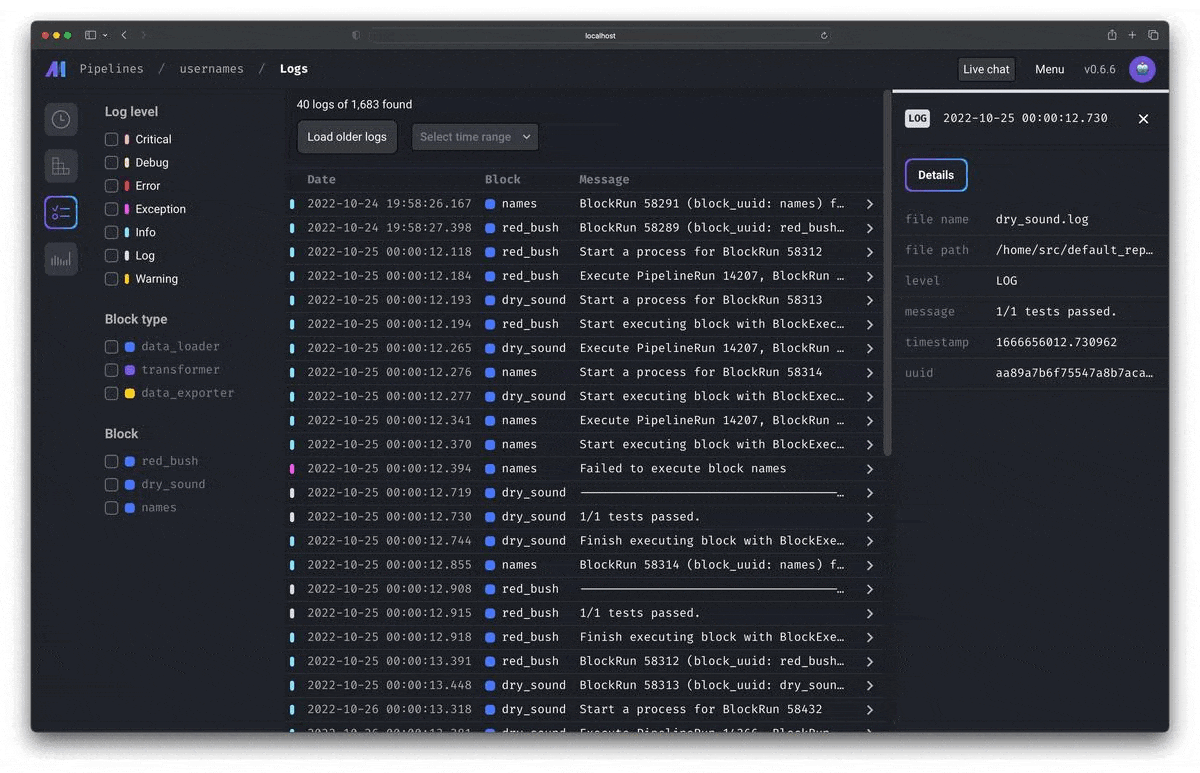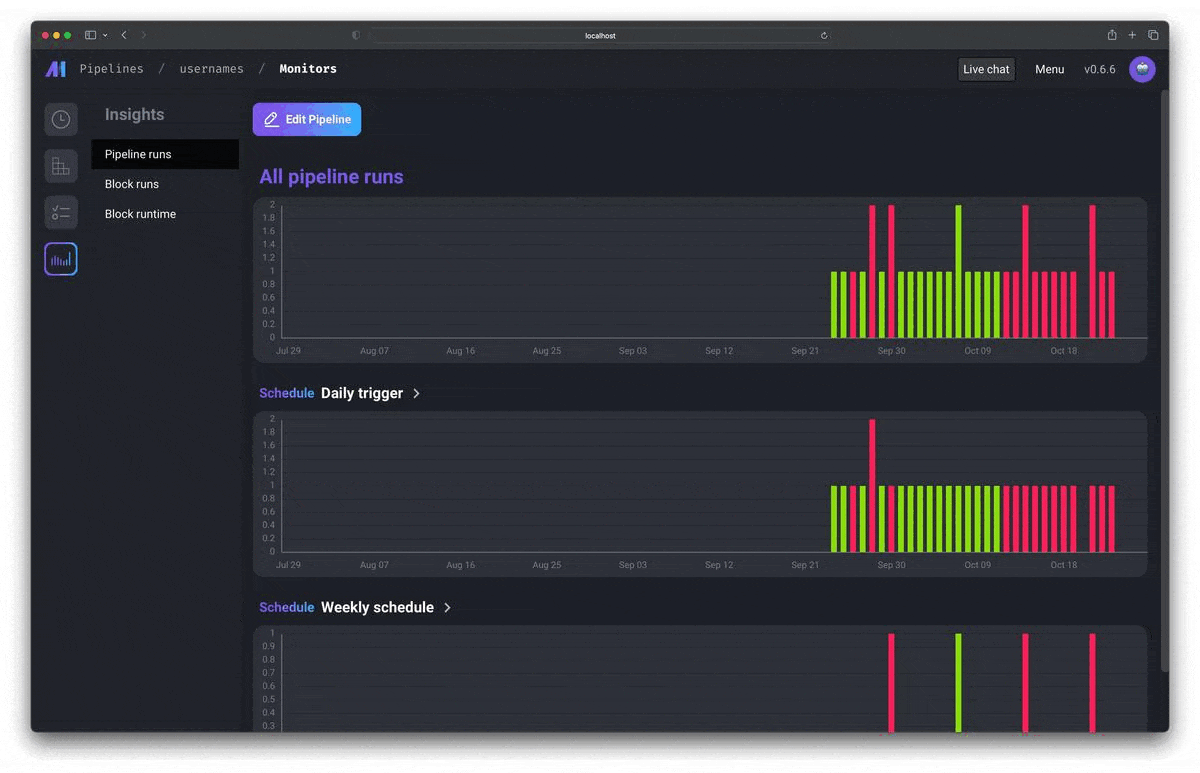
Run, monitor, and orchestrate thousands of pipelines without losing sleep
1️⃣ 🏗️
Have you met anyone who said they loved developing in Airflow?
That’s why we designed an easy developer experience that you’ll enjoy.
| Easy developer experience Start developing locally with a single command or launch a dev environment in your cloud using Terraform. Language of choice Write code in Python, SQL, or R in the same data pipeline for ultimate flexibility. Engineering best practices built-in Each step in your pipeline is a standalone file containing modular code that’s reusable and testable with data validations. No more DAGs with spaghetti code. |
 |
↓
2️⃣ 🔮
Stop wasting time waiting around for your DAGs to finish testing.
Get instant feedback from your code each time you run it.
| Interactive code Immediately see results from your code’s output with an interactive notebook UI. Data is a first-class citizen Each block of code in your pipeline produces data that can be versioned, partitioned, and cataloged for future use. Collaborate on cloud Develop collaboratively on cloud resources, version control with Git, and test pipelines without waiting for an available shared staging environment. |
 |
↓
3️⃣ 🚀
Don’t have a large team dedicated to Airflow?
Mage makes it easy for a single developer or small team to scale up and manage thousands of pipelines.
| Fast deploy Deploy Mage to AWS, GCP, or Azure with only 2 commands using maintained Terraform templates. Scaling made simple Transform very large datasets directly in your data warehouse or through a native integration with Spark. Observability Operationalize your pipelines with built-in monitoring, alerting, and observability through an intuitive UI. |
 |
Mage is an open-source data pipeline tool for transforming and integrating data.
- Quick start
- Demo
- Tutorials
- Documentation
- Features
- Core design principles
- Core abstractions
- Contributing
You can install and run Mage using Docker (recommended), pip, or conda.
-
Create a new project and launch tool (change
demo_projectto any other name if you want):docker run -it -p 6789:6789 -v $(pwd):/home/src mageai/mageai \ mage start demo_projectWant to use Spark or other integrations? Read more about integrations.
-
Open http://localhost:6789 in your browser and build a pipeline.
-
Install Mage
pip install mage-ai
or
conda install -c conda-forge mage-ai
For additional packages (e.g.
spark,postgres, etc), please see Installing extra packages.If you run into errors, please see Install errors.
-
Create new project and launch tool (change
demo_projectto any other name if you want):mage start demo_project
-
Open http://localhost:6789 in your browser and build a pipeline.
Build and run a data pipeline with our demo app.
WARNING
The live demo is public to everyone, please don’t save anything sensitive (e.g. passwords, secrets, etc).

Click the image to play video
- Load data from API, transform it, and export it to PostgreSQL
- Integrate Mage into an existing Airflow project
- Train model on Titanic dataset
- Set up DBT models and orchestrate DBT runs

🔮 Features
| 🎶 | Orchestration | Schedule and manage data pipelines with observability. |
| 📓 | Notebook | Interactive Python, SQL, & R editor for coding data pipelines. |
| 🏗️ | Data integrations | Synchronize data from 3rd party sources to your internal destinations. |
| 🚰 | Streaming pipelines | Ingest and transform real-time data. |
| ❎ | DBT | Build, run, and manage your DBT models with Mage. |
A sample data pipeline defined across 3 files ➝
- Load data ➝
@data_loader def load_csv_from_file(): return pd.read_csv('default_repo/titanic.csv')
- Transform data ➝
@transformer def select_columns_from_df(df, *args): return df[['Age', 'Fare', 'Survived']]
- Export data ➝
@data_exporter def export_titanic_data_to_disk(df) -> None: df.to_csv('default_repo/titanic_transformed.csv')
What the data pipeline looks like in the UI ➝

New? We recommend reading about blocks and learning from a hands-on tutorial.
Every user experience and technical design decision adheres to these principles.
| 💻 | Easy developer experience | Open-source engine that comes with a custom notebook UI for building data pipelines. |
| 🚢 | Engineering best practices built-in | Build and deploy data pipelines using modular code. No more writing throwaway code or trying to turn notebooks into scripts. |
| 💳 | Data is a first-class citizen | Designed from the ground up specifically for running data-intensive workflows. |
| 🪐 | Scaling is made simple | Analyze and process large data quickly for rapid iteration. |
These are the fundamental concepts that Mage uses to operate.
| Project | Like a repository on GitHub; this is where you write all your code. |
| Pipeline | Contains references to all the blocks of code you want to run, charts for visualizing data, and organizes the dependency between each block of code. |
| Block | A file with code that can be executed independently or within a pipeline. |
| Data product | Every block produces data after it's been executed. These are called data products in Mage. |
| Trigger | A set of instructions that determine when or how a pipeline should run. |
| Run | Stores information about when it was started, its status, when it was completed, any runtime variables used in the execution of the pipeline or block, etc. |
Add features and instantly improve the experience for everyone.
Check out the contributing guide to setup your development environment and start building.
Individually, we’re a mage.
🧙 Mage
Magic is indistinguishable from advanced technology. A mage is someone who uses magic (aka advanced technology). Together, we’re Magers!
🧙♂️🧙 Magers (
/ˈmājər/)A group of mages who help each other realize their full potential! Let’s hang out and chat together ➝
For real-time news, fun memes, data engineering topics, and more, join us on ➝
| GitHub | |
| Slack |
Check out our FAQ page to find answers to some of our most asked questions.
See the LICENSE file for licensing information.
