图的结构比较复杂,我们需要表示顶点和边。一个图可能有任意多个(有限个)顶点,而且任何两个顶点之间都可能存在边。我们在实现图的存储时,重点需要关注边与顶点之间的关联关系,这是图的存储的关键。
图的存储可以通过「顺序存储结构」和「链式存储结构」来实现。其中顺序存储结构包括邻接矩阵和边集数组。链式存储结构包括邻接表、链式前向星、十字链表和邻接多重表。
接下来我们来介绍几个常用的图的存储结构。在下文中,我们约定用
邻接矩阵(Adjacency Matrix):使用一个二维数组
$adj\underline{\hspace{0.5em}}matrix$ 来存储顶点之间的邻接关系。
- 对于无权图来说,如果
$adj\underline{\hspace{0.5em}}matrix[i][j]$ 为$1$ ,则说明顶点$v_i$ 到$v_j$ 存在边,如果$adj\underline{\hspace{0.5em}}matrix[i][j]$ 为$0$ ,则说明顶点$v_i$ 到$v_j$ 不存在边。- 对于带权图来说,如果
$adj\underline{\hspace{0.5em}}matrix[i][j]$ 为$w$ ,并且$w \ne \infty$ (即w != float('inf')),则说明顶点$v_i$ 到$v_j$ 的权值为$w$ 。如果$adj\underline{\hspace{0.5em}}matrix[i][j]$ 为$\infty$ (即float('inf')),则说明顶点$v_i$ 到$v_j$ 不存在边。
在下面的示意图中,左侧是一个无向图,右侧则是该无向图对应的邻接矩阵结构。
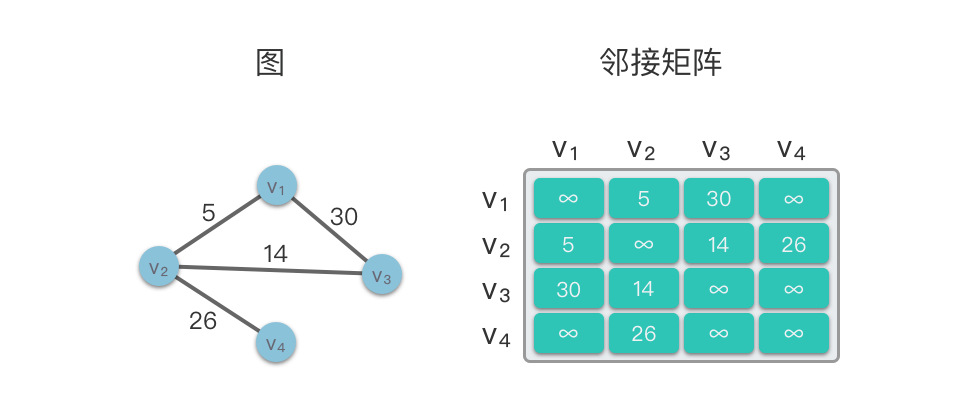
邻接矩阵的特点:
- 优点:实现简单,并且可以直接查询顶点
$v_i$ 与$v_j$ 之间是否有边存在,还可以直接查询边的权值。 - 缺点:初始化效率和遍历效率较低,空间开销大,空间利用率低,并且不能存储重复边,也不便于增删节点。如果当顶点数目过大(比如当
$n > 10^5$ )时,使用邻接矩阵建立一个$n \times n$ 的二维数组不太现实。
-
时间复杂度:
- 初始化操作:$O(n^2)$。
- 查询、添加或删除边操作:$O(1)$。
- 获取某个点的所有边操作:$O(n)$。
- 图的遍历操作 :$O(n^2)$。
-
空间复杂度:$O(n^2)$。
class Graph: # 基本图类,采用邻接矩阵表示
# 图的初始化操作,ver_count 为顶点个数
def __init__(self, ver_count):
self.ver_count = ver_count # 顶点个数
self.adj_matrix = [[None for _ in range(ver_count)] for _ in range(ver_count)] # 邻接矩阵
# 判断顶点 v 是否有效
def __valid(self, v):
return 0 <= v <= self.ver_count
# 图的创建操作,edges 为边信息
def creatGraph(self, edges=[]):
for vi, vj, val in edges:
self.add_edge(vi, vj, val)
# 向图的邻接矩阵中添加边:vi - vj,权值为 val
def add_edge(self, vi, vj, val):
if not self.__valid(vi) or not self.__valid(vj):
raise ValueError(str(vi) + ' or ' + str(vj) + " is not a valid vertex.")
self.adj_matrix[vi][vj] = val
# 获取 vi - vj 边的权值
def get_edge(self, vi, vj):
if not self.__valid(vi) or not self.__valid(vj):
raise ValueError(str(vi) + ' or ' + str(vj) + " is not a valid vertex.")
return self.adj_matrix[vi][vj]
# 根据邻接矩阵打印图的边
def printGraph(self):
for vi in range(self.ver_count):
for vj in range(self.ver_count):
val = self.get_edge(vi, vj)
if val:
print(str(vi) + ' - ' + str(vj) + ' : ' + str(val))
graph = Graph(5)
edges = [[1, 2, 5],[2, 1, 5],[1, 3, 30],[3, 1, 30],[2, 3, 14],[3, 2, 14],[2, 4, 26], [4, 2, 26]]
graph.creatGraph(edges)
print(graph.get_edge(3, 4))
graph.printGraph()边集数组(Edgeset Array):使用一个数组来存储存储顶点之间的邻接关系。数组中每个元素都包含一条边的起点
$v_i$ 、终点$v_j$ 和边的权值$val$ (如果是带权图)。
在下面的示意图中,左侧是一个有向图,右侧则是该有向图对应的边集数组结构。
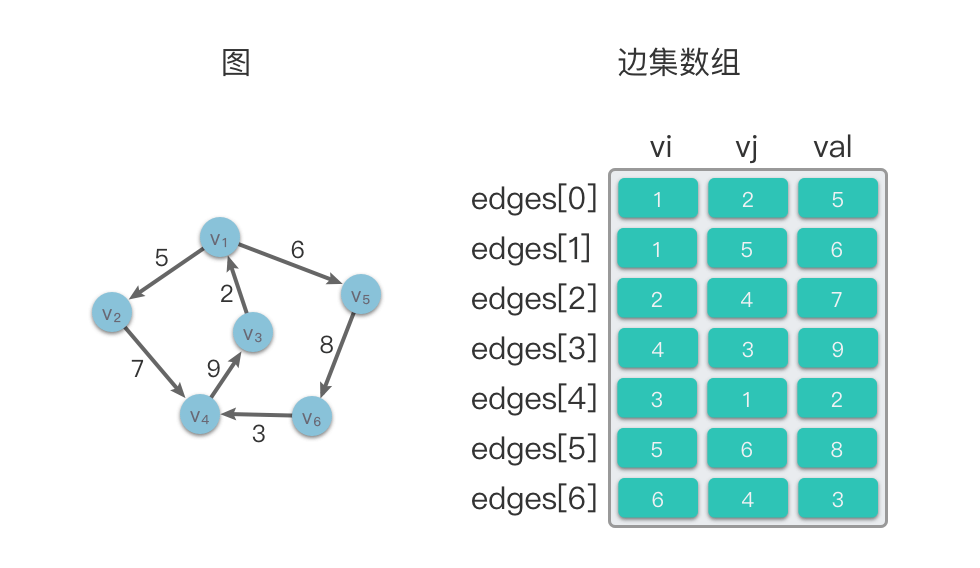
边集数组的时间复杂度:
- 图的初始化和创建操作:$O(m)$。
- 查询是否存在某条边:$O(m)$。
- 遍历某个点的所有边:$O(m)$。
- 遍历整张图:$O(nm)$。
边集数组的空间复杂度:
- 空间复杂度:$O(m)$。
采用边集数组计算节点的度或者查找某条边时,需要遍历整个边集数组,时间复杂度为 m 是边的数量。除非特殊必要,很少用使用边集数组来存储图。
一般来说,边集数组适合那些对边依次进行处理的运算,不适合对顶点的运算和对任何一条边的运算。
class EdgeNode: # 边信息类
def __init__(self, vi, vj, val):
self.vi = vi # 边的起点
self.vj = vj # 边的终点
self.val = val # 边的权值
class Graph: # 基本图类,采用边集数组表示
def __init__(self):
self.edges = [] # 边数组
# 图的创建操作,edges 为边信息
def creatGraph(self, edges=[]):
for vi, vj, val in edges:
self.add_edge(vi, vj, val)
# 向图的边数组中添加边:vi - vj,权值为 val
def add_edge(self, vi, vj, val):
edge = EdgeNode(vi, vj, val) # 创建边节点
self.edges.append(edge) # 将边节点添加到边数组中
# 获取 vi - vj 边的权值
def get_edge(self, vi, vj):
for edge in self.edges:
if vi == edge.vi and vj == edge.vj:
val = edge.val
return val
return None
# 根据边数组打印图
def printGraph(self):
for edge in self.edges:
print(str(edge.vi) + ' - ' + str(edge.vj) + ' : ' + str(edge.val))
graph = Graph()
edges = [[1, 2, 5],[1, 5, 6],[2, 4, 7],[4, 3, 9],[3, 1, 2],[5, 6, 8],[6, 4, 3]]
graph.creatGraph(edges)
print(graph.get_edge(3, 4))
graph.printGraph()邻接表(Adjacency List):使用顺序存储和链式存储相结合的存储结构来存储图的顶点和边。其数据结构包括两个部分,其中一个部分是数组,主要用来存放顶点的数据信息,另一个部分是链表,用来存放边信息。
在邻接表的存储方法中,对于对图中每个顶点 n 个顶点的图而言,其邻接表结构由 n 个线性链表组成。
然后我们在每个顶点前边设置一个表头节点,称之为「顶点节点」。每个顶点节点由「顶点域」和「指针域」组成。其中顶点域用于存放某个顶点的数据信息,指针域用于指出该顶点第 1 条边所对应的链节点。
为了方便随机访问任意顶点的链表,通常我们会使用一组顺序存储结构(数组)存储所有「顶点节点」部分,顺序存储结构(数组)的下标表示该顶点在图中的位置。
在下面的示意图中,左侧是一个有向图,右侧则是该有向图对应的邻接表结构。
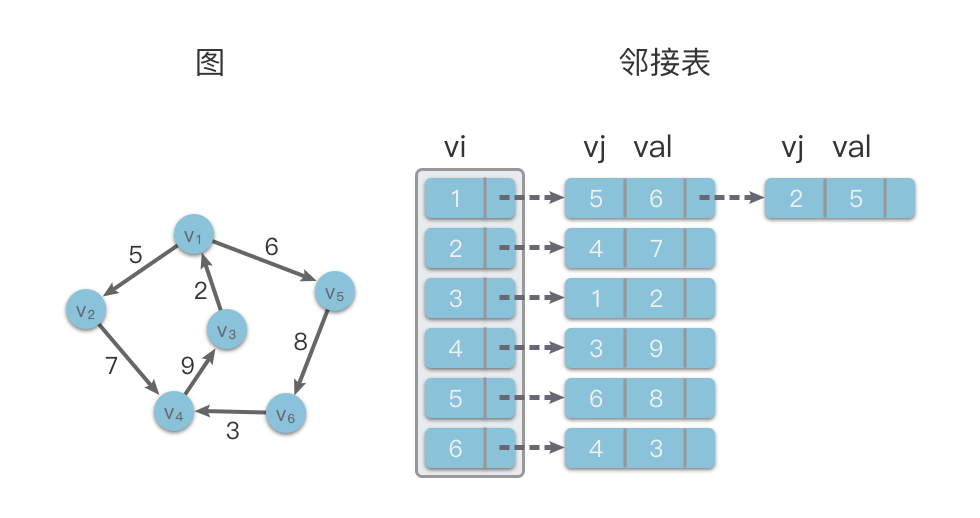
邻接表的时间复杂度:
- 图的初始化和创建操作:$O(n + m)$。
- 查询是否存在
$v_i$ 到$v_j$ 的边:$O(TD(v_i))$。 - 遍历某个点的所有边:$O(TD(v_i))$。
- 遍历整张图:$O(n + m)$。
邻接表的空间复杂度:
- 空间复杂度:$O(n + m)$。
class EdgeNode: # 边信息类
def __init__(self, vj, val):
self.vj = vj # 边的终点
self.val = val # 边的权值
self.next = None # 下一条边
class VertexNode: # 顶点信息类
def __init__(self, vi):
self.vi = vi # 边的起点
self.head = None # 下一个邻接点
class Graph:
def __init__(self, ver_count):
self.ver_count = ver_count
self.vertices = []
for vi in range(ver_count):
vertex = VertexNode(vi)
self.vertices.append(vertex)
# 判断顶点 v 是否有效
def __valid(self, v):
return 0 <= v <= self.ver_count
# 图的创建操作,edges 为边信息
def creatGraph(self, edges=[]):
for vi, vj, val in edges:
self.add_edge(vi, vj, val)
# 向图的邻接表中添加边:vi - vj,权值为 val
def add_edge(self, vi, vj, val):
if not self.__valid(vi) or not self.__valid(vj):
raise ValueError(str(vi) + ' or ' + str(vj) + " is not a valid vertex.")
vertex = self.vertices[vi]
edge = EdgeNode(vj, val)
edge.next = vertex.head
vertex.head = edge
# 获取 vi - vj 边的权值
def get_edge(self, vi, vj):
if not self.__valid(vi) or not self.__valid(vj):
raise ValueError(str(vi) + ' or ' + str(vj) + " is not a valid vertex.")
vertex = self.vertices[vi]
cur_edge = vertex.head
while cur_edge:
if cur_edge.vj == vj:
return cur_edge.val
cur_edge = cur_edge.next
return None
# 根据邻接表打印图的边
def printGraph(self):
for vertex in self.vertices:
cur_edge = vertex.head
while cur_edge:
print(str(vertex.vi) + ' - ' + str(cur_edge.vj) + ' : ' + str(cur_edge.val))
cur_edge = cur_edge.next
graph = Graph(7)
edges = [[1, 2, 5],[1, 5, 6],[2, 4, 7],[4, 3, 9],[3, 1, 2],[5, 6, 8],[6, 4, 3]]
graph.creatGraph(edges)
print(graph.get_edge(3, 4))
graph.printGraph()链式前向星(Linked Forward Star):也叫做静态邻接表,实质上就是使用静态链表实现的邻接表。链式前向星将边集数组和邻接表相结合,可以快速访问一个节点所有的邻接点,并且使用很少的额外空间。
链式前向星采用了一种静态链表的存储方式,可以说是目前建图和遍历效率最高的存储方式。
链式前向星由两种数据结构组成:
- 特殊的边集数组:
edges,其中edges[i]表示第i条边。edges[i].vj表示第i条边的终止点,edges[i].val表示第i条边的权值,edges[i].next表示与第i条边同起始点的下一条边的存储位置。 - 头节点数组:
head,其中head[i]存储以顶点i为起始点的第1条边在数组edges中的下标。
链式前向星其实并没有改变边集数组原来的存储数学,只是利用 head 数组构成静态链表,建立了顶点 1 条边的关系。
在下面的示意图中,左侧是一个有向图,右侧则是该有向图对应的链式前向星结构。
如果需要在该图中遍历顶点
- 找到以顶点
$v_1$ 为起始点的的1条边在数组edges中的下标,即index = head[1] = 1。则在edges数组中找到与顶点$v_1$ 相连的第1条边为edges[1],即$\langle v_1, v_5 \rangle$ ,权值为 6。 - 查找
index = self.edges[1].next = 0,则在edges数组中找到与顶点$v_1$ 相连的第2条边edges[0],即$\langle v_1, v_2 \rangle$ ,权值为 5。 - 继续查找
index = self.edges[0].next = -1,则不存在其余边,查找结束。
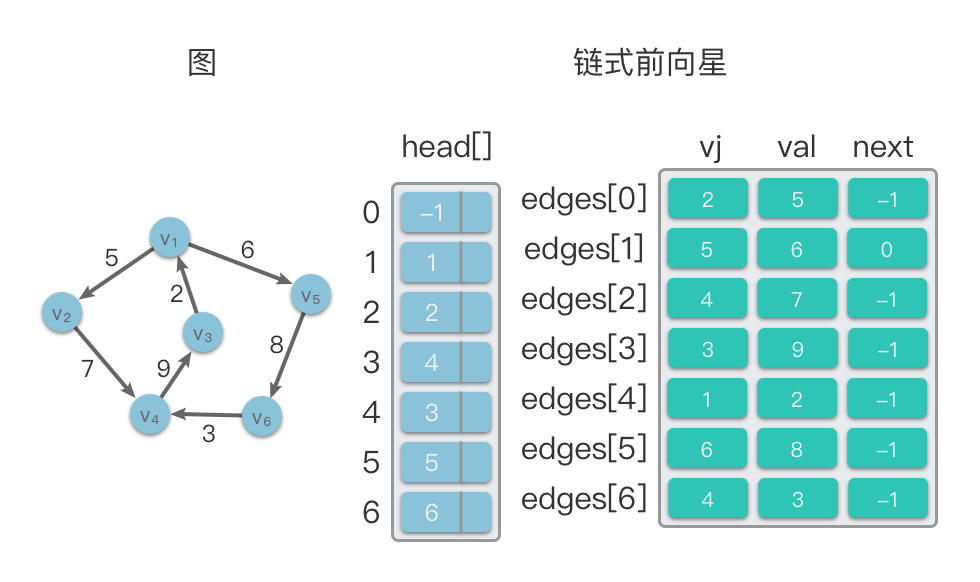
链式前向星的时间复杂度:
- 图的初始化和创建操作:$O(n + m)$。
- 查询是否存在
$v_i$ 到$v_j$ 的边:$O(TD(v_i))$。 - 遍历某个点的所有边:$O(TD(v_i))$。
- 遍历整张图:$O(n + m)$。
链式前向星的空间复杂度:
- 空间复杂度:$O(n + m)$。
class EdgeNode: # 边信息类
def __init__(self, vj, val):
self.vj = vj # 边的终点
self.val = val # 边的权值
self.next = None # 下一条边
class Graph:
def __init__(self, ver_count, edge_count):
self.ver_count = ver_count # 顶点个数
self.edge_count = edge_count # 边个数
self.head = [-1 for _ in range(ver_count)] # 头节点数组
self.edges = [] # 边集数组
# 判断顶点 v 是否有效
def __valid(self, v):
return 0 <= v <= self.ver_count
# 图的创建操作,edges 为边信息
def creatGraph(self, edges=[]):
for i in range(len(edges)):
vi, vj, val = edges[i]
self.add_edge(i, vi, vj, val)
# 向图的边集数组中添加边:vi - vj,权值为 val
def add_edge(self, index, vi, vj, val):
if not self.__valid(vi) or not self.__valid(vj):
raise ValueError(str(vi) + ' or ' + str(vj) + " is not a valid vertex.")
edge = EdgeNode(vj, val) # 构造边节点
edge.next = self.head[vi] # 边节点的 next 指向原来首指针
self.edges.append(edge) # 边集数组添加该边
self.head[vi] = index # 首指针指向新加边所在边集数组的下标
# 获取 vi - vj 边的权值
def get_edge(self, vi, vj):
if not self.__valid(vi) or not self.__valid(vj):
raise ValueError(str(vi) + ' or ' + str(vj) + " is not a valid vertex.")
index = self.head[vi] # 得到顶点 vi 相连的第一条边在边集数组的下标
while index != -1: # index == -1 时说明 vi 相连的边遍历完了
if vj == self.edges[index].vj: # 找到了 vi - vj 边
return self.edges[index].val # 返回 vi - vj 边的权值
index = self.edges[index].next # 取顶点 vi 相连的下一条边在边集数组的下标
return None # 没有找到 vi - vj 边
# 根据链式前向星打印图的边
def printGraph(self):
for vi in range(self.ver_count): # 遍历顶点 vi
index = self.head[vi] # 得到顶点 vi 相连的第一条边在边集数组的下标
while index != -1: # index == -1 时说明 vi 相连的边遍历完了
print(str(vi) + ' - ' + str(self.edges[index].vj) + ' : ' + str(self.edges[index].val))
index = self.edges[index].next # 取顶点 vi 相连的下一条边在边集数组的下标
graph = Graph(7, 7)
edges = [[1, 2, 5],[1, 5, 6],[2, 4, 7],[4, 3, 9],[3, 1, 2],[5, 6, 8],[6, 4, 3]]
graph.creatGraph(edges)
print(graph.get_edge(4, 3))
print(graph.get_edge(4, 5))
graph.printGraph()在 Python 中,通过哈希表(字典)可以轻松的实现邻接表。哈希表实现邻接表包含两个哈希表:第一个哈希表主要用来存放顶点的数据信息,哈希表的键是顶点,值是该点所有邻接边构成的另一个哈希表。另一个哈希表用来存放顶点相连的边信息,哈希表的键是边的终点,值是边的权重。
哈希表实现邻接表的时间复杂度:
- 图的初始化和创建操作:$O(n + m)$。
- 查询是否存在
$v_i$ 到$v_j$ 的边:$O(1)$。 - 遍历某个点的所有边:$O(TD(v_i))$。
- 遍历整张图:$O(n + m)$。
哈希表实现邻接表的空间复杂度:
- 空间复杂度:$O(n + m)$。
class VertexNode: # 顶点信息类
def __init__(self, vi):
self.vi = vi # 顶点
self.adj_edges = dict() # 顶点的邻接边
class Graph:
def __init__(self):
self.vertices = dict() # 顶点
# 图的创建操作,edges 为边信息
def creatGraph(self, edges=[]):
for vi, vj, val in edges:
self.add_edge(vi, vj, val)
# 向图中添加节点
def add_vertex(self, vi):
vertex = VertexNode(vi)
self.vertices[vi] = vertex
# 向图的邻接表中添加边:vi - vj,权值为 val
def add_edge(self, vi, vj, val):
if vi not in self.vertices:
self.add_vertex(vi)
if vj not in self.vertices:
self.add_vertex(vj)
self.vertices[vi].adj_edges[vj] = val
# 获取 vi - vj 边的权值
def get_edge(self, vi, vj):
if vi in self.vertices and vj in self.vertices[vi].adj_edges:
return self.vertices[vi].adj_edges[vj]
return None
# 根据邻接表打印图的边
def printGraph(self):
for vi in self.vertices:
for vj in self.vertices[vi].adj_edges:
print(str(vi) + ' - ' + str(vj) + ' : ' + str(self.vertices[vi].adj_edges[vj]))
graph = Graph()
edges = [[1, 2, 5],[1, 5, 6],[2, 4, 7],[4, 3, 9],[3, 1, 2],[5, 6, 8],[6, 4, 3]]
graph.creatGraph(edges)
print(graph.get_edge(3, 4))
graph.printGraph()图论和图论算法在计算机科学中扮演着很重要的角色,它提供了对很多问题都有效的一种简单而系统的建模方式。很多实际问题都可以转化为图论问题,然后使用图论的景点算法加以解决。例如:
- 集成电路的设计和布线。
- 互联网和路由移动电话网的路由设计。
- 工程项目的计划安排问题。
常见的图论问题应用大概可以分为以下几类:图的遍历问题、图的连通性问题、图的生成树问题、图的最短路径问题、图的网络流问题、二分图问题 等等。
图的遍历:与树的遍历类似,图的遍历指的是从图的某一个顶点出发,按照某种搜索方式对图中的所有节点都仅访问一次。
图的遍历是求解图的连通性问题、拓扑排序和求关键路径等算法的基础。
根据搜索方式的不同,可以将图的遍历分为「深度优先搜索」和「广度优先搜索」。
- 深度优先搜索:从某一顶点出发,沿着⼀条路径⼀直搜索下去,在⽆法搜索时,回退到刚刚访问过的节点。
- 广度优先搜索:从某个顶点出发,⼀次性访问所有未被访问的邻接点,再依次从这些已访问过的邻接点出发,⼀层⼀层地访问。
我们在「2.3 连通图和非连通图」中提到过「2.3.1 连通无向图和连通分量」和「2.3.2 强连通有向图和强连通分量」。
在无向图中,图的连通性问题主要包括:求无向图的连通分量、求点双连通分量(找割点)、求边双连通分量(找桥)、全局最小割问题 等等。
在有向图中,图的连通性问题主要包括:求有向图的强连通分量、最小点基、最小权点基、2-SAT 问题 等等。
图的生成树(Spanning Tree):如果连通图 G 的一个子图是一棵包含图 G 所有顶点的树,则称该子图为 G 的生成树。生成树是连通图的包含图中的所有顶点的极小连通子图。图的生成树不惟一。从不同的顶点出发进行遍历,可以得到不同的生成树。
图的生成树问题主要包括:最小生成树问题、次小生成树问题 和 有向图的最小树形图问题 等等。
-
无向图的最小生成树:如果连通图
$G$ 是一个带权无向图,则生成树的边也带权,则称该带权图中所有带权生成树中权值总和最小的生成树为最小生成树(也称为最小代价生成树)。 -
无向图的次小生成树:如果连通图
$G$ 是一个带权无向图,生成树$T$ 是图$G$ 的一个最小生成树,如果有另一棵生成树$T_1$ ,$T_1 \ne T$,满足不存在树$T^{'}$ ,$T^{'} \ne T$,且$w(T^{'}) < W(T_1)$ ,则称$T_1$ 是图$G$ 的次小生成树。 -
有向图的最小树形图:如果连通图
$G$ 是一个带权有向图,以顶点$v_i$ 为根节点的生成树$T$ 中,顶点$v_i$ 到任意非$v_i$ 顶点的路径存在且唯一,并且生成树$T$ 中权值总和最小,则该生成树被称为有向图$G$ 的最小树形图。
图的最短路径问题:如果用带权图来表示真实的交通、物流或社交网络,则边的权重可能代表交通运输费、距离或者熟悉程度。此时我们会考虑两个不同顶点之间的最短路径有多长,这一类问题统称为最短路径。并且我们称路径上的第一个顶点为源点,最后一个顶点为终点。
按照源点数目的不同,可以将图的最短路径问题分为 单源最短路径问题 和 多源最短路径问题。
- 单源最短路径问题:从一个顶点出发到图中其余各个顶点之间的最短路径问题。
- 多源最短路径问题:图中任意两点之间的最短路径问题。
单源最短路径问题 的求解还是 差分约束系统问题 的基础。
除此之外,在实际应用中,有时候除了需要知道最短路径外,还需要知道次最短路径或者第三最短路径。这样的多条最短路径问题称为 k 最短路径问题。
图的网络流:这里的「网络」指的是:带权的连通有向图。该有向图中的每条边都有一个权值(也称为容量值),当顶点之间不存在边时,两点之间的容量为 0。并且该有向图中有两个特殊的顶点:源点
$s$ 和汇点$t$ 。这里的「流」指的是:网络上的流。如果把网络想象成一个自来水管道网络,那么流就是其中流动的水。每条边的方向表示允许的流向,边上的权值表示这条边允许通过的最大流量,也就是说每条边上的流都不能超过它的容量。并且对于除了源点
$s$ 和汇点$t$ 外的所有点(即中继点),流入的流量都等于流出的流量。
图的网络流中最常见的问题就是 网络最大流问题。其次还有 网络最小费用最大流问题、网络最小割问题。
- 网络最大流:给定一个网络,要求计算从源点流向汇点的最大流量(可以有很多条路到达汇点)。
- 网络最小费用最大流:给定一个网络,并且每条边都有一个费用,代表单位流量流过这条边的开销。要求计算出最大流的同时,要求花费的费用最小。
-
网络最小割:割是删边的意思。给定一个网络,删掉其中
$x$ 条边,从而使原本连通的网络变得不连通,要求计算出$x$ 条边加起来最小的流量总和是多少。
二分图:设
$G = (V, E)$ 是一个无向图,如果顶点$V$ 可以分为两个互不相交的子集$(A, B)$ ,并且图中每条边$(u, v)$ 所关联的两个顶点$u$ 和$v$ 分别属于这两个不同的顶点集(即$u \in A, v \in B$ ),则称图$G$ 是一个二分图。
二分图中的常见问题有:二分图最大匹配问题、二分图最大权匹配问题、二分图多重匹配问题。
先来介绍一下匹配的概念:在二分图中,一个匹配就是一个边的集合,其中任意两条边之间都没有公共节点。
- 二分图最大匹配:在一个二分图的所有匹配中,边数最多的匹配叫做该二分图的最大匹配。
- 二分图最大权匹配:在一个二分图的所有匹配中,边的权值和最大的匹配叫做该二分图的最大权匹配。
- 二分图多重匹配:在二分图最大匹配问题中,每个点最多只能和一条匹配边相关联。但是在二分图多重匹配中,每个点可以多次匹配但是有匹配上限。
- 【书籍】ACM-ICPC 程序设计系列 - 图论及应用 - 陈宇 吴昊 主编
- 【书籍】数据结构教程 第 3 版 - 唐发根 著
- 【书籍】大话数据结构 - 程杰 著
- 【书籍】算法训练营 - 陈小玉 著
- 【书籍】Python 数据结构与算法分析 第 2 版 - 布拉德利·米勒 戴维·拉努姆 著
- 【博文】图的基础知识 | 小浩算法
- 【博文】链式前向星及其简单应用 | Malash's Blog
- 【博文】图论部分简介 - OI Wiki