| title | shortTitle | category | tag | description | head | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
10 张手绘图详解Java 优先级队列PriorityQueue |
优先级队列PriorityQueue详解 |
|
|
本文详细解析了 Java 优先级队列 PriorityQueue 的实现原理、功能特点以及源码,为您提供了 PriorityQueue 的实际应用示例和性能优化建议。阅读本文,将帮助您更深入地理解 PriorityQueue 在 Java 编程中的应用,从而在实际编程中充分发挥其优势。 |
|
继续有请王老师,来上台给大家讲讲优先级队列 PriorityQueue。
PriorityQueue 是 Java 中的一个基于优先级堆的优先队列实现,它能够在 O(log n) 的时间复杂度内实现元素的插入和删除操作,并且能够自动维护队列中元素的优先级顺序。
通俗来说,PriorityQueue 就是一个队列,但是它不是先进先出的,而是按照元素优先级进行排序的。当你往 PriorityQueue 中插入一个元素时,它会自动根据元素的优先级将其插入到合适的位置。当你从 PriorityQueue 中删除一个元素时,它会自动将优先级最高的元素出队。
下面👇🏻是一个简单的PriorityQueue示例:
// 创建 PriorityQueue 对象
PriorityQueue<String> priorityQueue = new PriorityQueue<>();
// 添加元素到 PriorityQueue
priorityQueue.offer("沉默王二");
priorityQueue.offer("陈清扬");
priorityQueue.offer("小转铃");
// 打印 PriorityQueue 中的元素
System.out.println("PriorityQueue 中的元素:");
while (!priorityQueue.isEmpty()) {
System.out.print(priorityQueue.poll() + " ");
}在上述代码中,我们首先创建了一个 PriorityQueue 对象,并向其中添加了三个元素。然后,我们使用 while 循环遍历 PriorityQueue 中的元素,并打印出来。来看输出结果:
PriorityQueue 中的元素:
小转铃 沉默王二 陈清扬
再来看一下示例。
// 创建 PriorityQueue 对象,并指定优先级顺序
PriorityQueue<String> priorityQueue = new PriorityQueue<>(Comparator.reverseOrder());
// 添加元素到 PriorityQueue
priorityQueue.offer("沉默王二");
priorityQueue.offer("陈清扬");
priorityQueue.offer("小转铃");
// 打印 PriorityQueue 中的元素
System.out.println("PriorityQueue 中的元素:");
while (!priorityQueue.isEmpty()) {
System.out.print(priorityQueue.poll() + " ");
}在上述代码中,我们使用了 Comparator.reverseOrder() 方法指定了 PriorityQueue 的优先级顺序为降序。也就是说,PriorityQueue 中的元素会按照从大到小的顺序排序。
其他部分的代码与之前的例子相同,我们再来看一下输出结果:
PriorityQueue 中的元素:
陈清扬 沉默王二 小转铃
对比一下两个例子的输出结果,不难发现,顺序正好相反。
PriorityQueue 的主要作用是维护一组数据的排序,使得取出数据时可以按照一定的优先级顺序进行,当我们调用 poll() 方法时,它会从队列的顶部弹出最高优先级的元素。它在很多场景下都有广泛的应用,例如任务调度、事件处理等场景,以及一些算法中需要对数据进行排序的场景。
在实际应用中,PriorityQueue 也经常用于实现 Dijkstra 算法、Prim 算法、Huffman 编码等算法。这里简单说一下这几种算法的作用,理解不了也没关系哈。
Dijkstra算法是一种用于计算带权图中的最短路径的算法。该算法采用贪心的策略,在遍历图的过程中,每次选取当前到源点距离最短的一个顶点,并以它为中心进行扩展,更新其他顶点的距离值。经过多次扩展,可以得到源点到其它所有顶点的最短路径。
Prim算法是一种用于求解最小生成树的算法,可以在加权连通图中找到一棵生成树,使得这棵生成树的所有边的权值之和最小。该算法从任意一个顶点开始,逐渐扩展生成树的规模,每次选择一个距离已生成树最近的顶点加入到生成树中。
Huffman编码是一种基于霍夫曼树的压缩算法,用于将一个字符串转换为二进制编码以进行压缩。该算法的主要思想是通过建立霍夫曼树,将出现频率较高的字符用较短的编码表示,而出现频率较低的字符用较长的编码表示,从而实现对字符串的压缩。在解压缩时,根据编码逐步解析出原字符串。
由于 PriorityQueue 的底层是基于堆实现的,因此在数据量比较大时,使用 PriorityQueue 可以获得较好的时间复杂度。
这里牵涉到了大小关系,元素大小的评判可以通过元素本身的自然顺序(natural ordering),也可以通过构造时传入的比较器(Comparator,或者元素自身实现 Comparable 接口)来决定。
在 PriorityQueue 中,每个元素都有一个优先级,这个优先级决定了元素在队列中的位置。队列内部通过小顶堆(也可以是大顶堆)的方式来维护元素的优先级关系。具体来说,小顶堆是一个完全二叉树,任何一个非叶子节点的权值,都不大于其左右子节点的权值,这样保证了队列的顶部元素(堆顶)一定是优先级最高的元素。
完全二叉树(Complete Binary Tree)是一种二叉树,其中除了最后一层,其他层的节点数都是满的,最后一层的节点都靠左对齐。下面是一个完全二叉树的示意图:
1
/ \
2 3
/ \ /
4 5 6
堆是一种完全二叉树,堆的特点是根节点的值最小(小顶堆)或最大(大顶堆),并且任意非根节点i的值都不大于(或不小于)其父节点的值。
这是一颗包含整数 1, 2, 3, 4, 5, 6, 7 的小顶堆:
1
/ \
2 3
/ \ / \
4 5 6 7
这是一颗大顶堆。
8
/ \
7 5
/ \ / \
6 4 2 1
因为完全二叉树的结构比较规则,所以可以使用数组来存储堆的元素,而不需要使用指针等额外的空间。
在堆中,每个节点的下标和其在数组中的下标是一一对应的,假设节点下标为i,则其父节点下标为i/2,其左子节点下标为2i,其右子节点下标为2i+1。
假设有一个数组arr=[10, 20, 15, 30, 40],现在要将其转化为一个小顶堆。
首先,我们将数组按照完全二叉树的形式排列,如下图所示:
10
/ \
20 15
/ \
30 40
从上往下、从左往右依次给每个节点编号,如下所示:
1
/ \
2 3
/ \
4 5
接下来,我们按照上述公式,依次确定每个节点在数组中的位置。例如,节点1的父节点下标为1/2=0,左子节点下标为2*1=2,右子节点下标为2*1+1=3,因此节点1在数组中的位置为0,节点2在数组中的位置为2,节点3在数组中的位置为3。
对应的数组为[10, 20, 15, 30, 40],符合小顶堆的定义,即每个节点的值都小于或等于其子节点的值。
好,我们画幅图再来理解一下。
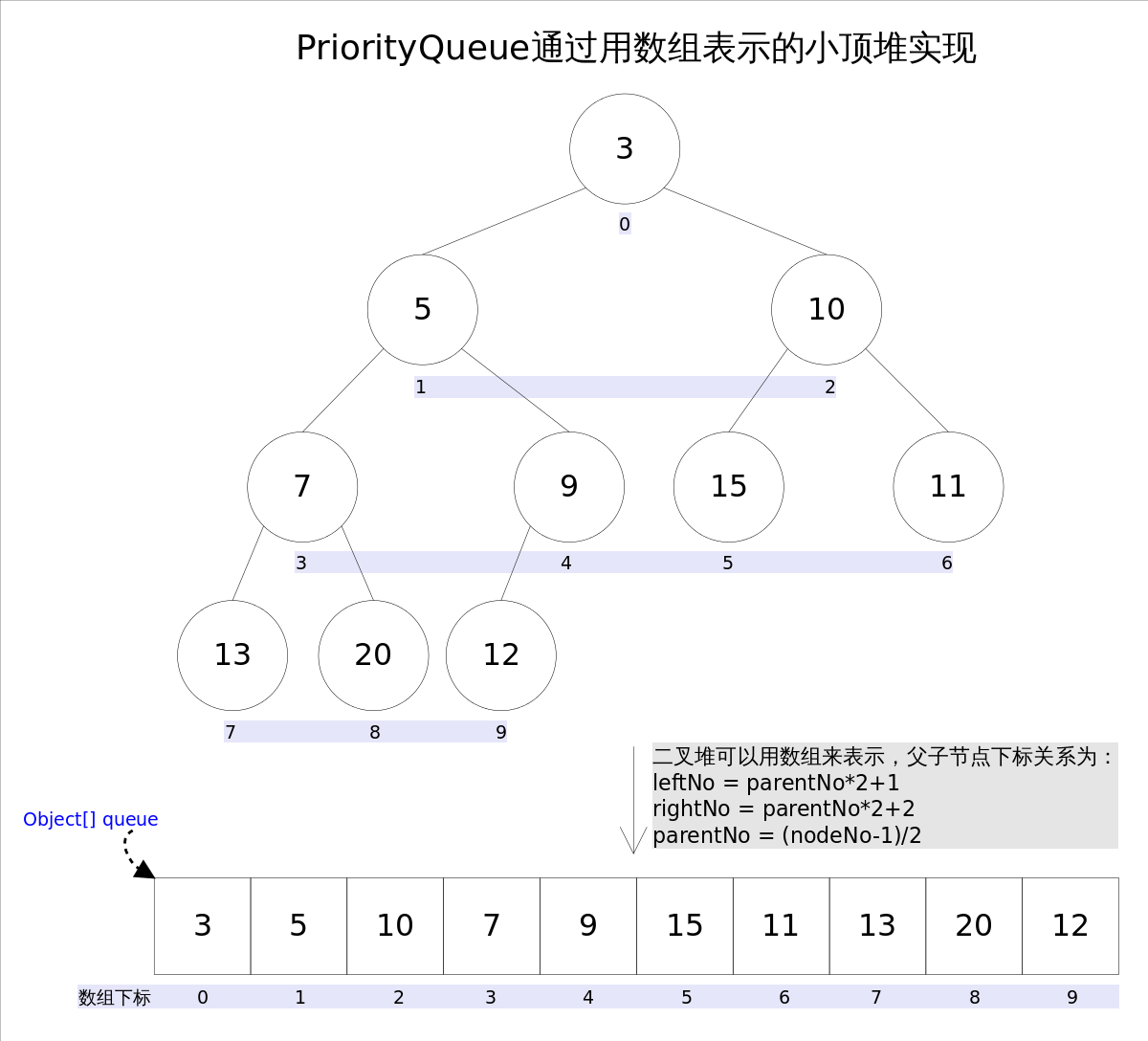
上图中我们给每个元素按照层序遍历的方式进行了编号,如果你足够细心,会发现父节点和子节点的编号是有联系的,更确切的说父子节点的编号之间有如下关系:
leftNo = parentNo\*2+1
rightNo = parentNo\*2+2
parentNo = (nodeNo-1)/2
通过上述三个公式,可以轻易计算出某个节点的父节点以及子节点的下标。这也就是为什么可以直接用数组来存储堆的原因。
add(E e)和offer(E e)的语义相同,都是向优先队列中插入元素,只是Queue接口规定二者对插入失败时的处理不同,前者在插入失败时抛出异常,后则则会返回false。对于PriorityQueue这两个方法其实没什么差别。

新加入的元素可能会破坏小顶堆的性质,因此需要进行必要的调整。
//offer(E e)
public boolean offer(E e) {
if (e == null)//不允许放入null元素
throw new NullPointerException();
modCount++;
int i = size;
if (i >= queue.length)
grow(i + 1);//自动扩容
size = i + 1;
if (i == 0)//队列原来为空,这是插入的第一个元素
queue[0] = e;
else
siftUp(i, e);//调整
return true;
}上述代码中,扩容函数grow()类似于ArrayList里的grow()函数,就是再申请一个更大的数组,并将原数组的元素复制过去,这里不再赘述。需要注意的是siftUp(int k, E x)方法,该方法用于插入元素x并维持堆的特性。
//siftUp()
private void siftUp(int k, E x) {
while (k > 0) {
int parent = (k - 1) >>> 1;//parentNo = (nodeNo-1)/2
Object e = queue[parent];
if (comparator.compare(x, (E) e) >= 0)//调用比较器的比较方法
break;
queue[k] = e;
k = parent;
}
queue[k] = x;
}调整的过程为:从k指定的位置开始,将x逐层与当前点的parent进行比较并交换,直到满足x >= queue[parent]为止。注意这里的比较可以是元素的自然顺序,也可以是依靠比较器的顺序。
element()和peek()的语义完全相同,都是获取但不删除队首元素,也就是队列中权值最小的那个元素,二者唯一的区别是当方法失败时前者抛出异常,后者返回null。根据小顶堆的性质,堆顶那个元素就是全局最小的那个;由于堆用数组表示,根据下标关系,0下标处的那个元素既是堆顶元素。所以直接返回数组0下标处的那个元素即可。
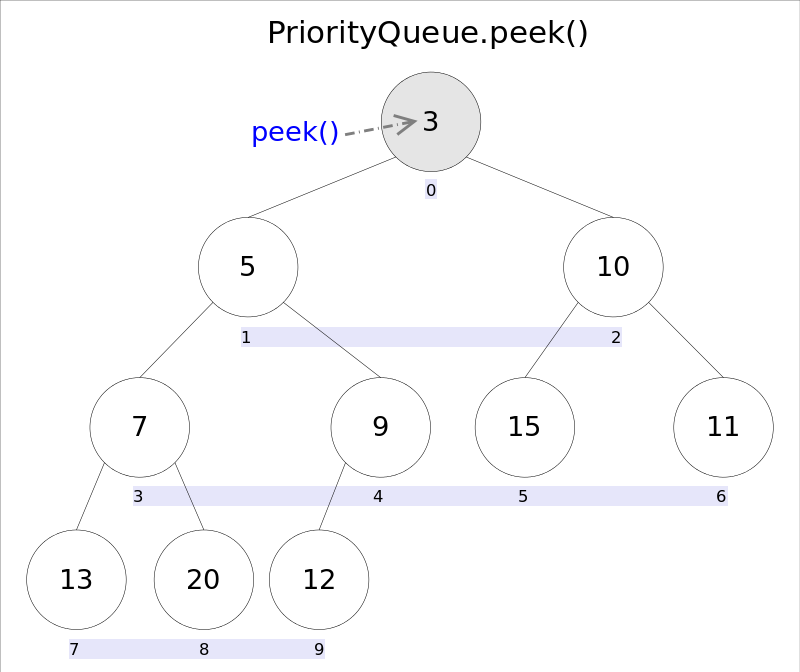
代码也就非常简洁:
//peek()
public E peek() {
if (size == 0)
return null;
return (E) queue[0];//0下标处的那个元素就是最小的那个
}remove()和poll()方法的语义也完全相同,都是获取并删除队首元素,区别是当方法失败时前者抛出异常,后者返回null。由于删除操作会改变队列的结构,为维护小顶堆的性质,需要进行必要的调整。
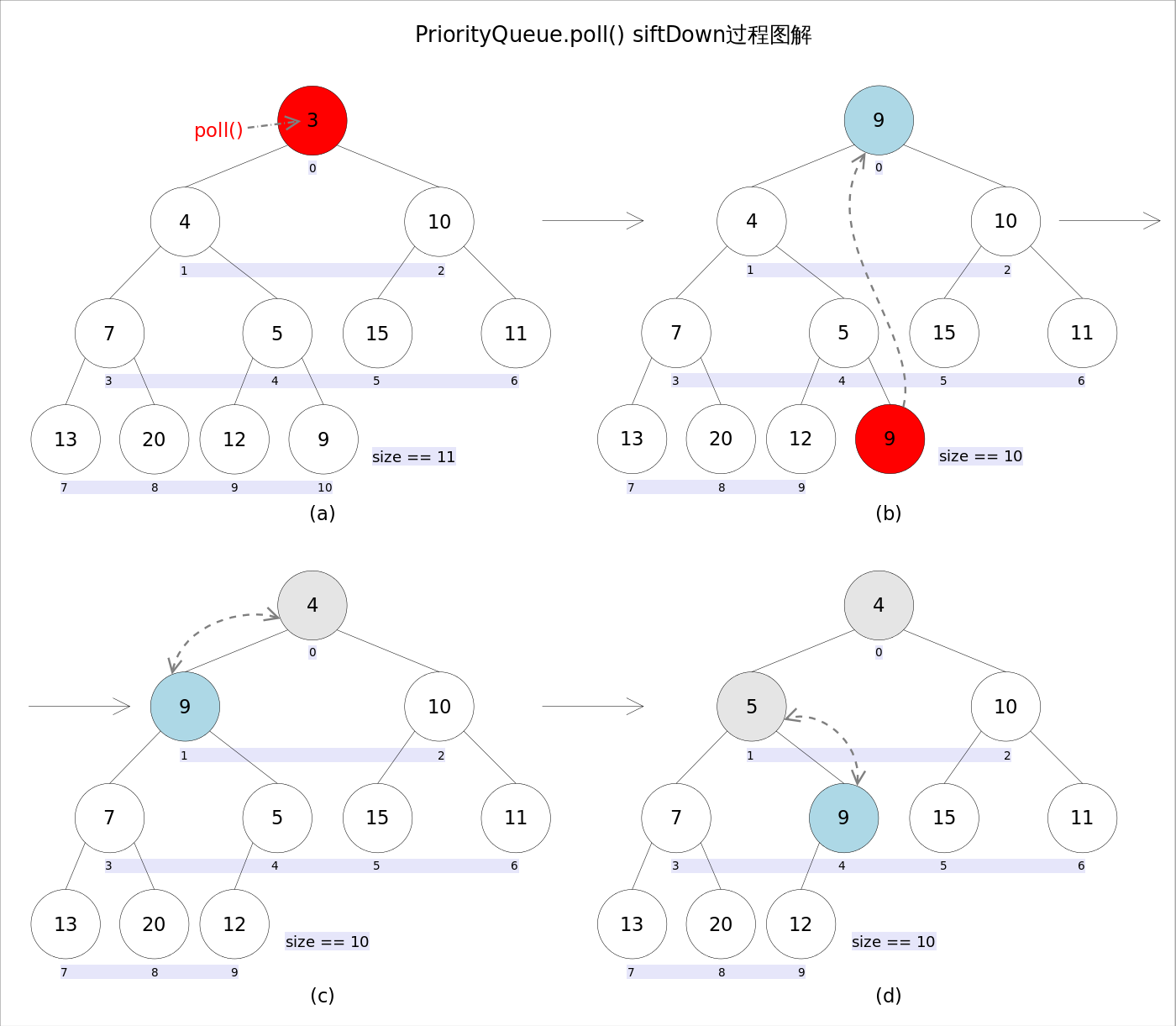
代码如下:
public E poll() {
if (size == 0)
return null;
int s = --size;
modCount++;
E result = (E) queue[0];//0下标处的那个元素就是最小的那个
E x = (E) queue[s];
queue[s] = null;
if (s != 0)
siftDown(0, x);//调整
return result;
}上述代码首先记录0下标处的元素,并用最后一个元素替换0下标位置的元素,之后调用siftDown()方法对堆进行调整,最后返回原来0下标处的那个元素(也就是最小的那个元素)。重点是siftDown(int k, E x)方法,该方法的作用是从k指定的位置开始,将x逐层向下与当前点的左右孩子中较小的那个交换,直到x小于或等于左右孩子中的任何一个为止。
//siftDown()
private void siftDown(int k, E x) {
int half = size >>> 1;
while (k < half) {
//首先找到左右孩子中较小的那个,记录到c里,并用child记录其下标
int child = (k << 1) + 1;//leftNo = parentNo*2+1
Object c = queue[child];
int right = child + 1;
if (right < size &&
comparator.compare((E) c, (E) queue[right]) > 0)
c = queue[child = right];
if (comparator.compare(x, (E) c) <= 0)
break;
queue[k] = c;//然后用c取代原来的值
k = child;
}
queue[k] = x;
}remove(Object o)方法用于删除队列中跟o相等的某一个元素(如果有多个相等,只删除一个),该方法不是Queue接口内的方法,而是Collection接口的方法。由于删除操作会改变队列结构,所以要进行调整;又由于删除元素的位置可能是任意的,所以调整过程比其它方法稍加繁琐。
具体来说,remove(Object o)可以分为 2 种情况:
- 删除的是最后一个元素。直接删除即可,不需要调整。
- 删除的不是最后一个元素,从删除点开始以最后一个元素为参照调用一次
siftDown()即可。此处不再赘述。
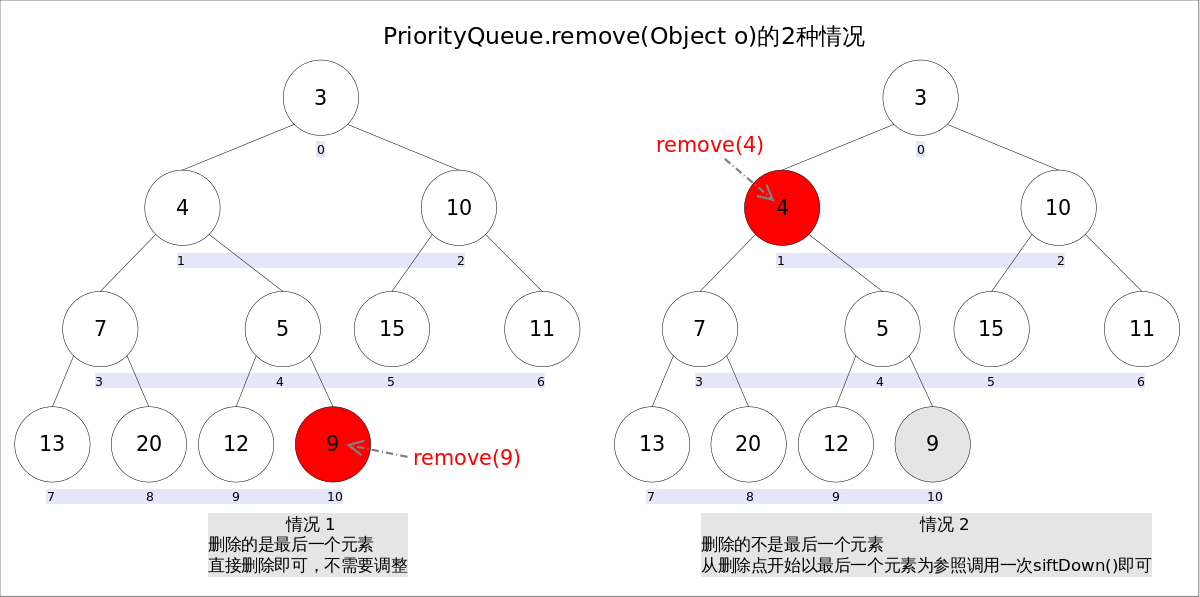
具体代码如下:
//remove(Object o)
public boolean remove(Object o) {
//通过遍历数组的方式找到第一个满足o.equals(queue[i])元素的下标
int i = indexOf(o);
if (i == -1)
return false;
int s = --size;
if (s == i) //情况1
queue[i] = null;
else {
E moved = (E) queue[s];
queue[s] = null;
siftDown(i, moved);//情况2
......
}
return true;
}PriorityQueue 是一个非常常用的数据结构,它是一种特殊的堆(Heap)实现,可以用来高效地维护一个有序的集合。
- 它的底层实现是一个数组,通过堆的性质来维护元素的顺序。
- 取出元素时按照优先级顺序(从小到大或者从大到小)进行取出。
- 如果需要指定排序,元素必须实现 Comparable 接口或者传入一个 Comparator 来进行比较。
可以通过 LeetCode 的第 23 题:合并K个升序链表 来练习 PriorityQueue 的使用。
我把题解已经放到了技术派中,大家可以去作为参考。
参考链接:https://github.com/CarpenterLee/JCFInternals,作者:李豪,整理:沉默王二
GitHub 上标星 10000+ 的开源知识库《二哥的 Java 进阶之路》第一版 PDF 终于来了!包括Java基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM等等,共计 32 万余字,500+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:太赞了,GitHub 上标星 10000+ 的 Java 教程
微信搜 沉默王二 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 222 即可免费领取。
