
# gateway config
maprcli cluster gateway list
# config of the services
maprcli cluster queryservice getconfig- Partition Id
- Hash of messageId
- Round-Robin
mapr streamanalyzer -path /mapr/dp.prod.zur/vantage/orchestr/streams/my-own-test -topics cherkavi-test -printMessages true -countMessages
- by partition number
- by message key
- round-robin ( without previous two )
- properties.put("streams.patitioner.class", "my.package.MyClassName.class")
public class MyClassName implements Partitioner{
public int partition( String topic, Object, key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster){}
}
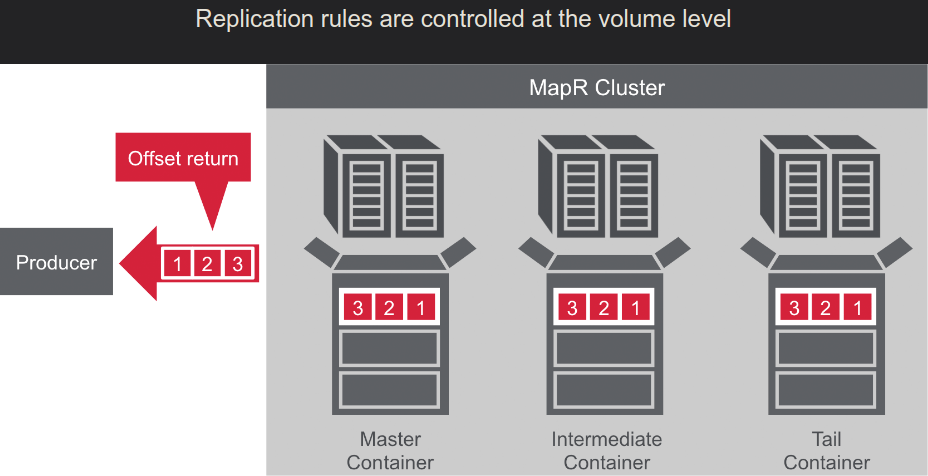


- Read cursor ( client request it and broker sent )
- Committed cursor ( client confirmed/commited reading )

- Master->Slave
- Many->One
- MultiMaster: Master<-->Master
- Stream replications: Node-->Node2-->Node3-->Node4 ... ( with loop preventing )
maprcli node listcldbs
## volume create
VOLUME_NAME=test_volume
VOLUME_PATH=/store/processed/test_creation
mkdir $VOLUME_PATH
maprcli volume create -name $VOLUME_NAME -path $VOLUME_PATH
## possible issue:
# Successfully created volume: 'test_volume'
# ERROR (10003) - Volume mount for /store/processed/test_creation failed, No such file or directoryor via REST API of MapR Control System
## volume remove
maprcli volume remove -name $VOLUME_NAME## list of MapR volumes in json format
# json, path , columns , local, global, system, unmounted, summary, sort, limit
maprcli volume list -json > ~/volume-list.json
hadoop mfs -ls $FOLDER_PATH
# volume: vrwxrwxrwx
# directory: drwxrwxrwx
maprcli volume info -path $FOLDER_PATHmaprcli stream create -path <filepath & name>
maprcli stream create -path <filepath & name> -consumeperm u:<userId> -produceperm u:<userId> -topicperm u:<userId>
maprcli stream create -path <filepath & name> -consumeperm "u:<userId>" -produceperm "u:<userId>" -topicperm "u:<userId>" -adminperm "u:<userId1> | u:<userId2>"maprcli stream info -path {filepath}maprcli stream delete -path <filepath & name>maprcli stream topic create -path <path and name of the stream> -topic <name of the topic>maprcli stream topic delete -path <path and name of the stream> -topic <name of the topic>maprcli stream topic list -path <path and name of the stream>maprcli stream cursor list -path $KAFKA_STREAM -topic $KAFKA_TOPIC -consumergroup $KAFKA_CONSUMER_GROUP -jsonjavac -classpath `mapr classpath` MyConsumer.java
java -classpath kafka-clients-1.1.1-mapr-1808.jar:slf4j-api-1.7.12.jar:slf4j-log4j12-1.7.12.jar:log4j-1.2.17.jar:mapr-streams-6.1.0-mapr.jar:maprfs-6.1.0-mapr.jar:protobuf-java-2.5.0.jar:hadoop-common-2.7.0.jar:commons-logging-1.1.3-api.jar:commons-logging-1.1.3.jar:guava-14.0.1.jar:commons-collections-3.2.2.jar:hadoop-auth-2.7.0-mapr-1808.jar:commons-configuration-1.6.jar:commons-lang-2.6.jar:jackson-core-2.9.5.jar:. MyConsumer
Properties properties = new Properties();
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// org.apache.kafka.common.serialization.ByteSerializer
// properties.put("client.id", <client id>)
import org.apache.kafka.clients.producer.KafkaProducer;
KafkaProducer producer = new KafkaProducer<String, String>(properties);
String streamTopic = "<streamname>:<topicname>"; // "/streams/my-stream:topic-name"
ProducerRecord<String, String> record = new ProducerRecord<String, String>(streamTopic, textOfMessage);
// ProducerRecord<String, String> record = new ProducerRecord<String, String>(streamTopic, messageTextKey, textOfMessage);
// ProducerRecord<String, String> record = new ProducerRecord<String, String>(streamTopic, partitionIntNumber, textOfMessage);
Callback callback = new Callback(){
public void onCompletion(RecordMetadata meta, Exception ex){
meta.offset();
}
};
producer.send(record, callback);
producer.close();

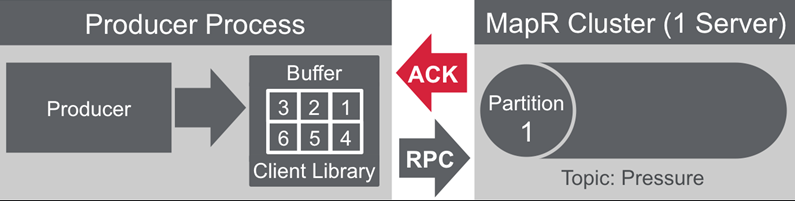
streams.parallel.flushers.per.partition default true:
- does not wait for ACK before sending more messages
- possible for messages to arrive out of order
streams.parallel.flushers.per.partition set to false:
- client library will wait for ACK from server
- slower than default setting
metadata.max.age.ms
How frequently to fetch metadata
Properties properties = new Properties();
properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// org.apache.kafka.common.serialization.ByteSerializer
// properties.put("auto.offset.reset", <Earliest, Latest, None>)
// properties.put("group.id", <group identificator>)
// properties.put("enable.auto.commit", <true - default | false >), use consumer.commitSync() if false
// properties.put("auto.commit.interval.ms", <default value 1000ms>)
import org.apache.kafka.clients.consumer.KafkaConsumer;
KafkaConsumer consumer = new KafkaConsumer<String, String>(properties);
String streamTopic = "<streamname>:<topicname>"; // "/streams/my-stream:topic-name"
consumer.subscribe(Arrays.asList(topic));
// consumer.subscribe(topic, new RebalanceListener());
ConsumerRecords<String, String> messages = consumer.poll(1000L); // reading with timeout
messages.iterator().next().toString(); // "/streams/my-stream:topic-name, parition=1, offset=256, key=one, value=text"
public class RebalanceListener implements ConsumerRebalanceListener{
onPartitionAssigned(Collection<TopicPartition> partitions)
onPartitionRevoked(Collection<TopicPartition> partitions)
}
(maven repository)[https://repository.mapr.com/nexus/content/repositories/releases/]
<repositories>
<repository>
<id>mapr-maven</id>
<url>http://repository.mapr.com/maven</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.9.0.0-mapr-1602-streams-5.1.0</version>
<scope>provided</scope>
</dependency>
</dependencies>
execute on cluster
mapr classpath
java -cp `mapr classpath`:my-own-app.jar mypackage.MainClass
curl_user="cluster_user"
curl_pass="cluster_user_password"
stream_path="%2Fvantage%2Forchestration%2Fstreams%2Fpipeline"
topic_name="gateway"
host="https://ubsdpdesp000001.vantage.org"
port=8082
# maprcli stream topic list -path $stream_path # need to replace %2 with /
curl -u $curl_user:$curl_pass \
--insecure -s -X GET \
-H "Content-Type: application/vnd.kafka.v2+json" \
$host:$port/topics/$stream_path%3A$topic_nameURL_REST_API=https://mapr-web.vantage.zur:20702
# x-www-browser $URL_REST_API/app/swagger/
REST_API=${URL_REST_API}/api/v2
REST_API_TABLE=${REST_API}/table/ # ends with slash !!!
MAPR_DB_PATH=/vantage/store/tables/signals
SESSION_ID=efba27777-313d
curl -X GET --insecure -L -u $USER_DATA_API_USER:$USER_DATA_API_PASSWORD ${REST_API_TABLE}${MAPR_DB_PATH}'?condition=\{"$eq":\{"session":"'$SESSION_ID'"\}\}&limit=1' | jq .maprlogin password -user {your cluster username}
# long term ticket
maprlogin password -user {your cluster username} -duration 30:0:0 -renewal 90:0:0
maprlogin print
maprlogin authtest
maprlogin logout
OCP_TICKET_NAME=maprticket
FILE_WITH_TICKET=prod.maprticket
oc get secret $OCP_TICKET_NAME -o json | jq .data.CONTAINER_TICKET -r | base64 --decode > $FILE_WITH_TICKET
maprlogin renew -ticketfile $FILE_WITH_TICKETexecution_string="echo '"$CLUSTER_PASS"' | maprlogin password -user cherkavi "
ssh $CLUSTER_USER@$CLUSTER_NODE $execution_string
maprlogin print -ticketfile <your ticketfile>
# you will see expiration date like
# on 07.05.2019 13:56:47 created = 'Tue Apr 23 13:56:47 UTC 2019', expires = 'Tue May 07 13:56:47 UTC 2019'
maprlogin generateticket -type service -cluster my61.cluster.com -duration 30:0:0 -out /tmp/mapr_ticket -user mapr
maprcli dashboard info -json
$ wget -O - https://package.mapr.com/releases/pub/maprgpg.key | sudo apt-key add -deb https://package.mapr.com/releases/v6.1.0/ubuntu binary trusty
deb https://package.mapr.com/releases/MEP/MEP-6.0.0/ubuntu binary trusty
apt-get update
# apt-get install mapr-posix-client-basic
apt-get install mapr-posix-client-platinumsudo mkdir /mapr
sudo scp $USERNAME@$EDGE_NODE:/opt/mapr/conf/mapr-clusters.conf /opt/mapr/conf/mapr-clusters.conf
sudo scp $USERNAME@$EDGE_NODE:/opt/mapr/conf/ssl_truststore /opt/mapr/conf/ssl_truststoreecho "$PASSWORD" | maprlogin password -user $USERNAME -out /tmp/mapruserticketyarn application -list -appStates ALL
yarn logs -applicationId application_1540813402987_9262
# map reduce job
mapred queue -showacls | grep SUBMIT_APPLICATIONSpreferred way for making connection to MapRDB - OJAI
Two possible types of MaprDB:
- (json/document database)[https://docs.datafabric.hpe.com/62/MapROverview/MaprDB-overview-json.html]
- (binary/column-oriented)[https://docs.datafabric.hpe.com/62/MapROverview/maprDB-overview-binary.html]
# maprdb create table binary table
maprcli table create -path <path_in_maprfs>
# drill
DRILL_HOST=https://mapr-web.vantage.zur:30101
MAPR_FS=/vantage/data/label/sessions
curl --request PUT --url ${DRILL_HOST}/api/v2/table/${MAPR_FS} --header 'Authorization: Basic '$BASE64_BASIC_AUTH_TOKEN
# maprdb create json table
maprcli table create -path <path_in_maprfs> -tabletype json
# configuration for maprdb table
maprcli config save -values {"mfs.db.max.rowsize.kb":<value in KB>}
# maprdb table show regions
maprcli table region list -path <path_in_maprfs>
maprcli table region list -path <path_in_maprfs> -json
# maprdb table split
maprcli table region split -path <path_in_maprfs> -fid <region id like: 5358777.43.26313># in case of such message - check your table type binary/json
OJAI APIs are currently not supported with binary tables
OJAI log4j logging
<Logger name="log4j.logger.com.mapr.ojai.store.impl" level="trace" additivity="false">
<AppenderRef ref="stdout" />
<AppenderRef ref="asyncFile" />
</Logger>
<Root level="trace">
<AppenderRef ref="stdout" />
<AppenderRef ref="asyncFile" />
</Root>maprcli table info -path /vantage/deploy/data-access-video/images -json
# !!! totalrows: Estimated number of rows in a table. Values may not match the actual number of rows. This variance occurs because the counter, for performance reasons, is not updated on each row.
# one of the fastest option - drill request: select count(*) from dfs.`/vantage/deploy/data-access-video/images`
# list of regions for table
maprcli table region list -path /vantage/deploy/data-access-video/images -jsonmapr copytable -src {path to source} -dst {path to destination}
# without yarn involvement
mapr copytable -src {path to source} -dst {path to destination} -mapreduce false
# move table can be fulfilled with:
hadoop fs -mvmaprcli table delete -path <path_in_maprfs>maprcli table cf list -path /vantage/deploy/data-access-video/images -cfname default -json!!! WARNING, pls, read list of existing users before set new !!!
maprcli table cf edit -path /vantage/deploy/data-access-video/images -cfname default -readperm u:tech_user_name
maprcli table cf edit -path /vantage/deploy/data-access-video/images -cfname default -readperm "u:tech_user_name | u:tech_user_name2"maprcli table cf edit -path $TABLE_NAME -cfname default -readperm u:tech_user_name
maprcli table cf edit -path $TABLE_NAME -cfname default -writeperm u:tech_user_name
maprcli table edit -path $TABLE_NAME -adminaccessperm u:tech_user_name_admin -indexperm u:tech_user_namemapr dbshell
jsonoptions# output to file stdout
mapr dbshell 'find /mapr/prod/vantage/orchestration/tables/metadata --fields _id --limit 5 --pretty' > out.txt
mapr dbshell 'find /mapr/prod/vantage/orchestration/tables/metadata --fields _id,sessionId --where {"$eq":{"sessionId":"test-001"}} --limit 1'
# request inside shell
mapr dbshell
## more prefered way of searching:
find /mapr/prod/vantage/orchestration/tables/metadata --query '{"$select":["mdf4Path.name","mdf4Path.fullPath"],"$limit":2}'
find /mapr/prod/vantage/orchestration/tables/metadata --query {"$select":["fullPath"],"$where":{"$lt":{"startTime":0}}} --pretty
find /mapr/prod/vantage/orchestration/tables/metadata --c {"$eq":{"session_id":"9aaa13577-ad80"}} --pretty
## fix issue with multiple document in output
# sed 's/^}$/},/g' $file_src > $file_dest
## less prefered way of searching:
# last records, default sort: ASC
find /mapr/prod/vantage/orchestration/tables/metadata --fields _id --orderby loggerStartTime.utcNanos:DESC --limit 5
# amount of records: `maprcli table info -path /mapr/prod/vantage/orchestration/tables/metadata -json | grep totalrows`
find /mapr/prod/vantage/orchestration/tables/metadata --fields mdf4Path.name,mdf4Path.fullPath --limit 2 --offset 2 --where {"$eq":{"session_id":"9aaa13577-ad80"}} --orderby created_time
# array in output and in condition
find /mapr/prod/vantage/orchestration/tables/metadata --fields documentId,object_types[].id --where {"$eq":{"object_types[].id":"44447f6d853dd"}}'
find /mapr/prod/vantage/orchestration/tables/metadata --fields documentId,object_types[].id --where {"$between":{"created_time":[159421119000000000,1595200100000000000]}} --limit 5!!! important !!!, id only, no data in output but "_id": if you don't see all fields in the output, try to change user ( you don't have enough rights )
complex query
find /tbl --q {"$select":"a.c.e",
"$where":{
"$and":[
{"$eq":{"a.b[0].boolean":false}},
{"$or":[
{"$ne":{"a.c.d":5}},
{"$gt":{"a.b[1].decimal":1}},
{"$lt":{"a.b[1].decimal":10}}
]
}
]
}
}query with counting amount of elements in array
find //tables/session --query {"$select":["_id"],"$where":{"$and":[{"$eq":{"vin":"BX77777"}},{"$sizeof":{"labelEvents":{"$ge":1}}}]}}for data:
"dag_data" : {
"name" : "drive_markers",
"number" : {
"$numberInt" : -1
}
},
// --limit 10 --pretty --c {"$notexists":"dag_data"}
// --limit 10 --pretty --c {"$eq":{"dag_data.number":-1}}example of inline execution
REQUEST="find /mapr/prod/vantage/orchestration/tables/metadata --fields mdf4Path.name,mdf4Path.fullPath --limit 2"
echo $REQUEST | tee script.sql
mapr dbshell --cmdfile script.sql > script.result
rm script.sqlexample of execution via mapr web, web mapr, MaprDB read document
MAPR_USER='user'
MAPR_PASSWORD='password'
DOCUMENT_ID='d99-4a-ac-0cbd'
TABLE_PATH=/vantage/orchestration/tables/sessions
curl --silent --insecure -X GET -u $MAPR_USER:$MAPR_PASSWORD https://mapr-web.vantage.zur:2002/api/v2/table/$TABLE_PATH/document/$DOCUMENT_ID | jq "." | grep labelEvent
# insert record - POST
# delete record - DELETEinsert --table /vantage/processed/tables/markers --id custom_id_1 --value '{"name": "Martha", "age": 35}'
# should be checked logic for inserting with "_id" inside document
# insert --table /vantage/processed/tables/markers --value '{"_id": "custom_id_1", "name": "Martha", "age": 35}'
FILE_CONTENT=$(cat my-record-in-file.json)
RECORD_ID=$(jq -r ._id my-record-in-file.json)
mapr dbshell "insert --table /vantage/processed/tables/markers --id $RECORD_ID --value '$FILE_CONTENT'"
possible error: You already provided '....' earlier
check your single quotas around json object for --value
delete --table /vantage/processed/tables/markers --id "custom_id_1"
Create an index for the thumbnail MapR JSON DB in order to speed up: (query to find all sessionIds with existing thumbnails)
maprcli table index add -path /vantage/deploy/data-access-video/images -index frameNumber_id -indexedfields frameThumbnail
# maprcli table index add -path <path> -index <name> -indexedfields<fields>
# mapr index information ( check isUpdate )
maprcli table index list -path <path>
maprcli table cfcreate / delete / listmapr dbshell
desc /full/path/to/maprdb/table
manipulate with MapRDB via DbShell
- DDL
- DML
you can check your current ticket using fs -ls
hadoop fs -mkdir -p /mapr/dp.stg/vantage/data/store/collected/car-data/MDF4/a889-017d6b9bc95b/
hadoop fs -ls /mapr/dp.stg/vantage/data/store/collected/car-data/MDF4/a889-017d6b9bc95b/
hadoop fs -rm -r /mapr/dp.stg/vantage/data/store/collected/car-data/MDF4/a889-017d6b9bc95b/WEB_HDFS=https://ubssp000007:14000
PATH_TO_FILE="tmp/1.txt"
# BASE_DIR=/mapr/dc.stg.zurich
vim ${BASE_DIR}/$PATH_TO_FILE
MAPR_USER=$USER_API_USER
MAPR_PASS=$USER_API_PASSWORD
# read file
curl -X GET "${WEB_HDFS}/webhdfs/v1/${PATH_TO_FILE}?op=open" -k -u ${MAPR_USER}:${MAPR_PASS}
# create folder
PATH_TO_NEW_FOLDER=tmp/example
curl -X PUT "${WEB_HDFS}/webhdfs/v1/${PATH_TO_NEW_FOLDER}?op=mkdirs" -k -u ${MAPR_USER}:${MAPR_PASS}TICKET_FILE=prod.maprticket
maprlogin renew -ticketfile $TICKET_FILE
# https://github.com/cherkavi/java-code-example/tree/master/console/java-bash-run
hadoop jar java-bash-run-1.0.jar utility.Main ls -la .
Can not find IP for host: maprdemo.mapr.io
solution
# hard way
rm -rf /opt/mapr
# soft way
vim /opt/mapr/conf/mapr-clusters.confCaused by: javax.security.auth.login.LoginException: Unable to obtain MapR credentials
at com.mapr.security.maprsasl.MaprSecurityLoginModule.login(MaprSecurityLoginModule.java:228)
echo "passw" | maprlogin password -user my_user_name
possible issue
- javax.security.sasl.SaslException: GSS initiate failed
- rm: Failed to move to trash: hdfs://eqstaging/user/my_user/equinix-staging-deployment-51: Permission denied: user=dataquality, access=WRITE, inode="/user/my_user/deployment-sensor_msgs":ubsdeployer:ubsdeployer:drwxr-xr-x
- No Kerberos credential available
solution:
- login into destination Edge node
- execute 'kinit'
how to build mapr container locally
# ERROR: Invalid MAPR_TZ timezone ()
IMAGE_ID='maprtech/pacc:6.1.0_6.0.0_ubuntu16'
docker run --env MAPR_TZ="UTC" --env MAPR_CONTAINER_USER="temp_user" --env MAPR_CLDB_HOSTS="build_new_container" -it $IMAGE_ID /bin/shFROM maprtech/pacc:6.1.0_6.0.0_ubuntu16permission for image scc
allowHostDirVolumePlugin: true
allowHostIPC: false
allowHostNetwork: false
allowHostPID: false
allowHostPorts: false
allowPrivilegeEscalation: true
allowPrivilegedContainer: true
allowedCapabilities:
- NET_RAW
- SYS_ADMIN
- NET_ADMIN
- SETGID
- SETUID
- SYS_CHROOT
- CAP_AUDIT_WRITE
apiVersion: security.openshift.io/v1
defaultAddCapabilities: null
fsGroup:
type: RunAsAny
groups:
- r-d-zur-func_engineer
- r-d-zur-engineer
kind: SecurityContextConstraints
metadata:
generation: 26
name: mapr-apps-netraw-scc
priority: 5
readOnlyRootFilesystem: false
requiredDropCapabilities: null
runAsUser:
type: RunAsAny
seLinuxContext:
type: MustRunAs
supplementalGroups:
type: RunAsAny
users:
- system:serviceaccount:custom-user:default
volumes:
- configMap
- downwardAPI
- emptyDir
- flexVolume
- hostPath
- persistentVolumeClaim
- projected
- secret
java application in docker container
/opt/mapr/installer/docker/mapr-setup.sh container
java -Dzookeeper.sasl.client=false -classpath /opt/mapr/lib/hadoop-common-2.7.0-mapr-1808.jar:/opt/mapr/kafka/kafka-1.1.1/libs/*:/usr/src/lib/dq-kafka2storage-service-jar-with-dependencies.jar:/usr/src/classes:/usr/src/lib/maprfs-6.1.0-mapr.jar:/usr/src/lib/maprfs-6.1.0-mapr-tests.jar:/usr/src/lib/maprfs-diagnostic-tools-6.1.0-mapr.jar:/usr/src/lib/maprdb-6.1.0-mapr.jar:/usr/src/lib/maprdb-6.1.0-mapr-tests.jar:/usr/src/lib/maprdb-cdc-6.1.0-mapr.jar:/usr/src/lib/maprdb-cdc-6.1.0-mapr-tests.jar:/usr/src/lib/maprdb-mapreduce-6.1.0-mapr.jar:/usr/src/lib/maprdb-mapreduce-6.1.0-mapr-tests.jar:/usr/src/lib/maprdb-shell-6.1.0-mapr.jar:/usr/src/lib/maprdb-shell-6.1.0-mapr-tests.jar:/usr/src/lib/mapr-hbase-6.1.0-mapr.jar:/usr/src/lib/mapr-hbase-6.1.0-mapr-tests.jar:/usr/src/lib/mapr-ojai-driver-6.1.0-mapr.jar:/usr/src/lib/mapr-ojai-driver-6.1.0-mapr-tests.jar:/usr/src/lib/mapr-streams-6.1.0-mapr.jar:/usr/src/lib/mapr-streams-6.1.0-mapr-tests.jar:/usr/src/lib/mapr-tools-6.1.0-mapr.jar:/usr/src/lib/mapr-tools-6.1.0-mapr-tests.jar:/usr/src/lib/mastgateway-6.1.0-mapr.jar:/usr/src/lib/slf4j-api-1.7.12.jar:/usr/src/lib/slf4j-log4j12-1.7.12.jar:/usr/src/lib/log4j-1.2.17.jar:/usr/src/lib/central-logging-6.1.0-mapr.jar:/usr/src/lib/antlr4-runtime-4.5.jar:/usr/src/lib/commons-logging-1.1.3-api.jar:/usr/src/lib/commons-logging-1.1.3.jar:/usr/src/lib/commons-lang-2.5.jar:/usr/src/lib/commons-configuration-1.8.jar:/usr/src/lib/commons-collections-3.2.2.jar:/usr/src/lib/jackson-core-2.11.1.jar:/usr/src/lib/jackson-databind-2.11.1.jar:/usr/src/lib/jline-2.11.jar:/usr/src/lib/joda-time-2.0.jar:/usr/src/lib/json-1.8.jar:/usr/src/lib/kafka-clients-1.1.1-mapr-1808.jar:/usr/src/lib/ojai-3.0-mapr-1808.jar:/usr/src/lib/ojai-mapreduce-3.0-mapr-1808.jar:/usr/src/lib/ojai-scala-3.0-mapr-1808.jar:/usr/src/lib/protobuf-java-2.5.0.jar:/usr/src/lib/trove4j-3.0.3.jar:/usr/src/lib/zookeeper-3.4.11-mapr-1808.jar:/usr/src/lib/jackson-annotations-2.11.1.jar com.ubs.ad.data.Kafka2Storage