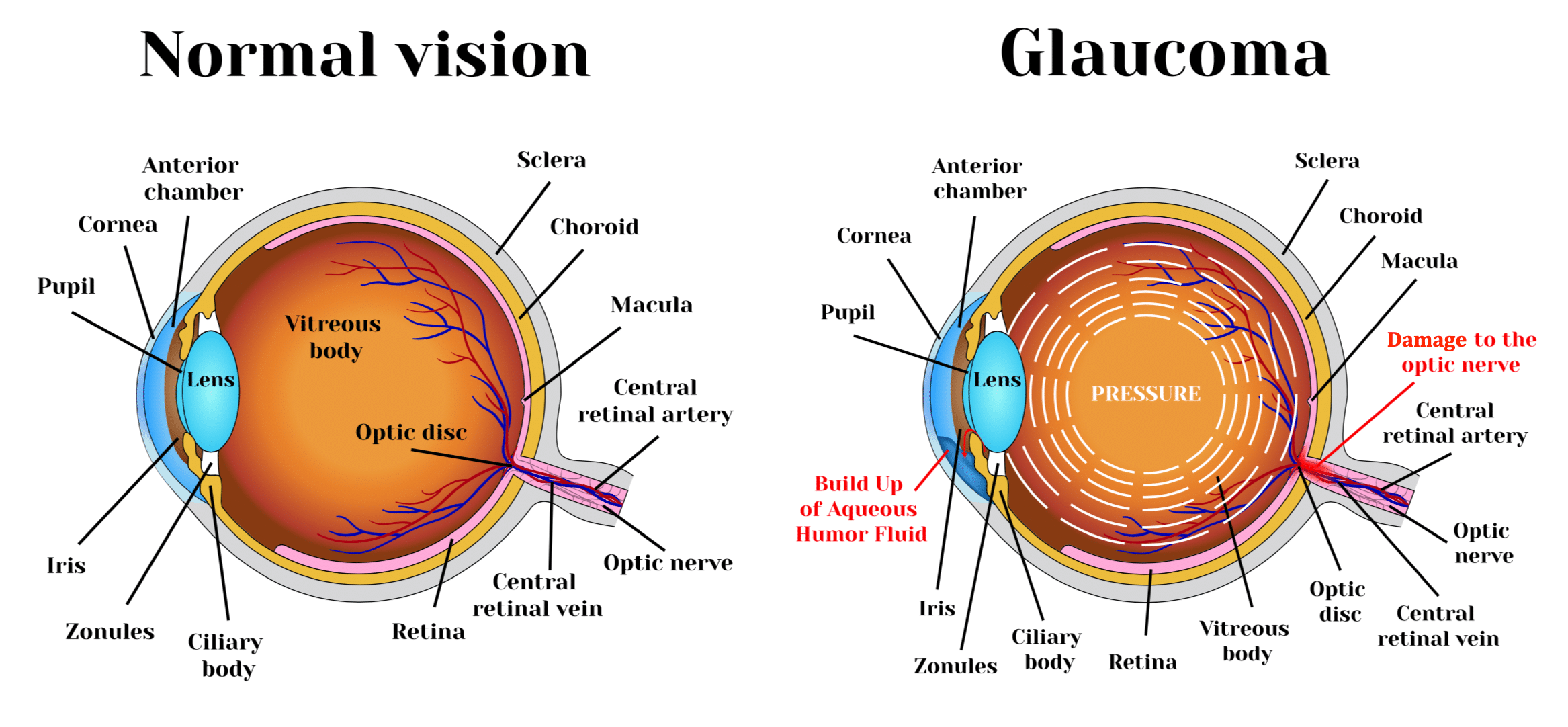
Glaucoma is a common eye condition where the optic nerve, which connects the eye to the brain, becomes damaged. It's usually caused by fluid building up in the front part of the eye, which increases pressure inside the eye. Glaucoma can lead to loss of vision if it's not diagnosed and treated early.
- densenet sequential with ben on himanchu dataset, using NLLLoss criterion, Adam optimizer
- very much dependent on dataset
- disk extraction is good but is very subjective to the dataset
- trained on very small dataset
- create a gmail account ([email protected])
- understand the difference between possibility of glaucoma by classification (vs measurements)
- ben transformation
- extract disk from fundus images
- improve extraction algorithms
- perform EDA on disk image to find troubling images (cases where crop does not work)
- convert python function to extract disk to torch transform class (failed)
- transformation to disk during training failed. create a disk dataset before training the model.
- train on new dataset with and without ben transformation
- handle imbalanced class with class weighting
- convert Kaggle dataset to the format that we have templated our notebooks with
- for kaggle dataset get disks using new algorithm
- extraction of disk does not help (too many vague areas left unfilled)
- however, cropping shows very good promise
- but, cropping requires somewhat similar of fundus images
- find datasets https://deepblue.lib.umich.edu/data/concern/data_sets/3b591905z, https://www.kaggle.com/andrewmvd/ocular-disease-recognition-odir5k
- create a dataset from Magrabia
- create a dataset from Messidor
- create a dataset from Ocular Disease Recognition
- create EDA on non measurement dataset (Ocular Disease Recognition)
- create a dataset from ocular disease recognition to include normal and glaucoma images
- (Kaggle dataset, custom generated, filtered)https://www.kaggle.com/sshikamaru/glaucoma-detection?select=glaucoma.csv
- train on Kaggle dataset (without changing anything)
- inception v3 with and without ben on ocular, kaggle, and himanchu dataset
- inception v3 with ben on ocular, kaggle, and himanchu dataset (disk extracted, normal, and cropped dataset)
- densenet linear with ben on ocular, kaggle, and himanchu dataset
- densenet linear with ben on ocular, kaggle, and himanchu dataset (disk extracted, normal, and cropped dataset)
- densenet sequential with ben on ocular, kaggle, and himanchu dataset
- densenet sequential with ben on ocular, kaggle, and himanchu dataset (disk extracted, normal, and cropped dataset)
- add datasets from cheers for testing
- add datasets from cheers for training

Diabetic retinopathy is a complication of diabetes, caused by high blood sugar levels damaging the back of the eye (retina). It can cause blindness if left undiagnosed and untreated. However, it usually takes several years for diabetic retinopathy to reach a stage where it could threaten your sight.
- Large dataset from EyePACS (Kaggle competition used training (30%) and testing data (70%) from Kaggle. After the competition, the labels were published). Flipped the ratios for our use case.
- Remove out of focus images
- Remove too bright, and too dark images.
- Link to clean dataset https://www.kaggle.com/ayushsubedi/drunstratified
- To handle class imbalanced issue, used weighted random samplers. Undersampling to match no of images in the least class (4) did not work. Pickled weights for future use.
- Ben Graham transformation and augmentations
- Inception v3 fine tuning, with aux logits trained (better results compared to other architecture)
- Perform EDA on inference to observe what images were causing issues
- Removed the images and created another dataset (Link to the new dataset https://www.kaggle.com/ayushsubedi/cleannonstratifieddiabeticretinopathy
- See 5, 6, and 7
Binary Stratified (cleaned): https://drive.google.com/drive/folders/12-60Gm7c_TMu1rhnMhSZjrkSqqAuSsQf?usp=sharing Categorical Stratified (cleaned): https://drive.google.com/drive/folders/1-A_Mx9GdeUwCd03TUxUS3vwcutQHFFSM?usp=sharing Non Stratified (cleaned): https://www.kaggle.com/ayushsubedi/drunstratified Recleaned Non Stratified: https://www.kaggle.com/ayushsubedi/cleannonstratifieddiabeticretinopathy
- create a new gmail account to store datasets ([email protected])
- https://www.youtube.com/watch?v=VIrkurR446s&ab_channel=khanacademymedicine What is diabetic retinopathy?
- collect all previous analysis notebooks
- conduct preliminary EDA (for balanced dataset, missing images etc)
- create balanced test train split for DR (stratify)
- store the dataset in drive for colab
- identify a few research papers, create a file to store subsequently found research papers
- identify right technology stack to use (for ML, training, PM, model versioning, stage deployment, actual deployment)
- perform basic augmentation
- create a version 0 base model
- apply a random transfer learning model
- create a metric for evaluation
- store the model in zenodo, or find something for version control
- create a model that takes image as an input
- create a streamlit app that reads model
- streamlit app to upload and test prediction
- test deployment to free tier heroku
- identify gaps
- create priliminary test set
- create folder structures for saved model in the drive
- figure out a way to move files from kaggle to drive (without download/upload)
- research saving model (the frugal way)
- research saving model to google drive after each epoch so that during unforseen interuptions, the training of the model can be continued
- upgrade to 25GB RAM in Google Colab possibly w/ Tesla P100 GPU
- upgrade to Colab Pro
- medicmind grading (accuracy: 0.8)
- medicmind classification (0.47)
- resnet
- alexnet
- vgg
- squeezenet
- densenet
- inception
- efficient net
- create a backup of primary dataset (zip so that kaggle kernels can consume them too)
- find algorithms to detect black/out of focus images
- identify correct threshold for dark and out of focus images
- remove black images
- remove out of focus images
- create a stratified dataset with 2015 data only (convert train and test both to train and use), remove black images and out of focus images (also create test set)
- create non-stratified dataset with 2015 clean data only (train, test, valid) (upload in kaggle if google drive full)
- create a binary dataset (train, test, valid)
- create confusion matrices (train, test, valid) after clean up (dark and blurry)
- the model is confusing labels 0 and 1 as 2, is this due to disturbance in image in 0.
- concluded that the result is due to the model not capturing class 0 enough (due to undersampling)
- create a csv with preds probability and real label
- calculate recall, precision, accuracy, confusion matrix
- identify different prediction issues
- relationship between difference in preds and accuracy
- inference issue: labels 0 being predicted as 4
- inference issue: Check images from Grade 2, 3 being predicted as Grade 0
- inference issue: Check images from Grade 4 being predicted as Grade 0
- inference issue: Check images from Grade 0 being predicted as Grade 4
- inference issue: A significant Grade 2 is being predicted as Grade 0
- inference issue: More than 50% of Grade 1 is being predicted as Grade 0
- create a new dataset
- research kaggle winning augmentation for DR
- research appropriate augmentation: optical distortion, grid distortion, piecewise affine transform, horizontal flip, vertical flip, random rotation, random shift, random scale, a shift of RGB values, random brightness and contrast, additive Gaussian noise, blur, sharpening, embossing, random gamma, and cutout
- train on various pretrained models or research which is supposed to be ideal for this case https://pytorch.org/vision/stable/models.html
- create several neural nets (test different layers)
- experiment with batch size
- Reducing lighting-condition effects
- Cropping uninformative area
- Create custom dataloader based on ben graham kaggle winning strategy
- finetune vs feature extract
- oversample
- undersample
- add specificity and sensitivity to indicators
- create train loss and valid loss charts
- test regression models (treat this as a grading problem)
- pickle weights
- check if left/right eye classification model is required
- make datasets more extensive (add test dataset with recoverd labels to train dataset 2015)
- add APTOS dataset
- request labelled datasets from cheers
- add datasets from cheers for testing
- add datasets from cheers for training
- find datasets for testing (dataset apart from APTOS and EyePACS)
- update folder structures to match our use case
- find dataset for testing after making sure old test datasets are not in vaid/train (4 will be empty)
- read reports from kaggle competition winning authors
- Deep Learning Approach to Diabetic Retinopathy Detection https://arxiv.org/pdf/2003.02261.pdf
- Google research https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/45732.pdf
- Nature article https://www.nature.com/articles/s41746-019-0172-3
- read ravi's article
- https://deim.urv.cat/~itaka/itaka2/PDF/acabats/PhD_Thesis/TESI_doctoral_Jordi_De_la_Torre.pdf
- what can go wrong https://yerevann.github.io/2015/08/17/diabetic-retinopathy-detection-contest-what-we-did-wrong/
- https://arxiv.org/pdf/1902.07208.pdf
- identify more papers