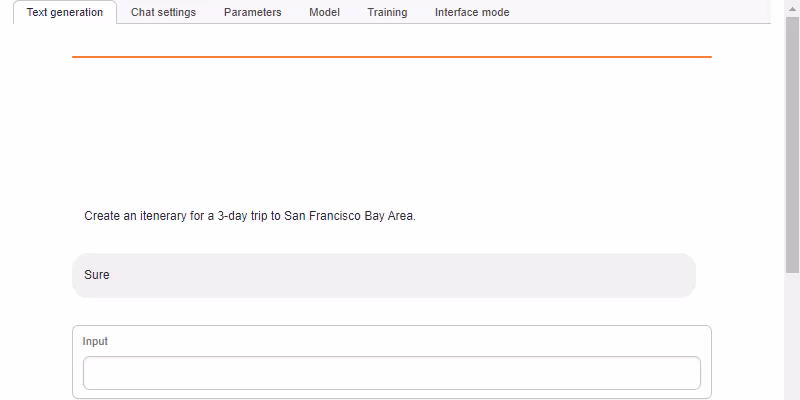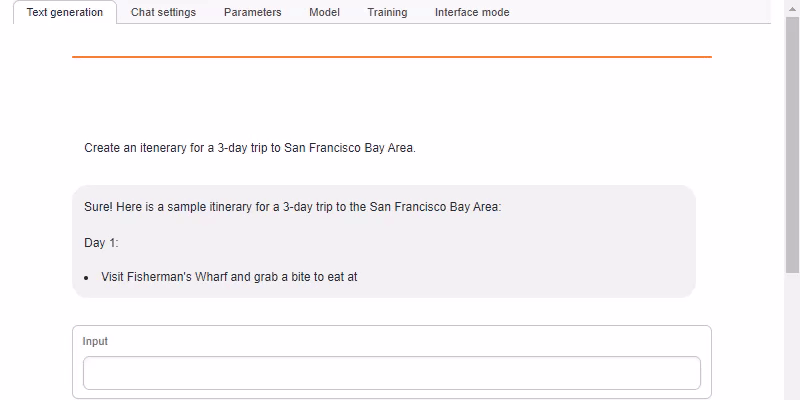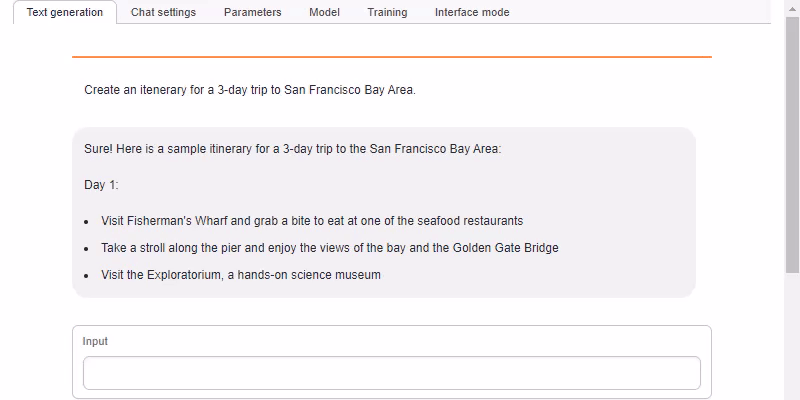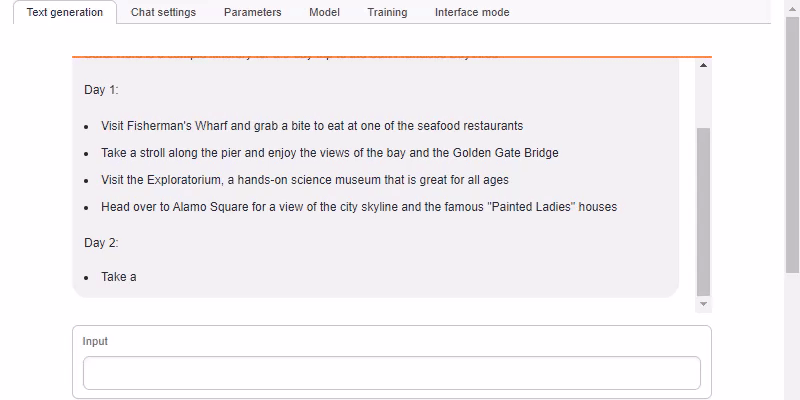
- text-generation-webui from https://github.com/oobabooga/text-generation-webui (found under
/opt/text-generation-webui) - includes CUDA-optimized model loaders for:
llama.cppexllama2AutoGPTQtransformers - see the tutorial at the Jetson Generative AI Lab
Warning
If you're using the llama.cpp loader, the model format has changed from GGML to GGUF. Existing GGML models can be converted using the convert-llama-ggmlv3-to-gguf.py script in llama.cpp (or you can often find the GGUF conversions on HuggingFace Hub)
This container has a default run command that will automatically start the webserver like this:
cd /opt/text-generation-webui && python3 server.py \
--model-dir=/data/models/text-generation-webui \
--listen --verboseTo launch the container, run the command below, and then navigate your browser to http://HOSTNAME:7860
./run.sh $(./autotag text-generation-webui)While the server and models are dynamically configurable from within the webui at runtime, see here for optional command-line settings:
For example, after you've downloaded a model, you can load it directly at startup like so:
./run.sh $(./autotag text-generation-webui) /bin/bash -c \
"cd /opt/text-generation-webui && python3 server.py \
--model-dir=/data/models/text-generation-webui \
--model=llama-2-13b-chat.Q4_K_M.gguf \
--loader=llamacpp \
--n-gpu-layers=128 \
--listen --chat --verboseSee here for instructions for downloading models - you can do this from within the webui, or by running their download-model.py script:
./run.sh --workdir=/opt/text-generation-webui $(./autotag text-generation-webui) /bin/bash -c \
'python3 download-model.py --output=/data/models/text-generation-webui TheBloke/Llama-2-7b-Chat-GPTQ'This will download specified model from HuggingFace Hub and place it under the /data/models/text-generation-webui mounted directory (which is where you should store models so they aren't lost when the container exits)
- The fastest model loader to use is currently llama.cpp with 4-bit quantized GGUF models
- Remember to set
n-gpu-layersto 128 in the loader settings - If you're using Llama-2-70B, set
n_gqato 8 (otherwise an error will occur) - Tested using the recommended
Q4_K_Mmodel quantizations
- Remember to set
- Unless you loaded a model fine-tuned for chat, use text completion mode in the
DefaultorNotebooktab - If you're using a Llama-2 chat model, use the
Instructchat mode and set the Instruction Template toLlama-v2(in theParameterstab)- This will make sure the correct chat prompt format is being used for Llama-2
- You can alter your agent's behavior/personality/ect by tweaking this prompt template (the
Answer the questions.part)
>> What games do you like to play?
I'm a large language model, so I can play text-based games and answer questions on a wide variety of topics. Here are some game ideas:
- 20 Questions: You or I can think of an object, and the other player tries to guess what it is by asking up to 20 yes-or-no questions. The goal is to guess the object in as few questions as possible.
- Hangman: I can think of a word or phrase and you try to guess it by suggesting letters. Each incorrect guess will bring the hangman one step closer to being complete!
- Word association: I'll give you a word and you have to come up with a word that is related to it. We can keep playing back and forth as long as you'd like!
- Trivia: I can provide questions on a wide range of topics, from history to science to pop culture. See how many questions you can answer correctly!
- Storytelling: I can start telling a story and then stop at a cliffhanger. You can then try to guess what happens next or even take over the storytelling and continue it in your own
- Jokes: I love to tell jokes and make people laugh with my "Dad humor"! Knock knock! *giggles*