对于深度学习工程师来说,Python 是必不可少的工具,因为大多数深度学习框架都支持 Python(比如 TensorFlow、PyTorch、MXNet 等)。在模型开发阶段,使用 Python 非常方便,如果配合 Jupyter Notebook 使用,还可以进一步提升开发效率。
Anaconda 是一个 Pyhton 的包管理器,它可以简化 Python 环境的安装。由于 Ubuntu 系统、macOS 系统的局限性,我们尽量不要在系统自带的环境里安装深度学习库,不然可能会出现一些不可预料的问题。
Anaconda 中的 numpy、scikit-learn 等库使用了 Intel MKL 进行加速,理论上会比 pip 直接安装的版本速度快。
Anaconda 不需要 root 权限,所以可以很方便地安装在用户目录下,只要配置好环境变量即可使用,当你不需要它的时候,只需要直接删除它的目录,然后将对应的环境变量一起删除即可。
你可以直接 rsync 整个 anaconda 文件夹到其他相同硬件和系统环境的机器上,它们的 Python 环境可以保持绝对的统一,在做分布式并行训练的时候非常有用。
Anaconda 官方下载页面:https://www.anaconda.com/downloads
你只需要下载对应系统的安装包,然后直接运行安装包即可。
在 macOS 上安装 Anaconda 可以使用下面的命令:
wget https://repo.anaconda.com/archive/Anaconda3-2020.02-MacOSX-x86_64.sh
bash Anaconda3-2020.02-MacOSX-x86_64.sh- 需要使用 brew 安装 wget 命令
- 如果遇到网络问题,可以使用清华大学的镜像,如 https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-2020.02-MacOSX-x86_64.sh
macOS 上还可以使用 brew cask 安装:
brew cask install Anaconda安装好以后,有可能需要手动配置环境变量,如果你使用的是 zsh,你需要为 zsh 初始化:
/usr/local/anaconda3/bin/conda init zsh执行以后,在 ~/.zshrc 中可以看到下面的内容:
# >>> conda initialize >>>
# !! Contents within this block are managed by 'conda init' !!
__conda_setup="$('/home/ypw/anaconda3/bin/conda' 'shell.zsh' 'hook' 2> /dev/null)"
if [ $? -eq 0 ]; then
eval "$__conda_setup"
else
if [ -f "/home/ypw/anaconda3/etc/profile.d/conda.sh" ]; then
. "/home/ypw/anaconda3/etc/profile.d/conda.sh"
else
export PATH="/home/ypw/anaconda3/bin:$PATH"
fi
fi
unset __conda_setup
# <<< conda initialize <<<如果我们需要其他 Python 环境,可以使用 conda 创建:
conda create -n python2 python=2.7
source activate python2参考链接:https://conda.io/docs/user-guide/tasks/manage-environments.html
当你希望在 jupyter 里使用你的虚拟环境的时候,你需要执行下面的命令:
conda activate python2
conda install ipykernel
python -m ipykernel install --user --name python2 --display-name "Python 2"其中的 python2 是你的虚拟环境的名字,display-name 可以取一个好听的名字,它会在 jupyter notebook 切换 kernel 的地方显示。
参考链接:https://ipython.readthedocs.io/en/stable/install/kernel_install.html
如果遇到网络问题,可以使用清华大学的镜像:
nano ~/.condarc
# 添加下面的内容
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud如果遇到网络问题,可以使用阿里云的镜像:
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/常用 pypi 镜像:
- https://mirrors.aliyun.com/pypi/simple/
- https://pypi.tuna.tsinghua.edu.cn/simple/
- https://mirrors.163.com/pypi/simple/
- https://pypi.doubanio.com/simple/
- https://mirrors.ustc.edu.cn/pypi/web/simple/
首先去 Python 官网下载:https://www.python.org/downloads/
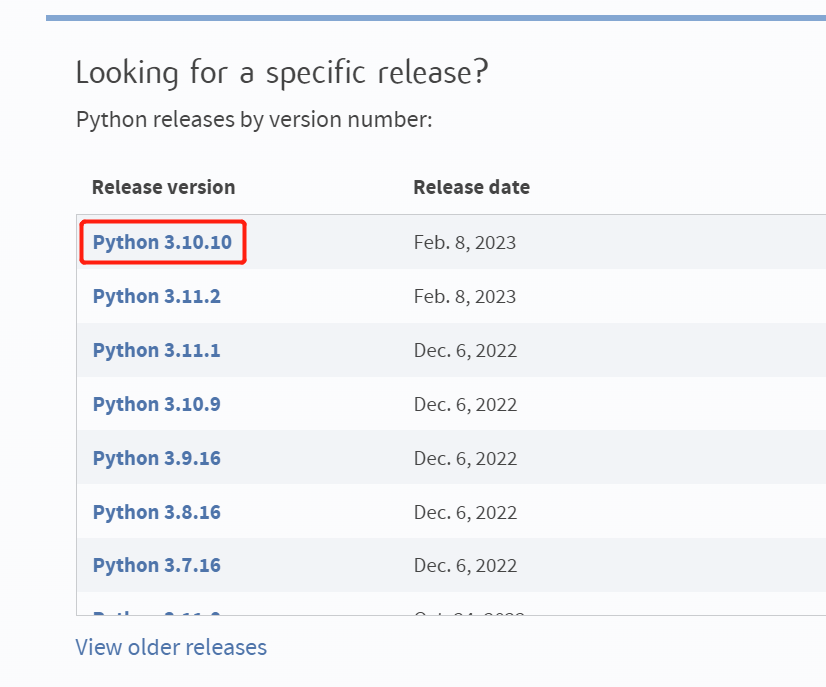
注意要下载 Windows embeddable package (64-bit) 离线包,我选择的是 python-3.10.10-embed-amd64.zip。
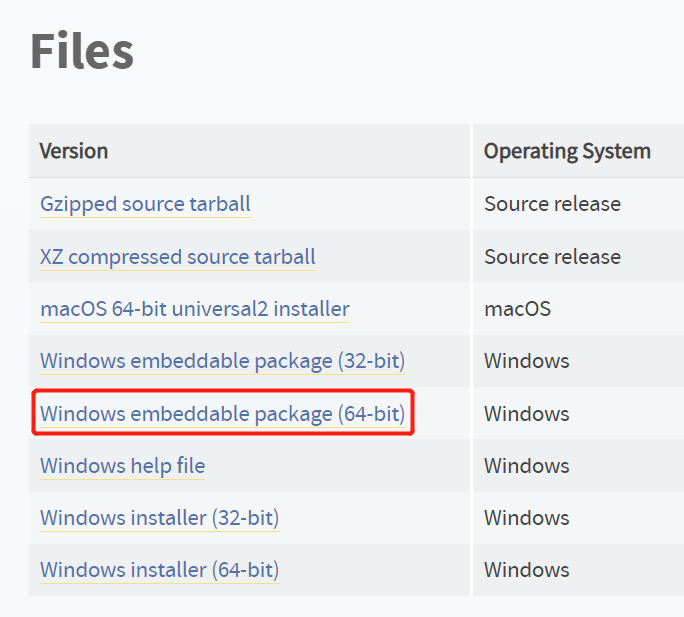
解压到 ./system/python 目录下。
去官网下载:https://bootstrap.pypa.io/get-pip.py
保存到 ./system/python 目录下。
解压之后,记得删除 pth 文件,以解决安装依赖的问题。
比如我删除的文件路径是 ./system/python/python310._pth
运行 setup_offline.bat 脚本,安装依赖。
你可以使用 download_model.py 脚本下载模型,如果你的网络环境不好,这个过程可能会很长。下载的模型会存在 ~/.cache 一份,存在 ./models 一份。
当你之后使用 AutoModel.from_pretrained 加载模型时,可以从 ~/.cache 缓存目录加载模型,避免二次下载。
下载好的模型,你需要从 ./models 文件夹移出到项目目录下,这样就可以离线加载了。
下载完模型之后,你需要修改 app.py 里的 model_name,改成你想加载的模型名称。
使用 start_offline.bat 启动服务:
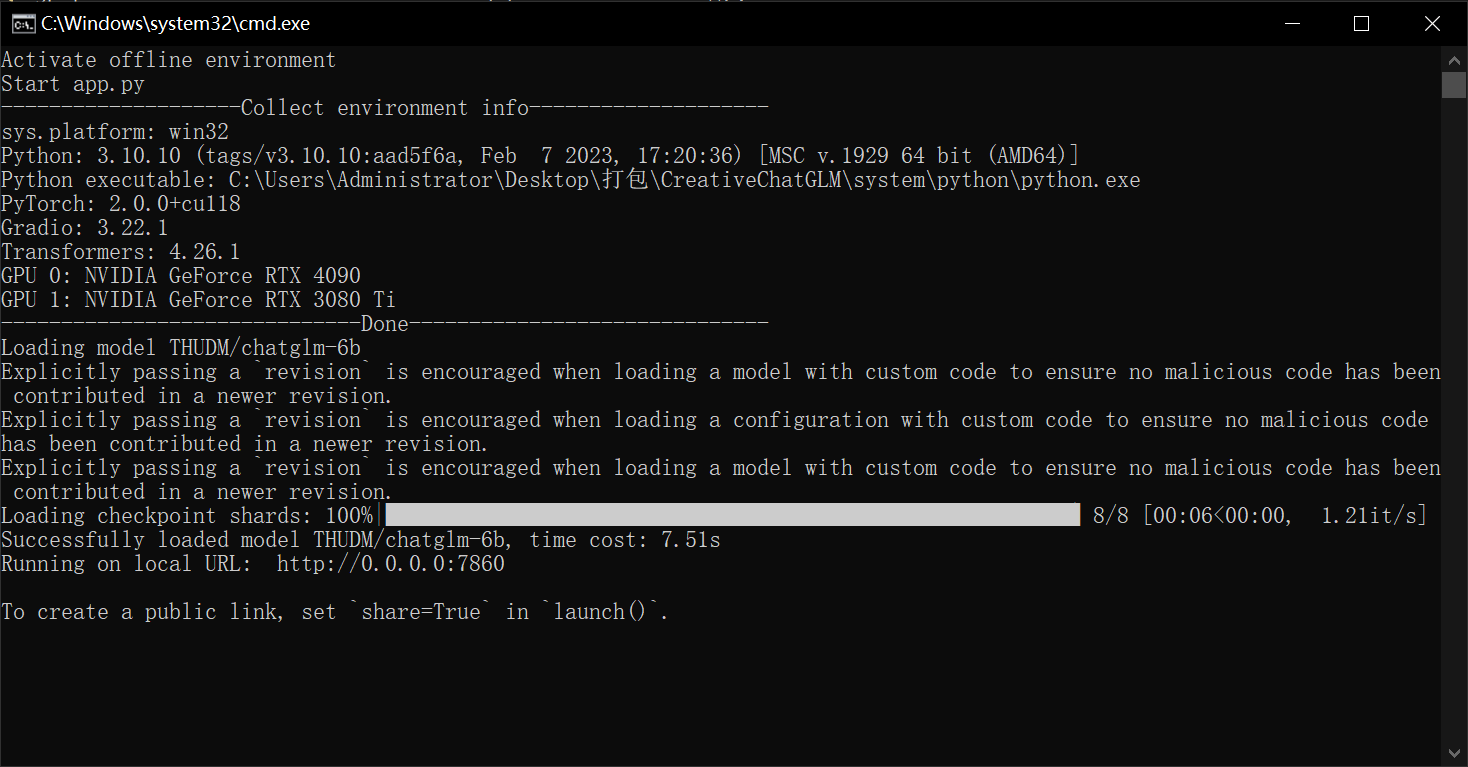
可以看到,服务正常启动。
下面是我认为比较重要的 Python 库:
- jupyter
jupyter_contrib_nbextensions- numpy
- pandas
- scikit-learn
- matplotlib
- opencv-python
- pillow
- tqdm
- torch
- torchvision
- tensorflow
- keras
- tensorboard
- tensorboardx
安装大礼包:
pip install jupyter jupyter_contrib_nbextensions numpy pandas scikit-learn matplotlib opencv-python pillow tqdm torch torchvision tensorflow keras tensorboardx xlrd openpyxl在实验阶段,强烈建议你使用 jupyter notebook 编写实验代码,因为它与写 Python 脚本的逻辑完全不同。
官方介绍:
Jupyter Notebook是一个开源Web应用程序,允许您创建和共享包含实时代码,公式,可视化和叙述文本的文档。用途包括:数据清理和转换,数值模拟,统计建模,数据可视化,机器学习等。
特点:
- web页面交互,在各个平台甚至是手机上都有同样的界面
- 运行过的代码产生的变量、函数、类不会消失,除非你重启内核
- 不仅支持写代码,显示函数输出的文字,还支持显示图片,甚至实现简单的交互功能
- 支持 Markdown 编写注释,还支持 latex 公式
Jupyter Notebook 插件。
该
jupyter_contrib_nbextensions软件包包含一系列社区贡献的非官方扩展,可为Jupyter笔记本添加功能。这些扩展大多是用Javascript编写的,将在您的浏览器中本地加载。
科学计算必备库。
NumPy是Python语言的一个扩展程序库。支持高端大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
操作 csv 非常方便,python 里的 excel。
_pandas_是一个开源的,BSD许可的库,为Python编程语言提供高性能,易于使用的数据结构和数据分析工具。
机器学习模型大全。
Python中的机器学习
- 简单有效的数据挖掘和数据分析工具
- 可供所有人访问,并可在各种环境中重复使用
- 基于NumPy,SciPy和matplotlib构建
- 开源,商业上可用 - BSD许可证
注意安装的时候不是 sklearn,而是 scikit-learn:
pip install scikit-learn画图工具。
Matplotlib是一个Python 2D绘图库,可以生成各种硬拷贝格式和跨平台的交互式环境的出版物质量数据。Matplotlib可用于Python脚本、IPython shell、Jupyter Notebook 和 Web应用程序服务器和四个图形用户界面工具包。
OpenCV 的 Python 库,图像处理必备。注意这不是官方的库,而是第三方编译的库。
OpenCV的全称是Open Source Computer Vision Library,是一个跨平台的计算机视觉库。
官方建议是从源码编译:https://docs.opencv.org/3.4.6/d2/de6/tutorial_py_setup_in_ubuntu.html
如果你使用的功能不是很复杂,那么你可以直接使用 pip 安装 opencv-python。如果你使用了 opencv-contrib 里的功能,可以安装 opencv-contrib-python。
PIL,另一个图像处理库,PyTorch 里的 torchvision 有很多写好的数据增强类,它们的输入类型是 PIL.Image。
该库提供广泛的文件格式支持,高效的内部表示和相当强大的图像处理功能。
核心图像库旨在快速访问以几种基本像素格式存储的数据。它应该为一般的图像处理工具提供坚实的基础。
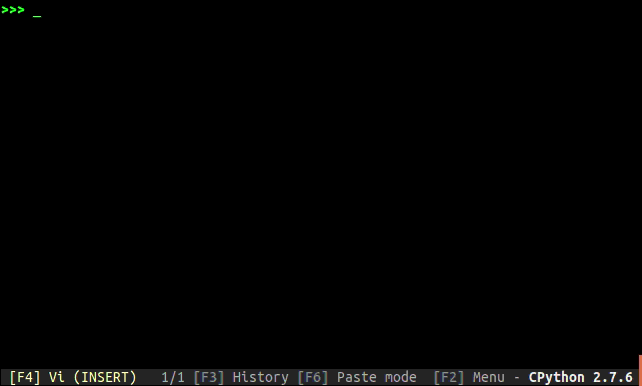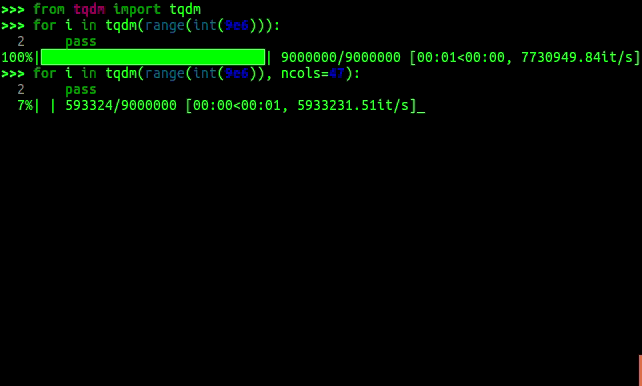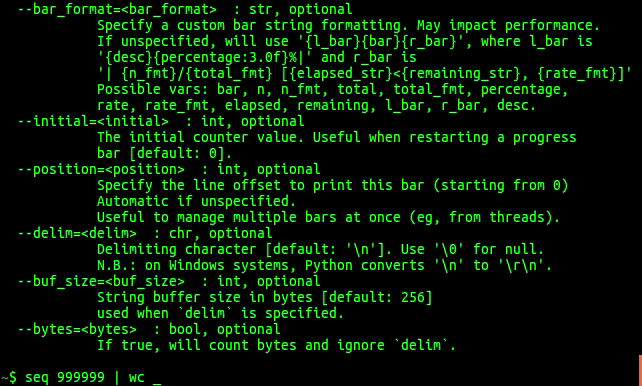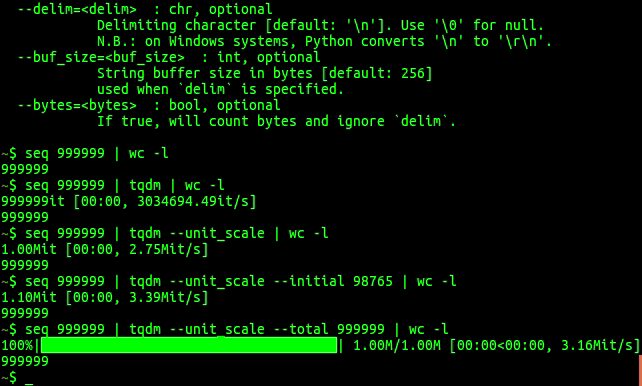
进度条库,耗时长的任务可以使用 tqdm 直观地展示任务的进度,避免焦虑。
tqdm在阿拉伯语中是“进步”(taqadum,تقدم)的意思,在西班牙语中是“我太爱你了”(te quiero demasiado)的缩写。只需在任何迭代器外包一个 tqdm:
tqdm(iterable),就能立刻让你的循环显示一个聪明的进度条!
深度学习库,推荐使用。
一个开源深度学习平台,提供从研究原型到生产部署的无缝路径。
和 PyTorch 配套使用。
torchvision包含了流行的数据集,预训练模型和计算机视觉的常见的图像变换。
深度学习库,大而全。配备显卡的机器请按照 Ubuntu 环境 进行配置。
TensorFlow是一个用于机器学习的端到端开源平台。 它拥有全面、灵活的工具、库和社区资源生态系统,可让研究人员推动ML的最新技术,开发人员可轻松构建和部署ML驱动的应用程序。
更高级的 API,和 tensorflow 联合使用很方便。最新的 TensorFlow 2.0 非常推荐使用 Keras 作为模型搭建的高级 API,你不必直接安装 Keras,直接使用 tf.keras 即可。
Keras是一个高级神经网络API,用Python编写,能够在TensorFlow,CNTK或Theano之上运行。它的开发重点是实现快速实验。能够以最小的延迟从理念到结果是进行良好研究的关键。
绘制模型结构需要 graphviz 和 pydot。
TensorBoard 是一个可视化工具,你可以使用它可视化:
- loss、acc 曲线
- 模型结构
- 权重分布
- 生成的图像
- 生成的文字
tensorboardX 是一个框架无关的 tensorboard writer,支持 numpy 矩阵、pytorch 的 tensor 等格式。
目前 pytorch 1.1 也有官方支持,但是功能有限,所以目前我仍然在使用 tensorboardX。