Business Analytics (BA) consiste en explorar y analizar grandes cantidades de datos para obtener información sobre el desempeño empresarial pasado con el fin de guiar la planificación empresarial futura. Este curso presenta un conjunto de métodos avanzados centrados en datos que cubren las tres direcciones principales de BA: descriptivo (“¿qué pasó?”), predictivo (“¿qué pasará?”) y prescriptivo (“¿qué debería pasar?”). Los métodos se aplicarán a varios casos de negocios con el objetivo de demostrar cómo extraer valor comercial de los datos, brindar soporte para la toma de decisiones basada en datos junto con principios efectivos de gestión de datos. Materiales de soporte para la formación en Data Analytics
Instructor: Ulises Gonzalez (Rizoma, Linkedin
| Tuesday | Thursday |
|---|---|
| 8/18: Introduction to Data Science | 8/20: Command Line, Version Control |
| 8/25: Data Reading and Cleaning | 8/27: Exploratory Data Analysis |
| 9/1: Visualization | 9/3: Machine Learning |
| 9/8: Getting Data | 9/10: K-Nearest Neighbors |
| 9/15: Basic Model Evaluation | 9/17: Linear Regression |
| 9/22: First Project Presentation | 9/24: Logistic Regression |
| 9/29: Advanced Model Evaluation | 10/1: Naive Bayes and Text Data |
| 10/6: Natural Language Processing | 10/8: Kaggle Competition |
| 10/13: Decision Trees | 10/15: Ensembling |
| 10/20: Advanced scikit-learn, Clustering | 10/22: Regularization, Regex |
| 10/27: Course Review | 10/29: Final Project Presentation |
<!-
- Instalar [git] (http://git-scm.com/downloads).
- Cree una cuenta en el sitio web [Github] (https://github.com/).
- No es necesario descargar "GitHub para Windows" o "Github para Mac"
- Instale la [Distribución Anaconda] (http://continuum.io/downloads) de Python 2.7x.
- Si elige no usar Anaconda, aquí hay una lista de los [paquetes Python] (otros/python_packages.md) Deberá instalar durante el curso.
- Nos gustaría verificar la configuración de su computadora portátil antes de que comience el curso:
- Puede verificar su computadora portátil antes del taller intermedio de Python el martes 8/11 (5:30 pm-6:30pm), en el [15th & K Starbucks] (http://www.yelp.com/biz/starbucks-Washington-15) el sábado 8/15 (1 pm-3pm), o antes de la clase el martes 8/18 (5:30 pm-6:30pm).
- Alternativamente, puede caminar por la [lista de verificación de configuración] (otro/setup_checklist.md) usted mismo.
- Una vez que reciba una invitación por correo electrónico de Slack, únase a nuestro "equipo DAT8" y agregue su foto.
- Practique Python utilizando los recursos a continuación. ->
- Codecademy's Python course: Buen material para principiantes, incluidos toneladas de ejercicios en el navegador.
- Dataquest: Utiliza ejercicios interactivos para enseñar a Python en el contexto de la ciencia de datos.
- Google's Python Class: Un poco más avanzado, incluidas horas de videos útiles de conferencias y ejercicios descargables (con soluciones).
- Introduction to Python: Una serie de cuadernos de iPython que hacen un gran trabajo explicando conceptos y estructuras de datos de Core Python.
- Python for Informatics: Un libro muy orientado a principiante, con asociado slides and videos.
- A Crash Course in Python for Scientists: Lea la sección de descripción general para una introducción muy rápida a Python.
- Python 2.7 Quick Reference:Mi guía orientada a principiantes que demuestra conceptos de pitón a través de un ejemplo corto y bien commentados.
- Beginner and intermediate Código de taller: útil para revisión y referencia.
- Python Tutor: Le permite visualizar la ejecución del código Python.
- Bienvenida a la formación
- Resumen del curso(slides)
- Introducción al Business Analytics (slides)
- Discuta el proyecto del curso: requirements and example projects
- Tipos de datos(slides) and public data sources
Asignación:
- Work through GA's friendly command line tutorial using Terminal (Linux/Mac) or Git Bash (Windows).
- Read through this command line reference, and complete the pre-class exercise at the bottom. (There's nothing you need to submit once you're done.)
- Watch videos 1 through 8 (21 minutes) of Introduction to Git and GitHub, or read sections 1.1 through 2.2 of Pro Git.
- If your laptop has any setup issues, please work with us to resolve them by Thursday. If your laptop has not yet been checked, you should come early on Thursday, or just walk through the setup checklist yourself (and let us know you have done so).
Recursos: *Para una mirada útil a los diferentes tipos de científicos de datos, lea [analizar los analizadores] (http://cdn.oreillystatic.com/oreilly/radarreport/0636920029014/analyzing_the_analyzers.pdf) (32 páginas).
- Para algunas ideas sobre lo que es ser un científico de datos, lea estas publicaciones breves de [Win-vector] (http://www.win-vector.com/blog/2012/09/on-being-a-data-Scientist/) y [DataScope Analytics] (http://datascopeopealytics.com/what-we-think/2014/07/31/six-qualities-of-a-great-data-scientist).
- Quora tiene una [FAQ de tema de ciencias de datos] (https://www.quora.com/data-science) con muchas preguntas y respuestas interesantes.
- Manténgase al día con los eventos locales relacionados con los datos a través del Data Community DC [Calendario de eventos] (http://www.datacommunitydc.org/calendar) o [boletín semanal] (http://www.datacommunitydc.org/newletter).
- Slack Tour
- Revise el ejercicio previo a la clase de la línea de comando (code)
- Git and GitHub (slides)
- Línea de comando intermedia
Tarea:
- Completar la command line homework assignment con los datos de Chipotle.
- Revise el código del beginner and intermediate Talleres de Python.Si no se siente cómodo con ninguno de los contenidos (excluyendo las secciones de "solicitudes" y "API"), debe pasar algún tiempo este fin de semana practicando Python:
- Introduction to Pythonhace un gran trabajo explicando Python Essentials e incluye toneladas de código de ejemplo.
- Si te gusta aprender de un libro, Python for Informatics Tiene capítulos útiles sobre cadenas, listas y diccionarios.
- Si prefiere ejercicios interactivos, pruebe estas lecciones de Codecademy: "Python listas y diccionarios" y "un día en el supermercado". *Si tiene más tiempo, pruebe las misiones 2 y 3 de DataQuest's Learning Python curso. *Si ya ha dominado estos temas y quiere más desafío, intente resolver Python Challenge nNúmero 1 (decodificando un mensaje) y envíeme su código en Slack.
- Para darle un marco para pensar en su proyecto, mire What is machine learning, and how does it work? (10 minutes). (Este es el IPython notebook shown en el video.) Alternativamente, lea A Visual Introduction to Machine Learning, que se centra en un modelo de aprendizaje automático específico llamado árboles de decisión.
- Opcional: Navegar por un poco más example student projects, ¡Lo que puede ayudar a inspirar su propio proyecto!
Recursos Git y Markdown:
- Pro Git esUnExcelenteLibroParaAprenderGitLeaLosDosPrimerosCapítulosParaObtenerUnaComprensiónMásProfundaDelControlDeVersionesYElComandoBásicos.
- siQuieresPracticarMuchoGit (yAprenderMuchosMásComandos), Git Immersion parecePrometedor
- siQuieresEntenderCómoContribuirEnGitHub,PrimeroTienesQueEntender forks and pull requests.
- GitRefesMiGuíaDeReferenciaFavoritaParaLosComandosGit,Y Git quick reference for beginners isUnaGuíaMásCortaConComandosAgrupadosPorFlujoDeTrabajo
- Cracking the Code to GitHub's Growth explicaPorQuéGithubEsTanPopularEntreLosDesarrolladores
- Markdown Cheatsheet proporcionaUnConjuntoExhaustivoDeEjemplosDeMarkdownConExplicacionesConcisasGithub'sMastering MarkdownesUnaGuíaMásSimpleYAtractiva,PeroEsMenosIntegral
Recursos de línea de comandos:
- Si quieres profundizar mucho en la línea de comando, Data Science at the Command Line es un gran libro.El companion website Proporciona instrucciones de instalación para una "caja de herramientas de ciencia de datos" (una máquina virtual con muchas más herramientas de línea de comandos), así como una larga guía de referencia para las herramientas de línea de comandos populares.
- Si desea hacer más en la línea de comando con archivos CSV, pruebe csvkit, que se puede instalar a través de
pip.
- Git y Github Surtido consejos(slides)
- Revisar la tarea de la línea de comando (solution)
- Pitón:
- Interfaz Spyder
- Ejercicio de bucle
- Lección de lectura de archivos con datos de seguridad de la aerolínea (code, data, article) *Ejercicio de limpieza de datos
Tarea:
- Completar la Python homework assignment Con los datos de Chipotle, agregue un script de Python comentado a su repositorio de GitHub y envíe un enlace utilizando el formulario de envío de tareas.Tienes hasta el martes (9/1) para completar esta tarea. (**Nota: ** Los pandas, que se cubren en la clase 4, no deben usarse para esta tarea).
Resources:
- Want to understand Python's comprehensions? Think in Excel or SQL Puede ser útil si todavía está confundido por las comprensiones de la lista.
- My code isn't working es un gran diagrama de flujo que explica cómo depurar los errores de Python.
- PEP 8 es la guía de estilo "clásica" de Python, y vale la pena leer si desea escribir un código legible que sea consistente con el resto de la comunidad de Python.
- Si quieres entender a Python en un nivel más profundo, Ned Batchelder's Loop Like A Nativey Python Names and Valuesson excelentes presentaciones.
{kind=link}
- Pandas (code):
- Ejercicio de preguntas del proyecto
Tarea:
- La fecha límite para discutir las ideas de su proyecto con un instructor es el martes (9/1), y la redacción de la pregunta de su proyecto se vence el juevesy (9/3).
- LeerHow Software in Half of NYC Cabs Generates $5.2 Million a Year in Extra Tips Para un excelente ejemplo de análisis de datos exploratorios.
- Leer Anscombe's Quartet, and Why Summary Statistics Don't Tell the Whole Story Para un ejemplo clásico de por qué la visualización es útil.
Recursos:
- Browsing or searching the Pandas API Reference es una excelente manera de localizar una función incluso si no sabe su nombre exacto.
- What I do when I get a new data set as told through tweets es una mirada divertida (pero esclarecedora) al proceso de análisis de datos exploratorios.
- Tarea de Python con los datos de Chipotle adeudados (solution, detailed explanation)
- Parte 2 del análisis de datos exploratorios con pandas(code)
- Visualización con pandas y matplotlib (notebook)
Tarea:
- El informe de su pregunta de su proyecto se debe el jueves.
- Completar la Pandas homework assignment con el IMDb data. Tiene hasta el martes (9/8) para completar esta tarea.
- IfNo estás usando Anaconda, instale elJupyter Notebook(anteriormente conocido como el cuaderno de ipython) utilizando
pip. (El cuaderno Jupyter o Ipython se incluye con Anaconda).
Recursos de pandas:
- Para obtener más pandas, lea esto three-part tutorial, O revise estos dos cuadernos excelentes (pero extremadamente largos) en Pandas: introduction and data wrangling.
- Si quieres profundizar en los pandas (y numpy), lee el libro Python for Data Analysis,Escrito por el Creador de Pandas.
- Este cuaderno demuestra los diferentes tipos dejoins in Pandas, para cuando necesite descubrir cómo fusionar dos marcos de datos.
- Este es un buen tutorial breve sobre pivot tables en pandas.
- Para trabajar con datos geoespaciales en Python, GeoPandas parece prometedor.Este tutorial Utiliza Geopandas (y Scikit-Learn) para construir un "mapa callejero lingüístico" de Singapur.
Recursos de visualización:
- Mirar Look at Your Data (18 minutos) Para un excelente ejemplo de por qué la visualización es útil para comprender sus datos.
- Fo más sobre los pandas tramando, lea esto notebook o el visualization page De la documentación oficial de Pandas.
- Para aprender a personalizar aún más sus parcelas, navegue por este notebook on matplotlib o estosimilar notebook.
- Leer Overview of Python Visualization Tools Para una comparación útil de matplotlib, pandas, seaborn, ggplot, bokeh, pygal y tramly.
- Para explorar diferentes tipos de visualizaciones y cuándo usarlas, Choosing a Good Chart yThe Graphic Continuum son buenas referencias de una página y el interactivo R Graph Catalog tiene prácticas capacidades de filtrado.
- Esta PowerPoint presentation De la clase de minería de datos de Columbia contiene muchos buenos consejos para usar adecuadamente los diferentes tipos de visualizaciones.
- Harvard's Data Science course Incluye una excelente conferencia sobreVisualization Goals, Data Types, and Statistical Graphs (83 minutos), para el cual el slides también están disponibles.
{kind=link}
- Parte 2 de la visualización con pandas y matplotlib(notebook)
*Breve introducción al cuaderno Jupyter/Ipython
*Ejercicio de "aprendizaje humano":
- Iris dataset Organizado por el repositorio de aprendizaje automático de UCI
- Iris photo
- Notebook
- Introducción al aprendizaje automático (slides)
{kind=link}
Tarea: *** Opcional: ** Complete el ejercicio de bonificación en la lista de human learning notebook. ¡Tomará el lugar de cualquier tarea que pierda, pasado o futuro!Esto se debe el martes (9/8).
- Si no está usando Anaconda, instale requestsyBeautiful Soup 4usando
pip. (Ambos paquetes están incluidos con Anaconda).
Recursos de aprendizaje automático:
- Para un resumen muy rápido de los puntos clave sobre el aprendizaje automático, mireWhat is machine learning, and how does it work? (10 minutos) o leer el associated notebook.
- Para una introducción más profunda al aprendizaje automático, lea la Sección 2.1 (14 páginas) del excelente libro de Hastie y Tibshirani, An Introduction to Statistical Learning. (¡Es una descarga gratuita de PDF!) *La Learning Paradigms Video (13 minutos) de Caltech's Learning From Data course Proporciona una buena comparación del aprendizaje supervisado versus no supervisado, así como una introducción al "aprendizaje de refuerzo".
- Real-World Active Learning es una introducción legible y exhaustiva al "aprendizaje activo", una variación del aprendizaje automático en la que los humanos etiquetan solo las observaciones más "importantes".
- Para obtener una vista previa de parte del contenido de aprendizaje automático que cubriremos durante el curso, lea Sebastian Raschka's overview of the supervised learning process.
- Data Science, Machine Learning, and Statistics: What is in a Name? Discute las diferencias entre estos (y otros) términos.
- The Emoji Translation Projectes una aplicación realmente divertida del aprendizaje automático.
- Busque elcharacteristics of your zip code, y luego lee sobre el 67 distinct segments en detalle.
Recursos de cuaderno de iPython
- Para un resumen de la introducción del cuaderno de iPython (y una vista previa de Scikit-Learn), mire scikit-learn and the IPython Notebook (15 minutos) o leer elassociated notebook. *Si desea aprender el cuaderno de iPython, el oficialNotebook tutorials Son útiles. *Esta Reddit discussion Compara las fortalezas relativas del cuaderno de Ipython y Spyder.
- Tarea de pandas con los datos de IMDB adeudados (solution)
- Ejercicio opcional de "aprendizaje humano" con los datos de iris adeudados (solution)
- APIs (code)
- Web scraping (code)
Tarea: *** Opcional: ** Complete el ejercicio de tarea enumerado en el web scraping code. ¡Tomará el lugar de cualquier tarea que pierda, pasado o futuro!Esto se debe el martes (15/09).
- **Opcional: ** Si no estás usando Anaconda, install Seaborn usando
pip. Si está utilizando Anaconda, instale SeaBorn corriendoconda install seabornen la línea de comando.(Tenga en cuenta que algunos estudiantes en cursos pasados han tenido problemas con Anaconda después de instalar Seorn).
Recursos API *Este guión de Python para query the U.S. Census API fue creado por un ex alumno de DA.Es un poco más complicado que el ejemplo que usamos en la clase, está muy bien comentado y puede proporcionar un marco útil para escribir su propio código para consultar las API.
- Mashape y ApigeePermitirle explorar toneladas de diferentes API.Alternativamente, un Python API wrapper está disponible para muchas API populares.
- the Data Science Toolkit es una colección de API basadas en la ubicación y relacionadas con el texto.
- API Integration in Python Proporciona una introducción muy legible a las API REST.
- Microsoft's Face Detection API, que poderesHow-Old.net, es un gran ejemplo de cómo se puede aprovechar una API de aprendizaje automático para producir una aplicación web convincente.
Recursos de raspado web:
- LaBeautiful Soup documentation es increíblemente minucioso, pero es difícil de usar como guía de referencia.Sin embargo, la sección enspecifying a parser Puede ser útil si la hermosa sopa parece estar analizando una página incorrectamente.
- Para más hermosos ejemplos de sopa y tutoriales, ver Web Scraping 101 with Python, Un cuaderno de un ex alumno de DAT bien comentado enscraping Craigslist, this notebook del texto de Stanford como curso de datos, y estonotebook y asociado videodel curso de ciencia de datos de Harvard.
- Para un tutorial de raspado web mucho más largo que cubre la hermosa sopa, LXML, XPath y Selenium, relojWeb Scraping with Python (3 horas 23 minutos) de Pycon 2014. La slides y code también están disponibles.
- Para proyectos de raspado web más complejos, Scrapy es un marco de aplicaciones popular que funciona con Python.Tiene excelente documentation, Y aquí hay un tutorial con diapositivas y código detallados.
- robotstxt.org tiene una explicación concisa de cómo escribir (y leer) el
robots.txtfile. - import.io y Kimono afirmar que le permite raspar sitios web sin escribir ningún código.
- How a Math Genius Hacked OkCupid to Find True Love and How Netflix Reverse Engineered Hollywood son dos ejemplos divertidos de cómo se ha utilizado el raspado web para crear conjuntos de datos interesantes.
- Breve revisión de pandas ([cuaderno] (cuadernos/08_pandas_review.ipynb)))
- K-Near más vecinos y scikit-learn ([cuaderno] (cuadernos/08_knn_sklearn.ipynb))
- Ejercicio con los datos del jugador de la NBA ([cuaderno] (cuaderno/08_nba_knn.ipynb), [data] (https://github.com/justmarkham/dat4-students/blob/master/kerry/final/nba_players_2015.csv), [Dicción de datos] (https://github.com/justmarkham/dat-project-examples/blob/master/pdf/nba_paper.pdf)))
- Explorando la compensación de varianza de sesgo ([cuaderno] (cuadernos/08_bias_variance.ipynb))
Tarea:
- Asignación de lectura en la [compensación de varianza de sesgo] (tarea/09_bias_variance.md)
- Lea la [Introducción a la reproducibilidad] de Kevin (http://www.dataschool.io/reproducibilidad-is-not-just-for-researchers/), lea la guía de Jeff Leek para crear un análisis reproducible] (https: // github.com/jtleek/dataHaring), y vea este video relacionado [Video de Informe de Colbert] (http://thecolberstreport.cc.com/videos/dcyvro/austerity-s-sepersheet-error) (8 minutos).
- Trabaje en su proyecto ... ¡su primera presentación del proyecto está en menos de dos semanas!
RECURSOS KNN
- Para un resumen de los puntos clave sobre Knn y Scikit-Learn, mira Getting started in scikit-learn with the famous iris dataset (15 minutos) y Training a machine learning model with scikit-learn (20 minutes).
- KNN soporta distance metrics aparte de la distancia euclidiana, como Mahalanobis distance, cual takes the scale of the data into account.
- A Detailed Introduction to KNN es un poco denso, pero proporciona una introducción más exhaustiva a KNN y sus aplicaciones.
- Esta conferencia en Image Classification sCómo se podría utilizar cómo se podría usar KNN para detectar imágenes similares, y también toca temas que cubriremos en clases futuras (ajuste de hiperparámetro y validación cruzada).
- Algunas aplicaciones para las cuales KNN es muy adecuada son object recognition, satellite image enhancement, document categorization,y gene expression analysis.
Recursos Seaborn:
- Para comenzar con Seaborn para la visualización, el sitio web oficial tiene una serie de detailed tutorials y un example gallery.
- Data visualization with Seaborn es un recorrido rápido por algunos de los tipos populares de parcelas marinas.
- Visualizing Google Forms Data with Seaborn y How to Create NBA Shot Charts in Python son buenos ejemplos de uso de marinas sobre datos del mundo real.
-
Tarea de raspado web opcional adeudado (solution)
-
Reproducibilidad
- Discuta las lecturas asignadas:introduction, Colbert Report video, cabs article, Tweet, creating a reproducible analysis
- Examples: Classic rock, student project 1, student project 2
-
Discuta la tarea de lectura en el bias-variance tradeoff
-
Evaluación del modelo utilizando la división de trenes/pruebas(notebook)
-
Explorando la documentación de Scikit-Learn: module reference, user guide, Documentación de clase y función
Recursos de evaluación del modelo *Para un resumen de algunos de los puntos clave de la lección de hoy, mira Comparing machine learning models in scikit-learn(27 minutos).
- For Otra explicación del error de entrenamiento versus el error de prueba, la compensación de varianza de sesgo y la división de trenes/pruebas (también conocido como "enfoque de conjunto de validación"), mira el video de Hastie y Tibshirani enestimating prediction error (12 minutos, comenzando a las 2:34).
- El aprendizaje de Caltech de los datos incluye un video fantástico en visualizing bias and variance (15 minutos).
- Random Test/Train Split is Not Always EnoughExplica por qué la división aleatoria de trenes/pruebas puede no ser un procedimiento de evaluación de modelo adecuado si sus datos tienen un elemento de tiempo significativo.
Recursos de reproducibilidad
- What We've Learned About Sharing Our Data Analysis Incluye consejos de BuzzFeed News sobre cómo publicar un análisis reproducible.
- Software development skills for data scientists Discute la importancia de escribir funciones y comentarios de código adecuados (entre otras habilidades), que son muy útiles para crear un análisis reproducible.
- Data science done well looks easy - and that is a big problem for data scientists Explica cómo un análisis reproducible demuestra todo el trabajo que entra en la ciencia de datos adecuada.
- Ejercicio de aprendizaje automático(article)
- Regresión lineal (notebook)
- Capital Bikeshare dataset used in a Kaggle competition
- Data dictionary
- Ejemplo de ingeniería de características: Predicting User Engagement in Corporate Collaboration Network
Tarea:
- ¡Su primera presentación del proyecto es el martes (9/22)!Envíe un enlace al repositorio de su proyecto (con diapositivas, código, datos y visualizaciones) a las 6pm del martes.
- Completar la homework assignment con el Yelp data. Esto se debe el jueves (9/24).
Recursos de regresión lineal
- Para ir mucho más en profundidad sobre la regresión lineal, lea el Capítulo 3 de An Introduction to Statistical Learning.Alternativamente, mira elrelated videos o leer mi quick reference guide a los puntos clave en ese capítulo.
- Estaintroduction to linear regression es más detallado y matemáticamente minucioso, e incluye muchos buenos consejos.
- Esta es una publicación relativamente rápida en el assumptions of linear regression. *Setosa tiene un interactive visualization of regresión lineal.
- Para una breve introducción a los intervalos de confianza, las pruebas de hipótesis, los valores P y el R-cuadrado, así como una comparación entre el código de Scikit-Learn y Statsmodels code, leer mi DAT7 lesson on linear regression.
- Aquí hay una explicación útil de confidence intervals de Quora.
- Hypothesis Testing: The Basics proporciona una buena visión general del tema, y la charla de John Rauser en Statistics Without the Agonizing Pain (12 minutos) da una gran explicación de cómo se rechaza la hipótesis nula.
- A principios de este año, una importante revista científica prohibió el uso de valores P:
- Scientific American tiene un buen summary of the ban.
- Esta response A la prohibición de la naturaleza argumenta que "las decisiones que se toman anteriormente en el análisis de datos tienen un impacto mucho mayor en los resultados".
- Andrew Gelman tiene un legible paperen el que argumenta que "es fácil encontrar una comparación P <.05 incluso si no está sucediendo nada, si miras lo suficiente".
- Science Isn't Broken iIncluye una herramienta ordenada que le permite "P-Hack" su camino hacia los resultados "estadísticamente significativos".
- Accurately Measuring Model Prediction Error Compara R-cuadrado ajustado, AIC y BIC, división de tren/prueba y validación cruzada. Otros recursos:
- Sección 3.3.1 de An Introduction to Statistical Learning (4 pages)Tiene una gran explicación de la codificación ficticia para características categóricas.
- Kaggle tiene algo agradable visualizations of the bikeshare data Usamos hoy.
- ¡Presentaciones del proyecto!
Tarea:
- Mira los videos de Rahul Patwari en [Probabilidad] (https://www.youtube.com/watch?v=o4qmonfw3bi) (5 minutos) y [probabilidades] (https://www.youtube.com/watch?v=GXBXQJX7FC0) (8 minutos) Si no se siente cómodo con ninguno de esos términos.
- Lea estos excelentes artículos de BetterExplained: [una guía intuitiva de funciones exponenciales y e] (http://betterexplained.com/articles/an-intuitive-guide-to-exponential-functions-e/) y [desmystificación del logaritmo natural(ln)] (http://betterexplained.com/articles/demystifying-the-natural-logarithm-ln/).Luego, revise este [breve resumen] (cuadernos/12_e_log_examples.ipynb) of exponential functions and logarithms.
- Yelp Votes Tarea Due ([Solución] (cuadernos/10_yelp_votes_homework.ipynb))
- Regresión logística ([cuaderno] (cuadernos/12_logistic_regression.ipynb))
- [Conjunto de datos de identificación de vidrio] (https://archive.ics.uci.edu/ml/datasets/glass+identification)
- Ejercicio con Titanic Data ([cuaderno] (cuaderno/12_titanic_confusion.ipynb), [data] (data/titanic.csv), [Data Dictionary] (https://www.kaggle.com/c/titanic/data)))
- Confusion Matrix ([diapositivas] (diapositivas/12_confusion_matrix.pdf), [cuaderno] (cuaderno/12_titanic_confusion.ipynb)))
Tarea:
- Si aún no se siente cómodo con toda la terminología de la matriz de confusión, mire los videos de Rahul Patwari en [Sensibilidad y especificidad intuitiva] (https://www.youtube.com/watch?v=U4_3fditnwg) (9 minutos) y [[9 minutos) y [[9 minutos) y [[La compensación entre sensibilidad y especificidad] (https://www.youtube.com/watch?v=vtydyggeqyo) (13 minutos).
- Asignación de video/lectura en [curvas ROC y AUC] (tarea/13_roc_auc.md)
- Asignación de video/lectura en [Validación cruzada] (tarea/13_cross_validation.md)
Recursos de regresión logística:
- Para profundizar en la regresión logística, lea las primeras tres secciones del Capítulo 4 de An Introduction to Statistical Learning,O mira el first three videos (30 minutos) de ese capítulo.
- Para una explicación matemática de la regresión logística, mire los primeros siete videos (71 minutos) de la semana 3 de Andrew Ng's machine learning course, o leer el related lecture notes compilado por un estudiante.
- Para obtener más información sobre la interpretación de los coeficientes de regresión logística, lea este excelente guidepor el idre de UCLA y estos lecture notes de la Universidad de Nuevo México.
- TLa documentación de Scikit-Learn tiene una buena explanation de lo que significa para una probabilidad prevista para ser calibrada.
- Supervised learning superstitions cheat sheetes una muy buena comparación de cuatro clasificadores que cubrimos en el curso (regresión logística, árboles de decisión, KNN, Naive Bayes) y un clasificador que no cubrimos (Máquinas de vectores de soporte).
Recursos de matriz de confusión:
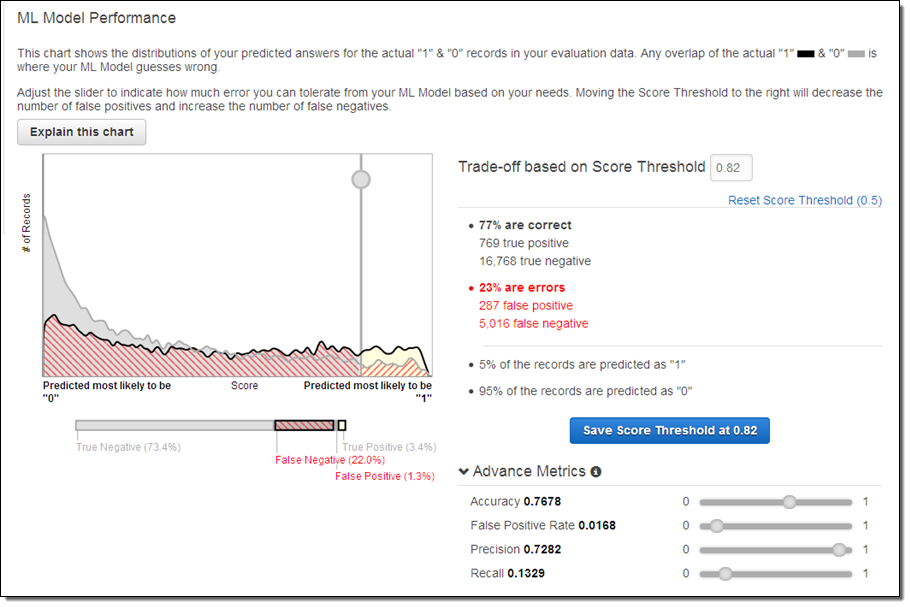
- Mi simple guide to confusion matrix terminology Puede ser útil para usted como referencia. *Esta publicación de blog sobre Amazon Machine Learning Contiene un ordenado graphic Mostrar cómo el umbral de clasificación afecta diferentes métricas de evaluación.
- Este cuaderno (de otro curso de datos) explicas how to calculate "expected value" fROM una matriz de confusión tratándola como una matriz de costo-beneficio.
{kind=link}
- Preparación de datosn (notebook)
- Manejo de valores faltantes
- Manejo de características categóricas (revisión)
- Curvas ROC y AUC
- Discutir elvideo/reading assignment
- Ejercicio: dibujar una curva ROC (slides)
- Volver al cuaderno principal
- Validación cruzada
- Discutir el video/reading assignment and associated notebook
- Volver al cuaderno principal
- Eejercicio con datos de marketing bancario (notebook, data, data dictionary)
Tareak:
- Tarea de lectura on spam filtering
- Lee esto Introduction to Probability slides, or skim section 2.1 of the OpenIntro Statistics textbook (12 pages).Preste atención específica a los siguientes términos: probabilidad, mutuamente excluyente, espacio muestral, independiente.
- Opcional: Intente obtener una comprensión de la probabilidad condicional de este visualization.
- Opcional: Para una introducción intuitiva al teorema de Bayes, lea estas publicaciones en wealth and happiness, ducks, o legos.
Recursos ROC:
- Rahul Patwari tiene un gran video ROC Curves (12 minutos).
- An introduction to ROC analysis es un artículo muy legible sobre el tema.
- Las curvas ROC se pueden usar en una amplia variedad de aplicaciones, como comparing different feature sets para detectar usuarios fraudulentos de Skype, ycomparing different classifiersen varios conjuntos de datos populares.
Recursos de validación cruzada:
- Para obtener más información sobre la validación cruzada, lea la sección 5.1 de An Introduction to Statistical Learning (11 páginas) o ver los videos relacionados: K-fold and leave-one-out cross-validation (14 minutos), cross-validation the right and wrong ways (10 minutos).
- Si desea comprender las diferentes variaciones de validación cruzada, esto paper Los examina y los compara en detalle.
- Para aprender a usar GridSearchCV and RandomizedSearchCV Para el ajuste de los parámetros, mira How to find the best model parameters in scikit-learn (28 minutos) o lea el associated notebook.
Otros recursos:
- Scikit-Learn tiene una amplia documentación en model evaluation.
- Evaluación contrafactual de modelos de aprendizaje automático (45 minutos) es una excelente charla sobre la forma sofisticada en que Stripe evalúa su modelo de detección de fraude.(Estos son los asociados slides.)
- Visualizar los umbrales de aprendizaje automático para tomar mejores decisiones comerciales dEmonstruye cómo la visualización de la precisión, el retiro y la "tasa de cola" en diferentes umbrales pueden ayudarlo a maximizar el valor comercial de su clasificador.
###Clase 14: Naive Bayes and Text Data *Probabilidad condicional y teorema de Bayes * Slides (adaptado de Visualizing Bayes' theorem) * Aplicar el teorema de Bayes a la clasificación de Iris(notebook)
- Naive Bayes classification
- AplicandoNaive Bayes Para enviar datos de texto en Scikit-Learn (notebook)
- CountVectorizer documentation
- SMS messages: data, data dictionary
Tarea:
- Completar otro homework assignment con el Yelp data. Esto se debe el martes (10/6).
- Confirma que tienes TextBlob instalado ejecutando
import textblobdesde dentro de su entorno Python preferido.Si no está instalado, ejecutepip install textbloben la línea de comando (no desde dentro de Python).
Recursos:
- Artículo de Sebastian Rakka en Naive Bayes and Text Classification Cubre el material conceptual de la clase de hoy con mucho más detalle.
- Para obtener más información sobre probabilidad condicional, lea estos slides, o leer la sección 2.2 delOpenIntro Statistics textbook (15 páginas). *Para una explicación intuitiva de la clasificación de Naive Bayes, lea esta publicación en airport security.
- Para más detalles sobre la clasificación de Naive Bayes, Wikipedia tiene dos artículos excelentes(Naive Bayes classifier y Naive Bayes spam filtering),Y Cross Valided tiene un buenQ&A.
- Al aplicar la clasificación ingenua de Bayes a un conjunto de datos con características continuas, es mejor usarlo GaussianNB en vez deMultinomialNB. Esta notebook Compara sus actuaciones en dicho conjunto de datos.Wikipedia tiene un cortodescriptionde Bayes ingenuos gaussianos, así como un excelente example de su uso. *Estasslides De la Universidad de Maryland, proporcione más detalles matemáticos sobre la regresión logística y los bayes ingenuos, y también explique cómo Naive Bayes es en realidad un "caso especial" de regresión logística.
- Andrew Ng tiene un paper Comparando el rendimiento de la regresión logística y los bayes ingenuos en una variedad de conjuntos de datos.
- Si disfrutas el artículo de Paul Graham, puedes leerhis follow-up article sobre cómo mejoró su filtro de spam y esto related paper sobre el filtrado de spam de última generación en 2004.
- YELP ha descubierto que Naive Bayes es más efectivo que los turcos mecánicos en categorizing businesses.
- Tarea de texto de revisión de Yelp debido (solution)
- Procesamiento natural del lenguaje (notebook)
- Introducción a nuestro Kaggle competition *Cree una cuenta de Kaggle, únase a la competencia utilizando el enlace de invitación, descargue el envío de la muestra y luego envíe el envío de muestra (que requerirá la verificación de la cuenta de SMS).
Tarea:
- ¡Su documento de borrador debe vencer el jueves (10/8)!Envíe un enlace al repositorio de su proyecto (con papel, código, datos y visualizaciones) antes de la clase. *MirarKaggle: How it Works (4 minutos) para una breve descripción de la plataforma Kaggle.
- Descargue los archivos de competencia, muévalos al
DAT8/datadIrectory, y asegúrese de que pueda abrir los archivos CSV con PANDAS.Si tiene algún problema para abrir los archivos, probablemente necesite desactivar el escaneo de virus en tiempo real (especialmente Microsoft Security Essentials). - Opcional: Elige algunas teorías sobre qué características pueden ser relevantes para predecir la respuesta, y luego explorar los datos para ver si esas teorías parecen ser ciertas.
- Opcional: Mira My project presentation video (16 minutos) para un recorrido por el proceso de aprendizaje automático de extremo a extremo para una competencia de Kaggle, incluida la ingeniería de características.(O, solo lea el slides.)
Recursos de PNL:
- Si quieres aprender mucho más PNL, mira el excelente video lectures and slides from this Coursera course (que ya no se ofreced).
- Este mazo de diapositivas define muchos de los key NLP terms.
- Natural Language Processing with Python es el libro más popular para ir profundamente con elNatural Language Toolkit (NLTK).
- A Smattering of NLP in Python proporciona una buena descripción de NLTK, al igual que esto notebook from DAT5.
- spaCy es una biblioteca de Python más nueva para el procesamiento de texto que se centra en el rendimiento (a diferencia de NLTK).
- Si quieres tomarte en serio sobre NLP, Stanford CoreNLP es un conjunto de herramientas (escritas en Java) que es muy apreciada. *Cuando trabaja con un cuerpo de texto grande en Scikit-Learn, HashingVectorizeres una alternativa útil a CountVectorizer.
- Automatically Categorizing Yelp Businesses Discute cómo Yelp usa NLP y Scikit-Learn para resolver el problema de las empresas no categorizadas.
- Modern Methods for Sentiment Analysis Muestra cómo se pueden usar "vectores de palabras" para un análisis de sentimientos más preciso.
- Identifying Humorous Cartoon Captions iS un artículo legible sobre la identificación de subtítulos divertidos presentados al concurso de subtítulos de New Yorker.
- DC Natural Language Processing es un grupo de reunión activo en nuestra área local.
- Descripción general de cómo funciona Kaggle (slides)
- Competencia en clase Kaggle: Predict whether a Stack Overflow question will be closed
- Complete code file
- Minimal code file: excludes all exploratory code
- Explanations of log loss
Homework:
- Se le asignará para revisar los borradores del proyecto de dos de sus pares.Tiene hasta el martes 10/20 para proporcionarles comentarios, según elpeer review guidelines.
- Leer A Visual Introduction to Machine Learning para una breve descripción de los árboles de decisión.
- Descargar e instalarGraphviz, que le permitirá visualizar los árboles de decisión en Scikit-Learn.
- Los usuarios de Windows también deben agregar GraphViz a su ruta: vaya al panel de control, el sistema, la configuración avanzada del sistema, las variables de entorno.En Variables del sistema, edite "ruta" para incluir la ruta a la carpeta "bin", como:
C:\Program Files (x86)\Graphviz2.38\bin
- Los usuarios de Windows también deben agregar GraphViz a su ruta: vaya al panel de control, el sistema, la configuración avanzada del sistema, las variables de entorno.En Variables del sistema, edite "ruta" para incluir la ruta a la carpeta "bin", como:
- Opcional: ¡Sigue trabajando en nuestra competencia de Kaggle!Puede formar hasta 5 presentaciones por día, y la competencia no se cierre hasta las 6:30 p.m. ET del martes 27/11 (Clase 21).
Recursos:
- Specialist Knowledge Is Useless and Unhelpful es una breve entrevista con Jeremy Howard (ex presidente de Kaggle) en la que argumenta que las habilidades de ciencia de datos son mucho más importantes que la experiencia de dominio para crear modelos predictivos efectivos.
- Getting in Shape for the Sport of Data Science (74 minutos), también por Jeremy Howard, contiene muchos consejos para el aprendizaje automático competitivo.
- Learning from the best es una excelente publicación de blog que cubre los mejores consejos de Kaggle Masters sobre cómo hacerlo bien en Kaggle.
- Feature Engineering Without Domain Expertise (17 minutos), una charla del maestro de Kaggle Nick Kridler, proporciona algunos consejos simples sobre cómo iterar rápidamente y dónde pasar su tiempo durante una competencia de Kaggle. *Estos ejemplos pueden ayudarlo a comprender mejor el proceso de ingeniería de características: predecir el número de passengers at a train station, identifying fraudulent users of an online store, identifying bots in an online auction, predicting who will subscribe to the next season of an orchestra, y evaluar el quality of e-commerce search engine results.
- Our perfect submission es una lectura divertida sobre cuán gran rendimiento en el public leaderboard no garantiza que un modelo se generalice a nuevos datos.
- Árboles de decisión (notebook)
- Ejercicio con los datos de Bikeshare de Capital(notebook, data, data dictionary)
Tarea:
- Lea la sección "Sabiduría de las multitudes" de la publicación de Mlwave en Human Ensemble Learning.
- Optional: Leer el resumen de Do We Need Hundreds of Classifiers to Solve Real World Classification Problems?, aS como Kaggle CTO Ben Namner's comment sobre el documento, prestando atención a las menciones de "bosques aleatorios".
Recursos:
- La documentación de Scikit-Learn en decision trees Incluye una buena descripción de los árboles, así como consejos para el uso adecuado.
- Para una introducción más exhaustiva a los árboles de decisión, lea la Sección 4.3 (23 páginas) de Introduction to Data Mining. (El Capítulo 4 está disponible como descarga gratuita).
- Si quieres profundizar en los diferentes algoritmos de árbol de decisión, este mazo de diapositivas contiene A Brief History of Classification and Regression Trees.
- The Science of Singing Along Contiene un árbol de regresión ordenado (página 136) para predecir el porcentaje de una audiencia en un lugar de música que cantará junto con una canción pop.
- Los árboles de decisión son comunes en el campo de la medicina para el diagnóstico diferencial, como este árbol de clasificación para identifying psychosis.
- Lección de árboles de decisión de finalización(notebook)
- Conjunto (notebook)
- Major League Baseball player data from 1986-87
- Data dictionary (page 7)
Recursos:
- La documentación de Scikit-Learn en ensemble methods cubre tanto los "métodos de promedio" (como el bolso y los bosques aleatorios), así como los "métodos de impulso" (como el impulso de Adaaboost y Gradient Tree). *MlwaveKaggle Ensembling Guide es muy minucioso y muestra las diferentes formas en que puede tener lugar el conjunto.
- Explorar lo excelente solution paper del ganador de Kaggle'sCrowdFlower competition fO un ejemplo del trabajo y la visión necesaria para ganar una competencia de Kaggle.
- Interpretable vs Powerful Predictive Models: Why We Need Them Both Es una breve publicación sobre cómo las tácticas útiles en una competencia de Kaggle no siempre son útiles en el mundo real.
- Not Even the People Who Write Algorithms Really Know How They Work Argumenta que la disminución de la interpretabilidad de los modelos de aprendizaje automático de última generación tiene un impacto negativo en la sociedad.
- Para una explicación intuitiva de los bosques aleatorios, lea la respuesta de Edwin Chen a How do random forests work in layman's terms?
- Large Scale Decision Forests: Lessons Learned es una excelente publicación de Sift Science sobre su implementación personalizada de bosques aleatorios.
- Unboxing the Random Forest ClassifierDescribe una forma de interpretar el funcionamiento interno de los bosques aleatorios más allá de las importantes importantes.
- Understanding Random Forests: From Theory to Practice es un análisis académico en profundidad de bosques aleatorios, incluidos los detalles de su implementación en Scikit-Learn.
- Advanced scikit-learn (notebook)
- StandardScaler: standardizing features
- Pipeline: chaining steps
- Clustering (slides, notebook)
- K-means: documentation, visualization 1, visualization 2
- DBSCAN: documentation, visualization
Tarea:
- ReleerUnderstanding the Bias-Variance Tradeoff. (The "answers" to the guiding questions he sido publicado y puede ser útil para usted).
- Opcional: Mire estos dos videos excelentes (y relacionados) del curso de Aprendizaje de Data de Caltech: bias-variance tradeoff (15 minutos) y regularization (8 minutos).
recursos de Scikit-Learn:
- Este es un ejemplo más largo de feature scaling En Scikit-Learn, con una discusión adicional de los tipos de escala que puede usar.
- Practical Data Science in Python iS un cuaderno largo y bien escrito que utiliza algunas características avanzadas de Scikit-Learn: tuberías, trazar una curva de aprendizaje y encurtir un modelo.
- Para aprender a usar GridSearchCV and RandomizedSearchCV Para el ajuste de los parámetros, miraHow to find the best model parameters in scikit-learn (28 minutos) o lea elassociated notebook.
- Sebastian Raschka tiene una serie de excelentes recursos para los usuarios de Scikit-Learn, incluido un repositorio detutorials and examples, Una biblioteca de aprendizaje automático tools and extensions, a new book, y un semi-activo blog.
- Scikit-Learn tiene un increíblemente activo mailing list Eso a menudo es mucho más útil que el desbordamiento de la pila para investigar las funciones y hacer preguntas.
- Si olvida cómo usar una función particular de Scikit-Learn que hemos usado en la clase, ¡no olvide que este repositorio es completamente búsqueda!
Recursos de Clustering:
- Para una introducción muy exhaustiva a la agrupación, lea el Capítulo 8 (69 páginas) de Introduction to Data Mining (Disponible como descarga gratuita), o navegar a través de las diapositivas del Capítulo 8.
- Guía del usuario de Scikit-Learn compara muchos diferentestypes of clustering.
- EstaPowerPoint presentation De la clase de minería de datos de Columbia proporciona una buena introducción a la agrupación, incluida la agrupación jerárquica y las métricas de distancia alternativa.
- Una introducción al aprendizaje estadístico tiene videos útiles sobreK-means clustering(17 minutos) y hierarchical clustering (15 minutos).
- Esta es una excelente visualización interactiva de hierarchical clustering.
- Esta es una buena explicación animada demean shift clustering.
- La K-modes algorithm Se puede utilizar para agrupar conjuntos de datos de características categóricas sin convertirlos en valores numéricos.Aquí hay una [implementación de Python] (https://github.com/nicodv/kmodes).
- Aquí hay algunos ejemplos divertidos de agrupación: A Statistical Analysis of the Work of Bob Ross (with data and Python code), How a Math Genius Hacked OkCupid to Find True Love, and characteristics of your zip code.
- Regularización (notebook)
- Regresión: Ridge, RidgeCV, Lasso, LassoCV
- Clasificación: LogisticRegression
- Funciones de ayudante: Pipeline, GridSearchCV
- Expresiones regulares
- Baltimore homicide data
- Regular expressions 101: real-time testing of regular expressions
- Reference guide
- Exercise
Tarea:
- ¡Su proyecto final se presentará la próxima semana!
- Opcional: ¡Haga sus presentaciones finales a nuestra competencia de Kaggle!Cierra a las 6:30 pm ET el martes 27/10.
- Opcional: Lea este artículo clásico, que puede ayudarlo a conectar muchos de los temas que hemos estudiado durante todo el curso: A Few Useful Things to Know about Machine Learning.
Recurso de regularizacións:
- La guía del usuario de Scikit-Learn paraGeneralized Linear Models explica diferentes variaciones de regularización.
- Sección 6.2 de An Introduction to Statistical Learning (14 páginas) introduces both lasso and ridge regression. Or, watch the related videos on ridge regression (13 minutos) and lasso regression (15 minutos).
- Para más detalles sobre la regresión de Lasso, lea Tibshiranioriginal paper.
- Para una explicación matemática de regularización, mire los últimos cuatro videos (30 minutos) de la semana 3 de Andrew Ng'smachine learning course, o leer elrelated lecture notes compilado por un estudiante.
- Esta notebook Del capítulo 7 deBuilding Machine Learning Systems with Python Tiene un buen ejemplo largo de regresión lineal regularizada.
- Hay algunas consideraciones especiales al usar la codificación ficticia para características categóricas con un modelo regularizado.Este Cross Validated Q&A debates si las variables ficticias deben estandarizarse (junto con el resto de las características), y un comentario sobre esto blog post Recomienda que el nivel de referencia no se elimine.
Regular Expressions Resources:
- Google's Python Class includes an excellent introductory lesson on regular expressions (which also has an associated video).
- Python for Informatics has a nice chapter on regular expressions. (If you want to run the examples, you'll need to download mbox.txt and mbox-short.txt.)
- Breaking the Ice with Regular Expressions is an interactive Code School course, though only the first "level" is free.
- If you want to go really deep with regular expressions, RexEgg includes endless articles and tutorials.
- 5 Tools You Didn't Know That Use Regular Expressions demonstrates how regular expressions can be used with Excel, Word, Google Spreadsheets, Google Forms, text editors, and other tools.
- Exploring Expressions of Emotions in GitHub Commit Messages is a fun example of how regular expressions can be used for data analysis, and Emojineering explains how Instagram uses regular expressions to detect emoji in hashtags.
- ¡Presentaciones del proyecto!
- Data science review
Recursos:
- scikitLearn's machine learning map Puede ayudarlo a elegir el "mejor" modelo para su tarea.
- Choosing a Machine Learning Classifier es una comparación corta y muy legible de varios modelos de clasificación, Classifier comparison es la visualización de Scikit-Learn de los límites de decisión del clasificador, Comparing supervised learning algorithms es una tabla de comparación de modelos que creé, y Supervised learning superstitions cheat sheet is a more thorough comparison (with links to lots of useful resources).
- Machine Learning Done Wrong, Machine Learning Gremlins (31 minutos), Clever Methods of Overfitting, and Common Pitfalls in Machine Learning Todos ofrecen consejos reflexivos sobre cómo evitar errores comunes en el aprendizaje automático.
- Practical machine learning tricks from the KDD 2011 best industry papery Andrew Ng's Advice for applying machine learning Incluya consejos un poco más avanzados que los recursos anteriores.
- An Empirical Comparison of Supervised Learning Algorithms es un trabajo de investigación legible de 2006, que también se presentó como untalk(77 minutos).
- ¡Presentaciones del proyecto!
- What's next?
- Good Data Management Practices for Data Analysis Resume brevemente los principios de "Datos ordenados".
- Hadley Wickham's paper explica los datos ordenados en detalle e incluye muchos buenos ejemplos.
- Ejemplo de un conjunto de datos ordenado: Bob Ross
- Ejemplos de conjuntos de datos desordenados: NFL ticket prices, airline safety, Jets ticket prices, Chipotle orders
- Si sus compañeros de trabajo tienden a crear hojas de cálculo que son unreadable by computers,pueden beneficiarse de leer estos tips for releasing data in spreadsheets. (Hay algunas sugerencias adicionales en este answer de cruzado validado.)
- Esta GA slide deck Proporciona una breve introducción a las bases de datos y SQL.The Python script De esa lección demuestra consultas básicas de SQL, así como cómo conectarse a una base de datos SQLite de Python y cómo consultarla usando pandas.
- El repositorio de esto SQL Bootcamp Contiene un script SQL extremadamente bien comencionado que es adecuado para caminar por su cuenta.
- Esta GA notebook Proporciona una introducción más corta a las bases de datos y SQL que contrasta útilmente las consultas SQL con la sintaxis PANDAS.
- SQLZOO, Mode Analytics, Khan Academy, Codecademy, Datamonkey, and Code School Todos tienen tutoriales SQL para principiantes en línea que parecen prometedores.Code School también ofrece unn advanced tutorial, aunque no es gratis.
- w3schools Tiene una base de datos de muestra que le permite practicar SQL desde su navegador.Del mismo modo, Kaggle le permite consultar una gran base de datos SQLite de Reddit Comments Uso de su aplicación en línea "Scripts".
- What Every Data Scientist Needs to Know about SQL es una breve serie de publicaciones sobre los conceptos básicos de SQL, y Introduction to SQL for Data Scientists es un artículo con objetivos similares.
- 10 Easy Steps to a Complete Understanding of SQL es un buen artículo para aquellos que tienen alguna experiencia SQL y quieren entenderlo en un nivel más profundo.
- SArtículo de Qlite en Query Planning Explica cómo las consultas SQL "funcionan".
- A Comparison Of Relational Database Management Systems Da los pros y los contras de SQLite, MySQL y PostgreSQL.
- Si desea profundizar en bases de datos y SQL, Stanford tiene una serie muy respetada de 14 mini-courses.
- Blaze es un paquete de Python que le permite usar una sintaxis similar a Pandas para consultar datos que viven en una variedad de sistemas de almacenamiento de datos.
- Esta GA slide deck provides a brief introduction to recommendation systems, and the Python script De esa lección demuestra cómo construir un simple recomendador. *Capítulo 9 de Mining of Massive Datasets (36 pages) es una introducción más exhaustiva a los sistemas de recomendación.
- Capítulos 2 a 4 de A Programmer's Guide to Data Mining (165 páginas) proporciona una introducción más amigable, con mucho código y ejercicios de Python.
- El Premio Netflix fue la famosa competencia para mejorar el sistema de recomendaciones de Netflix en un 10%.Aquí hay algunos artículos útiles sobre el premio Netflix:
- Netflix Recommendations: Beyond the 5 stars: Dos publicaciones del blog de Netflix que resume la competencia y su sistema de recomendación
- Winning the Netflix Prize: A Summary: Descripción general de los modelos y técnicas que entraron en la solución ganadora
- A Perspective on the Netflix Prize: Un resumen de la competencia del equipo ganador
- Esta paper resume cómo funciona el sistema de recomendación de Amazon.com, y estoStack Overflow Q&Atiene algunos pensamientos adicionales.
- Facebook y EtsyTenga publicaciones de blog sobre cómo funcionan sus sistemas de recomendación.
- The Global Network of Discovery Proporciona algunos recomendadores ordenados para música, autores y películas.
- The People Inside Your Machine (23 minutos) es un episodio de podcast de Money Planet sobre cómo Amazon Mechanical Turks puede ayudar con los motores de recomendación (y el aprendizaje automático en general).
- Coursera tiene un course En los sistemas de recomendación, si desea profundizar aún más en el material.