- {%- if project.redirect -%}
-
- {%- else -%}
-
- {%- endif -%}
-
-
- {%- if project.img -%}
-
- {% include figure.html path=project.img alt="project thumbnail" %}
-
-
- {%- else -%}
-
- {%- endif -%}
-
-
{{ project.title }}
-
{{ project.description }}
-
- {%- if project.github -%}
-
-
- {%- if project.github_stars -%}
-
-
-
-
- {%- endif -%}
-
- {%- endif -%}
-
-
-
-
-
-
-
- {% bibliography -f papers -q @*[selected=true]* %}
-
diff --git a/_includes/social.html b/_includes/social.html
deleted file mode 100644
index 38b5d3b..0000000
--- a/_includes/social.html
+++ /dev/null
@@ -1,96 +0,0 @@
- {%- if site.email -%}
-
- {% endif %}
- {%- if site.telegram_username -%}
-
- {% endif %}
- {%- if site.whatsapp_number -%}
-
- {% endif %}
- {%- if site.orcid_id -%}
-
- {% endif %}
- {%- if site.scholar_userid -%}
-
- {% endif %}
- {%- if site.semanticscholar_id -%}
-
- {% endif %}
- {%- if site.publons_id -%}
-
- {% endif %}
- {%- if site.research_gate_profile -%}
-
- {% endif %}
- {%- if site.github_username -%}
-
- {% endif %}
- {%- if site.linkedin_username -%}
-
- {% endif %}
- {%- if site.twitter_username -%}
-
- {% endif %}
- {%- if site.mastodon_username -%}
-
- {% endif %}
- {%- if site.medium_username -%}
-
- {% endif %}
- {%- if site.quora_username -%}
-
- {% endif %}
- {%- if site.blogger_url -%}
-
- {% endif %}
- {%- if site.work_url -%}
-
- {% endif %}
- {%- if site.wikidata_id -%}
-
- {% endif %}
- {%- if site.strava_userid -%}
-
- {% endif %}
- {%- if site.keybase_username -%}
-
- {% endif %}
- {%- if site.gitlab_username -%}
-
- {% endif %}
- {%- if site.dblp_url -%}
-
- {% endif %}
- {%- if site.stackoverflow_id -%}
-
- {% endif %}
- {%- if site.kaggle_id -%}
-
- {% endif %}
- {%- if site.lastfm_id -%}
-
- {% endif %}
- {%- if site.spotify_id -%}
-
- {% endif %}
- {%- if site.pinterest_id -%}
-
- {% endif %}
- {%- if site.unsplash_id -%}
-
- {% endif %}
- {%- if site.instagram_id -%}
-
- {% endif %}
- {%- if site.facebook_id -%}
-
- {% endif %}
- {%- if site.youtube_id -%}
-
- {% endif %}
- {%- if site.discord_id -%}
-
- {% endif %}
- {%- if site.rss_icon -%}
-
- {% endif %}
diff --git a/_layouts/about.html b/_layouts/about.html
deleted file mode 100644
index ab6674a..0000000
--- a/_layouts/about.html
+++ /dev/null
@@ -1,70 +0,0 @@
----
-layout: default
----
-
-
-
-
-
-
- {% if page.profile -%}
-
- {%- if page.profile.image %}
- {%- assign profile_image_path = page.profile.image | prepend: 'assets/img/' -%}
-
- {% if page.profile.image_circular %}
- {%- assign profile_image_class = "img-fluid z-depth-1 rounded-circle" -%}
- {% else %}
- {%- assign profile_image_class = "img-fluid z-depth-1 rounded" -%}
- {% endif %}
-
- {% include figure.html
- path=profile_image_path
- class=profile_image_class
- alt=page.profile.image -%}
- {% endif -%}
- {%- if page.profile.address %}
-
- {{ page.profile.address }}
-
- {%- endif %}
-
- {{ content }}
-
-
-
- {% if page.news -%}
-
- {%- include news.html %}
- {%- endif %}
-
-
- {% if page.selected_papers -%}
-
- {%- include selected_papers.html %}
- {%- endif %}
-
-
- {%- if page.social %}
-
-
- {% include social.html %}
-
-
-
- {{ site.contact_note }}
-
-
-
-
-
diff --git a/_layouts/archive-category.html b/_layouts/archive-category.html
deleted file mode 100644
index 79aad74..0000000
--- a/_layouts/archive-category.html
+++ /dev/null
@@ -1,27 +0,0 @@
----
-layout: default
----
-
-
-
-
-
-
-
-
- {% for post in page.posts %}
-
- | {{ post.date | date: "%b %-d, %Y" }} |
-
- {{ post.title }}
- |
-
- {% endfor %}
-
-
-
-
diff --git a/_layouts/archive-tag.html b/_layouts/archive-tag.html
deleted file mode 100644
index 66abaeb..0000000
--- a/_layouts/archive-tag.html
+++ /dev/null
@@ -1,27 +0,0 @@
----
-layout: default
----
-
-
-
-
-
-
-
-
- {% for post in page.posts %}
-
- | {{ post.date | date: "%b %-d, %Y" }} |
-
- {{ post.title }}
- |
-
- {% endfor %}
-
-
-
-
diff --git a/_layouts/archive-year.html b/_layouts/archive-year.html
deleted file mode 100644
index 8af1d29..0000000
--- a/_layouts/archive-year.html
+++ /dev/null
@@ -1,27 +0,0 @@
----
-layout: default
----
-
-
-
-
-
-
-
-
- {% for post in page.posts %}
-
- | {{ post.date | date: "%b %-d, %Y" }} |
-
- {{ post.title }}
- |
-
- {% endfor %}
-
-
-
-
diff --git a/_layouts/bib.html b/_layouts/bib.html
deleted file mode 100644
index 718570a..0000000
--- a/_layouts/bib.html
+++ /dev/null
@@ -1,209 +0,0 @@
----
----
-
-
-
- {%- if entry.preview -%}
- {% if entry.preview contains '://' -%}
-

- {%- else -%}
-

- {%- endif -%}
- {%- elsif entry.abbr -%}
- {%- if site.data.venues[entry.abbr] -%}
- {%- assign venue_style = nil -%}
- {%- if site.data.venues[entry.abbr].color != blank -%}
- {%- assign venue_style = site.data.venues[entry.abbr].color | prepend: 'style="background-color:' | append: '"' -%}
- {%- endif -%}
-
{{entry.abbr}}
- {%- else -%}
-
{{entry.abbr}}
- {%- endif -%}
- {%- endif -%}
-
-
-
-
-
-
{{entry.title}}
-
-
- {% assign author_array_size = entry.author_array | size %}
-
- {% assign author_array_limit = author_array_size %}
- {%- if site.max_author_limit and author_array_size > site.max_author_limit %}
- {% assign author_array_limit = site.max_author_limit %}
- {% endif %}
-
- {%- for author in entry.author_array limit: author_array_limit -%}
- {%- assign author_is_self = false -%}
- {%- assign author_last_name = author.last | remove: "¶" | remove: "&" | remove: "*" | remove: "†" | remove: "^" -%}
- {%- if site.scholar.last_name contains author_last_name -%}
- {%- if site.scholar.first_name contains author.first -%}
- {%- assign author_is_self = true -%}
- {%- endif -%}
- {%- endif -%}
- {%- assign coauthor_url = nil -%}
- {%- if site.data.coauthors[author_last_name] -%}
- {%- for coauthor in site.data.coauthors[author_last_name] -%}
- {%- if coauthor.firstname contains author.first -%}
- {%- assign coauthor_url = coauthor.url -%}
- {%- break -%}
- {%- endif -%}
- {%- endfor -%}
- {%- endif -%}
-
- {%- if forloop.length > 1 -%}
- {%- if forloop.first == false -%}, {%- endif -%}
- {%- if forloop.last and author_array_limit == author_array_size -%}and {%- endif -%}
- {%- endif -%}
- {%- if author_is_self -%}
-
{{author.first}} {{author.last}}
- {%- else -%}
- {%- if coauthor_url -%}
-
{{author.first}} {{author.last}}
- {%- else -%}
- {{author.first}} {{author.last}}
- {%- endif -%}
- {%- endif -%}
- {%- endfor -%}
- {%- assign more_authors = author_array_size | minus: author_array_limit -%}
-
- {%- assign more_authors_hide = more_authors | append: " more author" -%}
- {%- if more_authors > 0 -%}
- {%- if more_authors > 1 -%}
- {%- assign more_authors_hide = more_authors_hide | append: "s" -%}
- {%- endif -%}
- {%- assign more_authors_show = '' -%}
- {%- for author in entry.author_array offset: author_array_limit -%}
- {%- assign more_authors_show = more_authors_show | append: author.first | append: " " | append: author.last -%}
- {%- unless forloop.last -%}
- {%- assign more_authors_show = more_authors_show | append: ", " -%}
- {%- endunless -%}
- {%- endfor -%}
- , and
-
{{more_authors_hide}}
- {%- endif -%}
-
-
-
-
- {% assign proceedings = "inproceedings,incollection" | split: ','%}
- {% assign thesis = "thesis,mastersthesis,phdthesis" | split: ','%}
- {% if entry.type == "article" -%}
- {%- capture entrytype -%}
{{entry.journal}}{%- endcapture -%}
- {%- elsif proceedings contains entry.type -%}
- {%- capture entrytype -%}
In {{entry.booktitle}} {%- endcapture -%}
- {%- elsif thesis contains entry.type -%}
- {%- capture entrytype -%}
{{entry.school}} {%- endcapture -%}
- {%- else -%}
- {%- capture entrytype -%}{%- endcapture -%}
- {%- endif -%}
- {%- if entry.month -%}
- {%- capture entrymonth -%}{{ " " }}{{ entry.month | capitalize }}{%- endcapture -%}
- {%- endif -%}
- {%- if entry.year -%}
- {%- capture entryyear -%}{{ " " }}{{entry.year}}{%- endcapture -%}
- {%- endif -%}
- {% assign entrytype_text = entrytype | strip_html | strip %}
- {%- capture periodical -%}{{ entrytype }}{%- if entrytype_text != "" and entryyear != "" -%}, {%- endif -%}{{ entrymonth }}{{ entryyear }}{%- endcapture -%}
-
- {{ periodical | strip }}
-
-
- {{ entry.note | strip }}
-
-
-
-
- {%- if entry.abstract %}
-
Abs
- {%- endif %}
- {%- if entry.arxiv %}
-
arXiv
- {%- endif %}
- {%- if entry.bibtex_show %}
-
Bib
- {%- endif %}
- {%- if entry.html %}
-
HTML
- {%- endif %}
- {%- if entry.pdf %}
- {% if entry.pdf contains '://' -%}
-
PDF
- {%- else -%}
-
PDF
- {%- endif %}
- {%- endif %}
- {%- if entry.supp %}
- {% if entry.supp contains '://' -%}
-
Supp
- {%- else -%}
-
Supp
- {%- endif %}
- {%- endif %}
- {%- if entry.blog %}
-
Blog
- {%- endif %}
- {%- if entry.code %}
-
Code
- {%- endif %}
- {%- if entry.poster %}
- {% if entry.poster contains '://' -%}
-
Poster
- {%- else -%}
-
Poster
- {%- endif %}
- {%- endif %}
- {%- if entry.slides %}
- {% if entry.slides contains '://' -%}
-
Slides
- {%- else -%}
-
Slides
- {%- endif %}
- {%- endif %}
- {%- if entry.website %}
-
Website
- {%- endif %}
-
- {% if site.badges %}
-
- {%- if site.badges.altmetric_badge or entry.altmetric %}
-
- {%- endif %}
- {%- if site.badges.dimensions_badge or entry.dimensions %}
-
- {%- endif %}
-
- {%- endif %}
-
- {% if entry.abstract -%}
-
-
- {%- endif -%}
-
- {% if entry.bibtex_show -%}
-
-
- {% highlight bibtex %}{{ entry.bibtex | hideCustomBibtex }}{% endhighlight %}
-
- {%- endif %}
-
-
diff --git a/_layouts/cv.html b/_layouts/cv.html
deleted file mode 100644
index bb3d85a..0000000
--- a/_layouts/cv.html
+++ /dev/null
@@ -1,35 +0,0 @@
----
-layout: default
----
-
-
-
-
-
-
-
- {% for entry in site.data.cv %}
-
-
{{ entry.title }}
-
- {% if entry.type == "list" %}
- {% include cv/list.html %}
- {% elsif entry.type == "map" %}
- {% include cv/map.html %}
- {% elsif entry.type == "nested_list" %}
- {% include cv/nested_list.html %}
- {% elsif entry.type == "time_table" %}
- {% include cv/time_table.html %}
- {% else %}
- {{ entry.contents }}
- {% endif %}
-
-
- {% endfor %}
-
-
-
diff --git a/_layouts/default.html b/_layouts/default.html
deleted file mode 100644
index 6fdc4f7..0000000
--- a/_layouts/default.html
+++ /dev/null
@@ -1,36 +0,0 @@
-
-
-
-
-
- {%- if page.redirect -%}
-
- {%- endif -%}
- {% include head.html %}
-
-
-
-
-
-
- {%- include header.html %}
-
-
-
- {{ content }}
-
-
-
- {%- include footer.html %}
-
-
- {% include scripts/jquery.html %}
- {% include scripts/bootstrap.html %}
- {% include scripts/masonry.html %}
- {% include scripts/misc.html %}
- {% include scripts/badges.html %}
- {% include scripts/mathjax.html %}
- {% include scripts/analytics.html %}
- {% include scripts/progressBar.html %}
-
-
diff --git a/_layouts/distill.html b/_layouts/distill.html
deleted file mode 100644
index bc323ce..0000000
--- a/_layouts/distill.html
+++ /dev/null
@@ -1,117 +0,0 @@
-
-
-
-
- {%- include head.html %}
-
- {% include scripts/jquery.html %}
- {% include scripts/mathjax.html %}
-
-
-
-
- {% if page._styles %}
-
-
- {%- endif %}
-
-
-
-
-
-
-
-
-
- {%- include header.html %}
-
-
-
-
-
- {{ page.title }}
- {{ page.description }}
-
-
-
-
-
- {% if page.toc -%}
-
-
-
- {%- endif %}
-
- {{ content }}
-
-
-
-
-
-
-
-
-
- {%- if site.disqus_shortname and page.disqus_comments -%}
- {% include disqus.html %}
- {%- endif %}
- {%- if site.giscus.repo and page.giscus_comments -%}
- {% include giscus.html %}
- {%- endif -%}
-
-
-
-
- {%- include footer.html %}
-
- {% include scripts/bootstrap.html %}
- {% include scripts/analytics.html %}
- {% include scripts/progressBar.html %}
-
-
diff --git a/_layouts/none.html b/_layouts/none.html
deleted file mode 100644
index b92f652..0000000
--- a/_layouts/none.html
+++ /dev/null
@@ -1 +0,0 @@
-{{content}}
diff --git a/_layouts/page.html b/_layouts/page.html
deleted file mode 100644
index 9e34f40..0000000
--- a/_layouts/page.html
+++ /dev/null
@@ -1,16 +0,0 @@
----
-layout: default
----
-
-
-
-
-
-
- {{ content }}
-
-
-
diff --git a/_layouts/post.html b/_layouts/post.html
deleted file mode 100644
index ad513ff..0000000
--- a/_layouts/post.html
+++ /dev/null
@@ -1,53 +0,0 @@
----
-layout: default
----
-
-{%- assign year = page.date | date: "%Y" -%}
-{%- assign tags = page.tags | join: "" -%}
-{%- assign categories = page.categories | join: "" -%}
-
-{% if page._styles %}
-
-
-{% endif %}
-
-
-
-
-
-
- {{ content }}
-
-
- {%- if site.disqus_shortname and page.disqus_comments -%}
- {% include disqus.html %}
- {%- endif %}
- {%- if site.giscus.repo and page.giscus_comments -%}
- {% include giscus.html %}
- {%- endif -%}
-
-
diff --git a/_news/announcement_cmpb.md b/_news/announcement_cmpb.md
deleted file mode 100644
index e11e45b..0000000
--- a/_news/announcement_cmpb.md
+++ /dev/null
@@ -1,17 +0,0 @@
----
-layout: post
-title: One paper has been accepted by Computer Methods and Programs in Biomedicine (IF = 6.1)
-date: 2024-03-02 00:00:00
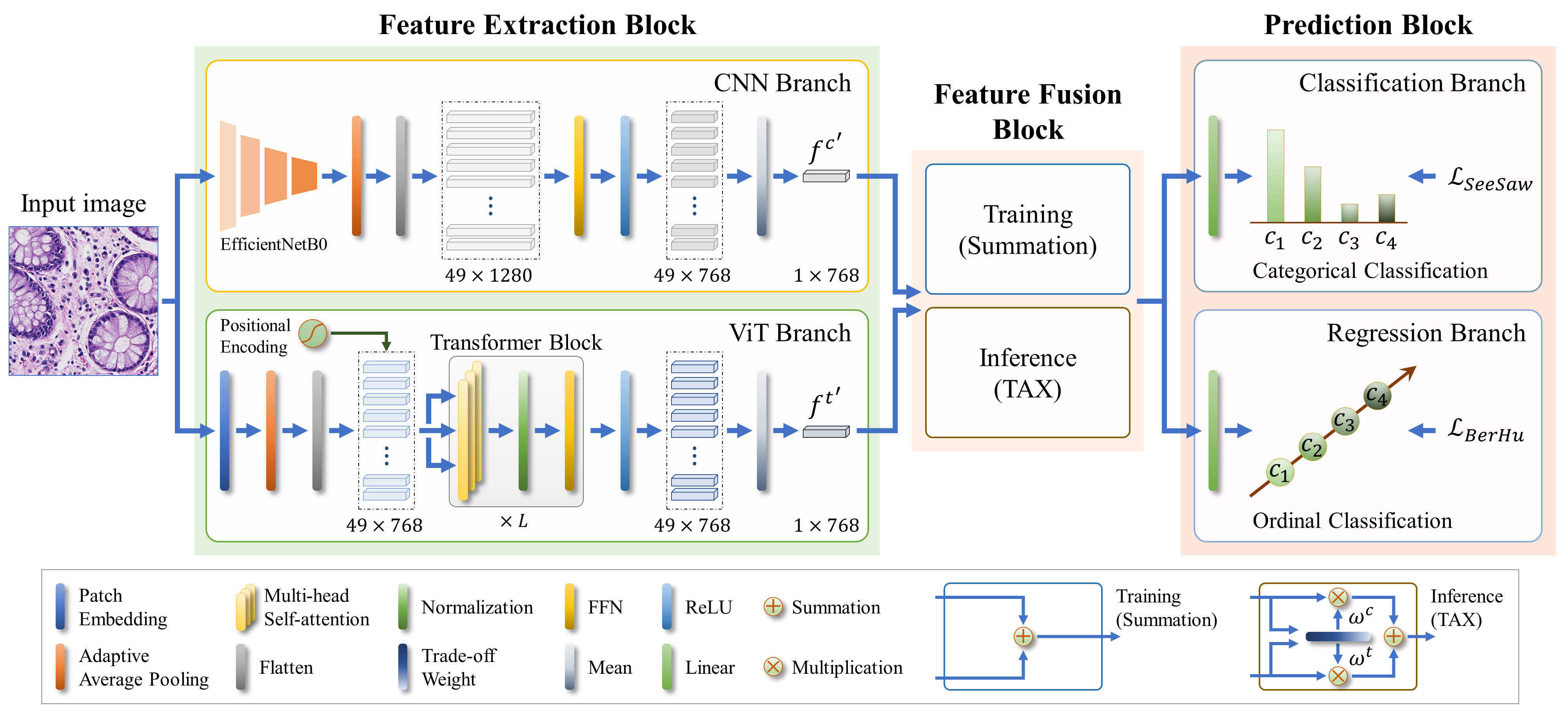
-description: Congratulations! Our paper "DAX-Net - a dual-branch dual-task adaptive cross-weight feature fusion network for robust multi-class cancer classification in pathology images" has been accepted in Computer Methods and Programs in Biomedicine (IF = 6.1)
-tags: formatting links
-categories: sample-posts
-inline: false
----
-
-We are pleased to announce that our paper titled "DAX-Net: A Dual-Branch Dual-Task Adaptive Cross-Weight Feature Fusion Network for Robust Multi-Class Cancer Classification in Pathology Images" has been accepted by Computer Methods and Programs in Biomedicine **(IF = 6.1)**.
-
-
-
-This is the study I conducted during my pursuit of a master's degree under the supervision of Prof. Jin Tae Kwak.
-
-The code, manuscript, and datasets will be released soon!
diff --git a/_news/announcement_hyundai.md b/_news/announcement_hyundai.md
deleted file mode 100644
index 6402961..0000000
--- a/_news/announcement_hyundai.md
+++ /dev/null
@@ -1,21 +0,0 @@
----
-layout: post
-title: I am accepted as the final recipient of the Hyundai Global Fellowship program!
-date: 2022-01-27 16:40:00
-description: Hyundai Motor Chung Mong-koo Scholarship
-tags: formatting links
-categories: sample-posts
-inline: false
----
-
-I am pleased to announce that I am selected as the final recipient of the Hyundai Global Fellowship program.
-
-This scholarship has a big coverage.
-- Full tuition fee (including entrance fee)
-- Learning support fee (1,000,000won per month)
-- Settlement allowance (only 1 time when I enter the school)
-- Graduation celebration incentive (only 1 time when graduate).
-
-In the 2023 Spring semester, I will pursue a Master’s degree in Computer Engineering at Korea University, Korea, with full support from this scholarship!
-
-Thank you for reading.
\ No newline at end of file
diff --git a/_news/announcement_miccai2024.md b/_news/announcement_miccai2024.md
deleted file mode 100644
index 13eb1b5..0000000
--- a/_news/announcement_miccai2024.md
+++ /dev/null
@@ -1,19 +0,0 @@
----
-layout: post
-title: One paper has been accepted by MICCAI2024
-date: 2024-06-17 00:00:00
-description: One paper has been accepted by MICCAI2024
-tags: formatting links
-categories: sample-posts
-inline: false
----
-
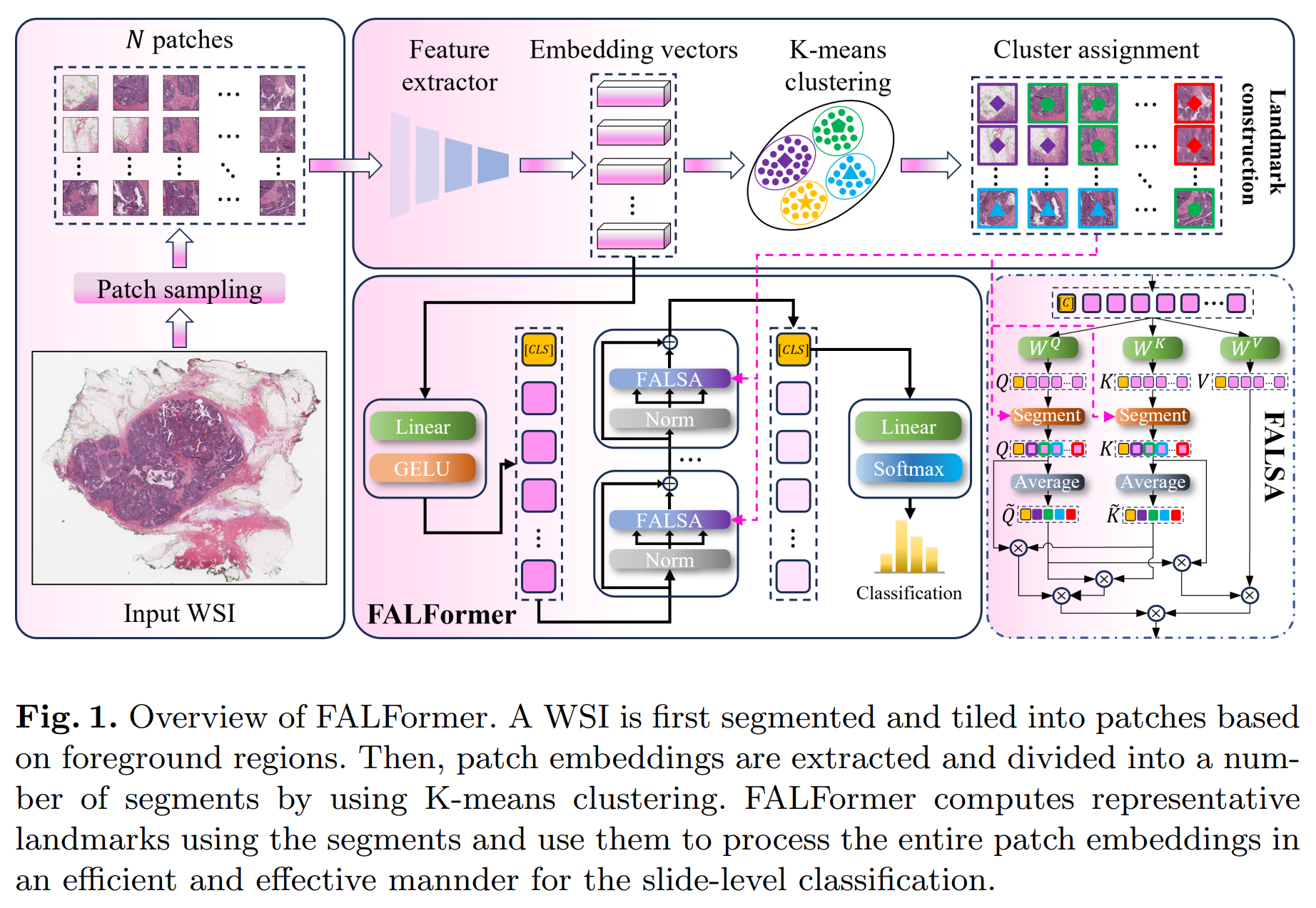
-## FALFormer: Feature-aware Landmarks self-attention for Whole-slide Image Classification
-*Doanh C. Bui, Trinh T. L. Vuong, Jin Tae Kwak*
-
-**Abstract:** Slide-level classification for whole-slide images (WSIs) has been widely recognized as a crucial problem in digital and computational pathology. Current approaches commonly consider WSIs as a bag of cropped patches and process them via multiple instance learning due to the large number of patches, which cannot fully explore the relationship among patches; in other words, the global information cannot be fully incorporated into decision making. Herein, we propose an efficient and effective slide-level classification model, named as FALFormer, that can process a WSI as a whole so as to fully exploit the relationship among the entire patches and to improve the classification performance. FALFormer is built based upon Transformers and self-attention mechanism. To lessen the computational burden of the original self-attention mechanism and to process the entire patches together in a WSI, FALFormer employs Nystrom self-attention which approximates the computation by using a smaller number of tokens or landmarks. For effective learning, FALFormer introduces feature-aware landmarks to enhance the representation power of the landmarks and the quality of the approximation. We systematically evaluate the performance of FALFormer using two public datasets, including CAMELYON16 and TCGA-BRCA. The experimental results demonstrate that FALFormer achieves superior performance on both datasets, outperforming the state-of-the-art methods for the slide-level classification. This suggests that FALFormer can facilitate an accurate and precise analysis of WSIs, potentially leading to improved diagnosis and prognosis on WSIs.
-
-
-
-This work was conducted under the supervision of Prof. Jin Tae Kwak during my master's degree.
-Paper and code will be released soon!
diff --git a/_news/announcement_prl.md b/_news/announcement_prl.md
deleted file mode 100644
index 67c110f..0000000
--- a/_news/announcement_prl.md
+++ /dev/null
@@ -1,30 +0,0 @@
----
-layout: post
-title: One paper has been accepted in Pattern Recognition Letters (IF = 5.1)
-date: 2023-09-26 00:00:00
-description: Congratulations! Improving Human-object Interaction with Auxiliary Semantic Information and Enhanced Instance Representation has been accepted by Pattern Recognition Letters (IF = 5.1)
-
-tags: formatting links
-categories: sample-posts
-inline: false
----
-
-Our study **"Improving Human-object Interaction with Auxiliary Semantic Information and Enhanced Instance Representation"** has been accepted to be published by "**Pattern Recognition Letters" (SCI, Q1, IF = 5.1).**
-I want to give special thanks to Thinh V. Le and Huyen Nguyen for their efforts in this work. This study is also the result of undergraduate thesis of Thinh & Huyen. This study is also on collaboration with UIT-Together Research Group.
-In this work, we propose three key modules: Enhanced Interaction Pointers (EIP), Semantic-guided (SG) and Multi-level cross-attention (MCA) based on the HOTR model to improve itself for human-object interaction (HOI) problem.
-
-Authorship contribution statement:
-- Khang Nguyen: Project administration, Supervision, Idea confirmation.
-- Thinh V. Le: Implementation (Idea implementation, feature extraction, training & evaluation on two benchmarks: V-COCO and HICO-DET), Writing – review & editing
-- Huyen Nguyen: Writing (specially focus on linguistic aspects) – review & editing
-- **Doanh C. Bui**: Conceptualization (EIP, SG, MCA), Implementation (only support Thinh V. Le), Writing – review & editing
-
-

-
-We will publish our source code and checkpoints for this study soon!
-
-**P/s**: I really appreciate the efforts of two undergraduate students: Thinh V. Le and Huyen Nguyen, who were working with me when we were all undergraduate students, to complete this study, specially Thinh. Thinh is a hard-working student. His self-study ability, knowledge, and coding are very good. Most of works of implementation in this study are done by him. I hope that in the future, I will have chance to continue to do research with Thinh. And I wish he will continue to develop himself, leverage all chances coming to him, to become an excellent student in the future! Huyen Nguyen also showed her effort and performed co-working ability pretty well, I also believe that she will achieve further achievements in the future.
-
-**P/s 2**: We all know that papers are just the results of researching period, and they are not that all, they are just some milestones. We should continue to try our best in the academic career, to bring not only theorical but also practical research to the community. There is a long road to go for achieving this.
-
-Thank you for reading!
diff --git a/_news/announcement_tcsvt.md b/_news/announcement_tcsvt.md
deleted file mode 100644
index 1a118de..0000000
--- a/_news/announcement_tcsvt.md
+++ /dev/null
@@ -1,17 +0,0 @@
----
-layout: post
-title: One paper has been accepted in IEEE Transactions on Circuits and Systems for Video Technology (IF = 8.4)
-date: 2024-03-06 00:00:00
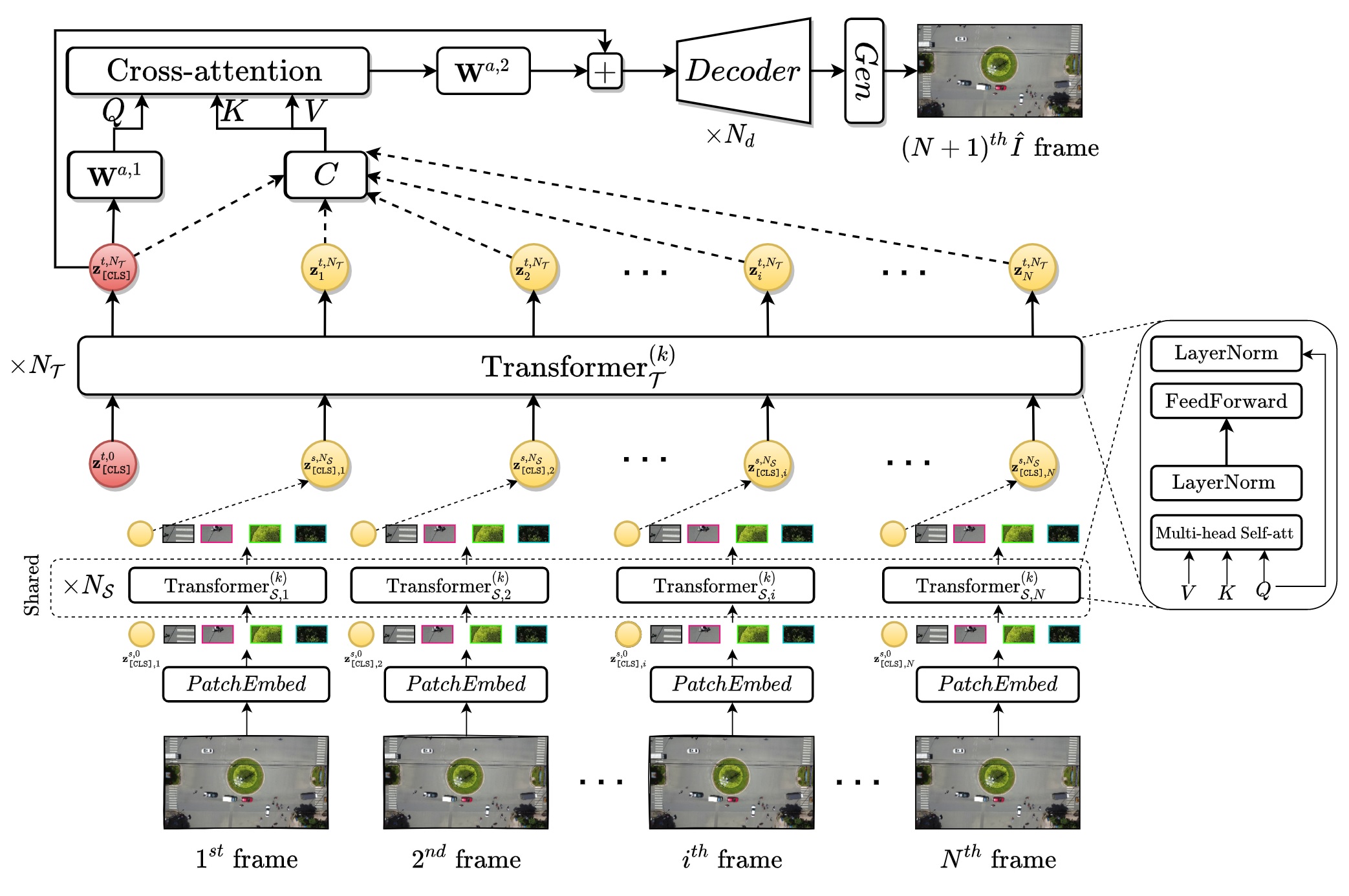
-description: Congratulations! Our paper "Transformer-based Spatio-Temporal Unsupervised Traffic Anomaly Detection in Aerial Videos" has been accepted by IEEE Transactions on Circuits and Systems for Video Technology (IF = 8.4)
-tags: formatting links
-categories: sample-posts
-inline: false
----
-
-We are pleased to announce that our paper titled "Transformer-based Spatio-Temporal Unsupervised Traffic Anomaly Detection in Aerial Videos" has been accepted by IEEE Transactions on Circuits and Systems for Video Technology **(IF = 8.4)**.
-
-Authors: Tung Minh Tran, Doanh C. Bui, Tam V. Nguyen, and Khang Nguyen. This paper is the result of a joint project between myself and Dr. Tung Minh Tran (University of Information Technology, VNU-HCM), Prof. Tam V. Nguyen (University of Dayton), and Prof. Khang Nguyen (University of Information Technology, VNU-HCM).
-
-In this paper, we present a Transformer-based method for unsupervised anomaly detection in the context of traffic at roundabouts. The full manuscript and code will be released soon!
-
-
diff --git a/_news/announcement_thompson b/_news/announcement_thompson
deleted file mode 100644
index 85bce64..0000000
--- a/_news/announcement_thompson
+++ /dev/null
@@ -1,11 +0,0 @@
----
-layout: post
-title: One paper has been accepted in MICCAI2023-Thompson (1st Place in Track 2 - Visual Question Answering)
-date: 2024-02-05 00:00:00
-description: Congratulations! Our paper "QuIIL at T3 challenge - Towards Automation in Life-Saving Intervention Procedures from First-Person View" has been accepted in MICCAI2023-Thompson workshop.
-tags: formatting links
-categories: sample-posts
-inline: false
----
-
-

\ No newline at end of file
diff --git a/_news/announcement_tmi.md b/_news/announcement_tmi.md
deleted file mode 100644
index 13f59c1..0000000
--- a/_news/announcement_tmi.md
+++ /dev/null
@@ -1,16 +0,0 @@
----
-layout: post
-title: One paper has been accepted by IEEE Transactions on Medical Imaging (IF = 8.9)
-date: 2024-07-25 00:00:00
-description: One paper has been accepted by IEEE Transactions on Medical Imaging (IF = 8.9)
-tags: formatting links
-categories: sample-posts
-inline: false
----
-
-## Spatially-constrained and -unconstrained bi-graph interaction network for multi-organ pathology image classification
-*Doanh C. Bui, Boram Song, Kyungeun Kim, and Jin Tae Kwak*
-
-

-
-This work was conducted under the supervision of Prof. Jin Tae Kwak during my master's degree.
diff --git a/_news/announcement_uitopenviic.md b/_news/announcement_uitopenviic.md
deleted file mode 100644
index 56c953e..0000000
--- a/_news/announcement_uitopenviic.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-layout: post
-title: UIT-OpenViIC - An Open-domain Benchmark for Evaluating Image Captioning in Vietnamese (Under review)
-date: 2023-07-04 13:50:00
-description: (Under review) UIT-OpenViIC - An Open-domain Benchmark for Evaluating Image Captioning in Vietnamese
-tags: formatting links
-categories: sample-posts
-inline: false
----
-
-Our collaborative project titled "UIT-OpenViIC: An Open-domain Benchmark for Evaluating Image Captioning in Vietnamese" is currently under review for the first round. The paper involves the joint efforts of BSc. Nghia Hieu Nguyen.
-
-

\ No newline at end of file
diff --git a/_news/announcement_upar.md b/_news/announcement_upar.md
deleted file mode 100644
index c6fa254..0000000
--- a/_news/announcement_upar.md
+++ /dev/null
@@ -1,23 +0,0 @@
----
-layout: post
-title: One paper has been accepted in WACVW (1st Place in Track 1 - UPAR challenge 2024)
-date: 2023-11-23 00:00:00
-description: Congratulations! 1st Place in Track 1 - UPAR challenge 2024 at WACV2024-RWS Workshop
-tags: formatting links
-categories: sample-posts
-inline: false
----
-
-We are thrilled to announce our outstanding achievement, securing the 1st position in Track 1 of the UPAR Challenge at the WACV2024-RWS Workshop. Our accomplishment is attributed to the development of an advanced AI-based solution addressing the crucial task of pedestrian attribute recognition, with significant implications for applications such as tracking and retrieval.
-
-Meet our dedicated team:
-
-1. Doanh C. Bui (Leader): Master's student at the School of Electrical Engineering, Korea University
-2. Thinh V. Le: Undergraduate researcher at the University of Information Technology, VNU-HCM
-3. Hung Ba Ngo: Postdoctoral researcher at the Graduate School of Data Science, Chonnam National University
-
-

-
-Furthermore, we are honored to share that our paper presenting this groundbreaking solution, titled "C2T-Net: Cross-Fused Transformer-Style Networks for Pedestrian Attribute Recognition," has been accepted, and we will be delivering an oral presentation at the WACV2024-RWS Workshop. This recognition underscores the innovation and impact of our work in advancing the field of pedestrian attribute recognition.
-
-Please check our published source code [here](https://github.com/caodoanh2001/upar_challenge).
\ No newline at end of file
diff --git a/_pages/about.md b/_pages/about.md
deleted file mode 100644
index 8b2e96f..0000000
--- a/_pages/about.md
+++ /dev/null
@@ -1,23 +0,0 @@
----
-layout: about
-title: about
-permalink: /
-subtitle:
University of Information Technology. Ho Chi Minh city, Vietnam.
-subtitle:
QuIIL, School of Electrical and Engineering, Korea University. Seoul, Republic of Korea.
-
-profile:
- align: right
- image: prof_pic.jpg
- image_circular: false # crops the image to make it circular
- address: >
-
Seoul, Republic of Korea
-
-news: true # includes a list of news items
-selected_papers: true # includes a list of papers marked as "selected={true}"
-social: true # includes social icons at the bottom of the page
----
-
-I am Doanh C. Bui, a Bachelor of Computer Science graduate from the University of Information Technology (UIT), VNU-HCM. I completed my degree in September 2022. For a brief period, from November 2022 to February 2023, I served as a teaching assistant at the Faculty of Software Engineering, UIT. Currently, I am pursuing a master's degree in the School of Electrical Engineering at Korea University, where I am in my third semester, under the supervision of Prof. Jin Tae Kwak.
-
-Throughout my academic journey, I have focused on various aspects of Computer Vision, specifically in areas such as Object Detection, Document Image Understanding, Image Captioning, and Human-Object Interaction. Presently, my research revolves around leveraging image processing techniques for histopathology images.
-
diff --git a/_pages/cv.md b/_pages/cv.md
deleted file mode 100644
index cf7e53c..0000000
--- a/_pages/cv.md
+++ /dev/null
@@ -1,8 +0,0 @@
----
-layout: cv
-permalink: /cv/
-title: cv
-nav: true
-nav_order: 4
-cv_pdf: doanhbc-2022_CV.pdf
----
diff --git a/_pages/dropdown.md b/_pages/dropdown.md
deleted file mode 100644
index a4d670c..0000000
--- a/_pages/dropdown.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-layout: page
-title: submenus
-nav: false
-nav_order: 6
-dropdown: true
-children:
- - title: publications
- permalink: /publications/
- - title: divider
- - title: projects
- permalink: /projects/
----
\ No newline at end of file
diff --git a/_pages/dropdown/index.html b/_pages/dropdown/index.html
new file mode 100644
index 0000000..9bb636c
--- /dev/null
+++ b/_pages/dropdown/index.html
@@ -0,0 +1 @@
+
submenus | Doanh C. Bui
\ No newline at end of file
diff --git a/_pages/projects.md b/_pages/projects.md
deleted file mode 100644
index d31459b..0000000
--- a/_pages/projects.md
+++ /dev/null
@@ -1,58 +0,0 @@
----
-layout: page
-title: projects
-permalink: /projects/
-description: A growing collection of your cool projects.
-nav: false
-nav_order: 2
-display_categories: [work, fun]
-horizontal: false
----
-
-
-
-{%- if site.enable_project_categories and page.display_categories %}
-
- {%- for category in page.display_categories %}
-
{{ category }}
- {%- assign categorized_projects = site.projects | where: "category", category -%}
- {%- assign sorted_projects = categorized_projects | sort: "importance" %}
-
- {% if page.horizontal -%}
-
-
- {%- for project in sorted_projects -%}
- {% include projects_horizontal.html %}
- {%- endfor %}
-
-
- {%- else -%}
-
- {%- for project in sorted_projects -%}
- {% include projects.html %}
- {%- endfor %}
-
- {%- endif -%}
- {% endfor %}
-
-{%- else -%}
-
- {%- assign sorted_projects = site.projects | sort: "importance" -%}
-
- {% if page.horizontal -%}
-
-
- {%- for project in sorted_projects -%}
- {% include projects_horizontal.html %}
- {%- endfor %}
-
-
- {%- else -%}
-
- {%- for project in sorted_projects -%}
- {% include projects.html %}
- {%- endfor %}
-
- {%- endif -%}
-{%- endif -%}
-
diff --git a/_pages/publications.md b/_pages/publications.md
deleted file mode 100644
index 9cb12e2..0000000
--- a/_pages/publications.md
+++ /dev/null
@@ -1,18 +0,0 @@
----
-layout: page
-permalink: /publications/
-title: publications
-description: Feel free to visit my Google Scholar profile at https://scholar.google.com/citations?user=WHviN4AAAAAJ&hl=vi&oi=ao
-years: [2021, 2022, 2023, 2024]
-nav: true
-nav_order: 1
----
-
-
-
-{%- for y in page.years %}
-
{{y}}
- {% bibliography -f papers -q @*[year={{y}}]* %}
-{% endfor %}
-
-
\ No newline at end of file
diff --git a/_pages/repositories.md b/_pages/repositories.md
deleted file mode 100644
index c7d95b8..0000000
--- a/_pages/repositories.md
+++ /dev/null
@@ -1,30 +0,0 @@
----
-layout: page
-permalink: /repositories/
-title: repositories
-description: Edit the `_data/repositories.yml` and change the `github_users` and `github_repos` lists to include your own GitHub profile and repositories.
-nav: false
-nav_order: 3
----
-
-## GitHub users
-
-{% if site.data.repositories.github_users %}
-
- {% for user in site.data.repositories.github_users %}
- {% include repository/repo_user.html username=user %}
- {% endfor %}
-
-{% endif %}
-
----
-
-## GitHub Repositories
-
-{% if site.data.repositories.github_repos %}
-
- {% for repo in site.data.repositories.github_repos %}
- {% include repository/repo.html repository=repo %}
- {% endfor %}
-
-{% endif %}
diff --git a/_pages/teaching.md b/_pages/teaching.md
deleted file mode 100644
index f120901..0000000
--- a/_pages/teaching.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-layout: page
-permalink: /teaching/
-title: teaching
-description: Materials for courses you taught. Replace this text with your description.
-nav: false
-nav_order: 5
----
-
-For now, this page is assumed to be a static description of your courses. You can convert it to a collection similar to `_projects/` so that you can have a dedicated page for each course.
-
-Organize your courses by years, topics, or universities, however you like!
\ No newline at end of file
diff --git a/_plugins/external-posts.rb b/_plugins/external-posts.rb
deleted file mode 100644
index e4fd5eb..0000000
--- a/_plugins/external-posts.rb
+++ /dev/null
@@ -1,36 +0,0 @@
-require 'feedjira'
-require 'httparty'
-require 'jekyll'
-
-module ExternalPosts
- class ExternalPostsGenerator < Jekyll::Generator
- safe true
- priority :high
-
- def generate(site)
- if site.config['external_sources'] != nil
- site.config['external_sources'].each do |src|
- p "Fetching external posts from #{src['name']}:"
- xml = HTTParty.get(src['rss_url']).body
- feed = Feedjira.parse(xml)
- feed.entries.each do |e|
- p "...fetching #{e.url}"
- slug = e.title.downcase.strip.gsub(' ', '-').gsub(/[^\w-]/, '')
- path = site.in_source_dir("_posts/#{slug}.md")
- doc = Jekyll::Document.new(
- path, { :site => site, :collection => site.collections['posts'] }
- )
- doc.data['external_source'] = src['name'];
- doc.data['feed_content'] = e.content;
- doc.data['title'] = "#{e.title}";
- doc.data['description'] = e.summary;
- doc.data['date'] = e.published;
- doc.data['redirect'] = e.url;
- site.collections['posts'].docs << doc
- end
- end
- end
- end
- end
-
-end
diff --git a/_plugins/hideCustomBibtex.rb b/_plugins/hideCustomBibtex.rb
deleted file mode 100644
index 4a852fd..0000000
--- a/_plugins/hideCustomBibtex.rb
+++ /dev/null
@@ -1,15 +0,0 @@
- module Jekyll
- module HideCustomBibtex
- def hideCustomBibtex(input)
- keywords = @context.registers[:site].config['filtered_bibtex_keywords']
-
- keywords.each do |keyword|
- input = input.gsub(/^.*#{keyword}.*$\n/, '')
- end
-
- return input
- end
- end
-end
-
-Liquid::Template.register_filter(Jekyll::HideCustomBibtex)
diff --git a/_posts/2023-07-08-faster-rcnn.md b/_posts/2023-07-08-faster-rcnn.md
deleted file mode 100644
index 672f13f..0000000
--- a/_posts/2023-07-08-faster-rcnn.md
+++ /dev/null
@@ -1,645 +0,0 @@
----
-layout: post
-title: Faster R-CNN - Phương pháp phát hiện đối tượng 02 giai đoạn và lịch sử
-date: 2023-07-08 13:50:00
-description: Faster R-CNN - Phương pháp phát hiện đối tượng 02 giai đoạn và lịch sử
-tags: formatting links
-categories: sample-posts
-inline: false
----
-
-## Lời dẫn
-
-Phát hiện đối tượng là một trong các bài toán cơ sở của lĩnh vực Thị giác máy tính, và hiện vẫn được nghiên cứu rất sôi nổi. Mỗi năm, tại các hội nghị lớn như CVPR, ICCV, ECCV, ICLR đều xuất hiện các công bố liên quan đến bài toán này. Nhận thấy phát hiện đối tượng là bài toán quan trọng và là nền tảng giúp phát triển các bài toán khác trong thực tế, nhóm sinh viên lựa chọn và thực hiện tìm hiểu về bài toán này.
-
-## Các nghiên cứu trước khi có Faster R-CNN
-
-Hiện nay, các phương pháp phát hiện đối tượng được phân thành 02 loại: 02 giai đoạn và 01 giai đoạn. Đối với 01 giai đoạn sẽ được chia thành 02 nhánh phương pháp khác: anchor-free và anchor-based. Tuy nhiên, trong nội dung tiểu luận này, nhóm sinh viên chỉ tìm hiểu về phương pháp Faster R-CNN, và phương pháp này thuộc nhóm phương pháp 02 giai đoạn. Trước khi Faster R-CNN ra đời, đã có sự xuất hiện của 02 phương pháp: R-CNN và Fast R-CNN, trong đó Fast R-CNN là một cải tiến vô cùng hiệu quả của R-CNN, và Faster R-CNN là một bước phát triển lớn từ Fast R-CNN. Để trình bày Faster R-CNN, nhóm sinh viên sẽ nói lại sơ qua về phương pháp R-CNN và Fast R-CNN.
-
-### R-CNN
-
-Vào thời điểm trước khi nhóm phương pháp R-CNN ra đời, các phương pháp phát hiện đối tượng thường dựa vào đặc điểm của ảnh như màu sắc, và các thuật toán sử dụng mang hơi hướng phân cụm. R-CNN ra đời đánh dấu kỷ nguyên sử dụng kỹ thuật học sâu cho bài toán phát hiện đối tượng.
-
-
-Hình 1. Minh họa phương pháp R-CNN [1].
-
-Phương pháp này có thể được mô tả đơn giản như sau: đầu tiên thuật toán **selective search** sẽ chọn ra khoảng $N$ vùng trên ảnh có khả năng cao chứa đối tượng. Thuật toán này chủ yếu dựa vào các đặc điểm bức ảnh như màu sắc. Trong bài báo gốc, các tác giả sử dụng $$N = 2000$$, tức sẽ có $$2000$$ vùng được đề xuất trên ảnh. Từ 2000 vùng này, ta sẽ tiến hành cắt ra từ ảnh gốc, và một mạng CNN sẽ được sử dụng để trích xuất đặc trưng của 2000 vùng ảnh này. Sau đó, từ lớp đặc trưng cuối cùng sẽ đi qua 1 lớp FC để tính toán một bộ offset $$(\delta x, \delta y, \delta w, \delta h)$$, trong đó $$(\delta x, \delta y)$$ là offset tọa độ tâm của đối tượng, $$(\delta w, \delta h)$$ là offset chiều rộng và chiều cao của đối tượng. Như vậy, mạng sẽ học cách bo sát đối tượng và phân lớp đối tượng từ N vùng truyền vào ban đầu. Đối tượng sẽ được phân lớp bằng thuật toán SVM (Support Vector Machine).
-
-> Q: offset là gì?
-
-> A: offset gọi là phần bù. Tức là ban đầu selective search chọn ra 2000 vùng. 2000 vùng này đều có tọa độ (x, y, w, h). Tuy nhiên nó chưa bo sát đối tượng, ta cần một nhánh FC học cách bo sát, nhưng ta không học ra tọa độ chính xác, mà từ tọa độ ở selective search ta căn chỉnh lại, đó gọi là offset.
-
-Vậy ở đây chúng ta thấy điều gì? R-CNN phải thực hiện trích xuất đặc trưng cho $$2000$$ vùng ảnh, như thế rất tốn thời gian. Cuộc sống luôn phải vận động và phát triển, do đó Fast R-CNN ra đời để khắc phục điểm yếu chí mạng này của R-CNN.
-
-### Fast R-CNN
-
-Về cơ bản, Fast R-CNN vẫn giữ ý tưởng 02 giai đoạn của R-CNN. Selective Search vẫn được sử dụng để tìm 2000 vùng có khả năng chứa đối tượng, tuy nhiên điểm khác biệt ở đây là Fast R-CNN **trích xuất đặc trưng ảnh trước**, sau đó mới sử dụng selective search để tìm ra 2000 vùng đặc trưng. Do đó, ta chỉ cần đưa 2000 vùng đặc trưng này để tiếp tục xử lý mà không cần rút trích lại. Điều này là một bước ngoặt, vì nó đã tăng tốc độ xử lý lên rất nhiều ($$\times 18.3$$) cho huấn luyện và $$\times 146$$ cho suy luận) nhưng vẫn giữ được độ chính xác.
-
-
-Hình 2. Minh họa mô hình Fast R-CNN [2].
-
-Một điều cải tiến khác, Fast R-CNN không dùng SVM để phân lớp đối tượng nữa, mà tác giả gắn vào mạng một đầu FC để phân lớp. Tức là bây giờ chúng ta có 02 lớp FC, 1 lớp FC để phân lớp đối tượng, 1 lớp FC còn lại để tính toán bộ offset để căn chỉnh tọa độ đối tượng lại cho chính xác (giống như bên R-CNN).
-
-Cùng xem lại bảng kết quả so sánh giữa R-CNN và Fast R-CNN. Có thể thấy
-
-
-
-Hình 3. Kết quả so sánh giữa Fast R-CNN và R-CNN [2].
-
-Hình 3 là hình chụp kết quả từ bài báo gốc của Fast R-CNN. Có thể thấy rằng Fast R-CNN có kết quả tương đương với R-CNN, nhưng tốc độ vượt trội hơn rất nhiều. Tuy nhiên ý tưởng sử dụng 1 lớp FC để phân lớp chỉ vượt trội ở việc phát hiện các đối tượng lớn (L), các loại đối tượng nhỏ (S), trung bình (M) có hiệu quả phát hiện tương đương như R-CNN. Tuy nhiên với tốc độ vượt trội thế này thì không có lý do gì phải dùng R-CNN nữa.
-
-Tuy nhiên, Fast R-CNN vẫn có điểm yếu chí mạng của nó. Đó là việc lựa chọn vùng đề xuất vẫn dựa vào thuật toán Selective Search. *Liệu có cách nào cải tiến chính xác hơn ở điểm này hay không? Một cách tiếp cận khác mà nó tự học để đề xuất luôn.*
-
-Trên đây nhóm sinh viên cung cấp một cái nhìn tương đối đầy đủ về hoàn cảnh ra đời của Faster R-CNN. Phần dưới đây nhóm sinh viên sẽ trình bày kỹ hơn về Faster R-CNN.
-
-## Faster R-CNN
-
-Khắc phục điểm yếu chí mạng của Fast R-CNN, Faster R-CNN ra đời với hai điểm nổi bật duy nhất:
-- Mạng đề xuất khu vực (Regional Proposal Network), gọi tắt là RPN. Mạng này được huấn luyện để phát hiện các vùng trên ảnh khả năng cao chứa đối tượng. Nói một cách đơn giản, RPN sẽ thay thế Selective Search.
-- Cơ chế chia sẻ trọng số giữa RPN và Fast R-CNN.
-
-Đơn giản dễ hiểu, Faster R-CNN là sự kết hợp của RPN và mạng Fast R-CNN đã trình bày ở phía trên. Sau đó các tác giả đã thử các cơ chế chia sẻ trọng số khác nhau để kết hợp hoàn hảo hai thứ này. Dưới đây chúng ta sẽ tìm hiểu kỹ về mạng đề xuất khu vực. Đáng chú ý, Faster R-CNN được công bố tại hội nghị NeurlPS, là một hội nghị có những công bố mang tính bước ngoặt. Vì lẽ đó, Faster R-CNN được coi là một bước ngoặt. Faster R-CNN không còn là một phương pháp, Faster R-CNN đã là một hệ tư tưởng khi nhắc về nhóm phương pháp 02 giai đoạn. Dưới đây nhóm sinh viên sẽ trình bày kỹ về mạng đề xuất khu vực, và cơ chế chia sẻ trọng số - những thứ làm nên thành công của Faster R-CNN.
-
-### Mạng đề xuất khu vực (Regional Proposal Network)
-
-Như đã nói, mạng đề xuất khu vực sẽ được dùng để đề xuất các vùng khả năng cao chứa đối tượng thay cho thuật toán Selective Search. Gọi nó là "mạng" vì nó có "học". Thế làm sao để chúng ta huấn luyện được mạng này?
-
-
-
-Hình 4. Minh họa cách chọn mẫu của Faster R-CNN [3].
-
-Để huấn luyện được mạng RPN, chúng ta cần tạo dữ liệu cho nó học, cơ chế này được gọi là chọn mẫu (sampling). Để giải thích về cơ chế này, dễ nhất các bạn đọc quan sát Hình 4. Từ đặc trưng của ảnh (conv feature map), sẽ có một cửa sổ trượt có kích thước $$N \times N$$ (sliding window) trượt qua một cách lần lượt. Tại mỗi lần trượt, nó sẽ tạo ra $$k$$ anchor box.
-
-> Q: khoan khoan, dừng lại khoảng chừng là 2 giây. Anchor box là gì vậy?
-> A: anchor box là một khái niệm chỉ các "hộp neo" được định nghĩa trước, làm tiền đề cho các bước phía sau. Tại sao gọi là "hộp neo", vì nó sẽ tạm thời neo đậu, dựa vào các hộp neo đậu này mà bằng một cách nào đó chúng ta sẽ sử dụng nó để xác định đối tượng trên ảnh. Khái niệm này sẽ còn gặp lại ở các nhóm phương pháp 01 giai đoạn.
-
-$$k$$ anchor box có $$k$$ kích thước khác nhau, trong bài báo gốc, tác giả chọn $$k=9$$. Mỗi anchor box sẽ được gán 2 thứ:
-
-- Lớp nhị phân xác định nó có đối tượng hay không. Nếu anchor box đó được xác định là mẫu có chứa đối tượng, ta gán là $$1$$, ngược lại là $$0$$.
-- Tọa độ của anchor box, bao gồm 04 phần tử $$(x, y, w, h)$$.
-
-Thế thì làm sao chúng ta xác định được liệu 1 anchor box có chứa đối tượng hay không? Câu trả lời đơn giản là ta đi so với mẫu dữ liệu thật. Mỗi 1 anchor box sẽ được đi tính toán độ đo IoU với các hộp dự đoán thật (ground-truth), sau đó ta sẽ lấy giá trị IoU cao nhất của anchor box đó so với các ground-truth. Anchor box đó sẽ được chọn là mẫu $$1$$ khi $$IoU > 0.7$$, và chọn là mẫu $$0$$ khi $$IoU \leq 0.3$$. Vậy còn một đoạn từ $$(0.3, 0.7]$$ ta sẽ không chọn.
-
-Như vậy, bây giờ ta đã có một tập dữ liệu bao gồm các anchor box có đối tượng và anchor box không đối tượng cho mạng RPN học.
-
-Để huấn luyện ta cần định nghĩa một hàm mất mát tối ưu hóa đa mục tiêu: 1) xác định có hoặc không chứa đối tượng (phân lớp nhị phân); 2) hồi quy tọa độ. Hàm mất mát để huấn luyện RPN được định nghĩa như sau:
-
-$$L(\{p_i\}, \{t_i\}) = \frac{1}{N_{cls}} \sum_i L_{cls} (p_i, \hat p_i) + \lambda \frac{1}{N_{reg}} \sum_i \hat p_i L_{reg}(t_i, \hat t_i)$$
-
-Trong đó, $$L_{cls}$$ là hàm binary cross-entropy, còn $$L_{reg}$$ là hàm mất mát hồi quy $$SmoothL1$$; $$\hat p_i$$ là phân phối xác suất dự đoán hộp đề xuất có đối tượng hay không, $$p_i$$ là nhãn thật sự; $$\hat t_i$$ là tọa độ dự đoán đã được tham số hóa; $$t_i$$ là tọa độ thật đã được tham số hóa, $$t=\{t_x, t_y, t_w, t_h\}$$ và $$\hat t=\{\hat t_x, \hat t_y, \hat t_w, \hat t_h\}$$ được định nghĩa như sau:
-
-$$ t_x = (x - x_a) / w_a; \hat t_x = (\hat x - x_a) / w_a $$
-$$ t_y = (y - y_a) / h_a; \hat t_y = (\hat y - y_a) / h_a $$
-$$ t_w = \log (w / w_a); \hat t_w = \log (\hat w / w_a) $$
-$$ t_h = \log (h / h_a); \hat t_h = \log (\hat h / h_a) $$
-
-Trong đó, $$x$$, $$\hat x$$, $$x_a$$ lần lượt là hoành độ tâm thật sự của hộp bao, hoành độ tâm dự đoán của hộp bao và hoành độ tâm anchor box. $$y$$, $$\hat y$$, $$y_a$$ là tung độ tâm. Như thế ta có thể thấy, ở đây RPN không cố gắng để dự đoán các vị trí giống như hộp mỏ neo (vì nếu thế thì sử dụng hộp mỏ neo luôn cần gì học nữa), mà nó sẽ cố gắng dự đoán các vùng đề xuất lân cận các anchor box, mà tại đó có nhiều hộp bao ground-truth.
-
-Thực tế, RPN sinh ra rất nhiều hộp đề xuất, trong khi chúng ta chỉ cần $$N=2000$$ hộp đề xuất. Có nhiều hộp đề xuất ban đầu bị chồng lấp lên nhau, lúc này tác giả sử dụng thuật toán non maximum suppression (NMS) với ngưỡng $$IoU=0.7$$ để loại đi các hộp đề xuất chồng lấp, chỉ giữ lại $$2000$$ hộp đề xuất để đưa vào Fast R-CNN huấn luyện. Tuy nhiên, khi huấn luyện thì $$N=2000$$, trong khi đó lúc đánh giá (test) thì $$N$$ là một con số khác (nhỏ hơn 2000).
-
-### Cơ chế chia sẻ trọng số giữa RPN và Fast R-CNN (Sharing Convolutional Features)
-
-Việc huấn luyện RPN và Fast R-CNN được thực hiện độc lập chứ không end-to-end. Lý do của việc này rất dễ hiểu: rất khó để huấn luyện hai thứ này cùng một lúc. Fast R-CNN cần có một cơ chế sinh mẫu cố định (sinh ra các hộp đề xuất) để học, và bản thân Fast R-CNN cũng có một hàm tối ưu hóa tương tự như RPN (tổng của hàm mất mát phân lớp đối tượng và hàm mất mát hồi quy, nhưng hàm mất mát ở Fast R-CNN dùng cho đa lớp). Do đó không biế rằng nếu cơ chế sinh mẫu liên tục thay đổi (liên tục cập nhật trọng số lại ở RPN) thì mạng hợp nhất này có hội tụ được hay không. Do đó, tác giả đã đề xuất một cơ chế huấn luyện chia sẻ trọng số gồm 4 bước sau đây:
-
-- Bước 1: Huấn luyện RPN trước
-- Bước 2: Đóng băng trọng số ở RPN, sử dụng mạng RPN vừa học được sinh ra các vùng đề xuất cho mạng Fast R-CNN.
-- Bước 3: Dùng trọng số vừa học được ở mạng Fast R-CNN làm trọng số khởi tạo của mạng RPN ở các lớp tích chập (RPN và Fast R-CNN chia sẻ trọng số ở một số lớp tích chập), và chỉ fine-tune các lớp tích chập của riêng FPN và 2 lớp FC.
-- Bước 4: Đóng băng trọng số ở mạng RPN vừa học để sinh các mẫu cho Fast R-CNN, và chỉ fine-tune Fast R-CNN ở 2 lớp FC.
-
-### Kết quả so với Fast R-CNN
-
-
-
-Hình 5. Kết quả so sánh giữa việc sử dụng RPN và thuật toán Selective Search [3].
-
-Có thể thấy, việc sử dụng thuật toán Selective Search cho kết quả thấp hơn khi sử dụng RPN. Hơn nữa, tốc độ xử lý của Fast R-CNN sử dụng RPN (Faster R-CNN) cũng nhanh hơn sử dụng thuật toán Selective Search. Vừa tốt hơn vừa nhanh hơn, Faster R-CNN đã trở thành một "hệ tư tưởng".
-
-## Hướng dẫn huấn luyện thử Faster R-CNN
-
-Faster R-CNN khá khó để có thể code from scratch. Do đó, trong nội dung bài viết này, nhóm sinh viên hướng dẫn bạn đọc cách huấn luyện thử một mô hình Faster R-CNN thông qua toolbox MMDetection [4].
-
-Lưu ý: source code được thực nghiệm trên Google Colab.
-
-Trong bài này, nhóm sinh viên sử dụng bộ dữ liệu UIT-VinaDeveS22 được cung cấp ở đây: https://github.com/nguyenvd-uit/uit-together-dataset/blob/main/UIT-VinaDeveS22.md
-
-UIT-VinaDeveS22 là bộ dữ liệu phát hiện phương tiện giao thông từ camera CCTV, các phương tiện trong bộ dữ liệu bao gồm: bicycle, motorcycle, car, van, truck, bus, fire truck.
-
-
-Hình 6. Hình ảnh bộ dữ liệu UIT-VinaDeveS22
-
-### 1. Cài đặt thư viện
-
-Đầu tiên, chúng ta cần clone toolbox MMDetection từ Github về, sau đó cài đặt các thư viện cần thiết:
-
-
-- Bước 1.1: git clone thư mục code
-```[python3]
-!git clone https://github.com/open-mmlab/mmdetection
-```
-
-- Bước 1.2: cài đặt thư viện
-```
-# Cài đặt thư viện
-%cd mmdetection
-!pip install -r requirements.txt
-!pip install -v -e .
-!pip install mmcv-full==1.3.8 -f https://download.openmmlab.com/mmcv/dist/cu101/torch1.7.0/index.html
-!pip install torch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2
-```
-
-### 2. Import thư viện
-
-- Bước 2.1: ta import các thư viện liên quan cần dùng, ở đây chúng ta cần import `mmdet`, `mmcv`.
-
-```[python3]
-# Dùng để build config
-import mmdet
-from mmdet.apis import set_random_seed
-from mmcv import Config
-
-# Dùng để xây dựng dataset
-from mmdet.datasets import build_dataset
-from mmdet.models import build_detector
-from mmdet.apis import train_detector
-
-# Dùng để dự đoán
-from mmdet.apis import init_detector, inference_detector, show_result_pyplot
-import mmcv
-```
-
-### 3. Chuẩn bị dữ liệu
-
-Tải dữ liệu tại đây: https://drive.google.com/file/d/1NhsIWyPdqF2KDqPWU926eZwCLk0gtjnv/view?usp=sharing
-
-Ta có thể tải bằng lệnh sau:
-
-```
-!gdown --id 1NhsIWyPdqF2KDqPWU926eZwCLk0gtjnv
-```
-
-Sau khi tải, chúng ta giải nén dữ liệu bằng lệnh `unzip`
-
-```
-!unzip UIT-VinaDeveS22.zip
-```
-
-Bộ dữ liệu được tổ chức theo cấu trúc sau:
-
-```
-UIT-VinaDeveS22
-|__ images
-|____ *.jpg
-|__ outputtrain.json
-|__ outputvalid.json
-|__ outputtest.json
-```
-
-Thư mục `images` chứa toàn bộ ảnh của bộ dữ liệu. 3 file `ouputtrain.json`, `outputvalid.json` và `outputtest.json` là 3 file annotation đã được chuẩn bị theo định dạng MS-COCO ứng với 3 tập: train, valid, test.
-
-### 4. Chuẩn bị config
-
-Bước này khá quan trọng. Hiện tại MMDetection đã hỗ trợ cho chúng ta rất nhiều config của nhiều phương pháp SOTA cho phát hiện đối tượng hiện tại, lên tới vài chục phương pháp. Tuy nhiên, chúng ta chỉ sử dụng config dành cho Faster R-CNN.
-
-- Bước 4.1: Config trong MMDetection được thiết kế theo cơ chế kế thừa, tức là từ config chuẩn bị sẵn, chúng ta sẽ tinh chỉnh cho phù hợp với bộ dữ liệu của chúng ta. Đầu tiên ta cần xác định config cha mà chúng ta sẽ kế thừa
-
-```[python3]
-cfg = Config.fromfile('configs/faster_rcnn/faster_rcnn_r101_fpn_1x_coco.py')
-```
-
-`faster_rcnn_r101_fpn_1x_coco.py` là file config của phương pháp Faster R-CNN, sử dụng kiến trúc CNN ResNet-101 để trích xuất đặc trưng ảnh (là các lớp conv chung của mạng RPN và Fast R-CNN). Trong đó có sử dụng FPN (một cơ chế multi-scale feature map, tức là thay vì qua mạng CNN chỉ có 1 đầu ra thì nó sẽ có nhiều đầu ra với các resolution khác nhau).
-
-- Bước 4.2: Ta cần định nghĩa lại dữ liệu. MMDetection hỗ trợ các bộ dữ liệu sẵn có như COCO, sử dụng bộ dữ liệu khác ta cần định nghĩa lại các lớp. Tuy nhiên do cấu trúc bộ dữ liệu cũng giống như COCO, ta chỉ kế thừa nó về chỉnh lại các lớp sao cho phù hợp:
-
-```[python3]
-from mmdet.datasets.builder import DATASETS
-from mmdet.datasets import CocoDataset
-
-@DATASETS.register_module()
-class VinaDeveS22(CocoDataset):
- CLASSES = ('bicycle', 'motorcycle', 'car', 'van', 'truck', 'bus', 'fire truck')
-```
-
-- Bước 4.3: ta đặt đường dẫn cho tập dữ liệu, bao gồm đường dẫn ảnh, annotation cho tập train, test, valid:
-
-```[python3]
-# Đường dẫn dữ liệu
-import os
-data_root_dir = '/content/drive/MyDrive/BDL_UIT/UIT-VinaDeveS22/'
-
-# Chuẩn bị config
-
-cfg = Config.fromfile('configs/faster_rcnn/faster_rcnn_r101_fpn_1x_coco.py')
-
-# Modify dataset type and path
-cfg.data_root = data_root_dir
-
-cfg.data.test.type = 'VinaDeveS22'
-cfg.data.test.ann_file = os.path.join(data_root_dir, 'outputtest.json')
-cfg.data.test.img_prefix = os.path.join(data_root_dir, 'images')
-
-cfg.data.train.type = 'VinaDeveS22'
-cfg.data.train.ann_file = os.path.join(data_root_dir, 'outputtrain.json')
-cfg.data.train.img_prefix = os.path.join(data_root_dir, 'images')
-
-cfg.data.val.type = 'VinaDeveS22'
-cfg.data.val.ann_file = os.path.join(data_root_dir, 'outputvalid.json')
-cfg.data.val.img_prefix = os.path.join(data_root_dir, 'images')
-```
-
-- Bước 4.4: Một số cấu hình khác như số epoch để save checkpoint 1 lần, learning rate, đường dẫn lưu checkpoint, số lớp cần classify của mô hình, ...
-
-```[python3]
-# Một số cấu hình khác
-
-cfg.optimizer.lr = 0.02 / 8
-cfg.lr_config.warmup = None
-cfg.log_config.interval = 500
-
-# We can set the evaluation interval to reduce the evaluation times
-cfg.evaluation.interval = 1
-# We can set the checkpoint saving interval to reduce the storage cost
-cfg.checkpoint_config.interval = 3
-
-# Set seed thus the results are more reproducible
-cfg.seed = 0
-set_random_seed(0, deterministic=False)
-cfg.gpu_ids = range(1)
-
-# Số class
-cfg.model.roi_head.bbox_head.num_classes = 7
-
-# Đường dẫn lưu checkpoints
-cfg.work_dir = './checkpoints'
-```
-
-### 5. Xây dựng model và huấn luyện
-
-Ta tiến hành xây dựng mô hình dựa trên config đã chuẩn bị:
-
-```[python3]
-# Build dataset
-datasets = [build_dataset(cfg.data.train)]
-
-# Build the detector
-model = build_detector(cfg.model, train_cfg=cfg.get('train_cfg'), test_cfg=cfg.get('test_cfg'))
-# Add an attribute for visualization convenience
-model.CLASSES = ('bicycle', 'motorcycle', 'car', 'van', 'truck', 'bus', 'fire truck')
-```
-
-Tiến hành huấn luyện:
-
-```[python3]
-train_detector(model, datasets, cfg, distributed=False, validate=True)
-```
-
-Log khi huấn luyện:
-
-```
-2022-06-20 02:41:11,989 - mmdet - INFO - Start running, host: root@1aa12ebaa861, work_dir: /content/drive/MyDrive/LvThs_OCR/mmdetection/checkpoints
-2022-06-20 02:41:11,997 - mmdet - INFO - Hooks will be executed in the following order:
-before_run:
-(VERY_HIGH ) StepLrUpdaterHook
-(NORMAL ) CheckpointHook
-(NORMAL ) EvalHook
-(VERY_LOW ) TextLoggerHook
- --------------------
-before_train_epoch:
-(VERY_HIGH ) StepLrUpdaterHook
-(NORMAL ) EvalHook
-(NORMAL ) NumClassCheckHook
-(LOW ) IterTimerHook
-(VERY_LOW ) TextLoggerHook
- --------------------
-before_train_iter:
-(VERY_HIGH ) StepLrUpdaterHook
-(LOW ) IterTimerHook
- --------------------
-after_train_iter:
-(ABOVE_NORMAL) OptimizerHook
-(NORMAL ) CheckpointHook
-(NORMAL ) EvalHook
-(LOW ) IterTimerHook
-(VERY_LOW ) TextLoggerHook
- --------------------
-after_train_epoch:
-(NORMAL ) CheckpointHook
-(NORMAL ) EvalHook
-(VERY_LOW ) TextLoggerHook
- --------------------
-before_val_epoch:
-(NORMAL ) NumClassCheckHook
-(LOW ) IterTimerHook
-(VERY_LOW ) TextLoggerHook
- --------------------
-before_val_iter:
-(LOW ) IterTimerHook
- --------------------
-after_val_iter:
-(LOW ) IterTimerHook
- --------------------
-after_val_epoch:
-(VERY_LOW ) TextLoggerHook
- --------------------
-2022-06-20 02:41:11,999 - mmdet - INFO - workflow: [('train', 1)], max: 12 epochs
-loading annotations into memory...
-Done (t=0.01s)
-creating index...
-index created!
-[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 173/173, 8.1 task/s, elapsed: 21s, ETA: 0s2022-06-20 02:44:30,061 - mmdet - INFO - Evaluating bbox...
-Loading and preparing results...
-DONE (t=0.15s)
-creating index...
-index created!
-Running per image evaluation...
-Evaluate annotation type *bbox*
-DONE (t=2.42s).
-Accumulating evaluation results...
-2022-06-20 02:44:33,060 - mmdet - INFO - Epoch(val) [1][327] bbox_mAP: 0.0060, bbox_mAP_50: 0.0200, bbox_mAP_75: 0.0010, bbox_mAP_s: 0.0090, bbox_mAP_m: 0.0060, bbox_mAP_l: 0.0000, bbox_mAP_copypaste: 0.006 0.020 0.001 0.009 0.006 0.000
-DONE (t=0.36s).
- Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.006
- Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=1000 ] = 0.020
- Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=1000 ] = 0.001
- Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = 0.009
- Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.006
- Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.000
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.029
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=300 ] = 0.029
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=1000 ] = 0.029
- Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = 0.050
- Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.027
- Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.000
-[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 173/173, 8.0 task/s, elapsed: 21s, ETA: 0s2022-06-20 02:47:51,860 - mmdet - INFO - Evaluating bbox...
-Loading and preparing results...
-DONE (t=0.15s)
-creating index...
-index created!
-Running per image evaluation...
-Evaluate annotation type *bbox*
-DONE (t=2.47s).
-Accumulating evaluation results...
-2022-06-20 02:47:54,962 - mmdet - INFO - Epoch(val) [2][327] bbox_mAP: 0.0280, bbox_mAP_50: 0.0750, bbox_mAP_75: 0.0150, bbox_mAP_s: 0.0180, bbox_mAP_m: 0.0340, bbox_mAP_l: 0.0140, bbox_mAP_copypaste: 0.028 0.075 0.015 0.018 0.034 0.014
-DONE (t=0.40s).
- Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.028
- Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=1000 ] = 0.075
- Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=1000 ] = 0.015
- Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = 0.018
- Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.034
- Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.014
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.092
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=300 ] = 0.092
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=1000 ] = 0.092
- Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = 0.051
- Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.071
- Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.095
-2022-06-20 02:50:51,428 - mmdet - INFO - Saving checkpoint at 3 epochs
-[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 173/173, 7.9 task/s, elapsed: 22s, ETA: 0s2022-06-20 02:51:15,654 - mmdet - INFO - Evaluating bbox...
-Loading and preparing results...
-DONE (t=0.02s)
-creating index...
-index created!
-Running per image evaluation...
-Evaluate annotation type *bbox*
-DONE (t=2.22s).
-Accumulating evaluation results...
-2022-06-20 02:51:18,523 - mmdet - INFO - Epoch(val) [3][327] bbox_mAP: 0.0970, bbox_mAP_50: 0.2000, bbox_mAP_75: 0.0800, bbox_mAP_s: 0.0340, bbox_mAP_m: 0.0750, bbox_mAP_l: 0.0900, bbox_mAP_copypaste: 0.097 0.200 0.080 0.034 0.075 0.090
-DONE (t=0.42s).
- Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.097
- Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=1000 ] = 0.200
- Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=1000 ] = 0.080
- Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = 0.034
- Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.075
- Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.090
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.158
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=300 ] = 0.158
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=1000 ] = 0.158
- Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = 0.084
- Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.117
- Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.161
-[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 173/173, 8.1 task/s, elapsed: 21s, ETA: 0s2022-06-20 02:54:37,466 - mmdet - INFO - Evaluating bbox...
-Loading and preparing results...
-DONE (t=0.03s)
-creating index...
-index created!
-Running per image evaluation...
-Evaluate annotation type *bbox*
-DONE (t=2.27s).
-Accumulating evaluation results...
-2022-06-20 02:54:40,383 - mmdet - INFO - Epoch(val) [4][327] bbox_mAP: 0.0960, bbox_mAP_50: 0.2050, bbox_mAP_75: 0.0710, bbox_mAP_s: 0.0400, bbox_mAP_m: 0.0910, bbox_mAP_l: 0.0930, bbox_mAP_copypaste: 0.096 0.205 0.071 0.040 0.091 0.093
-DONE (t=0.41s).
- Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.096
- Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=1000 ] = 0.205
- Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=1000 ] = 0.071
- Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = 0.040
- Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.091
- Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.093
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.166
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=300 ] = 0.166
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=1000 ] = 0.166
- Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = 0.092
- Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.152
- Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.162
-[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 173/173, 8.1 task/s, elapsed: 21s, ETA: 0s2022-06-20 02:57:58,671 - mmdet - INFO - Evaluating bbox...
-Loading and preparing results...
-DONE (t=0.14s)
-creating index...
-index created!
-Running per image evaluation...
-Evaluate annotation type *bbox*
-DONE (t=1.36s).
-Accumulating evaluation results...
-2022-06-20 02:58:00,468 - mmdet - INFO - Epoch(val) [5][327] bbox_mAP: 0.1600, bbox_mAP_50: 0.3140, bbox_mAP_75: 0.1440, bbox_mAP_s: 0.0670, bbox_mAP_m: 0.1430, bbox_mAP_l: 0.1490, bbox_mAP_copypaste: 0.160 0.314 0.144 0.067 0.143 0.149
-DONE (t=0.25s).
- Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.160
- Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=1000 ] = 0.314
- Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=1000 ] = 0.144
- Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = 0.067
- Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.143
- Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.149
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.238
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=300 ] = 0.238
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=1000 ] = 0.238
- Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = 0.125
- Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.218
- Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.232
-2022-06-20 03:00:58,010 - mmdet - INFO - Saving checkpoint at 6 epochs
-[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 173/173, 7.6 task/s, elapsed: 23s, ETA: 0s2022-06-20 03:01:22,836 - mmdet - INFO - Evaluating bbox...
-Loading and preparing results...
-DONE (t=0.15s)
-creating index...
-index created!
-Running per image evaluation...
-Evaluate annotation type *bbox*
-DONE (t=1.80s).
-Accumulating evaluation results...
-2022-06-20 03:01:25,153 - mmdet - INFO - Epoch(val) [6][327] bbox_mAP: 0.2180, bbox_mAP_50: 0.4040, bbox_mAP_75: 0.2040, bbox_mAP_s: 0.1180, bbox_mAP_m: 0.2210, bbox_mAP_l: 0.1760, bbox_mAP_copypaste: 0.218 0.404 0.204 0.118 0.221 0.176
-DONE (t=0.31s).
- Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.218
- Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=1000 ] = 0.404
- Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=1000 ] = 0.204
- Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = 0.118
- Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.221
- Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.176
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.321
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=300 ] = 0.321
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=1000 ] = 0.321
- Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = 0.175
- Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.347
- Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.261
-[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 173/173, 8.1 task/s, elapsed: 21s, ETA: 0s2022-06-20 03:04:44,056 - mmdet - INFO - Evaluating bbox...
-Loading and preparing results...
-DONE (t=0.02s)
-creating index...
-index created!
-Running per image evaluation...
-Evaluate annotation type *bbox*
-DONE (t=1.84s).
-Accumulating evaluation results...
-2022-06-20 03:04:46,289 - mmdet - INFO - Epoch(val) [7][327] bbox_mAP: 0.2310, bbox_mAP_50: 0.4290, bbox_mAP_75: 0.2300, bbox_mAP_s: 0.1720, bbox_mAP_m: 0.2770, bbox_mAP_l: 0.1790, bbox_mAP_copypaste: 0.231 0.429 0.230 0.172 0.277 0.179
-DONE (t=0.31s).
- Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.231
- Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=1000 ] = 0.429
- Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=1000 ] = 0.230
- Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = 0.172
- Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.277
- Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.179
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.369
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=300 ] = 0.369
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=1000 ] = 0.369
- Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = 0.256
- Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.407
- Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.306
-[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 173/173, 8.0 task/s, elapsed: 22s, ETA: 0s2022-06-20 03:08:05,146 - mmdet - INFO - Evaluating bbox...
-Loading and preparing results...
-DONE (t=0.01s)
-creating index...
-index created!
-Running per image evaluation...
-Evaluate annotation type *bbox*
-DONE (t=1.78s).
-Accumulating evaluation results...
-2022-06-20 03:08:07,322 - mmdet - INFO - Epoch(val) [8][327] bbox_mAP: 0.2610, bbox_mAP_50: 0.4790, bbox_mAP_75: 0.2570, bbox_mAP_s: 0.1560, bbox_mAP_m: 0.2850, bbox_mAP_l: 0.2110, bbox_mAP_copypaste: 0.261 0.479 0.257 0.156 0.285 0.211
-DONE (t=0.31s).
- Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.261
- Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=1000 ] = 0.479
- Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=1000 ] = 0.257
- Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = 0.156
- Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.285
- Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.211
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.379
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=300 ] = 0.379
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=1000 ] = 0.379
- Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = 0.223
- Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.392
- Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.337
-2022-06-20 03:11:04,360 - mmdet - INFO - Saving checkpoint at 9 epochs
-[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 173/173, 7.9 task/s, elapsed: 22s, ETA: 0s2022-06-20 03:11:28,443 - mmdet - INFO - Evaluating bbox...
-Loading and preparing results...
-DONE (t=0.01s)
-creating index...
-index created!
-Running per image evaluation...
-Evaluate annotation type *bbox*
-DONE (t=1.56s).
-Accumulating evaluation results...
-2022-06-20 03:11:30,381 - mmdet - INFO - Epoch(val) [9][327] bbox_mAP: 0.3230, bbox_mAP_50: 0.5630, bbox_mAP_75: 0.3410, bbox_mAP_s: 0.2510, bbox_mAP_m: 0.3380, bbox_mAP_l: 0.2390, bbox_mAP_copypaste: 0.323 0.563 0.341 0.251 0.338 0.239
-DONE (t=0.30s).
- Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.323
- Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=1000 ] = 0.563
- Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=1000 ] = 0.341
- Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = 0.251
- Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.338
- Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.239
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.442
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=300 ] = 0.442
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=1000 ] = 0.442
- Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = 0.365
- Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.465
- Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.375
-[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 173/173, 8.0 task/s, elapsed: 22s, ETA: 0s2022-06-20 03:14:49,643 - mmdet - INFO - Evaluating bbox...
-Loading and preparing results...
-DONE (t=0.02s)
-creating index...
-index created!
-Running per image evaluation...
-Evaluate annotation type *bbox*
-DONE (t=1.56s).
-Accumulating evaluation results...
-2022-06-20 03:14:51,582 - mmdet - INFO - Epoch(val) [10][327] bbox_mAP: 0.3260, bbox_mAP_50: 0.5650, bbox_mAP_75: 0.3490, bbox_mAP_s: 0.2750, bbox_mAP_m: 0.3510, bbox_mAP_l: 0.2430, bbox_mAP_copypaste: 0.326 0.565 0.349 0.275 0.351 0.243
-DONE (t=0.29s).
- Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.326
- Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=1000 ] = 0.565
- Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=1000 ] = 0.349
- Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = 0.275
- Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.351
- Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.243
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.454
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=300 ] = 0.454
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=1000 ] = 0.454
- Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = 0.380
- Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.470
- Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.394
-[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 173/173, 8.0 task/s, elapsed: 22s, ETA: 0s2022-06-20 03:18:11,238 - mmdet - INFO - Evaluating bbox...
-Loading and preparing results...
-DONE (t=0.14s)
-creating index...
-index created!
-Running per image evaluation...
-Evaluate annotation type *bbox*
-DONE (t=1.43s).
-Accumulating evaluation results...
-2022-06-20 03:18:13,126 - mmdet - INFO - Epoch(val) [11][327] bbox_mAP: 0.3320, bbox_mAP_50: 0.5600, bbox_mAP_75: 0.3570, bbox_mAP_s: 0.3060, bbox_mAP_m: 0.3600, bbox_mAP_l: 0.2460, bbox_mAP_copypaste: 0.332 0.560 0.357 0.306 0.360 0.246
-DONE (t=0.27s).
- Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.332
- Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=1000 ] = 0.560
- Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=1000 ] = 0.357
- Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = 0.306
- Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.360
- Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.246
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.457
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=300 ] = 0.457
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=1000 ] = 0.457
- Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = 0.370
- Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.477
- Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.393
-```
-
-### Bước 6: Dự đoán trên ảnh mới
-
-Sau khi huấn luyện xong, ta thử dự đoán trên 01 ảnh mới. Giả sử nhóm sinh viên chọn ảnh `000000100.jpg` trong tập dữ liệu:
-
-```[python3]
-# Show thử 1 vài ảnh
-img = mmcv.imread('/content/drive/MyDrive/BDL_UIT/UIT-VinaDeveS22/images/000000100.jpg')
-
-model.cfg = cfg
-result = inference_detector(model, img)
-show_result_pyplot(model, img, result)
-```
-
-Hình ảnh đầu ra:
-
-
-
-Một số hình ảnh khác:
-
-
-
-
-
-
-
-
-
-
-
-
-
-## Tài liệu tham khảo
-
-[1]. Girshick, R., Donahue, J., Darrell, T., & Malik, J. (2014). Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 580-587).
-
-[2]. Girshick, R. (2015). Fast r-cnn. In Proceedings of the IEEE international conference on computer vision (pp. 1440-1448).
-
-[3]. Ren, S., He, K., Girshick, R., & Sun, J. (2015). Faster r-cnn: Towards real-time object detection with region proposal networks. Advances in neural information processing systems, 28.
-
-[4]. Chen, K., Wang, J., Pang, J., Cao, Y., Xiong, Y., Li, X., ... & Lin, D. (2019). MMDetection: Open mmlab detection toolbox and benchmark. arXiv preprint arXiv:1906.07155.
diff --git a/_posts/2023-12-29-han-du-thi-tap.md b/_posts/2023-12-29-han-du-thi-tap.md
deleted file mode 100644
index ae29df4..0000000
--- a/_posts/2023-12-29-han-du-thi-tap.md
+++ /dev/null
@@ -1,285 +0,0 @@
----
-layout: post
-title: Hàn du thi tập
-date: 2023-12-29 00:00:00
-description: Tập thơ sáng tác tại Hàn
-tags: formatting links
-categories: sample-posts
-inline: false
----
-
-# Hàn du thi tập (Tập thơ sáng tác ở Hàn)
-
-## Lời nói đầu
-
-Kính chào quý bằng hữu,
-
-Tại hạ là Doanh (Công Danh), xin phép được gửi đến quý bằng hữu, những người cùng sở thích thi ca một tập thơ mà tại hạ đã sáng tác trong quá trình làm việc và sinh sống tại Thủ Nhĩ, Đại Hàn.
-
-Trong tập thơ này, tại hạ giới thiệu một số bài thơ mà tại hạ viết ở thể 5 chữ, hoặc 7 chữ, hoặc thơ 6-8. Tại hạ đặc biệt thích thể loại thơ 7 chữ, theo luật Đại Đường (thất ngôn tứ tuyệt Đường luật).
-
-Các bài thơ tại hạ viết chủ yếu có chủ đề về **nhân sinh** và **tình yêu**, và hầu hết được sáng tác vào lúc 1-2 giờ sáng, lúc mà tâm trạng dâng trào nhất. Về chủ đề **nhân sinh**, tại hạ thường viết về góc nhìn của mình về cuộc đời với tâm trạng hơi u tối một chút, nhưng đâu đó vẫn có màu tươi sáng. Về **tình yêu**, tại hạ thường viết về chủ đề mối tình đã lỡ. Câu cú có phần một chút trách móc, nhưng tiếc thương một mối tình đã lỡ, và da diết tôn trọng.
-
-Các bài thơ sẽ có các lỗi trong cách gieo vần, dùng từ. Nếu đọc thơ khiến các bằng hữu không thoải mái, tại hạ rất xin lỗi, và luôn đó nhận những lời góp ý.
-
-Mời quý bằng hữu thưởng thơ.
-
-Kính bút,
-
-Công Danh
-
-## Lập Thu Đại Hàn
-
-Lập thu nơi xóm nhỏ
-
-Cho nỗi niềm chơi vơi
-
-Đôi điều còn bỏ ngõ
-
-Tìm đâu phía chân trời.
-
-
-Công Danh, 6.9.2023
-
-## Cầu vồng tình lỡ
-
-Cầu vồng đẹp nhất sau mưa
-
-Ngày em đẹp nhất là vừa xa anh
-
-Buồn nào rồi cũng trôi nhanh
-
-Nhưng thành vết xẹo khó lành về sau
-
-
-Công Danh, 11.9.2023
-
-## Miền đất khác
-
-Một vệt nắng cuối trời
-
-Cho chiều buồn man mác
-
-Liệu một miền đất khác
-
-Có nỗi niềm chơi vơi?
-
-
-Công Danh, 12.9.2023
-
-## Lửa thủ đô
-
-*Bài thơ tỏ lòng tiếc thương cho các nạn nhân của một vụ cháy kinh hoàng ở thủ đô Hà Nội*
-
-Ở giữa lòng thủ đô
-
-Một màu buồn man mác
-
-Trời đêm mưa lác đác
-
-Lửa hóa kiếp hư vô...
-
-
-Công Danh, 14.9.2023
-
-## Tình tan
-
-Đượm nắng lập thu cuối chiều ta
-
-Niệm về ngày cũ vốn phôi pha
-
-Hoàng hôn chớm tắt, hồn vô ngã
-
-Chôn giấu tình tan, em với ta.
-
-
-Ánh mắt ai đậm đà
-
-Tiếng cười ai giòn giã,
-
-Tâm tư ai la cà
-
-Không phải em, là lá...
-
-
-Công Danh và Minh Niên, 20.9.2023
-
-## Hạnh phúc mới
-
-*Bài thơ được sáng tác từ bài hát Hạnh phúc mới, nhưng đổi vai hai nhân vật nam và nữ.*
-
-Ngày hôm nào em nói
-
-Mình chia tay thôi anh
-
-Nghe như lời trăn trối
-
-Gạt lệ buồn phai nhanh.
-
-
-Anh à, đừng buồn nữa
-
-Tình nào cũng thế thôi
-
-Hợp, yêu, tan, rồi mất
-
-Còn nỗi lòng đơn côi.
-
-
-Em đang ở đâu đó
-
-Để nỗi niềm chơi vơi
-
-Hồn em bay theo gió
-
-Tìm em cuối chân trời...
-
-
-Công Danh, 8.10.2023
-
-## Sài Gòn nhỏ
-
-*Bài thơ được sáng tác rất lâu, nhưng đến ngày này mới hoàn chỉnh*
-
-Có một Sài Gòn nhỏ
-
-Con phố đông người qua
-
-Có chuyến xe buýt nọ
-
-Từng chở cuộc tình ta.
-
-
-Ngày đôi mình chia xa,
-
-Hạ vẫn còn vương nắng
-
-Tình ngọt chợt thành đắng
-
-Chỉ còn dằm trong tim.
-
-
-Đôi mắt anh lim dim
-
-Mơ về ngày ngây dại
-
-Thấy em quay nhìn lại
-
-Như tình mình chưa phai.
-
-
-Công Danh, 12.10.2023
-
-## Cầu sông Hậu
-
-Nhớ về ngày cũ còn đâu,
-
-Bóng hình em gái hát câu gọi đò
-
-Ngân vang sông Hậu câu hò
-
-Giờ đây chẳng phải đi đò sang ngang
-
-Ai về Châu Đốc, An Giang,
-
-Qua cậu sông Hậu, gửi nàng yêu thương.
-
-
-Công Danh, 11.11.2023
-
-## Một kiếp người
-
-*Bài thơ sáng tác để tiếc thương cho một người bà của một người bạn đã mất.*
-
-Thoáng chốc là xong một kiếp người
-
-Hồng trần vướng bận cứ buông lơi
-
-Người đi về chốn hồn thanh thản
-
-Để lại ngàn năm nỗi đau đời.
-
-
-## Các bản dịch bài thơ nổi tiếng của William Shakespeare
-
-Ở phần này, tại hạ giới thiệu các bằng hữu bản dịch do tại hạ thực hiện cho một bài thơ nổi tiếng dưới phong cách của các nhà thơ lớn của thi văn Việt Nam.
-
-Bản gốc:
-
-> You say that you love rain, but you open your umbrella when it rains.
->
-> You say that you love the sun, but you find a shadow spot when the sun shines.
->
-> You say that you love the wind, but you close your windows when wind blows.
->
-> This is why I am afraid, you say that you love me too
-
-### Bản dịch phong cách Xuân Diệu:
-
-Em nói rất thích mưa
-
-Sao tìm dù mà tránh
-
-Em thích nhìn nắng hạ
-
-Sao đi tìm nơi râm.
-
-
-Em từng nói rằng em yêu gió lộng
-
-Vậy mà sao giờ chốt cửa cài then
-
-Chợt thổn thức, anh thẹn cười bẽn lẽn
-
-Thế thì còn... lời em nói yêu anh?
-
-
-### Bản dịch phong cách Hàn Mặc Tử:
-
-Sao em không còn yêu mưa nhỉ?
-
-Mà kéo dù lên tránh ướt mi
-
-Rồi kêu thích nắng, yêu hương Hạ
-
-Thế núp nơi râm là nghĩa gì?
-
-
-Em nói rằng yêu, gió vừa qua
-
-Thế sao cửa đóng, rèm bung ra?
-
-Bỗng nhiên anh thấy thật không ổn
-
-Ai biết tình em có đậm đà...
-
-
-### Bản dịch phong cách Tố Hữu:
-
-Từng nói yêu mưa, giờ khác lạ
-
-Rồi chợt mưa đến lấy ô ra
-
-Và em từng thì thầm yêu nắng
-
-Nắng rọi lên thì chẳng thiết tha.
-
-
-### Bản dịch phong cách Nguyễn Thị Hinh (Bà Huyện Thanh Quan):
-
-Nhớ nói trời mưa thích thế mà
-
-Chẳng mưa to mấy lấy ô ra
-
-Sao em muốn ngắm trời hừng nắng
-
-Nắng rọi lên cao lại núp nhà
-
-Ngắm gió mây làm em thích thích
-
-Bây giờ chốt cửa tránh xa xa
-
-Chợt sao thấy lạ lời em nói
-
-Thật giả tình yêu, em với ta.
-
diff --git a/_projects/1_project.md b/_projects/1_project.md
deleted file mode 100644
index 3f7cf78..0000000
--- a/_projects/1_project.md
+++ /dev/null
@@ -1,80 +0,0 @@
----
-layout: page
-title: project 1
-description: a project with a background image
-img: assets/img/12.jpg
-importance: 1
-category: work
----
-
-Every project has a beautiful feature showcase page.
-It's easy to include images in a flexible 3-column grid format.
-Make your photos 1/3, 2/3, or full width.
-
-To give your project a background in the portfolio page, just add the img tag to the front matter like so:
-
- ---
- layout: page
- title: project
- description: a project with a background image
- img: /assets/img/12.jpg
- ---
-
-
-
- {% include figure.html path="assets/img/1.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
- {% include figure.html path="assets/img/3.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
- {% include figure.html path="assets/img/5.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
-
- Caption photos easily. On the left, a road goes through a tunnel. Middle, leaves artistically fall in a hipster photoshoot. Right, in another hipster photoshoot, a lumberjack grasps a handful of pine needles.
-
-
-
- {% include figure.html path="assets/img/5.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
-
- This image can also have a caption. It's like magic.
-
-
-You can also put regular text between your rows of images.
-Say you wanted to write a little bit about your project before you posted the rest of the images.
-You describe how you toiled, sweated, *bled* for your project, and then... you reveal its glory in the next row of images.
-
-
-
-
- {% include figure.html path="assets/img/6.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
- {% include figure.html path="assets/img/11.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
-
- You can also have artistically styled 2/3 + 1/3 images, like these.
-
-
-
-The code is simple.
-Just wrap your images with `
` and place them inside `
` (read more about the
Bootstrap Grid system).
-To make images responsive, add `img-fluid` class to each; for rounded corners and shadows use `rounded` and `z-depth-1` classes.
-Here's the code for the last row of images above:
-
-{% raw %}
-```html
-
-
- {% include figure.html path="assets/img/6.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
- {% include figure.html path="assets/img/11.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
-```
-{% endraw %}
diff --git a/_projects/2_project.md b/_projects/2_project.md
deleted file mode 100644
index bebf796..0000000
--- a/_projects/2_project.md
+++ /dev/null
@@ -1,80 +0,0 @@
----
-layout: page
-title: project 2
-description: a project with a background image
-img: assets/img/3.jpg
-importance: 2
-category: work
----
-
-Every project has a beautiful feature showcase page.
-It's easy to include images in a flexible 3-column grid format.
-Make your photos 1/3, 2/3, or full width.
-
-To give your project a background in the portfolio page, just add the img tag to the front matter like so:
-
- ---
- layout: page
- title: project
- description: a project with a background image
- img: /assets/img/12.jpg
- ---
-
-
-
- {% include figure.html path="assets/img/1.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
- {% include figure.html path="assets/img/3.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
- {% include figure.html path="assets/img/5.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
-
- Caption photos easily. On the left, a road goes through a tunnel. Middle, leaves artistically fall in a hipster photoshoot. Right, in another hipster photoshoot, a lumberjack grasps a handful of pine needles.
-
-
-
- {% include figure.html path="assets/img/5.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
-
- This image can also have a caption. It's like magic.
-
-
-You can also put regular text between your rows of images.
-Say you wanted to write a little bit about your project before you posted the rest of the images.
-You describe how you toiled, sweated, *bled* for your project, and then... you reveal its glory in the next row of images.
-
-
-
-
- {% include figure.html path="assets/img/6.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
- {% include figure.html path="assets/img/11.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
-
- You can also have artistically styled 2/3 + 1/3 images, like these.
-
-
-
-The code is simple.
-Just wrap your images with `
` and place them inside `
` (read more about the
Bootstrap Grid system).
-To make images responsive, add `img-fluid` class to each; for rounded corners and shadows use `rounded` and `z-depth-1` classes.
-Here's the code for the last row of images above:
-
-{% raw %}
-```html
-
-
- {% include figure.html path="assets/img/6.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
- {% include figure.html path="assets/img/11.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
-```
-{% endraw %}
diff --git a/_projects/3_project.md b/_projects/3_project.md
deleted file mode 100644
index 3f3cbf7..0000000
--- a/_projects/3_project.md
+++ /dev/null
@@ -1,81 +0,0 @@
----
-layout: page
-title: project 3
-description: a project that redirects to another website
-img: assets/img/7.jpg
-redirect: https://unsplash.com
-importance: 3
-category: work
----
-
-Every project has a beautiful feature showcase page.
-It's easy to include images in a flexible 3-column grid format.
-Make your photos 1/3, 2/3, or full width.
-
-To give your project a background in the portfolio page, just add the img tag to the front matter like so:
-
- ---
- layout: page
- title: project
- description: a project with a background image
- img: /assets/img/12.jpg
- ---
-
-
-
- {% include figure.html path="assets/img/1.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
- {% include figure.html path="assets/img/3.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
- {% include figure.html path="assets/img/5.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
-
- Caption photos easily. On the left, a road goes through a tunnel. Middle, leaves artistically fall in a hipster photoshoot. Right, in another hipster photoshoot, a lumberjack grasps a handful of pine needles.
-
-
-
- {% include figure.html path="assets/img/5.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
-
- This image can also have a caption. It's like magic.
-
-
-You can also put regular text between your rows of images.
-Say you wanted to write a little bit about your project before you posted the rest of the images.
-You describe how you toiled, sweated, *bled* for your project, and then... you reveal its glory in the next row of images.
-
-
-
-
- {% include figure.html path="assets/img/6.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
- {% include figure.html path="assets/img/11.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
-
- You can also have artistically styled 2/3 + 1/3 images, like these.
-
-
-
-The code is simple.
-Just wrap your images with `
` and place them inside `
` (read more about the
Bootstrap Grid system).
-To make images responsive, add `img-fluid` class to each; for rounded corners and shadows use `rounded` and `z-depth-1` classes.
-Here's the code for the last row of images above:
-
-{% raw %}
-```html
-
-
- {% include figure.html path="assets/img/6.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
- {% include figure.html path="assets/img/11.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
-```
-{% endraw %}
diff --git a/_projects/4_project.md b/_projects/4_project.md
deleted file mode 100644
index edb5dd2..0000000
--- a/_projects/4_project.md
+++ /dev/null
@@ -1,80 +0,0 @@
----
-layout: page
-title: project 4
-description: another without an image
-img:
-importance: 3
-category: fun
----
-
-Every project has a beautiful feature showcase page.
-It's easy to include images in a flexible 3-column grid format.
-Make your photos 1/3, 2/3, or full width.
-
-To give your project a background in the portfolio page, just add the img tag to the front matter like so:
-
- ---
- layout: page
- title: project
- description: a project with a background image
- img: /assets/img/12.jpg
- ---
-
-
-
- {% include figure.html path="assets/img/1.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
- {% include figure.html path="assets/img/3.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
- {% include figure.html path="assets/img/5.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
-
- Caption photos easily. On the left, a road goes through a tunnel. Middle, leaves artistically fall in a hipster photoshoot. Right, in another hipster photoshoot, a lumberjack grasps a handful of pine needles.
-
-
-
- {% include figure.html path="assets/img/5.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
-
- This image can also have a caption. It's like magic.
-
-
-You can also put regular text between your rows of images.
-Say you wanted to write a little bit about your project before you posted the rest of the images.
-You describe how you toiled, sweated, *bled* for your project, and then... you reveal its glory in the next row of images.
-
-
-
-
- {% include figure.html path="assets/img/6.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
- {% include figure.html path="assets/img/11.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
-
- You can also have artistically styled 2/3 + 1/3 images, like these.
-
-
-
-The code is simple.
-Just wrap your images with `
` and place them inside `
` (read more about the
Bootstrap Grid system).
-To make images responsive, add `img-fluid` class to each; for rounded corners and shadows use `rounded` and `z-depth-1` classes.
-Here's the code for the last row of images above:
-
-{% raw %}
-```html
-
-
- {% include figure.html path="assets/img/6.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
- {% include figure.html path="assets/img/11.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
-```
-{% endraw %}
diff --git a/_projects/5_project.md b/_projects/5_project.md
deleted file mode 100644
index efd9b6c..0000000
--- a/_projects/5_project.md
+++ /dev/null
@@ -1,80 +0,0 @@
----
-layout: page
-title: project 5
-description: a project with a background image
-img: assets/img/1.jpg
-importance: 3
-category: fun
----
-
-Every project has a beautiful feature showcase page.
-It's easy to include images in a flexible 3-column grid format.
-Make your photos 1/3, 2/3, or full width.
-
-To give your project a background in the portfolio page, just add the img tag to the front matter like so:
-
- ---
- layout: page
- title: project
- description: a project with a background image
- img: /assets/img/12.jpg
- ---
-
-
-
- {% include figure.html path="assets/img/1.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
- {% include figure.html path="assets/img/3.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
- {% include figure.html path="assets/img/5.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
-
- Caption photos easily. On the left, a road goes through a tunnel. Middle, leaves artistically fall in a hipster photoshoot. Right, in another hipster photoshoot, a lumberjack grasps a handful of pine needles.
-
-
-
- {% include figure.html path="assets/img/5.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
-
- This image can also have a caption. It's like magic.
-
-
-You can also put regular text between your rows of images.
-Say you wanted to write a little bit about your project before you posted the rest of the images.
-You describe how you toiled, sweated, *bled* for your project, and then... you reveal its glory in the next row of images.
-
-
-
-
- {% include figure.html path="assets/img/6.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
- {% include figure.html path="assets/img/11.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
-
- You can also have artistically styled 2/3 + 1/3 images, like these.
-
-
-
-The code is simple.
-Just wrap your images with `
` and place them inside `
` (read more about the
Bootstrap Grid system).
-To make images responsive, add `img-fluid` class to each; for rounded corners and shadows use `rounded` and `z-depth-1` classes.
-Here's the code for the last row of images above:
-
-{% raw %}
-```html
-
-
- {% include figure.html path="assets/img/6.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
- {% include figure.html path="assets/img/11.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
-```
-{% endraw %}
diff --git a/_projects/6_project.md b/_projects/6_project.md
deleted file mode 100644
index 9a95d6e..0000000
--- a/_projects/6_project.md
+++ /dev/null
@@ -1,80 +0,0 @@
----
-layout: page
-title: project 6
-description: a project with no image
-img:
-importance: 4
-category: fun
----
-
-Every project has a beautiful feature showcase page.
-It's easy to include images in a flexible 3-column grid format.
-Make your photos 1/3, 2/3, or full width.
-
-To give your project a background in the portfolio page, just add the img tag to the front matter like so:
-
- ---
- layout: page
- title: project
- description: a project with a background image
- img: /assets/img/12.jpg
- ---
-
-
-
- {% include figure.html path="assets/img/1.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
- {% include figure.html path="assets/img/3.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
- {% include figure.html path="assets/img/5.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
-
- Caption photos easily. On the left, a road goes through a tunnel. Middle, leaves artistically fall in a hipster photoshoot. Right, in another hipster photoshoot, a lumberjack grasps a handful of pine needles.
-
-
-
- {% include figure.html path="assets/img/5.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
-
- This image can also have a caption. It's like magic.
-
-
-You can also put regular text between your rows of images.
-Say you wanted to write a little bit about your project before you posted the rest of the images.
-You describe how you toiled, sweated, *bled* for your project, and then... you reveal its glory in the next row of images.
-
-
-
-
- {% include figure.html path="assets/img/6.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
- {% include figure.html path="assets/img/11.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
-
- You can also have artistically styled 2/3 + 1/3 images, like these.
-
-
-
-The code is simple.
-Just wrap your images with `
` and place them inside `
` (read more about the
Bootstrap Grid system).
-To make images responsive, add `img-fluid` class to each; for rounded corners and shadows use `rounded` and `z-depth-1` classes.
-Here's the code for the last row of images above:
-
-{% raw %}
-```html
-
-
- {% include figure.html path="assets/img/6.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
- {% include figure.html path="assets/img/11.jpg" title="example image" class="img-fluid rounded z-depth-1" %}
-
-
-```
-{% endraw %}
diff --git a/_sass/_base.scss b/_sass/_base.scss
deleted file mode 100644
index 8954b6c..0000000
--- a/_sass/_base.scss
+++ /dev/null
@@ -1,726 +0,0 @@
-/*******************************************************************************
- * Styles for the base elements of the theme.
- ******************************************************************************/
-
-// Typography
-
-p, h1, h2, h3, h4, h5, h6, em, div, li, span, strong {
- color: var(--global-text-color);
-}
-
-hr {
- border-top: 1px solid var(--global-divider-color);
-}
-
-table {
- td, th {
- color: var(--global-text-color);
- }
- td {
- font-size: 1rem;
- }
-}
-
-a, table.table a {
- color: var(--global-theme-color);
- &:hover {
- color: var(--global-theme-color);
- text-decoration: underline;
- }
- &:hover:after :not(.nav-item.dropdown) {
- width: 100%;
- }
-}
-
-figure, img {
- max-width: 90vw;
-}
-
-blockquote {
- background: var(--global-bg-color);
- border-left: 2px solid var(--global-theme-color);
- margin: 1.5em 10px;
- padding: 0.5em 10px;
- font-size: 1.2rem;
-}
-
-// Math
-
-.equation {
- margin-bottom: 1rem;
- text-align: center;
-}
-
-// Caption
-
-.caption {
- font-size: 0.875rem;
- margin-top: 0.75rem;
- margin-bottom: 1.5rem;
- text-align: center;
-}
-
-// Card
-
-.card {
- background-color: var(--global-card-bg-color);
-
- img {
- width: 100%;
- }
-
- .card-title {
- color: var(--global-text-color);
- }
-
- .card-item {
- width: auto;
- margin-bottom: 10px;
-
- .row {
- display: flex;
- align-items: center;
- }
- }
-}
-
-// Citation
-
-.citation, .citation-number {
- color: var(--global-theme-color);
-}
-
-// Profile
-
-.profile {
- width: 100%;
-
- .address {
- margin-bottom: 5px;
- margin-top: 5px;
- font-family: monospace;
- p {
- display: inline-block;
- margin: 0;
- }
- }
-}
-.profile.float-right{
- margin-left: 1rem;
-}
-.profile.float-left{
- margin-right: 1rem;
-}
-
-@media (min-width: 576px) {
- .profile {
- width: 30%;
- .address {
- p { display: block; }
- }
- }
-}
-
-.post-description {
- margin-bottom: 2rem;
- font-size: 0.875rem;
- a {
- color: inherit;
- &:hover {
- color: var(--global-theme-color);
- text-decoration: none;
- }
- }
-}
-
-
-// Navbar customization
-
-.navbar {
- box-shadow: none;
- border-bottom: 1px solid var(--global-divider-color);
- background-color: var(--global-bg-color);
- opacity: 0.95;
-}
-.navbar .dropdown-menu {
- background-color: var(--global-bg-color);
- border: 1px solid var(--global-divider-color);
- a:not(.active) {
- color: var(--global-text-color);
- }
- a:hover {
- color: var(--global-hover-color);
- }
- .dropdown-divider {
- border-top: 1px solid var(--global-divider-color) !important;
- }
-}
-.dropdown-item {
- color: var(--global-text-color);
- &:hover {
- color: var(--global-hover-color);
- background-color: var(--global-bg-color);
- }
-}
-.navbar.navbar-light {
- a {
- &:hover {
- text-decoration: none;
- }
- }
- .navbar-brand {
- color: var(--global-text-color);
- }
- .navbar-nav .nav-item .nav-link {
- color: var(--global-text-color);
- &:hover {
- color: var(--global-hover-color);
- }
- }
- .navbar-nav .nav-item.active>.nav-link {
- background-color: inherit;
- font-weight: bolder;
- color: var(--global-theme-color);
- &:hover {
- color: var(--global-hover-color);
- }
- }
- .navbar-brand.social {
- padding-bottom: 0;
- padding-top: 0;
- font-size: 1.7rem;
- a {
- i::before {
- color: var(--global-text-color);
- transition-property: all 0.2s ease-in-out;
- }
- &:hover {
- i::before {
- color: var(--global-theme-color);
- }
- }
- }
- }
-}
-
-.navbar-toggler {
- .icon-bar {
- display: block;
- width: 22px;
- height: 2px;
- background-color: var(--global-text-color);
- border-radius: 1px;
- margin-bottom: 4px;
- transition: all 0.2s;
- }
- .top-bar {
- transform: rotate(45deg);
- transform-origin: 10% 10%;
- }
- .middle-bar {
- opacity: 0;
- }
- .bottom-bar {
- transform: rotate(-45deg);
- transform-origin: 10% 90%;
- }
-}
-
-.navbar-toggler.collapsed {
- .top-bar {
- transform: rotate(0);
- }
- .middle-bar {
- opacity: 1;
- }
- .bottom-bar {
- transform: rotate(0);
- }
-}
-
-#light-toggle {
- padding: 0;
- border: 0;
- background-color: inherit;
- color: var(--global-text-color);
- &:hover {
- color: var(--global-hover-color);
- }
-}
-
-// Social (bottom)
-
-.social {
- text-align: center;
- .contact-icons {
- font-size: 4rem;
- a {
- i::before {
- color: var(--global-text-color);
- transition-property: all 0.2s ease-in-out;
- }
- &:hover {
- i::before {
- color: var(--global-theme-color);
- }
- }
- }
- }
- .contact-note {
- font-size: 0.8rem;
- }
-}
-
-
-// Footer
-footer.fixed-bottom {
- background-color: var(--global-footer-bg-color);
- font-size: 0.75rem;
- .container {
- color: var(--global-footer-text-color);
- padding-top: 9px;
- padding-bottom: 8px;
- }
- a {
- color: var(--global-footer-link-color);
- &:hover {
- color: var(--global-theme-color);
- text-decoration: none;
- }
- }
-}
-
-footer.sticky-bottom {
- border-top: 1px solid var(--global-divider-color);
- padding-top: 40px;
- padding-bottom: 40px;
- font-size: 0.9rem;
-}
-
-// CV
-
-.cv {
- margin-bottom: 40px;
-
- .card {
- background-color: var(--global-card-bg-color);
- border: 1px solid var(--global-divider-color);
-
- .list-group-item {
- background-color: inherit;
- border-color: var(--global-divider-color);
-
- .badge {
- color: var(--global-card-bg-color) !important;
- background-color: var(--global-theme-color) !important;
- }
- }
- }
-}
-
-// Repositories
-
-@media (min-width: 768px) {
- .repo {
- max-width: 50%;
- }
-}
-
-// Blog
-
-.header-bar {
- border-bottom: 1px solid var(--global-divider-color);
- text-align: center;
- padding-top: 2rem;
- padding-bottom: 3rem;
- h1 {
- color: var(--global-theme-color);
- font-size: 5rem;
- }
-}
-
-.tag-list {
- border-bottom: 1px solid var(--global-divider-color);
- text-align: center;
- padding-top: 1rem;
-
- ul {
- justify-content: center;
- display: flow-root;
-
- p, li {
- list-style: none;
- display: inline-block;
- padding: 1rem 0.5rem;
- color: var(--global-text-color-light);
- }
- }
-}
-
-.post-list {
- margin: 0;
- margin-bottom: 40px;
- padding: 0;
- li {
- border-bottom: 1px solid var(--global-divider-color);
- list-style: none;
- padding-top: 2rem;
- padding-bottom: 2rem;
- .post-meta {
- color: var(--global-text-color-light);
- font-size: 0.875rem;
- margin-bottom: 0;
- }
- .post-tags {
- color: var(--global-text-color-light);
- font-size: 0.875rem;
- padding-top: 0.25rem;
- padding-bottom: 0;
- }
- a {
- color: var(--global-text-color);
- text-decoration: none;
- &:hover {
- color: var(--global-theme-color);
- }
- }
- }
-}
-
-.pagination {
- .page-item {
- .page-link {
- color: var(--global-text-color);
- &:hover {
- color: $black-color;
- }
- }
- &.active .page-link {
- color: $white-color;
- background-color: var(--global-theme-color);
- &:hover {
- background-color: var(--global-theme-color);
- }
- }
- }
-}
-
-
-// Distill
-
-.distill {
- a:hover {
- border-bottom-color: var(--global-theme-color);
- text-decoration: none;
- }
-}
-
-
-// Projects
-
-.projects {
- a {
- text-decoration: none;
-
- &:hover {
- .card-title {
- color: var(--global-theme-color);
- }
- }
- }
-
- .card {
- img {
- width: 100%;
- }
- }
-
- .card-item {
- width: auto;
- margin-bottom: 10px;
-
- .row {
- display: flex;
- align-items: center;
- }
- }
-
- .grid-sizer, .grid-item {
- width: 250px;
- margin-bottom: 10px;
- }
-
- h2.category {
- color: var(--global-divider-color);
- border-bottom: 1px solid var(--global-divider-color);
- padding-top: 0.5rem;
- margin-top: 2rem;
- margin-bottom: 1rem;
- text-align: right;
- }
-}
-
-
-// Publications
-
-.publications {
- margin-top: 2rem;
- h1 {
- color: var(--global-theme-color);
- font-size: 2rem;
- text-align: center;
- margin-top: 1em;
- margin-bottom: 1em;
- }
- h2 {
- margin-bottom: 1rem;
- span {
- font-size: 1.5rem;
- }
- }
- h2.year {
- color: var(--global-divider-color);
- border-top: 1px solid var(--global-divider-color);
- padding-top: 1rem;
- margin-top: 2rem;
- margin-bottom: -2rem;
- text-align: right;
- }
- ol.bibliography {
- list-style: none;
- padding: 0;
- margin-top: 0;
-
- li {
- margin-bottom: 1rem;
- .preview {
- width: 100%;
- min-width: 80px;
- max-width: 200px;
- }
- .abbr {
- height: 2rem;
- margin-bottom: 0.5rem;
- abbr {
- display: inline-block;
- background-color: var(--global-theme-color);
- padding-left: 1rem;
- padding-right: 1rem;
- a {
- color: white;
- &:hover {
- text-decoration: none;
- }
- }
- }
- .award {
- color: var(--global-theme-color) !important;
- border: 1px solid var(--global-theme-color);
- }
- }
- .title {
- font-weight: bolder;
- }
- .author {
- a {
- border-bottom: 1px dashed var(--global-theme-color);
- &:hover {
- border-bottom-style: solid;
- text-decoration: none;
- }
- }
- > em {
- border-bottom: 1px solid;
- font-style: normal;
- }
- > span.more-authors {
- color: var(--global-text-color-light);
- border-bottom: 1px dashed var(--global-text-color-light);
- cursor: pointer;
- &:hover {
- color: var(--global-text-color);
- border-bottom: 1px dashed var(--global-text-color);
- }
- }
- }
- .links {
- a.btn {
- color: var(--global-text-color);
- border: 1px solid var(--global-text-color);
- padding-left: 1rem;
- padding-right: 1rem;
- padding-top: 0.25rem;
- padding-bottom: 0.25rem;
- &:hover {
- color: var(--global-theme-color);
- border-color: var(--global-theme-color);
- }
- }
- }
- .badges {
- span {
- display: inline-block;
- color: $black-color;
- height: 100%;
- padding-left: 0.5rem;
- vertical-align: middle;
- &:hover {
- text-decoration: underline;
- }
- }
- }
- .hidden {
- font-size: 0.875rem;
- max-height: 0px;
- overflow: hidden;
- text-align: justify;
- transition-property: 0.15s ease;
- -moz-transition: 0.15s ease;
- -ms-transition: 0.15s ease;
- -o-transition: 0.15s ease;
- transition: all 0.15s ease;
-
- p {
- line-height: 1.4em;
- margin: 10px;
- }
- pre {
- font-size: 1em;
- line-height: 1.4em;
- padding: 10px;
- }
- }
- .hidden.open {
- max-height: 100em;
- transition-property: 0.15s ease;
- -moz-transition: 0.15s ease;
- -ms-transition: 0.15s ease;
- -o-transition: 0.15s ease;
- transition: all 0.15s ease;
- }
- div.abstract.hidden {
- border: dashed 1px var(--global-bg-color);
- }
- div.abstract.hidden.open {
- border-color: var(--global-text-color);
- }
- }
- }
-}
-
-// Rouge Color Customization
-figure.highlight {
- margin: 0 0 1rem;
-}
-
-pre {
- color: var(--global-theme-color);
- background-color: var(--global-code-bg-color);
- border-radius: 6px;
- padding: 6px 12px;
- pre, code {
- background-color: transparent;
- border-radius: 0;
- padding: 0;
- }
-}
-
-code {
- color: var(--global-theme-color);
- background-color: var(--global-code-bg-color);
- border-radius: 3px;
- padding: 3px 3px;
-}
-
-
-// Transitioning Themes
-html.transition,
-html.transition *,
-html.transition *:before,
-html.transition *:after {
- transition: all 750ms !important;
- transition-delay: 0 !important;
-}
-
-// Extra Markdown style (post Customization)
-.post{
- .post-meta{
- color: var(--global-text-color-light);
- font-size: 0.875rem;
- margin-bottom: 0;
- }
- .post-tags{
- color: var(--global-text-color-light);
- font-size: 0.875rem;
- padding-top: 0.25rem;
- padding-bottom: 1rem;
- a {
- color: var(--global-text-color-light);
- text-decoration: none;
- &:hover {
- color: var(--global-theme-color);
- }
- }
- }
- .post-content{
- blockquote {
- border-left: 5px solid var(--global-theme-color);
- padding: 8px;
- }
- }
-}
-
-progress {
- /* Positioning */
- position: fixed;
- left: 0;
- top: 56px;
- z-index: 10;
-
- /* Dimensions */
- width: 100%;
- height: 1px;
-
- /* Reset the appearance */
- -webkit-appearance: none;
- -moz-appearance: none;
- appearance: none;
-
- /* Get rid of the default border in Firefox/Opera. */
- border: none;
-
- /* Progress bar container for Firefox/IE10 */
- background-color: transparent;
-
- /* Progress bar value for IE10 */
- color: var(--global-theme-color);
- }
-
- progress::-webkit-progress-bar {
- background-color: transparent;
- }
-
- progress::-webkit-progress-value {
- background-color: var(--global-theme-color);
- }
-
- progress::-moz-progress-bar {
- background-color: var(--global-theme-color);
- }
-
- .progress-container {
- width: 100%;
- background-color: transparent;
- position: fixed;
- top: 56px;
- left: 0;
- height: 5px;
- display: block;
- }
-
- .progress-bar {
- background-color: var(--global-theme-color);
- width: 0%;
- display: block;
- height: inherit;
- }
diff --git a/_sass/_distill.scss b/_sass/_distill.scss
deleted file mode 100644
index 47837e7..0000000
--- a/_sass/_distill.scss
+++ /dev/null
@@ -1,129 +0,0 @@
-/*******************************************************************************
- * Style overrides for distill blog posts.
- ******************************************************************************/
-
-d-byline {
- border-top-color: var(--global-divider-color) !important;
-}
-
-d-byline h3 {
- color: var(--global-text-color) !important;
-}
-
-d-byline a, d-article d-byline a {
- color: var(--global-text-color) !important;
- &:hover {
- color: var(--global-hover-color) !important;
- }
-}
-
-d-article {
- border-top-color: var(--global-divider-color) !important;
- p, h1, h2, h3, h4, h5, h6, li, table {
- color: var(--global-text-color) !important;
- }
- h1, h2, hr, table, table th, table td {
- border-bottom-color: var(--global-divider-color) !important;
- }
- a {
- color: var(--global-theme-color) !important;
- &:hover {
- color: var(--global-theme-color) !important;
- }
- }
- b i {
- display: inline;
- }
-
- d-contents {
- align-self: start;
- grid-column: 1 / 4;
- grid-row: auto / span 4;
- justify-self: end;
- margin-top: 0em;
- padding-left: 2em;
- padding-right: 3em;
- border-right: 1px solid var(--global-divider-color);
- width: calc(max(70%, 300px));
- margin-right: 0px;
- margin-top: 0em;
- display: grid;
- grid-template-columns:
- minmax(8px, 1fr) [toc] auto
- minmax(8px, 1fr) [toc-line] 1px
- minmax(32px, 2fr);
-
- nav {
- grid-column: toc;
- a {
- border-bottom: none !important;
- &:hover {
- border-bottom: 1px solid var(--global-text-color) !important;
- }
- }
- h3 {
- margin-top: 0;
- margin-bottom: 1em;
- }
- div {
- display: block;
- outline: none;
- margin-bottom: 0.8em;
- color: rgba(0, 0, 0, 0.8);
- font-weight: bold;
- }
- ul {
- padding-left: 1em;
- margin-top: 0;
- margin-bottom: 6px;
- list-style-type: none;
- li {
- margin-bottom: 0.25em;
- }
- }
- }
- .figcaption {
- line-height: 1.4em;
- }
- toc-line {
- border-right: 1px solid var(--global-divider-color);
- grid-column: toc-line;
- }
- }
-
- d-footnote {
- scroll-margin-top: 66px;
- }
-}
-
-d-appendix {
- border-top-color: var(--global-divider-color) !important;
- color: var(--global-distill-app-color) !important;
- h3, li, span {
- color: var(--global-distill-app-color) !important;
- }
- a, a.footnote-backlink {
- color: var(--global-distill-app-color) !important;
- &:hover {
- color: var(--global-hover-color) !important;
- }
- }
-}
-
-@media (max-width: 1024px) {
- d-article {
- d-contents {
- display: block;
- grid-column-start: 2;
- grid-column-end: -2;
- padding-bottom: 0.5em;
- margin-bottom: 1em;
- padding-top: 0.5em;
- width: 100%;
- border: 1px solid var(--global-divider-color);
- nav {
- grid-column: none;
- }
- }
- }
-}
diff --git a/_sass/_layout.scss b/_sass/_layout.scss
deleted file mode 100644
index 29da4ad..0000000
--- a/_sass/_layout.scss
+++ /dev/null
@@ -1,51 +0,0 @@
-/******************************************************************************
- * Content
- ******************************************************************************/
-
-body {
- padding-bottom: 70px;
- color: var(--global-text-color);
- background-color: var(--global-bg-color);
- font-family: Arial, Helvetica, sans-serif;
-
- h1, h2, h3, h4, h5, h6 {
- scroll-margin-top: 66px;
- }
-}
-
-body.fixed-top-nav {
- // Add some padding for the nav-bar.
- padding-top: 56px;
-}
-
-body.sticky-bottom-footer {
- // Remove padding below footer.
- padding-bottom: 0;
-}
-
-.container {
- max-width: $max-content-width;
-}
-
-// Profile
-.profile {
- img {
- width: 100%;
- }
-}
-
-// TODO: redefine content layout.
-
-
-/******************************************************************************
- * Publications
- ******************************************************************************/
-
-// TODO: redefine publications layout.
-
-
-/*****************************************************************************
-* Projects
-*****************************************************************************/
-
-// TODO: redefine projects layout.
diff --git a/_sass/_themes.scss b/_sass/_themes.scss
deleted file mode 100644
index 2f681ef..0000000
--- a/_sass/_themes.scss
+++ /dev/null
@@ -1,65 +0,0 @@
-/*******************************************************************************
- * Themes
- ******************************************************************************/
-
-:root {
- --global-bg-color: #{$white-color};
- --global-code-bg-color: #{$code-bg-color-light};
- --global-text-color: #{$black-color};
- --global-text-color-light: #{$grey-color};
- --global-theme-color: #{$purple-color};
- --global-hover-color: #{$purple-color};
- --global-footer-bg-color: #{$grey-color-dark};
- --global-footer-text-color: #{$grey-color-light};
- --global-footer-link-color: #{$white-color};
- --global-distill-app-color: #{$grey-color};
- --global-divider-color: rgba(0,0,0,.1);
- --global-card-bg-color: #{$white-color};
-
- .fa-sun {
- display : none;
- }
- .fa-moon {
- padding-left: 10px;
- padding-top: 12px;
- display : block;
- }
-
- .repo-img-light {
- display: block;
- }
- .repo-img-dark {
- display: none;
- }
-}
-
-html[data-theme='dark'] {
- --global-bg-color: #{$grey-color-dark};
- --global-code-bg-color: #{$code-bg-color-dark};
- --global-text-color: #{$grey-color-light};
- --global-text-color-light: #{$grey-color-light};
- --global-theme-color: #{$cyan-color};
- --global-hover-color: #{$cyan-color};
- --global-footer-bg-color: #{$grey-color-light};
- --global-footer-text-color: #{$grey-color-dark};
- --global-footer-link-color: #{$black-color};
- --global-distill-app-color: #{$grey-color-light};
- --global-divider-color: #424246;
- --global-card-bg-color: #{$grey-900};
-
- .fa-sun {
- padding-left: 10px;
- padding-top: 12px;
- display : block;
- }
- .fa-moon {
- display : none;
- }
-
- .repo-img-light {
- display: none;
- }
- .repo-img-dark {
- display: block;
- }
-}
diff --git a/_sass/_variables.scss b/_sass/_variables.scss
deleted file mode 100644
index b050aa6..0000000
--- a/_sass/_variables.scss
+++ /dev/null
@@ -1,38 +0,0 @@
-/*******************************************************************************
- * Variables used throughout the theme.
- * To adjust anything, simply edit the variables below and rebuild the theme.
- ******************************************************************************/
-
-
-// Colors
-$red-color: #FF3636 !default;
-$red-color-dark: #B71C1C !default;
-$orange-color: #F29105 !default;
-$blue-color: #0076df !default;
-$blue-color-dark: #00369f !default;
-$cyan-color: #2698BA !default;
-$light-cyan-color: lighten($cyan-color, 25%);
-$green-color: #00ab37 !default;
-$green-color-lime: #B7D12A !default;
-$green-color-dark: #009f06 !default;
-$green-color-light: #ddffdd !default;
-$green-color-bright: #11D68B !default;
-$purple-color: #B509AC !default;
-$light-purple-color: lighten($purple-color, 25%);
-$pink-color: #f92080 !default;
-$pink-color-light: #ffdddd !default;
-$yellow-color: #efcc00 !default;
-
-$grey-color: #828282 !default;
-$grey-color-light: lighten($grey-color, 40%);
-$grey-color-dark: #1C1C1D;
-$grey-900: #212529;
-
-$white-color: #ffffff !default;
-$black-color: #000000 !default;
-
-
-// Theme colors
-
-$code-bg-color-light: rgba($purple-color, 0.05);
-$code-bg-color-dark: #2c3237 !default;
diff --git a/assets/css/main.css b/assets/css/main.css
new file mode 100644
index 0000000..db0880b
--- /dev/null
+++ b/assets/css/main.css
@@ -0,0 +1,4 @@
+:root{--global-bg-color:#fff;--global-code-bg-color:rgba(181,9,172,0.05);--global-text-color:#000;--global-text-color-light:#828282;--global-theme-color:#b509ac;--global-hover-color:#b509ac;--global-footer-bg-color:#1c1c1d;--global-footer-text-color:#e8e8e8;--global-footer-link-color:#fff;--global-distill-app-color:#828282;--global-divider-color:rgba(0,0,0,.1);--global-card-bg-color:#fff}:root .fa-sun{display:none}:root .fa-moon{padding-left:10px;padding-top:12px;display:block}:root .repo-img-light{display:block}:root .repo-img-dark{display:none}html[data-theme=dark]{--global-bg-color:#1c1c1d;--global-code-bg-color:#2c3237;--global-text-color:#e8e8e8;--global-text-color-light:#e8e8e8;--global-theme-color:#2698ba;--global-hover-color:#2698ba;--global-footer-bg-color:#e8e8e8;--global-footer-text-color:#1c1c1d;--global-footer-link-color:#000;--global-distill-app-color:#e8e8e8;--global-divider-color:#424246;--global-card-bg-color:#212529}html[data-theme=dark] .fa-sun{padding-left:10px;padding-top:12px;display:block}html[data-theme=dark] .fa-moon{display:none}html[data-theme=dark] .repo-img-light{display:none}html[data-theme=dark] .repo-img-dark{display:block}body{padding-bottom:70px;color:var(--global-text-color);background-color:var(--global-bg-color);font-family:Arial,Helvetica,sans-serif}body h1,body h2,body h3,body h4,body h5,body h6{scroll-margin-top:66px}body.fixed-top-nav{padding-top:56px}body.sticky-bottom-footer{padding-bottom:0}.container{max-width:800px}.profile img{width:100%}p,h1,h2,h3,h4,h5,h6,em,div,li,span,strong{color:var(--global-text-color)}hr{border-top:1px solid var(--global-divider-color)}table td,table th{color:var(--global-text-color)}table td{font-size:1rem}a,table.table a{color:var(--global-theme-color)}a:hover,table.table a:hover{color:var(--global-theme-color);text-decoration:underline}a:hover:after :not(.nav-item.dropdown),table.table a:hover:after :not(.nav-item.dropdown){width:100%}figure,img{max-width:90vw}blockquote{background:var(--global-bg-color);border-left:2px solid var(--global-theme-color);margin:1.5em 10px;padding:.5em 10px;font-size:1.2rem}.equation{margin-bottom:1rem;text-align:center}.caption{font-size:.875rem;margin-top:.75rem;margin-bottom:1.5rem;text-align:center}.card{background-color:var(--global-card-bg-color)}.card img{width:100%}.card .card-title{color:var(--global-text-color)}.card .card-item{width:auto;margin-bottom:10px}.card .card-item .row{display:flex;align-items:center}.citation,.citation-number{color:var(--global-theme-color)}.profile{width:100%}.profile .address{margin-bottom:5px;margin-top:5px;font-family:monospace}.profile .address p{display:inline-block;margin:0}.profile.float-right{margin-left:1rem}.profile.float-left{margin-right:1rem}@media(min-width:576px){.profile{width:30%}.profile .address p{display:block}}.post-description{margin-bottom:2rem;font-size:.875rem}.post-description a{color:inherit}.post-description a:hover{color:var(--global-theme-color);text-decoration:none}.navbar{box-shadow:none;border-bottom:1px solid var(--global-divider-color);background-color:var(--global-bg-color);opacity:.95}.navbar .dropdown-menu{background-color:var(--global-bg-color);border:1px solid var(--global-divider-color)}.navbar .dropdown-menu a:not(.active){color:var(--global-text-color)}.navbar .dropdown-menu a:hover{color:var(--global-hover-color)}.navbar .dropdown-menu .dropdown-divider{border-top:1px solid var(--global-divider-color)!important}.dropdown-item{color:var(--global-text-color)}.dropdown-item:hover{color:var(--global-hover-color);background-color:var(--global-bg-color)}.navbar.navbar-light a:hover{text-decoration:none}.navbar.navbar-light .navbar-brand{color:var(--global-text-color)}.navbar.navbar-light .navbar-nav .nav-item .nav-link{color:var(--global-text-color)}.navbar.navbar-light .navbar-nav .nav-item .nav-link:hover{color:var(--global-hover-color)}.navbar.navbar-light .navbar-nav .nav-item.active>.nav-link{background-color:inherit;font-weight:bolder;color:var(--global-theme-color)}.navbar.navbar-light .navbar-nav .nav-item.active>.nav-link:hover{color:var(--global-hover-color)}.navbar.navbar-light .navbar-brand.social{padding-bottom:0;padding-top:0;font-size:1.7rem}.navbar.navbar-light .navbar-brand.social a i::before{color:var(--global-text-color);transition-property:all .2s ease-in-out}.navbar.navbar-light .navbar-brand.social a:hover i::before{color:var(--global-theme-color)}.navbar-toggler .icon-bar{display:block;width:22px;height:2px;background-color:var(--global-text-color);border-radius:1px;margin-bottom:4px;transition:all .2s}.navbar-toggler .top-bar{transform:rotate(45deg);transform-origin:10% 10%}.navbar-toggler .middle-bar{opacity:0}.navbar-toggler .bottom-bar{transform:rotate(-45deg);transform-origin:10% 90%}.navbar-toggler.collapsed .top-bar{transform:rotate(0)}.navbar-toggler.collapsed .middle-bar{opacity:1}.navbar-toggler.collapsed .bottom-bar{transform:rotate(0)}#light-toggle{padding:0;border:0;background-color:inherit;color:var(--global-text-color)}
+#light-toggle:hover{color:var(--global-hover-color)}.social{text-align:center}.social .contact-icons{font-size:4rem}.social .contact-icons a i::before{color:var(--global-text-color);transition-property:all .2s ease-in-out}.social .contact-icons a:hover i::before{color:var(--global-theme-color)}.social .contact-note{font-size:.8rem}footer.fixed-bottom{background-color:var(--global-footer-bg-color);font-size:.75rem}footer.fixed-bottom .container{color:var(--global-footer-text-color);padding-top:9px;padding-bottom:8px}footer.fixed-bottom a{color:var(--global-footer-link-color)}footer.fixed-bottom a:hover{color:var(--global-theme-color);text-decoration:none}footer.sticky-bottom{border-top:1px solid var(--global-divider-color);padding-top:40px;padding-bottom:40px;font-size:.9rem}.cv{margin-bottom:40px}.cv .card{background-color:var(--global-card-bg-color);border:1px solid var(--global-divider-color)}.cv .card .list-group-item{background-color:inherit;border-color:var(--global-divider-color)}.cv .card .list-group-item .badge{color:var(--global-card-bg-color)!important;background-color:var(--global-theme-color)!important}@media(min-width:768px){.repo{max-width:50%}}.header-bar{border-bottom:1px solid var(--global-divider-color);text-align:center;padding-top:2rem;padding-bottom:3rem}.header-bar h1{color:var(--global-theme-color);font-size:5rem}.tag-list{border-bottom:1px solid var(--global-divider-color);text-align:center;padding-top:1rem}.tag-list ul{justify-content:center;display:flow-root}.tag-list ul p,.tag-list ul li{list-style:none;display:inline-block;padding:1rem .5rem;color:var(--global-text-color-light)}.post-list{margin:0;margin-bottom:40px;padding:0}.post-list li{border-bottom:1px solid var(--global-divider-color);list-style:none;padding-top:2rem;padding-bottom:2rem}.post-list li .post-meta{color:var(--global-text-color-light);font-size:.875rem;margin-bottom:0}.post-list li .post-tags{color:var(--global-text-color-light);font-size:.875rem;padding-top:.25rem;padding-bottom:0}.post-list li a{color:var(--global-text-color);text-decoration:none}.post-list li a:hover{color:var(--global-theme-color)}.pagination .page-item .page-link{color:var(--global-text-color)}.pagination .page-item .page-link:hover{color:#000}.pagination .page-item.active .page-link{color:#fff;background-color:var(--global-theme-color)}.pagination .page-item.active .page-link:hover{background-color:var(--global-theme-color)}.distill a:hover{border-bottom-color:var(--global-theme-color);text-decoration:none}.projects a{text-decoration:none}.projects a:hover .card-title{color:var(--global-theme-color)}.projects .card img{width:100%}.projects .card-item{width:auto;margin-bottom:10px}.projects .card-item .row{display:flex;align-items:center}.projects .grid-sizer,.projects .grid-item{width:250px;margin-bottom:10px}.projects h2.category{color:var(--global-divider-color);border-bottom:1px solid var(--global-divider-color);padding-top:.5rem;margin-top:2rem;margin-bottom:1rem;text-align:right}.publications{margin-top:2rem}.publications h1{color:var(--global-theme-color);font-size:2rem;text-align:center;margin-top:1em;margin-bottom:1em}.publications h2{margin-bottom:1rem}.publications h2 span{font-size:1.5rem}.publications h2.year{color:var(--global-divider-color);border-top:1px solid var(--global-divider-color);padding-top:1rem;margin-top:2rem;margin-bottom:-2rem;text-align:right}.publications ol.bibliography{list-style:none;padding:0;margin-top:0}.publications ol.bibliography li{margin-bottom:1rem}.publications ol.bibliography li .preview{width:100%;min-width:80px;max-width:200px}.publications ol.bibliography li .abbr{height:2rem;margin-bottom:.5rem}.publications ol.bibliography li .abbr abbr{display:inline-block;background-color:var(--global-theme-color);padding-left:1rem;padding-right:1rem}.publications ol.bibliography li .abbr abbr a{color:white}.publications ol.bibliography li .abbr abbr a:hover{text-decoration:none}.publications ol.bibliography li .abbr .award{color:var(--global-theme-color)!important;border:1px solid var(--global-theme-color)}.publications ol.bibliography li .title{font-weight:bolder}.publications ol.bibliography li .author a{border-bottom:1px dashed var(--global-theme-color)}.publications ol.bibliography li .author a:hover{border-bottom-style:solid;text-decoration:none}.publications ol.bibliography li .author>em{border-bottom:1px solid;font-style:normal}.publications ol.bibliography li .author>span.more-authors{color:var(--global-text-color-light);border-bottom:1px dashed var(--global-text-color-light);cursor:pointer}.publications ol.bibliography li .author>span.more-authors:hover{color:var(--global-text-color);border-bottom:1px dashed var(--global-text-color)}.publications ol.bibliography li .links a.btn{color:var(--global-text-color);border:1px solid var(--global-text-color);padding-left:1rem;padding-right:1rem;padding-top:.25rem;padding-bottom:.25rem}.publications ol.bibliography li .links a.btn:hover{color:var(--global-theme-color);border-color:var(--global-theme-color)}
+.publications ol.bibliography li .badges span{display:inline-block;color:#000;height:100%;padding-left:.5rem;vertical-align:middle}.publications ol.bibliography li .badges span:hover{text-decoration:underline}.publications ol.bibliography li .hidden{font-size:.875rem;max-height:0;overflow:hidden;text-align:justify;transition-property:.15s ease;-moz-transition:.15s ease;-ms-transition:.15s ease;-o-transition:.15s ease;transition:all .15s ease}.publications ol.bibliography li .hidden p{line-height:1.4em;margin:10px}.publications ol.bibliography li .hidden pre{font-size:1em;line-height:1.4em;padding:10px}.publications ol.bibliography li .hidden.open{max-height:100em;transition-property:.15s ease;-moz-transition:.15s ease;-ms-transition:.15s ease;-o-transition:.15s ease;transition:all .15s ease}.publications ol.bibliography li div.abstract.hidden{border:dashed 1px var(--global-bg-color)}.publications ol.bibliography li div.abstract.hidden.open{border-color:var(--global-text-color)}figure.highlight{margin:0 0 1rem}pre{color:var(--global-theme-color);background-color:var(--global-code-bg-color);border-radius:6px;padding:6px 12px}pre pre,pre code{background-color:transparent;border-radius:0;padding:0}code{color:var(--global-theme-color);background-color:var(--global-code-bg-color);border-radius:3px;padding:3px 3px}html.transition,html.transition *,html.transition *:before,html.transition *:after{transition:all 750ms!important;transition-delay:0!important}.post .post-meta{color:var(--global-text-color-light);font-size:.875rem;margin-bottom:0}.post .post-tags{color:var(--global-text-color-light);font-size:.875rem;padding-top:.25rem;padding-bottom:1rem}.post .post-tags a{color:var(--global-text-color-light);text-decoration:none}.post .post-tags a:hover{color:var(--global-theme-color)}.post .post-content blockquote{border-left:5px solid var(--global-theme-color);padding:8px}progress{position:fixed;left:0;top:56px;z-index:10;width:100%;height:1px;-webkit-appearance:none;-moz-appearance:none;appearance:none;border:0;background-color:transparent;color:var(--global-theme-color)}progress::-webkit-progress-bar{background-color:transparent}progress::-webkit-progress-value{background-color:var(--global-theme-color)}progress::-moz-progress-bar{background-color:var(--global-theme-color)}.progress-container{width:100%;background-color:transparent;position:fixed;top:56px;left:0;height:5px;display:block}.progress-bar{background-color:var(--global-theme-color);width:0;display:block;height:inherit}d-byline{border-top-color:var(--global-divider-color)!important}d-byline h3{color:var(--global-text-color)!important}d-byline a,d-article d-byline a{color:var(--global-text-color)!important}d-byline a:hover,d-article d-byline a:hover{color:var(--global-hover-color)!important}d-article{border-top-color:var(--global-divider-color)!important}d-article p,d-article h1,d-article h2,d-article h3,d-article h4,d-article h5,d-article h6,d-article li,d-article table{color:var(--global-text-color)!important}d-article h1,d-article h2,d-article hr,d-article table,d-article table th,d-article table td{border-bottom-color:var(--global-divider-color)!important}d-article a{color:var(--global-theme-color)!important}d-article a:hover{color:var(--global-theme-color)!important}d-article b i{display:inline}d-article d-contents{align-self:start;grid-column:1/4;grid-row:auto/span 4;justify-self:end;margin-top:0;padding-left:2em;padding-right:3em;border-right:1px solid var(--global-divider-color);width:max(70%,300px);margin-right:0;margin-top:0;display:grid;grid-template-columns:minmax(8px,1fr) [toc] auto minmax(8px,1fr) [toc-line] 1px minmax(32px,2fr)}d-article d-contents nav{grid-column:toc}d-article d-contents nav a{border-bottom:none!important}d-article d-contents nav a:hover{border-bottom:1px solid var(--global-text-color)!important}d-article d-contents nav h3{margin-top:0;margin-bottom:1em}d-article d-contents nav div{display:block;outline:0;margin-bottom:.8em;color:rgba(0,0,0,0.8);font-weight:bold}d-article d-contents nav ul{padding-left:1em;margin-top:0;margin-bottom:6px;list-style-type:none}d-article d-contents nav ul li{margin-bottom:.25em}d-article d-contents .figcaption{line-height:1.4em}d-article d-contents toc-line{border-right:1px solid var(--global-divider-color);grid-column:toc-line}d-article d-footnote{scroll-margin-top:66px}d-appendix{border-top-color:var(--global-divider-color)!important;color:var(--global-distill-app-color)!important}d-appendix h3,d-appendix li,d-appendix span{color:var(--global-distill-app-color)!important}d-appendix a,d-appendix a.footnote-backlink{color:var(--global-distill-app-color)!important}d-appendix a:hover,d-appendix a.footnote-backlink:hover{color:var(--global-hover-color)!important}@media(max-width:1024px){d-article d-contents{display:block;grid-column-start:2;grid-column-end:-2;padding-bottom:.5em;margin-bottom:1em;padding-top:.5em;width:100%;border:1px solid var(--global-divider-color)}d-article d-contents nav{grid-column:none}
+}
\ No newline at end of file
diff --git a/assets/css/main.css.map b/assets/css/main.css.map
new file mode 100644
index 0000000..7a0d73a
--- /dev/null
+++ b/assets/css/main.css.map
@@ -0,0 +1 @@
+{"version":3,"sourceRoot":"","sources":["../../_sass/_variables.scss","../../_sass/_themes.scss","../../_sass/_layout.scss","main.scss","../../_sass/_base.scss","../../_sass/_distill.scss"],"names":[],"mappings":"AAAA;AAAA;AAAA;AAAA;ACAA;AAAA;AAAA;AAIA;EACE;EACA;EACA;EACA;EACA;EACA;EACA;EACA;EACA;EACA;EACA;EACA;;AAEA;EACE;;AAEF;EACE;EACA;EACA;;AAGF;EACE;;AAEF;EACE;;;AAIJ;EACE;EACA;EACA;EACA;EACA;EACA;EACA;EACA;EACA;EACA;EACA;EACA;;AAEA;EACE;EACA;EACA;;AAEF;EACE;;AAGF;EACE;;AAEF;EACE;;;AC9DJ;AAAA;AAAA;AAIA;EACE;EACA;EACA;EACA;;AAEA;EACE;;;AAIJ;EAEE;;;AAGF;EAEE;;;AAGF;EACE,WCvBkB;;;AD4BlB;EACE;;;AAOJ;AAAA;AAAA;AAOA;AAAA;AAAA;AE9CA;AAAA;AAAA;AAMA;EACE;;;AAGF;EACE;;;AAIA;EACE;;AAEF;EACE;;;AAIJ;EACE;;AACA;EACE;EACA;;AAEF;EACE;;;AAIJ;EACE;;;AAGF;EACE;EACA;EACA;EACA;EACA;;;AAKF;EACE;EACA;;;AAKF;EACE;EACA;EACA;EACA;;;AAKF;EACE;;AAEA;EACE;;AAGF;EACE;;AAGF;EACE;EACA;;AAEA;EACE;EACA;;;AAON;EACE;;;AAKF;EACE;;AAEA;EACE;EACA;EACA;;AACA;EACE;EACA;;;AAIN;EACE;;;AAEF;EACE;;;AAGF;EACE;IACE;;EAEE;IAAI;;;AAKV;EACE;EACA;;AACA;EACE;;AACA;EACE;EACA;;;AAQN;EACE;EACA;EACA;EACA;;;AAEF;EACE;EACA;;AACA;EACE;;AAEF;EACE;;AAEF;EACE;;;AAGJ;EACE;;AACE;EACE;EACA;;;AAKF;EACE;;AAGJ;EACE;;AAEF;EACE;;AACA;EACE;;AAGJ;EACI;EACA;EACA;;AACA;EACE;;AAGN;EACE;EACA;EACA;;AAEE;EACE;EACA;;AAGA;EACE;;;AAQR;EACE;EACA;EACA;EACA;EACA;EACA;EACA;;AAEF;EACE;EACA;;AAEF;EACE;;AAEF;EACE;EACA;;;AAKF;EACE;;AAEF;EACE;;AAEF;EACE;;;AAIJ;EACE;EACA;EACA;EACA;;AACA;EACE;;;AAMJ;EACE;;AACA;EACE;;AAEE;EACE;EACA;;AAGA;EACE;;AAKR;EACE;;;AAMJ;EACE;EACA;;AACA;EACE;EACA;EACA;;AAEF;EACE;;AACA;EACE;EACA;;;AAKN;EACE;EACA;EACA;EACA;;;AAKF;EACE;;AAEA;EACE;EACA;;AAEA;EACE;EACA;;AAEA;EACE;EACA;;;AAQR;EACE;IACE;;;AAMJ;EACE;EACA;EACA;EACA;;AACA;EACE;EACA;;;AAIJ;EACE;EACA;EACA;;AAEA;EACE;EACA;;AAEA;EACE;EACA;EACA;EACA;;;AAKN;EACE;EACA;EACA;;AACA;EACE;EACA;EACA;EACA;;AACA;EACE;EACA;EACA;;AAEF;EACE;EACA;EACA;EACA;;AAEF;EACE;EACA;;AACA;EACE;;;AAQJ;EACE;;AACA;EACE,OJ3WM;;AI8WV;EACE,OJhXQ;EIiXR;;AACA;EACE;;;AAUN;EACE;EACA;;;AAQF;EACE;;AAGE;EACE;;AAMJ;EACE;;AAIJ;EACE;EACA;;AAEA;EACE;EACA;;AAIJ;EACE;EACA;;AAGF;EACE;EACA;EACA;EACA;EACA;EACA;;;AAOJ;EACE;;AACA;EACE;EACA;EACA;EACA;EACA;;AAEF;EACE;;AACA;EACE;;AAGJ;EACE;EACA;EACA;EACA;EACA;EACA;;AAEF;EACE;EACA;EACA;;AAEA;EACE;;AACA;EACE;EACA;EACA;;AAEF;EACE;EACA;;AACA;EACE;EACA;EACA;EACA;;AACA;EACE;;AACA;EACE;;AAIN;EACE;EACA;;AAGJ;EACE;;AAGA;EACE;;AACA;EACI;EACA;;AAGN;EACE;EACA;;AAEF;EACE;EACA;EACA;;AACA;EACI;EACA;;AAKN;EACE;EACA;EACA;EACA;EACA;EACA;;AACA;EACE;EACA;;AAKJ;EACE;EACA,OJnhBI;EIohBJ;EACA;EACA;;AACA;EACE;;AAIN;EACE;EACA;EACA;EACA;EACA;EACA;EACA;EACA;EACA;;AAEA;EACE;EACA;;AAEF;EACE;EACA;EACA;;AAGJ;EACE;EACA;EACA;EACA;EACA;EACA;;AAEF;EACE;;AAEF;EACE;;;AAOR;EACE;;;AAGF;EACE;EACA;EACA;EACA;;AACA;EACE;EACA;EACA;;;AAIJ;EACE;EACA;EACA;EACA;;;AAKF;AAAA;AAAA;AAAA;EAIE;EACA;;;AAKA;EACE;EACA;EACA;;AAEF;EACE;EACA;EACA;EACA;;AACA;EACE;EACA;;AACA;EACE;;AAKJ;EACE;EACA;;;AAKN;AACK;EACA;EACA;EACA;EACA;AAEA;EACA;EACA;AAEA;EACA;EACG;EACK;AAER;EACA;AAEA;EACA;AAEA;EACA;;;AAGJ;EACI;;;AAGJ;EACI;;;AAGJ;EACI;;;AAGJ;EACI;EACA;EACA;EACA;EACA;EACA;EACA;;;AAGJ;EACI;EACA;EACA;EACA;;;ACptBL;AAAA;AAAA;AAIA;EACE;;;AAGF;EACE;;;AAGF;EACE;;AACA;EACE;;;AAIJ;EACE;;AACA;EACE;;AAEF;EACE;;AAEF;EACE;;AACA;EACE;;AAGJ;EACE;;AAGF;EACE;EACA;EACA;EACA;EACA;EACA;EACA;EACA;EACA;EACA;EACA;EACA;EACA,uBACE;;AAIF;EACE;;AACA;EACE;;AACA;EACE;;AAGJ;EACE;EACA;;AAEF;EACE;EACA;EACA;EACA;EACA;;AAEF;EACE;EACA;EACA;EACA;;AACA;EACE;;AAIN;EACE;;AAEF;EACE;EACA;;AAIJ;EACE;;;AAIJ;EACE;EACA;;AACA;EACE;;AAEF;EACE;;AACA;EACE;;;AAKN;EAEI;IACE;IACA;IACA;IACA;IACA;IACA;IACA;IACA;;EACA;IACE","sourcesContent":["/*******************************************************************************\n * Variables used throughout the theme.\n * To adjust anything, simply edit the variables below and rebuild the theme.\n ******************************************************************************/\n\n\n// Colors\n$red-color: #FF3636 !default;\n$red-color-dark: #B71C1C !default;\n$orange-color: #F29105 !default;\n$blue-color: #0076df !default;\n$blue-color-dark: #00369f !default;\n$cyan-color: #2698BA !default;\n$light-cyan-color: lighten($cyan-color, 25%);\n$green-color: #00ab37 !default;\n$green-color-lime: #B7D12A !default;\n$green-color-dark: #009f06 !default;\n$green-color-light: #ddffdd !default;\n$green-color-bright: #11D68B !default;\n$purple-color: #B509AC !default;\n$light-purple-color: lighten($purple-color, 25%);\n$pink-color: #f92080 !default;\n$pink-color-light: #ffdddd !default;\n$yellow-color: #efcc00 !default;\n\n$grey-color: #828282 !default;\n$grey-color-light: lighten($grey-color, 40%);\n$grey-color-dark: #1C1C1D;\n$grey-900: #212529;\n\n$white-color: #ffffff !default;\n$black-color: #000000 !default;\n\n\n// Theme colors\n\n$code-bg-color-light: rgba($purple-color, 0.05);\n$code-bg-color-dark: #2c3237 !default;\n","/*******************************************************************************\n * Themes\n ******************************************************************************/\n \n:root {\n --global-bg-color: #{$white-color};\n --global-code-bg-color: #{$code-bg-color-light};\n --global-text-color: #{$black-color};\n --global-text-color-light: #{$grey-color};\n --global-theme-color: #{$purple-color};\n --global-hover-color: #{$purple-color};\n --global-footer-bg-color: #{$grey-color-dark};\n --global-footer-text-color: #{$grey-color-light};\n --global-footer-link-color: #{$white-color};\n --global-distill-app-color: #{$grey-color};\n --global-divider-color: rgba(0,0,0,.1);\n --global-card-bg-color: #{$white-color};\n\n .fa-sun {\n display : none;\n }\n .fa-moon {\n padding-left: 10px;\n padding-top: 12px;\n display : block;\n }\n\n .repo-img-light {\n display: block;\n }\n .repo-img-dark {\n display: none;\n }\n}\n\nhtml[data-theme='dark'] {\n --global-bg-color: #{$grey-color-dark};\n --global-code-bg-color: #{$code-bg-color-dark};\n --global-text-color: #{$grey-color-light};\n --global-text-color-light: #{$grey-color-light};\n --global-theme-color: #{$cyan-color};\n --global-hover-color: #{$cyan-color};\n --global-footer-bg-color: #{$grey-color-light};\n --global-footer-text-color: #{$grey-color-dark};\n --global-footer-link-color: #{$black-color};\n --global-distill-app-color: #{$grey-color-light};\n --global-divider-color: #424246;\n --global-card-bg-color: #{$grey-900};\n\n .fa-sun {\n padding-left: 10px;\n padding-top: 12px;\n display : block;\n }\n .fa-moon {\n display : none;\n }\n\n .repo-img-light {\n display: none;\n }\n .repo-img-dark {\n display: block;\n }\n}\n","/******************************************************************************\n * Content\n ******************************************************************************/\n\nbody {\n padding-bottom: 70px;\n color: var(--global-text-color);\n background-color: var(--global-bg-color);\n font-family: Arial, Helvetica, sans-serif;\n\n h1, h2, h3, h4, h5, h6 {\n scroll-margin-top: 66px;\n }\n}\n\nbody.fixed-top-nav {\n // Add some padding for the nav-bar.\n padding-top: 56px;\n}\n\nbody.sticky-bottom-footer {\n // Remove padding below footer.\n padding-bottom: 0;\n}\n\n.container {\n max-width: $max-content-width;\n}\n\n// Profile\n.profile {\n img {\n width: 100%;\n }\n}\n\n// TODO: redefine content layout.\n\n\n/******************************************************************************\n * Publications\n ******************************************************************************/\n\n// TODO: redefine publications layout.\n\n\n/*****************************************************************************\n* Projects\n*****************************************************************************/\n\n// TODO: redefine projects layout.\n","@charset \"utf-8\";\n\n// Dimensions\n$max-content-width: 800px;\n\n@import\n \"variables\",\n \"themes\",\n \"layout\",\n \"base\",\n \"distill\"\n;\n","/*******************************************************************************\n * Styles for the base elements of the theme.\n ******************************************************************************/\n\n// Typography\n\np, h1, h2, h3, h4, h5, h6, em, div, li, span, strong {\n color: var(--global-text-color);\n}\n\nhr {\n border-top: 1px solid var(--global-divider-color);\n}\n\ntable {\n td, th {\n color: var(--global-text-color);\n }\n td {\n font-size: 1rem;\n }\n}\n\na, table.table a {\n color: var(--global-theme-color);\n &:hover {\n color: var(--global-theme-color);\n text-decoration: underline;\n }\n &:hover:after :not(.nav-item.dropdown) {\n width: 100%;\n }\n}\n\nfigure, img {\n max-width: 90vw;\n}\n\nblockquote {\n background: var(--global-bg-color);\n border-left: 2px solid var(--global-theme-color);\n margin: 1.5em 10px;\n padding: 0.5em 10px;\n font-size: 1.2rem;\n}\n\n// Math\n\n.equation {\n margin-bottom: 1rem;\n text-align: center;\n}\n\n// Caption\n\n.caption {\n font-size: 0.875rem;\n margin-top: 0.75rem;\n margin-bottom: 1.5rem;\n text-align: center;\n}\n\n// Card\n\n.card {\n background-color: var(--global-card-bg-color);\n\n img {\n width: 100%;\n }\n\n .card-title {\n color: var(--global-text-color);\n }\n\n .card-item {\n width: auto;\n margin-bottom: 10px;\n\n .row {\n display: flex;\n align-items: center;\n }\n }\n}\n\n// Citation\n\n.citation, .citation-number {\n color: var(--global-theme-color);\n}\n\n// Profile\n\n.profile {\n width: 100%;\n\n .address {\n margin-bottom: 5px;\n margin-top: 5px;\n font-family: monospace;\n p {\n display: inline-block;\n margin: 0;\n }\n }\n}\n.profile.float-right{\n margin-left: 1rem;\n}\n.profile.float-left{\n margin-right: 1rem;\n}\n\n@media (min-width: 576px) {\n .profile {\n width: 30%;\n .address {\n p { display: block; }\n }\n }\n}\n\n.post-description {\n margin-bottom: 2rem;\n font-size: 0.875rem;\n a {\n color: inherit;\n &:hover {\n color: var(--global-theme-color);\n text-decoration: none;\n }\n }\n}\n\n\n// Navbar customization\n\n.navbar {\n box-shadow: none;\n border-bottom: 1px solid var(--global-divider-color);\n background-color: var(--global-bg-color);\n opacity: 0.95;\n}\n.navbar .dropdown-menu {\n background-color: var(--global-bg-color);\n border: 1px solid var(--global-divider-color);\n a:not(.active) {\n color: var(--global-text-color);\n }\n a:hover {\n color: var(--global-hover-color);\n }\n .dropdown-divider {\n border-top: 1px solid var(--global-divider-color) !important;\n }\n}\n.dropdown-item {\n color: var(--global-text-color);\n &:hover {\n color: var(--global-hover-color);\n background-color: var(--global-bg-color);\n }\n}\n.navbar.navbar-light {\n a {\n &:hover {\n text-decoration: none;\n }\n }\n .navbar-brand {\n color: var(--global-text-color);\n }\n .navbar-nav .nav-item .nav-link {\n color: var(--global-text-color);\n &:hover {\n color: var(--global-hover-color);\n }\n }\n .navbar-nav .nav-item.active>.nav-link {\n background-color: inherit;\n font-weight: bolder;\n color: var(--global-theme-color);\n &:hover {\n color: var(--global-hover-color);\n }\n }\n .navbar-brand.social {\n padding-bottom: 0;\n padding-top: 0;\n font-size: 1.7rem;\n a {\n i::before {\n color: var(--global-text-color);\n transition-property: all 0.2s ease-in-out;\n }\n &:hover {\n i::before {\n color: var(--global-theme-color);\n }\n }\n }\n }\n}\n\n.navbar-toggler {\n .icon-bar {\n display: block;\n width: 22px;\n height: 2px;\n background-color: var(--global-text-color);\n border-radius: 1px;\n margin-bottom: 4px;\n transition: all 0.2s;\n }\n .top-bar {\n transform: rotate(45deg);\n transform-origin: 10% 10%;\n }\n .middle-bar {\n opacity: 0;\n }\n .bottom-bar {\n transform: rotate(-45deg);\n transform-origin: 10% 90%;\n }\n}\n\n.navbar-toggler.collapsed {\n .top-bar {\n transform: rotate(0);\n }\n .middle-bar {\n opacity: 1;\n }\n .bottom-bar {\n transform: rotate(0);\n }\n}\n\n#light-toggle {\n padding: 0;\n border: 0;\n background-color: inherit;\n color: var(--global-text-color);\n &:hover {\n color: var(--global-hover-color);\n }\n}\n\n// Social (bottom)\n\n.social {\n text-align: center;\n .contact-icons {\n font-size: 4rem;\n a {\n i::before {\n color: var(--global-text-color);\n transition-property: all 0.2s ease-in-out;\n }\n &:hover {\n i::before {\n color: var(--global-theme-color);\n }\n }\n }\n }\n .contact-note {\n font-size: 0.8rem;\n }\n}\n\n\n// Footer\nfooter.fixed-bottom {\n background-color: var(--global-footer-bg-color);\n font-size: 0.75rem;\n .container {\n color: var(--global-footer-text-color);\n padding-top: 9px;\n padding-bottom: 8px;\n }\n a {\n color: var(--global-footer-link-color);\n &:hover {\n color: var(--global-theme-color);\n text-decoration: none;\n }\n }\n}\n\nfooter.sticky-bottom {\n border-top: 1px solid var(--global-divider-color);\n padding-top: 40px;\n padding-bottom: 40px;\n font-size: 0.9rem;\n}\n\n// CV\n\n.cv {\n margin-bottom: 40px;\n \n .card {\n background-color: var(--global-card-bg-color);\n border: 1px solid var(--global-divider-color);\n \n .list-group-item {\n background-color: inherit;\n border-color: var(--global-divider-color);\n\n .badge {\n color: var(--global-card-bg-color) !important;\n background-color: var(--global-theme-color) !important;\n }\n }\n }\n}\n\n// Repositories\n\n@media (min-width: 768px) {\n .repo {\n max-width: 50%;\n }\n}\n\n// Blog\n\n.header-bar {\n border-bottom: 1px solid var(--global-divider-color);\n text-align: center;\n padding-top: 2rem;\n padding-bottom: 3rem;\n h1 {\n color: var(--global-theme-color);\n font-size: 5rem;\n }\n}\n\n.tag-list {\n border-bottom: 1px solid var(--global-divider-color);\n text-align: center;\n padding-top: 1rem;\n\n ul {\n justify-content: center;\n display: flow-root;\n\n p, li {\n list-style: none;\n display: inline-block;\n padding: 1rem 0.5rem;\n color: var(--global-text-color-light);\n }\n }\n}\n\n.post-list {\n margin: 0;\n margin-bottom: 40px;\n padding: 0;\n li {\n border-bottom: 1px solid var(--global-divider-color);\n list-style: none;\n padding-top: 2rem;\n padding-bottom: 2rem;\n .post-meta {\n color: var(--global-text-color-light);\n font-size: 0.875rem;\n margin-bottom: 0;\n }\n .post-tags {\n color: var(--global-text-color-light);\n font-size: 0.875rem;\n padding-top: 0.25rem;\n padding-bottom: 0;\n }\n a {\n color: var(--global-text-color);\n text-decoration: none;\n &:hover {\n color: var(--global-theme-color);\n }\n }\n }\n}\n\n.pagination {\n .page-item {\n .page-link {\n color: var(--global-text-color);\n &:hover {\n color: $black-color;\n }\n }\n &.active .page-link {\n color: $white-color;\n background-color: var(--global-theme-color);\n &:hover {\n background-color: var(--global-theme-color);\n }\n }\n }\n}\n\n\n// Distill\n\n.distill {\n a:hover {\n border-bottom-color: var(--global-theme-color);\n text-decoration: none;\n }\n}\n\n\n// Projects\n\n.projects {\n a {\n text-decoration: none;\n\n &:hover {\n .card-title {\n color: var(--global-theme-color);\n }\n }\n }\n\n .card {\n img {\n width: 100%;\n }\n }\n\n .card-item {\n width: auto;\n margin-bottom: 10px;\n\n .row {\n display: flex;\n align-items: center;\n }\n }\n\n .grid-sizer, .grid-item {\n width: 250px;\n margin-bottom: 10px;\n }\n\n h2.category {\n color: var(--global-divider-color);\n border-bottom: 1px solid var(--global-divider-color);\n padding-top: 0.5rem;\n margin-top: 2rem;\n margin-bottom: 1rem;\n text-align: right;\n }\n}\n\n\n// Publications\n\n.publications {\n margin-top: 2rem;\n h1 {\n color: var(--global-theme-color);\n font-size: 2rem;\n text-align: center;\n margin-top: 1em;\n margin-bottom: 1em;\n }\n h2 {\n margin-bottom: 1rem;\n span {\n font-size: 1.5rem;\n }\n }\n h2.year {\n color: var(--global-divider-color);\n border-top: 1px solid var(--global-divider-color);\n padding-top: 1rem;\n margin-top: 2rem;\n margin-bottom: -2rem;\n text-align: right;\n }\n ol.bibliography {\n list-style: none;\n padding: 0;\n margin-top: 0;\n\n li {\n margin-bottom: 1rem;\n .preview {\n width: 100%;\n min-width: 80px;\n max-width: 200px;\n }\n .abbr {\n height: 2rem;\n margin-bottom: 0.5rem;\n abbr {\n display: inline-block;\n background-color: var(--global-theme-color);\n padding-left: 1rem;\n padding-right: 1rem;\n a {\n color: white;\n &:hover {\n text-decoration: none;\n }\n }\n }\n .award {\n color: var(--global-theme-color) !important;\n border: 1px solid var(--global-theme-color);\n }\n }\n .title {\n font-weight: bolder;\n }\n .author {\n a {\n border-bottom: 1px dashed var(--global-theme-color);\n &:hover {\n border-bottom-style: solid;\n text-decoration: none;\n }\n }\n > em {\n border-bottom: 1px solid;\n font-style: normal;\n }\n > span.more-authors {\n color: var(--global-text-color-light);\n border-bottom: 1px dashed var(--global-text-color-light);\n cursor: pointer;\n &:hover {\n color: var(--global-text-color);\n border-bottom: 1px dashed var(--global-text-color);\n }\n }\n }\n .links {\n a.btn {\n color: var(--global-text-color);\n border: 1px solid var(--global-text-color);\n padding-left: 1rem;\n padding-right: 1rem;\n padding-top: 0.25rem;\n padding-bottom: 0.25rem;\n &:hover {\n color: var(--global-theme-color);\n border-color: var(--global-theme-color);\n }\n }\n }\n .badges {\n span {\n display: inline-block;\n color: $black-color;\n height: 100%;\n padding-left: 0.5rem;\n vertical-align: middle;\n &:hover {\n text-decoration: underline;\n }\n }\n }\n .hidden {\n font-size: 0.875rem;\n max-height: 0px;\n overflow: hidden;\n text-align: justify;\n transition-property: 0.15s ease;\n -moz-transition: 0.15s ease;\n -ms-transition: 0.15s ease;\n -o-transition: 0.15s ease;\n transition: all 0.15s ease;\n\n p {\n line-height: 1.4em;\n margin: 10px;\n }\n pre {\n font-size: 1em;\n line-height: 1.4em;\n padding: 10px;\n }\n }\n .hidden.open {\n max-height: 100em;\n transition-property: 0.15s ease;\n -moz-transition: 0.15s ease;\n -ms-transition: 0.15s ease;\n -o-transition: 0.15s ease;\n transition: all 0.15s ease;\n }\n div.abstract.hidden {\n border: dashed 1px var(--global-bg-color);\n }\n div.abstract.hidden.open {\n border-color: var(--global-text-color);\n }\n }\n }\n}\n\n// Rouge Color Customization\nfigure.highlight {\n margin: 0 0 1rem;\n}\n\npre {\n color: var(--global-theme-color);\n background-color: var(--global-code-bg-color);\n border-radius: 6px;\n padding: 6px 12px;\n pre, code {\n background-color: transparent;\n border-radius: 0;\n padding: 0;\n }\n}\n\ncode {\n color: var(--global-theme-color);\n background-color: var(--global-code-bg-color);\n border-radius: 3px;\n padding: 3px 3px;\n}\n\n\n// Transitioning Themes\nhtml.transition,\nhtml.transition *,\nhtml.transition *:before,\nhtml.transition *:after {\n transition: all 750ms !important;\n transition-delay: 0 !important;\n}\n\n// Extra Markdown style (post Customization)\n.post{\n .post-meta{\n color: var(--global-text-color-light);\n font-size: 0.875rem;\n margin-bottom: 0;\n }\n .post-tags{\n color: var(--global-text-color-light);\n font-size: 0.875rem;\n padding-top: 0.25rem;\n padding-bottom: 1rem;\n a {\n color: var(--global-text-color-light);\n text-decoration: none;\n &:hover {\n color: var(--global-theme-color);\n }\n }\n }\n .post-content{\n blockquote {\n border-left: 5px solid var(--global-theme-color);\n padding: 8px;\n }\n }\n}\n\nprogress {\n /* Positioning */\n position: fixed;\n left: 0;\n top: 56px;\n z-index: 10;\n \n /* Dimensions */\n width: 100%;\n height: 1px;\n \n /* Reset the appearance */\n -webkit-appearance: none;\n -moz-appearance: none;\n appearance: none;\n \n /* Get rid of the default border in Firefox/Opera. */\n border: none;\n \n /* Progress bar container for Firefox/IE10 */\n background-color: transparent;\n \n /* Progress bar value for IE10 */\n color: var(--global-theme-color);\n }\n \n progress::-webkit-progress-bar {\n background-color: transparent;\n }\n \n progress::-webkit-progress-value {\n background-color: var(--global-theme-color);\n }\n \n progress::-moz-progress-bar {\n background-color: var(--global-theme-color);\n }\n \n .progress-container {\n width: 100%;\n background-color: transparent;\n position: fixed;\n top: 56px;\n left: 0;\n height: 5px;\n display: block;\n }\n \n .progress-bar {\n background-color: var(--global-theme-color);\n width: 0%;\n display: block;\n height: inherit;\n }\n","/*******************************************************************************\n * Style overrides for distill blog posts.\n ******************************************************************************/\n\nd-byline {\n border-top-color: var(--global-divider-color) !important;\n}\n\nd-byline h3 {\n color: var(--global-text-color) !important;\n}\n\nd-byline a, d-article d-byline a {\n color: var(--global-text-color) !important;\n &:hover {\n color: var(--global-hover-color) !important;\n }\n}\n\nd-article {\n border-top-color: var(--global-divider-color) !important;\n p, h1, h2, h3, h4, h5, h6, li, table {\n color: var(--global-text-color) !important;\n }\n h1, h2, hr, table, table th, table td {\n border-bottom-color: var(--global-divider-color) !important;\n }\n a {\n color: var(--global-theme-color) !important;\n &:hover {\n color: var(--global-theme-color) !important;\n }\n }\n b i {\n display: inline;\n }\n\n d-contents {\n align-self: start;\n grid-column: 1 / 4;\n grid-row: auto / span 4;\n justify-self: end;\n margin-top: 0em;\n padding-left: 2em;\n padding-right: 3em;\n border-right: 1px solid var(--global-divider-color);\n width: calc(max(70%, 300px));\n margin-right: 0px;\n margin-top: 0em;\n display: grid;\n grid-template-columns:\n minmax(8px, 1fr) [toc] auto\n minmax(8px, 1fr) [toc-line] 1px\n minmax(32px, 2fr);\n\n nav {\n grid-column: toc;\n a {\n border-bottom: none !important;\n &:hover {\n border-bottom: 1px solid var(--global-text-color) !important;\n }\n }\n h3 {\n margin-top: 0;\n margin-bottom: 1em;\n }\n div {\n display: block;\n outline: none;\n margin-bottom: 0.8em;\n color: rgba(0, 0, 0, 0.8);\n font-weight: bold;\n }\n ul {\n padding-left: 1em;\n margin-top: 0;\n margin-bottom: 6px;\n list-style-type: none;\n li {\n margin-bottom: 0.25em;\n }\n }\n }\n .figcaption {\n line-height: 1.4em;\n }\n toc-line {\n border-right: 1px solid var(--global-divider-color);\n grid-column: toc-line;\n }\n }\n\n d-footnote {\n scroll-margin-top: 66px;\n }\n}\n\nd-appendix {\n border-top-color: var(--global-divider-color) !important;\n color: var(--global-distill-app-color) !important;\n h3, li, span {\n color: var(--global-distill-app-color) !important;\n }\n a, a.footnote-backlink {\n color: var(--global-distill-app-color) !important;\n &:hover {\n color: var(--global-hover-color) !important;\n }\n }\n}\n\n@media (max-width: 1024px) {\n d-article {\n d-contents {\n display: block;\n grid-column-start: 2;\n grid-column-end: -2;\n padding-bottom: 0.5em;\n margin-bottom: 1em;\n padding-top: 0.5em;\n width: 100%;\n border: 1px solid var(--global-divider-color);\n nav {\n grid-column: none;\n }\n }\n }\n}\n"],"file":"main.css"}
\ No newline at end of file
diff --git a/assets/css/main.scss b/assets/css/main.scss
deleted file mode 100644
index fd8c311..0000000
--- a/assets/css/main.scss
+++ /dev/null
@@ -1,15 +0,0 @@
----
-# Only the main Sass file needs front matter (the dashes are enough)
----
-@charset "utf-8";
-
-// Dimensions
-$max-content-width: {{ site.max_width }};
-
-@import
- "variables",
- "themes",
- "layout",
- "base",
- "distill"
-;
diff --git a/assets/img/1-1400.webp b/assets/img/1-1400.webp
new file mode 100644
index 0000000000000000000000000000000000000000..3a5a4d603021f8ff089035a6d9da48377a0fbf75
GIT binary patch
literal 59658
zcmV(vK
Py%MM6+kP&gp==l}qa0|T7_Dj)+E0zT1PrA;U$BdDwxdif9<
z31@BN4$@iH^VA;F8hNRA4=E{pe68)AAjrei~Fzrd@)(!VR|z(d=+&t+^fE8
z)}NUly8iwCoB!9bCNujg)KkO%`+C>@zrH`1`h=FJ0(X0KB|Nr09PXLRGDe@Q
zqAF>o5<2Y(`RSL?i-TnlVSCW2AhO+1e>Ivs?VF$#PGp53;kNaYlSDeoa0FVD-`V9W
zi6X64kU{16DDjlZ!*x@fa+W^)3?<&dV|8ti#Q~ASM5&WIn3)Y*v@?V5Yl1QmWi|ZN
zz{kpQvK0djjtTg^~yFV;KIrP=xiD1muYs?mp8(hI7@CiDrlM8yTstJam#9b$G1QIS2y069w1P@DJ`Se=9h%Od2^I`h$@Jlee!0QnW(GMQc(
zYIRVy=NJKrC(A$l0-QGZ{Wb#iiJ!y#&<0JmU?1Phf?6j7x_P`DN-8W_+Ft={iwe%
zr5_bL8pgqU$QPYIiW>4y*AY9_1J41Mwa4Kld;dJ^4lf2wAgm?}GdzZ>JJzH?Vcng@
zKfnjgTru%tOWE+g)=;KZ^f!v*Dv0x5>FcQIPVQ6HUyZE$1BQly2SY-Z-xaS+N}Lv5
zGq>|=V`iEMWseY0pL|k5!nf6l|QIN3buI)U-32S
zlu2VO60@x3@=p;ew&fz(+yp5jUH`?N0KT|<{TiegZ`hc?&Mc}bih_KTfd6i<*3pQ-
zzslxeRvtazIHcERy)uxlVu`X`bp}yk5&_%h*MBHoNh7$rd^h<86G>sx=Hq2cg?IWI
zse{)Nvs=LXNvdWwMLQL{!gIfnz}H?%#h!ItdO&@mXL0aE>{~kd(W$8J4o~jAXR~J$
zP}~AOt}o@;eR2e~2Cfe*?}yLRX-@c(z?`8?loaO!qWY-zX_qJ`eBJ_=VA5p^a;af~
zZ3+-q>>3U7;YyJ-}9bck&wD_sU#DRqaYbaXs!bH1s%9Viva4|;>ZyXNl^X0ccIT~>sK1Zo9#8NKL_J68g3UaW<8|FLJCts;KL65O
z<^{ugr6qHDOia9BDuBo~PT;@fN(N*-k&JJd))+%2EjTCdWsGsgh_g
z@2yqKqXJC#L`+T{^3DIY4hdg&3%SZJe|Wg}%5MowB4@v~&X+6m+bbv!LNk}I^NX7u
zO=rwBRpg1-9!dERHr)TC;{5{JCF7clOjx&*OzVN=9;R-Hv%p#kZn@>d@8c;ot;s*t
z2H}@qf^upSGpMZ39PI~9Z;qM$wO5R-0To_Q*}isofi0(>HrjhRxU1!2s>o0G!8D6Z
zN-FcK0rm{MXox+5ck5(+)SZMMQo%MaiE;egjg0?fMWKPPh`>=bsHU}@C0c^S>4r
zeMudE{V*KE$%x17mnSMNnWHZJF#0YCRy`#ijvKS0M-#^KpG18C6;u{6(!6)_<2wKv
z#+sq9`kA2%%WTF{02bkOXu+N)0nFz!U;cn-hTYn6YxI7slQ^Ks2Yky!w1cIu=)*Qc
zHP4#ioD_=SKWge7hfFN@M4c4mN52dHONPIn?DT;ykhpkF&aZe#4D=SCpHiepknMi
zE!l;9jlxuxd+_BUfn$ERgS&L@D7#FA8~VS)rBb`Q~gH}o77WNt|v(c
zC=#_poj@|z7BX27+z{xyD4~d)lDmksadrC8vu^CMG@!^g{!6kdU4>J!TI}g~-PC-I
zWu{^U%&n|*6kp0pSpn0|T`#Hhv+Q4#Zz-khUrH(ln`kV6#aIj`)}!|K>-D_0n3rDp
z>kUE`z$aT{!+&*Fgx~58#Yo{$aD1v%{|ylznvu+;R?k
zIds5a4GZ2fx-XoRj{L_;yF8A8xIH+Sj`i@+d&nnRZrwOs(XZZ7pgOl~_QUHdd@OYx
zsa>i?eqls)r{vt5;^8hWeg8*h+837aXXKnkEM;P|>d4g~$-!UY4S~SGSSdr>6JgPx
zT=(fe`!|)`Ia`Y>=MM8+{Jsey-$i|QS&F!EQMLlLp&X(O3Z!;t4G8K?y6C>vM{psc
z&0fF&&eF3vbM(z>{uA$5R$gAD+T8%Eetlz6M$N}WpFOJIT~NkF%uyDc29S)ex02I(
zX3k&mqO^_q2cwTAjHYBaME
z!z<`FXGc&SGXUuMTdsk17OyGb3E^n@=I#;e-4xlMOT!MGlUGWtw90*=5I*speLp^4q^@fy%*K>bP~OVgMhQQb0ILCp=411#CcS$~GNd*H
zXPMt8XRo-euKe?iv5L#Rb-tDdb9HI(#RYJl6s5Vng2?-jY%8RPyd;ed+f1R9+Ns}Wa3Ad`O5#(=v&ezxL->-7G0*aNrwPc1?dx9uD@
zcx6OA@0%B@rX`g6VhHkgAag2>RsmB$}hXYQqFs@J0vJMI@WFO<*3gq9+2
zS^K}VOSVn3`(QQ!_4)ksQ~f2uXU?jv{L&wc>}J>cR7W}iC^WXeK;
zU$2Cv(LitPvN^rm?6k8pnQbr5m*pCbi6H8^xyd5rSk6zLwe_;+7!%MVYofPmM@0Rp
zCF^J1%F;?bJ|$k)%n*A+kX@zgI~*^ovMHnU-?%%%;l?
z6OAMIAqFf6}$T+Ol{!Ch(Yz_rxe
zhH0xsq%|~$u%y_4;~Si9$OlV%#8B^Tw|4FSx{A%<=M1=|JhD=khVju36{Ov`zb<>#
znN1(bxrkb8dZ=-!Kx41#f}YRYlEv_R@x&0yX>5HK5J}Fk_q47!)AR3)Lk61a7SSLo
z*OdjPr(ZGs?KS1BG+I(%sNNf@h)!}Ay^6s@s|EYIEJAS_o>vwwig(bQTyRVjIaib>
zZIx=}PC1V|KZjf?^!G|I#ilR@vv%5~9Q58cHcZRn^E&x{uD0+rko}5un$&Ivh9bz+
z&PGm~J{q;|ICKRb3MCvtaMKU<5mtOwTI5q^L9PX^Ekz0CEJ9U^VPB3s9DZ#w8Q(VK
zc*XRu5mhdEd+)ZRV61joF`<_Sk=+>2wvVIRCoCp=`-*y%@AZsS(QKo}^I?=t*vVz~
zeq&p`6eoCagwZ(UL4Ev@3|bySS3YA6L+kq>64WXe`$1gtU3B4jr%1%Xp&hWWht}Mg
z@f{q|ae?Be$%vT3@ivPDktlq6J)~Skp7}jfn<{+f8!bRxrcJEMVP^2+&>_uHL@rIX#Zj2
zbw!zGuf_~=#0V9>vKId`O$uIRWLPlHmCVKz7v%=uMC{?3eUN6&fwF4cp?2*20Vu
z?25>^0wg#<00J`ImhqK)fyxtoT-lZ(1W#(yu%{|lsUd_MBDVf>a{(JVBlyvkL+1J^
z=<|Oi;OC{C+zicdDqc}Ec?b!8prmT78?SDf#1~7|SAq`cTKTjCR;}OuC634Ya
zolf4-w5Q&=`~P1q|B*1KU0%T4WHpcF7j8%8H8p00x#f0m*cos)
z$&*qY4AQd9S)B#nAiku*g7DzQ3>)B}-XRwe%j>gJ^`6a`!2$Fd70P#L+3B~-({z`+
zelDE{ZGLW1zRuztH}iaiZ4`dgc|W~fU}G-3SmTkjcMr)yaLOyqlAVM58Ga`g>i2n(
zl}XeSXWP`{xt&UjeFbtFPenY;V#ayf+6Y&;+)|)HV&m@{8=k?pAkLLfOya)Jh5>d+
zsUd2xyKi-CI4-wygEaX+7(h($x%W
zZzG%Mbx4*NowutC<^9xAsPL%eUf!0ie|i>018T7hBtsbFQAr7ZHW!5Ts&6fN$yMZP
zvsXln$?}q%rYhNGmySu8DcHxPtBhP@``#ff$9=i{cw9HPnHT&T
z_53@M(fYM({#j9nd67#odB5oSVkHJNhP}Hg$ILqFd%H4UEt&uCu-z5W1uTV+?)B8N
zTtfMO)cGA(@+ay)Pnmmfv+SN%1RLhff5CFRt8rh{0Q+kAVs|cyJGaNIuT%Dl`y{I2
zEtVd2y({V(RC9L!1Q$Gtc(f3D;
z!7cA(U(6u3wi&7S0}Ac=Z@uPgmBed)K5=CP32Gg$aTELFILzW75WYU$o9*W!<`3JY
zAy0*)c)6KOS0dNg!)x%^*fH@%CgYZnUplbhH$v)yB7A8=j~qWp!IJV#Eu|G8#E33^
zicyO_s>ng`RHGBjCvE&;>vV$i<2F!(%Fu_=%y*`{aw6cOTts;F3
zY`FcB;S}*Y~h)hsmNe
z-8V6L^p|{*)-Ea1`YmmFi%))q)ZFetnozgn7RM(8Bgu4Y=#vFOT!edDe>nCD26ET1
zEF&V7JL1VdL%Sm#-2vFi&4-Ven2JE89^Xgei?1c?*38=wUD4jG4swVVku`I#;TXulf4^YCKBfq81?!rxh&N6lFmcV=k-h6P!o$WM5xxh1x6
zMk^CNF9!S;b2v2d)c%>4=0NY3>&MC%^UVDr~Wu&2S2J9owYn=~Gm*5WpXjE-5EGIS7iuFyk8
z@C7&VhpN0feTXbh?0zgbWO?;%Uhkg}h#$LEQO{;BIFxA?C)&>F)@PjXh
z#4+t9)5SZGR>6TDP!&WnqHSaF=6zT_yMK5o)Pk3uBf9b5;xTuuyu
z^}TI1tptZ3Q#!dQQ?00lfOFB^)O=n30eKI{22bqKR;6^xQ%g-lZXA1hEPVsbfL--B
z>PfpwUfRPA$%JpZejqgRU4x;U!rau8z$r_I3GI&_G=^pjS{;3+K^AZzanGA{BBh8Da3TE>qTh1mJWDd-bjBBe1M96r~yW~ut!*+M-Xa>xnT
z0Fh1ovFmqv>rQM1J>IS0>Rcz_HVY^dAPVkgX0^Gx5Dto?tuNiOY-dVFHA0O@@TkMdnKzAfbe%3RuhKxT$|V#fR*%wfqt
z5TwAt-c7B<5fr}SPKGI{f|%uvA#W?F3*7bQ&Vy#_izb)THePMq!ja8NU6ywLri_qJ
z`2k$Kj!xO*lH}KojT&mkRPtCW_?!xpb5E0Pd64@kHw{>+21qlRC*$}m4a&j(A;02{
z+@u?|r<~6FEbQWOPs!5QW3}$NfDiCXOPgA$I$y9}
zo~pe!#(jpXA(V*t7LtGvArNRkBKl|$%9sLzu~e-EtBfQ9WfXILiXX2cPF9nS^WZp5O6OEd4!i98@0t?m
zFEq!v?WtvS&m7l#93MeJ9Y=KjZNC9*n9=OF;8?WnmJp~UmF%z-kKSW3>V8B(iYuo{eFI;*@ZVNv8W~%t19HC---|rkFrfpBkl^G`GF-E2e~Wg-
zR=|Ca{&kpP1*hgPo=Y1wF=fK=XA&;sbh;o$vGyd|uZLW#)@?%q
z4XHPHxq%DSp(vYzLJgEv4~oWYY-|h?NE)P`phJzUTD5VwrqY&Ei%xA$xHTvY>k%!7
z@G^f-KR+OR8>Gb*9Gs2j_jHl=fXTDSGS5!mt_3VZ4O!1b$UI;G)rN%2G{V`u-?8B;
zL(E#Ae=OmimOFBg*DiJ^zkhj#pS1=nK&4!Z_WDQ=-!~e@hBgCV$0UvdM`tw)HYs&3
z6WjzjnDu#-OU9J#jeCAr8N`6bh;9TruR;_~7%|`){SEk$ZNvz&b{PA?AsS_j3anju
zkTD-Z5S%<3S0+~MXEH$K?4raRfrO?mXQQ!LY7)f~THUT>PGtTVubj)$R_y|K;yaUR
zI~zAjbw?>J-?rHSeXI9QF|vVu;mE?oUIG*vN+N)M2BAbIw1b@Vh*Hd)gx2w&n0
zJVMQ;$yvB?(?mdx>zC1K@-c~eO#*V!LbZZ;(I?GM`0(ZDJ>^1Fd>hbTLUov+z^t^_
z7*XloaPQR3@A&F!RUfpA^?~#NS{sS$Jv&sG%G51qO=>?_RwE7+xf^B0P6}GMUPJrG
z4j$qDumGW!qO$M_!{&HtyPT;~PGKXKC>gPt3LvTXqcb2>ODKW
zkEf8}`05YULPMz3bWZv6p;YU;$U*pJ^iW-62&HdHOXKj
zgBd`gq63~5_4l3+#EkRPsEf04SAz`LdSyG&&2LO>(z_pxGP8^;KcXEHr2&Pj2+TXz
zDxnkqd9dIjRNsc#SGV>;v=w3%F!t+oQ}mUZ_cui^Vu5Ug1`6!MnOLADJ^+)gYD!`lPupnC-`j|9eTtNg}+7BIW^(
z94}+yk}aw!*^B5lm}JG=@%d)+0Aiumo43a;B;iE1Tq;EXUdgR0T87GDjBrNfKlRy~
zyO++aHMBU%%(`t$-c(a<9H}M?Zw@caoXq{;^n~h-y1p{h>FGf^dWKXrdiC2`x0Yau
zihIDwz0`-5z3z_a2h;P&mWi}@O=3y$v>@-^^{G^rXvL;flu|YYrSvf}7l5KWctw&`
zf21BA!6E^WL9lX3FyaY4bY#{%3Kw8ZLKY`qbt%VyAF`;x2joXQap1UKh7wqmf!Ky(
ze~y~F?8tY}3RAt?Jh7?Elg6MR2n7K`iJjQLc*L1p4Yv>hMI9P=Z5H$&iL`tOvYri4
z!{C_&bz0BM?6wmqg+9LN%>6`bP*YSUN!R=P#euF6kpKG@fsVhX0R1l#Y}qIauhRDU
zGPIow6ln8z)mpS3ybU7_VgRDRNN!q`88_{i|0*jarE{8(nzsjB4bYq|iEG!~=!A=}
z4;o&(VhwNP;}p9}k#5s6FI(jSl@yS@_?j+R->J`>FY+ruWXUnV4k;@$3vqfS^d6XqUXV;%%QghW
z=3^20vsJ}5h&tQ6)Tg?i7a<7V;q)P{`Nkk-;$Uy3fbd_pOp=L5+ZJwPUT_{gJYPa*
zn_^X!2O8=|mf4cx)mJdHa`Kky#v}Z2Bf0}f9e6O;vRwwCaO-vbN}+d1DiJYN`Djwt
znpV-}&Wo9_>)?#n=KJ%Hcy=?Jl(ufmGWuSZkHsB3RFB`DISbqRW4UEg{&`EhPRqd%Y8tgbpeR+cjSYb;g^rfecfl2gdpV)&s(^f5OF8rhP>#f`f6&&46lwMKNC7`>QrN%+7{>sV1nZKvfp
z`R6lH$67y%cCl%E+$Nz>uitC+9BzoTZm=1OqsefPa*=|V?PK`>+nHhYyH`UOXSWE4;Rbnq-AG!YwmUj>61qqSgreQObo2@+5-
z6yCyCxB3IK>TT3bm?st?=#Lo3-m+%=5iHHI4jC8lwQ!oaCnvYvkTV0!W1W|1X96{w
zn7BITBmgveIPTPo_|*ZJ6TPS=292R25k^FN%w4)Sc*yTPb}=mfMTRcxZda8ZQrdnV
zW$T!-kMwqp2ebSBi?=~ZoII_;FKv;%U{yY%{&jdeZ27bVcVUdxV$(9@sc^Omv3b{5
z?8q)-UKV_tVXAH$=;>kU!B)^u=9Sv-eSR)*NSy2P8Gp7V=^LShr{Vp2)c6q&G6qY?
zsBo&yn;Fb0RmqjOMtrBUG~L^kJR_6e(`Fuii2muEL-|j})vgM*De1UzthN-JB^Wlw
zQ5hKJ!dOac>}@5Fb%g^oYA`Q7V9904cfy8Esu*l`2n%Gvpv(CgbfGcB|nlFWiWh#FrSbWxm+Jab>INc8&q+m=<1Lz9!mCRqDZtDn(P@jr5!(^
zpoVw2t{tdYd{*1YGNsds%~SI`-b?ReIhmd=IWBNS03uv}lPdH$O+TfYQ=(Z?^=rcP
zmqau@0>Bp_Ci<>f6B;P=;Q*0-)!g~Y0(NmeQo(W70W??WE8VT
z4Y*&EUSe;5E4**@I$Tncr&laYZ3rtKB;!_vvYR#)3>fM{<;)6<;(f+!5G>neD_~bx
z!BriYfH(v0nPu89#m>DnaORt6;ycvAAg}azV?^LNPmCo)IK}{;@=zk$eq};aEo^i<
zxRdw>`a#V8$&|GT2I(KU>$--FbiZj|?HFv@W_M#hFr~DBYw+wgt!cPK3w29+E<%drMT
zbYU<;=(m<)R=|hi!sscS^9u`V}uP
z2&Kv+Z-zr!u2Q#j5t$INBd~Jbx^fRMwCEJcFx&Uj&UCiuoAWkif+6DEkvM7;A?_=^
z@ON-;x8Cb-f*W3MEvHl0F`0YCwr`qo5F!&CxVfxBERRLFDn`b#JFYX-8+xTt0{iFD
zsxv`V$POVPm)z2%&Hfr|%1APIn+S!ig~rDeXA-!ur?xG^tq_Uz6(s3{ne>NDoYX~_
zFToOv=tGwMaJB64N@M~jz~Odp|CEHUuj?Fl`CMw!=y8U-ZtYcTQ~1C|2)RsJq3Kdl
zGMdD%*m1qW>nnprxfJKJS`qr^c~3k+!Q3_+AaMy8L@|ONiRD(#cHEOzSOeYIq>9fm
znyUp(;^p1e$KD8ObJo;Vwr#sCYA~t*hJwag`pP+;IJ66P@ONGx28eAGS!3G@+p}9X
z_81p3?O@Ig>G^B(oMoU;u&DGzjQ&;{Kq^
zM!OL6x$GJn{~H4lgJTNHWH8sG&ku9{olc>35Cw*vC)
z0DVg%CTKbKiSKC%|K^?o=Zu-i*?|vCcf~S9-lBgPVnD66_S5HJzk`b1F-Q*Cc}pbi
zW4>_ZFf2mRSqYgh2!MGoJVN!tCGoVpgdgbcj}IBQ{F91!=QnVY;UcNod3&R_A&$~J
zw_0lj{{GTIBgb*t6l~VjTAK^*YU`$Iv5jf?pQyG1xM7Ds0ke}FV8
z!FDk)&N#z{$S{G&W9v~V_)n`qx!{k>hVhT{+JsY<LC(3UqFQ5@S
zAWdfSo--Yf52aYg?EZRkttJ_SJ(OzgPk}A<;ypS__-%T4)+aKsR|!o
zy#=XGM23zahaX}?81$WUV%OVG1{_XE&a(!>G#r%Q<#c5B$oP)d(B?pEAf^#JOJW}#
z%+5_v6f|zXKW@i3b58F*%)w2yLQ;U@YB)?t4s0UvyXW}aK&|eD{{^%Ixwau0g-~p%
z%f)YX8cXK9O+Sf~+r>>(x#b;4Wq%@Ch3axQWBE;TczMf&CWBFf6z~w<1{4=lPkE`u
zo_)AYdBQI&otYl)&y>*uJll;ZB)c||X5Pke<8~t|YM)#SU^D@L90$~hU?|bb#~yyx
z+Lk}WML+aZFJh<+WG7?BGTfVB7r`hAE~kJ6s`5y>v>cpQ0Zp34$-~J-m{`GN=s+pl
zr{-%z>@W~SL;kF}TC{O;lT%k*k0wIP4SjJ%sw`L_I4b`L-Qt1Z8ql4O)UqKH
zqsQGuyvEhb6)4>l_HwGWzxNj38EsOl`*0<#spVr;(aE^|hBG(Au0vE2J4NrqP!l3W
z#U9{2HGm3=y>H)y`#Y~WggS)q+
z0bojSC$a%OWfCF#)vvXCCtv^uFL-_y$}3;+ta^2E;Yr?W&Rkf6oC1k1_m?i{c+X&-
z2^UA4rB|zDxAROTL;k%My;`@_0D}^o3{_c0q+q?%zp=UzE+%>J37So1$P`8_+E(Sq
zKP6n82I-gy6K~kx#sp5yx`LBmZ}GCewb2N@)C*nb*o}c~Y>C;#aRA3E8V}QMq9$yi
zG?)v^C$+R^WVavn6N}1%G}yf+rDfYoB*gQ6<>l{KU$cke(a>j$vNHVL6_-Ixd|pzN
zGZE{Vsn-;h_kXsD%X(xuejQ?3ZxP<%!Vlz(B_Q3oitEnBaMcFmBZ4u#|9Qb(IQ5RXYyE*Blqz@CeOZA}p$$@-^~oS+I3(wOVV~7fy@w4?i9T^sGORL#d9vSrYL*
zCGPbxX>`AmQi41NfOCZy)^B>#9tnDPV4I^Npe4Lrm#x$;bAKF#8DU4DTWTfzE5f
zzC#gr2}2BV<+7S~>;>XIEUmNv;{2Ouh~X}nVm>g^u*7kprv>adrpYQS_a9z%qwO9J
z^x`D$7C)sFXpog^L9cH$)f1vY1d?i^lNgr6&4}pj4$|Lhpl8&dHrjNfN&}Qr=|jre
z3GRYO8UI|B2ibeFB@Z0BUW7CR(hP?V4>)OEGIi1CL_raWdeB{+391J*$xRuHWv{c2
z`JS`7q
zVF&zRv#6-fm{01?8T@H+-!@O5C$bZp3q=8+H9rD|SV+hzyXh=D2P8d5o+&fuMVP#<
zxxd0sk!r^m(lG6HLGZYSey2b^ktCmu3B0GdpZLHy`h{sh#-Qw%Wyy7d^~HMf+Ma}Z
zQ2pjzgJ~vkH^8$hAGnpS;6bzI2*B)GK__RtQ2*^=f
zV{&Fz0FpzPQ{@U>RsV5+gDT{mKr*Z1=th!ZX2IO%%9Os9!&cS`hJoiGJHEcU
zKc0!i)b~Rw=2J26L5xyKlY$^MBgP^@5~{`u?WE$;`Rt<&fID+v{zU4_5bE&hO=ntG
zvP-i;O7K~uq4Hx=&Rm5do$Ao=W=`kcTV)N}P&f6{+4qnSDwc1|FkxYE;lqi`M&1&j
zjVS53P&aUCLaT|U)(1>XCrh@^#su9*w`}n>E`9;dT6+wv&JHvTBdJ!t7|(!ykI729
zb`e}Rg9GR<6=tWUclE4ccw2Tr)sus~*tb8j-`2#C<_|R*-82&xS@0LA&kV-)V!S!1GY@
zLo&J-e|W@BO>9{l{E#Sy9?}5ezVz6B#vs;u$$9)2pmg`*1=*UhM=TJdq7QXgt%plq
zYL$@Ct*j(})q-f@OAt@K;{*m8O9h5xVmBqtg0ZF*r?%dOqBGf7#s2&~dM3A~bv7f_
zAAa{K&;TcjU@ICMc=VLnsH{L}x|lWXQZ)|D36qZYm~cbMD4^fMFbI*Nf;>1Otcm9f
z!*%t`tnmzcgv2WZ%DX!#)gjwB%;~eWwMI2h){q083tt6nq`--d?;#D2^fY1OeN%!
z#BunO)r7&4r>$6LMq@<9uB)nWtIqo{Mweh*eQ=Ao?k)?9<6VC!t2sLwes`=uU9qse
z=Xv!GoNp$rW`@(K2X-qq(2H~Md_;{D{Wk9f&er4QR{SvTCb2;hllPmCMUf;}4YeA#
zCe4jcBwIuYA0ye?{gjwB(L0)!~nvy9Z#c@;%<_)sy3u=dy_$J$ooDvMjuyT7~zN(Mr5dfQ~s>=?;g
zd3mbkYN>o5C&Q+Jf#pmdJB0gM*G#r~`jj9A0z3dH>wPK#FVu(UH4FxcUKY@3|GXW*
z5^+5LB$M5|(-f^*N+6lpt?XoD(0}vJ%df~n0mHYJmQa^iblHQGR3J)ASg5-;AL|B_
znv`6mcz0!_|H!+4-`#82FmT3*%JCw6?0w}0+1Srm$B&<1j{NHgPGenyUaK?Ooe0y1
zJ`F{#q2?8aWozH&vVGf1_H?y3NAcwM&_3c&BqTEIgELgEMk6E_J%X#+;*wgq-%kdg
z@c#7AS)QcdpTghaPxucOsoDWI0OjbhT8c^4Eh62K3X|HwqavW~Dy3LeLD~*Dsb2)K
z|G|&b+)1AWcZl-d;Y@2_6M8gd-Hh)4X3xzSau*NVq&4B;u8;#J8>s|xCf9`V<+T(I
z(`MCrfG5Q+*5Zp)K<;niUhJBUj5=G2_CEujCOd};2!e7+7*d8|OlO_j;fPHm<;FV7
zYq0yBU-e_f`h41JZ5w~wx>8lcK+*s^Meiww4u;IJp}Fw>@)?-M?jz}79!$XSd)~(a
zaS*(OqPPqlx%th+VRrh+?TM;0ACM12(2!Qg3urhq2@%oZzzd&65C(Kb{qk_Jhhm+W
z5t{LE_Dr6Ko2T%pL_5gh1oF|fsV!CGu^(N>d0@)`6R2h6g&k~c7BvrE}<*h-hHQ_@kC*T31Xc&S-5|_QNWt*eUjzqj|TOWJ~E$<~4F9g0<=S79AZe
zc$-(Q1}tKP8%+qYz1U%XUq+ZBj{fE+Ru~B={-I!tX6d}e=539o1zur!AVluJ%}~Vn
zyxX3A^cJIEaVg-kw^x2cd%T~FZ$aEkX=fV{JRBzXnqlFN5TqdIfL2H7mAdH{icd4I
z6ZuG%wwxkSA;XwR{B8agqvJ-SvP_XKFM0FMEm7oO&eqeaK=BeT4sT~<2I?vjCcc6G
zkkhw*P!`)OzF3fW#q~e#`6mQO*u*3On=*ngl@{hblpk<(Y*-KjPA$&9>ihwxDZ?Vn
z)~{qVI&a%d!hJ?4DL`y(4IMG0O-ieEoDGRm*L7@t(-gsxUcOoj9SG{(f0q}Uv#120
zD7xAcMwDBDhg>n`jB%wbBP}VIh~I4r`_qm?R@$S@GHL(a0S{WHv_ZM#xyC*LUl$+2
z^1OD)z0*vKri6z$XP$V~POu<1EmHOv%yw{ma5F7B6f*;<}!QRqD^c~-N#+lf%kntAKrTrKy^g;udM#ao0V
zibHz@r~lv2jvGw8WNX%FjDg$q{if2z-T>L0iogqrv*<zpT9<;-YnQd*R25{OrR8?Nx?7)}rg4DFzdt{>3ZNx@}=A
zgce`Qa0$(8haNB(RbSy=l`w71B6TgIml3H(y5=UaDPDlURq(Hv1B0H>fLw}
zY5^H7fA5qtS?K*{_OI8H&E*!}8X8I^Xs(Z$+lPAiG4I9zg?OCiqwXEcap^6wug0vc
zPYy5@HE51}1xZd9qe3v^feBZq3ml7R4{0RH7jq6>p}|d_1UK;8S`Dk2>RR(UN!e3J
zJy*YmWP{rH`ckY1ZtEt^JDuDTNfs{2DSyq#D6hE2X*EwZ`T|4c=8SoGq4L%qPYNh2W$tXttr(Rqnf3KFb=;XS6NJMfLqB#C+{
zn)e9}8z+bqo>wxs8U(BG=*E^kB^^x!9OqT4
zh`%xkA%6vWp$!<#)?*D}s>g22nL6RptKsYh){$7%p_o>Nb~};Hi2G^~*Xk(v9wuV@
zMI`bjyr)H3S{bcLc_OYJCrwh4p}0c;g*`xL`p7^GFnwB~daABlb$*h)kWiVt
z`5*JY+|oyptgFXxqe>PKW4W`6Iy7_>(y>kY;Bj0
zN2UMewn70%y&L^+C|s98ymHNlE!<$bIc2gzv)+V}Xt4%eV5dh?)jiNY6(GS>zaTyd!rCA18`0oGZ
zeTPP^?2keOk==t1gRO*l`lfcj?z*__exK>hG;VQQb*SZoKSjmGWi#oJ;!Gb>Gn}%#
zQ0Z2Ie^8AWVpE^vT53a&g(4-m7tE%41$A;-}E*{fAoo&E|4T1SN+PgxLu03;0
zc&IPj4v5^R*v6(;@KLIfWDdwHKuX7U%&AJ9TDlMoXnOnndZnPqP+2vYJ=^xanl*jP
zcJu~bD*!G;d6cRdyF!h0bnsB%AqCL&O^vU(YG)N>QsASpzr`5h@YG#I?OpTL>Bx$(
z1EjF+F2!F(kaxmqsRw2pvcC)f|FB0g1N}}w=`Dazc#XU(dah@!^4(db@tmtcM94VJ
zMX83^2BqA8GCZ-qa=W?4;{2ve(}t6veYqUV2ew~Kv4Q=T!(X4_vK8sx)C1;YhCrcd
z2K5n-=1?HXR>otuvKXq$^%Nhg3=k4_##2slP=S7z{FTA><2)BCbU}>yZnlN`=##9r
z)X8hGHSY*?n4?wFppRu|W%+UBJIH8|9RU*tL^vfZL7H~idC=lA0OJy??`i_xv`z6k
z1-2`-((2INym(+Q<<03nZr9uVRnQwGRbdi$@s(ay%hJ7=y1eF$E8z(M1)fSI?SW(=
ztyNR3!Qd^(xA27P%9{X6Y!?*&afUtk{desO!HoW?mdkE#PiAtMuQmhGKHeLu4&Pr$
z(FrYDF6i?2#MDpTEZC1D$GfrqOCpu&ptT}AMH^-dak^;1D_c~GiI|Nx2ZwJ*b`em6!xqNQd9^{NSxU5^)N2=kOu#MTS&G9TsUqvRe6TU
z5$D3IrG?3MfLq$cAs^~XNI>{98au`tTTVpyG>xg9@+7M(rMc%Q0XCTR#5FbYA(Q@O
z(w48@etuE)KIlOQL$}0wBni5f)wu~Gda1u_rn82kbEY-o==orh_*y=eHa>Yz;~r@W
zN$@+(e$%QgALMpYIXu7H8?&e(kl(~SW}E=>)~7?Sd`>@pkOPRpiuE0$KFNpf)7!`9
zKdcj-nSZ~n5i6L_2pDl(Ru83$CBuaHj!Vce%SYRM8E9V69N!_E1f-q8mIMwP5H?9!
z%KX@%fq@`6X_2wtb=e3YYsa12g;?I_EIvl#ajI&zUzp>iXC)go&p%=4NEx#?KSbIR
zvH`VOeT+1WHntf>8qc_Ucy1I64<`3IU`~fTN6KRQC
zcN`j~;Q@|@baT3n46yP%G>$-=dwd&oG}}X(Rgg|EWQP=-z9jP`
zb+r=8!?8>lx3lgt)vRc4Q{G~CYBHBxA_laZOeWDFN@b~!tdYOykCtcHxDh=T3i*!Mj`QBTH>vrYse
z)}w~7KhTjEQSUn5U;|K&R02B2hGM@7F;{MT$Qp5Vb9>HNwl>ry&;Se>UjAL=EKMW&vL2P-NO?YoK+fpL
z3aF5>uKKJ|MU15>=)wmuSq4G-O#4VkzB
z#^wez2#-y>e5BmQnhgSYZkK&nH5uEnDf;9DYtwKyVnFogzEv0eogPo*DqZvE62!W<
zJ(7n(^%F~{H>mct6+J|N@DSW5@tR<4<$>-yvc8UFQdKHCMKH2k_AS(jkgZ6B?+pM9SrNszC*C>7ShHs
zt|y4lpM*gtosB*)^Ka$+9vuesrxcSxEEp$`E>pUQ)h$G{?t33?y~?Tx#XshCIW3WN
zx~keIQ8QV339RG?jX0D)iDj)!Lgb2|cta)^(_B^Nug|2_y9C^nm|TqE4d_GWR~YJM
z6@RJ3u$_eqw=B~}p-8d6McKe#`$029Wm=!zQptD`2A$Hriu
zyF6Zcl9PWK9`<#p{ysYRySGya=88$nXy$l4Bn-
zduYf&Z;SVsT)fu@yFcQLBaIWW$P&?-msmN)m>IdI3@mtL&b64~@>liE12Z^U&@V~o
z9=>d{DE*USNnlN+0b@hQGKDa_7Unq$yN0|ye~!&T42lxcW_@ZwkMK!Aba@>_#Sh07
z>q9uGnVpM#tvBGC67~AC&;%qnyE+kg!O?Pq2vIi#{0&AMc28q;OGRG>9%Vo7qe==m>QV7}9y((h>up@|momF(}#zw*RR
z3Q$5RKwO)Lq5)(ld=L0M<8H(}6LS43sG{$9eK!e|M}n==poR$-4N}=`qvHR>O95C|
zWVna-sDKtPebJEWoESofKb0Qpt0g5a3z=XH}9_F7z>~>V8XgR6?+u+Rlrd
z1JRqY`qR65Ny*trZN+7(U5d78?8n*tZdz{IsLU9-u#rVi!;Pll>u-7WK
z??atK2260#)5?Hwdfq)o^o1}IQDM@Q6qXxdXpOA#PMPrxxYp>iPFEcG8=Sw%^#Z4o
zT#kvDwjuq-2E`VvYUN_oq~p(dyXVYw)ByZ_t&7x7w2tjl(%+o-(Ba|WP$W9@qgjc~
zPvr*aL*^apJOo1SkqF4Ro||ZlPP{shxui(DPlZ`}75!%Erfh8Ec=OR5QvK5jcTi+*
zV?011aY~xC_Fltn#jMEpl2hhF*OB*8pv8Mn(h78W~!icHm_%54
znA~%}R`MpGPHwur#1O3*2(JTP$Fu>I)K$FR9wdbFAi?#}(~+!O3P!~!S<-Q$8<(4A
zlyX3X&xrbV)+uCTC9utrW|A^Gsg9d!-Q;cYJUh2g{f3p#T|z+TY1q93;O$sL1jEeX
zw>t(hQ!PVBg-UI_iRqFtWOiE_A=cMJm{qqNq#Byk3Ag6LLbBY%J+=QzH*}WULVP4P#d(E>
zFGe^G#ccFI556@=;+5SxOZ>t&9GcN{Lgx*~Wn@G0on>fg8J<*vB5{G}7RCdalRt#y
zw(1m+Q-&2~j$>M};r3+81PnT3b5BKfiI3V+bBulOdaB>e5dTd^L;J5VD)nbDQu
z4tY!J=y$Sub)(o$)&o<56bOcw1PUTep?w?JxE9p>5_{(!wIsjhhtvoObeN{d${34Z#B{QQ@Q&5MAmjx#l!iJG+nWBi7w=vaO%dkrO>+yn)E%cogQni1aYW4Ay~k0A_L
zsFPNG%D;`ss=0ePS|KI1rVbHb#ktex5WTo@OK;P=$_T<*O~$a&A8azb$Xu8StNx$T;|_!nv?zEKF;0
z7HOvRmdV0*PyfJZ2&`T}Dgcvl?h9rGn^RPq+U)@F*RK#YS#V2OItgLbwuCZpEzSb>
ztbdXlSJlwf99?d$S%}9GFAaacl8@Eu;ztWO9KSPx-WUCd9WAP24PWt%GQ-TZIsVTn
z?lwveJ!(l@Shx4nAE$A-T>g+)^RQ92ZjG<~k)cS(X@jq>dF^(4>qV@vL<;(w1Z$qo
z5jBO~n<@h>Fut)=y+H`}4;VX5V~2I*c9P5*LjukN>E!C+npxf59$)r*m1-x%yq3@n
zwEyhFro3hYO8{nQ^x!bB0}a6kMA(Tk1YCofRUR#`Ui2R#;~562-N_rE3phFvtS4~#
zcx6>OwCy3Exa_(-?j#4gp@O}1>)jLAI$@5W%~D5se!RPx&ncE;2|1^q@2YOx@|3Wm
z+oXRN+fW)p=jozsCfPUkwf)lH>iTi3@f?CCA94;kVba^ZNTT7xfcLLRxt}ismyxSJ
zI+%n0=((6pv#uyF#<+x+tFabJ@`Y0XZpr?Xn+XME$|l2TB?W02Z3fW(CUY+`&k>PO
zX9CZ~AFhecbs$I)U^&_V|1a{eAFTR&%B3fQ_h-4K-K3xIKutsy@vY1`r^DXQ4s$r@
z$4I0oV0DXgX{_hP^ACMb`u0RfmsZh#ZT=7J%GYPvwdlveX<~B5=gNy3Xqzjr_2xM0
ziDWnhFH7|1@5V|Z{PnByH#PE0J6DT0Pmg8|8Y0sS+nvMmFz0S#Lq
zL+5uB#@lp+m2`Uw)4JSwj=-EWgPAGi+q4)<3iON(druzxRx?;XKvtF7af@S3bF&i1
z`OnfGpsCfB$=lQxm;1JQj68GR{qnzigpO&nSS-bP0&*^+Z1df}I>?Z*NY310V3>72
zxZoq3p4t2w)?#%nAUUkquh#$UQ3LxX(K2%`11K%T+`9sTQV-CSWSLWt?1sqFNMi%i
zhIV&@ifFref88-1c})+LBY#=K$4=u`G((
zhaib>v(`*dupJ$dauBrVRbZi0uF~(m*ni{H{2*uOgaP3@aHX{{O`5bM4)
zXO3Rr@((f3yY5`@L0Zw0*xBqLs31MD(eM(tR@E(19sfIvODCo@^!%}{V3b=9N)
z3K6#&S+=rMm|tx%(CbA#o$pI^=$Q|(+wzY-p#OKbGLrjZ^4T0iDazCJ0y1-#iWxowtFc_km2GQt4z}C|PHCYM``&sNpj2L(^MsHH_yE6FOQTY>Wlpp{>X@ia)RN?H
zXlmb7w7$TNStI0k??u>&&}joukYRB~U>(SmDHW3nhvLg6walmfhQwo@Pa&DN4JX>t
zx{j-pDqWIBw(LKDW@r72;Ow5?k_AK~KSlWFEoJrC0fLK-7iN>;WOG(}9V<=2#l4YQ
zKLSbsA0o!Yy$e@nRwEOqjiq5nkq|9<4O7&HMR|
zanC5u!29x)iA89Y4UMITKG6q7@dW>g`1b2tDX$1HkFzwF%`vQ`T(kgATUqf0m>$6z0y
zuUFO|iklk4ZuJ(Dd4EeZgXtT>=l9K@X}jd68UL1|^;bIFHYD3`Ou1+Nf_3h!6adFb
zvotNcA@VL0TLtS1Y8~`6*UX%cR>UQc;F#XESPWK&7$8S(S>>LfruRj}K$y@MhVhIT
zq0<)CRIs_NR5BY`fo5Psk#Yx?>wmSAA=$KDP#vDFn#Ff$FnuO?@~F(IXR5zq93Vfe
zVh}Wg%iD`>6{&XN4LVuHxLxL?Yg`?GnbLMoCod(3^|GpBhGDYa?(qHoh^Xx7*jrIvOmI7d^+|#k~Do%
zwv>RT-c(#sMu1;Jma&URu}-^XOROF1io){FO%RAZ%6(>}_zC6{^k)q20@P<=UnQCU
z`H%&1=#%fTJHPk@YGg%_d}UEI#ncAkJCv6?b*{w9tm26Y!Z=vxp+f7i9@6=Qv^=qW
zx}a*Ae!9x2(t@EhTr2>0^bEmD#Y8}-m*KJtQ3X)@!=w+0oJVSP(aB;PDOHFmuFvG}
zxe~B2%}{10tknD%h&3ux#NZ-V5~L@nNWf*K)}%gF6Gr=!PAq
zn@#}c;t~)pQKGMF&IHhrFBZsR>>4LFySrC7B2-XbC2m9h@P4CtOArcmVexgsrT8+3
z1>U2R8E)U24U2^Vl3X{(bW*#z2T*#&>9{7+(hiNX2}ygTg_!M*1Pd>o|1Z9Tp;SW2z-L5G6uZ_s7G_*6
zbyR2(4Cc4kjME-2W)U?BqATwsbJq1@#izWj2AKD371KTnB{!yRzH>RQ9C&3nL0jy-
zQdbe!?{vmP#`f@ne$9y?2WkIziVz++^q;h!-jK7%RmWcPWU6e&rcpl^d8RCDTPAv1
zz2(_1=6Qug^L1>Wka&{3ARY-I8Stw~+#nB85mun5w|8TuV_~&`8pd&Kn8ZIGttK3H
znXq7ZC29SyP-#!Bk#(?Lw~A|;RvzC{lUkCGg5Y<|_cXDzpHG0RLKbCP*j)D?^PzgG
z5cj4KH$b)b+x)^J#}MFr2E=1(rVrjbb(Hj{Z7^y}_wH3&-JX_E>jqLFCrXAH$cKL$
z5kowgkr)J?CV@A!Tl8)zxP1ziV9XURdiu}`sX=fBmf2QIe0P9&l%2jK2=O_K4}znZ
z-^P8rdb8%DoUb+5X>y)Ml_grWC#|!5-cL2Yv!{*32_h
zWuSrMJHS1GRyhCwnhE_n0BP;9e?9&P&kk}A3}of5h~#NHn{H`(b4+zRJ|?}fogAL^
z58M2u{0%?e1Yx8@f+94B3nNSC?4Lw7zp#K+08Z-CZ9xxU3`Ktqn?*@|HlMr?Rv6i4TfYG~k7aFj>WV
zY#QqBzaE}9D#7-Q2>zubRRJfC8ay(W-$H*U@~
zPnch-LR|<;%WXxtirY_-45h*jtyKi>wy8^4@B6~awfHm2frnyPgk<4oL6Py_OEea^
z39-S0EYxz+RmW~_PQrmGZdBWgG1WN;jXbl_p0KgTL2&z54-j`djR$USL!Bg=ahP68Y
zKNT!b%t(5+krc0jDCY}>Lf=U3pF0>D)Ev=nza8Y6G}kaV0VGsg)&3*jan
z>Jw&HPOM{k)b;4yoD50stnO!@XYUL(mZvEzHsY*=U+L5eV9zo0HOau7TR#Y+68iB4kbzqL@TQ-*b{z;f?f1_;$s9)YA_Y`d~bT>X3qSDkA!&+5dU(9PNwd~
zvs@s|vT;U9eww>S$3F$4?dr41-L6|G)s-~BesSRWh7%
zv-fkaAhSa|d7K!7qJ)X5Ne{J^p|^M;{=1sn<4C=3!h_PYC1_xTgsP03{5L*CM|ecg
z?ml}=R!=$nl8~knD$f36Ir>T(4o(v0p%k*B06UGbrC-1Ts&6sI!e}Ssa<-jv9lUQs
z=P5;U_V#p5Y;@&=9r#BSRM84o)zGZ1j!sO!hb=qb^nd^552g6Yq|B`#(HhQgKwTp&R)J_A%T
zGPv9ZK?j8~q@OlEmCS>qa`7FeU1nHB&?B}XROpKcElK4N3YM`3)E^b*WN?C07;sqPg6Qjz#n``JY)nX}C#69vtp4Z4tKQ|!PHo?c|Q77=eW
zs;3NPUnh|0&U?TlwTnfkK&r0D*HqRUOXg9y`rmk6jl;bxyqQ^8wBvo0Y
zCXvsR`RS@Fz!#~wXbldiRi-~f#Vv1XH&)VRwH`6D=c<;jfKF5YZ?DiL;9oEm-
zO3Vp8FbkzyZT%gO@9OK`%*XMwa5QqK7^cJL@iUpIcYK{UCDDZDS-n_W@D8;#Rv4DMYvpJ1;D(Z2=0#i;cvhjXc0(v0V=%c?7T@xjh>!
zEP=?pebb`=VT<7y;(UGBxMF(zp3-+!nrYj5H#-AlU`LAzN3tQxjJ;>7Tk)ZgXK8N9
z>Y35CpYslS>DOfd5k~4++XK>dJNUhYpAsP)V#R?NtNArZ-@WFJw^9n&ci0MhNoQ$Mp?-&PP)b^Te~i<%_e~z!*scmqA&K+
za@)yI&JCsml5-4EXJo}Tv^?zHHu`a?rfm^O8c>)!n7qw`8w@Lr8x!V+4jV~W7UC@&
zBC#91wSsd#ihpZhr|#8cSDEPRVKRc48AV{T0AqK&Lj@`-
zo>A@t`rBoX>skG$E@R#YH^B`ocHjUK`Q4p|)y>7;e+zqZgq;}>km(#kmeN`4-HqF<
z0c8xu4
zf+CFP+Hg;U%QyIV1%>$BACDx|rgRkm$Va7JjNg0*FO4#GfOD+lWQ)qC3+r;gAKL70
z<0a0gvs{Y&CUxbC)nsWi|8NHXGp+!%>LYD64zdK1-U|et$PdA8e4uW
zE=CwzAY_RkJuL^ix1)a*HpD4iZJncB>cnI&SgmLB&v>D@nLs)QL3_SFw|@X?bdf2<
z_%M-QhRnP{nQww`c+%gg$o&=qDN}XCiFDBGcZh>9*U#XPQEO;c0HK$0Ze&!RxE>^m|}|XV{!pzFz%25LsmMka_a~O
z2F_x1onX;kW97h0rW;`8yD~jV{*Nf-d6-5c&;sIY@-(*TA-KzW-t>9nxXg~{I8!aY
z3u1Ps0PQNW!a60q4+dX!0Z3;t)y-e47XvRHD2HEKPyj}7Jy)GoRHUo4mGxlBf0%$~=Z+
zRO9V8uSHNKz(&j2l}~|n{;<@s$Vhd;qAZLT>C>Z8$yD|}!~1_*CaJT~(Wj`GBCdxl
zR+0QBCe-F4yc&%(qtdl#(bIsHe99^U*hgF%zURXQ&pAO!)_q6%l{0_Sxnx2oiGZta
zvJP0u;xt1)X`t2TvR7u)OCR!jPIvPrr23C
z=5`FDR|^7tBpg#51OtPQklKHhGsOlvyo9>-Z5OGXhl!}u�dxiURlvoSK4W&(MK
z{rnXaWY6p@uZa;3C5}w!_%1B+l!+u4-9qW{M<4(NVV{q~KQP!_7JdHwr0cs2Se$TV
z`$yHo;W*9AsPadROe!^_ccjycr5h#i3B4~UQg3OemE8+R$_rfwJzIc=(!#p2QkwM=
zf~pBo0+U<`Eg3nUNML^+q5{`Xgc!MC{LX)Dun!?>tS$g8e!d$hxq
zIUh5W2=L>jHeXDbOqf_MtNHOG!BG%5`j0W)5<5eZv4cW@KC4+c2W~%a(5fh&W24N$
z4shWjlP(CC`vR~S#8
z^kl&=-b#S>nYtJQ$u7{93N;01J*{^#_AM9eU33^VvezM%1z%&WYHWG<9?toTiI3M9
zGylXbKABW!y#){tK;}Gda`69xBjZ#B(dhmexU6p(E%3U)H}9xvq@ijkwzNX{OS%sf
zZ407KahY=pr9htKdDoZ~w!^qazc=6%_SVa%44G|GOl+H-0hN@o+~<0Ai3K4@CdT2R
zI*TdW?C)uCY&(*r!JficWEF*8SHa4SB-M0~2=Jw_Q`*L#Ofg3x?_ApDZ@H({LOO0n
z09*SpmH}x(s
znFiJEQYC25UI7wfG88m4)Ga17&}paZoUrei9eCK;g~{@)o-&u*3S{egqP;
zCSG=@tRw|d@q|Wqgdz#fNVxw+c{novh5+oRTDx#=mz^ZgYL5@Hzc0Mk9d$s+rDfU`
zXeb19dUadw)4k1CL?0;DrgM(H*C@#~6T0Jd3bsX#W|7=yEns!NPUF0*|Pb=kM>
z%aCFzkoY{4sF9?t%;0v$mYIq|pz(q*Iq!)#WP5pw>F)(C@J{Y9tfH^JBAfGs>&a_5
zxa_&wh<*M)WOYmWFtHc21fyda)AaKb9QIx%|DX_QM-3mMIL+6oSP{(D*968TX|ih4
zrm2~@dEDTSqYpA>c&bi`KD_ZQR3_`J&ke9By)$HbQ`8S-lFSN{?uMTwm8V1$E^s3m
zk$ho>koJ@X^LcuO_!A&VkfyiKT;<@pI21UEev}re>Mpkns~KHt4MGnLt9~oKvAYwY
zZp|oJi2HTjtllQs$0o^t!H<^YZ_r;t-fdrxh+9MU!?p@_QAzAb7LdKC+d($JS+FMu
zFHY@*Mr4@+Q!c#1i~G62VBW1(>K7JQiL^prWt
zOB&5^QMPi6CHVX4q6Thw?xy!f2IRP*u*~%uwn&yb5R
zS^LRz+;5-hAPx)f;J)E5F>10zaYHelR*{cYjNu$Y$9RGMqCyRfy4LKeU`HNs3zIc|
zz>b>2BxCPId;Q}-l#@w|+)^8t
zbm}~qW{tsCW#y~cjA3Bar$bnckSS?5LvJ)Y{-554m5L>O?hLp6jWPa9XL}%FopaLk
z#!vr`UZ#-#=mxJ0&}5>nscfEwKIny`oH)U|A|KGb9sPGYHUUkkr~`OU#Yz(C#6vdZ
z=zB-9wedZP3b3XWgZKO)IDS$0;
zoHn!nEFsRR`AB!hOn~SKX1+Hx_F|B>Br2MBke<4DZ4f653%5==Z}I6z;rA;w*9sAt^YkN!8ih`+Ja=g
zcHkbb_X-!^BpbOpv0RXEmn)7R^P1xil2vs7$(Vx*`e=4^SDn&MPM`}4gfK~y6oP_>
zrUaorplGiEx7?`MIsK`6(G=b4p|I`Qew^tls`~*AVRdr`iu=t&pIkfo0|n2Ony=&
z)y7BKYE9@;cosv9LuPY&hG;Q`S-iZG_qjjspGWBNSVIfbzf?iX3ilk~2?_7^cr!`<
z(`3AdGKEAa1YK
z^elDfthi*WW7Lm!_9lhnwM^WE-@1Qu_V|PO(KsS+@?_g#0j%eD#=x{(B!jvJOVL;z
z@&_2rXu(?OTR^Faz0<=%55^a>H>tkXIk^*Ta(HH
zQHHBn#Ae-fR;J&HzgrqPs|>};0aOE%8%9LQfQ;vdGF|ewAdfO!Yi&UX@k=;pwd9`_
zQn83C6UfLE6%fCf<+Q^kBJCyLxF#1_$2qJ#6VtwcHeeisQtGXn^K$wPJAq*}BruR{
zQ)mPIsAVEzx+Ibc;;84p+0Q8Vcc1eaw|N&j!QsqJ^ld-0W$M}x^VsKX9i*N*;-E5{
z5(%WpJ_AC`v#RpXS}e^P_946cMWc+%(vw(BU^53HRPy;eprrW5FyeueFaTzdPY5Vt
zv{*nLp*Rr-g;da7!AMg@!K(nk+?b>4<0Nt+HpC5KQ9h`yAV8*4I)RuJ_;
zIm_q9C)wXZHpsEA(ZwJag)d#;YSwYXxqn$OV|3~C?(xGRA?a67)6)#qv$?tz|N_ZlN1OthrU6APR
zO}@^=6edHN@jDeS8`h)>`G5m^w7x#4sdYAppDuAF2Y$Sp
z#O6G5*C0d}@t1#{s)|dXO+K-iOXR%)Gh76D+mW0jH|A?$c^n=S^dM7*p|<2>8#~XI
z@h1=w7u6ProoXSS?^qI*QrE|GvoD@1ENsg+3Vy=&FKfIa$z58!g}O6a4n1Evdx6<6
zW1b>UaGv+w4Ty$d)*0odly$A06q;0#4wgW67hLIL$e0}4C%YwY54Q@KFA%04N`Mve
zDcq~9PiE}ZQ$Mj-KtXhn{lQ`ilemLR^d`xdz#I87#d+TMzIleBT@&3|*IW#m?PU%p
z{PxMT{)}gsn^mG*KH26BqB(krg6xLW=7Rlu#qGdA$ovJsJM11vQYYf|*kbxXs1C)V
z7fqK%pXkQs*CroO;Kbg3bQ5vPi!q(wTiH#zuY9g+28ncRslb$h1~?jZyAG^xV++#H
zZ`c&&k!mxW=_De?OgeN+Ui+1Rwl(#B9V=7qb!D;H-=EM~u``fO(Ze6{Y5JC%)hQ?n
zCPl~$WQm)sEt`B=j$EkHB?tT_EE_<|(ianMl%h&V;1}=Cc^`yA!o5F*uxHRN
zzceULh8WJ&q+eg`xdh#(4K#H6I#@g*#qLd0)r`K~vhw
z4NoNdmzsC2ND~u~Joz*og+~PAVr&EDY2L^9^oZxgIF}}@xfyN7B6FG2Pei7h!aBFc
zVkpQ2XO6&{XQva0<8Y<{h*IEK2pxR2oRf}Q5F@e!X06?Z012~=?g?~8te%pFK~rl{
z&dfNYx`nv~;BL_M!HzF0%}*NTDNoSdN9v0rpK6!DTAcmNq);5%mg4c6Kfeda5sZi<7SN~d
zwgxcjw8>B%1TQDbSDTcZ2=d<&QJ>(NiY$W4Xt~m0dgVIaD@XbE@$Af`A02J6kdcDU
zn?zY;3m;eLUQ8iM?*_B(0yH=BJA5Fh#MrdT{f!0|clL8)n-f194s~rV0MD+-dfSX8
ziCk~M3_X`s2ia4;$g0ET{gcktXTpc*s&zSS@TGMnS|BrZTe{)~avJ(xJ5z&=!nHBG
z6A2@Kmi8q({l!`{$sR5t&nK>Y)Kh*t`sC|Ggif!(BFJRWgWa_4H#Vy#ymK>l*rH0E
zX30y>mNvoj91#6iP$oUfmG{c&MJ0}wybd%=bt%)-cYhlAPY=!&ME;Yv9tlX8(x`_Z
zn%GTQz)Ipd8W**PM7X@!MF&UKA<*$bdwM?1Kys;Iz|4t5ym%a^0~29GNNAqYP=-)u
z*4kdX-Qe_+l^|Ao*Iyfg7oHYfX2ae#(nL()t@2=Oh?1%c%VCm>azJ`n$aM$=F|dO#
zeg}jRJ_A2c0CMbvx2`Z?vkuL|?ONd*PK?h~zrT;s
zrzPy}hpbJ&-JY55aOKI7TJGcq+QutyQinTfXd!r>Zo1y`F>@IeNfE+3DxK)YOWs1&
zLT34U^eBo1_`?Mih>YH^IQZSbXyR5{K)4nADPi_&*~p5wT=y>&gL-TF#pW(FNMgML
z0~E=St@$b>eorJ3#M9-Alp;A*1#p~3ujW6vtGzj1>jKAD?AA^La6AAvQ6di}hh=;Fo@s*mnR+73j?A_x7uT5xwuz0)b25r&=yV*+=LjxjZ9l!i
zMZDLGGfYc%ww3E`Uclk`CkqVh6y4XM
zvE>#S*Nuw9CKLrOM=}?%oC?NblE1Pu^aTN$rY`rmLlr2?EcPj9+T22!wI}kiS8RWG
z%=GW4JbiG+kvvjr2ZLWG>8s=djwAM
zmufXOv@Jo*68*JP8CrkWa-aX$xcbH6Cjrb3ou%;7z@ik8O3C;W{xHN+Ca;gaAd*F#
zkFc8uiz!VzLqJe(`Av8Zv8Dx@7dLe?!i-qQktTikzW}S0U|8uNm7-~Gl6oj-`-%*5
zT&o;4FvFsJk_84GqC1*TkG}b02jsP+Npwj-f~BZfqa!?YA~(1}JmLC5%qHg@q=(L~;U20odcq3gazVdF4dFeP!Rq
z&tOTiwu}^S@^EDk%&K2(%V=CEn^V!)Fh;~St(s)*nPVwlZ{%F_>C8imA9)Nx7%hBw
zyBJo>gg@wB=xaG>b@}VzH_3SrkZQNO={4TdPTLZ*oLLvk57t
zaNZRKu5-DoCDw5WOQ@19>X$Si$P@!o3lr2J9Y?%cF;a|y95h+{v0NuaF#hYZOPv0(l9g~=Au%1-hx#We(y>mItAAj`EYxe|X~C6y
zp52cj=z`4}+}Ys>Jv*`7z)>{-dx@%r>$y{yYabY?h>C9q)KNw@ULUH>!CZ=S*o_h{
z2L2A#0#vA_bOF85_c>#sdwANOl0=faKDpL+aafH5(>8j5(0akh*J|3`?AuR_fL(Nk
zF{DAW2Rt{OOSoLlFDFbofc$T#3WR*Lt|I>I*Wr*laGAdFkCORWwv;!#r;+#A?lQ15
z7#Ce|8~1JQVu^UEIru_Lf-LAE~9Kj<|7i>
zk3+4&!n!#=9z(Lex(OKm{!E@<^_x~Ec@#H
zv~Q&Xn8LjtIu?O9!?rSQdeXw(OYoc0h?P16Hsm2AsAN|a*)uZ*Qi;F+=dpY|lfMnk
zNeEBMftA1jylgpQLU_@hI`gW)ubbU~aGu-Iqk751IO)f}G}n7a2@y!<$#UEZ{PMCv6lgZ->k<+jca
z?~?OpW>J{raM|kdWLO@-0DPi7=h9^ZfVR&;44;`G>LOHbCO}_3-B3k{5;me93|?zC
z!h@sHsuw*08vPmPe5~vis9{hOrYuUp&IL-hHUd*r3~M
zZdVkq{}2x!*u?kzUs%YFM3{#lOJJRS7r3nxR}n93D}EZMiqYB42jO36FX=>O9+DcY
z^60+WZXpD)4Htr@e*O*xr!F1-9Vy6Br*YCMNEj+=-&AP(vhEZ&3xx3E`3BkcIRoyt
z-%J02YJ7z}Q!2f7$Lcb&pEFmqYrzddj2u)ZsWS@~@cv&y9s|I2%f}v#pG5uAYoU(v
za9Z8@02(W)iP_oPMmNOZ8{MF>mq2Qt=rI;d
zBXQ5qgXe`+`Q<4wor;V`qS%YJL@wPkHeG8+o1z@z1JtB`C|<~F4;w?iP&tMQcJB9$DHTpU;xkm!(B3r#L>MZrhQ;*0lFdjsC=7@
zUqMPbQLCQPMt2=+n)W*zX35U;Vo~Sh#e*!9wL#N9R{Fc8#Y8d8#r=t<(mYhxcg
zSLh9>*yYc4T)Sssu?c|}dvW#&(emImr?lh~zf6L!v4`iq<#A(JrF^5kye&qYhS0k0
zL~>E2TUB9KgS~eu!1A4NvstSHG=RY5a}X|7J2~mae0}Y)mf`MJDLWaGJsd8|N*1=T
zT;hd;EP|SRrNfp47HuV;yf7xPjUyxvM*pU%KlO|ikGY-?JsEU1tNrxlO(@0gbLlU|tmxp*5MPHh!SJ5LCX&1`9)ay>0?Xgk8Bcry()!tF&E{2NYy~$4PSJ}y;
z^0neG-21|I)oe1{yQ6Jg+vn{Ls^G85lCeR}Db=024Ue7IAsYo+E`bF*<+F19qH@`<
zD;XWka>RE$lUrvAzDq#BHE+K)6lW31wPzjfp1ZAI5YN;CGp^Lml){xm|Cyv#+$XyM
z5^9wpbhvJp_W()Qy)a&alK-JdAV}zB*Lv;`OaIiP({VHdPTzaw#9lgyMU8`zPm<++
zBQDwK2Ts##HD31O&kOs$wgxX|lZX)ocOC8mbkc)i4jLN3RQW26B^Je%4p;(<1=j#2
zB)6H(uFFiP;S$hxm|aCjeJ)>@rV?gGWXgfuGOQV@FGz`kJ=}RTX{8yc|0_nlFhbq`
zW2N84#k0&8WB7eg^G>V!sdYQU((i|h7#okIJ2{H$ttjl}&bk+Pi!c@XA5gb|&1>(}D5Wv?yiv8Oo{s-C^
z?u_{&8U9YIHlq@rQ{Ajp0IsB2N&=c|xQhOGtSxmLJ8g_88*H$EYC4$PV8@$t(}zoB
z1$ivHUDPgm)GD;1g#`WXYdO@Xc#D1)Zu3j_*%cvpastzC+Vr10%DV7mN5;3@qJHFGRQsGR?(F
z_|~^S0l5wA=9u%`}0SARC
z4e9oA=4Y~YSK;4tO^7YpPxJx8$BC6bO4ku7>SdeJdXBB{q0TJjdavjq;^$TN!FAu%
zymVv@$be#FL3*NBedlDS0t=RmrJ51U3NS17Q_S+pnS2f+X{W=WcmY
zdFfeh(~_IwO}1X`^y#4xvsoKX7Z@X^1E`|dW4u@KbE}w%?p}+kY|1t@77*R)tu7%j{;d&JsLBxFIyO)Q{T_xbV>&Gfc9
zxE3UZH(6tvbri`?j5rEu5{*tu5DF;YV2XhfND32OpbtvqXo9$6|K`zs%ZO}4EY_4i
z1WNW5YtO#0eExG=_zZ2e`K*kK7}Yw5*Vc+4Be_|dud(fom$X4blOv{+F0X?lverBy
z6VKqNAC^)&71}N{pAPC*25q|_9?`>-ZzgG*CJs8lHlud}y6v!2(fX4E1k>}k*(ly$
zOHnZ7`&oPRox>OzC#KKW;(#M9HSeKKp04#`vrs*Zh38{WI}GrbXspr54#K#Hp}B(4
zE;!&W$3enrIy(w(80IDr%w=B<+wX<#p}$kpQ}jMSgrJ&R9pC&6I;t9
z>LD2M^{DSXCB#?|>ekX)Fiy(;Y_M;QO_0-_&%-k`MhNGsT-~hG0tnT3
zb>(QV;u=<`M-$)W4waCV?XCO@aFu#yG`6z#{^NYHcqBo~X{)CqBZ-?V*m=pHDFu94
z=VlO#bCI^37z*=bv2Dr-^SgQN48m_6>qL8=9`O=4KN!Ey(
zw|B#`QjyrvEOM&dZoC`_a?cw)@4l>vP%5T%Y9r-*+dao9WVH_il?n3)fn2v=yoak*
zLD&{ZPBZ!%J|PleCp4TuG3S`4SMfc(%#EZihi6rg1AL8$junNH*E+@VtdR_oIcf!w
z)T4K%j2LB{8ZERz=oZv07vOB;|mVs
zl}zo=*iP@tsLqF4)cmIfXnK|LA5`gcZXblUDM#YgYGL>Q1x-e__PhSd(MEw8*S@QX
zjg)_Yn1jajhtYBzGt2+!ZFT5;i17xdj{znrS*&M00j>DgEN*B5^iEKbJfYzFw^jDC
z4MO3JjZaLyVXVxeBw#WGL_hk1sts$0*7jI^0s%O@E`$Ckt|GEnf1V(y;j0kZy(59O
zCD69Nl%VBKb0v^_;V`aLq`@gy9)L4FWK7Y6B!AbTiC=4a4ZYI8T`2SEgAb*6EstD9
z^jq#OM7JI~N;Jsgh6WaeI8A5b8Uki;KJr-5_yw6RKBMd9^s0(BpwCijJ4#Z_pCXTF
z|H6^0%!<~^Iv|^E7CY1OaT#$s8f+nf$Bmf%&i|FuM6_D#iafpznX!qWOY)+aJH~+L
zx%*S%@R~dM{yZa{W7dfD(8yrMu5vGuE$kFy3deYLLjS4VMX`p&sY?X{1Djp!=|{Pq
zhzvj!J)x}D+pKhnDL7*6!ZPS?Rl0iB4Z!7JViR;l&$Gw00rz6Epx3PoZ3l&DNO~jZ
zX9UZNkkNfMEPn7hXsGM*kPw`@gk-wtpuiErY@28IU!bX5gVr}FJS+Vak6zhcs_SQD!x#nO3Zqq?H2wwhYFkvePeKfrS
zm7TmZO4*zx@c_%ROG7Y|`IG}+-)qX}s2r8piIb09HdLrEjMP4%7
z69AiP2gnG;edK)s*X2BXRLt76qnA)1op~F+V@;ZPu9GZU^Sx9PjpET_NE!A#MTUDt
zv+L@c!kR%H%@_jRXFVy)9!dZGP9wFe^8i(6_ABPHOT(L$>ijvbfH`E~LB3S^YS`|&
z29h4w(4jo()86QIc5iqGpmSC;pF8pp@u>
z&K@^Wz|;TGvd?z#Z{RhsVB%vq0-6iZX_zH}vLyOtQ5(GV;c`T{`^$TwucTs9!Ro){
zzi|oHV0v^YJ)4xzeL-17pDu@jx4F9s>N5JbxfVjAgR&`lhqcCuxBr>Ol-*U6QY8wg
zc~El$Ri1v!Wd2&q+d!nmXf%<(`6Xt#SL{nPc>A3hs(?S#_2)S2(HH>`8lCV01gs-4^{cB
znJM#8&Xb;%w1D99xFO#xaEz7YGbOJgWt>A!4f*-Y#Tt{@XB`2hUhsQ|Ic&=B7H(_}QdUKCNad8T1VbCAfVX
z9BvI!rgu0lQx9UGILJvT6a6B!A6DrLI>Ekty^uCaK4+ASV3>B=6~CV!$!ltTl(u@+
zS^xY#N^^>Y1O2-V)Dia(7FQ~Iy$>w~`!|e@94D3%`4PwjOKes`tz&O(uFEXY{MvmO
zm<*68NgnSUYz<1`;v#^Bs?R9T3j-AYl!B2@Gz9w0%<}litjm-5SJ_jON7!TTF=wc_Wd|b_8Bg?&dw>Ej-k*@!25&Gl;4po@rgQUa~Z+5kZCtX{=#s;d#z5q^=-$U;!Xw$i
zWaU`2BwmfKo_U3NJCZgllY02L`W-GZVrh*%BthZr2av45TuPCtp@f#@ihJ`HHStp$
zIqZ0;>T4AxzfXCI1fD4Q4cf?dOGsN4o;m0tV#mRMgfHh
z)XralK`RF^vTRhkHJ1W$)*Dh1z!FI&GA00KP!@h{w#YNr>(vzDZwz%oqrhoY-Wy7_
zlJdQqVI-^qzm5z1X1tpQ%DMY+2j3Bp3UDz%E5M9?aoNFrMQ9$i4|kFs^N`eG
zYk|w05w*fmYT$E-`B>du%s3C0Xz)XWZQx3#7Xmf*dm@7RKoKg#TP}})cz+wMRlm`Z
z&J=ANzja1?5E$$mb?q~cE=s1x@GQYSN}Rs@hyG@s!IZ$dGsz9R`$HFg_HAF3ur+8#
zz_s#B>I9NjYP8zlh&V}s#EwR*)^{d=3Y_&qaFMxf=%1ODo$C2|$d4_FmG^co
zwsB-zh-gWGXs^JoHGq9P%B4COyaD{P4W>P-1SpTQn0*4&1sBB^wy{A18Fgg
zqLpBq%U#NbVSX+*Ww*vHVvS
zeVntB$vQc}SaDBJ_0E`F200q6WR$%An=N_p3&-Z{a`qwu%w|f}SU!S~8`h|FE4q9n
zLaTNa))SA!|56!}MGf$!?0<`+n?IlFHQ5xcg7ho$O%GKK$gX@_3XJ``4A7#pwH4#T
zmq@K1K-7)4ZfLN{85x^RWj`+;$zlMl#(zcl1_Has(<`^P+4^b*t^xzF?D4TbEwEU1
z*a^Ho=GeycDtt?n{E+9u2Z&75yOJI`njuqsG1hD>tAYCjTzW5gb_p7-_F*KA4}AC=
zFy&bMe7a#Q$f;v08;V|~^G20?H}7nG_-pE;%?%4q
zC=b}sOsXGeWUtuRibqGRy6kMrDr$0jW}xkPJJ!>}N#a?}fCn%xuRGBS+dS3-qlZ=p
zXrR>TC2J!&2_<4_ifq1IZ^wZh$mlfTojRIX6mKNe)&ISSHvLn5x+2x3XM8p%{xPv{mhKwrf_WPAYl_S
zS-_dVHV!UF1lAP}QkZAQROX_a;q%#z9(!%NE`;rHuitl%a-$utJvD4^!AX}U1dGR2
zgt%>EBJ3<%*e3R80GQig4q3nnPV~nW`J+>X+5FJv9@HV-`7xoIs#3j{ZFU$*CZr1c
zO|eT5wEi}g9nwX!ln@<2gJB>B&v3?`xrS`V0b_NMGeOCEjWXctLETuxechTnXYqu~h?EN4qNgM75U>;Po;`-4!2?a;g9?JDhO
z?-ny{x^{MYrMwM;R0=5=OTO^0pG9;4Ncb}0a6*ih*(1n*4OlkfLzDg&$^9Ik`U6zB
zA_?xsIFe9yD_xtevg%0~Q>o>7GDOZW?;^kjk9Z1eFa{QvA+{bdqcEQ%Ury`lil>8y
z)jF+cRQd4!Feb4Ih>_J9i@`z$7VrCY#WHftV;P{)lkl2I`D(zl6L_?_rEt7YDj%_2
zn`8o-Z1=I-y4K1Kb3tXn7Pj%aufu1Unn|yC3??sV?hD^!-3_uezo{4A-EaBH2hSmF
zh8W#>muTj3VdRLcn`QQ190o$qnuOR>uT33;|D-yc|Guf
zFudJhcTe|*`2C_mb>kAb)xB*nVv;Sw3SeJOh)!Uv#Xfw|D(&OM!f%^;W{w?u3d$xf
z{ezuUim!>Dc;o;{V#$BNAb*eD?T&z04bdmUbaa@nM2c=lvE@l?F7hIe5&5eKNZ5oq
zP2Zr0Mz^Wg5X
zJ|3dU^FGt>W4|?os9>sTn$w{*Xo~zEN$%YRYspVa4}A{?YXUL7N;hHPVBi~hFahaq
z1PMlqV86r2a;kTWVoGag1|qtESRy&%$&woY00SS@pCtrPvs1VQ%YzW{*gSNOtFQ$U
z7cpmE*E7V7!%Zp@);zHZ(DPU@K3Cq@W3+9$@><61dZ#L6OS8_t-1+((rXYfeQN7<@
zk$=_0cf2)Ax!#WKtCq%D!UT0
zSMbKU4yxmZ+vAW`*7O!FpOy~?f;954Y7BHgSHI}!{`E7Uw0|ivqu>npWpKRp_pzZg
zhad_!)C!%Xqlk6Z$-q7>>mkXuslRvQpYU(!fi0;$(6oWH85yW*Xa)ky#LH0+u+YyP
zS>@^=x4FVAS7Xz|k$OYuK#5&|kvGyT9*1f)3jIp$zT&tFLrpcZ5=O6NV*i)vv??*o+!h#o$JZ#(}Z
zzk#kHtTect6a1f9w8+OqlQ+4)QG7YXJGn3>z#CQzy&dp!6IeK@bjeL{vP@cJV9U?r
z2}z_-%#O{VPrZ2djF|wocUjlv2x-~mj265y0j{o~V@^+*m_}9eNCcH}wSsaJa8=+*
z)8fA%!v1
zgys3mK&@zPP}|a8LD3U;dW^1hv&~cYYn>dGiR1=H+<-j_Ah}5Rz%jR|Vh)(3dV)IoKd}y8Fbd@;LcO>GH4vIEJa=Y$r)-w>Bzy?LhCh@Ny+|%e=uFBE
z@oKlhDcFWCi%IC|PXggeMMiLGt!@DCtJMcT94PRDZa;Ici<>^8C=HVFzSKvCq6*Bz
z*6YVA$1Igg3vVFkobE{Y!x{7$b~B%0*X%B2bZ7Vb>zqyw9NDkZ;2MUi7zs}X$ZI9Q
zH}2;@c&VrGPO3r~MX{quu-ye8rxAZ}`-At;RtB6zB;jtGnU@9b;2o>27eM-J4XDE3EohQQ+xg8C!W&EF>E$Lg4U
zldOLvtPGB$)S6HNTU7G79blX9%l9NVv{OV)1cwU*xLr>Mx5BBx%ZuTi#c(vs1>gOy
zgd8f607$=m0`s)H)8*#n5;ILYgD$T>PAG#y=95A^k;}Gu40Wx5w#|;|*_yXYKj6V^
zY|N47WvA_>gSzIa-9@A@BiTs|;g^lIYHx4sQI%uXh;8u7h|^ZDHAh@JlDfO#3A_Gf
zuR;#3c(KmYM84miOe2o%Izhe>YJ01X?h8y!-#oih41=wBEQ{tw#(
zA6SY;3eCfO6kxTIh>Dt>-Azeb>Tsk30ZC>kp1Tczqqg_MJ6=40(zvj{SB&jPTv-b
zX8%HSc~|wB&_710T(hYofcGEvW4gc3xDBC|t%}TlOFpTSc_V?byec#w)Qvt^V8rF)
z0FEbAORO)SX**wS2;Xz7RjK$ZQGEW?88LWH0**b*8342K-2=^HDtEDmc~W__WTbm{XX&(-yj
zIRxoTF;X~UJ~(yJccr`m!_*$S_L?o{55O`e9Y+-yh{Du>T6%8>-7o(@4MgKNu@s$0
zktHmFyT`P%XS;kSmoBA=-*6~IRuZs@Chhd(FPqB)u{i$eTYH_`WEu
zIX}bYx|=<3XrP7>T@6HeZ};qIVp2_{2r_!Sdz_=GBbR$(Acjo)T8sr8dHh!U`Wxd@
zuy(vNJneMBIx@SWW=C-EWAYCOEh52!Ax6~DcjK8Tn!B4($1Kr!AsrqsO~