diff --git a/.github/workflows/llm_unit_tests.yml b/.github/workflows/llm_unit_tests.yml
index 0590531a372..583cbf2c31e 100644
--- a/.github/workflows/llm_unit_tests.yml
+++ b/.github/workflows/llm_unit_tests.yml
@@ -375,7 +375,7 @@ jobs:
shell: bash
run: |
python -m pip uninstall datasets -y
- python -m pip install transformers==4.34.0 datasets peft==0.5.0 accelerate==0.23.0
+ python -m pip install transformers==4.36.0 datasets peft==0.10.0 accelerate==0.23.0
python -m pip install bitsandbytes scipy
# Specific oneapi position on arc ut test machines
if [[ '${{ matrix.pytorch-version }}' == '2.1' ]]; then
@@ -422,4 +422,4 @@ jobs:
if: ${{ always() }}
shell: bash
run: |
- pip uninstall sentence-transformers -y || true
\ No newline at end of file
+ pip uninstall sentence-transformers -y || true
diff --git a/.github/workflows/manually_build_for_testing.yml b/.github/workflows/manually_build_for_testing.yml
index 5150bada7b5..00eeb7a9d58 100644
--- a/.github/workflows/manually_build_for_testing.yml
+++ b/.github/workflows/manually_build_for_testing.yml
@@ -18,6 +18,7 @@ on:
- ipex-llm-finetune-qlora-cpu
- ipex-llm-finetune-qlora-xpu
- ipex-llm-xpu
+ - ipex-llm-cpp-xpu
- ipex-llm-cpu
- ipex-llm-serving-xpu
- ipex-llm-serving-cpu
@@ -150,6 +151,35 @@ jobs:
sudo docker push 10.239.45.10/arda/${image}:${TAG}
sudo docker rmi -f ${image}:${TAG} 10.239.45.10/arda/${image}:${TAG}
+ ipex-llm-cpp-xpu:
+ if: ${{ github.event.inputs.artifact == 'ipex-llm-cpp-xpu' || github.event.inputs.artifact == 'all' }}
+ runs-on: [self-hosted, Shire]
+
+ steps:
+ - uses: actions/checkout@f43a0e5ff2bd294095638e18286ca9a3d1956744 # actions/checkout@v3
+ with:
+ ref: ${{ github.event.inputs.sha }}
+ - name: docker login
+ run: |
+ docker login -u ${DOCKERHUB_USERNAME} -p ${DOCKERHUB_PASSWORD}
+ - name: ipex-llm-cpp-xpu
+ run: |
+ echo "##############################################################"
+ echo "####### ipex-llm-cpp-xpu ########"
+ echo "##############################################################"
+ export image=intelanalytics/ipex-llm-cpp-xpu
+ cd docker/llm/cpp/
+ sudo docker build \
+ --no-cache=true \
+ --build-arg http_proxy=${HTTP_PROXY} \
+ --build-arg https_proxy=${HTTPS_PROXY} \
+ --build-arg no_proxy=${NO_PROXY} \
+ -t ${image}:${TAG} -f ./Dockerfile .
+ sudo docker push ${image}:${TAG}
+ sudo docker tag ${image}:${TAG} 10.239.45.10/arda/${image}:${TAG}
+ sudo docker push 10.239.45.10/arda/${image}:${TAG}
+ sudo docker rmi -f ${image}:${TAG} 10.239.45.10/arda/${image}:${TAG}
+
ipex-llm-cpu:
if: ${{ github.event.inputs.artifact == 'ipex-llm-cpu' || github.event.inputs.artifact == 'all' }}
runs-on: [self-hosted, Shire]
diff --git a/README.md b/README.md
index 61eef9117e0..ab44c7a3edd 100644
--- a/README.md
+++ b/README.md
@@ -183,6 +183,8 @@ Over 50 models have been optimized/verified on `ipex-llm`, including *LLaMA/LLaM
| DeciLM-7B | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/deciLM-7b) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/deciLM-7b) |
| Deepseek | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/deepseek) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/deepseek) |
| StableLM | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/stablelm) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/stablelm) |
+| CodeGemma | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/codegemma) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/codegemma) |
+| Command-R/cohere | [link](python/llm/example/CPU/HF-Transformers-AutoModels/Model/cohere) | [link](python/llm/example/GPU/HF-Transformers-AutoModels/Model/cohere) |
## Get Support
- Please report a bug or raise a feature request by opening a [Github Issue](https://github.com/intel-analytics/ipex-llm/issues)
diff --git a/docker/llm/README.md b/docker/llm/README.md
index 47a2fac7f7a..52cc64c6fa7 100644
--- a/docker/llm/README.md
+++ b/docker/llm/README.md
@@ -28,7 +28,7 @@ This guide provides step-by-step instructions for installing and using IPEX-LLM
### 1. Prepare ipex-llm-cpu Docker Image
-Run the following command to pull image from dockerhub:
+Run the following command to pull image:
```bash
docker pull intelanalytics/ipex-llm-cpu:2.1.0-SNAPSHOT
```
diff --git a/docker/llm/finetune/qlora/cpu/docker/Dockerfile b/docker/llm/finetune/qlora/cpu/docker/Dockerfile
index 15b96d6c371..553c4d3ac7a 100644
--- a/docker/llm/finetune/qlora/cpu/docker/Dockerfile
+++ b/docker/llm/finetune/qlora/cpu/docker/Dockerfile
@@ -20,7 +20,8 @@ RUN echo "deb [signed-by=/usr/share/keyrings/intel-oneapi-archive-keyring.gpg] h
RUN mkdir -p /ipex_llm/data && mkdir -p /ipex_llm/model && \
# Install python 3.11.1
- apt-get update && apt-get install -y curl wget gpg gpg-agent software-properties-common git gcc g++ make libunwind8-dev zlib1g-dev libssl-dev libffi-dev && \
+ apt-get update && \
+ apt-get install -y curl wget gpg gpg-agent software-properties-common git gcc g++ make libunwind8-dev libbz2-dev zlib1g-dev libssl-dev libffi-dev && \
mkdir -p /opt/python && \
cd /opt/python && \
wget https://www.python.org/ftp/python/3.11.1/Python-3.11.1.tar.xz && \
@@ -39,15 +40,16 @@ RUN mkdir -p /ipex_llm/data && mkdir -p /ipex_llm/model && \
rm -rf /var/lib/apt/lists/* && \
pip install --upgrade pip && \
export PIP_DEFAULT_TIMEOUT=100 && \
- pip install --upgrade torch==2.1.0 && \
+ # install torch CPU version
+ pip install --upgrade torch==2.1.0 --index-url https://download.pytorch.org/whl/cpu && \
# install CPU ipex-llm
pip install --pre --upgrade ipex-llm[all] && \
# install ipex and oneccl
pip install https://intel-extension-for-pytorch.s3.amazonaws.com/ipex_stable/cpu/intel_extension_for_pytorch-2.1.0%2Bcpu-cp311-cp311-linux_x86_64.whl && \
pip install oneccl_bind_pt -f https://developer.intel.com/ipex-whl-stable && \
# install huggingface dependencies
- pip install datasets transformers==4.35.0 && \
- pip install fire peft==0.5.0 && \
+ pip install datasets transformers==4.36.0 && \
+ pip install fire peft==0.10.0 && \
pip install accelerate==0.23.0 && \
pip install bitsandbytes && \
# get qlora example code
diff --git a/docker/llm/finetune/qlora/cpu/docker/Dockerfile.k8s b/docker/llm/finetune/qlora/cpu/docker/Dockerfile.k8s
index 7757a23162a..469a1bbf631 100644
--- a/docker/llm/finetune/qlora/cpu/docker/Dockerfile.k8s
+++ b/docker/llm/finetune/qlora/cpu/docker/Dockerfile.k8s
@@ -61,8 +61,8 @@ RUN mkdir -p /ipex_llm/data && mkdir -p /ipex_llm/model && \
pip install intel_extension_for_pytorch==2.0.100 && \
pip install oneccl_bind_pt -f https://developer.intel.com/ipex-whl-stable && \
# install huggingface dependencies
- pip install datasets transformers==4.35.0 && \
- pip install fire peft==0.5.0 && \
+ pip install datasets transformers==4.36.0 && \
+ pip install fire peft==0.10.0 && \
pip install accelerate==0.23.0 && \
# install basic dependencies
apt-get update && apt-get install -y curl wget gpg gpg-agent && \
diff --git a/docker/llm/finetune/qlora/xpu/docker/Dockerfile b/docker/llm/finetune/qlora/xpu/docker/Dockerfile
index e53d4ec9394..8123b057381 100644
--- a/docker/llm/finetune/qlora/xpu/docker/Dockerfile
+++ b/docker/llm/finetune/qlora/xpu/docker/Dockerfile
@@ -3,7 +3,7 @@ ARG http_proxy
ARG https_proxy
ENV TZ=Asia/Shanghai
ARG PIP_NO_CACHE_DIR=false
-ENV TRANSFORMERS_COMMIT_ID=95fe0f5
+ENV TRANSFORMERS_COMMIT_ID=1466677
# retrive oneapi repo public key
RUN curl -fsSL https://apt.repos.intel.com/intel-gpg-keys/GPG-PUB-KEY-INTEL-SW-PRODUCTS-2023.PUB | gpg --dearmor | tee /usr/share/keyrings/intel-oneapi-archive-keyring.gpg && \
@@ -33,7 +33,7 @@ RUN curl -fsSL https://apt.repos.intel.com/intel-gpg-keys/GPG-PUB-KEY-INTEL-SW-P
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/ && \
# install huggingface dependencies
pip install git+https://github.com/huggingface/transformers.git@${TRANSFORMERS_COMMIT_ID} && \
- pip install peft==0.5.0 datasets accelerate==0.23.0 && \
+ pip install peft==0.6.0 datasets accelerate==0.23.0 && \
pip install bitsandbytes scipy && \
git clone https://github.com/intel-analytics/IPEX-LLM.git && \
mv IPEX-LLM/python/llm/example/GPU/LLM-Finetuning/common /common && \
diff --git a/docs/readthedocs/source/_templates/sidebar_quicklinks.html b/docs/readthedocs/source/_templates/sidebar_quicklinks.html
index d821185ab70..b720c4f7e49 100644
--- a/docs/readthedocs/source/_templates/sidebar_quicklinks.html
+++ b/docs/readthedocs/source/_templates/sidebar_quicklinks.html
@@ -37,6 +37,9 @@
Run Coding Copilot (Continue) in VSCode with Intel GPU
+
+ Run Dify on Intel GPU
+
Run Open WebUI with IPEX-LLM on Intel GPU
@@ -58,6 +61,13 @@
Finetune LLM with Axolotl on Intel GPU
+
+ Run PrivateGPT with IPEX-LLM on Intel GPU
+
+
+ Run IPEX-LLM serving on Multiple Intel GPUs
+ using DeepSpeed AutoTP and FastApi
+
diff --git a/docs/readthedocs/source/_toc.yml b/docs/readthedocs/source/_toc.yml
index 482210e6442..2e408b1a0e9 100644
--- a/docs/readthedocs/source/_toc.yml
+++ b/docs/readthedocs/source/_toc.yml
@@ -26,13 +26,16 @@ subtrees:
- file: doc/LLM/Quickstart/chatchat_quickstart
- file: doc/LLM/Quickstart/webui_quickstart
- file: doc/LLM/Quickstart/open_webui_with_ollama_quickstart
+ - file: doc/LLM/Quickstart/privateGPT_quickstart
- file: doc/LLM/Quickstart/continue_quickstart
+ - file: doc/LLM/Quickstart/dify_quickstart
- file: doc/LLM/Quickstart/benchmark_quickstart
- file: doc/LLM/Quickstart/llama_cpp_quickstart
- file: doc/LLM/Quickstart/ollama_quickstart
- file: doc/LLM/Quickstart/llama3_llamacpp_ollama_quickstart
- file: doc/LLM/Quickstart/fastchat_quickstart
- file: doc/LLM/Quickstart/axolotl_quickstart
+ - file: doc/LLM/Quickstart/deepspeed_autotp_fastapi_quickstart
- file: doc/LLM/Overview/KeyFeatures/index
title: "Key Features"
subtrees:
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/axolotl_quickstart.md b/docs/readthedocs/source/doc/LLM/Quickstart/axolotl_quickstart.md
index 615f104d3a4..afbdc7c9234 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/axolotl_quickstart.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/axolotl_quickstart.md
@@ -33,7 +33,7 @@ git clone https://github.com/OpenAccess-AI-Collective/axolotl/tree/v0.4.0
cd axolotl
# replace requirements.txt
remove requirements.txt
-wget -O requirements.txt https://github.com/intel-analytics/ipex-llm/blob/main/python/llm/example/GPU/LLM-Finetuning/axolotl/requirements-xpu.txt
+wget -O requirements.txt https://raw.githubusercontent.com/intel-analytics/ipex-llm/main/python/llm/example/GPU/LLM-Finetuning/axolotl/requirements-xpu.txt
pip install -e .
pip install transformers==4.36.0
# to avoid https://github.com/OpenAccess-AI-Collective/axolotl/issues/1544
@@ -92,7 +92,14 @@ Configure oneAPI variables by running the following command:
```
-Configure accelerate to avoid training with CPU
+Configure accelerate to avoid training with CPU. You can download a default `default_config.yaml` with `use_cpu: false`.
+
+```cmd
+mkdir -p ~/.cache/huggingface/accelerate/
+wget -O ~/.cache/huggingface/accelerate/default_config.yaml https://raw.githubusercontent.com/intel-analytics/ipex-llm/main/python/llm/example/GPU/LLM-Finetuning/axolotl/default_config.yaml
+```
+
+As an alternative, you can config accelerate based on your requirements.
```cmd
accelerate config
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/chatchat_quickstart.md b/docs/readthedocs/source/doc/LLM/Quickstart/chatchat_quickstart.md
index 1d465f3ef8f..b43b8cbd3c0 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/chatchat_quickstart.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/chatchat_quickstart.md
@@ -39,17 +39,30 @@ Follow the guide that corresponds to your specific system and device from the li
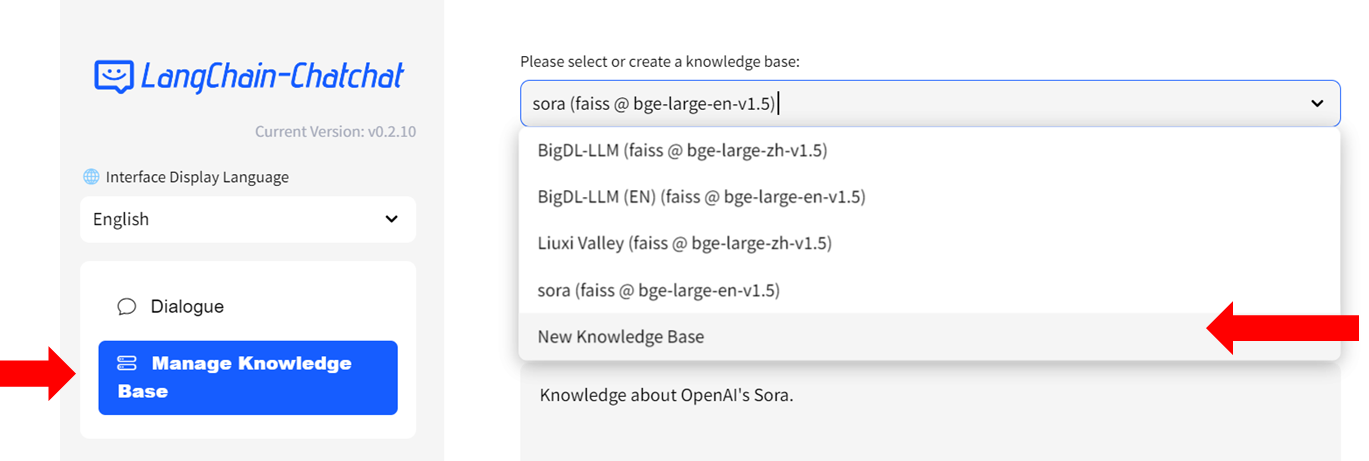
#### Step 1: Create Knowledge Base
- Select `Manage Knowledge Base` from the menu on the left, then choose `New Knowledge Base` from the dropdown menu on the right side.
- 
+
+
+
+
+
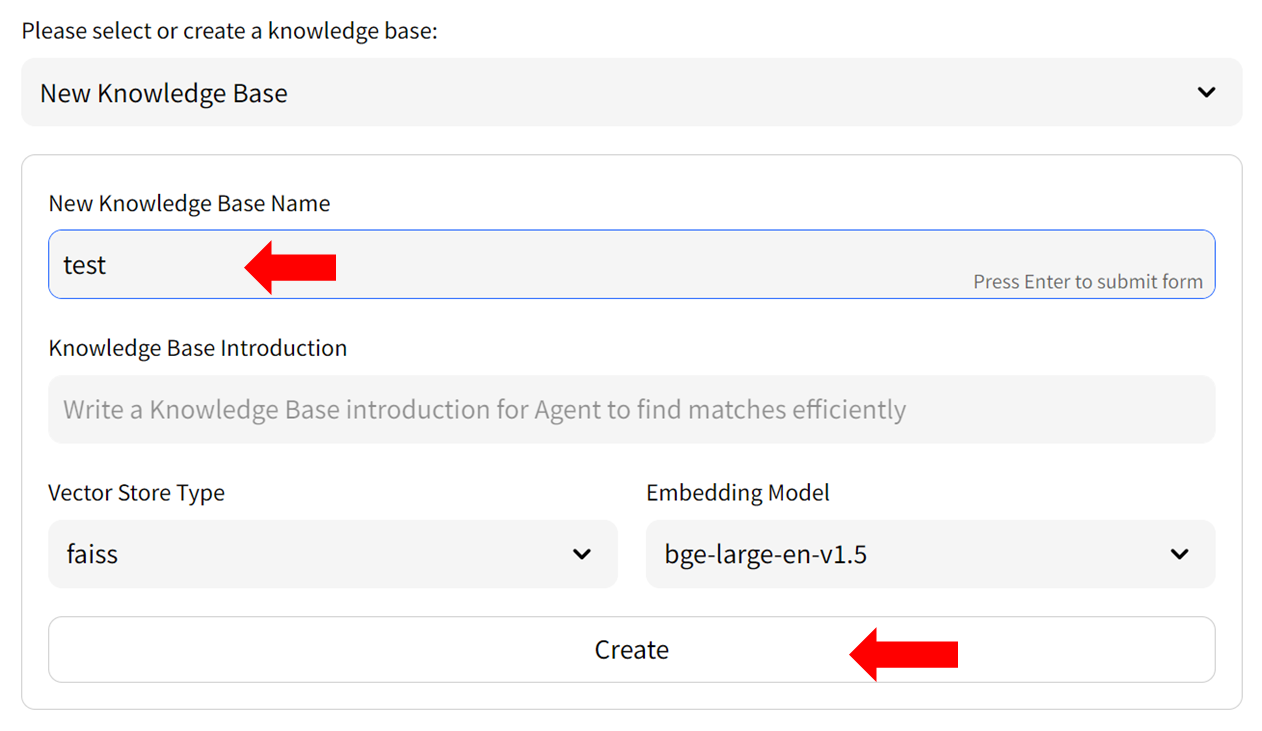
- Fill in the name of your new knowledge base (example: "test") and press the `Create` button. Adjust any other settings as needed.
- 
+
+
+
+
+
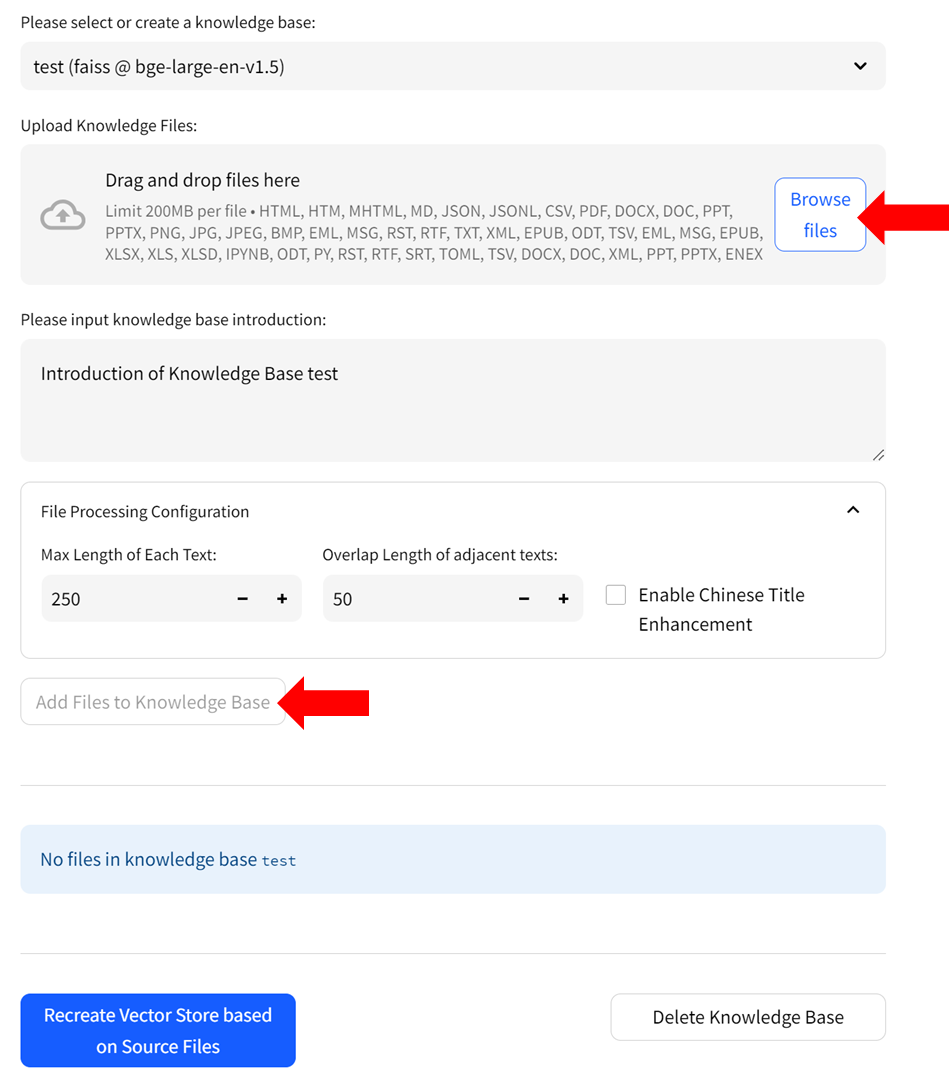
- Upload knowledge files from your computer and allow some time for the upload to complete. Once finished, click on `Add files to Knowledge Base` button to build the vector store. Note: this process may take several minutes.
- 
+
+
+
+
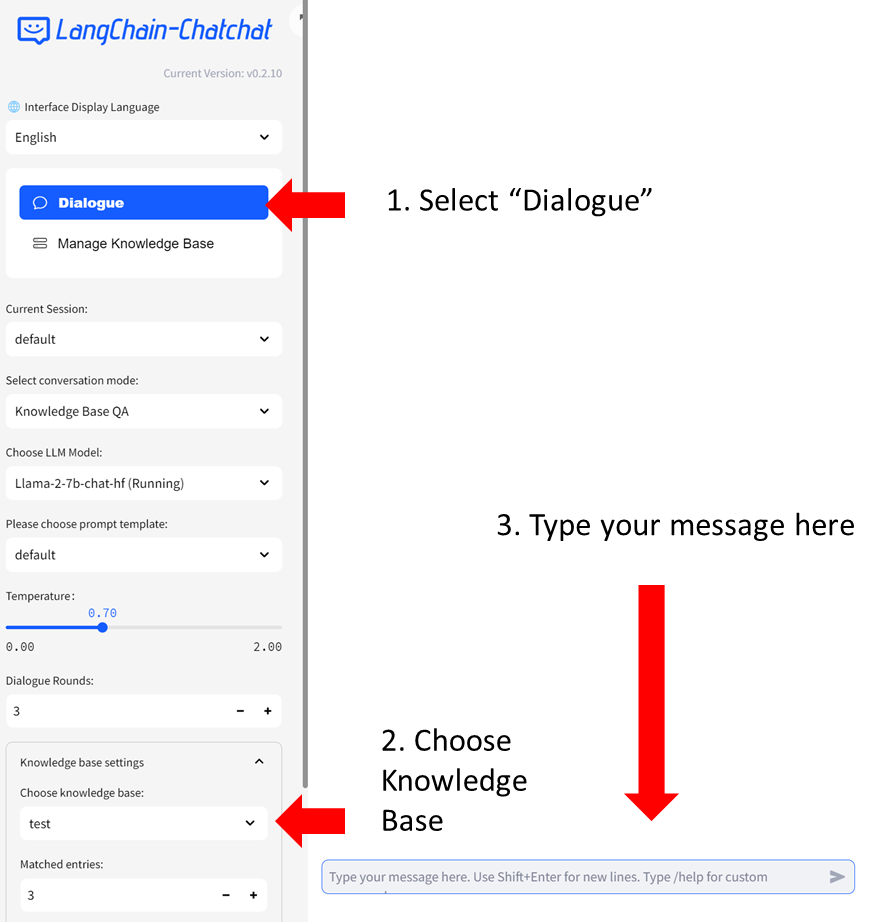
#### Step 2: Chat with RAG
You can now click `Dialogue` on the left-side menu to return to the chat UI. Then in `Knowledge base settings` menu, choose the Knowledge Base you just created, e.g, "test". Now you can start chatting.
-
+
+
+
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/deepspeed_autotp_fastapi_quickstart.md b/docs/readthedocs/source/doc/LLM/Quickstart/deepspeed_autotp_fastapi_quickstart.md
new file mode 100644
index 00000000000..f99c673190f
--- /dev/null
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/deepspeed_autotp_fastapi_quickstart.md
@@ -0,0 +1,102 @@
+# Run IPEX-LLM serving on Multiple Intel GPUs using DeepSpeed AutoTP and FastApi
+
+This example demonstrates how to run IPEX-LLM serving on multiple [Intel GPUs](../README.md) by leveraging DeepSpeed AutoTP.
+
+## Requirements
+
+To run this example with IPEX-LLM on Intel GPUs, we have some recommended requirements for your machine, please refer to [here](../README.md#recommended-requirements) for more information. For this particular example, you will need at least two GPUs on your machine.
+
+## Example
+
+### 1. Install
+
+```bash
+conda create -n llm python=3.11
+conda activate llm
+# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
+pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
+pip install oneccl_bind_pt==2.1.100 --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
+# configures OneAPI environment variables
+source /opt/intel/oneapi/setvars.sh
+pip install git+https://github.com/microsoft/DeepSpeed.git@ed8aed5
+pip install git+https://github.com/intel/intel-extension-for-deepspeed.git@0eb734b
+pip install mpi4py fastapi uvicorn
+conda install -c conda-forge -y gperftools=2.10 # to enable tcmalloc
+```
+
+> **Important**: IPEX 2.1.10+xpu requires Intel® oneAPI Base Toolkit's version == 2024.0. Please make sure you have installed the correct version.
+
+### 2. Run tensor parallel inference on multiple GPUs
+
+When we run the model in a distributed manner across two GPUs, the memory consumption of each GPU is only half of what it was originally, and the GPUs can work simultaneously during inference computation.
+
+We provide example usage for `Llama-2-7b-chat-hf` model running on Arc A770
+
+Run Llama-2-7b-chat-hf on two Intel Arc A770:
+
+```bash
+
+# Before run this script, you should adjust the YOUR_REPO_ID_OR_MODEL_PATH in last line
+# If you want to change server port, you can set port parameter in last line
+
+# To avoid GPU OOM, you could adjust --max-num-seqs and --max-num-batched-tokens parameters in below script
+bash run_llama2_7b_chat_hf_arc_2_card.sh
+```
+
+If you successfully run the serving, you can get output like this:
+
+```bash
+[0] INFO: Started server process [120071]
+[0] INFO: Waiting for application startup.
+[0] INFO: Application startup complete.
+[0] INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
+```
+
+> **Note**: You could change `NUM_GPUS` to the number of GPUs you have on your machine. And you could also specify other low bit optimizations through `--low-bit`.
+
+### 3. Sample Input and Output
+
+We can use `curl` to test serving api
+
+```bash
+# Set http_proxy and https_proxy to null to ensure that requests are not forwarded by a proxy.
+export http_proxy=
+export https_proxy=
+
+curl -X 'POST' \
+ 'http://127.0.0.1:8000/generate/' \
+ -H 'accept: application/json' \
+ -H 'Content-Type: application/json' \
+ -d '{
+ "prompt": "What is AI?",
+ "n_predict": 32
+}'
+```
+
+And you should get output like this:
+
+```json
+{
+ "generated_text": "What is AI? Artificial intelligence (AI) refers to the development of computer systems able to perform tasks that would normally require human intelligence, such as visual perception, speech",
+ "generate_time": "0.45149803161621094s"
+}
+
+```
+
+**Important**: The first token latency is much larger than rest token latency, you could use [our benchmark tool](https://github.com/intel-analytics/ipex-llm/blob/main/python/llm/dev/benchmark/README.md) to obtain more details about first and rest token latency.
+
+### 4. Benchmark with wrk
+
+We use wrk for testing end-to-end throughput, check [here](https://github.com/wg/wrk).
+
+You can install by:
+```bash
+sudo apt install wrk
+```
+
+Please change the test url accordingly.
+
+```bash
+# set t/c to the number of concurrencies to test full throughput.
+wrk -t1 -c1 -d5m -s ./wrk_script_1024.lua http://127.0.0.1:8000/generate/ --timeout 1m
+```
\ No newline at end of file
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/dify_quickstart.md b/docs/readthedocs/source/doc/LLM/Quickstart/dify_quickstart.md
index 7d4af4c83be..f1d444b9132 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/dify_quickstart.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/dify_quickstart.md
@@ -1,39 +1,73 @@
# Run Dify on Intel GPU
-We recommend start the project following [Dify docs](https://docs.dify.ai/getting-started/install-self-hosted/local-source-code)
-## Server Deployment
-### Clone code
+
+[**Dify**](https://dify.ai/) is an open-source production-ready LLM app development platform; by integrating it with [`ipex-llm`](https://github.com/intel-analytics/ipex-llm), users can now easily leverage local LLMs running on Intel GPU (e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max) for building complex AI workflows (e.g. RAG).
+
+
+*See the demo of a RAG workflow in Dify running LLaMA2-7B on Intel A770 GPU below.*
+
+
+
+
+## Quickstart
+
+### 1. Install and Start `Ollama` Service on Intel GPU
+
+Follow the steps in [Run Ollama on Intel GPU Guide](./ollama_quickstart.md) to install and run Ollama on Intel GPU. Ensure that `ollama serve` is running correctly and can be accessed through a local URL (e.g., `https://127.0.0.1:11434`) or a remote URL (e.g., `http://your_ip:11434`).
+
+
+
+### 2. Install and Start `Dify`
+
+
+#### 2.1 Download `Dify`
+
+You can either clone the repository or download the source zip from [github](https://github.com/langgenius/dify/archive/refs/heads/main.zip):
```bash
git clone https://github.com/langgenius/dify.git
```
-### Installation of the basic environment
-Server startup requires Python 3.10.x. Anaconda is recommended to create and manage python environment.
-```bash
-conda create -n dify python=3.10
-conda activate dify
-cd api
-cp .env.example .env
-openssl rand -base64 42
-sed -i 's/SECRET_KEY=.*/SECRET_KEY=/' .env
-pip install -r requirements.txt
+
+#### 2.2 Setup Redis and PostgreSQL
+
+Next, deploy PostgreSQL and Redis. You can choose to utilize Docker, following the steps in the [Local Source Code Start Guide](https://docs.dify.ai/getting-started/install-self-hosted/local-source-code#clone-dify), or proceed without Docker using the following instructions:
+
+
+- Install Redis by executing `sudo apt-get install redis-server`. Refer to [this guide](https://www.hostinger.com/tutorials/how-to-install-and-setup-redis-on-ubuntu/) for Redis environment setup, including password configuration and daemon settings.
+
+- Install PostgreSQL by following either [the Official PostgreSQL Tutorial](https://www.postgresql.org/docs/current/tutorial.html) or [a PostgreSQL Quickstart Guide](https://www.digitalocean.com/community/tutorials/how-to-install-postgresql-on-ubuntu-20-04-quickstart). After installation, proceed with the following PostgreSQL commands for setting up Dify. These commands create a username/password for Dify (e.g., `dify_user`, change `'your_password'` as desired), create a new database named `dify`, and grant privileges:
+ ```sql
+ CREATE USER dify_user WITH PASSWORD 'your_password';
+ CREATE DATABASE dify;
+ GRANT ALL PRIVILEGES ON DATABASE dify TO dify_user;
+ ```
+
+Configure Redis and PostgreSQL settings in the `.env` file located under dify source folder `dify/api/`:
+
+```bash dify/api/.env
+### Example dify/api/.env
+## Redis settings
+REDIS_HOST=localhost
+REDIS_PORT=6379
+REDIS_USERNAME=your_redis_user_name # change if needed
+REDIS_PASSWORD=your_redis_password # change if needed
+REDIS_DB=0
+
+## postgreSQL settings
+DB_USERNAME=dify_user # change if needed
+DB_PASSWORD=your_dify_password # change if needed
+DB_HOST=localhost
+DB_PORT=5432
+DB_DATABASE=dify # change if needed
```
-### Prepare for redis, postgres, node and npm.
-* Install Redis by `sudo apt-get install redis-server`. Refer to [page](https://www.hostinger.com/tutorials/how-to-install-and-setup-redis-on-ubuntu/) to setup the Redis environment, including password, demon, etc.
-* install postgres by `sudo apt-get install postgres` and `sudo apt-get install postgres-client`. Setup username, create a database and grant previlidge according to [page](https://www.ruanyifeng.com/blog/2013/12/getting_started_with_postgresql.html)
-* install npm and node by `brew install node@20` according to [nodejs page](https://nodejs.org/en/download/package-manager)
-> Note that set redis and postgres related environment in .env under dify/api/ and set web related environment variable in .env.local under dify/web
-### Install Ollama
-Please install ollama refer to [ollama quick start](./ollama_quickstart.md). Ensure that ollama could run successfully on Intel GPU.
+#### 2.3 Server Deployment
+
+Follow the steps in the [`Server Deployment` section in Local Source Code Start Guide](https://docs.dify.ai/getting-started/install-self-hosted/local-source-code#server-deployment) to deploy and start the Dify Server.
+
+Upon successful deployment, you will see logs in the terminal similar to the following:
+
-### Start service
-1. Open the terminal and set `export no_proxy=localhost,127.0.0.1`
```bash
-flask db upgrade
-flask run --host 0.0.0.0 --port=5001 --debug
-```
-You will see log like below if successfully start the service.
-```
INFO:werkzeug:
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:5001
@@ -43,51 +77,70 @@ INFO:werkzeug: * Restarting with stat
WARNING:werkzeug: * Debugger is active!
INFO:werkzeug: * Debugger PIN: 227-697-894
```
-2. Open another terminal and also set `export no_proxy=localhost,127.0.0.1`.
-If Linux system, use the command below.
-```bash
-celery -A app.celery worker -P gevent -c 1 -Q dataset,generation,mail --loglevel INFO
-```
-If windows system, use the command below.
+
+
+#### 2.4 Deploy the frontend page
+
+Refer to the instructions provided in the [`Deploy the frontend page` section in Local Source Code Start Guide](https://docs.dify.ai/getting-started/install-self-hosted/local-source-code#deploy-the-frontend-page) to deploy the frontend page.
+
+Below is an example of environment variable configuration found in `dify/web/.env.local`:
+
+
```bash
-celery -A app.celery worker -P solo --without-gossip --without-mingle -Q dataset,generation,mail --loglevel INFO
+# For production release, change this to PRODUCTION
+NEXT_PUBLIC_DEPLOY_ENV=DEVELOPMENT
+NEXT_PUBLIC_EDITION=SELF_HOSTED
+NEXT_PUBLIC_API_PREFIX=http://localhost:5001/console/api
+NEXT_PUBLIC_PUBLIC_API_PREFIX=http://localhost:5001/api
+NEXT_PUBLIC_SENTRY_DSN=
```
-3. Open another terminal and also set `export no_proxy=localhost,127.0.0.1`. Run the commands below to start the front-end service.
-```bash
-cd web
-npm install
-npm run build
-npm run start
+
+```eval_rst
+
+.. note::
+
+ If you encounter connection problems, you may run `export no_proxy=localhost,127.0.0.1` before starting API servcie, Worker service and frontend.
+
```
-## Example: RAG
-See the demo of running dify with Ollama on an Intel Core Ultra laptop below.
-
+### 3. How to Use `Dify`
+
+For comprehensive usage instructions of Dify, please refer to the [Dify Documentation](https://docs.dify.ai/). In this section, we'll only highlight a few key steps for local LLM setup.
+
+
+#### Setup Ollama
+
+Open your browser and access the Dify UI at `http://localhost:3000`.
+
+
+Configure the Ollama URL in `Settings > Model Providers > Ollama`. For detailed instructions on how to do this, see the [Ollama Guide in the Dify Documentation](https://docs.dify.ai/tutorials/model-configuration/ollama).
+
+
+
+Once Ollama is successfully connected, you will see a list of Ollama models similar to the following:
+
+ 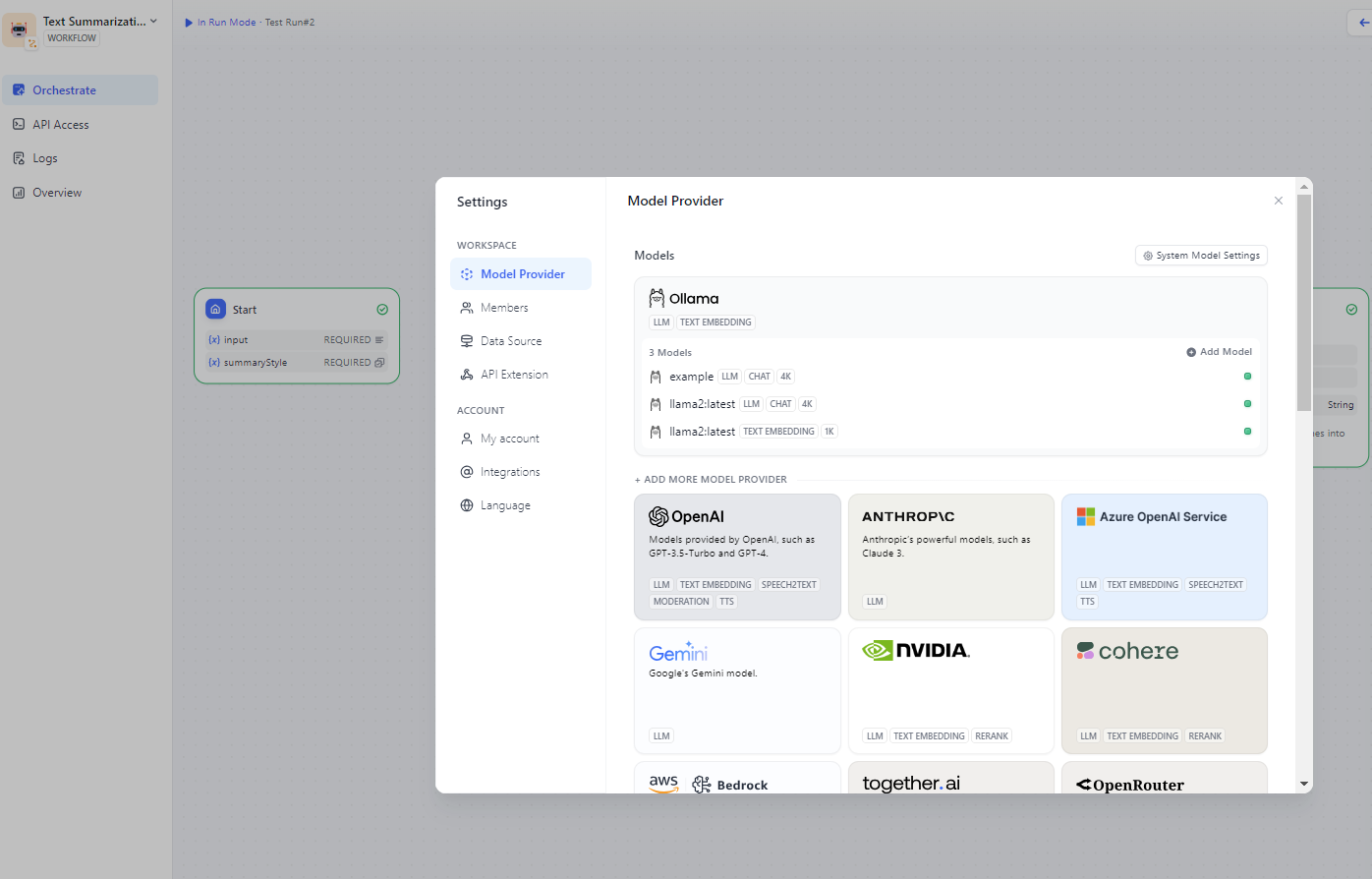 +
+
-1. Set up the environment `export no_proxy=localhost,127.0.0.1` and start Ollama locally by `ollama serve`.
-2. Open http://localhost:3000 to view dify and change the model provider in setting including both LLM and embedding. For example, choose ollama.
-
-
-
-
-
-
-
+
+
-5. Enter input and start to generate. You could find retrieval results and answers generated on the right.
-4. Add knowledge base and specify which type of embedding model to use.
-
-
-
+
+
+- Enter your input in the workflow and execute it. You'll find retrieval results and generated answers on the right.
+
+
+
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/fastchat_quickstart.md b/docs/readthedocs/source/doc/LLM/Quickstart/fastchat_quickstart.md
index 726b7684a72..2eb44aced0c 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/fastchat_quickstart.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/fastchat_quickstart.md
@@ -61,6 +61,23 @@ export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
python3 -m ipex_llm.serving.fastchat.ipex_llm_worker --model-path REPO_ID_OR_YOUR_MODEL_PATH --low-bit "sym_int4" --trust-remote-code --device "xpu"
```
+#### For self-speculative decoding example:
+
+You can use IPEX-LLM to run `self-speculative decoding` example. Refer to [here](https://github.com/intel-analytics/ipex-llm/tree/c9fac8c26bf1e1e8f7376fa9a62b32951dd9e85d/python/llm/example/GPU/Speculative-Decoding) for more details on intel MAX GPUs. Refer to [here](https://github.com/intel-analytics/ipex-llm/tree/c9fac8c26bf1e1e8f7376fa9a62b32951dd9e85d/python/llm/example/GPU/Speculative-Decoding) for more details on intel CPUs.
+
+```bash
+# Available low_bit format only including bf16 on CPU.
+source ipex-llm-init -t
+python3 -m ipex_llm.serving.fastchat.ipex_llm_worker --model-path lmsys/vicuna-7b-v1.5 --low-bit "bf16" --trust-remote-code --device "cpu" --speculative
+
+# Available low_bit format only including fp16 on GPU.
+source /opt/intel/oneapi/setvars.sh
+export ENABLE_SDP_FUSION=1
+export SYCL_CACHE_PERSISTENT=1
+export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
+python3 -m ipex_llm.serving.fastchat.ipex_llm_worker --model-path lmsys/vicuna-7b-v1.5 --low-bit "fp16" --trust-remote-code --device "xpu" --speculative
+```
+
You can get output like this:
```bash
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/index.rst b/docs/readthedocs/source/doc/LLM/Quickstart/index.rst
index 750f84af166..a5c5877117e 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/index.rst
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/index.rst
@@ -16,12 +16,16 @@ This section includes efficient guide to show you how to:
* `Run Local RAG using Langchain-Chatchat on Intel GPU <./chatchat_quickstart.html>`_
* `Run Text Generation WebUI on Intel GPU <./webui_quickstart.html>`_
* `Run Open WebUI on Intel GPU <./open_webui_with_ollama_quickstart.html>`_
+* `Run PrivateGPT with IPEX-LLM on Intel GPU <./privateGPT_quickstart.html>`_
* `Run Coding Copilot (Continue) in VSCode with Intel GPU <./continue_quickstart.html>`_
+* `Run Dify on Intel GPU <./dify_quickstart.html>`_
* `Run llama.cpp with IPEX-LLM on Intel GPU <./llama_cpp_quickstart.html>`_
* `Run Ollama with IPEX-LLM on Intel GPU <./ollama_quickstart.html>`_
* `Run Llama 3 on Intel GPU using llama.cpp and ollama with IPEX-LLM <./llama3_llamacpp_ollama_quickstart.html>`_
* `Run IPEX-LLM Serving with FastChat <./fastchat_quickstart.html>`_
* `Finetune LLM with Axolotl on Intel GPU <./axolotl_quickstart.html>`_
+* `Run IPEX-LLM serving on Multiple Intel GPUs using DeepSpeed AutoTP and FastApi <./deepspeed_autotp_fastapi_quickstart.html>`
+
.. |bigdl_llm_migration_guide| replace:: ``bigdl-llm`` Migration Guide
.. _bigdl_llm_migration_guide: bigdl_llm_migration.html
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/llama3_llamacpp_ollama_quickstart.md b/docs/readthedocs/source/doc/LLM/Quickstart/llama3_llamacpp_ollama_quickstart.md
index 2003360e942..cedb256fea2 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/llama3_llamacpp_ollama_quickstart.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/llama3_llamacpp_ollama_quickstart.md
@@ -29,9 +29,9 @@ Suppose you have downloaded a [Meta-Llama-3-8B-Instruct-Q4_K_M.gguf](https://hug
#### 1.3 Run Llama3 on Intel GPU using llama.cpp
-##### Set Environment Variables
+#### Runtime Configuration
-Configure oneAPI variables by running the following command:
+To use GPU acceleration, several environment variables are required or recommended before running `llama.cpp`.
```eval_rst
.. tabs::
@@ -40,16 +40,24 @@ Configure oneAPI variables by running the following command:
.. code-block:: bash
source /opt/intel/oneapi/setvars.sh
+ export SYCL_CACHE_PERSISTENT=1
.. tab:: Windows
+
+ .. code-block:: bash
- .. note::
+ set SYCL_CACHE_PERSISTENT=1
- This is a required step for APT or offline installed oneAPI. Skip this step for PIP-installed oneAPI.
+```
- .. code-block:: bash
+```eval_rst
+.. tip::
- call "C:\Program Files (x86)\Intel\oneAPI\setvars.bat"
+ If your local LLM is running on Intel Arc™ A-Series Graphics with Linux OS (Kernel 6.2), it is recommended to additionaly set the following environment variable for optimal performance:
+
+ .. code-block:: bash
+
+ export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
```
@@ -122,9 +130,9 @@ Launch the Ollama service:
export no_proxy=localhost,127.0.0.1
export ZES_ENABLE_SYSMAN=1
- export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
export OLLAMA_NUM_GPU=999
source /opt/intel/oneapi/setvars.sh
+ export SYCL_CACHE_PERSISTENT=1
./ollama serve
@@ -137,13 +145,23 @@ Launch the Ollama service:
set no_proxy=localhost,127.0.0.1
set ZES_ENABLE_SYSMAN=1
set OLLAMA_NUM_GPU=999
- # Below is a required step for APT or offline installed oneAPI. Skip below step for PIP-installed oneAPI.
- call "C:\Program Files (x86)\Intel\oneAPI\setvars.bat"
+ set SYCL_CACHE_PERSISTENT=1
ollama serve
```
+```eval_rst
+.. tip::
+
+ If your local LLM is running on Intel Arc™ A-Series Graphics with Linux OS (Kernel 6.2), it is recommended to additionaly set the following environment variable for optimal performance before executing `ollama serve`:
+
+ .. code-block:: bash
+
+ export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
+
+```
+
```eval_rst
.. note::
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/llama_cpp_quickstart.md b/docs/readthedocs/source/doc/LLM/Quickstart/llama_cpp_quickstart.md
index 9fc7e02b130..5b681babd37 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/llama_cpp_quickstart.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/llama_cpp_quickstart.md
@@ -18,17 +18,37 @@ For Linux system, we recommend Ubuntu 20.04 or later (Ubuntu 22.04 is preferred)
Visit the [Install IPEX-LLM on Linux with Intel GPU](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/install_linux_gpu.html), follow [Install Intel GPU Driver](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/install_linux_gpu.html#install-intel-gpu-driver) and [Install oneAPI](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/install_linux_gpu.html#install-oneapi) to install GPU driver and Intel® oneAPI Base Toolkit 2024.0.
#### Windows
-Visit the [Install IPEX-LLM on Windows with Intel GPU Guide](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/install_windows_gpu.html), and follow [Install Prerequisites](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/install_windows_gpu.html#install-prerequisites) to install [Visual Studio 2022](https://visualstudio.microsoft.com/downloads/) Community Edition, latest [GPU driver](https://www.intel.com/content/www/us/en/download/785597/intel-arc-iris-xe-graphics-windows.html) and Intel® oneAPI Base Toolkit 2024.0.
+Visit the [Install IPEX-LLM on Windows with Intel GPU Guide](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/install_windows_gpu.html), and follow [Install Prerequisites](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Quickstart/install_windows_gpu.html#install-prerequisites) to install [Visual Studio 2022](https://visualstudio.microsoft.com/downloads/) Community Edition and latest [GPU driver](https://www.intel.com/content/www/us/en/download/785597/intel-arc-iris-xe-graphics-windows.html).
**Note**: IPEX-LLM backend only supports the more recent GPU drivers. Please make sure your GPU driver version is equal or newer than `31.0.101.5333`, otherwise you might find gibberish output.
### 1 Install IPEX-LLM for llama.cpp
To use `llama.cpp` with IPEX-LLM, first ensure that `ipex-llm[cpp]` is installed.
-```cmd
-conda create -n llm-cpp python=3.11
-conda activate llm-cpp
-pip install --pre --upgrade ipex-llm[cpp]
+
+```eval_rst
+.. tabs::
+ .. tab:: Linux
+
+ .. code-block:: bash
+
+ conda create -n llm-cpp python=3.11
+ conda activate llm-cpp
+ pip install --pre --upgrade ipex-llm[cpp]
+
+ .. tab:: Windows
+
+ .. note::
+
+ for Windows, we use pip to install oneAPI.
+
+ .. code-block:: cmd
+
+ conda create -n llm-cpp python=3.11
+ conda activate llm-cpp
+ pip install dpcpp-cpp-rt==2024.0.2 mkl-dpcpp==2024.0.0 onednn==2024.0.0 # install oneapi
+ pip install --pre --upgrade ipex-llm[cpp]
+
```
**After the installation, you should have created a conda environment, named `llm-cpp` for instance, for running `llama.cpp` commands with IPEX-LLM.**
@@ -78,13 +98,9 @@ Then you can use following command to initialize `llama.cpp` with IPEX-LLM:
**Now you can use these executable files by standard llama.cpp's usage.**
-### 3 Example: Running community GGUF models with IPEX-LLM
-
-Here we provide a simple example to show how to run a community GGUF model with IPEX-LLM.
-
-#### Set Environment Variables
+#### Runtime Configuration
-Configure oneAPI variables by running the following command:
+To use GPU acceleration, several environment variables are required or recommended before running `llama.cpp`.
```eval_rst
.. tabs::
@@ -93,19 +109,31 @@ Configure oneAPI variables by running the following command:
.. code-block:: bash
source /opt/intel/oneapi/setvars.sh
+ export SYCL_CACHE_PERSISTENT=1
.. tab:: Windows
+
+ .. code-block:: bash
- .. note::
+ set SYCL_CACHE_PERSISTENT=1
- This is a required step for APT or offline installed oneAPI. Skip this step for PIP-installed oneAPI.
+```
- .. code-block:: bash
+```eval_rst
+.. tip::
+
+ If your local LLM is running on Intel Arc™ A-Series Graphics with Linux OS (Kernel 6.2), it is recommended to additionaly set the following environment variable for optimal performance:
- call "C:\Program Files (x86)\Intel\oneAPI\setvars.bat"
+ .. code-block:: bash
+
+ export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
```
+### 3 Example: Running community GGUF models with IPEX-LLM
+
+Here we provide a simple example to show how to run a community GGUF model with IPEX-LLM.
+
#### Model Download
Before running, you should download or copy community GGUF model to your current directory. For instance, `mistral-7b-instruct-v0.1.Q4_K_M.gguf` of [Mistral-7B-Instruct-v0.1-GGUF](https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.1-GGUF/tree/main).
@@ -273,3 +301,6 @@ If your program hang after `llm_load_tensors: SYCL_Host buffer size = xx.xx
#### How to set `-ngl` parameter
`-ngl` means the number of layers to store in VRAM. If your VRAM is enough, we recommend putting all layers on GPU, you can just set `-ngl` to a large number like 999 to achieve this goal.
+
+#### How to specificy GPU
+If your machine has multi GPUs, `llama.cpp` will default use all GPUs which may slow down your inference for model which can run on single GPU. You can add `-sm none` in your command to use one GPU only. Also, you can use `ONEAPI_DEVICE_SELECTOR=level_zero:[gpu_id]` to select device before excuting your command, more details can refer to [here](https://ipex-llm.readthedocs.io/en/latest/doc/LLM/Overview/KeyFeatures/multi_gpus_selection.html#oneapi-device-selector).
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/ollama_quickstart.md b/docs/readthedocs/source/doc/LLM/Quickstart/ollama_quickstart.md
index 695a41dfef0..96d63ed82a4 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/ollama_quickstart.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/ollama_quickstart.md
@@ -56,6 +56,7 @@ You may launch the Ollama service as below:
export no_proxy=localhost,127.0.0.1
export ZES_ENABLE_SYSMAN=1
source /opt/intel/oneapi/setvars.sh
+ export SYCL_CACHE_PERSISTENT=1
./ollama serve
@@ -68,8 +69,7 @@ You may launch the Ollama service as below:
set OLLAMA_NUM_GPU=999
set no_proxy=localhost,127.0.0.1
set ZES_ENABLE_SYSMAN=1
- # Below is a required step for APT or offline installed oneAPI. Skip below step for PIP-installed oneAPI.
- call "C:\Program Files (x86)\Intel\oneAPI\setvars.bat"
+ set SYCL_CACHE_PERSISTENT=1
ollama serve
@@ -81,6 +81,17 @@ You may launch the Ollama service as below:
Please set environment variable ``OLLAMA_NUM_GPU`` to ``999`` to make sure all layers of your model are running on Intel GPU, otherwise, some layers may run on CPU.
```
+```eval_rst
+.. tip::
+
+ If your local LLM is running on Intel Arc™ A-Series Graphics with Linux OS (Kernel 6.2), it is recommended to additionaly set the following environment variable for optimal performance before executing `ollama serve`:
+
+ .. code-block:: bash
+
+ export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
+
+```
+
```eval_rst
.. note::
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/open_webui_with_ollama_quickstart.md b/docs/readthedocs/source/doc/LLM/Quickstart/open_webui_with_ollama_quickstart.md
index ed45d582d16..1eb2ec05418 100644
--- a/docs/readthedocs/source/doc/LLM/Quickstart/open_webui_with_ollama_quickstart.md
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/open_webui_with_ollama_quickstart.md
@@ -2,7 +2,7 @@
[Open WebUI](https://github.com/open-webui/open-webui) is a user friendly GUI for running LLM locally; by porting it to [`ipex-llm`](https://github.com/intel-analytics/ipex-llm), users can now easily run LLM in [Open WebUI](https://github.com/open-webui/open-webui) on Intel **GPU** *(e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max)*.
-See the demo of running Mistral:7B on Intel Arc A770 below.
+*See the demo of running Mistral:7B on Intel Arc A770 below.*
diff --git a/docs/readthedocs/source/doc/LLM/Quickstart/privateGPT_quickstart.md b/docs/readthedocs/source/doc/LLM/Quickstart/privateGPT_quickstart.md
new file mode 100644
index 00000000000..b8d662ab691
--- /dev/null
+++ b/docs/readthedocs/source/doc/LLM/Quickstart/privateGPT_quickstart.md
@@ -0,0 +1,102 @@
+# Run PrivateGPT with IPEX-LLM on Intel GPU
+
+[PrivateGPT](https://github.com/zylon-ai/private-gpt) is a production-ready AI project that allows users to chat over documents, etc.; by integrating it with [`ipex-llm`](https://github.com/intel-analytics/ipex-llm), users can now easily leverage local LLMs running on Intel GPU (e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max).
+
+*See the demo of privateGPT running Mistral:7B on Intel Arc A770 below.*
+
+
+
+
+## Quickstart
+
+
+### 1. Install and Start `Ollama` Service on Intel GPU
+
+Follow the steps in [Run Ollama on Intel GPU Guide](./ollama_quickstart.md) to install and run Ollama on Intel GPU. Ensure that `ollama serve` is running correctly and can be accessed through a local URL (e.g., `https://127.0.0.1:11434`) or a remote URL (e.g., `http://your_ip:11434`).
+
+
+### 2. Install PrivateGPT
+
+#### Download PrivateGPT
+
+You can either clone the repository or download the source zip from [github](https://github.com/zylon-ai/private-gpt/archive/refs/heads/main.zip):
+```bash
+git clone https://github.com/zylon-ai/private-gpt
+```
+
+#### Install Dependencies
+
+Execute the following commands in a terminal to install the dependencies of PrivateGPT:
+
+```cmd
+cd private-gpt
+pip install poetry
+pip install ffmpy==0.3.1
+poetry install --extras "ui llms-ollama embeddings-ollama vector-stores-qdrant"
+```
+For more details, refer to the [PrivateGPT installation Guide](https://docs.privategpt.dev/installation/getting-started/main-concepts).
+
+
+### 3. Start PrivateGPT
+
+#### Configure PrivateGPT
+
+Change PrivateGPT settings by modifying `settings.yaml` and `settings-ollama.yaml`.
+
+* `settings.yaml` is always loaded and contains the default configuration. In order to run PrivateGPT locally, you need to replace the tokenizer path under the `llm` option with your local path.
+* `settings-ollama.yaml` is loaded if the ollama profile is specified in the PGPT_PROFILES environment variable. It can override configuration from the default `settings.yaml`. You can modify the settings in this file according to your preference. It is worth noting that to use the options `llm_model: ` and `embedding_model: `, you need to first use `ollama pull` to fetch the models locally.
+
+To learn more about the configuration of PrivatePGT, please refer to [PrivateGPT Main Concepts](https://docs.privategpt.dev/installation/getting-started/main-concepts).
+
+
+#### Start the service
+Please ensure that the Ollama server continues to run in a terminal while you're using the PrivateGPT.
+
+Run below commands to start the service in another terminal:
+
+```eval_rst
+.. tabs::
+ .. tab:: Linux
+
+ .. code-block:: bash
+
+ export no_proxy=localhost,127.0.0.1
+ PGPT_PROFILES=ollama make run
+
+ .. note:
+
+ Setting ``PGPT_PROFILES=ollama`` will load the configuration from ``settings.yaml`` and ``settings-ollama.yaml``.
+
+ .. tab:: Windows
+
+ .. code-block:: bash
+
+ set no_proxy=localhost,127.0.0.1
+ set PGPT_PROFILES=ollama
+ make run
+
+ .. note:
+
+ Setting ``PGPT_PROFILES=ollama`` will load the configuration from ``settings.yaml`` and ``settings-ollama.yaml``.
+```
+
+### 4. Using PrivateGPT
+
+#### Chat with the Model
+
+To chat with the LLM, select the "LLM Chat" option located in the upper left corner of the page. Type your messages at the bottom of the page and click the "Submit" button to receive responses from the model.
+
+
+
+  +
+
+
+
+
+#### Chat over Documents (RAG)
+
+To interact with documents, select the "Query Files" option in the upper left corner of the page. Click the "Upload File(s)" button to upload documents. After the documents have been vectorized, you can type your messages at the bottom of the page and click the "Submit" button to receive responses from the model based on the uploaded content.
+
+
+  +
diff --git a/docs/readthedocs/source/index.rst b/docs/readthedocs/source/index.rst
index 5a307f3f8b1..53b33be96c8 100644
--- a/docs/readthedocs/source/index.rst
+++ b/docs/readthedocs/source/index.rst
@@ -580,6 +580,20 @@ Verified Models
+
diff --git a/docs/readthedocs/source/index.rst b/docs/readthedocs/source/index.rst
index 5a307f3f8b1..53b33be96c8 100644
--- a/docs/readthedocs/source/index.rst
+++ b/docs/readthedocs/source/index.rst
@@ -580,6 +580,20 @@ Verified Models
link |
+
+ | CodeGemma |
+
+ link |
+
+ link |
+
+
+ | Command-R/cohere |
+
+ link |
+
+ link |
+
diff --git a/python/llm/dev/benchmark/all-in-one/run.py b/python/llm/dev/benchmark/all-in-one/run.py
index 31c3ecee8b2..714bb2e915a 100644
--- a/python/llm/dev/benchmark/all-in-one/run.py
+++ b/python/llm/dev/benchmark/all-in-one/run.py
@@ -33,6 +33,7 @@
sys.path.append(benchmark_util_path)
from benchmark_util import BenchmarkWrapper
from ipex_llm.utils.common.log4Error import invalidInputError
+from ipex_llm.utils.common import invalidInputError
LLAMA_IDS = ['meta-llama/Llama-2-7b-chat-hf','meta-llama/Llama-2-13b-chat-hf',
'meta-llama/Llama-2-70b-chat-hf','decapoda-research/llama-7b-hf',
@@ -50,7 +51,7 @@ def run_model_in_thread(model, in_out, tokenizer, result, warm_up, num_beams, in
for i in range(num_trials + warm_up):
st = time.perf_counter()
output_ids = model.generate(input_ids, do_sample=False, max_new_tokens=out_len,
- num_beams=num_beams)
+ min_new_tokens=out_len, num_beams=num_beams)
torch.xpu.synchronize()
end = time.perf_counter()
output_ids = output_ids.cpu()
@@ -110,6 +111,8 @@ def run_model(repo_id, test_api, in_out_pairs, local_model_hub=None, warm_up=1,
result = run_speculative_gpu(repo_id, local_model_hub, in_out_pairs, warm_up, num_trials, num_beams, batch_size)
elif test_api == 'pipeline_parallel_gpu':
result = run_pipeline_parallel_gpu(repo_id, local_model_hub, in_out_pairs, warm_up, num_trials, num_beams, low_bit, batch_size, cpu_embedding, fp16=use_fp16_torch_dtype, n_gpu=n_gpu)
+ else:
+ invalidInputError(False, "Unknown test_api " + test_api + ", please check your config.yaml.")
for in_out_pair in in_out_pairs:
if result and result[in_out_pair]:
@@ -238,7 +241,7 @@ def run_transformer_int4(repo_id,
for i in range(num_trials + warm_up):
st = time.perf_counter()
output_ids = model.generate(input_ids, do_sample=False, max_new_tokens=out_len,
- num_beams=num_beams)
+ min_new_tokens=out_len, num_beams=num_beams)
end = time.perf_counter()
print("model generate cost: " + str(end - st))
output = tokenizer.batch_decode(output_ids)
@@ -304,7 +307,7 @@ def run_pytorch_autocast_bf16(repo_id,
for i in range(num_trials + warm_up):
st = time.perf_counter()
output_ids = model.generate(input_ids, do_sample=False, max_new_tokens=out_len,
- num_beams=num_beams)
+ min_new_tokens=out_len, num_beams=num_beams)
end = time.perf_counter()
print("model generate cost: " + str(end - st))
output = tokenizer.batch_decode(output_ids)
@@ -374,7 +377,7 @@ def run_optimize_model(repo_id,
for i in range(num_trials + warm_up):
st = time.perf_counter()
output_ids = model.generate(input_ids, do_sample=False, max_new_tokens=out_len,
- num_beams=num_beams)
+ min_new_tokens=out_len, num_beams=num_beams)
end = time.perf_counter()
print("model generate cost: " + str(end - st))
output = tokenizer.batch_decode(output_ids)
@@ -558,7 +561,7 @@ def run_optimize_model_gpu(repo_id,
for i in range(num_trials + warm_up):
st = time.perf_counter()
output_ids = model.generate(input_ids, do_sample=False, max_new_tokens=out_len,
- num_beams=num_beams)
+ min_new_tokens=out_len, num_beams=num_beams)
torch.xpu.synchronize()
end = time.perf_counter()
output_ids = output_ids.cpu()
@@ -630,7 +633,7 @@ def run_ipex_fp16_gpu(repo_id,
for i in range(num_trials + warm_up):
st = time.perf_counter()
output_ids = model.generate(input_ids, do_sample=False, max_new_tokens=out_len,
- num_beams=num_beams)
+ min_new_tokens=out_len, num_beams=num_beams)
torch.xpu.synchronize()
end = time.perf_counter()
output_ids = output_ids.cpu()
@@ -708,7 +711,7 @@ def run_bigdl_fp16_gpu(repo_id,
for i in range(num_trials + warm_up):
st = time.perf_counter()
output_ids = model.generate(input_ids, do_sample=False, max_new_tokens=out_len,
- num_beams=num_beams)
+ min_new_tokens=out_len, num_beams=num_beams)
torch.xpu.synchronize()
end = time.perf_counter()
output_ids = output_ids.cpu()
@@ -800,7 +803,7 @@ def run_deepspeed_transformer_int4_cpu(repo_id,
for i in range(num_trials + warm_up):
st = time.perf_counter()
output_ids = model.generate(input_ids, do_sample=False, max_new_tokens=out_len,
- num_beams=num_beams)
+ min_new_tokens=out_len, num_beams=num_beams)
end = time.perf_counter()
if local_rank == 0:
print("model generate cost: " + str(end - st))
@@ -887,10 +890,12 @@ def run_transformer_int4_gpu_win(repo_id,
for i in range(num_trials + warm_up):
st = time.perf_counter()
if streaming:
- output_ids = model.generate(input_ids, do_sample=False, max_new_tokens=out_len,
+ output_ids = model.generate(input_ids, do_sample=False,
+ max_new_tokens=out_len, min_new_tokens=out_len,
num_beams=num_beams, streamer=streamer)
else:
- output_ids = model.generate(input_ids, do_sample=False, max_new_tokens=out_len,
+ output_ids = model.generate(input_ids, do_sample=False,
+ max_new_tokens=out_len, min_new_tokens=out_len,
num_beams=num_beams)
torch.xpu.synchronize()
end = time.perf_counter()
@@ -994,10 +999,12 @@ def run_transformer_int4_fp16_gpu_win(repo_id,
for i in range(num_trials + warm_up):
st = time.perf_counter()
if streaming:
- output_ids = model.generate(input_ids, do_sample=False, max_new_tokens=out_len,
+ output_ids = model.generate(input_ids, do_sample=False,
+ max_new_tokens=out_len, min_new_tokens=out_len,
num_beams=num_beams, streamer=streamer)
else:
- output_ids = model.generate(input_ids, do_sample=False, max_new_tokens=out_len,
+ output_ids = model.generate(input_ids, do_sample=False,
+ max_new_tokens=out_len, min_new_tokens=out_len,
num_beams=num_beams)
torch.xpu.synchronize()
end = time.perf_counter()
@@ -1096,10 +1103,12 @@ def run_transformer_int4_loadlowbit_gpu_win(repo_id,
for i in range(num_trials + warm_up):
st = time.perf_counter()
if streaming:
- output_ids = model.generate(input_ids, do_sample=False, max_new_tokens=out_len,
+ output_ids = model.generate(input_ids, do_sample=False,
+ max_new_tokens=out_len, min_new_tokens=out_len,
num_beams=num_beams, streamer=streamer)
else:
- output_ids = model.generate(input_ids, do_sample=False, max_new_tokens=out_len,
+ output_ids = model.generate(input_ids, do_sample=False,
+ max_new_tokens=out_len, min_new_tokens=out_len,
num_beams=num_beams)
torch.xpu.synchronize()
end = time.perf_counter()
@@ -1183,7 +1192,7 @@ def run_transformer_autocast_bf16( repo_id,
for i in range(num_trials + warm_up):
st = time.perf_counter()
output_ids = model.generate(input_ids, do_sample=False, max_new_tokens=out_len,
- num_beams=num_beams)
+ min_new_tokens=out_len, num_beams=num_beams)
end = time.perf_counter()
print("model generate cost: " + str(end - st))
output = tokenizer.batch_decode(output_ids)
@@ -1254,7 +1263,7 @@ def run_bigdl_ipex_bf16(repo_id,
for i in range(num_trials + warm_up):
st = time.perf_counter()
output_ids, total_list = model.generate(input_ids, do_sample=False, max_new_tokens=out_len,
- num_beams=num_beams)
+ min_new_tokens=out_len, num_beams=num_beams)
end = time.perf_counter()
print("model generate cost: " + str(end - st))
output = tokenizer.batch_decode(output_ids)
@@ -1324,7 +1333,7 @@ def run_bigdl_ipex_int4(repo_id,
for i in range(num_trials + warm_up):
st = time.perf_counter()
output_ids, total_list = model.generate(input_ids, do_sample=False, max_new_tokens=out_len,
- num_beams=num_beams)
+ min_new_tokens=out_len, num_beams=num_beams)
end = time.perf_counter()
print("model generate cost: " + str(end - st))
output = tokenizer.batch_decode(output_ids)
@@ -1394,7 +1403,7 @@ def run_bigdl_ipex_int8(repo_id,
for i in range(num_trials + warm_up):
st = time.perf_counter()
output_ids, total_list = model.generate(input_ids, do_sample=False, max_new_tokens=out_len,
- num_beams=num_beams)
+ min_new_tokens=out_len, num_beams=num_beams)
end = time.perf_counter()
print("model generate cost: " + str(end - st))
output = tokenizer.batch_decode(output_ids)
@@ -1505,7 +1514,7 @@ def get_int_from_env(env_keys, default):
for i in range(num_trials + warm_up):
st = time.perf_counter()
output_ids = model.generate(input_ids, do_sample=False, max_new_tokens=out_len,
- num_beams=num_beams)
+ min_new_tokens=out_len, num_beams=num_beams)
torch.xpu.synchronize()
end = time.perf_counter()
output_ids = output_ids.cpu()
@@ -1584,11 +1593,12 @@ def run_speculative_cpu(repo_id,
for i in range(num_trials + warm_up):
st = time.perf_counter()
if _enable_ipex:
- output_ids = model.generate(input_ids, do_sample=False, max_new_tokens=out_len,
- num_beams=num_beams, attention_mask=attention_mask)
+ output_ids = model.generate(input_ids, do_sample=False,
+ max_new_tokens=out_len, min_new_tokens=out_len,
+ num_beams=num_beams, attention_mask=attention_mask)
else:
- output_ids = model.generate(input_ids, do_sample=False, max_new_tokens=out_len,
- num_beams=num_beams)
+ output_ids = model.generate(input_ids, do_sample=False,max_new_tokens=out_len,
+ min_new_tokens=out_len, num_beams=num_beams)
end = time.perf_counter()
print("model generate cost: " + str(end - st))
output = tokenizer.batch_decode(output_ids)
@@ -1659,7 +1669,7 @@ def run_speculative_gpu(repo_id,
for i in range(num_trials + warm_up):
st = time.perf_counter()
output_ids = model.generate(input_ids, do_sample=False, max_new_tokens=out_len,
- num_beams=num_beams)
+ min_new_tokens=out_len, num_beams=num_beams)
torch.xpu.synchronize()
end = time.perf_counter()
output_ids = output_ids.cpu()
@@ -1779,7 +1789,7 @@ def run_pipeline_parallel_gpu(repo_id,
for i in range(num_trials + warm_up):
st = time.perf_counter()
output_ids = model.generate(input_ids, do_sample=False, max_new_tokens=out_len,
- num_beams=num_beams)
+ min_new_tokens=out_len, num_beams=num_beams)
torch.xpu.synchronize()
end = time.perf_counter()
output_ids = output_ids.cpu()
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/codegemma/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/codegemma/README.md
new file mode 100644
index 00000000000..a959d278db6
--- /dev/null
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/codegemma/README.md
@@ -0,0 +1,75 @@
+# CodeGemma
+In this directory, you will find examples on how you could apply IPEX-LLM INT4 optimizations on CodeGemma models. For illustration purposes, we utilize the [google/codegemma-7b-it](https://huggingface.co/google/codegemma-7b-it) as reference CodeGemma models.
+
+## 0. Requirements
+To run these examples with IPEX-LLM, we have some recommended requirements for your machine, please refer to [here](../README.md#recommended-requirements) for more information.
+
+## Example: Predict Tokens using `generate()` API
+In the example [generate.py](./generate.py), we show a basic use case for a CodeGemma model to predict the next N tokens using `generate()` API, with IPEX-LLM INT4 optimizations.
+### 1. Install
+We suggest using conda to manage the Python environment. For more information about conda installation, please refer to [here](https://docs.conda.io/en/latest/miniconda.html#).
+
+After installing conda, create a Python environment for IPEX-LLM:
+```bash
+conda create -n llm python=3.11 # recommend to use Python 3.11
+conda activate llm
+
+# install ipex-llm with 'all' option
+pip install ipex-llm[all]
+
+# According to CodeGemma's requirement, please make sure you are using a stable version of Transformers, 4.38.1 or newer.
+pip install transformers==4.38.1
+```
+
+### 2. Run
+```
+python ./generate.py --repo-id-or-model-path REPO_ID_OR_MODEL_PATH --prompt PROMPT --n-predict N_PREDICT
+```
+
+Arguments info:
+- `--repo-id-or-model-path REPO_ID_OR_MODEL_PATH`: argument defining the huggingface repo id for the CodeGemma model to be downloaded, or the path to the huggingface checkpoint folder. It is default to be `'google/codegemma-7b-it'`.
+- `--prompt PROMPT`: argument defining the prompt to be infered (with integrated prompt format for chat). It is default to be `'Write a hello world program'`.
+- `--n-predict N_PREDICT`: argument defining the max number of tokens to predict. It is default to be `32`.
+
+> **Note**: When loading the model in 4-bit, IPEX-LLM converts linear layers in the model into INT4 format. In theory, a *X*B model saved in 16-bit will requires approximately 2*X* GB of memory for loading, and ~0.5*X* GB memory for further inference.
+>
+> Please select the appropriate size of the CodeLlama model based on the capabilities of your machine.
+
+#### 2.1 Client
+On client Windows machine, it is recommended to run directly with full utilization of all cores:
+```powershell
+python ./generate.py
+```
+
+#### 2.2 Server
+For optimal performance on server, it is recommended to set several environment variables (refer to [here](../README.md#best-known-configuration-on-linux) for more information), and run the example with all the physical cores of a single socket.
+
+E.g. on Linux,
+```bash
+# set IPEX-LLM env variables
+source ipex-llm-init
+
+# e.g. for a server with 48 cores per socket
+export OMP_NUM_THREADS=48
+numactl -C 0-47 -m 0 python ./generate.py
+```
+
+#### 2.3 Sample Output
+#### [google/codegemma-7b-it](https://huggingface.co/google/codegemma-7b-it)
+```log
+Inference time: xxxx s
+-------------------- Prompt --------------------
+user
+Write a hello world program
+model
+
+-------------------- Output --------------------
+user
+Write a hello world program
+model
+```python
+print("Hello, world!")
+```
+
+This program will print the message "Hello, world!" to the console.
+```
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/codegemma/generate.py b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/codegemma/generate.py
new file mode 100644
index 00000000000..8e370f75214
--- /dev/null
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/codegemma/generate.py
@@ -0,0 +1,71 @@
+#
+# Copyright 2016 The BigDL Authors.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+import torch
+import time
+import argparse
+
+from ipex_llm.transformers import AutoModelForCausalLM
+from transformers import AutoTokenizer
+
+# The instruction-tuned models use a chat template that must be adhered to for conversational use.
+# see https://huggingface.co/google/codegemma-7b-it#chat-template.
+chat = [
+ { "role": "user", "content": "Write a hello world program" },
+]
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser(description='Predict Tokens using `generate()` API for CodeGemma model')
+ parser.add_argument('--repo-id-or-model-path', type=str, default="google/codegemma-7b-it",
+ help='The huggingface repo id for the CodeGemma to be downloaded'
+ ', or the path to the huggingface checkpoint folder')
+ parser.add_argument('--prompt', type=str, default="Write a hello world program",
+ help='Prompt to infer')
+ parser.add_argument('--n-predict', type=int, default=32,
+ help='Max tokens to predict')
+
+ args = parser.parse_args()
+ model_path = args.repo_id_or_model_path
+
+ # Load model in 4 bit,
+ # which convert the relevant layers in the model into INT4 format
+ # To fix the issue that the output of codegemma-7b-it is abnormal, skip the 'lm_head' module during optimization
+ model = AutoModelForCausalLM.from_pretrained(model_path,
+ load_in_4bit=True,
+ trust_remote_code=True,
+ use_cache=True,
+ modules_to_not_convert=["lm_head"])
+
+ # Load tokenizer
+ tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
+
+ # Generate predicted tokens
+ with torch.inference_mode():
+ chat[0]['content'] = args.prompt
+ prompt = tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
+ input_ids = tokenizer.encode(prompt, return_tensors="pt")
+
+ # start inference
+ st = time.time()
+ output = model.generate(input_ids,
+ max_new_tokens=args.n_predict)
+ end = time.time()
+ output_str = tokenizer.decode(output[0], skip_special_tokens=True)
+ print(f'Inference time: {end-st} s')
+ print('-'*20, 'Prompt', '-'*20)
+ print(prompt)
+ print('-'*20, 'Output', '-'*20)
+ print(output_str)
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/cohere/README.md b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/cohere/README.md
new file mode 100644
index 00000000000..d104c84d89e
--- /dev/null
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/cohere/README.md
@@ -0,0 +1,64 @@
+# CoHere/command-r
+In this directory, you will find examples on how you could apply IPEX-LLM INT4 optimizations on cohere models. For illustration purposes, we utilize the [CohereForAI/c4ai-command-r-v01](https://huggingface.co/CohereForAI/c4ai-command-r-v01) as reference model.
+
+## 0. Requirements
+To run these examples with IPEX-LLM, we have some recommended requirements for your machine, please refer to [here](../README.md#recommended-requirements) for more information.
+
+## Example: Predict Tokens using `generate()` API
+In the example [generate.py](./generate.py), we show a basic use case for a cohere model to predict the next N tokens using `generate()` API, with IPEX-LLM INT4 optimizations.
+### 1. Install
+We suggest using conda to manage environment:
+```bash
+conda create -n llm python=3.11
+conda activate llm
+
+pip install --pre --upgrade ipex-llm[all] # install ipex-llm with 'all' option
+pip install tansformers==4.40.0
+```
+
+### 2. Run
+```
+python ./generate.py --repo-id-or-model-path REPO_ID_OR_MODEL_PATH --prompt PROMPT --n-predict N_PREDICT
+```
+
+Arguments info:
+- `--repo-id-or-model-path REPO_ID_OR_MODEL_PATH`: argument defining the huggingface repo id for the cohere model to be downloaded, or the path to the huggingface checkpoint folder. It is default to be `'CohereForAI/c4ai-command-r-v01'`.
+- `--prompt PROMPT`: argument defining the prompt to be infered (with integrated prompt format for chat). It is default to be `'What is AI?'`.
+- `--n-predict N_PREDICT`: argument defining the max number of tokens to predict. It is default to be `32`.
+
+> **Note**: When loading the model in 4-bit, IPEX-LLM converts linear layers in the model into INT4 format. In theory, a *X*B model saved in 16-bit will requires approximately 2*X* GB of memory for loading, and ~0.5*X* GB memory for further inference.
+>
+> Please select the appropriate size of the cohere model based on the capabilities of your machine.
+
+#### 2.1 Client
+On client Windows machine, it is recommended to run directly with full utilization of all cores:
+```powershell
+python ./generate.py
+```
+
+#### 2.2 Server
+For optimal performance on server, it is recommended to set several environment variables (refer to [here](../README.md#best-known-configuration-on-linux) for more information), and run the example with all the physical cores of a single socket.
+
+E.g. on Linux,
+```bash
+# set IPEX-LLM env variables
+source ipex-llm-init -t
+
+# e.g. for a server with 48 cores per socket
+export OMP_NUM_THREADS=48
+numactl -C 0-47 -m 0 python ./generate.py
+```
+
+#### 2.3 Sample Output
+#### [CohereForAI/c4ai-command-r-v01](https://huggingface.co/CohereForAI/c4ai-command-r-v01)
+```log
+Inference time: xxxxx s
+-------------------- Prompt --------------------
+
+<|START_OF_TURN_TOKEN|><|USER_TOKEN|>What is AI?<|END_OF_TURN_TOKEN|><|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>
+
+-------------------- Output --------------------
+
+<|START_OF_TURN_TOKEN|><|USER_TOKEN|>What is AI?<|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>
+Artificial Intelligence, or AI, is a fascinating field of study that aims to create intelligent machines that can mimic human cognitive functions and perform complex tasks. AI strives to
+```
diff --git a/python/llm/example/CPU/HF-Transformers-AutoModels/Model/cohere/generate.py b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/cohere/generate.py
new file mode 100644
index 00000000000..d215b00b153
--- /dev/null
+++ b/python/llm/example/CPU/HF-Transformers-AutoModels/Model/cohere/generate.py
@@ -0,0 +1,69 @@
+#
+# Copyright 2016 The BigDL Authors.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+import torch
+import time
+import argparse
+
+from ipex_llm.transformers import AutoModelForCausalLM
+from transformers import AutoTokenizer
+
+# you could tune the prompt based on your own model,
+# Refer to https://huggingface.co/CohereForAI/c4ai-command-r-v01
+COHERE_PROMPT_FORMAT = """
+<|START_OF_TURN_TOKEN|><|USER_TOKEN|>{prompt}<|END_OF_TURN_TOKEN|><|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>
+"""
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser(description='Predict Tokens using `generate()` API for cohere model')
+ parser.add_argument('--repo-id-or-model-path', type=str, default="CohereForAI/c4ai-command-r-v01",
+ help='The huggingface repo id for the cohere to be downloaded'
+ ', or the path to the huggingface checkpoint folder')
+ parser.add_argument('--prompt', type=str, default="What is AI?",
+ help='Prompt to infer')
+ parser.add_argument('--n-predict', type=int, default=32,
+ help='Max tokens to predict')
+
+ args = parser.parse_args()
+ model_path = args.repo_id_or_model_path
+
+ # Load model in 4 bit,
+ # which convert the relevant layers in the model into INT4 format
+ model = AutoModelForCausalLM.from_pretrained(model_path,
+ load_in_4bit=True,
+ trust_remote_code=True)
+
+ # Load tokenizer
+ tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
+
+ # Generate predicted tokens
+ with torch.inference_mode():
+ prompt = COHERE_PROMPT_FORMAT.format(prompt=args.prompt)
+ input_ids = tokenizer.encode(prompt, return_tensors="pt")
+ st = time.time()
+ # if your selected model is capable of utilizing previous key/value attentions
+ # to enhance decoding speed, but has `"use_cache": false` in its model config,
+ # it is important to set `use_cache=True` explicitly in the `generate` function
+ # to obtain optimal performance with IPEX-LLM INT4 optimizations
+ output = model.generate(input_ids,
+ max_new_tokens=args.n_predict)
+ end = time.time()
+ output_str = tokenizer.decode(output[0], skip_special_tokens=True)
+ print(f'Inference time: {end-st} s')
+ print('-'*20, 'Prompt', '-'*20)
+ print(prompt)
+ print('-'*20, 'Output', '-'*20)
+ print(output_str)
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/codegemma/README.md b/python/llm/example/CPU/PyTorch-Models/Model/codegemma/README.md
new file mode 100644
index 00000000000..22bdabc5763
--- /dev/null
+++ b/python/llm/example/CPU/PyTorch-Models/Model/codegemma/README.md
@@ -0,0 +1,73 @@
+# CodeGemma
+In this directory, you will find examples on how you could use IPEX-LLM `optimize_model` API to accelerate CodeGemma models. For illustration purposes, we utilize the [google/codegemma-7b-it](https://huggingface.co/google/codegemma-7b-it) as reference CodeGemma models.
+
+## 0. Requirements
+To run these examples with IPEX-LLM, we have some recommended requirements for your machine, please refer to [here](../README.md#recommended-requirements) for more information.
+
+## Example: Predict Tokens using `generate()` API
+In the example [generate.py](./generate.py), we show a basic use case for a CodeGemma model to predict the next N tokens using `generate()` API, with IPEX-LLM INT4 optimizations.
+### 1. Install
+We suggest using conda to manage the Python environment. For more information about conda installation, please refer to [here](https://docs.conda.io/en/latest/miniconda.html#).
+
+After installing conda, create a Python environment for IPEX-LLM:
+```bash
+conda create -n llm python=3.11 # recommend to use Python 3.11
+conda activate llm
+
+# install ipex-llm with 'all' option
+pip install --pre --upgrade ipex-llm[all]
+
+# According to CodeGemma's requirement, please make sure you are using a stable version of Transformers, 4.38.1 or newer.
+pip install transformers==4.38.1
+```
+
+### 2. Run
+After setting up the Python environment, you could run the example by following steps.
+
+#### 2.1 Client
+On client Windows machines, it is recommended to run directly with full utilization of all cores:
+```powershell
+python ./generate.py --repo-id-or-model-path REPO_ID_OR_MODEL_PATH --prompt PROMPT --n-predict N_PREDICT
+```
+More information about arguments can be found in [Arguments Info](#23-arguments-info) section. The expected output can be found in [Sample Output](#24-sample-output) section.
+
+#### 2.2 Server
+For optimal performance on server, it is recommended to set several environment variables (refer to [here](../README.md#best-known-configuration-on-linux) for more information), and run the example with all the physical cores of a single socket.
+
+E.g. on Linux,
+```bash
+# set IPEX-LLM env variables
+source ipex-llm-init
+
+# e.g. for a server with 48 cores per socket
+export OMP_NUM_THREADS=48
+numactl -C 0-47 -m 0 python ./generate.py --repo-id-or-model-path REPO_ID_OR_MODEL_PATH --prompt PROMPT --n-predict N_PREDICT
+```
+More information about arguments can be found in [Arguments Info](#23-arguments-info) section. The expected output can be found in [Sample Output](#24-sample-output) section.
+
+#### 2.3 Arguments Info
+In the example, several arguments can be passed to satisfy your requirements:
+
+- `--repo-id-or-model-path REPO_ID_OR_MODEL_PATH`: argument defining the huggingface repo id for the CodeGemma model to be downloaded, or the path to the huggingface checkpoint folder. It is default to be `'google/codegemma-7b-it'`.
+- `--prompt PROMPT`: argument defining the prompt to be infered (with integrated prompt format for chat). It is default to be `'Write a hello world program'`.
+- `--n-predict N_PREDICT`: argument defining the max number of tokens to predict. It is default to be `32`.
+
+#### 2.4 Sample Output
+#### [google/codegemma-7b-it](https://huggingface.co/google/codegemma-7b-it)
+```log
+Inference time: xxxx s
+-------------------- Prompt --------------------
+user
+Write a hello world program
+model
+
+-------------------- Output --------------------
+user
+Write a hello world program
+model
+```python
+print("Hello, world!")
+```
+
+This program will print the message "Hello, world!" to the console.
+```
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/codegemma/generate.py b/python/llm/example/CPU/PyTorch-Models/Model/codegemma/generate.py
new file mode 100644
index 00000000000..e64d842b87a
--- /dev/null
+++ b/python/llm/example/CPU/PyTorch-Models/Model/codegemma/generate.py
@@ -0,0 +1,68 @@
+#
+# Copyright 2016 The BigDL Authors.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+import torch
+import time
+import argparse
+
+from transformers import AutoModelForCausalLM, AutoTokenizer
+from ipex_llm import optimize_model
+
+# The instruction-tuned models use a chat template that must be adhered to for conversational use.
+# see https://huggingface.co/google/codegemma-7b-it#chat-template.
+chat = [
+ { "role": "user", "content": "Write a hello world program" },
+]
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser(description='Predict Tokens using `generate()` API for CodeGemma model')
+ parser.add_argument('--repo-id-or-model-path', type=str, default="google/codegemma-7b-it",
+ help='The huggingface repo id for the CodeGemma model to be downloaded'
+ ', or the path to the huggingface checkpoint folder')
+ parser.add_argument('--prompt', type=str, default="Write a hello world program",
+ help='Prompt to infer')
+ parser.add_argument('--n-predict', type=int, default=32,
+ help='Max tokens to predict')
+
+ args = parser.parse_args()
+ model_path = args.repo_id_or_model_path
+
+ # Load model
+ model = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True)
+
+ # With only one line to enable IPEX-LLM optimization on model
+ # To fix the issue that the output of codegemma-7b-it is abnormal, skip the 'lm_head' module during optimization
+ model = optimize_model(model, modules_to_not_convert=["lm_head"])
+
+ # Load tokenizer
+ tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
+
+ # Generate predicted tokens
+ with torch.inference_mode():
+ chat[0]['content'] = args.prompt
+ prompt = tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
+ input_ids = tokenizer.encode(prompt, return_tensors="pt")
+ st = time.time()
+ output = model.generate(input_ids,
+ max_new_tokens=args.n_predict)
+ end = time.time()
+ output_str = tokenizer.decode(output[0], skip_special_tokens=True)
+ print(f'Inference time: {end-st} s')
+ print('-'*20, 'Prompt', '-'*20)
+ print(prompt)
+ print('-'*20, 'Output', '-'*20)
+ print(output_str)
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/cohere/README.md b/python/llm/example/CPU/PyTorch-Models/Model/cohere/README.md
new file mode 100644
index 00000000000..d104c84d89e
--- /dev/null
+++ b/python/llm/example/CPU/PyTorch-Models/Model/cohere/README.md
@@ -0,0 +1,64 @@
+# CoHere/command-r
+In this directory, you will find examples on how you could apply IPEX-LLM INT4 optimizations on cohere models. For illustration purposes, we utilize the [CohereForAI/c4ai-command-r-v01](https://huggingface.co/CohereForAI/c4ai-command-r-v01) as reference model.
+
+## 0. Requirements
+To run these examples with IPEX-LLM, we have some recommended requirements for your machine, please refer to [here](../README.md#recommended-requirements) for more information.
+
+## Example: Predict Tokens using `generate()` API
+In the example [generate.py](./generate.py), we show a basic use case for a cohere model to predict the next N tokens using `generate()` API, with IPEX-LLM INT4 optimizations.
+### 1. Install
+We suggest using conda to manage environment:
+```bash
+conda create -n llm python=3.11
+conda activate llm
+
+pip install --pre --upgrade ipex-llm[all] # install ipex-llm with 'all' option
+pip install tansformers==4.40.0
+```
+
+### 2. Run
+```
+python ./generate.py --repo-id-or-model-path REPO_ID_OR_MODEL_PATH --prompt PROMPT --n-predict N_PREDICT
+```
+
+Arguments info:
+- `--repo-id-or-model-path REPO_ID_OR_MODEL_PATH`: argument defining the huggingface repo id for the cohere model to be downloaded, or the path to the huggingface checkpoint folder. It is default to be `'CohereForAI/c4ai-command-r-v01'`.
+- `--prompt PROMPT`: argument defining the prompt to be infered (with integrated prompt format for chat). It is default to be `'What is AI?'`.
+- `--n-predict N_PREDICT`: argument defining the max number of tokens to predict. It is default to be `32`.
+
+> **Note**: When loading the model in 4-bit, IPEX-LLM converts linear layers in the model into INT4 format. In theory, a *X*B model saved in 16-bit will requires approximately 2*X* GB of memory for loading, and ~0.5*X* GB memory for further inference.
+>
+> Please select the appropriate size of the cohere model based on the capabilities of your machine.
+
+#### 2.1 Client
+On client Windows machine, it is recommended to run directly with full utilization of all cores:
+```powershell
+python ./generate.py
+```
+
+#### 2.2 Server
+For optimal performance on server, it is recommended to set several environment variables (refer to [here](../README.md#best-known-configuration-on-linux) for more information), and run the example with all the physical cores of a single socket.
+
+E.g. on Linux,
+```bash
+# set IPEX-LLM env variables
+source ipex-llm-init -t
+
+# e.g. for a server with 48 cores per socket
+export OMP_NUM_THREADS=48
+numactl -C 0-47 -m 0 python ./generate.py
+```
+
+#### 2.3 Sample Output
+#### [CohereForAI/c4ai-command-r-v01](https://huggingface.co/CohereForAI/c4ai-command-r-v01)
+```log
+Inference time: xxxxx s
+-------------------- Prompt --------------------
+
+<|START_OF_TURN_TOKEN|><|USER_TOKEN|>What is AI?<|END_OF_TURN_TOKEN|><|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>
+
+-------------------- Output --------------------
+
+<|START_OF_TURN_TOKEN|><|USER_TOKEN|>What is AI?<|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>
+Artificial Intelligence, or AI, is a fascinating field of study that aims to create intelligent machines that can mimic human cognitive functions and perform complex tasks. AI strives to
+```
diff --git a/python/llm/example/CPU/PyTorch-Models/Model/cohere/generate.py b/python/llm/example/CPU/PyTorch-Models/Model/cohere/generate.py
new file mode 100644
index 00000000000..d215b00b153
--- /dev/null
+++ b/python/llm/example/CPU/PyTorch-Models/Model/cohere/generate.py
@@ -0,0 +1,69 @@
+#
+# Copyright 2016 The BigDL Authors.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+import torch
+import time
+import argparse
+
+from ipex_llm.transformers import AutoModelForCausalLM
+from transformers import AutoTokenizer
+
+# you could tune the prompt based on your own model,
+# Refer to https://huggingface.co/CohereForAI/c4ai-command-r-v01
+COHERE_PROMPT_FORMAT = """
+<|START_OF_TURN_TOKEN|><|USER_TOKEN|>{prompt}<|END_OF_TURN_TOKEN|><|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>
+"""
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser(description='Predict Tokens using `generate()` API for cohere model')
+ parser.add_argument('--repo-id-or-model-path', type=str, default="CohereForAI/c4ai-command-r-v01",
+ help='The huggingface repo id for the cohere to be downloaded'
+ ', or the path to the huggingface checkpoint folder')
+ parser.add_argument('--prompt', type=str, default="What is AI?",
+ help='Prompt to infer')
+ parser.add_argument('--n-predict', type=int, default=32,
+ help='Max tokens to predict')
+
+ args = parser.parse_args()
+ model_path = args.repo_id_or_model_path
+
+ # Load model in 4 bit,
+ # which convert the relevant layers in the model into INT4 format
+ model = AutoModelForCausalLM.from_pretrained(model_path,
+ load_in_4bit=True,
+ trust_remote_code=True)
+
+ # Load tokenizer
+ tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
+
+ # Generate predicted tokens
+ with torch.inference_mode():
+ prompt = COHERE_PROMPT_FORMAT.format(prompt=args.prompt)
+ input_ids = tokenizer.encode(prompt, return_tensors="pt")
+ st = time.time()
+ # if your selected model is capable of utilizing previous key/value attentions
+ # to enhance decoding speed, but has `"use_cache": false` in its model config,
+ # it is important to set `use_cache=True` explicitly in the `generate` function
+ # to obtain optimal performance with IPEX-LLM INT4 optimizations
+ output = model.generate(input_ids,
+ max_new_tokens=args.n_predict)
+ end = time.time()
+ output_str = tokenizer.decode(output[0], skip_special_tokens=True)
+ print(f'Inference time: {end-st} s')
+ print('-'*20, 'Prompt', '-'*20)
+ print(prompt)
+ print('-'*20, 'Output', '-'*20)
+ print(output_str)
diff --git a/python/llm/example/CPU/QLoRA-FineTuning/README.md b/python/llm/example/CPU/QLoRA-FineTuning/README.md
index 88106180d1e..e03e5683260 100644
--- a/python/llm/example/CPU/QLoRA-FineTuning/README.md
+++ b/python/llm/example/CPU/QLoRA-FineTuning/README.md
@@ -19,8 +19,8 @@ This example is ported from [bnb-4bit-training](https://colab.research.google.co
conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all]
-pip install transformers==4.34.0
-pip install peft==0.5.0
+pip install transformers==4.36.0
+pip install peft==0.10.0
pip install datasets
pip install accelerate==0.23.0
pip install bitsandbytes scipy
diff --git a/python/llm/example/CPU/QLoRA-FineTuning/alpaca-qlora/README.md b/python/llm/example/CPU/QLoRA-FineTuning/alpaca-qlora/README.md
index a3d0ba36e46..441926720cf 100644
--- a/python/llm/example/CPU/QLoRA-FineTuning/alpaca-qlora/README.md
+++ b/python/llm/example/CPU/QLoRA-FineTuning/alpaca-qlora/README.md
@@ -8,8 +8,8 @@ This example ports [Alpaca-LoRA](https://github.com/tloen/alpaca-lora/tree/main)
conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all]
-pip install datasets transformers==4.35.0
-pip install fire peft==0.5.0
+pip install datasets transformers==4.36.0
+pip install fire peft==0.10.0
pip install accelerate==0.23.0
pip install bitsandbytes scipy
```
diff --git a/python/llm/example/CPU/Speculative-Decoding/llama3/README.md b/python/llm/example/CPU/Speculative-Decoding/llama3/README.md
index bf7875ed64d..35d7eec0096 100644
--- a/python/llm/example/CPU/Speculative-Decoding/llama3/README.md
+++ b/python/llm/example/CPU/Speculative-Decoding/llama3/README.md
@@ -18,7 +18,8 @@ We suggest using conda to manage environment:
conda create -n llm python=3.11
conda activate llm
pip install --pre --upgrade ipex-llm[all]
-pip install intel_extension_for_pytorch==2.1.0
+# transformers>=4.33.0 is required for Llama3 with IPEX-LLM optimizations
+pip install transformers==4.37.0
```
### 2. Configures high-performing processor environment variables
diff --git a/python/llm/example/CPU/Speculative-Decoding/llama3/speculative.py b/python/llm/example/CPU/Speculative-Decoding/llama3/speculative.py
index f7eeb917bab..efb7215ec00 100644
--- a/python/llm/example/CPU/Speculative-Decoding/llama3/speculative.py
+++ b/python/llm/example/CPU/Speculative-Decoding/llama3/speculative.py
@@ -54,13 +54,13 @@ def get_prompt(user_input: str, chat_history: list[tuple[str, str]],
prompt_texts = [f'<|begin_of_text|>']
if system_prompt != '':
- prompt_texts.append(f'<|start_header_id|>system<|end_header_id|>\n{system_prompt}<|eot_id|>')
+ prompt_texts.append(f'<|start_header_id|>system<|end_header_id|>\n\n{system_prompt}<|eot_id|>')
for history_input, history_response in chat_history:
- prompt_texts.append(f'<|start_header_id|>user<|end_header_id|>\n{history_input.strip()}<|eot_id|>')
- prompt_texts.append(f'<|start_header_id|>assistant<|end_header_id|>\n{history_response.strip()}<|eot_id|>')
+ prompt_texts.append(f'<|start_header_id|>user<|end_header_id|>\n\n{history_input.strip()}<|eot_id|>')
+ prompt_texts.append(f'<|start_header_id|>assistant<|end_header_id|>\n\n{history_response.strip()}<|eot_id|>')
- prompt_texts.append(f'<|start_header_id|>user<|end_header_id|>\n{user_input.strip()}<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n')
+ prompt_texts.append(f'<|start_header_id|>user<|end_header_id|>\n\n{user_input.strip()}<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n')
return ''.join(prompt_texts)
if __name__ == '__main__':
@@ -89,7 +89,13 @@ def get_prompt(user_input: str, chat_history: list[tuple[str, str]],
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
-
+
+ # here the terminators refer to https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct#transformers-automodelforcausallm
+ terminators = [
+ tokenizer.eos_token_id,
+ tokenizer.convert_tokens_to_ids("<|eot_id|>"),
+ ]
+
# Generate predicted tokens
with torch.inference_mode():
prompt = get_prompt(args.prompt, [], system_prompt=DEFAULT_SYSTEM_PROMPT)
@@ -102,6 +108,7 @@ def get_prompt(user_input: str, chat_history: list[tuple[str, str]],
# warmup
output = model.generate(input_ids,
max_new_tokens=args.n_predict,
+ eos_token_id=terminators,
attention_mask=attention_mask,
do_sample=False)
output_str = tokenizer.decode(output[0])
@@ -110,6 +117,7 @@ def get_prompt(user_input: str, chat_history: list[tuple[str, str]],
st = time.perf_counter()
output = model.generate(input_ids,
max_new_tokens=args.n_predict,
+ eos_token_id=terminators,
attention_mask=attention_mask,
do_sample=False)
output_str = tokenizer.decode(output[0], skip_special_tokens=True)
diff --git a/python/llm/example/GPU/Deepspeed-AutoTP-FastAPI/README.md b/python/llm/example/GPU/Deepspeed-AutoTP-FastAPI/README.md
index 4903f6e789e..f99c673190f 100644
--- a/python/llm/example/GPU/Deepspeed-AutoTP-FastAPI/README.md
+++ b/python/llm/example/GPU/Deepspeed-AutoTP-FastAPI/README.md
@@ -38,6 +38,8 @@ Run Llama-2-7b-chat-hf on two Intel Arc A770:
# Before run this script, you should adjust the YOUR_REPO_ID_OR_MODEL_PATH in last line
# If you want to change server port, you can set port parameter in last line
+
+# To avoid GPU OOM, you could adjust --max-num-seqs and --max-num-batched-tokens parameters in below script
bash run_llama2_7b_chat_hf_arc_2_card.sh
```
@@ -82,3 +84,19 @@ And you should get output like this:
```
**Important**: The first token latency is much larger than rest token latency, you could use [our benchmark tool](https://github.com/intel-analytics/ipex-llm/blob/main/python/llm/dev/benchmark/README.md) to obtain more details about first and rest token latency.
+
+### 4. Benchmark with wrk
+
+We use wrk for testing end-to-end throughput, check [here](https://github.com/wg/wrk).
+
+You can install by:
+```bash
+sudo apt install wrk
+```
+
+Please change the test url accordingly.
+
+```bash
+# set t/c to the number of concurrencies to test full throughput.
+wrk -t1 -c1 -d5m -s ./wrk_script_1024.lua http://127.0.0.1:8000/generate/ --timeout 1m
+```
\ No newline at end of file
diff --git a/python/llm/example/GPU/Deepspeed-AutoTP-FastAPI/benchmark_util.py b/python/llm/example/GPU/Deepspeed-AutoTP-FastAPI/benchmark_util.py
new file mode 100644
index 00000000000..cbbd6c6a9e3
--- /dev/null
+++ b/python/llm/example/GPU/Deepspeed-AutoTP-FastAPI/benchmark_util.py
@@ -0,0 +1,4791 @@
+#
+# Copyright 2016 The BigDL Authors.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+# This file is adapted from
+# https://github.com/huggingface/transformers/blob/main/src/transformers/generation/utils.py
+
+# coding=utf-8
+# Copyright 2020 The Google AI Language Team Authors, Facebook AI Research authors and The HuggingFace Inc. team.
+# Copyright (c) 2020, NVIDIA CORPORATION. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import copy
+import inspect
+import warnings
+from dataclasses import dataclass
+from typing import TYPE_CHECKING, Any, Callable, Dict, List, Optional, Tuple, Union
+import time
+import numpy as np
+import torch
+import torch.distributed as dist
+from torch import nn
+
+from transformers.deepspeed import is_deepspeed_zero3_enabled
+from transformers.modeling_outputs import CausalLMOutputWithPast, Seq2SeqLMOutput
+from transformers.models.auto import (
+ MODEL_FOR_CAUSAL_IMAGE_MODELING_MAPPING,
+ MODEL_FOR_CAUSAL_LM_MAPPING,
+ MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING,
+ MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING,
+ MODEL_FOR_VISION_2_SEQ_MAPPING,
+)
+from transformers.utils import ModelOutput, logging
+from transformers.generation.beam_constraints import DisjunctiveConstraint, PhrasalConstraint
+from transformers.generation.beam_search import BeamScorer, BeamSearchScorer, ConstrainedBeamSearchScorer
+from transformers.generation.configuration_utils import GenerationConfig
+from transformers.generation.logits_process import (
+ EncoderNoRepeatNGramLogitsProcessor,
+ EncoderRepetitionPenaltyLogitsProcessor,
+ EpsilonLogitsWarper,
+ EtaLogitsWarper,
+ ExponentialDecayLengthPenalty,
+ ForcedBOSTokenLogitsProcessor,
+ ForcedEOSTokenLogitsProcessor,
+ ForceTokensLogitsProcessor,
+ HammingDiversityLogitsProcessor,
+ InfNanRemoveLogitsProcessor,
+ LogitNormalization,
+ LogitsProcessorList,
+ MinLengthLogitsProcessor,
+ MinNewTokensLengthLogitsProcessor,
+ NoBadWordsLogitsProcessor,
+ NoRepeatNGramLogitsProcessor,
+ PrefixConstrainedLogitsProcessor,
+ RepetitionPenaltyLogitsProcessor,
+ SuppressTokensAtBeginLogitsProcessor,
+ SuppressTokensLogitsProcessor,
+ TemperatureLogitsWarper,
+ TopKLogitsWarper,
+ TopPLogitsWarper,
+ TypicalLogitsWarper,
+)
+from transformers.generation.stopping_criteria import (
+ MaxLengthCriteria,
+ MaxTimeCriteria,
+ StoppingCriteria,
+ StoppingCriteriaList,
+ validate_stopping_criteria,
+)
+
+
+if TYPE_CHECKING:
+ from transformers.modeling_utils import PreTrainedModel
+ from transformers.generation.streamers import BaseStreamer
+
+logger = logging.get_logger(__name__)
+
+
+@dataclass
+class GreedySearchDecoderOnlyOutput(ModelOutput):
+ """
+ Base class for outputs of decoder-only generation models using greedy search.
+
+
+ Args:
+ sequences (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ The generated sequences. The second dimension (sequence_length) is either equal to `max_length` or shorter
+ if all batches finished early due to the `eos_token_id`.
+ scores (`tuple(torch.FloatTensor)` *optional*, returned when `output_scores=True` is passed or when `config.output_scores=True`):
+ Processed prediction scores of the language modeling head (scores for each vocabulary token before SoftMax)
+ at each generation step. Tuple of `torch.FloatTensor` with up to `max_new_tokens` elements (one element for
+ each generated token), with each tensor of shape `(batch_size, config.vocab_size)`.
+ attentions (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
+ Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
+ `torch.FloatTensor` of shape `(batch_size, num_heads, generated_length, sequence_length)`.
+ hidden_states (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
+ `torch.FloatTensor` of shape `(batch_size, generated_length, hidden_size)`.
+ """
+
+ sequences: torch.LongTensor = None
+ scores: Optional[Tuple[torch.FloatTensor]] = None
+ attentions: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ hidden_states: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+
+
+@dataclass
+class ContrastiveSearchEncoderDecoderOutput(ModelOutput):
+ """
+ Base class for outputs of decoder-only generation models using contrastive search.
+
+ Args:
+ sequences (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ The generated sequences. The second dimension (sequence_length) is either equal to `max_length` or shorter
+ if all batches finished early due to the `eos_token_id`.
+ scores (`tuple(torch.FloatTensor)` *optional*, returned when `output_scores=True` is passed or when `config.output_scores=True`):
+ Processed prediction scores of the language modeling head (scores for each vocabulary token before SoftMax)
+ at each generation step. Tuple of `torch.FloatTensor` with up to `max_new_tokens` elements (one element for
+ each generated token), with each tensor of shape `(batch_size, config.vocab_size)`.
+ encoder_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer of the decoder) of shape `(batch_size, num_heads,
+ sequence_length, sequence_length)`.
+ encoder_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
+ shape `(batch_size, sequence_length, hidden_size)`.
+ decoder_attentions (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
+ Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
+ `torch.FloatTensor` of shape `(batch_size, num_heads, generated_length, sequence_length)`.
+ cross_attentions (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
+ Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
+ `torch.FloatTensor` of shape `(batch_size, num_heads, generated_length, sequence_length)`.
+ decoder_hidden_states (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
+ `torch.FloatTensor` of shape `(batch_size, generated_length, hidden_size)`.
+ """
+
+ sequences: torch.LongTensor = None
+ scores: Optional[Tuple[torch.FloatTensor]] = None
+ encoder_attentions: Optional[Tuple[torch.FloatTensor]] = None
+ encoder_hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ decoder_attentions: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ cross_attentions: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ decoder_hidden_states: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+
+
+@dataclass
+class ContrastiveSearchDecoderOnlyOutput(ModelOutput):
+ """
+ Base class for outputs of decoder-only generation models using contrastive search.
+
+ Args:
+ sequences (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ The generated sequences. The second dimension (sequence_length) is either equal to `max_length` or shorter
+ if all batches finished early due to the `eos_token_id`.
+ scores (`tuple(torch.FloatTensor)` *optional*, returned when `output_scores=True` is passed or when
+ `config.output_scores=True`):
+ Processed prediction scores of the language modeling head (scores for each vocabulary token before SoftMax)
+ at each generation step. Tuple of `torch.FloatTensor` with up to `max_new_tokens` elements (one element for
+ each generated token), with each tensor of shape `(batch_size, config.vocab_size)`.
+ attentions (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
+ Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
+ `torch.FloatTensor` of shape `(batch_size, num_heads, generated_length, sequence_length)`.
+ hidden_states (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `output_hidden_states=True` is
+ passed or when `config.output_hidden_states=True`):
+ Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
+ `torch.FloatTensor` of shape `(batch_size, generated_length, hidden_size)`.
+ """
+
+ sequences: torch.LongTensor = None
+ scores: Optional[Tuple[torch.FloatTensor]] = None
+ attentions: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ hidden_states: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+
+
+@dataclass
+class GreedySearchEncoderDecoderOutput(ModelOutput):
+ """
+ Base class for outputs of encoder-decoder generation models using greedy search. Hidden states and attention
+ weights of the decoder (respectively the encoder) can be accessed via the encoder_attentions and the
+ encoder_hidden_states attributes (respectively the decoder_attentions and the decoder_hidden_states attributes)
+
+
+ Args:
+ sequences (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ The generated sequences. The second dimension (sequence_length) is either equal to `max_length` or shorter
+ if all batches finished early due to the `eos_token_id`.
+ scores (`tuple(torch.FloatTensor)` *optional*, returned when `output_scores=True` is passed or when `config.output_scores=True`):
+ Processed prediction scores of the language modeling head (scores for each vocabulary token before SoftMax)
+ at each generation step. Tuple of `torch.FloatTensor` with up to `max_new_tokens` elements (one element for
+ each generated token), with each tensor of shape `(batch_size, config.vocab_size)`.
+ encoder_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer of the decoder) of shape `(batch_size, num_heads,
+ sequence_length, sequence_length)`.
+ encoder_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
+ shape `(batch_size, sequence_length, hidden_size)`.
+ decoder_attentions (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
+ Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
+ `torch.FloatTensor` of shape `(batch_size, num_heads, generated_length, sequence_length)`.
+ cross_attentions (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
+ Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
+ `torch.FloatTensor` of shape `(batch_size, num_heads, generated_length, sequence_length)`.
+ decoder_hidden_states (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
+ `torch.FloatTensor` of shape `(batch_size, generated_length, hidden_size)`.
+ """
+
+ sequences: torch.LongTensor = None
+ scores: Optional[Tuple[torch.FloatTensor]] = None
+ encoder_attentions: Optional[Tuple[torch.FloatTensor]] = None
+ encoder_hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ decoder_attentions: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ cross_attentions: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ decoder_hidden_states: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+
+
+@dataclass
+class SampleDecoderOnlyOutput(ModelOutput):
+ """
+ Base class for outputs of decoder-only generation models using sampling.
+
+
+ Args:
+ sequences (`torch.LongTensor` of shape `(batch_size*num_return_sequences, sequence_length)`):
+ The generated sequences. The second dimension (sequence_length) is either equal to `max_length` or shorter
+ if all batches finished early due to the `eos_token_id`.
+ scores (`tuple(torch.FloatTensor)` *optional*, returned when `output_scores=True` is passed or when `config.output_scores=True`):
+ Processed prediction scores of the language modeling head (scores for each vocabulary token before SoftMax)
+ at each generation step. Tuple of `torch.FloatTensor` with up to `max_new_tokens` elements (one element for
+ each generated token), with each tensor of shape `(batch_size*num_return_sequences, config.vocab_size)`.
+ attentions (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
+ Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
+ `torch.FloatTensor` of shape `(num_return_sequences*batch_size, num_heads, generated_length,
+ sequence_length)`.
+ hidden_states (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
+ `torch.FloatTensor` of shape `(num_return_sequences*batch_size, generated_length, hidden_size)`.
+ """
+
+ sequences: torch.LongTensor = None
+ scores: Optional[Tuple[torch.FloatTensor]] = None
+ attentions: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ hidden_states: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+
+
+@dataclass
+class SampleEncoderDecoderOutput(ModelOutput):
+ """
+ Base class for outputs of encoder-decoder generation models using sampling. Hidden states and attention weights of
+ the decoder (respectively the encoder) can be accessed via the encoder_attentions and the encoder_hidden_states
+ attributes (respectively the decoder_attentions and the decoder_hidden_states attributes)
+
+
+ Args:
+ sequences (`torch.LongTensor` of shape `(batch_size*num_return_sequences, sequence_length)`):
+ The generated sequences. The second dimension (sequence_length) is either equal to `max_length` or shorter
+ if all batches finished early due to the `eos_token_id`.
+ scores (`tuple(torch.FloatTensor)` *optional*, returned when `output_scores=True` is passed or when `config.output_scores=True`):
+ Processed prediction scores of the language modeling head (scores for each vocabulary token before SoftMax)
+ at each generation step. Tuple of `torch.FloatTensor` with up to `max_new_tokens` elements (one element for
+ each generated token), with each tensor of shape `(batch_size*num_return_sequences, config.vocab_size)`.
+ encoder_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer of the decoder) of shape
+ `(batch_size*num_return_sequences, num_heads, sequence_length, sequence_length)`.
+ encoder_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
+ shape `(batch_size*num_return_sequences, sequence_length, hidden_size)`.
+ decoder_attentions (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
+ Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
+ `torch.FloatTensor` of shape `(batch_size*num_return_sequences, num_heads, generated_length,
+ sequence_length)`.
+ cross_attentions (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
+ Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
+ `torch.FloatTensor` of shape `(batch_size, num_heads, generated_length, sequence_length)`.
+ decoder_hidden_states (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
+ `torch.FloatTensor` of shape `(batch_size*num_return_sequences, generated_length, hidden_size)`.
+ """
+
+ sequences: torch.LongTensor = None
+ scores: Optional[Tuple[torch.FloatTensor]] = None
+ encoder_attentions: Optional[Tuple[torch.FloatTensor]] = None
+ encoder_hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ decoder_attentions: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ cross_attentions: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ decoder_hidden_states: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+
+
+@dataclass
+class BeamSearchDecoderOnlyOutput(ModelOutput):
+ """
+ Base class for outputs of decoder-only generation models using beam search.
+
+ Args:
+ sequences (`torch.LongTensor` of shape `(batch_size*num_return_sequences, sequence_length)`):
+ The generated sequences. The second dimension (sequence_length) is either equal to `max_length` or shorter
+ if all batches finished early due to the `eos_token_id`.
+ sequences_scores (`torch.FloatTensor` of shape `(batch_size*num_return_sequences)`, *optional*, returned when `output_scores=True` is passed or when `config.output_scores=True`):
+ Final beam scores of the generated `sequences`.
+ scores (`tuple(torch.FloatTensor)` *optional*, returned when `output_scores=True` is passed or when `config.output_scores=True`):
+ Beam transition scores for each vocabulary token at each generation step. Beam transition scores consisting
+ of log probabilities of tokens conditioned on log softmax of previously generated tokens in this beam.
+ Tuple of `torch.FloatTensor` with up to `max_new_tokens` elements (one element for each generated token),
+ with each tensor of shape `(batch_size*num_beams*num_return_sequences, config.vocab_size)`.
+ beam_indices (`torch.LongTensor`, *optional*, returned when `output_scores=True` is passed or when `config.output_scores=True`):
+ Beam indices of generated token id at each generation step. `torch.LongTensor` of shape
+ `(batch_size*num_return_sequences, sequence_length)`.
+ attentions (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
+ Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
+ `torch.FloatTensor` of shape `(batch_size*num_beams, num_heads, generated_length, sequence_length)`.
+ hidden_states (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
+ `torch.FloatTensor` of shape `(batch_size*num_beams*num_return_sequences, generated_length, hidden_size)`.
+ """
+
+ sequences: torch.LongTensor = None
+ sequences_scores: Optional[torch.FloatTensor] = None
+ scores: Optional[Tuple[torch.FloatTensor]] = None
+ beam_indices: Optional[torch.LongTensor] = None
+ attentions: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ hidden_states: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+
+
+@dataclass
+class BeamSearchEncoderDecoderOutput(ModelOutput):
+ """
+ Base class for outputs of encoder-decoder generation models using beam search. Hidden states and attention weights
+ of the decoder (respectively the encoder) can be accessed via the encoder_attentions and the encoder_hidden_states
+ attributes (respectively the decoder_attentions and the decoder_hidden_states attributes)
+
+ Args:
+ sequences (`torch.LongTensor` of shape `(batch_size*num_return_sequences, sequence_length)`):
+ The generated sequences. The second dimension (sequence_length) is either equal to `max_length` or shorter
+ if all batches finished early due to the `eos_token_id`.
+ sequences_scores (`torch.FloatTensor` of shape `(batch_size*num_return_sequences)`, *optional*, returned when `output_scores=True` is passed or when `config.output_scores=True`):
+ Final beam scores of the generated `sequences`.
+ scores (`tuple(torch.FloatTensor)` *optional*, returned when `output_scores=True` is passed or when `config.output_scores=True`):
+ Beam transition scores for each vocabulary token at each generation step. Beam transition scores consisting
+ of log probabilities of tokens conditioned on log softmax of previously generated tokens in this beam.
+ Tuple of `torch.FloatTensor` with up to `max_new_tokens` elements (one element for each generated token),
+ with each tensor of shape `(batch_size*num_beams, config.vocab_size)`.
+ beam_indices (`torch.LongTensor`, *optional*, returned when `output_scores=True` is passed or when `config.output_scores=True`):
+ Beam indices of generated token id at each generation step. `torch.LongTensor` of shape
+ `(batch_size*num_return_sequences, sequence_length)`.
+ encoder_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer of the decoder) of shape `(batch_size, num_heads,
+ sequence_length, sequence_length)`.
+ encoder_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
+ shape `(batch_size*num_beams*num_return_sequences, sequence_length, hidden_size)`.
+ decoder_attentions (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
+ Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
+ `torch.FloatTensor` of shape `(batch_size*num_beams*num_return_sequences, num_heads, generated_length,
+ sequence_length)`.
+ cross_attentions (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
+ Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
+ `torch.FloatTensor` of shape `(batch_size, num_heads, generated_length, sequence_length)`.
+ decoder_hidden_states (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
+ `torch.FloatTensor` of shape `(batch_size*num_beams*num_return_sequences, generated_length, hidden_size)`.
+ """
+
+ sequences: torch.LongTensor = None
+ sequences_scores: Optional[torch.FloatTensor] = None
+ scores: Optional[Tuple[torch.FloatTensor]] = None
+ beam_indices: Optional[torch.LongTensor] = None
+ encoder_attentions: Optional[Tuple[torch.FloatTensor]] = None
+ encoder_hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ decoder_attentions: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ cross_attentions: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ decoder_hidden_states: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+
+
+@dataclass
+class BeamSampleDecoderOnlyOutput(ModelOutput):
+ """
+ Base class for outputs of decoder-only generation models using beam sample.
+
+ Args:
+ sequences (`torch.LongTensor` of shape `(batch_size*num_return_sequences, sequence_length)`):
+ The generated sequences. The second dimension (sequence_length) is either equal to `max_length` or shorter
+ if all batches finished early due to the `eos_token_id`.
+ sequences_scores (`torch.FloatTensor` of shape `(batch_size * num_return_sequence)`, *optional*, returned when `output_scores=True` is passed or when `config.output_scores=True`):
+ Final beam scores of the generated `sequences`.
+ scores (`tuple(torch.FloatTensor)` *optional*, returned when `output_scores=True` is passed or when `config.output_scores=True`):
+ Beam transition scores for each vocabulary token at each generation step. Beam transition scores consisting
+ of log probabilities of tokens conditioned on log softmax of previously generated tokens in this beam.
+ Tuple of `torch.FloatTensor` with up to `max_new_tokens` elements (one element for each generated token),
+ with each tensor of shape `(batch_size*num_beams*num_return_sequences, config.vocab_size)`.
+ beam_indices (`torch.LongTensor`, *optional*, returned when `output_scores=True` is passed or when `config.output_scores=True`):
+ Beam indices of generated token id at each generation step. `torch.LongTensor` of shape
+ `(batch_size*num_return_sequences, sequence_length)`.
+ attentions (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
+ Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
+ `torch.FloatTensor` of shape `(batch_size*num_beams, num_heads, generated_length, sequence_length)`.
+ hidden_states (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
+ `torch.FloatTensor` of shape `(batch_size*num_beams, generated_length, hidden_size)`.
+ """
+
+ sequences: torch.LongTensor = None
+ sequences_scores: Optional[torch.FloatTensor] = None
+ scores: Optional[Tuple[torch.FloatTensor]] = None
+ beam_indices: Optional[torch.LongTensor] = None
+ attentions: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ hidden_states: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+
+
+@dataclass
+class BeamSampleEncoderDecoderOutput(ModelOutput):
+ """
+ Base class for outputs of encoder-decoder generation models using beam sampling. Hidden states and attention
+ weights of the decoder (respectively the encoder) can be accessed via the encoder_attentions and the
+ encoder_hidden_states attributes (respectively the decoder_attentions and the decoder_hidden_states attributes)
+
+ Args:
+ sequences (`torch.LongTensor` of shape `(batch_size*num_beams, sequence_length)`):
+ The generated sequences. The second dimension (sequence_length) is either equal to `max_length` or shorter
+ if all batches finished early due to the `eos_token_id`.
+ sequences_scores (`torch.FloatTensor` of shape `(batch_size * num_return_sequence)`, *optional*, returned when `output_scores=True` is passed or when `config.output_scores=True`):
+ Final beam scores of the generated `sequences`.
+ scores (`tuple(torch.FloatTensor)` *optional*, returned when `output_scores=True` is passed or when `config.output_scores=True`):
+ Beam transition scores for each vocabulary token at each generation step. Beam transition scores consisting
+ of log probabilities of tokens conditioned on log softmax of previously generated tokens in this beam.
+ Tuple of `torch.FloatTensor` with up to `max_new_tokens` elements (one element for each generated token),
+ with each tensor of shape `(batch_size*num_beams, config.vocab_size)`).
+ beam_indices (`torch.LongTensor`, *optional*, returned when `output_scores=True` is passed or when `config.output_scores=True`):
+ Beam indices of generated token id at each generation step. `torch.LongTensor` of shape
+ `(batch_size*num_return_sequences, sequence_length)`.
+ encoder_attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
+ Tuple of `torch.FloatTensor` (one for each layer of the decoder) of shape `(batch_size, num_heads,
+ sequence_length, sequence_length)`.
+ encoder_hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
+ shape `(batch_size*num_beams, sequence_length, hidden_size)`.
+ decoder_attentions (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
+ Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
+ `torch.FloatTensor` of shape `(batch_size*num_beams, num_heads, generated_length, sequence_length)`.
+ cross_attentions (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
+ Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
+ `torch.FloatTensor` of shape `(batch_size, num_heads, generated_length, sequence_length)`.
+ decoder_hidden_states (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
+ Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
+ `torch.FloatTensor` of shape `(batch_size*num_beams, generated_length, hidden_size)`.
+ """
+
+ sequences: torch.LongTensor = None
+ sequences_scores: Optional[torch.FloatTensor] = None
+ scores: Optional[Tuple[torch.FloatTensor]] = None
+ beam_indices: Optional[torch.LongTensor] = None
+ encoder_attentions: Optional[Tuple[torch.FloatTensor]] = None
+ encoder_hidden_states: Optional[Tuple[torch.FloatTensor]] = None
+ decoder_attentions: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ cross_attentions: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+ decoder_hidden_states: Optional[Tuple[Tuple[torch.FloatTensor]]] = None
+
+
+GreedySearchOutput = Union[GreedySearchEncoderDecoderOutput, GreedySearchDecoderOnlyOutput]
+SampleOutput = Union[SampleEncoderDecoderOutput, SampleDecoderOnlyOutput]
+BeamSearchOutput = Union[BeamSearchEncoderDecoderOutput, BeamSearchDecoderOnlyOutput]
+BeamSampleOutput = Union[BeamSampleEncoderDecoderOutput, BeamSampleDecoderOnlyOutput]
+ContrastiveSearchOutput = Union[ContrastiveSearchEncoderDecoderOutput, ContrastiveSearchDecoderOnlyOutput]
+GenerateOutput = Union[GreedySearchOutput, SampleOutput, BeamSearchOutput, BeamSampleOutput, ContrastiveSearchOutput]
+
+
+class BenchmarkWrapper:
+ """
+ A class containing all functions for auto-regressive text generation, to be used as a mixin in [`PreTrainedModel`].
+
+ The class exposes [`~generation.GenerationMixin.generate`], which can be used for:
+ - *greedy decoding* by calling [`~generation.GenerationMixin.greedy_search`] if `num_beams=1` and
+ `do_sample=False`
+ - *contrastive search* by calling [`~generation.GenerationMixin.contrastive_search`] if `penalty_alpha>0` and
+ `top_k>1`
+ - *multinomial sampling* by calling [`~generation.GenerationMixin.sample`] if `num_beams=1` and
+ `do_sample=True`
+ - *beam-search decoding* by calling [`~generation.GenerationMixin.beam_search`] if `num_beams>1` and
+ `do_sample=False`
+ - *beam-search multinomial sampling* by calling [`~generation.GenerationMixin.beam_sample`] if `num_beams>1`
+ and `do_sample=True`
+ - *diverse beam-search decoding* by calling [`~generation.GenerationMixin.group_beam_search`], if `num_beams>1`
+ and `num_beam_groups>1`
+ - *constrained beam-search decoding* by calling [`~generation.GenerationMixin.constrained_beam_search`], if
+ `constraints!=None` or `force_words_ids!=None`
+
+ You do not need to call any of the above methods directly. Pass custom parameter values to 'generate' instead. To
+ learn more about decoding strategies refer to the [text generation strategies guide](../generation_strategies).
+ """
+
+ def __init__(self, model, do_print=False, verbose=False):
+ self.model = model
+ self.do_print = do_print
+ self.verbose = verbose
+ self.encoder_time = 0.0
+ self.first_cost = 0.0
+ self.rest_cost_mean = 0.0
+ self.peak_memory = 0.0
+ print(self.model.__class__)
+
+ def __getattr__(self, attr):
+ if hasattr(self.model, attr):
+ return getattr(self.model, attr)
+ else:
+ raise AttributeError(f"'{type(self).__name__}' object and its model have no attribute '{attr}'")
+
+ def prepare_inputs_for_generation(self, *args, **kwargs):
+ return self.model.prepare_inputs_for_generation(*args, **kwargs)
+
+ def __call__(self, *args, **kwargs):
+ return self.model(*args, **kwargs)
+
+ def _prepare_model_inputs(
+ self,
+ inputs: Optional[torch.Tensor] = None,
+ bos_token_id: Optional[int] = None,
+ model_kwargs: Optional[Dict[str, torch.Tensor]] = None,
+ ) -> Tuple[torch.Tensor, Optional[str], Dict[str, torch.Tensor]]:
+ """
+ This function extracts the model-specific `inputs` for generation.
+ """
+ # 1. retrieve all kwargs that are non-None or non-model input related.
+ # some encoder-decoder models have different names for model and encoder
+ if (
+ self.config.is_encoder_decoder
+ and hasattr(self, "encoder")
+ and self.encoder.main_input_name != self.main_input_name
+ ):
+ input_name = self.encoder.main_input_name
+ else:
+ input_name = self.main_input_name
+
+ model_kwargs = {k: v for k, v in model_kwargs.items() if v is not None or k != input_name}
+
+ # 2. check whether model_input_name is passed as kwarg
+ # if yes and `inputs` is None use kwarg inputs
+ inputs_kwarg = model_kwargs.pop(input_name, None)
+ if inputs_kwarg is not None and inputs is not None:
+ raise ValueError(
+ f"`inputs`: {inputs}` were passed alongside {input_name} which is not allowed."
+ f"Make sure to either pass {inputs} or {input_name}=..."
+ )
+ elif inputs_kwarg is not None:
+ inputs = inputs_kwarg
+
+ # 3. In the presence of `inputs_embeds` for text models:
+ # - decoder-only models should complain if the user attempts to pass `inputs_embeds`, but the model
+ # doesn't have its forwarding implemented. `inputs_embeds` is kept in `model_kwargs` and can coexist with
+ # input_ids (`inputs_embeds` will be used in the 1st generation step, as opposed to `input_ids`)
+ # - encoder-decoder models should complain if the user attempts to pass `inputs_embeds` and `input_ids`, and
+ # pull the former to inputs. It will be used in place of `input_ids` to get the encoder hidden states.
+ if input_name == "input_ids" and "inputs_embeds" in model_kwargs:
+ if not self.config.is_encoder_decoder:
+ has_inputs_embeds_forwarding = "inputs_embeds" in set(
+ inspect.signature(self.prepare_inputs_for_generation).parameters.keys()
+ )
+ if not has_inputs_embeds_forwarding:
+ raise ValueError(
+ f"You passed `inputs_embeds` to `.generate()`, but the model class {self.__class__.__name__} "
+ "doesn't have its forwarding implemented. See the GPT2 implementation for an example "
+ "(https://github.com/huggingface/transformers/pull/21405), and feel free to open a PR with it!"
+ )
+ # In this case, `input_ids` is moved to the `model_kwargs`, so a few automations (like the creation of
+ # the attention mask) can rely on the actual model input.
+ model_kwargs["input_ids"] = self._maybe_initialize_input_ids_for_generation(
+ inputs, bos_token_id, model_kwargs=model_kwargs
+ )
+ else:
+ if inputs is not None:
+ raise ValueError("You passed `inputs_embeds` and `input_ids` to `.generate()`. Please pick one.")
+ inputs, input_name = model_kwargs["inputs_embeds"], "inputs_embeds"
+
+ # 4. if `inputs` is still None, try to create `input_ids` from BOS token
+ inputs = self._maybe_initialize_input_ids_for_generation(inputs, bos_token_id, model_kwargs)
+ return inputs, input_name, model_kwargs
+
+ def adjust_logits_during_generation(self, logits: torch.FloatTensor, **kwargs) -> torch.FloatTensor:
+ """
+ Implement in subclasses of [`PreTrainedModel`] for custom behavior to adjust the logits in the generate method.
+ """
+ return logits
+
+ def _maybe_initialize_input_ids_for_generation(
+ self,
+ inputs: Optional[torch.Tensor] = None,
+ bos_token_id: Optional[int] = None,
+ model_kwargs: Optional[Dict[str, torch.Tensor]] = None,
+ ) -> torch.LongTensor:
+ """Initializes input ids for generation, if necessary."""
+ if inputs is not None:
+ return inputs
+
+ encoder_outputs = model_kwargs.get("encoder_outputs")
+ if self.config.is_encoder_decoder and encoder_outputs is not None:
+ # make dummy input_ids with value -100, as a sanity check ensuring that they won't be used for encoding
+ shape = encoder_outputs.last_hidden_state.size()[:-1]
+ return torch.ones(shape, dtype=torch.long, device=self.device) * -100
+
+ if bos_token_id is None:
+ raise ValueError("`bos_token_id` has to be defined when no `input_ids` are provided.")
+
+ # If there is some tensor in `model_kwargs`, we can infer the batch size from it. This is helpful with
+ # soft-prompting or in multimodal implementations built on top of decoder-only language models.
+ batch_size = 1
+ for value in model_kwargs.values():
+ if isinstance(value, torch.Tensor):
+ batch_size = value.shape[0]
+ break
+ return torch.ones((batch_size, 1), dtype=torch.long, device=self.device) * bos_token_id
+
+ def _prepare_attention_mask_for_generation(
+ self,
+ inputs: torch.Tensor,
+ pad_token_id: Optional[int],
+ eos_token_id: Optional[Union[int, List[int]]],
+ ) -> torch.LongTensor:
+ is_input_ids = len(inputs.shape) == 2 and inputs.dtype in [torch.int, torch.long]
+ is_pad_token_in_inputs = (pad_token_id is not None) and (pad_token_id in inputs)
+ if isinstance(eos_token_id, int):
+ eos_token_id = [eos_token_id]
+ is_pad_token_not_equal_to_eos_token_id = (eos_token_id is None) or (pad_token_id not in eos_token_id)
+
+ # Check if input is input_ids and padded -> only then is attention_mask defined
+ if is_input_ids and is_pad_token_in_inputs and is_pad_token_not_equal_to_eos_token_id:
+ return inputs.ne(pad_token_id).long()
+ else:
+ return torch.ones(inputs.shape[:2], dtype=torch.long, device=inputs.device)
+
+ def _prepare_encoder_decoder_kwargs_for_generation(
+ self, inputs_tensor: torch.Tensor, model_kwargs, model_input_name: Optional[str] = None
+ ) -> Dict[str, Any]:
+ # 1. get encoder
+ encoder = self.get_encoder()
+ # Compatibility with Accelerate big model inference: we need the encoder to outputs stuff on the same device
+ # as the inputs.
+ if hasattr(encoder, "_hf_hook"):
+ encoder._hf_hook.io_same_device = True
+
+ # 2. Prepare encoder args and encoder kwargs from model kwargs.
+ irrelevant_prefix = ["decoder_", "cross_attn", "use_cache"]
+ encoder_kwargs = {
+ argument: value
+ for argument, value in model_kwargs.items()
+ if not any(argument.startswith(p) for p in irrelevant_prefix)
+ }
+ encoder_signature = set(inspect.signature(encoder.forward).parameters)
+ encoder_accepts_wildcard = "kwargs" in encoder_signature or "model_kwargs" in encoder_signature
+ if not encoder_accepts_wildcard:
+ encoder_kwargs = {
+ argument: value for argument, value in encoder_kwargs.items() if argument in encoder_signature
+ }
+
+ # 3. make sure that encoder returns `ModelOutput`
+ model_input_name = model_input_name if model_input_name is not None else self.main_input_name
+ encoder_kwargs["return_dict"] = True
+ encoder_kwargs[model_input_name] = inputs_tensor
+ model_kwargs["encoder_outputs"]: ModelOutput = encoder(**encoder_kwargs)
+
+ return model_kwargs
+
+ def _prepare_decoder_input_ids_for_generation(
+ self,
+ batch_size: int,
+ model_input_name: str,
+ model_kwargs: Dict[str, torch.Tensor],
+ decoder_start_token_id: int = None,
+ bos_token_id: int = None,
+ device: torch.device = None,
+ ) -> Tuple[torch.LongTensor, Dict[str, torch.Tensor]]:
+ """Prepares `decoder_input_ids` for generation with encoder-decoder models"""
+ # 1. Check whether the user has defined `decoder_input_ids` manually. To facilitate in terms of input naming,
+ # we also allow the user to pass it under `input_ids`, if the encoder does not use it as the main input.
+ if model_kwargs is not None and "decoder_input_ids" in model_kwargs:
+ decoder_input_ids = model_kwargs.pop("decoder_input_ids")
+ elif "input_ids" in model_kwargs and model_input_name != "input_ids":
+ decoder_input_ids = model_kwargs.pop("input_ids")
+ else:
+ decoder_input_ids = None
+
+ # 2. Encoder-decoder models expect the `decoder_input_ids` to start with a special token. Let's ensure that.
+ decoder_start_token_id = self._get_decoder_start_token_id(decoder_start_token_id, bos_token_id)
+ if device is None:
+ device = self.device
+ decoder_input_ids_start = torch.ones((batch_size, 1), dtype=torch.long, device=device) * decoder_start_token_id
+
+ # no user input -> use decoder_start_token_id as decoder_input_ids
+ if decoder_input_ids is None:
+ decoder_input_ids = decoder_input_ids_start
+ # exception: Donut checkpoints have task-specific decoder starts and don't expect a BOS token
+ elif self.config.model_type == "vision-encoder-decoder" and "donut" in self.name_or_path.lower():
+ pass
+ # user input but doesn't start with decoder_start_token_id -> prepend decoder_start_token_id (and adjust
+ # decoder_attention_mask if provided)
+ elif (decoder_input_ids[:, 0] != decoder_start_token_id).all().item():
+ decoder_input_ids = torch.cat([decoder_input_ids_start, decoder_input_ids], dim=-1)
+ if "decoder_attention_mask" in model_kwargs:
+ decoder_attention_mask = model_kwargs["decoder_attention_mask"]
+ decoder_attention_mask = torch.cat(
+ (torch.ones_like(decoder_attention_mask)[:, :1], decoder_attention_mask),
+ dim=-1,
+ )
+ model_kwargs["decoder_attention_mask"] = decoder_attention_mask
+
+ return decoder_input_ids, model_kwargs
+
+ def _get_decoder_start_token_id(self, decoder_start_token_id: int = None, bos_token_id: int = None) -> int:
+ decoder_start_token_id = (
+ decoder_start_token_id
+ if decoder_start_token_id is not None
+ else self.generation_config.decoder_start_token_id
+ )
+ bos_token_id = bos_token_id if bos_token_id is not None else self.generation_config.bos_token_id
+
+ if decoder_start_token_id is not None:
+ return decoder_start_token_id
+ elif bos_token_id is not None:
+ return bos_token_id
+ raise ValueError(
+ "`decoder_start_token_id` or `bos_token_id` has to be defined for encoder-decoder generation."
+ )
+
+ @staticmethod
+ def _expand_inputs_for_generation(
+ expand_size: int = 1,
+ is_encoder_decoder: bool = False,
+ input_ids: Optional[torch.LongTensor] = None,
+ **model_kwargs,
+ ) -> Tuple[torch.LongTensor, Dict[str, Any]]:
+ """Expands tensors from [batch_size, ...] to [batch_size * expand_size, ...]"""
+
+ def _expand_dict_for_generation(dict_to_expand):
+ for key in dict_to_expand:
+ if dict_to_expand[key] is not None and isinstance(dict_to_expand[key], torch.Tensor):
+ dict_to_expand[key] = dict_to_expand[key].repeat_interleave(expand_size, dim=0)
+ return dict_to_expand
+
+ if input_ids is not None:
+ input_ids = input_ids.repeat_interleave(expand_size, dim=0)
+
+ model_kwargs = _expand_dict_for_generation(model_kwargs)
+
+ if is_encoder_decoder:
+ if model_kwargs.get("encoder_outputs") is None:
+ raise ValueError("If `is_encoder_decoder` is True, make sure that `encoder_outputs` is defined.")
+ model_kwargs["encoder_outputs"] = _expand_dict_for_generation(model_kwargs["encoder_outputs"])
+
+ return input_ids, model_kwargs
+
+ def _extract_past_from_model_output(self, outputs: ModelOutput, standardize_cache_format: bool = False):
+ past_key_values = None
+ if "past_key_values" in outputs:
+ past_key_values = outputs.past_key_values
+ elif "mems" in outputs:
+ past_key_values = outputs.mems
+ elif "past_buckets_states" in outputs:
+ past_key_values = outputs.past_buckets_states
+
+ # Bloom fix: standardizes the cache format when requested
+ if standardize_cache_format and hasattr(self, "_convert_to_standard_cache"):
+ batch_size = outputs.logits.shape[0]
+ past_key_values = self._convert_to_standard_cache(past_key_values, batch_size=batch_size)
+ return past_key_values
+
+ def _update_model_kwargs_for_generation(
+ self,
+ outputs: ModelOutput,
+ model_kwargs: Dict[str, Any],
+ is_encoder_decoder: bool = False,
+ standardize_cache_format: bool = False,
+ ) -> Dict[str, Any]:
+ # update past_key_values
+ if hasattr(self.model, "_update_model_kwargs_for_generation"):
+ return self.model._update_model_kwargs_for_generation(outputs, model_kwargs, is_encoder_decoder, standardize_cache_format)
+ model_kwargs["past_key_values"] = self._extract_past_from_model_output(
+ outputs, standardize_cache_format=standardize_cache_format
+ )
+ if getattr(outputs, "state", None) is not None:
+ model_kwargs["state"] = outputs.state
+
+ # update token_type_ids with last value
+ if "token_type_ids" in model_kwargs:
+ token_type_ids = model_kwargs["token_type_ids"]
+ model_kwargs["token_type_ids"] = torch.cat([token_type_ids, token_type_ids[:, -1].unsqueeze(-1)], dim=-1)
+
+ if not is_encoder_decoder:
+ # update attention mask
+ if "attention_mask" in model_kwargs:
+ attention_mask = model_kwargs["attention_mask"]
+ model_kwargs["attention_mask"] = torch.cat(
+ [attention_mask, attention_mask.new_ones((attention_mask.shape[0], 1))], dim=-1
+ )
+ else:
+ # update decoder attention mask
+ if "decoder_attention_mask" in model_kwargs:
+ decoder_attention_mask = model_kwargs["decoder_attention_mask"]
+ model_kwargs["decoder_attention_mask"] = torch.cat(
+ [decoder_attention_mask, decoder_attention_mask.new_ones((decoder_attention_mask.shape[0], 1))],
+ dim=-1,
+ )
+
+ return model_kwargs
+
+ def _reorder_cache(self, past_key_values, beam_idx):
+ return self.model._reorder_cache(past_key_values, beam_idx)
+
+ def _get_logits_warper(
+ self,
+ generation_config: GenerationConfig,
+ ) -> LogitsProcessorList:
+ """
+ This class returns a [`LogitsProcessorList`] list object that contains all relevant [`LogitsWarper`] instances
+ used for multinomial sampling.
+ """
+
+ # instantiate warpers list
+ warpers = LogitsProcessorList()
+
+ # the following idea is largely copied from this PR: https://github.com/huggingface/transformers/pull/5420/files
+ # all samplers can be found in `generation_utils_samplers.py`
+ if generation_config.temperature is not None and generation_config.temperature != 1.0:
+ warpers.append(TemperatureLogitsWarper(generation_config.temperature))
+ min_tokens_to_keep = 2 if generation_config.num_beams > 1 else 1
+ if generation_config.top_k is not None and generation_config.top_k != 0:
+ warpers.append(TopKLogitsWarper(top_k=generation_config.top_k, min_tokens_to_keep=min_tokens_to_keep))
+ if generation_config.top_p is not None and generation_config.top_p < 1.0:
+ warpers.append(TopPLogitsWarper(top_p=generation_config.top_p, min_tokens_to_keep=min_tokens_to_keep))
+ if generation_config.typical_p is not None and generation_config.typical_p < 1.0:
+ warpers.append(
+ TypicalLogitsWarper(mass=generation_config.typical_p, min_tokens_to_keep=min_tokens_to_keep)
+ )
+ if generation_config.epsilon_cutoff is not None and 0.0 < generation_config.epsilon_cutoff < 1.0:
+ warpers.append(
+ EpsilonLogitsWarper(epsilon=generation_config.epsilon_cutoff, min_tokens_to_keep=min_tokens_to_keep)
+ )
+ if generation_config.eta_cutoff is not None and 0.0 < generation_config.eta_cutoff < 1.0:
+ warpers.append(
+ EtaLogitsWarper(epsilon=generation_config.eta_cutoff, min_tokens_to_keep=min_tokens_to_keep)
+ )
+ # `LogitNormalization` should always be the last logit processor, when present
+ if generation_config.renormalize_logits is True:
+ warpers.append(LogitNormalization())
+ return warpers
+
+ def _get_logits_processor(
+ self,
+ generation_config: GenerationConfig,
+ input_ids_seq_length: int,
+ encoder_input_ids: torch.LongTensor,
+ prefix_allowed_tokens_fn: Callable[[int, torch.Tensor], List[int]],
+ logits_processor: Optional[LogitsProcessorList],
+ ) -> LogitsProcessorList:
+ """
+ This class returns a [`LogitsProcessorList`] list object that contains all relevant [`LogitsProcessor`]
+ instances used to modify the scores of the language model head.
+ """
+ # instantiate processors list
+ processors = LogitsProcessorList()
+
+ # the following idea is largely copied from this PR: https://github.com/huggingface/transformers/pull/5420/files
+ # all samplers can be found in `generation_utils_samplers.py`
+ if generation_config.diversity_penalty is not None and generation_config.diversity_penalty > 0.0:
+ processors.append(
+ HammingDiversityLogitsProcessor(
+ diversity_penalty=generation_config.diversity_penalty,
+ num_beams=generation_config.num_beams,
+ num_beam_groups=generation_config.num_beam_groups,
+ )
+ )
+ if (
+ generation_config.encoder_repetition_penalty is not None
+ and generation_config.encoder_repetition_penalty != 1.0
+ ):
+ processors.append(
+ EncoderRepetitionPenaltyLogitsProcessor(
+ penalty=generation_config.encoder_repetition_penalty, encoder_input_ids=encoder_input_ids
+ )
+ )
+ if generation_config.repetition_penalty is not None and generation_config.repetition_penalty != 1.0:
+ processors.append(RepetitionPenaltyLogitsProcessor(penalty=generation_config.repetition_penalty))
+ if generation_config.no_repeat_ngram_size is not None and generation_config.no_repeat_ngram_size > 0:
+ processors.append(NoRepeatNGramLogitsProcessor(generation_config.no_repeat_ngram_size))
+ if (
+ generation_config.encoder_no_repeat_ngram_size is not None
+ and generation_config.encoder_no_repeat_ngram_size > 0
+ ):
+ if self.config.is_encoder_decoder:
+ processors.append(
+ EncoderNoRepeatNGramLogitsProcessor(
+ generation_config.encoder_no_repeat_ngram_size, encoder_input_ids
+ )
+ )
+ else:
+ raise ValueError(
+ "It's impossible to use `encoder_no_repeat_ngram_size` with decoder-only architecture"
+ )
+ if generation_config.bad_words_ids is not None:
+ processors.append(
+ NoBadWordsLogitsProcessor(generation_config.bad_words_ids, generation_config.eos_token_id)
+ )
+ if (
+ generation_config.min_length is not None
+ and generation_config.eos_token_id is not None
+ and generation_config.min_length > 0
+ ):
+ processors.append(MinLengthLogitsProcessor(generation_config.min_length, generation_config.eos_token_id))
+ if (
+ generation_config.min_new_tokens is not None
+ and generation_config.eos_token_id is not None
+ and generation_config.min_new_tokens > 0
+ ):
+ processors.append(
+ MinNewTokensLengthLogitsProcessor(
+ input_ids_seq_length, generation_config.min_new_tokens, generation_config.eos_token_id
+ )
+ )
+ if prefix_allowed_tokens_fn is not None:
+ processors.append(
+ PrefixConstrainedLogitsProcessor(
+ prefix_allowed_tokens_fn, generation_config.num_beams // generation_config.num_beam_groups
+ )
+ )
+ if generation_config.forced_bos_token_id is not None:
+ processors.append(ForcedBOSTokenLogitsProcessor(generation_config.forced_bos_token_id))
+ if generation_config.forced_eos_token_id is not None:
+ processors.append(
+ ForcedEOSTokenLogitsProcessor(generation_config.max_length, generation_config.forced_eos_token_id)
+ )
+ if generation_config.remove_invalid_values is True:
+ processors.append(InfNanRemoveLogitsProcessor())
+ if generation_config.exponential_decay_length_penalty is not None:
+ processors.append(
+ ExponentialDecayLengthPenalty(
+ generation_config.exponential_decay_length_penalty,
+ generation_config.eos_token_id,
+ input_ids_seq_length,
+ )
+ )
+ if generation_config.suppress_tokens is not None:
+ processors.append(SuppressTokensLogitsProcessor(generation_config.suppress_tokens))
+ if generation_config.begin_suppress_tokens is not None:
+ begin_index = input_ids_seq_length
+ begin_index = (
+ begin_index
+ if (input_ids_seq_length > 1 or generation_config.forced_bos_token_id is None)
+ else begin_index + 1
+ )
+ if generation_config.forced_decoder_ids is not None:
+ # generation starts after the last token that is forced
+ begin_index += generation_config.forced_decoder_ids[-1][0]
+ processors.append(
+ SuppressTokensAtBeginLogitsProcessor(generation_config.begin_suppress_tokens, begin_index)
+ )
+ if generation_config.forced_decoder_ids is not None:
+ processors.append(ForceTokensLogitsProcessor(generation_config.forced_decoder_ids))
+ processors = self._merge_criteria_processor_list(processors, logits_processor)
+ # `LogitNormalization` should always be the last logit processor, when present
+ if generation_config.renormalize_logits is True:
+ processors.append(LogitNormalization())
+ return processors
+
+ def _get_stopping_criteria(
+ self, generation_config: GenerationConfig, stopping_criteria: Optional[StoppingCriteriaList]
+ ) -> StoppingCriteriaList:
+ criteria = StoppingCriteriaList()
+ if generation_config.max_length is not None:
+ criteria.append(MaxLengthCriteria(max_length=generation_config.max_length))
+ if generation_config.max_time is not None:
+ criteria.append(MaxTimeCriteria(max_time=generation_config.max_time))
+ criteria = self._merge_criteria_processor_list(criteria, stopping_criteria)
+ return criteria
+
+ def _merge_criteria_processor_list(
+ self,
+ default_list: Union[LogitsProcessorList, StoppingCriteriaList],
+ custom_list: Union[LogitsProcessorList, StoppingCriteriaList],
+ ) -> Union[LogitsProcessorList, StoppingCriteriaList]:
+ if len(custom_list) == 0:
+ return default_list
+ for default in default_list:
+ for custom in custom_list:
+ if type(custom) is type(default):
+ object_type = "stopping criteria" if isinstance(custom, StoppingCriteria) else "logits processor"
+ raise ValueError(
+ f"A custom {object_type} of type {type(custom)} with values {custom} has been passed to"
+ f" `.generate()`, but it has already been created with the values {default}. {default} has been"
+ " created by passing the corresponding arguments to generate or by the model's config default"
+ f" values. If you just want to change the default values of {object_type} consider passing"
+ f" them as arguments to `.generate()` instead of using a custom {object_type}."
+ )
+ default_list.extend(custom_list)
+ return default_list
+
+ def compute_transition_scores(
+ self,
+ sequences: torch.Tensor,
+ scores: Tuple[torch.Tensor],
+ beam_indices: Optional[torch.Tensor] = None,
+ normalize_logits: bool = False,
+ ) -> torch.Tensor:
+ """
+ Computes the transition scores of sequences given the generation scores (and beam indices, if beam search was
+ used). This is a convenient method to quicky obtain the scores of the selected tokens at generation time.
+
+ Parameters:
+ sequences (`torch.LongTensor`):
+ The generated sequences. The second dimension (sequence_length) is either equal to `max_length` or
+ shorter if all batches finished early due to the `eos_token_id`.
+ scores (`tuple(torch.FloatTensor)`):
+ Transition scores for each vocabulary token at each generation step. Beam transition scores consisting
+ of log probabilities of tokens conditioned on log softmax of previously generated tokens Tuple of
+ `torch.FloatTensor` with up to `max_new_tokens` elements (one element for each generated token), with
+ each tensor of shape `(batch_size*num_beams, config.vocab_size)`.
+ beam_indices (`torch.LongTensor`, *optional*):
+ Beam indices of generated token id at each generation step. `torch.LongTensor` of shape
+ `(batch_size*num_return_sequences, sequence_length)`. Only required if a `num_beams>1` at
+ generate-time.
+ normalize_logits (`bool`, *optional*, defaults to `False`):
+ Whether to normalize the logits (which, for legacy reasons, may be unnormalized).
+
+ Return:
+ `torch.Tensor`: A `torch.Tensor` of shape `(batch_size*num_return_sequences, sequence_length)` containing
+ the transition scores (logits)
+
+ Examples:
+
+ ```python
+ >>> from transformers import GPT2Tokenizer, AutoModelForCausalLM
+ >>> import numpy as np
+
+ >>> tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
+ >>> model = AutoModelForCausalLM.from_pretrained("gpt2")
+ >>> tokenizer.pad_token_id = tokenizer.eos_token_id
+ >>> inputs = tokenizer(["Today is"], return_tensors="pt")
+
+ >>> # Example 1: Print the scores for each token generated with Greedy Search
+ >>> outputs = model.generate(**inputs, max_new_tokens=5, return_dict_in_generate=True, output_scores=True)
+ >>> transition_scores = model.compute_transition_scores(
+ ... outputs.sequences, outputs.scores, normalize_logits=True
+ ... )
+ >>> # input_length is the length of the input prompt for decoder-only models, like the GPT family, and 1 for
+ >>> # encoder-decoder models, like BART or T5.
+ >>> input_length = 1 if model.config.is_encoder_decoder else inputs.input_ids.shape[1]
+ >>> generated_tokens = outputs.sequences[:, input_length:]
+ >>> for tok, score in zip(generated_tokens[0], transition_scores[0]):
+ ... # | token | token string | logits | probability
+ ... print(f"| {tok:5d} | {tokenizer.decode(tok):8s} | {score.numpy():.3f} | {np.exp(score.numpy()):.2%}")
+ | 262 | the | -1.414 | 24.33%
+ | 1110 | day | -2.609 | 7.36%
+ | 618 | when | -2.010 | 13.40%
+ | 356 | we | -1.859 | 15.58%
+ | 460 | can | -2.508 | 8.14%
+
+ >>> # Example 2: Reconstruct the sequence scores from Beam Search
+ >>> outputs = model.generate(
+ ... **inputs,
+ ... max_new_tokens=5,
+ ... num_beams=4,
+ ... num_return_sequences=4,
+ ... return_dict_in_generate=True,
+ ... output_scores=True,
+ ... )
+ >>> transition_scores = model.compute_transition_scores(
+ ... outputs.sequences, outputs.scores, outputs.beam_indices, normalize_logits=False
+ ... )
+ >>> # If you sum the generated tokens' scores and apply the length penalty, you'll get the sequence scores.
+ >>> # Tip: recomputing the scores is only guaranteed to match with `normalize_logits=False`. Depending on the
+ >>> # use case, you might want to recompute it with `normalize_logits=True`.
+ >>> output_length = input_length + np.sum(transition_scores.numpy() < 0, axis=1)
+ >>> length_penalty = model.generation_config.length_penalty
+ >>> reconstructed_scores = transition_scores.sum(axis=1) / (output_length**length_penalty)
+ >>> print(np.allclose(outputs.sequences_scores, reconstructed_scores))
+ True
+ ```"""
+ # 1. In absence of `beam_indices`, we can assume that we come from e.g. greedy search, which is equivalent
+ # to a beam search approach were the first (and only) beam is always selected
+ if beam_indices is None:
+ beam_indices = torch.arange(scores[0].shape[0]).view(-1, 1).to(sequences.device)
+ beam_indices = beam_indices.expand(-1, len(scores))
+
+ # 2. reshape scores as [batch_size*vocab_size, # generation steps] with # generation steps being
+ # seq_len - input_length
+ scores = torch.stack(scores).reshape(len(scores), -1).transpose(0, 1)
+
+ # 3. Optionally normalize the logits (across the vocab dimension)
+ if normalize_logits:
+ scores = scores.reshape(-1, self.config.vocab_size, scores.shape[-1])
+ scores = torch.nn.functional.log_softmax(scores, dim=1)
+ scores = scores.reshape(-1, scores.shape[-1])
+
+ # 4. cut beam_indices to longest beam length
+ beam_indices_mask = beam_indices < 0
+ max_beam_length = (1 - beam_indices_mask.long()).sum(-1).max()
+ beam_indices = beam_indices.clone()[:, :max_beam_length]
+ beam_indices_mask = beam_indices_mask[:, :max_beam_length]
+
+ # 5. Set indices of beams that finished early to 0; such indices will be masked correctly afterwards
+ beam_indices[beam_indices_mask] = 0
+
+ # 6. multiply beam_indices with vocab size to gather correctly from scores
+ beam_sequence_indices = beam_indices * self.config.vocab_size
+
+ # 7. Define which indices contributed to scores
+ cut_idx = sequences.shape[-1] - max_beam_length
+ indices = sequences[:, cut_idx:] + beam_sequence_indices
+
+ # 8. Compute scores
+ transition_scores = scores.gather(0, indices)
+
+ # 9. Mask out transition_scores of beams that stopped early
+ transition_scores[beam_indices_mask] = 0
+
+ return transition_scores
+
+ def _validate_model_class(self):
+ """
+ Confirms that the model class is compatible with generation. If not, raises an exception that points to the
+ right class to use.
+ """
+ if not self.can_generate():
+ generate_compatible_mappings = [
+ MODEL_FOR_CAUSAL_LM_MAPPING,
+ MODEL_FOR_CAUSAL_IMAGE_MODELING_MAPPING,
+ MODEL_FOR_VISION_2_SEQ_MAPPING,
+ MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING,
+ MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING,
+ ]
+ generate_compatible_classes = set()
+ for model_mapping in generate_compatible_mappings:
+ supported_models = model_mapping.get(type(self.config), default=None)
+ if supported_models is not None:
+ generate_compatible_classes.add(supported_models.__name__)
+ exception_message = (
+ f"The current model class ({self.__class__.__name__}) is not compatible with `.generate()`, as "
+ "it doesn't have a language model head."
+ )
+ if generate_compatible_classes:
+ exception_message += f" Please use one of the following classes instead: {generate_compatible_classes}"
+ raise TypeError(exception_message)
+
+ def _validate_model_kwargs(self, model_kwargs: Dict[str, Any]):
+ """Validates model kwargs for generation. Generate argument typos will also be caught here."""
+ # Excludes arguments that are handled before calling any model function
+ if self.config.is_encoder_decoder:
+ for key in ["decoder_input_ids"]:
+ model_kwargs.pop(key, None)
+
+ unused_model_args = []
+ model_args = set(inspect.signature(self.prepare_inputs_for_generation).parameters)
+ # `kwargs`/`model_kwargs` is often used to handle optional forward pass inputs like `attention_mask`. If
+ # `prepare_inputs_for_generation` doesn't accept them, then a stricter check can be made ;)
+ if "kwargs" in model_args or "model_kwargs" in model_args:
+ model_args |= set(inspect.signature(self.forward).parameters)
+ for key, value in model_kwargs.items():
+ if value is not None and key not in model_args:
+ unused_model_args.append(key)
+
+ if unused_model_args:
+ raise ValueError(
+ f"The following `model_kwargs` are not used by the model: {unused_model_args} (note: typos in the"
+ " generate arguments will also show up in this list)"
+ )
+
+ @torch.no_grad()
+ def generate(
+ self,
+ inputs: Optional[torch.Tensor] = None,
+ generation_config: Optional[GenerationConfig] = None,
+ logits_processor: Optional[LogitsProcessorList] = None,
+ stopping_criteria: Optional[StoppingCriteriaList] = None,
+ prefix_allowed_tokens_fn: Optional[Callable[[int, torch.Tensor], List[int]]] = None,
+ synced_gpus: Optional[bool] = None,
+ assistant_model: Optional["PreTrainedModel"] = None,
+ streamer: Optional["BaseStreamer"] = None,
+ **kwargs,
+ ) -> Union[GenerateOutput, torch.LongTensor]:
+ r"""
+
+ Generates sequences of token ids for models with a language modeling head.
+
+
+
+ Most generation-controlling parameters are set in `generation_config` which, if not passed, will be set to the
+ model's default generation configuration. You can override any `generation_config` by passing the corresponding
+ parameters to generate(), e.g. `.generate(inputs, num_beams=4, do_sample=True)`.
+
+ For an overview of generation strategies and code examples, check out the [following
+ guide](../generation_strategies).
+
+
+
+ Parameters:
+ inputs (`torch.Tensor` of varying shape depending on the modality, *optional*):
+ The sequence used as a prompt for the generation or as model inputs to the encoder. If `None` the
+ method initializes it with `bos_token_id` and a batch size of 1. For decoder-only models `inputs`
+ should of in the format of `input_ids`. For encoder-decoder models *inputs* can represent any of
+ `input_ids`, `input_values`, `input_features`, or `pixel_values`.
+ generation_config (`~generation.GenerationConfig`, *optional*):
+ The generation configuration to be used as base parametrization for the generation call. `**kwargs`
+ passed to generate matching the attributes of `generation_config` will override them. If
+ `generation_config` is not provided, the default will be used, which had the following loading
+ priority: 1) from the `generation_config.json` model file, if it exists; 2) from the model
+ configuration. Please note that unspecified parameters will inherit [`~generation.GenerationConfig`]'s
+ default values, whose documentation should be checked to parameterize generation.
+ logits_processor (`LogitsProcessorList`, *optional*):
+ Custom logits processors that complement the default logits processors built from arguments and
+ generation config. If a logit processor is passed that is already created with the arguments or a
+ generation config an error is thrown. This feature is intended for advanced users.
+ stopping_criteria (`StoppingCriteriaList`, *optional*):
+ Custom stopping criteria that complement the default stopping criteria built from arguments and a
+ generation config. If a stopping criteria is passed that is already created with the arguments or a
+ generation config an error is thrown. This feature is intended for advanced users.
+ prefix_allowed_tokens_fn (`Callable[[int, torch.Tensor], List[int]]`, *optional*):
+ If provided, this function constraints the beam search to allowed tokens only at each step. If not
+ provided no constraint is applied. This function takes 2 arguments: the batch ID `batch_id` and
+ `input_ids`. It has to return a list with the allowed tokens for the next generation step conditioned
+ on the batch ID `batch_id` and the previously generated tokens `inputs_ids`. This argument is useful
+ for constrained generation conditioned on the prefix, as described in [Autoregressive Entity
+ Retrieval](https://arxiv.org/abs/2010.00904).
+ synced_gpus (`bool`, *optional*):
+ Whether to continue running the while loop until max_length. Unless overridden this flag will be set to
+ `True` under DeepSpeed ZeRO Stage 3 multiple GPUs environment to avoid hanging if one GPU finished
+ generating before other GPUs. Otherwise it'll be set to `False`.
+ assistant_model (`PreTrainedModel`, *optional*):
+ An assistant model that can be used to accelerate generation. The assistant model must have the exact
+ same tokenizer. The acceleration is achieved when forecasting candidate tokens with the assistent model
+ is much faster than running generation with the model you're calling generate from. As such, the
+ assistant model should be much smaller.
+ streamer (`BaseStreamer`, *optional*):
+ Streamer object that will be used to stream the generated sequences. Generated tokens are passed
+ through `streamer.put(token_ids)` and the streamer is responsible for any further processing.
+ kwargs:
+ Ad hoc parametrization of `generate_config` and/or additional model-specific kwargs that will be
+ forwarded to the `forward` function of the model. If the model is an encoder-decoder model, encoder
+ specific kwargs should not be prefixed and decoder specific kwargs should be prefixed with *decoder_*.
+
+ Return:
+ [`~utils.ModelOutput`] or `torch.LongTensor`: A [`~utils.ModelOutput`] (if `return_dict_in_generate=True`
+ or when `config.return_dict_in_generate=True`) or a `torch.FloatTensor`.
+
+ If the model is *not* an encoder-decoder model (`model.config.is_encoder_decoder=False`), the possible
+ [`~utils.ModelOutput`] types are:
+
+ - [`~generation.GreedySearchDecoderOnlyOutput`],
+ - [`~generation.SampleDecoderOnlyOutput`],
+ - [`~generation.BeamSearchDecoderOnlyOutput`],
+ - [`~generation.BeamSampleDecoderOnlyOutput`]
+
+ If the model is an encoder-decoder model (`model.config.is_encoder_decoder=True`), the possible
+ [`~utils.ModelOutput`] types are:
+
+ - [`~generation.GreedySearchEncoderDecoderOutput`],
+ - [`~generation.SampleEncoderDecoderOutput`],
+ - [`~generation.BeamSearchEncoderDecoderOutput`],
+ - [`~generation.BeamSampleEncoderDecoderOutput`]
+ """
+
+ if synced_gpus is None:
+ if is_deepspeed_zero3_enabled() and dist.get_world_size() > 1:
+ synced_gpus = True
+ else:
+ synced_gpus = False
+
+ # 1. Handle `generation_config` and kwargs that might update it, and validate the `.generate()` call
+ self._validate_model_class()
+
+ # priority: `generation_config` argument > `model.generation_config` (the default generation config)
+ if generation_config is None:
+ # legacy: users may modify the model configuration to control generation -- update the generation config
+ # model attribute accordingly, if it was created from the model config
+ if self.generation_config._from_model_config:
+ new_generation_config = GenerationConfig.from_model_config(self.config)
+ if new_generation_config != self.generation_config:
+ warnings.warn(
+ "You have modified the pretrained model configuration to control generation. This is a"
+ " deprecated strategy to control generation and will be removed soon, in a future version."
+ " Please use a generation configuration file (see"
+ " https://huggingface.co/docs/transformers/main_classes/text_generation)"
+ )
+ self.generation_config = new_generation_config
+ generation_config = self.generation_config
+
+ generation_config = copy.deepcopy(generation_config)
+ model_kwargs = generation_config.update(**kwargs) # All unused kwargs must be model kwargs
+ generation_config.validate()
+ self._validate_model_kwargs(model_kwargs.copy())
+
+ # 2. Set generation parameters if not already defined
+ logits_processor = logits_processor if logits_processor is not None else LogitsProcessorList()
+ stopping_criteria = stopping_criteria if stopping_criteria is not None else StoppingCriteriaList()
+
+ if generation_config.pad_token_id is None and generation_config.eos_token_id is not None:
+ if model_kwargs.get("attention_mask", None) is None:
+ logger.warning(
+ "The attention mask and the pad token id were not set. As a consequence, you may observe "
+ "unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results."
+ )
+ eos_token_id = generation_config.eos_token_id
+ if isinstance(eos_token_id, list):
+ eos_token_id = eos_token_id[0]
+ logger.warning(f"Setting `pad_token_id` to `eos_token_id`:{eos_token_id} for open-end generation.")
+ generation_config.pad_token_id = eos_token_id
+
+ # 3. Define model inputs
+ # inputs_tensor has to be defined
+ # model_input_name is defined if model-specific keyword input is passed
+ # otherwise model_input_name is None
+ # all model-specific keyword inputs are removed from `model_kwargs`
+ inputs_tensor, model_input_name, model_kwargs = self._prepare_model_inputs(
+ inputs, generation_config.bos_token_id, model_kwargs
+ )
+ batch_size = inputs_tensor.shape[0]
+
+ # 4. Define other model kwargs
+ model_kwargs["output_attentions"] = generation_config.output_attentions
+ model_kwargs["output_hidden_states"] = generation_config.output_hidden_states
+ model_kwargs["use_cache"] = generation_config.use_cache
+
+ accepts_attention_mask = "attention_mask" in set(inspect.signature(self.forward).parameters.keys())
+ requires_attention_mask = "encoder_outputs" not in model_kwargs
+
+ if model_kwargs.get("attention_mask", None) is None and requires_attention_mask and accepts_attention_mask:
+ model_kwargs["attention_mask"] = self._prepare_attention_mask_for_generation(
+ inputs_tensor, generation_config.pad_token_id, generation_config.eos_token_id
+ )
+
+ # decoder-only models should use left-padding for generation
+ if not self.config.is_encoder_decoder:
+ # If `input_ids` was given, check if the last id in any sequence is `pad_token_id`
+ # Note: If using, `inputs_embeds` this check does not work, because we want to be more hands-off.
+ if (
+ generation_config.pad_token_id is not None
+ and len(inputs_tensor.shape) == 2
+ and torch.sum(inputs_tensor[:, -1] == generation_config.pad_token_id) > 0
+ ):
+ logger.warning(
+ "A decoder-only architecture is being used, but right-padding was detected! For correct "
+ "generation results, please set `padding_side='left'` when initializing the tokenizer."
+ )
+
+ if self.config.is_encoder_decoder and "encoder_outputs" not in model_kwargs:
+ # if model is encoder decoder encoder_outputs are created
+ # and added to `model_kwargs`
+ enc_st = time.perf_counter()
+ model_kwargs = self._prepare_encoder_decoder_kwargs_for_generation(
+ inputs_tensor, model_kwargs, model_input_name
+ )
+ enc_end = time.perf_counter()
+ self.encoder_time = enc_end - enc_st
+ if self.do_print:
+ print(f"=====================encoder cost {enc_end - enc_st} s=======================")
+
+ # 5. Prepare `input_ids` which will be used for auto-regressive generation
+ if self.config.is_encoder_decoder:
+ input_ids, model_kwargs = self._prepare_decoder_input_ids_for_generation(
+ batch_size=batch_size,
+ model_input_name=model_input_name,
+ model_kwargs=model_kwargs,
+ decoder_start_token_id=generation_config.decoder_start_token_id,
+ bos_token_id=generation_config.bos_token_id,
+ device=inputs_tensor.device,
+ )
+ else:
+ input_ids = inputs_tensor if model_input_name == "input_ids" else model_kwargs.pop("input_ids")
+
+ if streamer is not None:
+ streamer.put(input_ids.cpu())
+
+ # 6. Prepare `max_length` depending on other stopping criteria.
+ input_ids_seq_length = input_ids.shape[-1]
+ has_default_max_length = kwargs.get("max_length") is None and generation_config.max_length is not None
+ if has_default_max_length and generation_config.max_new_tokens is None:
+ warnings.warn(
+ f"Using `max_length`'s default ({generation_config.max_length}) to control the generation length. "
+ "This behaviour is deprecated and will be removed from the config in v5 of Transformers -- we"
+ " recommend using `max_new_tokens` to control the maximum length of the generation.",
+ UserWarning,
+ )
+ elif generation_config.max_new_tokens is not None:
+ if not has_default_max_length:
+ logger.warning(
+ f"Both `max_new_tokens` (={generation_config.max_new_tokens}) and `max_length`(="
+ f"{generation_config.max_length}) seem to have been set. `max_new_tokens` will take precedence. "
+ "Please refer to the documentation for more information. "
+ "(https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)"
+ )
+ generation_config.max_length = generation_config.max_new_tokens + input_ids_seq_length
+
+ if generation_config.min_length is not None and generation_config.min_length > generation_config.max_length:
+ raise ValueError(
+ f"Unfeasible length constraints: the minimum length ({generation_config.min_length}) is larger than"
+ f" the maximum length ({generation_config.max_length})"
+ )
+ if input_ids_seq_length >= generation_config.max_length:
+ input_ids_string = "decoder_input_ids" if self.config.is_encoder_decoder else "input_ids"
+ logger.warning(
+ f"Input length of {input_ids_string} is {input_ids_seq_length}, but `max_length` is set to"
+ f" {generation_config.max_length}. This can lead to unexpected behavior. You should consider"
+ " increasing `max_new_tokens`."
+ )
+
+ # 7. determine generation mode
+ is_constraint_gen_mode = (
+ generation_config.constraints is not None or generation_config.force_words_ids is not None
+ )
+
+ is_contrastive_search_gen_mode = (
+ (generation_config.num_beams == 1)
+ and generation_config.top_k is not None
+ and generation_config.top_k > 1
+ and generation_config.do_sample is False
+ and generation_config.penalty_alpha is not None
+ and generation_config.penalty_alpha > 0
+ )
+
+ is_greedy_gen_mode = (
+ (generation_config.num_beams == 1)
+ and (generation_config.num_beam_groups == 1)
+ and generation_config.do_sample is False
+ and not is_constraint_gen_mode
+ and not is_contrastive_search_gen_mode
+ )
+ is_sample_gen_mode = (
+ (generation_config.num_beams == 1)
+ and (generation_config.num_beam_groups == 1)
+ and generation_config.do_sample is True
+ and not is_constraint_gen_mode
+ and not is_contrastive_search_gen_mode
+ )
+ is_beam_gen_mode = (
+ (generation_config.num_beams > 1)
+ and (generation_config.num_beam_groups == 1)
+ and generation_config.do_sample is False
+ and not is_constraint_gen_mode
+ and not is_contrastive_search_gen_mode
+ )
+ is_beam_sample_gen_mode = (
+ (generation_config.num_beams > 1)
+ and (generation_config.num_beam_groups == 1)
+ and generation_config.do_sample is True
+ and not is_constraint_gen_mode
+ and not is_contrastive_search_gen_mode
+ )
+ is_group_beam_gen_mode = (
+ (generation_config.num_beams > 1)
+ and (generation_config.num_beam_groups > 1)
+ and not is_constraint_gen_mode
+ and not is_contrastive_search_gen_mode
+ )
+ is_assisted_gen_mode = False
+ if assistant_model is not None:
+ if not (is_greedy_gen_mode or is_sample_gen_mode):
+ raise ValueError(
+ "You've set `assistant_model`, which triggers assisted generate. Currently, assisted generate "
+ "is only supported with Greedy Search and Sample."
+ )
+ is_assisted_gen_mode = True
+
+ if generation_config.num_beam_groups > generation_config.num_beams:
+ raise ValueError("`num_beam_groups` has to be smaller or equal to `num_beams`")
+ if is_group_beam_gen_mode and generation_config.do_sample is True:
+ raise ValueError(
+ "Diverse beam search cannot be used in sampling mode. Make sure that `do_sample` is set to `False`."
+ )
+
+ if streamer is not None and (generation_config.num_beams > 1):
+ raise ValueError(
+ "`streamer` cannot be used with beam search (yet!). Make sure that `num_beams` is set to 1."
+ )
+
+ if self.device.type != input_ids.device.type:
+ warnings.warn(
+ "You are calling .generate() with the `input_ids` being on a device type different"
+ f" than your model's device. `input_ids` is on {input_ids.device.type}, whereas the model"
+ f" is on {self.device.type}. You may experience unexpected behaviors or slower generation."
+ " Please make sure that you have put `input_ids` to the"
+ f" correct device by calling for example input_ids = input_ids.to('{self.device.type}') before"
+ " running `.generate()`.",
+ UserWarning,
+ )
+
+ # 8. prepare distribution pre_processing samplers
+ logits_processor = self._get_logits_processor(
+ generation_config=generation_config,
+ input_ids_seq_length=input_ids_seq_length,
+ encoder_input_ids=inputs_tensor,
+ prefix_allowed_tokens_fn=prefix_allowed_tokens_fn,
+ logits_processor=logits_processor,
+ )
+
+ # 9. prepare stopping criteria
+ stopping_criteria = self._get_stopping_criteria(
+ generation_config=generation_config, stopping_criteria=stopping_criteria
+ )
+ # 10. go into different generation modes
+ if is_assisted_gen_mode:
+ if generation_config.num_return_sequences > 1:
+ raise ValueError(
+ "num_return_sequences has to be 1 when doing assisted generate, "
+ f"but is {generation_config.num_return_sequences}."
+ )
+ if batch_size > 1:
+ raise ValueError("assisted generate is only supported for batch_size = 1")
+ if not model_kwargs["use_cache"]:
+ raise ValueError("assisted generate requires `use_cache=True`")
+
+ # 11. If the assistant model is an encoder-decoder, prepare its encoder outputs
+ if assistant_model.config.is_encoder_decoder:
+ assistant_model_kwargs = copy.deepcopy(model_kwargs)
+ inputs_tensor, model_input_name, assistant_model_kwargs = assistant_model._prepare_model_inputs(
+ inputs_tensor, assistant_model.generation_config.bos_token_id, assistant_model_kwargs
+ )
+ assistant_model_kwargs = assistant_model._prepare_encoder_decoder_kwargs_for_generation(
+ inputs_tensor, assistant_model_kwargs, model_input_name
+ )
+ model_kwargs["assistant_encoder_outputs"] = assistant_model_kwargs["encoder_outputs"]
+
+ # 12. run assisted generate
+ return self.assisted_decoding(
+ input_ids,
+ assistant_model=assistant_model,
+ do_sample=generation_config.do_sample,
+ logits_processor=logits_processor,
+ logits_warper=self._get_logits_warper(generation_config) if generation_config.do_sample else None,
+ stopping_criteria=stopping_criteria,
+ pad_token_id=generation_config.pad_token_id,
+ eos_token_id=generation_config.eos_token_id,
+ output_scores=generation_config.output_scores,
+ return_dict_in_generate=generation_config.return_dict_in_generate,
+ synced_gpus=synced_gpus,
+ streamer=streamer,
+ **model_kwargs,
+ )
+ if is_greedy_gen_mode:
+ if generation_config.num_return_sequences > 1:
+ raise ValueError(
+ "num_return_sequences has to be 1 when doing greedy search, "
+ f"but is {generation_config.num_return_sequences}."
+ )
+
+ # 11. run greedy search
+ return self.greedy_search(
+ input_ids,
+ logits_processor=logits_processor,
+ stopping_criteria=stopping_criteria,
+ pad_token_id=generation_config.pad_token_id,
+ eos_token_id=generation_config.eos_token_id,
+ output_scores=generation_config.output_scores,
+ return_dict_in_generate=generation_config.return_dict_in_generate,
+ synced_gpus=synced_gpus,
+ streamer=streamer,
+ **model_kwargs,
+ )
+
+ elif is_contrastive_search_gen_mode:
+ if generation_config.num_return_sequences > 1:
+ raise ValueError(
+ "num_return_sequences has to be 1 when doing contrastive search, "
+ f"but is {generation_config.num_return_sequences}."
+ )
+ if not model_kwargs["use_cache"]:
+ raise ValueError("Contrastive search requires `use_cache=True`")
+
+ return self.contrastive_search(
+ input_ids,
+ top_k=generation_config.top_k,
+ penalty_alpha=generation_config.penalty_alpha,
+ logits_processor=logits_processor,
+ stopping_criteria=stopping_criteria,
+ pad_token_id=generation_config.pad_token_id,
+ eos_token_id=generation_config.eos_token_id,
+ output_scores=generation_config.output_scores,
+ return_dict_in_generate=generation_config.return_dict_in_generate,
+ synced_gpus=synced_gpus,
+ streamer=streamer,
+ **model_kwargs,
+ )
+
+ elif is_sample_gen_mode:
+ # 11. prepare logits warper
+ logits_warper = self._get_logits_warper(generation_config)
+
+ # 12. expand input_ids with `num_return_sequences` additional sequences per batch
+ input_ids, model_kwargs = self._expand_inputs_for_generation(
+ input_ids=input_ids,
+ expand_size=generation_config.num_return_sequences,
+ is_encoder_decoder=self.config.is_encoder_decoder,
+ **model_kwargs,
+ )
+
+ # 13. run sample
+ return self.sample(
+ input_ids,
+ logits_processor=logits_processor,
+ logits_warper=logits_warper,
+ stopping_criteria=stopping_criteria,
+ pad_token_id=generation_config.pad_token_id,
+ eos_token_id=generation_config.eos_token_id,
+ output_scores=generation_config.output_scores,
+ return_dict_in_generate=generation_config.return_dict_in_generate,
+ synced_gpus=synced_gpus,
+ streamer=streamer,
+ **model_kwargs,
+ )
+
+ elif is_beam_gen_mode:
+ if generation_config.num_return_sequences > generation_config.num_beams:
+ raise ValueError("`num_return_sequences` has to be smaller or equal to `num_beams`.")
+
+ if stopping_criteria.max_length is None:
+ raise ValueError("`max_length` needs to be a stopping_criteria for now.")
+
+ # 11. prepare beam search scorer
+ beam_scorer = BeamSearchScorer(
+ batch_size=batch_size,
+ num_beams=generation_config.num_beams,
+ device=inputs_tensor.device,
+ length_penalty=generation_config.length_penalty,
+ do_early_stopping=generation_config.early_stopping,
+ num_beam_hyps_to_keep=generation_config.num_return_sequences,
+ max_length=generation_config.max_length,
+ )
+ # 12. interleave input_ids with `num_beams` additional sequences per batch
+ input_ids, model_kwargs = self._expand_inputs_for_generation(
+ input_ids=input_ids,
+ expand_size=generation_config.num_beams,
+ is_encoder_decoder=self.config.is_encoder_decoder,
+ **model_kwargs,
+ )
+ # 13. run beam search
+ return self.beam_search(
+ input_ids,
+ beam_scorer,
+ logits_processor=logits_processor,
+ stopping_criteria=stopping_criteria,
+ pad_token_id=generation_config.pad_token_id,
+ eos_token_id=generation_config.eos_token_id,
+ output_scores=generation_config.output_scores,
+ return_dict_in_generate=generation_config.return_dict_in_generate,
+ synced_gpus=synced_gpus,
+ **model_kwargs,
+ )
+
+ elif is_beam_sample_gen_mode:
+ # 11. prepare logits warper
+ logits_warper = self._get_logits_warper(generation_config)
+
+ if stopping_criteria.max_length is None:
+ raise ValueError("`max_length` needs to be a stopping_criteria for now.")
+ # 12. prepare beam search scorer
+ beam_scorer = BeamSearchScorer(
+ batch_size=batch_size * generation_config.num_return_sequences,
+ num_beams=generation_config.num_beams,
+ device=inputs_tensor.device,
+ length_penalty=generation_config.length_penalty,
+ do_early_stopping=generation_config.early_stopping,
+ max_length=generation_config.max_length,
+ )
+
+ # 13. interleave input_ids with `num_beams` additional sequences per batch
+ input_ids, model_kwargs = self._expand_inputs_for_generation(
+ input_ids=input_ids,
+ expand_size=generation_config.num_beams * generation_config.num_return_sequences,
+ is_encoder_decoder=self.config.is_encoder_decoder,
+ **model_kwargs,
+ )
+
+ # 14. run beam sample
+ return self.beam_sample(
+ input_ids,
+ beam_scorer,
+ logits_processor=logits_processor,
+ logits_warper=logits_warper,
+ stopping_criteria=stopping_criteria,
+ pad_token_id=generation_config.pad_token_id,
+ eos_token_id=generation_config.eos_token_id,
+ output_scores=generation_config.output_scores,
+ return_dict_in_generate=generation_config.return_dict_in_generate,
+ synced_gpus=synced_gpus,
+ **model_kwargs,
+ )
+
+ elif is_group_beam_gen_mode:
+ if generation_config.num_return_sequences > generation_config.num_beams:
+ raise ValueError("`num_return_sequences` has to be smaller or equal to `num_beams`.")
+
+ if generation_config.num_beams % generation_config.num_beam_groups != 0:
+ raise ValueError("`num_beams` should be divisible by `num_beam_groups` for group beam search.")
+
+ if stopping_criteria.max_length is None:
+ raise ValueError("`max_length` needs to be a stopping_criteria for now.")
+
+ has_default_typical_p = kwargs.get("typical_p") is None and generation_config.typical_p == 1.0
+ if not has_default_typical_p:
+ raise ValueError("Decoder argument `typical_p` is not supported with beam groups.")
+
+ # 11. prepare beam search scorer
+ beam_scorer = BeamSearchScorer(
+ batch_size=batch_size,
+ num_beams=generation_config.num_beams,
+ device=inputs_tensor.device,
+ length_penalty=generation_config.length_penalty,
+ do_early_stopping=generation_config.early_stopping,
+ num_beam_hyps_to_keep=generation_config.num_return_sequences,
+ num_beam_groups=generation_config.num_beam_groups,
+ max_length=generation_config.max_length,
+ )
+ # 12. interleave input_ids with `num_beams` additional sequences per batch
+ input_ids, model_kwargs = self._expand_inputs_for_generation(
+ input_ids=input_ids,
+ expand_size=generation_config.num_beams,
+ is_encoder_decoder=self.config.is_encoder_decoder,
+ **model_kwargs,
+ )
+ # 13. run beam search
+ return self.group_beam_search(
+ input_ids,
+ beam_scorer,
+ logits_processor=logits_processor,
+ stopping_criteria=stopping_criteria,
+ pad_token_id=generation_config.pad_token_id,
+ eos_token_id=generation_config.eos_token_id,
+ output_scores=generation_config.output_scores,
+ return_dict_in_generate=generation_config.return_dict_in_generate,
+ synced_gpus=synced_gpus,
+ **model_kwargs,
+ )
+
+ elif is_constraint_gen_mode:
+ if generation_config.num_return_sequences > generation_config.num_beams:
+ raise ValueError("`num_return_sequences` has to be smaller or equal to `num_beams`.")
+
+ if stopping_criteria.max_length is None:
+ raise ValueError("`max_length` needs to be a stopping_criteria for now.")
+
+ if generation_config.num_beams <= 1:
+ raise ValueError("`num_beams` needs to be greater than 1 for constrained generation.")
+
+ if generation_config.do_sample:
+ raise ValueError("`do_sample` needs to be false for constrained generation.")
+
+ if generation_config.num_beam_groups is not None and generation_config.num_beam_groups > 1:
+ raise ValueError("`num_beam_groups` not supported yet for constrained generation.")
+
+ final_constraints = []
+ if generation_config.constraints is not None:
+ final_constraints = generation_config.constraints
+
+ if generation_config.force_words_ids is not None:
+
+ def typeerror():
+ raise ValueError(
+ "`force_words_ids` has to either be a `List[List[List[int]]]` or `List[List[int]]`"
+ f"of positive integers, but is {generation_config.force_words_ids}."
+ )
+
+ if (
+ not isinstance(generation_config.force_words_ids, list)
+ or len(generation_config.force_words_ids) == 0
+ ):
+ typeerror()
+
+ for word_ids in generation_config.force_words_ids:
+ if isinstance(word_ids[0], list):
+ if not isinstance(word_ids, list) or len(word_ids) == 0:
+ typeerror()
+ if any(not isinstance(token_ids, list) for token_ids in word_ids):
+ typeerror()
+ if any(
+ any((not isinstance(token_id, int) or token_id < 0) for token_id in token_ids)
+ for token_ids in word_ids
+ ):
+ typeerror()
+
+ constraint = DisjunctiveConstraint(word_ids)
+ else:
+ if not isinstance(word_ids, list) or len(word_ids) == 0:
+ typeerror()
+ if any((not isinstance(token_id, int) or token_id < 0) for token_id in word_ids):
+ typeerror()
+
+ constraint = PhrasalConstraint(word_ids)
+ final_constraints.append(constraint)
+
+ # 11. prepare beam search scorer
+ constrained_beam_scorer = ConstrainedBeamSearchScorer(
+ constraints=final_constraints,
+ batch_size=batch_size,
+ num_beams=generation_config.num_beams,
+ device=inputs_tensor.device,
+ length_penalty=generation_config.length_penalty,
+ do_early_stopping=generation_config.early_stopping,
+ num_beam_hyps_to_keep=generation_config.num_return_sequences,
+ max_length=generation_config.max_length,
+ )
+ # 12. interleave input_ids with `num_beams` additional sequences per batch
+ input_ids, model_kwargs = self._expand_inputs_for_generation(
+ input_ids=input_ids,
+ expand_size=generation_config.num_beams,
+ is_encoder_decoder=self.config.is_encoder_decoder,
+ **model_kwargs,
+ )
+ # 13. run beam search
+ return self.constrained_beam_search(
+ input_ids,
+ constrained_beam_scorer=constrained_beam_scorer,
+ logits_processor=logits_processor,
+ stopping_criteria=stopping_criteria,
+ pad_token_id=generation_config.pad_token_id,
+ eos_token_id=generation_config.eos_token_id,
+ output_scores=generation_config.output_scores,
+ return_dict_in_generate=generation_config.return_dict_in_generate,
+ synced_gpus=synced_gpus,
+ **model_kwargs,
+ )
+
+ @torch.no_grad()
+ def contrastive_search(
+ self,
+ input_ids: torch.LongTensor,
+ top_k: Optional[int] = 1,
+ penalty_alpha: Optional[float] = 0,
+ logits_processor: Optional[LogitsProcessorList] = None,
+ logits_warper: Optional[LogitsProcessorList] = None,
+ stopping_criteria: Optional[StoppingCriteriaList] = None,
+ pad_token_id: Optional[int] = None,
+ eos_token_id: Optional[Union[int, List[int]]] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ output_scores: Optional[bool] = None,
+ return_dict_in_generate: Optional[bool] = None,
+ synced_gpus: bool = False,
+ streamer: Optional["BaseStreamer"] = None,
+ **model_kwargs,
+ ) -> Union[ContrastiveSearchOutput, torch.LongTensor]:
+ r"""
+ Generates sequences of token ids for models with a language modeling head using **contrastive search** and can
+ be used for text-decoder, text-to-text, speech-to-text, and vision-to-text models.
+
+
+
+ In most cases, you do not need to call [`~generation.GenerationMixin.contrastive_search`] directly. Use
+ generate() instead. For an overview of generation strategies and code examples, check the [following
+ guide](../generation_strategies).
+
+
+
+ Parameters:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ The sequence used as a prompt for the generation.
+ top_k (`int`, *optional*, defaults to 1):
+ The size of the candidate set that is used to re-rank for contrastive search
+ penalty_alpha (`float`, *optional*, defaults to 0):
+ The degeneration penalty for contrastive search; activate when it is larger than 0
+ logits_processor (`LogitsProcessorList`, *optional*):
+ An instance of [`LogitsProcessorList`]. List of instances of class derived from [`LogitsProcessor`]
+ used to modify the prediction scores of the language modeling head applied at each generation step.
+ logits_warper (`LogitsProcessorList`, *optional*):
+ An instance of [`LogitsProcessorList`]. List of instances of class derived from [`LogitsWarper`] used
+ to warp the prediction score distribution of the language modeling head applied before multinomial
+ sampling at each generation step.
+ stopping_criteria (`StoppingCriteriaList`, *optional*):
+ An instance of [`StoppingCriteriaList`]. List of instances of class derived from [`StoppingCriteria`]
+ used to tell if the generation loop should stop.
+ pad_token_id (`int`, *optional*):
+ The id of the *padding* token.
+ eos_token_id (`Union[int, List[int]]`, *optional*):
+ The id of the *end-of-sequence* token. Optionally, use a list to set multiple *end-of-sequence* tokens.
+ output_attentions (`bool`, *optional*, defaults to `False`):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more details.
+ output_hidden_states (`bool`, *optional*, defaults to `False`):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
+ for more details.
+ output_scores (`bool`, *optional*, defaults to `False`):
+ Whether or not to return the prediction scores. See `scores` under returned tensors for more details.
+ return_dict_in_generate (`bool`, *optional*, defaults to `False`):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+ synced_gpus (`bool`, *optional*, defaults to `False`):
+ Whether to continue running the while loop until max_length (needed for ZeRO stage 3)
+ streamer (`BaseStreamer`, *optional*):
+ Streamer object that will be used to stream the generated sequences. Generated tokens are passed
+ through `streamer.put(token_ids)` and the streamer is responsible for any further processing.
+ model_kwargs:
+ Additional model specific keyword arguments will be forwarded to the `forward` function of the model.
+ If model is an encoder-decoder model the kwargs should include `encoder_outputs`.
+
+ Return:
+ [`~generation.ContrastiveSearchDecoderOnlyOutput`], [`~generation.ContrastiveSearchEncoderDecoderOutput`]
+ or `torch.LongTensor`: A `torch.LongTensor` containing the generated tokens (default behaviour) or a
+ [`~generation.ContrastiveSearchDecoderOnlyOutput`] if `model.config.is_encoder_decoder=False` and
+ `return_dict_in_generate=True` or a [`~generation.ContrastiveSearchEncoderDecoderOutput`] if
+ `model.config.is_encoder_decoder=True`.
+
+ Examples:
+ ```python
+ >>> from transformers import (
+ ... AutoTokenizer,
+ ... AutoModelForCausalLM,
+ ... StoppingCriteriaList,
+ ... MaxLengthCriteria,
+ ... )
+
+ >>> tokenizer = AutoTokenizer.from_pretrained("facebook/opt-125m")
+ >>> model = AutoModelForCausalLM.from_pretrained("facebook/opt-125m")
+ >>> # set pad_token_id to eos_token_id because OPT does not have a PAD token
+ >>> model.config.pad_token_id = model.config.eos_token_id
+ >>> input_prompt = "DeepMind Company is"
+ >>> input_ids = tokenizer(input_prompt, return_tensors="pt")
+ >>> stopping_criteria = StoppingCriteriaList([MaxLengthCriteria(max_length=64)])
+ >>> outputs = model.contrastive_search(
+ ... **input_ids, penalty_alpha=0.6, top_k=4, stopping_criteria=stopping_criteria
+ ... )
+ >>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
+ ['DeepMind Company is a company that focuses on the development and commercialization of artificial intelligence (AI). DeepMind’s mission is to help people understand and solve problems that are difficult to solve in the world today.\n\nIn this post, we talk about the benefits of deep learning in business and how it']
+ ```"""
+ # init values
+ logits_processor = logits_processor if logits_processor is not None else LogitsProcessorList()
+ logits_warper = logits_warper if logits_warper is not None else LogitsProcessorList()
+ stopping_criteria = stopping_criteria if stopping_criteria is not None else StoppingCriteriaList()
+ pad_token_id = pad_token_id if pad_token_id is not None else self.generation_config.pad_token_id
+ eos_token_id = eos_token_id if eos_token_id is not None else self.generation_config.eos_token_id
+ if isinstance(eos_token_id, int):
+ eos_token_id = [eos_token_id]
+ eos_token_id_tensor = torch.tensor(eos_token_id).to(input_ids.device) if eos_token_id is not None else None
+ output_scores = output_scores if output_scores is not None else self.generation_config.output_scores
+ output_attentions = (
+ output_attentions if output_attentions is not None else self.generation_config.output_attentions
+ )
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.generation_config.output_hidden_states
+ )
+ return_dict_in_generate = (
+ return_dict_in_generate
+ if return_dict_in_generate is not None
+ else self.generation_config.return_dict_in_generate
+ )
+
+ # init attention / hidden states / scores tuples
+ scores = () if (return_dict_in_generate and output_scores) else None
+ decoder_attentions = () if (return_dict_in_generate and output_attentions) else None
+ cross_attentions = () if (return_dict_in_generate and output_attentions) else None
+ decoder_hidden_states = () if (return_dict_in_generate and output_hidden_states) else None
+
+ # if model is an encoder-decoder, retrieve encoder attention weights and hidden states
+ if return_dict_in_generate and self.config.is_encoder_decoder:
+ encoder_attentions = model_kwargs["encoder_outputs"].get("attentions") if output_attentions else None
+ encoder_hidden_states = (
+ model_kwargs["encoder_outputs"].get("hidden_states") if output_hidden_states else None
+ )
+
+ # keep track of which sequences are already finished
+ unfinished_sequences = torch.ones(input_ids.shape[0], dtype=torch.long, device=input_ids.device)
+
+ this_peer_finished = False # used by synced_gpus only
+ batch_size = input_ids.shape[0]
+
+ while True:
+ if synced_gpus:
+ # Under synced_gpus the `forward` call must continue until all gpus complete their sequence.
+ # The following logic allows an early break if all peers finished generating their sequence
+ this_peer_finished_flag = torch.tensor(0.0 if this_peer_finished else 1.0).to(input_ids.device)
+ # send 0.0 if we finished, 1.0 otherwise
+ dist.all_reduce(this_peer_finished_flag, op=dist.ReduceOp.SUM)
+ # did all peers finish? the reduced sum will be 0.0 then
+ if this_peer_finished_flag.item() == 0.0:
+ break
+
+ # if the first step in the loop, encode all the prefix and obtain: (1) past_key_values;
+ # (2) last_hidden_states; (3) logit_for_next_step; (4) update model kwargs for the next step
+ if model_kwargs.get("past_key_values") is None:
+ # prepare inputs
+ model_kwargs["use_cache"] = True
+ model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)
+
+ # encode the given prefix and prepare model inputs; encoder-decoder model process the prefix and save
+ # the `encoder_outputs`
+ outputs = self(
+ **model_inputs, return_dict=True, output_hidden_states=True, output_attentions=output_attentions
+ )
+
+ # last decoder hidden states will be used to compute the degeneration penalty (cosine similarity with
+ # previous tokens)
+ if self.config.is_encoder_decoder:
+ last_hidden_states = outputs.decoder_hidden_states[-1]
+ else:
+ last_hidden_states = outputs.hidden_states[-1]
+ # next logit for contrastive search to select top-k candidate tokens
+ logit_for_next_step = outputs.logits[:, -1, :]
+
+ model_kwargs = self._update_model_kwargs_for_generation(
+ outputs,
+ model_kwargs,
+ is_encoder_decoder=self.config.is_encoder_decoder,
+ standardize_cache_format=True,
+ )
+
+ # Expands model inputs top_k times, for batched forward passes (akin to beam search).
+ _, model_kwargs = self._expand_inputs_for_generation(
+ expand_size=top_k, is_encoder_decoder=self.config.is_encoder_decoder, **model_kwargs
+ )
+
+ past_key_values = model_kwargs.get("past_key_values")
+ if past_key_values is None:
+ raise ValueError(
+ f"{self.__class__.__name__} does not support caching and therefore **can't** be used "
+ "for contrastive search."
+ )
+ elif (
+ not isinstance(past_key_values[0], (tuple, torch.Tensor))
+ or past_key_values[0][0].shape[0] != batch_size
+ ):
+ raise ValueError(
+ f"{self.__class__.__name__} does not have a standard cache format and therefore **can't** be "
+ "used for contrastive search without further modifications."
+ )
+
+ # contrastive_search main logic start:
+ # contrastive search decoding consists of two steps: (1) candidate tokens recall; (2) candidate re-rank by
+ # degeneration penalty
+
+ logit_for_next_step = logits_processor(input_ids, logit_for_next_step)
+ logit_for_next_step = logits_warper(input_ids, logit_for_next_step)
+ next_probs = nn.functional.softmax(logit_for_next_step, dim=-1)
+ top_k_probs, top_k_ids = torch.topk(next_probs, dim=-1, k=top_k)
+
+ # Store scores, attentions and hidden_states when required
+ if return_dict_in_generate:
+ if output_scores:
+ scores += (logit_for_next_step,)
+ if output_attentions:
+ decoder_attentions += (
+ (outputs.decoder_attentions,) if self.config.is_encoder_decoder else (outputs.attentions,)
+ )
+ if self.config.is_encoder_decoder:
+ cross_attentions += (outputs.cross_attentions,)
+
+ if output_hidden_states:
+ decoder_hidden_states += (
+ (outputs.decoder_hidden_states,)
+ if self.config.is_encoder_decoder
+ else (outputs.hidden_states,)
+ )
+
+ # Replicates the new past_key_values to match the `top_k` candidates
+ new_key_values = []
+ for layer in model_kwargs["past_key_values"]:
+ items = []
+ # item is either the key or the value matrix
+ for item in layer:
+ items.append(item.repeat_interleave(top_k, dim=0))
+ new_key_values.append(items)
+ model_kwargs["past_key_values"] = new_key_values
+
+ # compute the candidate tokens by the language model and collects their hidden_states
+ next_model_inputs = self.prepare_inputs_for_generation(top_k_ids.view(-1, 1), **model_kwargs)
+ outputs = self(
+ **next_model_inputs, return_dict=True, output_hidden_states=True, output_attentions=output_attentions
+ )
+ next_past_key_values = self._extract_past_from_model_output(outputs, standardize_cache_format=True)
+
+ logits = outputs.logits[:, -1, :]
+ # name is different for encoder-decoder and decoder-only models
+ if self.config.is_encoder_decoder:
+ next_hidden = outputs.decoder_hidden_states[-1]
+ full_hidden_states = outputs.decoder_hidden_states
+ else:
+ next_hidden = outputs.hidden_states[-1]
+ full_hidden_states = outputs.hidden_states
+ context_hidden = last_hidden_states.repeat_interleave(top_k, dim=0)
+
+ # compute the degeneration penalty and re-rank the candidates based on the degeneration penalty and the
+ # model confidence
+ selected_idx = _ranking_fast(context_hidden, next_hidden, top_k_probs, penalty_alpha, top_k)
+
+ # prepare for the next step: (1) next token_id; (2) past_key_values; (3) last_hidden_states for computing
+ # the degeneration penalty; (4) logits for selecting next top-k candidates; (5) selected tokens scores
+ # (model confidence minus degeneration penalty); (6) decoder hidden_states
+ next_tokens = top_k_ids[range(len(top_k_ids)), selected_idx]
+ next_hidden = torch.stack(torch.split(next_hidden.squeeze(dim=1), top_k))
+ next_hidden = next_hidden[range(batch_size), selected_idx, :]
+ last_hidden_states = torch.cat([last_hidden_states, next_hidden.unsqueeze(1)], dim=1)
+
+ next_decoder_hidden_states = ()
+ for layer in full_hidden_states:
+ layer = torch.stack(torch.split(layer, top_k))[range(batch_size), selected_idx, :]
+ next_decoder_hidden_states += (layer,)
+
+ # select the past_key_value
+ new_key_values = ()
+ for layer in next_past_key_values:
+ items = ()
+ # item is either the key or the value matrix
+ for item in layer:
+ item = torch.stack(torch.split(item, top_k, dim=0)) # [B, K, num_head, seq_len, esz]
+ item = item[range(batch_size), selected_idx, ...] # [B, num_head, seq_len, esz]
+ items += (item,)
+ new_key_values += (items,)
+ next_past_key_values = new_key_values
+
+ logit_for_next_step = torch.stack(torch.split(logits, top_k))[range(batch_size), selected_idx, :]
+
+ # Rebuilds the relevant parts of the model output for the selected token, for use in the next iteration
+ if self.config.is_encoder_decoder:
+ next_step_cross_attentions = ()
+ next_step_decoder_attentions = ()
+ if output_attentions:
+ for layer in outputs.cross_attentions:
+ layer = torch.stack(torch.split(layer, top_k, dim=0))[range(batch_size), selected_idx, ...]
+ next_step_cross_attentions += (layer,)
+ for layer in outputs.decoder_attentions:
+ layer = torch.stack(torch.split(layer, top_k, dim=0))[range(batch_size), selected_idx, ...]
+ next_step_decoder_attentions += (layer,)
+ outputs = Seq2SeqLMOutput(
+ past_key_values=next_past_key_values,
+ decoder_hidden_states=next_decoder_hidden_states,
+ decoder_attentions=next_step_decoder_attentions or None,
+ cross_attentions=next_step_cross_attentions or None,
+ )
+ else:
+ next_step_attentions = ()
+ if output_attentions:
+ for layer in outputs.attentions:
+ layer = torch.stack(torch.split(layer, top_k, dim=0))[range(batch_size), selected_idx, ...]
+ next_step_attentions += (layer,)
+ outputs = CausalLMOutputWithPast(
+ past_key_values=next_past_key_values,
+ hidden_states=next_decoder_hidden_states,
+ attentions=next_step_attentions or None,
+ )
+ # contrastive_search main logic end
+
+ if synced_gpus and this_peer_finished:
+ continue # don't waste resources running the code we don't need
+
+ # finished sentences should have their next token be a padding token
+ if eos_token_id is not None:
+ if pad_token_id is None:
+ raise ValueError("If `eos_token_id` is defined, make sure that `pad_token_id` is defined.")
+ next_tokens = next_tokens * unfinished_sequences + pad_token_id * (1 - unfinished_sequences)
+
+ # update generated ids, model inputs, and length for next step
+ input_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1)
+ if streamer is not None:
+ streamer.put(next_tokens.cpu())
+ model_kwargs = self._update_model_kwargs_for_generation(
+ outputs, model_kwargs, is_encoder_decoder=self.config.is_encoder_decoder
+ )
+
+ # if eos_token was found in one sentence, set sentence to finished
+ if eos_token_id_tensor is not None:
+ unfinished_sequences = unfinished_sequences.mul(
+ next_tokens.tile(eos_token_id_tensor.shape[0], 1).ne(eos_token_id_tensor.unsqueeze(1)).prod(dim=0)
+ )
+
+ # stop when each sentence is finished
+ if unfinished_sequences.max() == 0:
+ this_peer_finished = True
+
+ # stop if we exceed the maximum length
+ if stopping_criteria(input_ids, scores):
+ this_peer_finished = True
+
+ if this_peer_finished and not synced_gpus:
+ break
+
+ if streamer is not None:
+ streamer.end()
+
+ if return_dict_in_generate:
+ if self.config.is_encoder_decoder:
+ return ContrastiveSearchEncoderDecoderOutput(
+ sequences=input_ids,
+ scores=scores,
+ encoder_attentions=encoder_attentions,
+ encoder_hidden_states=encoder_hidden_states,
+ decoder_attentions=decoder_attentions,
+ cross_attentions=cross_attentions,
+ decoder_hidden_states=decoder_hidden_states,
+ )
+ else:
+ return ContrastiveSearchDecoderOnlyOutput(
+ sequences=input_ids,
+ scores=scores,
+ attentions=decoder_attentions,
+ hidden_states=decoder_hidden_states,
+ )
+ else:
+ return input_ids
+
+ def greedy_search(
+ self,
+ input_ids: torch.LongTensor,
+ logits_processor: Optional[LogitsProcessorList] = None,
+ stopping_criteria: Optional[StoppingCriteriaList] = None,
+ max_length: Optional[int] = None,
+ pad_token_id: Optional[int] = None,
+ eos_token_id: Optional[Union[int, List[int]]] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ output_scores: Optional[bool] = None,
+ return_dict_in_generate: Optional[bool] = None,
+ synced_gpus: bool = False,
+ streamer: Optional["BaseStreamer"] = None,
+ **model_kwargs,
+ ) -> Union[GreedySearchOutput, torch.LongTensor]:
+ r"""
+ Generates sequences of token ids for models with a language modeling head using **greedy decoding** and can be
+ used for text-decoder, text-to-text, speech-to-text, and vision-to-text models.
+
+
+
+ In most cases, you do not need to call [`~generation.GenerationMixin.greedy_search`] directly. Use generate()
+ instead. For an overview of generation strategies and code examples, check the [following
+ guide](../generation_strategies).
+
+
+
+
+ Parameters:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ The sequence used as a prompt for the generation.
+ logits_processor (`LogitsProcessorList`, *optional*):
+ An instance of [`LogitsProcessorList`]. List of instances of class derived from [`LogitsProcessor`]
+ used to modify the prediction scores of the language modeling head applied at each generation step.
+ stopping_criteria (`StoppingCriteriaList`, *optional*):
+ An instance of [`StoppingCriteriaList`]. List of instances of class derived from [`StoppingCriteria`]
+ used to tell if the generation loop should stop.
+
+ max_length (`int`, *optional*, defaults to 20):
+ **DEPRECATED**. Use `logits_processor` or `stopping_criteria` directly to cap the number of generated
+ tokens. The maximum length of the sequence to be generated.
+ pad_token_id (`int`, *optional*):
+ The id of the *padding* token.
+ eos_token_id (`Union[int, List[int]]`, *optional*):
+ The id of the *end-of-sequence* token. Optionally, use a list to set multiple *end-of-sequence* tokens.
+ output_attentions (`bool`, *optional*, defaults to `False`):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more details.
+ output_hidden_states (`bool`, *optional*, defaults to `False`):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
+ for more details.
+ output_scores (`bool`, *optional*, defaults to `False`):
+ Whether or not to return the prediction scores. See `scores` under returned tensors for more details.
+ return_dict_in_generate (`bool`, *optional*, defaults to `False`):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+ synced_gpus (`bool`, *optional*, defaults to `False`):
+ Whether to continue running the while loop until max_length (needed for ZeRO stage 3)
+ streamer (`BaseStreamer`, *optional*):
+ Streamer object that will be used to stream the generated sequences. Generated tokens are passed
+ through `streamer.put(token_ids)` and the streamer is responsible for any further processing.
+ model_kwargs:
+ Additional model specific keyword arguments will be forwarded to the `forward` function of the model.
+ If model is an encoder-decoder model the kwargs should include `encoder_outputs`.
+
+ Return:
+ [`~generation.GreedySearchDecoderOnlyOutput`], [`~generation.GreedySearchEncoderDecoderOutput`] or
+ `torch.LongTensor`: A `torch.LongTensor` containing the generated tokens (default behaviour) or a
+ [`~generation.GreedySearchDecoderOnlyOutput`] if `model.config.is_encoder_decoder=False` and
+ `return_dict_in_generate=True` or a [`~generation.GreedySearchEncoderDecoderOutput`] if
+ `model.config.is_encoder_decoder=True`.
+
+ Examples:
+
+ ```python
+ >>> from transformers import (
+ ... AutoTokenizer,
+ ... AutoModelForCausalLM,
+ ... LogitsProcessorList,
+ ... MinLengthLogitsProcessor,
+ ... StoppingCriteriaList,
+ ... MaxLengthCriteria,
+ ... )
+
+ >>> tokenizer = AutoTokenizer.from_pretrained("gpt2")
+ >>> model = AutoModelForCausalLM.from_pretrained("gpt2")
+
+ >>> # set pad_token_id to eos_token_id because GPT2 does not have a PAD token
+ >>> model.generation_config.pad_token_id = model.generation_config.eos_token_id
+
+ >>> input_prompt = "It might be possible to"
+ >>> input_ids = tokenizer(input_prompt, return_tensors="pt").input_ids
+
+ >>> # instantiate logits processors
+ >>> logits_processor = LogitsProcessorList(
+ ... [
+ ... MinLengthLogitsProcessor(10, eos_token_id=model.generation_config.eos_token_id),
+ ... ]
+ ... )
+ >>> stopping_criteria = StoppingCriteriaList([MaxLengthCriteria(max_length=20)])
+
+ >>> outputs = model.greedy_search(
+ ... input_ids, logits_processor=logits_processor, stopping_criteria=stopping_criteria
+ ... )
+
+ >>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
+ ["It might be possible to get a better understanding of the nature of the problem, but it's not"]
+ ```"""
+ # init values
+ logits_processor = logits_processor if logits_processor is not None else LogitsProcessorList()
+ stopping_criteria = stopping_criteria if stopping_criteria is not None else StoppingCriteriaList()
+ if max_length is not None:
+ warnings.warn(
+ "`max_length` is deprecated in this function, use"
+ " `stopping_criteria=StoppingCriteriaList([MaxLengthCriteria(max_length=max_length)])` instead.",
+ UserWarning,
+ )
+ stopping_criteria = validate_stopping_criteria(stopping_criteria, max_length)
+ pad_token_id = pad_token_id if pad_token_id is not None else self.generation_config.pad_token_id
+ eos_token_id = eos_token_id if eos_token_id is not None else self.generation_config.eos_token_id
+ if isinstance(eos_token_id, int):
+ eos_token_id = [eos_token_id]
+ eos_token_id_tensor = torch.tensor(eos_token_id).to(input_ids.device) if eos_token_id is not None else None
+ output_scores = output_scores if output_scores is not None else self.generation_config.output_scores
+ output_attentions = (
+ output_attentions if output_attentions is not None else self.generation_config.output_attentions
+ )
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.generation_config.output_hidden_states
+ )
+ return_dict_in_generate = (
+ return_dict_in_generate
+ if return_dict_in_generate is not None
+ else self.generation_config.return_dict_in_generate
+ )
+
+ # init attention / hidden states / scores tuples
+ scores = () if (return_dict_in_generate and output_scores) else None
+ decoder_attentions = () if (return_dict_in_generate and output_attentions) else None
+ cross_attentions = () if (return_dict_in_generate and output_attentions) else None
+ decoder_hidden_states = () if (return_dict_in_generate and output_hidden_states) else None
+
+ # if model is an encoder-decoder, retrieve encoder attention weights and hidden states
+ if return_dict_in_generate and self.config.is_encoder_decoder:
+ encoder_attentions = model_kwargs["encoder_outputs"].get("attentions") if output_attentions else None
+ encoder_hidden_states = (
+ model_kwargs["encoder_outputs"].get("hidden_states") if output_hidden_states else None
+ )
+
+ # keep track of which sequences are already finished
+ unfinished_sequences = torch.ones(input_ids.shape[0], dtype=torch.long, device=input_ids.device)
+
+ this_peer_finished = False # used by synced_gpus only
+
+ first_token_time = None
+ last_token_time = []
+ memory_every_token = []
+ while True:
+ st = time.perf_counter()
+ if synced_gpus:
+ # Under synced_gpus the `forward` call must continue until all gpus complete their sequence.
+ # The following logic allows an early break if all peers finished generating their sequence
+ this_peer_finished_flag = torch.tensor(0.0 if this_peer_finished else 1.0).to(input_ids.device)
+ # send 0.0 if we finished, 1.0 otherwise
+ dist.all_reduce(this_peer_finished_flag, op=dist.ReduceOp.SUM)
+ # did all peers finish? the reduced sum will be 0.0 then
+ if this_peer_finished_flag.item() == 0.0:
+ break
+
+ # prepare model inputs
+ model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)
+
+ # forward pass to get next token
+ outputs = self(
+ **model_inputs,
+ return_dict=True,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ )
+ if synced_gpus and this_peer_finished:
+ continue # don't waste resources running the code we don't need
+
+ next_token_logits = outputs.logits[:, -1, :]
+
+ # pre-process distribution
+ next_tokens_scores = logits_processor(input_ids, next_token_logits)
+
+ # Store scores, attentions and hidden_states when required
+ if return_dict_in_generate:
+ if output_scores:
+ scores += (next_tokens_scores,)
+ if output_attentions:
+ decoder_attentions += (
+ (outputs.decoder_attentions,) if self.config.is_encoder_decoder else (outputs.attentions,)
+ )
+ if self.config.is_encoder_decoder:
+ cross_attentions += (outputs.cross_attentions,)
+
+ if output_hidden_states:
+ decoder_hidden_states += (
+ (outputs.decoder_hidden_states,)
+ if self.config.is_encoder_decoder
+ else (outputs.hidden_states,)
+ )
+
+ # argmax
+ next_tokens = torch.argmax(next_tokens_scores, dim=-1)
+
+ # finished sentences should have their next token be a padding token
+ if eos_token_id is not None:
+ if pad_token_id is None:
+ raise ValueError("If `eos_token_id` is defined, make sure that `pad_token_id` is defined.")
+ next_tokens = next_tokens * unfinished_sequences + pad_token_id * (1 - unfinished_sequences)
+
+ # update generated ids, model inputs, and length for next step
+ input_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1)
+ if streamer is not None:
+ streamer.put(next_tokens.cpu())
+ model_kwargs = self._update_model_kwargs_for_generation(
+ outputs, model_kwargs, is_encoder_decoder=self.config.is_encoder_decoder
+ )
+
+ # if eos_token was found in one sentence, set sentence to finished
+ if eos_token_id_tensor is not None:
+ unfinished_sequences = unfinished_sequences.mul(
+ next_tokens.tile(eos_token_id_tensor.shape[0], 1).ne(eos_token_id_tensor.unsqueeze(1)).prod(dim=0)
+ )
+
+ # stop when each sentence is finished
+ if unfinished_sequences.max() == 0:
+ this_peer_finished = True
+
+ if self.device.type == "xpu":
+ torch.xpu.synchronize()
+ memory_every_token.append(torch.xpu.memory.memory_reserved(self.device) / (1024**3))
+ self.peak_memory = np.max(memory_every_token)
+ end = time.perf_counter()
+ if first_token_time is None:
+ first_token_time = end - st
+ else:
+ last_token_time.append(end - st)
+
+ # stop if we exceed the maximum length
+ if stopping_criteria(input_ids, scores):
+ this_peer_finished = True
+
+ if this_peer_finished and not synced_gpus:
+ break
+
+ if self.do_print:
+ if self.device.type == "xpu":
+ print(f"=========First token cost {first_token_time:.4f} s and {memory_every_token[0]} GB=========")
+ else:
+ print(f"=========First token cost {first_token_time:.4f} s=========")
+ if len(last_token_time) > 1:
+ self.first_cost = first_token_time
+ self.rest_cost_mean = np.mean(last_token_time)
+ if self.do_print:
+ if self.device.type == "xpu":
+ print(f"=========Rest tokens cost average {self.rest_cost_mean:.4f} s ({len(last_token_time)}"
+ f" tokens in all) and {np.max(memory_every_token[1:])} GB=========")
+ if self.verbose:
+ print(f"Peak memory for every token: {memory_every_token}")
+ else:
+ print(f"=========Rest tokens cost average {self.rest_cost_mean:.4f} s ({len(last_token_time)}"
+ f" tokens in all)=========")
+
+ if streamer is not None:
+ streamer.end()
+
+ if return_dict_in_generate:
+ if self.config.is_encoder_decoder:
+ return GreedySearchEncoderDecoderOutput(
+ sequences=input_ids,
+ scores=scores,
+ encoder_attentions=encoder_attentions,
+ encoder_hidden_states=encoder_hidden_states,
+ decoder_attentions=decoder_attentions,
+ cross_attentions=cross_attentions,
+ decoder_hidden_states=decoder_hidden_states,
+ )
+ else:
+ return GreedySearchDecoderOnlyOutput(
+ sequences=input_ids,
+ scores=scores,
+ attentions=decoder_attentions,
+ hidden_states=decoder_hidden_states,
+ )
+ else:
+ return input_ids
+
+ def sample(
+ self,
+ input_ids: torch.LongTensor,
+ logits_processor: Optional[LogitsProcessorList] = None,
+ stopping_criteria: Optional[StoppingCriteriaList] = None,
+ logits_warper: Optional[LogitsProcessorList] = None,
+ max_length: Optional[int] = None,
+ pad_token_id: Optional[int] = None,
+ eos_token_id: Optional[Union[int, List[int]]] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ output_scores: Optional[bool] = None,
+ return_dict_in_generate: Optional[bool] = None,
+ synced_gpus: bool = False,
+ streamer: Optional["BaseStreamer"] = None,
+ **model_kwargs,
+ ) -> Union[SampleOutput, torch.LongTensor]:
+ r"""
+ Generates sequences of token ids for models with a language modeling head using **multinomial sampling** and
+ can be used for text-decoder, text-to-text, speech-to-text, and vision-to-text models.
+
+
+
+ In most cases, you do not need to call [`~generation.GenerationMixin.sample`] directly. Use generate() instead.
+ For an overview of generation strategies and code examples, check the [following
+ guide](../generation_strategies).
+
+
+
+ Parameters:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ The sequence used as a prompt for the generation.
+ logits_processor (`LogitsProcessorList`, *optional*):
+ An instance of [`LogitsProcessorList`]. List of instances of class derived from [`LogitsProcessor`]
+ used to modify the prediction scores of the language modeling head applied at each generation step.
+ stopping_criteria (`StoppingCriteriaList`, *optional*):
+ An instance of [`StoppingCriteriaList`]. List of instances of class derived from [`StoppingCriteria`]
+ used to tell if the generation loop should stop.
+ logits_warper (`LogitsProcessorList`, *optional*):
+ An instance of [`LogitsProcessorList`]. List of instances of class derived from [`LogitsWarper`] used
+ to warp the prediction score distribution of the language modeling head applied before multinomial
+ sampling at each generation step.
+ max_length (`int`, *optional*, defaults to 20):
+ **DEPRECATED**. Use `logits_processor` or `stopping_criteria` directly to cap the number of generated
+ tokens. The maximum length of the sequence to be generated.
+ pad_token_id (`int`, *optional*):
+ The id of the *padding* token.
+ eos_token_id (`Union[int, List[int]]`, *optional*):
+ The id of the *end-of-sequence* token. Optionally, use a list to set multiple *end-of-sequence* tokens.
+ output_attentions (`bool`, *optional*, defaults to `False`):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more details.
+ output_hidden_states (`bool`, *optional*, defaults to `False`):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
+ for more details.
+ output_scores (`bool`, *optional*, defaults to `False`):
+ Whether or not to return the prediction scores. See `scores` under returned tensors for more details.
+ return_dict_in_generate (`bool`, *optional*, defaults to `False`):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+ synced_gpus (`bool`, *optional*, defaults to `False`):
+ Whether to continue running the while loop until max_length (needed for ZeRO stage 3)
+ streamer (`BaseStreamer`, *optional*):
+ Streamer object that will be used to stream the generated sequences. Generated tokens are passed
+ through `streamer.put(token_ids)` and the streamer is responsible for any further processing.
+ model_kwargs:
+ Additional model specific kwargs will be forwarded to the `forward` function of the model. If model is
+ an encoder-decoder model the kwargs should include `encoder_outputs`.
+
+ Return:
+ [`~generation.SampleDecoderOnlyOutput`], [`~generation.SampleEncoderDecoderOutput`] or `torch.LongTensor`:
+ A `torch.LongTensor` containing the generated tokens (default behaviour) or a
+ [`~generation.SampleDecoderOnlyOutput`] if `model.config.is_encoder_decoder=False` and
+ `return_dict_in_generate=True` or a [`~generation.SampleEncoderDecoderOutput`] if
+ `model.config.is_encoder_decoder=True`.
+
+ Examples:
+
+ ```python
+ >>> from transformers import (
+ ... AutoTokenizer,
+ ... AutoModelForCausalLM,
+ ... LogitsProcessorList,
+ ... MinLengthLogitsProcessor,
+ ... TopKLogitsWarper,
+ ... TemperatureLogitsWarper,
+ ... StoppingCriteriaList,
+ ... MaxLengthCriteria,
+ ... )
+ >>> import torch
+
+ >>> tokenizer = AutoTokenizer.from_pretrained("gpt2")
+ >>> model = AutoModelForCausalLM.from_pretrained("gpt2")
+
+ >>> # set pad_token_id to eos_token_id because GPT2 does not have a EOS token
+ >>> model.config.pad_token_id = model.config.eos_token_id
+ >>> model.generation_config.pad_token_id = model.config.eos_token_id
+
+ >>> input_prompt = "Today is a beautiful day, and"
+ >>> input_ids = tokenizer(input_prompt, return_tensors="pt").input_ids
+
+ >>> # instantiate logits processors
+ >>> logits_processor = LogitsProcessorList(
+ ... [
+ ... MinLengthLogitsProcessor(15, eos_token_id=model.generation_config.eos_token_id),
+ ... ]
+ ... )
+ >>> # instantiate logits processors
+ >>> logits_warper = LogitsProcessorList(
+ ... [
+ ... TopKLogitsWarper(50),
+ ... TemperatureLogitsWarper(0.7),
+ ... ]
+ ... )
+
+ >>> stopping_criteria = StoppingCriteriaList([MaxLengthCriteria(max_length=20)])
+
+ >>> torch.manual_seed(0) # doctest: +IGNORE_RESULT
+ >>> outputs = model.sample(
+ ... input_ids,
+ ... logits_processor=logits_processor,
+ ... logits_warper=logits_warper,
+ ... stopping_criteria=stopping_criteria,
+ ... )
+
+ >>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
+ ['Today is a beautiful day, and we must do everything possible to make it a day of celebration.']
+ ```"""
+ # init values
+ logits_processor = logits_processor if logits_processor is not None else LogitsProcessorList()
+ stopping_criteria = stopping_criteria if stopping_criteria is not None else StoppingCriteriaList()
+ if max_length is not None:
+ warnings.warn(
+ "`max_length` is deprecated in this function, use"
+ " `stopping_criteria=StoppingCriteriaList(MaxLengthCriteria(max_length=max_length))` instead.",
+ UserWarning,
+ )
+ stopping_criteria = validate_stopping_criteria(stopping_criteria, max_length)
+ logits_warper = logits_warper if logits_warper is not None else LogitsProcessorList()
+ pad_token_id = pad_token_id if pad_token_id is not None else self.generation_config.pad_token_id
+ eos_token_id = eos_token_id if eos_token_id is not None else self.generation_config.eos_token_id
+ if isinstance(eos_token_id, int):
+ eos_token_id = [eos_token_id]
+ eos_token_id_tensor = torch.tensor(eos_token_id).to(input_ids.device) if eos_token_id is not None else None
+ output_scores = output_scores if output_scores is not None else self.generation_config.output_scores
+ output_attentions = (
+ output_attentions if output_attentions is not None else self.generation_config.output_attentions
+ )
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.generation_config.output_hidden_states
+ )
+ return_dict_in_generate = (
+ return_dict_in_generate
+ if return_dict_in_generate is not None
+ else self.generation_config.return_dict_in_generate
+ )
+
+ # init attention / hidden states / scores tuples
+ scores = () if (return_dict_in_generate and output_scores) else None
+ decoder_attentions = () if (return_dict_in_generate and output_attentions) else None
+ cross_attentions = () if (return_dict_in_generate and output_attentions) else None
+ decoder_hidden_states = () if (return_dict_in_generate and output_hidden_states) else None
+
+ # if model is an encoder-decoder, retrieve encoder attention weights and hidden states
+ if return_dict_in_generate and self.config.is_encoder_decoder:
+ encoder_attentions = model_kwargs["encoder_outputs"].get("attentions") if output_attentions else None
+ encoder_hidden_states = (
+ model_kwargs["encoder_outputs"].get("hidden_states") if output_hidden_states else None
+ )
+
+ # keep track of which sequences are already finished
+ unfinished_sequences = torch.ones(input_ids.shape[0], dtype=torch.long, device=input_ids.device)
+
+ this_peer_finished = False # used by synced_gpus only
+
+ first_token_time = None
+ last_token_time = []
+ memory_every_token = []
+ # auto-regressive generation
+ while True:
+ st = time.perf_counter()
+ if synced_gpus:
+ # Under synced_gpus the `forward` call must continue until all gpus complete their sequence.
+ # The following logic allows an early break if all peers finished generating their sequence
+ this_peer_finished_flag = torch.tensor(0.0 if this_peer_finished else 1.0).to(input_ids.device)
+ # send 0.0 if we finished, 1.0 otherwise
+ dist.all_reduce(this_peer_finished_flag, op=dist.ReduceOp.SUM)
+ # did all peers finish? the reduced sum will be 0.0 then
+ if this_peer_finished_flag.item() == 0.0:
+ break
+
+ # prepare model inputs
+ model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)
+
+ # forward pass to get next token
+ outputs = self(
+ **model_inputs,
+ return_dict=True,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ )
+
+ if synced_gpus and this_peer_finished:
+ continue # don't waste resources running the code we don't need
+
+ next_token_logits = outputs.logits[:, -1, :]
+
+ # pre-process distribution
+ next_token_scores = logits_processor(input_ids, next_token_logits)
+ next_token_scores = logits_warper(input_ids, next_token_scores)
+
+ # Store scores, attentions and hidden_states when required
+ if return_dict_in_generate:
+ if output_scores:
+ scores += (next_token_scores,)
+ if output_attentions:
+ decoder_attentions += (
+ (outputs.decoder_attentions,) if self.config.is_encoder_decoder else (outputs.attentions,)
+ )
+ if self.config.is_encoder_decoder:
+ cross_attentions += (outputs.cross_attentions,)
+
+ if output_hidden_states:
+ decoder_hidden_states += (
+ (outputs.decoder_hidden_states,)
+ if self.config.is_encoder_decoder
+ else (outputs.hidden_states,)
+ )
+
+ # sample
+ probs = nn.functional.softmax(next_token_scores, dim=-1)
+ next_tokens = torch.multinomial(probs, num_samples=1).squeeze(1)
+
+ # finished sentences should have their next token be a padding token
+ if eos_token_id is not None:
+ if pad_token_id is None:
+ raise ValueError("If `eos_token_id` is defined, make sure that `pad_token_id` is defined.")
+ next_tokens = next_tokens * unfinished_sequences + pad_token_id * (1 - unfinished_sequences)
+
+ # update generated ids, model inputs, and length for next step
+ input_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1)
+ if streamer is not None:
+ streamer.put(next_tokens.cpu())
+ model_kwargs = self._update_model_kwargs_for_generation(
+ outputs, model_kwargs, is_encoder_decoder=self.config.is_encoder_decoder
+ )
+
+ # if eos_token was found in one sentence, set sentence to finished
+ if eos_token_id_tensor is not None:
+ unfinished_sequences = unfinished_sequences.mul(
+ next_tokens.tile(eos_token_id_tensor.shape[0], 1).ne(eos_token_id_tensor.unsqueeze(1)).prod(dim=0)
+ )
+
+ # stop when each sentence is finished
+ if unfinished_sequences.max() == 0:
+ this_peer_finished = True
+
+ if self.device.type == "xpu":
+ torch.xpu.synchronize()
+ memory_every_token.append(torch.xpu.memory.memory_reserved(self.device) / (1024 ** 3))
+ self.peak_memory = np.max(memory_every_token)
+ end = time.perf_counter()
+ if first_token_time is None:
+ first_token_time = end - st
+ else:
+ last_token_time.append(end - st)
+
+ # stop if we exceed the maximum length
+ if stopping_criteria(input_ids, scores):
+ this_peer_finished = True
+
+ if this_peer_finished and not synced_gpus:
+ break
+
+ if self.do_print:
+ if self.device.type == "xpu":
+ print(f"=========First token cost {first_token_time:.4f} s and {memory_every_token[0]} GB=========")
+ else:
+ print(f"=========First token cost {first_token_time:.4f} s=========")
+ if len(last_token_time) > 1:
+ self.first_cost = first_token_time
+ self.rest_cost_mean = np.mean(last_token_time)
+ if self.do_print:
+ if self.device.type == "xpu":
+ print(f"=========Rest tokens cost average {self.rest_cost_mean:.4f} s ({len(last_token_time)}"
+ f" tokens in all) and {np.max(memory_every_token[1:])} GB=========")
+ if self.verbose:
+ print(f"Peak memory for every token: {memory_every_token}")
+ else:
+ print(f"=========Rest tokens cost average {self.rest_cost_mean:.4f} s ({len(last_token_time)}"
+ f" tokens in all)=========")
+
+ if streamer is not None:
+ streamer.end()
+
+ if return_dict_in_generate:
+ if self.config.is_encoder_decoder:
+ return SampleEncoderDecoderOutput(
+ sequences=input_ids,
+ scores=scores,
+ encoder_attentions=encoder_attentions,
+ encoder_hidden_states=encoder_hidden_states,
+ decoder_attentions=decoder_attentions,
+ cross_attentions=cross_attentions,
+ decoder_hidden_states=decoder_hidden_states,
+ )
+ else:
+ return SampleDecoderOnlyOutput(
+ sequences=input_ids,
+ scores=scores,
+ attentions=decoder_attentions,
+ hidden_states=decoder_hidden_states,
+ )
+ else:
+ return input_ids
+
+ def beam_search(
+ self,
+ input_ids: torch.LongTensor,
+ beam_scorer: BeamScorer,
+ logits_processor: Optional[LogitsProcessorList] = None,
+ stopping_criteria: Optional[StoppingCriteriaList] = None,
+ max_length: Optional[int] = None,
+ pad_token_id: Optional[int] = None,
+ eos_token_id: Optional[Union[int, List[int]]] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ output_scores: Optional[bool] = None,
+ return_dict_in_generate: Optional[bool] = None,
+ synced_gpus: bool = False,
+ **model_kwargs,
+ ) -> Union[BeamSearchOutput, torch.LongTensor]:
+ r"""
+ Generates sequences of token ids for models with a language modeling head using **beam search decoding** and
+ can be used for text-decoder, text-to-text, speech-to-text, and vision-to-text models.
+
+
+
+ In most cases, you do not need to call [`~generation.GenerationMixin.beam_search`] directly. Use generate()
+ instead. For an overview of generation strategies and code examples, check the [following
+ guide](../generation_strategies).
+
+
+
+ Parameters:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ The sequence used as a prompt for the generation.
+ beam_scorer (`BeamScorer`):
+ An derived instance of [`BeamScorer`] that defines how beam hypotheses are constructed, stored and
+ sorted during generation. For more information, the documentation of [`BeamScorer`] should be read.
+ logits_processor (`LogitsProcessorList`, *optional*):
+ An instance of [`LogitsProcessorList`]. List of instances of class derived from [`LogitsProcessor`]
+ used to modify the prediction scores of the language modeling head applied at each generation step.
+ stopping_criteria (`StoppingCriteriaList`, *optional*):
+ An instance of [`StoppingCriteriaList`]. List of instances of class derived from [`StoppingCriteria`]
+ used to tell if the generation loop should stop.
+ max_length (`int`, *optional*, defaults to 20):
+ **DEPRECATED**. Use `logits_processor` or `stopping_criteria` directly to cap the number of generated
+ tokens. The maximum length of the sequence to be generated.
+ pad_token_id (`int`, *optional*):
+ The id of the *padding* token.
+ eos_token_id (`Union[int, List[int]]`, *optional*):
+ The id of the *end-of-sequence* token. Optionally, use a list to set multiple *end-of-sequence* tokens.
+ output_attentions (`bool`, *optional*, defaults to `False`):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more details.
+ output_hidden_states (`bool`, *optional*, defaults to `False`):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
+ for more details.
+ output_scores (`bool`, *optional*, defaults to `False`):
+ Whether or not to return the prediction scores. See `scores` under returned tensors for more details.
+ return_dict_in_generate (`bool`, *optional*, defaults to `False`):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+ synced_gpus (`bool`, *optional*, defaults to `False`):
+ Whether to continue running the while loop until max_length (needed for ZeRO stage 3)
+ model_kwargs:
+ Additional model specific kwargs will be forwarded to the `forward` function of the model. If model is
+ an encoder-decoder model the kwargs should include `encoder_outputs`.
+
+ Return:
+ [`generation.BeamSearchDecoderOnlyOutput`], [`~generation.BeamSearchEncoderDecoderOutput`] or
+ `torch.LongTensor`: A `torch.LongTensor` containing the generated tokens (default behaviour) or a
+ [`~generation.BeamSearchDecoderOnlyOutput`] if `model.config.is_encoder_decoder=False` and
+ `return_dict_in_generate=True` or a [`~generation.BeamSearchEncoderDecoderOutput`] if
+ `model.config.is_encoder_decoder=True`.
+
+
+ Examples:
+
+ ```python
+ >>> from transformers import (
+ ... AutoTokenizer,
+ ... AutoModelForSeq2SeqLM,
+ ... LogitsProcessorList,
+ ... MinLengthLogitsProcessor,
+ ... BeamSearchScorer,
+ ... )
+ >>> import torch
+
+ >>> tokenizer = AutoTokenizer.from_pretrained("t5-base")
+ >>> model = AutoModelForSeq2SeqLM.from_pretrained("t5-base")
+
+ >>> encoder_input_str = "translate English to German: How old are you?"
+ >>> encoder_input_ids = tokenizer(encoder_input_str, return_tensors="pt").input_ids
+
+
+ >>> # lets run beam search using 3 beams
+ >>> num_beams = 3
+ >>> # define decoder start token ids
+ >>> input_ids = torch.ones((num_beams, 1), device=model.device, dtype=torch.long)
+ >>> input_ids = input_ids * model.config.decoder_start_token_id
+
+ >>> # add encoder_outputs to model keyword arguments
+ >>> model_kwargs = {
+ ... "encoder_outputs": model.get_encoder()(
+ ... encoder_input_ids.repeat_interleave(num_beams, dim=0), return_dict=True
+ ... )
+ ... }
+
+ >>> # instantiate beam scorer
+ >>> beam_scorer = BeamSearchScorer(
+ ... batch_size=1,
+ ... num_beams=num_beams,
+ ... device=model.device,
+ ... )
+
+ >>> # instantiate logits processors
+ >>> logits_processor = LogitsProcessorList(
+ ... [
+ ... MinLengthLogitsProcessor(5, eos_token_id=model.config.eos_token_id),
+ ... ]
+ ... )
+
+ >>> outputs = model.beam_search(input_ids, beam_scorer, logits_processor=logits_processor, **model_kwargs)
+
+ >>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
+ ['Wie alt bist du?']
+ ```"""
+ # init values
+ logits_processor = logits_processor if logits_processor is not None else LogitsProcessorList()
+ stopping_criteria = stopping_criteria if stopping_criteria is not None else StoppingCriteriaList()
+ if max_length is not None:
+ warnings.warn(
+ "`max_length` is deprecated in this function, use"
+ " `stopping_criteria=StoppingCriteriaList(MaxLengthCriteria(max_length=max_length))` instead.",
+ UserWarning,
+ )
+ stopping_criteria = validate_stopping_criteria(stopping_criteria, max_length)
+ if len(stopping_criteria) == 0:
+ warnings.warn("You don't have defined any stopping_criteria, this will likely loop forever", UserWarning)
+ pad_token_id = pad_token_id if pad_token_id is not None else self.generation_config.pad_token_id
+ eos_token_id = eos_token_id if eos_token_id is not None else self.generation_config.eos_token_id
+ if isinstance(eos_token_id, int):
+ eos_token_id = [eos_token_id]
+ output_scores = output_scores if output_scores is not None else self.generation_config.output_scores
+ output_attentions = (
+ output_attentions if output_attentions is not None else self.generation_config.output_attentions
+ )
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.generation_config.output_hidden_states
+ )
+ return_dict_in_generate = (
+ return_dict_in_generate
+ if return_dict_in_generate is not None
+ else self.generation_config.return_dict_in_generate
+ )
+
+ batch_size = len(beam_scorer._beam_hyps)
+ num_beams = beam_scorer.num_beams
+
+ batch_beam_size, cur_len = input_ids.shape
+
+ if num_beams * batch_size != batch_beam_size:
+ raise ValueError(
+ f"Batch dimension of `input_ids` should be {num_beams * batch_size}, but is {batch_beam_size}."
+ )
+
+ # init attention / hidden states / scores tuples
+ scores = () if (return_dict_in_generate and output_scores) else None
+ beam_indices = (
+ tuple(() for _ in range(batch_beam_size)) if (return_dict_in_generate and output_scores) else None
+ )
+ decoder_attentions = () if (return_dict_in_generate and output_attentions) else None
+ cross_attentions = () if (return_dict_in_generate and output_attentions) else None
+ decoder_hidden_states = () if (return_dict_in_generate and output_hidden_states) else None
+
+ # if model is an encoder-decoder, retrieve encoder attention weights and hidden states
+ if return_dict_in_generate and self.config.is_encoder_decoder:
+ encoder_attentions = model_kwargs["encoder_outputs"].get("attentions") if output_attentions else None
+ encoder_hidden_states = (
+ model_kwargs["encoder_outputs"].get("hidden_states") if output_hidden_states else None
+ )
+
+ # initialise score of first beam with 0 and the rest with -1e9. This makes sure that only tokens
+ # of the first beam are considered to avoid sampling the exact same tokens across all beams.
+ beam_scores = torch.zeros((batch_size, num_beams), dtype=torch.float, device=input_ids.device)
+ beam_scores[:, 1:] = -1e9
+ beam_scores = beam_scores.view((batch_size * num_beams,))
+
+ first_token_time = None
+ last_token_time = []
+ this_peer_finished = False # used by synced_gpus only
+ memory_every_token = []
+ while True:
+ st = time.perf_counter()
+ if synced_gpus:
+ # Under synced_gpus the `forward` call must continue until all gpus complete their sequence.
+ # The following logic allows an early break if all peers finished generating their sequence
+ this_peer_finished_flag = torch.tensor(0.0 if this_peer_finished else 1.0).to(input_ids.device)
+ # send 0.0 if we finished, 1.0 otherwise
+ dist.all_reduce(this_peer_finished_flag, op=dist.ReduceOp.SUM)
+ # did all peers finish? the reduced sum will be 0.0 then
+ if this_peer_finished_flag.item() == 0.0:
+ break
+
+ model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)
+
+ outputs = self(
+ **model_inputs,
+ return_dict=True,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ )
+
+ if synced_gpus and this_peer_finished:
+ cur_len = cur_len + 1
+ continue # don't waste resources running the code we don't need
+
+ next_token_logits = outputs.logits[:, -1, :]
+ # hack: adjust tokens for Marian. For Marian we have to make sure that the `pad_token_id`
+ # cannot be generated both before and after the `nn.functional.log_softmax` operation.
+ next_token_logits = self.adjust_logits_during_generation(next_token_logits, cur_len=cur_len)
+ next_token_scores = nn.functional.log_softmax(
+ next_token_logits, dim=-1
+ ) # (batch_size * num_beams, vocab_size)
+
+ next_token_scores_processed = logits_processor(input_ids, next_token_scores)
+ next_token_scores = next_token_scores_processed + beam_scores[:, None].expand_as(next_token_scores)
+
+ # Store scores, attentions and hidden_states when required
+ if return_dict_in_generate:
+ if output_scores:
+ scores += (next_token_scores_processed,)
+ if output_attentions:
+ decoder_attentions += (
+ (outputs.decoder_attentions,) if self.config.is_encoder_decoder else (outputs.attentions,)
+ )
+ if self.config.is_encoder_decoder:
+ cross_attentions += (outputs.cross_attentions,)
+
+ if output_hidden_states:
+ decoder_hidden_states += (
+ (outputs.decoder_hidden_states,)
+ if self.config.is_encoder_decoder
+ else (outputs.hidden_states,)
+ )
+
+ # reshape for beam search
+ vocab_size = next_token_scores.shape[-1]
+ next_token_scores = next_token_scores.view(batch_size, num_beams * vocab_size)
+
+ # Sample 2 next tokens for each beam (so we have some spare tokens and match output of beam search)
+ next_token_scores, next_tokens = torch.topk(
+ next_token_scores, 2 * num_beams, dim=1, largest=True, sorted=True
+ )
+
+ next_indices = torch.div(next_tokens, vocab_size, rounding_mode="floor")
+ next_tokens = next_tokens % vocab_size
+
+ # stateless
+ beam_outputs = beam_scorer.process(
+ input_ids,
+ next_token_scores,
+ next_tokens,
+ next_indices,
+ pad_token_id=pad_token_id,
+ eos_token_id=eos_token_id,
+ beam_indices=beam_indices,
+ )
+
+ beam_scores = beam_outputs["next_beam_scores"]
+ beam_next_tokens = beam_outputs["next_beam_tokens"]
+ beam_idx = beam_outputs["next_beam_indices"]
+
+ input_ids = torch.cat([input_ids[beam_idx, :], beam_next_tokens.unsqueeze(-1)], dim=-1)
+
+ model_kwargs = self._update_model_kwargs_for_generation(
+ outputs, model_kwargs, is_encoder_decoder=self.config.is_encoder_decoder
+ )
+ if model_kwargs["past_key_values"] is not None:
+ model_kwargs["past_key_values"] = self._reorder_cache(model_kwargs["past_key_values"], beam_idx)
+
+ if return_dict_in_generate and output_scores:
+ beam_indices = tuple((beam_indices[beam_idx[i]] + (beam_idx[i],) for i in range(len(beam_indices))))
+
+ # increase cur_len
+ cur_len = cur_len + 1
+
+ if self.device.type == "xpu":
+ torch.xpu.synchronize()
+ memory_every_token.append(torch.xpu.memory.memory_reserved(self.device) / (1024 ** 3))
+ self.peak_memory = np.max(memory_every_token)
+ end = time.perf_counter()
+ if first_token_time is None:
+ first_token_time = end - st
+ else:
+ last_token_time.append(end - st)
+
+ if beam_scorer.is_done or stopping_criteria(input_ids, scores):
+ if not synced_gpus:
+ break
+ else:
+ this_peer_finished = True
+
+ sequence_outputs = beam_scorer.finalize(
+ input_ids,
+ beam_scores,
+ next_tokens,
+ next_indices,
+ pad_token_id=pad_token_id,
+ eos_token_id=eos_token_id,
+ max_length=stopping_criteria.max_length,
+ beam_indices=beam_indices,
+ )
+
+ if self.do_print:
+ if self.device.type == "xpu":
+ print(f"=========First token cost {first_token_time:.4f} s and {memory_every_token[0]} GB=========")
+ else:
+ print(f"=========First token cost {first_token_time:.4f} s=========")
+ if len(last_token_time) > 1:
+ self.first_cost = first_token_time
+ self.rest_cost_mean = np.mean(last_token_time)
+ if self.do_print:
+ if self.device.type == "xpu":
+ print(f"=========Rest tokens cost average {self.rest_cost_mean:.4f} s ({len(last_token_time)}"
+ f" tokens in all) and {np.max(memory_every_token[1:])} GB=========")
+ if self.verbose:
+ print(f"Peak memory for every token: {memory_every_token}")
+ else:
+ print(f"=========Rest tokens cost average {self.rest_cost_mean:.4f} s ({len(last_token_time)}"
+ f" tokens in all)=========")
+
+ if return_dict_in_generate:
+ if not output_scores:
+ sequence_outputs["sequence_scores"] = None
+
+ if self.config.is_encoder_decoder:
+ return BeamSearchEncoderDecoderOutput(
+ sequences=sequence_outputs["sequences"],
+ sequences_scores=sequence_outputs["sequence_scores"],
+ scores=scores,
+ beam_indices=sequence_outputs["beam_indices"],
+ encoder_attentions=encoder_attentions,
+ encoder_hidden_states=encoder_hidden_states,
+ decoder_attentions=decoder_attentions,
+ cross_attentions=cross_attentions,
+ decoder_hidden_states=decoder_hidden_states,
+ )
+ else:
+ return BeamSearchDecoderOnlyOutput(
+ sequences=sequence_outputs["sequences"],
+ sequences_scores=sequence_outputs["sequence_scores"],
+ scores=scores,
+ beam_indices=sequence_outputs["beam_indices"],
+ attentions=decoder_attentions,
+ hidden_states=decoder_hidden_states,
+ )
+ else:
+ return sequence_outputs["sequences"]
+
+ def beam_sample(
+ self,
+ input_ids: torch.LongTensor,
+ beam_scorer: BeamScorer,
+ logits_processor: Optional[LogitsProcessorList] = None,
+ stopping_criteria: Optional[StoppingCriteriaList] = None,
+ logits_warper: Optional[LogitsProcessorList] = None,
+ max_length: Optional[int] = None,
+ pad_token_id: Optional[int] = None,
+ eos_token_id: Optional[Union[int, List[int]]] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ output_scores: Optional[bool] = None,
+ return_dict_in_generate: Optional[bool] = None,
+ synced_gpus: bool = False,
+ **model_kwargs,
+ ) -> Union[BeamSampleOutput, torch.LongTensor]:
+ r"""
+ Generates sequences of token ids for models with a language modeling head using **beam search multinomial
+ sampling** and can be used for text-decoder, text-to-text, speech-to-text, and vision-to-text models.
+
+
+
+ In most cases, you do not need to call [`~generation.GenerationMixin.beam_sample`] directly. Use generate()
+ instead. For an overview of generation strategies and code examples, check the [following
+ guide](../generation_strategies).
+
+
+
+ Parameters:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ The sequence used as a prompt for the generation.
+ beam_scorer (`BeamScorer`):
+ A derived instance of [`BeamScorer`] that defines how beam hypotheses are constructed, stored and
+ sorted during generation. For more information, the documentation of [`BeamScorer`] should be read.
+ logits_processor (`LogitsProcessorList`, *optional*):
+ An instance of [`LogitsProcessorList`]. List of instances of class derived from [`LogitsProcessor`]
+ used to modify the prediction scores of the language modeling head applied at each generation step.
+ stopping_criteria (`StoppingCriteriaList`, *optional*):
+ An instance of [`StoppingCriteriaList`]. List of instances of class derived from [`StoppingCriteria`]
+ used to tell if the generation loop should stop.
+ logits_warper (`LogitsProcessorList`, *optional*):
+ An instance of [`LogitsProcessorList`]. List of instances of class derived from [`LogitsWarper`] used
+ to warp the prediction score distribution of the language modeling head applied before multinomial
+ sampling at each generation step.
+ max_length (`int`, *optional*, defaults to 20):
+ **DEPRECATED**. Use `logits_processor` or `stopping_criteria` directly to cap the number of generated
+ tokens. The maximum length of the sequence to be generated.
+ pad_token_id (`int`, *optional*):
+ The id of the *padding* token.
+ eos_token_id (`Union[int, List[int]]`, *optional*):
+ The id of the *end-of-sequence* token. Optionally, use a list to set multiple *end-of-sequence* tokens.
+ output_attentions (`bool`, *optional*, defaults to `False`):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more details.
+ output_hidden_states (`bool`, *optional*, defaults to `False`):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
+ for more details.
+ output_scores (`bool`, *optional*, defaults to `False`):
+ Whether or not to return the prediction scores. See `scores` under returned tensors for more details.
+ return_dict_in_generate (`bool`, *optional*, defaults to `False`):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+ synced_gpus (`bool`, *optional*, defaults to `False`):
+ Whether to continue running the while loop until max_length (needed for ZeRO stage 3)
+ model_kwargs:
+ Additional model specific kwargs will be forwarded to the `forward` function of the model. If model is
+ an encoder-decoder model the kwargs should include `encoder_outputs`.
+
+ Return:
+ [`~generation.BeamSampleDecoderOnlyOutput`], [`~generation.BeamSampleEncoderDecoderOutput`] or
+ `torch.LongTensor`: A `torch.LongTensor` containing the generated tokens (default behaviour) or a
+ [`~generation.BeamSampleDecoderOnlyOutput`] if `model.config.is_encoder_decoder=False` and
+ `return_dict_in_generate=True` or a [`~generation.BeamSampleEncoderDecoderOutput`] if
+ `model.config.is_encoder_decoder=True`.
+
+ Examples:
+
+ ```python
+ >>> from transformers import (
+ ... AutoTokenizer,
+ ... AutoModelForSeq2SeqLM,
+ ... LogitsProcessorList,
+ ... MinLengthLogitsProcessor,
+ ... TopKLogitsWarper,
+ ... TemperatureLogitsWarper,
+ ... BeamSearchScorer,
+ ... )
+ >>> import torch
+
+ >>> tokenizer = AutoTokenizer.from_pretrained("t5-base")
+ >>> model = AutoModelForSeq2SeqLM.from_pretrained("t5-base")
+
+ >>> encoder_input_str = "translate English to German: How old are you?"
+ >>> encoder_input_ids = tokenizer(encoder_input_str, return_tensors="pt").input_ids
+
+ >>> # lets run beam search using 3 beams
+ >>> num_beams = 3
+ >>> # define decoder start token ids
+ >>> input_ids = torch.ones((num_beams, 1), device=model.device, dtype=torch.long)
+ >>> input_ids = input_ids * model.config.decoder_start_token_id
+
+ >>> # add encoder_outputs to model keyword arguments
+ >>> model_kwargs = {
+ ... "encoder_outputs": model.get_encoder()(
+ ... encoder_input_ids.repeat_interleave(num_beams, dim=0), return_dict=True
+ ... )
+ ... }
+
+ >>> # instantiate beam scorer
+ >>> beam_scorer = BeamSearchScorer(
+ ... batch_size=1,
+ ... max_length=model.config.max_length,
+ ... num_beams=num_beams,
+ ... device=model.device,
+ ... )
+
+ >>> # instantiate logits processors
+ >>> logits_processor = LogitsProcessorList(
+ ... [MinLengthLogitsProcessor(5, eos_token_id=model.config.eos_token_id)]
+ ... )
+ >>> # instantiate logits processors
+ >>> logits_warper = LogitsProcessorList(
+ ... [
+ ... TopKLogitsWarper(50),
+ ... TemperatureLogitsWarper(0.7),
+ ... ]
+ ... )
+
+ >>> outputs = model.beam_sample(
+ ... input_ids, beam_scorer, logits_processor=logits_processor, logits_warper=logits_warper, **model_kwargs
+ ... )
+
+ >>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
+ ['Wie alt bist du?']
+ ```"""
+ # init values
+ logits_processor = logits_processor if logits_processor is not None else LogitsProcessorList()
+ stopping_criteria = stopping_criteria if stopping_criteria is not None else StoppingCriteriaList()
+ if max_length is not None:
+ warnings.warn(
+ "`max_length` is deprecated in this function, use"
+ " `stopping_criteria=StoppingCriteriaList(MaxLengthCriteria(max_length=max_length))` instead.",
+ UserWarning,
+ )
+ stopping_criteria = validate_stopping_criteria(stopping_criteria, max_length)
+ pad_token_id = pad_token_id if pad_token_id is not None else self.generation_config.pad_token_id
+ eos_token_id = eos_token_id if eos_token_id is not None else self.generation_config.eos_token_id
+ if isinstance(eos_token_id, int):
+ eos_token_id = [eos_token_id]
+ output_scores = output_scores if output_scores is not None else self.generation_config.output_scores
+ output_attentions = (
+ output_attentions if output_attentions is not None else self.generation_config.output_attentions
+ )
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.generation_config.output_hidden_states
+ )
+ return_dict_in_generate = (
+ return_dict_in_generate
+ if return_dict_in_generate is not None
+ else self.generation_config.return_dict_in_generate
+ )
+
+ batch_size = len(beam_scorer._beam_hyps)
+ num_beams = beam_scorer.num_beams
+
+ batch_beam_size, cur_len = input_ids.shape
+
+ # init attention / hidden states / scores tuples
+ scores = () if (return_dict_in_generate and output_scores) else None
+ beam_indices = (
+ tuple(() for _ in range(batch_beam_size)) if (return_dict_in_generate and output_scores) else None
+ )
+ decoder_attentions = () if (return_dict_in_generate and output_attentions) else None
+ cross_attentions = () if (return_dict_in_generate and output_attentions) else None
+ decoder_hidden_states = () if (return_dict_in_generate and output_hidden_states) else None
+
+ # if model is an encoder-decoder, retrieve encoder attention weights and hidden states
+ if return_dict_in_generate and self.config.is_encoder_decoder:
+ encoder_attentions = model_kwargs["encoder_outputs"].get("attentions") if output_attentions else None
+ encoder_hidden_states = (
+ model_kwargs["encoder_outputs"].get("hidden_states") if output_hidden_states else None
+ )
+
+ beam_scores = torch.zeros((batch_size, num_beams), dtype=torch.float, device=input_ids.device)
+ beam_scores = beam_scores.view((batch_size * num_beams,))
+
+ this_peer_finished = False # used by synced_gpus only
+
+ first_token_time = None
+ last_token_time = []
+ memory_every_token = []
+ while True:
+ st = time.perf_counter()
+ if synced_gpus:
+ # Under synced_gpus the `forward` call must continue until all gpus complete their sequence.
+ # The following logic allows an early break if all peers finished generating their sequence
+ this_peer_finished_flag = torch.tensor(0.0 if this_peer_finished else 1.0).to(input_ids.device)
+ # send 0.0 if we finished, 1.0 otherwise
+ dist.all_reduce(this_peer_finished_flag, op=dist.ReduceOp.SUM)
+ # did all peers finish? the reduced sum will be 0.0 then
+ if this_peer_finished_flag.item() == 0.0:
+ break
+
+ model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)
+
+ outputs = self(
+ **model_inputs,
+ return_dict=True,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ )
+
+ if synced_gpus and this_peer_finished:
+ cur_len = cur_len + 1
+ continue # don't waste resources running the code we don't need
+
+ next_token_logits = outputs.logits[:, -1, :]
+
+ # hack: adjust tokens for Marian. For Marian we have to make sure that the `pad_token_id`
+ # cannot be generated both before and after the `nn.functional.log_softmax` operation.
+ next_token_logits = self.adjust_logits_during_generation(next_token_logits, cur_len=cur_len)
+ next_token_scores = nn.functional.log_softmax(
+ next_token_logits, dim=-1
+ ) # (batch_size * num_beams, vocab_size)
+
+ next_token_scores_processed = logits_processor(input_ids, next_token_scores)
+ next_token_scores = next_token_scores_processed + beam_scores[:, None].expand_as(next_token_scores)
+ # Note: logits warpers are intentionally applied after adding running beam scores. On some logits warpers
+ # (like top_p) this is indiferent, but on others (like temperature) it is not. For reference, see
+ # https://github.com/huggingface/transformers/pull/5420#discussion_r449779867
+ next_token_scores = logits_warper(input_ids, next_token_scores)
+
+ # Store scores, attentions and hidden_states when required
+ if return_dict_in_generate:
+ if output_scores:
+ scores += (logits_warper(input_ids, next_token_scores_processed),)
+ if output_attentions:
+ decoder_attentions += (
+ (outputs.decoder_attentions,) if self.config.is_encoder_decoder else (outputs.attentions,)
+ )
+ if self.config.is_encoder_decoder:
+ cross_attentions += (outputs.cross_attentions,)
+
+ if output_hidden_states:
+ decoder_hidden_states += (
+ (outputs.decoder_hidden_states,)
+ if self.config.is_encoder_decoder
+ else (outputs.hidden_states,)
+ )
+
+ # reshape for beam search
+ vocab_size = next_token_scores.shape[-1]
+ next_token_scores = next_token_scores.view(batch_size, num_beams * vocab_size)
+
+ probs = nn.functional.softmax(next_token_scores, dim=-1)
+
+ next_tokens = torch.multinomial(probs, num_samples=2 * num_beams)
+ next_token_scores = torch.gather(next_token_scores, -1, next_tokens)
+
+ next_token_scores, _indices = torch.sort(next_token_scores, descending=True, dim=1)
+ next_tokens = torch.gather(next_tokens, -1, _indices)
+
+ next_indices = torch.div(next_tokens, vocab_size, rounding_mode="floor")
+ next_tokens = next_tokens % vocab_size
+
+ # stateless
+ beam_outputs = beam_scorer.process(
+ input_ids,
+ next_token_scores,
+ next_tokens,
+ next_indices,
+ pad_token_id=pad_token_id,
+ eos_token_id=eos_token_id,
+ beam_indices=beam_indices,
+ )
+ beam_scores = beam_outputs["next_beam_scores"]
+ beam_next_tokens = beam_outputs["next_beam_tokens"]
+ beam_idx = beam_outputs["next_beam_indices"]
+
+ input_ids = torch.cat([input_ids[beam_idx, :], beam_next_tokens.unsqueeze(-1)], dim=-1)
+
+ model_kwargs = self._update_model_kwargs_for_generation(
+ outputs, model_kwargs, is_encoder_decoder=self.config.is_encoder_decoder
+ )
+ if model_kwargs["past_key_values"] is not None:
+ model_kwargs["past_key_values"] = self._reorder_cache(model_kwargs["past_key_values"], beam_idx)
+
+ if return_dict_in_generate and output_scores:
+ beam_indices = tuple((beam_indices[beam_idx[i]] + (beam_idx[i],) for i in range(len(beam_indices))))
+
+ # increase cur_len
+ cur_len = cur_len + 1
+
+ if beam_scorer.is_done or stopping_criteria(input_ids, scores):
+ if not synced_gpus:
+ break
+ else:
+ this_peer_finished = True
+
+ if self.device.type == "xpu":
+ torch.xpu.synchronize()
+ memory_every_token.append(torch.xpu.memory.memory_reserved(self.device) / (1024 ** 3))
+ self.peak_memory = np.max(memory_every_token)
+ end = time.perf_counter()
+ if first_token_time is None:
+ first_token_time = end - st
+ else:
+ last_token_time.append(end - st)
+
+ sequence_outputs = beam_scorer.finalize(
+ input_ids,
+ beam_scores,
+ next_tokens,
+ next_indices,
+ pad_token_id=pad_token_id,
+ eos_token_id=eos_token_id,
+ max_length=stopping_criteria.max_length,
+ beam_indices=beam_indices,
+ )
+
+ if self.do_print:
+ if self.device.type == "xpu":
+ print(f"=========First token cost {first_token_time:.4f} s and {memory_every_token[0]} GB=========")
+ else:
+ print(f"=========First token cost {first_token_time:.4f} s=========")
+ if len(last_token_time) > 1:
+ self.first_cost = first_token_time
+ self.rest_cost_mean = np.mean(last_token_time)
+ if self.do_print:
+ if self.device.type == "xpu":
+ print(f"=========Rest tokens cost average {self.rest_cost_mean:.4f} s ({len(last_token_time)}"
+ f" tokens in all) and {np.max(memory_every_token[1:])} GB=========")
+ if self.verbose:
+ print(f"Peak memory for every token: {memory_every_token}")
+ else:
+ print(f"=========Rest tokens cost average {self.rest_cost_mean:.4f} s ({len(last_token_time)}"
+ f" tokens in all)=========")
+
+ if return_dict_in_generate:
+ if not output_scores:
+ sequence_outputs["sequence_scores"] = None
+
+ if self.config.is_encoder_decoder:
+ return BeamSampleEncoderDecoderOutput(
+ sequences=sequence_outputs["sequences"],
+ sequences_scores=sequence_outputs["sequence_scores"],
+ scores=scores,
+ beam_indices=sequence_outputs["beam_indices"],
+ encoder_attentions=encoder_attentions,
+ encoder_hidden_states=encoder_hidden_states,
+ decoder_attentions=decoder_attentions,
+ cross_attentions=cross_attentions,
+ decoder_hidden_states=decoder_hidden_states,
+ )
+ else:
+ return BeamSampleDecoderOnlyOutput(
+ sequences=sequence_outputs["sequences"],
+ sequences_scores=sequence_outputs["sequence_scores"],
+ scores=scores,
+ beam_indices=sequence_outputs["beam_indices"],
+ attentions=decoder_attentions,
+ hidden_states=decoder_hidden_states,
+ )
+ else:
+ return sequence_outputs["sequences"]
+
+ def group_beam_search(
+ self,
+ input_ids: torch.LongTensor,
+ beam_scorer: BeamScorer,
+ logits_processor: Optional[LogitsProcessorList] = None,
+ stopping_criteria: Optional[StoppingCriteriaList] = None,
+ max_length: Optional[int] = None,
+ pad_token_id: Optional[int] = None,
+ eos_token_id: Optional[Union[int, List[int]]] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ output_scores: Optional[bool] = None,
+ return_dict_in_generate: Optional[bool] = None,
+ synced_gpus: bool = False,
+ **model_kwargs,
+ ):
+ r"""
+ Generates sequences of token ids for models with a language modeling head using **diverse beam search
+ decoding** and can be used for text-decoder, text-to-text, speech-to-text, and vision-to-text models.
+
+
+
+ In most cases, you do not need to call [`~generation.GenerationMixin.group_beam_search`] directly. Use
+ generate() instead. For an overview of generation strategies and code examples, check the [following
+ guide](../generation_strategies).
+
+
+
+ Parameters:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ The sequence used as a prompt for the generation.
+ beam_scorer (`BeamScorer`):
+ An derived instance of [`BeamScorer`] that defines how beam hypotheses are constructed, stored and
+ sorted during generation. For more information, the documentation of [`BeamScorer`] should be read.
+ logits_processor (`LogitsProcessorList`, *optional*):
+ An instance of [`LogitsProcessorList`]. List of instances of class derived from [`LogitsProcessor`]
+ used to modify the prediction scores of the language modeling head applied at each generation step.
+ stopping_criteria (`StoppingCriteriaList`, *optional*):
+ An instance of [`StoppingCriteriaList`]. List of instances of class derived from [`StoppingCriteria`]
+ used to tell if the generation loop should stop.
+ max_length (`int`, *optional*, defaults to 20):
+ **DEPRECATED**. Use `logits_processor` or `stopping_criteria` directly to cap the number of generated
+ tokens. The maximum length of the sequence to be generated.
+ pad_token_id (`int`, *optional*):
+ The id of the *padding* token.
+ eos_token_id (`Union[int, List[int]]`, *optional*):
+ The id of the *end-of-sequence* token. Optionally, use a list to set multiple *end-of-sequence* tokens.
+ output_attentions (`bool`, *optional*, defaults to `False`):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more details.
+ output_hidden_states (`bool`, *optional*, defaults to `False`):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
+ for more details.
+ output_scores (`bool`, *optional*, defaults to `False`):
+ Whether or not to return the prediction scores. See `scores` under returned tensors for more details.
+ return_dict_in_generate (`bool`, *optional*, defaults to `False`):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+ synced_gpus (`bool`, *optional*, defaults to `False`):
+ Whether to continue running the while loop until max_length (needed for ZeRO stage 3)
+
+ model_kwargs:
+ Additional model specific kwargs that will be forwarded to the `forward` function of the model. If
+ model is an encoder-decoder model the kwargs should include `encoder_outputs`.
+
+ Return:
+ [`~generation.BeamSearchDecoderOnlyOutput`], [`~generation.BeamSearchEncoderDecoderOutput`] or
+ `torch.LongTensor`: A `torch.LongTensor` containing the generated tokens (default behaviour) or a
+ [`~generation.BeamSearchDecoderOnlyOutput`] if [`~generation.BeamSearchDecoderOnlyOutput`] if
+ `model.config.is_encoder_decoder=False` and `return_dict_in_generate=True` or a
+ [`~generation.BeamSearchEncoderDecoderOutput`] if `model.config.is_encoder_decoder=True`.
+
+ Examples:
+
+ ```python
+ >>> from transformers import (
+ ... AutoTokenizer,
+ ... AutoModelForSeq2SeqLM,
+ ... LogitsProcessorList,
+ ... MinLengthLogitsProcessor,
+ ... HammingDiversityLogitsProcessor,
+ ... BeamSearchScorer,
+ ... )
+ >>> import torch
+
+ >>> tokenizer = AutoTokenizer.from_pretrained("t5-base")
+ >>> model = AutoModelForSeq2SeqLM.from_pretrained("t5-base")
+
+ >>> encoder_input_str = "translate English to German: How old are you?"
+ >>> encoder_input_ids = tokenizer(encoder_input_str, return_tensors="pt").input_ids
+
+
+ >>> # lets run diverse beam search using 6 beams
+ >>> num_beams = 6
+ >>> # define decoder start token ids
+ >>> input_ids = torch.ones((num_beams, 1), device=model.device, dtype=torch.long)
+ >>> input_ids = input_ids * model.config.decoder_start_token_id
+
+ >>> # add encoder_outputs to model keyword arguments
+ >>> model_kwargs = {
+ ... "encoder_outputs": model.get_encoder()(
+ ... encoder_input_ids.repeat_interleave(num_beams, dim=0), return_dict=True
+ ... )
+ ... }
+
+ >>> # instantiate beam scorer
+ >>> beam_scorer = BeamSearchScorer(
+ ... batch_size=1,
+ ... max_length=model.config.max_length,
+ ... num_beams=num_beams,
+ ... device=model.device,
+ ... num_beam_groups=3,
+ ... )
+
+ >>> # instantiate logits processors
+ >>> logits_processor = LogitsProcessorList(
+ ... [
+ ... HammingDiversityLogitsProcessor(5.5, num_beams=6, num_beam_groups=3),
+ ... MinLengthLogitsProcessor(5, eos_token_id=model.config.eos_token_id),
+ ... ]
+ ... )
+
+ >>> outputs = model.group_beam_search(
+ ... input_ids, beam_scorer, logits_processor=logits_processor, **model_kwargs
+ ... )
+
+ >>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
+ ['Wie alt bist du?']
+ ```"""
+ # init values
+ logits_processor = logits_processor if logits_processor is not None else LogitsProcessorList()
+ stopping_criteria = stopping_criteria if stopping_criteria is not None else StoppingCriteriaList()
+ if max_length is not None:
+ warnings.warn(
+ "`max_length` is deprecated in this function, use"
+ " `stopping_criteria=StoppingCriteriaList(MaxLengthCriteria(max_length=max_length))` instead.",
+ UserWarning,
+ )
+ stopping_criteria = validate_stopping_criteria(stopping_criteria, max_length)
+ pad_token_id = pad_token_id if pad_token_id is not None else self.generation_config.pad_token_id
+ eos_token_id = eos_token_id if eos_token_id is not None else self.generation_config.eos_token_id
+ if isinstance(eos_token_id, int):
+ eos_token_id = [eos_token_id]
+ output_scores = output_scores if output_scores is not None else self.generation_config.output_scores
+ output_attentions = (
+ output_attentions if output_attentions is not None else self.generation_config.output_attentions
+ )
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.generation_config.output_hidden_states
+ )
+ return_dict_in_generate = (
+ return_dict_in_generate
+ if return_dict_in_generate is not None
+ else self.generation_config.return_dict_in_generate
+ )
+
+ batch_size = len(beam_scorer._beam_hyps)
+ num_beams = beam_scorer.num_beams
+ num_beam_groups = beam_scorer.num_beam_groups
+ num_sub_beams = num_beams // num_beam_groups
+ device = input_ids.device
+
+ batch_beam_size, cur_len = input_ids.shape
+
+ if return_dict_in_generate and output_scores:
+ beam_indices = [tuple(() for _ in range(num_sub_beams * batch_size)) for _ in range(num_beam_groups)]
+ else:
+ beam_indices = None
+
+ if num_beams * batch_size != batch_beam_size:
+ raise ValueError(
+ f"Batch dimension of `input_ids` should be {num_beams * batch_size}, but is {batch_beam_size}."
+ )
+
+ # init attention / hidden states / scores tuples
+ scores = () if (return_dict_in_generate and output_scores) else None
+ decoder_attentions = () if (return_dict_in_generate and output_attentions) else None
+ cross_attentions = () if (return_dict_in_generate and output_attentions) else None
+ decoder_hidden_states = () if (return_dict_in_generate and output_hidden_states) else None
+
+ # if model is an encoder-decoder, retrieve encoder attention weights and hidden states
+ if return_dict_in_generate and self.config.is_encoder_decoder:
+ encoder_attentions = model_kwargs["encoder_outputs"].get("attentions") if output_attentions else None
+ encoder_hidden_states = (
+ model_kwargs["encoder_outputs"].get("hidden_states") if output_hidden_states else None
+ )
+
+ # initialise score of first beam of each group with 0 and the rest with -1e9. This ensures that the beams in
+ # the same group don't produce same tokens everytime.
+ beam_scores = torch.full((batch_size, num_beams), -1e9, dtype=torch.float, device=device)
+ beam_scores[:, ::num_sub_beams] = 0
+ beam_scores = beam_scores.view((batch_size * num_beams,))
+
+ this_peer_finished = False # used by synced_gpus only
+ while True:
+ if synced_gpus:
+ # Under synced_gpus the `forward` call must continue until all gpus complete their sequence.
+ # The following logic allows an early break if all peers finished generating their sequence
+ this_peer_finished_flag = torch.tensor(0.0 if this_peer_finished else 1.0).to(input_ids.device)
+ # send 0.0 if we finished, 1.0 otherwise
+ dist.all_reduce(this_peer_finished_flag, op=dist.ReduceOp.SUM)
+ # did all peers finish? the reduced sum will be 0.0 then
+ if this_peer_finished_flag.item() == 0.0:
+ break
+
+ # predicted tokens in cur_len step
+ current_tokens = torch.zeros(batch_size * num_beams, dtype=input_ids.dtype, device=device)
+
+ # indices which will form the beams in the next time step
+ reordering_indices = torch.zeros(batch_size * num_beams, dtype=torch.long, device=device)
+
+ # do one decoder step on all beams of all sentences in batch
+ model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)
+ outputs = self(
+ **model_inputs,
+ return_dict=True,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ )
+
+ if synced_gpus and this_peer_finished:
+ cur_len = cur_len + 1
+ continue # don't waste resources running the code we don't need
+
+ if output_scores:
+ processed_score = torch.zeros_like(outputs.logits[:, -1, :])
+
+ for beam_group_idx in range(num_beam_groups):
+ group_start_idx = beam_group_idx * num_sub_beams
+ group_end_idx = min(group_start_idx + num_sub_beams, num_beams)
+ group_size = group_end_idx - group_start_idx
+
+ # indices of beams of current group among all sentences in batch
+ batch_group_indices = []
+
+ for batch_idx in range(batch_size):
+ batch_group_indices.extend(
+ [batch_idx * num_beams + idx for idx in range(group_start_idx, group_end_idx)]
+ )
+ group_input_ids = input_ids[batch_group_indices]
+
+ # select outputs of beams of current group only
+ next_token_logits = outputs.logits[batch_group_indices, -1, :]
+
+ # hack: adjust tokens for Marian. For Marian we have to make sure that the `pad_token_id`
+ # cannot be generated both before and after the `nn.functional.log_softmax` operation.
+ next_token_logits = self.adjust_logits_during_generation(next_token_logits, cur_len=cur_len)
+ next_token_scores = nn.functional.log_softmax(
+ next_token_logits, dim=-1
+ ) # (batch_size * group_size, vocab_size)
+ vocab_size = next_token_scores.shape[-1]
+
+ next_token_scores_processed = logits_processor(
+ group_input_ids, next_token_scores, current_tokens=current_tokens, beam_group_idx=beam_group_idx
+ )
+ next_token_scores = next_token_scores_processed + beam_scores[batch_group_indices].unsqueeze(-1)
+ next_token_scores = next_token_scores.expand_as(next_token_scores_processed)
+
+ if output_scores:
+ processed_score[batch_group_indices] = next_token_scores_processed
+
+ # reshape for beam search
+ next_token_scores = next_token_scores.view(batch_size, group_size * vocab_size)
+
+ # Sample 2 next tokens for each beam (so we have some spare tokens and match output of beam search)
+ next_token_scores, next_tokens = torch.topk(
+ next_token_scores, 2 * group_size, dim=1, largest=True, sorted=True
+ )
+
+ next_indices = torch.div(next_tokens, vocab_size, rounding_mode="floor")
+ next_tokens = next_tokens % vocab_size
+
+ # stateless
+ process_beam_indices = sum(beam_indices, ()) if beam_indices is not None else None
+ beam_outputs = beam_scorer.process(
+ group_input_ids,
+ next_token_scores,
+ next_tokens,
+ next_indices,
+ pad_token_id=pad_token_id,
+ eos_token_id=eos_token_id,
+ beam_indices=process_beam_indices,
+ )
+ beam_scores[batch_group_indices] = beam_outputs["next_beam_scores"]
+ beam_next_tokens = beam_outputs["next_beam_tokens"]
+ beam_idx = beam_outputs["next_beam_indices"]
+
+ if return_dict_in_generate and output_scores:
+ beam_indices[beam_group_idx] = tuple(
+ beam_indices[beam_group_idx][beam_idx[i]] + (beam_idx[i],) for i in range(len(beam_indices[0]))
+ )
+
+ input_ids[batch_group_indices] = group_input_ids[beam_idx]
+ group_input_ids = torch.cat([group_input_ids[beam_idx, :], beam_next_tokens.unsqueeze(-1)], dim=-1)
+ current_tokens[batch_group_indices] = group_input_ids[:, -1]
+
+ # (beam_idx // group_size) -> batch_idx
+ # (beam_idx % group_size) -> offset of idx inside the group
+ reordering_indices[batch_group_indices] = (
+ num_beams * torch.div(beam_idx, group_size, rounding_mode="floor")
+ + group_start_idx
+ + (beam_idx % group_size)
+ )
+
+ # Store scores, attentions and hidden_states when required
+ if return_dict_in_generate:
+ if output_scores:
+ scores += (processed_score,)
+ if output_attentions:
+ decoder_attentions += (
+ (outputs.decoder_attentions,) if self.config.is_encoder_decoder else (outputs.attentions,)
+ )
+ if self.config.is_encoder_decoder:
+ cross_attentions += (outputs.cross_attentions,)
+
+ if output_hidden_states:
+ decoder_hidden_states += (
+ (outputs.decoder_hidden_states,)
+ if self.config.is_encoder_decoder
+ else (outputs.hidden_states,)
+ )
+
+ input_ids = torch.cat([input_ids, current_tokens.unsqueeze(-1)], dim=-1)
+
+ model_kwargs = self._update_model_kwargs_for_generation(
+ outputs, model_kwargs, is_encoder_decoder=self.config.is_encoder_decoder
+ )
+ if model_kwargs["past_key_values"] is not None:
+ model_kwargs["past_key_values"] = self._reorder_cache(
+ model_kwargs["past_key_values"], reordering_indices
+ )
+
+ # increase cur_len
+ cur_len = cur_len + 1
+
+ if beam_scorer.is_done or stopping_criteria(input_ids, scores):
+ if not synced_gpus:
+ break
+ else:
+ this_peer_finished = True
+
+ final_beam_indices = sum(beam_indices, ()) if beam_indices is not None else None
+ sequence_outputs = beam_scorer.finalize(
+ input_ids,
+ beam_scores,
+ next_tokens,
+ next_indices,
+ pad_token_id=pad_token_id,
+ eos_token_id=eos_token_id,
+ max_length=stopping_criteria.max_length,
+ beam_indices=final_beam_indices,
+ )
+
+ if return_dict_in_generate:
+ if not output_scores:
+ sequence_outputs["sequence_scores"] = None
+
+ if self.config.is_encoder_decoder:
+ return BeamSearchEncoderDecoderOutput(
+ sequences=sequence_outputs["sequences"],
+ sequences_scores=sequence_outputs["sequence_scores"],
+ scores=scores,
+ beam_indices=sequence_outputs["beam_indices"],
+ encoder_attentions=encoder_attentions,
+ encoder_hidden_states=encoder_hidden_states,
+ decoder_attentions=decoder_attentions,
+ cross_attentions=cross_attentions,
+ decoder_hidden_states=decoder_hidden_states,
+ )
+ else:
+ return BeamSearchDecoderOnlyOutput(
+ sequences=sequence_outputs["sequences"],
+ sequences_scores=sequence_outputs["sequence_scores"],
+ scores=scores,
+ beam_indices=sequence_outputs["beam_indices"],
+ attentions=decoder_attentions,
+ hidden_states=decoder_hidden_states,
+ )
+ else:
+ return sequence_outputs["sequences"]
+
+ def constrained_beam_search(
+ self,
+ input_ids: torch.LongTensor,
+ constrained_beam_scorer: ConstrainedBeamSearchScorer,
+ logits_processor: Optional[LogitsProcessorList] = None,
+ stopping_criteria: Optional[StoppingCriteriaList] = None,
+ max_length: Optional[int] = None,
+ pad_token_id: Optional[int] = None,
+ eos_token_id: Optional[Union[int, List[int]]] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ output_scores: Optional[bool] = None,
+ return_dict_in_generate: Optional[bool] = None,
+ synced_gpus: Optional[bool] = None,
+ **model_kwargs,
+ ) -> Union[BeamSearchOutput, torch.LongTensor]:
+ r"""
+ Generates sequences of token ids for models with a language modeling head using **constrained beam search
+ decoding** and can be used for text-decoder, text-to-text, speech-to-text, and vision-to-text models.
+
+
+
+ In most cases, you do not need to call [`~generation.GenerationMixin.constrained_beam_search`] directly. Use
+ generate() instead. For an overview of generation strategies and code examples, check the [following
+ guide](../generation_strategies).
+
+
+
+ Parameters:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ The sequence used as a prompt for the generation.
+ constrained_beam_scorer (`ConstrainedBeamSearchScorer`):
+ A derived instance of [`BeamScorer`] that defines how beam hypotheses are constructed, stored and
+ sorted during generation, while satisfying a list of positive constraints. For more information, the
+ documentation of [`ConstrainedBeamSearchScorer`] should be read.
+ logits_processor (`LogitsProcessorList`, *optional*):
+ An instance of [`LogitsProcessorList`]. List of instances of class derived from [`LogitsProcessor`]
+ used to modify the prediction scores of the language modeling head applied at each generation step.
+ stopping_criteria (`StoppingCriteriaList`, *optional*):
+ An instance of [`StoppingCriteriaList`]. List of instances of class derived from [`StoppingCriteria`]
+ used to tell if the generation loop should stop.
+ logits_warper (`LogitsProcessorList`, *optional*):
+ An instance of [`LogitsProcessorList`]. List of instances of class derived from [`LogitsWarper`] used
+ to warp the prediction score distribution of the language modeling head applied before multinomial
+ sampling at each generation step.
+ max_length (`int`, *optional*, defaults to 20):
+ **DEPRECATED**. Use `logits_processor` or `stopping_criteria` directly to cap the number of generated
+ tokens. The maximum length of the sequence to be generated.
+ pad_token_id (`int`, *optional*):
+ The id of the *padding* token.
+ eos_token_id (`Union[int, List[int]]`, *optional*):
+ The id of the *end-of-sequence* token. Optionally, use a list to set multiple *end-of-sequence* tokens.
+ output_attentions (`bool`, *optional*, defaults to `False`):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more details.
+ output_hidden_states (`bool`, *optional*, defaults to `False`):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
+ for more details.
+ output_scores (`bool`, *optional*, defaults to `False`):
+ Whether or not to return the prediction scores. See `scores` under returned tensors for more details.
+ return_dict_in_generate (`bool`, *optional*, defaults to `False`):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+ synced_gpus (`bool`, *optional*, defaults to `False`):
+ Whether to continue running the while loop until max_length (needed for ZeRO stage 3)
+ model_kwargs:
+ Additional model specific kwargs will be forwarded to the `forward` function of the model. If model is
+ an encoder-decoder model the kwargs should include `encoder_outputs`.
+
+ Return:
+ [`generation.BeamSearchDecoderOnlyOutput`], [`~generation.BeamSearchEncoderDecoderOutput`] or
+ `torch.LongTensor`: A `torch.LongTensor` containing the generated tokens (default behaviour) or a
+ [`~generation.BeamSearchDecoderOnlyOutput`] if `model.config.is_encoder_decoder=False` and
+ `return_dict_in_generate=True` or a [`~generation.BeamSearchEncoderDecoderOutput`] if
+ `model.config.is_encoder_decoder=True`.
+
+
+ Examples:
+
+ ```python
+ >>> from transformers import (
+ ... AutoTokenizer,
+ ... AutoModelForSeq2SeqLM,
+ ... LogitsProcessorList,
+ ... MinLengthLogitsProcessor,
+ ... ConstrainedBeamSearchScorer,
+ ... PhrasalConstraint,
+ ... )
+ >>> import torch
+
+ >>> tokenizer = AutoTokenizer.from_pretrained("t5-base")
+ >>> model = AutoModelForSeq2SeqLM.from_pretrained("t5-base")
+
+ >>> encoder_input_str = "translate English to German: How old are you?"
+ >>> encoder_input_ids = tokenizer(encoder_input_str, return_tensors="pt").input_ids
+
+
+ >>> # lets run beam search using 3 beams
+ >>> num_beams = 3
+ >>> # define decoder start token ids
+ >>> input_ids = torch.ones((num_beams, 1), device=model.device, dtype=torch.long)
+ >>> input_ids = input_ids * model.config.decoder_start_token_id
+
+ >>> # add encoder_outputs to model keyword arguments
+ >>> model_kwargs = {
+ ... "encoder_outputs": model.get_encoder()(
+ ... encoder_input_ids.repeat_interleave(num_beams, dim=0), return_dict=True
+ ... )
+ ... }
+
+ >>> constraint_str = "Sie"
+ >>> constraint_token_ids = tokenizer.encode(constraint_str)[:-1] # slice to remove eos token
+ >>> constraints = [PhrasalConstraint(token_ids=constraint_token_ids)]
+
+
+ >>> # instantiate beam scorer
+ >>> beam_scorer = ConstrainedBeamSearchScorer(
+ ... batch_size=1, num_beams=num_beams, device=model.device, constraints=constraints
+ ... )
+
+ >>> # instantiate logits processors
+ >>> logits_processor = LogitsProcessorList(
+ ... [
+ ... MinLengthLogitsProcessor(5, eos_token_id=model.config.eos_token_id),
+ ... ]
+ ... )
+
+ >>> outputs = model.constrained_beam_search(
+ ... input_ids, beam_scorer, constraints=constraints, logits_processor=logits_processor, **model_kwargs
+ ... )
+
+ >>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
+ ['Wie alt sind Sie?']
+ ```"""
+ # init values
+ logits_processor = logits_processor if logits_processor is not None else LogitsProcessorList()
+ stopping_criteria = stopping_criteria if stopping_criteria is not None else StoppingCriteriaList()
+ if max_length is not None:
+ warnings.warn(
+ "`max_length` is deprecated in this function, use"
+ " `stopping_criteria=StoppingCriteriaList(MaxLengthCriteria(max_length=max_length))` instead.",
+ UserWarning,
+ )
+ stopping_criteria = validate_stopping_criteria(stopping_criteria, max_length)
+ if len(stopping_criteria) == 0:
+ warnings.warn("You don't have defined any stopping_criteria, this will likely loop forever", UserWarning)
+ pad_token_id = pad_token_id if pad_token_id is not None else self.generation_config.pad_token_id
+ eos_token_id = eos_token_id if eos_token_id is not None else self.generation_config.eos_token_id
+ if isinstance(eos_token_id, int):
+ eos_token_id = [eos_token_id]
+ output_scores = output_scores if output_scores is not None else self.generation_config.output_scores
+ output_attentions = (
+ output_attentions if output_attentions is not None else self.generation_config.output_attentions
+ )
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.generation_config.output_hidden_states
+ )
+ return_dict_in_generate = (
+ return_dict_in_generate
+ if return_dict_in_generate is not None
+ else self.generation_config.return_dict_in_generate
+ )
+
+ # init attention / hidden states / scores tuples
+ scores = () if (return_dict_in_generate and output_scores) else None
+ decoder_attentions = () if (return_dict_in_generate and output_attentions) else None
+ cross_attentions = () if (return_dict_in_generate and output_attentions) else None
+ decoder_hidden_states = () if (return_dict_in_generate and output_hidden_states) else None
+
+ # if model is an encoder-decoder, retrieve encoder attention weights and hidden states
+ if return_dict_in_generate and self.config.is_encoder_decoder:
+ encoder_attentions = model_kwargs["encoder_outputs"].get("attentions") if output_attentions else None
+ encoder_hidden_states = (
+ model_kwargs["encoder_outputs"].get("hidden_states") if output_hidden_states else None
+ )
+
+ batch_size = len(constrained_beam_scorer._beam_hyps)
+ num_beams = constrained_beam_scorer.num_beams
+
+ batch_beam_size, cur_len = input_ids.shape
+
+ if num_beams * batch_size != batch_beam_size:
+ raise ValueError(
+ f"Batch dimension of `input_ids` should be {num_beams * batch_size}, but is {batch_beam_size}."
+ )
+
+ # initialise score of first beam with 0 and the rest with -1e9. This makes sure that only tokens
+ # of the first beam are considered to avoid sampling the exact same tokens across all beams.
+ beam_scores = torch.zeros((batch_size, num_beams), dtype=torch.float, device=input_ids.device)
+ beam_scores[:, 1:] = -1e9
+ beam_scores = beam_scores.view((batch_size * num_beams,))
+
+ this_peer_finished = False # used by synced_gpus only
+ while True:
+ if synced_gpus:
+ # Under synced_gpus the `forward` call must continue until all gpus complete their sequence.
+ # The following logic allows an early break if all peers finished generating their sequence
+ this_peer_finished_flag = torch.tensor(0.0 if this_peer_finished else 1.0).to(input_ids.device)
+ # send 0.0 if we finished, 1.0 otherwise
+ dist.all_reduce(this_peer_finished_flag, op=dist.ReduceOp.SUM)
+ # did all peers finish? the reduced sum will be 0.0 then
+ if this_peer_finished_flag.item() == 0.0:
+ break
+
+ model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)
+
+ outputs = self(
+ **model_inputs,
+ return_dict=True,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ )
+
+ if synced_gpus and this_peer_finished:
+ cur_len = cur_len + 1
+ continue # don't waste resources running the code we don't need
+
+ next_token_logits = outputs.logits[:, -1, :]
+ # hack: adjust tokens for Marian. For Marian we have to make sure that the `pad_token_id`
+ # cannot be generated both before and after the `nn.functional.log_softmax` operation.
+ next_token_logits = self.adjust_logits_during_generation(next_token_logits, cur_len=cur_len)
+ next_token_scores = nn.functional.log_softmax(
+ next_token_logits, dim=-1
+ ) # (batch_size * num_beams, vocab_size)
+
+ next_token_scores_processed = logits_processor(input_ids, next_token_scores)
+
+ next_token_scores = next_token_scores_processed + beam_scores[:, None].expand_as(next_token_scores)
+
+ scores_for_all_vocab = next_token_scores.clone()
+
+ # Store scores, attentions and hidden_states when required
+ if return_dict_in_generate:
+ if output_scores:
+ scores += (next_token_scores,)
+ if output_attentions:
+ decoder_attentions += (
+ (outputs.decoder_attentions,) if self.config.is_encoder_decoder else (outputs.attentions,)
+ )
+ if self.config.is_encoder_decoder:
+ cross_attentions += (outputs.cross_attentions,)
+
+ if output_hidden_states:
+ decoder_hidden_states += (
+ (outputs.decoder_hidden_states,)
+ if self.config.is_encoder_decoder
+ else (outputs.hidden_states,)
+ )
+
+ # reshape for beam search
+ vocab_size = next_token_scores.shape[-1]
+ next_token_scores = next_token_scores.view(batch_size, num_beams * vocab_size)
+
+ # Sample 2 next tokens for each beam (so we have some spare tokens and match output of beam search)
+ next_token_scores, next_tokens = torch.topk(
+ next_token_scores, 2 * num_beams, dim=1, largest=True, sorted=True
+ )
+
+ next_indices = (next_tokens / vocab_size).long()
+ next_tokens = next_tokens % vocab_size
+
+ # stateless
+ beam_outputs = constrained_beam_scorer.process(
+ input_ids,
+ next_token_scores,
+ next_tokens,
+ next_indices,
+ scores_for_all_vocab,
+ pad_token_id=pad_token_id,
+ eos_token_id=eos_token_id,
+ )
+ beam_scores = beam_outputs["next_beam_scores"]
+ beam_next_tokens = beam_outputs["next_beam_tokens"]
+ beam_idx = beam_outputs["next_beam_indices"]
+
+ input_ids = torch.cat([input_ids[beam_idx, :], beam_next_tokens.unsqueeze(-1)], dim=-1)
+ model_kwargs = self._update_model_kwargs_for_generation(
+ outputs, model_kwargs, is_encoder_decoder=self.config.is_encoder_decoder
+ )
+ if model_kwargs["past_key_values"] is not None:
+ model_kwargs["past_key_values"] = self._reorder_cache(model_kwargs["past_key_values"], beam_idx)
+
+ # increase cur_len
+ cur_len = cur_len + 1
+
+ if constrained_beam_scorer.is_done or stopping_criteria(input_ids, scores):
+ if not synced_gpus:
+ break
+ else:
+ this_peer_finished = True
+
+ sequence_outputs = constrained_beam_scorer.finalize(
+ input_ids,
+ beam_scores,
+ next_tokens,
+ next_indices,
+ pad_token_id=pad_token_id,
+ eos_token_id=eos_token_id,
+ max_length=stopping_criteria.max_length,
+ )
+
+ if return_dict_in_generate:
+ if not output_scores:
+ sequence_outputs["sequence_scores"] = None
+ if self.config.is_encoder_decoder:
+ return BeamSearchEncoderDecoderOutput(
+ sequences=sequence_outputs["sequences"],
+ sequences_scores=sequence_outputs["sequence_scores"],
+ scores=scores,
+ encoder_attentions=encoder_attentions,
+ encoder_hidden_states=encoder_hidden_states,
+ decoder_attentions=decoder_attentions,
+ cross_attentions=cross_attentions,
+ decoder_hidden_states=decoder_hidden_states,
+ )
+ else:
+ return BeamSearchDecoderOnlyOutput(
+ sequences=sequence_outputs["sequences"],
+ sequences_scores=sequence_outputs["sequence_scores"],
+ scores=scores,
+ attentions=decoder_attentions,
+ hidden_states=decoder_hidden_states,
+ )
+ else:
+ return sequence_outputs["sequences"]
+
+ def assisted_decoding(
+ self,
+ input_ids: torch.LongTensor,
+ assistant_model: "PreTrainedModel",
+ do_sample: bool = False,
+ logits_processor: Optional[LogitsProcessorList] = None,
+ logits_warper: Optional[LogitsProcessorList] = None,
+ stopping_criteria: Optional[StoppingCriteriaList] = None,
+ pad_token_id: Optional[int] = None,
+ eos_token_id: Optional[Union[int, List[int]]] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ output_scores: Optional[bool] = None,
+ return_dict_in_generate: Optional[bool] = None,
+ synced_gpus: bool = False,
+ streamer: Optional["BaseStreamer"] = None,
+ **model_kwargs,
+ ):
+ r"""
+ Generates sequences of token ids for models with a language modeling head using **greedy decoding** or
+ **sample** (depending on `do_sample`), assisted by a smaller model. Can be used for text-decoder, text-to-text,
+ speech-to-text, and vision-to-text models.
+
+
+
+ In most cases, you do not need to call [`~generation.GenerationMixin.assisted_decoding`] directly. Use
+ generate() instead. For an overview of generation strategies and code examples, check the [following
+ guide](../generation_strategies).
+
+
+
+ Parameters:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ The sequence used as a prompt for the generation.
+ assistant_model (`PreTrainedModel`, *optional*):
+ An assistant model that can be used to accelerate generation. The assistant model must have the exact
+ same tokenizer. The acceleration is achieved when forecasting candidate tokens with the assistent model
+ is much faster than running generation with the model you're calling generate from. As such, the
+ assistant model should be much smaller.
+ do_sample (`bool`, *optional*, defaults to `False`):
+ Whether or not to use sampling ; use greedy decoding otherwise.
+ logits_processor (`LogitsProcessorList`, *optional*):
+ An instance of [`LogitsProcessorList`]. List of instances of class derived from [`LogitsProcessor`]
+ used to modify the prediction scores of the language modeling head applied at each generation step.
+ logits_warper (`LogitsProcessorList`, *optional*):
+ An instance of [`LogitsProcessorList`]. List of instances of class derived from [`LogitsWarper`] used
+ to warp the prediction score distribution of the language modeling head applied before multinomial
+ sampling at each generation step.
+ stopping_criteria (`StoppingCriteriaList`, *optional*):
+ An instance of [`StoppingCriteriaList`]. List of instances of class derived from [`StoppingCriteria`]
+ used to tell if the generation loop should stop.
+ pad_token_id (`int`, *optional*):
+ The id of the *padding* token.
+ eos_token_id (`Union[int, List[int]]`, *optional*):
+ The id of the *end-of-sequence* token. Optionally, use a list to set multiple *end-of-sequence* tokens.
+ output_attentions (`bool`, *optional*, defaults to `False`):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more details.
+ output_hidden_states (`bool`, *optional*, defaults to `False`):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
+ for more details.
+ output_scores (`bool`, *optional*, defaults to `False`):
+ Whether or not to return the prediction scores. See `scores` under returned tensors for more details.
+ return_dict_in_generate (`bool`, *optional*, defaults to `False`):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+ synced_gpus (`bool`, *optional*, defaults to `False`):
+ Whether to continue running the while loop until max_length (needed for ZeRO stage 3)
+ streamer (`BaseStreamer`, *optional*):
+ Streamer object that will be used to stream the generated sequences. Generated tokens are passed
+ through `streamer.put(token_ids)` and the streamer is responsible for any further processing.
+ model_kwargs:
+ Additional model specific keyword arguments will be forwarded to the `forward` function of the model.
+ If model is an encoder-decoder model the kwargs should include `encoder_outputs`.
+
+ Return:
+ [`~generation.GreedySearchDecoderOnlyOutput`], [`~generation.GreedySearchEncoderDecoderOutput`] or
+ `torch.LongTensor`: A `torch.LongTensor` containing the generated tokens (default behaviour) or a
+ [`~generation.GreedySearchDecoderOnlyOutput`] if `model.config.is_encoder_decoder=False` and
+ `return_dict_in_generate=True` or a [`~generation.GreedySearchEncoderDecoderOutput`] if
+ `model.config.is_encoder_decoder=True`.
+
+ Examples:
+
+ ```python
+ >>> from transformers import (
+ ... AutoTokenizer,
+ ... AutoModelForCausalLM,
+ ... LogitsProcessorList,
+ ... MinLengthLogitsProcessor,
+ ... StoppingCriteriaList,
+ ... MaxLengthCriteria,
+ ... )
+
+ >>> tokenizer = AutoTokenizer.from_pretrained("gpt2")
+ >>> model = AutoModelForCausalLM.from_pretrained("gpt2")
+ >>> assistant_model = AutoModelForCausalLM.from_pretrained("distilgpt2")
+ >>> # set pad_token_id to eos_token_id because GPT2 does not have a PAD token
+ >>> model.generation_config.pad_token_id = model.generation_config.eos_token_id
+ >>> input_prompt = "It might be possible to"
+ >>> input_ids = tokenizer(input_prompt, return_tensors="pt").input_ids
+ >>> # instantiate logits processors
+ >>> logits_processor = LogitsProcessorList(
+ ... [
+ ... MinLengthLogitsProcessor(10, eos_token_id=model.generation_config.eos_token_id),
+ ... ]
+ ... )
+ >>> stopping_criteria = StoppingCriteriaList([MaxLengthCriteria(max_length=20)])
+ >>> outputs = model.assisted_decoding(
+ ... input_ids,
+ ... assistant_model=assistant_model,
+ ... logits_processor=logits_processor,
+ ... stopping_criteria=stopping_criteria,
+ ... )
+ >>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
+ ["It might be possible to get a better understanding of the nature of the problem, but it's not"]
+ ```"""
+ # Assistant: initialize assistant-related variables
+ if not hasattr(assistant_model, "max_assistant_tokens"):
+ assistant_model.max_assistant_tokens = 5 # this value, which will be updated, persists across calls
+
+ # init values
+ logits_processor = logits_processor if logits_processor is not None else LogitsProcessorList()
+ logits_warper = logits_warper if logits_warper is not None else LogitsProcessorList()
+ stopping_criteria = stopping_criteria if stopping_criteria is not None else StoppingCriteriaList()
+ pad_token_id = pad_token_id if pad_token_id is not None else self.generation_config.pad_token_id
+ eos_token_id = eos_token_id if eos_token_id is not None else self.generation_config.eos_token_id
+ if eos_token_id is not None and pad_token_id is None:
+ raise ValueError("If `eos_token_id` is defined, make sure that `pad_token_id` is defined.")
+ if isinstance(eos_token_id, int):
+ eos_token_id = [eos_token_id]
+ eos_token_id_tensor = torch.tensor(eos_token_id).to(input_ids.device) if eos_token_id is not None else None
+ output_scores = output_scores if output_scores is not None else self.generation_config.output_scores
+ output_attentions = (
+ output_attentions if output_attentions is not None else self.generation_config.output_attentions
+ )
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.generation_config.output_hidden_states
+ )
+ return_dict_in_generate = (
+ return_dict_in_generate
+ if return_dict_in_generate is not None
+ else self.generation_config.return_dict_in_generate
+ )
+
+ # init attention / hidden states / scores tuples
+ scores = () if (return_dict_in_generate and output_scores) else None
+ decoder_attentions = () if (return_dict_in_generate and output_attentions) else None
+ cross_attentions = () if (return_dict_in_generate and output_attentions) else None
+ decoder_hidden_states = () if (return_dict_in_generate and output_hidden_states) else None
+
+ # if model is an encoder-decoder, retrieve encoder attention weights and hidden states
+ if return_dict_in_generate and self.config.is_encoder_decoder:
+ encoder_attentions = model_kwargs["encoder_outputs"].get("attentions") if output_attentions else None
+ encoder_hidden_states = (
+ model_kwargs["encoder_outputs"].get("hidden_states") if output_hidden_states else None
+ )
+
+ # keep track of which sequences are already finished
+ unfinished_sequences = input_ids.new(input_ids.shape[0]).fill_(1)
+
+ # other auxiliary variables
+ max_len = stopping_criteria[0].max_length
+
+ this_peer_finished = False # used by synced_gpus only
+ while True:
+ if synced_gpus:
+ # Under synced_gpus the `forward` call must continue until all gpus complete their sequence.
+ # The following logic allows an early break if all peers finished generating their sequence
+ this_peer_finished_flag = torch.tensor(0.0 if this_peer_finished else 1.0).to(input_ids.device)
+ # send 0.0 if we finished, 1.0 otherwise
+ dist.all_reduce(this_peer_finished_flag, op=dist.ReduceOp.SUM)
+ # did all peers finish? the reduced sum will be 0.0 then
+ if this_peer_finished_flag.item() == 0.0:
+ break
+
+ # Assistant: main logic start
+ cur_len = input_ids.shape[-1]
+ assistant_kv_indexing = 0 if "bloom" not in assistant_model.__class__.__name__.lower() else 1
+
+ # 1. Forecast next N tokens using the assistant model. This `for` block can be replaced with a
+ # `.generate()` call if we decide to add `past_key_values` as a possible output of generate, as we
+ # need access to the assistant cache to secure strong speedups.
+ candidate_input_ids = input_ids
+ for _ in range(int(assistant_model.max_assistant_tokens)):
+ # 1.1. use the assistant model to obtain the next candidate logits
+ if "assistant_past_key_values" in model_kwargs:
+ prev_seq_len = model_kwargs["assistant_past_key_values"][0][assistant_kv_indexing].shape[-2]
+ # `new_token_len` can be 1 or 2 (next token in assistant + last token picked by the larger model)
+ new_token_len = candidate_input_ids.shape[1] - prev_seq_len
+ assist_inputs = candidate_input_ids[:, -new_token_len:]
+ assist_attn = torch.ones_like(candidate_input_ids)
+ # TODO (joao): make it compatible with models that use unconventional fwd pass logic, like blip2
+ if assistant_model.config.is_encoder_decoder:
+ assistant_model_outputs = assistant_model(
+ decoder_input_ids=assist_inputs,
+ decoder_attention_mask=assist_attn,
+ past_key_values=model_kwargs["assistant_past_key_values"],
+ encoder_outputs=model_kwargs["assistant_encoder_outputs"],
+ )
+ else:
+ assistant_model_outputs = assistant_model(
+ assist_inputs,
+ attention_mask=assist_attn,
+ past_key_values=model_kwargs["assistant_past_key_values"],
+ )
+ else:
+ if assistant_model.config.is_encoder_decoder:
+ assistant_model_outputs = assistant_model(
+ decoder_input_ids=candidate_input_ids,
+ encoder_outputs=model_kwargs["assistant_encoder_outputs"],
+ )
+ else:
+ assistant_model_outputs = assistant_model(candidate_input_ids)
+
+ # 1.2. greedily select the next candidate token
+ model_kwargs["assistant_past_key_values"] = assistant_model_outputs.past_key_values
+ if len(logits_processor) > 0:
+ assistant_model_outputs.logits[:, -1, :] = logits_processor(
+ candidate_input_ids, assistant_model_outputs.logits[:, -1, :]
+ )
+ new_token = assistant_model_outputs.logits[:, -1, :].argmax(dim=-1)
+ candidate_input_ids = torch.cat((candidate_input_ids, new_token[:, None]), dim=-1)
+
+ # 1.3. stop assistant generation on EOS
+ if eos_token_id_tensor is not None:
+ last_assistant_token_is_eos = new_token.tile(eos_token_id_tensor.shape[0], 1)
+ last_assistant_token_is_eos = (
+ ~last_assistant_token_is_eos.ne(eos_token_id_tensor.unsqueeze(1)).prod(dim=0).bool()
+ )
+ if last_assistant_token_is_eos:
+ break
+ else:
+ last_assistant_token_is_eos = False
+
+ candidate_length = candidate_input_ids.shape[1] - input_ids.shape[1]
+
+ # 2. Use the original model to obtain the next token logits given the candidate sequence. We obtain
+ # `candidate_length + 1` relevant logits from this process: in the event that all candidates are correct,
+ # we use this forward pass to also pick the subsequent logits in the original model.
+
+ # 2.1. Run a forward pass on the candidate sequence
+ if "past_key_values" in model_kwargs:
+ model_attn = torch.ones_like(candidate_input_ids)
+ model_input_ids = candidate_input_ids[:, -candidate_length - 1 :]
+ if self.config.is_encoder_decoder:
+ outputs = self(
+ decoder_input_ids=model_input_ids,
+ decoder_attention_mask=model_attn,
+ past_key_values=model_kwargs["past_key_values"],
+ encoder_outputs=model_kwargs["encoder_outputs"],
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ )
+ else:
+ outputs = self(
+ model_input_ids,
+ attention_mask=model_attn,
+ past_key_values=model_kwargs["past_key_values"],
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ )
+ else:
+ if self.config.is_encoder_decoder:
+ outputs = self(
+ decoder_input_ids=candidate_input_ids,
+ encoder_outputs=model_kwargs["encoder_outputs"],
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ )
+ else:
+ outputs = self(
+ candidate_input_ids,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ )
+
+ # 2.2. Process the new logits
+ new_logits = outputs.logits[:, -candidate_length - 1 :] # excludes the input prompt if present
+ if len(logits_processor) > 0:
+ for i in range(candidate_length):
+ new_logits[:, i, :] = logits_processor(candidate_input_ids[:, : cur_len + i], new_logits[:, i, :])
+ if len(logits_warper) > 0:
+ for i in range(candidate_length):
+ new_logits[:, i, :] = logits_warper(candidate_input_ids[:, : cur_len + i], new_logits[:, i, :])
+
+ # 3. Obtain the next tokens from the original model logits.
+ if do_sample:
+ probs = new_logits[:, -candidate_length - 1 :, :].softmax(dim=-1)
+ selected_tokens = torch.multinomial(probs[0, :, :], num_samples=1).squeeze(1)[None, :]
+ else:
+ selected_tokens = new_logits[:, -candidate_length - 1 :, :].argmax(dim=-1)
+
+ # 4. Compare the argmax from the original model logits with the assistant forecasted tokens. We can keep
+ # the assistant forecasted tokens until the first mismatch, or until the max length is reached.
+ candidate_new_tokens = candidate_input_ids[:, -candidate_length:]
+ n_matches = ((~(candidate_new_tokens == selected_tokens[:, :-1])).cumsum(dim=-1) < 1).sum()
+
+ # 5. Update variables according to the number of matching assistant tokens. Remember: the token generated
+ # by the model after the last candidate match is also valid, as it is generated from a correct sequence.
+ # Because of this last token, assisted generation search reduces to a normal greedy search/sample if there
+ # is no match.
+
+ # 5.1. Ensure we don't generate beyond max_len or an EOS token
+ if last_assistant_token_is_eos and n_matches == candidate_length:
+ n_matches -= 1
+ n_matches = min(n_matches, max_len - cur_len - 1)
+
+ # 5.2. Get the valid continuation, after the matching tokens
+ valid_tokens = selected_tokens[:, : n_matches + 1]
+ input_ids = torch.cat((input_ids, valid_tokens), dim=-1)
+ if streamer is not None:
+ streamer.put(valid_tokens.cpu())
+ new_cur_len = input_ids.shape[-1]
+
+ # 5.3. Discard past key values relative to unused assistant tokens
+ new_cache_size = new_cur_len - 1
+ outputs.past_key_values = _crop_past_key_values(self, outputs.past_key_values, new_cache_size)
+ model_kwargs["assistant_past_key_values"] = _crop_past_key_values(
+ assistant_model, model_kwargs["assistant_past_key_values"], new_cache_size - 1
+ ) # the assistant does not have the token after the last match, hence the -1
+
+ # 6. Adjust the max number of assistant tokens to use in the next iteration. This is a simple heuristic,
+ # probably can be improved -- we want to balance the benefits of getting assistant tokens correct with the
+ # cost of forecasting incorrect assistant tokens.
+ if n_matches == int(assistant_model.max_assistant_tokens):
+ assistant_model.max_assistant_tokens += 2.0
+ else:
+ assistant_model.max_assistant_tokens = max(1.0, assistant_model.max_assistant_tokens - 1.0)
+
+ # Assistant: main logic end
+
+ if synced_gpus and this_peer_finished:
+ continue # don't waste resources running the code we don't need
+
+ # Store scores, attentions and hidden_states when required
+ # Assistant: modified to append one tuple element per token, as in the other generation methods.
+ if return_dict_in_generate:
+ if output_scores:
+ scores += tuple(new_logits[:, i, :] for i in range(n_matches + 1))
+
+ if "past_key_values" not in model_kwargs:
+ added_len = new_cur_len
+ else:
+ added_len = n_matches + 1
+
+ if output_attentions:
+ if self.config.is_encoder_decoder:
+ cross_attentions = _split_model_outputs(
+ cross_attentions, outputs.cross_attentions, cur_len, added_len
+ )
+ decoder_attentions = _split_model_outputs(
+ decoder_attentions,
+ outputs.decoder_attentions,
+ cur_len,
+ added_len,
+ is_decoder_attention=True,
+ )
+ else:
+ decoder_attentions = _split_model_outputs(
+ decoder_attentions,
+ outputs.attentions,
+ cur_len,
+ added_len,
+ is_decoder_attention=True,
+ )
+ if output_hidden_states:
+ if self.config.is_encoder_decoder:
+ decoder_hidden_states = _split_model_outputs(
+ decoder_hidden_states, outputs.decoder_hidden_states, cur_len, added_len
+ )
+ else:
+ decoder_hidden_states = _split_model_outputs(
+ decoder_hidden_states, outputs.hidden_states, cur_len, added_len
+ )
+
+ model_kwargs = self._update_model_kwargs_for_generation(
+ outputs, model_kwargs, is_encoder_decoder=self.config.is_encoder_decoder
+ )
+
+ # if eos_token was found in one sentence, set sentence to finished
+ if eos_token_id_tensor is not None:
+ unfinished_sequences = unfinished_sequences.mul(
+ input_ids[:, -1]
+ .tile(eos_token_id_tensor.shape[0], 1)
+ .ne(eos_token_id_tensor.unsqueeze(1))
+ .prod(dim=0)
+ )
+
+ # stop when each sentence is finished
+ if unfinished_sequences.max() == 0:
+ this_peer_finished = True
+
+ # stop if we exceed the maximum length
+ if stopping_criteria(input_ids, scores):
+ this_peer_finished = True
+
+ if this_peer_finished and not synced_gpus:
+ break
+
+ if streamer is not None:
+ streamer.end()
+
+ if return_dict_in_generate:
+ if self.config.is_encoder_decoder:
+ return GreedySearchEncoderDecoderOutput(
+ sequences=input_ids,
+ scores=scores,
+ encoder_attentions=encoder_attentions,
+ encoder_hidden_states=encoder_hidden_states,
+ decoder_attentions=decoder_attentions,
+ cross_attentions=cross_attentions,
+ decoder_hidden_states=decoder_hidden_states,
+ )
+ else:
+ return GreedySearchDecoderOnlyOutput(
+ sequences=input_ids,
+ scores=scores,
+ attentions=decoder_attentions,
+ hidden_states=decoder_hidden_states,
+ )
+ else:
+ return input_ids
+
+
+def _crop_past_key_values(model, past_key_values, maximum_length):
+ """Crops the past key values up to a certain maximum length."""
+ new_past = []
+ if model.config.is_encoder_decoder:
+ for idx in range(len(past_key_values)):
+ new_past.append(
+ (
+ past_key_values[idx][0][:, :, :maximum_length, :],
+ past_key_values[idx][1][:, :, :maximum_length, :],
+ past_key_values[idx][2],
+ past_key_values[idx][3],
+ )
+ )
+ past_key_values = tuple(new_past)
+ elif "bloom" in model.__class__.__name__.lower(): # bloom is special
+ for idx in range(len(past_key_values)):
+ new_past.append(
+ (
+ past_key_values[idx][0][:, :, :maximum_length],
+ past_key_values[idx][1][:, :maximum_length, :],
+ )
+ )
+ past_key_values = tuple(new_past)
+ elif "gptbigcode" in model.__class__.__name__.lower(): # gptbigcode is too
+ if model.config.multi_query:
+ for idx in range(len(past_key_values)):
+ past_key_values[idx] = past_key_values[idx][:, :maximum_length, :]
+ else:
+ for idx in range(len(past_key_values)):
+ past_key_values[idx] = past_key_values[idx][:, :, :maximum_length, :]
+ else:
+ for idx in range(len(past_key_values)):
+ new_past.append(
+ (
+ past_key_values[idx][0][:, :, :maximum_length, :],
+ past_key_values[idx][1][:, :, :maximum_length, :],
+ )
+ )
+ past_key_values = tuple(new_past)
+ return past_key_values
+
+
+def _split_model_outputs(outputs, new_outputs, cur_len, added_len, is_decoder_attention=False):
+ """
+ Given the (decoder/cross attentions)/(decoder hidden states) for multiple generated tokens, splits it into a tuple
+ where each member corresponds to a single generated token.
+ """
+ # Retrocompatibility: in our generation functions, the first iteration includes the attention/hidden states for the
+ # prompt.
+ if len(outputs) == 0:
+ new_tuple = ()
+ for layer in new_outputs:
+ last_dim_size = cur_len if is_decoder_attention else layer.shape[-1]
+ new_tuple += (layer[..., :cur_len, :last_dim_size],)
+ outputs += (new_tuple,)
+ # The first iteration contains the prompt + 1 generated token, let's update the length variables accordingly
+ cur_len += 1
+ added_len -= cur_len
+
+ for i in range(added_len):
+ new_tuple = ()
+ for layer in new_outputs:
+ last_dim_size = cur_len + i if is_decoder_attention else layer.shape[-1]
+ new_tuple += (layer[..., i : i + 1, :last_dim_size],)
+ outputs += (new_tuple,)
+ return outputs
+
+
+def top_k_top_p_filtering(
+ logits: torch.FloatTensor,
+ top_k: int = 0,
+ top_p: float = 1.0,
+ filter_value: float = -float("Inf"),
+ min_tokens_to_keep: int = 1,
+) -> torch.FloatTensor:
+ """
+ Filter a distribution of logits using top-k and/or nucleus (top-p) filtering
+
+ Args:
+ logits: logits distribution shape (batch size, vocabulary size)
+ top_k (`int`, *optional*, defaults to 0):
+ If > 0, only keep the top k tokens with highest probability (top-k filtering)
+ top_p (`float`, *optional*, defaults to 1.0):
+ If < 1.0, only keep the top tokens with cumulative probability >= top_p (nucleus filtering). Nucleus
+ filtering is described in Holtzman et al. (http://arxiv.org/abs/1904.09751)
+ min_tokens_to_keep (`int`, *optional*, defaults to 1):
+ Minimumber of tokens we keep per batch example in the output.
+
+ From: https://gist.github.com/thomwolf/1a5a29f6962089e871b94cbd09daf317
+ """
+ if top_k > 0:
+ logits = TopKLogitsWarper(top_k=top_k, filter_value=filter_value, min_tokens_to_keep=min_tokens_to_keep)(
+ None, logits
+ )
+
+ if 0 <= top_p <= 1.0:
+ logits = TopPLogitsWarper(top_p=top_p, filter_value=filter_value, min_tokens_to_keep=min_tokens_to_keep)(
+ None, logits
+ )
+
+ return logits
+
+
+def _ranking_fast(
+ context_hidden: torch.FloatTensor,
+ next_hidden: torch.FloatTensor,
+ next_top_k_probs: torch.FloatTensor,
+ alpha: float,
+ beam_width: int,
+) -> torch.FloatTensor:
+ """
+ Reranks the top_k candidates based on a degeneration penalty (cosine similarity with previous tokens), as described
+ in the paper "A Contrastive Framework for Neural Text Generation". Returns the index of the best candidate for each
+ row in the batch.
+ """
+ norm_context_hidden = context_hidden / context_hidden.norm(dim=2, keepdim=True)
+ norm_next_hidden = next_hidden / next_hidden.norm(dim=2, keepdim=True)
+ cosine_matrix = torch.matmul(norm_context_hidden, norm_next_hidden.transpose(1, 2)).squeeze(-1) # [B*K, S]
+ degeneration_penalty, _ = torch.max(cosine_matrix, dim=-1) # [B*K]
+ next_top_k_probs = next_top_k_probs.view(-1) # [B*K]
+ contrastive_score = (1.0 - alpha) * next_top_k_probs - alpha * degeneration_penalty
+ contrastive_score = torch.stack(torch.split(contrastive_score, beam_width)) # [B, K]
+ _, selected_idx = contrastive_score.max(dim=-1) # [B]
+ return selected_idx
diff --git a/python/llm/example/GPU/Deepspeed-AutoTP-FastAPI/run_llama2_7b_chat_hf_arc_2_card.sh b/python/llm/example/GPU/Deepspeed-AutoTP-FastAPI/run_llama2_7b_chat_hf_arc_2_card.sh
index 283499f2de2..86e737cb93b 100644
--- a/python/llm/example/GPU/Deepspeed-AutoTP-FastAPI/run_llama2_7b_chat_hf_arc_2_card.sh
+++ b/python/llm/example/GPU/Deepspeed-AutoTP-FastAPI/run_llama2_7b_chat_hf_arc_2_card.sh
@@ -31,8 +31,7 @@ export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=2
export TORCH_LLM_ALLREDUCE=0
export WORLD_SIZE=2
-export MAX_NUM_SEQS=16
mpirun -np $NUM_GPUS --prepend-rank \
- python serving.py --repo-id-or-model-path YOUR_REPO_ID_OR_MODEL_PATH --low-bit 'sym_int4' --port 8000
+ python serving.py --repo-id-or-model-path YOUR_REPO_ID_OR_MODEL_PATH --low-bit 'sym_int4' --port 8000 --max-num-seqs 8 --max-num-batched-tokens 8192
diff --git a/python/llm/example/GPU/Deepspeed-AutoTP-FastAPI/serving.py b/python/llm/example/GPU/Deepspeed-AutoTP-FastAPI/serving.py
index da4cc8df95f..6690e0941d0 100644
--- a/python/llm/example/GPU/Deepspeed-AutoTP-FastAPI/serving.py
+++ b/python/llm/example/GPU/Deepspeed-AutoTP-FastAPI/serving.py
@@ -31,6 +31,9 @@
from transformers.utils import logging
logger = logging.get_logger(__name__)
+from benchmark_util import BenchmarkWrapper
+
+
def get_int_from_env(env_keys, default):
"""Returns the first positive env value found in the `env_keys` list or the default."""
for e in env_keys:
@@ -39,9 +42,11 @@ def get_int_from_env(env_keys, default):
return val
return int(default)
+global max_num_seqs
+global max_num_batched_tokens
+
local_rank = get_int_from_env(["LOCAL_RANK","PMI_RANK"], "0")
world_size = get_int_from_env(["WORLD_SIZE","PMI_SIZE"], "1")
-max_num_seqs = get_int_from_env(["MAX_NUM_SEQS"], "16")
os.environ["RANK"] = str(local_rank)
os.environ["WORLD_SIZE"] = str(world_size)
os.environ["MASTER_PORT"] = os.environ.get("MASTER_PORT", "29500")
@@ -92,6 +97,7 @@ def load_model(model_path, low_bit):
# Move model back to xpu
model = model.to(f'xpu:{local_rank}')
+ model = BenchmarkWrapper(model)
# Modify backend related settings
if world_size > 1:
@@ -133,6 +139,8 @@ class PromptRequest(BaseModel):
app = FastAPI()
+from collections import deque
+rest_req_deque = deque(maxlen=128)
request_queue: asyncio.Queue = asyncio.Queue()
result_dict: Dict[str, str] = {}
@@ -150,16 +158,39 @@ async def generate(prompt_request: PromptRequest):
async def process_requests():
while True:
request_ids, prompt_requests = [], []
- for _ in range(max_num_seqs):
- if request_queue.empty():
- break
- request_id, prompt_request = await request_queue.get()
- request_ids.append(request_id)
- prompt_requests.append(prompt_request)
+ cur_batched_tokens = 0
+
+ if local_rank == 0:
+ while rest_req_deque:
+ request_id, rest_request = rest_req_deque.popleft()
+ prompt = rest_request.prompt
+ cur_prompt_len = tokenizer(prompt_request.prompt, return_tensors="pt").input_ids.size(1)
+ cur_batched_tokens += cur_prompt_len
+ if cur_batched_tokens > max_num_batched_tokens:
+ cur_batched_tokens -= cur_prompt_len
+ rest_req_deque.appendleft((request_id, rest_request))
+ break
+ request_ids.append(request_id)
+ prompt_requests.append(rest_request)
+ if len(prompt_requests) == max_num_seqs:
+ break
+
+ for _ in range(max_num_seqs - len(prompt_requests)):
+ if request_queue.empty():
+ break
+ request_id, prompt_request = await request_queue.get()
+ # import pdb
+ # pdb.set_trace()
+ cur_prompt_len = tokenizer(prompt_request.prompt, return_tensors="pt").input_ids.size(1)
+ cur_batched_tokens += cur_prompt_len
+ if cur_batched_tokens > max_num_batched_tokens:
+ cur_batched_tokens -= cur_prompt_len
+ rest_req_deque.appendleft((request_id, prompt_request))
+ break
+ request_ids.append(request_id)
+ prompt_requests.append(prompt_request)
if local_rank == 0 and prompt_requests:
- # import pdb
- # pdb.set_trace()
object_list = prompt_requests
if len(object_list) < max_num_seqs:
object_list = object_list + [empty_req] * (max_num_seqs - len(object_list))
@@ -174,13 +205,15 @@ async def process_requests():
for request_id, output_str in zip(request_ids, output_strs):
result_dict[request_id] = output_str
+ logger.info(f"First token latency: {model.first_cost}, next token latency: {model.rest_cost_mean}, generate time: {generate_time}")
await asyncio.sleep(0.1)
@app.on_event("startup")
async def startup_event():
- asyncio.create_task(process_requests())
+ if local_rank == 0:
+ asyncio.create_task(process_requests())
if __name__ == "__main__":
@@ -192,10 +225,16 @@ async def startup_event():
help='The quantization type the model will convert to.')
parser.add_argument('--port', type=int, default=8000,
help='The port number on which the server will run.')
-
+ parser.add_argument('--max-num-batched-tokens', type=int, default=4096,
+ help='Max tokens can be batched by this service.')
+ parser.add_argument('--max-num-seqs', type=int, default=8,
+ help='Max requests can be batched by this service.')
+
args = parser.parse_args()
model_path = args.repo_id_or_model_path
low_bit = args.low_bit
+ max_num_seqs = args.max_num_seqs
+ max_num_batched_tokens = args.max_num_batched_tokens
load_model(model_path, low_bit)
if local_rank == 0:
uvicorn.run(app, host="0.0.0.0", port=args.port)
diff --git a/python/llm/example/GPU/Deepspeed-AutoTP-FastAPI/wrk_script_1024.lua b/python/llm/example/GPU/Deepspeed-AutoTP-FastAPI/wrk_script_1024.lua
new file mode 100644
index 00000000000..8118dec088e
--- /dev/null
+++ b/python/llm/example/GPU/Deepspeed-AutoTP-FastAPI/wrk_script_1024.lua
@@ -0,0 +1,10 @@
+wrk.method = "POST"
+wrk.headers["accept"] = "application/json"
+wrk.headers["Content-Type"] = "application/json"
+wrk.body = '{"prompt": "Once upon a time, there existed a little girl who liked to have adventures. She wanted to go to places and meet new people, and have fun. However, her parents were always telling her to stay close to home, to be careful, and to avoid any danger. But the little girl was stubborn, and she wanted to see what was on the other side of the mountain. So she sneaked out of the house one night, leaving a note for her parents, and set off on her journey. As she climbed the mountain, the little girl felt a sense of excitement and wonder. She had never been this far away from home before, and she couldnt wait to see what she would find on the other side. She climbed higher and higher, her lungs burning from the thin air, until she finally reached the top of the mountain. And there, she found a beautiful meadow filled with wildflowers and a sparkling stream. The little girl danced and played in the meadow, feeling free and alive. She knew she had to return home eventually, but for now, she was content to enjoy her adventure. As the sun began to set, the little girl reluctantly made her way back down the mountain, but she knew that she would never forget her adventure and the joy of discovering something new and exciting. And whenever she felt scared or unsure, she would remember the thrill of climbing the mountain and the beauty of the meadow on the other side, and she would know that she could face any challenge that came her way, with courage and determination. She carried the memories of her journey in her heart, a constant reminder of the strength she possessed. The little girl returned home to her worried parents, who had discovered her note and anxiously awaited her arrival. They scolded her for disobeying their instructions and venturing into the unknown. But as they looked into her sparkling eyes and saw the glow on her face, their anger softened. They realized that their little girl had grown, that she had experienced something extraordinary. The little girl shared her tales of the mountain and the meadow with her parents, painting vivid pictures with her words. She spoke of the breathtaking view from the mountaintop, where the world seemed to stretch endlessly before her. She described the delicate petals of the wildflowers, vibrant hues that danced in the gentle breeze. And she recounted the soothing melody of the sparkling stream, its waters reflecting the golden rays of the setting sun. Her parents listened intently, captivated by her story. They realized that their daughter had discovered a part of herself on that journey—a spirit of curiosity and a thirst for exploration. They saw that she had learned valuable lessons about independence, resilience, and the beauty that lies beyond ones comfort zone. From that day forward, the little girls parents encouraged her to pursue her dreams and embrace new experiences. They understood that while there were risks in the world, there were also rewards waiting to be discovered. They supported her as she continued to embark on adventures, always reminding her to stay safe but never stifling her spirit. As the years passed, the little girl grew into a remarkable woman, fearlessly exploring the world and making a difference wherever she went. The lessons she had learned on that fateful journey stayed with her, guiding her through challenges and inspiring her to live life to the fullest. And so, the once timid little girl became a symbol of courage and resilience, a reminder to all who knew her that the greatest joys in life often lie just beyond the mountains we fear to climb. Her story spread far and wide, inspiring others to embrace their own journeys and discover the wonders that awaited them. In the end, the little girls adventure became a timeless tale, passed down through generations, reminding us all that sometimes, the greatest rewards come to those who dare to step into the unknown and follow their hearts. With each passing day, the little girls story continued to inspire countless individuals, igniting a spark within their souls and encouraging them to embark on their own extraordinary adventures. The tale of her bravery and determination resonated deeply with people from all walks of life, reminding them of the limitless possibilities that awaited them beyond the boundaries of their comfort zones. People marveled at the little girls unwavering spirit and her unwavering belief in the power of dreams. They saw themselves reflected in her journey, finding solace in the knowledge that they too could overcome their fears and pursue their passions. The little girl\'s story became a beacon of hope, a testament to the human spirit", "n_predict":128}'
+
+logfile = io.open("wrk.log", "w");
+
+response = function(status, header, body)
+ logfile:write("status:" .. status .. "\n" .. body .. "\n-------------------------------------------------\n");
+end
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/codegemma/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/codegemma/README.md
new file mode 100644
index 00000000000..606284da360
--- /dev/null
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/codegemma/README.md
@@ -0,0 +1,144 @@
+# CodeGemma
+In this directory, you will find examples on how you could apply IPEX-LLM INT4 optimizations on CodeGemma models on [Intel GPUs](../../../README.md). For illustration purposes, we utilize the [google/codegemma-7b-it](https://huggingface.co/google/codegemma-7b-it) as reference CodeGemma models.
+
+## 0. Requirements
+To run these examples with IPEX-LLM on Intel GPUs, we have some recommended requirements for your machine, please refer to [here](../../../README.md#requirements) for more information.
+
+**Important: According to CodeGemma's requirement, please make sure you have installed `transformers==4.38.1` to run the example.**
+
+## Example: Predict Tokens using `generate()` API
+In the example [generate.py](./generate.py), we show a basic use case for a CodeGemma model to predict the next N tokens using `generate()` API, with IPEX-LLM INT4 optimizations on Intel GPUs.
+### 1. Install
+#### 1.1 Installation on Linux
+We suggest using conda to manage the Python environment. For more information about conda installation, please refer to [here](https://docs.conda.io/en/latest/miniconda.html#).
+
+After installing conda, create a Python environment for IPEX-LLM:
+```bash
+conda create -n llm python=3.11 # recommend to use Python 3.11
+conda activate llm
+# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
+pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
+
+# According to CodeGemma's requirement, please make sure you are using a stable version of Transformers, 4.38.1 or newer.
+pip install transformers==4.38.1
+```
+
+#### 1.2 Installation on Windows
+We suggest using conda to manage environment:
+```bash
+conda create -n llm python=3.11 libuv
+conda activate llm
+# below command will use pip to install the Intel oneAPI Base Toolkit 2024.0
+pip install dpcpp-cpp-rt==2024.0.2 mkl-dpcpp==2024.0.0 onednn==2024.0.0
+
+# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
+pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
+
+# According to CodeGemma's requirement, please make sure you are using a stable version of Transformers, 4.38.1 or newer.
+pip install transformers==4.38.1
+```
+
+### 2. Configures OneAPI environment variables for Linux
+
+> [!NOTE]
+> Skip this step if you are running on Windows.
+
+This is a required step on Linux for APT or offline installed oneAPI. Skip this step for PIP-installed oneAPI.
+
+```bash
+source /opt/intel/oneapi/setvars.sh
+```
+
+### 3. Runtime Configurations
+For optimal performance, it is recommended to set several environment variables. Please check out the suggestions based on your device.
+#### 3.1 Configurations for Linux
+
+
+For Intel Arc™ A-Series Graphics and Intel Data Center GPU Flex Series
+
+```bash
+export USE_XETLA=OFF
+export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
+export SYCL_CACHE_PERSISTENT=1
+```
+
+
+
+
+
+For Intel Data Center GPU Max Series
+
+```bash
+export LD_PRELOAD=${LD_PRELOAD}:${CONDA_PREFIX}/lib/libtcmalloc.so
+export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
+export SYCL_CACHE_PERSISTENT=1
+export ENABLE_SDP_FUSION=1
+```
+> Note: Please note that `libtcmalloc.so` can be installed by `conda install -c conda-forge -y gperftools=2.10`.
+
+
+
+
+For Intel iGPU
+
+```bash
+export SYCL_CACHE_PERSISTENT=1
+export BIGDL_LLM_XMX_DISABLED=1
+```
+
+
+
+#### 3.2 Configurations for Windows
+
+
+For Intel iGPU
+
+```cmd
+set SYCL_CACHE_PERSISTENT=1
+set BIGDL_LLM_XMX_DISABLED=1
+```
+
+
+
+
+
+For Intel Arc™ A-Series Graphics
+
+```cmd
+set SYCL_CACHE_PERSISTENT=1
+```
+
+
+
+> [!NOTE]
+> For the first time that each model runs on Intel iGPU/Intel Arc™ A300-Series or Pro A60, it may take several minutes to compile.
+### 4. Running examples
+
+```
+python ./generate.py --repo-id-or-model-path REPO_ID_OR_MODEL_PATH --prompt PROMPT --n-predict N_PREDICT
+```
+
+Arguments info:
+- `--repo-id-or-model-path REPO_ID_OR_MODEL_PATH`: argument defining the huggingface repo id for the CodeGemma model to be downloaded, or the path to the huggingface checkpoint folder. It is default to be `'google/codegemma-7b-it'`.
+- `--prompt PROMPT`: argument defining the prompt to be infered (with integrated prompt format for chat). It is default to be `'Write a hello world program'`.
+- `--n-predict N_PREDICT`: argument defining the max number of tokens to predict. It is default to be `32`.
+
+##### Sample Output
+##### [google/codegemma-7b-it](https://huggingface.co/google/codegemma-7b-it)
+```log
+Inference time: xxxx s
+-------------------- Prompt --------------------
+user
+Write a hello world program
+model
+
+-------------------- Output --------------------
+user
+Write a hello world program
+model
+```python
+print("Hello, world!")
+```
+
+This program will print the message "Hello, world!" to the console.
+```
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/codegemma/generate.py b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/codegemma/generate.py
new file mode 100644
index 00000000000..9add373b080
--- /dev/null
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/codegemma/generate.py
@@ -0,0 +1,80 @@
+#
+# Copyright 2016 The BigDL Authors.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+import torch
+import time
+import argparse
+
+from ipex_llm.transformers import AutoModelForCausalLM
+from transformers import AutoTokenizer
+
+# The instruction-tuned models use a chat template that must be adhered to for conversational use.
+# see https://huggingface.co/google/codegemma-7b-it#chat-template.
+chat = [
+ { "role": "user", "content": "Write a hello world program" },
+]
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser(description='Predict Tokens using `generate()` API for CodeGemma model')
+ parser.add_argument('--repo-id-or-model-path', type=str, default="google/codegemma-7b-it",
+ help='The huggingface repo id for the CodeGemma to be downloaded'
+ ', or the path to the huggingface checkpoint folder')
+ parser.add_argument('--prompt', type=str, default="Write a hello world program",
+ help='Prompt to infer')
+ parser.add_argument('--n-predict', type=int, default=32,
+ help='Max tokens to predict')
+
+ args = parser.parse_args()
+ model_path = args.repo_id_or_model_path
+
+ # Load model in 4 bit,
+ # which convert the relevant layers in the model into INT4 format
+ # To fix the issue that the output of codegemma-7b-it is abnormal, skip the 'lm_head' module during optimization
+ # When running LLMs on Intel iGPUs for Windows users, we recommend setting `cpu_embedding=True` in the from_pretrained function.
+ # This will allow the memory-intensive embedding layer to utilize the CPU instead of iGPU.
+ model = AutoModelForCausalLM.from_pretrained(model_path,
+ load_in_4bit=True,
+ optimize_model=True,
+ trust_remote_code=True,
+ use_cache=True,
+ modules_to_not_convert=["lm_head"])
+ model = model.to('xpu')
+
+ # Load tokenizer
+ tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
+
+ # Generate predicted tokens
+ with torch.inference_mode():
+ chat[0]['content'] = args.prompt
+ prompt = tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
+ input_ids = tokenizer.encode(prompt, return_tensors="pt").to('xpu')
+ # ipex_llm model needs a warmup, then inference time can be accurate
+ output = model.generate(input_ids,
+ max_new_tokens=args.n_predict)
+
+ # start inference
+ st = time.time()
+ output = model.generate(input_ids,
+ max_new_tokens=args.n_predict)
+ torch.xpu.synchronize()
+ end = time.time()
+ output = output.cpu()
+ output_str = tokenizer.decode(output[0], skip_special_tokens=True)
+ print(f'Inference time: {end-st} s')
+ print('-'*20, 'Prompt', '-'*20)
+ print(prompt)
+ print('-'*20, 'Output', '-'*20)
+ print(output_str)
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/cohere/README.md b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/cohere/README.md
new file mode 100644
index 00000000000..8ab61799636
--- /dev/null
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/cohere/README.md
@@ -0,0 +1,101 @@
+# CoHere/command-r
+In this directory, you will find examples on how you could apply IPEX-LLM INT4 optimizations on cohere models on [Intel GPUs](../../../README.md). For illustration purposes, we utilize the [CohereForAI/c4ai-command-r-v01](https://huggingface.co/CohereForAI/c4ai-command-r-v01) as a reference model.
+> **Note**: Because the size of this cohere model is 35B, even running low_bit `sym_int4` still requires about 17.5GB. So currently it can only be run on MAX GPU, or run with [Pipeline-Parallel-Inference](https://github.com/intel-analytics/ipex-llm/tree/main/python/llm/example/GPU/Pipeline-Parallel-Inference) on multiple Arc GPUs.
+>
+> Please select the appropriate size of the cohere model based on the capabilities of your machine.
+
+## 0. Requirements
+To run these examples with IPEX-LLM on Intel GPUs, we have some recommended requirements for your machine, please refer to [here](../../../README.md#requirements) for more information.
+
+## Example: Predict Tokens using `generate()` API
+In the example [generate.py](./generate.py), we show a basic use case for a cohere model to predict the next N tokens using `generate()` API, with IPEX-LLM INT4 optimizations on Intel GPUs.
+### 1. Install
+#### 1.1 Installation on Linux
+We suggest using conda to manage environment:
+```bash
+conda create -n llm python=3.11
+conda activate llm
+# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
+pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
+pip install tansformers==4.40.0
+conda install -c conda-forge -y gperftools=2.10 # to enable tcmalloc
+```
+
+#### 1.2 Installation on Windows
+We suggest using conda to manage environment:
+```bash
+conda create -n llm python=3.11 libuv
+conda activate llm
+# below command will use pip to install the Intel oneAPI Base Toolkit 2024.0
+pip install dpcpp-cpp-rt==2024.0.2 mkl-dpcpp==2024.0.0 onednn==2024.0.0
+
+# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
+pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
+pip install tansformers==4.40.0
+```
+
+### 2. Configures OneAPI environment variables for Linux
+
+> [!NOTE]
+> Skip this step if you are running on Windows.
+
+This is a required step on Linux for APT or offline installed oneAPI. Skip this step for PIP-installed oneAPI.
+
+```bash
+source /opt/intel/oneapi/setvars.sh
+```
+
+### 3. Runtime Configurations
+For optimal performance, it is recommended to set several environment variables. Please check out the suggestions based on your device.
+#### 3.1 Configurations for Linux
+
+
+For Intel Arc™ A-Series Graphics and Intel Data Center GPU Flex Series
+
+```bash
+export USE_XETLA=OFF
+export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
+export SYCL_CACHE_PERSISTENT=1
+```
+
+
+
+
+
+For Intel Data Center GPU Max Series
+
+```bash
+export LD_PRELOAD=${LD_PRELOAD}:${CONDA_PREFIX}/lib/libtcmalloc.so
+export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
+export SYCL_CACHE_PERSISTENT=1
+export ENABLE_SDP_FUSION=1
+```
+> Note: Please note that `libtcmalloc.so` can be installed by `conda install -c conda-forge -y gperftools=2.10`.
+
+
+### 4. Running examples
+
+```
+python ./generate.py --repo-id-or-model-path REPO_ID_OR_MODEL_PATH --prompt PROMPT --n-predict N_PREDICT
+```
+
+Arguments info:
+- `--repo-id-or-model-path REPO_ID_OR_MODEL_PATH`: argument defining the huggingface repo id for the cohere model to be downloaded, or the path to the huggingface checkpoint folder. It is default to be `'CohereForAI/c4ai-command-r-v01'`.
+- `--prompt PROMPT`: argument defining the prompt to be infered (with integrated prompt format for chat). It is default to be `'What is AI?'`.
+- `--n-predict N_PREDICT`: argument defining the max number of tokens to predict. It is default to be `32`.
+
+#### Sample Output
+#### [CohereForAI/c4ai-command-r-v01](https://huggingface.co/CohereForAI/c4ai-command-r-v01)
+```log
+Inference time: xxxxx s
+-------------------- Prompt --------------------
+
+<|START_OF_TURN_TOKEN|><|USER_TOKEN|>What is AI?<|END_OF_TURN_TOKEN|><|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>
+
+-------------------- Output --------------------
+
+<|START_OF_TURN_TOKEN|><|USER_TOKEN|>What is AI?<|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>
+Artificial Intelligence Quora User,
+
+Artificial Intelligence (AI) is the simulation of human intelligence in machines, typically by machines, that have become a very complex
+```
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/cohere/generate.py b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/cohere/generate.py
new file mode 100644
index 00000000000..69c74ad4a75
--- /dev/null
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/cohere/generate.py
@@ -0,0 +1,81 @@
+#
+# Copyright 2016 The BigDL Authors.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+import torch
+import time
+import argparse
+
+from ipex_llm.transformers import AutoModelForCausalLM
+from transformers import AutoTokenizer
+
+# you could tune the prompt based on your own model,
+# Refer to https://huggingface.co/CohereForAI/c4ai-command-r-v01
+COHERE_PROMPT_FORMAT = """
+<|START_OF_TURN_TOKEN|><|USER_TOKEN|>{prompt}<|END_OF_TURN_TOKEN|><|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>
+"""
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser(description='Predict Tokens using `generate()` API for cohere model')
+ parser.add_argument('--repo-id-or-model-path', type=str, default="CohereForAI/c4ai-command-r-v01",
+ help='The huggingface repo id for the cohere to be downloaded'
+ ', or the path to the huggingface checkpoint folder')
+ parser.add_argument('--prompt', type=str, default="What is AI?",
+ help='Prompt to infer')
+ parser.add_argument('--n-predict', type=int, default=32,
+ help='Max tokens to predict')
+
+ args = parser.parse_args()
+ model_path = args.repo_id_or_model_path
+
+ # Load model in 4 bit,
+ # which convert the relevant layers in the model into INT4 format
+ # When running LLMs on Intel iGPUs for Windows users, we recommend setting `cpu_embedding=True` in the from_pretrained function.
+ # This will allow the memory-intensive embedding layer to utilize the CPU instead of iGPU.
+ model = AutoModelForCausalLM.from_pretrained(model_path,
+ load_in_4bit=True,
+ optimize_model=True,
+ trust_remote_code=True,
+ use_cache=True)
+ model = model.half().to('xpu')
+
+ # Load tokenizer
+ tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
+
+ # Generate predicted tokens
+ with torch.inference_mode():
+ prompt = COHERE_PROMPT_FORMAT.format(prompt=args.prompt)
+ input_ids = tokenizer.encode(prompt, return_tensors="pt").to('xpu')
+ # ipex_llm model needs a warmup, then inference time can be accurate
+ output = model.generate(input_ids,
+ max_new_tokens=args.n_predict)
+
+ # start inference
+ st = time.time()
+ # if your selected model is capable of utilizing previous key/value attentions
+ # to enhance decoding speed, but has `"use_cache": false` in its model config,
+ # it is important to set `use_cache=True` explicitly in the `generate` function
+ # to obtain optimal performance with IPEX-LLM INT4 optimizations
+ output = model.generate(input_ids,
+ max_new_tokens=args.n_predict)
+ torch.xpu.synchronize()
+ end = time.time()
+ output = output.cpu()
+ output_str = tokenizer.decode(output[0], skip_special_tokens=True)
+ print(f'Inference time: {end-st} s')
+ print('-'*20, 'Prompt', '-'*20)
+ print(prompt)
+ print('-'*20, 'Output', '-'*20)
+ print(output_str)
diff --git a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/gemma/generate.py b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/gemma/generate.py
index bbe4f68b190..2ca0ab905c5 100644
--- a/python/llm/example/GPU/HF-Transformers-AutoModels/Model/gemma/generate.py
+++ b/python/llm/example/GPU/HF-Transformers-AutoModels/Model/gemma/generate.py
@@ -48,6 +48,7 @@
load_in_4bit=True,
optimize_model=True,
trust_remote_code=True,
+ mixed_precision=True,
use_cache=True)
model = model.to('xpu')
diff --git a/python/llm/example/GPU/LLM-Finetuning/DPO/README.md b/python/llm/example/GPU/LLM-Finetuning/DPO/README.md
index 076e564206b..0eae68c64ae 100644
--- a/python/llm/example/GPU/LLM-Finetuning/DPO/README.md
+++ b/python/llm/example/GPU/LLM-Finetuning/DPO/README.md
@@ -17,8 +17,8 @@ conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
-pip install transformers==4.34.0 datasets
-pip install trl peft==0.5.0
+pip install transformers==4.36.0 datasets
+pip install trl peft==0.10.0
pip install accelerate==0.23.0
pip install bitsandbytes
```
diff --git a/python/llm/example/GPU/LLM-Finetuning/HF-PEFT/README.md b/python/llm/example/GPU/LLM-Finetuning/HF-PEFT/README.md
index 7da65981cbf..fb2a628867d 100644
--- a/python/llm/example/GPU/LLM-Finetuning/HF-PEFT/README.md
+++ b/python/llm/example/GPU/LLM-Finetuning/HF-PEFT/README.md
@@ -14,8 +14,8 @@ conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
-pip install transformers==4.34.0 datasets
-pip install fire peft==0.5.0
+pip install transformers==4.36.0 datasets
+pip install fire peft==0.10.0
pip install oneccl_bind_pt==2.1.100 --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/ # necessary to run distributed finetuning
pip install accelerate==0.23.0
pip install bitsandbytes scipy
diff --git a/python/llm/example/GPU/LLM-Finetuning/LoRA/README.md b/python/llm/example/GPU/LLM-Finetuning/LoRA/README.md
index 8ef75a28949..52e9aad457d 100644
--- a/python/llm/example/GPU/LLM-Finetuning/LoRA/README.md
+++ b/python/llm/example/GPU/LLM-Finetuning/LoRA/README.md
@@ -12,8 +12,8 @@ conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
-pip install transformers==4.34.0 datasets
-pip install fire peft==0.5.0
+pip install transformers==4.36.0 datasets
+pip install fire peft==0.10.0
pip install oneccl_bind_pt==2.1.100 --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/ # necessary to run distributed finetuning
pip install accelerate==0.23.0
pip install bitsandbytes scipy
diff --git a/python/llm/example/GPU/LLM-Finetuning/QA-LoRA/README.md b/python/llm/example/GPU/LLM-Finetuning/QA-LoRA/README.md
index 006f6630872..511787f39b4 100644
--- a/python/llm/example/GPU/LLM-Finetuning/QA-LoRA/README.md
+++ b/python/llm/example/GPU/LLM-Finetuning/QA-LoRA/README.md
@@ -12,8 +12,8 @@ conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
-pip install transformers==4.34.0 datasets
-pip install fire peft==0.5.0
+pip install transformers==4.36.0 datasets
+pip install fire peft==0.10.0
pip install oneccl_bind_pt==2.1.100 --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/ # necessary to run distributed finetuning
pip install accelerate==0.23.0
pip install bitsandbytes scipy
diff --git a/python/llm/example/GPU/LLM-Finetuning/QLoRA/alpaca-qlora/README.md b/python/llm/example/GPU/LLM-Finetuning/QLoRA/alpaca-qlora/README.md
index 4cdb3d26241..10cdd1c6572 100644
--- a/python/llm/example/GPU/LLM-Finetuning/QLoRA/alpaca-qlora/README.md
+++ b/python/llm/example/GPU/LLM-Finetuning/QLoRA/alpaca-qlora/README.md
@@ -14,8 +14,8 @@ conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
-pip install transformers==4.34.0 datasets
-pip install fire peft==0.5.0
+pip install transformers==4.36.0 datasets
+pip install fire peft==0.10.0
pip install oneccl_bind_pt==2.1.100 --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/ # necessary to run distributed finetuning
pip install accelerate==0.23.0
pip install bitsandbytes scipy
diff --git a/python/llm/example/GPU/LLM-Finetuning/QLoRA/simple-example/README.md b/python/llm/example/GPU/LLM-Finetuning/QLoRA/simple-example/README.md
index fe682829c7c..68741b3f536 100644
--- a/python/llm/example/GPU/LLM-Finetuning/QLoRA/simple-example/README.md
+++ b/python/llm/example/GPU/LLM-Finetuning/QLoRA/simple-example/README.md
@@ -17,8 +17,8 @@ conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
-pip install transformers==4.34.0 datasets
-pip install peft==0.5.0
+pip install transformers==4.36.0 datasets
+pip install peft==0.10.0
pip install accelerate==0.23.0
pip install bitsandbytes scipy
```
diff --git a/python/llm/example/GPU/LLM-Finetuning/QLoRA/trl-example/README.md b/python/llm/example/GPU/LLM-Finetuning/QLoRA/trl-example/README.md
index 46e8992b902..303856f02fc 100644
--- a/python/llm/example/GPU/LLM-Finetuning/QLoRA/trl-example/README.md
+++ b/python/llm/example/GPU/LLM-Finetuning/QLoRA/trl-example/README.md
@@ -17,8 +17,8 @@ conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
-pip install transformers==4.34.0 datasets
-pip install peft==0.5.0
+pip install transformers==4.36.0 datasets
+pip install peft==0.10.0
pip install accelerate==0.23.0
pip install bitsandbytes scipy trl
```
diff --git a/python/llm/example/GPU/LLM-Finetuning/ReLora/README.md b/python/llm/example/GPU/LLM-Finetuning/ReLora/README.md
index 0e94a63a1fb..7cf0c53988b 100644
--- a/python/llm/example/GPU/LLM-Finetuning/ReLora/README.md
+++ b/python/llm/example/GPU/LLM-Finetuning/ReLora/README.md
@@ -12,8 +12,8 @@ conda create -n llm python=3.11
conda activate llm
# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
-pip install transformers==4.34.0 datasets
-pip install fire peft==0.5.0
+pip install transformers==4.36.0 datasets
+pip install fire peft==0.10.0
pip install oneccl_bind_pt==2.1.100 --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/ # necessary to run distributed finetuning
pip install accelerate==0.23.0
pip install bitsandbytes scipy
diff --git a/python/llm/example/GPU/LLM-Finetuning/axolotl/README.md b/python/llm/example/GPU/LLM-Finetuning/axolotl/README.md
index 22d7d7546f8..773202e6974 100644
--- a/python/llm/example/GPU/LLM-Finetuning/axolotl/README.md
+++ b/python/llm/example/GPU/LLM-Finetuning/axolotl/README.md
@@ -36,13 +36,22 @@ source /opt/intel/oneapi/setvars.sh
#### 2.2 Configures `accelerate` in command line interactively.
+You can download a default `default_config.yaml` with `use_cpu: false`.
+
+```bash
+mkdir -p ~/.cache/huggingface/accelerate/
+wget -O ~/.cache/huggingface/accelerate/default_config.yaml https://raw.githubusercontent.com/intel-analytics/ipex-llm/main/python/llm/example/GPU/LLM-Finetuning/axolotl/default_config.yaml
+```
+
+As an alternative, you can config accelerate based on your requirements.
+
```bash
accelerate config
```
Please answer `NO` in option `Do you want to run your training on CPU only (even if a GPU / Apple Silicon device is available)? [yes/NO]:`.
-After finish accelerate config, check if `use_cpu` is disable (i.e., ` use_cpu: false`) in accelerate config file (`~/.cache/huggingface/accelerate/default_config.yaml`).
+After finish accelerate config, check if `use_cpu` is disable (i.e., `use_cpu: false`) in accelerate config file (`~/.cache/huggingface/accelerate/default_config.yaml`).
#### 2.3 (Optional) Set ` HF_HUB_OFFLINE=1` to avoid huggingface hug signing.
diff --git a/python/llm/example/GPU/LLM-Finetuning/axolotl/default_config.yaml b/python/llm/example/GPU/LLM-Finetuning/axolotl/default_config.yaml
new file mode 100644
index 00000000000..237160c4faf
--- /dev/null
+++ b/python/llm/example/GPU/LLM-Finetuning/axolotl/default_config.yaml
@@ -0,0 +1,18 @@
+compute_environment: LOCAL_MACHINE
+debug: false
+distributed_type: 'NO'
+downcast_bf16: 'no'
+gpu_ids: all
+ipex_config:
+ use_xpu: true
+machine_rank: 0
+main_training_function: main
+mixed_precision: 'no'
+num_machines: 1
+num_processes: 1
+rdzv_backend: static
+same_network: true
+tpu_env: []
+tpu_use_cluster: false
+tpu_use_sudo: false
+use_cpu: false
diff --git a/python/llm/example/GPU/LLM-Finetuning/axolotl/requirements-xpu.txt b/python/llm/example/GPU/LLM-Finetuning/axolotl/requirements-xpu.txt
index 5326b05f9aa..4f1df3767ca 100644
--- a/python/llm/example/GPU/LLM-Finetuning/axolotl/requirements-xpu.txt
+++ b/python/llm/example/GPU/LLM-Finetuning/axolotl/requirements-xpu.txt
@@ -1,7 +1,7 @@
# This file is copied from https://github.com/OpenAccess-AI-Collective/axolotl/blob/v0.4.0/requirements.txt
--extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/
packaging==23.2
-peft==0.5.0
+peft==0.10.0
tokenizers
bitsandbytes>=0.41.1
accelerate==0.23.0
diff --git a/python/llm/example/GPU/PyTorch-Models/Model/codegemma/README.md b/python/llm/example/GPU/PyTorch-Models/Model/codegemma/README.md
new file mode 100644
index 00000000000..fa7363b3bda
--- /dev/null
+++ b/python/llm/example/GPU/PyTorch-Models/Model/codegemma/README.md
@@ -0,0 +1,145 @@
+# CodeGemma
+In this directory, you will find examples on how you could use IPEX-LLM `optimize_model` API to accelerate CodeGemma models. For illustration purposes, we utilize the [google/codegemma-7b-it](https://huggingface.co/google/codegemma-7b-it) as reference CodeGemma models.
+
+## 0. Requirements
+To run these examples with IPEX-LLM on Intel GPUs, we have some recommended requirements for your machine, please refer to [here](../../../README.md#requirements) for more information.
+
+**Important: According to CodeGemma's requirement, please make sure you have installed `transformers==4.38.1` to run the example.**
+
+## Example: Predict Tokens using `generate()` API
+In the example [generate.py](./generate.py), we show a basic use case for a CodeGemma model to predict the next N tokens using `generate()` API, with IPEX-LLM INT4 optimizations on Intel GPUs.
+### 1. Install
+#### 1.1 Installation on Linux
+We suggest using conda to manage the Python environment. For more information about conda installation, please refer to [here](https://docs.conda.io/en/latest/miniconda.html#).
+
+After installing conda, create a Python environment for IPEX-LLM:
+```bash
+conda create -n llm python=3.11 # recommend to use Python 3.11
+conda activate llm
+# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
+pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
+
+# According to CodeGemma's requirement, please make sure you are using a stable version of Transformers, 4.38.1 or newer.
+pip install transformers==4.38.1
+```
+
+#### 1.2 Installation on Windows
+We suggest using conda to manage environment:
+```bash
+conda create -n llm python=3.11 libuv
+conda activate llm
+# below command will use pip to install the Intel oneAPI Base Toolkit 2024.0
+pip install dpcpp-cpp-rt==2024.0.2 mkl-dpcpp==2024.0.0 onednn==2024.0.0
+
+# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
+pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
+
+# According to CodeGemma's requirement, please make sure you are using a stable version of Transformers, 4.38.1 or newer.
+pip install transformers==4.38.1
+```
+
+### 2. Configures OneAPI environment variables for Linux
+
+> [!NOTE]
+> Skip this step if you are running on Windows.
+
+This is a required step on Linux for APT or offline installed oneAPI. Skip this step for PIP-installed oneAPI.
+
+```bash
+source /opt/intel/oneapi/setvars.sh
+```
+
+### 3. Runtime Configurations
+For optimal performance, it is recommended to set several environment variables. Please check out the suggestions based on your device.
+#### 3.1 Configurations for Linux
+
+
+For Intel Arc™ A-Series Graphics and Intel Data Center GPU Flex Series
+
+```bash
+export USE_XETLA=OFF
+export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
+export SYCL_CACHE_PERSISTENT=1
+```
+
+
+
+
+
+For Intel Data Center GPU Max Series
+
+```bash
+export LD_PRELOAD=${LD_PRELOAD}:${CONDA_PREFIX}/lib/libtcmalloc.so
+export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
+export SYCL_CACHE_PERSISTENT=1
+export ENABLE_SDP_FUSION=1
+```
+> Note: Please note that `libtcmalloc.so` can be installed by `conda install -c conda-forge -y gperftools=2.10`.
+
+
+
+
+For Intel iGPU
+
+```bash
+export SYCL_CACHE_PERSISTENT=1
+export BIGDL_LLM_XMX_DISABLED=1
+```
+
+
+
+#### 3.2 Configurations for Windows
+
+
+For Intel iGPU
+
+```cmd
+set SYCL_CACHE_PERSISTENT=1
+set BIGDL_LLM_XMX_DISABLED=1
+```
+
+
+
+
+
+For Intel Arc™ A-Series Graphics
+
+```cmd
+set SYCL_CACHE_PERSISTENT=1
+```
+
+
+
+> [!NOTE]
+> For the first time that each model runs on Intel iGPU/Intel Arc™ A300-Series or Pro A60, it may take several minutes to compile.
+### 4. Running examples
+
+```bash
+python ./generate.py --repo-id-or-model-path REPO_ID_OR_MODEL_PATH --prompt PROMPT --n-predict N_PREDICT
+```
+
+In the example, several arguments can be passed to satisfy your requirements:
+
+- `--repo-id-or-model-path REPO_ID_OR_MODEL_PATH`: argument defining the huggingface repo id for the CodeGemma model to be downloaded, or the path to the huggingface checkpoint folder. It is default to be `'google/codegemma-7b-it'`.
+- `--prompt PROMPT`: argument defining the prompt to be infered (with integrated prompt format for chat). It is default to be `Write a hello world program'`.
+- `--n-predict N_PREDICT`: argument defining the max number of tokens to predict. It is default to be `32`.
+
+#### 4.1 Sample Output
+#### [google/codegemma-7b-it](https://huggingface.co/google/codegemma-7b-it)
+```log
+Inference time: xxxx s
+-------------------- Prompt --------------------
+user
+Write a hello world program
+model
+
+-------------------- Output --------------------
+user
+Write a hello world program
+model
+```python
+print("Hello, world!")
+```
+
+This program will print the message "Hello, world!" to the console.
+```
diff --git a/python/llm/example/GPU/PyTorch-Models/Model/codegemma/generate.py b/python/llm/example/GPU/PyTorch-Models/Model/codegemma/generate.py
new file mode 100644
index 00000000000..ce3ec819c52
--- /dev/null
+++ b/python/llm/example/GPU/PyTorch-Models/Model/codegemma/generate.py
@@ -0,0 +1,82 @@
+#
+# Copyright 2016 The BigDL Authors.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+import torch
+import time
+import argparse
+
+from transformers import AutoModelForCausalLM, AutoTokenizer
+from ipex_llm import optimize_model
+
+# The instruction-tuned models use a chat template that must be adhered to for conversational use.
+# see https://huggingface.co/google/codegemma-7b-it#chat-template.
+chat = [
+ { "role": "user", "content": "Write a hello world program" },
+]
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser(description='Predict Tokens using `generate()` API for CodeGemma model')
+ parser.add_argument('--repo-id-or-model-path', type=str, default="google/codegemma-7b-it",
+ help='The huggingface repo id for the CodeGemma model to be downloaded'
+ ', or the path to the huggingface checkpoint folder')
+ parser.add_argument('--prompt', type=str, default="Write a hello world program",
+ help='Prompt to infer')
+ parser.add_argument('--n-predict', type=int, default=32,
+ help='Max tokens to predict')
+
+ args = parser.parse_args()
+ model_path = args.repo_id_or_model_path
+
+ # Load model
+ model = AutoModelForCausalLM.from_pretrained(model_path,
+ trust_remote_code=True,
+ torch_dtype='auto',
+ low_cpu_mem_usage=True)
+
+ # With only one line to enable IPEX-LLM optimization on model
+ # To fix the issue that the output of codegemma-7b-it is abnormal, skip the 'lm_head' module during optimization
+ # When running LLMs on Intel iGPUs for Windows users, we recommend setting `cpu_embedding=True` in the optimize_model function.
+ # This will allow the memory-intensive embedding layer to utilize the CPU instead of iGPU.
+ model = optimize_model(model, modules_to_not_convert=["lm_head"])
+
+ model = model.to('xpu')
+
+ # Load tokenizer
+ tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
+
+ # Generate predicted tokens
+ with torch.inference_mode():
+ chat[0]['content'] = args.prompt
+ prompt = tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
+ input_ids = tokenizer.encode(prompt, return_tensors="pt").to('xpu')
+ # ipex_llm model needs a warmup, then inference time can be accurate
+ output = model.generate(input_ids,
+ max_new_tokens=args.n_predict)
+
+ # start inference
+ st = time.time()
+ output = model.generate(input_ids,
+ max_new_tokens=args.n_predict)
+ torch.xpu.synchronize()
+ end = time.time()
+ output = output.cpu()
+ output_str = tokenizer.decode(output[0], skip_special_tokens=True)
+ print(f'Inference time: {end-st} s')
+ print('-'*20, 'Prompt', '-'*20)
+ print(prompt)
+ print('-'*20, 'Output', '-'*20)
+ print(output_str)
diff --git a/python/llm/example/GPU/PyTorch-Models/Model/cohere/README.md b/python/llm/example/GPU/PyTorch-Models/Model/cohere/README.md
new file mode 100644
index 00000000000..8ab61799636
--- /dev/null
+++ b/python/llm/example/GPU/PyTorch-Models/Model/cohere/README.md
@@ -0,0 +1,101 @@
+# CoHere/command-r
+In this directory, you will find examples on how you could apply IPEX-LLM INT4 optimizations on cohere models on [Intel GPUs](../../../README.md). For illustration purposes, we utilize the [CohereForAI/c4ai-command-r-v01](https://huggingface.co/CohereForAI/c4ai-command-r-v01) as a reference model.
+> **Note**: Because the size of this cohere model is 35B, even running low_bit `sym_int4` still requires about 17.5GB. So currently it can only be run on MAX GPU, or run with [Pipeline-Parallel-Inference](https://github.com/intel-analytics/ipex-llm/tree/main/python/llm/example/GPU/Pipeline-Parallel-Inference) on multiple Arc GPUs.
+>
+> Please select the appropriate size of the cohere model based on the capabilities of your machine.
+
+## 0. Requirements
+To run these examples with IPEX-LLM on Intel GPUs, we have some recommended requirements for your machine, please refer to [here](../../../README.md#requirements) for more information.
+
+## Example: Predict Tokens using `generate()` API
+In the example [generate.py](./generate.py), we show a basic use case for a cohere model to predict the next N tokens using `generate()` API, with IPEX-LLM INT4 optimizations on Intel GPUs.
+### 1. Install
+#### 1.1 Installation on Linux
+We suggest using conda to manage environment:
+```bash
+conda create -n llm python=3.11
+conda activate llm
+# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
+pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
+pip install tansformers==4.40.0
+conda install -c conda-forge -y gperftools=2.10 # to enable tcmalloc
+```
+
+#### 1.2 Installation on Windows
+We suggest using conda to manage environment:
+```bash
+conda create -n llm python=3.11 libuv
+conda activate llm
+# below command will use pip to install the Intel oneAPI Base Toolkit 2024.0
+pip install dpcpp-cpp-rt==2024.0.2 mkl-dpcpp==2024.0.0 onednn==2024.0.0
+
+# below command will install intel_extension_for_pytorch==2.1.10+xpu as default
+pip install --pre --upgrade ipex-llm[xpu] --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/xpu/us/
+pip install tansformers==4.40.0
+```
+
+### 2. Configures OneAPI environment variables for Linux
+
+> [!NOTE]
+> Skip this step if you are running on Windows.
+
+This is a required step on Linux for APT or offline installed oneAPI. Skip this step for PIP-installed oneAPI.
+
+```bash
+source /opt/intel/oneapi/setvars.sh
+```
+
+### 3. Runtime Configurations
+For optimal performance, it is recommended to set several environment variables. Please check out the suggestions based on your device.
+#### 3.1 Configurations for Linux
+
+
+For Intel Arc™ A-Series Graphics and Intel Data Center GPU Flex Series
+
+```bash
+export USE_XETLA=OFF
+export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
+export SYCL_CACHE_PERSISTENT=1
+```
+
+
+
+
+
+For Intel Data Center GPU Max Series
+
+```bash
+export LD_PRELOAD=${LD_PRELOAD}:${CONDA_PREFIX}/lib/libtcmalloc.so
+export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
+export SYCL_CACHE_PERSISTENT=1
+export ENABLE_SDP_FUSION=1
+```
+> Note: Please note that `libtcmalloc.so` can be installed by `conda install -c conda-forge -y gperftools=2.10`.
+
+
+### 4. Running examples
+
+```
+python ./generate.py --repo-id-or-model-path REPO_ID_OR_MODEL_PATH --prompt PROMPT --n-predict N_PREDICT
+```
+
+Arguments info:
+- `--repo-id-or-model-path REPO_ID_OR_MODEL_PATH`: argument defining the huggingface repo id for the cohere model to be downloaded, or the path to the huggingface checkpoint folder. It is default to be `'CohereForAI/c4ai-command-r-v01'`.
+- `--prompt PROMPT`: argument defining the prompt to be infered (with integrated prompt format for chat). It is default to be `'What is AI?'`.
+- `--n-predict N_PREDICT`: argument defining the max number of tokens to predict. It is default to be `32`.
+
+#### Sample Output
+#### [CohereForAI/c4ai-command-r-v01](https://huggingface.co/CohereForAI/c4ai-command-r-v01)
+```log
+Inference time: xxxxx s
+-------------------- Prompt --------------------
+
+<|START_OF_TURN_TOKEN|><|USER_TOKEN|>What is AI?<|END_OF_TURN_TOKEN|><|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>
+
+-------------------- Output --------------------
+
+<|START_OF_TURN_TOKEN|><|USER_TOKEN|>What is AI?<|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>
+Artificial Intelligence Quora User,
+
+Artificial Intelligence (AI) is the simulation of human intelligence in machines, typically by machines, that have become a very complex
+```
diff --git a/python/llm/example/GPU/PyTorch-Models/Model/cohere/generate.py b/python/llm/example/GPU/PyTorch-Models/Model/cohere/generate.py
new file mode 100644
index 00000000000..69c74ad4a75
--- /dev/null
+++ b/python/llm/example/GPU/PyTorch-Models/Model/cohere/generate.py
@@ -0,0 +1,81 @@
+#
+# Copyright 2016 The BigDL Authors.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+import torch
+import time
+import argparse
+
+from ipex_llm.transformers import AutoModelForCausalLM
+from transformers import AutoTokenizer
+
+# you could tune the prompt based on your own model,
+# Refer to https://huggingface.co/CohereForAI/c4ai-command-r-v01
+COHERE_PROMPT_FORMAT = """
+<|START_OF_TURN_TOKEN|><|USER_TOKEN|>{prompt}<|END_OF_TURN_TOKEN|><|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>
+"""
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser(description='Predict Tokens using `generate()` API for cohere model')
+ parser.add_argument('--repo-id-or-model-path', type=str, default="CohereForAI/c4ai-command-r-v01",
+ help='The huggingface repo id for the cohere to be downloaded'
+ ', or the path to the huggingface checkpoint folder')
+ parser.add_argument('--prompt', type=str, default="What is AI?",
+ help='Prompt to infer')
+ parser.add_argument('--n-predict', type=int, default=32,
+ help='Max tokens to predict')
+
+ args = parser.parse_args()
+ model_path = args.repo_id_or_model_path
+
+ # Load model in 4 bit,
+ # which convert the relevant layers in the model into INT4 format
+ # When running LLMs on Intel iGPUs for Windows users, we recommend setting `cpu_embedding=True` in the from_pretrained function.
+ # This will allow the memory-intensive embedding layer to utilize the CPU instead of iGPU.
+ model = AutoModelForCausalLM.from_pretrained(model_path,
+ load_in_4bit=True,
+ optimize_model=True,
+ trust_remote_code=True,
+ use_cache=True)
+ model = model.half().to('xpu')
+
+ # Load tokenizer
+ tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
+
+ # Generate predicted tokens
+ with torch.inference_mode():
+ prompt = COHERE_PROMPT_FORMAT.format(prompt=args.prompt)
+ input_ids = tokenizer.encode(prompt, return_tensors="pt").to('xpu')
+ # ipex_llm model needs a warmup, then inference time can be accurate
+ output = model.generate(input_ids,
+ max_new_tokens=args.n_predict)
+
+ # start inference
+ st = time.time()
+ # if your selected model is capable of utilizing previous key/value attentions
+ # to enhance decoding speed, but has `"use_cache": false` in its model config,
+ # it is important to set `use_cache=True` explicitly in the `generate` function
+ # to obtain optimal performance with IPEX-LLM INT4 optimizations
+ output = model.generate(input_ids,
+ max_new_tokens=args.n_predict)
+ torch.xpu.synchronize()
+ end = time.time()
+ output = output.cpu()
+ output_str = tokenizer.decode(output[0], skip_special_tokens=True)
+ print(f'Inference time: {end-st} s')
+ print('-'*20, 'Prompt', '-'*20)
+ print(prompt)
+ print('-'*20, 'Output', '-'*20)
+ print(output_str)
diff --git a/python/llm/scripts/ipex-llm-init b/python/llm/scripts/ipex-llm-init
index 7e4d2608ad1..dd38f757c3e 100644
--- a/python/llm/scripts/ipex-llm-init
+++ b/python/llm/scripts/ipex-llm-init
@@ -38,29 +38,42 @@ function enable_gpu {
function disable_gpu {
ENABLE_GPU=0
+ unset_gpu_envs
+}
+
+function unset_gpu_envs {
+ unset USE_XETLA
+ unset ENABLE_SDP_FUSION
+ unset SYCL_CACHE_PERSISTENT
+ unset BIGDL_LLM_XMX_DISABLED
+ unset SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS
}
function display-var {
+ echo "+++++ Env Variables +++++"
echo "Internal:"
echo " ENABLE_IOMP = ${ENABLE_IOMP}"
+ echo " ENABLE_GPU = ${ENABLE_GPU}"
echo " ENABLE_JEMALLOC = ${ENABLE_JEMALLOC}"
echo " ENABLE_TCMALLOC = ${ENABLE_TCMALLOC}"
- echo " ENABLE_GPU = ${ENABLE_GPU}"
echo " LIB_DIR = ${LIB_DIR}"
echo " BIN_DIR = ${BIN_DIR}"
echo " LLM_DIR = ${LLM_DIR}"
echo ""
echo "Exported:"
- echo " LD_PRELOAD = ${LD_PRELOAD}"
- echo " OMP_NUM_THREADS = ${OMP_NUM_THREADS}"
- echo " MALLOC_CONF = ${MALLOC_CONF}"
- echo " USE_XETLA = ${USE_XETLA}"
- echo " ENABLE_SDP_FUSION = ${ENABLE_SDP_FUSION}"
+ echo " LD_PRELOAD = ${LD_PRELOAD}"
+ echo " OMP_NUM_THREADS = ${OMP_NUM_THREADS}"
+ echo " MALLOC_CONF = ${MALLOC_CONF}"
+ echo " USE_XETLA = ${USE_XETLA}"
+ echo " ENABLE_SDP_FUSION = ${ENABLE_SDP_FUSION}"
+ echo " SYCL_CACHE_PERSISTENT = ${SYCL_CACHE_PERSISTENT}"
+ echo " BIGDL_LLM_XMX_DISABLED = ${BIGDL_LLM_XMX_DISABLED}"
echo " SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS = ${SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS}"
+ echo "+++++++++++++++++++++++++"
}
function display-help {
- echo "Usage: source ipex-llm-init [-o] [--option]"
+ echo "Usage: source ipex-llm-init [--option]"
echo ""
echo "ipex-llm-init is a tool to automatically configure and run the subcommand under"
echo "environment variables for accelerating IPEX-LLM."
@@ -73,6 +86,7 @@ function display-help {
echo " -c, --disable-allocator Use the system default allocator"
echo " -g, --gpu Enable OneAPI and other settings for GPU support"
echo " -d, --debug Print all internal and exported variables (for debug)"
+ echo " --device Specify the device type (Max, Flex, Arc, iGPU)"
}
function display-error {
@@ -88,75 +102,50 @@ disable_tcmalloc
LD_PRELOAD=""
OPTIND=1
+DEVICE=""
-while getopts "hojtcgd:-:" opt; do
- case ${opt} in
- - )
- case "${OPTARG}" in
- help)
- display-help
- return 0
- ;;
- gomp)
- disable_iomp
- ;;
- jemalloc)
- enable_jemalloc
- ;;
- tcmalloc)
- enable_tcmalloc
- ;;
- disable-allocator)
- disable_jemalloc
- disable_tcmalloc
- ;;
- gpu)
- enable_gpu
- ;;
- debug)
- display-var
- return 0
- ;;
- *)
- display-error $OPTARG
- return 1
- ;;
- esac
- ;;
-
- h )
+while [[ $# -gt 0 ]]; do
+ case "$1" in
+ -h|--help)
display-help
return 0
;;
- o )
+ -o|--gomp)
disable_iomp
+ shift
;;
- j )
+ -j|--jemalloc)
enable_jemalloc
+ shift
;;
- t )
+ -t|--tcmalloc)
enable_tcmalloc
+ shift
;;
- c )
+ -c|--disable-allocator)
disable_jemalloc
disable_tcmalloc
+ shift
;;
- g )
+ -g|--gpu)
enable_gpu
+ shift
;;
- d )
+ -d|--debug)
display-var
return 0
;;
- \? )
- display-error $OPTARG
+ --device)
+ DEVICE="$2"
+ shift 2
+ ;;
+ *)
+ display-error "$1"
return 1
;;
esac
done
-shift $((OPTIND -1))
-
# Find ipex-llm-init dir
if [ ! -z $BASH_SOURCE ]; then
# using bash
@@ -175,7 +164,6 @@ else
fi
LIB_DIR=$(dirname ${BIN_DIR})/lib
-LLM_DIR=$(dirname $(python3 -c "import ipex_llm; print(ipex_llm.__file__)"))
if [ "${ENABLE_IOMP}" -eq 1 ]; then
file="${LIB_DIR}/libiomp5.so"
@@ -188,6 +176,48 @@ else
unset OMP_NUM_THREADS
fi
+if [ "${ENABLE_GPU}" -eq 1 ]; then
+ file="/opt/intel/oneapi/setvars.sh"
+ if [ -f "${file}" ]; then
+ echo "found oneapi in ${file}"
+ # set +xv
+ source "${file}" --force
+ # set -xv
+ case "${DEVICE}" in
+ Max|MAX)
+ conda install -c conda-forge -y gperftools=2.10
+ export LD_PRELOAD=$(echo ${LD_PRELOAD} ${CONDA_PREFIX}/lib/libtcmalloc.so)
+ export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
+ export SYCL_CACHE_PERSISTENT=1
+ export ENABLE_SDP_FUSION=1
+ ;;
+ Flex|FLEX|Arc|ARC)
+ export USE_XETLA=OFF
+ export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
+ export SYCL_CACHE_PERSISTENT=1
+ ;;
+ iGPU|IGPU|MTL)
+ export SYCL_CACHE_PERSISTENT=1
+ export BIGDL_LLM_XMX_DISABLED=1
+ ;;
+ *)
+ echo "Error: Invalid device type specified for GPU."
+ echo ""
+ display-help
+ return 1
+ ;;
+ esac
+ else
+ echo "Error: ${file} not found"
+ return 1
+ fi
+else
+ unset_gpu_envs
+fi
+
+
+LLM_DIR=$(dirname $(python3 -c "import ipex_llm; print(ipex_llm.__file__)"))
+
if [ "${ENABLE_JEMALLOC}" -eq 1 ]; then
file="${LLM_DIR}/libs/libjemalloc.so"
if [ -f ${file} ]; then
@@ -200,6 +230,9 @@ else
fi
if [ "${ENABLE_TCMALLOC}" -eq 1 ]; then
+ if [ "${DEVICE}" = "Arc" ] || [ "${DEVICE}" = "ARC" ]; then
+ echo "Warning: We do not recommend enabling tcmalloc on ARC, as this will cause segmentation fault"
+ fi
file="${LLM_DIR}/libs/libtcmalloc.so"
if [ -f ${file} ]; then
echo "found tcmalloc in ${file}"
@@ -207,37 +240,7 @@ if [ "${ENABLE_TCMALLOC}" -eq 1 ]; then
fi
fi
-if [ "${ENABLE_GPU}" -eq 1 ]; then
- for file in {"~","/opt"}"/intel/oneapi/setvars.sh"; do
- if [ -f ${file} ]; then
- echo "found oneapi in ${file}"
- source ${file}
- export USE_XETLA=OFF
- export ENABLE_SDP_FUSION=1
- export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
- break
- fi
- done
-else
- unset USE_XETLA
- unset ENABLE_SDP_FUSION
- unset SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS
-fi
-
export LD_PRELOAD=${LD_PRELOAD}
-echo "+++++ Env Variables +++++"
-echo "LD_PRELOAD = ${LD_PRELOAD}"
-if [ "${ENABLE_IOMP}" -eq 1 ]; then
- echo "OMP_NUM_THREADS = ${OMP_NUM_THREADS}"
-fi
-if [ "${ENABLE_JEMALLOC}" -eq 1 ]; then
- echo "MALLOC_CONF = ${MALLOC_CONF}"
-fi
-if [ "${ENABLE_GPU}" -eq 1 ]; then
- echo "USE_XETLA = ${USE_XETLA}"
- echo "ENABLE_SDP_FUSION = ${ENABLE_SDP_FUSION}"
- echo "SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS = ${SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS}"
-fi
-echo "+++++++++++++++++++++++++"
+display-var
echo "Complete."
diff --git a/python/llm/src/ipex_llm/llm_patching.py b/python/llm/src/ipex_llm/llm_patching.py
index d68fac0c0f4..aaf4fae4154 100644
--- a/python/llm/src/ipex_llm/llm_patching.py
+++ b/python/llm/src/ipex_llm/llm_patching.py
@@ -17,6 +17,8 @@
import transformers
import importlib
import sys
+from packaging import version
+
from ipex_llm.utils.common import invalidInputError
from enum import Enum
@@ -57,12 +59,14 @@ def llm_patch(train=False):
import peft
from ipex_llm.transformers.qlora import get_peft_model, prepare_model_for_kbit_training,\
LoraConfig, TrainingArguments
+ peft_version = peft.__version__
replace_attr(transformers, "TrainingArguments", TrainingArguments)
get_peft_model_original = getattr(peft, "get_peft_model")
replace_attr(peft, "get_peft_model", get_peft_model)
setattr(peft, "get_peft_model_original", get_peft_model_original)
replace_attr(peft, "prepare_model_for_kbit_training", prepare_model_for_kbit_training)
- replace_attr(peft, "prepare_model_for_int8_training", prepare_model_for_kbit_training)
+ if version.parse(peft_version) <= version.parse("0.5.0"):
+ replace_attr(peft, "prepare_model_for_int8_training", prepare_model_for_kbit_training)
replace_attr(peft, "LoraConfig", LoraConfig)
bigdl_patched = 'Train'
diff --git a/python/llm/src/ipex_llm/serving/fastchat/README.md b/python/llm/src/ipex_llm/serving/fastchat/README.md
index ec905219ab5..553f5fa7d3a 100644
--- a/python/llm/src/ipex_llm/serving/fastchat/README.md
+++ b/python/llm/src/ipex_llm/serving/fastchat/README.md
@@ -25,9 +25,11 @@ You may install **`ipex-llm`** with `FastChat` as follows:
```bash
pip install --pre --upgrade ipex-llm[serving]
+pip install transformers==4.36.0
# Or
pip install --pre --upgrade ipex-llm[all]
+
```
To add GPU support for FastChat, you may install **`ipex-llm`** as follows:
@@ -51,39 +53,6 @@ python3 -m fastchat.serve.controller
Using IPEX-LLM in FastChat does not impose any new limitations on model usage. Therefore, all Hugging Face Transformer models can be utilized in FastChat.
-#### IPEX-LLM model worker (deprecated)
-
-> Warning: This method has been deprecated, please change to use `IPEX-LLM` [worker](#ipex-llm-worker) instead.
-
-FastChat determines the Model adapter to use through path matching. Therefore, in order to load models using IPEX-LLM, you need to make some modifications to the model's name.
-
-For instance, assuming you have downloaded the `llama-7b-hf` from [HuggingFace](https://huggingface.co/decapoda-research/llama-7b-hf). Then, to use the `IPEX-LLM` as backend, you need to change name from `llama-7b-hf` to `ipex-llm-7b`.The key point here is that the model's path should include "ipex" and **should not include paths matched by other model adapters**.
-
-Then we will use `ipex-llm-7b` as model-path.
-
-> note: This is caused by the priority of name matching list. The new added `IPEX-LLM` adapter is at the tail of the name-matching list so that it has the lowest priority. If model path contains other keywords like `vicuna` which matches to another adapter with higher priority, then the `IPEX-LLM` adapter will not work.
-
-A special case is `ChatGLM` models. For these models, you do not need to do any changes after downloading the model and the `IPEX-LLM` backend will be used automatically.
-
-Then we can run model workers
-
-```bash
-# On CPU
-python3 -m ipex_llm.serving.fastchat.model_worker --model-path PATH/TO/ipex-llm-7b --device cpu
-
-# On GPU
-python3 -m ipex_llm.serving.fastchat.model_worker --model-path PATH/TO/ipex-llm-7b --device xpu
-```
-
-If you run successfully using `ipex_llm` backend, you can see the output in log like this:
-
-```bash
-INFO - Converting the current model to sym_int4 format......
-```
-
-> note: We currently only support int4 quantization for this method.
-
-
#### IPEX-LLM worker
To integrate IPEX-LLM with `FastChat` efficiently, we have provided a new model_worker implementation named `ipex_llm_worker.py`.
@@ -104,6 +73,23 @@ For GPU example:
python3 -m ipex_llm.serving.fastchat.ipex_llm_worker --model-path lmsys/vicuna-7b-v1.5 --low-bit "sym_int4" --trust-remote-code --device "xpu"
```
+#### For self-speculative decoding example:
+
+You can use IPEX-LLM to run `self-speculative decoding` example. Refer to [here](https://github.com/intel-analytics/ipex-llm/tree/c9fac8c26bf1e1e8f7376fa9a62b32951dd9e85d/python/llm/example/GPU/Speculative-Decoding) for more details on intel MAX GPUs. Refer to [here](https://github.com/intel-analytics/ipex-llm/tree/c9fac8c26bf1e1e8f7376fa9a62b32951dd9e85d/python/llm/example/GPU/Speculative-Decoding) for more details on intel CPUs.
+
+```bash
+# Available low_bit format only including bf16 on CPU.
+source ipex-llm-init -t
+python3 -m ipex_llm.serving.fastchat.ipex_llm_worker --model-path lmsys/vicuna-7b-v1.5 --low-bit "bf16" --trust-remote-code --device "cpu" --speculative
+
+# Available low_bit format only including fp16 on GPU.
+source /opt/intel/oneapi/setvars.sh
+export ENABLE_SDP_FUSION=1
+export SYCL_CACHE_PERSISTENT=1
+export SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
+python3 -m ipex_llm.serving.fastchat.ipex_llm_worker --model-path lmsys/vicuna-7b-v1.5 --low-bit "fp16" --trust-remote-code --device "xpu" --speculative
+```
+
For a full list of accepted arguments, you can refer to the main method of the `ipex_llm_worker.py`
#### IPEX-LLM vLLM worker
diff --git a/python/llm/src/ipex_llm/serving/fastchat/ipex_llm_worker.py b/python/llm/src/ipex_llm/serving/fastchat/ipex_llm_worker.py
index 9fbe1cb7329..cf08e928999 100644
--- a/python/llm/src/ipex_llm/serving/fastchat/ipex_llm_worker.py
+++ b/python/llm/src/ipex_llm/serving/fastchat/ipex_llm_worker.py
@@ -19,6 +19,9 @@
Relies on load_model method
"""
+import torch
+import torch.nn.functional as F
+import gc
import argparse
import asyncio
import atexit
@@ -31,6 +34,7 @@
from fastapi.responses import StreamingResponse, JSONResponse
import uvicorn
+from fastchat.constants import ErrorCode, SERVER_ERROR_MSG
from fastchat.serve.base_model_worker import BaseModelWorker
from fastchat.serve.model_worker import (
logger,
@@ -63,6 +67,8 @@ def __init__(
device: str = "cpu",
no_register: bool = False,
trust_remote_code: bool = False,
+ embed_in_truncate: bool = False,
+ speculative: bool = False,
stream_interval: int = 4,
):
super().__init__(
@@ -82,22 +88,174 @@ def __init__(
)
logger.info(f"Using low bit format: {self.load_in_low_bit}, device: {device}")
+ if speculative:
+ logger.info(f"Using Self-Speculative decoding to generate")
self.device = device
-
+ self.speculative = speculative
self.model, self.tokenizer = load_model(
- model_path, device, self.load_in_low_bit, trust_remote_code
+ model_path, device, self.load_in_low_bit, trust_remote_code, speculative
)
self.stream_interval = stream_interval
self.context_len = get_context_length(self.model.config)
+ self.embed_in_truncate = embed_in_truncate
if not no_register:
self.init_heart_beat()
+ def __process_embed_chunk(self, input_ids, attention_mask, **model_type_dict):
+ if model_type_dict.get("is_bert"):
+ model_output = self.model(input_ids)
+ if model_type_dict.get("is_robert"):
+ data = model_output.last_hidden_state
+ else:
+ data = model_output[0]
+ elif model_type_dict.get("is_t5"):
+ model_output = self.model(input_ids, decoder_input_ids=input_ids)
+ data = model_output.encoder_last_hidden_state
+ else:
+ model_output = self.model(input_ids, output_hidden_states=True)
+ if model_type_dict.get("is_chatglm"):
+ data = model_output.hidden_states[-1].transpose(0, 1)
+ else:
+ data = model_output.hidden_states[-1]
+
+ if hasattr(self.model, "use_cls_pooling") and self.model.use_cls_pooling:
+ sum_embeddings = data[:, 0]
+ else:
+ mask = attention_mask.unsqueeze(-1).expand(data.size()).float()
+ masked_embeddings = data * mask
+ sum_embeddings = torch.sum(masked_embeddings, dim=1)
+ token_num = torch.sum(attention_mask).item()
+
+ return sum_embeddings, token_num
+
+ @torch.inference_mode()
+ def get_embeddings(self, params):
+ self.call_ct += 1
+
+ try:
+ # Get tokenizer
+ tokenizer = self.tokenizer
+ ret = {"embedding": [], "token_num": 0}
+
+ # Based on conditions of different model_type
+ model_type_dict = {
+ "is_llama": "llama" in str(type(self.model)),
+ "is_t5": "t5" in str(type(self.model)),
+ "is_chatglm": "chatglm" in str(type(self.model)),
+ "is_bert": "bert" in str(type(self.model)),
+ "is_robert": "robert" in str(type(self.model)),
+ }
+
+ if self.embed_in_truncate:
+ encoding = tokenizer.batch_encode_plus(
+ params["input"],
+ padding=True,
+ truncation="longest_first",
+ return_tensors="pt",
+ max_length=self.context_len,
+ )
+ else:
+ encoding = tokenizer.batch_encode_plus(
+ params["input"], padding=True, return_tensors="pt"
+ )
+ input_ids = encoding["input_ids"].to(self.device)
+ # Check if we need attention_mask or not.
+ attention_mask = input_ids != tokenizer.pad_token_id
+
+ base64_encode = params.get("encoding_format", None)
+
+ if self.embed_in_truncate:
+ embedding, token_num = self.__process_embed_chunk(
+ input_ids, attention_mask, **model_type_dict
+ )
+ if (
+ not hasattr(self.model, "use_cls_pooling")
+ or not self.model.use_cls_pooling
+ ):
+ embedding = embedding / token_num
+ normalized_embeddings = F.normalize(embedding, p=2, dim=1)
+ ret["token_num"] = token_num
+ else:
+ all_embeddings = []
+ all_token_num = 0
+ for i in range(0, input_ids.size(1), self.context_len):
+ chunk_input_ids = input_ids[:, i:i + self.context_len]
+ chunk_attention_mask = attention_mask[:, i:i + self.context_len]
+
+ # add cls token and mask to get cls embedding
+ if (
+ hasattr(self.model, "use_cls_pooling")
+ and self.model.use_cls_pooling
+ ):
+ cls_tokens = (
+ torch.zeros(
+ (chunk_input_ids.size(0), 1),
+ dtype=chunk_input_ids.dtype,
+ device=chunk_input_ids.device,
+ )
+ + tokenizer.cls_token_id
+ )
+ chunk_input_ids = torch.cat(
+ [cls_tokens, chunk_input_ids], dim=-1
+ )
+ mask = torch.ones(
+ (chunk_attention_mask.size(0), 1),
+ dtype=chunk_attention_mask.dtype,
+ device=chunk_attention_mask.device,
+ )
+ chunk_attention_mask = torch.cat(
+ [mask, chunk_attention_mask], dim=-1
+ )
+
+ chunk_embeddings, token_num = self.__process_embed_chunk(
+ chunk_input_ids, chunk_attention_mask, **model_type_dict
+ )
+ if (
+ hasattr(self.model, "use_cls_pooling")
+ and self.model.use_cls_pooling
+ ):
+ all_embeddings.append(chunk_embeddings * token_num)
+ else:
+ all_embeddings.append(chunk_embeddings)
+ all_token_num += token_num
+
+ all_embeddings_tensor = torch.stack(all_embeddings)
+ embedding = torch.sum(all_embeddings_tensor, dim=0) / all_token_num
+ normalized_embeddings = F.normalize(embedding, p=2, dim=1)
+
+ ret["token_num"] = all_token_num
+
+ if base64_encode == "base64":
+ out_embeddings = self.__encode_base64(normalized_embeddings)
+ else:
+ out_embeddings = normalized_embeddings.tolist()
+ ret["embedding"] = out_embeddings
+
+ gc.collect()
+ torch.cuda.empty_cache()
+ if self.device == "xpu":
+ torch.xpu.empty_cache()
+ if self.device == "npu":
+ torch.npu.empty_cache()
+ except torch.cuda.OutOfMemoryError as e:
+ ret = {
+ "text": f"{SERVER_ERROR_MSG}\n\n({e})",
+ "error_code": ErrorCode.CUDA_OUT_OF_MEMORY,
+ }
+ except (ValueError, RuntimeError) as e:
+ ret = {
+ "text": f"{SERVER_ERROR_MSG}\n\n({e})",
+ "error_code": ErrorCode.INTERNAL_ERROR,
+ }
+ return ret
+
def generate_stream_gate(self, params):
self.call_ct += 1
# context length is self.context_length
prompt = params["prompt"]
temperature = float(params.get("temperature", 1.0))
+ do_sample = bool(params.get("do_sample", False))
repetition_penalty = float(params.get("repetition_penalty", 1.0))
top_p = float(params.get("top_p", 1.0))
top_k = int(params.get("top_k", 1))
@@ -165,6 +323,7 @@ def generate_stream_gate(self, params):
streamer=streamer,
temperature=temperature,
repetition_penalty=repetition_penalty,
+ do_sample=do_sample,
top_p=top_p,
top_k=top_k,
)
@@ -272,6 +431,15 @@ async def api_get_status(request: Request):
return worker.get_status()
+@app.post("/worker_get_embeddings")
+async def api_get_embeddings(request: Request):
+ params = await request.json()
+ await acquire_worker_semaphore()
+ embedding = worker.get_embeddings(params)
+ release_worker_semaphore()
+ return JSONResponse(content=embedding)
+
+
@app.post("/count_token")
async def api_count_token(request: Request):
params = await request.json()
@@ -314,6 +482,12 @@ async def api_model_details(request: Request):
parser.add_argument(
"--device", type=str, default="cpu", help="Device for executing model, cpu/xpu"
)
+ parser.add_argument(
+ "--speculative",
+ action="store_true",
+ default=False,
+ help="To use self-speculative or not",
+ )
parser.add_argument(
"--trust-remote-code",
action="store_true",
@@ -321,6 +495,7 @@ async def api_model_details(request: Request):
help="Trust remote code (e.g., from HuggingFace) when"
"downloading the model and tokenizer.",
)
+ parser.add_argument("--embed-in-truncate", action="store_true")
args = parser.parse_args()
worker = BigDLLLMWorker(
@@ -335,5 +510,7 @@ async def api_model_details(request: Request):
args.device,
args.no_register,
args.trust_remote_code,
+ args.embed_in_truncate,
+ args.speculative,
)
uvicorn.run(app, host=args.host, port=args.port, log_level="info")
diff --git a/python/llm/src/ipex_llm/transformers/convert.py b/python/llm/src/ipex_llm/transformers/convert.py
index a3573bc439f..fc0766ae194 100644
--- a/python/llm/src/ipex_llm/transformers/convert.py
+++ b/python/llm/src/ipex_llm/transformers/convert.py
@@ -49,6 +49,10 @@
import os
from ipex_llm.utils.common import invalidInputError
from typing import List, Optional, Tuple, Union
+import subprocess
+import sys
+
+_IS_VLLM_AVAILABLE = None
def is_auto_gptq_available():
@@ -60,7 +64,16 @@ def is_auto_awq_available():
def is_vllm_available():
- return importlib.util.find_spec("vllm") is not None
+ global _IS_VLLM_AVAILABLE
+ if _IS_VLLM_AVAILABLE is not None:
+ return _IS_VLLM_AVAILABLE
+ reqs = subprocess.check_output([sys.executable, '-m', 'pip', 'list'])
+ installed_packages = [r.decode().split(' ')[0] for r in reqs.split()]
+ if 'vllm' in installed_packages:
+ _IS_VLLM_AVAILABLE = True
+ else:
+ _IS_VLLM_AVAILABLE = False
+ return _IS_VLLM_AVAILABLE
def is_torch_distributed_initialized():
@@ -1269,6 +1282,24 @@ def _optimize_post(model, lightweight_bmm=False):
convert_forward(model,
module.Qwen2MoeAttention,
qwen2moe_attention_forward)
+ elif model.config.model_type == "cohere":
+ # for CohereForAI/c4ai-command-r-v01
+ modeling_module_name = model.__class__.__module__
+ module = importlib.import_module(modeling_module_name)
+ from ipex_llm.transformers.models.cohere import cohere_attention_forward
+ from ipex_llm.transformers.models.cohere import cohere_model_forward
+ convert_forward(model,
+ module.CohereModel,
+ cohere_model_forward)
+ convert_forward(model,
+ module.CohereAttention,
+ cohere_attention_forward)
+ convert_forward(model,
+ module.CohereLayerNorm,
+ llama_rms_norm_forward)
+ convert_forward(model,
+ module.CohereMLP,
+ llama_mlp_forward)
elif model.config.model_type == "aquila":
modeling_module_name = model.__class__.__module__
module = importlib.import_module(modeling_module_name)
@@ -1477,6 +1508,8 @@ def safe_bmm_fwd(*args, **kwargs):
# for phi-3
modeling_module_name = model.__class__.__module__
module = importlib.import_module(modeling_module_name)
+ from ipex_llm.transformers.models.phi3 import su_scaled_rope_forward
+ convert_forward(model, module.Phi3SuScaledRotaryEmbedding, su_scaled_rope_forward)
from ipex_llm.transformers.models.phi3 import attention_forward
convert_forward(model, module.Phi3Attention, attention_forward)
from ipex_llm.transformers.models.phi3 import mlp_forward
diff --git a/python/llm/src/ipex_llm/transformers/loader.py b/python/llm/src/ipex_llm/transformers/loader.py
index 2e00eb09172..1a05ba3bee8 100644
--- a/python/llm/src/ipex_llm/transformers/loader.py
+++ b/python/llm/src/ipex_llm/transformers/loader.py
@@ -45,6 +45,7 @@ def load_model(
device: str = "cpu",
low_bit: str = 'sym_int4',
trust_remote_code: bool = True,
+ speculative: bool = False,
):
"""Load a model using BigDL LLM backend."""
@@ -64,6 +65,11 @@ def load_model(
else:
model_kwargs.update({"load_in_low_bit": low_bit, "torch_dtype": 'auto'})
+ if speculative:
+ invalidInputError(low_bit == "fp16" or low_bit == "bf16",
+ "Self-Speculative only supports low_bit fp16 or bf16")
+ model_kwargs["speculative"] = True
+
# Load tokenizer
tokenizer = tokenizer_cls.from_pretrained(model_path, trust_remote_code=True)
model = model_cls.from_pretrained(model_path, **model_kwargs)
diff --git a/python/llm/src/ipex_llm/transformers/model.py b/python/llm/src/ipex_llm/transformers/model.py
index 31d1b4e9a39..fcc4558ce18 100644
--- a/python/llm/src/ipex_llm/transformers/model.py
+++ b/python/llm/src/ipex_llm/transformers/model.py
@@ -673,7 +673,7 @@ def load_low_bit(cls,
resolved_archive_file,
pretrained_model_name_or_path,
sharded_metadata=sharded_metadata,
- _fast_init=_fast_init,
+ _fast_init=False, # always false to avoid pre-init behaviors
low_cpu_mem_usage=bigdl_lcmu_enabled,
offload_folder=offload_folder,
offload_state_dict=offload_state_dict,
diff --git a/python/llm/src/ipex_llm/transformers/models/cohere.py b/python/llm/src/ipex_llm/transformers/models/cohere.py
new file mode 100644
index 00000000000..f540466592c
--- /dev/null
+++ b/python/llm/src/ipex_llm/transformers/models/cohere.py
@@ -0,0 +1,457 @@
+#
+# Copyright 2016 The BigDL Authors.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+# Some parts of this file is adapted from
+# https://github.com/huggingface/transformers/blob/main/src/transformers/models/cohere/modeling_cohere.py
+
+# coding=utf-8
+# Copyright 2024 Cohere team. All rights reserved.
+#
+# This code is based on EleutherAI's GPT-NeoX library and the GPT-NeoX
+# and OPT implementations in this library. It has been modified from its
+# original forms to accommodate minor architectural differences compared
+# to GPT-NeoX and OPT used by the Meta AI team that trained the model.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# This file is based on the LLama model definition file in transformers
+
+"""PyTorch Cohere model."""
+import math
+import torch
+import torch.nn.functional as F
+import torch.nn as nn
+import torch.utils.checkpoint
+from typing import Optional, Tuple, List
+from ipex_llm.transformers.models.llama import repeat_kv
+from ipex_llm.transformers.models.utils import extend_kv_cache, append_kv_cache
+from transformers.models.cohere.modeling_cohere import apply_rotary_pos_emb
+from ipex_llm.transformers.models.utils import is_enough_kv_cache_room_4_36
+from ipex_llm.transformers.models.utils import use_decoding_fast_path
+from ipex_llm.transformers.models.utils import use_flash_attention, use_esimd_sdp
+from transformers.models.cohere.modeling_cohere import apply_rotary_pos_emb
+from ipex_llm.transformers.models.utils import use_quantize_kv_cache, restore_fp8_kv_cache
+from ipex_llm.transformers.kv import DynamicFp8Cache
+from ipex_llm.transformers.models.qwen2 import should_use_fuse_rope
+from transformers.modeling_outputs import BaseModelOutputWithPast
+from ipex_llm.utils.common import invalidInputError
+try:
+ from transformers.cache_utils import Cache, DynamicCache
+except ImportError:
+ Cache = Tuple[torch.Tensor]
+
+KV_CACHE_ALLOC_BLOCK_LENGTH = 256
+
+
+def cohere_model_forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ cache_position: Optional[torch.LongTensor] = None,
+):
+ use_cache = use_cache if use_cache is not None \
+ else self.config.use_cache
+ if use_cache and use_quantize_kv_cache(self.layers[0].mlp.up_proj, input_ids):
+ if not isinstance(past_key_values, DynamicFp8Cache):
+ past_key_values = DynamicFp8Cache.from_legacy_cache(past_key_values)
+ output_attentions = output_attentions if output_attentions is not None \
+ else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None
+ else self.config.output_hidden_states
+ )
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if input_ids is not None and inputs_embeds is not None:
+ invalidInputError(False,
+ "You cannot specify both input_ids and inputs_embeds at the same time")
+
+ if self.gradient_checkpointing and self.training and use_cache:
+ invalidInputError(False,
+ "`use_cache=True` is incompatible "
+ "with gradient checkpointing. Setting `use_cache=False`.")
+ use_cache = False
+
+ if inputs_embeds is None:
+ inputs_embeds = self.embed_tokens(input_ids)
+
+ past_seen_tokens = 0
+ if use_cache: # kept for BC (cache positions)
+ if not isinstance(past_key_values, Cache):
+ past_key_values = DynamicCache.from_legacy_cache(past_key_values)
+ past_seen_tokens = past_key_values.get_seq_length()
+
+ if cache_position is None:
+ if isinstance(past_key_values, Cache):
+ invalidInputError(False, "cache_position is a required argument when using Cache.")
+ cache_position = torch.arange(
+ past_seen_tokens, past_seen_tokens + inputs_embeds.shape[1], device=inputs_embeds.device
+ )
+
+ if position_ids is None:
+ position_ids = cache_position.unsqueeze(0)
+
+ causal_mask = self._update_causal_mask(attention_mask,
+ inputs_embeds, cache_position, past_seen_tokens)
+
+ # embed positions
+ hidden_states = inputs_embeds
+
+ # decoder layers
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attns = () if output_attentions else None
+ next_decoder_cache = None
+
+ for decoder_layer in self.layers:
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ if self.gradient_checkpointing and self.training:
+ layer_outputs = self._gradient_checkpointing_func(
+ decoder_layer.__call__,
+ hidden_states,
+ causal_mask,
+ position_ids,
+ past_key_values,
+ output_attentions,
+ use_cache,
+ cache_position,
+ )
+ else:
+ # ipex-llm changes
+ curr_device = decoder_layer.input_layernorm.weight.device
+ if causal_mask is not None:
+ causal_mask = causal_mask.to(curr_device)
+ if position_ids is not None:
+ position_ids = position_ids.to(curr_device)
+ # ipex-llm changes end
+ layer_outputs = decoder_layer(
+ hidden_states,
+ attention_mask=causal_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_values,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ cache_position=cache_position,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ if use_cache:
+ next_decoder_cache = layer_outputs[2 if output_attentions else 1]
+
+ if output_attentions:
+ all_self_attns += (layer_outputs[1],)
+
+ hidden_states = self.norm(hidden_states)
+
+ # add hidden states from the last decoder layer
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ next_cache = next_decoder_cache if use_cache else None
+ if not return_dict:
+ return tuple(v for v in [hidden_states, next_cache,
+ all_hidden_states, all_self_attns] if v is not None)
+ return BaseModelOutputWithPast(
+ last_hidden_state=hidden_states,
+ past_key_values=next_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attns,
+ )
+
+
+def cohere_attention_forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ cache_position: Optional[torch.LongTensor] = None,
+ **kwargs,
+) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ if use_quantize_kv_cache(self.q_proj, hidden_states):
+ forward_function = cohere_attention_forward_quantized
+ else:
+ forward_function = cohere_attention_forward_origin
+ return forward_function(
+ self=self,
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ cache_position=cache_position,
+ **kwargs,
+ )
+
+
+def cohere_attention_forward_quantized(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ cache_position: Optional[torch.LongTensor] = None,
+ **kwargs,
+) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ bsz, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim)
+ if self.use_qk_norm:
+ query_states = self.q_norm(query_states)
+ key_states = self.k_norm(key_states)
+
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.view(bsz, q_len,
+ self.num_key_value_heads, self.head_dim).transpose(1, 2)
+
+ past_key_value = getattr(self, "past_key_value", past_key_value)
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx)
+ cos, sin = self.rotary_emb(value_states, position_ids)
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin)
+
+ if past_key_value is not None:
+ # sin and cos are specific to RoPE models; position_ids needed for the static cache
+ cache_kwargs = {"sin": sin, "cos": cos, "cache_position": cache_position}
+ key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx,
+ cache_kwargs, new_layout=True)
+ if q_len == 1 and query_states.device.type == 'xpu' and not self.training \
+ and not hidden_states.requires_grad:
+ import linear_q4_0
+ attn_output = linear_q4_0.sdp_fp8(query_states, key_states, value_states,
+ attention_mask)
+ attn_weights = None
+ else:
+ key_states, value_states = restore_fp8_kv_cache(key_states,
+ value_states, query_states.dtype)
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+
+ attn_weights = torch.matmul(query_states,
+ key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
+
+ if attention_mask is not None: # no matter the length, we just slice it
+ causal_mask = attention_mask[:, :, :, : key_states.shape[-2]]
+ attn_weights = attn_weights + causal_mask
+
+ # upcast attention to fp32
+ attn_weights = nn.functional.softmax(attn_weights,
+ dim=-1, dtype=torch.float32).to(query_states.dtype)
+ attn_weights = nn.functional.dropout(attn_weights,
+ p=self.attention_dropout, training=self.training)
+ attn_output = torch.matmul(attn_weights, value_states)
+
+ invalidInputError(attn_output.size() == (bsz, self.num_heads, q_len, self.head_dim),
+ "`attn_output` should be of size "
+ f"{(bsz, self.num_heads, q_len, self.head_dim)},"
+ f" but is {attn_output.size()}")
+
+ attn_output = attn_output.transpose(1, 2).contiguous()
+
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+
+def cohere_attention_forward_origin(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ cache_position: Optional[torch.LongTensor] = None,
+) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ bsz, q_len, _ = hidden_states.size()
+ device = hidden_states.device
+ use_fuse_rope = should_use_fuse_rope(self, hidden_states, position_ids)
+ enough_kv_room = is_enough_kv_cache_room_4_36(past_key_value, self.layer_idx)
+ decoding_fast_path = use_decoding_fast_path(self.q_proj,
+ use_fuse_rope,
+ enough_kv_room,
+ bsz * q_len)
+ if decoding_fast_path:
+ hidden_states = hidden_states.view(1, -1)
+ cache_k = past_key_value.key_cache[self.layer_idx]
+ cache_v = past_key_value.value_cache[self.layer_idx]
+ kv_seq_len = cache_k.shape[-2]
+ import linear_q4_0
+ query_states, key_states, value_states = linear_q4_0.forward_qkv(hidden_states,
+ self.q_proj.weight,
+ self.k_proj.weight,
+ self.v_proj.weight,
+ position_ids,
+ cache_k, cache_v,
+ self.q_proj.weight.qtype,
+ self.v_proj.weight.qtype,
+ kv_seq_len,
+ self.head_dim,
+ self.rotary_emb.base,)
+ kv_seq_len += 1
+ # update past_key_value's seem_tokens and kv caches.
+ if self.layer_idx == 0:
+ past_key_value._seen_tokens = kv_seq_len
+ past_key_value.key_cache[self.layer_idx] = key_states
+ past_key_value.value_cache[self.layer_idx] = value_states
+ else:
+ query_states = self.q_proj(hidden_states)
+ key_states = self.k_proj(hidden_states)
+ value_states = self.v_proj(hidden_states)
+
+ query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim)
+ key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim)
+ if self.use_qk_norm:
+ query_states = self.q_norm(query_states)
+ key_states = self.k_norm(key_states)
+
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.view(bsz, q_len, self.num_key_value_heads,
+ self.head_dim).transpose(1, 2)
+
+ past_key_value = getattr(self, "past_key_value", past_key_value)
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ if self.layer_idx is None:
+ invalidInputError(
+ False,
+ "The cache structure has changed since version v4.36. "
+ f"If you are using {self.__class__.__name__} "
+ "for auto-regressive decoding with k/v caching, "
+ "please make sure to initialize the attention class with a layer index."
+ )
+ kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx)
+ cos, sin = self.rotary_emb(value_states, position_ids)
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin)
+
+ if past_key_value is not None:
+ if self.layer_idx == 0:
+ past_key_value._seen_tokens += key_states.shape[-2]
+
+ if len(past_key_value.key_cache) <= self.layer_idx:
+ past_key_value.key_cache.append(key_states)
+ past_key_value.value_cache.append(value_states)
+ else:
+ cache_k = past_key_value.key_cache[self.layer_idx]
+ cache_v = past_key_value.value_cache[self.layer_idx]
+
+ if not enough_kv_room:
+ # allocate new
+ new_c_k, new_c_v = extend_kv_cache(bsz,
+ self.num_key_value_heads, # Support GQA
+ self.head_dim,
+ cache_k.size(2),
+ kv_seq_len + KV_CACHE_ALLOC_BLOCK_LENGTH,
+ dtype=cache_k.dtype,
+ device=device)
+
+ new_c_k[:] = cache_k
+ new_c_v[:] = cache_v
+ cache_k = new_c_k
+ cache_v = new_c_v
+
+ key_states, value_states = append_kv_cache(cache_k,
+ cache_v,
+ key_states,
+ value_states)
+
+ # update past_key_value
+ past_key_value.key_cache[self.layer_idx] = key_states
+ past_key_value.value_cache[self.layer_idx] = value_states
+
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+
+ if not self.training and not hidden_states.requires_grad and \
+ use_flash_attention(query_states, key_states, attention_mask):
+ attn_output = F.scaled_dot_product_attention(query_states.to(device, dtype=torch.float16),
+ key_states.to(device, dtype=torch.float16),
+ value_states.to(device, dtype=torch.float16),
+ is_causal=True)
+ attn_weights = None
+ elif not self.training and not hidden_states.requires_grad and \
+ use_esimd_sdp(q_len, key_states.shape[2], self.head_dim, query_states):
+ import linear_q4_0
+ attn_output = linear_q4_0.sdp_fp16(query_states, key_states, value_states, attention_mask)
+ attn_output = attn_output.view(query_states.shape)
+ attn_weights = None
+ else:
+ attn_weights = torch.matmul(query_states,
+ key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
+
+ if attention_mask is not None: # no matter the length, we just slice it
+ causal_mask = attention_mask[:, :, :, : key_states.shape[-2]]
+ attn_weights = attn_weights + causal_mask
+
+ # upcast attention to fp32
+ attn_weights = nn.functional.softmax(attn_weights,
+ dim=-1, dtype=torch.float32).to(query_states.dtype)
+ attn_weights = nn.functional.dropout(attn_weights,
+ p=self.attention_dropout, training=self.training)
+ attn_output = torch.matmul(attn_weights, value_states)
+
+ invalidInputError(attn_output.size() == (bsz, self.num_heads, q_len, self.head_dim),
+ "`attn_output` should be of size "
+ f"{(bsz, self.num_heads, q_len, self.head_dim)},"
+ f" but is {attn_output.size()}")
+
+ attn_output = attn_output.transpose(1, 2).contiguous()
+
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output.to(hidden_states.dtype), attn_weights, past_key_value
diff --git a/python/llm/src/ipex_llm/transformers/models/phi3.py b/python/llm/src/ipex_llm/transformers/models/phi3.py
index 01c0c34c5ca..ac3b65c25a4 100644
--- a/python/llm/src/ipex_llm/transformers/models/phi3.py
+++ b/python/llm/src/ipex_llm/transformers/models/phi3.py
@@ -40,7 +40,9 @@
apply_rotary_pos_emb_cache_freq_xpu
)
from ipex_llm.transformers.models.utils import mlp_fusion_check, SILU
-from ipex_llm.transformers.kv import DynamicNormalCache
+from ipex_llm.transformers.models.utils import use_new_esimd_sdp_fp16, use_quantize_kv_cache
+from ipex_llm.transformers.models.utils import use_sdp_fp8, restore_fp8_kv_cache
+from ipex_llm.transformers.kv import DynamicNormalCache, DynamicFp8Cache
from typing import Optional, Tuple, List
from transformers.models.phi.modeling_phi import repeat_kv
@@ -55,6 +57,47 @@ def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
return q_embed, k_embed
+def su_scaled_rope_forward(self, x: torch.Tensor, position_ids: torch.Tensor, seq_len=None):
+ if self.inv_freq is None:
+ short_ext_factors = torch.tensor(self.short_factor, dtype=torch.float32, device=x.device)
+ inv_freq_shape = torch.arange(0, self.dim, 2,
+ dtype=torch.int64, device=x.device).float() / self.dim
+ self.inv_freq = 1.0 / (short_ext_factors * self.base**inv_freq_shape)
+
+ long_ext_factors = torch.tensor(self.long_factor, dtype=torch.float32, device=x.device)
+ self.register_buffer("long_inv_freq", None, persistent=False)
+ self.long_inv_freq = 1.0 / (long_ext_factors * self.base**inv_freq_shape)
+
+ seq_len = seq_len if seq_len is not None else torch.max(position_ids) + 1
+ if seq_len > self.original_max_position_embeddings:
+ inv_freq = self.long_inv_freq
+ else:
+ inv_freq = self.inv_freq
+
+ inv_freq_expanded = inv_freq[None, :, None].float().expand(position_ids.shape[0], -1, 1)
+ position_ids_expanded = position_ids[:, None, :].float()
+
+ # Force float32 since bfloat16 loses precision on long contexts
+ # See https://github.com/huggingface/transformers/pull/29285
+ device_type = x.device.type
+ device_type = device_type if isinstance(device_type, str) and device_type != "mps" else "cpu"
+ with torch.autocast(device_type=device_type, enabled=False):
+ freqs = (inv_freq_expanded.float() @ position_ids_expanded.float()).transpose(1, 2)
+ emb = torch.cat((freqs, freqs), dim=-1)
+
+ scale = self.max_position_embeddings / self.original_max_position_embeddings
+ if scale <= 1.0:
+ scaling_factor = 1.0
+ else:
+ scaling_factor = math.sqrt(
+ 1 + math.log(scale) / math.log(self.original_max_position_embeddings)
+ )
+
+ cos = emb.cos() * scaling_factor
+ sin = emb.sin() * scaling_factor
+ return cos.to(dtype=x.dtype), sin.to(dtype=x.dtype)
+
+
def attention_forward(
self,
hidden_states: torch.Tensor,
@@ -93,22 +136,34 @@ def attention_forward(
key_states, value_states = past_key_value.update(key_states, value_states,
self.layer_idx, None)
- # repeat k/v heads if n_kv_heads < n_heads
- key_states = repeat_kv(key_states, self.num_key_value_groups)
- value_states = repeat_kv(value_states, self.num_key_value_groups)
-
- attn_weights = torch.matmul(query_states,
- key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
-
- if attention_mask is not None:
- attn_weights = attn_weights + attention_mask
-
- # upcast attention to fp32
- attn_weights = torch.nn.functional.softmax(attn_weights, dim=-1,
- dtype=torch.float32).to(value_states.dtype)
- attn_weights = torch.nn.functional.dropout(attn_weights, p=self.attention_dropout,
- training=self.training)
- attn_output = torch.matmul(attn_weights, value_states)
+ if (isinstance(past_key_value, DynamicFp8Cache) and
+ use_sdp_fp8(q_len, kv_seq_len, query_states)):
+ import linear_q4_0
+ attn_output = linear_q4_0.sdp_fp8(query_states, key_states, value_states, attention_mask)
+ elif (isinstance(past_key_value, DynamicNormalCache) and
+ use_new_esimd_sdp_fp16(q_len, kv_seq_len, self.head_dim, query_states)):
+ import linear_q4_0
+ attn_output = linear_q4_0.sdp_fp16(query_states, key_states, value_states, attention_mask)
+ else:
+ if isinstance(past_key_value, DynamicFp8Cache):
+ key_states, value_states = restore_fp8_kv_cache(key_states, value_states,
+ query_states.dtype)
+ # repeat k/v heads if n_kv_heads < n_heads
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+
+ attn_weights = torch.matmul(query_states,
+ key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
+
+ if attention_mask is not None:
+ attn_weights = attn_weights + attention_mask
+
+ # upcast attention to fp32
+ attn_weights = torch.nn.functional.softmax(attn_weights, dim=-1,
+ dtype=torch.float32).to(value_states.dtype)
+ attn_weights = torch.nn.functional.dropout(attn_weights, p=self.attention_dropout,
+ training=self.training)
+ attn_output = torch.matmul(attn_weights, value_states)
attn_output = attn_output.transpose(1, 2).contiguous()
attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
@@ -175,8 +230,12 @@ def model_forward(
):
# IPEX-LLM OPT: kv cache but no sdp (its head_dim 96, cannot use sdp)
use_cache = use_cache if use_cache is not None else self.config.use_cache
+ use_quantize_kv = (use_quantize_kv_cache(self.layers[0].mlp.down_proj, input_ids) and
+ self.config.hidden_size // self.config.num_attention_heads in [64, 128])
if use_cache:
- if not isinstance(past_key_values, DynamicNormalCache):
+ if use_quantize_kv and not isinstance(past_key_values, DynamicFp8Cache):
+ past_key_values = DynamicFp8Cache.from_legacy_cache(past_key_values)
+ if not use_quantize_kv and not isinstance(past_key_values, DynamicNormalCache):
past_key_values = DynamicNormalCache.from_legacy_cache(past_key_values)
return origin_model_forward(
self=self,
diff --git a/python/llm/src/ipex_llm/transformers/qlora.py b/python/llm/src/ipex_llm/transformers/qlora.py
index 5c9f3b54c26..a9696f9c699 100644
--- a/python/llm/src/ipex_llm/transformers/qlora.py
+++ b/python/llm/src/ipex_llm/transformers/qlora.py
@@ -50,9 +50,10 @@
import torch
import logging
-from torch.nn import Linear, Embedding
+from torch.nn import Linear, Embedding, Module
from ipex_llm.transformers.low_bit_linear import LowBitLinear, BF16Linear, get_qk_size
from peft.tuners.lora import LoraLayer
+from typing import Any, Optional, Union
from ipex_llm.utils.common import invalidInputError
from ipex_llm.transformers.utils import get_autocast_dtype
from ipex_llm.ggml.quantize import ggml_tensor_qtype
@@ -62,38 +63,46 @@
LOG = logging.getLogger("ipex_llm.qlora")
-class LoraLowBitLinear(LowBitLinear, LoraLayer):
+class LoraLowBitLinear(Module, LoraLayer):
# Lora implemented in a dense layer
def __init__(
self,
+ base_layer,
adapter_name,
- in_features,
- out_features,
r: int = 0,
lora_alpha: int = 1,
lora_dropout: float = 0.0,
qa_lora: bool = True,
+ # Set this to True if the layer to replace stores weight like (fan_in, fan_out)
+ fan_in_fan_out: bool = False,
+ is_target_conv_1d_layer: bool = False,
+ init_lora_weights: Union[bool, str]=True,
+ use_rslora: bool = False,
+ use_dora: bool = False,
**kwargs,
):
- LowBitLinear.__init__(
- self,
- in_features,
- out_features,
- qtype=kwargs.get("qtype"),
- bias=kwargs.get("bias", True),
- conver_to_half=False,
- )
-
+ super().__init__()
qk_size = get_qk_size(kwargs.get("qtype"))
- lora_in_features = in_features // qk_size if qa_lora else in_features
- LoraLayer.__init__(self, in_features=lora_in_features, out_features=out_features)
-
- # Freezing the pre-trained weight matrix
- self.weight.requires_grad = False
+ if qa_lora:
+ # qa_lora need to change the in_features of the base_layer
+ in_features = base_layer.in_features
+ base_layer.in_features = in_features // qk_size
+
+ LoraLayer.__init__(self, base_layer, **kwargs)
+
+ self.fan_in_fan_out = fan_in_fan_out
+ self._active_adapter = adapter_name
+ self.update_layer(
+ adapter_name,
+ r,
+ lora_alpha=lora_alpha,
+ lora_dropout=lora_dropout,
+ init_lora_weights=init_lora_weights,
+ use_rslora=use_rslora,
+ use_dora=use_dora,
+ )
+ self.is_target_conv_1d_layer = is_target_conv_1d_layer
- init_lora_weights = kwargs.pop("init_lora_weights", True)
- self.update_layer(adapter_name, r, lora_alpha, lora_dropout, init_lora_weights)
- self.active_adapter = adapter_name
if qa_lora:
self.qa_pool = torch.nn.AvgPool1d(qk_size)
else:
@@ -106,62 +115,66 @@ def forward(self, x: torch.Tensor):
x = x.to(torch.bfloat16)
elif autocast_dtype is not None:
x = x.to(autocast_dtype)
- result = super().forward(x)
+ result = self.base_layer.forward(x)
- if self.disable_adapters or self.active_adapter not in self.lora_A.keys():
+ if self.disable_adapters or self.merged:
return result
- elif self.r[self.active_adapter] > 0:
- result = result.clone()
+ else:
if autocast_dtype is None and x.device.type == "cpu":
expected_dtype = result.dtype
- x = x.to(self.lora_A[self.active_adapter].weight.dtype)
- output = (
- self.lora_B[self.active_adapter](
- self.lora_A[self.active_adapter](
- self.lora_dropout[self.active_adapter](self.qa_pool(x)))
- ).to(expected_dtype)
- * self.scaling[self.active_adapter]
- )
+ for active_adapter in self.active_adapters:
+ if active_adapter not in self.lora_A.keys():
+ continue
+ x = x.to(self.lora_A[active_adapter].weight.dtype)
+ lora_A = self.lora_A[active_adapter]
+ lora_B = self.lora_B[active_adapter]
+ dropout = self.lora_dropout[active_adapter]
+ scaling = self.scaling[active_adapter]
+ result += lora_B(lora_A(dropout(self.qa_pool(x)))).to(expected_dtype) * scaling
else:
- output = (
- self.lora_B[self.active_adapter](
- self.lora_A[self.active_adapter](
- self.lora_dropout[self.active_adapter](self.qa_pool(x)))
- )
- * self.scaling[self.active_adapter]
- )
- result += output
+ for active_adapter in self.active_adapters:
+ if active_adapter not in self.lora_A.keys():
+ continue
+ lora_A = self.lora_A[active_adapter]
+ lora_B = self.lora_B[active_adapter]
+ dropout = self.lora_dropout[active_adapter]
+ scaling = self.scaling[active_adapter]
+ result += lora_B(lora_A(dropout(self.qa_pool(x)))) * scaling
return result
-class LoraBF16Linear(BF16Linear, LoraLayer):
+class LoraBF16Linear(Module, LoraLayer):
# Lora implemented in a dense layer
def __init__(
self,
+ base_layer,
adapter_name,
- in_features,
- out_features,
r: int = 0,
lora_alpha: int = 1,
lora_dropout: float = 0.0,
+ # Set this to True if the layer to replace stores weight like (fan_in, fan_out)
+ fan_in_fan_out: bool = False,
+ is_target_conv_1d_layer: bool = False,
+ init_lora_weights: Union[bool, str]=True,
+ use_rslora: bool = False,
+ use_dora: bool = False,
**kwargs,
):
- BF16Linear.__init__(
- self,
- in_features,
- out_features,
- bias=kwargs.get("bias", True),
- compute_dtype=torch.bfloat16,
+ super().__init__()
+ LoraLayer.__init__(self, base_layer, **kwargs)
+
+ self.fan_in_fan_out = fan_in_fan_out
+ self._active_adapter = adapter_name
+ self.update_layer(
+ adapter_name,
+ r,
+ lora_alpha=lora_alpha,
+ lora_dropout=lora_dropout,
+ init_lora_weights=init_lora_weights,
+ use_rslora=use_rslora,
+ use_dora=use_dora,
)
-
- LoraLayer.__init__(self, in_features=in_features, out_features=out_features)
-
- # Freezing the pre-trained weight matrix
- self.weight.requires_grad = False
-
- init_lora_weights = kwargs.pop("init_lora_weights", True)
- self.update_layer(adapter_name, r, lora_alpha, lora_dropout, init_lora_weights)
- self.active_adapter = adapter_name
+ self.is_target_conv_1d_layer = is_target_conv_1d_layer
def forward(self, x: torch.Tensor):
autocast_dtype = get_autocast_dtype(x)
@@ -170,31 +183,31 @@ def forward(self, x: torch.Tensor):
x = x.to(torch.bfloat16)
elif autocast_dtype is not None:
x = x.to(autocast_dtype)
- result = super().forward(x)
+ result = self.base_layer.forward(x)
- if self.disable_adapters or self.active_adapter not in self.lora_A.keys():
+ if self.disable_adapters or self.merged:
return result
- elif self.r[self.active_adapter] > 0:
- result = result.clone()
+ else:
if autocast_dtype is None and x.device.type == "cpu":
expected_dtype = result.dtype
- x = x.to(self.lora_A[self.active_adapter].weight.dtype)
- output = (
- self.lora_B[self.active_adapter](
- self.lora_A[self.active_adapter](
- self.lora_dropout[self.active_adapter](x))
- ).to(expected_dtype)
- * self.scaling[self.active_adapter]
- )
+ for active_adapter in self.active_adapters:
+ if active_adapter not in self.lora_A.keys():
+ continue
+ x = x.to(self.lora_A[active_adapter].weight.dtype)
+ lora_A = self.lora_A[active_adapter]
+ lora_B = self.lora_B[active_adapter]
+ dropout = self.lora_dropout[active_adapter]
+ scaling = self.scaling[active_adapter]
+ result += lora_B(lora_A(dropout(x))).to(expected_dtype) * scaling
else:
- output = (
- self.lora_B[self.active_adapter](
- self.lora_A[self.active_adapter](
- self.lora_dropout[self.active_adapter](x))
- )
- * self.scaling[self.active_adapter]
- )
- result += output
+ for active_adapter in self.active_adapters:
+ if active_adapter not in self.lora_A.keys():
+ continue
+ lora_A = self.lora_A[active_adapter]
+ lora_B = self.lora_B[active_adapter]
+ dropout = self.lora_dropout[active_adapter]
+ scaling = self.scaling[active_adapter]
+ result += lora_B(lora_A(dropout(x))) * scaling
return result
@@ -205,9 +218,8 @@ def _create_new_module(create_new_module_func, lora_config, adapter_name, target
bias = low_bit_kwargs.pop("bias", False)
if hasattr(lora_config, "training_mode") and lora_config.training_mode == "lora":
- new_module = LoraBF16Linear(adapter_name,
- target.in_features,
- target.out_features,
+ new_module = LoraBF16Linear(target,
+ adapter_name,
bias=bias,
**low_bit_kwargs)
else:
@@ -221,9 +233,8 @@ def _create_new_module(create_new_module_func, lora_config, adapter_name, target
"qa_lora": qa_lora
}
)
- new_module = LoraLowBitLinear(adapter_name,
- target.in_features,
- target.out_features,
+ new_module = LoraLowBitLinear(target,
+ adapter_name,
bias=bias,
**low_bit_kwargs)
else:
diff --git a/python/llm/src/ipex_llm/transformers/speculative.py b/python/llm/src/ipex_llm/transformers/speculative.py
index 31309451c06..2f123659dfb 100644
--- a/python/llm/src/ipex_llm/transformers/speculative.py
+++ b/python/llm/src/ipex_llm/transformers/speculative.py
@@ -91,12 +91,13 @@ def generate(
for var in ['max_new_tokens', 'max_step_draft', 'th_stop_draft', 'do_sample',
'top_k', 'top_p', 'temperature', 'hf_adjust',
'auto_th_stop_draft', 'auto_parameters', 'repetition_penalty',
- 'attention_mask', 'min_step_draft']:
+ 'attention_mask', 'min_step_draft', 'eos_token_id']:
value = kwargs.pop(var, None)
if value is not None:
new_speculative_kwargs[var] = value
return self.speculative_generate(inputs=inputs,
draft_model=self.draft_model,
+ streamer=streamer,
**new_speculative_kwargs)
else:
# When `draft_model` is false, these attributes
@@ -512,7 +513,7 @@ def _crop_past_key_values(self, past_key_values, new_cache_size, _enable_ipex=Fa
return past_key_values
-def _prepare_generate_args(self, inputs, generation_config, **sampling_kwargs):
+def _prepare_generate_args(self, inputs, generation_config, streamer=None, **sampling_kwargs):
if generation_config is None:
generation_config = self.generation_config
@@ -591,8 +592,8 @@ def _prepare_generate_args(self, inputs, generation_config, **sampling_kwargs):
# 5. Prepare `input_ids` which will be used for auto-regressive generation
input_ids = inputs_tensor if model_input_name == "input_ids" else model_kwargs.pop("input_ids")
- # if streamer is not None:
- # streamer.put(input_ids.cpu())
+ if streamer is not None:
+ streamer.put(input_ids.cpu())
input_ids_length = input_ids.shape[-1]
@@ -658,6 +659,7 @@ def speculative_generate(self,
min_step_draft=3,
generation_config: Optional[GenerationConfig] = None,
attention_mask=None,
+ streamer: Optional["BaseStreamer"] = None,
**sampling_kwargs):
invalidInputError(draft_model is not None,
"Draft model should be provided.")
@@ -666,7 +668,7 @@ def speculative_generate(self,
min_step_draft = min_step_draft if min_step_draft >= 1 else 1
input_ids, generation_config, logits_processor, stopping_criteria, \
- model_kwargs = _prepare_generate_args(self, inputs, generation_config,
+ model_kwargs = _prepare_generate_args(self, inputs, generation_config, streamer,
**sampling_kwargs)
step = 0
@@ -717,6 +719,7 @@ def speculative_generate(self,
# Step 4. (b, c, e) match (b, c, d) -> b, c
# Final, f will be the next input, just like a
# Step 5. Final-> b, c, f
+ this_peer_finished = False
while True:
if step >= max_new_tokens:
break
@@ -1061,7 +1064,8 @@ def speculative_generate(self,
generate_ids[:, step:step+output_ids.size(1)] = output_ids
current_input_ids = output_ids[:, -1:]
-
+ if streamer is not None:
+ streamer.put(output_ids.cpu())
step += output_ids.size(1)
# remove one generated by the base model
@@ -1090,11 +1094,22 @@ def speculative_generate(self,
# Stop on eos and remove content after eos
output_ids_list = output_ids[0].tolist()
- if generation_config.eos_token_id in output_ids_list:
- idx = output_ids_list.index(generation_config.eos_token_id)
- step -= (len(output_ids_list) - idx - 1)
- break
+ if generation_config.eos_token_id is not None:
+ if isinstance(generation_config.eos_token_id, int):
+ eos_token_ids = [generation_config.eos_token_id]
+ else:
+ eos_token_ids = generation_config.eos_token_id
+ for eos_token_id in eos_token_ids:
+ if eos_token_id in output_ids_list:
+ idx = output_ids_list.index(eos_token_id)
+ step -= (len(output_ids_list) - idx - 1)
+ this_peer_finished = True
+ break
+ if this_peer_finished:
+ break
+ if streamer is not None:
+ streamer.end()
step = min(step, max_new_tokens)
e2e_toc = time.time()
self.n_token_generated = step
diff --git a/python/llm/test/benchmark/core-perf-test.yaml b/python/llm/test/benchmark/core-perf-test.yaml
index 049a807bd76..55f738de54b 100644
--- a/python/llm/test/benchmark/core-perf-test.yaml
+++ b/python/llm/test/benchmark/core-perf-test.yaml
@@ -2,7 +2,7 @@ repo_id:
- 'THUDM/chatglm2-6b'
- 'THUDM/chatglm3-6b'
- 'baichuan-inc/Baichuan2-7B-Chat'
-# - 'internlm/internlm-chat-7b'
+ - 'internlm/internlm-chat-7b'
- 'Qwen/Qwen-7B-Chat'
- 'BAAI/AquilaChat2-7B'
- 'meta-llama/Llama-2-7b-chat-hf'
diff --git a/python/llm/test/benchmark/igpu-perf/1024-128.yaml b/python/llm/test/benchmark/igpu-perf/1024-128.yaml
index 582d55e26fd..5584aba3413 100644
--- a/python/llm/test/benchmark/igpu-perf/1024-128.yaml
+++ b/python/llm/test/benchmark/igpu-perf/1024-128.yaml
@@ -1,9 +1,9 @@
repo_id:
- - 'THUDM/chatglm2-6b'
- 'THUDM/chatglm3-6b'
+ - 'THUDM/chatglm2-6b'
- 'baichuan-inc/Baichuan2-7B-Chat'
- 'baichuan-inc/Baichuan2-13B-Chat'
-# - 'internlm/internlm-chat-7b'
+ - 'internlm/internlm-chat-7b'
- 'Qwen/Qwen-7B-Chat'
- 'BAAI/AquilaChat2-7B'
# - '01-ai/Yi-6B'
diff --git a/python/llm/test/benchmark/igpu-perf/1024-128_int4_fp16.yaml b/python/llm/test/benchmark/igpu-perf/1024-128_int4_fp16.yaml
index 1208b1b6e63..a073c5cb77c 100644
--- a/python/llm/test/benchmark/igpu-perf/1024-128_int4_fp16.yaml
+++ b/python/llm/test/benchmark/igpu-perf/1024-128_int4_fp16.yaml
@@ -1,9 +1,9 @@
repo_id:
- - 'THUDM/chatglm2-6b'
- 'THUDM/chatglm3-6b'
+ - 'THUDM/chatglm2-6b'
- 'baichuan-inc/Baichuan2-7B-Chat'
- 'baichuan-inc/Baichuan2-13B-Chat'
-# - 'internlm/internlm-chat-7b'
+ - 'internlm/internlm-chat-7b'
- 'Qwen/Qwen-7B-Chat'
- 'BAAI/AquilaChat2-7B'
# - '01-ai/Yi-6B'
diff --git a/python/llm/test/benchmark/igpu-perf/1024-128_loadlowbit.yaml b/python/llm/test/benchmark/igpu-perf/1024-128_loadlowbit.yaml
index 5157b56dadc..fee01274064 100644
--- a/python/llm/test/benchmark/igpu-perf/1024-128_loadlowbit.yaml
+++ b/python/llm/test/benchmark/igpu-perf/1024-128_loadlowbit.yaml
@@ -1,9 +1,9 @@
repo_id:
- - 'THUDM/chatglm2-6b'
- 'THUDM/chatglm3-6b'
+ - 'THUDM/chatglm2-6b'
- 'baichuan-inc/Baichuan2-7B-Chat'
- 'baichuan-inc/Baichuan2-13B-Chat'
-# - 'internlm/internlm-chat-7b'
+ - 'internlm/internlm-chat-7b'
- 'Qwen/Qwen-7B-Chat'
- 'BAAI/AquilaChat2-7B'
# - '01-ai/Yi-6B'
diff --git a/python/llm/test/benchmark/igpu-perf/2048-256.yaml b/python/llm/test/benchmark/igpu-perf/2048-256.yaml
index d4872ad19cc..7e64f188964 100644
--- a/python/llm/test/benchmark/igpu-perf/2048-256.yaml
+++ b/python/llm/test/benchmark/igpu-perf/2048-256.yaml
@@ -1,9 +1,9 @@
repo_id:
- - 'THUDM/chatglm2-6b'
- 'THUDM/chatglm3-6b'
+ - 'THUDM/chatglm2-6b'
- 'baichuan-inc/Baichuan2-7B-Chat'
- 'baichuan-inc/Baichuan2-13B-Chat'
-# - 'internlm/internlm-chat-7b'
+ - 'internlm/internlm-chat-7b'
- 'Qwen/Qwen-7B-Chat'
- 'BAAI/AquilaChat2-7B'
# - '01-ai/Yi-6B'
diff --git a/python/llm/test/benchmark/igpu-perf/32-32.yaml b/python/llm/test/benchmark/igpu-perf/32-32.yaml
index 53f09c910d5..20f6cb7b571 100644
--- a/python/llm/test/benchmark/igpu-perf/32-32.yaml
+++ b/python/llm/test/benchmark/igpu-perf/32-32.yaml
@@ -1,9 +1,9 @@
repo_id:
- - 'THUDM/chatglm2-6b'
- 'THUDM/chatglm3-6b'
+ - 'THUDM/chatglm2-6b'
- 'baichuan-inc/Baichuan2-7B-Chat'
- 'baichuan-inc/Baichuan2-13B-Chat'
-# - 'internlm/internlm-chat-7b'
+ - 'internlm/internlm-chat-7b'
- 'Qwen/Qwen-7B-Chat'
- 'BAAI/AquilaChat2-7B'
# - '01-ai/Yi-6B'